
Cluster Nested Loop k-Farthest Neighbor Join Algorithm for Spatial Networks


Abstract
:1. Introduction
- This paper presents a cluster nested loop join algorithm for quickly evaluating spatial network kFN join queries. The CNLJ algorithm clusters query points before retrieving candidate data points for clustered query points all at once. As a result, it does not retrieve candidate data points for each query point multiple times.
- The CNLJ algorithm’s correctness is demonstrated through mathematical reasoning. In addition, a theoretical analysis is provided to clarify the benefits and drawbacks of the CNLJ algorithm concerning query point spatial compactness.
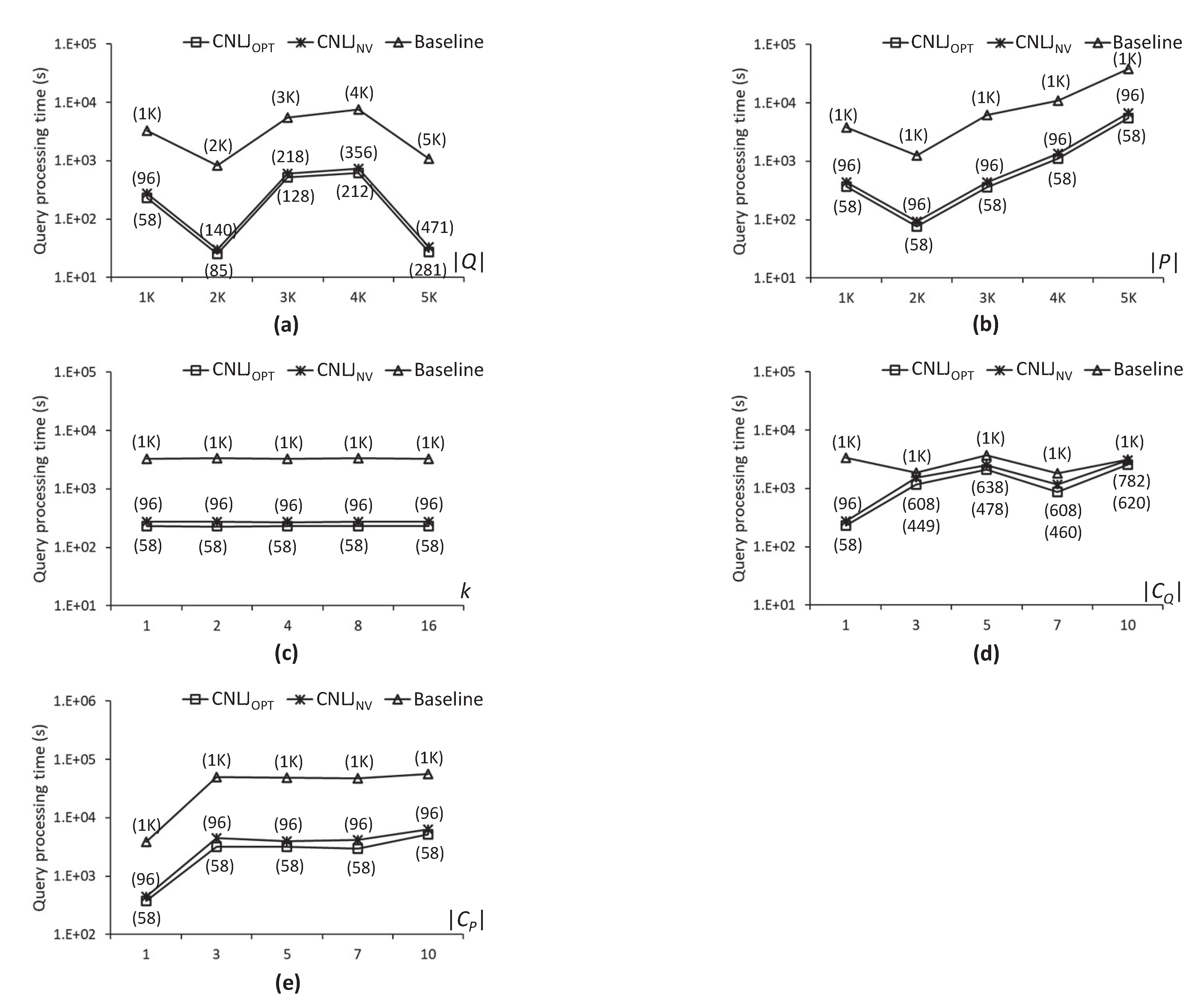
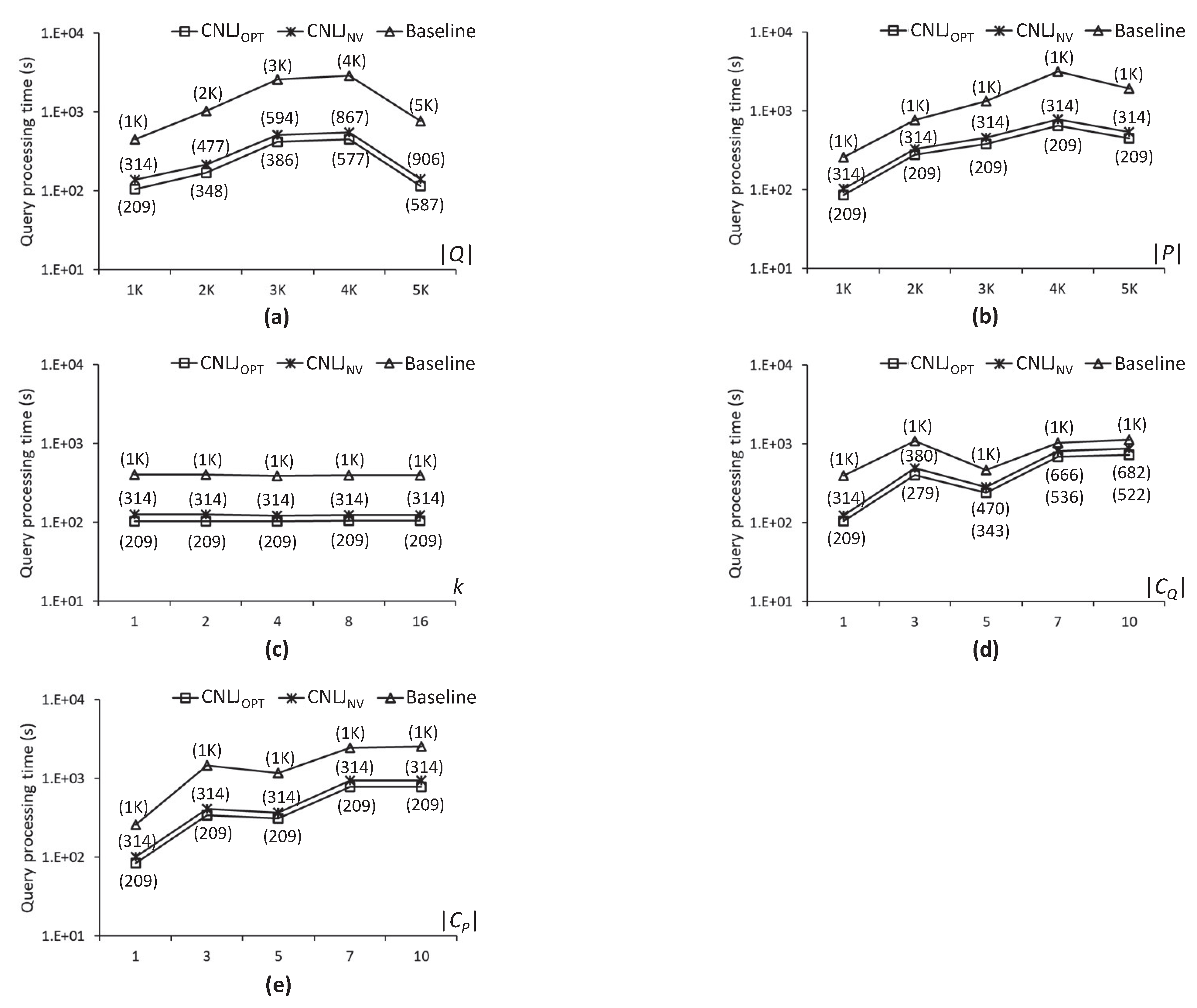
- An empirical study with various setups was conducted to demonstrate the superiority and scalability of the CNLJ algorithm. The CNLJ algorithm outperforms the conventional join algorithms by up to 50.8 times according to the results.
2. Background
2.1. Related Work
2.2. Notation and Formal Problem Description
3. Clustering Points and Computing Distances
3.1. Clustering Query and Data Points Using Spatial Network Connection
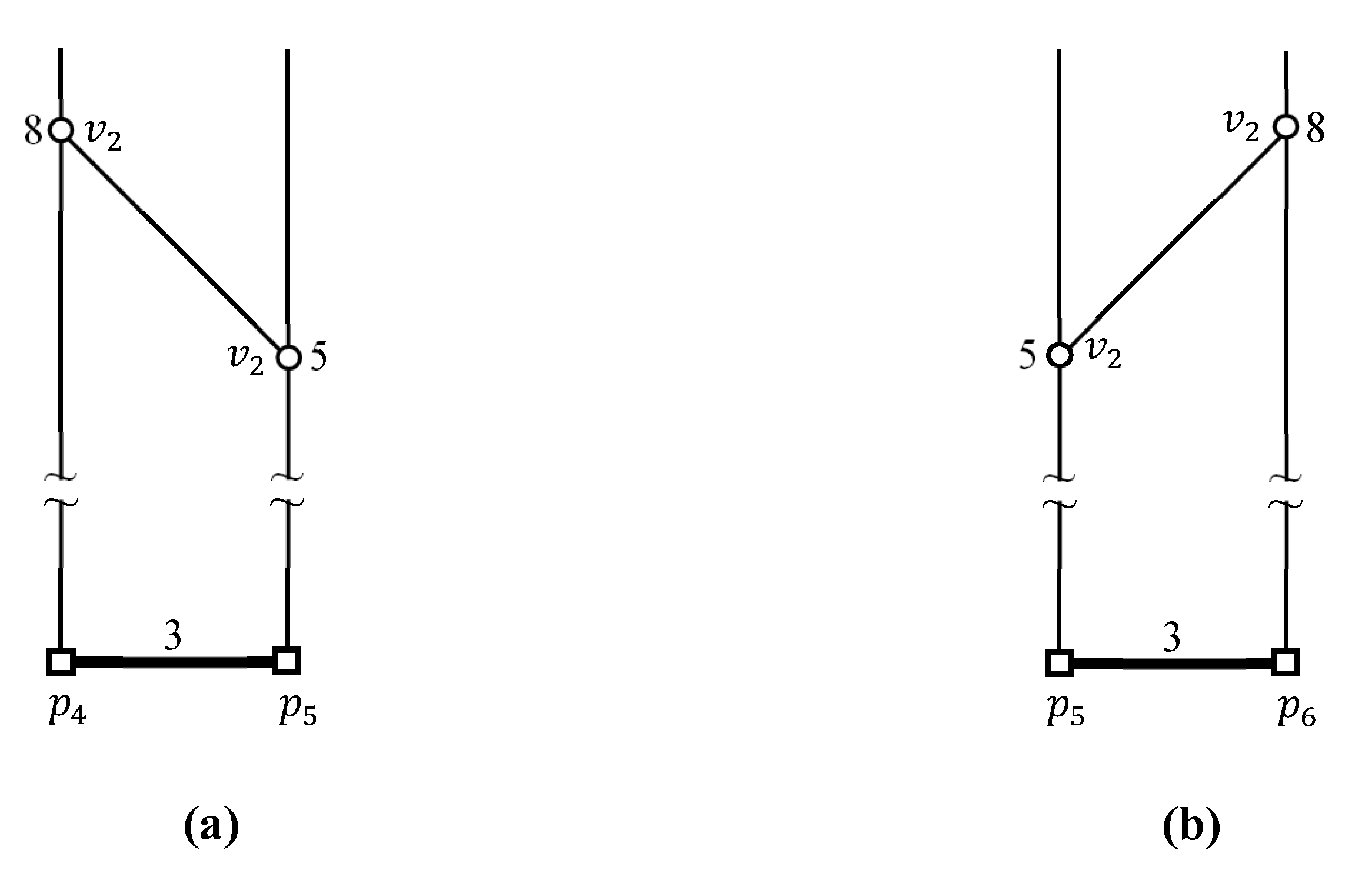
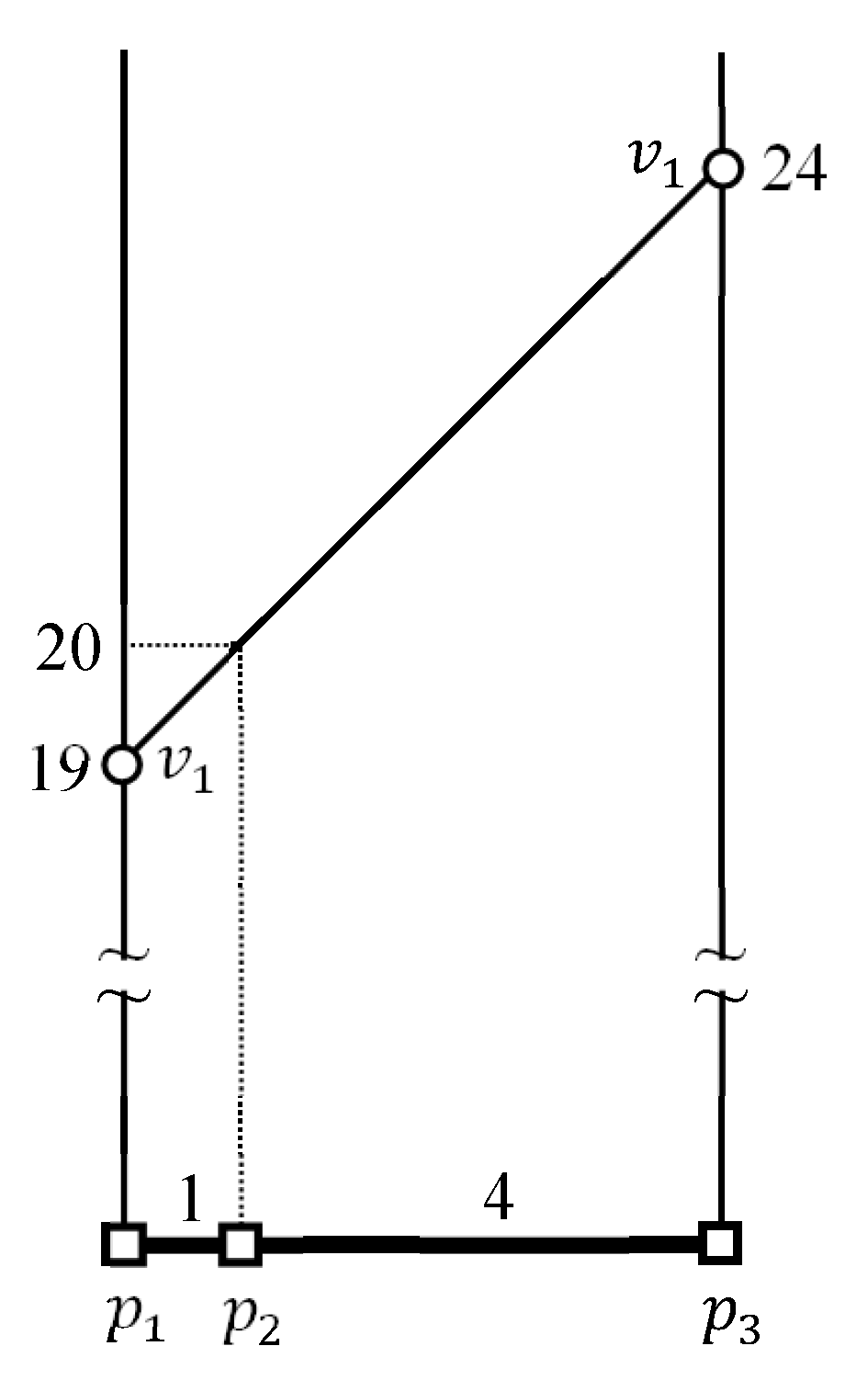
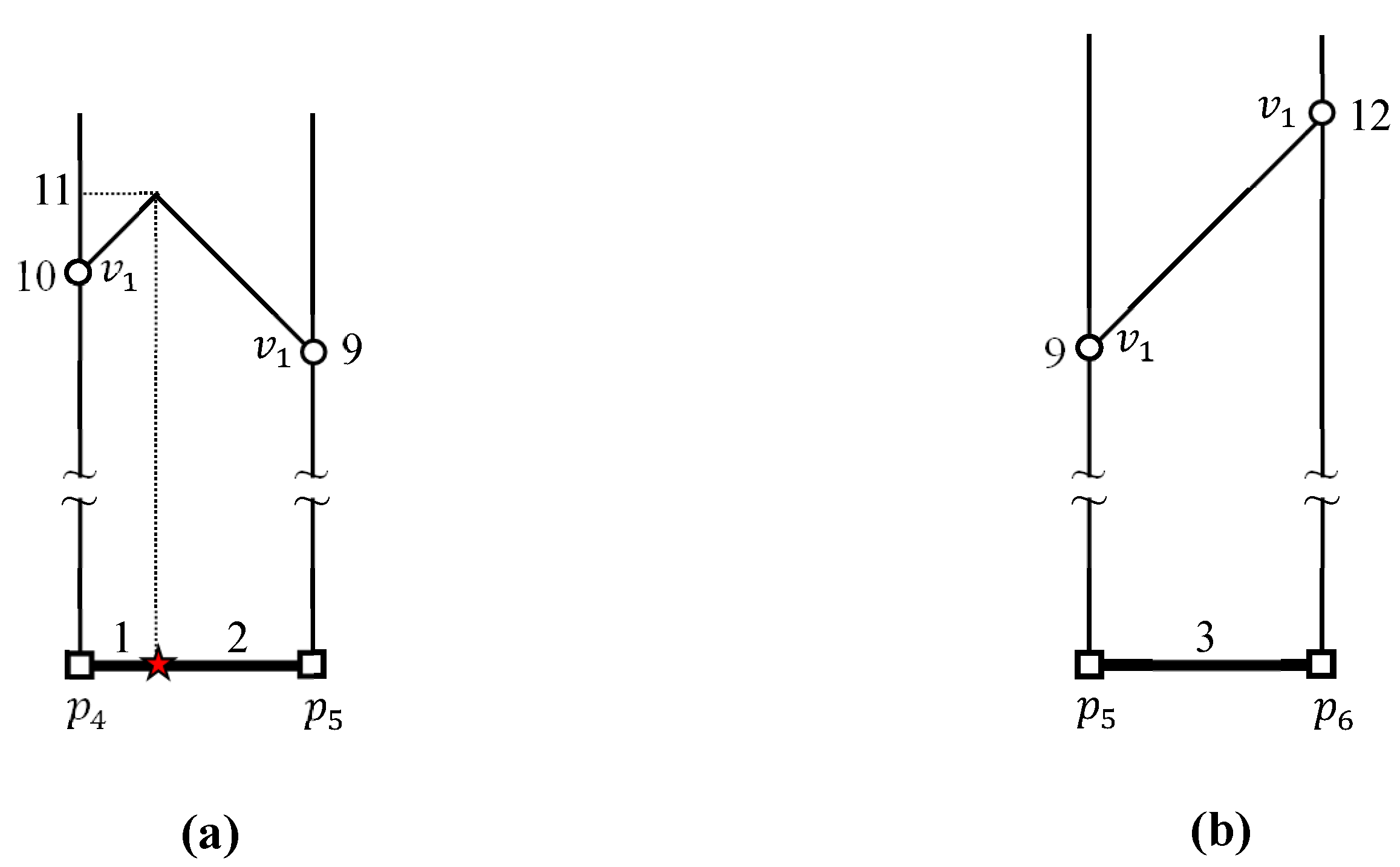
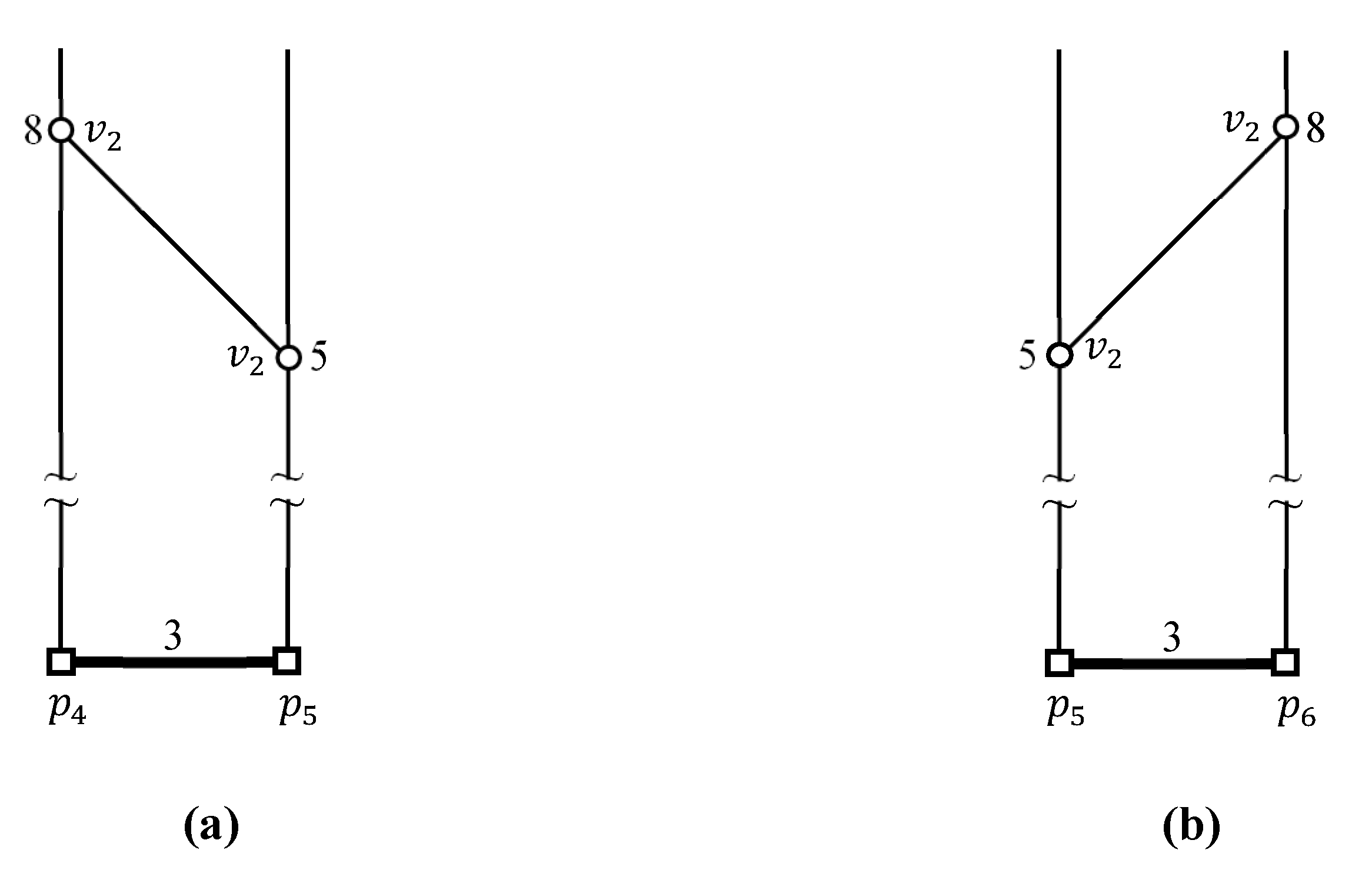
3.2. Computing Maximum and Minimum Distances from a Border Point to a Data Cluster
4. Cluster Nested Loop Join Algorithm for Spatial Networks
4.1. Cluster Nested Loop Join Algorithm
| Algorithm 1 CNLJ(). |
| Input:k: number of FNs for q, Q: set of query points, and P: set of data points Output:: Set of ordered pairs of each query point q in Q and a set of k FNs for q, i.e., .
|
| Algorithm 2. |
| Input:k: number of FNs for q, : query cluster, and : set of data clusters Output:: Set of ordered pairs of each query point q in and a set of k FNs for q, i.e.,
|
| Algorithm 3. |
| Input:k: number of FNs for q, l: maximum distance between border points in , : border point of , and : set of data clusters Output:: Set of k FNs for
|
| Algorithm 4. |
| Input:k: number of FNs for q, q: query point in , : set of candidate data points for q Output: : set of k FNs for q
|
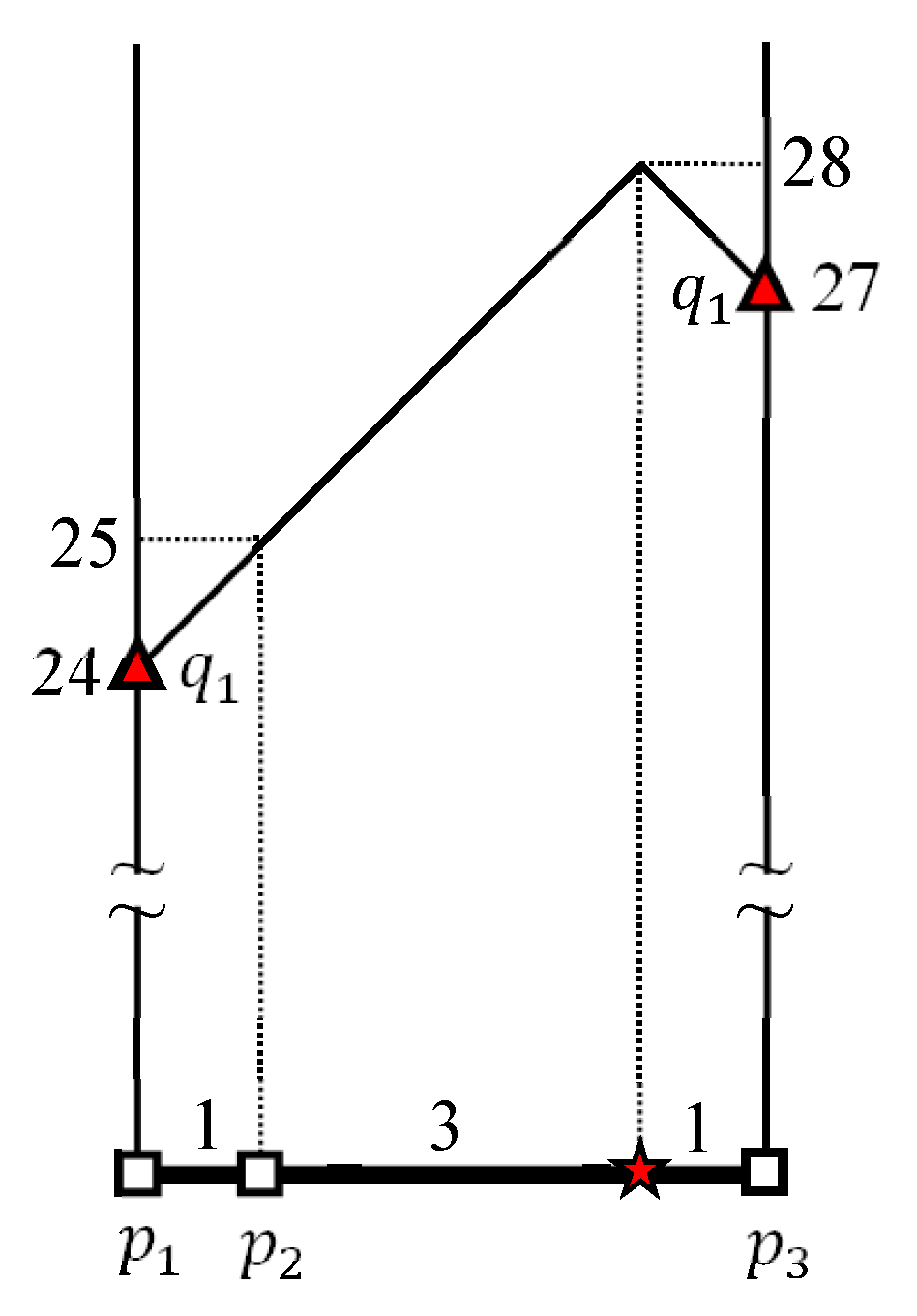
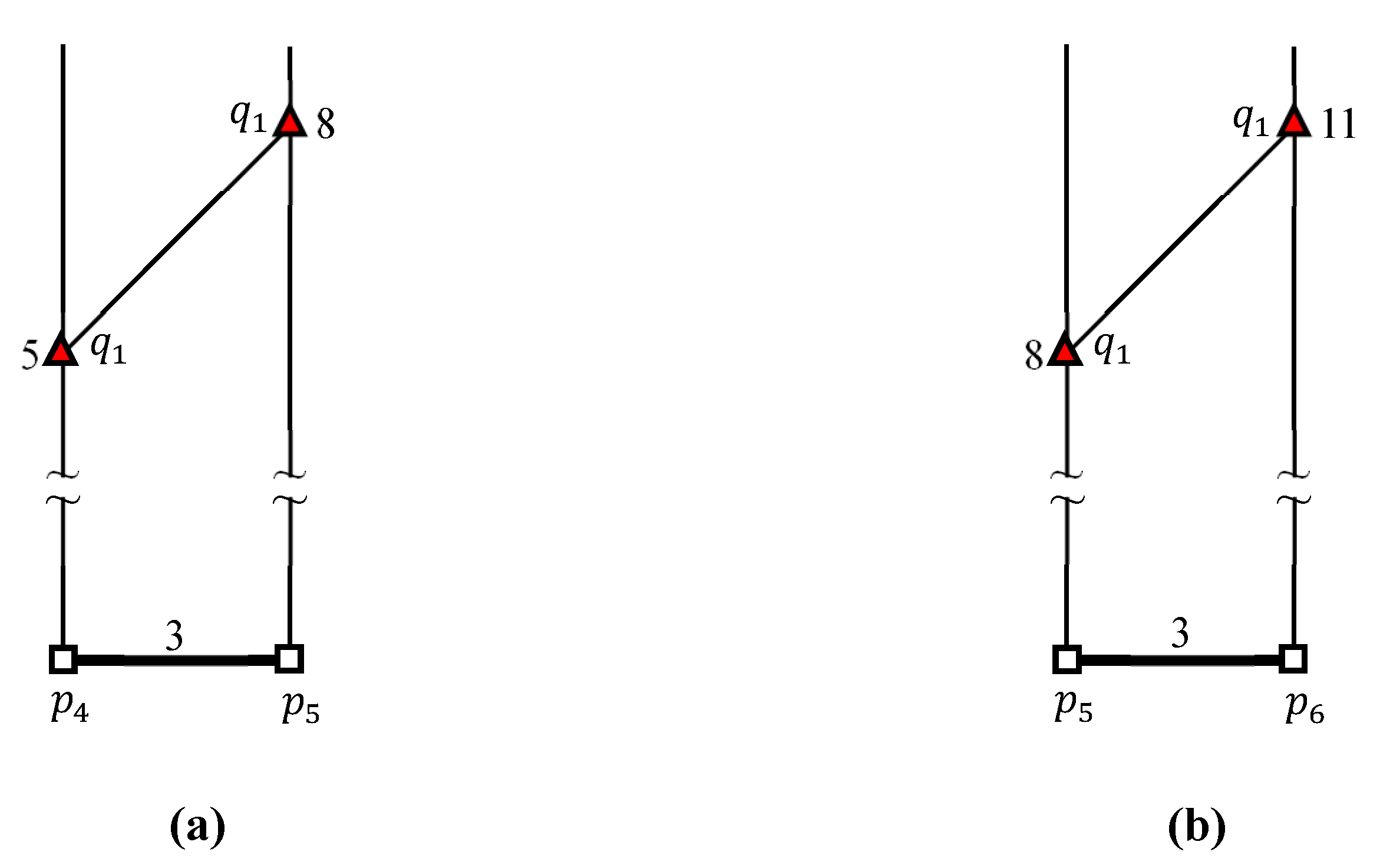
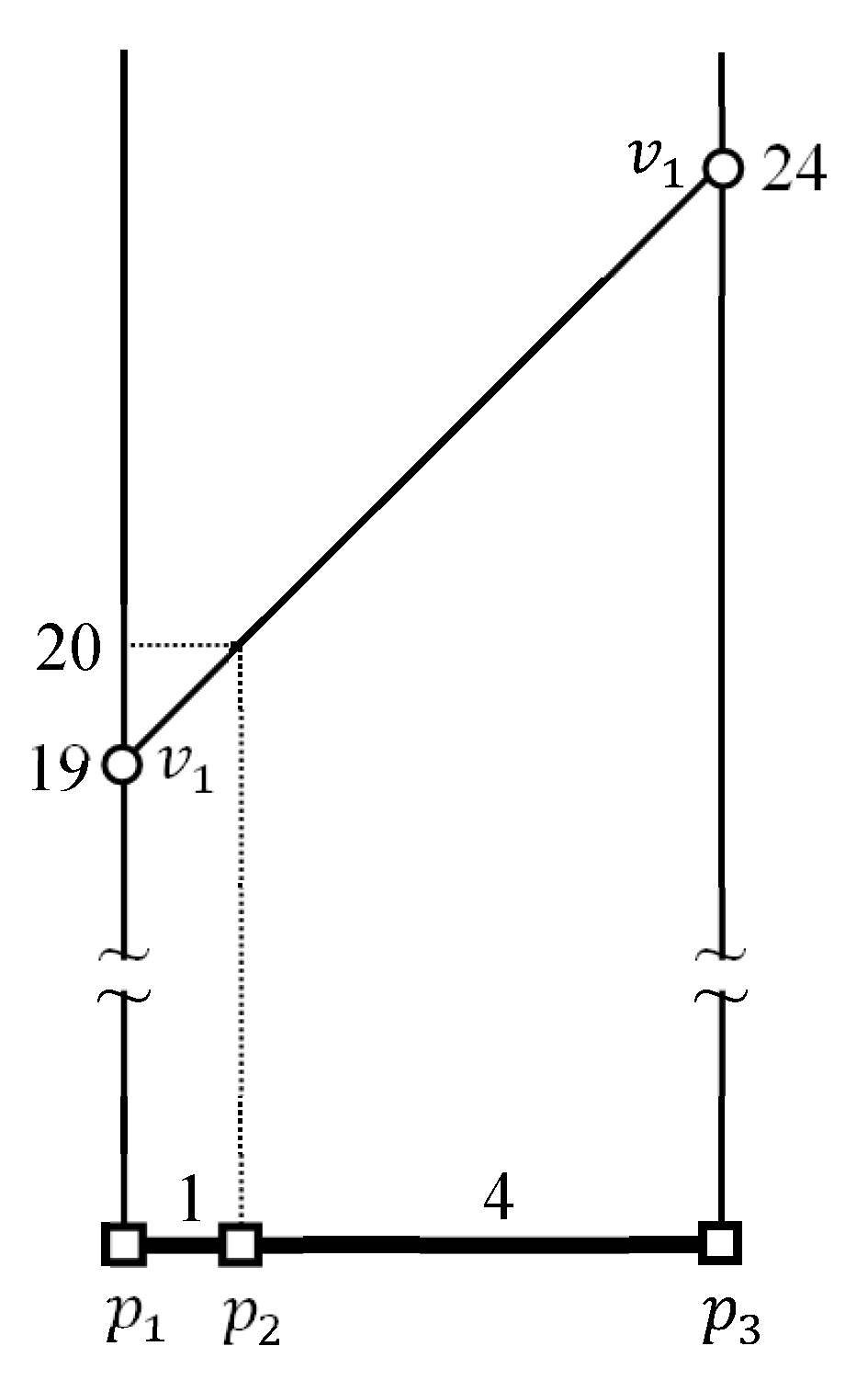
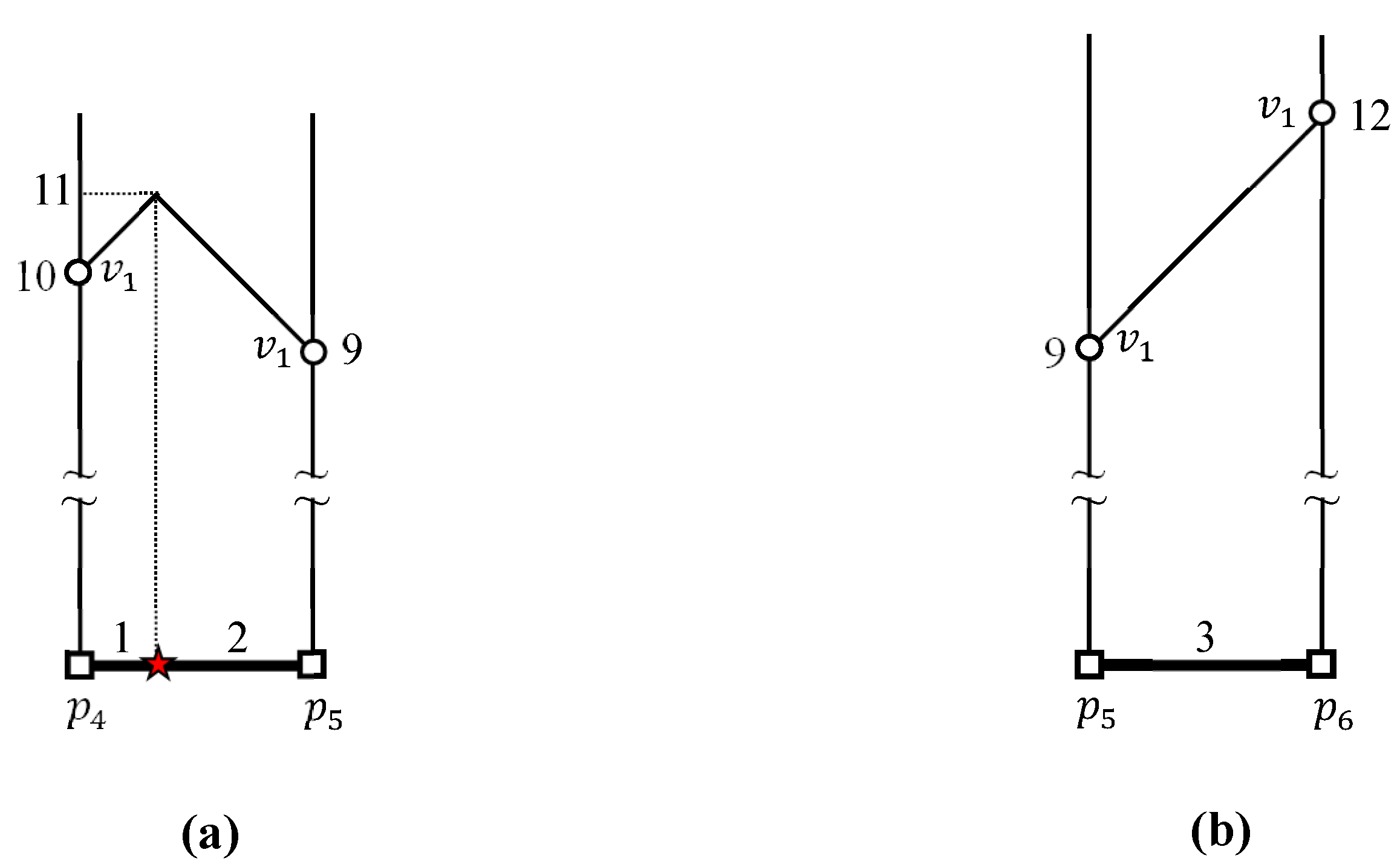
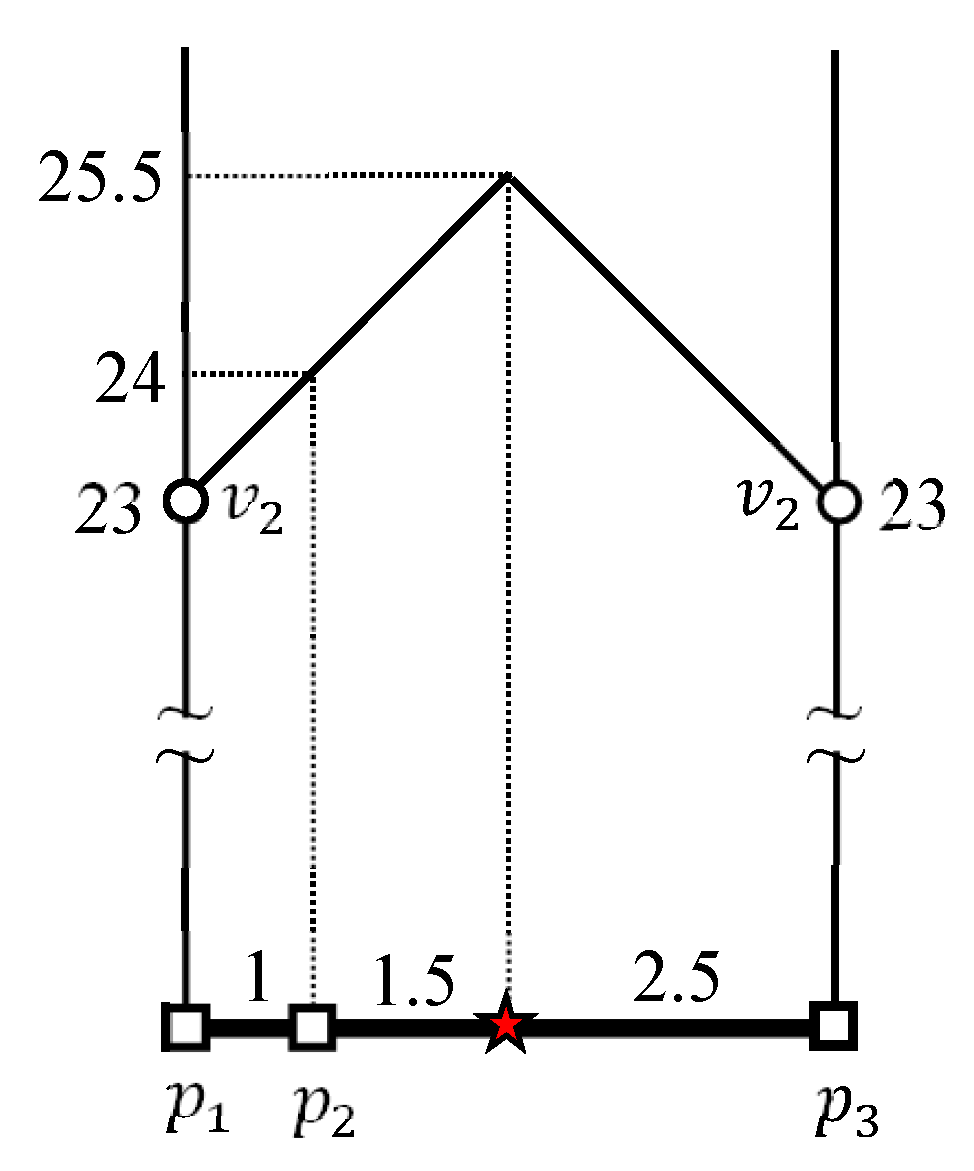
4.2. Evaluating kFN Queries at Border Points
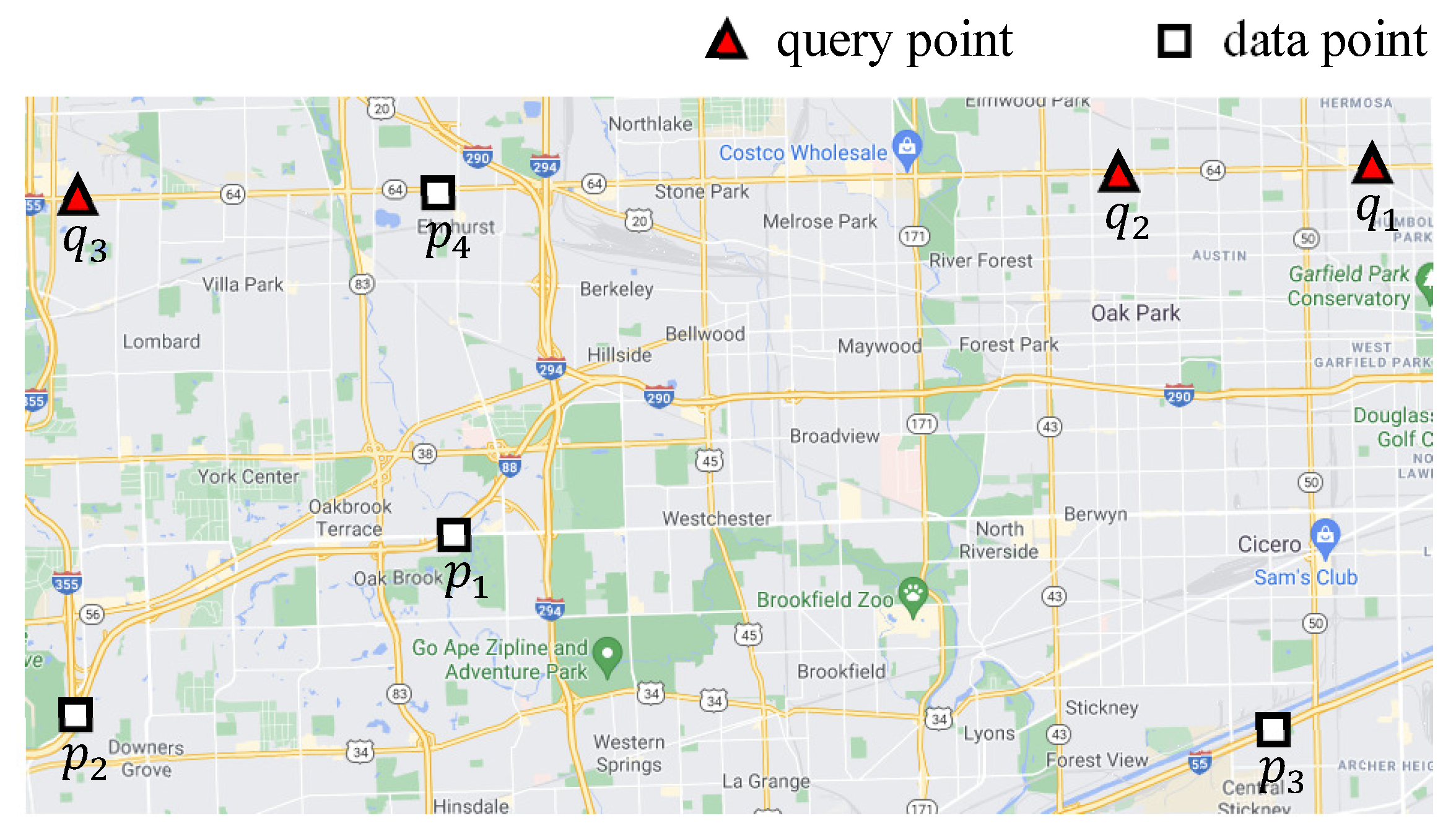
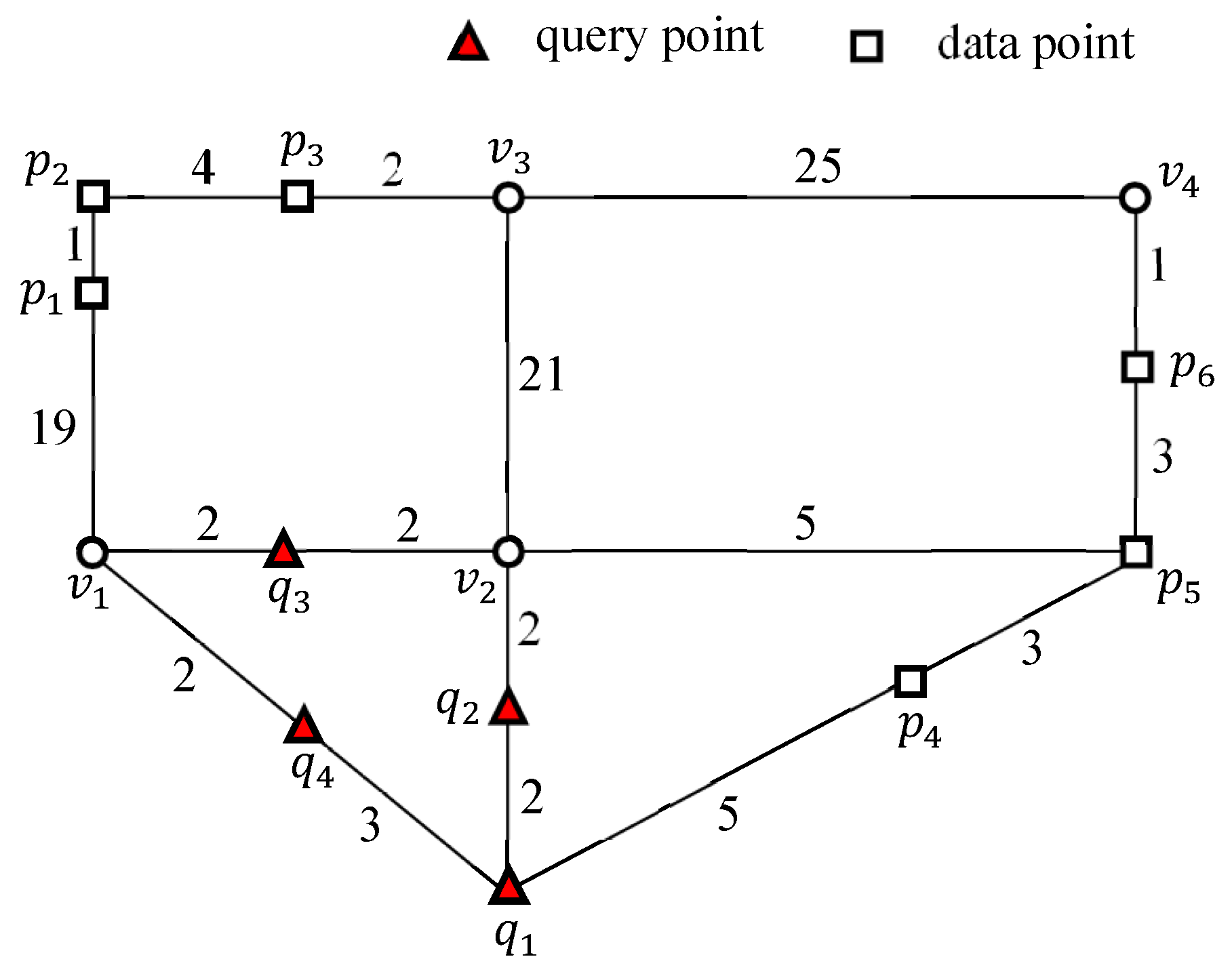
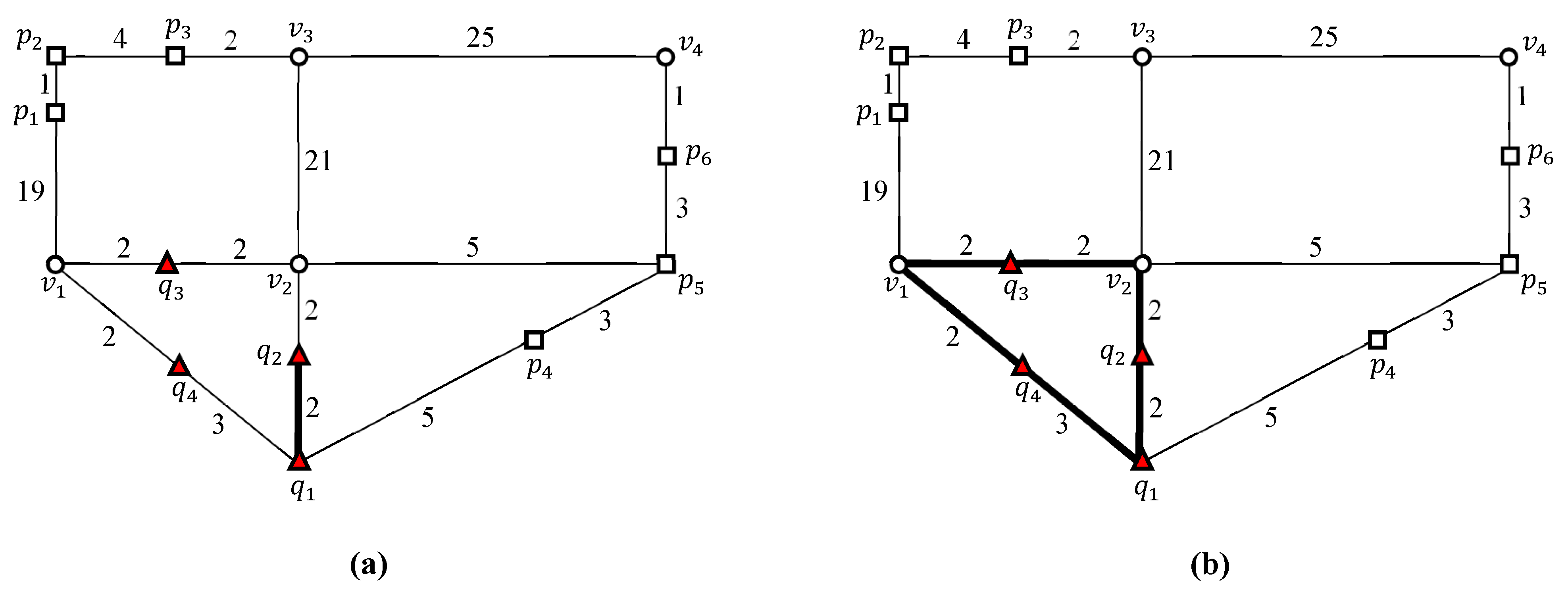
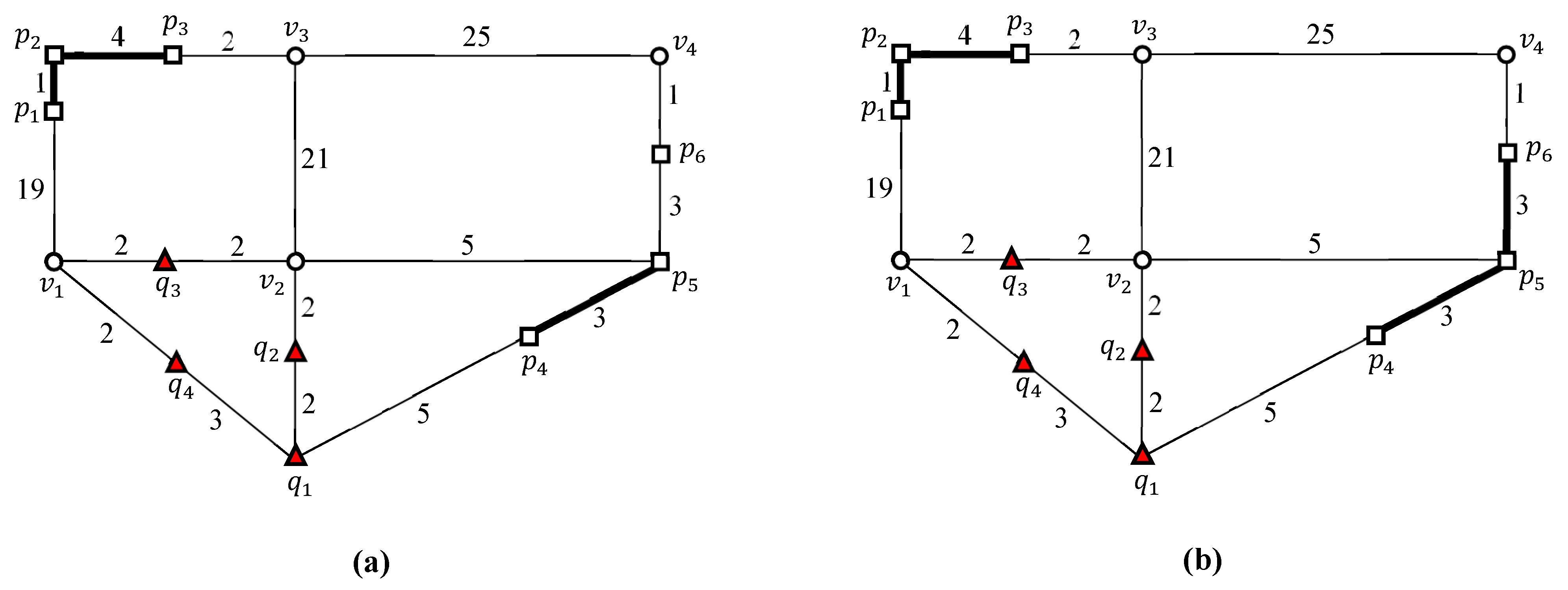
4.3. Evaluating an Example kFN Join Query
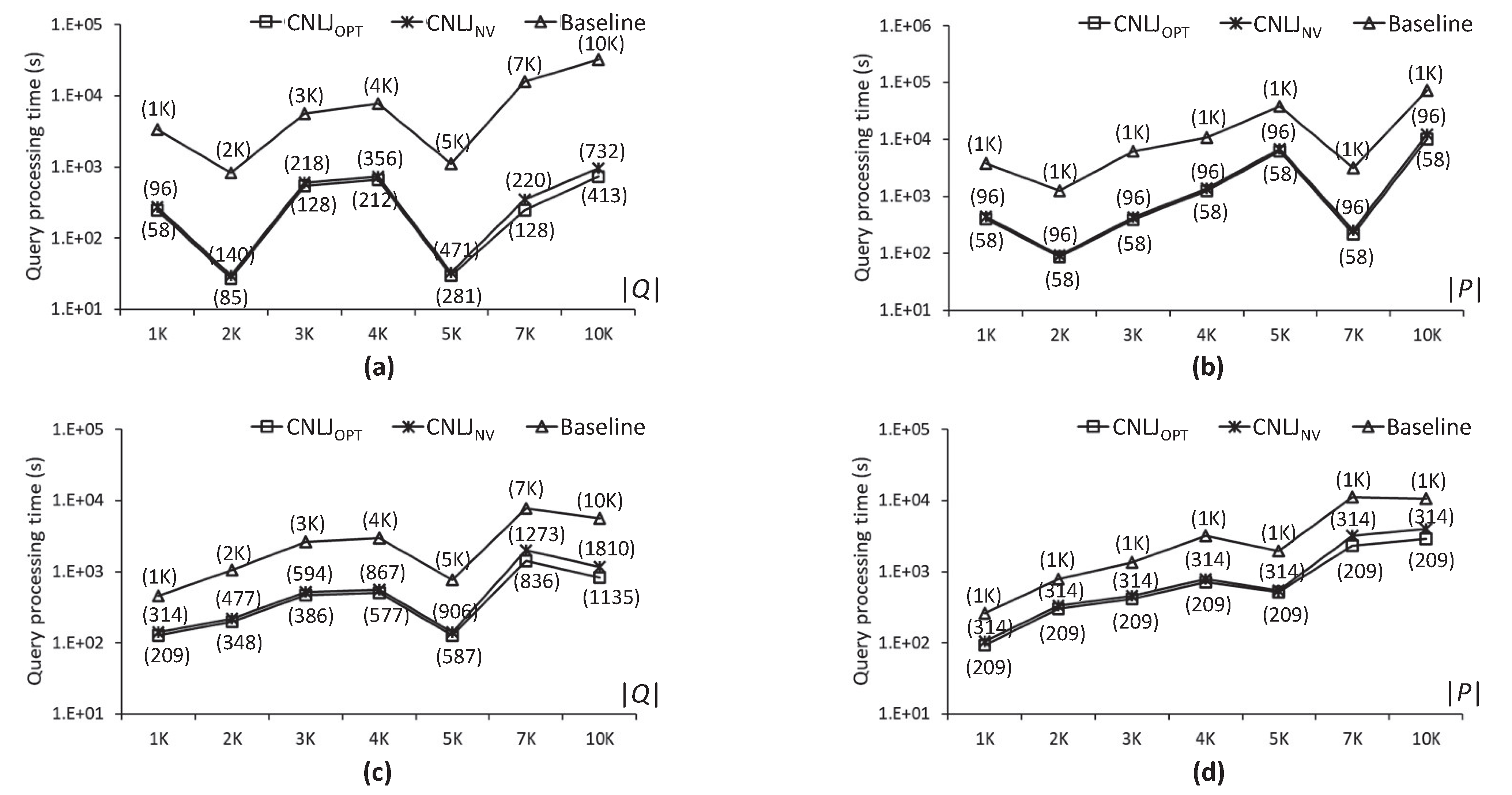
5. Performance Evaluation
5.1. Experimental Settings
5.2. Experimental Results
6. Discussion and Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Said, A.; Kille, B.; Jain, B.J.; Albayrak, S. Increasing diversity through furthest neighbor-based recommendation. In Proceedings of the International Workshop on Diversity in Document Retrieval, Seattle, WA, USA, 12 February 2012; pp. 1–4. [Google Scholar]
- Said, A.; Fields, B.; Jain, B.J.; Albayrak, S. User-centric evaluation of a k-furthest neighbor collaborative filtering recommender algorithm. In Proceedings of the International Conference on Computer Supported Cooperative Work and Social Computing, San Antonio, TX, USA, 23–27 February 2013; pp. 1399–1408. [Google Scholar]
- Veenman, C.J.; Reinders, M.J.T.; Backer, E. A maximum variance cluster algorithm. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1273–1280. [Google Scholar] [CrossRef] [Green Version]
- Defays, D. An efficient algorithm for a complete link method. Comput. J. 1977, 20, 364–366. [Google Scholar] [CrossRef] [Green Version]
- Vasiloglou, N.; Gray, A.G.; Anderson, D.V. Scalable semidefinite manifold learning. In Proceedings of the IEEE Workshop on Machine Learning for Signal Processing, Cancun, Mexico, 16–19 October 2008; pp. 368–373. [Google Scholar]
- Curtin, R.R.; Echauz, J.; Gardner, A.B. Exploiting the structure of furthest neighbor search for fast approximate results. Inf. Syst. 2019, 80, 124–135. [Google Scholar] [CrossRef]
- Gao, Y.; Shou, L.; Chen, K.; Chen, G. Aggregate farthest-neighbor queries over spatial data. In Proceedings of the International Conference on Database Systems for Advanced Applications, Hong Kong, China, 22–25 April 2011; pp. 149–163. [Google Scholar]
- Liu, J.; Chen, H.; Furuse, K.; Kitagawa, H. An efficient algorithm for arbitrary reverse furthest neighbor queries. In Proceedings of the Asia-Pacific Web Conference on Web Technologies and Applications, Kunming, China, 11–13 April 2012; pp. 60–72. [Google Scholar]
- Liu, W.; Yuan, Y. New ideas for FN/RFN queries based nearest Voronoi diagram. In Proceedings of the International Conference on Bio-Inspired Computing: Theories and Applications, Huangshan, China, 12–14 July 2013; pp. 917–927. [Google Scholar]
- Tran, Q.T.; Taniar, D.; Safar, M. Reverse k nearest neighbor and reverse farthest neighbor search on spatial networks. Trans. Large-Scale Data-Knowl.-Cent. Syst. 2009, 1, 353–372. [Google Scholar]
- Wang, H.; Zheng, K.; Su, H.; Wang, J.; Sadiq, S.W.; Zhou, X. Efficient aggregate farthest neighbour query processing on road networks. In Proceedings of the Australasian Database Conference on Databases Theory and Applications, Brisbane, Australia, 14–16 July 2014; pp. 13–25. [Google Scholar]
- Xiao, Y.; Liu, B.; Hao, Z.; Cao, L. A k-farthest-neighbor-based approach for support vector data description. Appl. Intell. 2014, 41, 196–211. [Google Scholar] [CrossRef]
- Xu, X.-J.; Bao, J.-S.; Yao, B.; Zhou, J.-Y.; Tang, F.-L.; Guo, M.-Y.; Xu, J.-Q. Reverse furthest neighbors query in road networks. J. Comput. Sci. Technol. 2017, 32, 155–167. [Google Scholar] [CrossRef]
- Yao, B.; Li, F.; Kumar, P. Reverse furthest neighbors in spatial databases. In Proceedings of the International Conference on Data Engineering, Shanghai, China, 29 March–2 April 2009; pp. 664–675. [Google Scholar]
- Dutta, B.; Karmakar, A.; Roy, S. Optimal facility location problem on polyhedral terrains using descending paths. Theor. Comput. Sci. 2020, 847, 68–75. [Google Scholar] [CrossRef]
- Gao, X.; Park, C.; Chen, X.; Xie, E.; Huang, G.; Zhang, D. Globally optimal facility locations for continuous-space facility location problems. Appl. Sci. 2021, 11, 7321. [Google Scholar] [CrossRef]
- Liu, W.; Wang, H.; Zhang, Y.; Qin, L.; Zhang, W. I/O efficient algorithm for c-approximate furthest neighbor search in high-dimensional space. In Proceedings of the International Conference on Database Systems for Advanced Applications, Jeju, Korea, 24–27 September 2020; pp. 221–236. [Google Scholar]
- Huang, Q.; Feng, J.; Fang, Q.; Ng, W. Two efficient hashing schemes for high-dimensional furthest neighbor search. IEEE Trans. Knowl. Data Eng. 2017, 29, 2772–2785. [Google Scholar] [CrossRef]
- Liu, Y.; Gong, X.; Kong, D.; Hao, T.; Yan, X. A Voronoi-based group reverse k farthest neighbor query method in the obstacle space. IEEE Access 2020, 8, 50659–50673. [Google Scholar] [CrossRef]
- Pagh, R.; Silvestri, F.; Sivertsen, J.; Skala, M. Approximate furthest neighbor in high dimensions. In Proceedings of the International Conference on Similarity Search and Applications, Glasgow, UK, 12–14 October 2015; pp. 3–14. [Google Scholar]
- Korn, F.; Muthukrishnan, S. Influence sets based on reverse nearest neighbor queries. In Proceedings of the International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 201–212. [Google Scholar]
- Wang, S.; Cheema, M.A.; Lin, X.; Zhang, Y.; Liu, D. Efficiently computing reverse k furthest neighbors. In Proceedings of the International Conference on Data Engineering, Helsinki, Finland, 16–20 May 2016; pp. 1110–1121. [Google Scholar]
- Beckmann, N.; Kriegel, H.-P.; Schneider, R.; Seeger, B. The R*-tree: An efficient and robust access method for points and rectangles. In Proceedings of the International Conference on Management of Data, Atlantic City, NJ, USA, 23–25 May 1990; pp. 322–331. [Google Scholar]
- Guttman, A. R-trees: A dynamic index structure for spatial searching. In Proceedings of the International Conference on Management of Data, Boston, MA, USA, 18–21 June 1984; pp. 47–57. [Google Scholar]
- Huang, Q.; Feng, J.; Fang, Q. Reverse query-aware locality-sensitive hashing for high-dimensional furthest neighbor search. In Proceedings of the International Conference on Data Engineering, San Diego, CA, USA, 19–22 April 2017; pp. 167–170. [Google Scholar]
- Lu, H.; Yiu, M.L. On computing farthest dominated locations. IEEE Trans. Knowl. Data Eng. 2011, 23, 928–941. [Google Scholar] [CrossRef]
- Cho, H.-J. Efficient shared execution processing of k-nearest neighbor joins in road networks. Mob. Inf. Syst. 2018, 2018, 55–66. [Google Scholar] [CrossRef] [Green Version]
- He, D.; Wang, S.; Zhou, X.; Cheng, R. GLAD: A grid and labeling framework with scheduling for conflict-aware knn Queries. IEEE Trans. Knowl. Data Eng. 2021, 33, 1554–1566. [Google Scholar] [CrossRef]
- Yang, R.; Niu, B. Continuous k nearest neighbor queries over large-scale spatial-textual data streams. ISPRS Int. J. Geo-Inf. 2020, 9, 694. [Google Scholar] [CrossRef]
- Cho, H.-J.; Attique, M. Group processing of multiple k-farthest neighbor queries in road networks. IEEE Access 2020, 8, 110959–110973. [Google Scholar] [CrossRef]
- Reza, R.M.; Ali, M.E.; Hashem, T. Group processing of simultaneous shortest path queries in road networks. In Proceedings of the International Conference on Mobile Data Management, Pittsburgh, PA, USA, 15–18 June 2015; pp. 128–133. [Google Scholar]
- Zhang, M.; Li, L.; Hua, W.; Zhou, X. Efficient batch processing of shortest path queries in road networks. In Proceedings of the International Conference on Mobile Data Management, Hong Kong, China, 10–13 June 2019; pp. 100–105. [Google Scholar]
- Zhang, M.; Li, L.; Hua, W.; Zhou, X. Batch processing of shortest path queries in road networks. In Proceedings of the Australasian Database Conference on Databases Theory and Applications, Sydney, Australia, 29 January–1 February 2019; pp. 3–16. [Google Scholar]
- Reza, R.M.; Ali, M.E.; Cheema, M.A. The optimal route and stops for a group of users in a road network. In Proceedings of the International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–10 November 2017; pp. 1–10. [Google Scholar]
- Kim, T.; Cho, H.-J.; Hong, H.J.; Nam, H.; Cho, H.; Do, G.Y.; Jeon, P. Efficient processing of k-farthest neighbor queries for road networks. J. Korea Soc. Comput. Inf. 2019, 24, 79–89. [Google Scholar]
- Abeywickrama, T.; Cheema, M.A.; Taniar, D. k-nearest neighbors on road networks: A journey in experimentation and in-memory implementation. In Proceedings of the International Conference on Very Large Data Bases, New Delhi, India, 5–9 September 2016; pp. 492–503. [Google Scholar]
- Lee, K.C.K.; Lee, W.-C.; Zheng, B.; Tian, Y. ROAD: A new spatial object search framework for road networks. IEEE Trans. Knowl. Data Eng. 2012, 24, 547–560. [Google Scholar] [CrossRef]
- Zhong, R.; Li, G.; Tan, K.-L.; Zhou, L.; Gong, Z. G-tree: An efficient and scalable index for spatial search on road networks. IEEE Trans. Knowl. Data Eng. 2015, 27, 2175–2189. [Google Scholar] [CrossRef]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 3rd ed.; MIT Press and McGraw-Hill: Cambridge, MA, USA, 2009; pp. 643–683. [Google Scholar]
- Real Datasets for Spatial Databases. Available online: https://www.cs.utah.edu/~lifeifei/SpatialDataset.htm (accessed on 4 October 2021).
- Wu, L.; Xiao, X.; Deng, D.; Cong, G.; Zhu, A.D.; Zhou, S. Shortest path and distance queries on road networks: An experimental evaluation. In Proceedings of the International Conference on Very Large Data Bases, Istanbul, Turkey, 27–31 August 2012; pp. 406–417. [Google Scholar]
- Bast, H.; Funke, S.; Matijevic, D. Ultrafast shortest-path queries via transit nodes. In Proceedings of the International Workshop on Shortest Path Problem, Piscataway, NJ, USA, 13–14 November 2006; pp. 175–192. [Google Scholar]
- Geisberger, R.; Sanders, P.; Schultes, D.; Delling, D. Contraction hierarchies: Faster and simpler hierarchical routing in road networks. In Proceedings of the International Workshop on Experimental Algorithms, Cape Cod, MA, USA, 30 May–2 June 2008; pp. 319–333. [Google Scholar]
- Li, Z.; Chen, L.; Wang, Y. G*-tree: An efficient spatial index on road networks. In Proceedings of the International Conference on Data Engineering, Macao, China, 8–11 April 2019; pp. 268–279. [Google Scholar]
- Samet, H.; Sankaranarayanan, J.; Alborzi, H. Scalable network distance browsing in spatial databases. In Proceedings of the International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 43–54. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Space Domain | Query Type | Data Type |
|---|---|---|---|
| [8,9,14,19] | Euclidean space | RkFN search | Monochromatic |
| [14,22] | Euclidean space | RkFN search | Bichromatic |
| [6,9,17,18,20,25] | Euclidean space | kFN search | |
| [7] | Euclidean space | AkFN search | |
| [26] | Euclidean space | FDL search | |
| [13] | Spatial network | RkFN search | Monochromatic |
| [10,13] | Spatial network | RkFN search | Bichromatic |
| [35] | Spatial network | kFN search | |
| [11] | Spatial network | AkFN search | |
| This study | Spatial network | kFN join |
| Symbol | Definition |
|---|---|
| k | Number of requested FNs |
| Q and q | A set Q of query points and query point q in Q, respectively |
| P and p | A set P of data points and data point p in P, respectively |
| Vertex sequence where and are either an intersection vertex or a terminal vertex and the other vertices, , are intermediate vertices | |
| Query segment connecting query points in a vertex sequence (in short, ) | |
| Data segment connecting data points in a vertex sequence (in short, ) | |
| and | Set of query segments and set of data segments, respectively |
| and | Set of query clusters and set of data clusters, respectively |
| and | Sets of border points of and , respectively |
| and | Border points of and , respectively |
| Set of k data points farthest from a query point q | |
| Length of the shortest path connecting points q and p | |
| Length of the segment |
| CNLJ Algorithm | Nonclustering Join Algorithm | |
|---|---|---|
| Number of kFN queries to be evaluated | ||
| Time complexity to evaluate the kFN search | ||
| Time complexity to evaluate the kFN join |
| q | ||
|---|---|---|
| or | ||
| Name | Description | Vertices | Edges | Vertex Sequences |
|---|---|---|---|---|
| NA | Highways in North America (NA) | 175,813 | 179,179 | 12,416 |
| SJ | City streets in San Joaquin (SJ), California | 18,263 | 23,874 | 20,040 |
| Parameter | Range |
|---|---|
| Number of query points () | 1, 2, 3, 4, 5, 7, 10 () |
| Number of data points () | 1, 2, 3, 4, 5, 7, 10 () |
| Number of FNs required (k) | 1, 2, 4, 8, 16 |
| Distribution of query and data points | Centroid distribution |
| Number of centroids for query points in Q () | 1, 3, 5, 7, 10 |
| Number of centroids for data points in P () | 1, 3, 5, 7, 10 |
| The standard deviation for normal distribution () | |
| Roadmap | NA, SJ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, H.-J. Cluster Nested Loop k-Farthest Neighbor Join Algorithm for Spatial Networks. ISPRS Int. J. Geo-Inf. 2022, 11, 123. https://doi.org/10.3390/ijgi11020123
Cho H-J. Cluster Nested Loop k-Farthest Neighbor Join Algorithm for Spatial Networks. ISPRS International Journal of Geo-Information. 2022; 11(2):123. https://doi.org/10.3390/ijgi11020123
Chicago/Turabian StyleCho, Hyung-Ju. 2022. "Cluster Nested Loop k-Farthest Neighbor Join Algorithm for Spatial Networks" ISPRS International Journal of Geo-Information 11, no. 2: 123. https://doi.org/10.3390/ijgi11020123
APA StyleCho, H.-J. (2022). Cluster Nested Loop k-Farthest Neighbor Join Algorithm for Spatial Networks. ISPRS International Journal of Geo-Information, 11(2), 123. https://doi.org/10.3390/ijgi11020123