
Time-Series-Based Queries on Stable Transportation Networks Equipped with Sensors


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction and Motivation
2. Related Work
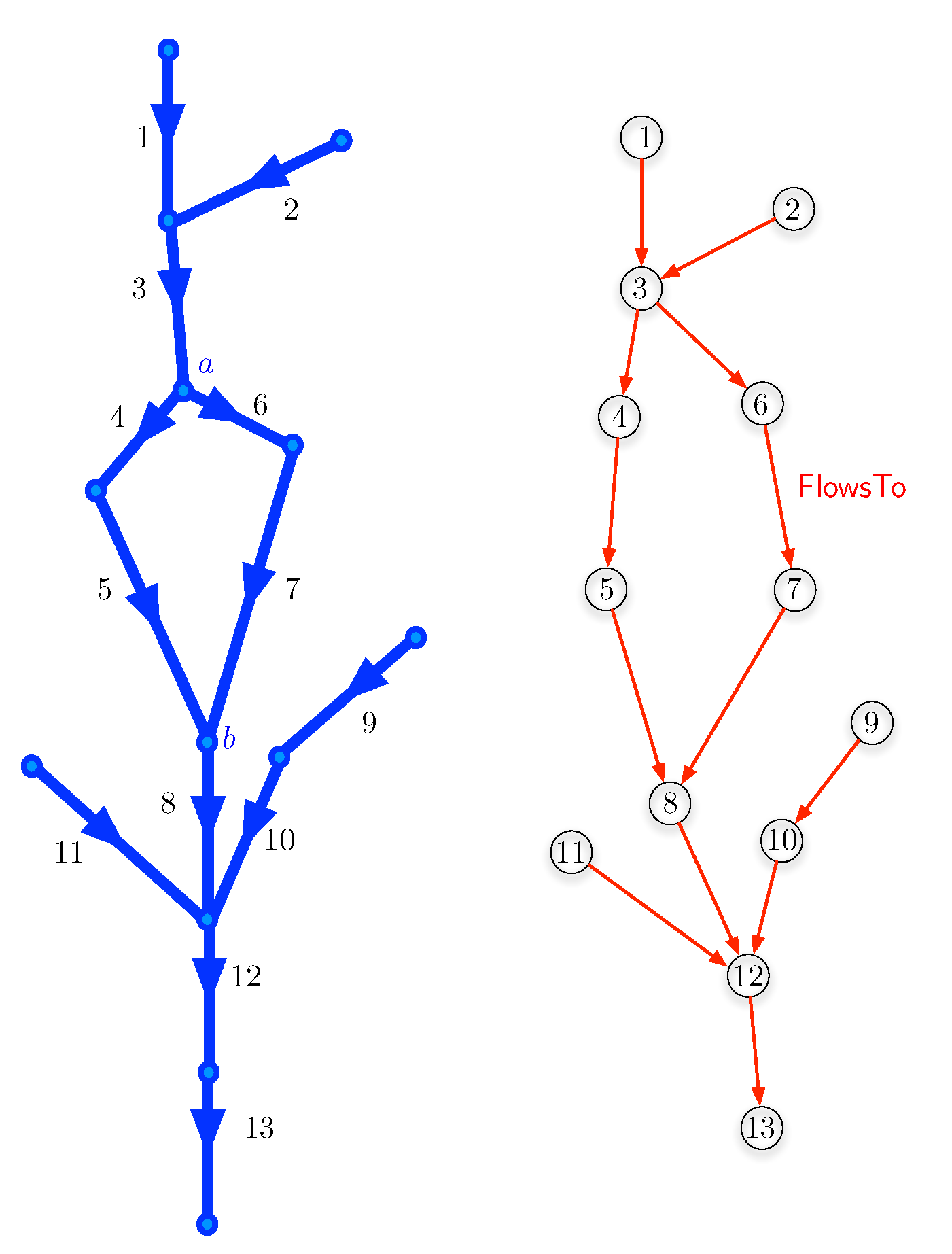
3. Transportation Networks Equipped with Sensors That Produce Time-Series Data
4. A Formal Language for Querying Transportation Networks Equipped with Sensors
4.1. The Time-Series Calculus to Query Sensor Networks
- produce a value in or ,
- produce a new time series,
- give a Boolean answer,
- etc.
- ;
- , where T is a linear polynomial in some time variables and some value variables ; and
- , for a ℓ-ary predicate .
4.2. Example Queries
4.2.1. Time- and Value-Queries
4.2.2. Time-Series Queries
4.2.3. Node Selection Queries
4.2.4. Boolean Queries
4.2.5. Path Selection Queries
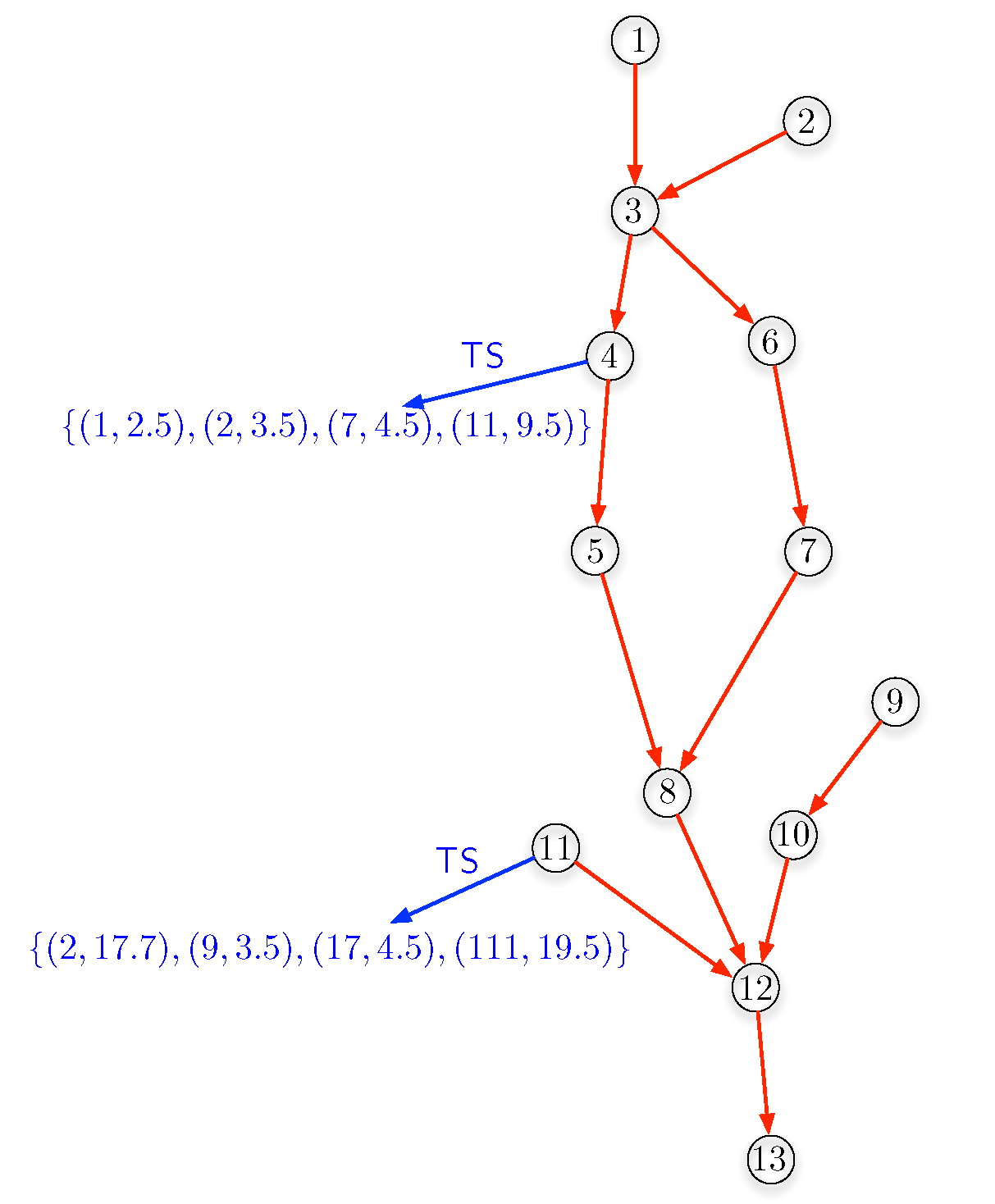
4.3. Extensions of the Time-Series Calculus for Sensor Networks
4.3.1. Reachability Queries
4.3.2. Aggregation Primitives on Time Series
- , returning the sum of the selected values (per node tuple);
- , returning the average of the selected values (per node tuple);
- , returning the count of the selected values (per node tuple);
- , returning the maximum of the selected values (per node tuple); and
- , returning the minimum of the selected values (per node tuple).
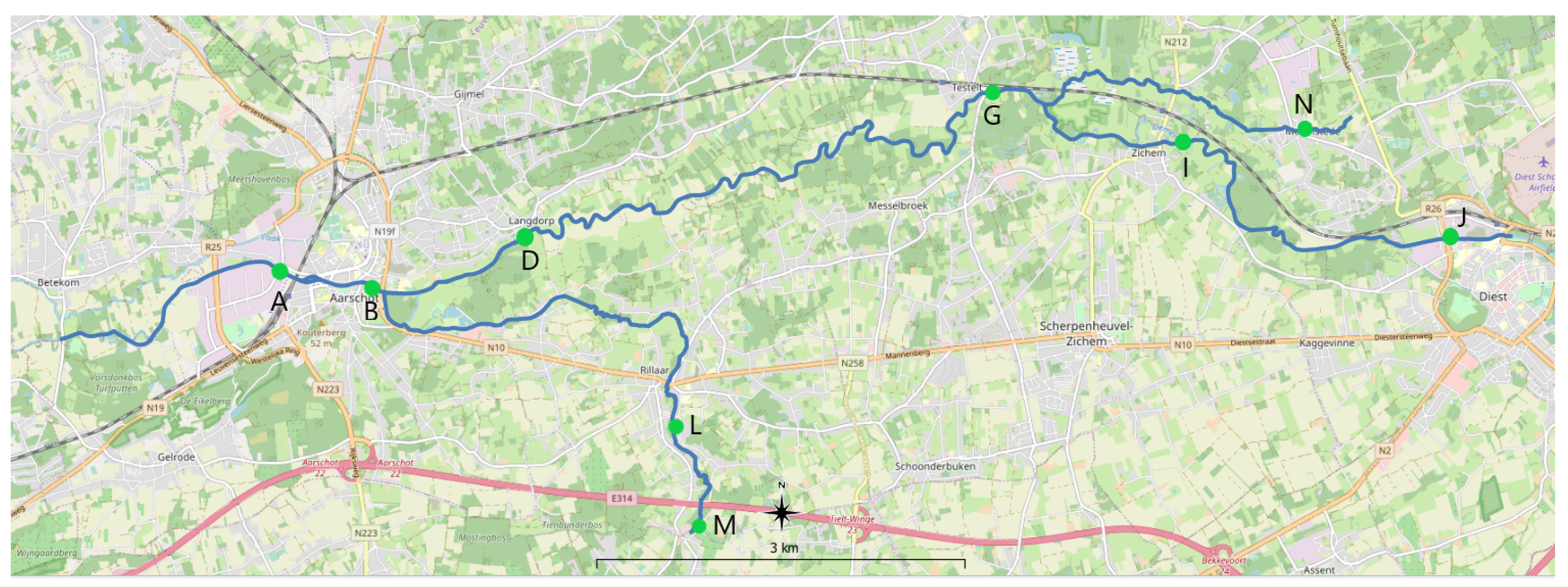
5. Use Case Study: The Flanders River System
- : What is the current status of the network?
- : Give the state of the network during the last hour.
- : What is the average of the measurements for sensor during 15th March 2020?
- : What was the highest measured value in the network during January, at which node was that?
- : What are the last 10 values of the nearest upstream sensor for node E?
- : What are the upstream sensor values at the moment that location G has its max value during 15th March?
- : What is the average value in each series for all downstream sensors of a location F?
- : What is the time difference between the moments where sensor G and D reach their maximum during the last day of 2020?
- : Do all sensors on a path from J to A have all measurements below a threshold value during interval I?
- : Return the paths where the sensors on a path from J to A have all measurements below a threshold value during interval I?
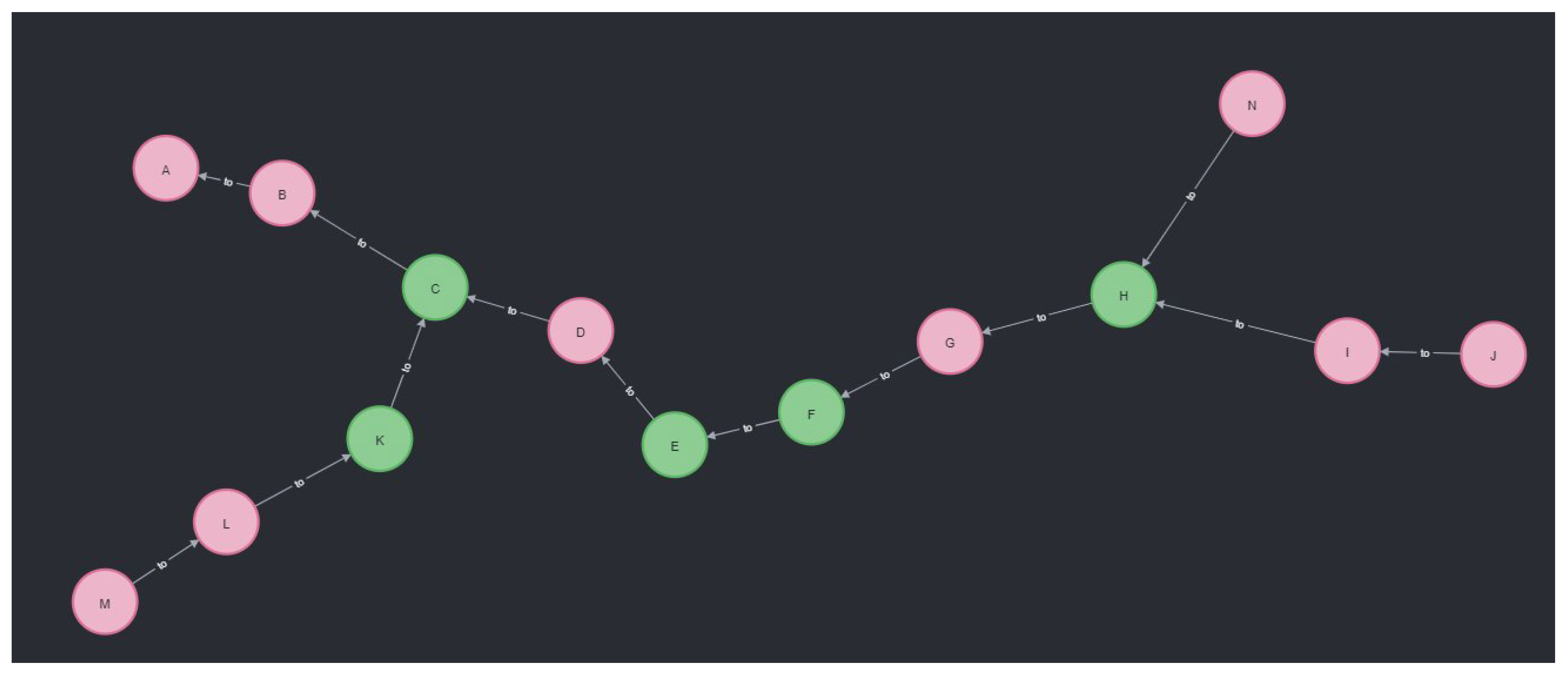
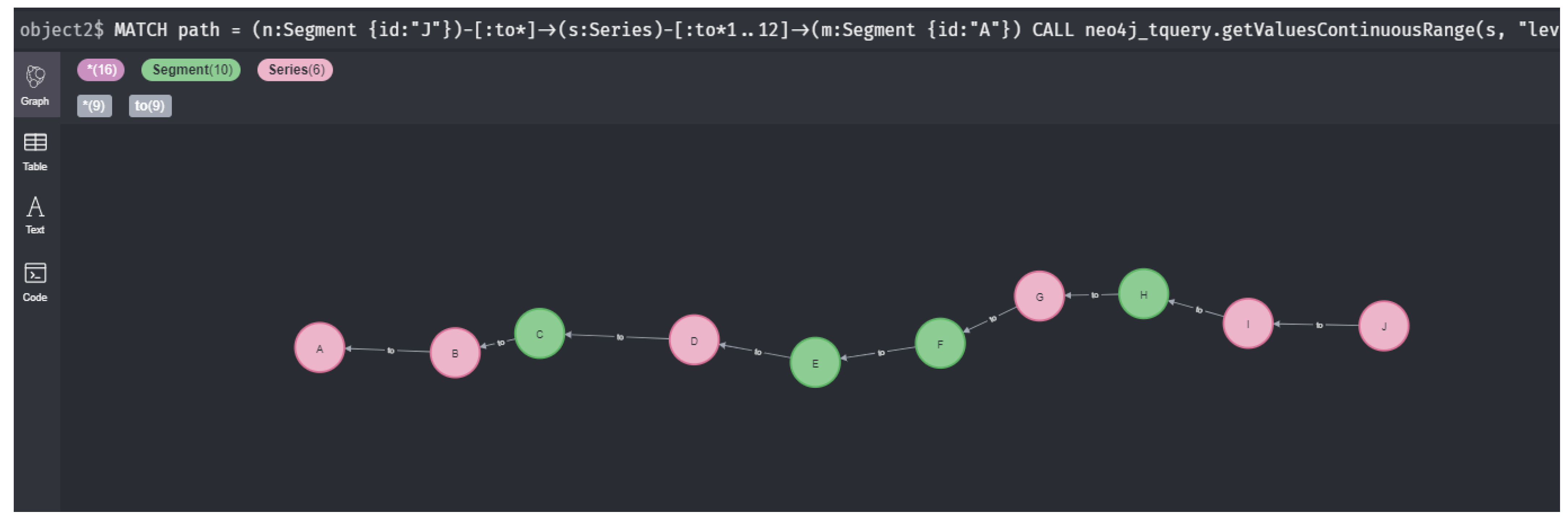
5.1. River System and Time-Series Data
5.2. Data Model and Cypher Extensions
- getValueDiscrete(node, name, timepoint)
- getValueContinuous(node, name, timestamp)
- getValuesDiscrete(node, name, List<timepoint>)
- getValuesContinuous(node, name, List<timestamp>)
- getValuesDiscreteRange(node, name, begin, until)
- getValuesContinuousRange(node, name, begin, until)
5.3. Example Queries with Their Expression in and Their Implementation in Cypher
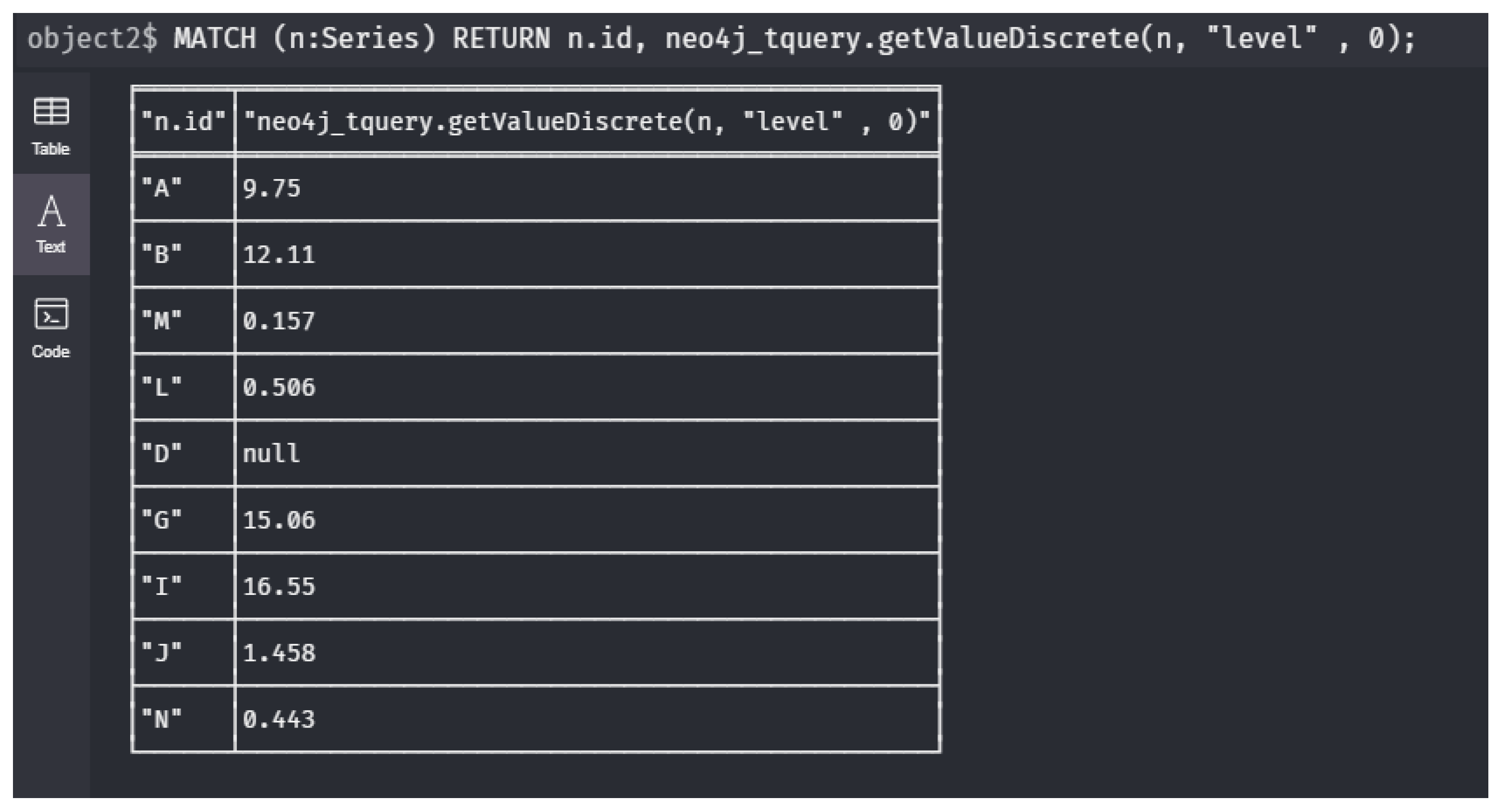
- : What is the current status of the network? (meaning: Give me all sensor nodes with their latest measurement.We already discussed this query in Example 5 and we have .
1 MATCH (n:Series) 2 RETURN n.id, neo4j_tquery.getValueDiscrete(n, 3 "level" 0);
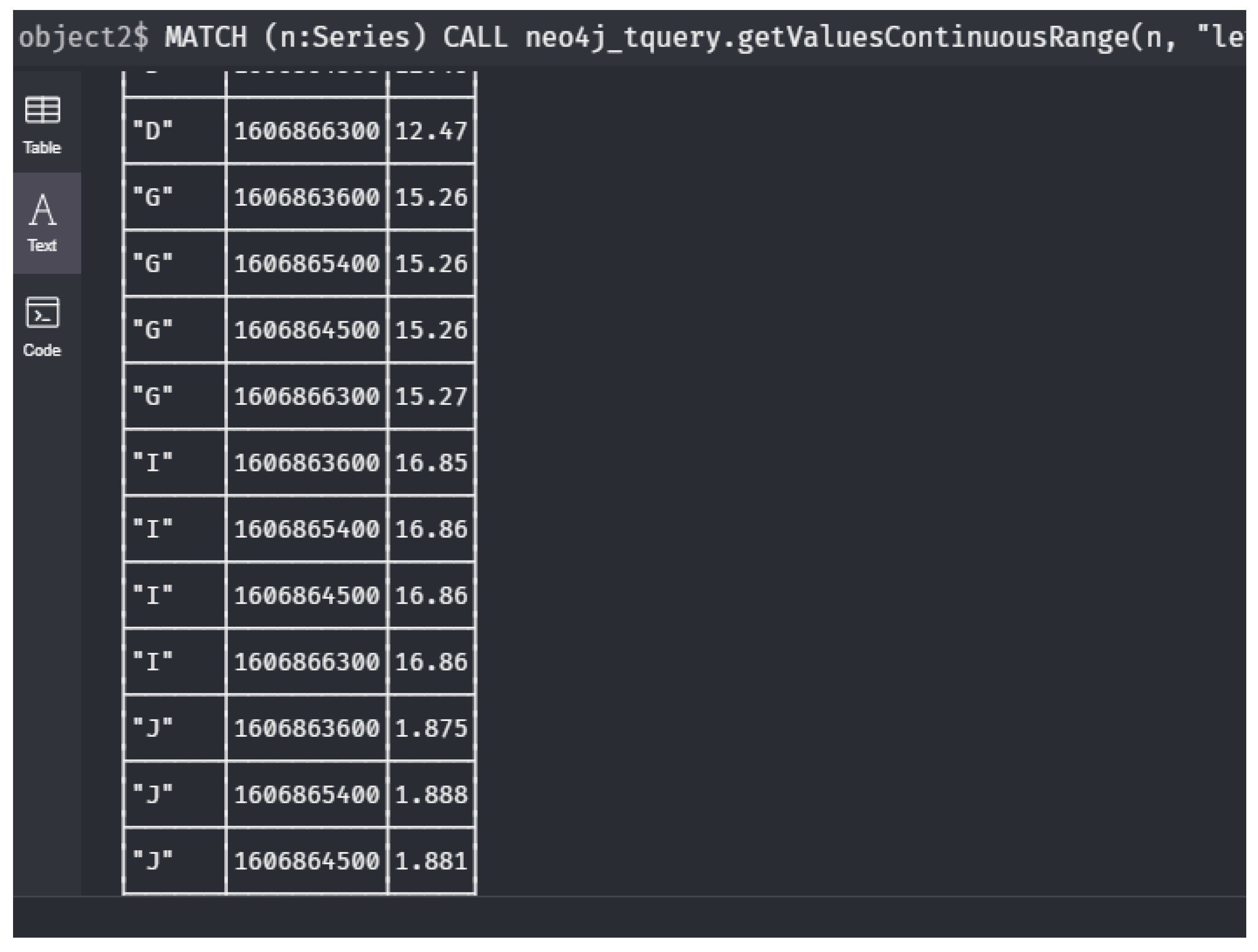
- : Give me the state of the network during the last hour? (meaning: Give all sensor nodes with all their measurements during the last hour).Let be the current time and let be a real number that corresponds to one hour. Then, we can express this query as
1 MATCH (n:Series)
2 CALL neo4j_tquery.getValuesDiscrete(n, "level" ,
3 [0,1,2,3])
4 YIELD timestamp AS t, value AS v
5 RETURN n.id, t, v;1 MATCH (n:Series)
2 CALL neo4j_tquery.getValuesContinuousRange(n, "level",
3 left(toString(datetime("2020-12-01T23:59")
4 -duration({hours:1})), 19),
5 left(toString(datetime("2020-12-01T23:59")), 19))
6 YIELD timestamp AS t, value AS v
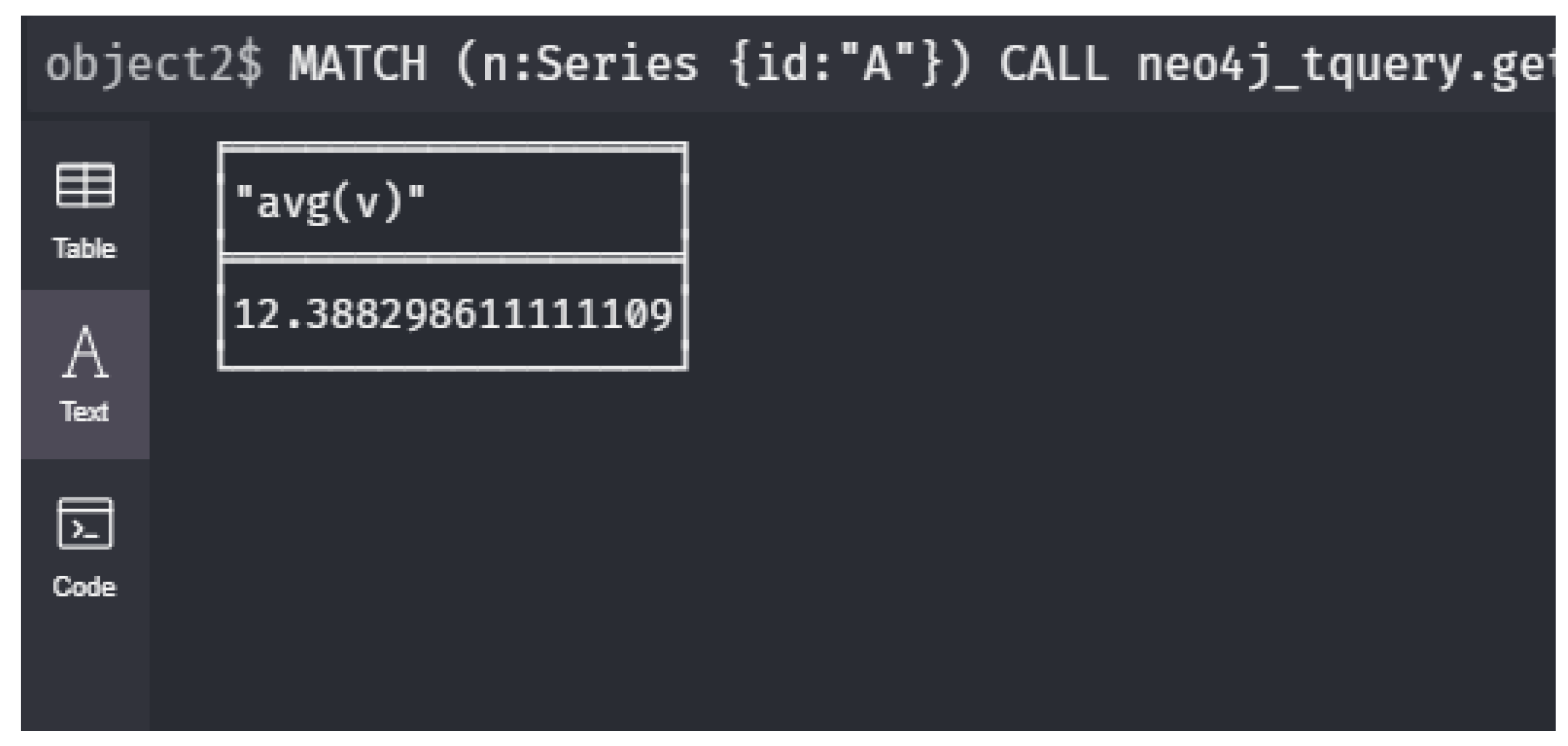
7 RETURN n.id, t, v;- : What is the average of the measurements for sensor during 15th March 2020?Let be the timestamp defined as “2020-03-15T23:59”, thus it is the end of 15th March and let be equal to one hour as in . Then gives us all values measured during the specific day in node n. Using standard notation from logic, let be the evaluation of this formula in the constant node . Then, we obtain
1 MATCH (n:Series {id:"A"})
2 CALL neo4j_tquery.getValuesContinuousRange(
3 n, "level",
4 left(toString(datetime("2020-03-15T23:59")
5 -duration({days:1})), 19),
6 "2020-03-15T23:59")
7 YIELD timestamp AS t, value AS v
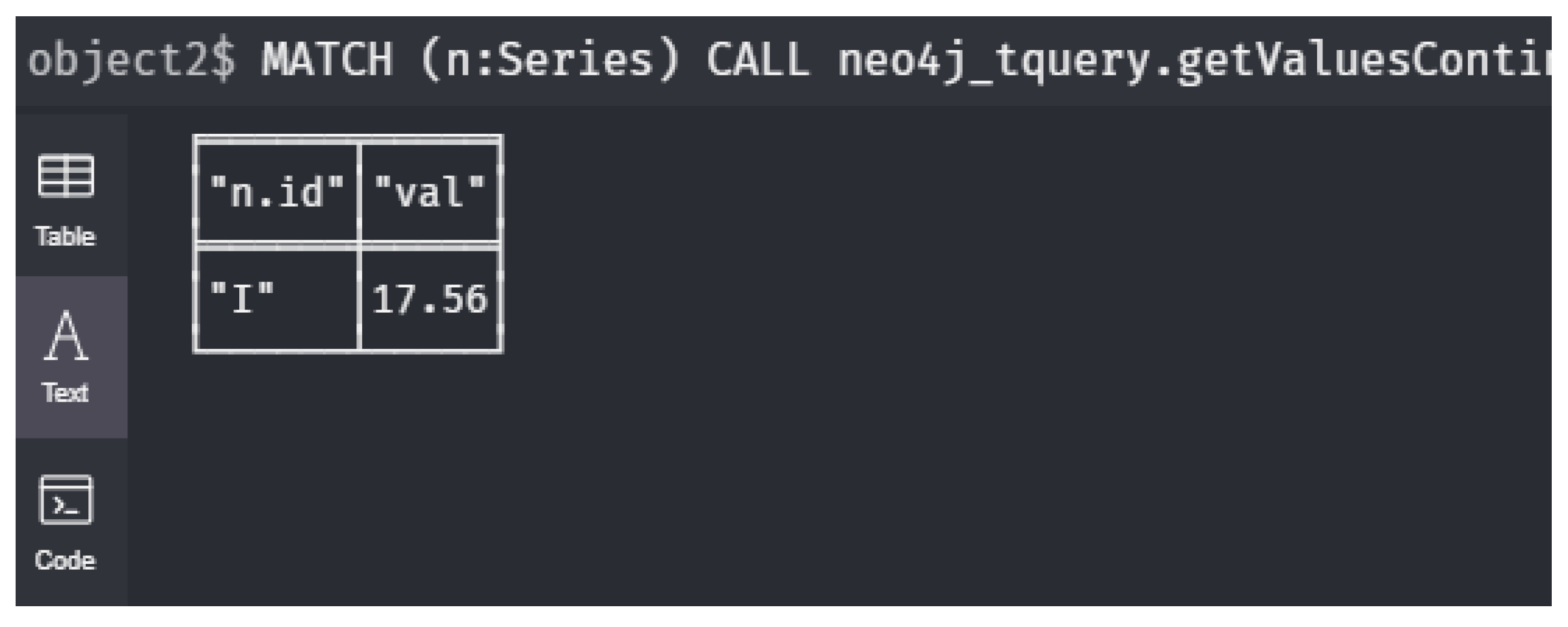
8 RETURN avg(v);- : What was the highest measured value in the network during January, at which Node was that?In Example 12, we have already defined, assuming that January is given by the time interval , the -formula which selects, for each sensor node n, the part of its time series belonging to January. Then, produces couples , where is the maximum of the time series for January of node n. expresses the above query Obviously, it can output multiple couples, since the maximum may occur at more than one node.
1 MATCH (n:Series)
2 CALL neo4j_tquery.getValuesContinuousRange(n, "level",
3 "2020-01-01T00:00", "2020-01-31T23:59")
4 YIELD timestamp AS t, value AS v
5 RETURN n.id, max(v) AS val
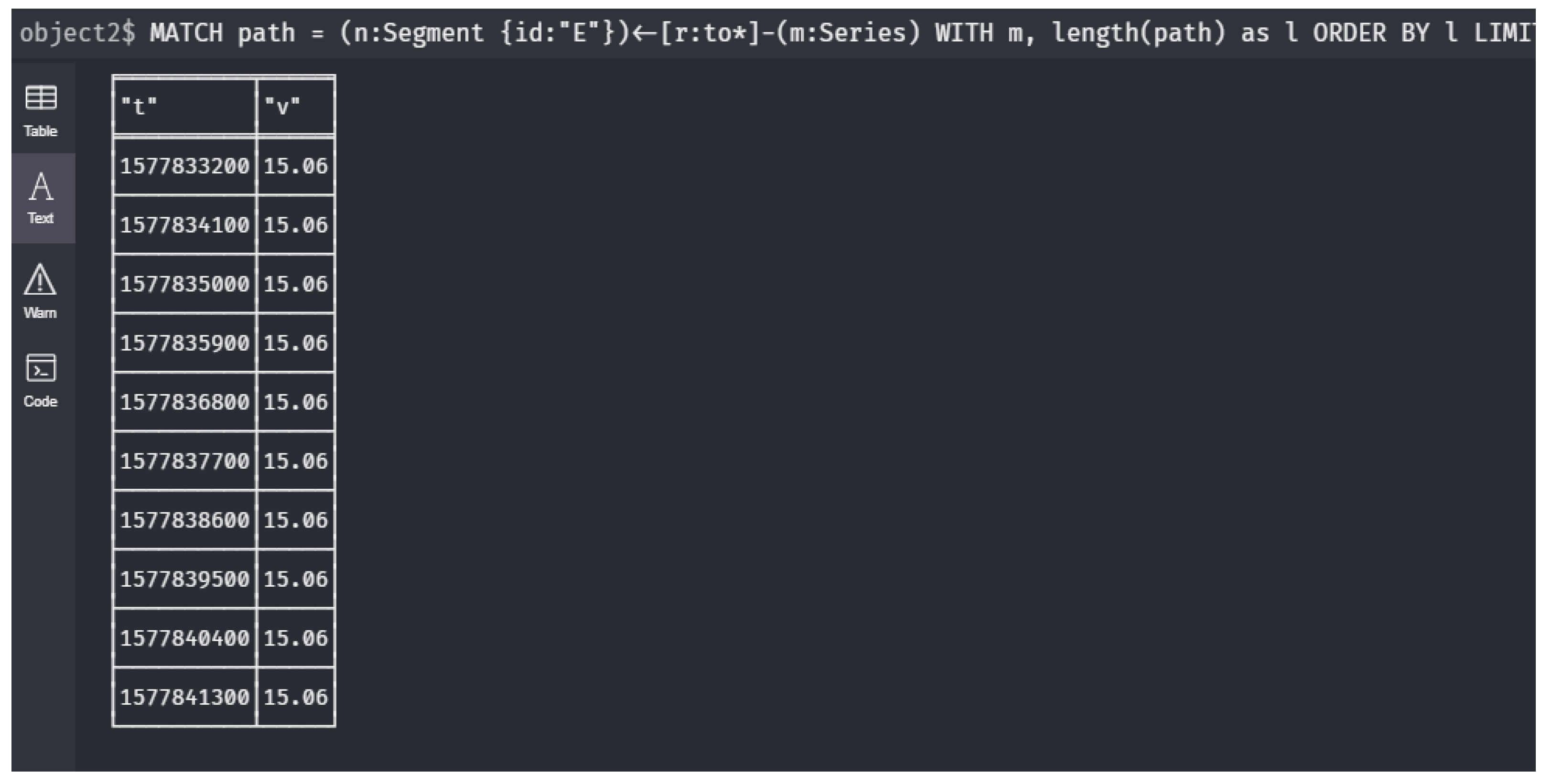
6 ORDER BY val DESC LIMIT 1;- : What are the last 10 values of the nearest upstream sensor for node ?Let us, first of all, define the predicate that expresses that is a nearest upstream sensor of node n. We write, using the abbreviation ,
1 MATCH path = (n:Segment {id:"E"})<-[r:to*]-(m:Series)
2 WITH m, length(path) AS l
3 ORDER BY l LIMIT 1
4 CALL neo4j_tquery.getValuesDiscreteRange(m, "level",
5 0, 10)
6 YIELD timestamp AS t, value AS v
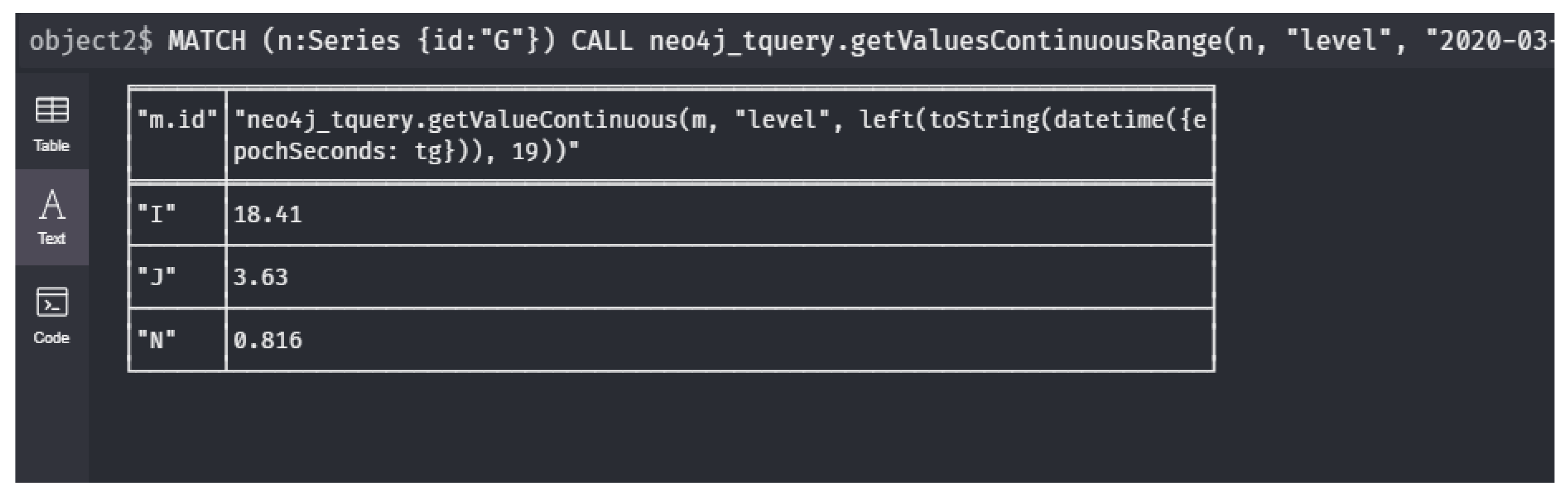
7 RETURN t, v;- : What are the upstream sensor values at the moment that location G has its maximal value during 15th March?We assume that 15th March is given by the time interval . The maximal value of a sensor during that day is given by the expression The time t this maximum could be reached is then given by . Thus, the time this maximum is reached during 15th March in node is given by . Thus, query is expressed as
1 MATCH (n:Series {id:"G"})
2 CALL neo4j_tquery.getValuesContinuousRange(n, "level",
3 "2020-03-15T00:00", "2020-03-15T23:59")
4 YIELD timestamp AS t, value AS v
5 WITH n, t AS tg, v AS vg ORDER BY vg DESC LIMIT 1
6 MATCH (n)<-[:to*]-(m:Series)
7 RETURN m.id, neo4j_tquery.getValueContinuous(m, "level",
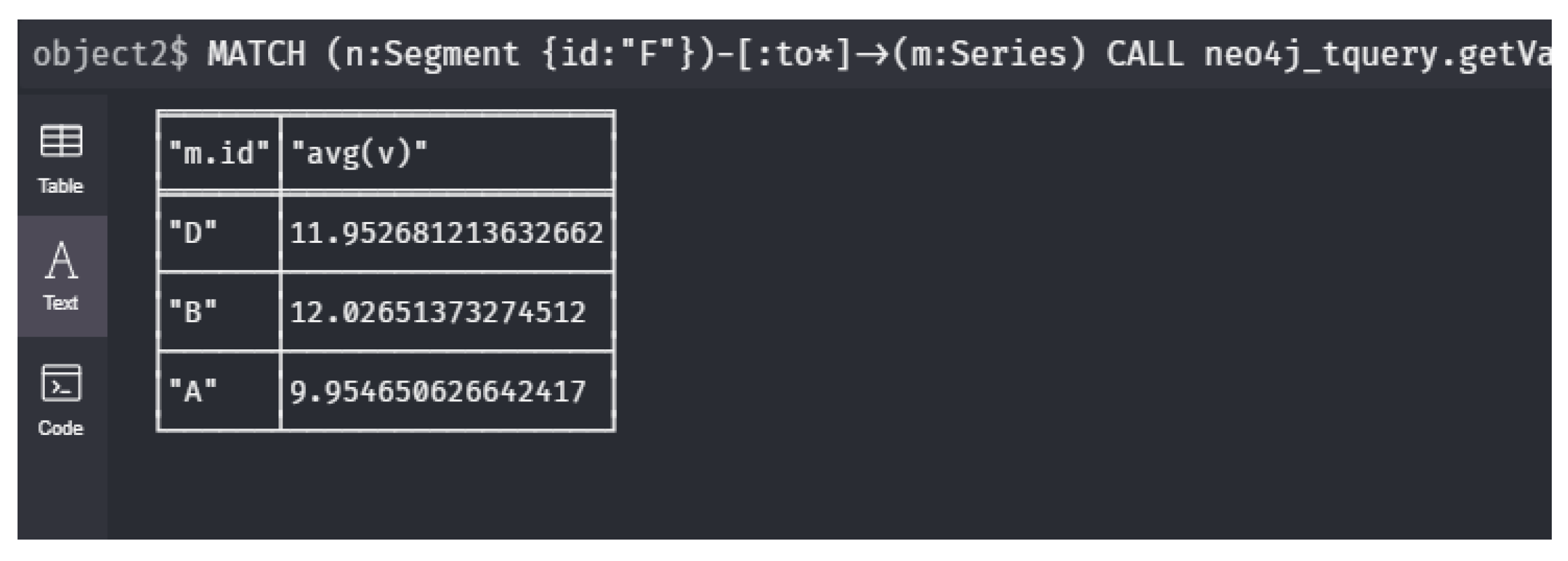
8 left(toString(datetime({epochSeconds: tg})), 19));- : What is the average value in each series for all downstream sensors of a location F?The formula defines the set of sensor nodes n that are downstream with respect to the node . With this in mind, all values for those nodes need to be selected. Therefore, a separate predicate is defined and then the average can be taken.
1 MATCH (n:Segment {id:"F"})-[:to*]->(m:Series)
2 CALL neo4j_tquery.getValuesContinuousRange(
3 m, "level", "epoch", "now")
4 YIELD timestamp AS t, value AS v
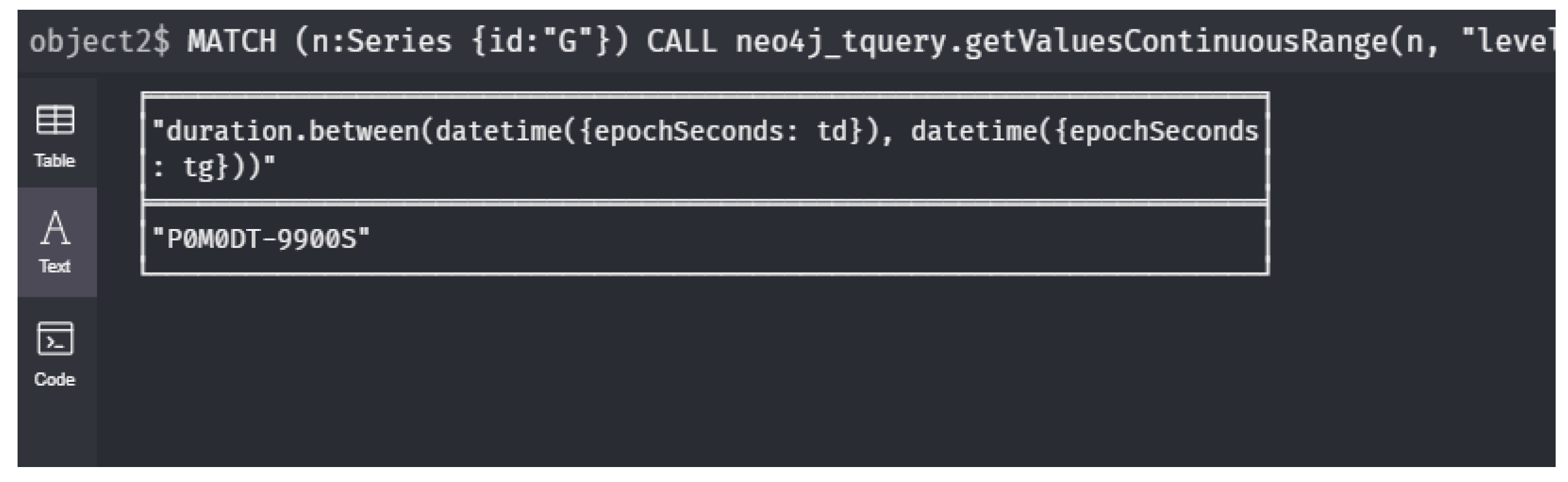
5 RETURN m.id, avg(v);- : What is the time difference between the moments where sensor G and D reach their maximum during the last day of 2020?
1 MATCH (n:Series {id:"G"})
2 CALL neo4j_tquery.getValuesContinuousRange(n, "level",
3 "2020-12-31T00:00", "2020-12-31T23:59")
4 YIELD timestamp AS t, value AS v
5 WITH t AS tg, v AS vg ORDER BY vg DESC LIMIT 1
6 MATCH (m:Series {id:"D"})
7 CALL neo4j_tquery.getValuesContinuousRange(m, "level",
8 "2020-12-31T00:00", "2020-12-31T23:59")
9 YIELD timestamp AS t, value AS v
10 WITH tg, vg, v AS vd, t AS td ORDER BY vd DESC LIMIT 1
11 RETURN duration.between(
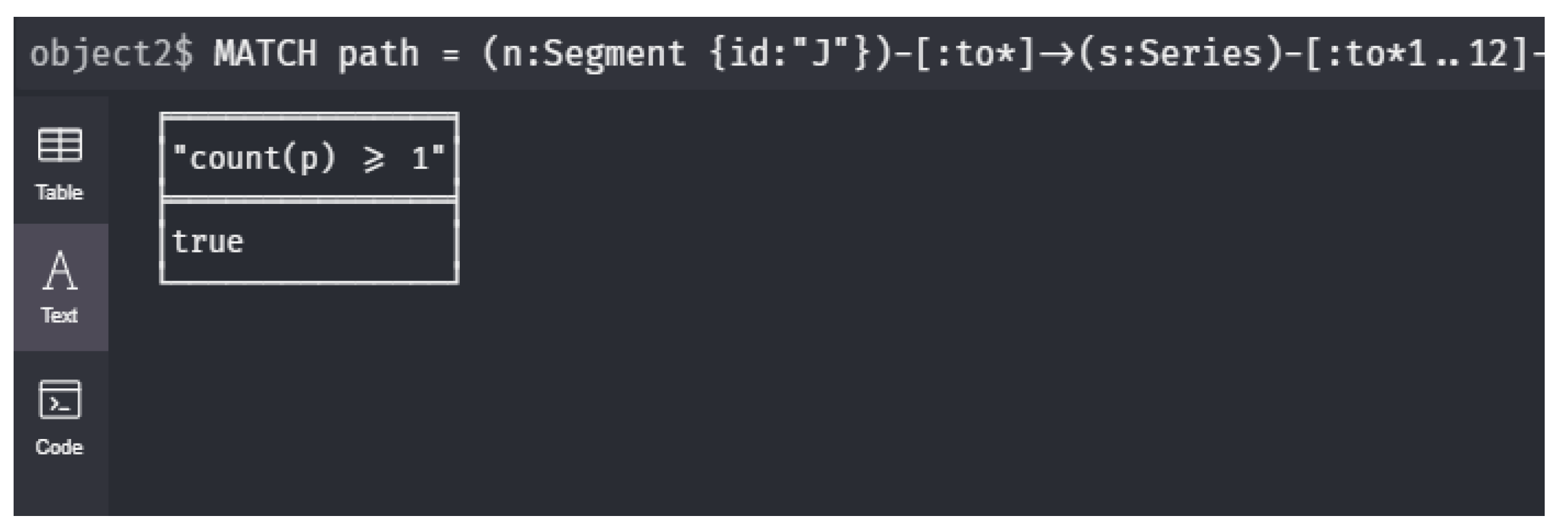
12 datetime({epochSeconds: td}), datetime({epochSeconds: tg}));- : Do all sensors on a path from J to A have all measurements below a threshold value during intervalI?We write this query by an expression that depends on the parameter Let represent the time interval I. Then, the query is expressed as follows:
1 MATCH path =
2 (n:Segment {id:"J"})-[:to*]->(s:Series)-[:to*1..12]->(m:Segment {id:"A"})
3 CALL neo4j_tquery.getValuesContinuousRange(
4 s, "level", "2020-03-01T00:00", "2020-03-31T01:00")
5 YIELD timestamp AS t, value AS v
6 WITH path AS p, collect(v) AS vs
7 WHERE all(i IN vs WHERE i < 20)
8 RETURN count(p) >= 1;- : Return the paths where the sensors on a path from J to A have all measurements below a threshold value during intervalI?
1 MATCH path =
2 (n:Segment {id:"J"})-[:to*]->(s:Series)-[:to*1..12]->(m:Segment {id:"A"})
3 CALL neo4j_tquery.getValuesContinuousRange(
4 s, "level", "2020-03-01T00:00", "2020-03-31T01:00")
5 YIELD timestamp AS t, value AS v
6 WITH path AS p, collect(v) AS vs
7 WHERE all(i IN vs WHERE i < 20)
8 RETURN p;6. Discussion and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- has exactly one node (call it ) with indegree 0 and outdegree 1 in (With “in ”, we mean the in- and outdegree in the subgraph of induced by .);
- has exactly one node (call it ) with indegree 1 and outdegree 0 in ;
- all nodes in have indegree 1 and outdegree 1 in .
References
- Akyildiz, I.F.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. A survey on sensor networks. IEEE Commun. Mag. 2002, 40, 102–114. [Google Scholar] [CrossRef]
- Cozza, V.; Guagliardi, I.; Rubino, M.; Cozza, R.; Martello, A.; Picelli, M.; Zhupa, E. Esopo: Sensors and Social Pollution Measurements. In Proceedings of the 2nd Annual International Symposium on Information Management and Big Data, Cusco, Peru, 2–4 September 2015; Lossio-Ventura, J.A., Alatrista-Salas, H., Eds.; Volume 1478, pp. 52–57. [Google Scholar]
- Buttafuoco, G.; Guagliardi, I.; Tarvainen, T.; Jarva, J. A multivariate approach to study the geochemistry of urban topsoil in the city of Tampere, Finland. J. Geochem. Explor. 2017, 181, 191–204. [Google Scholar] [CrossRef]
- Zuzolo, D.; Cicchella, D.; Lima, A.; Guagliardi, I.; Cerino, P.; Pizzolante, A.; Thiombane, M.; De Vivo, B.; Albanese, S. Potentially toxic elements in soils of Campania region (Southern Italy): Combining raw and compositional data. J. Geochem. Explor. 2020, 213, 106524. [Google Scholar] [CrossRef]
- Joseph, A.D.; Beresford, A.R.; Bacon, J.; Cottingham, D.N.; Davies, J.J.; Jones, B.D.; Guo, H.; Guan, W.; Lin, Y.; Song, H.; et al. Intelligent Transportation Systems. IEEE Pervasive Comput. 2006, 5, 63–67. [Google Scholar] [CrossRef]
- Karami, Z.; Kashef, R. Smart transportation planning: Data, models, and algorithms. Transp. Eng. 2020, 2, 100013. [Google Scholar] [CrossRef]
- Malinowski, P.; Ziembicki, P. Analysis of district heating network monitoring by neural networks classification. J. Civ. Eng. Manag. 2006, 12, 21–28. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, T.; Bompard, E. Big data analytics in smart grids: A review. Energy Inf. 2018, 1, 1–24. [Google Scholar] [CrossRef]
- Unknown. What is Internet of Water? Website Internet of Water. Available online: https://www.internetofwater.be/wat-is-internet-of-water/ (accessed on 10 December 2019).
- Cozza, V.; Messina, A.; Montesi, D.; Arietta, L.; Magnani, M. Spatio-Temporal Keyword Queries in Social Networks. In Proceedings of the Advances in Databases and Information Systems—17th East European Conference, ADBIS 2013, Genoa, Italy, 1–4 September 2013; Catania, B., Guerrini, G., Pokorný, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8133, pp. 70–83. [Google Scholar]
- Wu, J.; Zhong, L.; Li, L.; Lu, A. A Prediction Model Based on Time Series Data in Intelligent Transportation System. In Information Computing and Applications; Yang, Y., Ma, M., Liu, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 420–429. [Google Scholar]
- Bhandari, S.; Bergmann, N.; Jurdak, R.; Kusy, B. Time Series Data Analysis of Wireless Sensor Network Measurements of Temperature. Sensors 2017, 17, 1221. [Google Scholar] [CrossRef] [PubMed]
- Bhandari, S.; Bergmann, N.; Jurdak, R.; Kusy, B. Time Series Analysis for Spatial Node Selection in Environment Monitoring Sensor Networks. Sensors 2018, 18, 11. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Yao, Y.; Hu, J.; Zhao, Y.; Li, S.; Hu, J. Deep Autoencoder Neural Networks for Short-Term Traffic Congestion Prediction of Transportation Networks. Sensors 2019, 19, 2229. [Google Scholar] [CrossRef] [PubMed]
- Jensen, S.K.; Pedersen, T.B.; Thomsen, C. Time Series Management Systems: A Survey. IEEE Trans. Knowl. Data Eng. 2017, 29, 2581–2600. [Google Scholar] [CrossRef]
- Lerner, A.; Shasha, D. AQuery: Query language for ordered data, optimization techniques, and experiments. Johann-Christoph Freytag, Peter Lockemann, Serge Abiteboul, Michael Carey, Patricia Selinger, Andreas Heuer. In Proceedings 2003 VLDB Conference; Morgan Kaufmann: Burlington, MA, USA, 2003; pp. 345–356. ISBN 9780127224428. [Google Scholar] [CrossRef]
- Abiteboul, S.; Hull, R.; Vianu, V. Foundations of Databases; Addison-Wesley: Reading, MA, USA, 1995. [Google Scholar]
- Paredaens, J.; Kuper, G.; Libkin, L. (Eds.) Constraint Databases; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Revesz, P. Introduction to Constraint Data Bases; Springer: New York, NY, USA, 2002. [Google Scholar]
- Grumbach, S.; Rigaux, P.; Scholl, M.; Segoufin, L. DEDALE, A Spatial Constraint Database. In Proceedings of the 13ème Journées Bases de Données Avancées, Grenoble, France, 9–12 September 1997; (Informal Proceedings). Ferrié, J., Ed.; 1997. [Google Scholar]
- Grumbach, S.; Rigaux, P.; Scholl, M.; Segoufin, L. DEDALE, A Spatial Constraint Database. Database Programming Languages. In Proceedings of the 6th International Workshop, DBPL-6, Estes Park, CO, USA, 18–20 August 1997; Cluet, S., Hull, R., Eds.; Springer: Berlin/Heidelberg, Germany, 1997; Volume 1369, pp. 38–59. [Google Scholar]
- Revesz, P.Z. The DISCO System. In Constraint Databases; Kuper, G.M., Libkin, L., Paredaens, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2000; pp. 383–389. [Google Scholar]
- Revesz, P.Z.; Chen, R.; Kanjamala, P.; Li, Y.; Liu, Y.; Wang, Y. The MLPQ/GIS Constraint Database System. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; Chen, W., Naughton, J.F., Bernstein, P.A., Eds.; p. 601. [Google Scholar] [CrossRef]
- Robinson, I.; Webber, J.; Eifrem, E. Graph Databases; O’Reilly Media, Inc.: Newton, MA, USA, 2013. [Google Scholar]
- Francis, N.; Green, A.; Guagliardo, P.; Libkin, L.; Lindaaker, T.; Marsault, V.; Plantikow, S.; Rydberg, M.; Selmer, P.; Taylor, A. Cypher: An Evolving Query Language for Property Graphs. In Proceedings of the 2018 International Conference on Management of Data, SIGMOD Conference 2018, Houston, TX, USA, 10–15 June 2018; pp. 1433–1445. [Google Scholar] [CrossRef]
- Stonebraker, M.; Brown, P.; Moore, D. Object-Relational DBMSs, 2nd ed.; Morgan Kaufmann: San Francisco, CA, USA, 1998. [Google Scholar]
- Delin, K.A.; Jackson, S.P. The Sensor Web: A new instrument concept. In Proceedings of the SPIE International of Optical Engineering, San Jose, CA, USA, 15 May 2001; pp. 1–9. [Google Scholar]
- Ventura, B.; Vianello, A.; Frisinghelli, D.; Rossi, M.; Monsorno, R.; Costa, A. A Methodology for Heterogeneous Sensor Data Organization and Near Real-Time Data Sharing by Adopting OGC SWE Standards. ISPRS Int. J. Geo Inf. 2019, 8, 167. [Google Scholar] [CrossRef]
- Cannata, M.; Antonovic, M.; Molinari, M.; Pozzoni, M. istSOS, a new sensor observation management system: Software architecture and a real-case application for flood protection. Geomat. Nat. Hazards Risk 2015, 6, 635–650. [Google Scholar] [CrossRef]
- Sánchez, C.S.; Wieder, A.; Sottovia, P.; Bortoli, S.; Baumbach, J.; Axenie, C. GANNSTER: Graph-Augmented Neural Network Spatio-Temporal Reasoner for Traffic Forecasting. In Proceedings of the Advanced Analytics and Learning on Temporal Data—5th ECML PKDD Workshop, Ghent, Belgium, 18 September 2020; Revised Selected Papers. Lemaire, V., Malinowski, S., Bagnall, A.J., Guyet, T., Tavenard, R., Ifrim, G., Eds.; Springer: Cham, Switzerland, 2020; Volume 12588, pp. 63–76. [Google Scholar] [CrossRef]
- Peng, T.; Sellami, S.; Boucelma, O. Trust Assessment on Streaming Data: A Real Time Predictive Approach. In Advanced Analytics and Learning on Temporal Data; Lemaire, V., Malinowski, S., Bagnall, A., Guyet, T., Tavenard, R., Ifrim, G., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 204–219. [Google Scholar]
- Atzori, L.; Iera, A.; Morabito, G. The Internet of Things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Krishnamurthi, R.; Kumar, A.; Gopinathan, D.; Nayyar, A.; Qureshi, B. An Overview of IoT Sensor Data Processing, Fusion, and Analysis Techniques. Sensors 2020, 20, 6076. [Google Scholar] [CrossRef] [PubMed]
- Bollen, E.; Hendrix, R.; Kuijpers, B.; Vaisman, A. Towards the Internet of Water: Using Graph Databases for Hydrological Analysis on the Flemish River System. Trans. GIS 2021. [Google Scholar] [CrossRef]
- Sadri, R.; Zaniolo, C.; Zarkesh, A.M.; Adibi, J. A Sequential Pattern Query Language for Supporting Instant Data Mining for e-Services. In Proceedings of the 27th International Conference on Very Large Data Bases, Roma, Italy, 11–14 September 2001; Apers, P.M.G., Atzeni, P., Ceri, S., Paraboschi, S., Ramamohanarao, K., Snodgrass, R.T., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 2001; pp. 653–656. [Google Scholar]
- Seshadri, P.; Livny, M.; Ramakrishnan, R. The Design and Implementation of a Sequence Database System. In Proceedings of the 22th International Conference on Very Large Data Bases, Mumbai, India, 3–6 September 1996; pp. 99–110. [Google Scholar]
- Seshadri, P. Management Of Sequence Data; Technical Report; The University of Wisconsin-Madison: Madison, WI, USA, 1996. [Google Scholar]
- Kvet, M.; Kršák, E.; Matiaško, K. Study on Effective Temporal Data Retrieval Leveraging Complex Indexed Architecture. Appl. Sci. 2021, 11, 916. [Google Scholar] [CrossRef]
- Angles, R. The Property Graph Database Model. CEUR Workshop Proc. 2018, 2100. Available online: https://dblp.uni-trier.de/rec/conf/amw/Angles18.html?view=bibtex (accessed on 26 July 2021).
- Angles, R. A Comparison of Current Graph Database Models. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering Workshops, Arlington, VA, USA, 1–5 April 2012; pp. 171–177. [Google Scholar]
- Angles, R.; Arenas, M.; Barceló, P.; Hogan, A.; Reutter, J.L.; Vrgoc, D. Foundations of Modern Query Languages for Graph Databases. ACM Comput. Surv. 2017, 50, 1–40. [Google Scholar] [CrossRef]
- Green, A.; Guagliardo, P.; Libkin, L.; Lindaaker, T.; Marsault, V.; Plantikow, S.; Schuster, M.; Selmer, P.; Voigt, H. Updating Graph Databases with Cypher. Proc. VLDB Endow. 2019, 12, 2242–2253. [Google Scholar] [CrossRef]
- Libkin, L. Elements of Finite Model Theory; Texts in Theoretical Computer Science; An EATCS Series; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Geerts, F.; Kuijpers, B. On the decidability of termination of query evaluation in transitive-closure logics for polynomial constraint databases. Theor. Comput. Sci. 2005, 336, 125–151. [Google Scholar] [CrossRef][Green Version]
- Geerts, F.; Kuijpers, B.; Van den Bussche, J. Linearization and Completeness Results for Terminating Transitive Closure Queries on Spatial Databases. SIAM J. Comput. 2006, 35, 1386–1439. [Google Scholar] [CrossRef]
- Geerts, F.; Kuijpers, B. Expressing Topological Connectivity of Spatial Databases. Research Issues in Structured and Semistructured Database Programming. In Proceedings of the 7th International Workshop on Database Programming Languages, DBPL’99, Kinloch Rannoch, Scotland, UK, 1–3 September 1999; Revised Papers. Connor, R.C.H., Mendelzon, A.O., Eds.; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1949, pp. 224–238. [Google Scholar]














Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bollen, E.; Hendrix, R.; Kuijpers, B.; Vaisman, A. Time-Series-Based Queries on Stable Transportation Networks Equipped with Sensors. ISPRS Int. J. Geo-Inf. 2021, 10, 531. https://doi.org/10.3390/ijgi10080531
Bollen E, Hendrix R, Kuijpers B, Vaisman A. Time-Series-Based Queries on Stable Transportation Networks Equipped with Sensors. ISPRS International Journal of Geo-Information. 2021; 10(8):531. https://doi.org/10.3390/ijgi10080531
Chicago/Turabian StyleBollen, Erik, Rik Hendrix, Bart Kuijpers, and Alejandro Vaisman. 2021. "Time-Series-Based Queries on Stable Transportation Networks Equipped with Sensors" ISPRS International Journal of Geo-Information 10, no. 8: 531. https://doi.org/10.3390/ijgi10080531
APA StyleBollen, E., Hendrix, R., Kuijpers, B., & Vaisman, A. (2021). Time-Series-Based Queries on Stable Transportation Networks Equipped with Sensors. ISPRS International Journal of Geo-Information, 10(8), 531. https://doi.org/10.3390/ijgi10080531