
Mining the Spatial Distribution Pattern of the Typical Fast-Food Industry Based on Point-of-Interest Data: The Case Study of Hangzhou, China

Abstract
:1. Introduction
2. Materials and Methods
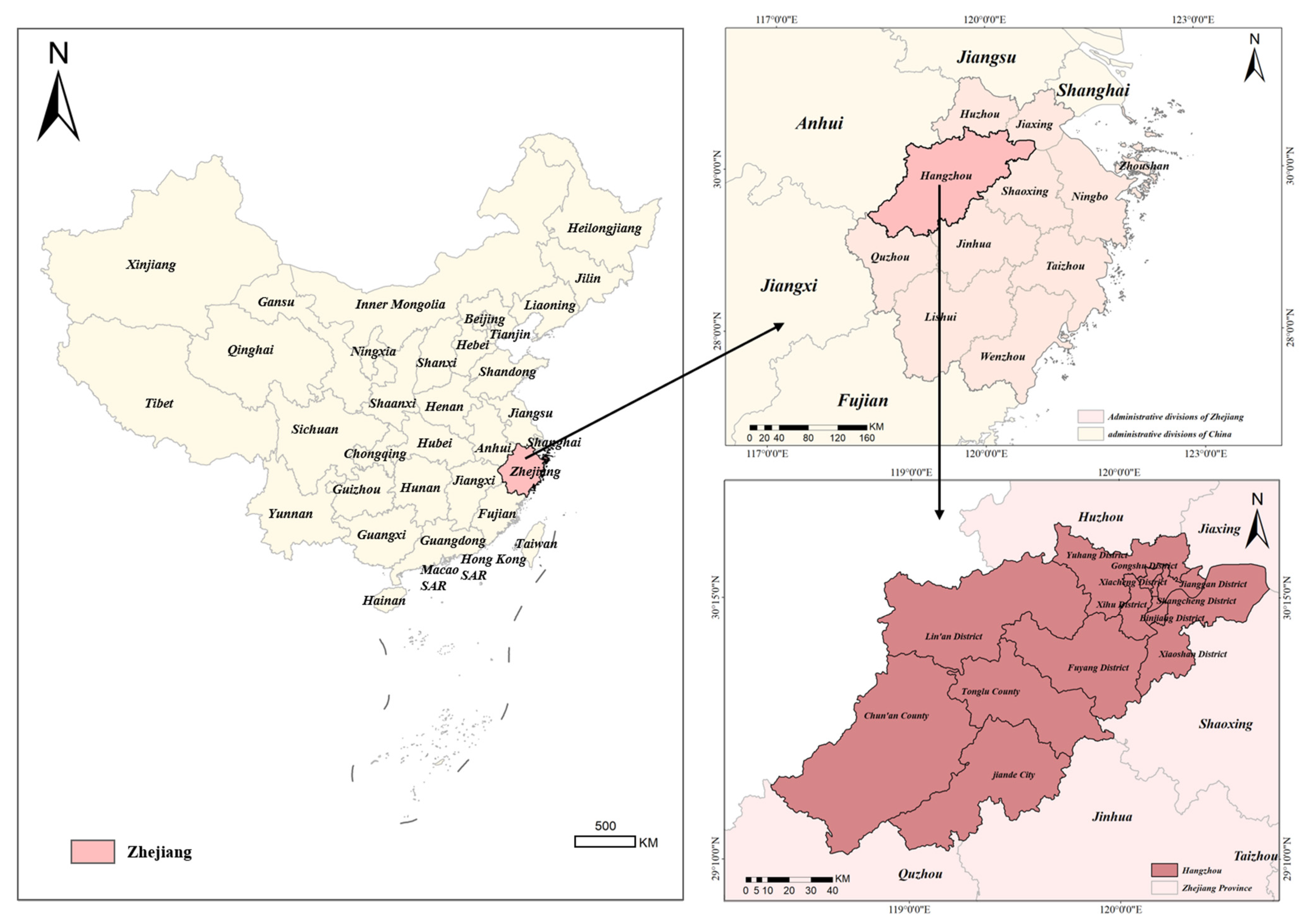
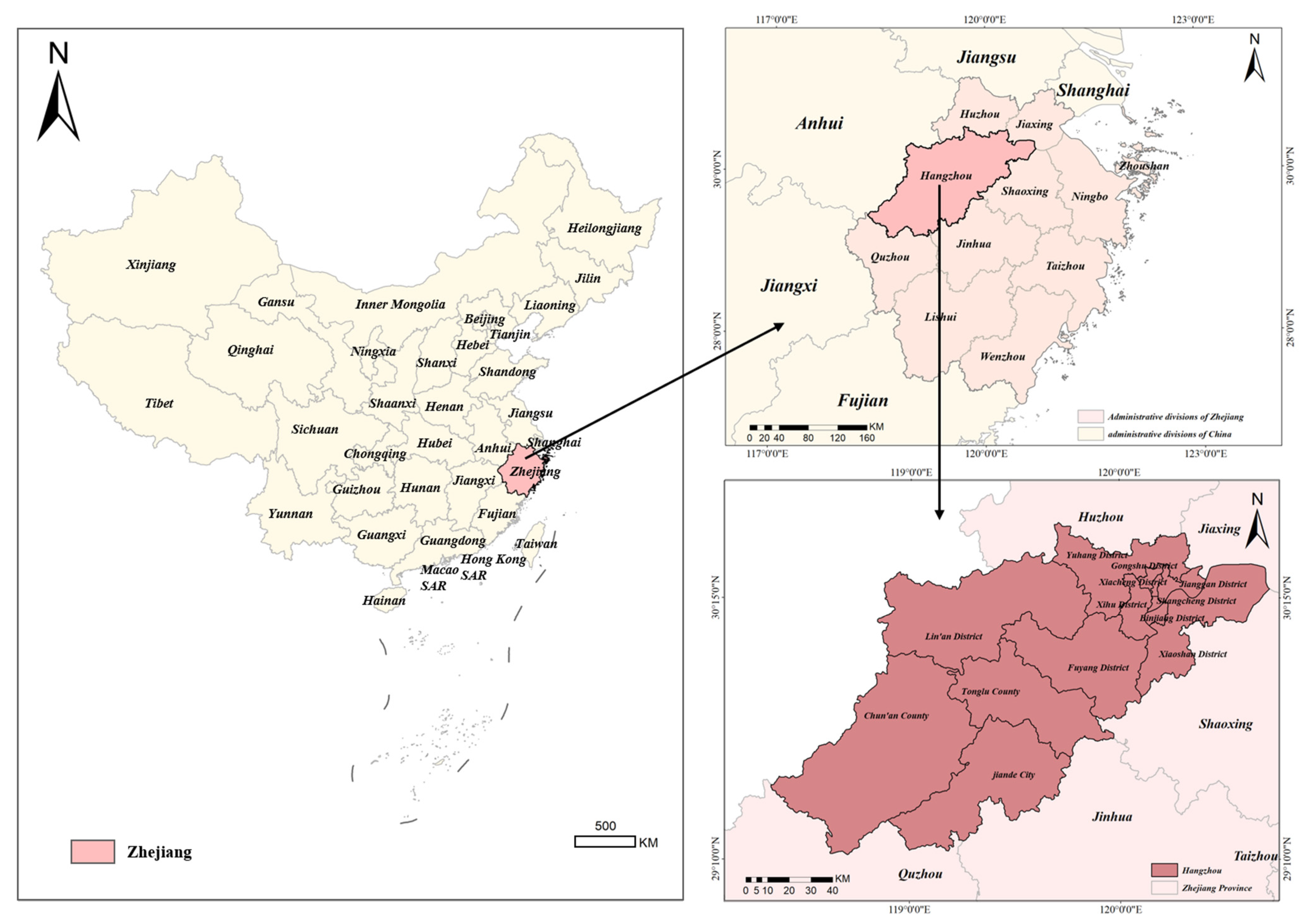
2.1. Data
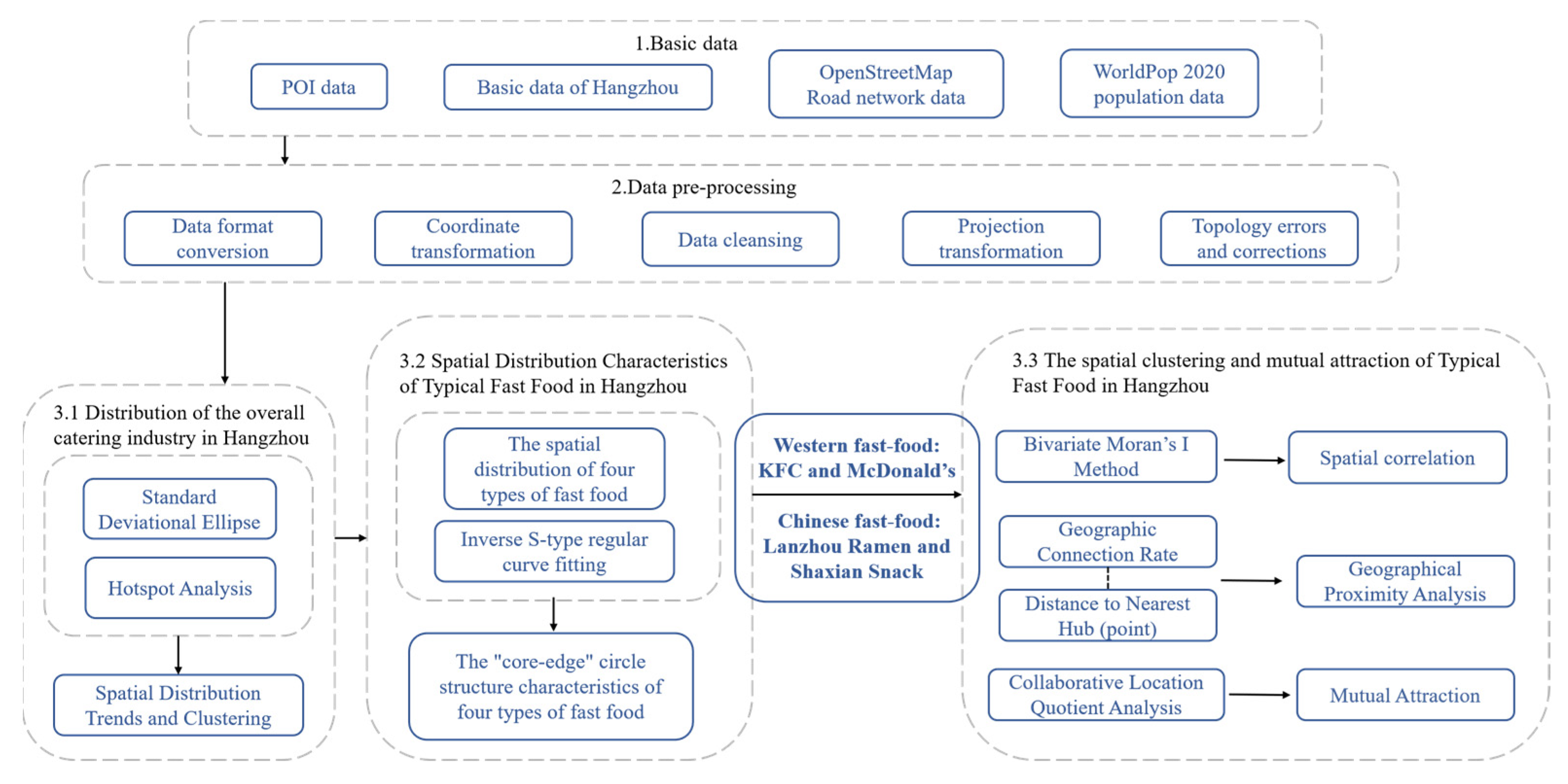
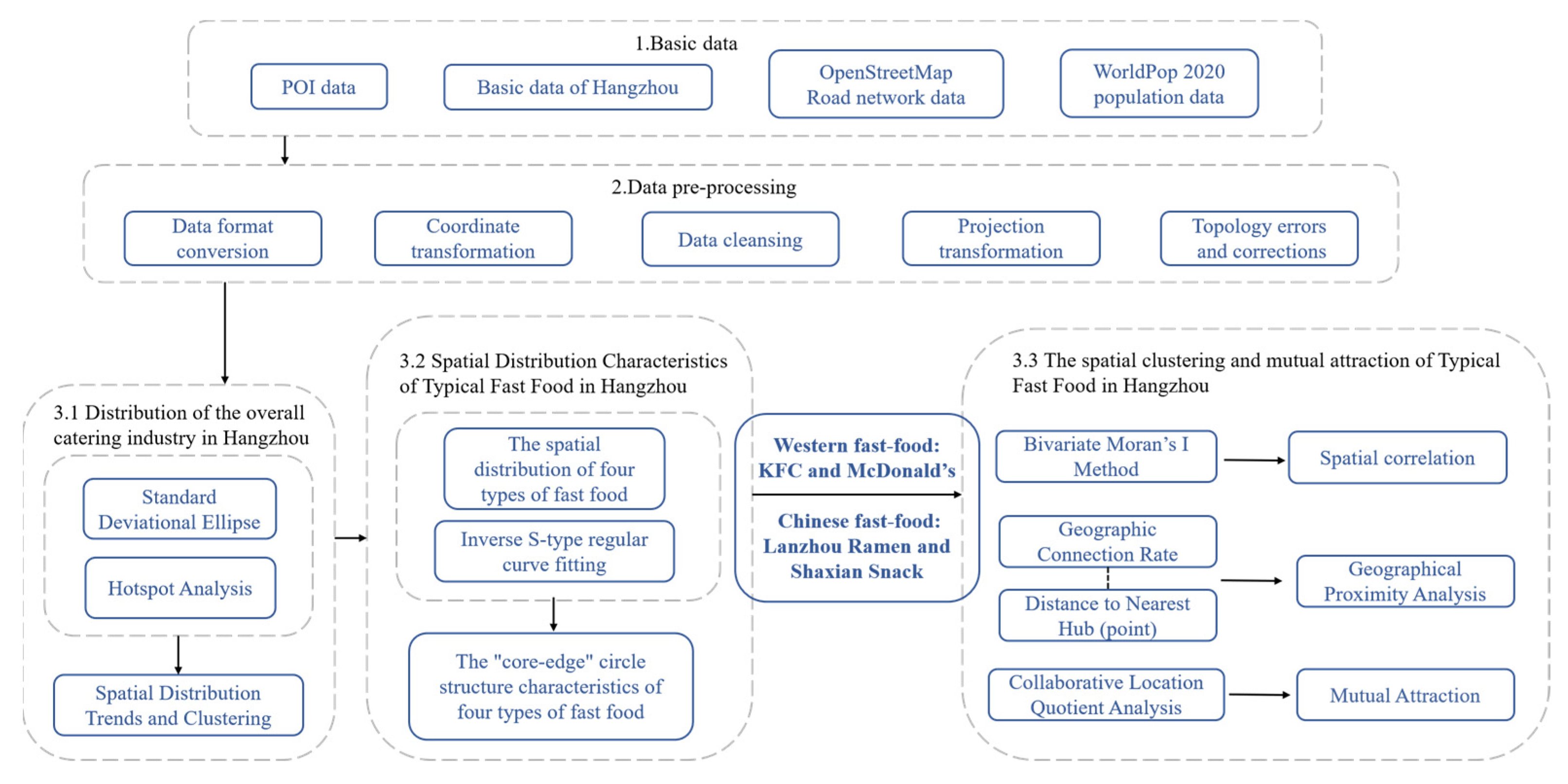
2.2. Methodology and Analysis Flowcharts
2.2.1. Hotspot Analysis
2.2.2. Spatial Clustering and Mutual Attraction Analysis
- (1)
- Bivariate Moran’s I method.
- (2)
- Geographical Proximity Analysis
- (3)
- Collaborative Location Quotient analysis.
3. Results
3.1. Distribution of the Overall Catering Industry in Hangzhou
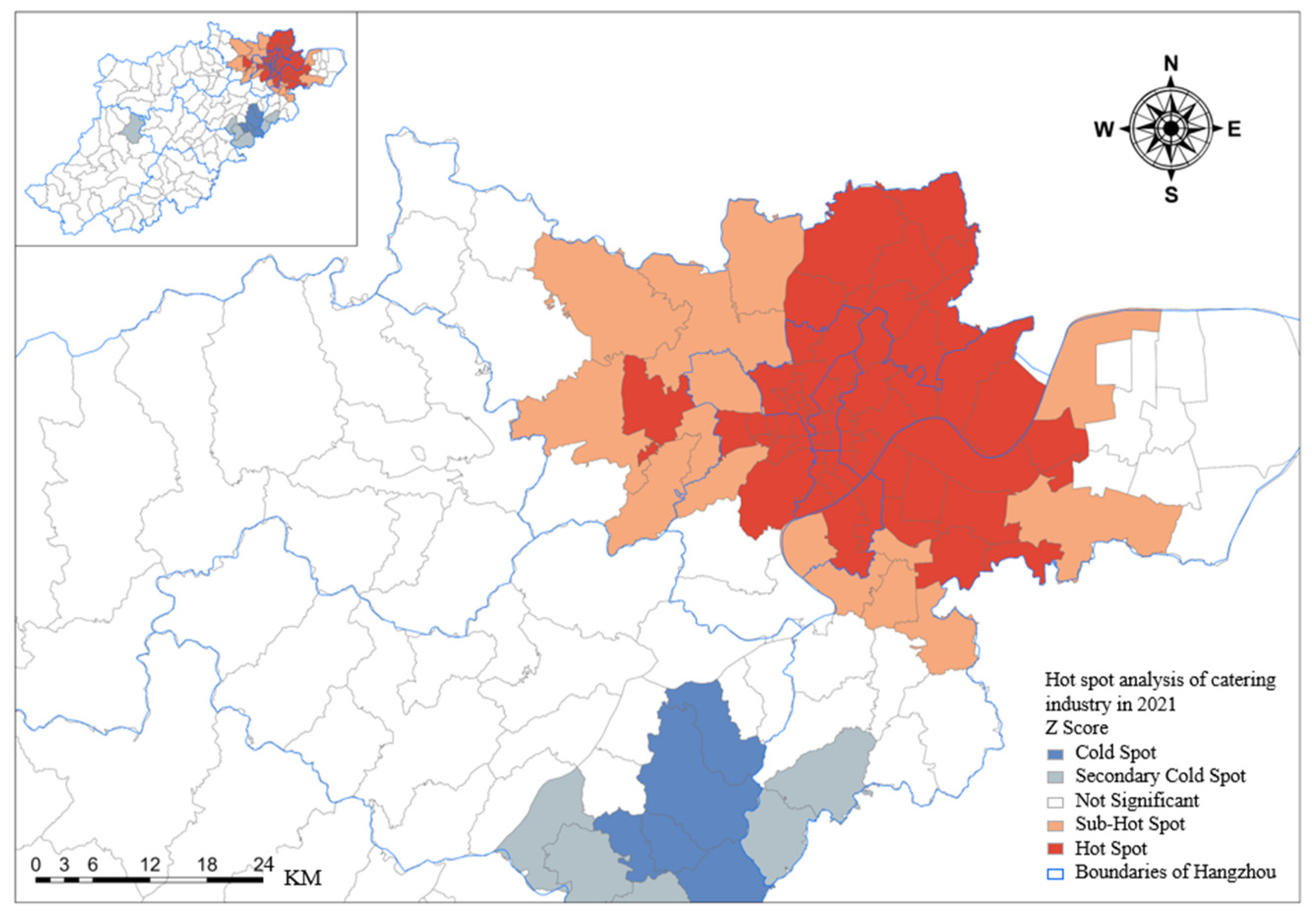
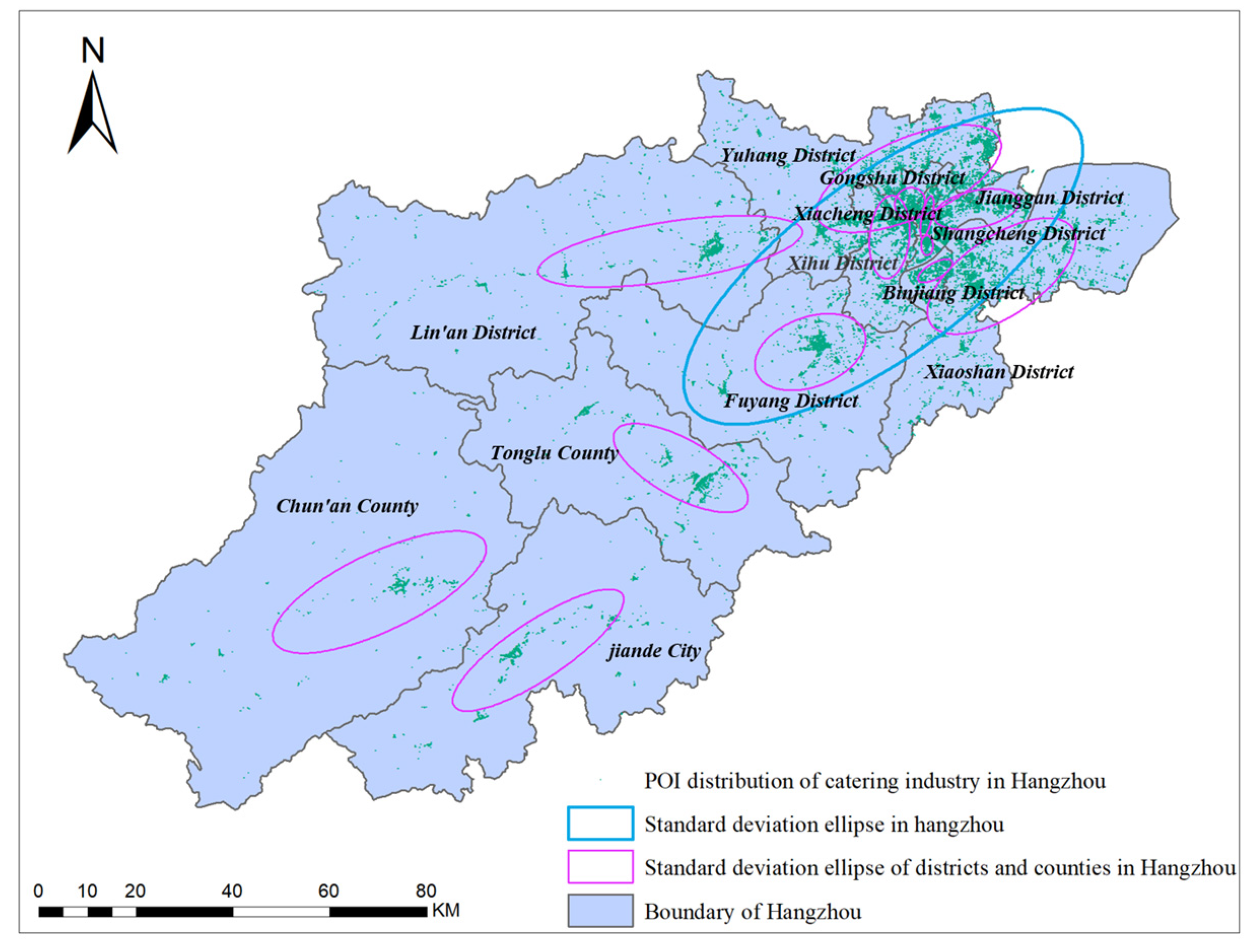
3.1.1. Spatial Distribution of the Overall Catering Industry
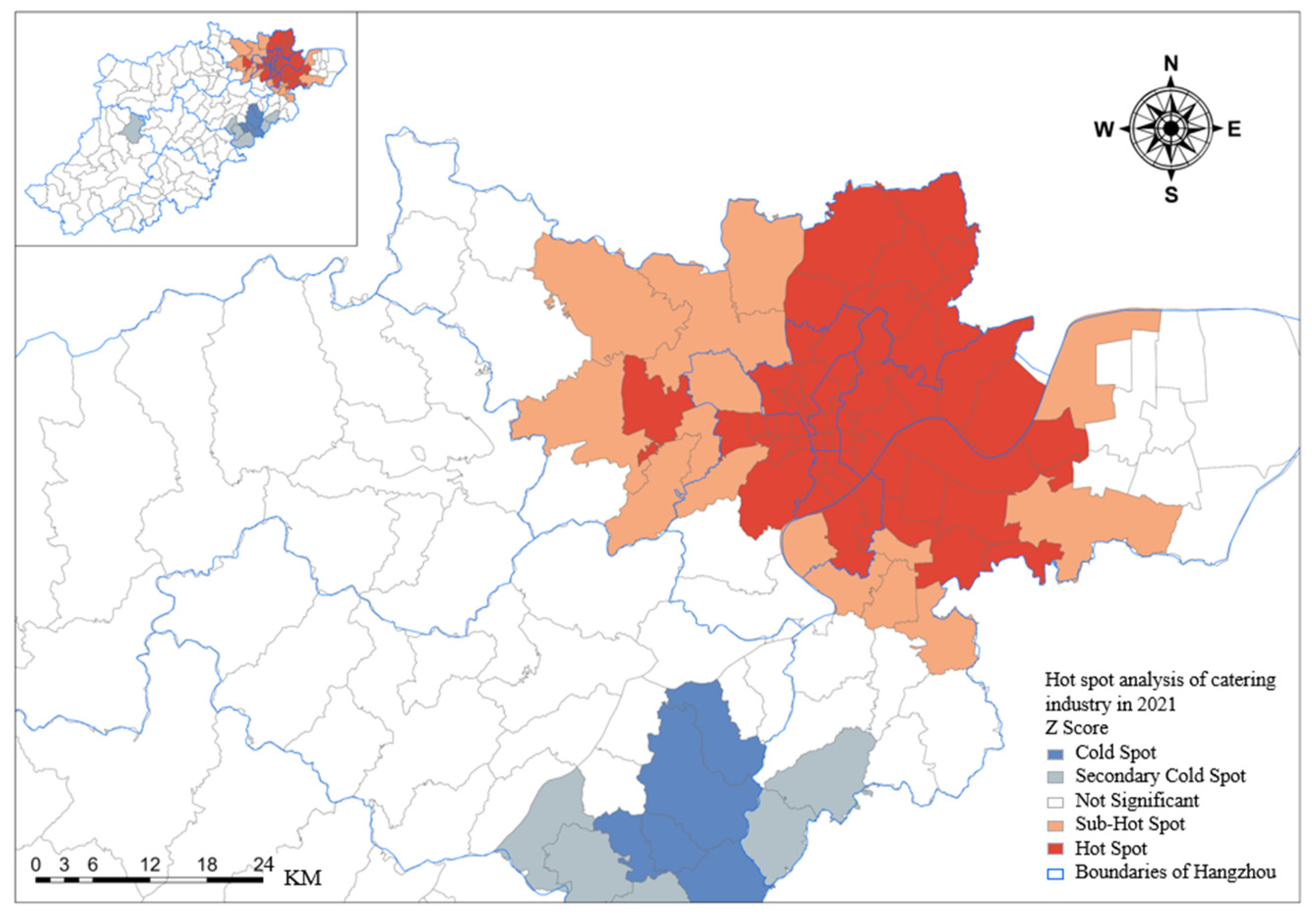
3.1.2. Clustering Analysis of the Overall Catering Industry
3.2. Spatial Distribution Characteristics of Typical Fast Food in Hangzhou
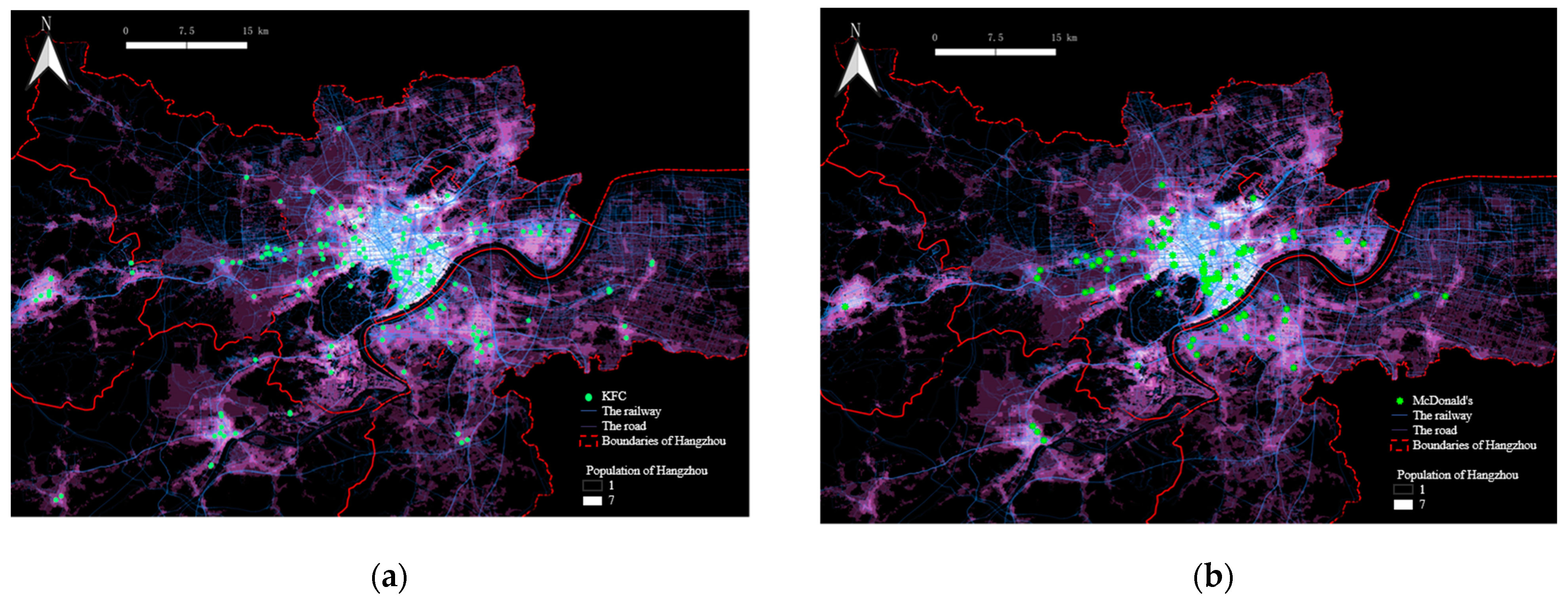
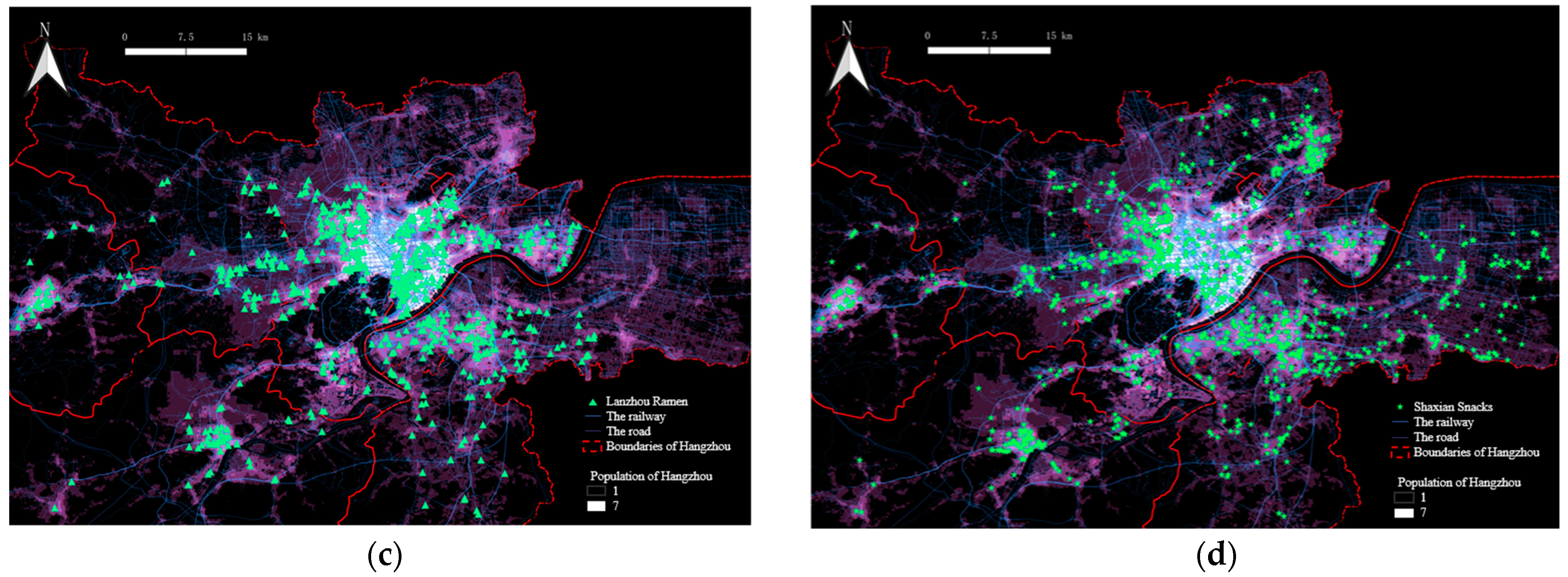
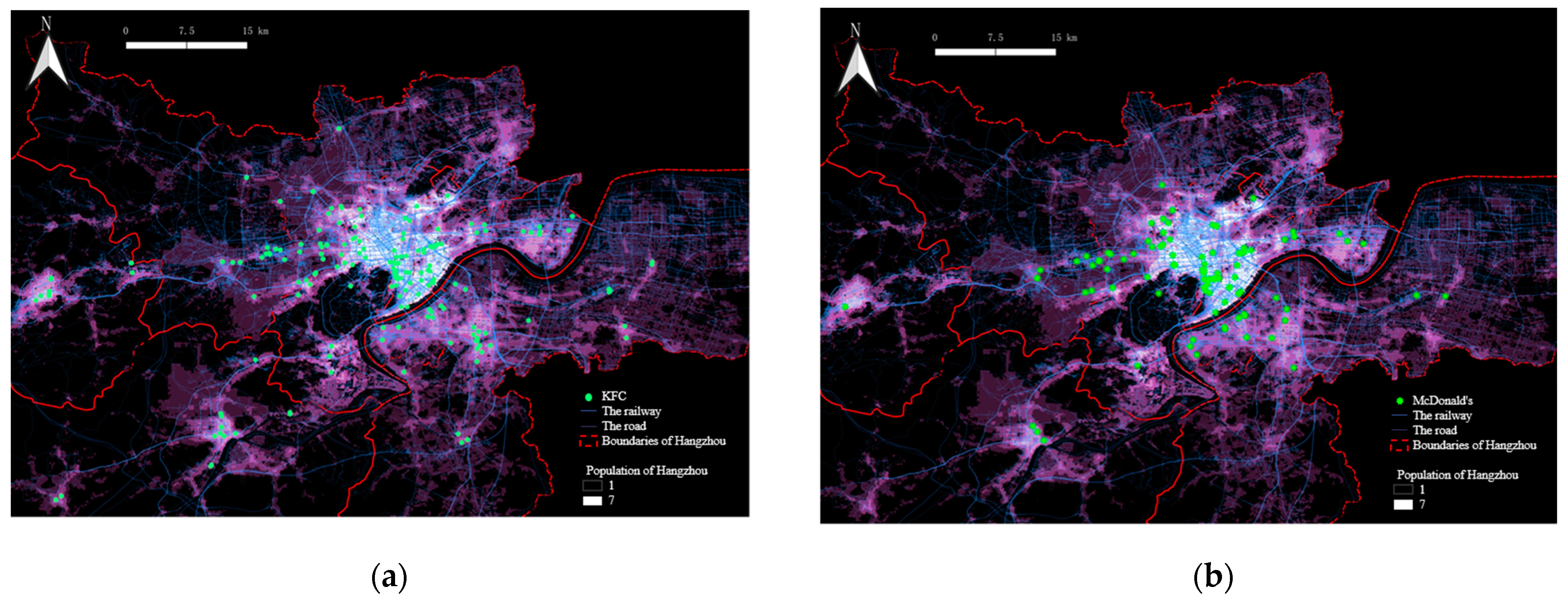
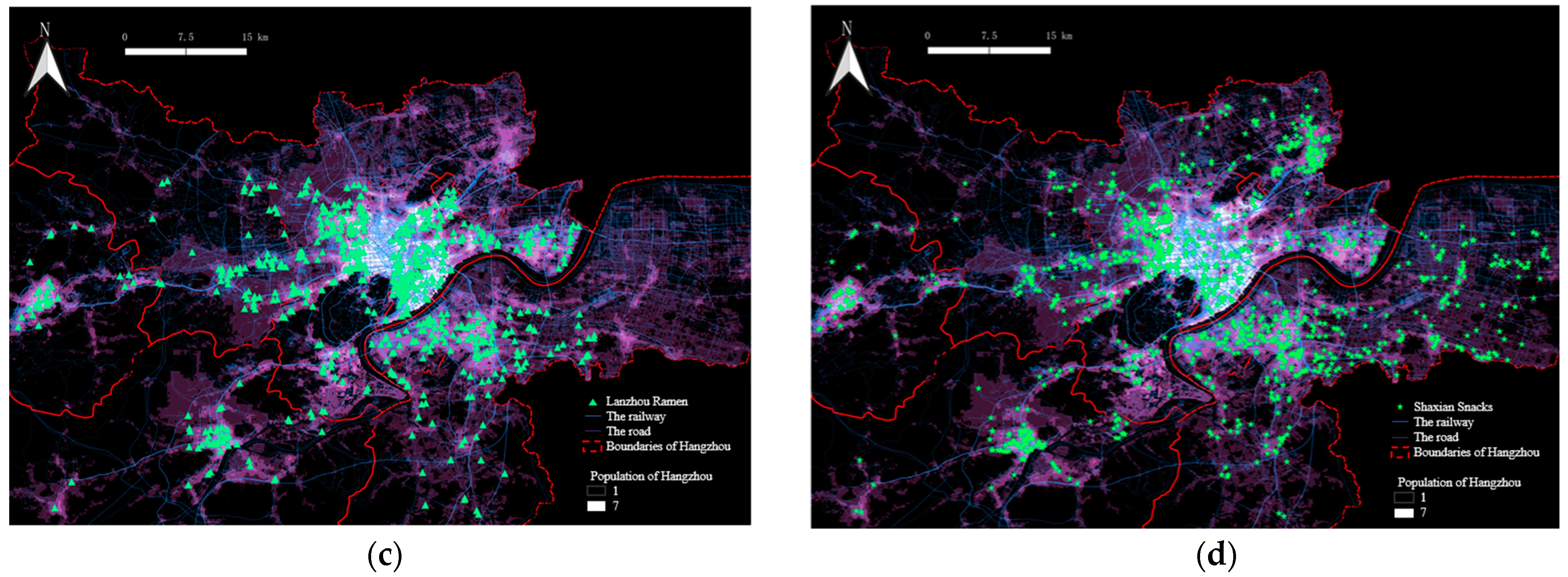
3.2.1. The Spatial Distribution of Four Kinds of Typical Fast Food
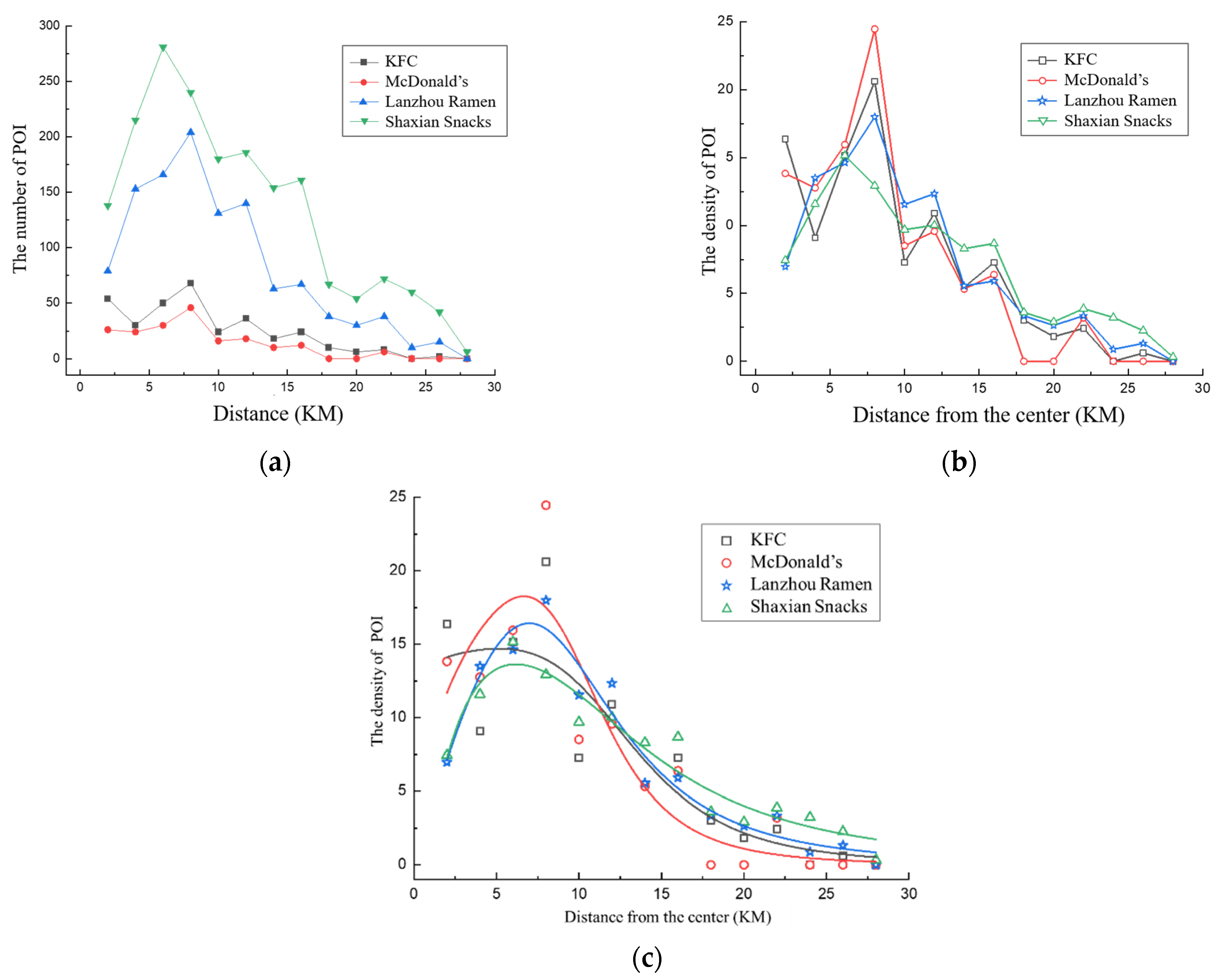
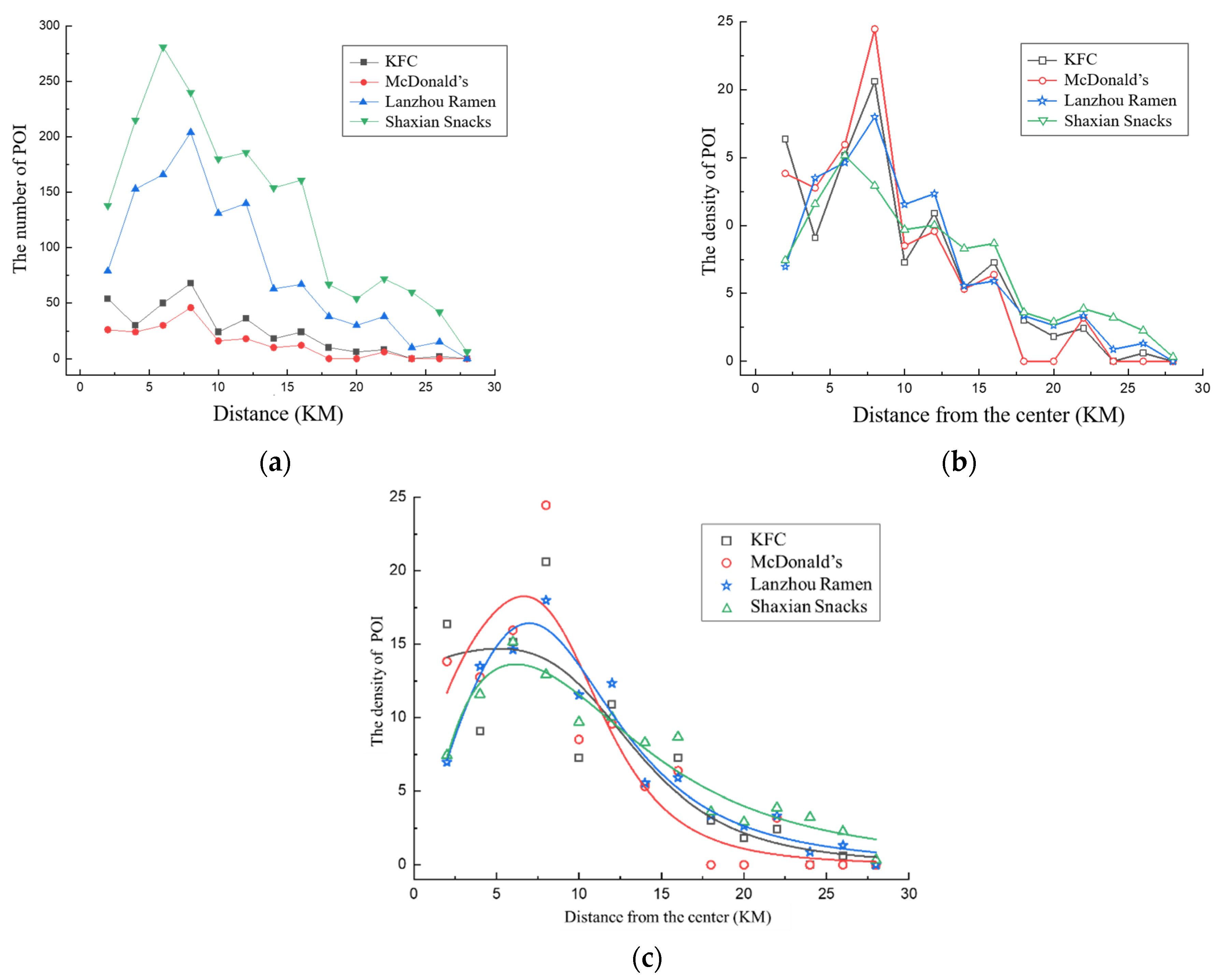
3.2.2. The “Core-Edge” Circle Structure Characteristics of Four Types of Fast Food
3.3. The Spatial Clustering and Mutual Attraction of Typical Fast Food in Hangzhou
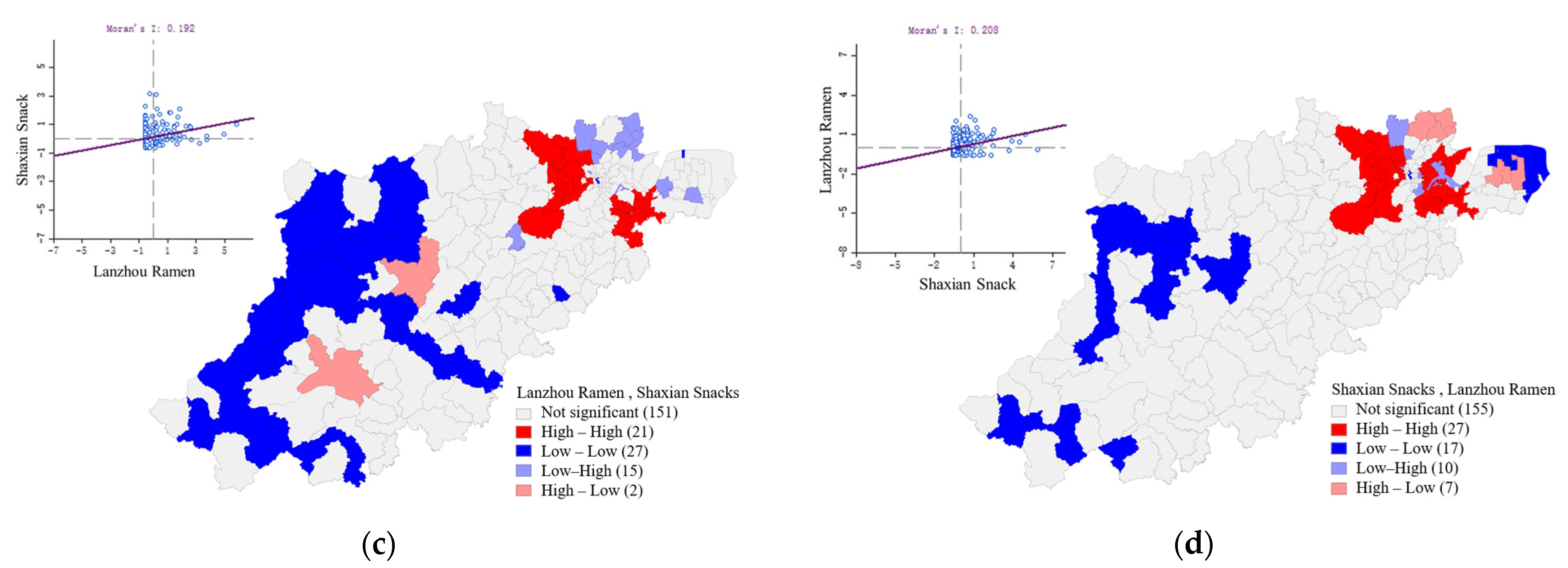
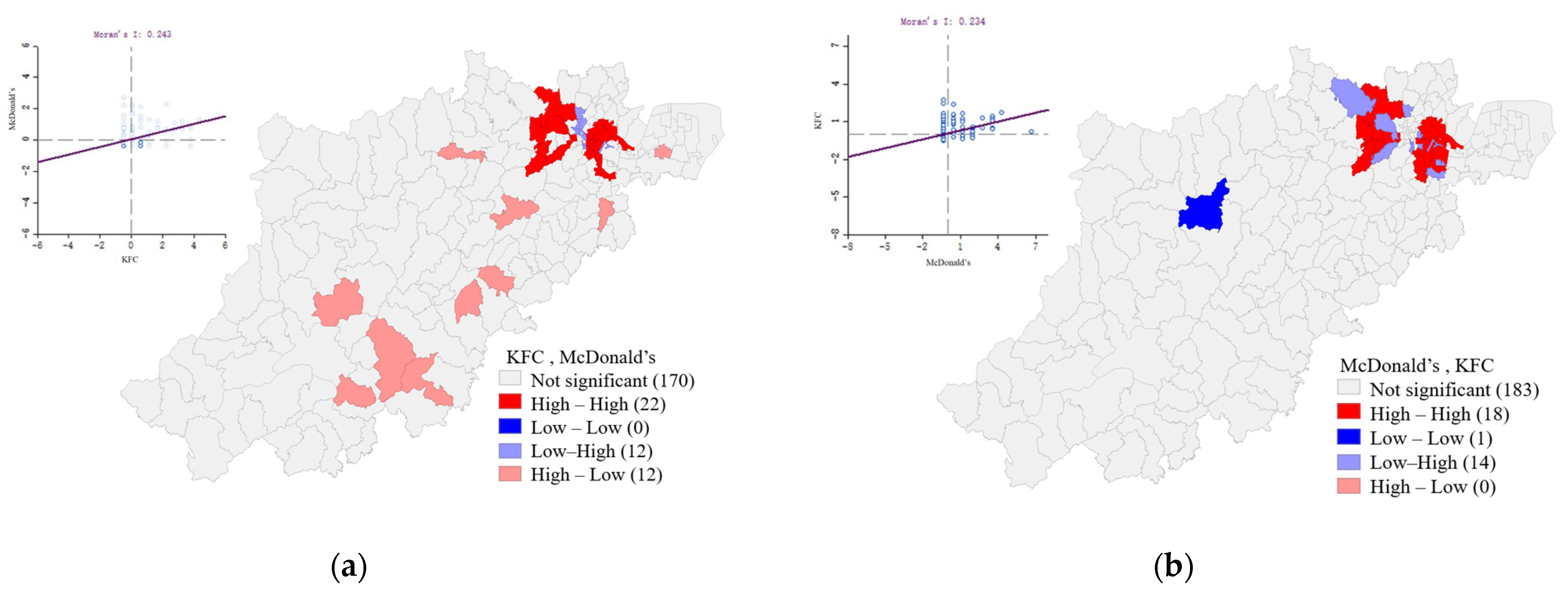
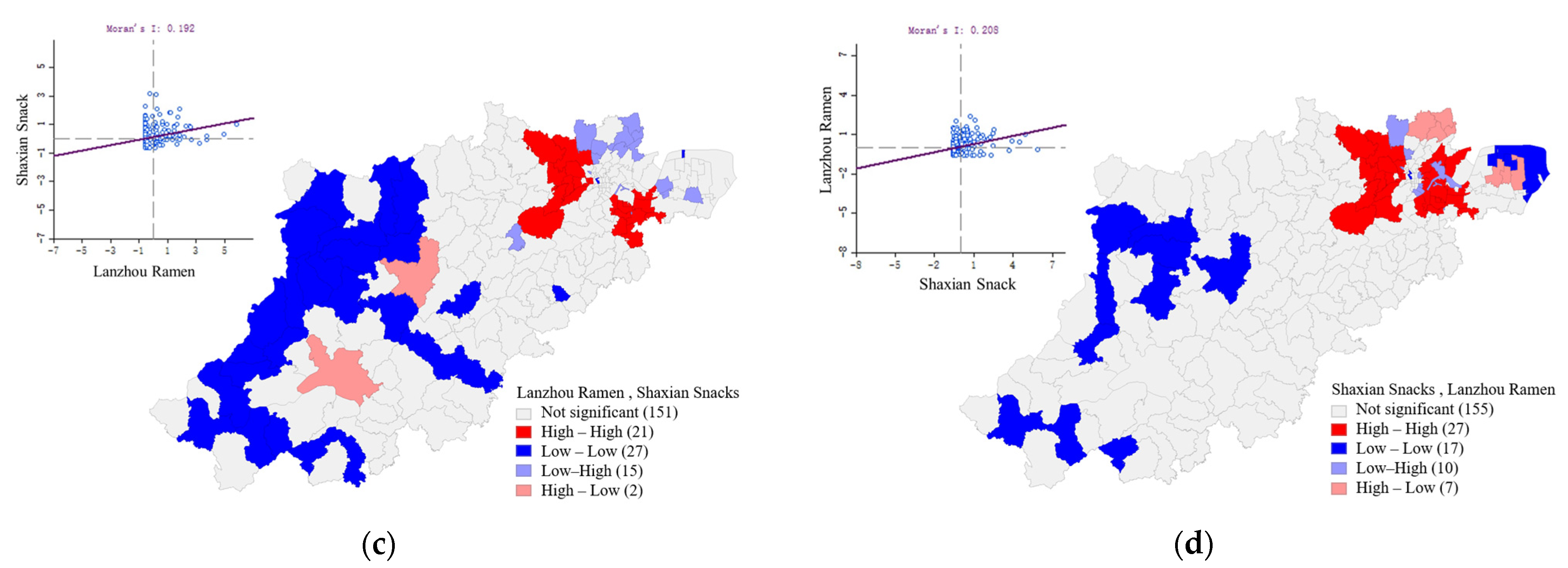
3.3.1. Bivariate Moran’s I Method
3.3.2. Geographical Proximity Analysis of the Four Kinds of Food
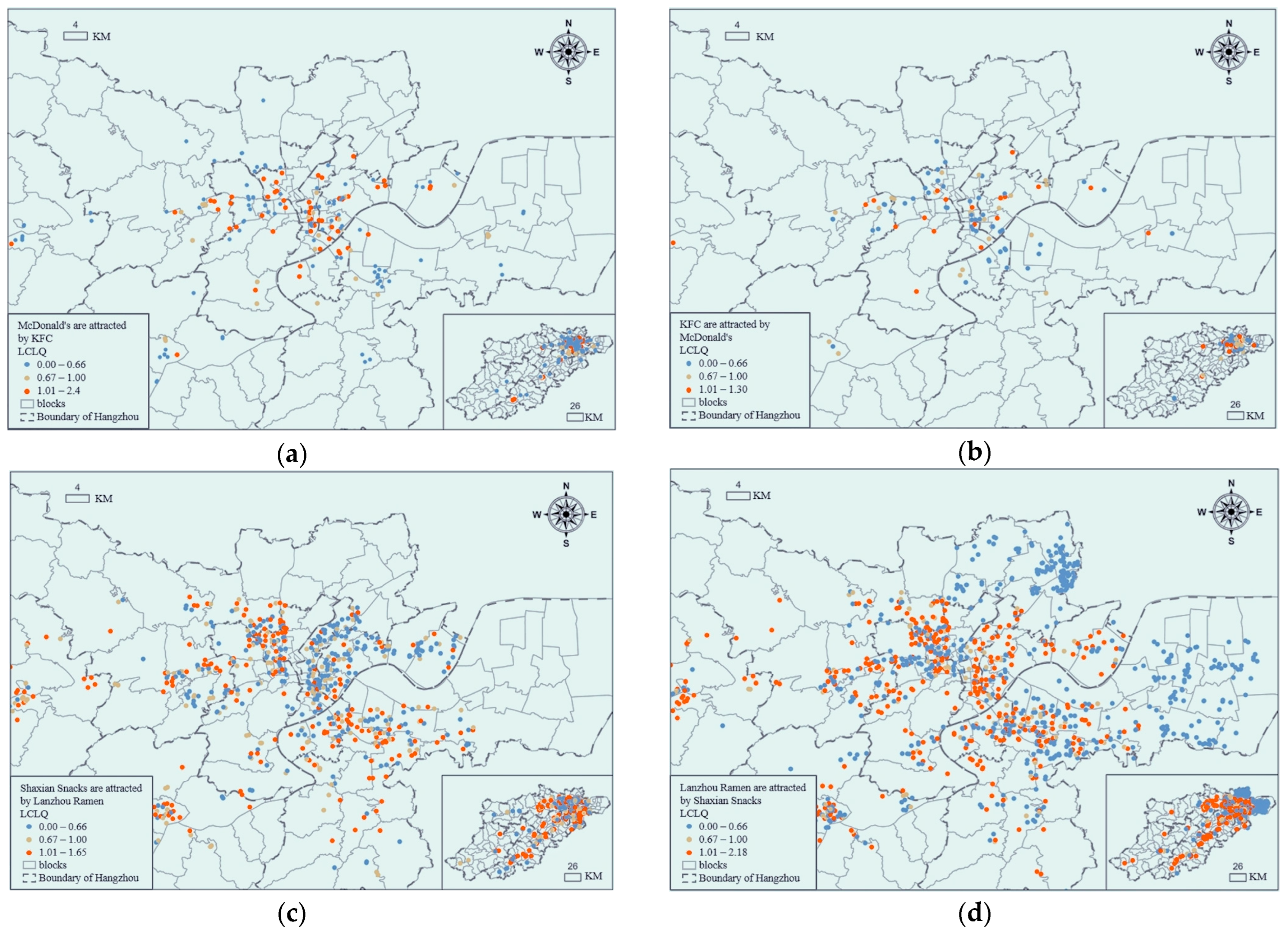
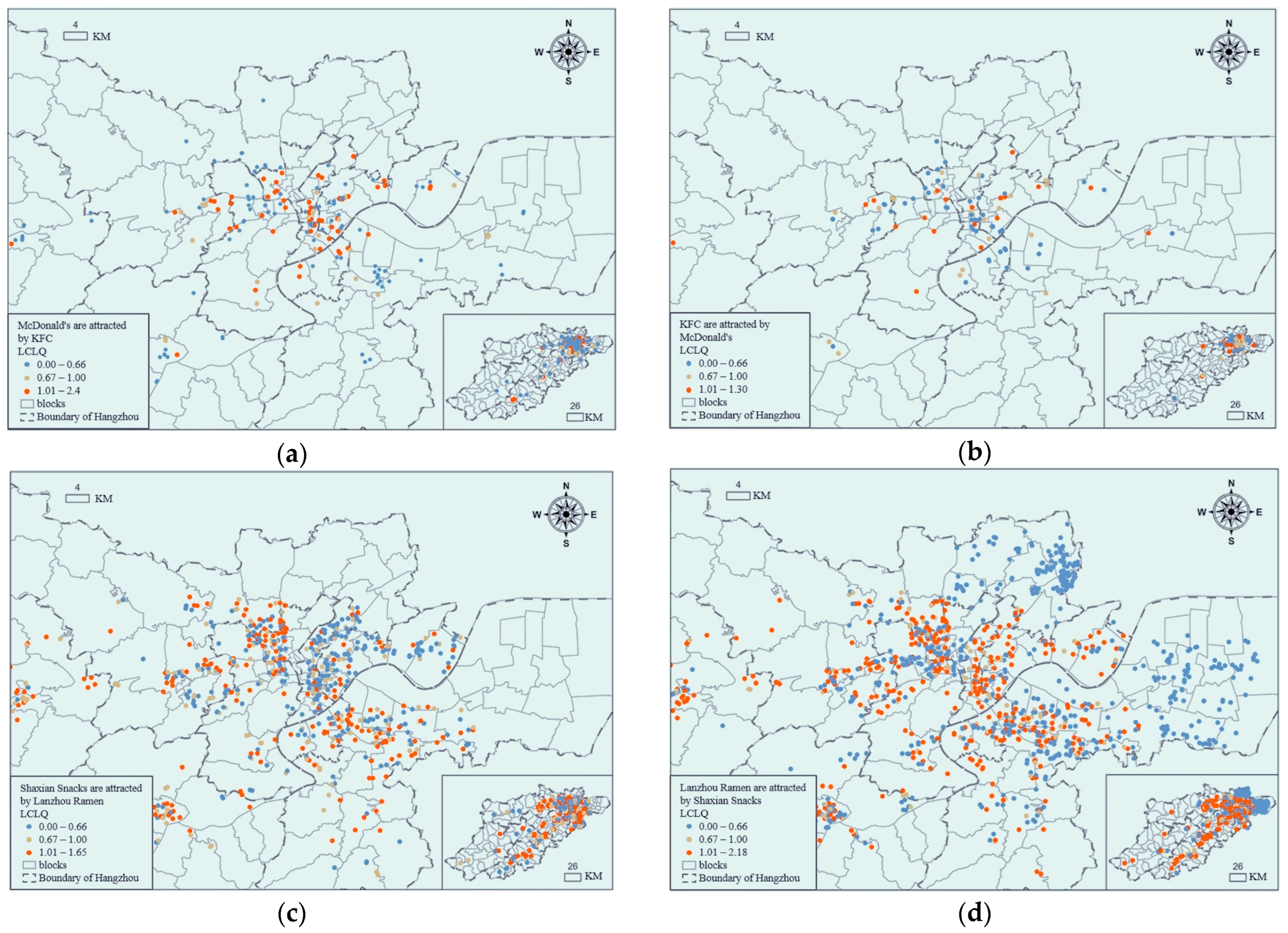
3.3.3. Collaborative Location Quotient Analysis of the Four Kinds of Food
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fang, J. The Distribution Characteristics and Clustering Mechanism of Korean Catering Service in Wudaokou District, Beijing. Econ. Geogr. 2014, 34, 106–113. [Google Scholar] [CrossRef]
- Zhang, F.; Zu, J.; Hu, M.; Zhu, D.; Kang, Y.; Gao, S.; Zhang, Y.; Huang, Z. Uncovering inconspicuous places using social media check-ins and street view images. Comput. Environ. Urban Syst. 2019, 81, 101478. [Google Scholar] [CrossRef]
- Psyllidis, A.; Gao, S.; Hu, Y.; Kim, E.-K.; McKenzie, G.; Purves, R.; Yuan, M.; Andris, C. Points of Interest (POI): A commentary on the state of the art, challenges, and prospects for the future. Comput. Urban Sci. 2022, 2, 20. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.; Liu, L.; Tian, Y.; Xiao, C.; Liu, L. Spatial Pattern Analysis of Geographic Features Using Network K-Function Methods with a Case Study of Restaurant Distribution in Hong Kong Island. Geogr. Geo-Inf. Sci. 2013, 29, 7–11. [Google Scholar] [CrossRef]
- Putri, S.R.; Wijayanto, A.W.; Sakti, A.D. Developing Relative Spatial Poverty Index Using Integrated Remote Sensing and Geospatial Big Data Approach: A Case Study of East Java, Indonesia. ISPRS Int. J. Geo-Inf. 2022, 11, 275. [Google Scholar] [CrossRef]
- Andrade, R.; Alves, A.; Bento, C. POI Mining for Land Use Classification: A Case Study. ISPRS Int. J. Geo-Inf. 2020, 9, 493. [Google Scholar] [CrossRef]
- Cichosz, P. Urban Crime Risk Prediction Using Point of Interest Data. ISPRS Int. J. Geo-Inf. 2020, 9, 459. [Google Scholar] [CrossRef]
- Sheng, Q.; Li, M.; Zhang, X. Location Does Not Matters in Informational Age?: A Case Study on the Distribution of Restaurants Listed in Dazhong Dianping in Beijing. In Proceedings of the 11th International Symposium on Environmental Behavior Research, Guangzhou, China, 7–9 November 2014; pp. 1325–1335. [Google Scholar]
- Xu, Y.; Hu, L.; Gao, S.; Wang, M.; Ding, J.; Qiu, Y.; Zhang, F.; Du, Z.; Liu, R. Perception of urban population characteristics through dietary taste patterns based on takeout data. Cities 2022, 131, 103910. [Google Scholar] [CrossRef]
- Lai, J.; Lansley, G.; Haworth, J.; Cheng, T. A name-led approach to profile urban places based on geotagged Twitter data. Trans. GIS 2019, 24, 858–879. [Google Scholar] [CrossRef]
- Shabrina, Z.; Buyuklieva, B.; Ng, M.K.M. Short-Term Rental Platform in the Urban Tourism Context: A Geographically Weighted Regression (GWR) and a Multiscale GWR (MGWR) Approaches. Geogr. Anal. 2020, 53, 686–707. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, S.; Liu, X.; Liu, C. Near “real-time” estimation of excess commuting from open-source data: Evidence from China’s megacities. J. Transp. Geogr. 2021, 91, 102929. [Google Scholar] [CrossRef]
- Meng, B.; Zhan, D.; Hao, L. The Influence of Residents’ Residential Behavior on the Separation of Work and Housing in Beijing. Urban Issues 2013, 10, 33–39. [Google Scholar] [CrossRef]
- Kang, Y.; Wu, K.; Gao, S.; Ignavier, N.; Rao, J.; Ye, S.; Zhang, F.; Fei, T. STICC: A multivariate spatial clustering method for repeated geographic pattern discovery with consideration of spatial contiguity. Int. J. Geogr. Inf. Sci. 2022, 36, 1–32. [Google Scholar] [CrossRef]
- Dam, A.; Gomez-Lievano, A.; Neffke, F.; Frenken, K. An information-theoretic approach to the analysis of location and colocation patterns. J. Reg. Sci. 2022, 1–41. [Google Scholar] [CrossRef]
- Xue, B.; Xiao, X.; Li, J. Identification method and empirical study of urban industrial spatial relationship based on POI big data: A case of Shenyang City, China. Geogr. Sustain. 2020, 1, 152–162. [Google Scholar] [CrossRef]
- Zhang, H.; Zhou, X.; Tang, G.; Xiong, L.; Dong, K. Mining spatial patterns of food culture in China using restaurant POI data. Trans. GIS 2020, 25, 579–601. [Google Scholar] [CrossRef]
- Qiu, L.; Shen, Y.; Ren, W. Industrial Relevancy and Spatial Distribution between Producer Services and Manufacturing in Beijing City. Acta Geogr. Sin. 2008, 63, 1299–1310. [Google Scholar]
- Yu, W.; Ai, T.; He, Y.; Shao, S. Spatial co-location pattern mining of facility points-of-interest improved by network neighborhood and distance decay effects. Int. J. Geogr. Inf. Sci. 2017, 31, 280–296. [Google Scholar] [CrossRef]
- Meng, B.; Gao, L.; Li, R. Spatial correlation analysis of residential and employment elements in Beijing based on collaborative location quotient. Acta Geogr. Sin. 2021, 76, 1380–1393. [Google Scholar]
- Li, Q.; Cui, C.; Liu, F.; Wu, Q.; Run, Y.; Han, Z. Multidimensional Urban Vitality on Streets: Spatial Patterns and Influence Factor Identification Using Multisource Urban Data. ISPRS Int. J. Geo-Inf. 2021, 11, 2. [Google Scholar] [CrossRef]
- Du, P. Analysis of Shenyang Food Space Pattern Based on POI Big Data. Geomat. Spat. Inf. Technol. 2021, 44, 130–134. [Google Scholar]
- Li, X. Recognition of Urban Polycentric Structure Based on Spatial Aggregation Characteristics of POI Elements: A Case of Zhengzhou City. Acta Sci. Nat. Univ. Pekin. 2020, 56, 692–702. [Google Scholar]
- Lu, C.; Pang, M.; Zhang, Y.; Li, H.; Lu, C.; Tang, X.; Cheng, W. Mapping Urban Spatial Structure Based on POI (Point of Interest) Data: A Case Study of the Central City of Lanzhou, China. ISPRS Int. J. Geo-Inf. 2020, 9, 92. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Liu, L.; Liang, Y. Retail center recognition and spatial aggregating feature analysis of retail formats in Guangzhou based on POI data. Geogr. Res. 2016, 35, 703–716. [Google Scholar]
- Rogerson, P.A. Getis–Ord Statistic for Spatially. Geogr. Anal. 2015, 47, 20–33. [Google Scholar] [CrossRef]
- Xue, B.; Xiao, X.; Li, J.; Jiang, L.; Xie, X. POI-Based Analysis on Retail’s Spatial Hot Blocks at a City Level: A Case Study of Shenyang, China. Econ. Geogr. 2018, 38, 36–43. [Google Scholar]
- Chen, L.; Liu, Y.; Huang, K. Spatial Agglomeration Characteristics of Leisure Industry: Economic Geography Explanation of ‘Sensual Pleasure’[A]. The Economic Geography Committee of China Geography Association. The Summary Collection of the Academic Annual Meeting of the Economic Geography Committee of China Geography Association in 2019[C]. The Economic Geography Committee of China Geography Association: China Geography Associatio. 2019, pp. 200–201. Available online: https://kns.cnki.net/kcms/detail/detail.aspx?FileName=ZGDQ201906001191&DbName=CPFD2019 (accessed on 8 November 2022).
- Wang, J.; Zhang, X.; Hao, J.; Gao, Z. Square Function Research Using POI Data: A Case Study of Chengguan District, Lanzhou City. J. Geomat. 2021, 46, 103–106. [Google Scholar]
- Wu, T.; Tang, Z. Division and Identification of Urban Functional Areas based on POI-take Main Urban Area of Quanzhou as an Example. J. Liaoning Univ. (Nat. Sci. Ed.) 2021, 48, 28–37. [Google Scholar]
- Wang, X.; Chen, J.; Pei, T.; Song, C.; Liu, Y.; Shu, H.; Guo, S.; Chen, X. I-index for quantifying an urban location’s irreplaceability. Comput. Environ. Urban Syst. 2021, 90, 101711. [Google Scholar] [CrossRef]
- Huang, W.; Cui, L.; Chen, M.; Zhang, D.; Yao, Y. Estimating urban functional distributions with semantics preserved POI embedding. Int. J. Geogr. Inf. Sci. 2022, 36, 1905–1930. [Google Scholar] [CrossRef]
- Liu, W.; Liu, Q.; Deng, M.; Cai, J.; Yang, J. Discovery of statistically significant regional co-location patterns on urban road networks. Int. J. Geogr. Inf. Sci. 2022, 36, 749–772. [Google Scholar] [CrossRef]
- Jiao, L.; Dong, T. Inverse S-Shape Rule of Urban Land Density Distribution and Its Applications. J. Geomat. 2018, 43, 8–16. [Google Scholar] [CrossRef]
- Lan, T.; Yu, M.; Xu, Z.; Wu, Y. Temporal and Spatial Variation Characteristics of Catering Facilities Based on POI Data: A Case Study within 5th Ring Road in Beijing. Procedia Comput. Sci. 2018, 131, 1260–1268. [Google Scholar] [CrossRef]
- Belcastro, L.; Kechadi, M.T.; Marozzo, F.; Pastore, L.; Talia, D.; Trunfio, P. Parallel extraction of regions-of-interest from social media data. Concurr. Comput. Pract. Exper. 2021, 33, e5638. [Google Scholar] [CrossRef]
- Yang, J.; Yi, D.; Qiao, B.; Zhang, J. Spatio-Temporal Change Characteristics of Spatial-Interaction Networks: Case Study within the Sixth Ring Road of Beijing, China. ISPRS Int. J. Geo-Inf. 2019, 8, 273. [Google Scholar] [CrossRef] [Green Version]
- Qian, J.; Liu, Z.; Du, Y.; Liang, F.; Yi, J.; Ma, T.; Pei, T. Quantify city-level dynamic functions across China using social media and POIs data. Comput. Environ. Urban Syst. 2021, 85, 101552. [Google Scholar] [CrossRef]
- Shah, T.I.; Bell, S. Exploring the Intra-Urban Variations in the Relationship among Geographic Accessibility to PHC Services and Socio-demographic Factors. In Proceedings of the HealthGIS 2013—Second SIGSPATIAL International Workshop on the use of GIS in Public Health, Orlando, FL, USA, 5 November 2013. [Google Scholar]
- Wang, B.; Lei, Y.; Xue, D.; Liu, J.; Wei, C. Elaborating Spatiotemporal Associations Between the Built Environment and Urban Vibrancy: A Case of Guangzhou City, China. Chin. Geogr. Sci. 2022, 32, 480–492. [Google Scholar] [CrossRef]
- Environmental Systems Research Institute. A Quick Tour of Geoprocessing Tool References. [EB/OL]. Available online: https://desktop.arcgis.com/zh-cn/arcmap/10.3/main/tools/a-quick-tour-of-geoprocessing-tool-references.html (accessed on 11 July 2021).
- QGIS Desktop User Guide/Manual. [EB/OL]. Available online: https://docs.qgis.org/testing/en/docs/user_manual/processing_algs/qgis/vectoranalysis.html#id16 (accessed on 11 July 2021).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Area | Total Area (km2) | Number of POI | ||||
|---|---|---|---|---|---|---|
| KFC | Lanzhou Ramen | McDonald’s | Shaxian Snacks | Food | ||
| Binjiang District | 72.22 | 24 | 83 | 20 | 130 | 8915 |
| Chun’an County | 4417.48 | 6 | 18 | 0 | 44 | 3234 |
| Fuyang District | 1821.03 | 30 | 95 | 6 | 196 | 10,568 |
| Gongshu District | 69.25 | 10 | 48 | 16 | 106 | 8533 |
| Jiande City | 2314.19 | 10 | 59 | 5 | 58 | 4844 |
| Jianggan District | 200 | 66 | 224 | 36 | 136 | 23,574 |
| Lin’an District | 3118.77 | 18 | 73 | 2 | 90 | 7972 |
| Shangcheng District | 26.06 | 32 | 76 | 24 | 46 | 4431 |
| Tonglu County | 1829.59 | 12 | 95 | 4 | 78 | 6976 |
| Xihu district | 309.41 | 56 | 164 | 20 | 240 | 14,316 |
| Xiacheng District | 29.33 | 32 | 96 | 26 | 40 | 7334 |
| Xiaoshan District | 1417.83 | 54 | 220 | 14 | 626 | 24,748 |
| Yuhang District | 1228.41 | 52 | 220 | 32 | 506 | 29,748 |
| total | 16,853.57 | 402 | 1471 | 206 | 2296 | 155,193 |
| KFC | 30.50502 | 8.31157 | 13.42412 | 0.10449 | 4.6426 | 0.79191 |
| McDonald’s | 50.95868 | 13.9226 | 10.8151 | 0.62391 | 5.22435 | 0.8401 |
| Lanzhou Ramen | 41.56137 | 7.6926 | 10.73029 | 1.17192 | 3.82797 | 0.95093 |
| Shaxian Snacks | 17.47867 | 2.38217 | 13.41645 | 1.88095 | 2.98541 | 0.93035 |
| Elements of Interest | Adjacent Elements | GCLQ | p-Value |
|---|---|---|---|
| KFC | McDonald’s | 0.928448 | 0.04 |
| McDonald’s | KFC | 0.908902 | 0.02 |
| Lanzhou Ramen | Shaxian Snacks | 0.826835 | 0.02 |
| Shaxian Snacks | Lanzhou Ramen | 0.854509 | 0.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Shen, X.; Wang, C.; Liao, Y.; Li, J. Mining the Spatial Distribution Pattern of the Typical Fast-Food Industry Based on Point-of-Interest Data: The Case Study of Hangzhou, China. ISPRS Int. J. Geo-Inf. 2022, 11, 559. https://doi.org/10.3390/ijgi11110559
Zhou Y, Shen X, Wang C, Liao Y, Li J. Mining the Spatial Distribution Pattern of the Typical Fast-Food Industry Based on Point-of-Interest Data: The Case Study of Hangzhou, China. ISPRS International Journal of Geo-Information. 2022; 11(11):559. https://doi.org/10.3390/ijgi11110559
Chicago/Turabian StyleZhou, Yan, Xuan Shen, Chen Wang, Yixue Liao, and Junli Li. 2022. "Mining the Spatial Distribution Pattern of the Typical Fast-Food Industry Based on Point-of-Interest Data: The Case Study of Hangzhou, China" ISPRS International Journal of Geo-Information 11, no. 11: 559. https://doi.org/10.3390/ijgi11110559
APA StyleZhou, Y., Shen, X., Wang, C., Liao, Y., & Li, J. (2022). Mining the Spatial Distribution Pattern of the Typical Fast-Food Industry Based on Point-of-Interest Data: The Case Study of Hangzhou, China. ISPRS International Journal of Geo-Information, 11(11), 559. https://doi.org/10.3390/ijgi11110559