
Serverless Geospatial Data Processing Workflow System Design


Abstract
:1. Introduction
2. Related Works
2.1. Cloud Workflow Services
2.2. Containerised Workflow Engines
2.3. Review
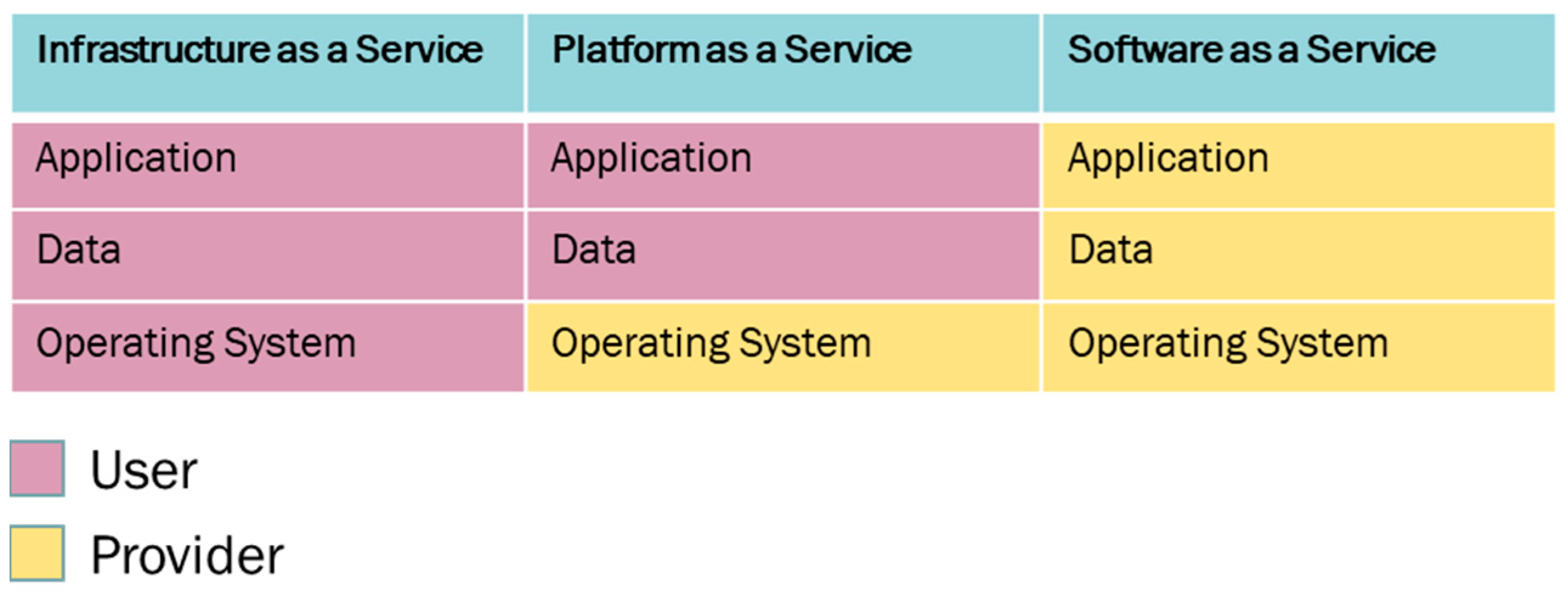
3. Materials and Methods
3.1. Workflow and Task Definition Models
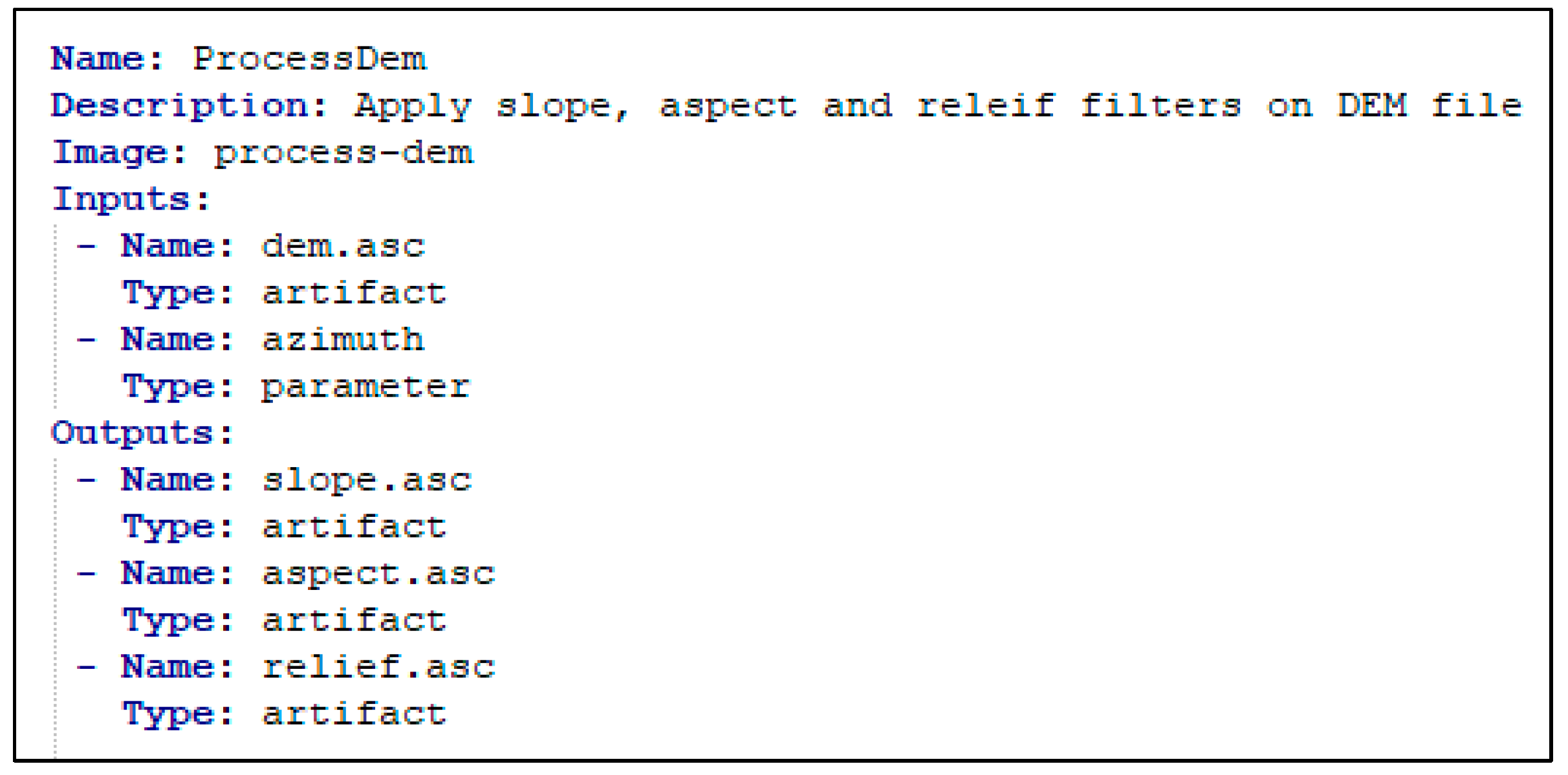
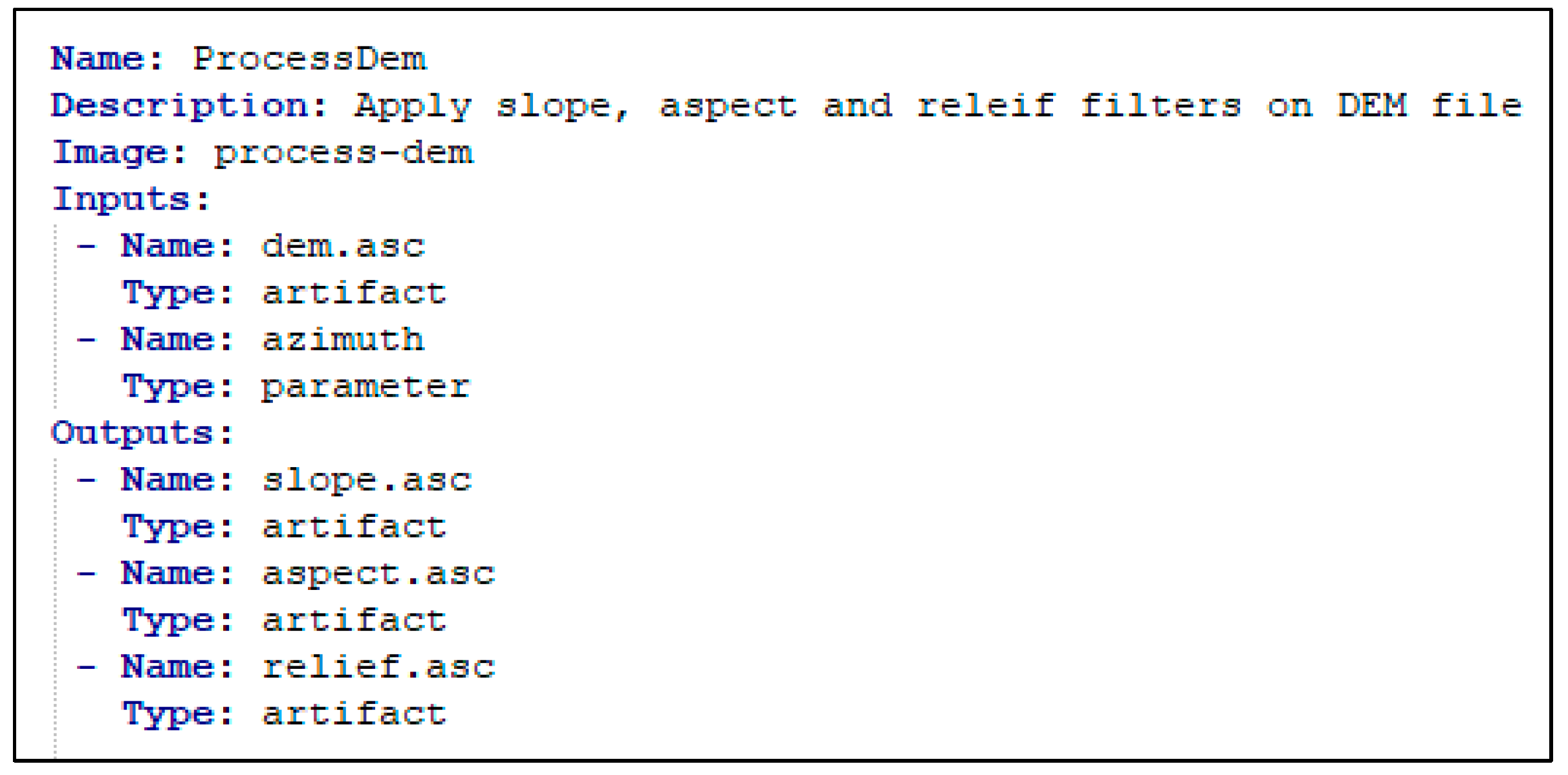
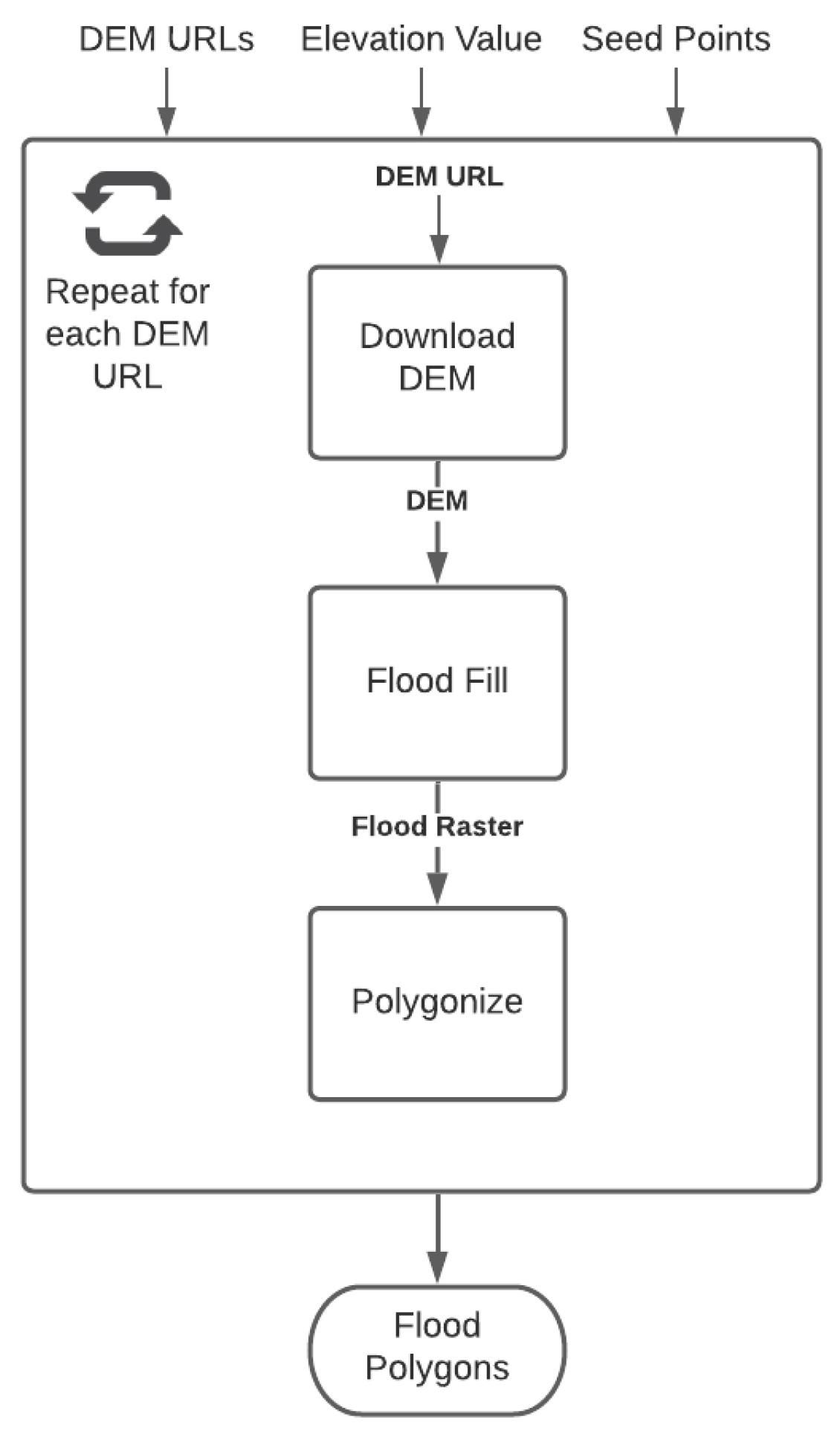
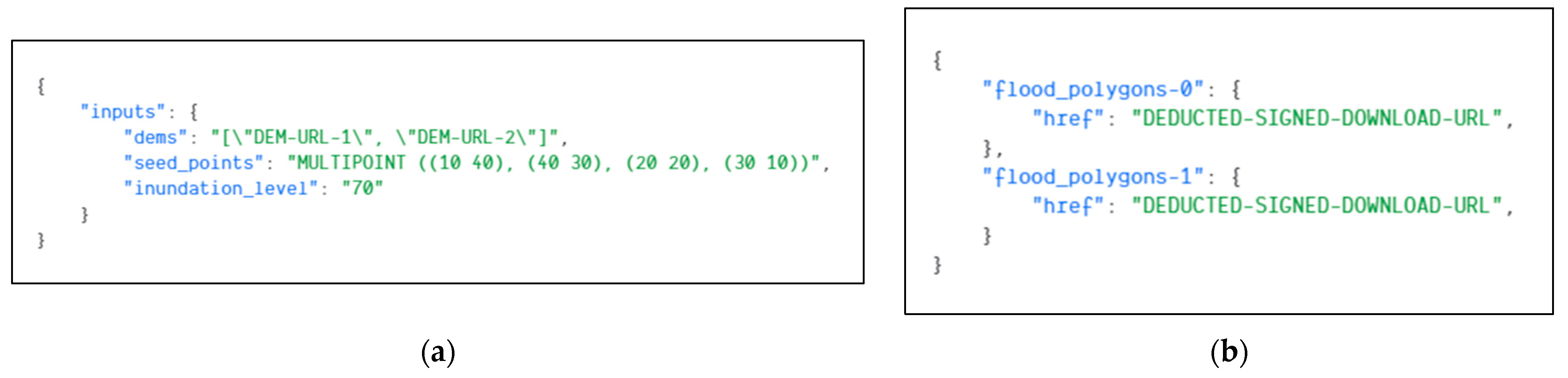
3.1.1. Task Definition
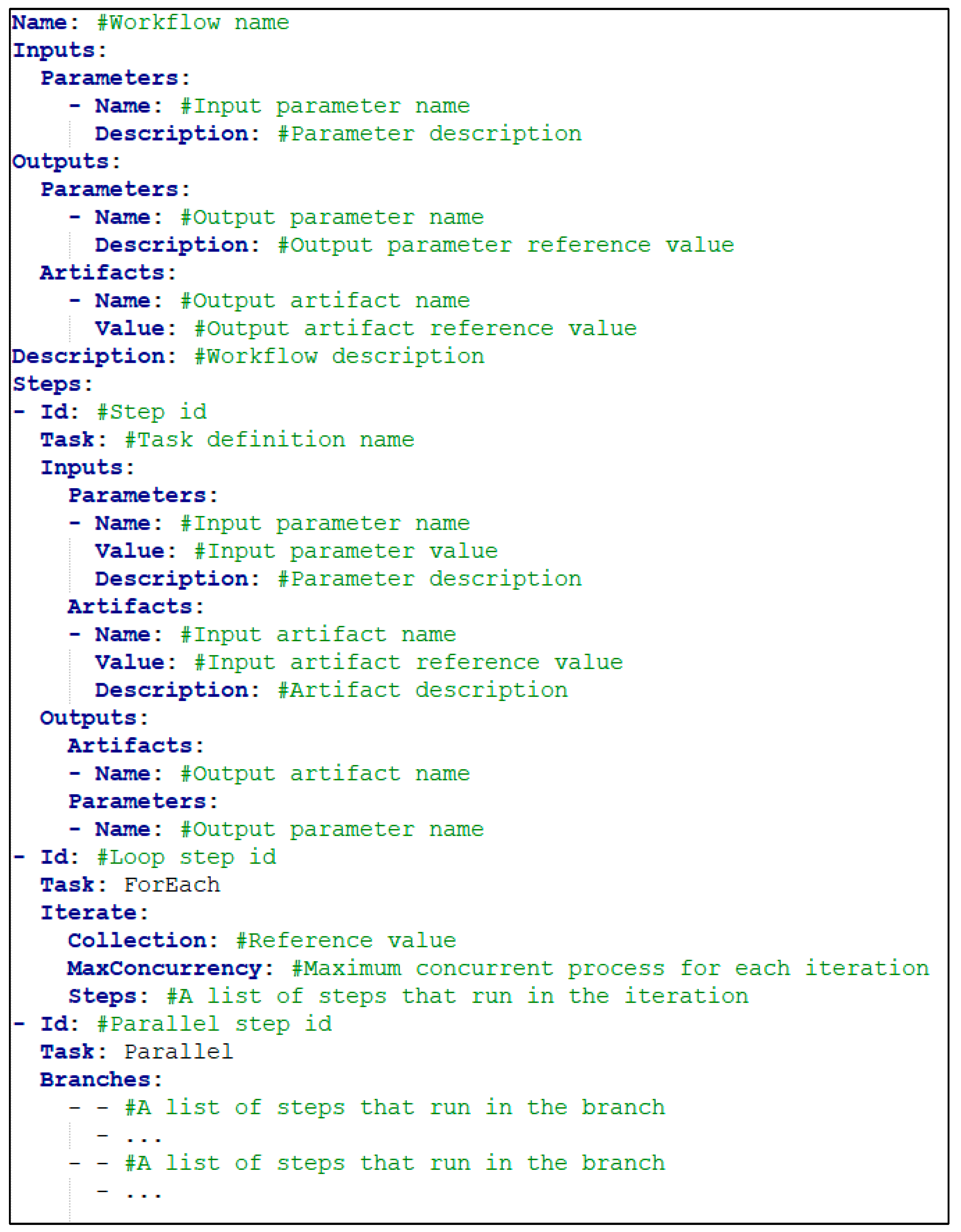
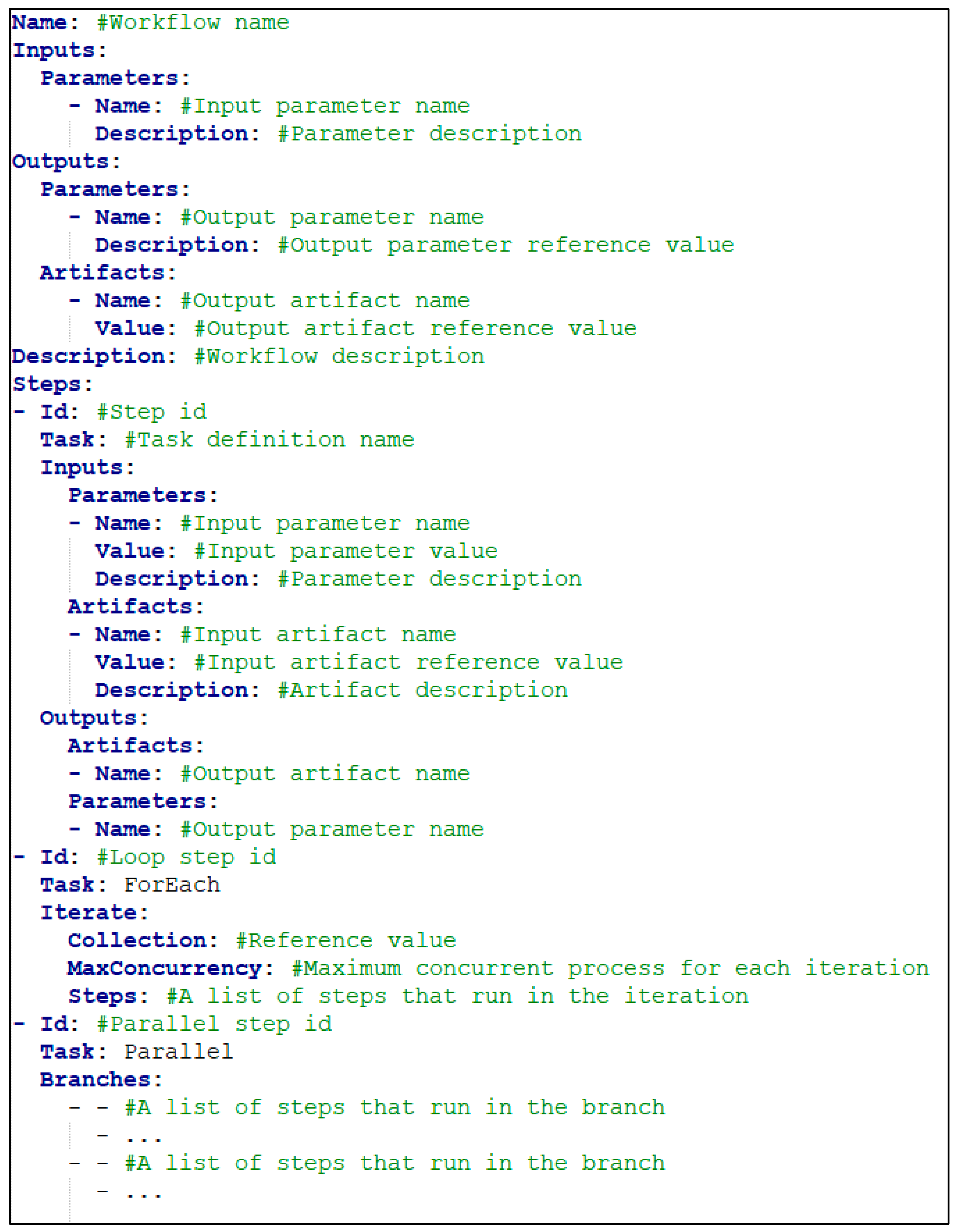
3.1.2. Workflow Definition
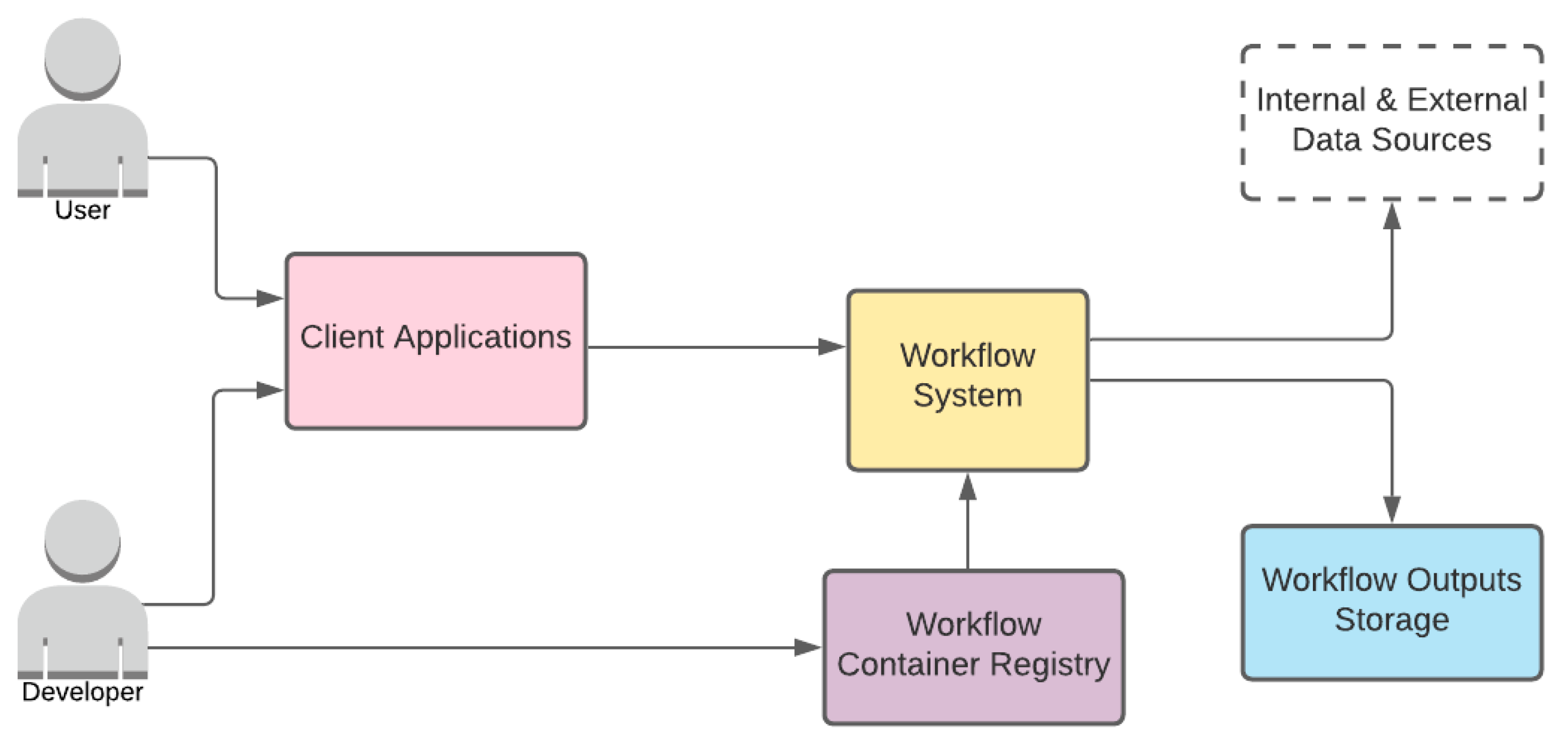
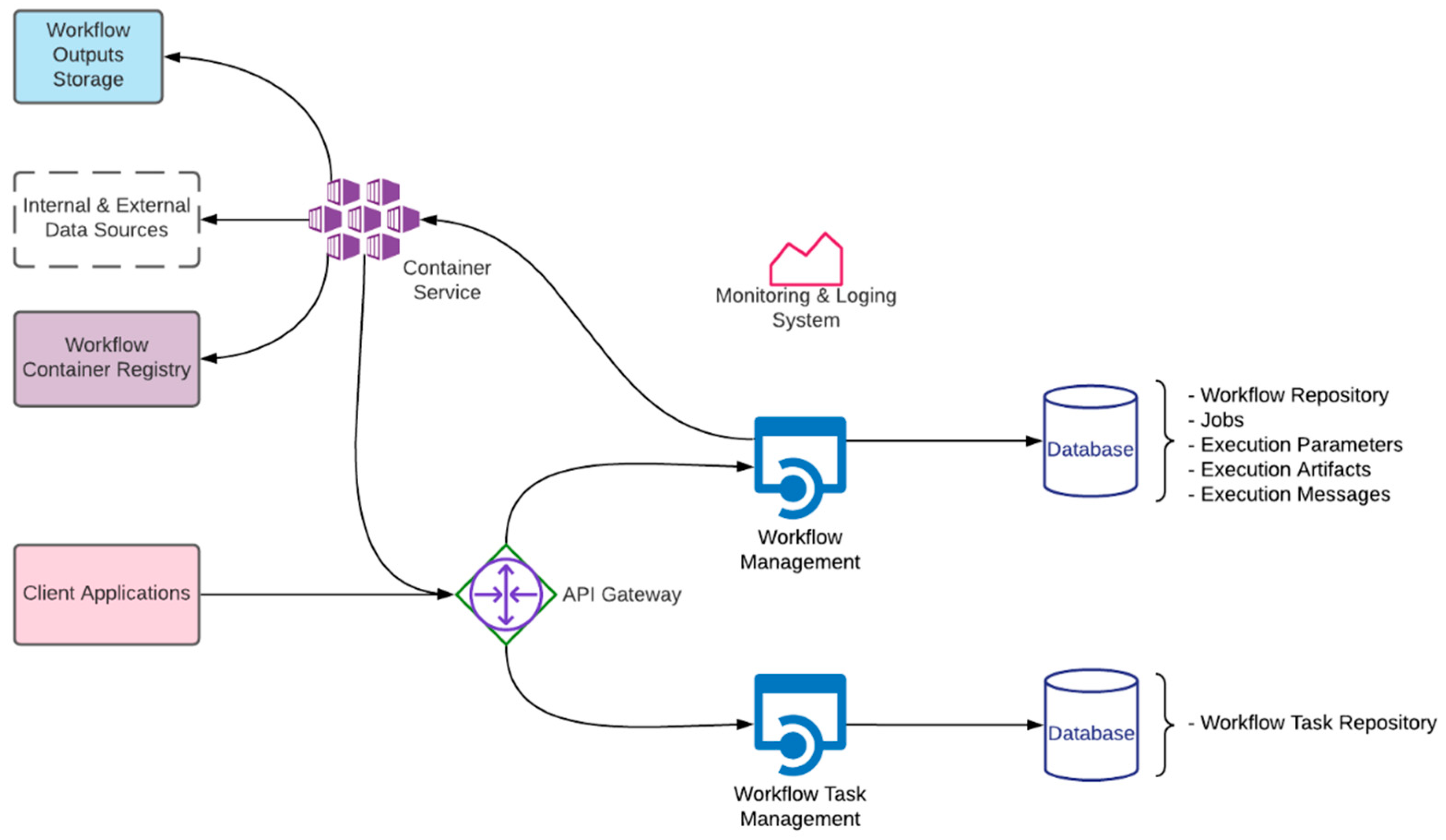
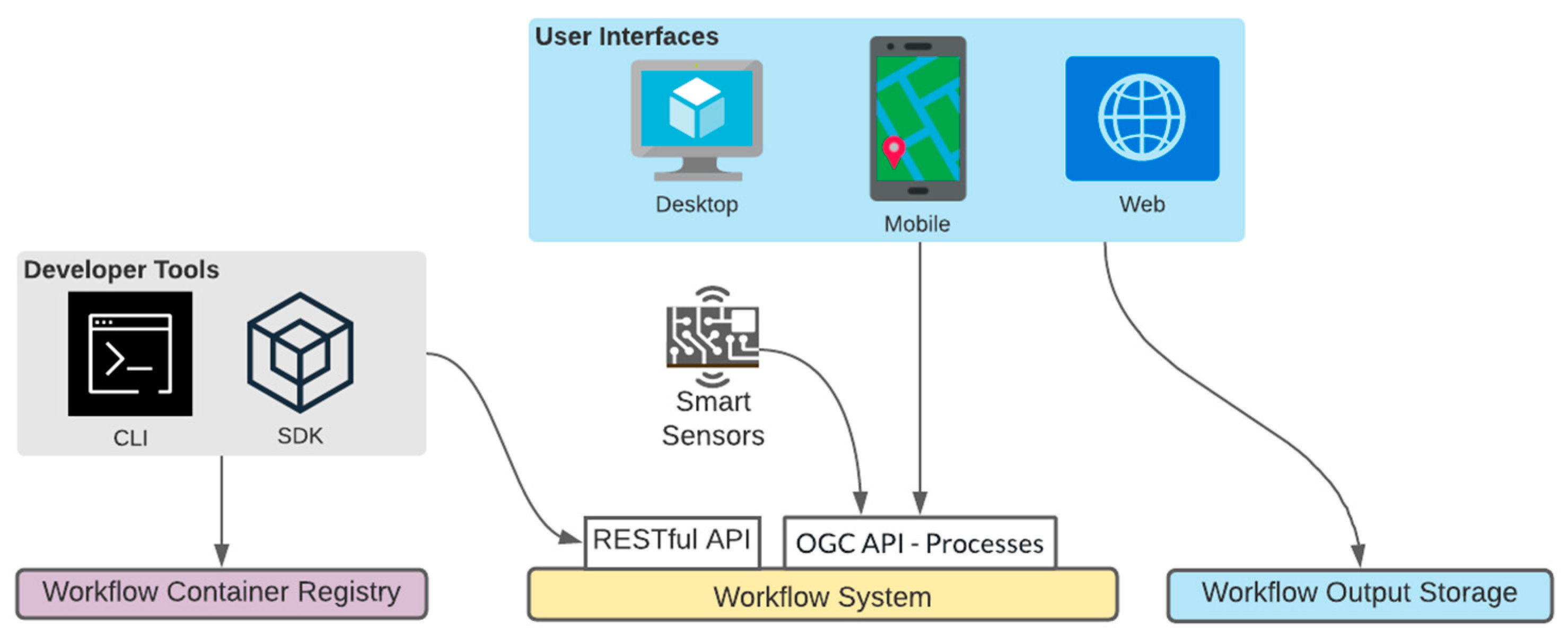
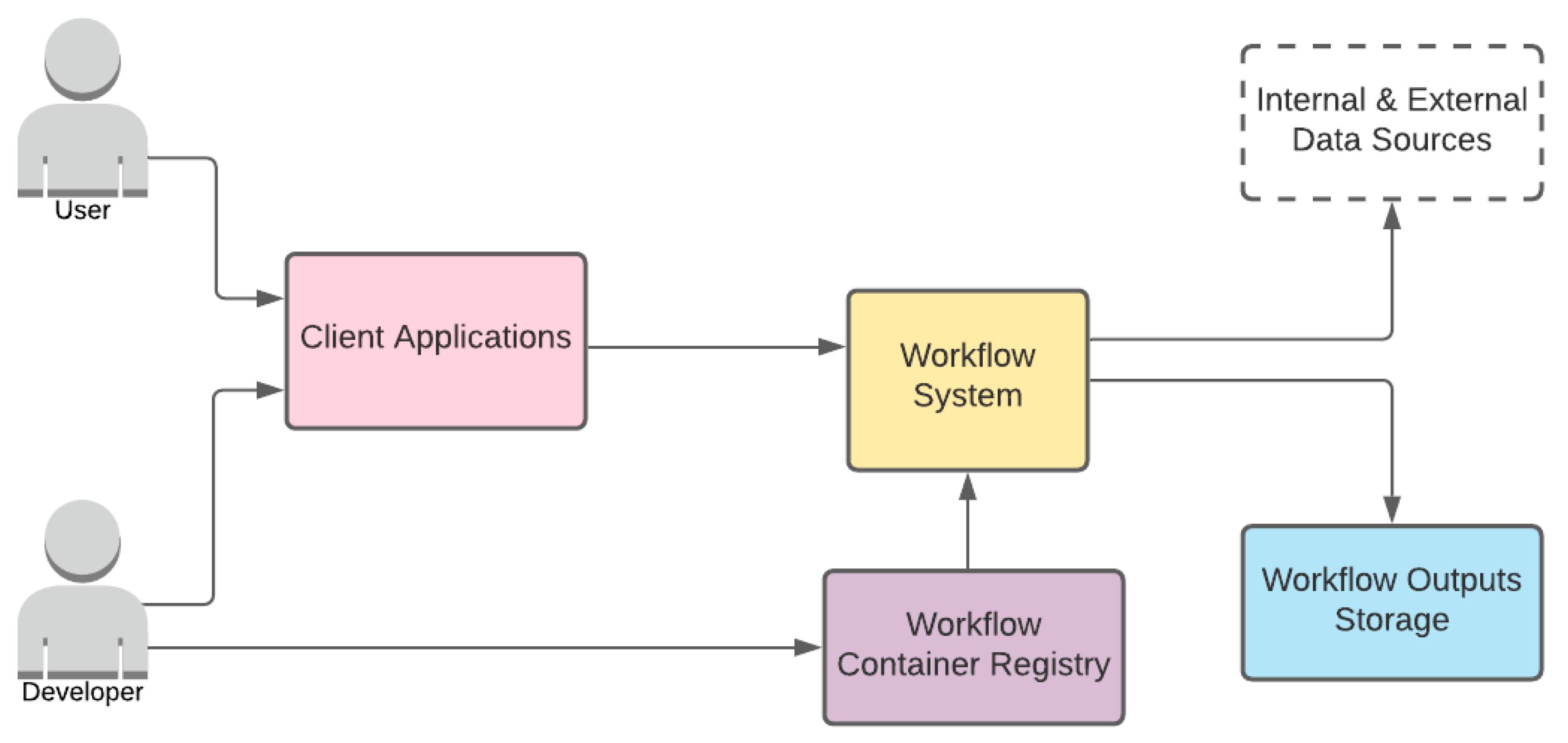
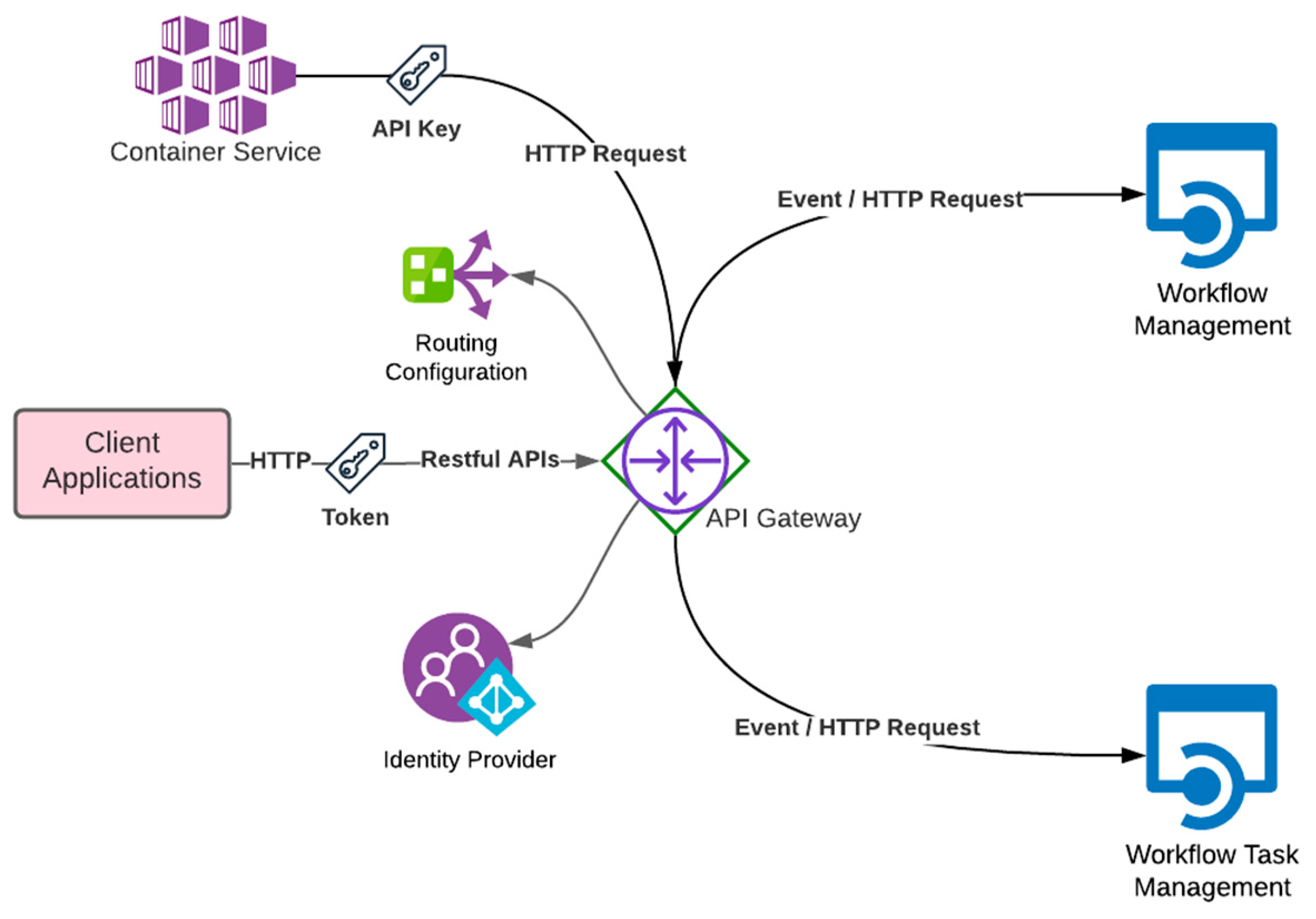
3.2. System Architecture
- Workflow System
- Workflow Container Registry
- Workflow Outputs Storage
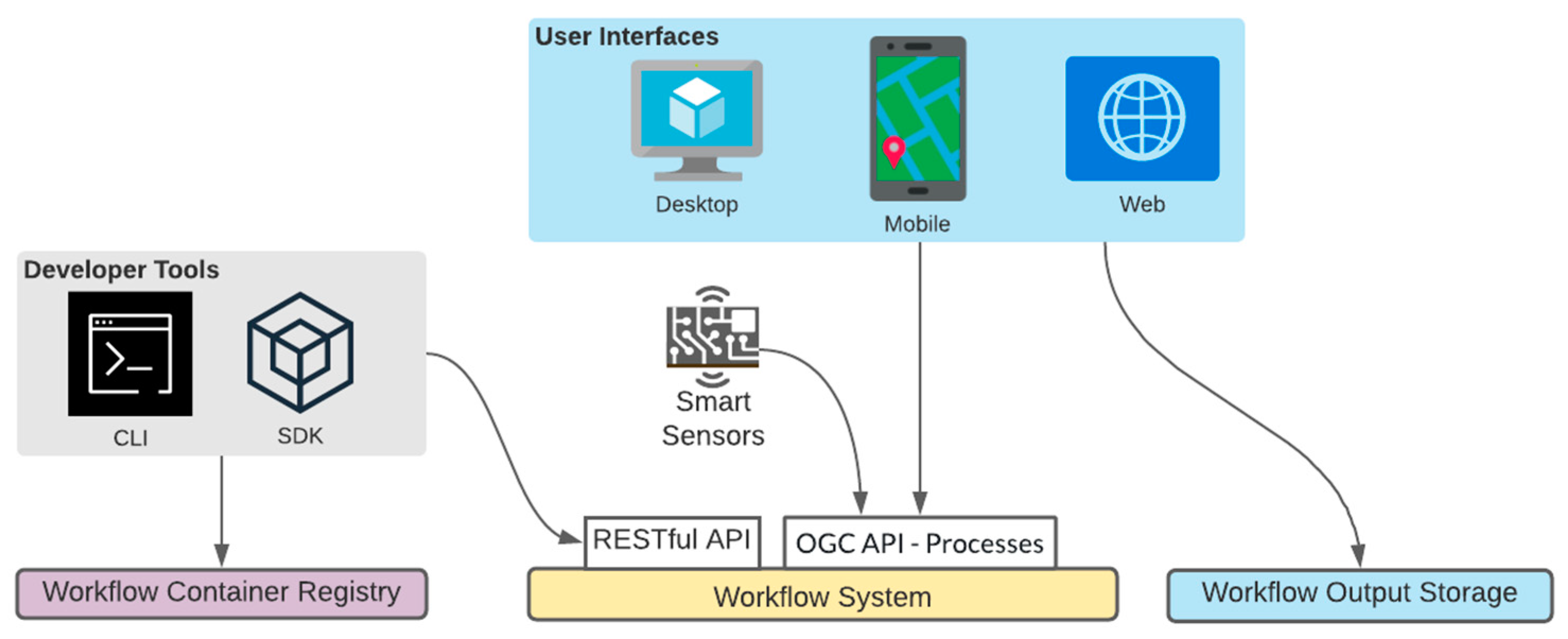
- Client Applications
- User
- Developer
3.2.1. Roles
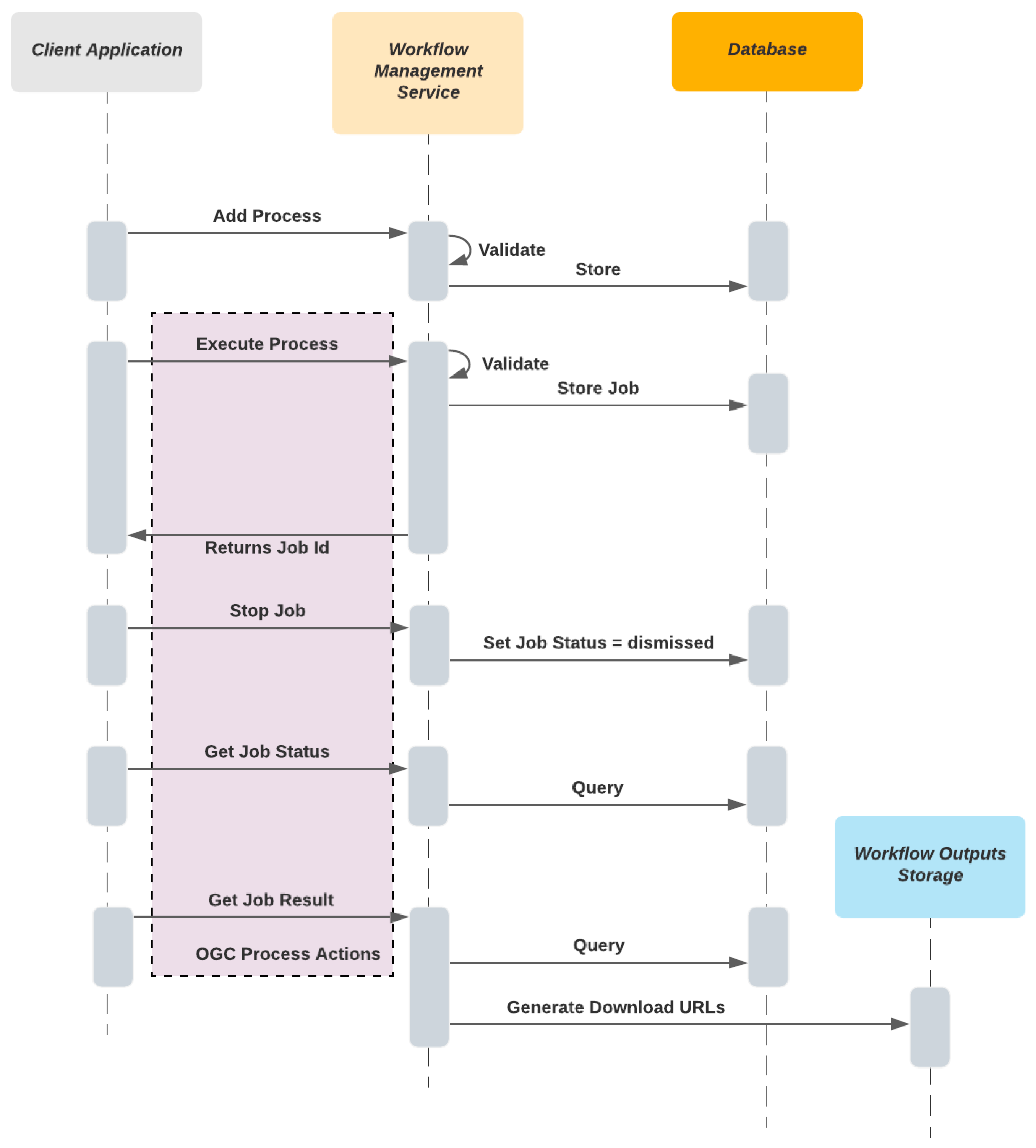
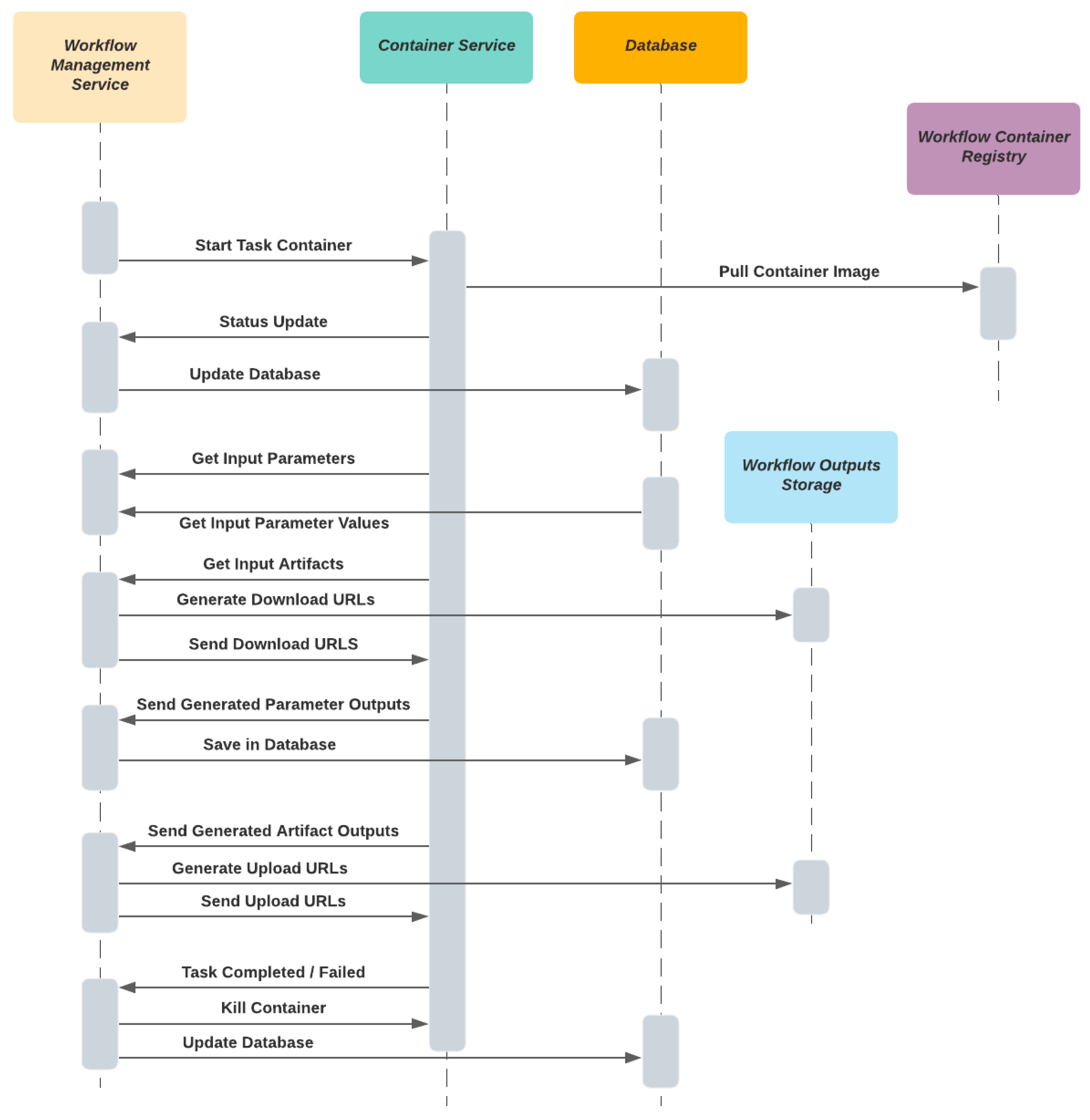
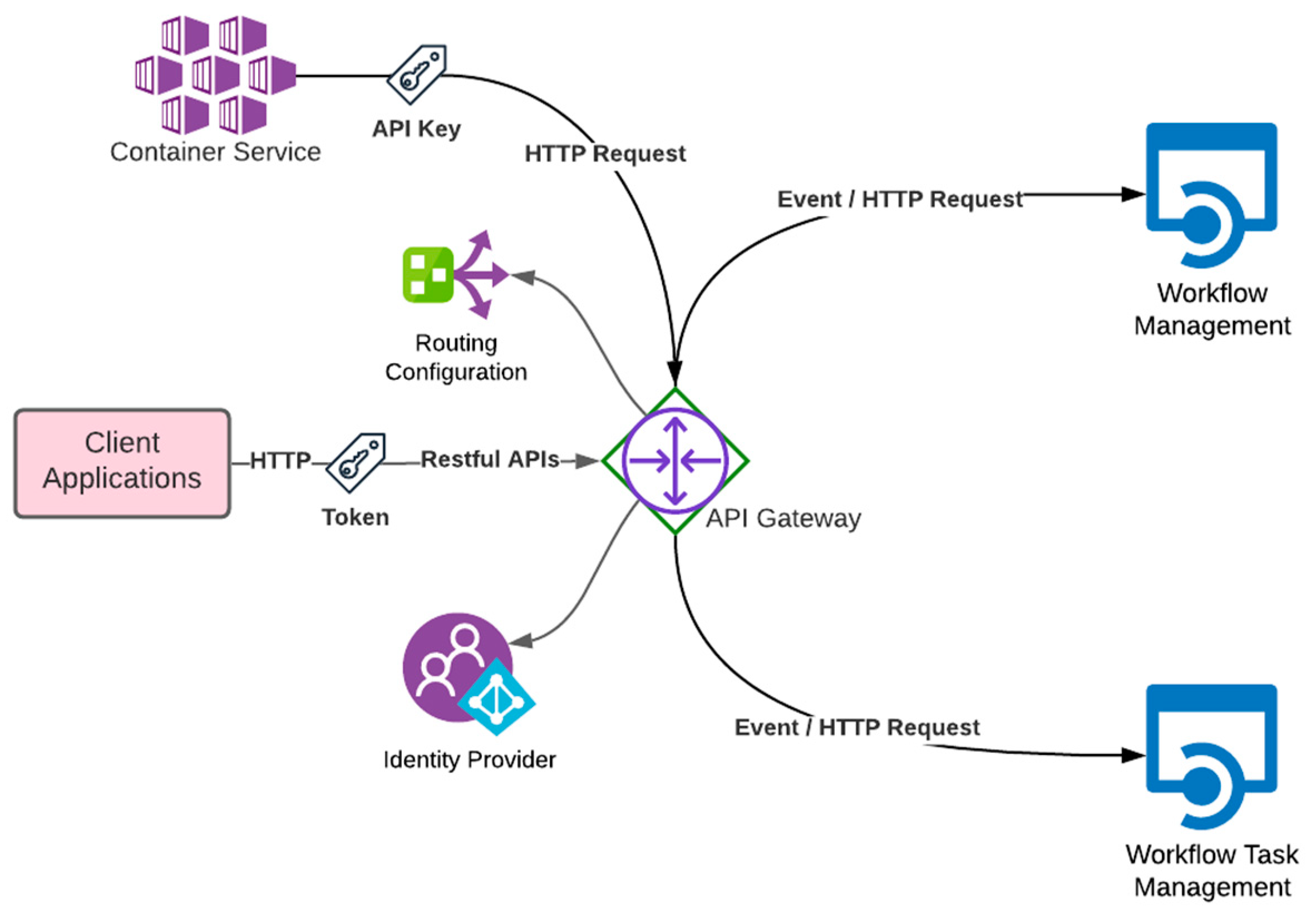
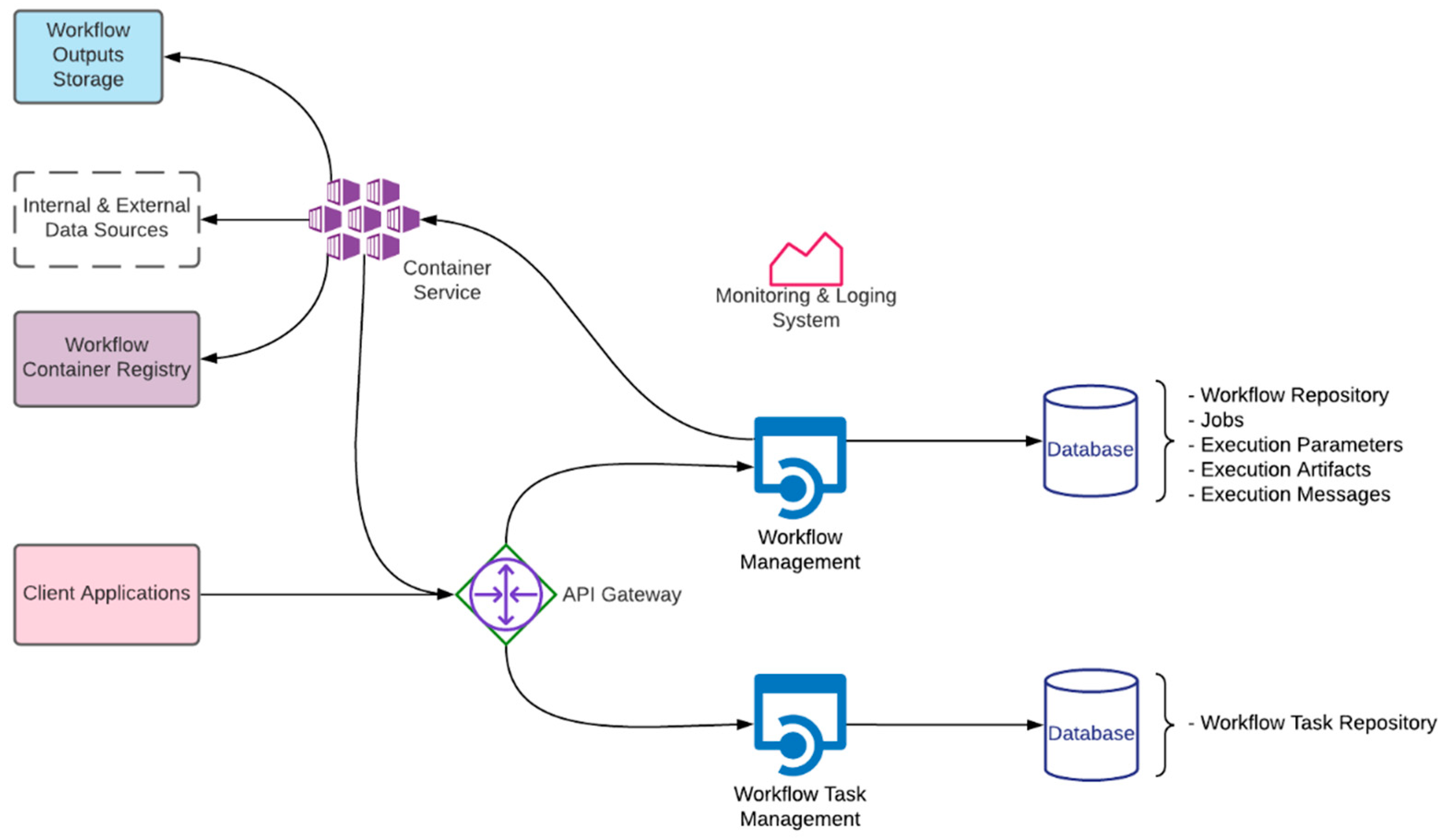
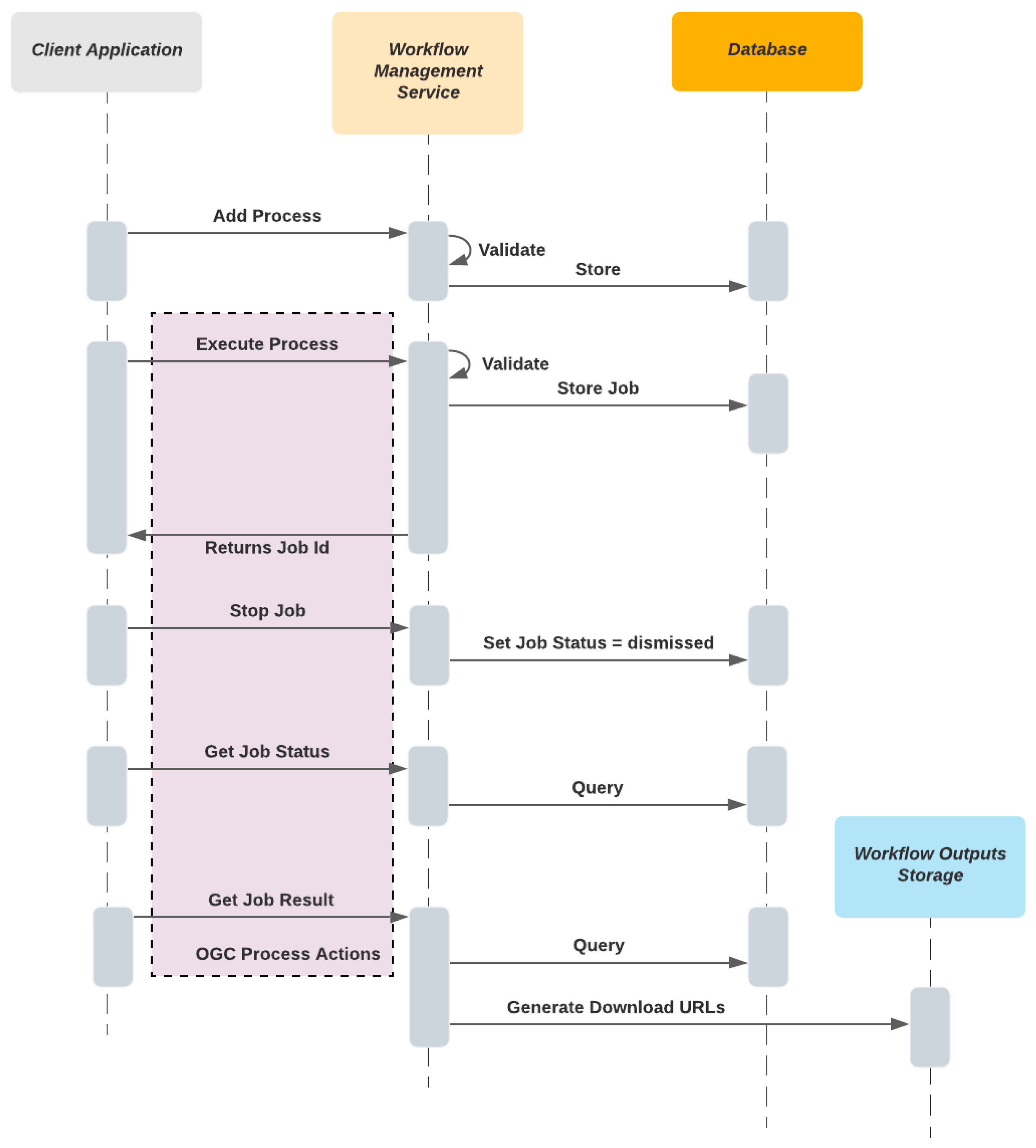
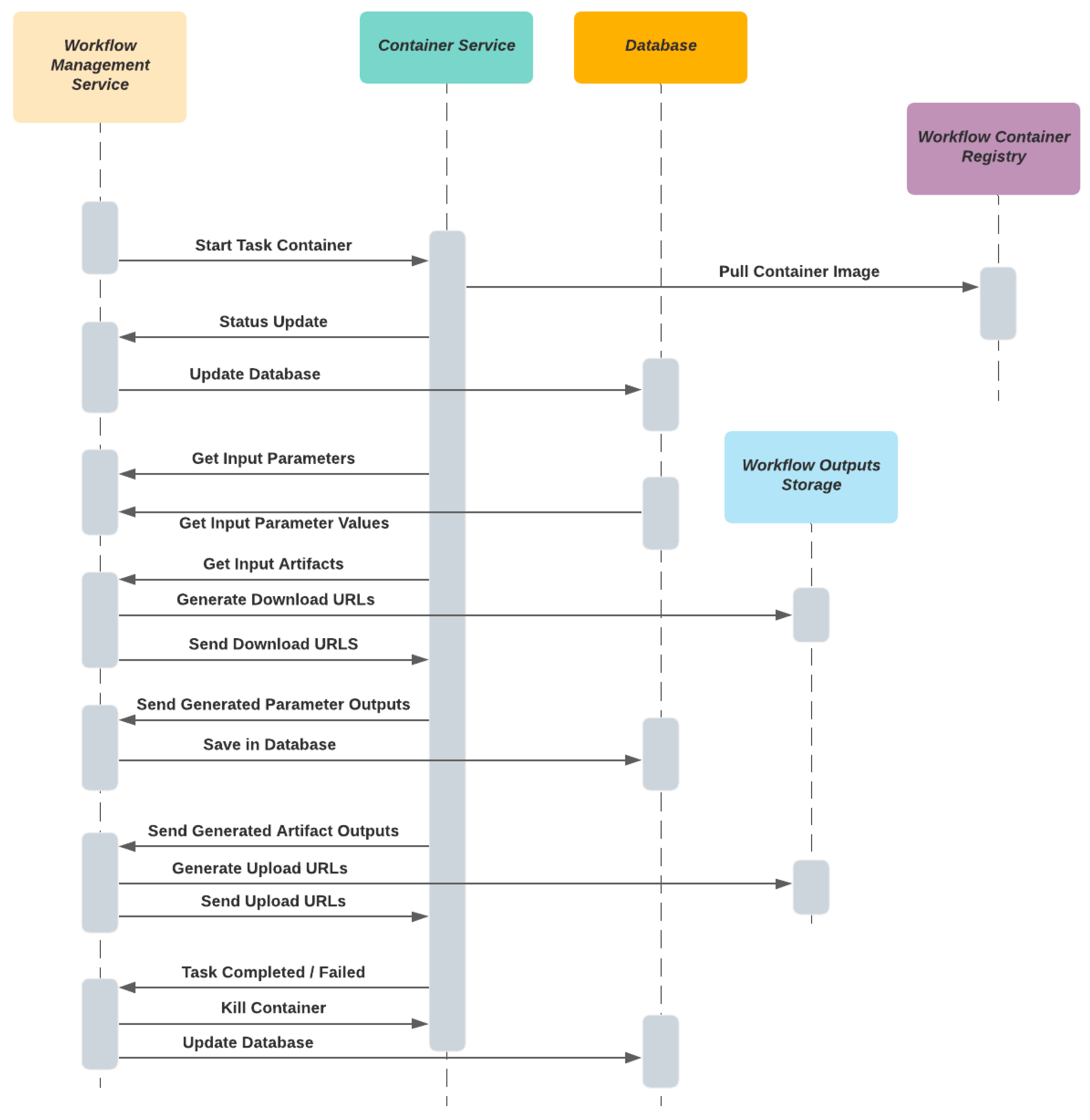
3.2.2. Workflow System
- Workflow Management
- API Gateway
- Container Service
- Workflow Task Management
- Database
- Monitoring and Logging System
- Validate and store workflow definitions
- Run, stop and monitor workflow executions
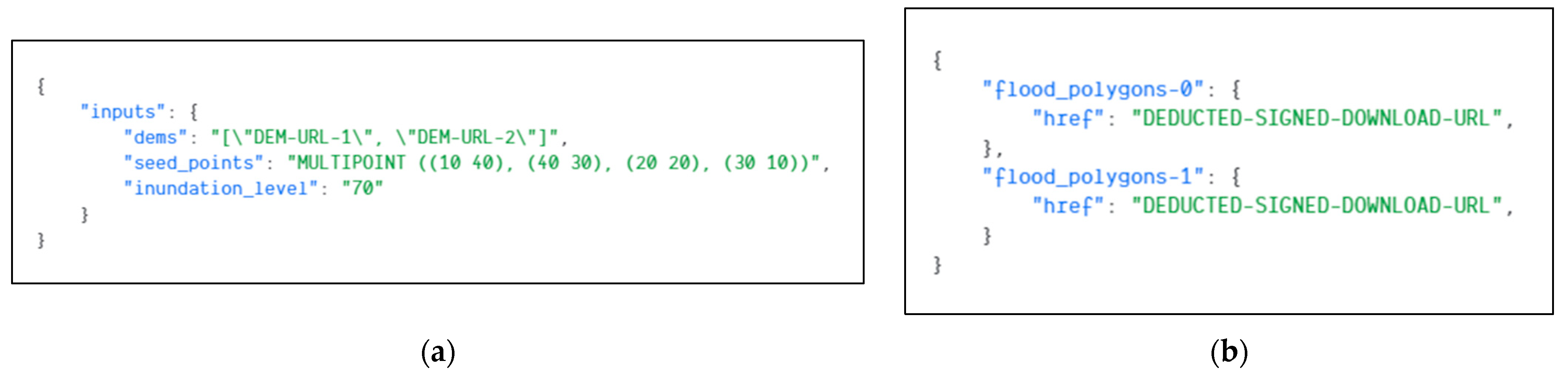
- Present workflow execution deliverables such as literal and binary outputs
3.2.3. Workflow Container Registry
3.2.4. Workflow Output Storage
3.2.5. Client Applications
4. Implementation
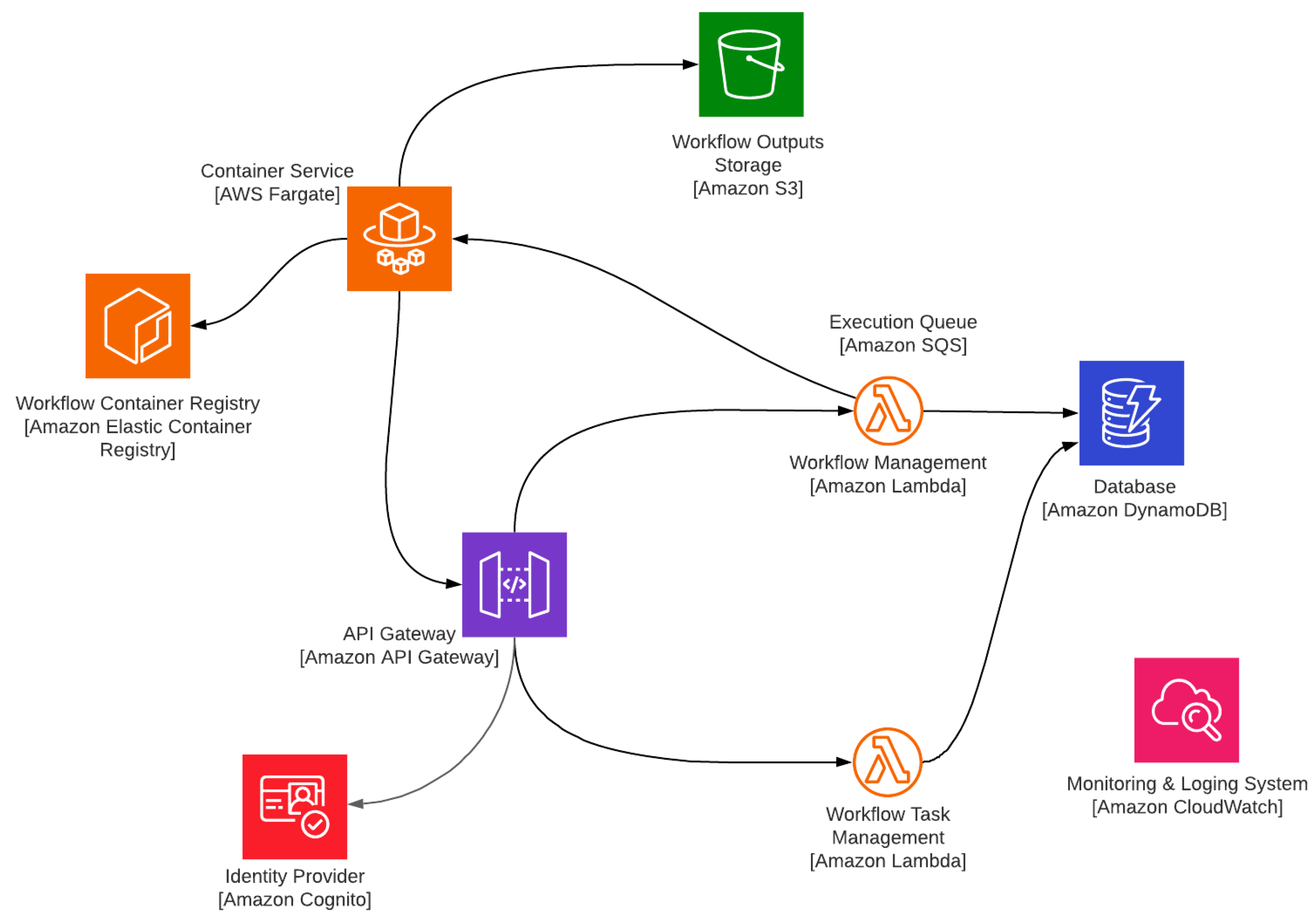
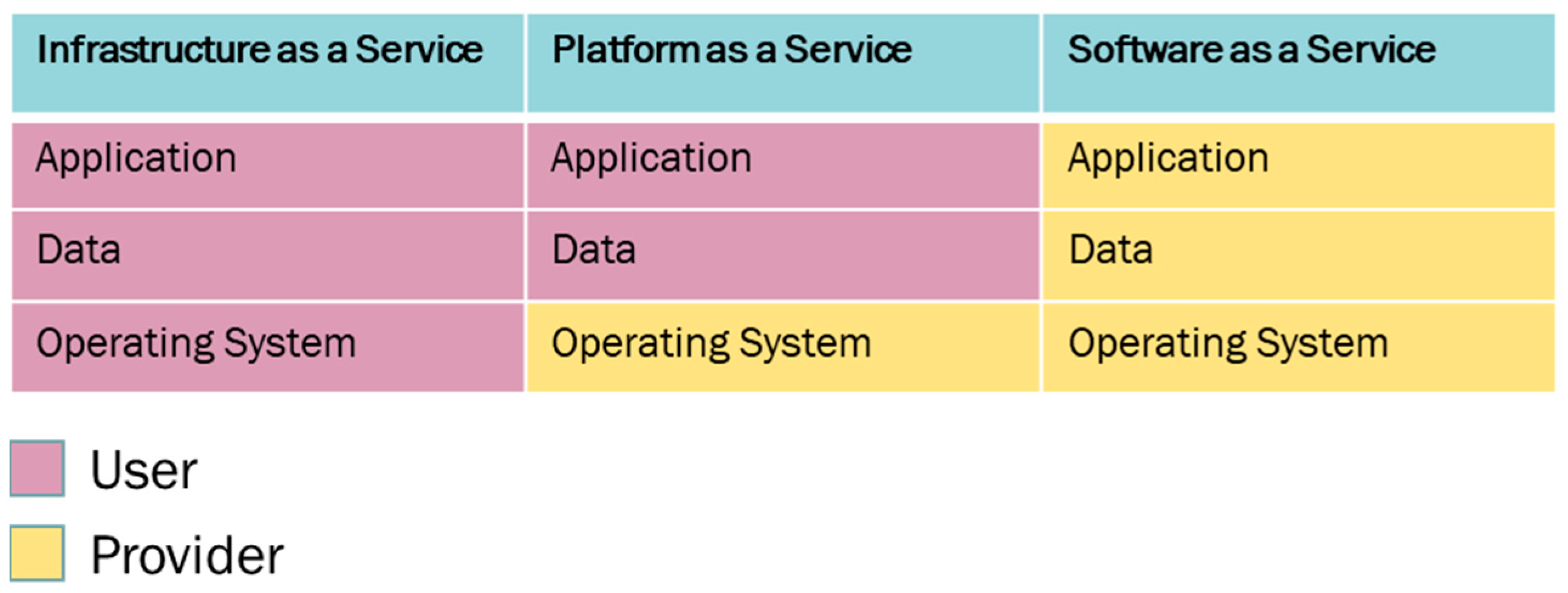
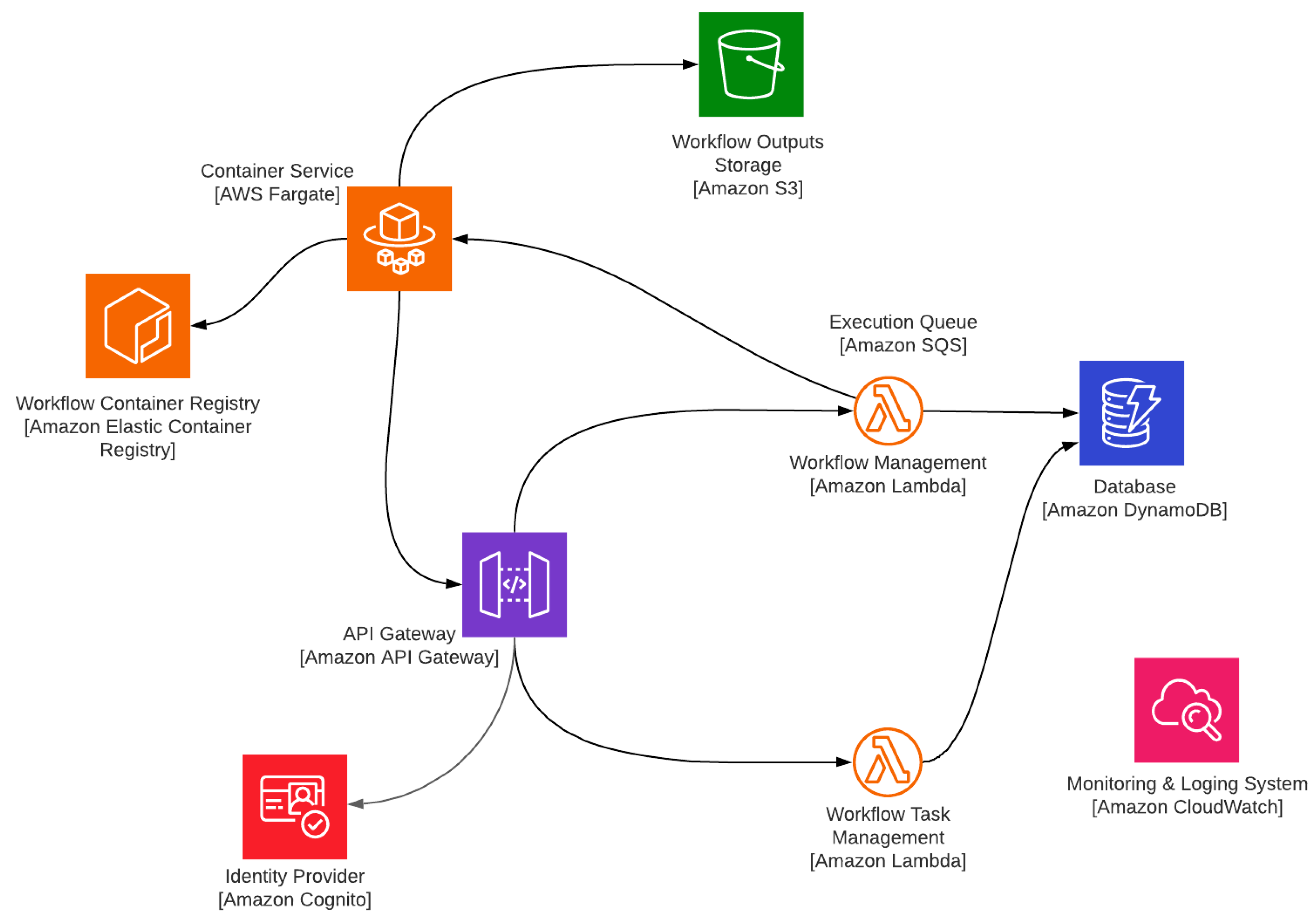
4.1. Cloud Implementation
4.1.1. Used Services in Amazon Web Service
4.1.2. Backend Development
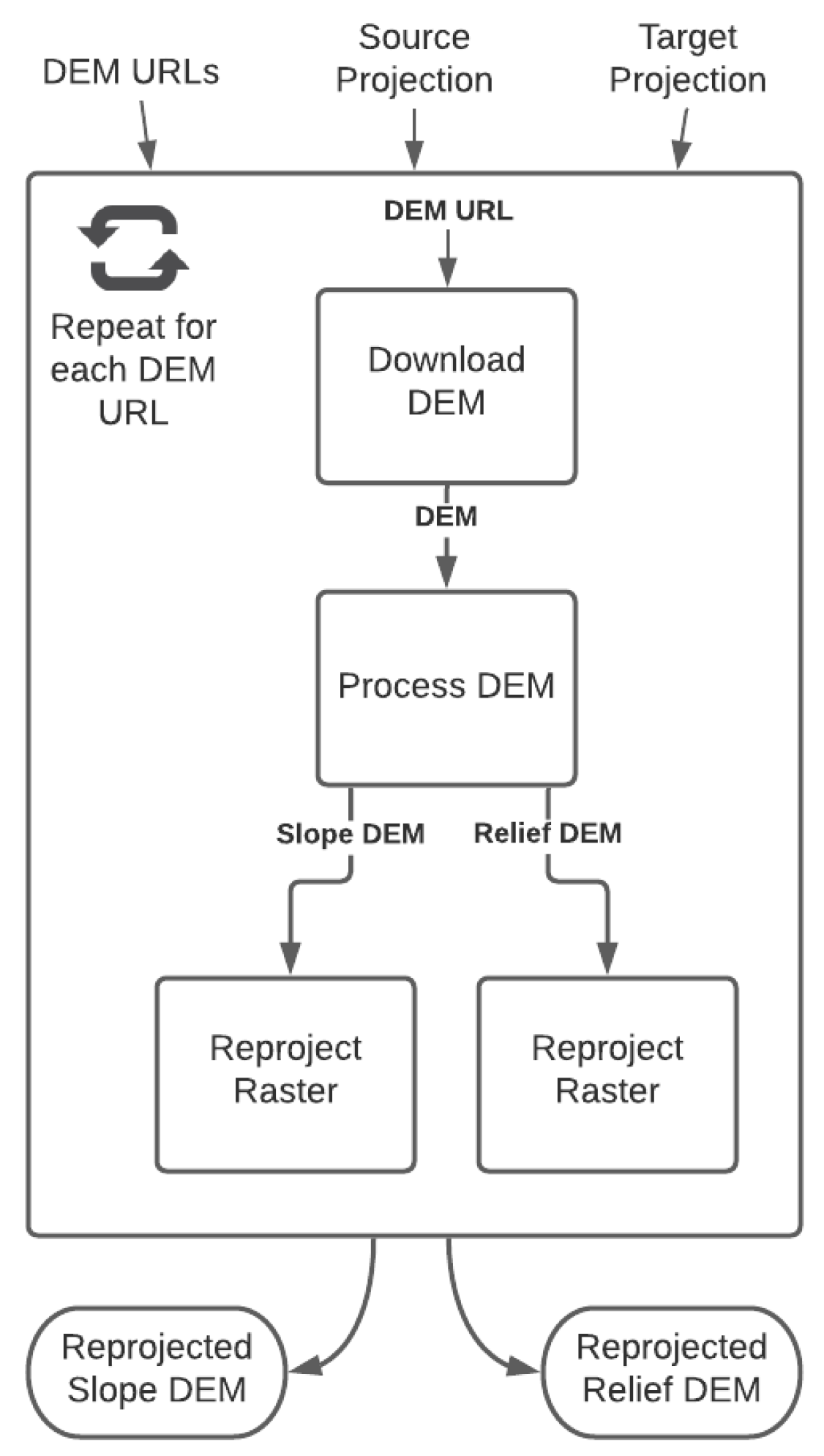
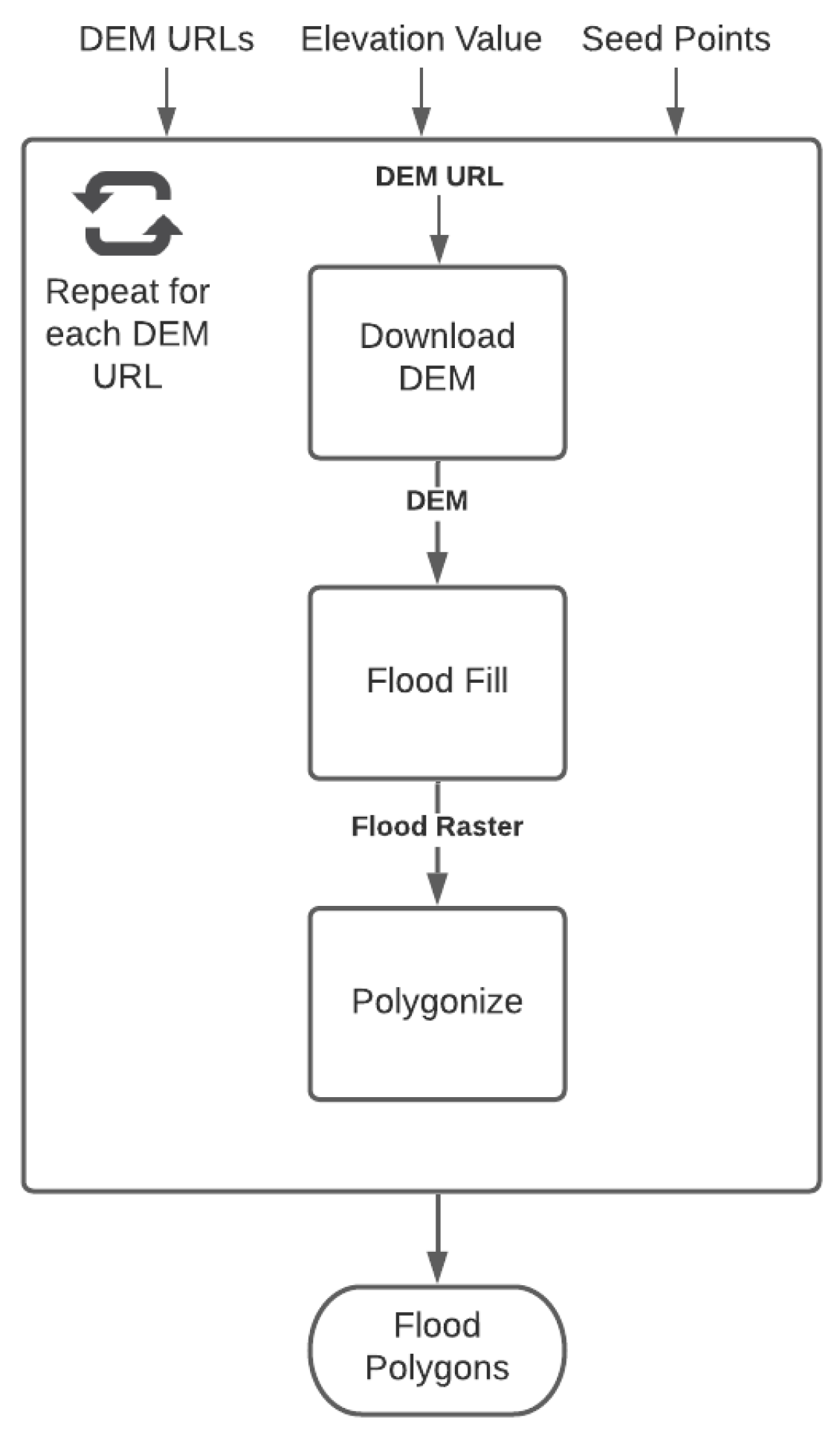
4.2. Evaluation
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- de Oliveira, D.; Ogasawara, E.; Baião, F.; Mattoso, M. SciCumulus: A Lightweight Cloud Middleware to Explore Many Task Computing Paradigm in Scientific Workflows. In Proceedings of the 2010 IEEE 3rd International Conference on Cloud Computing, Miami, FL, USA, 5–10 July 2010; pp. 378–385. [Google Scholar]
- Mell, P.M.; Grance, T. The NIST Definition of Cloud Computing. NIST 2011, SP 800-145, 2–3. [Google Scholar]
- Lloyd, W.; Ramesh, S.; Chinthalapati, S.; Ly, L.; Pallickara, S. Serverless Computing: An Investigation of Factors Influencing Microservice Performance. In Proceedings of the 2018 IEEE International Conference on Cloud Engineering, Orlando, FL, USA, 17–20 April 2018; pp. 159–169. [Google Scholar]
- Rahman, M.M.; Hasan, M.H. Serverless Architecture for Big Data Analytics. In Proceedings of the 2019 Global Conference for Advancement in Technology, Bangaluru, India, 18–20 October 2019; pp. 1–5. [Google Scholar]
- Krämer, M. A Microservice Architecture for the Processing of Large Geospatial Data in the Cloud. Ph.D. Thesis, Technische Universität Darmstadt, Darmstadt, Germany, 2018. [Google Scholar]
- Agarwal, G. Modern DevOps Practices; Packt: Birmingham, UK, 2021. [Google Scholar]
- Baldini, I.; Castro, P.; Chang, K.; Cheng, P.; Fink, S.; Ishakian, V.; Mitchell, N.; Muthusamy, V.; Rabbah, R.; Slominski, A.; et al. Serverless Computing: Current Trends and Open Problems. In Research Advances in Cloud Computing; Chaudhary, S., Somani, G., Buyya, R., Eds.; Springer: Singapore, 2017; pp. 1–20. [Google Scholar]
- Kim, Y.; Lin, J. Serverless Data Analytics with Flint. In Proceedings of the 2018 IEEE 11th International Conference on Cloud Computing, San Francisco, CA, USA, 2–7 July 2018; pp. 451–455. [Google Scholar]
- Malawski, M.; Gajek, A.; Zima, A.; Balis, B.; Figiela, K. Serverless Execution of Scientific Workflows: Experiments with HyperFlow, AWS Lambda and Google Cloud Functions. Future Gen. Comput. Sys. 2020, 110, 502–514. [Google Scholar] [CrossRef]
- Lee, H.; Satyam, K.; Fox, G. Evaluation of Production Serverless Computing Environments. In Proceedings of the IEEE 11th International Conference on Cloud Computing, San Francisco, CA, USA, 2–7 July 2018; pp. 442–450. [Google Scholar]
- Ji, X.; Chen, B.; Huang, Z.; Sui, Z.; Fang, Y. On the Use of Cloud Computing for Geospatial Workflow Applications. In Proceedings of the IEEE 20th International Conference on Geoinformatics, Hong Kong, China, 15–17 June 2012; pp. 1–6. [Google Scholar]
- Krämer, M.; Würz, H.M.; Altenhofen, C. Executing Cyclic Scientific Workflows in the Cloud. J. Cloud Comp. 2021, 10, 25. [Google Scholar] [CrossRef]
- Serverless Workflow. Available online: https://serverlessworkflow.io/ (accessed on 23 October 2021).
- AWS Step Functions. Available online: https://aws.amazon.com/step-functions (accessed on 23 October 2021).
- Azure Logic Apps documentation. Available online: https://docs.microsoft.com/en-us/azure/logic-apps/ (accessed on 23 October 2021).
- Google Cloud Workflows. Available online: https://cloud.google.com/workflows (accessed on 23 October 2021).
- Huang, W.; Zhang, W.; Zhang, D.; Meng, L. Elastic Spatial Query Processing in OpenStack Cloud Computing Environment for Time-Constraint Data Analysis. ISPRS Int. J. Geo-Inf. 2017, 6, 84. [Google Scholar] [CrossRef] [Green Version]
- Argo Workflows. Available online: https://argoproj.github.io/argo-workflows/ (accessed on 23 October 2021).
- Kubeflow. Available online: https://www.kubeflow.org/ (accessed on 23 October 2021).
- van der Aalst, W.M.P.; ter Hofstede, A.H.M. YAWL: Yet Another Workflow Language. Info. Sys. 2005, 30, 245–275. [Google Scholar] [CrossRef] [Green Version]
- YAML Ain’t Markup Language. Available online: https://yaml.org/ (accessed on 23 October 2021).
- Pross, B.; Vretanos, P.A. OGC API—Processes—Part 1: Core, 1.0-Draft.7; Open Geospatial Consortium: Arlington, VA, USA, 2021; Available online: https://docs.ogc.org/is/18-062r2/18-062r2.html (accessed on 23 October 2021).
- Taibi, D.; Spillner, J.; Wawruch, K. Serverless Computing-Where Are We Now, and Where Are We Heading? IEEE Softw. 2021, 38, 25–31. [Google Scholar] [CrossRef]
- Taibi, D.; Lenarduzzi, V. On the Definition of Microservice Bad Smells. IEEE Softw. 2018, 35, 56–62. [Google Scholar] [CrossRef]
- Ingeno, J. Software Architect’s Handbook; Packt: Birmingham, UK, 2018. [Google Scholar]
- Karavisileiou, A.; Mainas, N.; Petrakis, E.G.M. Ontology for OpenAPI REST Services Descriptions. In Proceedings of the IEEE 32nd International Conference on Tools with Artificial Intelligence, Baltimore, MD, USA, 9–11 November 2020; pp. 35–40. [Google Scholar]
- Messina, A.; Rizzo, R.; Storniolo, P.; Urso, A. A Simplified Database Pattern for the Microservice Architecture. In Proceedings of the 8th International Conference on Advances in Databases, Knowledge and Data Applications, Lisbon, Portugal, 2–4 June 2016; pp. 35–40. [Google Scholar]
- Cinque, M.; Corte, R.D.; Pecchia, A. Microservices Monitoring with Event Logs and Black Box Execution Tracing. In IEEE Transactions on Services Computing; IEEE: Greenvile, SC, USA, 2019. [Google Scholar]
- Raj, P.; Raman, A.; Subramanian, H. Architectural Patterns; Packt: Birmingham, UK, 2017. [Google Scholar]
- Klimovic, A.; Wang, Y.; Kozyrakis, C.; Stuedi, P.; Pfefferle, J.; Trivedi, A. Understanding ephemeral storage for serverless analytics. In Proceedings of the 2018 USENIX Conference on Usenix Annual Technical Conference, Boston, MA, USA, 9–13 July 2018; pp. 789–794. [Google Scholar]
- McKendrick, R. Kubernetes for Serverless Applications; Packt: Birmingham, UK, 2018. [Google Scholar]
- Nickoloff, J.; Kuenzli, S.; Fisher, B. Docker in Action, 2nd ed.; Manning Publications Co.: Shelter Island, NY, USA, 2019. [Google Scholar]
- AWS Well-Architected. Available online: https://aws.amazon.com/architecture/well-architected (accessed on 23 October 2021).
- Sisák, M. Cost-optimal AWS Deployment Configuration for Containerized Event-driven Systems. Master’s Thesis, Masaryk University, Brno, Czechia, 2021. [Google Scholar]
- Diagboya, E. Infrastructure Monitoring with Amazon CloudWatch; Packt: Birmingham, UK, 2021. [Google Scholar]
- Beach, B.; Armentrout, S.; Bozo, R.; Tsouris, E. Simple Storage Service. In Pro PowerShell for Amazon Web Services; Apress: Berkeley, CA, USA, 2019; pp. 275–299. [Google Scholar]
- Vijayakumar, T. API Gateways. In Practical API Architecture and Development with Azure and AWS; Apress: Berkeley, CA, USA, 2018; pp. 51–96. [Google Scholar]
- Poccia, D. AWS Lambda in Action: Event-Driven Serverless Applications; Manning Publications: Shelter Island, NY, USA, 2017. [Google Scholar]
- Guo, D.; Onstein, E. State-of-the-Art Geospatial Information Processing in NoSQL Databases. ISPRS Int. J. Geo-Inf. 2020, 9, 331. [Google Scholar] [CrossRef]
- Mete, M.O.; Yomralioglu, T. Implementation of Serverless Cloud GIS Platform for Land Valuation. Int. J. Dig. Earth 2021, 14, 836–850. [Google Scholar] [CrossRef]
- Amazon Fargate Service. Available online: https://aws.amazon.com/fargate/ (accessed on 24 October 2021).
- The Twelve-Factor App. Available online: https://12factor.net/ (accessed on 24 October 2021).
- Marcotte, C.-H.; Zebdi, A. An Atypical ASP.NET Core 5 Design Patterns; Packt: Birmingham, UK, 2020. [Google Scholar]
- AWS Documentation. Available online: https://docs.aws.amazon.com/index.html (accessed on 6 December 2021).
- Lawhead, J. Learning Geospatial Analysis with Python, 3rd ed.; Packt: Birmingham, UK, 2019. [Google Scholar]
- Mueller, M. OGC WPS 2.0.2 Interface Standard Corrigendum 2, 2.0.2; Open Geospatial Consortium: Arlington, VA, USA, 2015; Available online: http://docs.opengeospatial.org/is/14-065/14-065.html (accessed on 1 December 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property Name | Validation Rules |
|---|---|
| Name | It cannot be empty. Allowed characters: “Alphanumeric, -, _”. It must be a unique name and should be not used by any other existing stored tasks. |
| Description | It cannot be empty |
| Image | It cannot be empty. The container image must be available in the container registry. |
| Inputs[n]: Name Outputs[n]: Name | It cannot be empty. Allowed characters: Alphanumeric, -, _ It must be a unique name along with other inputs/outputs in the task |
| Inputs[n]: Type Outputs[n]: Type | It cannot be empty The value must be “artifact” or “parameter”. |
| Property Name | Validation Rules |
|---|---|
| Name | It cannot be empty. Allowed characters: “Alphanumeric, -, _”. It must be a unique name and should be not used by any other existing stored workflows. |
| Inputs Outputs | It is optional. It can be neglected if there is no need to pass input to workflow. |
| Inputs: Parameters[n]: Name | It cannot be empty. |
| Outputs: Parameters [n]: Name Outputs: Artifacts [n]: Name | It cannot be empty. It must name one of the task definition’s parameter/artifact output names. |
| Steps | It must contain at least one step. |
| Steps[n]: Id | It cannot be empty. Allowed characters: “Alphanumeric, -, _”. It must be a unique name along with other steps in the workflow definition. |
| Steps[n]: Task | It cannot be empty. It must be a value of one of these: A registered task name ForEach Parallel |
| Steps[n]: Inputs | It is optional. It can be neglected if there is no need to pass an input. |
| Steps[n]: Inputs: Parameters Steps[n]: Inputs: Artifacts | It is optional. It can be neglected if there is no need to pass a parameter/artifact input. |
| Steps[n]: Inputs: Parameters[n]: Name Steps[n]: Inputs: Artifacts [n]: Name | It cannot be empty. It must name one of the task definition’s parameter/artifact inputs names. |
| Steps[n]: Inputs: Parameters[n]: Value | It cannot be empty. It must be a scalar or reference value. |
| Steps[n]: Inputs: Artifacts [n]: Value | It cannot be empty. It must be a reference value. |
| Steps[n]: Outputs | It is optional. It can be neglected if there is no output from the step. |
| Steps[n]: Outputs: Parameters Steps[n]: Outputs: Artifacts | It is optional. It can be neglected if there is no need to store and use generated parameter/artifact outputs. |
| Steps[n]: Outputs: Parameters[n]: Name Steps[n]: Outputs: Artifacts [n]: Name | It cannot be empty It must name one of the task definition’s parameter/artifact output names |
| Steps[n]: Iterate | It must be used if Steps[n]: Task value is “ForEach”. |
| Steps[n]: Iterate: Collection | It cannot be empty. It must be a reference value. |
| Steps[n]: Iterate: MaxConcurreny | It must be a number greater than 1. |
| Steps[n]: Iterate: Steps | It must contain at least one step to iterate. All validation rules for the step above are also valid for iteration steps. |
| Steps[n]: Branches | It must be used if Steps[n]: Task value is “Parallel”. It must contain a multidimensional array Each row represents branches that will execute in parallel Each column represents a list of steps It must contain at least two rows Each row must contain at least one step All validation rules for the step above are also valid for parallel steps |
| Path | Description | Backend Service | Role |
|---|---|---|---|
| /processes/* /jobs/* | OGC API Processes Endpoints[X] | Workflow Management | User/Developer |
| /workflows/* | Workflow Management Endpoints | ||
| /stepexecutions/* | Workflow Execution Endpoints | Workflow Management | Container |
| /tasks/* | Workflow Task Management Endpoints | Workflow Task Management | Developer |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pakdil, M.E.; Çelik, R.N. Serverless Geospatial Data Processing Workflow System Design. ISPRS Int. J. Geo-Inf. 2022, 11, 20. https://doi.org/10.3390/ijgi11010020
Pakdil ME, Çelik RN. Serverless Geospatial Data Processing Workflow System Design. ISPRS International Journal of Geo-Information. 2022; 11(1):20. https://doi.org/10.3390/ijgi11010020
Chicago/Turabian StylePakdil, Mete Ercan, and Rahmi Nurhan Çelik. 2022. "Serverless Geospatial Data Processing Workflow System Design" ISPRS International Journal of Geo-Information 11, no. 1: 20. https://doi.org/10.3390/ijgi11010020
APA StylePakdil, M. E., & Çelik, R. N. (2022). Serverless Geospatial Data Processing Workflow System Design. ISPRS International Journal of Geo-Information, 11(1), 20. https://doi.org/10.3390/ijgi11010020