
Semantic Segmentation of High-Resolution Airborne Images with Dual-Stream DeepLabV3+



Abstract
1. Introduction
2. Methods
2.1. Data Augmentation
2.2. Dual-Stream DeepLabV3+
2.3. Training Approaches
3. Results
3.1. Evaluation of Single-Stream Models
3.2. Evaluation of Dual-Stream Models
3.3. Evaluation of the Vaihingen Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Masouleh, M.K.; Shah-Hosseini, R. Development and evaluation of a deep learning model for real-time ground vehicle semantic segmentation from UAV-based thermal infrared imagery. ISPRS J. Photogramm. Remote Sens. 2019, 155, 172–186. [Google Scholar] [CrossRef]
- Venugopal, N. Automatic semantic segmentation with DeepLab dilated learning network for change detection in remote sensing images. Neural Processing Lett. 2020, 51, 2355–2377. [Google Scholar] [CrossRef]
- Xu, Z.; Su, C.; Zhang, X. A semantic segmentation method with category boundary for Land Use and Land Cover (LULC) mapping of Very-High Resolution (VHR) remote sensing image. Int. J. Remote Sens. 2021, 42, 3146–3165. [Google Scholar] [CrossRef]
- Touzani, S.; Granderson, J. Open Data and Deep Semantic Segmentation for Automated Extraction of Building Footprints. Remote Sens. 2021, 13, 2578. [Google Scholar] [CrossRef]
- Bragagnolo, L.; Rezende, L.; da Silva, R.; Grzybowski, J. Convolutional neural networks applied to semantic segmentation of landslide scars. CATENA 2021, 201, 105189. [Google Scholar] [CrossRef]
- Kanwal, S.; Uzair, M.; Ullah, H. A Survey of Hand Crafted and Deep Learning Methods for Image Aesthetic Assessment. arXiv 2021, arXiv:2103.11616. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P. Support vector machines for classification in remote sensing. Int. J. Remote Sens. 2005, 26, 1007–1011. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Mas, J.F.; Flores, J.J. The application of artificial neural networks to the analysis of remotely sensed data. Int. J. Remote Sens. 2008, 29, 617–663. [Google Scholar] [CrossRef]
- Moen, E.; Bannon, D.; Kudo, T.; Graf, W.; Covert, M.; Van Valen, D. Deep learning for cellular image analysis. Nat. Methods 2019, 16, 1233–1246. [Google Scholar] [CrossRef] [PubMed]
- Hameed, K.; Chai, D.; Rassau, A. Score-based mask edge improvement of Mask-RCNN for segmentation of fruit and vegetables. Expert Syst. Appl. 2021, 190, 116205. [Google Scholar] [CrossRef]
- Wei, X.S.; Cui, Q.; Yang, L.; Wang, P.; Liu, L. RPC: A large-scale retail product checkout dataset. arXiv 2019, arXiv:1901.07249. [Google Scholar]
- Hamian, M.H.; Beikmohammadi, A.; Ahmadi, A.; Nasersharif, B. Semantic Segmentation of Autonomous Driving Images by the combination of Deep Learning and Classical Segmentation. In Proceedings of the 2021 26th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 3–4 March 2021; pp. 1–6. [Google Scholar]
- Müller, D.; Ehlen, A.; Valeske, B. Convolutional neural networks for semantic segmentation as a tool for multiclass face analysis in thermal infrared. J. Nondestruct. Eval. 2021, 40, 1–10. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef]
- Neubert, M.; Herold, H.; Meinel, G. Evaluation of remote sensing image segmentation quality–further results and concepts. In Proceedings of the International Conference on Object-Based Image Analysis (ICOIA), Salzburg, Austria, 4–5 July 2006; pp. 1–6. [Google Scholar]
- Akcay, O.; Avsar, E.; Inalpulat, M.; Genc, L.; Cam, A. Assessment of Segmentation Parameters for Object-Based Land Cover Classification Using Color-Infrared Imagery. ISPRS Int. J. Geo-Inf. 2018, 7, 424. [Google Scholar] [CrossRef]
- Schwartzman, A.; Kagan, M.; Mackey, L.; Nachman, B.; De Oliveira, L. Image Processing, Computer Vision, and Deep Learning: New Approaches to the Analysis and Physics Interpretation of LHC Events; IOP Publishing: Bristol, UK, 2016; Volume 762, p. 012035. [Google Scholar]
- Sherrah, J. Fully Convolutional Networks for Dense Semantic Labelling of High-Resolution Aerial Imagery. arXiv 2016, arXiv:1606.02585. [Google Scholar]
- Wang, J.; Shen, L.; Qiao, W.; Dai, Y.; Li, Z. Deep feature fusion with integration of residual connection and attention model for classification of VHR remote sensing images. Remote Sens. 2019, 11, 1617. [Google Scholar] [CrossRef]
- Sun, Y.; Tian, Y.; Xu, Y. Problems of encoder-decoder frameworks for high-resolution remote sensing image segmentation: Structural stereotype and insufficient learning. Neurocomputing 2019, 330, 297–304. [Google Scholar] [CrossRef]
- Marcu, A.; Leordeanu, M. Dual Local-Global Contextual Pathways for Recognition in Aerial Imagery. arXiv 2016, arXiv:1605.05462. [Google Scholar]
- Piramanayagam, S.; Saber, E.; Schwartzkopf, W.; Koehler, F.W. Supervised classification of multisensor remotely sensed images using a deep learning framework. Remote Sens. 2018, 10, 1429. [Google Scholar] [CrossRef]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Du, S.; Du, S.; Liu, B.; Zhang, X. Incorporating DeepLabv3+ and object-based image analysis for semantic segmentation of very high resolution remote sensing images. Int. J. Digit. Earth 2021, 14, 357–378. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef]
- Song, A.; Kim, Y. Semantic Segmentation of Remote-Sensing Imagery Using Heterogeneous Big Data: International Society for Photogrammetry and Remote Sensing Potsdam and Cityscape Datasets. ISPRS Int. J. Geo-Inf. 2020, 9, 601. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2020, 169, 114417. [Google Scholar] [CrossRef]
- Nikparvar, B.; Thill, J.C. Machine Learning of Spatial Data. ISPRS Int. J. Geo-Inf. 2021, 10, 600. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, J.; Huang, K.; Liang, K.; Yu, Y. Fastfcn: Rethinking dilated convolution in the backbone for semantic segmentation. arXiv 2019, arXiv:1903.11816. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-scnn: Gated shape cnns for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 5229–5238. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. arXiv 2020, arXiv:2001.05566. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- ISPRS. International Society for Photogrammetry and Remote Sensing. 2D Semantic Labeling Challenge. 2016. Available online: http://www2.isprs.org/commissions/comm3/wg4/semantic-labeling.html (accessed on 5 October 2021).
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Cramer, M. The DGPF-test on digital airborne camera evaluation overview and test design. PFG Photogramm. Fernerkund. Geoinf. 2010, 2010, 73–82. [Google Scholar] [CrossRef] [PubMed]
- Akcay, O.; Kinaci, A.C.; Avsar, E.O.; Aydar, U. Boundary Extraction Based on Dual Stream Deep Learning Model in High Resolution Remote Sensing Images. J. Adv. Res. Nat. Appl. Sci. 2021, 7, 358–368. [Google Scholar] [CrossRef]
- Gerke, M. Use of the Stair Vision Library within the ISPRS 2D Semantic Labeling Benchmark (Vaihingen); Technical Report; University of Twente: Enschede, The Netherlands, 2015. [Google Scholar] [CrossRef]
- McNeely-White, D.; Beveridge, J.R.; Draper, B.A. Inception and ResNet features are (almost) equivalent. Cogn. Syst. Res. 2020, 59, 312–318. [Google Scholar] [CrossRef]
- Hao, S.; Zhou, Y.; Guo, Y. A brief survey on semantic segmentation with deep learning. Neurocomputing 2020, 406, 302–321. [Google Scholar] [CrossRef]
- Azimi, S.M.; Henry, C.; Sommer, L.; Schumann, A.; Vig, E. Skyscapes fine-grained semantic understanding of aerial scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 7393–7403. [Google Scholar]
- Boguszewski, A.; Batorski, D.; Ziemba-Jankowska, N.; Zambrzycka, A.; Dziedzic, T. Landcover. ai: Dataset for automatic mapping of buildings, woodlands and water from aerial imagery. arXiv 2020, arXiv:2005.02264. [Google Scholar]
- Abraham, N.; Khan, N.M. A novel focal tversky loss function with improved attention u-net for lesion segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 683–687. [Google Scholar]
- Gragera, A.; Suppakitpaisarn, V. Semimetric properties of sørensen-dice and tversky indexes. In International Workshop on Algorithms and Computation; Springer: Cham, Switzerland, 2016; pp. 339–350. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Augmen- Tation | Dataset | Input Data | # of Sub-Images for Each Patch | Operations | # of Total Sub-Images | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Rotation | Flipping | Contrast | Brightness | Hue | Saturation | Training | Test | ||||
| DA-I | sub | RGB IR | 81 | non, 90°, 180°, 270° | yes/no | non, −50%, +50% | - | - | - | 3499 | 389 |
| nDSM NDVI Label | 81 | non, 90°, 180°, 270° | yes/no | - | - | - | - | 1166 | 130 | ||
| full | RGB IR | 81 | non, 90°, 180°, 270° | yes/no | non, −50%, +50% | 46,656 | 1134 | ||||
| nDSM NDVI Label | 81 | non, 90°, 180°, 270° | yes/no | - | - | - | - | 15,552 | 1134 | ||
| DA-II | full | RGB IR | 100 | non, 90°, 180°, 270° randomly | yes/no randomly | (0.7–1.3) | (−0.05, 0.05) | (−0.08,0.08) | (0.6,1.6) | 96,000 | 1134 |
| nDSM NDVI Label | 100 | non, 90°, 180°, 270° randomly | yes/no randomly | - | - | - | - | ∼19,200 | 1334 | ||
| Usage Status | Patch Coverage | Imp. Surf. (%) | Building (%) | Low Veg. (%) | Tree (%) | Car (%) | Clutter (%) |
|---|---|---|---|---|---|---|---|
| - | 2_10 | 20.65 | 15.13 | 42.17 | 7.44 | 0.87 | 13.73 |
| - | 5_12 | 31.23 | 48.62 | 8.92 | 5.92 | 3.06 | 2.26 |
| sub-dataset for Training | 2_10 and 5_12 | 25.94 | 31.87 | 25.55 | 6.68 | 1.96 | 8.00 |
| Full dataset for Training | 24 patches including 2_10 and 5_12 | 28.46 | 26.72 | 23.54 | 14.62 | 1.69 | 4.96 |
| Test dataset | 14 patches | 31.47 | 23.92 | 21.01 | 17.04 | 1.96 | 4.59 |
| Model | Loss Function | Transfer Learning | Fine Tuning | Patch Size | Data Augmentation (DA) | Inputs Based on Stream Structure | Dataset | |
|---|---|---|---|---|---|---|---|---|
| First Stream | Second Stream | |||||||
| M1 | cross entropy | - | - | 800 × 800 | DA-I | nDSM | - | sub |
| M2 | cross entropy | - | - | 800 × 800 | DA-I | nDSM + IR | - | sub |
| M3 | cross entropy | - | - | 800 × 800 | DA-I | nDSM + NDVI | - | sub |
| M4 | cross entropy | - | - | 800 × 800 | DA-I | nDSM + IR + NDVI | - | sub |
| M5 | cross entropy | + | - | 800 × 800 | DA-I | nDSM + IR + NDVI | - | sub |
| M6 | cross entropy | + | + | 800 × 800 | DA-I | nDSM + IR + NDVI | - | sub |
| M7 | cross entropy | + | - | 800 × 800 | DA-I | R + G + B | - | sub |
| M8 | cross entropy | + | + | 800 × 800 | DA-I | R + G + B | - | sub |
| Model | M1 | M2 | M3 | M4 | M5 | M6 | M7 | M8 |
|---|---|---|---|---|---|---|---|---|
| Overall (%) | 30.15 | 48.52 | 35.30 | 52.39 | 68.62 | 86.67 | 69.85 | 87.74 |
| Model | Loss Function | Transfer Learning | Fine Tuning | Patch Size | Data Augmentation (DA) | Inputs Based on Stream Structure | Dataset | |
|---|---|---|---|---|---|---|---|---|
| First Stream | Second Stream | |||||||
| M9 | cross entropy | + | - | 800 × 800 | DA-I | nDSM + IR + NDVI | - | full |
| M10 | cross entropy | + | + | 800 × 800 | DA-I | nDSM + IR + NDVI | - | full |
| M11 | focal Tversky | + | + | 600 × 600 | DA-II | nDSM + IR + NDVI | - | full |
| M12 | cross entropy | + | - | 800 × 800 | DA-I | R + G + B | - | full |
| M13 | cross entropy | + | + | 800 × 800 | DA-I | R + G + B | - | full |
| M14 | focal Tversky | + | + | 600 × 600 | DA-II | R + G + B | - | full |
| Model | Imp. Surf. (%) | Building (%) | Low Veg. (%) | Tree (%) | Car (%) | Overall (%) |
|---|---|---|---|---|---|---|
| M9 | 59.38 | 54.34 | 49.15 | 42.53 | 8.75 | 51.74 |
| M10 | 82.97 | 93.61 | 75.91 | 77.14 | 63.82 | 81.08 |
| M11 | 89.95 | 95.83 | 83.34 | 84.07 | 88.71 | 87.46 |
| M12 | 65.25 | 69.94 | 57.42 | 65.40 | 53.13 | 63.19 |
| M13 | 88.52 | 92.69 | 82.44 | 83.59 | 84.97 | 85.80 |
| M14 | 90.95 | 95.12 | 83.86 | 85.12 | 88.81 | 87.98 |
| Model | Transfer Learning | Fine Tuning | Patch Size | Loss Function | Data Augmentation (DA) | Inputs Based on Stream Structure | Dataset | |
|---|---|---|---|---|---|---|---|---|
| First Stream | Second Stream | |||||||
| M15 | + | + | 800 × 800 | cross entropy | DA-I | R + G + B | nDSM + IR + NDVI | full |
| M16 | + | + | 600 × 600 | focal Tversky | DA-II | R + G + B | nDSM + IR + NDVI | full |
| Model | Imp. Surf. (%) | Building (%) | Low Veg. (%) | Tree (%) | Car (%) | Overall (%) |
|---|---|---|---|---|---|---|
| M15 | 89.71 | 89.71 | 83.49 | 84.97 | 86.39 | 87.20 |
| M16 | 91.18 | 96.14 | 84.85 | 85.56 | 89.07 | 88.71 |
| M16* | 91.34 | 96.07 | 85.17 | 85.80 | 89.58 | 88.87 |
| Imp. Surf. (%) | Building (%) | Low Veg. (%) | Tree (%) | Car (%) | Clutter (%) | |
|---|---|---|---|---|---|---|
| Imp. surf. | 91.92 | 1.39 | 3.47 | 1.46 | 0.50 | 1.26 |
| Building | 1.33 | 96.92 | 0.69 | 0.25 | 0.01 | 0.80 |
| Low veg. | 4.03 | 0.80 | 88.69 | 5.20 | 0.03 | 1.24 |
| Tree | 3.39 | 0.60 | 12.57 | 82.66 | 0.39 | 0.39 |
| Car | 5.33 | 0.24 | 0.23 | 0.56 | 92.73 | 0.92 |
| Clutter | 23.74 | 9.71 | 15.48 | 1.85 | 1.02 | 48.19 |
| Model | Imp. Surf. (%) | Building (%) | Low Veg. (%) | Tree (%) | Car (%) | Overall (%) |
|---|---|---|---|---|---|---|
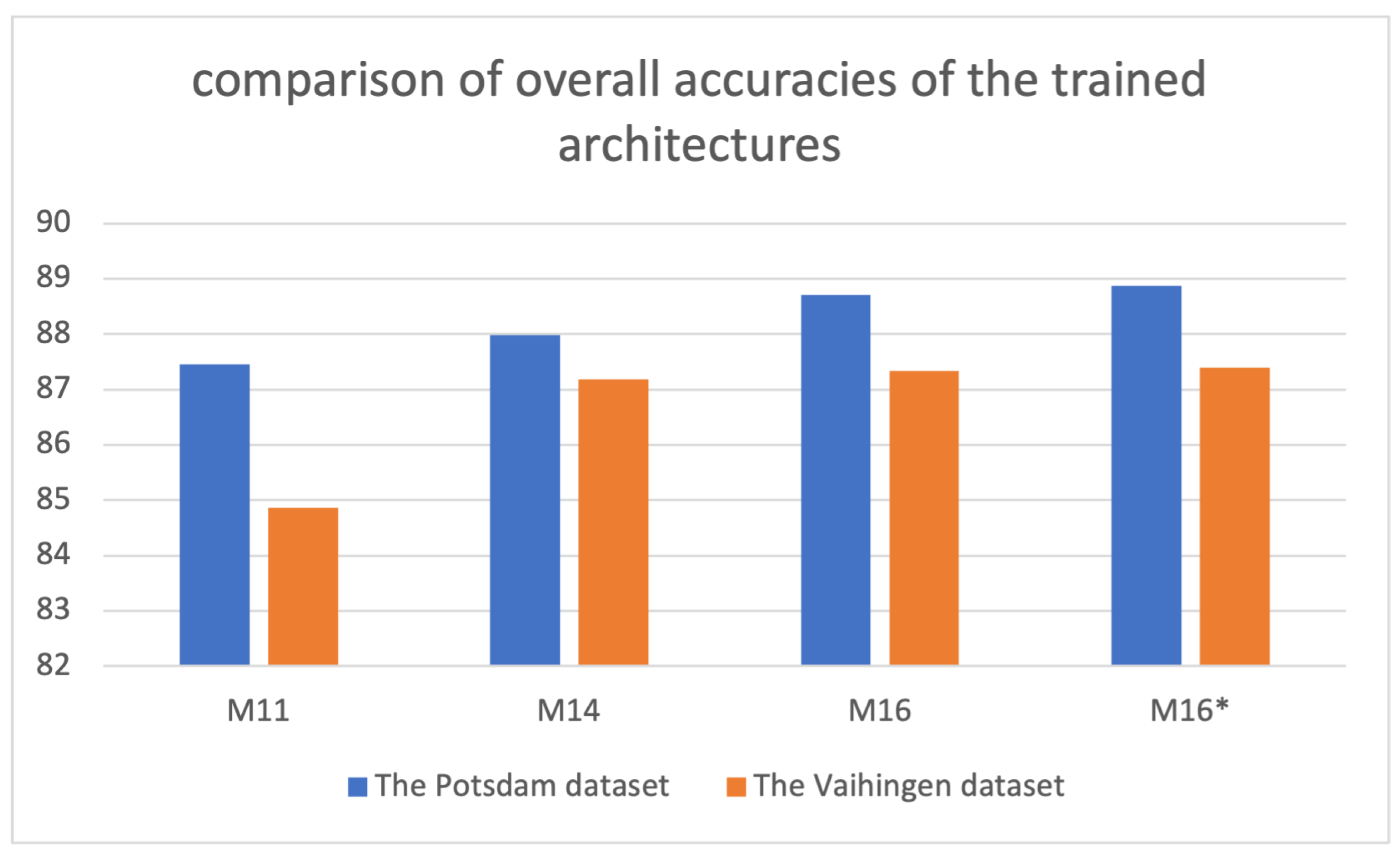
| M11 | 86.51 | 90.84 | 77.83 | 85.59 | 20.78 | 84.86 |
| M14 | 89.06 | 93.40 | 79.32 | 86.61 | 78.75 | 87.18 |
| M16 | 89.21 | 93.53 | 79.26 | 86.87 | 78.64 | 87.33 |
| M16* | 89.58 | 93.72 | 78.88 | 86.74 | 78.85 | 87.39 |
| Model | Motivation | Imp. Surf. (%) | Building (%) | Low Veg. (%) | Tree (%) | Car (%) | Clutter (%) | Based Architecture |
|---|---|---|---|---|---|---|---|---|
| SWJ_2 [21] | (1) Multi-connection (2) Fusion of Multi-scale features | 94.4 | 97.4 | 87.8 | 87.6 | 94.7 | 91.7 | Resnet |
| V-FuseNet [29] | (1) Multi-modal architecture (2) Optimal fusion time | 92.7 | 96.3 | 87.3 | 88.5 | 95.4 | 90.6 | Segnet Resnet |
| Our Proposal | (1) Dual-stream architecture (2) Different training, loss function and training strategies | 91.3 | 96.1 | 85.2 | 85.8 | 89.6 | 88.9 | DeepLabV3+ |
| RIT (LaFSN) [24] | (1) Dual-stream architecture (2) Investigation of optimal fusion time | 90.6 | 95.9 | 83.5 | 83.3 | 93.1 | 87.9 | FCN-8 Segnet |
| Combined U-net Case2 [30] | From U-net study | 89.2 | 92.9 | 79.7 | 79.8 | 88.5 | 87.2 | U-net |
| DeepLabV3+ (4 Band) [30] | From U-net study 4Band | 88.8 | 91.9 | 80.1 | 82.4 | 87.7 | 86 | DeepLabV3+ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akcay, O.; Kinaci, A.C.; Avsar, E.O.; Aydar, U. Semantic Segmentation of High-Resolution Airborne Images with Dual-Stream DeepLabV3+. ISPRS Int. J. Geo-Inf. 2022, 11, 23. https://doi.org/10.3390/ijgi11010023
Akcay O, Kinaci AC, Avsar EO, Aydar U. Semantic Segmentation of High-Resolution Airborne Images with Dual-Stream DeepLabV3+. ISPRS International Journal of Geo-Information. 2022; 11(1):23. https://doi.org/10.3390/ijgi11010023
Chicago/Turabian StyleAkcay, Ozgun, Ahmet Cumhur Kinaci, Emin Ozgur Avsar, and Umut Aydar. 2022. "Semantic Segmentation of High-Resolution Airborne Images with Dual-Stream DeepLabV3+" ISPRS International Journal of Geo-Information 11, no. 1: 23. https://doi.org/10.3390/ijgi11010023
APA StyleAkcay, O., Kinaci, A. C., Avsar, E. O., & Aydar, U. (2022). Semantic Segmentation of High-Resolution Airborne Images with Dual-Stream DeepLabV3+. ISPRS International Journal of Geo-Information, 11(1), 23. https://doi.org/10.3390/ijgi11010023