
Efficient Group K Nearest-Neighbor Spatial Query Processing in Apache Spark


Abstract
:1. Introduction
- We present improvements of this algorithm, based on specific functionalities of the Spark framework.
- We extensively compare the new algorithm against the best Hadoop based algorithm of [14], using big real and synthetic datasets.
- Using synthetic datasets, we experimentally study the scalability of the Spark-based algorithm and the effect of each of its embedded improvements on performance.
2. Related Work
2.1. Spatial Query Processing in Apache Spark
2.2. GKNN Query in Distributed Environments
3. Background
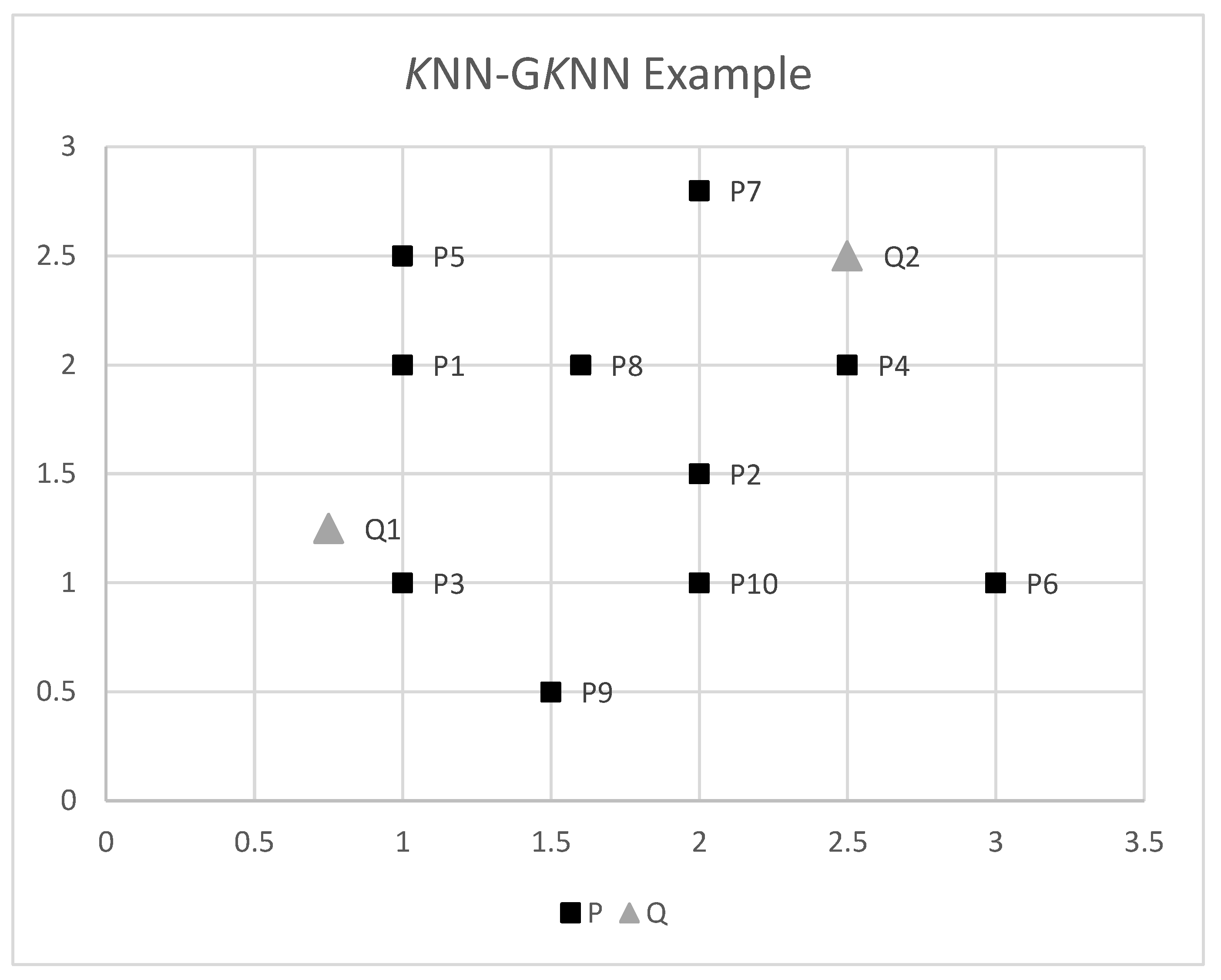
3.1. Group (K) Nearest-Neighbor (GKNN) Query
3.2. Apache Spark
4. GKNNQ Algorithm Essentials
4.1. MapReduce Algorithm Overview
- Preliminary step. Local calculation of a sample-based quadtree, the sorted list of query points, query MBR and centroid coordinates, the sum of distances from centroid to Q. These are needed by most of the pruning heuristics.
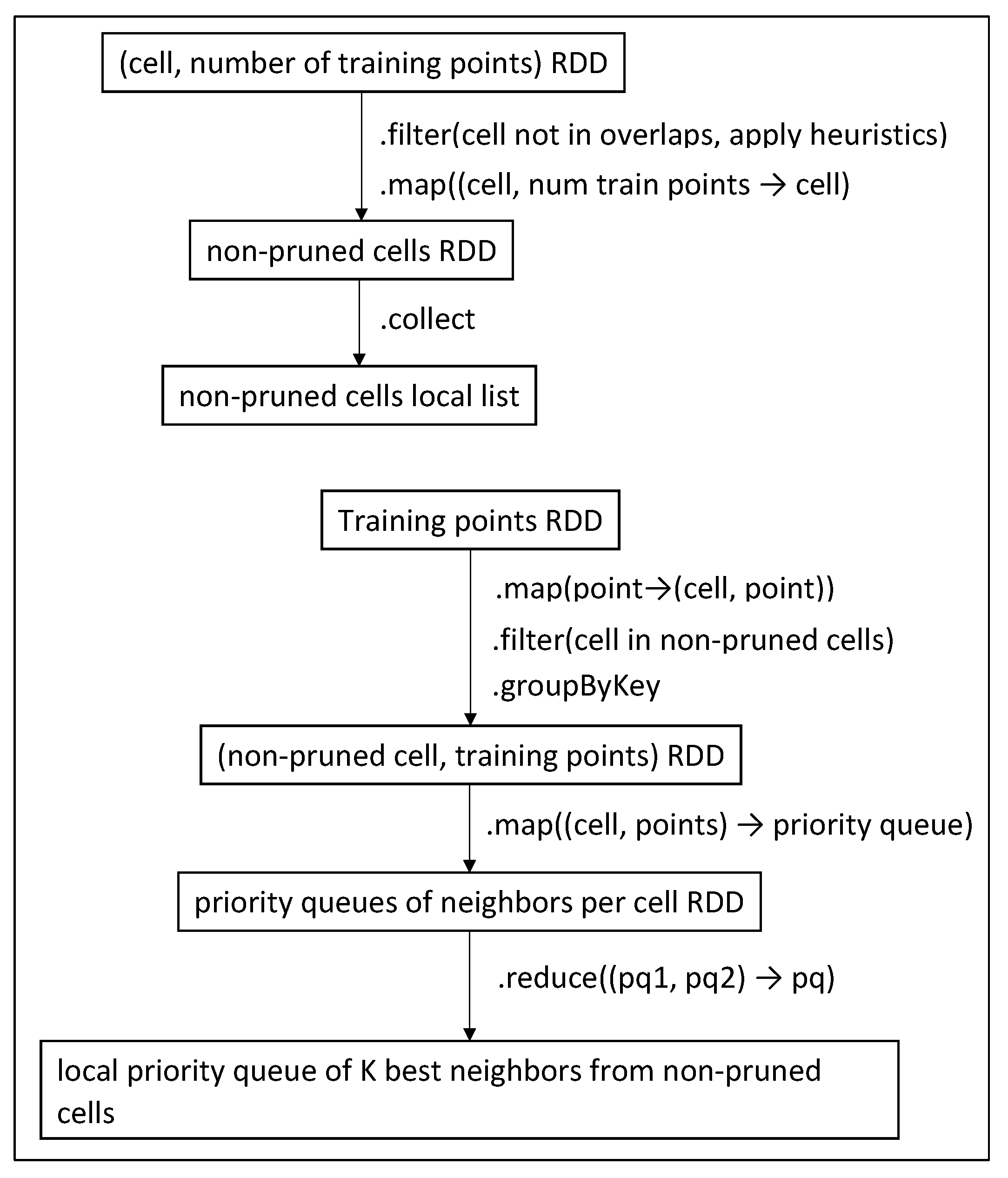
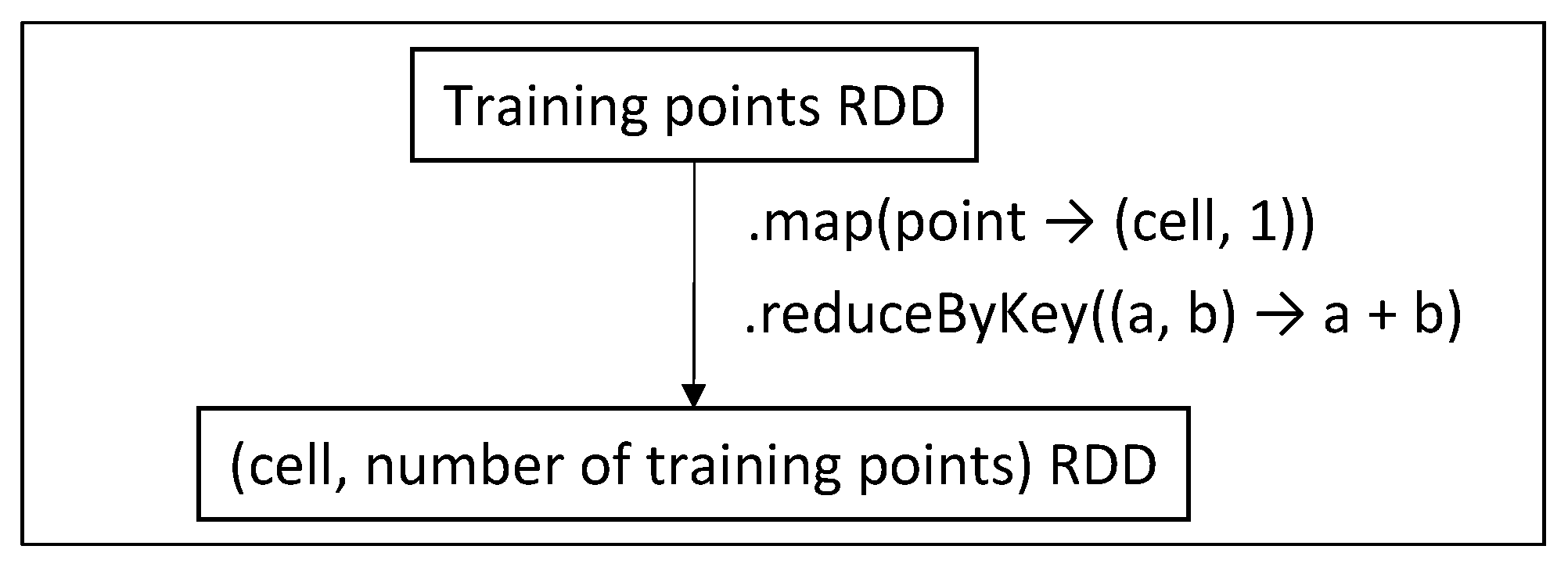
- Phase 1. Distributed computation of the number of training points per cell (needed by Phase 1.5).
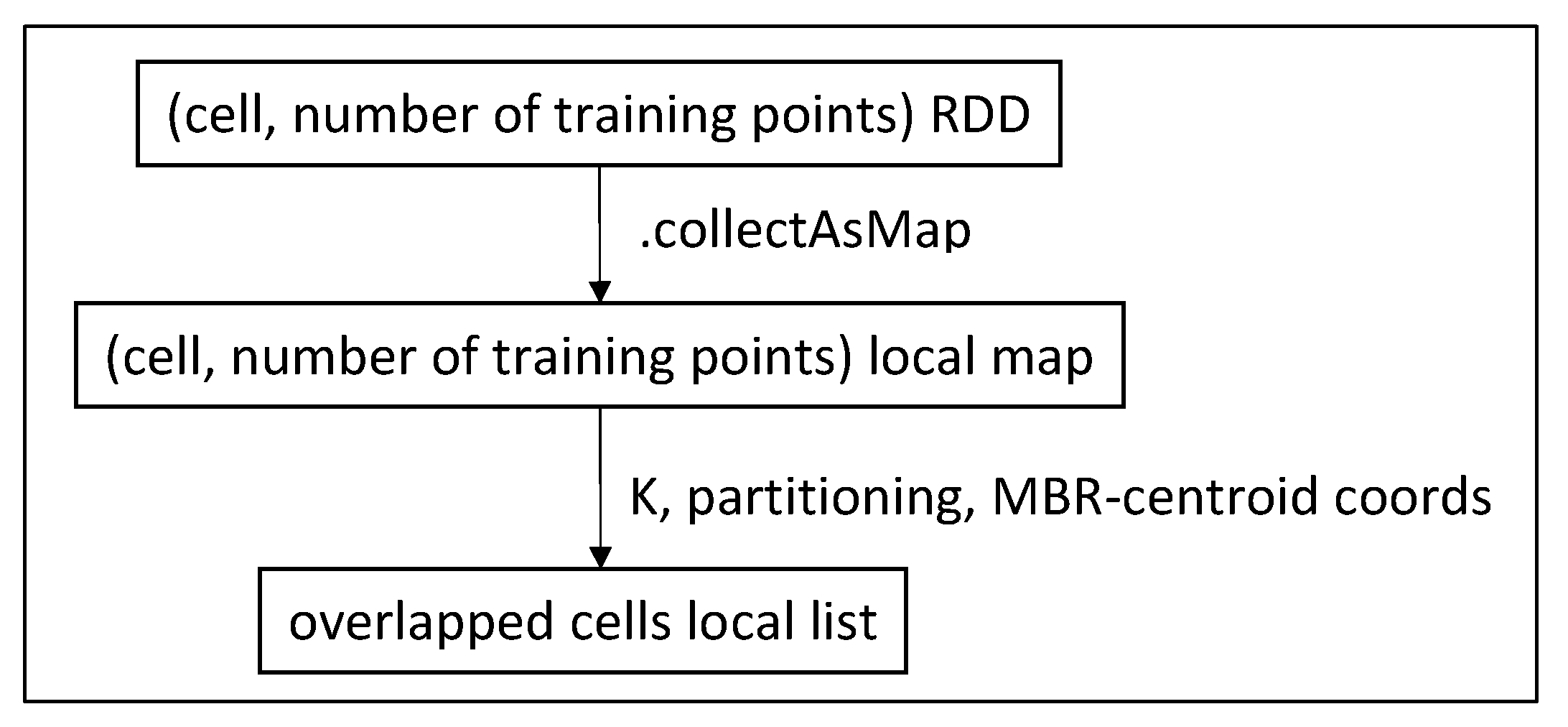
- Phase 1.5. Local discovery of a group of cells that contain at least K training points in total. Two methods are available so far: MBR and centroid circle overlapping. The second method is proved to be much more efficient because it includes fewer but generally better candidate points.
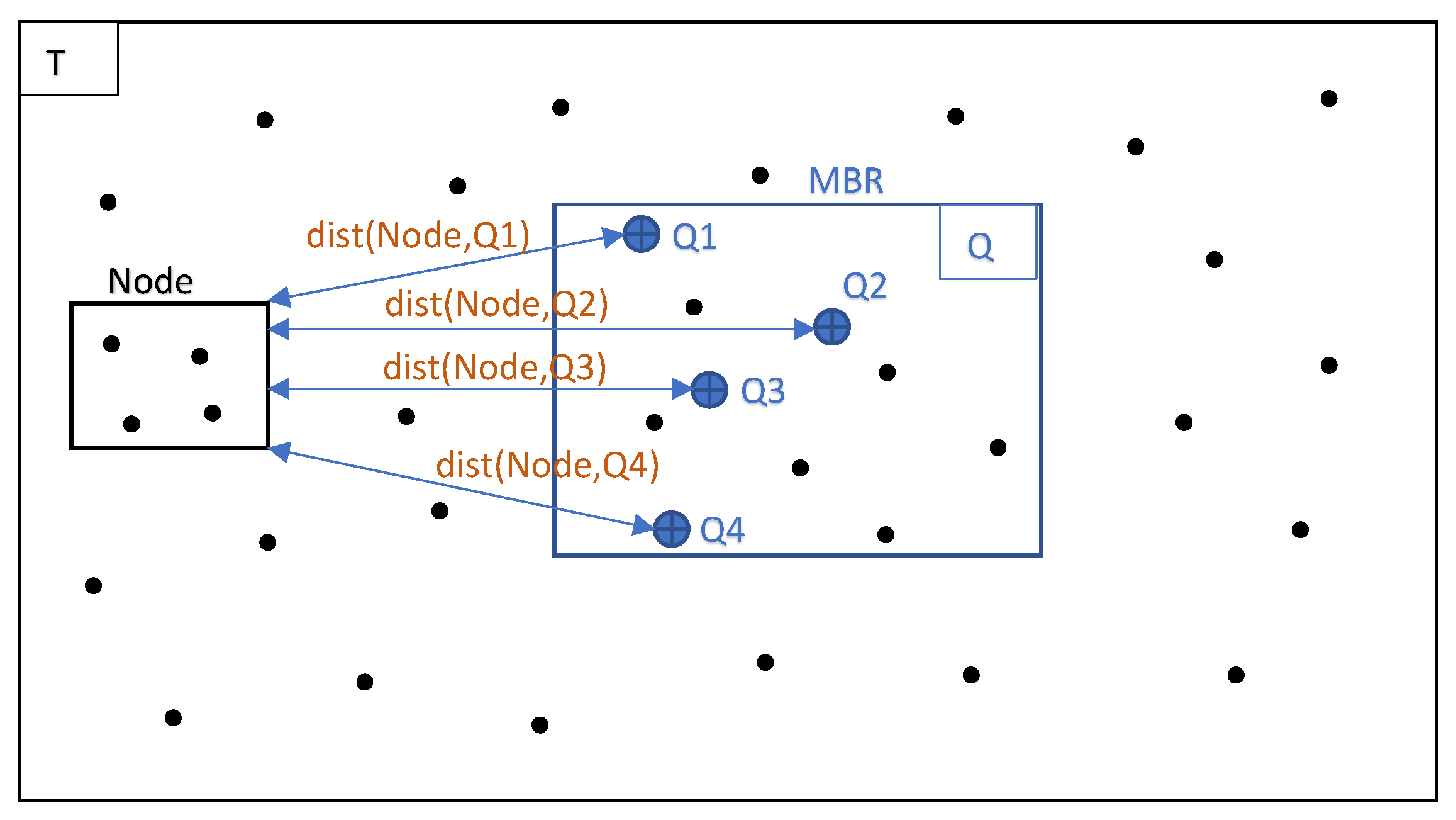
- Phase 2. Distributed computation of GKNN lists, one per intersected cell. Pruning heuristics are applied.
- Phase 2.5. Local merging of the GKNN lists into one with the best points found so far.
- Phase 3. Distributed computation of GKNN lists for the non-intersected cells. Heuristics are applied to prune distant cells to save unnecessary calculations. All new candidate neighbors are checked against the best ones from Phase 2.5.
- Phase 3.5. Local phase (final) that merges the list of Phase 2.5 with lists from Phase 3 into the final one.
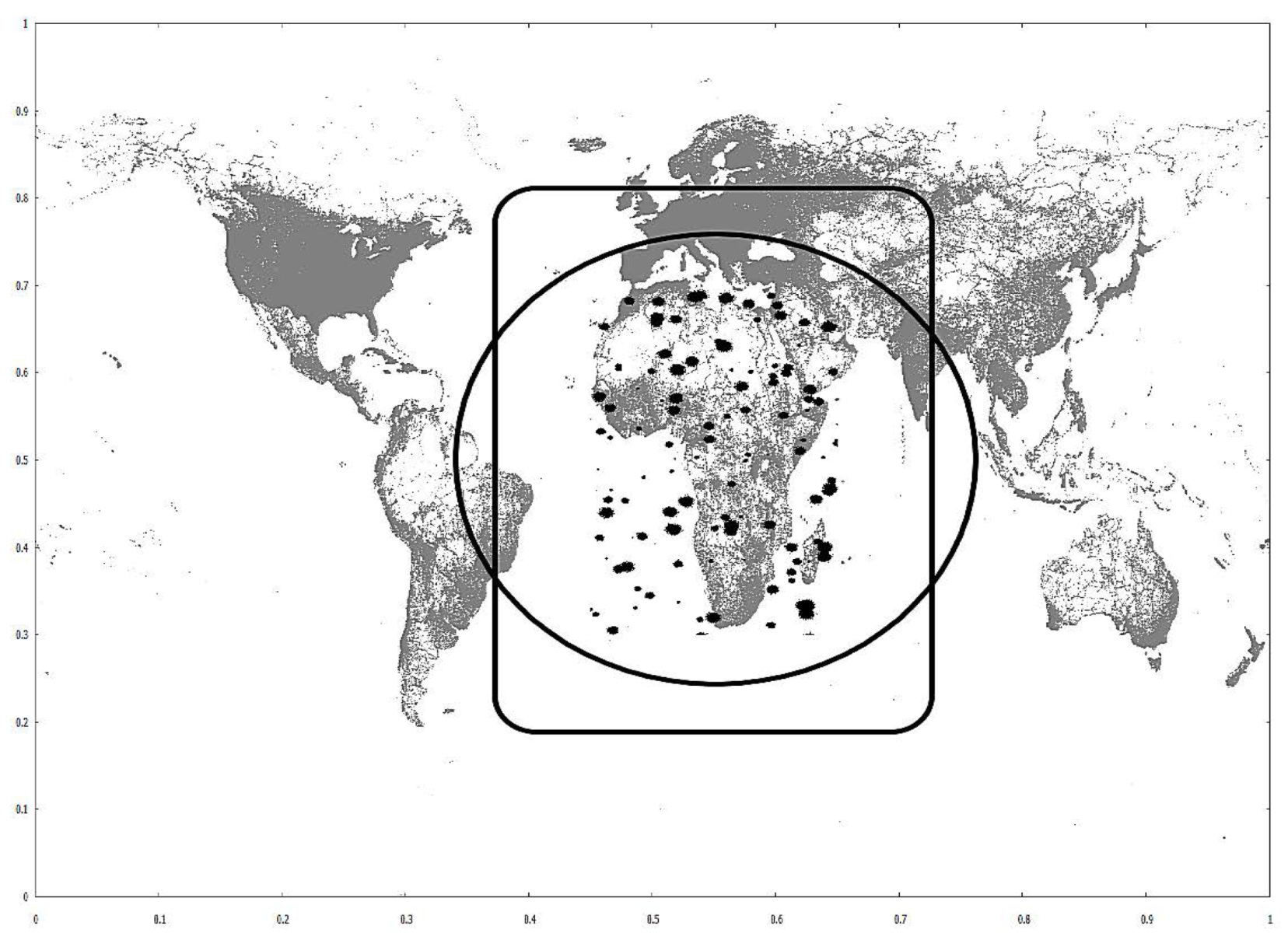
4.2. MBR and Centroid Circle Selection Methods
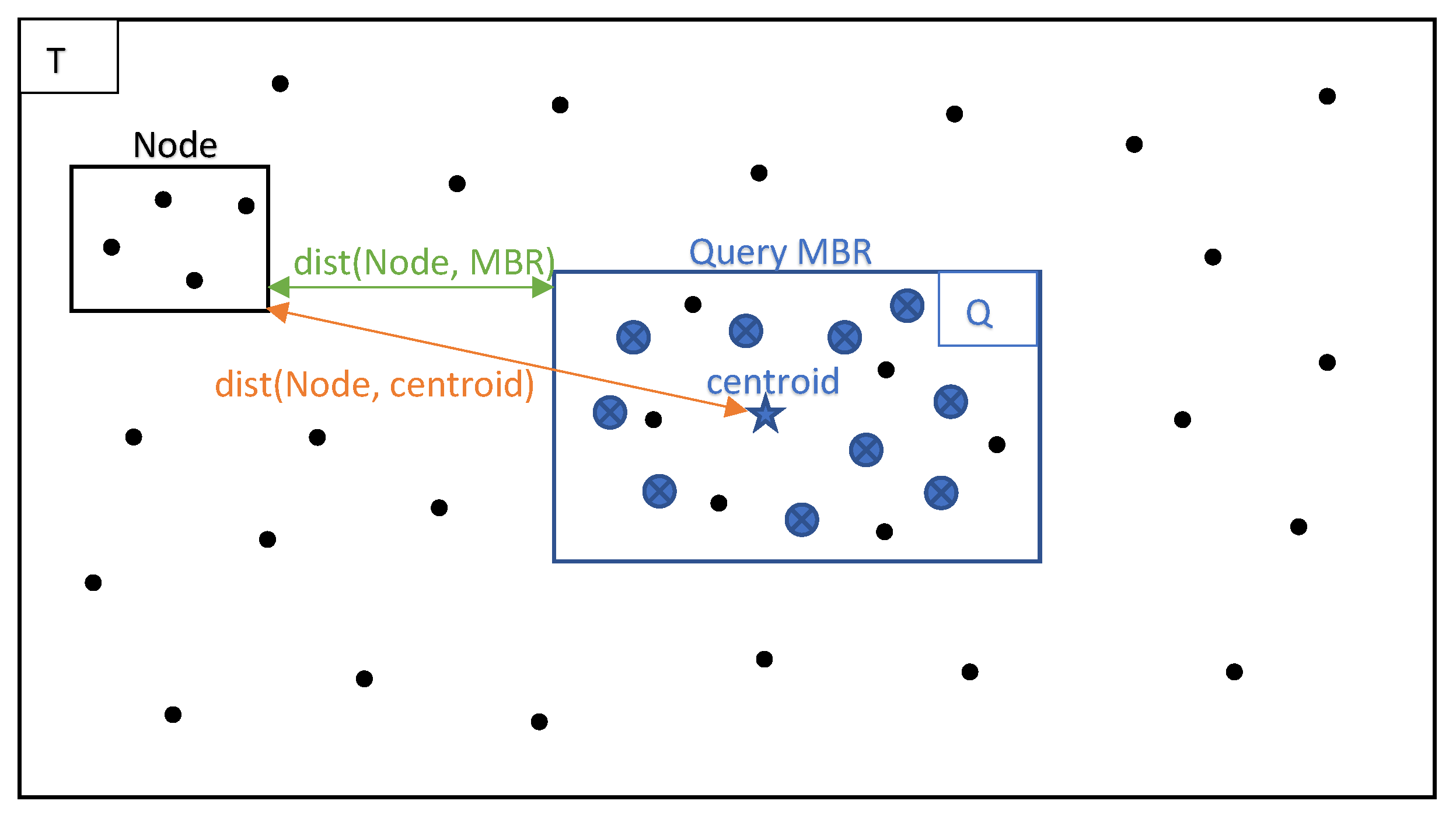
4.3. Pruning Heuristics
- Heuristic 1: can be pruned if:
- Heuristic 2: cannot contain qualified points if:
- Heuristic 3: can be pruned if:
- Heuristic 4: Training point p can be pruned if:
4.4. Grid Partitioning
4.5. Brute-Force Computation Method
4.6. Usage of Techniques per Phase
5. A Spark-Based GKNN Query Processing Algorithm
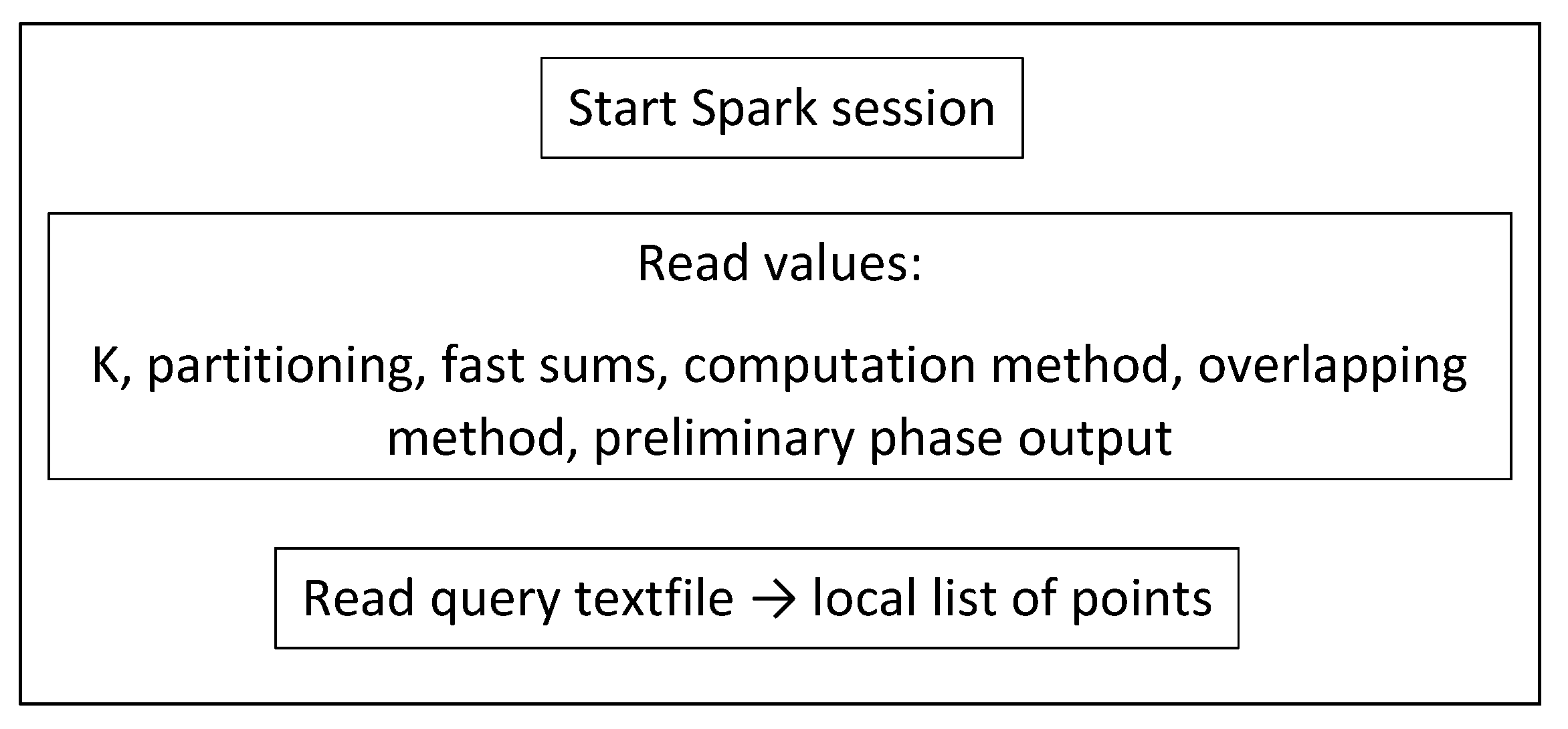
5.1. Preliminary Phase
5.2. Starting Spark Session
5.3. Computing the Number of Training Points per Cell (Phase 1)
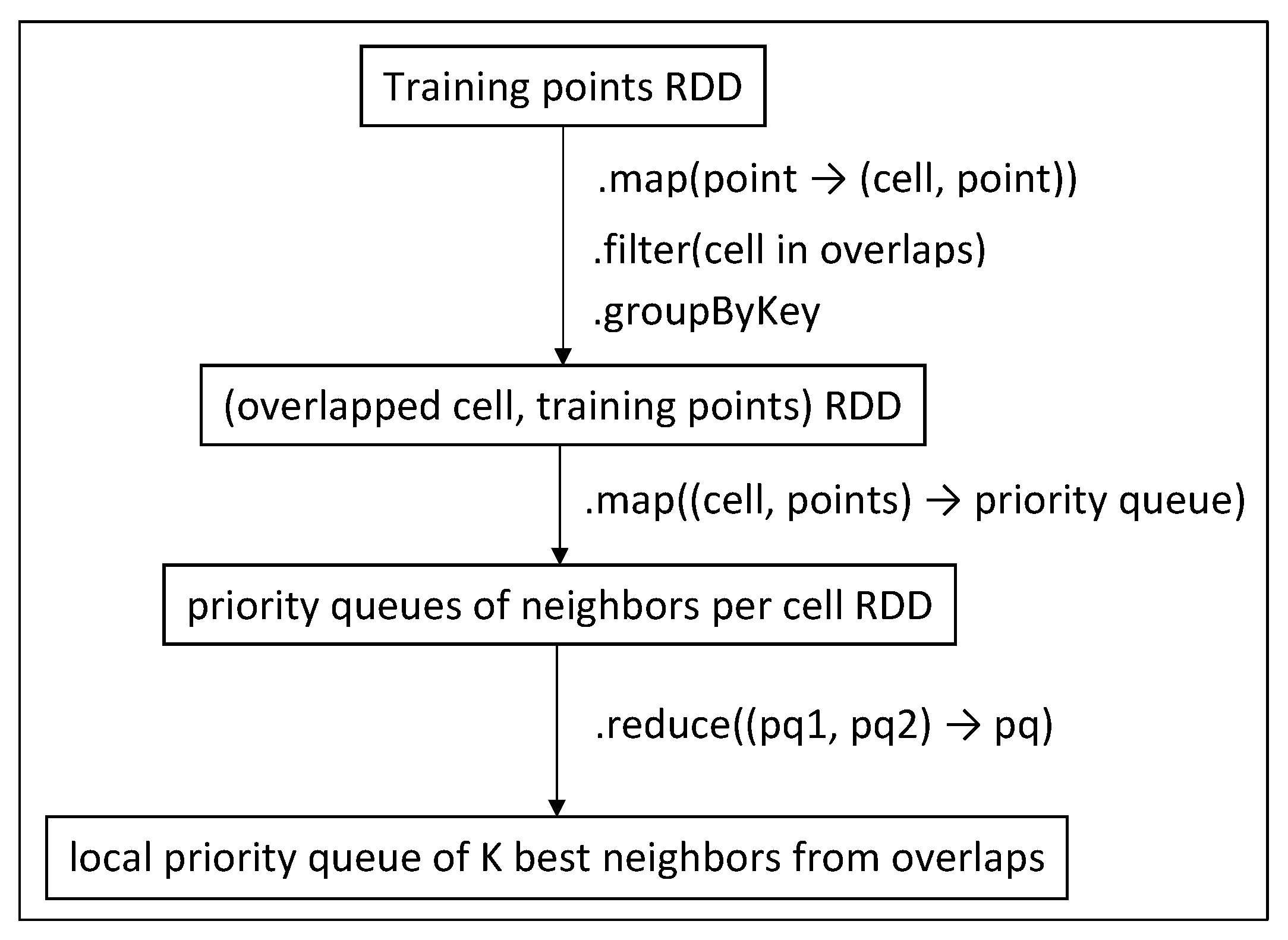
5.4. Searching for Overlapped Cells (Phase 1.5)
5.5. Creating a First Approach of the Neighbors List (Phases 2 and 2.5)
5.6. Searching for Neighbors in Distant Cells (Phase 3)
5.7. Creating the Final List of K Neighbors (Phase 3.5)
5.8. Review of the Similarities and Differences in Spark and MapReduce Implementation
6. Improvements on the Spark-Based GKNN Query Processing Algorithm
Spark DAG
7. Experimental Results
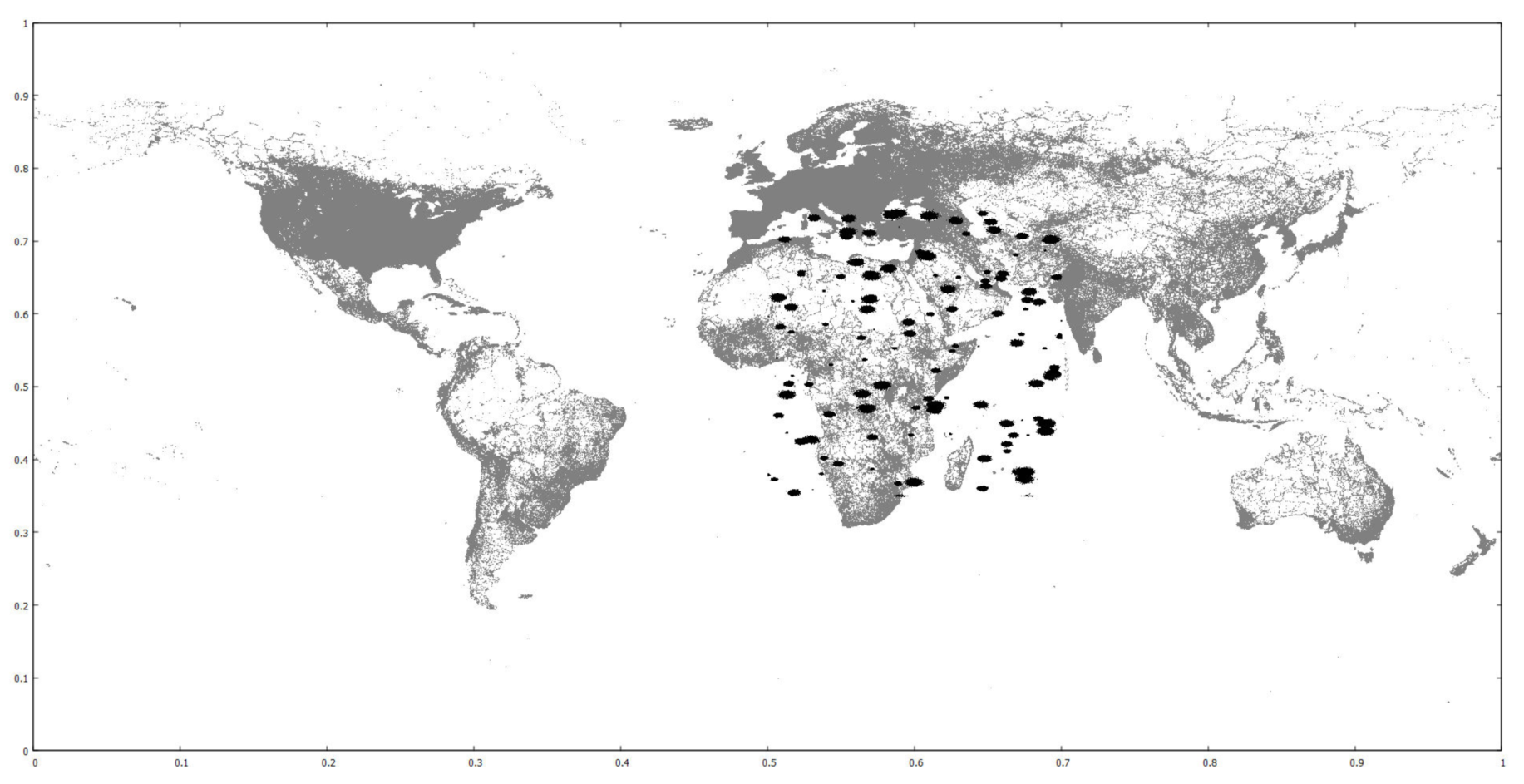
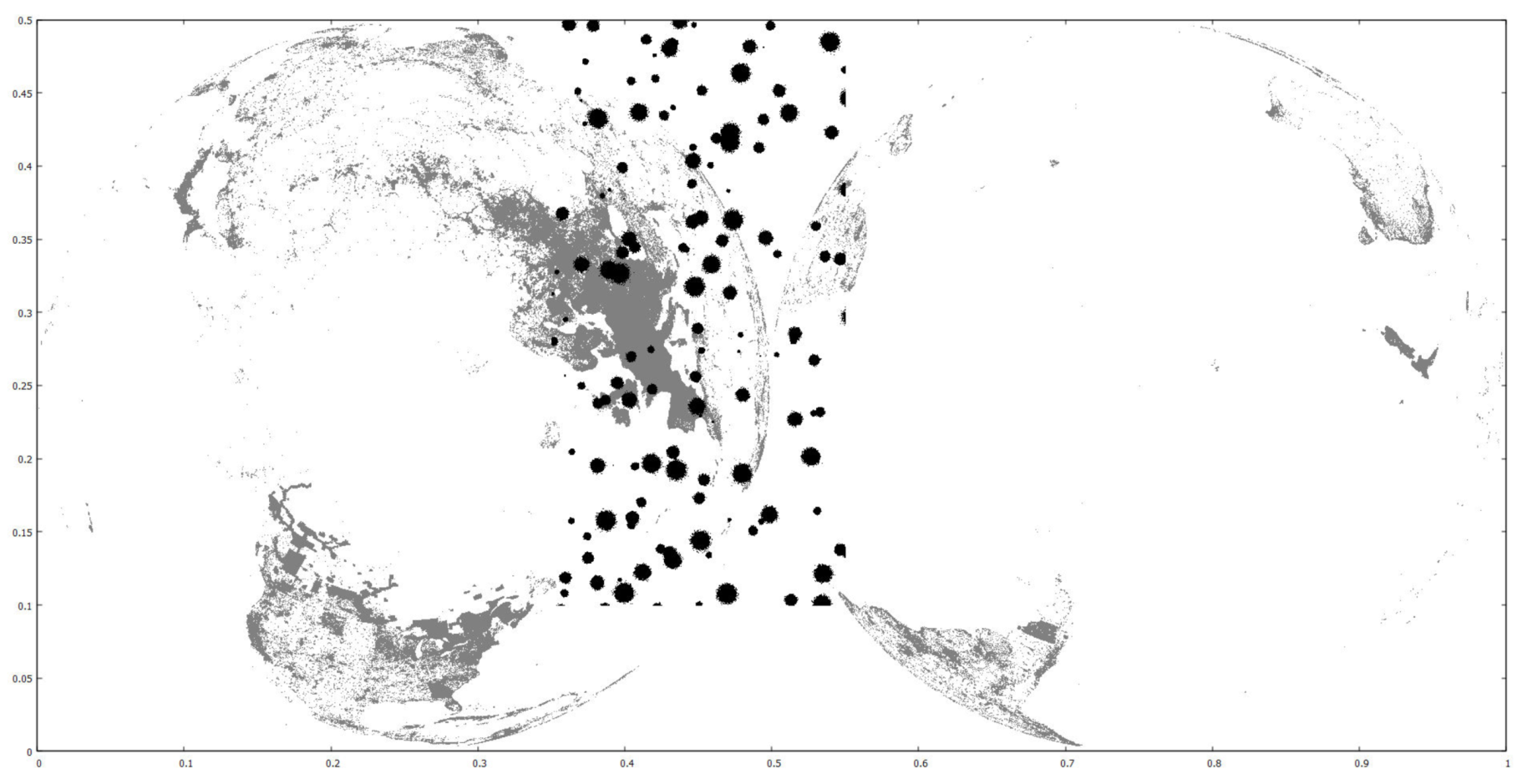
7.1. Datasets and Test System Configuration
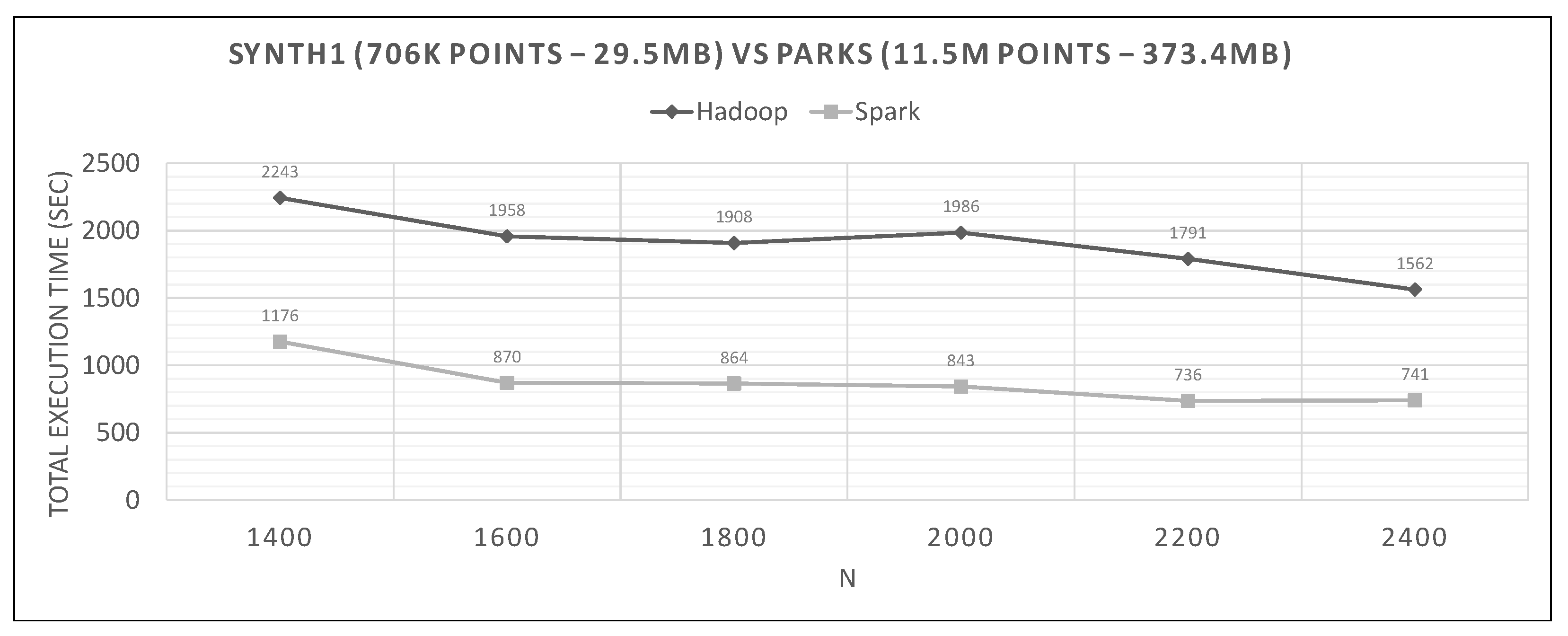
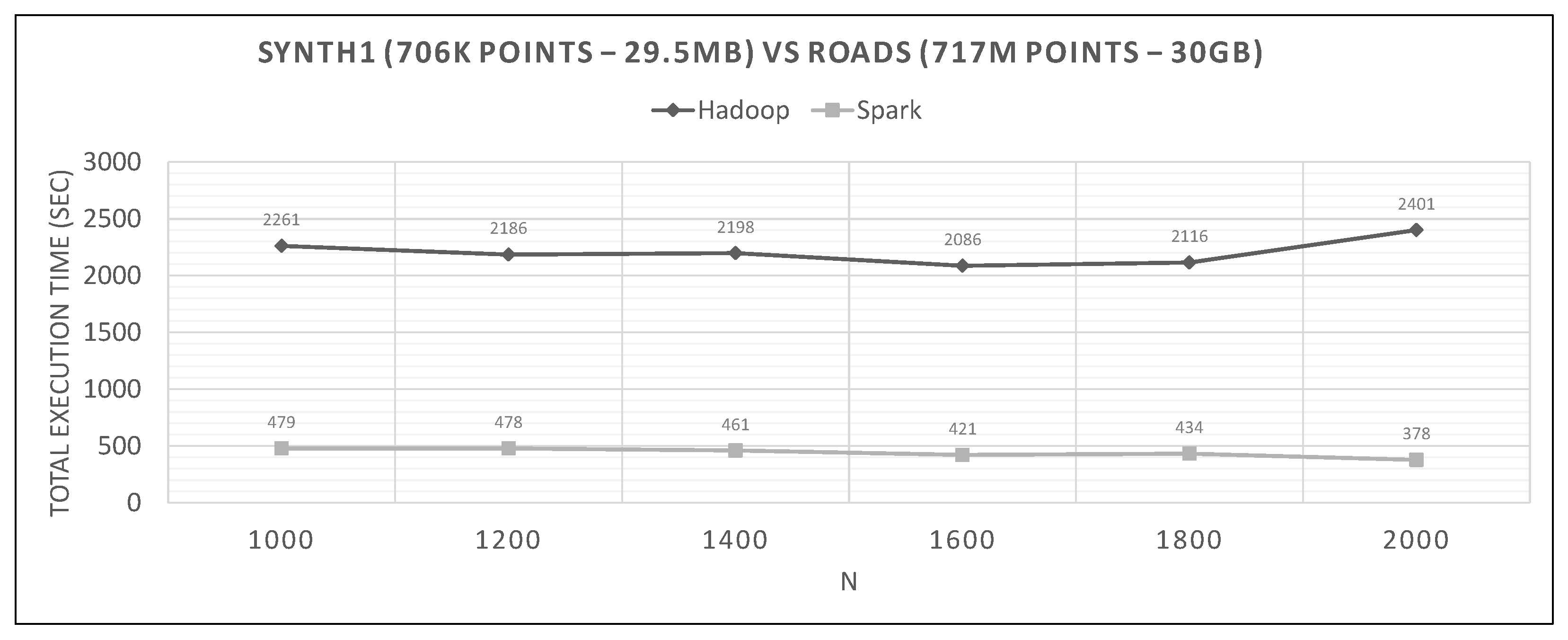
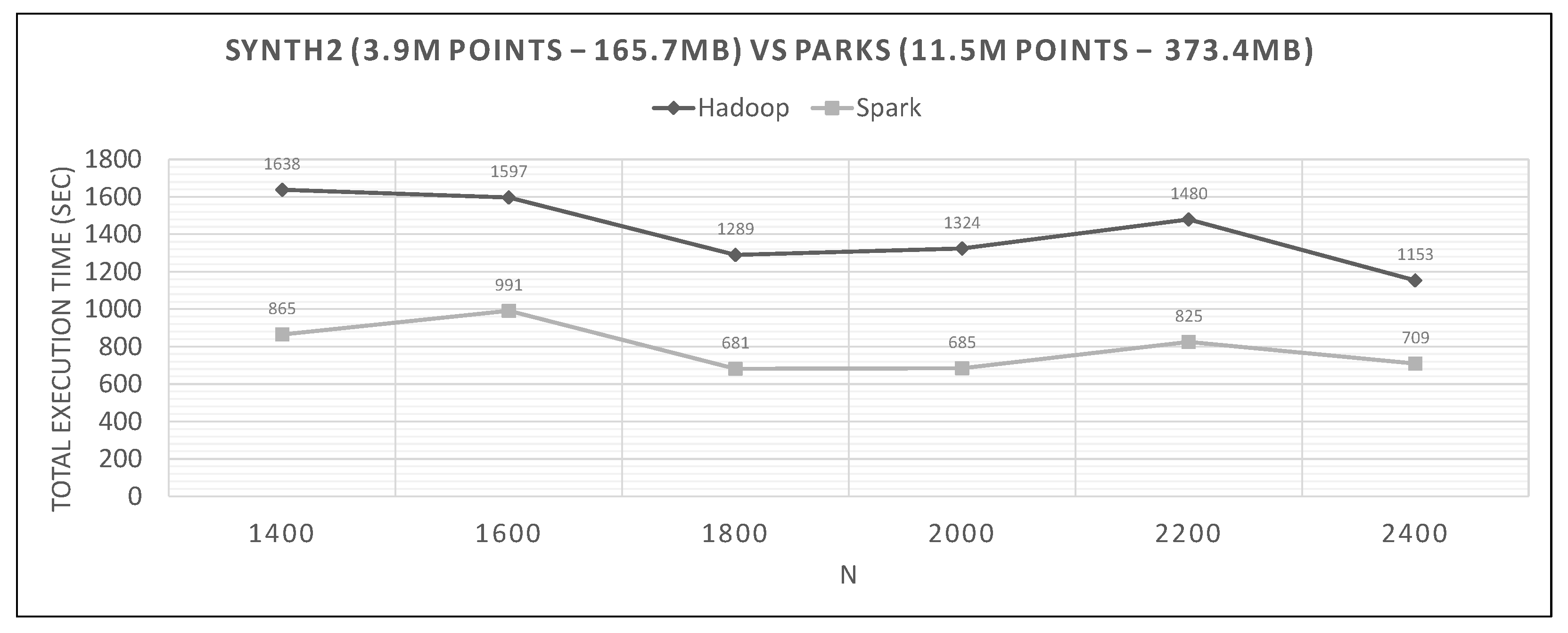
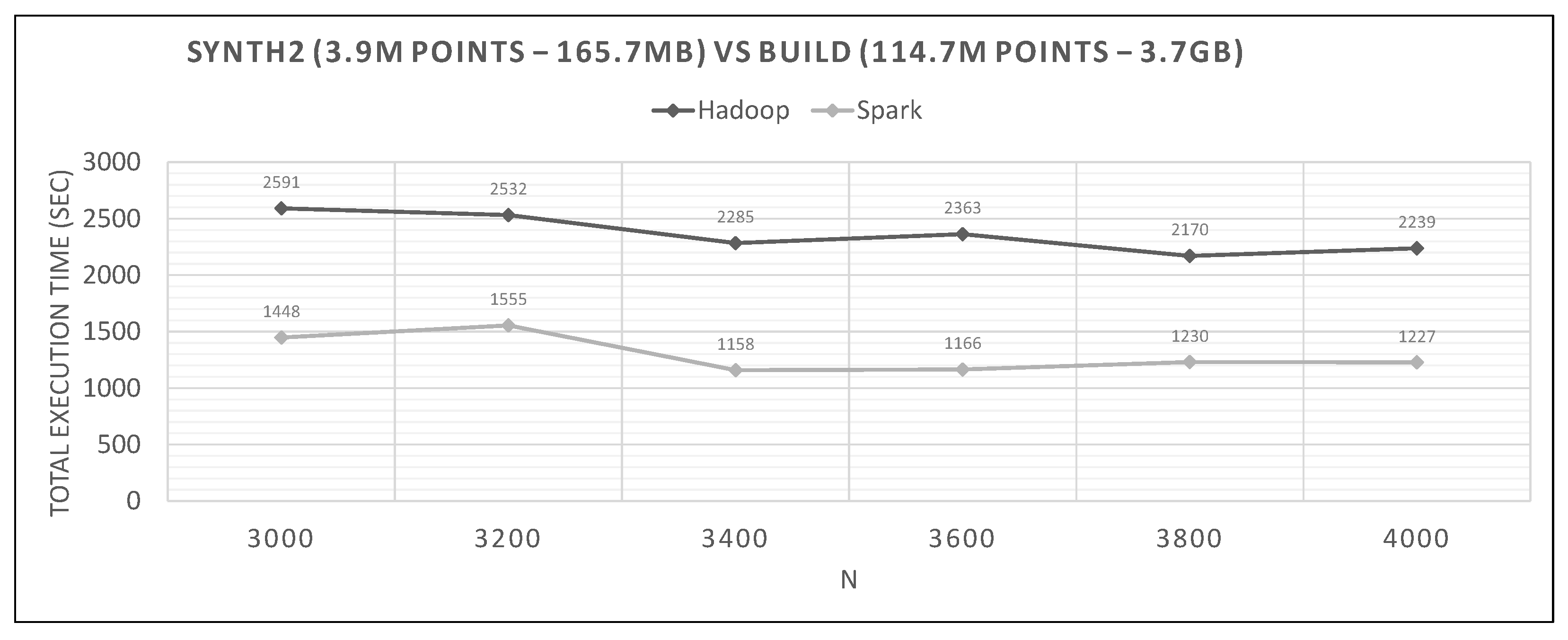
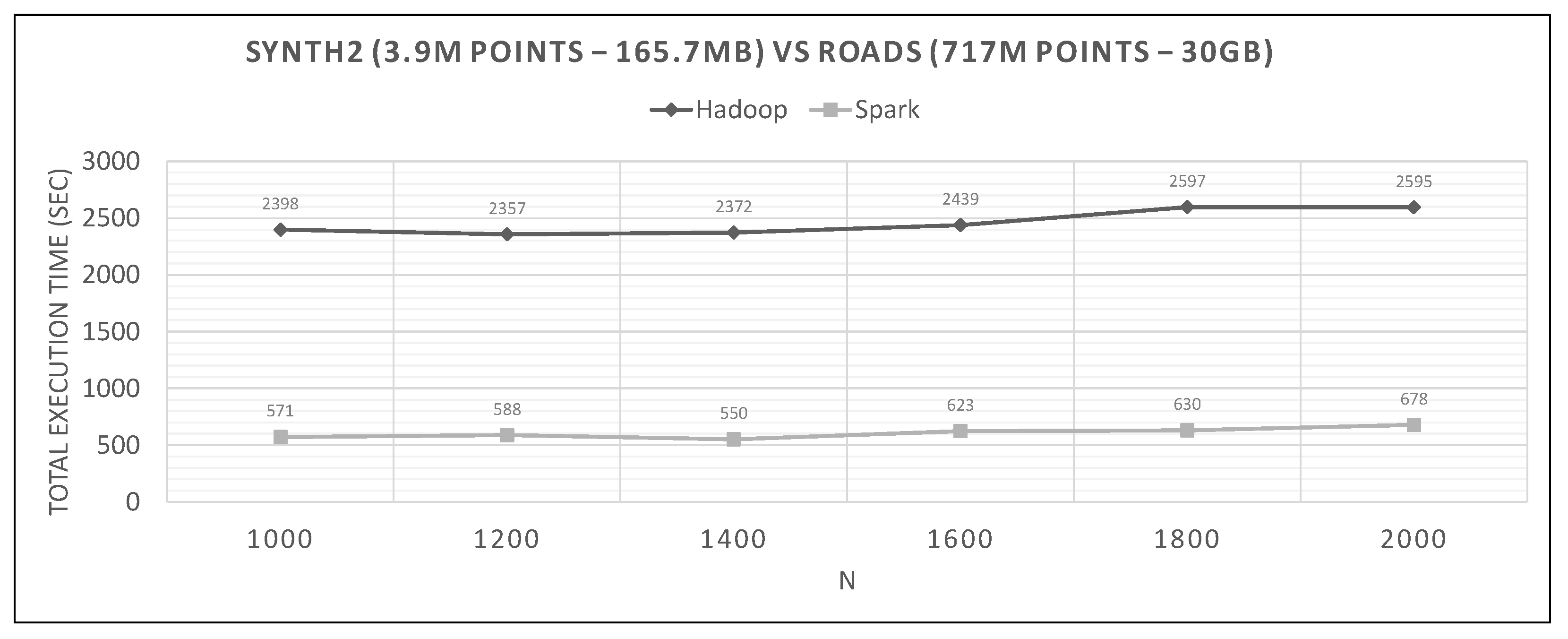
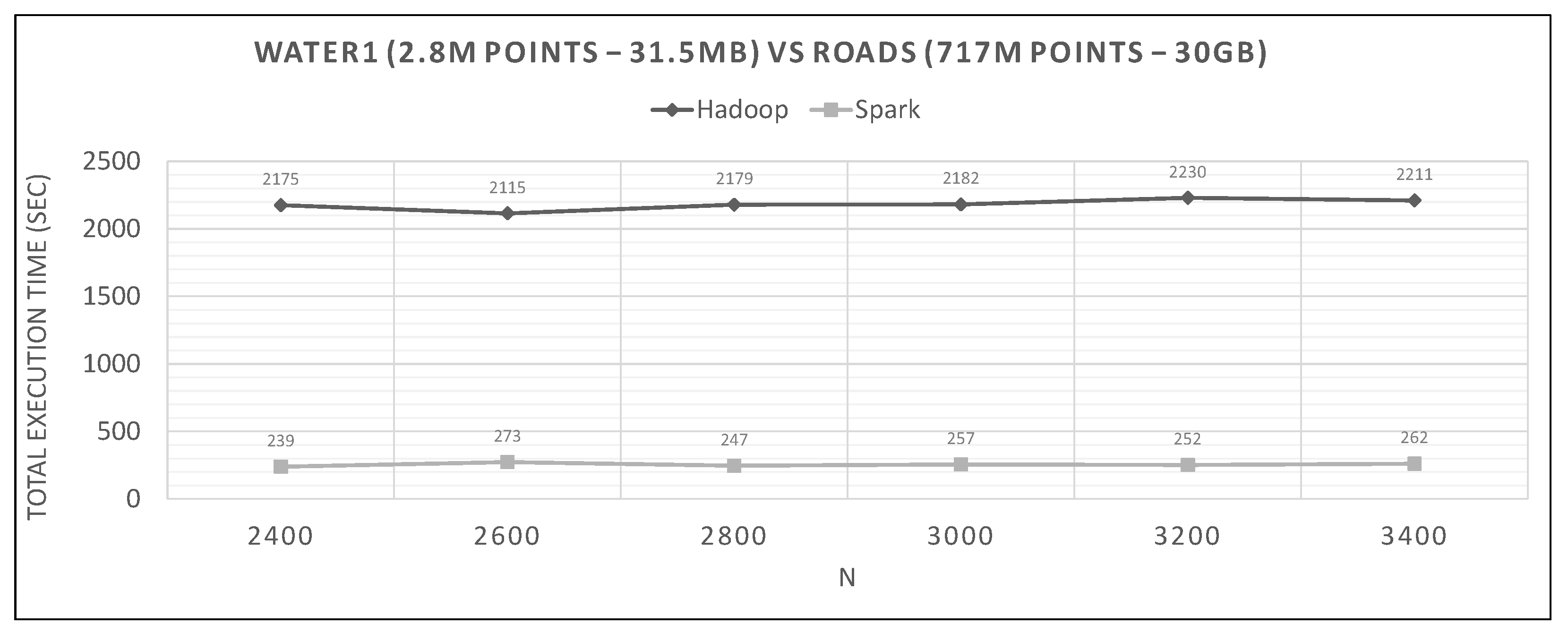
7.2. Hadoop vs. Spark Experiments
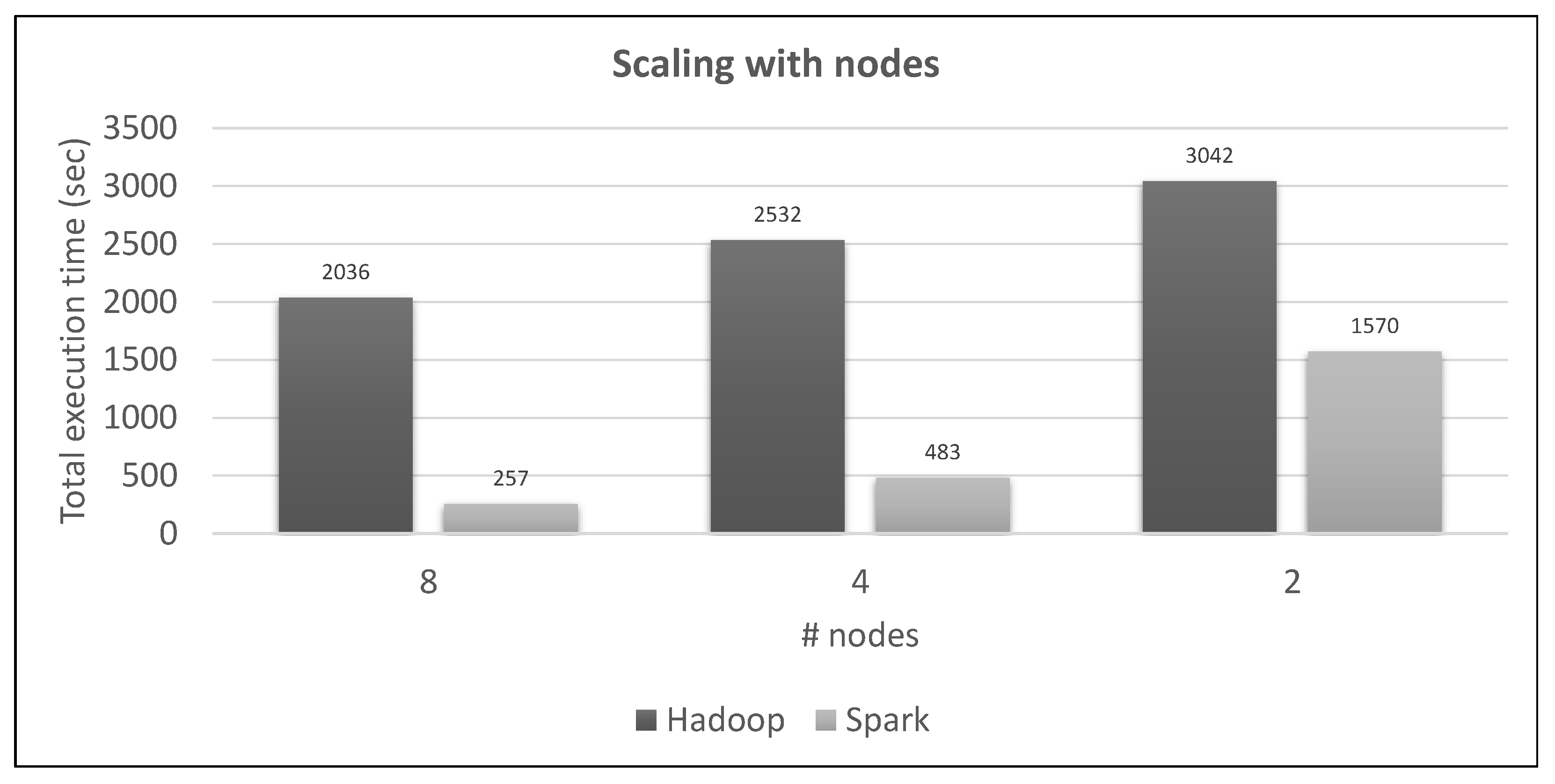
7.3. Scaling Experiments
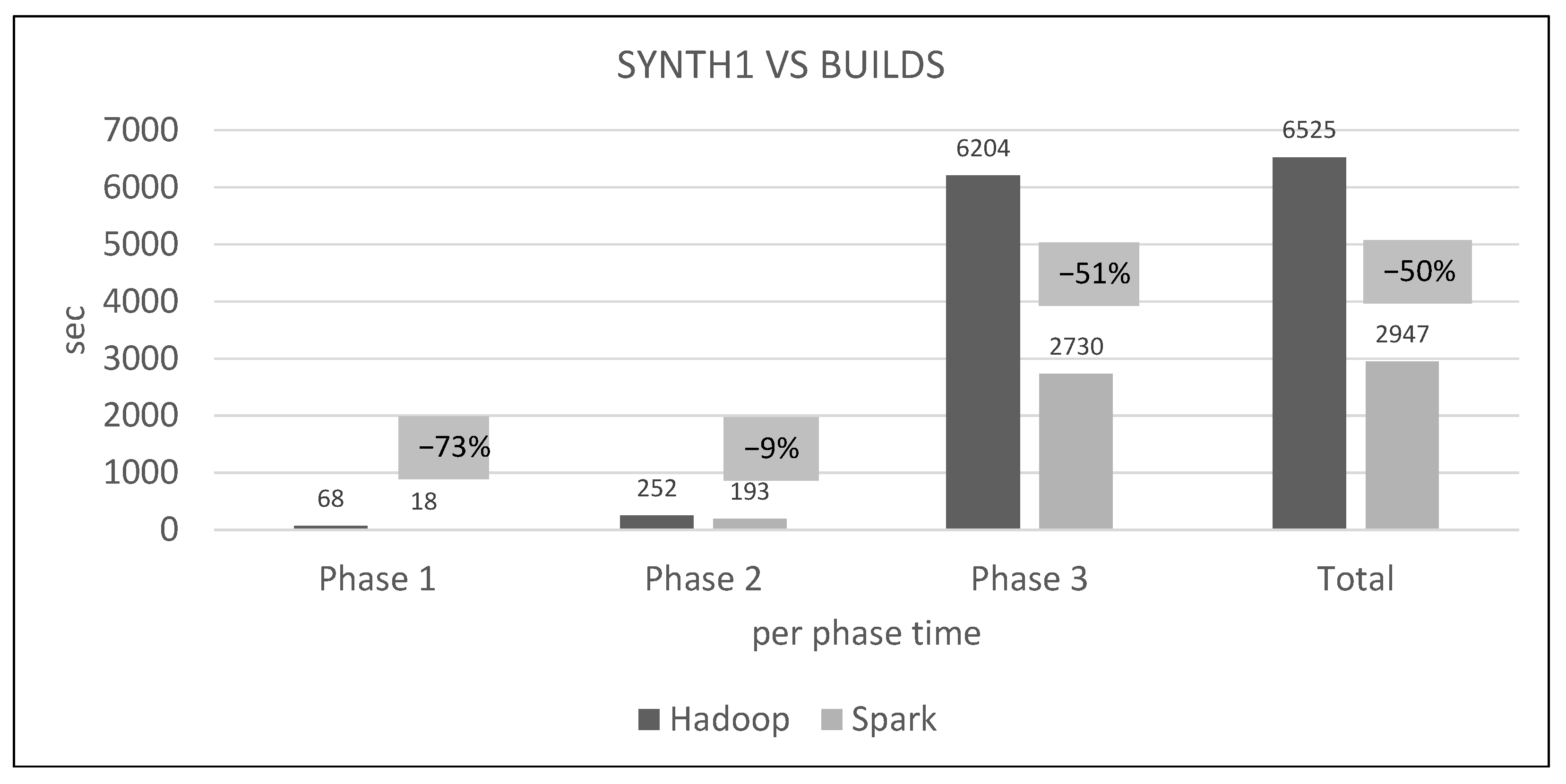
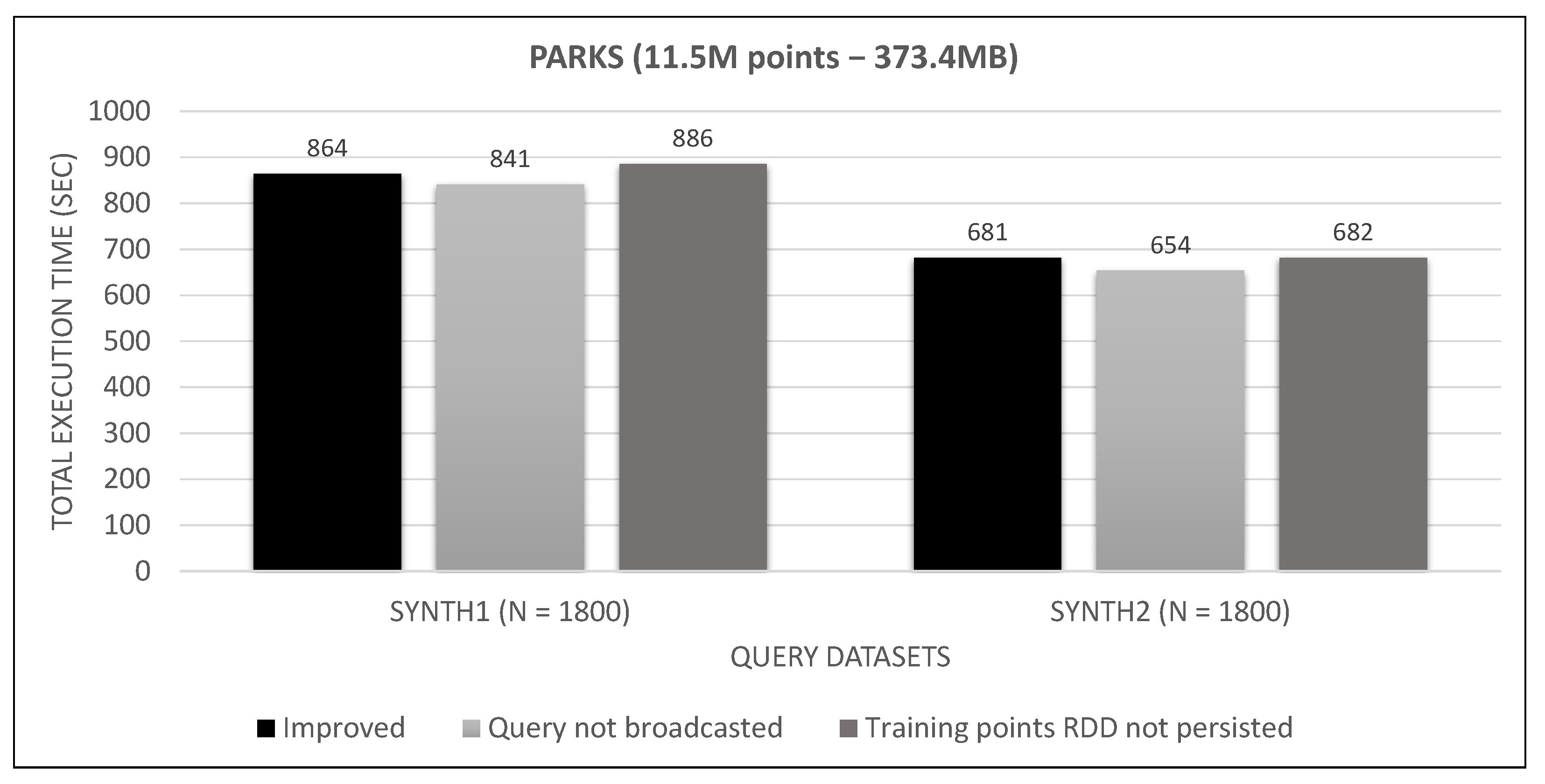
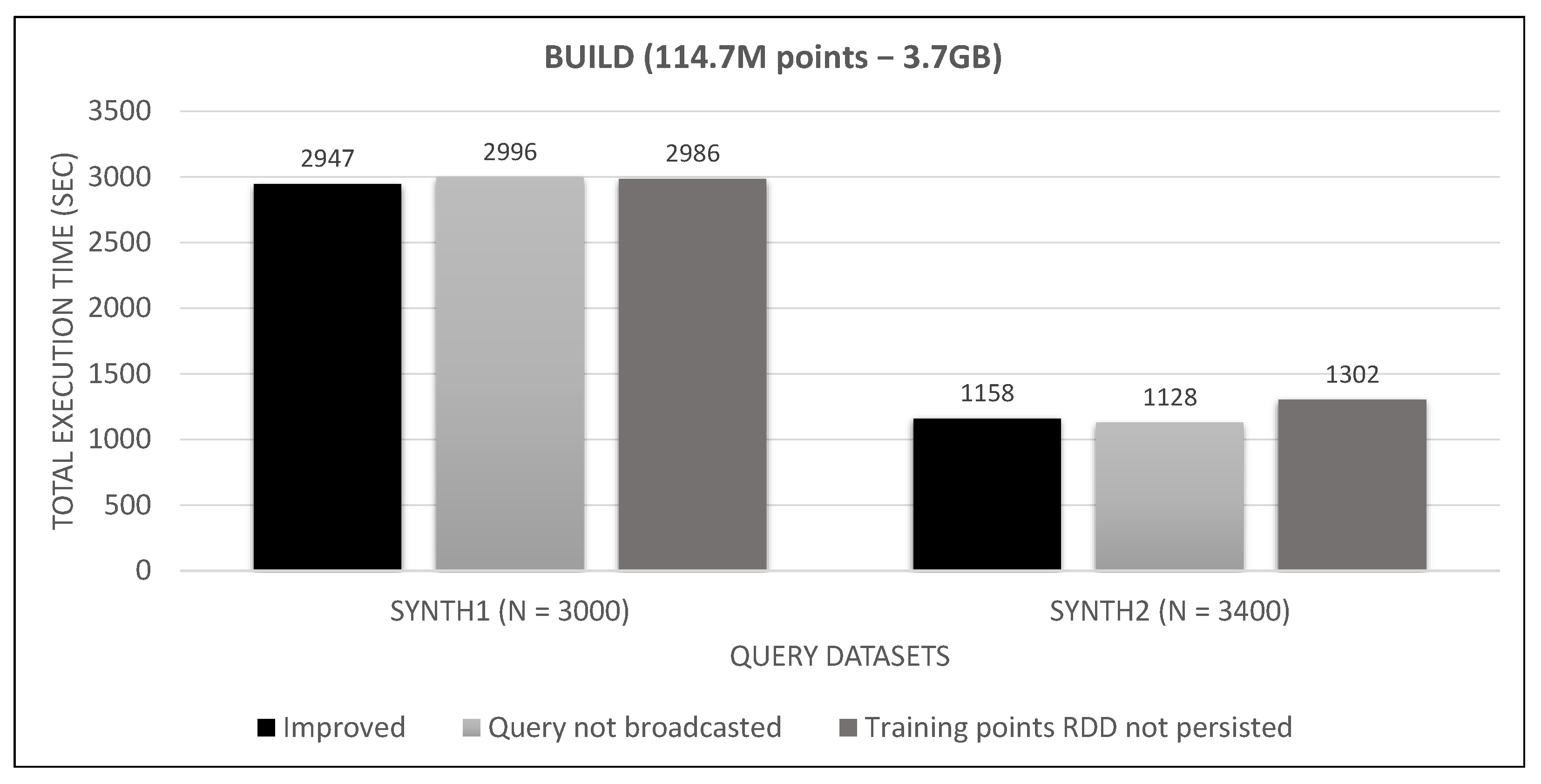
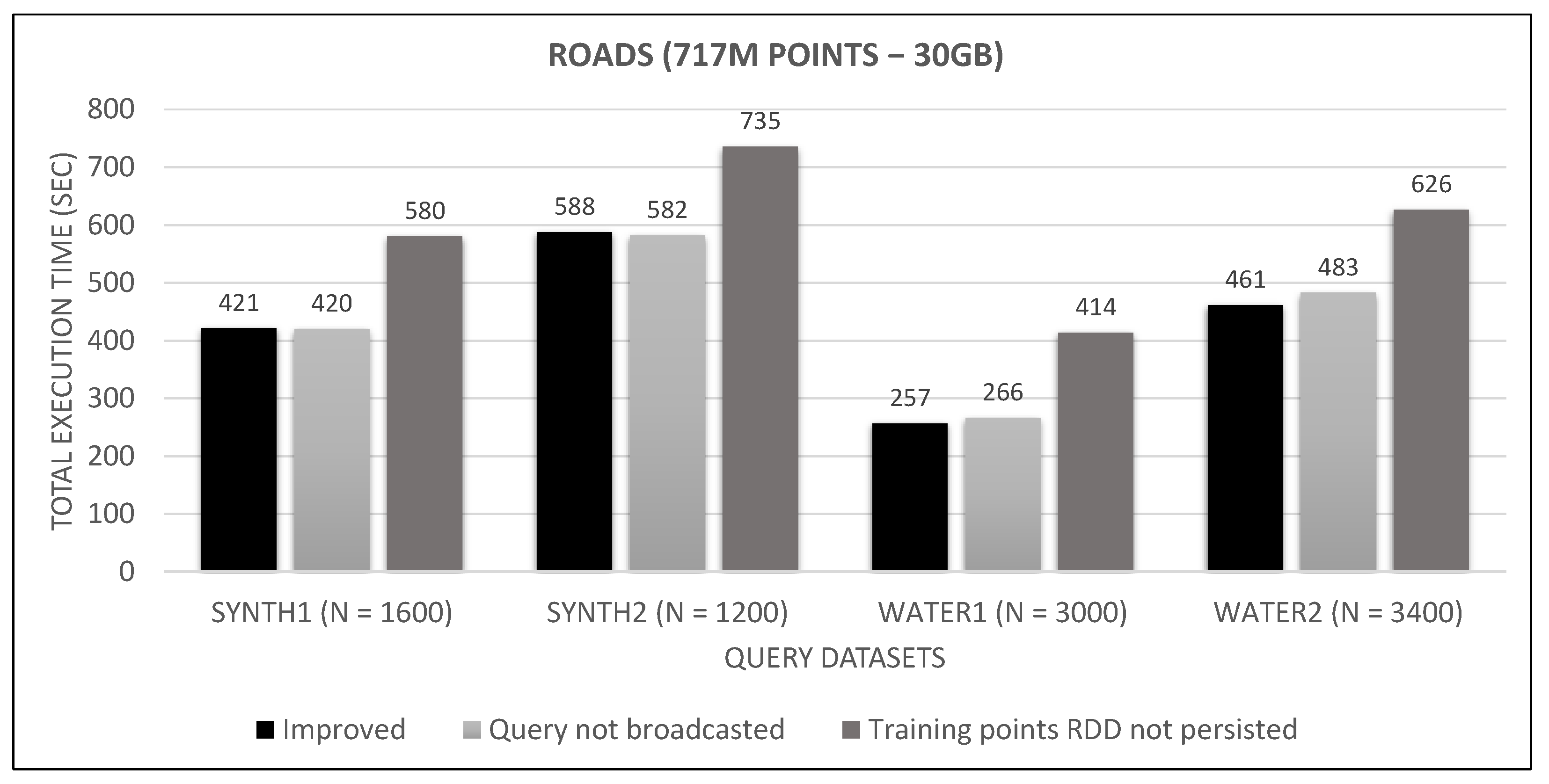
7.4. Spark Algorithm, Improved vs. Base
8. Discussion
- Spark finishes 50–90% faster than Hadoop. Similar percentages apply to each distributed phase of the algorithm.
- Spark’s performance remains mostly unchanged for a wide variation of N; it is an almost flat line in many graphs. However, the best performing Ns are the larger ones, as can also be observed for Hadoop in these experiments and in the literature (Section 2.2). More cells mean fewer points inside each and, therefore, fewer calculations per cell.
- The optimal value of N varies significantly for each dataset couple, and it is hard if not impossible to foresee it without experimentation, mostly because of the unpredictable behavior of the fast sums calculation savings and the pruning heuristics, both of which depend on partitioning.
- The per phase time is proportional to the number of training points it has to process (not shown in the graphs), for a specific query dataset. Phase 2 is generally very fast because of the few cells that Phase 1.5 feeds it (usually about 10), while Phase 3 gets several hundred or even thousands of cells (after pruning has finished), which means thousands or millions of points. As an example, in Figure 21, we can see that the total time is much larger than any other graph, for both frameworks, which is the result of about 11 million training points not pruned and processed by Phase 3. In other dataset combinations, Phase 3 processes only a few hundreds or thousands of training points.
- In most figures, the performance curves of both systems are almost parallel. Both curves have the same slope with varying N, meaning that differences in partitioning have the same effect in both frameworks (number of points per cell, number of pruned cells and points, etc.). This is further proof that Spark’s constant performance distance must derive mostly from its I/O savings.
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dean, J.; Ghemawat, S. MapReduce: Simplified Data Processing on Large Clusters. In Proceedings of the 6th Symposium on Operating System Design and Implementation (OSDI 2004), San Francisco, CA, USA, 6–8 December 2004; pp. 137–150. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster Computing with Working Sets. In Proceedings of the 2nd USENIX Workshop on Hot Topics in Cloud Computing, HotCloud’10, Boston, MA, USA, 22 June 2010. [Google Scholar]
- Eldawy, A.; Mokbel, M.F. SpatialHadoop: A MapReduce framework for spatial data. In Proceedings of the 31st IEEE International Conference on Data Engineering, ICDE 2015, Seoul, Korea, 13–17 April 2015; pp. 1352–1363. [Google Scholar] [CrossRef]
- Yu, J.; Zhang, Z.; Sarwat, M. Spatial data management in apache spark: The GeoSpark perspective and beyond. GeoInformatica 2019, 23, 37–78. [Google Scholar] [CrossRef]
- Papadias, D.; Shen, Q.; Tao, Y.; Mouratidis, K. Group Nearest Neighbor Queries. In Proceedings of the 20th International Conference on Data Engineering, ICDE 2004, Boston, MA, USA, 30 March–2 April 2004; pp. 301–312. [Google Scholar] [CrossRef] [Green Version]
- Papadopoulos, A.N.; Manolopoulos, Y. Nearest Neighbor Search: A Database Perspective; Series in Computer Science; Springer: New York, NY, USA, 2005. [Google Scholar] [CrossRef]
- Papadias, D.; Tao, Y.; Mouratidis, K.; Hui, C.K. Aggregate nearest neighbor queries in spatial databases. ACM Trans. Database Syst. 2005, 30, 529–576. [Google Scholar] [CrossRef]
- Nghiem, T.P.; Green, D.; Taniar, D. Peer-to-Peer Group k-Nearest Neighbours in Mobile Ad-Hoc Networks. In Proceedings of the 19th IEEE International Conference on Parallel and Distributed Systems, ICPADS 2013, Seoul, Korea, 15–18 December 2013; pp. 166–173. [Google Scholar] [CrossRef]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data Clustering: A Review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Liu, X.; Chen, F.; Lu, C. Robust Prediction and Outlier Detection for Spatial Datasets. In Proceedings of the 12th IEEE International Conference on Data Mining, ICDM 2012, Brussels, Belgium, 10–13 December 2012; pp. 469–478. [Google Scholar] [CrossRef]
- Roumelis, G.; Vassilakopoulos, M.; Corral, A.; Manolopoulos, Y. Plane-Sweep Algorithms for the K Group Nearest-Neighbor Query. In Proceedings of the GISTAM 2015—1st International Conference on Geographical Information Systems Theory, Applications and Management, Barcelona, Spain, 28–30 April 2015; pp. 83–93. [Google Scholar] [CrossRef]
- Roumelis, G.; Vassilakopoulos, M.; Corral, A.; Manolopoulos, Y. The K Group Nearest-Neighbor Query on Non-indexed RAM-Resident Data. In Geographical Information Systems Theory, Applications and Management; Springer: Cham, Switzerland, 2016; pp. 69–89. [Google Scholar] [CrossRef] [Green Version]
- Moutafis, P.; García-García, F.; Mavrommatis, G.; Vassilakopoulos, M.; Corral, A.; Iribarne, L. MapReduce algorithms for the K group nearest-neighbor query. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, SAC 2019, Limassol, Cyprus, 8–12 April 2019; pp. 448–455. [Google Scholar] [CrossRef]
- Moutafis, P.; García-García, F.; Mavrommatis, G.; Vassilakopoulos, M.; Corral, A.; Iribarne, L. Algorithms for processing the group K nearest-neighbor query on distributed frameworks. Distrib. Parallel Databases 2020. [Google Scholar] [CrossRef]
- Pandey, V.; Kipf, A.; Neumann, T.; Kemper, A. How Good Are Modern Spatial Analytics Systems? Proc. VLDB Endow. 2018, 11, 1661–1673. [Google Scholar] [CrossRef] [Green Version]
- de Carvalho Castro, J.P.; Carniel, A.C.; de Aguiar Ciferri, C.D. Analyzing spatial analytics systems based on Hadoop and Spark: A user perspective. Softw. Pract. Exp. 2020, 50, 2121–2144. [Google Scholar] [CrossRef]
- Velentzas, P.; Corral, A.; Vassilakopoulos, M. Big Spatial and Spatio-Temporal Data Analytics Systems. Trans. Large-Scale Data- Knowl.-Cent. Syst. 2021, 47, 155–180. [Google Scholar] [CrossRef]
- Alam, M.M.; Torgo, L.; Bifet, A. A Survey on Spatio-temporal Data Analytics Systems. arXiv 2021, arXiv:2103.09883. [Google Scholar]
- You, S.; Zhang, J.; Gruenwald, L. Large-scale spatial join query processing in Cloud. In Proceedings of the 31st IEEE International Conference on Data Engineering Workshops, ICDE Workshops 2015, Seoul, Korea, 13–17 April 2015; pp. 34–41. [Google Scholar] [CrossRef]
- Xie, D.; Li, F.; Yao, B.; Li, G.; Zhou, L.; Guo, M. Simba: Efficient In-Memory Spatial Analytics. In Proceedings of the 2016 International Conference on Management of Data, SIGMOD Conference 2016, San Francisco, CA, USA, 26 June–1 July 2016; pp. 1071–1085. [Google Scholar] [CrossRef] [Green Version]
- Tang, M.; Yu, Y.; Mahmood, A.R.; Malluhi, Q.M.; Ouzzani, M.; Aref, W.G. LocationSpark: In-memory Distributed Spatial Query Processing and Optimization. Front. Big Data 2020, 3, 30. [Google Scholar] [CrossRef]
- Hagedorn, S.; Götze, P.; Sattler, K. The STARK Framework for Spatio-Temporal Data Analytics on Spark. In Proceedings of the Datenbanksysteme für Business, Technologie und Web (BTW 2017), 17. Fachtagung des GI-Fachbereichs, Datenbanken und Informationssysteme (DBIS), Stuttgart, Germany, 6–10 March 2017; pp. 123–142. [Google Scholar]
- Baig, F.; Vo, H.; Kurç, T.M.; Saltz, J.H.; Wang, F. SparkGIS: Resource Aware Efficient In-Memory Spatial Query Processing. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, GIS 2017, Redondo Beach, CA, USA, 7–10 November 2017; pp. 28:1–28:10. [Google Scholar] [CrossRef]
- Engélinus, J.; Badard, T. Elcano: A Geospatial Big Data Processing System based on SparkSQL. In Proceedings of the 4th International Conference on Geographical Information Systems Theory, Applications and Management, GISTAM 2018, Funchal, Madeira, Portugal, 17–19 March 2018; pp. 119–128. [Google Scholar] [CrossRef]
- Zhang, Y.; Eldawy, A. Evaluating computational geometry libraries for big spatial data exploration. In Proceedings of the Sixth International ACM SIGMOD Workshop on Managing and Mining Enriched Geo-Spatial Data, GeoRich@SIGMOD 2020, Portland, OR, USA, 14 June 2020; pp. 3:1–3:6. [Google Scholar] [CrossRef]
- Papadopoulos, A.N.; Sioutas, S.; Zaroliagis, C.D.; Zacharatos, N. Efficient Distributed Range Query Processing in Apache Spark. In Proceedings of the 19th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, CCGRID 2019, Larnaca, Cyprus, 14–17 May 2019; pp. 569–575. [Google Scholar] [CrossRef]
- Aljawarneh, I.M.; Bellavista, P.; Corradi, A.; Montanari, R.; Foschini, L.; Zanotti, A. Efficient spark-based framework for big geospatial data query processing and analysis. In Proceedings of the 2017 IEEE Symposium on Computers and Communications, ISCC 2017, Heraklion, Greece, 3–6 July 2017; pp. 851–856. [Google Scholar] [CrossRef]
- Aghbari, Z.A.; Ismail, T.; Kamel, I. SparkNN: A Distributed In-Memory Data Partitioning for KNN Queries on Big Spatial Data. Data Sci. J. 2020, 19, 35. [Google Scholar] [CrossRef]
- Mamoulis, N. Spatial Data Management; Synthesis Lectures on Data Management; Morgan & Claypool Publishers: San Rafael, CA, USA, 2011. [Google Scholar] [CrossRef]
- Guttman, A. R-Trees: A Dynamic Index Structure for Spatial Searching. SIGMOD Rec. 1984, 14, 47–57. [Google Scholar] [CrossRef]
- Manolopoulos, Y.; Nanopoulos, A.; Papadopoulos, A.N.; Theodoridis, Y. R-Trees: Theory and Applications; Advanced Information and Knowledge Processing; Springer: London, UK, 2006. [Google Scholar] [CrossRef]
- Samet, H. The Quadtree and Related Hierarchical Data Structures. ACM Comput. Surv. 1984, 16, 187–260. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Zhou, J.; Liu, R.; Du, Z.; Ye, X. A New Design of High-Performance Large-Scale GIS Computing at a Finer Spatial Granularity: A Case Study of Spatial Join with Spark for Sustainability. Sustainability 2016, 8, 926. [Google Scholar] [CrossRef] [Green Version]
- Whitman, R.T.; Marsh, B.G.; Park, M.B.; Hoel, E.G. Distributed Spatial and Spatio-Temporal Join on Apache Spark. ACM Trans. Spat. Algorithms Syst. 2019, 5, 6:1–6:28. [Google Scholar] [CrossRef]
- Phan, A.; Phan, T.; Trieu, N. A Comparative Study of Join Algorithms in Spark. In Proceedings of the Future Data and Security Engineering—7th International Conference, FDSE 2020, Quy Nhon, Vietnam, 25–27 November 2020; pp. 185–198. [Google Scholar] [CrossRef]
- Qiao, B.; Hu, B.; Zhu, J.; Wu, G.; Giraud-Carrier, C.; Wang, G. A top-k spatial join querying processing algorithm based on spark. Inf. Syst. 2020, 87. [Google Scholar] [CrossRef]
- Ji, J.; Chung, Y. Research on K nearest neighbor join for big data. In Proceedings of the IEEE International Conference on Information and Automation, ICIA 2017, Macau, China, 18–20 July 2017; pp. 1077–1081. [Google Scholar] [CrossRef]
- Du, Z.; Zhao, X.; Ye, X.; Zhou, J.; Zhang, F.; Liu, R. An Effective High-Performance Multiway Spatial Join Algorithm with Spark. ISPRS Int. J. Geo-Inf. 2017, 6, 96. [Google Scholar] [CrossRef] [Green Version]
- Qiao, B.; Zhang, J.; Qiao, X.; Hu, B.; Zheng, Y.; Wu, G. An Efficient Spatio-Textual Skyline Query Processing Algorithm Based on Spark. In Proceedings of the Advances in Natural Computation, Fuzzy Systems and Knowledge Discovery—Proceedings of the 15th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD 2019), Kunming, China, 20–22 July 2019; Volume 2, pp. 659–667. [Google Scholar] [CrossRef]
- Mavrommatis, G.; Moutafis, P.; Vassilakopoulos, M.; García-García, F.; Corral, A. SliceNBound: Solving Closest Pairs and Distance Join Queries in Apache Spark. In Proceedings of the Advances in Databases and Information Systems—21st European Conference, ADBIS 2017, Nicosia, Cyprus, 24–27 September 2017; pp. 199–213. [Google Scholar] [CrossRef]
- Mavrommatis, G.; Moutafis, P.; Vassilakopoulos, M. Closest-Pairs Query Processing in Apache Spark. In Proceedings of the CLOUD COMPUTING 2017, Eighth International Conference on Cloud Computing, GRIDs, and Virtualization, Athens, Greece, 19–23 February 2017; pp. 26–31. [Google Scholar]
- Mavrommatis, G.; Moutafis, P.; Vassilakopoulos, M. Binary Space Partitioning for Parallel and Distributed Closest-Pairs Query Processing. Int. J. Adv. Softw. 2017, 10, 275–285. [Google Scholar]
- Roumelis, G.; Corral, A.; Vassilakopoulos, M.; Manolopoulos, Y. New plane-sweep algorithms for distance-based join queries in spatial databases. GeoInformatica 2016, 20, 571–628. [Google Scholar] [CrossRef] [Green Version]
- Moutafis, P.; Mavrommatis, G.; Velentzas, P. Prepartitioning in MapReduce Processing of Group Nearest-Neighbor Query. In Proceedings of the PCI 2020: 24th Pan-Hellenic Conference on Informatics, Athens, Greece, 20–22 November 2020; pp. 380–385. [Google Scholar] [CrossRef]
- Damji, J.S.; Wenig, B.; Das, T.; Lee, D. Learning Spark: Lightning-Fast Data Analytics, 2nd ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2020. [Google Scholar]
- Stoica, I. Apache Spark and Hadoop: Working Together. 2014. Available online: https://databricks.com/blog/2014/01/21/spark-and-hadoop.htm (accessed on 13 October 2021).
- Verma, A.; Mansuri, A.H.; Jain, N. Big data management processing with Hadoop MapReduce and spark technology: A comparison. In Proceedings of the 2016 Symposium on Colossal Data Analysis and Networking (CDAN), Indore, India, 18–19 March 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache Spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Samadi, Y.; Zbakh, M.; Tadonki, C. Performance comparison between Hadoop and Spark frameworks using HiBench benchmarks. Concurr. Comput. Pract. Exp. 2018, 30. [Google Scholar] [CrossRef]
- Mostafaeipour, A.; Rafsanjani, A.J.; Ahmadi, M.; Dhanraj, J.A. Investigating the performance of Hadoop and Spark platforms on machine learning algorithms. J. Supercomput. 2021, 77, 1273–1300. [Google Scholar] [CrossRef]
- Döschl, A.; Keller, M.; Mandl, P. Performance evaluation of Apache Hadoop and Apache Spark for parallelization of compute-intensive tasks. In Proceedings of the iiWAS ’20: The 22nd International Conference on Information Integration and Web-Based Applications & Services, Virtual Event, Chiang Mai, Thailand, 30 November–2 December 2020; Indrawan-Santiago, M., Pardede, E., Salvadori, I.L., Steinbauer, M., Khalil, I., Kotsis, G., Eds.; ACM: New York, NY, USA, 2020; pp. 313–321. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spatial Analytics System | RQ | KNNQ | SJ | KNNJQ | DJ |
|---|---|---|---|---|---|
| SpatialSpark [19] | ✓ | ✗ | ✓ | ✗ | ✗ |
| GeoSpark [4] | ✓ | ✓ | ✓ | ✗ | ✓ |
| Simba [20] | ✓ | ✓ | ✗ | ✓ | ✓ |
| LocationSpark [21] | ✓ | ✓ | ✗ | ✓ | ✓ |
| STARK [22] | ✓ | ✓ | ✓ | ✗ | ✗ |
| SparkGIS [23] | ✓ | ✓ | ✓ | ✗ | ✗ |
| Elcano [24] | ✗ | ✗ | ✓ | ✗ | ✗ |
| Beast [25] | ✓ | ✗ | ✓ | ✗ | ✗ |
| Spatial Query | Ref. | Algorithms/Applied Techniques for Query Processing |
|---|---|---|
| RQ | [26] | Spark-based Interpolation Search (SPIS) |
| KNNQ | [27] | Generic framework using clustering methods |
| [28] | In-memory partitioning and indexing system (SparkNN) | |
| SJQ | [33] | Spatial Join with Spark (SJS), uniform grid partitioning |
| [34] | Distributed join methods: Broadcast Join and Bin Join | |
| [35] | Comparative study of common join algorithms in Spark | |
| TKSJQ | [36] | Uniform grid partitioning and improved plane-sweeping |
| KNNJQ | [37] | Locality-Sensitive Hashing (LSH) algorithm in Spark |
| MwSJQ | [38] | Multiway Spatial Join algorithm in Spark (MSJS), using |
| cascaded pairwise join technique | ||
| STSQ | [39] | Spark-based spatio-textual skyline query alg. (Multi-PSS) |
| KCPQ, DJQ | [40] | SliceNBound (SnB), parent-child and common-merged |
| strip partitioning and, plane-sweep technique | ||
| [41] | Strip-based partitioning and plane-sweep technique | |
| [42] | Binary Space Partitioning (BSP). Two criteria: R-split | |
| (equal size) and Q-split (equal width) of the child strip |
| 0.79 | 1.58 | 2.37 | |
| 1.27 | 1.12 | 2.39 | |
| 0.35 | 2.12 | 2.47 | |
| 1.9 | 0.5 | 2.4 | |
| 1.27 | 1.5 | 2.77 | |
| 2.26 | 1.58 | 3.84 | |
| 1.99 | 0.58 | 2.57 | |
| 1.13 | 1.03 | 2.16 | |
| 1.06 | 2.24 | 3.3 | |
| 1.27 | 1.58 | 2.85 |
| Symbol | Description |
|---|---|
| cardinality of Q | |
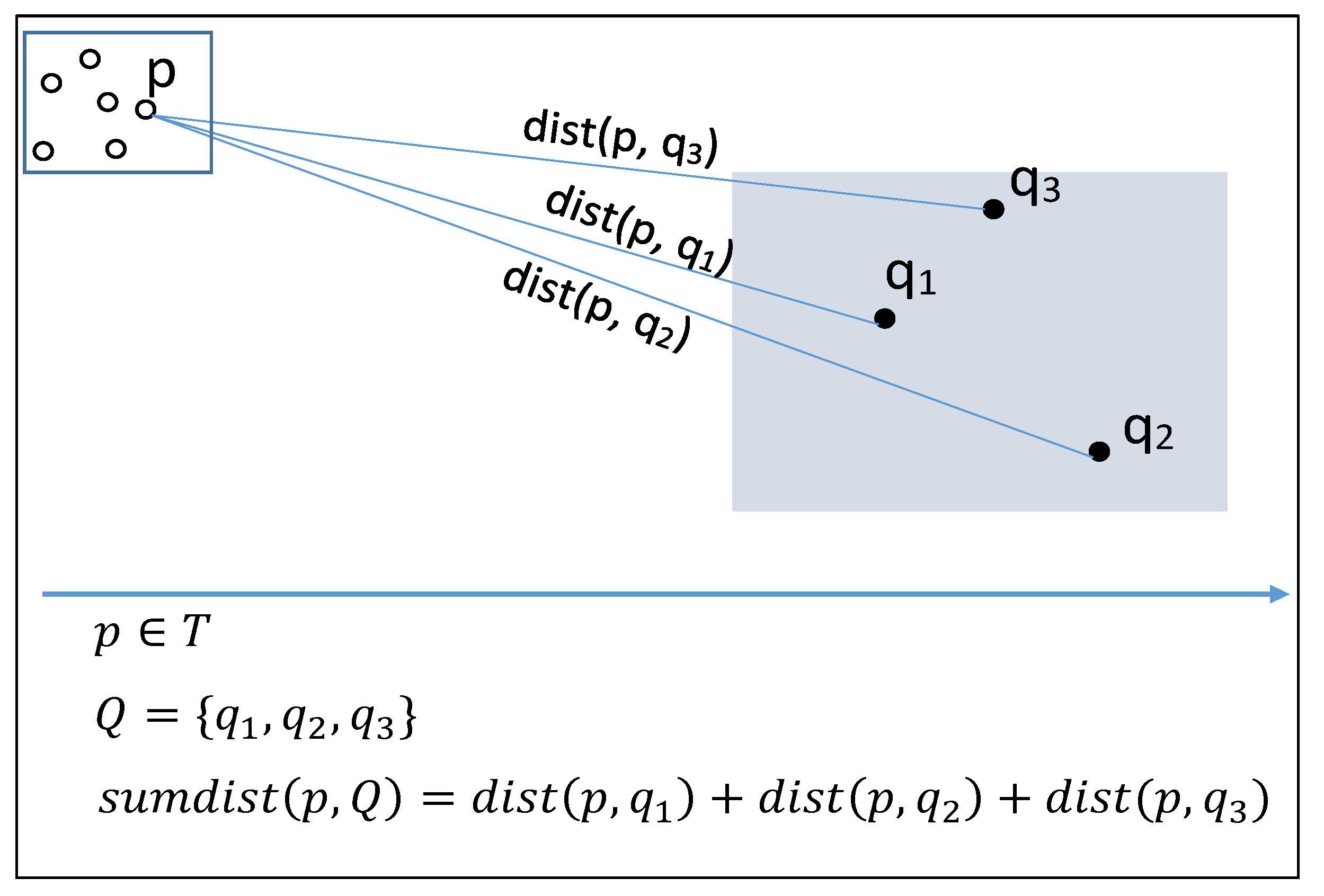
| sum of distances from point p to all points of Q | |
| K-th nearest-neighbor distance | |
| min distance between and point p | |
| min distance between and Query |
| Type | Dataset | Num. of Pts | Disk Size |
|---|---|---|---|
| Training | parks | 11.5 million | 373 MB |
| buildings | 114.7 million | 3.7 GB | |
| roads | 717 million | 30 GB | |
| Query | hydro (def. loc.) | 2.8 million | 91.4 MB |
| hydro (new. loc.) | 2.8 million | 91.4 MB | |
| small synth. | 706,000 | 29.5 MB | |
| large synth. | 39 million | 165.7 MB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moutafis, P.; Mavrommatis, G.; Vassilakopoulos, M.; Corral, A. Efficient Group K Nearest-Neighbor Spatial Query Processing in Apache Spark. ISPRS Int. J. Geo-Inf. 2021, 10, 763. https://doi.org/10.3390/ijgi10110763
Moutafis P, Mavrommatis G, Vassilakopoulos M, Corral A. Efficient Group K Nearest-Neighbor Spatial Query Processing in Apache Spark. ISPRS International Journal of Geo-Information. 2021; 10(11):763. https://doi.org/10.3390/ijgi10110763
Chicago/Turabian StyleMoutafis, Panagiotis, George Mavrommatis, Michael Vassilakopoulos, and Antonio Corral. 2021. "Efficient Group K Nearest-Neighbor Spatial Query Processing in Apache Spark" ISPRS International Journal of Geo-Information 10, no. 11: 763. https://doi.org/10.3390/ijgi10110763
APA StyleMoutafis, P., Mavrommatis, G., Vassilakopoulos, M., & Corral, A. (2021). Efficient Group K Nearest-Neighbor Spatial Query Processing in Apache Spark. ISPRS International Journal of Geo-Information, 10(11), 763. https://doi.org/10.3390/ijgi10110763