
Encoding a Categorical Independent Variable for Input to TerrSet’s Multi-Layer Perceptron



Abstract
:1. Introduction
2. Materials and Methods
2.1. Flow of Methods
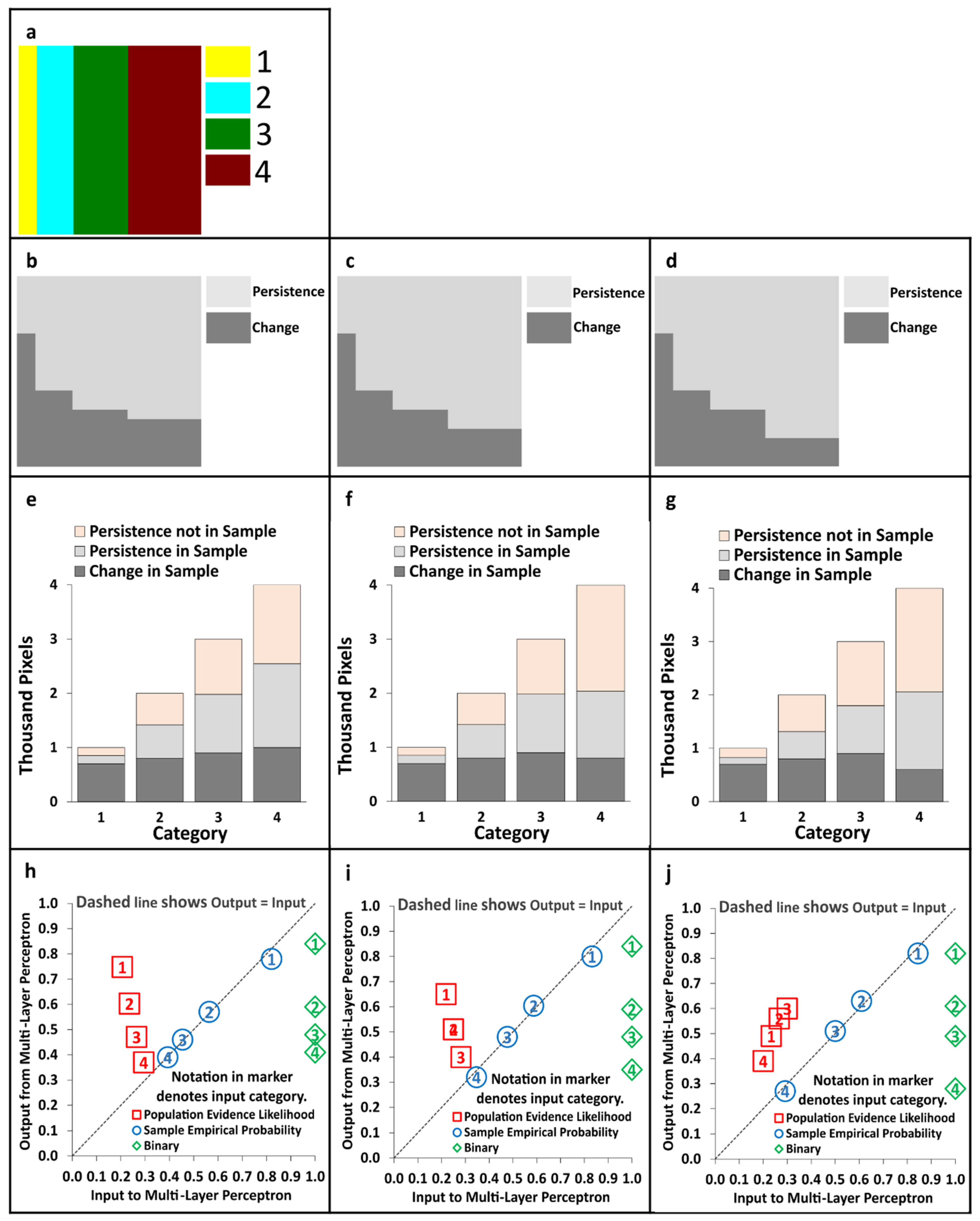
2.2. Theoretical Analysis Illustrated with Designed Data
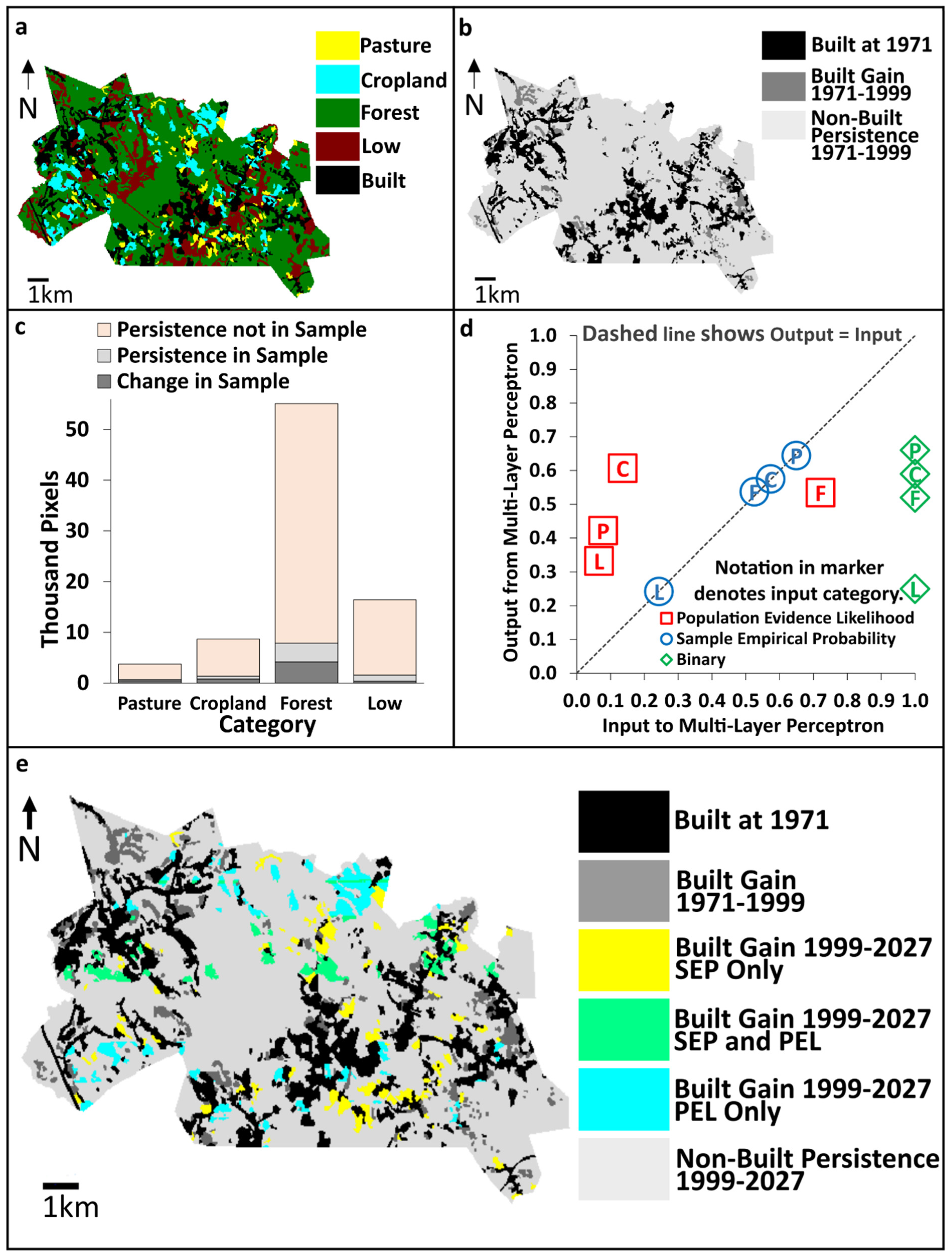
2.3. Practical Application
3. Results
4. Discussion
4.1. Implications of Results
4.2. Next Steps
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Costanza, R.; Ruth, M. Using dynamic modeling to scope environmental problems and build consensus. Environ. Manag. 1998, 22, 183–195. [Google Scholar] [CrossRef] [PubMed]
- Verburg, P.; Schot, P.; Dijst, M.; Veldkamp, A. Land-use change modeling: Current practice and research priorities. GeoJournal 2004, 61, 309–324. [Google Scholar] [CrossRef]
- Mas, J.; Kolb, M.; Paegelow, M.; Camacho Olmedo, M.T.; Houet, T. Inductive pattern-based land use/cover change models: A comparison of four software packages. Environ. Model. Softw. 2014, 51, 94–111. [Google Scholar] [CrossRef] [Green Version]
- Eastman, J.R.; Van Fossen, M.; Solorzano, L. Transition potential modeling for land cover change. In GIS, Spatial Analysis and Modeling; ESRI Press: Redlands, CA, USA, 2005; pp. 339–368. [Google Scholar]
- Eastman, J.R. TerrSet Geospatial Monitoring and Modeling System; Clark University: Worcester, MA, USA, 2020; Available online: https://clarklabs.org (accessed on 1 October 2021).
- Areendran, G.; Raj, K.; Mazumdar, S.; Puri, K.; Shah, B.; Mukerjee, R.; Medhi, K. Modeling REDD+ baselines using mapping technologies: A pilot study from Balpakram-Baghmara Landscape (BBL) in Meghalaya, India. Int. J. Geoinformat. 2013, 9, 61–71. [Google Scholar] [CrossRef]
- Gong, H.; Simwanda, M.; Murayama, Y. An Internet-based gis platform providing data for visualization and spatial analysis of urbanization in major Asian and African cities. ISPRS Int. J. Geo-Inf. 2017, 6, 257. [Google Scholar] [CrossRef] [Green Version]
- Kefi, M.; Mishra, B.K.; Kumar, P.; Masago, Y.; Fukushi, K. Assessment of tangible direct flood damage using a spatial analysis approach under the effects of climate change: Case study in an urban watershed in Hanoi, Vietnam. ISPRS Int. J. Geo-Inf. 2018, 7, 29. [Google Scholar] [CrossRef] [Green Version]
- Megahed, Y.; Cabral, P.; Silva, J.; Caetano, M. Land cover mapping analysis and urban growth modelling using remote sensing techniques in greater Cairo Region—Egypt. ISPRS Int. J. Geo-Inf. 2015, 4, 1750. [Google Scholar] [CrossRef] [Green Version]
- Nath, B.; Wang, Z.; Ge, Y.; Islam, K.; Singh, R.P.; Niu, Z. Land use and land cover change modeling and future potential landscape risk assessment using Markov-CA model and analytical hierarchy process. ISPRS Int. J. Geo-Inf. 2020, 9, 134. [Google Scholar] [CrossRef] [Green Version]
- Rimal, B.; Zhang, L.; Keshtkar, H.; Haack, B.N.; Rijal, S.; Zhang, P. Land Use/land cover dynamics and modeling of urban land expansion by the integration of cellular automata and Markov chain. ISPRS Int. J. Geo-Inf. 2018, 7, 154. [Google Scholar] [CrossRef] [Green Version]
- Pijanowski, B.; Shellito, B.; Bauer, M.; Sawaya, K. Calibrating a neural network-based urban change model for two metropolitan areas of the upper Midwest of the United States. Int. J. Geogr. Inf. Sci. 2005, 19, 197–215. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning internal representations by error propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Vol. 1: Foundations; MIT Press: Cambridge, MA, USA, 1986; pp. 318–362. [Google Scholar]
- Potdar, K.; Pardawala, T.; Pai, C. A Comparative study of categorical variable encoding techniques for neural network classifiers. Int. J. Comput. Appl. 2017, 175, 7–9. [Google Scholar] [CrossRef]
- Hancock, J.T.; Khoshgoftaar, T.M. Survey on categorical data for neural networks. J. Big Data 2020, 7, 28. [Google Scholar] [CrossRef] [Green Version]
- Sangermano, F.; Toledano, J.; Eastman, J.R. Land cover change in the Bolivian Amazon and its implications for REDD+ and endemic biodiversity. Landsc. Ecol. 2012, 27, 571–584. [Google Scholar] [CrossRef]
- Bradley, A.V.; Rosa, I.M.D.; Brandão, A.; Crema, S.; Dobler, C.; Moulds, S.; Ahmed, S.E.; Carneiro, T.; Smith, M.J.; Ewers, R.M. An ensemble of spatially explicit land-cover model projections: Prospects and challenges to retrospectively evaluate deforestation policy. Model. Earth Syst. Environ. 2017, 3, 1215–1228. [Google Scholar] [CrossRef]
- Zheng, X.; He, G.; Wang, S.; Wang, Y.; Wang, G.; Yang, Z.; Yu, J.; Wang, N. Comparison of machine learning methods for potential active landslide hazards identification with multi-source data. ISPRS Int. J. Geo-Inf. 2021, 10, 253. [Google Scholar] [CrossRef]
- Fitkov-Norris, E.; Vahid, S.; Hand, C. Evaluating the impact of categorical data encoding and scaling on neural network classification performance: The case of repeat consumption of identical cultural goods. In Engineering Applications of Neural Networks; Jayne, C., Yue, S., Iliadis, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 343–352. [Google Scholar]
- Pontius, R.G., Jr.; Cornell, J.D.; Hall, C.A.S. Modeling the spatial pattern of land-use change with GEOMOD2: Application and validation for Costa Rica. Agric. Ecosyst. Environ. 2001, 85, 191–203. [Google Scholar] [CrossRef] [Green Version]
- Andaryani, S.; Sloan, S.; Nourani, V.; Keshthar, H. The utility of a hybrid GEOMOD-Markov Chain model of land-use change in the context of highly water-demanding agriculture in a semi-arid region. Ecol. Inform. 2021, 64, 101332. [Google Scholar] [CrossRef]
- Quan, B.; Pontius, R.G., Jr.; Song, H. Intensity analysis to communicate land change during three time intervals in two regions of Quanzhou City, China. GIScience Remote Sens. 2020, 57, 21–36. [Google Scholar] [CrossRef]
- Amadlou, M.; Karimi, M.; Pontius, R.G., Jr. A new framework to deal with the class imbalance problem in urban gain modeling based on clustering and ensemble models. Geocarto Int. 2021. [Google Scholar] [CrossRef]
- Hsieh, W.W. Machine Learning Methods in the Environmental Sciences: Neural Networks and Kernels; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar] [CrossRef] [Green Version]
- Commonwealth of Massachusetts. 2016. Available online: https://www.gismanual.com/lookup/MassGISLandUse.html (accessed on 1 October 2021).
- Varga, O.G.; Pontius, R.G., Jr.; Singh, S.K.; Szabó, S. Intensity analysis and the figure of merit’s components for assessment of a Cellular Automata—Markov simulation model. Ecol. Indic. 2013, 101, 933–942. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| k | Identifier for an arbitrary category in the independent variable |
| K | Number of categories in the independent variable |
| Ck | Number of change pixels on category k |
| Dk | Number of persistence pixels on category k |
| Ek | Expected number of sampled persistence pixels on category k |
| Sk | Sample Empirical Probability for category k |
| Pk | Population Evidence Likelihood for category k |
| Symbol | Meaning |
|---|---|
| k | Identifier for an arbitrary category in the independent variable |
| K | Number of categories in the independent variable |
| Ck | Number of change pixels in category k |
| Dk | Number of persistence pixels in category k |
| R | Extent’s proportion of change |
| Gk | Population empirical probability for category k |
| Ek | Expected number of sampled persistence pixels in category k |
| Sk | Sample Empirical Probability for category k |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Evenden, E.; Pontius Jr, R.G. Encoding a Categorical Independent Variable for Input to TerrSet’s Multi-Layer Perceptron. ISPRS Int. J. Geo-Inf. 2021, 10, 686. https://doi.org/10.3390/ijgi10100686
Evenden E, Pontius Jr RG. Encoding a Categorical Independent Variable for Input to TerrSet’s Multi-Layer Perceptron. ISPRS International Journal of Geo-Information. 2021; 10(10):686. https://doi.org/10.3390/ijgi10100686
Chicago/Turabian StyleEvenden, Emily, and Robert Gilmore Pontius Jr. 2021. "Encoding a Categorical Independent Variable for Input to TerrSet’s Multi-Layer Perceptron" ISPRS International Journal of Geo-Information 10, no. 10: 686. https://doi.org/10.3390/ijgi10100686
APA StyleEvenden, E., & Pontius Jr, R. G. (2021). Encoding a Categorical Independent Variable for Input to TerrSet’s Multi-Layer Perceptron. ISPRS International Journal of Geo-Information, 10(10), 686. https://doi.org/10.3390/ijgi10100686