CAPTCHA Recognition Using Deep Learning with Attached Binary Images


 ,
,  and
and
Abstract
1. Introduction
- We propose an Attached Binary Images (ABI) algorithm that is used to recognize CAPTCHA characters without the need for segmenting CAPTCHA into individual characters.
- With the adoption of ABI algorithm, we significantly reduce the storage size of our model and simplify the entire architecture of CNN model.
- We conduct our experiments on two CAPTCHA dataset schemes. The proposed model has efficiently improved the recognition accuracy and simplified the structure of the CAPTCHA recognition system as compared to other competitive CAPTCHA recognition methods.
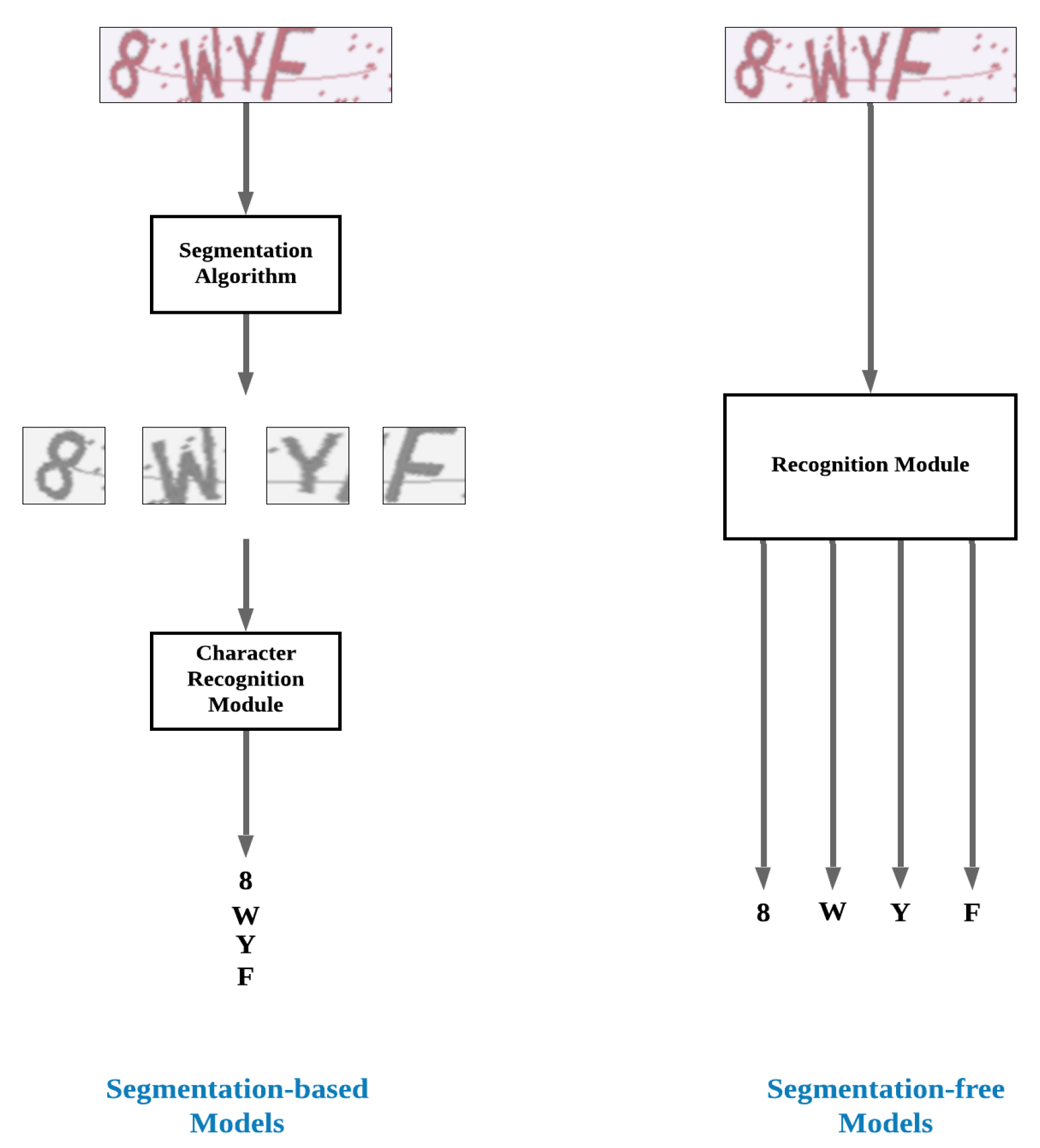
2. Related Work
3. Proposed Method
3.1. Basic Concept of Proposed Recognition Approach
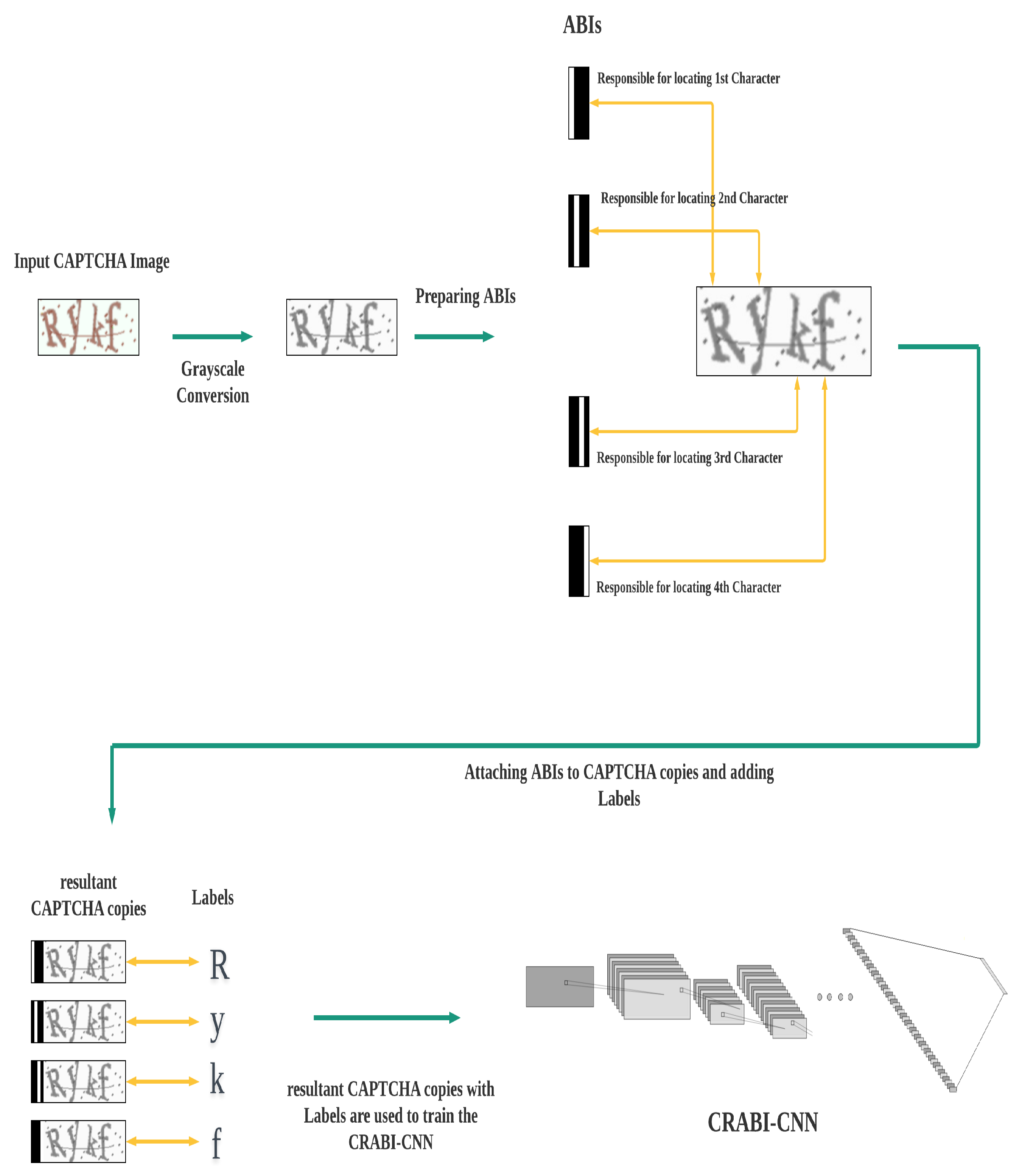
3.1.1. Training Phase
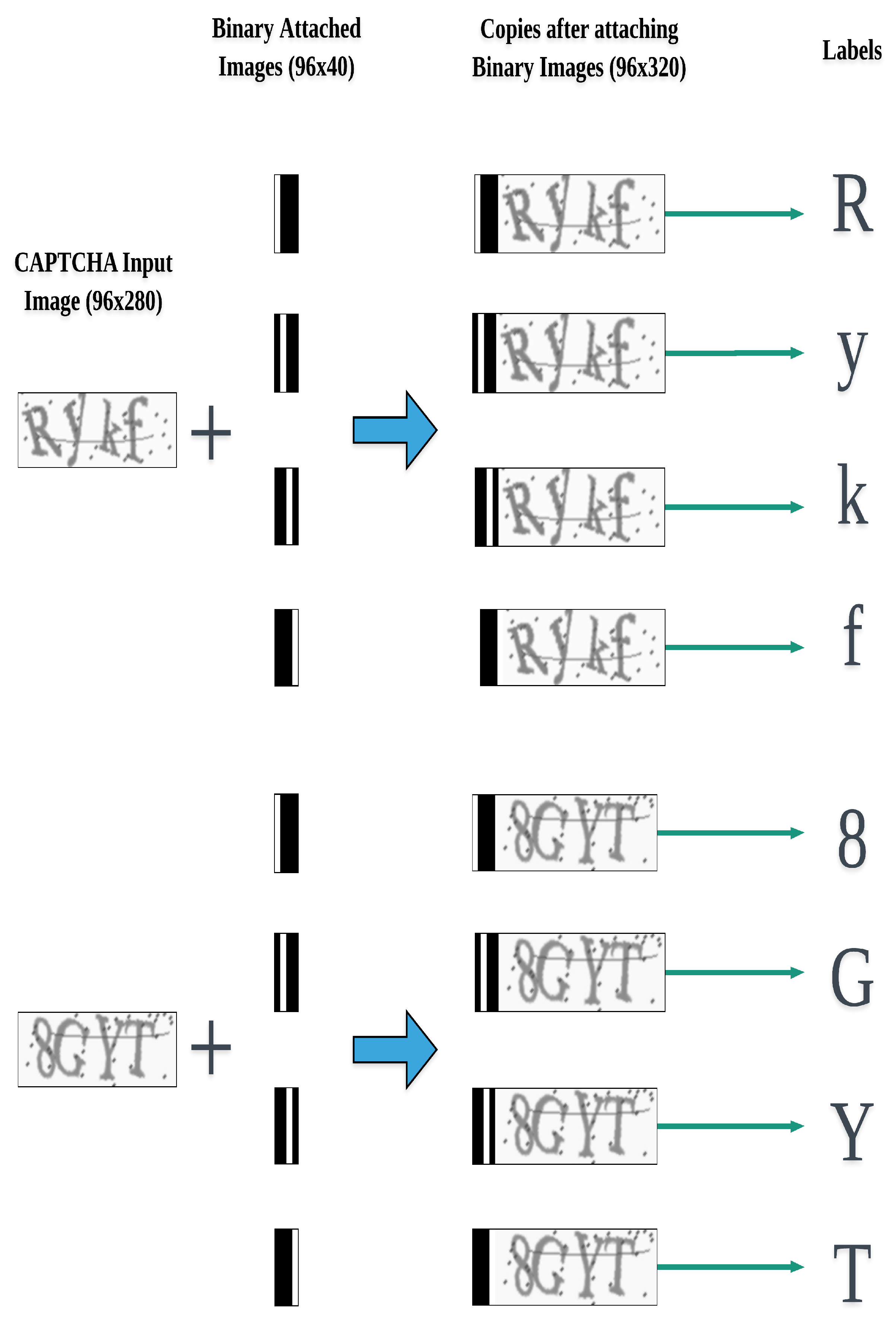
- Making Copies: We make n copies of each CAPTCHA image in the original training set. We end up with n identical copies of the training set.
- Preparing ABIs: We have to define n external distinct fixed-size binary (black and white) images. These distinct binary images are used to represent the position or location information of the CAPTCHA characters. Each of the n distinct binary images is always responsible for locating exactly one character of the n CAPTCHA characters. That is, the first binary image will be always responsible for locating the first character in each CAPTCHA image, the second binary image is always responsible for locating the second character in each CAPTCHA image, and so on. The specific design of the binary images is presented in Section 3.2.
- Attaching ABIs: We attach the distinct binary images to the CAPTCHA copies. The first distinct binary image is attached to the first copy of each CAPTCHA image in the training set, the second distinct binary image is attached to the second copy of each CAPTCHA image in the training set, and so on. We end up with a new training set consisting of n × M images. We refer to this new dataset as the “resultant dataset”, and each image in this dataset is referred to as the “resultant CAPTCHA copy”. Each resultant CAPTCHA copy consists of a CAPTCHA image and its ABI.
- Labeling: We add labels to each resultant CAPTCHA copy in the resultant dataset. Every resultant CAPTCHA copy is given only one character class to be its label. Every resultant CAPTCHA copy consists of a CAPTCHA image and an ABI. The ABI of each resultant CAPTCHA copy determines the location of the character class on the CAPTCHA copy that is added as a label. In this way, labels can be added directly to all resultant CAPTCHA copies on the resultant dataset.
- Training: The resultant CAPTCHA copies and their labels are used to train a CNN model to classify and recognize CAPTCHA characters. This CNN is trained to use attached binary images for locating CAPTCHA characters, and labels for recognizing character classes.
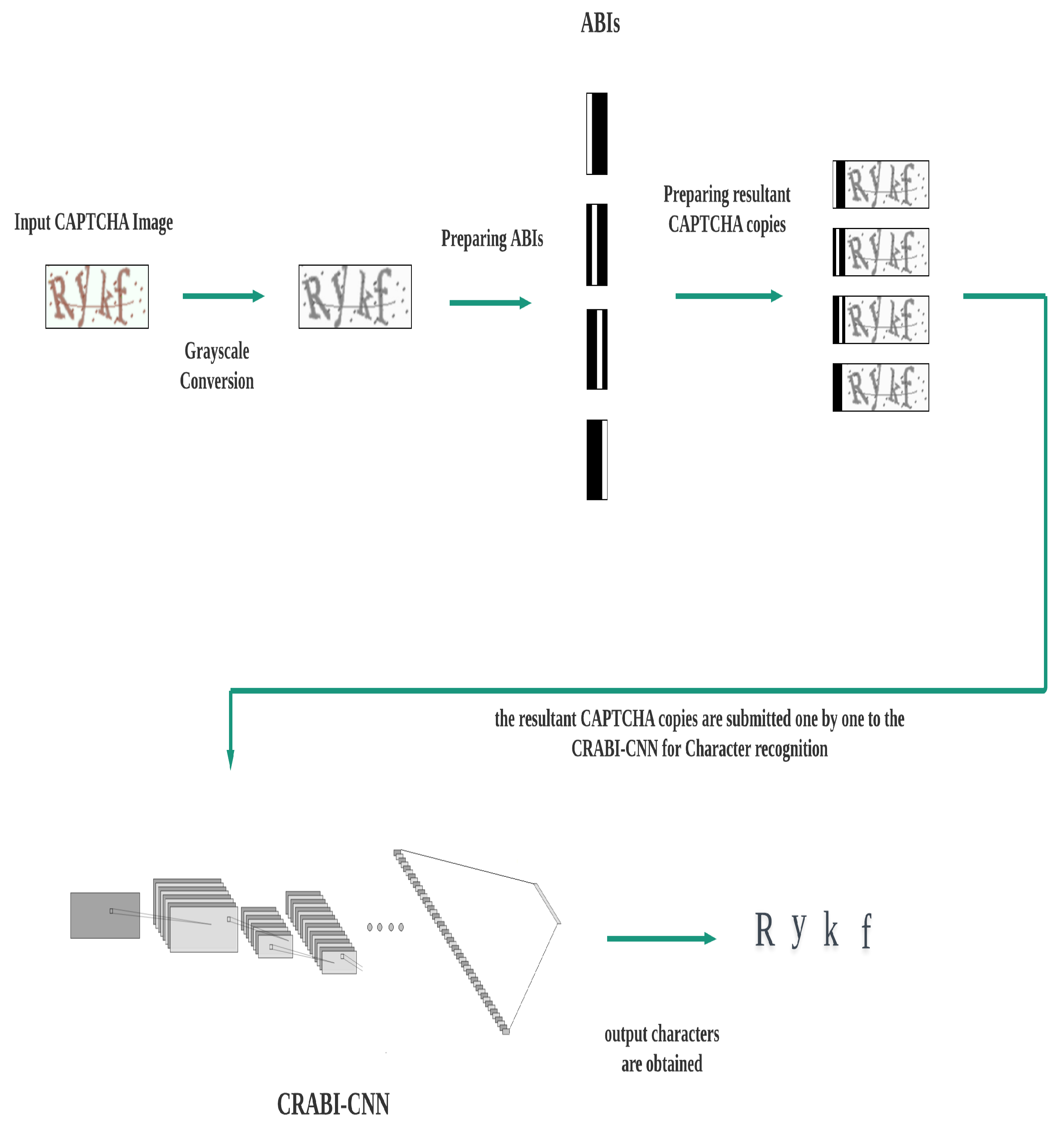
3.1.2. Testing Phase
- We make n copies of the CAPTCHA input image.
- We attach each one of the n distinct binary images to one of the n copies of the CAPTCHA input image.
- We submit the resultant n CAPTCHA copies directly to the trained CAPTCHA recognition CNN.
- The CNN locates and classifies the characters of each resultant CAPTCHA copy, and the desired output is obtained. A complete framework description of the whole pipeline in testing phase is shown in Figure 4.
3.2. Characteristics of Attached Binary Images Adopted in Our Captcha Recognition Model
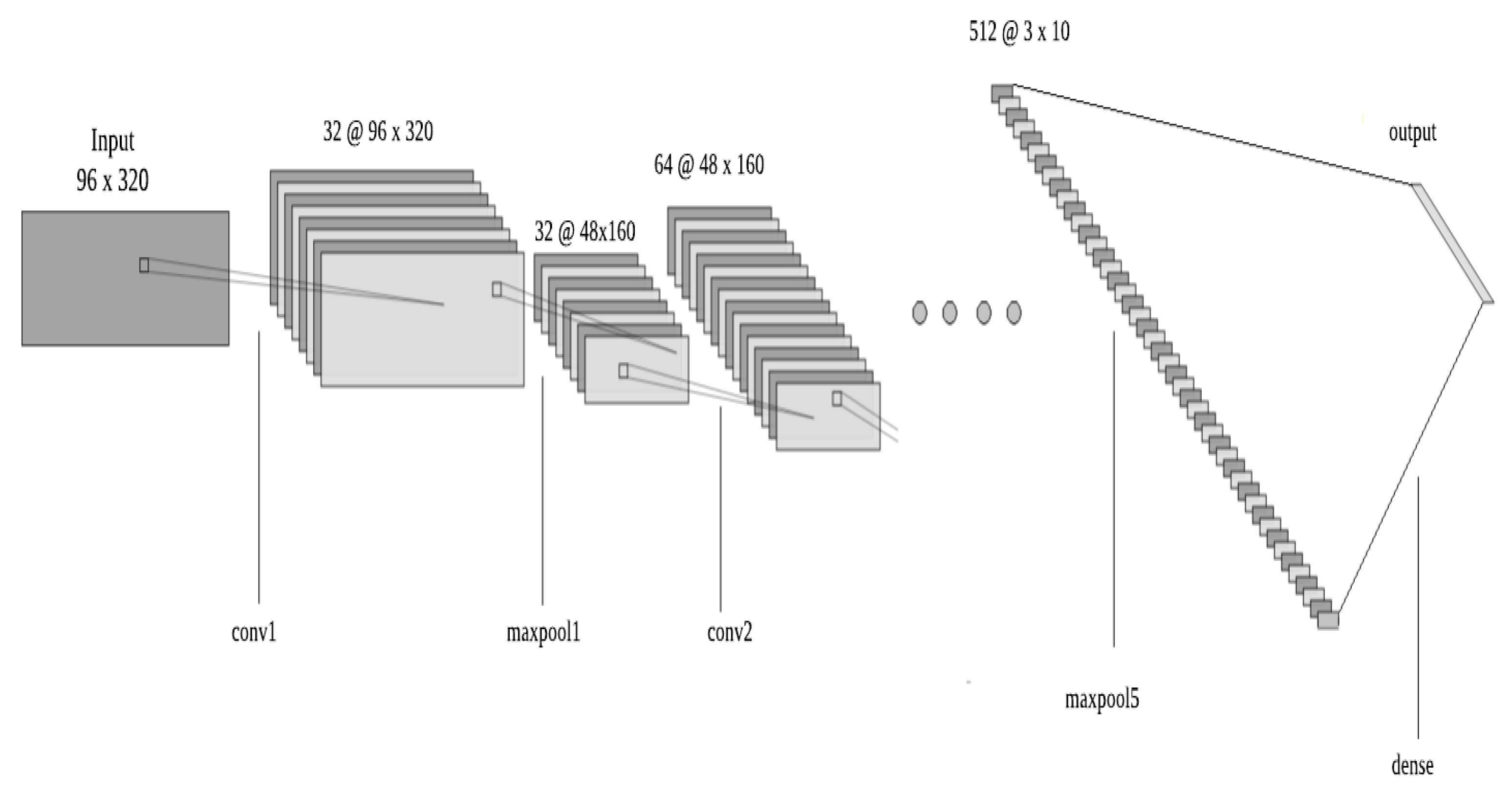
3.3. Structure and Parameters of the Proposed CRABI-CNN
4. Experiments and Results
4.1. Used Dataset and Labeling Description
4.1.1. Weibo Captcha Scheme
4.1.2. Gregwar Captcha Scheme
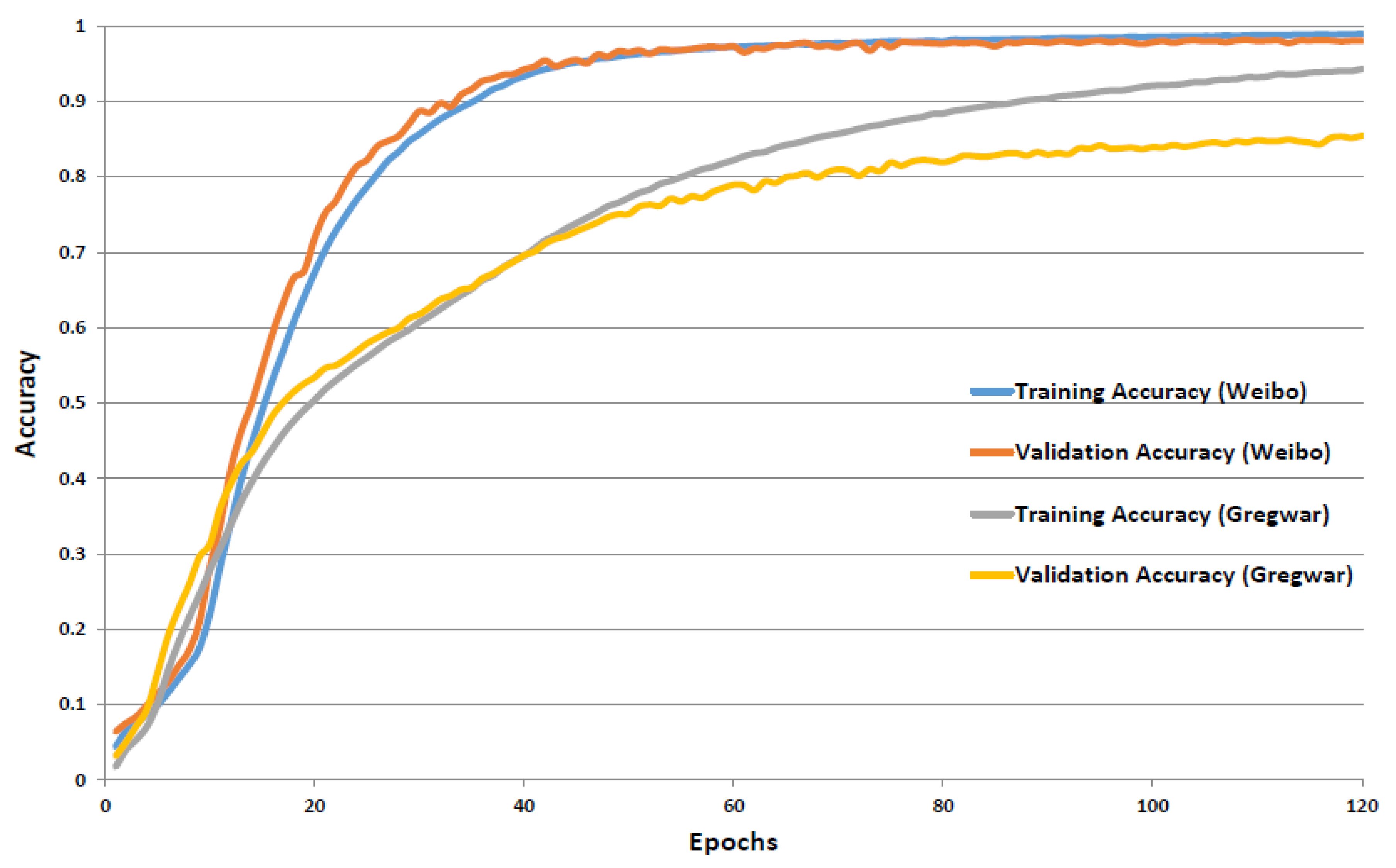
4.2. Accuracy and Training Description
4.3. Comparison Results
4.4. Discussion of the Proposed Crabi Algorithm
4.4.1. Captcha Breaking Ability
4.4.2. Avoiding Segmentation
4.4.3. Small Storage
4.4.4. Simplicity and Flexibility
4.4.5. Long Training and Testing Time
4.4.6. Memory Use
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hussain, R.; Kumar, K.; Gao, H.; Khan, I. Recognition of merged characters in text based CAPTCHAs. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 3917–3921. [Google Scholar]
- von Ahn, L.; Blum, M.; Hopper, N.J.; Langford, J. CAPTCHA: Using Hard AI Problems for Security. In Proceedings of the Advances in Cryptology—EUROCRYPT 2003, Warsaw, Poland, 4–8 May 2003; Biham, E., Ed.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 294–311. [Google Scholar]
- von Ahn, L.; Blum, M.; Langford, J. Telling Humans and Computers Apart Automatically. Commun. ACM 2004, 47, 56–60. [Google Scholar] [CrossRef]
- Gao, H.; Tang, M.; Liu, Y.; Zhang, P.; Liu, X. Research on the Security of Microsoft’s Two-Layer Captcha. IEEE Trans. Inf. Forensics Secur. 2017, 12. [Google Scholar] [CrossRef]
- Tang, M.; Gao, H.; Zhang, Y.; Liu, Y.; Zhang, P.; Wang, P. Research on Deep Learning Techniques in Breaking Text-Based Captchas and Designing Image-Based Captcha. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2522–2537. [Google Scholar] [CrossRef]
- Wang, P.; Gao, H.; Rao, Q.; Luo, S.; Yuan, Z.; Shi, Z. A Security Analysis of Captchas with Large Character Sets. IEEE Trans. Dependable Secur. Comput. 2020, 1. [Google Scholar] [CrossRef]
- Ye, G.; Tang, Z.; Fang, D.; Zhu, Z.; Feng, Y.; Xu, P.; Chen, X.; Wang, Z. Yet Another Text Captcha Solver: A Generative Adversarial Network Based Approach. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 332–348. [Google Scholar]
- Gao, H.; Wang, W.; Qi, J.; Wang, X.; Liu, X.; Yan, J. The Robustness of Hollow CAPTCHAs. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, Berlin, Germany, 4–8 November 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 1075–1086. [Google Scholar]
- Malik, S.; Soundararajan, R. Llrnet: A Multiscale Subband Learning Approach for Low Light Image Restoration. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 779–783. [Google Scholar]
- Jin, Z.; Iqbal, M.Z.; Bobkov, D.; Zou, W.; Li, X.; Steinbach, E. A Flexible Deep CNN Framework for Image Restoration. IEEE Trans. Multimedia 2020, 22, 1055–1068. [Google Scholar] [CrossRef]
- Dong, W.; Wang, P.; Yin, W.; Shi, G.; Wu, F.; Lu, X. Denoising Prior Driven Deep Neural Network for Image Restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2305–2318. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y. An Improved Faster R-CNN for Object Detection. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; Volume 2, pp. 119–123. [Google Scholar]
- Abdussalam, A.; Sun, S.; Fu, M.; Sun, H.; Khan, I. License Plate Segmentation Method Using Deep Learning Techniques. In Proceedings of the Signal and Information Processing, Networking and Computers; Sun, S., Ed.; Springer: Singapore, 2019; pp. 58–65. [Google Scholar]
- Abdussalam, A.; Sun, S.; Fu, M.; Ullah, Y.; Ali, S. Robust Model for Chinese License Plate Character Recognition Using Deep Learning Techniques. In CSPS 2018: Communications, Signal Processing, and Systems; Liang, Q., Liu, X., Na, Z., Wang, W., Mu, J., Zhang, B., Eds.; Springer: Singapore, 2020; Volume 517, pp. 121–127. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Jmour, N.; Zayen, S.; Abdelkrim, A. Convolutional neural networks for image classification. In Proceedings of the 2018 International Conference on Advanced Systems and Electric Technologies (IC-ASET), Hammamet, Tunisia, 22–25 March 2018; pp. 397–402. [Google Scholar]
- Zhang, L.; Xie, Y.; Luan, X.; He, J. Captcha automatic segmentation and recognition based on improved vertical projection. In Proceedings of the 2017 IEEE 9th International Conference on Communication Software and Networks (ICCSN), Guangzhou, China, 6–8 May 2017; pp. 1167–1172. [Google Scholar]
- Chen, C.J.; Wang, Y.W.; Fang, W.P. A Study on Captcha Recognition. In Proceedings of the 2014 Tenth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Kitakyushu, Japan, 27–29 August 2014; pp. 395–398. [Google Scholar]
- Anagnostopoulos, C.E.; Anagnostopoulos, I.E.; Psoroulas, I.D.; Loumos, V.; Kayafas, E. License Plate Recognition From Still Images and Video Sequences: A Survey. IEEE Trans. Intell. Transp. Syst. 2008, 9, 377–391. [Google Scholar] [CrossRef]
- Wang, Q. License plate recognition via convolutional neural networks. In Proceedings of the 2017 8th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 24–26 November 2017; pp. 926–929. [Google Scholar]
- Chellapilla, K.; Simard, P.Y. Using Machine Learning to Break Visual Human Interaction Proofs (HIPs). In Proceedings of the 17th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 13–18 December 2004; MIT Press: Cambridge, MA, USA, 2004; pp. 265–272. [Google Scholar]
- Saleem, N.; Muazzam, H.; Tahir, H.M.; Farooq, U. Automatic license plate recognition using extracted features. In Proceedings of the 2016 4th International Symposium on Computational and Business Intelligence (ISCBI), Olten, Switzerland, 5–7 September 2016; pp. 221–225. [Google Scholar]
- Sasi, A.; Sharma, S.; Cheeran, A.N. Automatic car number plate recognition. In Proceedings of the 2017 International Conference on Innovations in Information, Embedded and Communication Systems (ICIIECS), Coimbatore, India, 17–18 March 2017; pp. 1–6. [Google Scholar]
- Hussain, R.; Gao, H.; Shaikh, R.A.; Soomro, S.P. Recognition based segmentation of connected characters in text based CAPTCHAs. In Proceedings of the 2016 8th IEEE International Conference on Communication Software and Networks (ICCSN), Beijing, China, 4–6 June 2016; pp. 673–676. [Google Scholar]
- Sakkatos, P.; Theerayut, W.; Nuttapol, V.; Surapong, P. Analysis of text-based CAPTCHA images using Template Matching Correlation technique. In Proceedings of the 4th Joint International Conference on Information and Communication Technology, Electronic and Electrical Engineering (JICTEE), Chiang Rai, Thailand, 5–8 March 2014; pp. 1–5. [Google Scholar]
- Wu, C.; On, L.C.; Weng, C.H.; Kuan, T.S.; Ng, K. A Macao license plate recognition system. In Proceedings of the 2005 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2005; Volume 7, pp. 4506–4510. [Google Scholar]
- Baten, R.A.; Omair, Z.; Sikder, U. Bangla license plate reader for metropolitan cities of Bangladesh using template matching. In Proceedings of the 8th International Conference on Electrical and Computer Engineering, Dhaka, Bangladesh, 20–22 December 2014; pp. 776–779. [Google Scholar]
- Chen, J.; Luo, X.; Liu, Y.; Wang, J.; Ma, Y. Selective Learning Confusion Class for Text-Based CAPTCHA Recognition. IEEE Access 2019, 7, 22246–22259. [Google Scholar] [CrossRef]
- Hu, Y.; Chen, L.; Cheng, J. A CAPTCHA recognition technology based on deep learning. In Proceedings of the 2018 13th IEEE Conference on Industrial Electronics and Applications (ICIEA), Wuhan, China, 31 May–2 June 2018; pp. 617–620. [Google Scholar]
- Stark, F.; Hazırbaş, C.; Triebel, R.; Cremers, D. CAPTCHA Recognition with Active Deep Learning. In Proceedings of the German Conference on Pattern Recognition Workshop, Aachen, Germany, 7–10 October 2015. [Google Scholar]
- Qing, K.; Zhang, R. A Multi-Label Neural Network Approach to Solving Connected CAPTCHAs. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1313–1317. [Google Scholar]
- Zi, Y.; Gao, H.; Cheng, Z.; Liu, Y. An End-to-End Attack on Text CAPTCHAs. IEEE Trans. Inf. Forensics Secur. 2020, 15, 753–766. [Google Scholar] [CrossRef]
- Wang, P.; Gao, H.; Shi, Z.; Yuan, Z.; Hu, J. Simple and Easy: Transfer Learning-Based Attacks to Text CAPTCHA. IEEE Access 2020, 8, 59044–59058. [Google Scholar] [CrossRef]
- Fu, M.; Chen, N.; Hou, X.; Sun, H.; Abdussalam, A.; Sun, S. Real-Time Vehicle License Plate Recognition Using Deep Learning. In ICSINC 2018: Signal and Information Processing, Networking and Computers; Sun, S., Ed.; Springer: Singapore, 2019; Volume 494, pp. 35–41. [Google Scholar]
- Sun, H.; Fu, M.; Abdussalam, A.; Huang, Z.; Sun, S.; Wang, W. License Plate Detection and Recognition Based on the YOLO Detector and CRNN-12. In Proceedings of the Signal and Information Processing, Networking and Computers; Sun, S., Ed.; Springer: Singapore, 2019; pp. 66–74. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Corvallis, ON, USA, 25–29 June 2006; Volume 148, pp. 369–376. [Google Scholar] [CrossRef]
- Bursztein, E.; Martin, M.; Mitchell, J. Text-Based CAPTCHA Strengths and Weaknesses. In Proceedings of the Proceedings of the 18th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 17–21 October 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 125–138. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CRABI-CNN Layers |
|---|
| Convolutional (3 × 3), 32 |
| Maxpooling (2 × 2), 2 |
| Convolutional (3 × 3), 64 |
| Maxpooling (2 × 2), 2 |
| Convolutional (3 × 3), 128 |
| Convolutional (1 × 1), 64 |
| Convolutional (3 × 3), 128 |
| Maxpooling (2 × 2), 2 |
| Convolutional (3 × 3), 256 |
| Convolutional (1 × 1), 128 |
| Convolutional (3 × 3), 256 |
| Convolutional (1 × 1), 128 |
| Convolutional (3 × 3), 256 |
| Maxpooling (2 × 2), 2 |
| Convolutional (3 × 3), 512 |
| Convolutional (1 × 1), 256 |
| Convolutional (3 × 3), 512 |
| Convolutional (1 × 1), 256 |
| Convolutional (3 × 3), 512 |
| Convolutional (1 × 1), 256 |
| Convolutional (3 × 3), 512 |
| Maxpooling (2 × 2), 2 |
| Flatten |
| Dropout (0.5) |
| Softmax Layer |
| Weibo CAPTCHA Scheme | Gregwar CAPTCHA Scheme | |||||
|---|---|---|---|---|---|---|
| Training Set | Validating Set | Testing Set | Training Set | Validating Set | Testing Set | |
| 1st Character Accuracy | 99.75% (49,874/50,000) | 98.71% (9871/10,000) | 98.70% (9870/10,000) | 99.84% (49,920/50,000) | 93.56% (9356/10,000) | 93.12% (9312/10,000) |
| 2nd Character Accuracy | 99.84% (49,919/50,000) | 98.57% (9857/10,000) | 98.35% (9835/10,000) | 99.57% (49,784/50,000) | 84.93% (8493/10,000) | 85.28% (8528/10,000) |
| 3rd Character Accuracy | 99.26% (49,629/50,000) | 96.01% (9601/10,000) | 95.83% (9583/10,000) | 98.15% (49,075/50,000) | 74.20% (7420/10,000) | 74.03% (7403/10,000) |
| 4th Character Accuracy | 99.37% (49684/50,000) | 98.94% (9894/10,000) | 98.68% (9868/10,000) | 98.44% (49,221/50,000) | 89.09% (8909/10,000) | 88.68% (8868/10,000) |
| Total Character Accuracy | 99.55% (199,106/20,0000) | 98.06% (39,223/40,000) | 97.89% (39,156/40,000) | 99.00% (198,000/20,0000) | 85.45% (34,178/40,000) | 85.28% (34,111/40,000) |
| Overall CAPTCHA Accuracy | 98.45% (49,226/50,000) | 93.26% (93.26/10,000) | 92.68% (9268/10,000) | 96.26% (48,130/50,000) | 54.30% (5430/10,000) | 54.20% (5420/10,000) |
| Weibo CAPTCHA Scheme | Gregwar CAPTCHA Scheme | |||||
|---|---|---|---|---|---|---|
| CRABI CNN | Multilabel CNN | CRNN | CRABI CNN | Multilabel CNN | CRNN | |
| Testing Total Character Accuracy | 97.89% (39,156/40,000) | 96.03% (38,411/40,000) | – | 85.28% (34,111/40,000) | 83.31% (33,322/40,000) | – |
| Testing Overall CAPTCHA Accuracy | 92.68% (9268/10,000) | 86.24% (8624/10,000) | 91.05% (9105/10,000) | 54.20% (5420/10,000) | 51.23% (5123/10,000) | 49.98% (4998/10,000) |
| Validating Total Character Accuracy | 98.06% (39,223/40,000) | 96.27% (38,506/40,000) | – | 85.45% (34,178/40,000) | 83.62% (33,448/40,000) | – |
| Validating Overall CAPTCHA Accuracy | 93.26% (9326/10,000) | 86.89% (8689/10,000) | 91.09% (9109/10,000) | 54.30% (5430/10,000) | 51.63% (5163/10,000) | 49.67% (4967/10,000) |
| Non-trainable and Trainable Parameters | 6,670,812 | 7,961,136 | 10,477,853 | 7,193,086 | 10,050,232 | 10,486,591 |
| Size of Weights on Hard Disk | 25.5 MB | 30.4 MB | 40 MB | 27.5 MB | 38.4 MB | 40.1 MB |
| Average Training Epoch Time | 936,729 ms | 240,109 ms | 375,892 ms | 936,303 ms | 237,199 ms | 202,300 ms |
| Testing Time on Entire Testing Set | 68,170 ms | 17,558 ms | 16,125 ms | 68,427 ms | 19,055 ms | 16,921 ms |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thobhani, A.; Gao, M.; Hawbani, A.; Ali, S.T.M.; Abdussalam, A. CAPTCHA Recognition Using Deep Learning with Attached Binary Images. Electronics 2020, 9, 1522. https://doi.org/10.3390/electronics9091522
Thobhani A, Gao M, Hawbani A, Ali STM, Abdussalam A. CAPTCHA Recognition Using Deep Learning with Attached Binary Images. Electronics. 2020; 9(9):1522. https://doi.org/10.3390/electronics9091522
Chicago/Turabian StyleThobhani, Alaa, Mingsheng Gao, Ammar Hawbani, Safwan Taher Mohammed Ali, and Amr Abdussalam. 2020. "CAPTCHA Recognition Using Deep Learning with Attached Binary Images" Electronics 9, no. 9: 1522. https://doi.org/10.3390/electronics9091522
APA StyleThobhani, A., Gao, M., Hawbani, A., Ali, S. T. M., & Abdussalam, A. (2020). CAPTCHA Recognition Using Deep Learning with Attached Binary Images. Electronics, 9(9), 1522. https://doi.org/10.3390/electronics9091522