Bagged Tree Based Frame-Wise Beforehand Prediction Approach for HEVC Intra-Coding Unit Partitioning



Abstract
1. Introduction
- Several novel and meaningful features are proposed. Especially, features designed based on Haar wavelet transform and interest points contribute a lot to the prediction performance. Besides, an importance rank of features is generated in the training phase of bagged tree models. The ranking process is very important for feature analysis and saves time.
- A more general and accurate model is proposed. Different from traditional decision tree based methods, a more general and accurate bagged tree method is implied to CU partitioning problem. In particular, one bagged tree model is used for CUs of three sizes, i.e., 64 × 64, 32 × 32, 16 × 16.
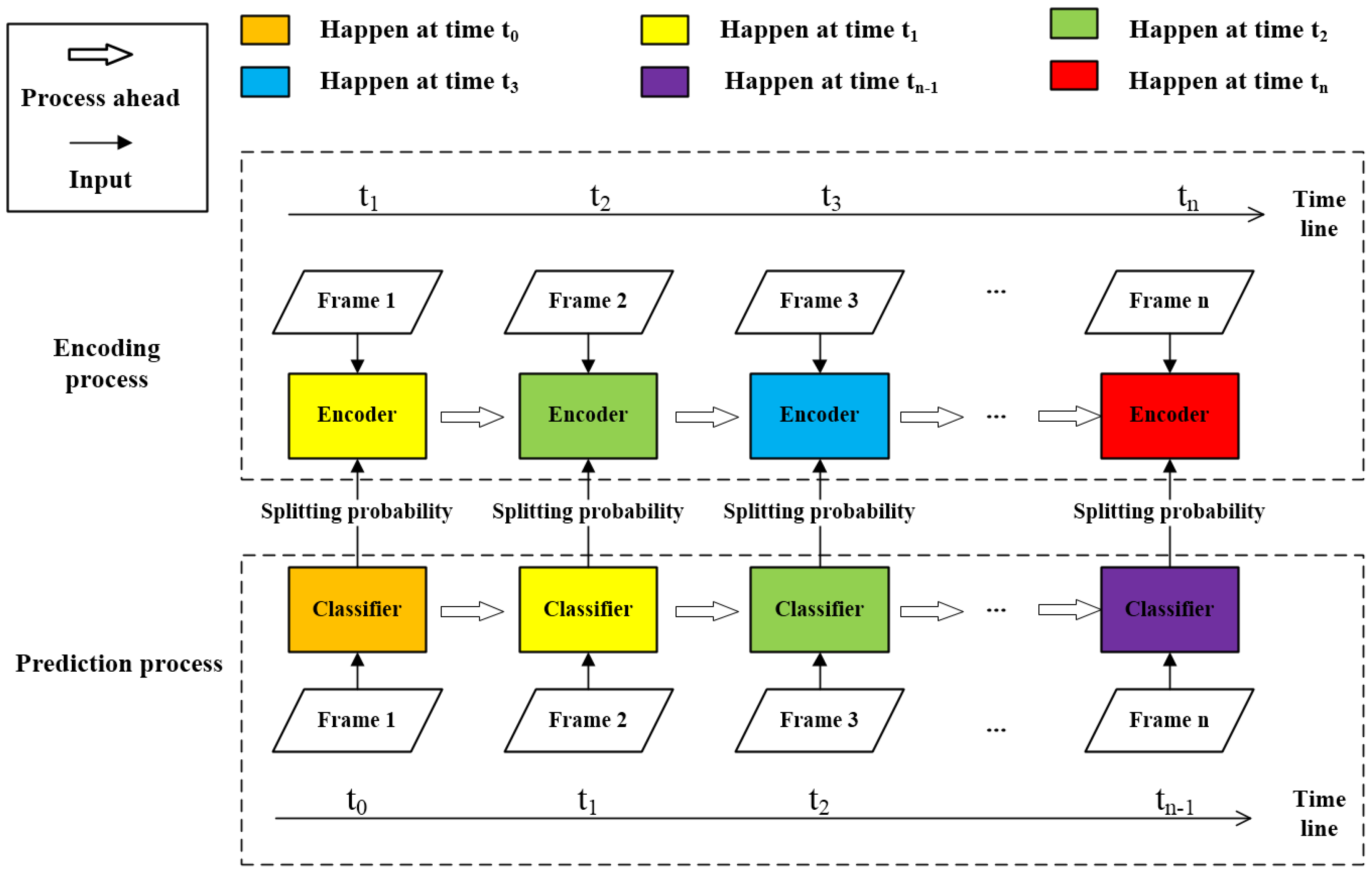
- Parallel frame-wise prediction process is applied. This before-hand processing allows encoder to execute CU splitting directly according to the prediction results output ahead of schedule. So that the time spent on features extraction and prediction can be saved.
- Advanced mathematical fitting technique is employed. In this paper, to calculate optimal thresholds under a certain constraint, neural network is used to find the best value of thresholds which are needed for CU splitting label prediction. In this way, the prediction accuracy is improved, and the proposed ABTFA has the best performance under a certain constraint of BD-rate loss or time saving.
2. Related Work
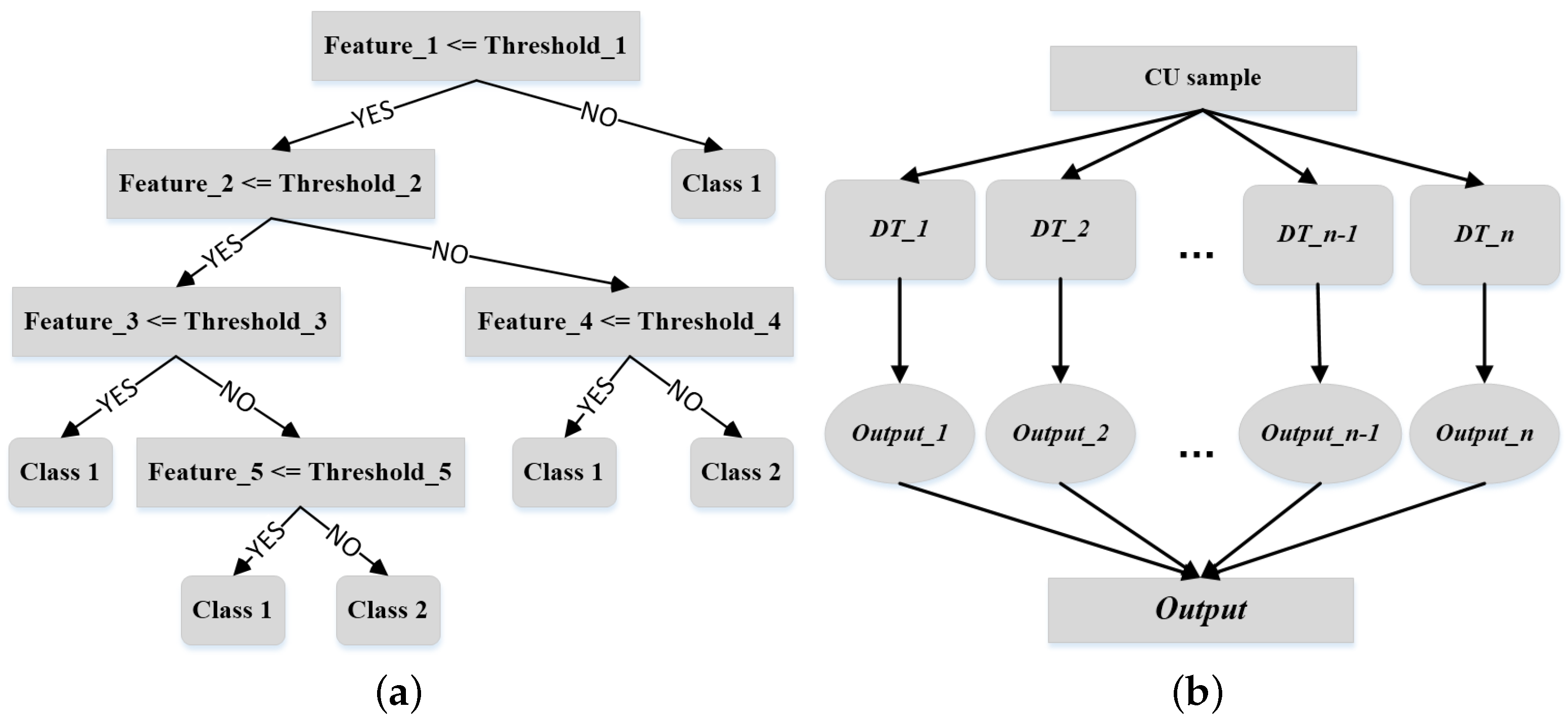
3. Fundamental Knowledge on Bagged Tree
4. Our Fast CU Partitioning Approach
4.1. Framework of the Frame-Wise Beforehand Prediction
4.2. Flowchart of the Proposed Bagged Tree Based Fast CU Size Determination Algorithm
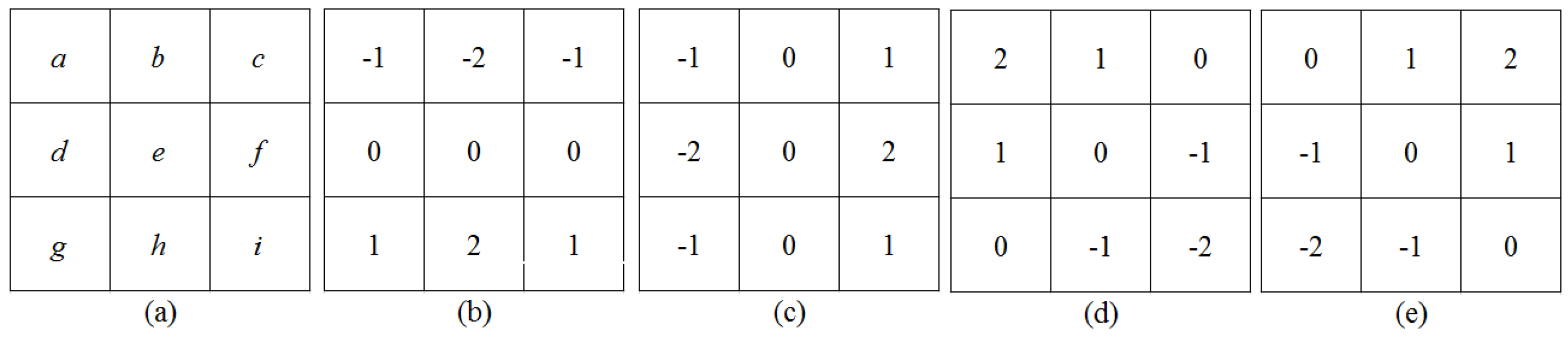
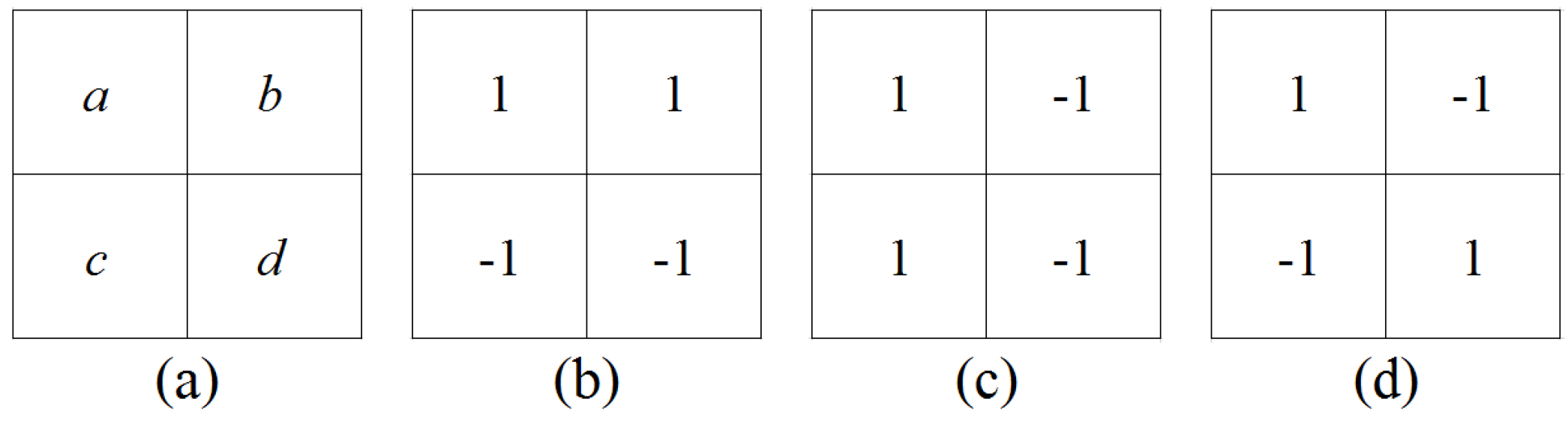
4.3. Feature Analysis And Extraction
4.4. Training Data Generation
4.5. Bagged Tree Design
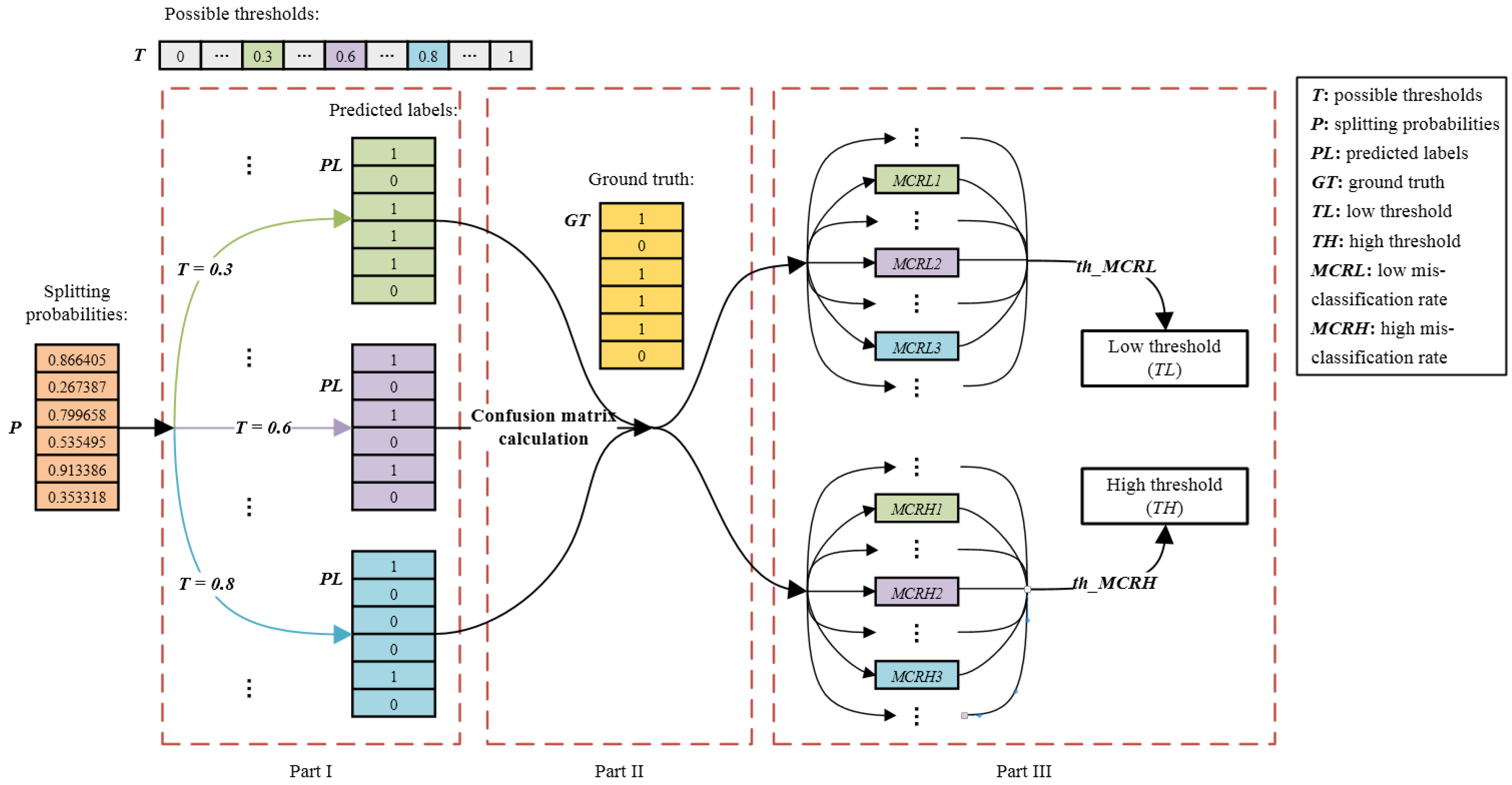
4.6. Adaptive Threshold Determination
5. ABTFA
6. Experiments
6.1. Experiment Results Of BTFA
6.2. Experiment Results Of ABTFA
6.3. Comparison with State-of-the-Art
6.4. CU Partition Result Comparison between ABTFA and the Original HM16.7
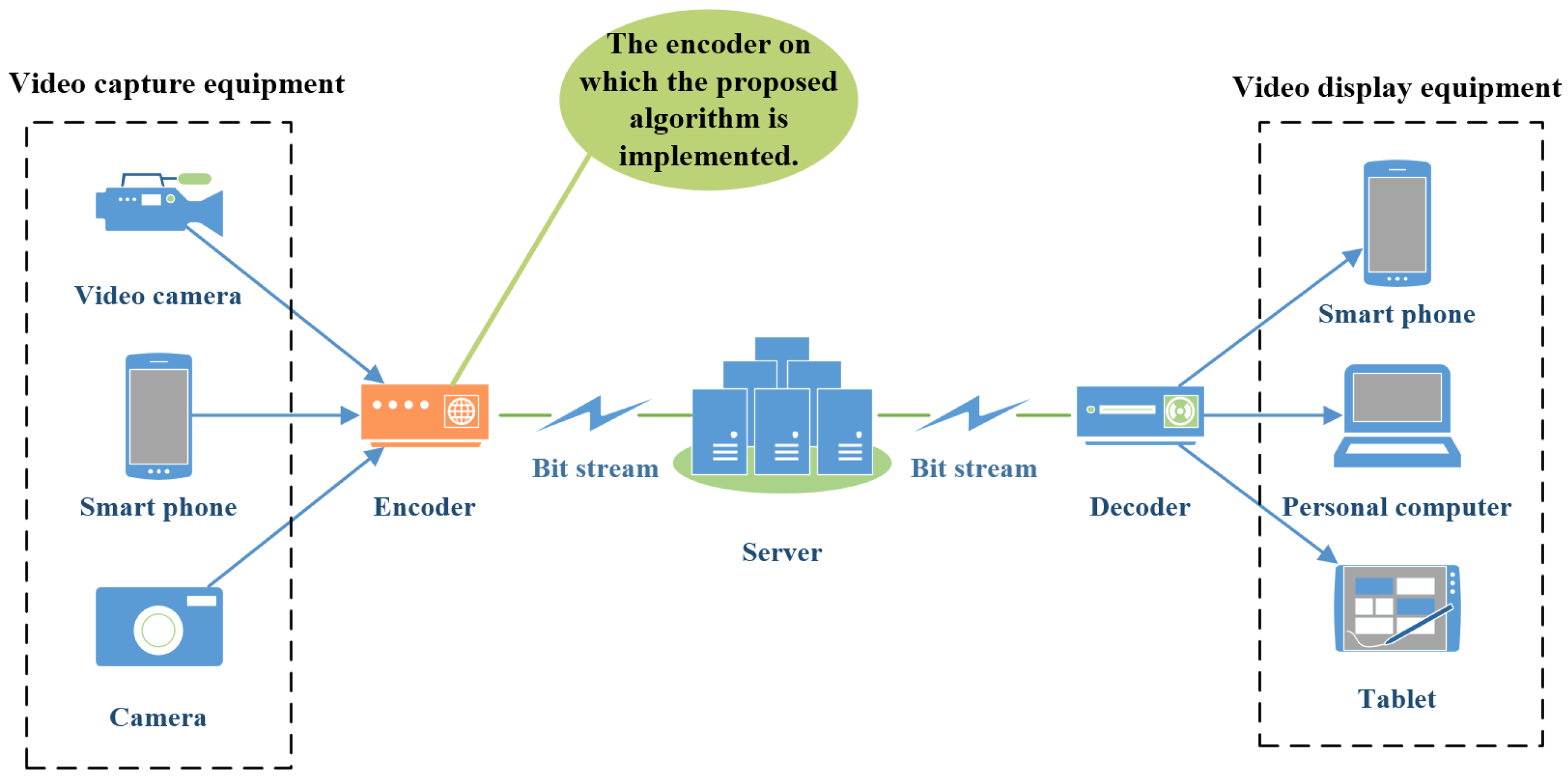
6.5. Application of the Proposed Research
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| HEVC | High Efficiency Video Coding |
| BTFA | Bagged Tree based Fast Approach |
| ABTFA | Advanced Bagged Tree based Fast Approach |
| CTU | Coding Tree Unit |
| CU | Coding Unit |
| PU | Prediction Unit |
| JCT-VC | Joint Collaborative Team on Video Coding |
| AVC | Advanced Video Coding |
| RDO | Rate-Distortion Optimization |
| SVM | Support Vector Machine |
| SHVC | Scalable High efficiency Video Coding |
| RD | Rate Distortion |
| BD-rate | Bit-Distortion rate |
| BDBR | Bjontegaard Delta Bit Rate |
| QP | Quantization Parameter |
| CBF | Coded Block Flag |
| negative misclassification rate | |
| positive misclassification rate | |
| Ground Truth | |
| P | Probability |
| T | Threshold |
| Low Threshold | |
| High Threshold | |
| G1 | Group One |
| G2 | Group Two |
| G3 | Group Three |
| G4 | Group Four |
| G5 | Group Five |
| G6 | Group Six |
| DDET | the algorithm proposed by [32] |
| FADT | the algorithm proposed by [33] |
| FARF | the algorithm proposed by [34] |
| DA-SVM | the algorithm poposed by [17] |
References
- Sullivan, G.J.; Ohm, J.; Han, W.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Topiwala, P.N.; Luthra, A. The H. 264/AVC advanced video coding standard: Overview and introduction to the fidelity range extensions. In Applications of Digital Image Processing XXVII; International Society for Optics and Photonics: Denver, CO, USA, 2–6 August 2004; pp. 454–474. [Google Scholar]
- Sze, V.; Budagavi, M.; Sullivan, G.J. High efficiency video coding (HEVC). In Integrated Circuit and Systems, Algorithms and Architectures; Springer: New York, NY, USA, 2014; pp. 49–90. [Google Scholar]
- Sullivan, G.J.; Wiegand, T. Rate-distortion optimization for video compression. IEEE Signal Process. Mag. 1998, 15, 74–90. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, D.; Sun, Y.; Hang, B. A fast intra-coding algorithm for HEVC by jointly utilizing naive Bayesian and SVM. Multimed. Tools Appl. 2020, 79, 1–15. [Google Scholar]
- Linwei, Z.; Yun, Z.; Kwong, S.; Xu, W.; Tiesong, T. Fuzzy SVM-Based Coding Unit Decision in HEVC. IEEE Trans. Broadcast. 2018, 64, 681–694. [Google Scholar]
- Kuo, Y.T.; Chen, P.Y.; Lin, H.C. A Spatiotemporal Content-Based CU Size Decision Algorithm for HEVC. IEEE Trans. Broadcast. 2020, 66, 100–112. [Google Scholar] [CrossRef]
- Heidari, B.; Ramezanpour, M. Reduction of intra-coding time for HEVC based on temporary direction map. J. Real-Time Image Process. 2020, 17, 567–579. [Google Scholar] [CrossRef]
- Liu, X.; Li, Y.; Liu, D.; Wang, P.; Yang, L.T. An Adaptive CU Size Decision Algorithm for HEVC Intra-Prediction Based on Complexity Classification Using Machine Learning. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 144–155. [Google Scholar]
- Tahir, M.; Taj, I.A.; Assuncao, P.A.; Asif, M. Fast video encoding based on random forests. J. -Real-Time Image Process. 2019, 16, 1–21. [Google Scholar] [CrossRef]
- Zhang, J.; Kwong, S.; Wang, X. Two-Stage Fast Inter-CU Decision for HEVC Based on Bayesian Method and Conditional Random Fields. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 3223–3235. [Google Scholar] [CrossRef]
- Chen, Z.; Shi, J.; Li, W. Learned fast HEVC intra-coding. IEEE Trans. Image Process. 2020, 29, 5431–5446. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.; Ro, W.W. Fast CU Depth Decision for HEVC using Neural Networks. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1462–1473. [Google Scholar] [CrossRef]
- Fu, C.H.; Chen, H.; Chan, Y.L.; Tsang, S.H.; Zhu, X. Early termination for fast intra-mode decision in depth map coding using DIS-inheritance. Signal Process. Image Commun. 2020, 80, 115644. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, N.; Yang, G.; Zhu, Y.; Ding, X. Self-learning residual model for fast intra-CU size decision in 3D-HEVC. Signal Process. Image Commun. 2020, 80, 115660. [Google Scholar] [CrossRef]
- Zhu, L.; Yun, Z.; Pan, Z.; Ran, W.; Kwong, S.; Peng, Z. Binary and Multi-Class Learning Based Low Complexity Optimization for HEVC Encoding. IEEE Trans. Broadcast. 2017, 63, 547–561. [Google Scholar] [CrossRef]
- Zhang, Y.; Pan, Z.; Li, N.; Wang, X.; Jiang, G.; Kwong, S. Effective Data Driven Coding Unit Size Decision Approaches for HEVC INTRA Coding. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 3208–3222. [Google Scholar] [CrossRef]
- Moslemnejad, S.; Hamidzadeh, J. A hybrid method for increasing the speed of SVM training using belief function theory and boundary region. Int. J. Mach. Learn. Cybern. 2019, 10, 3557–3574. [Google Scholar] [CrossRef]
- Shi, J.; Gao, C.; Chen, Z. Asymmetric-Kernel CNN Based Fast CTU Partition for HEVC Intra-Coding. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar]
- Duarte, D.; Ståhl, N. Machine learning: A concise overview. In Data Science in Practice; Springer: Cham, Switzerland, 2019; pp. 27–58. [Google Scholar]
- Wang, D.; Sun, Y.; Zhu, C.; Li, W.; Dufaux, F. Fast depth and inter-mode prediction for quality scalable high efficiency video coding. IEEE Trans. Multimed. 2019, 22, 833–845. [Google Scholar] [CrossRef]
- Wang, D.; Zhu, C.; Sun, Y.; Dufaux, F.; Huang, Y. Efficient multi-strategy intra-prediction for quality scalable high efficiency video coding. IEEE Trans. Image Process. 2019, 28, 2063–2074. [Google Scholar] [CrossRef] [PubMed]
- Kuang, W.; Chan, Y.L.; Tsang, S.H.; Siu, W.C. Online-learning-based Bayesian decision rule for fast intra-mode and CU partitioning algorithm in HEVC screen content coding. IEEE Trans. Image Process. 2019, 29, 170–185. [Google Scholar] [CrossRef]
- Kuang, W.; Chan, Y.L.; Tsang, S.H.; Siu, W.C. Machine Learning-Based Fast Intra-Mode Decision for HEVC Screen Content Coding via Decision Trees. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1481–1496. [Google Scholar] [CrossRef]
- Fu, B.; Zhang, Q.; Hu, J. Fast prediction mode selection and CU partition for HEVC intra coding. IET Image Process. 2020, 14, 1892–1900. [Google Scholar]
- Utgoff, P.E.; Berkman, N.C.; Clouse, J.A. Decision Tree Induction Based on Efficient Tree Restructuring. Mach. Learn. 1997, 29, 5–44. [Google Scholar] [CrossRef]
- Shen, X.; Yu, L. CU splitting early termination based on weighted SVM. EURASIP J. Image Video Process. 2013, 2013, 4. [Google Scholar]
- Grellert, M.; Bampi, S.; Correa, G.; Zatt, B.; da Silva Cruz, L.A. Learning-based complexity reduction and scaling for HEVC encoders. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, South Korea, 22–27 April 2018; pp. 1208–1212. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar]
- Caruana, R.; Elhawary, M.; Munson, A.; Riedewald, M.; Sorokina, D.; Fink, D.; Hochachka, W.M.; Kelling, S. Mining citizen science data to predict orevalence of wild bird species. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 1 August 2006. [Google Scholar]
- Bossen, F. Common test conditions and software reference configurations. In Proceedings of the Joint Collaborative Team on Video Coding of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG11, Geneva, Switzerland, 21–28 July 2010. [Google Scholar]
- Zhang, Y.; Kwong, S.; Zhang, G.; Pan, Z.; Yuan, H.; Jiang, G. Low Complexity HEVC INTRA Coding for High-Quality Mobile Video Communication. IEEE Trans. Ind. Inform. 2015, 11, 1492–1504. [Google Scholar] [CrossRef]
- Zhu, S.; Zhang, C. A fast algorithm of intra-prediction modes pruning for HEVC based on decision trees and a new three-step search. Multimed. Tools Appl. 2016, 76, 21707–21728. [Google Scholar]
- Du, B.; Siu, W.C.; Yang, X. Fast CU partition strategy for HEVC intra-frame coding using learning approach via random forests. In Proceedings of the Asia-Pacific Signal and Information Processing Association Summit and Conference, Jeju, Korea, 13–16 December 2016. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Feature Candidates | Feature Description |
|---|---|---|
| 1 | variance of four sub CUs’ mean | |
| 2 | variance of four sub CUs’ variance | |
| 3 | average value of current CU’s Coded Block Flag | |
| 4 | RD cost of current CU’s above CTU | |
| 5 | RD cost of current CU’s left CTU | |
| 6 | RD cost of current CU’s above left CTU | |
| 7 | RD cost of current CU’s above right CTU | |
| 8 | depth of current CU’s above CTU | |
| 9 | depth of current CU’s left CTU | |
| 10 | depth of current CU’s above left CTU | |
| 11 | depth of current CU’s above right CTU | |
| 12 | total cost of current CU encoded with planar | |
| 13 | total distortion of current CU encoded with planar | |
| 14 | total bins of current CU encoded with planar | |
| 15 | hadamard cost of planar mode | |
| 16 | distortion of residual after hadamard transfer | |
| 17 | hadamard bits of planar mode | |
| 18 | edge detection result using Sobel | |
| 19 | mean square error of neighbor pixels | |
| 20 | mean of gradients of four directions | |
| 21 | number of interesting points of current CU | |
| 22 | sum of horizontal value after Haar wavelet transfer | |
| 23 | sum of vertical value after Haar wavelet transfer | |
| 24 | sum of diagonal value after Haar wavelet transfer | |
| 25 | sum of horizontal absolute value after Haar | |
| 26 | sum of vertical absolute value after Haar | |
| 27 | sum of diagonal absolute value after Haar | |
| 28 | mean of current CU | |
| 29 | variance of current CU | |
| 30 | if current depth is 0 | |
| 31 | if current depth is 1 | |
| 32 | if current depth is 2 |
| Class | Sequence | QP | Prediction Accuracy | ||
|---|---|---|---|---|---|
| Depth0 | Depth1 | Depth2 | |||
| A | Traffic (2560 × 1600) | 22 | 86.80% | 82.50% | 79.71% |
| 27 | 91.76% | 84.19% | 77.35% | ||
| 32 | 87.36% | 82.63% | 70.05% | ||
| 37 | 79.17% | 79.19% | 75.00% | ||
| B | ParkScene (1920 × 1080) | 22 | 86.34% | 81.17% | 77.65% |
| 27 | 88.66% | 85.14% | 77.27% | ||
| 32 | 88.50% | 83.98% | 75.33% | ||
| 37 | 85.77% | 79.99% | 74.54% | ||
| C | BasketballDrill (832 × 480) | 22 | 99.87% | 91.39% | 70.84% |
| 27 | 99.49% | 77.89% | 70.74% | ||
| 32 | 98.33% | 74.36% | 77.40% | ||
| 37 | 92.27% | 76.83% | 84.23% | ||
| D | BQSquare (416 × 240) | 22 | 99.91% | 91.29% | 85.90% |
| 27 | 98.86% | 93.10% | 90.86% | ||
| 32 | 98.24% | 94.42% | 91.09% | ||
| 37 | 96.65% | 94.68% | 91.35% | ||
| E | FourPeople (1280 × 720) | 22 | 93.17% | 85.04% | 80.85% |
| 27 | 94.20% | 89.54% | 79.88% | ||
| 32 | 94.88% | 88.55% | 79.46% | ||
| 37 | 92.86% | 85.06% | 78.47% | ||
| Average | 92.65% | 85.05% | 79.40% | ||
| Predicted Label | |||
|---|---|---|---|
| 0 | 1 | ||
| True Label | 0 | true negative () | false positive () |
| 1 | false negative () | true positive () | |
| Class | Sequence | BTFA-G1 | BTFA-G2 | BTFA-G3 | BTFA-G4 | BTFA-G5 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BD-Rate (%) | TS (%) | BD-Rate (%) | TS (%) | BD-Rrate (%) | TS (%) | BD-Rate (%) | TS (%) | BD-Rate (%) | TS (%) | ||
| A | Traffic | 0.57 | 31.82 | 0.72 | 38.26 | 0.91 | 35.43 | 1.03 | 40.09 | 0.97 | 38.54 |
| PeopleOnStreet | 0.50 | 30.34 | 0.58 | 34.90 | 1.11 | 35.48 | 1.16 | 38.06 | 1.15 | 38.67 | |
| Average | 0.53 | 31.08 | 0.65 | 36.58 | 1.01 | 35.46 | 1.09 | 39.07 | 1.06 | 38.61 | |
| B | Kimono | 1.98 | 55.95 | 2.00 | 57.31 | 3.31 | 58.51 | 3.32 | 59.23 | 3.33 | 58.95 |
| ParkScene | 0.35 | 31.01 | 0.48 | 37.61 | 0.57 | 35.21 | 0.67 | 39.69 | 0.63 | 37.84 | |
| Cactus | 0.57 | 34.80 | 0.84 | 42.33 | 0.89 | 39.50 | 1.11 | 44.95 | 0.99 | 42.50 | |
| BasketballDrive | 1.58 | 41.25 | 1.70 | 46.44 | 2.35 | 45.17 | 2.46 | 49.09 | 2.40 | 47.85 | |
| BQTerrace | 0.52 | 39.09 | 0.68 | 45.46 | 1.06 | 44.31 | 1.09 | 46.88 | 1.18 | 49.22 | |
| Average | 1.00 | 40.42 | 1.14 | 45.83 | 1.64 | 44.54 | 1.73 | 47.97 | 1.71 | 47.27 | |
| C | BasketballDrill | 0.23 | 25.41 | 0.51 | 30.91 | 0.46 | 28.88 | 0.67 | 33.24 | 0.55 | 31.30 |
| BQMall | 0.31 | 32.12 | 0.97 | 41.52 | 0.45 | 35.01 | 0.97 | 41.52 | 0.63 | 38.96 | |
| PartyScene | 0.49 | 30.47 | 1.56 | 37.56 | 0.51 | 34.34 | 1.36 | 37.68 | 0.79 | 38.95 | |
| RaceHorses | 0.28 | 36.74 | 0.58 | 45.85 | 0.38 | 40.39 | 0.60 | 47.49 | 0.50 | 43.71 | |
| Average | 0.33 | 31.18 | 0.90 | 38.96 | 0.45 | 34.66 | 0.90 | 39.98 | 0.62 | 38.23 | |
| D | BasketballPass | 0.17 | 29.36 | 0.40 | 36.59 | 0.47 | 32.27 | 0.67 | 36.34 | 0.57 | 35.14 |
| BQSquare | 0.35 | 35.46 | 1.26 | 40.00 | 0.41 | 36.79 | 1.18 | 38.64 | 0.57 | 39.25 | |
| BlowingBubbles | 0.01 | 22.70 | 0.16 | 25.76 | 0.05 | 25.07 | 0.14 | 25.95 | 0.11 | 26.93 | |
| RaceHorses | 0.25 | 27.20 | 0.82 | 33.29 | 0.29 | 30.11 | 0.73 | 33.76 | 0.48 | 32.86 | |
| Average | 0.20 | 28.68 | 0.66 | 33.91 | 0.31 | 31.06 | 0.68 | 33.67 | 0.43 | 33.55 | |
| E | FourPeople | 0.34 | 37.18 | 0.74 | 44.96 | 0.89 | 41.87 | 1.14 | 47.65 | 1.08 | 45.87 |
| Johnny | 0.91 | 55.17 | 1.32 | 61.62 | 2.15 | 58.49 | 2.38 | 63.13 | 2.41 | 62.23 | |
| KristenAndSara | 0.86 | 49.10 | 1.21 | 56.38 | 1.89 | 52.56 | 2.09 | 58.57 | 2.19 | 55.90 | |
| Average | 0.70 | 47.15 | 1.09 | 54.32 | 1.65 | 50.97 | 1.87 | 56.45 | 1.89 | 54.67 | |
| Overall Average | 0.57 | 35.84 | 0.92 | 42.04 | 1.01 | 39.41 | 1.26 | 43.44 | 1.14 | 42.48 | |
| Class | Sequence | ABTFA B = 0.6% | ABTFA T = 45% | B T = 50% | |||
|---|---|---|---|---|---|---|---|
| BD-Rate (%) | TS (%) | BD-Rate (%) | TS (%) | BD-Rate (%) | TS (%) | ||
| A | Traffic | 0.94 | 32.87 | 1.74 | 44.64 | 3.49 | 62.12 |
| PeopleOnStreet | 0.91 | 32.04 | 1.75 | 43.68 | 3.01 | 54.99 | |
| Average | 0.92 | 32.45 | 1.74 | 44.16 | 3.25 | 58.55 | |
| B | Kimono | 1.23 | 56.05 | 1.87 | 66.80 | 3.36 | 78.40 |
| ParkScene | 0.63 | 32.95 | 1.12 | 44.18 | 2.40 | 61.01 | |
| Cactus | 0.89 | 34.42 | 1.43 | 45.07 | 2.74 | 60.30 | |
| BasketballDrive | 1.67 | 43.17 | 2.58 | 55.22 | 4.38 | 67.74 | |
| BQTerrace | 0.79 | 39.32 | 1.09 | 46.53 | 1.60 | 54.03 | |
| Average | 1.04 | 41.18 | 1.62 | 51.56 | 2.89 | 64.30 | |
| C | BasketballDrill | 0.25 | 24.53 | 1.14 | 39.10 | 3.71 | 58.12 |
| BQMall | 0.38 | 32.25 | 1.12 | 44.21 | 2.55 | 57.08 | |
| PartyScene | 0.10 | 31.57 | 0.36 | 36.99 | 0.85 | 43.47 | |
| RaceHorses | 0.41 | 39.26 | 0.96 | 51.76 | 1.85 | 62.84 | |
| Average | 0.28 | 31.90 | 0.89 | 43.02 | 2.24 | 55.38 | |
| D | BasketballPass | 0.20 | 30.91 | 0.82 | 41.44 | 1.76 | 49.75 |
| BQSquare | 0.08 | 30.03 | 0.21 | 35.36 | 0.42 | 39.52 | |
| BlowingBubbles | 0.06 | 25.82 | 0.25 | 30.36 | 0.51 | 34.56 | |
| RaceHorses | 0.16 | 30.29 | 0.60 | 37.91 | 1.31 | 45.56 | |
| Average | 0.13 | 29.26 | 0.47 | 36.27 | 1.00 | 42.35 | |
| E | FourPeople | 1.15 | 36.20 | 1.85 | 47.20 | 3.06 | 59.58 |
| Johnny | 1.26 | 54.97 | 2.15 | 63.23 | 3.69 | 70.82 | |
| KristenAndSara | 1.15 | 46.71 | 1.78 | 57.04 | 3.35 | 68.15 | |
| Average | 1.19 | 45.96 | 1.93 | 55.82 | 3.37 | 66.19 | |
| Overall Average | 0.68 | 36.30 | 1.27 | 46.15 | 2.45 | 57.11 | |
| Class | Sequence | DDET | FADT | FARF | DA-SVM | BTFA-G6 | ABTFA (B = 0.9) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BD-Rate (%) | TS (%) | BD-Rate (%) | TS (%) | BD-Rrate (%) | TS (%) | BD-Rate (%) | TS (%) | BD-Rate (%) | TS (%) | BD-Rate (%) | TS (%) | ||
| A | Traffic | 0.72 | 39.75 | 1.27 | 38.96 | 0.90 | 44.80 | 0.98 | 45.69 | 0.80 | 38.06 | 1.01 | 48.66 |
| PeopleOnStreet | 0.52 | 36.23 | 1.03 | 38.06 | 0.60 | 40.60 | 1.20 | 44.81 | 0.80 | 36.42 | 0.59 | 42.54 | |
| Average | 0.62 | 37.99 | 1.15 | 38.51 | 0.75 | 42.70 | 1.09 | 45.25 | 0.80 | 37.24 | 0.80 | 45.60 | |
| B | Kimono | 1.00 | 55.26 | 2.22 | 39.66 | 1.80 | 76.10 | 3.72 | 80.53 | 2.50 | 57.92 | 1.99 | 72.06 |
| ParkScene | 0.73 | 37.79 | 1.00 | 37.90 | 0.60 | 47.00 | 0.67 | 40.01 | 0.50 | 37.89 | 0.82 | 48.43 | |
| Cactus | 1.32 | 42.05 | 0.73 | 34.83 | 0.70 | 45.80 | 1.02 | 45.50 | 0.80 | 42.59 | 1.02 | 49.00 | |
| BasketballDrive | 0.67 | 48.07 | 1.69 | 40.57 | 1.80 | 63.40 | 1.87 | 61.09 | 1.90 | 45.99 | 2.20 | 58.21 | |
| BQTerrace | 1.03 | 46.96 | 1.00 | 38.50 | 0.30 | 47.80 | 1.05 | 51.03 | 0.80 | 45.63 | 0.62 | 44.97 | |
| Average | 0.95 | 46.03 | 1.33 | 38.29 | 1.04 | 56.02 | 1.67 | 55.63 | 1.30 | 46.00 | 1.33 | 54.54 | |
| C | BasketballDrill | 0.36 | 31.07 | 1.38 | 37.99 | 0.60 | 38.10 | 0.99 | 39.74 | 0.50 | 32.28 | 1.50 | 44.12 |
| BQMall | 1.05 | 36.10 | 0.48 | 36.93 | 0.20 | 35.30 | 1.07 | 38.38 | 0.70 | 40.18 | 1.10 | 46.49 | |
| PartyScene | 0.91 | 30.77 | 0.32 | 36.01 | 0.00 | 31.20 | 0.24 | 28.82 | 1.20 | 37.57 | 0.32 | 35.92 | |
| RaceHorses | 1.86 | 28.50 | 0.71 | 38.67 | 0.40 | 37.90 | 1.18 | 40.11 | 0.50 | 43.94 | 0.94 | 54.51 | |
| Average | 1.05 | 31.61 | 0.72 | 37.40 | 0.30 | 35.63 | 0.87 | 36.76 | 0.73 | 38.49 | 0.96 | 45.26 | |
| D | BasketballPass | 0.91 | 41.21 | 1.54 | 34.29 | 1.10 | 48.20 | 1.34 | 45.99 | 0.40 | 36.29 | 0.86 | 43.76 |
| BQSquare | 1.32 | 23.38 | 0.65 | 40.31 | 0.10 | 39.90 | 0.50 | 36.29 | 0.80 | 39.25 | 0.17 | 35.60 | |
| BlowingBubbles | 0.42 | 21.45 | 0.63 | 29.68 | 0.20 | 38.20 | 0.48 | 27.95 | 0.10 | 26.27 | 0.17 | 28.50 | |
| RaceHorses | 1.14 | 30.69 | 0.10 | 33.10 | 0.60 | 33.16 | 0.57 | 36.93 | |||||
| Average | 0.88 | 28.68 | 0.99 | 33.74 | 0.38 | 39.85 | 0.77 | 36.74 | 0.48 | 33.74 | 0.44 | 36.20 | |
| E | FourPeople | 1.09 | 43.73 | 0.39 | 40.75 | 0.60 | 40.00 | 1.70 | 51.76 | 0.80 | 44.01 | 0.78 | 47.07 |
| Johnny | 1.17 | 55.94 | 2.62 | 45.75 | 1.90 | 57.10 | 3.01 | 67.99 | 1.60 | 61.65 | 1.40 | 64.21 | |
| KristenAndSara | 1.15 | 54.78 | 1.92 | 42.15 | 1.30 | 52.30 | 2.39 | 63.56 | 1.50 | 56.41 | 1.23 | 60.73 | |
| Average | 1.14 | 51.48 | 1.64 | 42.88 | 1.27 | 49.80 | 2.37 | 61.10 | 1.30 | 54.02 | 1.14 | 57.34 | |
| Overall Average | 0.95 | 39.59 | 1.15 | 37.87 | 1.30 | 52.30 | 1.38 | 47.60 | 0.92 | 41.90 | 0.96 | 47.87 | |
| Sequence | Huang [5] | Liu [9] | Fu [25] | BTFA-G1 | ABTFA( B = 0.9) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| BD-Rate (%) | TS (%) | BD-Rate (%) | TS (%) | BD-Rate (%) | TS (%) | BD-Rate (%) | TS (%) | BD-Rate (%) | TS (%) | |
| BasketballDrill | 1.02 | 48.23 | 1.06 | 43.25 | 1.49 | 42.20 | 0.23 | 25.41 | 1.50 | 44.12 |
| BasketballDrive | 1.43 | 65.37 | 1.38 | 50.73 | 1.32 | 59.80 | 1.58 | 41.25 | 2.20 | 58.21 |
| Johnny | 1.89 | 66.21 | 1.93 | 63.15 | 1.45 | 62.90 | 0.91 | 55.17 | 1.40 | 64.21 |
| KristenAndSara | 1.65 | 67.41 | 1.68 | 59.25 | 1.17 | 59.20 | 0.86 | 49.10 | 1.23 | 60.73 |
| ParkScene | 0.74 | 49.86 | 0.79 | 45.21 | 0.72 | 48.30 | 0.35 | 31.01 | 0.82 | 48.43 |
| Average | 1.34 | 59.41 | 1.36 | 52.31 | 1.23 | 54.48 | 0.78 | 40.38 | 1.43 | 55.14 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Li, L.; Fang, Y.; Peng, H.; Yang, Y. Bagged Tree Based Frame-Wise Beforehand Prediction Approach for HEVC Intra-Coding Unit Partitioning. Electronics 2020, 9, 1523. https://doi.org/10.3390/electronics9091523
Li Y, Li L, Fang Y, Peng H, Yang Y. Bagged Tree Based Frame-Wise Beforehand Prediction Approach for HEVC Intra-Coding Unit Partitioning. Electronics. 2020; 9(9):1523. https://doi.org/10.3390/electronics9091523
Chicago/Turabian StyleLi, Yixiao, Lixiang Li, Yuan Fang, Haipeng Peng, and Yixian Yang. 2020. "Bagged Tree Based Frame-Wise Beforehand Prediction Approach for HEVC Intra-Coding Unit Partitioning" Electronics 9, no. 9: 1523. https://doi.org/10.3390/electronics9091523
APA StyleLi, Y., Li, L., Fang, Y., Peng, H., & Yang, Y. (2020). Bagged Tree Based Frame-Wise Beforehand Prediction Approach for HEVC Intra-Coding Unit Partitioning. Electronics, 9(9), 1523. https://doi.org/10.3390/electronics9091523