1. Introduction
Phishing is an offense in which the phisher seeks to trick users into disclosing critical and personal information such as credit card details and passwords. The intent of phishers to carry out a phishing attack is to sell the personality of the victims, to get ransom, to exploit the system’s weaknesses, or to receive financial profits [
1]. One of these common offenses is to design deceptive sites which are imitations of benign websites (e.g., PayPal, eBay, etc.) and host them in a hacked domain.
It is hard for human eyes to distinguish between benign and deceptive web pages because they look identical. Once the user accesses the imitated site, critical information will be robbed using scripts. Phishing offenses increase every year due to the rapid growth of the e-commerce users. Phishers can use malware (i.e., malicious software), web pages, and emails to carry out phishing offenses.
According to the Anti-Phishing Working Group (APWG), the total number of phishing sites detected by the APWG in the 1st quarter (Q) of 2019 was 180,768, that was up notably from the 138,328 seen in 4Q of 2018, and from the 151,014 seen in 3Q of 2018 [
2]. A non-profit industry association has focused on rubbing identity theft and fraud resulting from the phishing raising problem, spyware, and e-mail fraud. Phishing has become a serious problem due to the extensive damage to its target industry e.g., payment, financial institutions, email, etc. The rating of annual direct economic losses to the US economy as result of phishing offenses range from 61 million to 3 billion [
3].
As reported by Internet Security Threat Report (ISTR) submitted by Symantec [
4], the number of new mobile malware in 2017 grew 54% compared to 2016. The new malware programs are multitasking, they perform many tasks, i.e., downloading and installing other malicious programs without user’s permission, theft of critical information, etc. Kaspersky Lab reported that the anti-phishing technique was operated 246,231,645 times in Kaspersky Lab [
5].
Some existing techniques use a blacklist to reveal phishing sites. This policy fails to reveal non-blacklisted phishing sites (i.e., zero day attacks). Many heuristic-based detection techniques extract features based on webpage content features and third-party service features to detect phishing sites. However, the use of third-party services such as page rank, network traffic measures, search engine indexing, and WHOIS (domain age) may be restricted to reveal phishing sites hosted on compromised servers and these sites are incorrectly labeled as benign because they are included in the search results. Furthermore, webpage content features and third-party features are time consuming.
Machine learning techniques have also been used to investigate the URL of the web page with different hand-crafted feature sets in order to refine detection efficiency [
6,
7]. The URLs are first analyzed to perform the feature adaptation from phishing websites. Then, a training set is constructed by machine learning experts using the extracted features along with their labels. Finally, the advantage of classification supervised machine learning algorithms is used to develop a model for phishing detection. However, there are still drawbacks due to the fact that the human effort needs time and additional maintenance labor costs.
Deep learning has also been integrated into phishing detection, driven by recent rapid development and many successful applications [
8,
9,
10]. Unlike conventional machine learning methods, deep learning techniques implicitly extract hand-crafted features as machine learning specialists can use data directly without the knowledge of cybersecurity experts.
In this paper, we propose a deep learning-based solution for phishing URL detection. Deep learning [
11,
12] uses layers of stacked nonlinear projections to learn representations of multiple levels of abstraction. It has shown advanced performance in many applications, e.g., natural language processing, computer vision, speech recognition, etc. Specifically, convolutional neural networks (CNNs) have shown auspicious text classification achievement recently [
13,
14]. After their success, we propose using character level CNN [
14] to learn a URL embedding to detect phishing URLs.
The proposed model receives a URL string as an input and applies CNN at the character level in the URL. The model first identifies the individual characters in the training set based on prescribing character vocabulary, and then represents each character as a fixed-length vector using one-hot encoding. Using this, the URL sequence characters are converted into a matrix representation, where the convolution and pooling can be applied. In order to generate the final output, fully connected layers are used to generate an output that depends on the number of classes.
Character level CNN determines important information from specific combinations of characters that appear together which could be symptomatic of wickedness. Basically, a URL is a sequence of characters or words where some words have few semantic meanings. As a result that some URLs contain separable combined words without separators and these combined words may not contain any significance, it is difficult to extract semantic meanings from words in a URL. Furthermore, the phishers may change unnoticeable characters in official website URLs, e.g., “
www.icbc.com” as “
www.1cbc.com” to make people unable to differentiate the similar view of phishing URLs from benign URLs.
The advantages of the proposed method are listed below:
Independence of third-party services: Use of third-party services such as web-based blacklist/whitelist, page rank, search engine indexing, network traffic measures, the domain age, etc. raise the efficiency of the detection system. However, these services also raise the detection time, so they cannot be helpful. The proposed method does not rely on any third-party features. It relies only on the URL of the website and the detection time for the URL classification is only 0.47 ms per URL.
Language independence: The proposed method works effectively for websites with content in all languages because the features are extracted from the URL string and embedded depending on predefined character vocabulary of size M for the input language.
New websites detection: Due to character level embedding features, character-level embedding for new URLs can be easily generalized. The proposed model can detect new phishing sites that have not been classified as fraudulent phishing before. Using this feature, the proposed method is sturdy in the zero-day attack, which is one of the most serious types of phishing offenses.
Independence of cybersecurity experts: The required expert features engineering is reduced, as CNN automatically recognizes features to represent the URL not relying on any other complex or expert features during the learning task.
The main contributions of this paper are summarized as follows:
This paper proposes a phishing detection model with a deep learning-based solution, which can speedily and precisely detect phishing sites using only URL features of the webpage.
We define four different types of feature sets as hand-crafted, character embedding, character level TF-IDF, and character level count vectors features, and then compare different machine and deep learning algorithms using these various feature sets in order to measure the efficiency.
We use four datasets D1, D2, D3, and D4 to evaluate the performance of the proposed model, where D1 is our dataset consisting of 318,642 empirical URLs and D2, D3, D4 are used in existing baseline works. The accuracy of the experimental results was 95.02% on our dataset, and 98.58%, 95.46%, 95.22% on benchmark datasets, which is much better than the existing phishing URL models.
The remainder of the paper is organized as follows:
Section 2 reviews related works about existing phishing detection techniques. In
Section 3, the proposed work is introduced in detail.
Section 4 conducts different comparative experiments and discusses the results. Finally, the summary and future works of the paper are presented in
Section 5.
2. Related Work
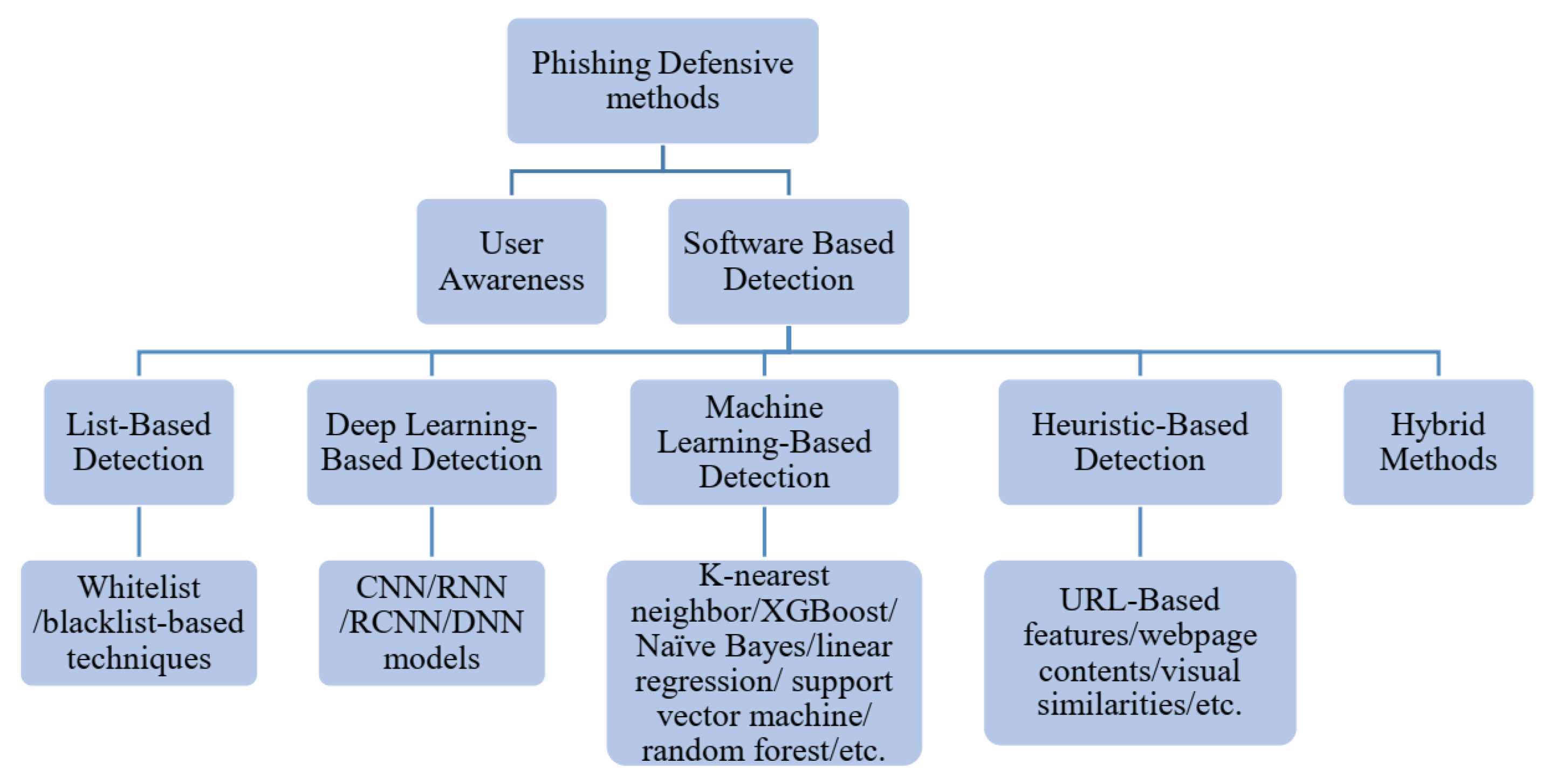
Generally, phishing can be detected through list-based detection, machine learning-based detection, heuristic-based detection, or deep learning-based detection methods. However, the problem of phishing is so complicated that there is no decisive solution to effectively override all threats; therefore, multiple techniques are often involved to prevent specific attacks. The protection methods are categorized into two main groups: expanding the user knowledge and using some additional software as described in
Figure 1.
2.1. List-Based Detection
List-based phishing detection techniques can be classified into whitelist and blacklist-based techniques. The whitelist is a list of benign URLs and IP addresses used to validate a suspicious URL. Wang et al. [
15], Chou et al. [
16], and Han et al. [
17] use a whitelist-based technique to detect phishing URLs.
Blacklist-based techniques are vastly used in overtly available anti-phishing toolbars e.g., Google safe browsing, which checks URLs versus Google’s periodically updated blacklist of browser phishing sites and gives warnings to users once a URL is counted as phishing. Although these list-based methods can be comparatively high precision, it is hard to keep a comprehensive list of phishing URLs since new URLs are created on a daily basis.
In Felegyhazi et al. [
18], domain name and server information of blacklisted URLs are used to detect new phishing URLs where registration information and Domain Name System (DNS) zone of new phishing URLs are compared to the information of blacklisted URLs. Rao and Pais [
19] developed an improved blacklisted method for detecting phishing URLs. Instead of using blacklist of URLs, a blacklist of signatures is generated using content-based features. Prakash et al. [
20] developed an enhanced two-component method to block hackers from avoiding the blacklist detection. One of the components is used to extend the blacklist through simple sets of blacklist phishing sites using five heuristics elements (i.e., the top-level range, the IP address, the directory structure, the query string, and the brand name), whereas the other component is used to make an approximate match to a particular URL to determine whether the phishing URL is a phishing one. However, list-based techniques cannot catch zero-day attacks, which means that they can only react to the newly unexpected phishing URLs when the developers update the blacklist.
2.2. Heuristic-Based Detection
The essence of the heuristic-based detection techniques, which have been developed from list-based detection techniques, is the creation of phishing site characteristics based on many hand-crafted features, for example, URL-based features, webpage contents, website visual similarities, etc.
Zhang et al. [
21] proposed a method of detecting phishing called Cantina based on Google search engine to retrieve keywords and domain names in a webpage. It uses the results returned by research and other heuristic rules to determine whether the webpage is legitimate or phishing. However, the method is responsive only to the English language. Another version of previous work called Cantina+ was proposed by Xiang et al. [
22]. It takes 15 heuristic features as the input to train a classifier for detection of phishing sites. Ramesh et al. [
23] proposed a method to detect phishing sites by checking web pages and identifying all direct or indirect links to the web pages. Although the method provides high detection accuracy, it is time consuming because it relies on search engines and third-party services such as DNS query. A phishing detection algorithm (PDA) is proposed by Jain and Gupta [
24] to decide whether a suspicious URL is a phishing website by calculating the number of hyperlinks in the suspicious webpage. The study gives a true positive test result of 86.07% and a false negative of 1.48% on 405 benign pages and 1120 phishing pages, which indicates that the method has failed to attain the expected level of efficiency.
2.3. Machine Learning-Based Detection
While more information can improve the accuracy of phishing detection, it is often not feasible to obtain a lot of features because of the limited time and computation resources available. To deal with these limitations, in recent years phishing detection has received much research using machine learning techniques (e.g., K-nearest neighbor, XGBoost, Naïve Bayes, linear regression, support vector machine, and random forest).
In Zhang et al. [
25], the features are extracted from URLs based on bag-of-words and then trained by a classifier through online learning. Similarly, in Sahingoz et al. [
7], distributed representations of words are adopted in a particular URL, and then seven different machine learning algorithms are used to predict whether the URL is a phishing URL. Although these methods have shown satisfying performances, they cannot deal with unseen information that does not exist in the training set.
Mogimi et al. [
26] proposed a phish detector, in which support vector machine (SVM) algorithm is used first to train a phishing detection model, and then the decision tree (DT) algorithm is used to extract the hidden phishing. The true positive and false negative of the proposed method are 0.99 and 0.001, respectively in a large dataset. However, this method supposes that phishing web pages only use benign page content, which does not apply in practice. Recently, Rao et al. [
6] proposed a light-weight application, CatchPhish which predicts the URL legitimacy without visiting the content of the website. The proposed model extracts hand-crafted and Term Frequency-Inverse Document Frequency (TF-IDF) features from the suspicious URL for classification using the random forest classifier.
2.4. Deep Learning-Based Detection
Due to the success of the Natural Language Processing (NLP) achieved by deep learning techniques, some of them have recently been employed for phishing detection e.g., CNN, recurrent neural network (RNN), recurrent convolutional neural networks (RCNN), and deep neural network (DNN). Although deep learning techniques are not exploited much in phishing detection due to the extensive training time, they often provide more accuracy and automatically extract the features from raw data without any prior knowledge.
Wang et al. [
8] proposed a fast phishing website detection method called precise phishing detection with recurrent convolutional neural networks (PDRCNN) that depends only on the URL of the website. It encodes the information of a URL into a two-dimensional tensor and feeds the tensor into a deep learning neural network to classify the original URL. They use first a bidirectional long short-term memory (LSTM) network, and then a convolutional neural network (CNN) to extract global and local features of the URL. YANG et al. [
9] developed a multidimensional feature phishing detection method based on two steps. In the first step, character sequence features of the given URL are extracted and used for classification by LSTM-CNN deep learning networks. In the second step, URL statistical features, webpage content features, and the classification result of deep learning are combined into multidimensional features. Wei et al. [
27] present a light-weight deep learning algorithm. They use a novel character-level multi-spatial deep learning model to detect phishing URLs.
Yuan et al. [
10] developed a method that combines character embedding (word2vec) with the structures of URLs to obtain the URLs vector representations. They partition the URL into five parts: URL protocol, sub-domain name, domain name, domain suffix, and URL path. The vector representations of URLs are trained by existing classification algorithms to identify the phishing URLs. Le et al. [
28] developed a URLNet method for malicious website URL detection. In this method, character-level and word level features are extracted based on URL strings and CNN network is used for training and testing. Huang et al. [
29] proposed the PhishingNet deep learning-based method for detection of phishing URLs. They use a CNN network to extract character-level features of URLs; meanwhile, they employ an attention-based hierarchical recurrent neural network (RNN) to extract word-level features of URLs. After that, they fuse and train these features through three convolutional layers and two fully connected layers. Bahnsen et al. [
30] compared a random forest classifier against recurrent neural networks based on a hand-crafted features method. The recurrent neural network model achieved an accuracy of 98.7%, which is 5% higher than the random forest classifier without the need of manual feature creation.
2.5. Hybrid Method-Based Detection
Hybrid detection techniques rely on combining more than one of the previous techniques in order to achieve good performance in the detection of phishing sites. Yang et al. [
9] propose a multidimensional feature phishing detection approach which consists of two steps. In the first step deep learning algorithms (CNN-LSTM) are used to extract URL features. In the second step, they combine URL statistical features, webpage code features, webpage text features, and the classification result of deep learning into multidimensional features, which are then classified by a machine learning algorithm (XGBoost).
In Sahingoz et al. [
7] and Rao et al. [
6], heuristic-based features are extracted from different parts of the URL and fed to a machine learning algorithm i.e., random forest (RF) to reveal the legitimacy of the URL. Jain et al. [
31] present a two-level validation approach of phishing detection using third-party services and webpage contents. In the first level of validation, the search engine-based technique is proposed which uses a simple query to validate the webpage. The second level of validation processes the validity of various hyperlinks within the source code of the web page to detect phishing websites.
In this paper, we propose a convolutional neural network (CNN) to extract features automatically from only the URL without using any manually designated features by humans. Character level CNN is used instead of word level due to the difficulty of extracting semantic meanings from words in a URL where the URL typically contains meaningless combined words.
3. Proposed Methodologies
In general, attackers intend to create phishing URLs so that they appear as legitimate websites to the users. Attackers use different URL jamming techniques to trick users into revealing personal information that can be misused. The main idea of this paper is to quickly detect phishing websites using lightweight features. This is achieved by extracting only features from the URL without visiting the website content. Before going to the proposed model architecture, a brief description of the component of URLs is debated in the section below.
3.1. URL Components
The URL refers to the resource locator. It is used for locating a resource on the web such as hypertext pages, images, files, and audio.
Figure 2 illustrates the different components of a URL with an example.
The first component of the URL is a protocol (https, http, ftp, etc.) that is an established set of regulations that governs how data will be transmitted from source to destination. The second component refers to the host IP address or resource’s location. The host name is divided into primary domain and Top Level Domain (TLD). The primary domain and TLD together represent the host name of the URL. The host name is followed by a port number that is an optional field. In the third component, the path is used to recognize the particular resource within the domain requested by the user. The path is followed by optional field such as query. The base URL is concatenated by protocol, hostname, and URL path.
Although the second level domain name commonly shows the type of site or company name, the attacker can easily find or purchase it for phishing. The second domain name can be specified only once at the inception. However, unlimited number of URLs can be created by an attacker who has expanded the second level by file and path names, because the internal address design depends directly on the phishers. The unique part of the URL is the composition of the second domain and top level domain names, which are called the host domain. Thus, cybersecurity companies are making a great effort to identify the fraudster domains by name, which are used for phishing offenses. If a hostname is specified as phishing, an IP address can be simply blocked to prevent it from obtaining the web pages existing in it.
3.2. Model Design
In this section, we present the details of the proposed model configuration. The implicit deep neural network for the proposed model is a convolutional neural network (CNN). The CNNs are used to learn sequential information from the URL. Particularly, CNNs are applied at the character-level. A URL
u is basically a concatenation of characters. We aim to get a matrix representation
, so that the instance
G includes a set of adjacent components
in a concatenation. Each
k-dimensional vector is depicted by an embedding such that
. Normally, this dimensional depiction of the component is the embedding vector extracted from the embedding matrix that is initialized manually. An instance can be depicted in concatenation of
L components as follows [
28]:
where ⊕ refers to the concatenation operator. Usually all sequences are filled as 0 or amputated to the same length
L. The CNN network will convolve up via this instance
using a convolution operator. The
h-length convolution consists of convolving a filter
followed by a non-linear activation
f (i.e., rectified linear units) to generate a new feature:
where
is the bias.
The output of this convolution layer applies the
X filter with a nonlinear activation for each
h-length portion of its inputs separated by a predetermined stride value. These outputs are then concatenated to generate output
Y as follows:
After convolution, the pooling step (temporal max-pooling or average pooling) is applied to trim the dimension of the feature, to determine the most important features, and to train deeper models. Using a filter X to convolve each portion of length h, the CNN is able to take advantage of the temporal relationship of length h in its input. The CNN model usually consists of multiple groups of filters with different lengths (h), and each group consists of several filters.
The convolution that the pooling layer follows is made up of a block in this deep neural network. There can be many of these blocks that can be stacked on top of each other. The pooled features of the final block are grouped and passed to fully connected (FC) layers for classification purpose. The algorithm stochastic gradient descent (SGD) can then be used to train the network, where the gradients are obtained by back-propagation [
32] to carry out optimization.
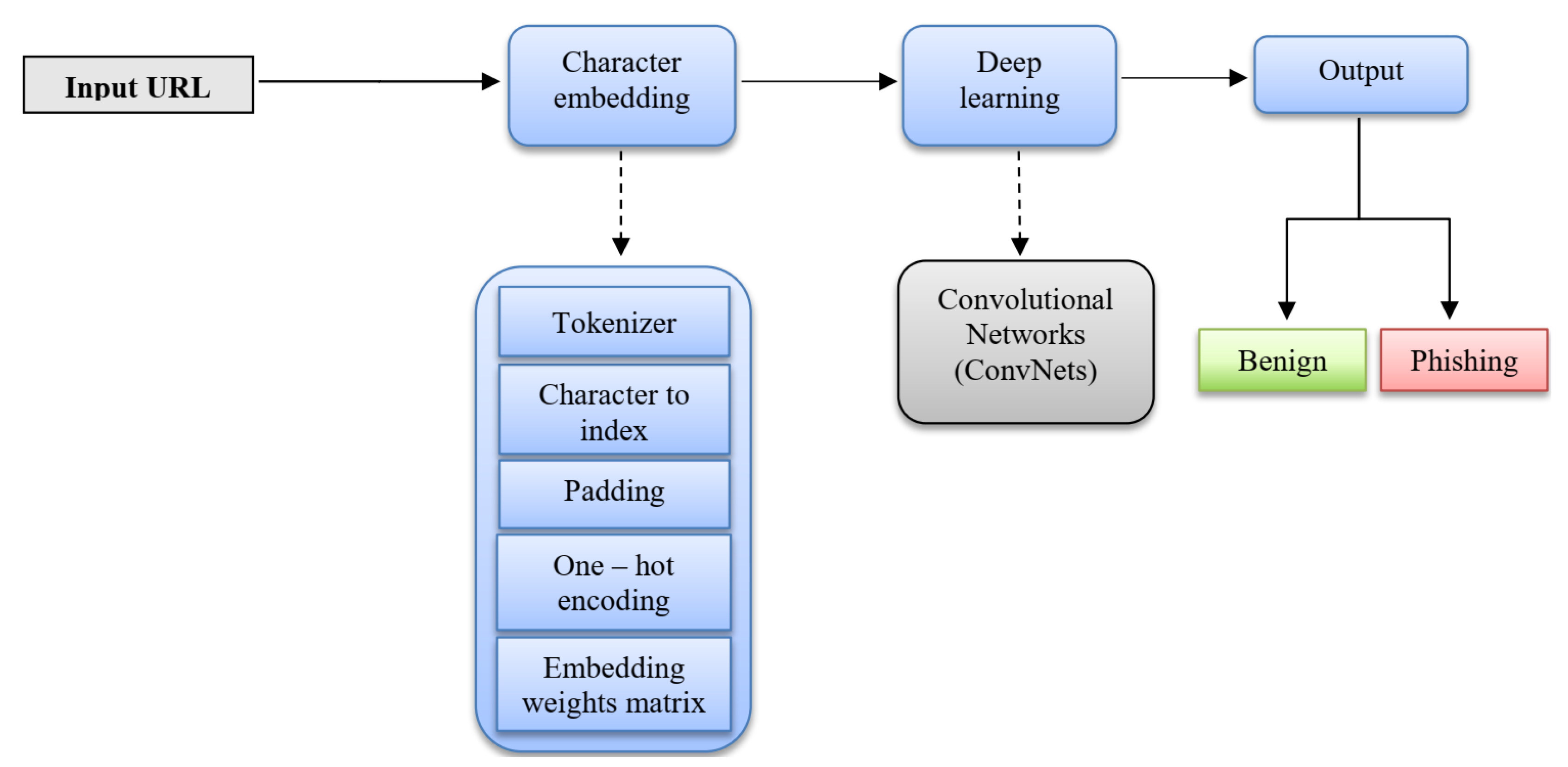
More specifically, the URL is taken as a raw input and indexed according to the
Table 1. We can see, besides the 94 characters, we also have an unknown token(UNK) to represent the rare characters in vocabulary. After that, the URL is settled into fixed-size sequence by truncating or zero-filling, and one-hot vector is then used to represent these 95 words, which means that each character has 95 dimensions. The URL features are extracted and reduced from the embedding matrix via the convolutional and max pooling layers. However, to generate the final output, the two fully connected layers receive the result of the pooling to generate an output equal to the number of classes. An overview can be seen in
Figure 3.
3.2.1. Character Level Embedding Features
We employ the method used in [
14] to represent and embed the URL with expanding of the character vocabulary used. The processing of URL at the character level is a solution to a problem out of vocabulary. Character-level embedding is used instead of word-level embedding because URLs typically use words without any significance.
More information is included at the character level. Attackers also simulate the URLs of original websites by changing several unnoticeable characters. For example, they might change google.com to g00gle.com, replace “oo” with “00”. Character-level embedding helps to find this imitative information, and improve the performance of detecting malicious URLs.
At the embedding stage of the URL, embedding is done by determined an m-sized alphabet for the input language, then embedding each character using one-hot encoding (see
Figure 4). After that, the sequence of characters is converted into a sequence of these m-sized vectors with a fixed-length
L. Any character overriding length
L is truncated, and any character that is not in the alphabet including blank character is embedded as all-zero vectors.
The main processes of character level embedding are:
Tokenizer: The tokenizer is used to process URL in char level and add a UNK token to the vocabulary. After fitting the training data, the tokenizer will contain all the necessary information about the data.
The vocabulary: The alphabet used consists of 95 characters, including 26 lower-case English letters, 26 upper-case English letters, 10 numbers, and 33 other characters (e.g., ,;.!?: ’ /_@#
$...etc.) as illustrated in
Table 1.
Character to index: After getting the right vocabulary according to
Table 1, we can represent all URLs by using character index as shown in
Figure 5 and
Figure 6.
Padding: URL has a different length and the neural network can only handle fixed-length vectors, therefore all URLs must be of equal length so the CNN can process the batch data. Here, we define the maximum length of URL as 200. If the length of the URL is smaller than 200, the remaining part will be filled as 0. If the length of the URL is bigger than 200, the part longer will be amputated. Therefore, all URLs will preserve the same length.
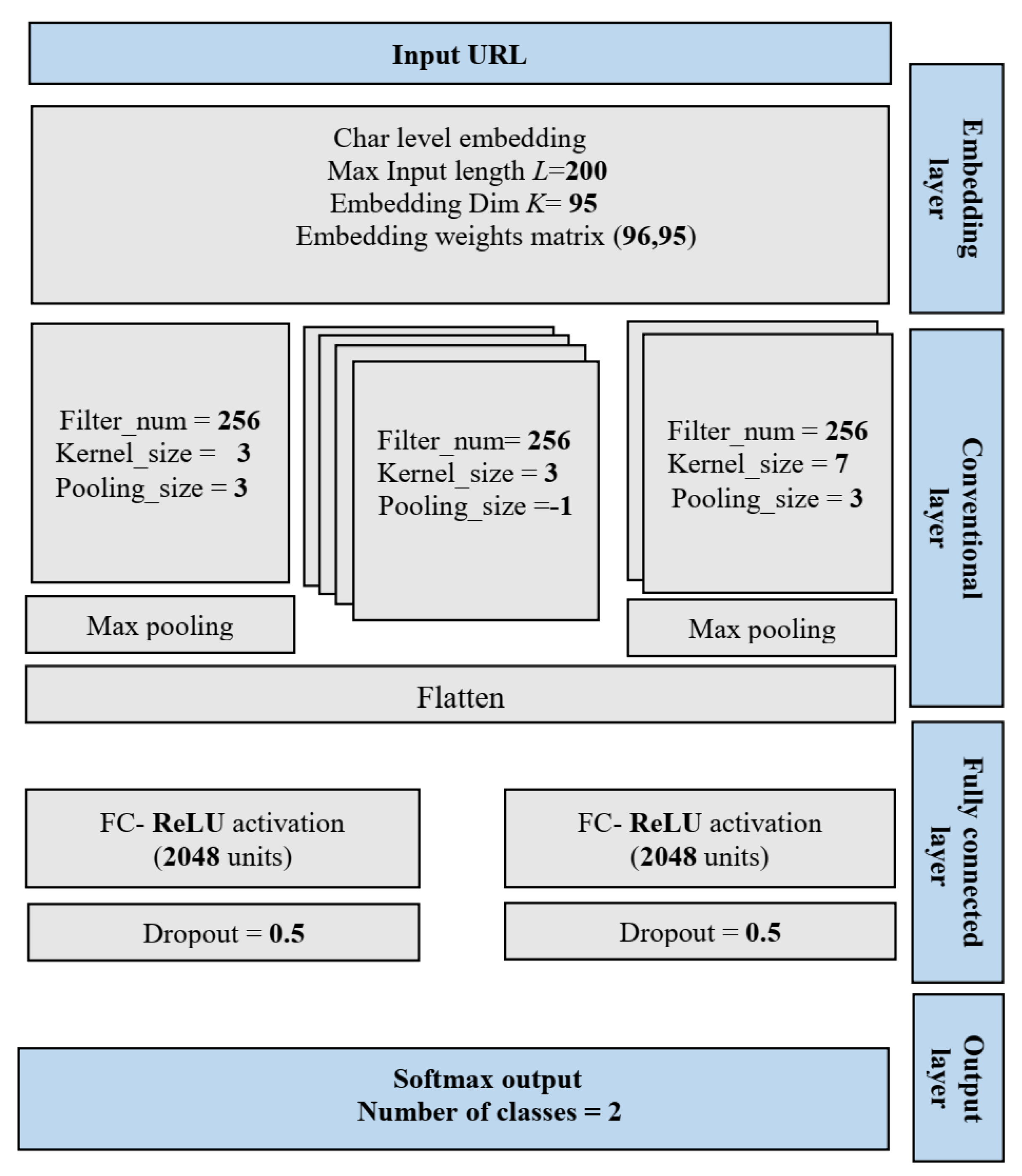
3.2.2. Structure of the Convolutional Neural Networks
As shown in
Figure 7, the proposed convolutional neural network (CNN) model has the following layers: (1) embedding layer; (2) convolutional layers; (3) fully connected layers; (4) output layer.
Embedding layer: The embedding layer is generally used in the first layer of the CNN structure for a Natural Language Processing (NLP) problem. In addition to tokenization, the sparse one-hot matrix is reduced and converted into a dense character through the embedding layer. The multiplier of the vector that is returned from the embedding layer can indicate the relations between characters, which can help improve the performance.
Convolutional layers: Following the embedding layer, 7 convolutional layers are used. The convolutional filters (i.e., filter number, filter size or kernel, and pooling size) are applied for each convolutional layer to extract the most valuable features and remove unnecessary learning features. Following each convolutional layer, the rectified linear unit (ReLU) activation function is used. Then, the output of the convolutional layers is flattened.
Fully connected layers: Three fully connected (FC) layers are used to analyze the local deep association features from the convolutional and max pooling layers, each FC layer is followed by one ReLU activation function, and 2 dropout modules in between the 3 fully connected layers are used to prevent overfitting.
Output layer: The number of output units for the last FC layer is set to 2. The softmax function is used in this layer to identify the possibility that the URL belongs to a phishing website, whereas the output range of softmax function is between 0 and 1.
3.3. URL Features
We used different types of URL features to measure the performance of the proposed model. The URL-based extracted features are categorized into four groups:
Character embedding level features.
Character level TF-IDF features.
Hand-crafted features.
Character level count vectors features.
We discussed the character embedding level features in
Section 3.2.1.
3.3.1. Character Level TF-IDF Features
TF-IDF stands for Term Frequency-Inverse Document Frequency. TF-IDF score represents the relative importance of a term in the document and the entire corpus. TF-IDF score is composed of two terms: the first computes the normalized Term Frequency (TF), the second term is the Inverse Document Frequency (IDF), computed as the logarithm of the number of the documents in the corpus divided by the number of documents where the specific term appears [
33].
TF-IDF Vectors can be generated at different levels of input tokens (words, characters, n-grams):
Word level TF-IDF: Matrix representing TF-IDF scores of every term in different documents.
Character level TF-IDF: Matrix representing TF-IDF scores of character level n-grams in the corpus.
N-gram level TF-IDF: N-grams are the combination of N terms together. This matrix represents TF-IDF scores of N-grams.
It is noted that TF-IDF has been applied in several works to detect phishing of websites by inspecting URLs [
6], to get the indirect associated links [
34], target website [
22], and legitimacy of suspicious website [
21]. Although TF-IDF extracts eminent keywords from the textual content, it has some restrictions. One of the restrictions is that the technique fails when misspelled keywords are extracted. Since URL might contain meaningless words, we applied character level TF-IDF technique with max features as 5000.
3.3.2. Hand-Crafted Features
These are manually crafted features obtained from Python when a URL is provided as input. Depending on the URL parts (host name, path, file, or query) used to extract features, hand-crafted features are categorized into five groups as follows:
Full URL-based features.
Domain-based features.
Path-based features.
File-based features.
Query-based features.
Table 2 provides a list of URL hand-crafted features. Most of these features are taken from existing works [
6,
35,
36,
37,
38,
39] and classified into three categories.
Count-based features: These features get the number of specific characters in the URL. The importance of these features is that, if the number or length is higher, it denotes that entered URL is probably a phishing URL. For example, take into consideration the feature that gets the count of dots in the URL. The higher number of dots, the more likely that URL is deceptive as the dots are used to hide the brand name in the URL. U1, U17∼U18, U20, H1, H17∼H18, P1, P17∼P18, F1, F17∼F18, Q1, and Q17∼Q19 features fall under this category.
Infrequent symbols in benign sites but frequent in phishing sites: There are many special characters (e.g., -, ., " ", /, ?, =, @, &, !, ", ",", +, *, #, $, %) that appear frequently in the URL of phishing sites but not in benign sites. An unusual amount of these characters can indicate the presence of a malicious URL. For example, take into consideration the feature that detects the presence of @ in the URL. If it exists, it could be phishing site otherwise a benign site. Features U10, U2∼U16, H2, H4∼H16, P2∼P16, F2∼F16, and Q2∼Q16 fall under this category.
Other features: Some of the other features do not fall in any of the previous categories. Feature U19 checks if there is an email in URL is set to true; otherwise, is set to false. Features U20 and Q20 check the amount of top-level domains (TLD) present in the URL. Top-level domains are obtained from Internet Assigned Numbers Authority (IANA) (
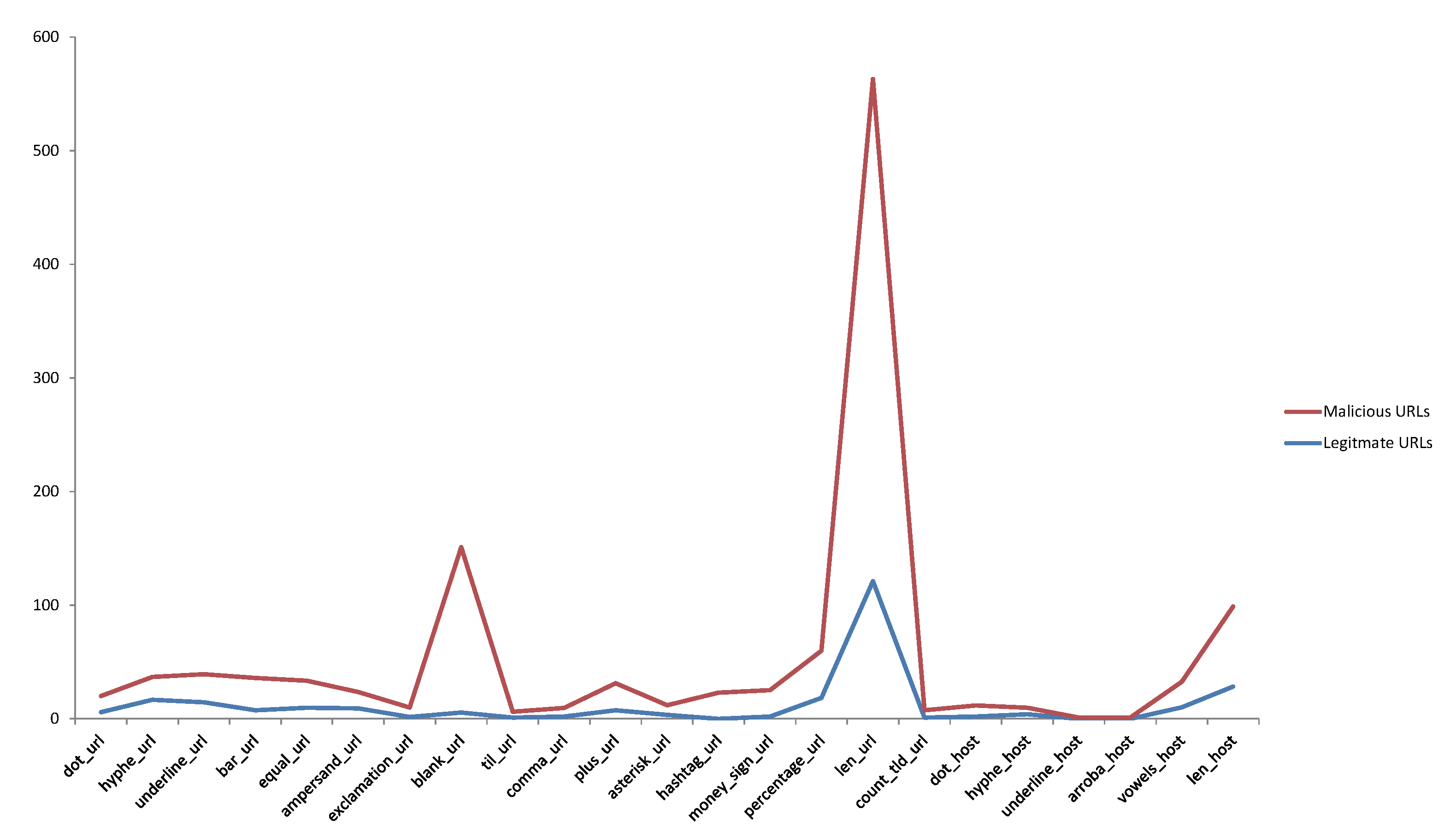
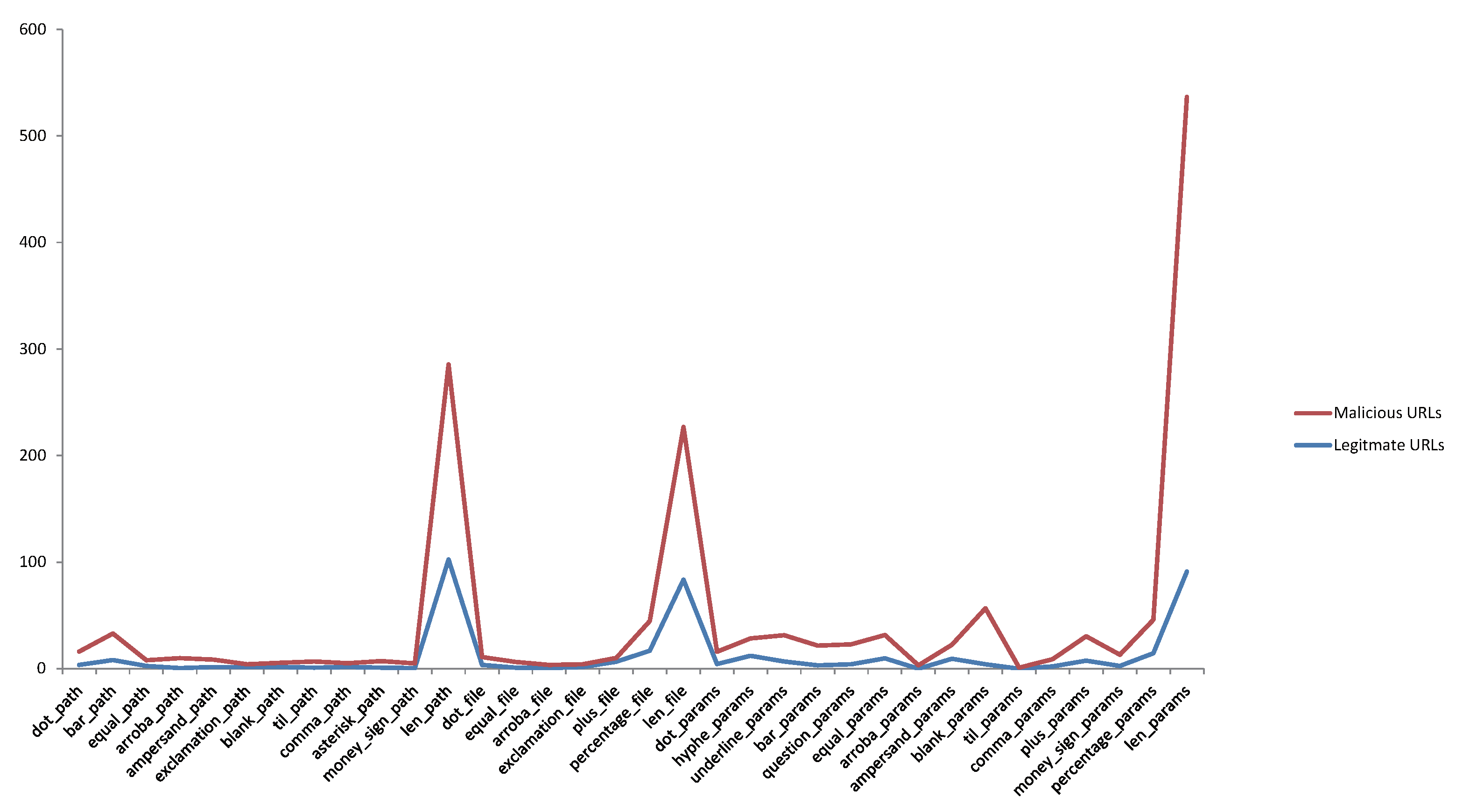
https://www.icann.org/resources/pages/tlds-2012-02-25-en) and stored in a file. A list of all valid top-level domains is maintained by the IANA and is updated from time to time. Feature H19 checks if the domain has an IP address. Feature H3 checks the total count of vowels in domain name. Based on our dataset, we observed that there are more vowels in phishing URLs than in benign URLs.
Figure 8 and
Figure 9 illustrate a comparison between fishing and benign hand-crafted features of URL based on the average occurrence rate per feature within each URL in our dataset.
3.3.3. Count Vectors Features
Count vector is a matrix notation of the dataset in which every row represents a document from the corpus, every column represents a term from the corpus, and every cell represents the frequency count of a particular term in a particular document [
33]. The basic count vectors (bag-of-words) technique does not consider the meaning of the word in the document. It completely ignores the context in which it is used. The same word can be used in multiple places based on the context or nearby words. For the large document, the vector size can be huge resulting in a lot of computation and time. Here, we applied this technique at the character level instead of word level on URLs corpus.
3.4. Classification Algorithms
To evaluate the performance of URL features, we applied different classification models (Naïve Bayes, Logistic Regression, random forest, XGBoost, and deep neural networks). The main objective of comparing different models is to choose the best model. To implement many machine and deep learning models, the Scikit-learn (
http://scikit-learn.org) and Keras (
https://keras.io) packages are used.
The Naïve Bayes is a classification technique based on Bayes’ Theorem with an assumption of independence among predictors. In simple terms, a Naïve Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature. Naïve Bayes model is easy to build and particularly useful for very large datasets [
40]. Equation (
7) provides a way of calculating posterior probability
from
,
and
.
where:
P(c|x) is the posterior probability of class (c, target) given predictor (x, attributes).
P(c) is the prior probability of class.
P(x|c) is the likelihood which is the probability of predictor given class.
P(x) is the prior probability of predictor.
Logistic regression classification is an estimation of logit function that measures the relationship between the categorical dependent variable and one or more independent variables by estimating probabilities using a logistic/sigmoid function. Logit function is simply a log of odds in favor of the event. This function creates a s-shaped curve with the probability estimate [
41].
Figure 10 shows the definition of logit function.
Random forest models are a type of ensemble models, particularly bagging models. They are part of the tree-based model family. It is like the bootstrapping algorithm with decision tree (CART) model. Suppose we have 1000 observation in the complete population with 10 variables. Random forest tries to build multiple CART models with different samples and different initial variables. For instance, it will take a random sample of 100 observation and 5 randomly chosen initial variables to build a CART model. It will repeat the process (suppose) 10 times and then make a final prediction on each observation. Final prediction is a function of each prediction. This final prediction can simply be the mean of each prediction [
42].
Boosting models are another type of ensemble model part of tree-based models. Boosting is a machine learning ensemble meta-algorithm for primarily reducing bias, and also variance in supervised learning, and a family of machine learning algorithms that convert weak learners to strong ones. A weak learner is defined to be a classifier that is only slightly correlated with the true classification [
33]. XGBoost algorithm is a type of boosting models and short form for eXtreme Gradient Boosting. It has both a linear model solver and tree learning algorithms. What makes it fast is its capacity to do parallel computation on a single machine [
43].
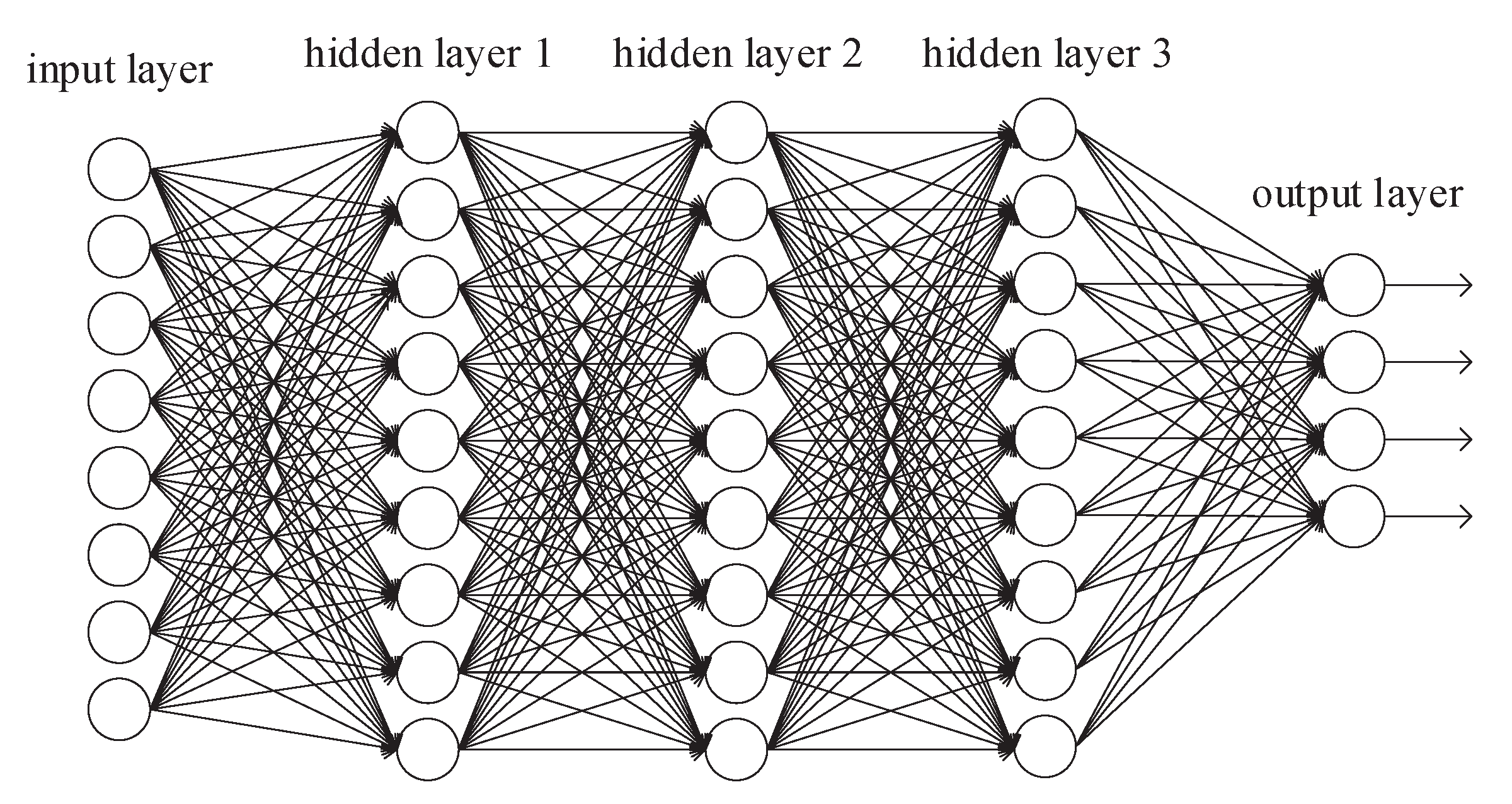
A neural network is a mathematical model that is designed to behave similar to biological neurons and nervous system. These models are used to recognize complex patterns and relationships that exists within labeled data. Deep neural networks are more complex neural networks in which the hidden layers perform much more complex operations than simple sigmoid or ReLU activations [
33].
Figure 11 shows the structure of deep neural networks.
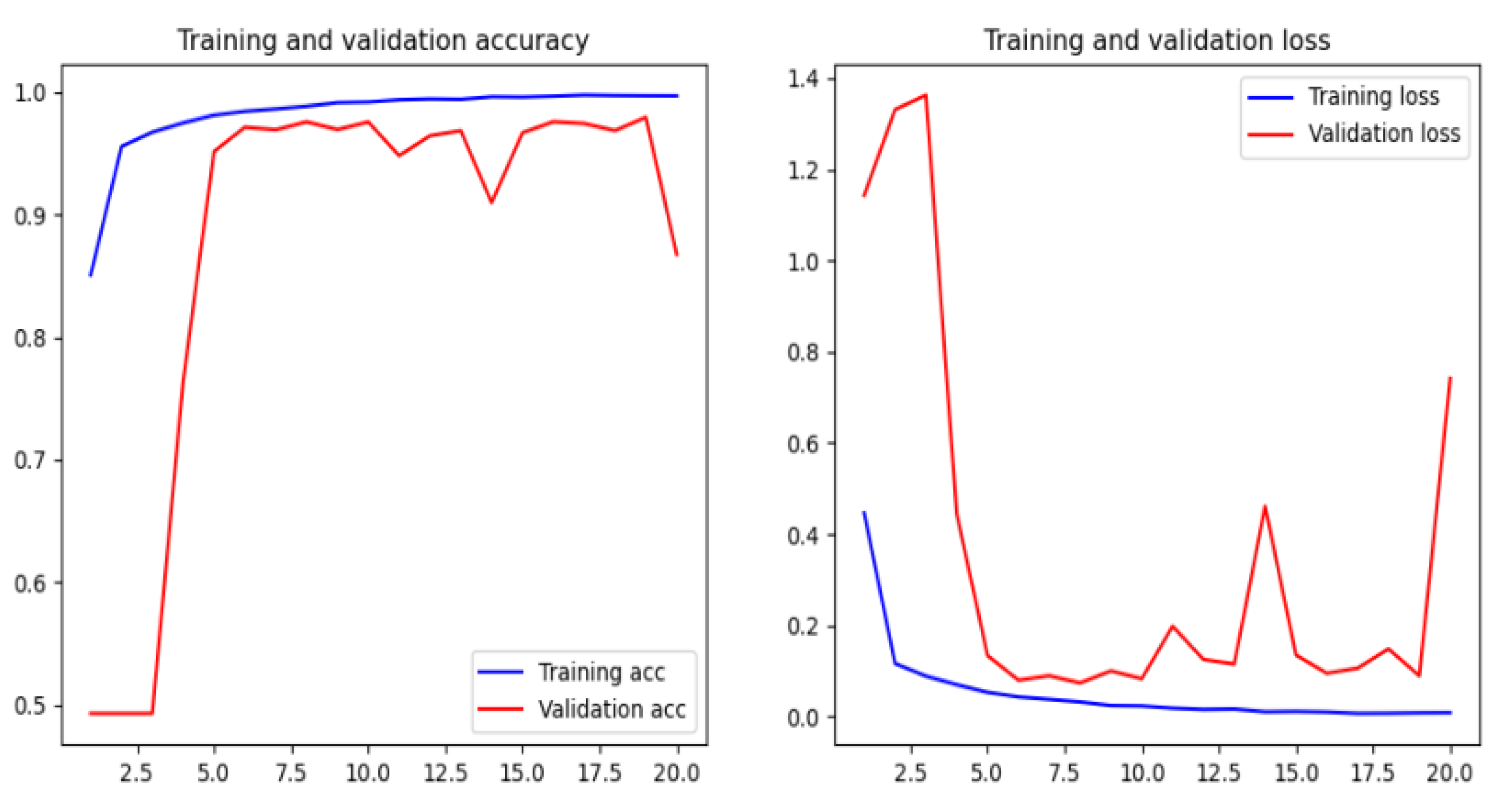
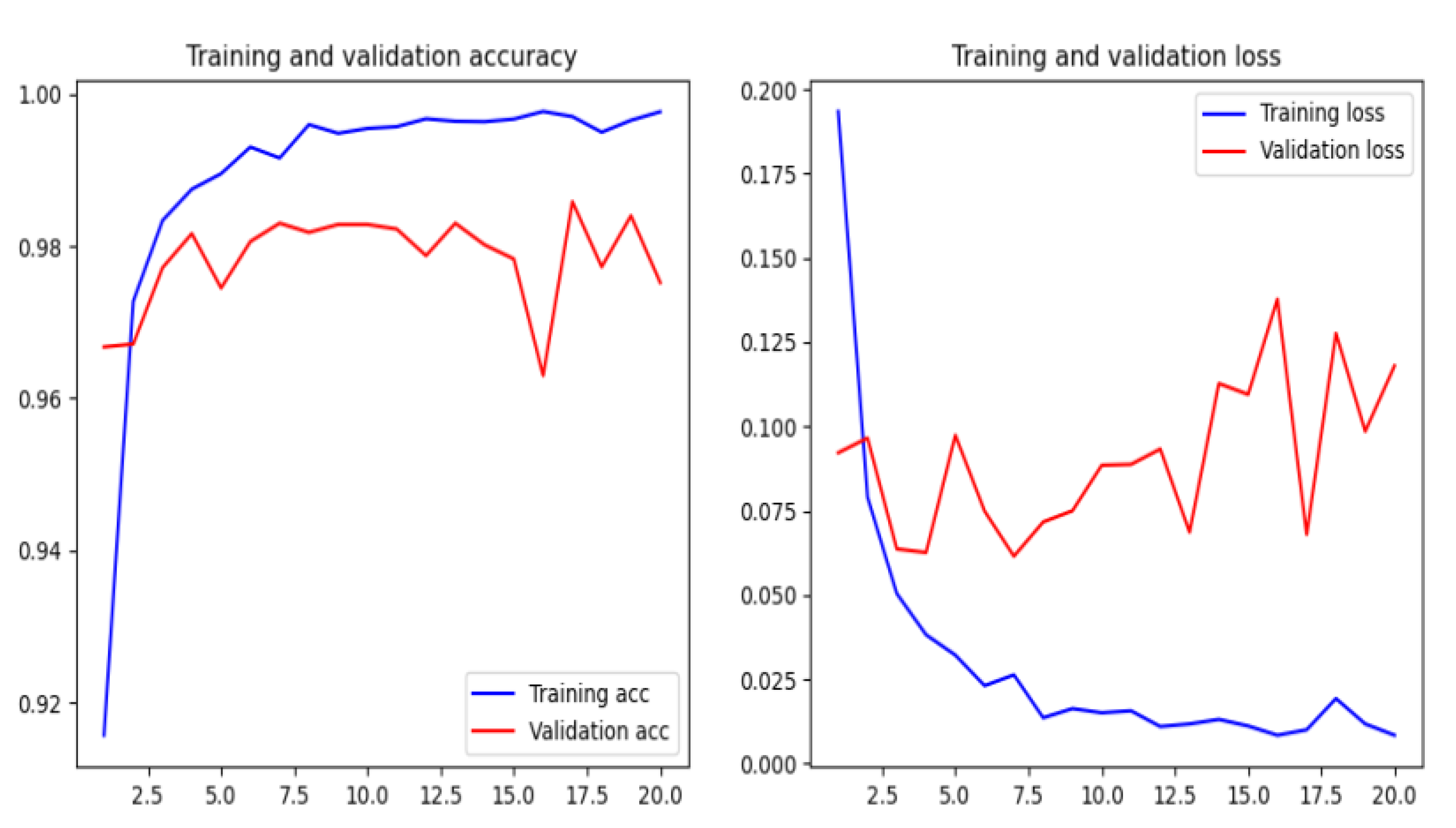
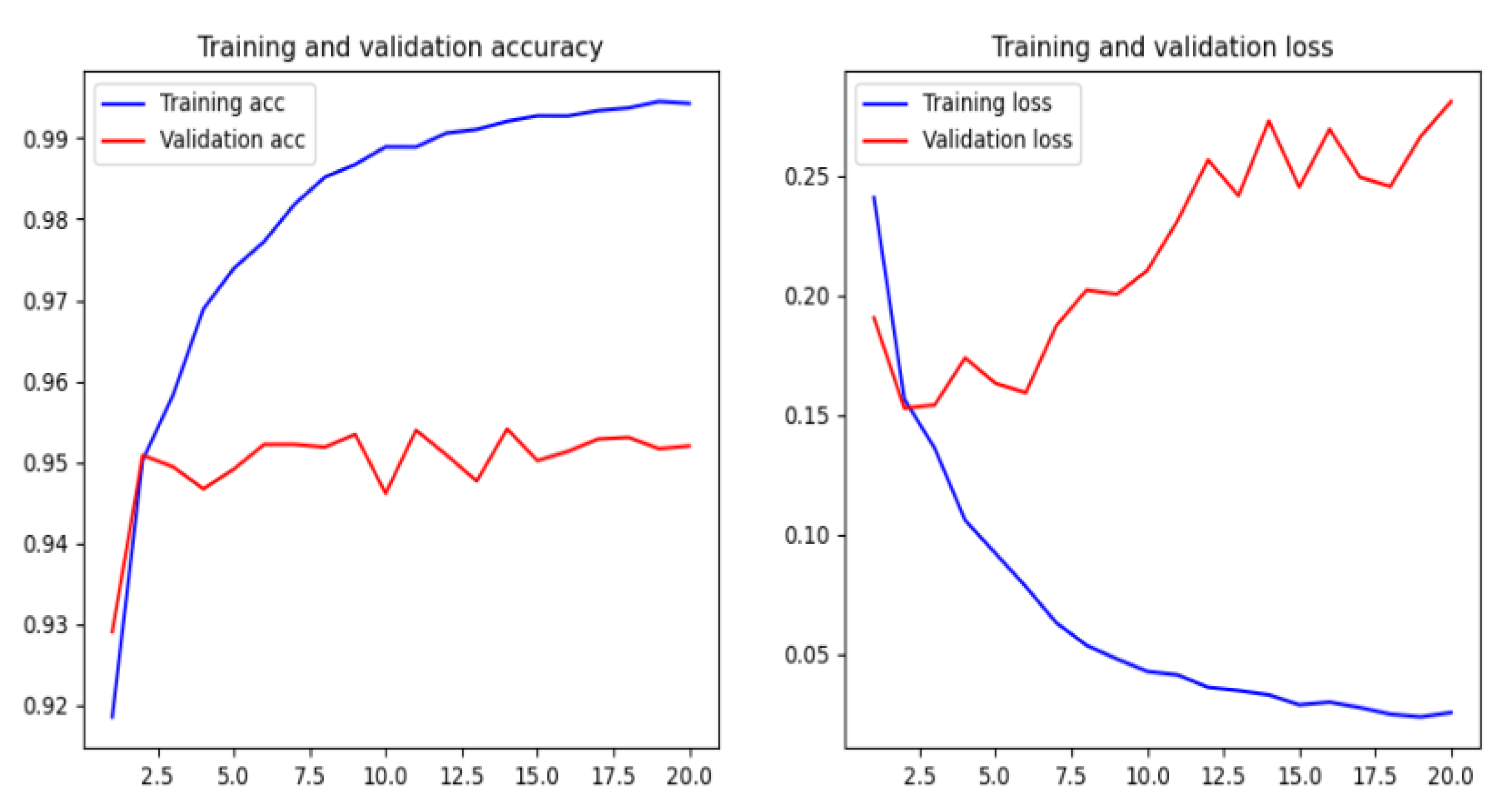
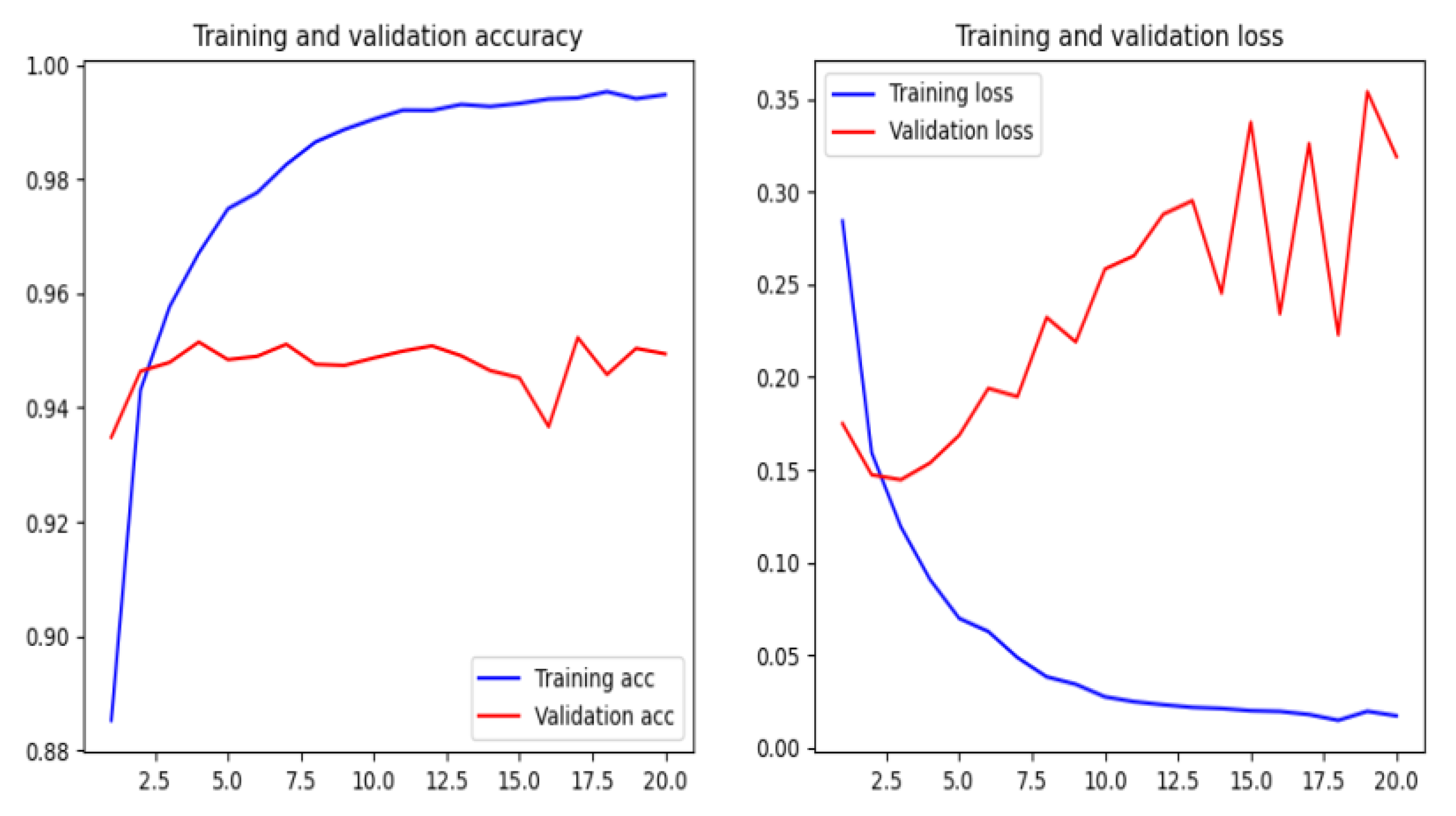
5. Conclusions
In this paper, we have implemented a phishing detection model by using a character level convolutional neural network (CNN). The proposed model based on the features extracted from URL does not need manually designed hand-crafted features, and it is independent of network accessing. This conduct makes the technique suitable at the client side because of its low response time.
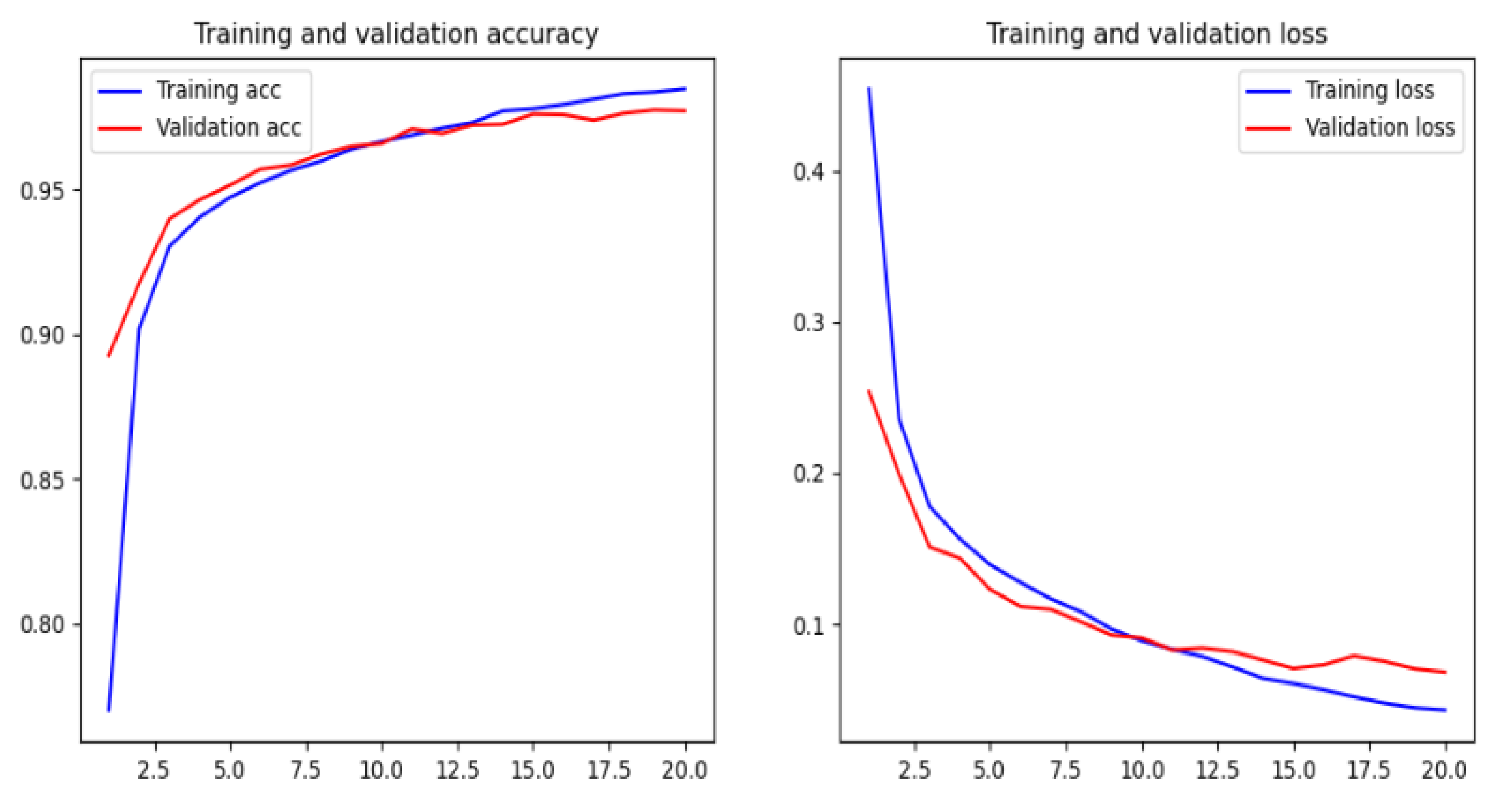
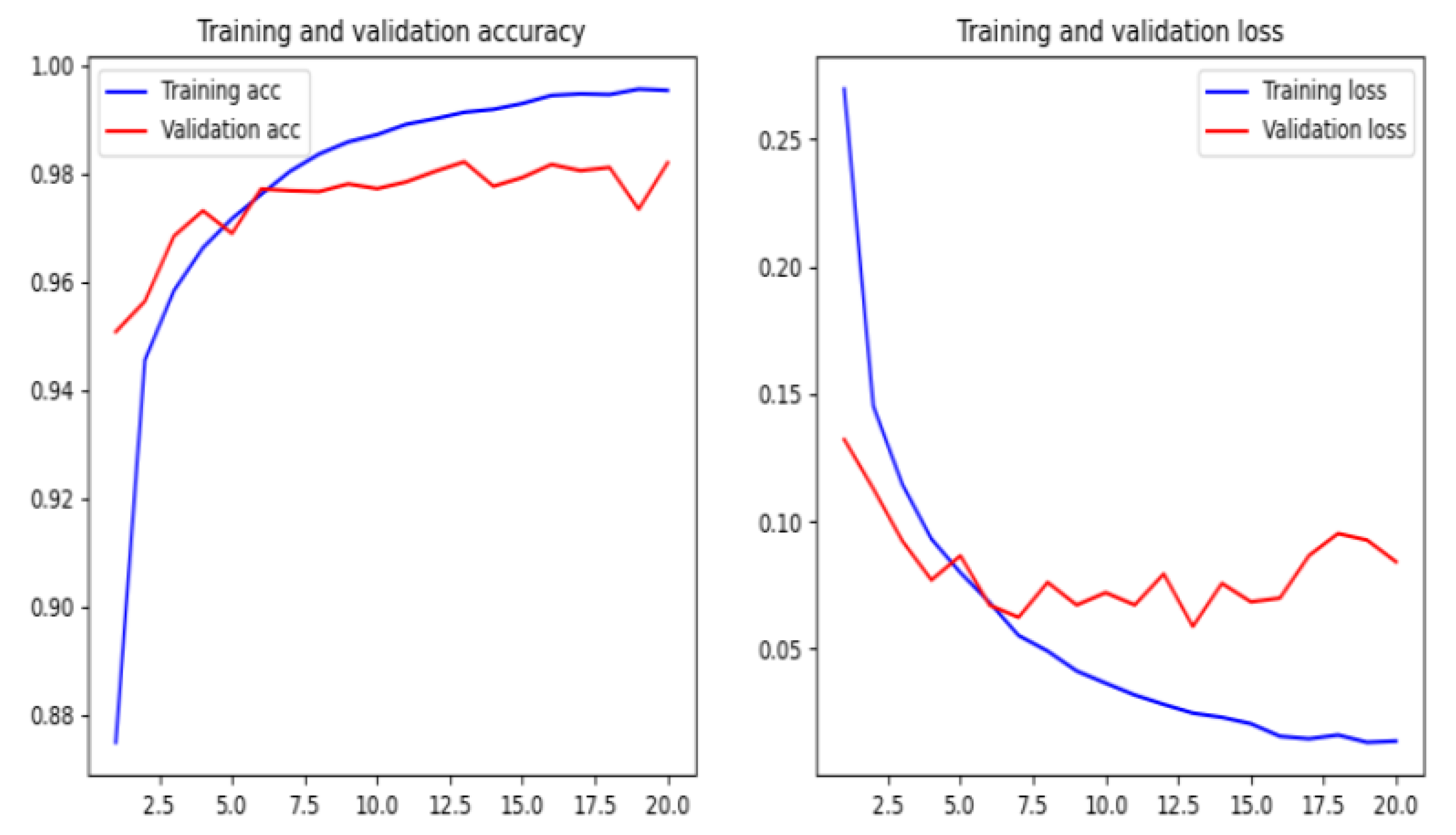
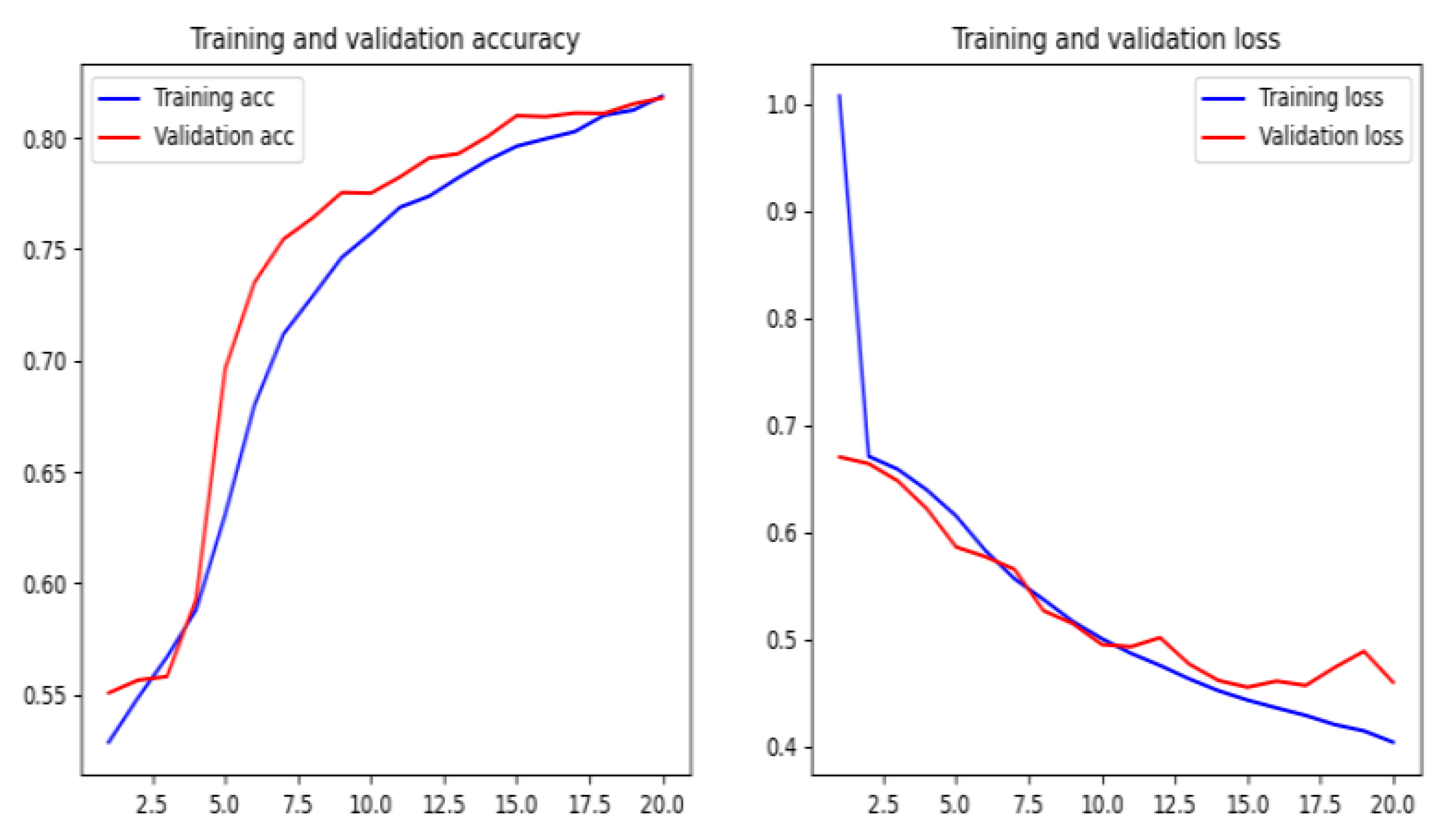
We have compared the proposed method by using different machine and deep learning algorithms, such as Naïve Bayes, Logistic Regression, random forest, XGBoost, deep neural networks, recurrent neural networks, recurrent convolutional neural networks, and various types of features as character level TF-IDF features, character embedding features, character level count vectors, and hand-crafted features. The proposed model achieved an accuracy of 95.02% on our dataset and an accuracy of 98.58%, 95.46%, and 95.22% on benchmark datasets.
There are some disadvantages to the model. The main disadvantage is that the training time is rather long, but the trained model is much better than the existing phishing models in terms of accuracy. One of the drawbacks is that the model is not interested if the URL of the website is active or if there is an error. So it is crucial to check the rationality of the URL in anticipation.
Another drawback is that the model may misclassify some of the phishing sites when the URL is short or contains sensitive words such as “login” or “registered”, these sensitive words may cause a misclassification of such URLs as phishing websites. Moreover, some URLs for deceptive websites, that are not necessary an imitation of other websites, may not be detected based on a URL string. So our intention in future work is to apply deep learning techniques to feature extraction of webpage code and webpage text.


























{kind=link}
{kind=link}
{kind=link}
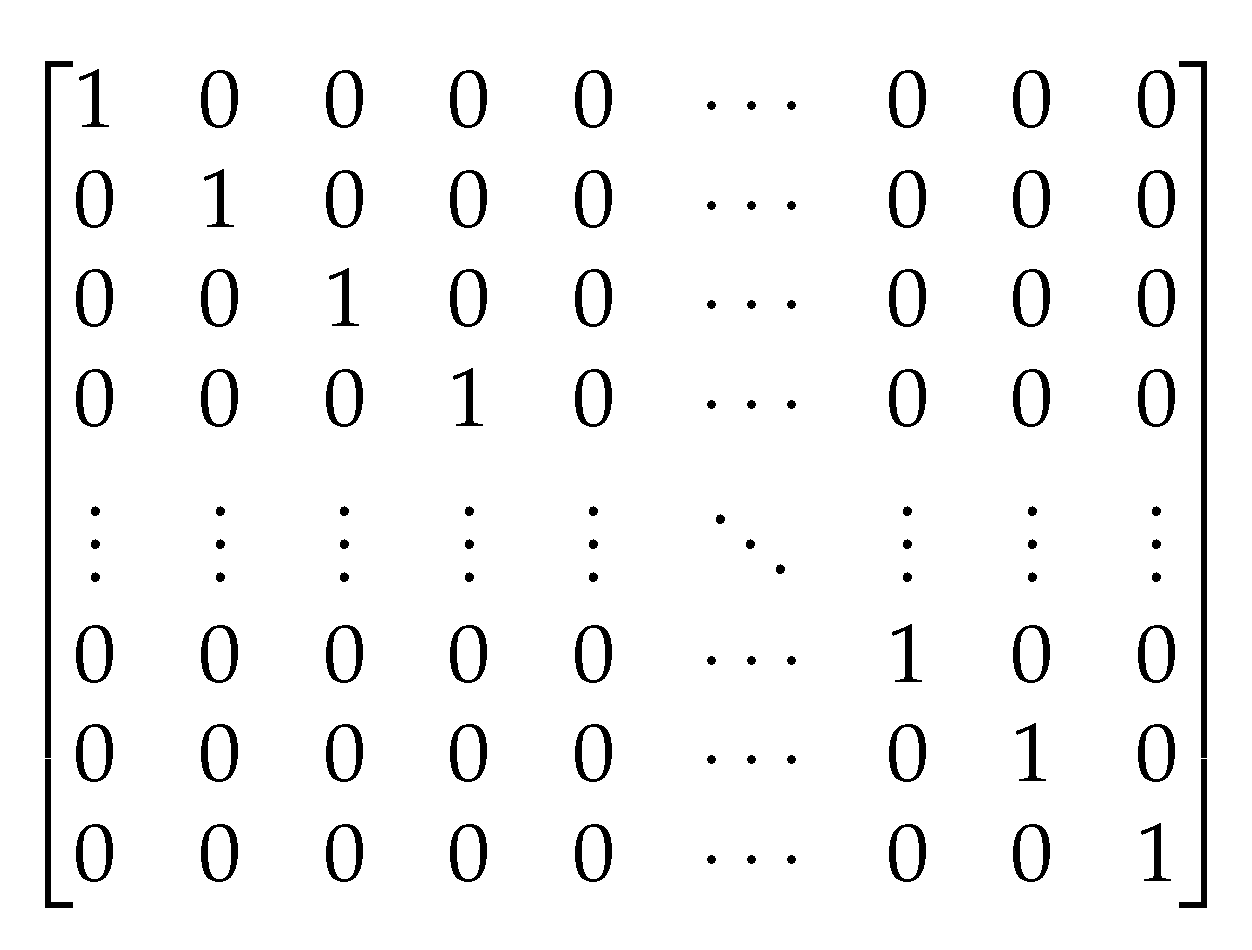{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
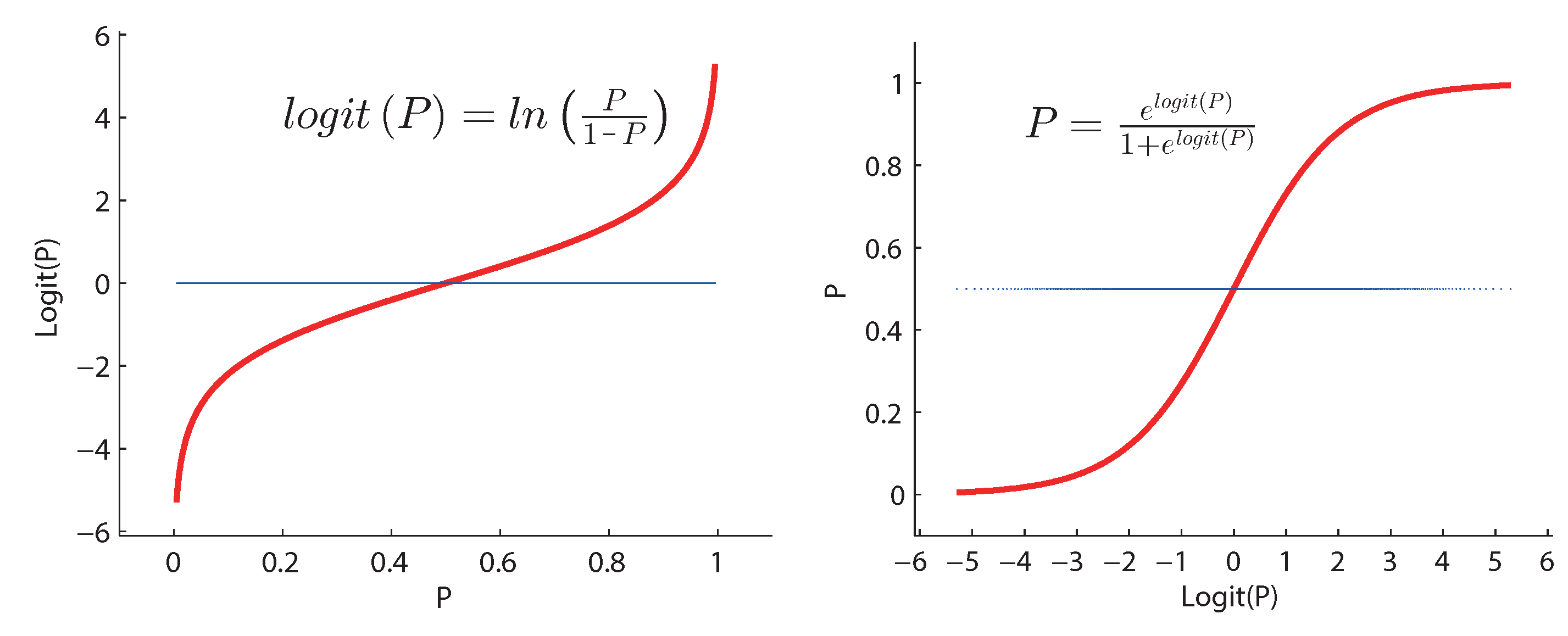{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}