Intellino: Processor for Embedded Artificial Intelligence

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Artificial Intelligence Algorithm
2.1. k-NN and RBF-NN
2.2. Optimization for Hardware Realization
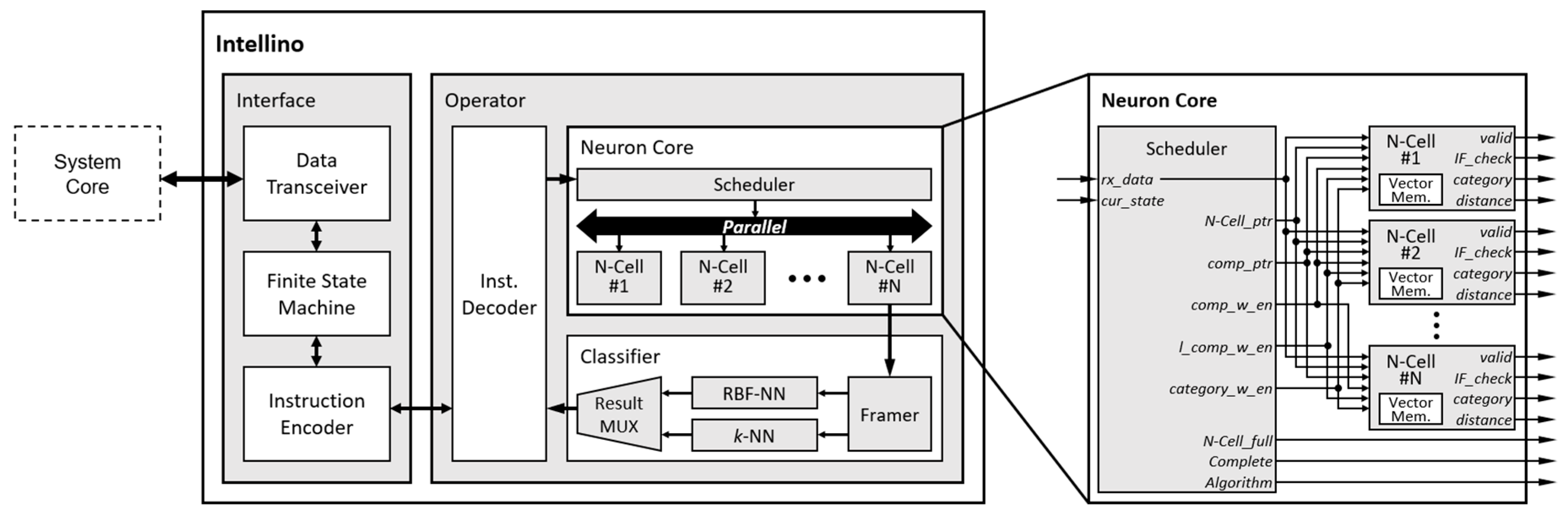
3. Intellino Architecture
3.1. Microarchitecture
3.2. Optimization for Embedded System
4. Simulator
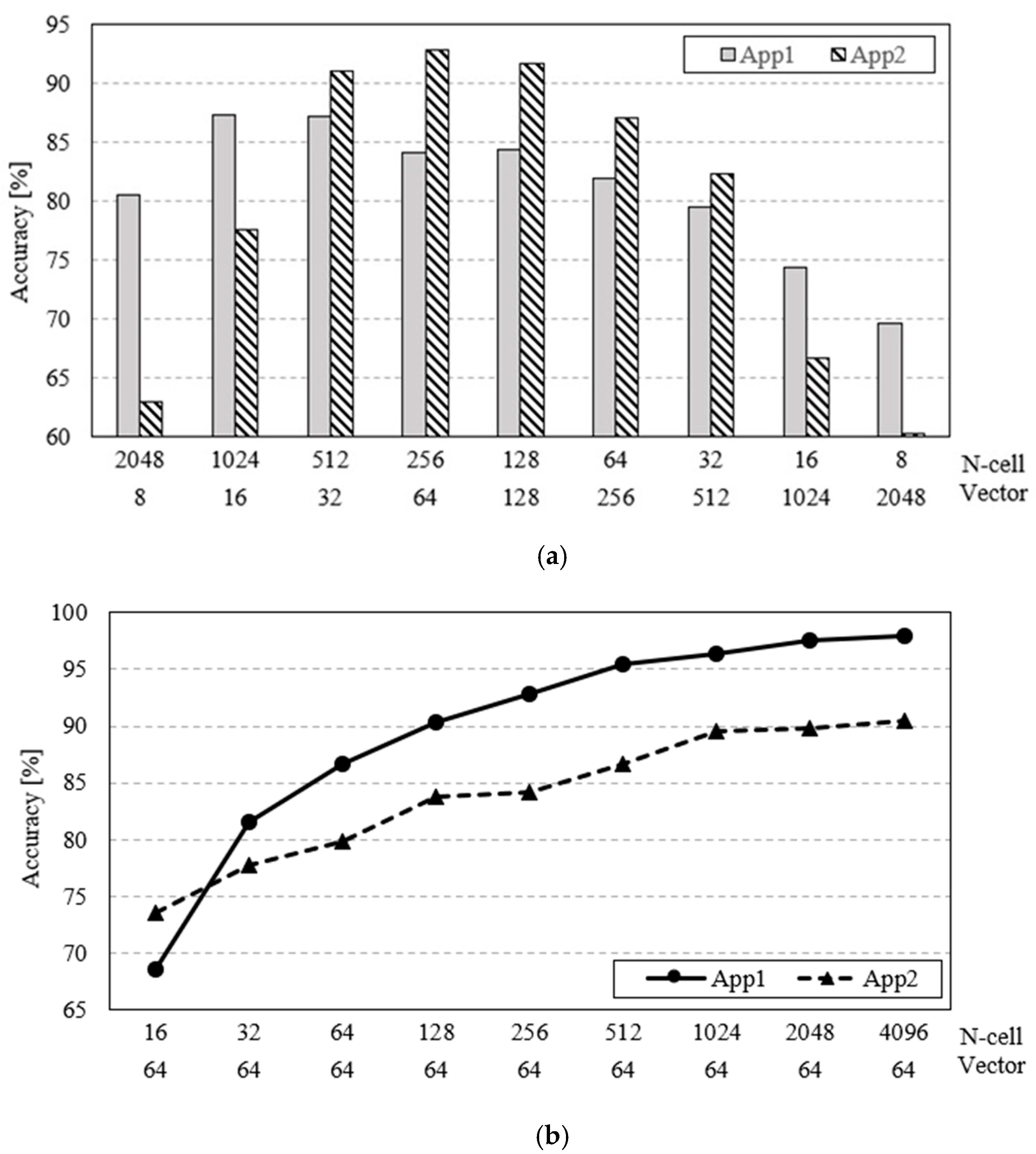
5. Workload Analysis
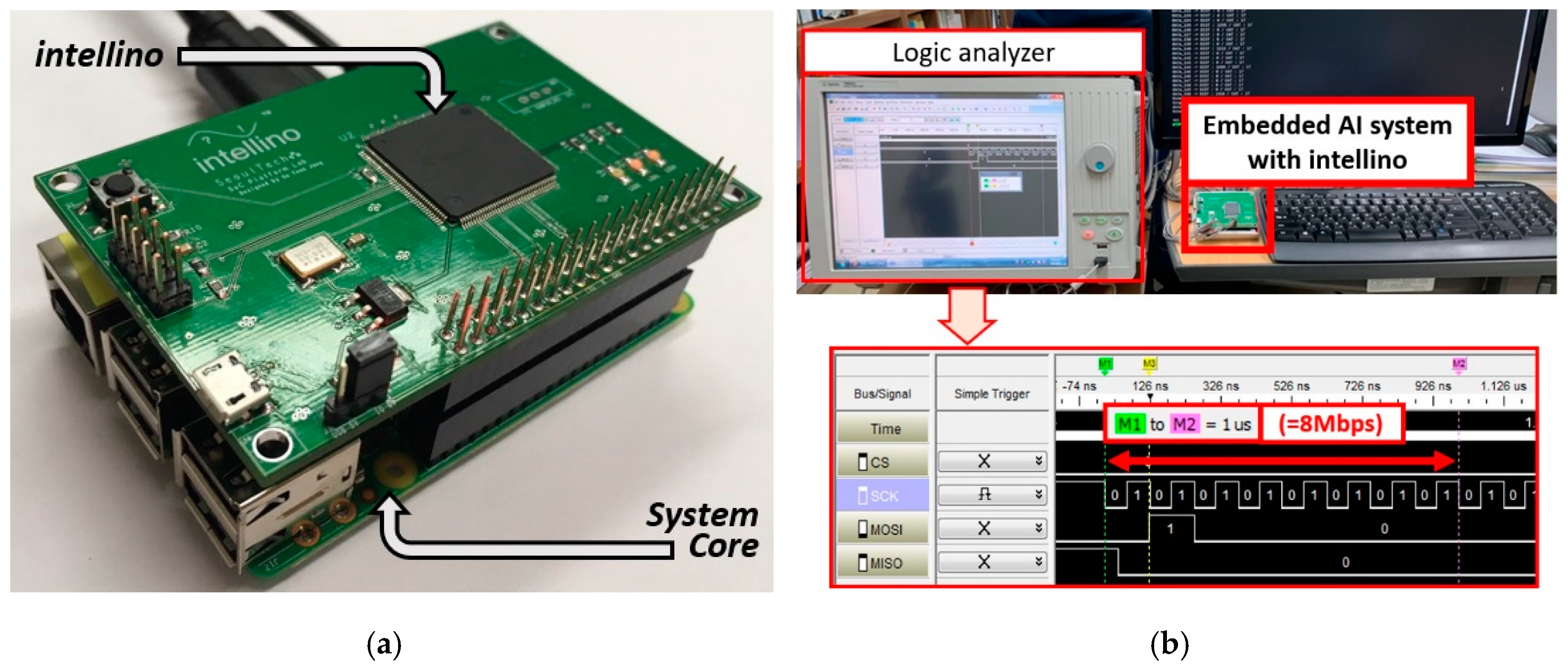
6. Realization
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Choi, H.S.; Park, Y.J.; Lee, J.H.; Kim, Y. 3-D Synapse Array Architecture Based on Charge-Trap Flash Memory for Neuromorphic Application. Electronics 2020, 9, 57. [Google Scholar] [CrossRef]
- Sun, S.Y.; Li, J.; Li, Z.W.; Liu, H.S.; Liu, H.J.; Li, Q.J. Quaternary synapses network for memristor-based spiking convolutional neural networks. IEICE Electron. Express 2019, 16, 1–6. [Google Scholar] [CrossRef]
- Amirhossein, T.; Anthony, S.M. A spiking network that learns to extract spike signatures from speech signals. Elsevier Neurocomput. 2017, 240, 191–199. [Google Scholar] [CrossRef]
- Cai, W.; Hu, D. QRS Complex Detection Using Novel Deep Learning Neural Networks. IEEE Access 2020, 8, 97082–97089. [Google Scholar] [CrossRef]
- Dang, H.; Liang, Y.; Wei, L.; Li, C.; Dang, S. Artificial Neural Network Design for Enabling Relay Selection by Supervised Machine Learning. In Proceedings of the 2018 Eighth International Conference on Instrumentation & Measurement, Computer, Communication and Control (IMCCC), Harbin, China, 19–21 July 2018; pp. 1464–1468. [Google Scholar] [CrossRef]
- Shen, G.; Yuan, Y. On Theoretical Analysis of Single Hidden Layer Feedforward Neural Networks with Relu Activations. In Proceedings of the 2019 34rd Youth Academic Annual Conference of Chinese Association of Automation (YAC), Jinzhou, China, 6–8 June 2019; pp. 706–709. [Google Scholar] [CrossRef]
- Moon, S.; Shin, J.; Shin, C. Understanding of Polarization-Induced Threshold Voltage Shift in Ferroelectric-Gated Field Effect Transistor for Neuromorphic Applications. Electronics 2020, 9, 704. [Google Scholar] [CrossRef]
- Adarsha, B.; Anup, D.; Yuefeng, W.; Khanh, H.; Francesco, G.D.; Giacomo, I.; Jeffrey, L.K.; Nikil, D.D.; Siebren, S.; Francky, C. Mapping Spiking Neural Networks to Neuromorphic Hardware. IEEE Trans. VLSI 2020, 28, 76–86. [Google Scholar] [CrossRef]
- Mantas, M.; David R., L.; Delong, S.; Steve, F.; Gengting, L.; Jim, G.; Stefan, S.; Sebastian, H.; Andreas, D. Approximate Fixed-Point Elementary Function Accelerator for the SpiNNaker-2 Neuromorphic Chip. In Proceedings of the 2018 IEEE 25th Symposium on Computer Arithmetic (ARITH), Amherst, MA, USA, 25–27 June 2018; pp. 37–44. [Google Scholar] [CrossRef]
- Yun, Y.S.; Kim, S.; Park, J.; Kim, H.; Jung, J.; Eun, S. Development of Neuromorphic Architecture Integrated Development Environment. In Proceedings of the 2020 International Conference on Green and Human Information Technology (ICGHIT), Hanoi, Vietnam, 5–7 February 2020; pp. 47–49. [Google Scholar] [CrossRef]
- Alexandre, S. Neuromorphic microelectronics from devices to hardware systems and applications. IEICE NOLTA 2016, 7, 468–498. [Google Scholar] [CrossRef]
- Xiang, W.; Yongli, H.; Sha, N.; Yi, S.; Qing, W. Biological Band-Pass Filtering Emulated by Oxide-Based Neuromorphic Transistors. IEEE EDL 2018, 39, 1764–1767. [Google Scholar] [CrossRef]
- Zheqi, Y.; Amir, M.A.; Adnan, Z.; Hadi, H.; Muhammad, A.I.; Qammer, H.A. An Overview of Neuromorphic Computing for Artificial Intelligence Enabled Hardware-Based Hopfield Neural Network. IEEE Access 2020, 8, 2169–3536. [Google Scholar] [CrossRef]
- Antara, G.; Rajeev, M.; Virendra, S. Towards Energy Efficient non-von Neumann Architectures for Deep Learning. In Proceedings of the 20th International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 6–7 March 2019; pp. 335–342. [Google Scholar] [CrossRef]
- Neeru, S.; Supriya, P.P. Enhancing the Proficiency of Artificial Neural Network on Prediction with GPU. In Proceedings of the 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019; pp. 67–71. [Google Scholar] [CrossRef]
- Ian, S.; Amirhossein, A. Parallel GPU-Accelerated Spike Sorting. In Proceedings of the 2019 IEEE Canadian Conference of Electrical and Computer Engineering (CCECE), Edmonton, AB, Canada, 5–8 May 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Khomenko, V.; Shyshkov, O.; Radyvonenko, O.; Bokhan, K. Accelerating recurrent neural network training using sequence bucketing and multi-GPU data parallelization. In Proceedings of the 2016 IEEE First International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 23–27 August 2016; pp. 100–103. [Google Scholar] [CrossRef]
- Mike, D.; Narayan, S.; Lin, T.H.; Gautham, C.; Cao, Y.; Sri, H.C.; Georgios, D.; Prasad, J.; Nabil, I.; Shweta, J.; et al. Loihi: A Neuromorphic Manycore Processor with On-Chip Learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Andrew, Y. Deep Learning Training At Scale Spring Crest Deep Learning Accelerator (Intel® Nervana™ NNP-T). In Proceedings of the 2019 IEEE Hot Chips 31 Symposium (HCS), Cupertino, CA, USA, 15–20 August 2019; pp. 1–20. [Google Scholar] [CrossRef]
- Paul, A.M.; John, V.A.; Rodrigo, A.; Andrew, S.C.; Jun, S.; Filipp, A.; Bryan, L.J.; Nabil, I.; Chen, G.; Yutaka, N.; et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 2014, 345, 668–673. [Google Scholar] [CrossRef]
- Yu, E.; Cho, S.; Park, B. A Silicon-Compatible Synaptic Transistor Capable of Multiple Synaptic Weights toward Energy-Efficient Neuromorphic Systems. Electronics 2019, 8, 1102. [Google Scholar] [CrossRef]
- Lee, S.M.; Jang, J.H.; Oh, J.H.; Kim, J.K.; Lee, S.E. Design of Hardware Accelerator for Lempel-Ziv 4 (LZ4) Compression. IEICE Electron. Express 2017, 14, 1–6. [Google Scholar] [CrossRef][Green Version]
- Kim, J.K.; Oh, J.H.; Hwang, G.B.; Gwon, O.S.; Lee, S.E. Design of Low-Power SoC for Wearable Healthcare Device. JCSC 2020, 29, 1–14. [Google Scholar] [CrossRef]
- Bert, M.; Marian, V. An Energy-Efficient Precision-Scalable ConvNet Processor in 40-nm CMOS. IEEE JSSC 2017, 52, 903–914. [Google Scholar] [CrossRef]
- Jang, S.Y.; Oh, J.H.; Yoon, Y.H.; Lee, S.M.; Lee, S.E. Design of a DMA Controller for Augmented Reality in Embedded System. JKIICE 2019, 23, 822–828. [Google Scholar] [CrossRef]
- Lee, J.; Kim, C.; Kang, S.; Shin, D.; Kim, S.; Yoo, H.J. UNPU: A 50.6TOPS/W unified deep neural network accelerator with 1b-to-16b fully-variable weight bit-precision. In Proceedings of the 2018 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 11–15 February 2018; pp. 218–220. [Google Scholar] [CrossRef]
- Kang, H.J. Short floating-point representation for convolutional neural network inference. IEICE Electron. Express 2019, 16, 1–11. [Google Scholar] [CrossRef]
- Kota, A.; Kodai, U.; Yuka, O.; Kazutoshi, H.; Ryota, U.; Takumi, K.; Masayuki, I.; Tetsuya, A.; Shinya, T.Y.; Masato, M. Dither NN: Hardware/Algorithm Co-Design for Accurate Quantized Neural Networks. IEICE Trans. Inf. Syst. 2019, E102.D, 2341–2353. [Google Scholar] [CrossRef]
- Kim, J.K.; Oh, J.H.; Yang, J.H.; Lee, S.E. 2D Line Draw Hardware Accelerator for Tiny Embedded Processor in Consumer Electronics. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–13 January 2019; pp. 1–2. [Google Scholar] [CrossRef]
- Mengyue, Z.; Weihan, L.; Jianlian, Z.; Huisheng, G.; Fanyi, W.; Bin, L. Embedded Face Recognition System Based on Multi-task Convolutional Neural Network and LBP Features. In Proceedings of the 2019 IEEE International Conference of Intelligent Applied Systems on Engineering (ICIASE), Fuzhou, China, 26–29 April 2019; pp. 132–135. [Google Scholar] [CrossRef]
- Kim, Y.H.; An, G.J.; Sunwoo, M.H. CASA: A Convolution Accelerator using Skip Algorithm for Deep Neural Network. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Bo, Y.; John, P.; Lu, L.; Nick, A.; Yao, L. An Inductive Content-Augmented Network Embedding Model for Edge Artificial Intelligence. IEEE Trans. Ind. Inf. 2019, 15, 4249–4305. [Google Scholar] [CrossRef]
- Fengbin, T.; Shouyi, Y.; Peng, O.; Shibin, T.; Leibo, L.; Shaojun, W. Deep Convolutional Neural Network Architecture With Reconfigurable Computation Patterns. IEEE Trans. VLSI 2017, 25, 2220–2233. [Google Scholar] [CrossRef]
- Pete, W. Speech commands: A dataset for limited-vocabulary speech recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar]
- Yann, L.; L´eon, B.; Yoshua, B.; Patrick, H. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Schafer, R.; Rabiner, L. Design and simulation of a speech analysis-synthesis system based on short-time Fourier analysis. IEEE Trans. Audio Electroacoust. 1973, 21, 165–174. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001; pp. 511–518. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Steve, B.F.; Francesco, G.; Steve, T.; Luis, A.P. The SpiNNaker Project. Proc. IEEE 2014, 102, 652–665. [Google Scholar] [CrossRef]
- Arnon, A.; Brian, T.; David, B.; Timothy, M.; Jeffrey, M.; Carmelo, D.N.; Tapan, N.; Alexander, A.; Guillaume, G.; Marcela, M.; et al. A Low Power, Fully Event-Based Gesture Recognition System. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7388–7397. [Google Scholar] [CrossRef]
- Yoon, Y.H.; Jang, S.Y.; Choi, D.Y.; Lee, S.E. Flexible Embedded AI System with High-speed Neuromorphic Controller. In Proceedings of the 2019 International SoC Design Conference (ISOCC), Jeju, Korea, 6–9 October 2019; pp. 265–266. [Google Scholar] [CrossRef]





© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoon, Y.H.; Hwang, D.H.; Yang, J.H.; Lee, S.E. Intellino: Processor for Embedded Artificial Intelligence. Electronics 2020, 9, 1169. https://doi.org/10.3390/electronics9071169
Yoon YH, Hwang DH, Yang JH, Lee SE. Intellino: Processor for Embedded Artificial Intelligence. Electronics. 2020; 9(7):1169. https://doi.org/10.3390/electronics9071169
Chicago/Turabian StyleYoon, Young Hyun, Dong Hyun Hwang, Jun Hyeok Yang, and Seung Eun Lee. 2020. "Intellino: Processor for Embedded Artificial Intelligence" Electronics 9, no. 7: 1169. https://doi.org/10.3390/electronics9071169
APA StyleYoon, Y. H., Hwang, D. H., Yang, J. H., & Lee, S. E. (2020). Intellino: Processor for Embedded Artificial Intelligence. Electronics, 9(7), 1169. https://doi.org/10.3390/electronics9071169