Assessment of QoE for Video and Audio in WebRTC Applications Using Full-Reference Models



Abstract
1. Introduction
1.1. Background
1.1.1. WebRTC
1.1.2. QoE
- Human IFs: the properties related to the user as a human being, such as demographic and socioeconomic background or emotional state.
- System IFs: technical properties that determine the quality of an application or service, such as media capture, encoding, transmission, or rendering.
- Context IFs: factors of the user’s environment in terms of physical (e.g., location, space, and movement), temporal (e.g., time of day, duration, and frequency of use), or economic characteristics (e.g., costs, subscription type, or brand of the service).
- Full-Reference (FR): these models use some reference for audio or video together with the distorted signal (impairment) to compute the value of QoE.
- Reduced-Reference (RR): these methods have access to partial information regarding the original reference (typically statistical) together with the impairment signal.
- No-Reference (NR): these methods estimate the value of QoE without any knowledge of the original reference.
1.1.3. Related Work
1.2. Motivation
1.3. Contributions
2. Material and Methods
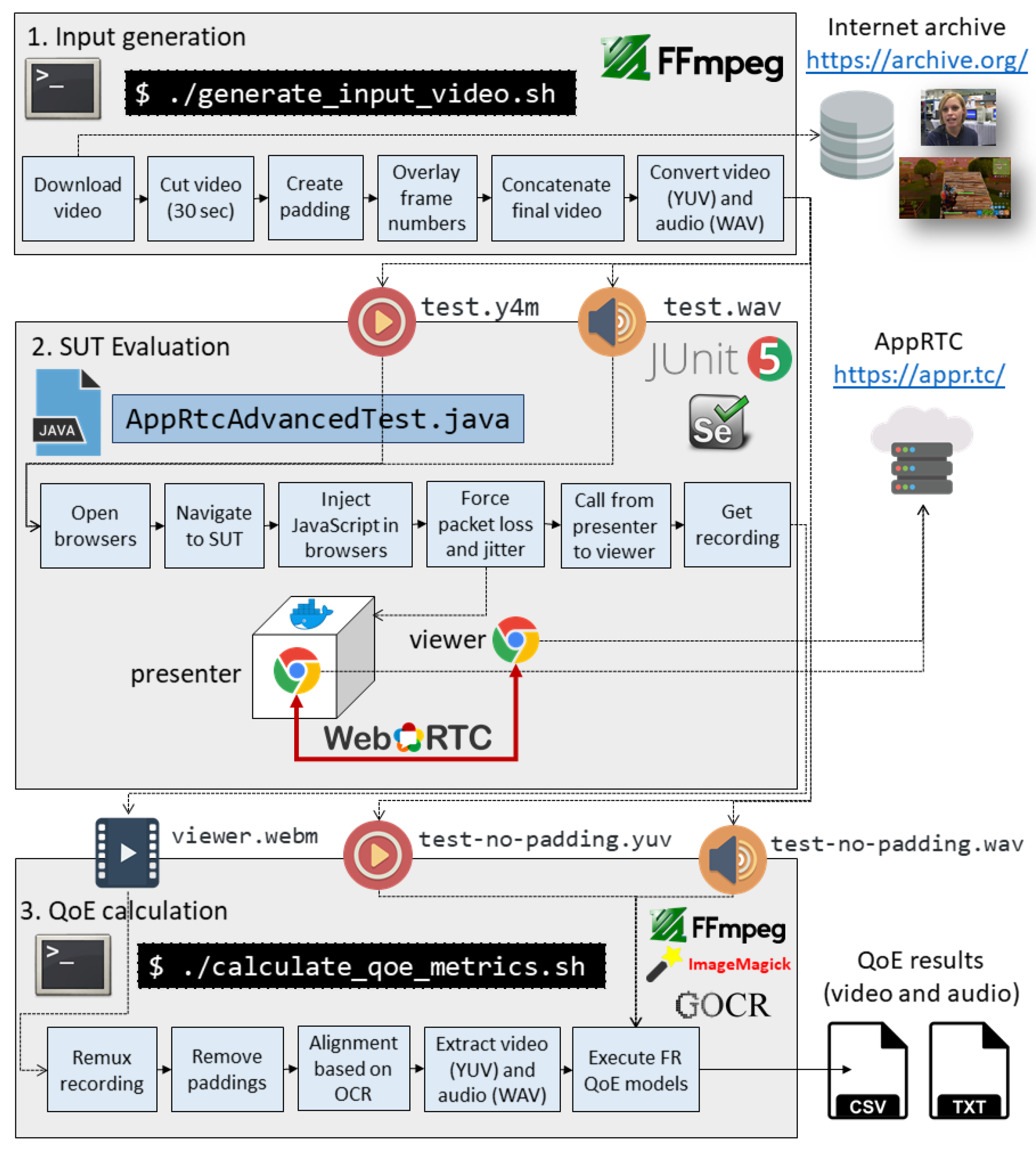
2.1. Benchmark for Objective Evaluation
2.1.1. Input Generation
- –use-file-for-fake-video-capture=/path/to/test.y4m: This flag allows feeding a custom video file (instead of using the actual media from the camera) for WebRTC communications. Chrome requires the format of this file follows a YUV color encoding system (raw format).
- –use-file-for-fake-audio-capture=/path/to/test.wav: This flag allows to feed a custom audio file (instead of using the actual audio from the microphone) for WebRTC communications. Chrome requires a WAV file format for this (raw format).
- We place the media source in between two padding signals, discarded in the third stage (QoE calculation).
- We encode the reference video in YUV and the audio in WAV, which are the formats supported by Chrome.
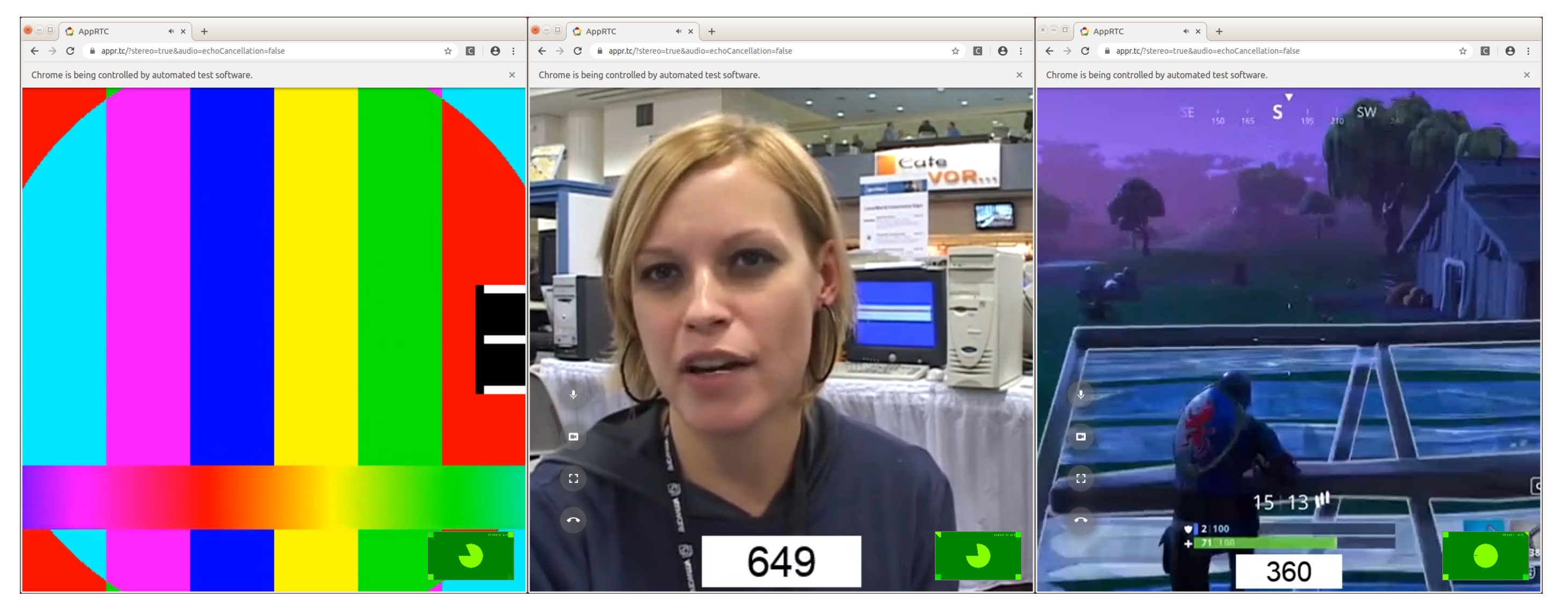
- We use a fixed value of the video frame rate (24 fps). Then, we overlay the frame number within the media to ensure perfect alignment in the third stage (see more details on Section 2.1.3).
- Download the video sample from the Internet Archive (using the command-line tool wget).
- Cut the original video. As explained later, we use the impairment sequences also for subjective analysis. To avoid a very long experiment time, we limit the duration of the reference sequences to 30 s.
- Overlay each frame number in the video content. As explained later, each frame number is recognized directly from the video content using an OCR tool. For this reason, first, we need to attach each frame number in the video at this point.
- Create padding video based on a test pattern. This padding video sequence is a test source pattern composed of different colored bars (see Figure 3a).
- Concatenate the final video, attaching the padding at the beginning and the end of the sequence, and the actual content (interview or game) in the middle.
- Convert the final video to Y4M and the final audio to WAV, as required by Google Chrome.
2.1.2. SUT Evaluation
 |
| Listing 1: Monkey Patching for RTCPeerConnection objects (JavaScriptWebRTC API). |
- 1 for the ideal scenario, in which no packet loss nor jitter happens.
- 3 for scenarios with packet loss: 15%, 30%, and 45%, respectively).
- 3 for scenarios with jitter: 25 ms, 50 ms, and 75 ms, respectively (75 ms is the maximum recommended value to avoid jitter distortions [49]).
2.1.3. QoE Calculation
| Algorithm 1: Alignment process algorithm |
 |
2.2. Survey for Subjective Evaluation
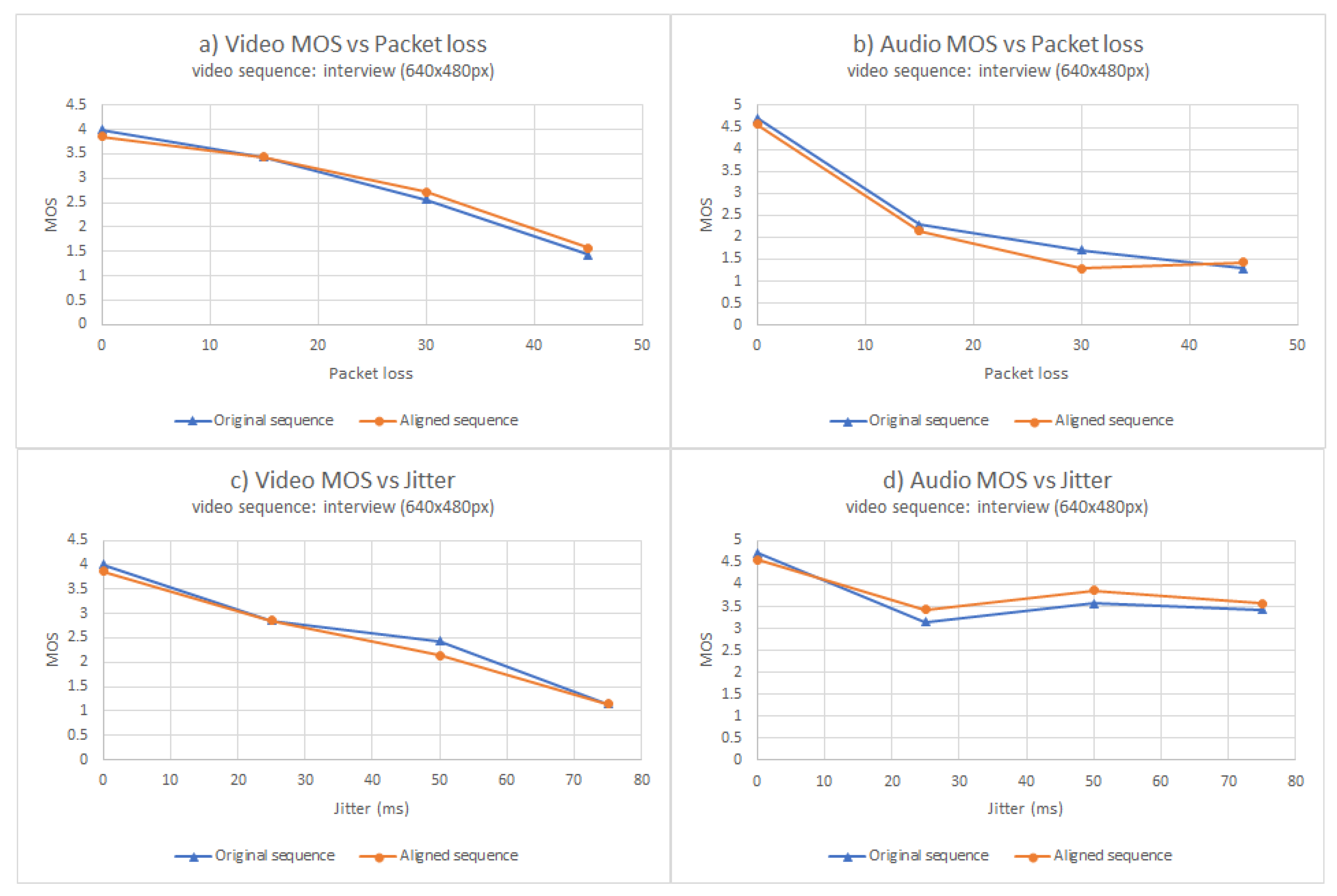
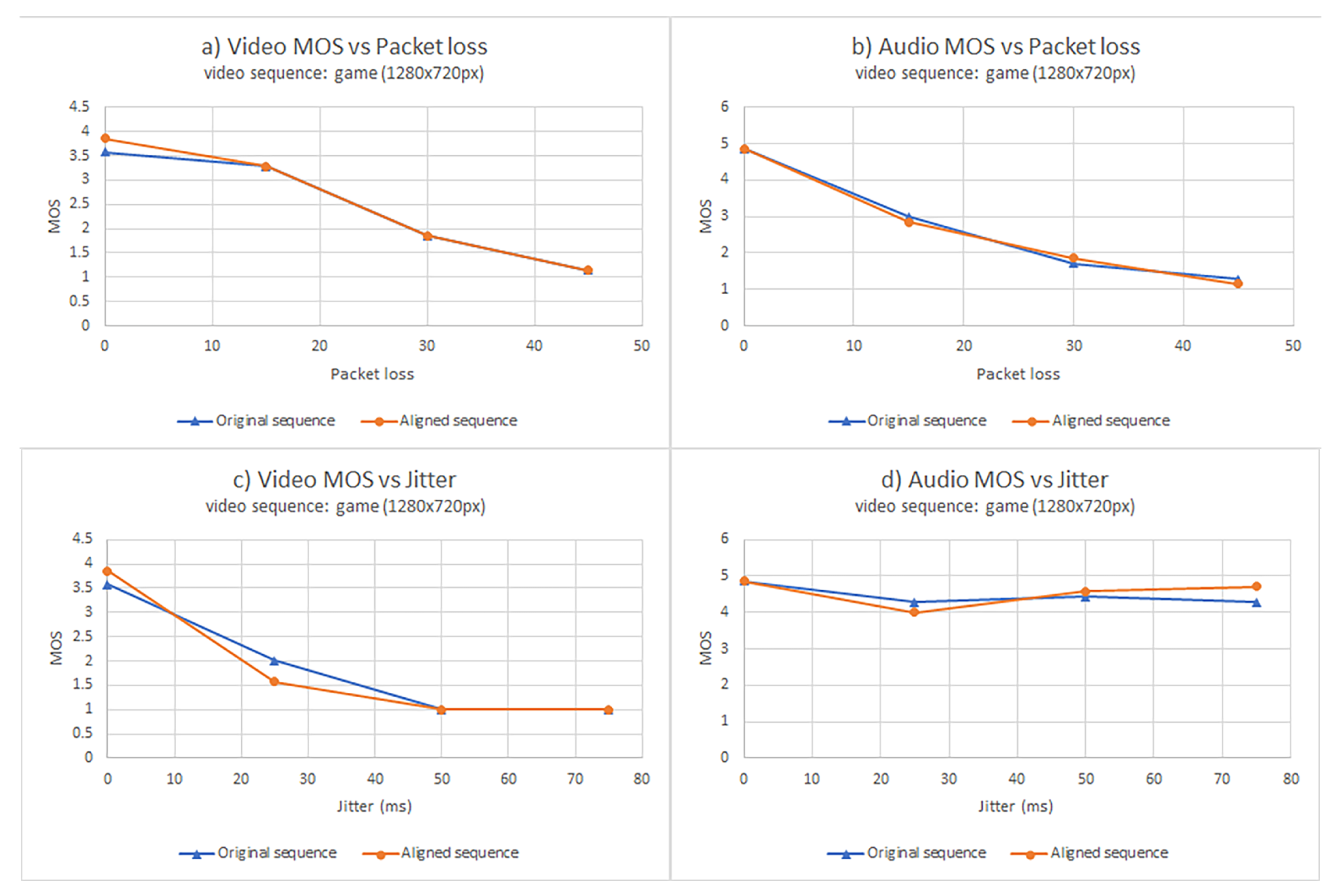
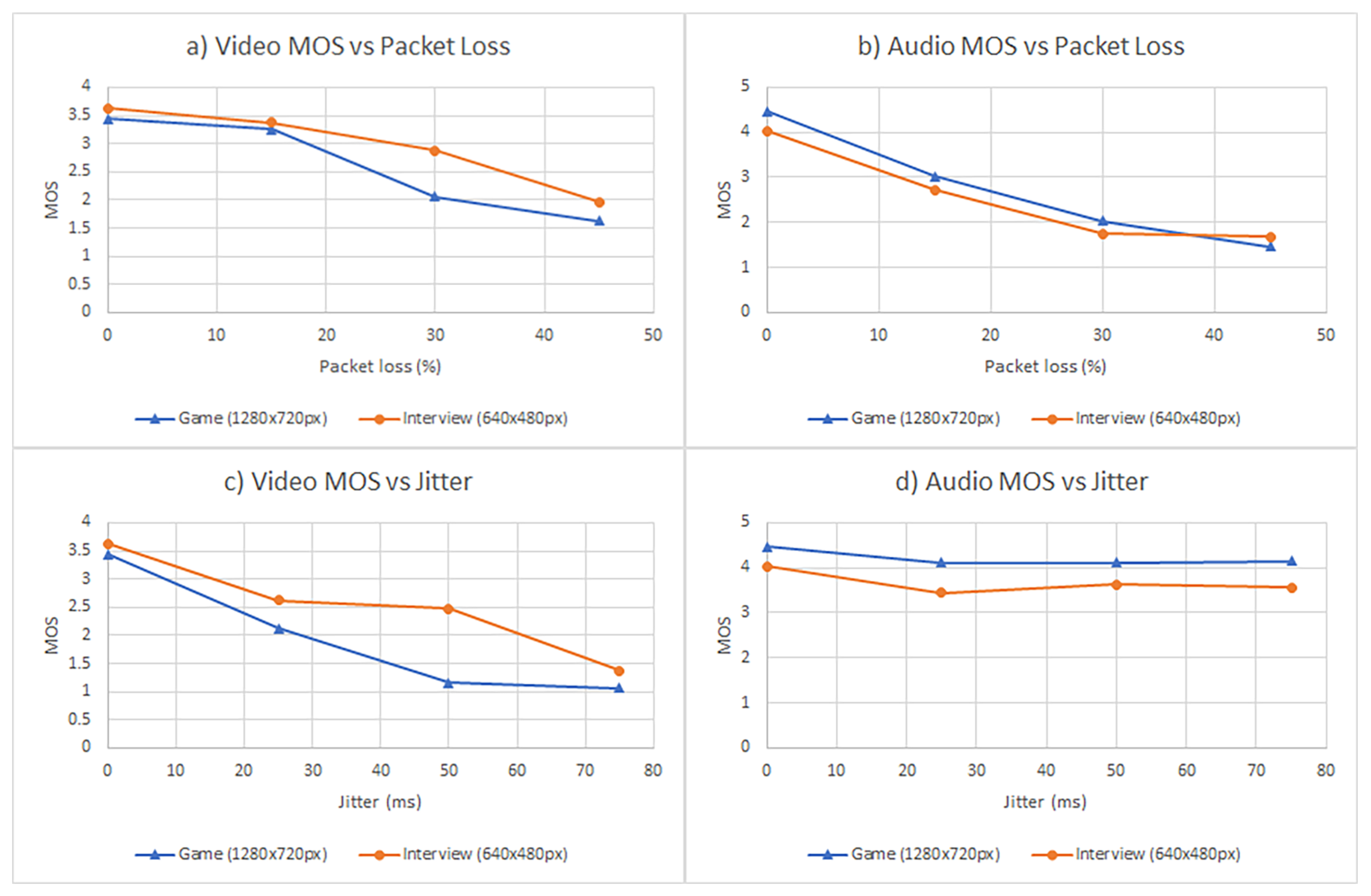
3. Results
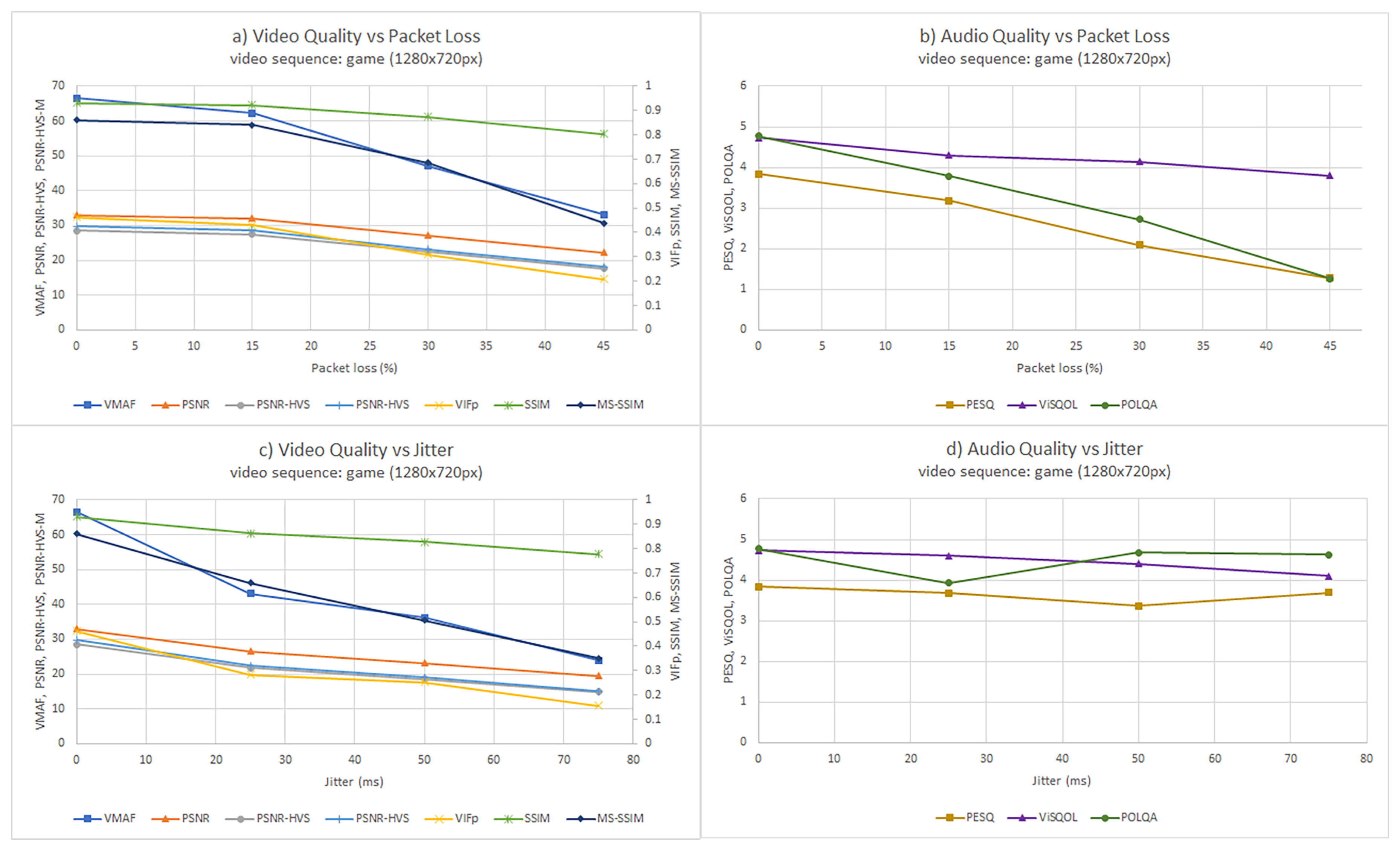
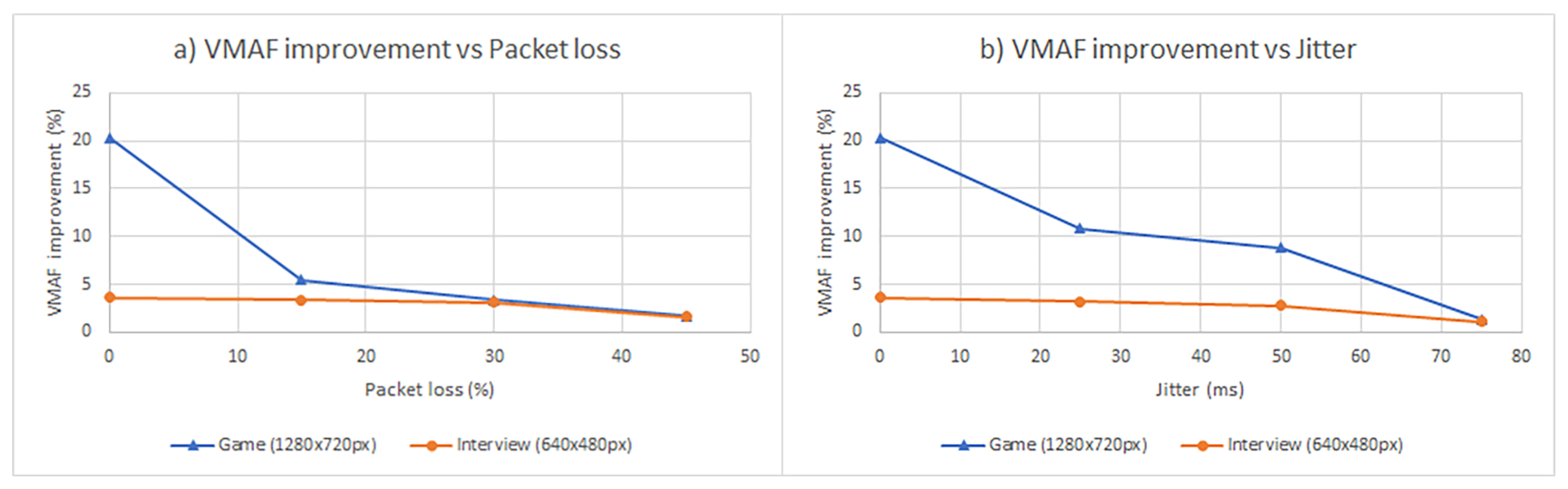
3.1. Objective Analysis
3.2. Subjective Analysis
3.3. Limitations
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- García, B.; Gallego, M.; Gortazar, F.; López, L. ElasTest, an Open-source Platform to Ease End-to-End Testing; Challenges and Opportunities in ICT Research Projects—Volume 1; INSTICC: Setubal, Portugal; SciTePress: Setubal, Portugal, 2017; pp. 3–21. [Google Scholar] [CrossRef]
- Amirante, A.; Castaldi, T.; Miniero, L.; Romano, S.P. On the seamless interaction between WebRTC browsers and SIP-based conferencing systems. IEEE Commun. Mag. 2013, 51, 42–47. [Google Scholar] [CrossRef]
- Grigorik, I. High Performance Browser Networking: What Every Web Developer Should Know about Networking and Web Performance; O’Reilly Media, Inc.: Newton, MA, USA, 2013. [Google Scholar]
- García, B.; Gallego, M.; Gortázar, F.; Bertolino, A. Understanding and estimating quality of experience in WebRTC applications. Computing 2018, 101, 1–23. [Google Scholar] [CrossRef]
- Johnston, A.B.; Burnett, D.C. WebRTC: APIs and RTCWEB Protocols of the HTML5 Real-Time Web; Digital Codex LLC: Lilburn, GA, USA, 2012. [Google Scholar]
- Carlucci, G.; De Cicco, L.; Holmer, S.; Mascolo, S. Analysis and design of the google congestion control for web real-time communication (WebRTC). In Proceedings of the 7th International Conference on Multimedia Systems, Klagenfurt, Austria, 10–13 May 2016; pp. 1–12. [Google Scholar]
- Brunnström, K.; Beker, S.A.; De Moor, K.; Dooms, A.; Egger, S.; Garcia, M.N.; Hossfeld, T.; Jumisko-Pyykkö, S.; Keimel, C.; Larabi, M.C.; et al. Qualinet White Paper on definitions of Quality of Experience. In Proceedings of the Output from the Fifth Qualinet Meeting, Novi Sad, Serbia, 12 March 2013. [Google Scholar]
- Liu, T.J.; Lin, Y.C.; Lin, W.; Kuo, C.C.J. Visual quality assessment: Recent developments, coding applications and future trends. APSIPA Trans. Signal Inf. Process. 2013, 2. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; Volume 3. [Google Scholar]
- Thakur, N.; Devi, S. A new method for color image quality assessment. Int. J. Comput. Appl. 2011, 15, 10–17. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the IEEE Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Karim, S.; He, H.; Junejo, A.; Sattar, M. Measurement of Objective Video Quality in Social Cloud Based on Reference Metric. Wirel. Commun. Mob. Comput. 2020, 2020. [Google Scholar] [CrossRef]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Egiazarian, K.; Astola, J.; Ponomarenko, N.; Lukin, V.; Battisti, F.; Carli, M. New full-reference quality metrics based on HVS. In Proceedings of the Second International Workshop on Video Processing and Quality Metrics, Scottsdale, AZ, USA, 22–24 January 2006; Volume 4. [Google Scholar]
- Ponomarenko, N.; Silvestri, F.; Egiazarian, K.; Carli, M.; Astola, J.; Lukin, V. On between-coefficient contrast masking of DCT basis functions. In Proceedings of the Third International Workshop on Video Processing and Quality Metrics, Scottsdale, AZ, USA, 1–13 January 2007; Volume 4. [Google Scholar]
- Pinson, M.H.; Wolf, S. A new standardized method for objectively measuring video quality. IEEE Trans. Broadcast. 2004, 50, 312–322. [Google Scholar] [CrossRef]
- Rix, A.W.; Hollier, M.P.; Hekstra, A.P.; Beerends, J.G. Perceptual Evaluation of Speech Quality (PESQ) the New ITU Standard for End-to-End Speech Quality Assessment Part I–Time-Delay Compensation. J. Audio Eng. Soc. 2002, 50, 755–764. [Google Scholar]
- Sloan, C.; Harte, N.; Kelly, D.; Kokaram, A.C.; Hines, A. Objective assessment of perceptual audio quality using ViSQOLAudio. IEEE Trans. Broadcas. 2017, 63, 693–705. [Google Scholar] [CrossRef]
- Beerends, J.G.; Schmidmer, C.; Berger, J.; Obermann, M.; Ullmann, R.; Pomy, J.; Keyhl, M. Perceptual objective listening quality assessment (POLQA), the third generation ITU-T standard for end-to-end speech quality measurement part I—Temporal alignment. J. Audio Eng. Soc. 2013, 61, 366–384. [Google Scholar]
- García, B. Mastering Software Testing with JUnit 5: Comprehensive Guide to Develop High Quality Java Applications; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Vucic, D.; Skorin-Kapov, L. QoE evaluation of WebRTC-based Mobile Multiparty Video Calls in Light of Different Video Codec Settings. In Proceedings of the IEEE 15th International Conference on Telecommunications (ConTEL), Graz, Austria, 3–5 July 2019; pp. 1–8. [Google Scholar]
- Vucic, D.; Skorin-Kapov, L. The Impact of Packet Loss and Google Congestion Control on QoE for WebRTC-Based Mobile Multiparty Audiovisual Telemeetings. In Proceedings of the International Conference on Multimedia Modeling, Thessaloniki, Greece, 8–11 January 2019; Springer: Berlin, Germany, 2019; pp. 459–470. [Google Scholar]
- Nunome, T.; Miyazaki, R. The Effect of Contents and Available Viewpoints on QoE of Multi-view Video and Audio over WebRTC. In Proceedings of the IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), New York, NY, USA, 1–3 August 2019; pp. 80–85. [Google Scholar]
- Maehara, Y.; Nunome, T. WebRTC-based multi-view video and audio transmission and its QoE. In Proceedings of the IEEE International Conference on Information Networking (ICOIN), Kuala Lumpur, Malaysia, 9–11 January 2019; pp. 181–186. [Google Scholar]
- Husić, J.B.; Alagić, E.; Baraković, S.; Mrkaja, M. The Influence of Task Complexity and Duration when Testing QoE in WebRTC. In Proceedings of the IEEE 18th International Symposium INFOTEH-JAHORINA (INFOTEH), Jahorina, Bosnia and Herzegovina, 20–22 March 2019; pp. 1–6. [Google Scholar]
- Kilinc, C.; Andersson, K. A congestion avoidance mechanism for WebRTC interactive video sessions in LTE networks. Wirel. Pers. Commun. 2014, 77, 2417–2443. [Google Scholar] [CrossRef][Green Version]
- Muñoz-Gea, J.P.; Aparicio-Pardo, R.; Wehbe, H.; Simon, G.; Nuaymi, L. Optimization framework for uplink video transmission in HetNets. In Proceedings of the Workshop on Mobile Video Delivery, Singapore, 19–21 March 2014; ACM: New York, NY, USA, 2014; p. 6. [Google Scholar]
- Tsiaras, C.; Rösch, M.; Stiller, B. VoIP-based Calibration of the DQX Model. In Proceedings of the IEEE IFIP Networking Conference (IFIP Networking), Toulouse, France, 20–22 May 2015; pp. 1–9. [Google Scholar]
- Vucic, D.; Skorin-Kapov, L. The impact of mobile device factors on QoE for multi-party video conferencing via WebRTC. In Proceedings of the IEEE 13th International Conference on Telecommunications (ConTEL), Graz, Austria, 13–15 July 2015; pp. 1–8. [Google Scholar]
- Boubendir, A.; Bertin, E.; Simoni, N. On-demand, dynamic and at-the-edge VNF deployment model application to Web Real-Time Communications. In Proceedings of the IEEE 12th International Conference on Network and Service Management (CNSM), Las Vegas, NV, USA, 22–26 October 2016; pp. 318–323. [Google Scholar]
- Komperda, O.; Melvin, H.; Počta, P. A black box analysis of WebRTC mouth-to-ear delays. Commun. Sci. Lett. 2016, 18, 3–10. [Google Scholar] [CrossRef]
- Carullo, G.; Tambasco, M.; Di Mauro, M.; Longo, M. A performance evaluation of WebRTC over LTE. In Proceedings of the IEEE 12th Annual Conference on Wireless On-demand Network Systems and Services (WONS), Cortina d’Ampezzo, Italy, 20–22 January 2016; pp. 1–6. [Google Scholar]
- Ammar, D.; De Moor, K.; Xie, M.; Fiedler, M.; Heegaard, P. Video QoE killer and performance statistics in WebRTC-based video communication. In Proceedings of the IEEE Sixth International Conference on Communications and Electronics (ICCE), Antalya, Turkey, 17–20 November 2016; pp. 429–436. [Google Scholar]
- Santos-González, I.; Rivero-García, A.; Molina-Gil, J.; Caballero-Gil, P. Implementation and Analysis of Real-Time Streaming Protocols. Sensors 2017, 17, 846. [Google Scholar] [CrossRef]
- Herrero, R. Integrating HEC with circuit breakers and multipath RTP to improve RTC media quality. Telecommun. Syst. 2017, 64, 211–221. [Google Scholar] [CrossRef]
- Chodorek, R.R.; Chodorek, A.; Rzym, G.; Wajda, K. A comparison of QoS parameters of WebRTC videoconference with conference bridge placed in private and public cloud. In Proceedings of the IEEE 26th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE), Poznan, Poland, 21–23 June 2017; pp. 86–91. [Google Scholar]
- Zhang, L.; Amin, S.O.; Westphal, C. VR video conferencing over named data networks. In Proceedings of the Workshop on Virtual Reality and Augmented Reality Network; ACM: New York, NY, USA, 2017; pp. 7–12. [Google Scholar]
- García, B.; Gortázar, F.; López-Fernández, L.; Gallego, M. WebRTC testing: Challenges and practical solutions. IEEE Commun. Stand. Mag. 2017, 1, 36–42. [Google Scholar] [CrossRef]
- Edan, N.M.; Al-Sherbaz, A.; Turner, S. WebNSM: A novel scalable WebRTC signalling mechanism for many-to-many video conferencing. In Proceedings of the IEEE 3rd International Conference on Collaboration and Internet Computing (CIC), San Jose, CA, USA, 15–17 October 2017; pp. 27–33. [Google Scholar]
- Bandung, Y.; Subekti, L.B.; Tanjung, D.; Chrysostomou, C. QoS analysis for WebRTC videoconference on bandwidth-limited network. In Proceedings of the 20th International Symposium on Wireless Personal Multimedia Communications (WPMC), Bali, Indonesia, 17–20 December 2017; pp. 547–553. [Google Scholar]
- García, B.; López-Fernández, L.; Gortázar, F.; Gallego, M. Practical Evaluation of VMAF Perceptual Video Quality for WebRTC Applications. Electronics 2019, 8, 854. [Google Scholar] [CrossRef]
- Garcia, B.; Lopez-Fernandez, L.; Gallego, M.; Gortazar, F. Kurento: The Swiss army knife of WebRTC media servers. IEEE Commun. Stand. Mag. 2017, 1, 44–51. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, K.; Zhang, Q. From QoS to QoE: A tutorial on video quality assessment. IEEE Commun. Surv. Tutor. 2014, 17, 1126–1165. [Google Scholar] [CrossRef]
- Gouaillard, A.; Roux, L. Real-time communication testing evolution with WebRTC 1.0. Proceedeings of the IEEE Principles, Systems and Applications of IP Telecommunications (IPTComm), Chicago, IL, USA, 25–28 September 2017; pp. 1–8. [Google Scholar]
- Collin, M. Mastering Selenium WebDriver 3.0: Boost the Performance and Reliability of Your Automated Checks by Mastering Selenium WebDriver; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Merkel, D. Docker: Lightweight Linux containers for consistent development and deployment. Linux J. 2014, 2014, 2. [Google Scholar]
- Hemminger, S. Network emulation with NetEm. In Proceedings of the Linux Conference, Canberra, Australia, 18–23 April 2005; pp. 18–23. [Google Scholar]
- Chong, H.M.; Matthews, H.S. Comparative analysis of traditional telephone and voice-over-Internet protocol (VoIP) systems. In Proceedings of the IEEE International Symposium on Electronics and the Environment, 2004. Conference Record, Scottsdale, AZ, USA, 10–13 May 2004; pp. 106–111. [Google Scholar]
- International Telecommunication Union. Recommendation G. 1030. Estimating End-to-End Performance in IP Networks for Data Applications; International Telecommunication Union: Geneva, Switzerland, 2005; Volume 42. [Google Scholar]
- International Telecommunication Union. Recommendation BT.500-11. Methodology for the Subjective Assessment of the Quality of Television Pictures; International Telecommunication Union: Geneva, Switzerland, 2002. [Google Scholar]
- Li, Z.; Aaron, A.; Katsavounidis, I.; Moorthy, A.; Manohara, M. Toward a practical perceptual video quality metric. The Netflix Tech Blog, 6 June 2016. [Google Scholar]
- Alvarez, A.; Cabrero, S.; Pañeda, X.G.; Garcia, R.; Melendi, D.; Orea, R. A flexible QoE framework for video streaming services. In Proceedings of the IEEE GLOBECOM Workshops (GC Wkshps), Houston, TX, USA, 5–9 December 2011; pp. 1226–1230. [Google Scholar]
- Hines, A.; Skoglund, J.; Kokaram, A.C.; Harte, N. ViSQOL: An objective speech quality model. EURASIP J. Audio Speech Music Process. 2015, 2015, 1–18. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Berlin, Germany, 2009; pp. 1–4. [Google Scholar]
- Amrhein, V.; Greenland, S.; McShane, B. Scientists rise up against statistical significance. Nature 2019. [Google Scholar] [CrossRef]
- Wasserstein, R.L.; Schirm, A.L.; Lazar, N.A. Moving to a world beyond “p < 0.05”. Am. Stat. 2019. [Google Scholar] [CrossRef]
- Počta, P.; Melvin, H.; Hines, A. An analysis of the impact of playout delay adjustments introduced by voip jitter buffers on listening speech quality. Acta Acust. United Acust. 2015, 101, 616–631. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | FR Model | Description |
|---|---|---|
| Video | VMAF (Video Multi-Method Assessment Fusion) | Perceptual video quality assessment algorithm developed by Netflix, combining human vision modeling with machine learning [8] |
| VIF (Visual Information Fidelity) | Image assessment method based on the characteristics of the Human Visual System (HVS) [9]. There are some variants, such VIFp (VIF in the pixel domain) [10]. | |
| SSIM (Structural Similarity) | It measures the difference of structure between some original and impairment image in terms of luminance, contrast, and structure [11]. There are several models derived from SSIM, for example, MS-SSIM (Multi-Scale SSIM), conducted over multiples scales of subsampling [12]. | |
| MSE (Mean Squared Error) | It is a straightforward metric to compute differences between two video signals [13]. | |
| PSNR (Peak Signal-to-Noise Ratio) | It is the proportion between the maximum signal and the impairment noise [14]. PSNR has several variants, such as PSNR-HVS (extension of PSNR using properties of the HVS) [15] or PSNR-HVS-M (improvement of PSNR-HVS using visual masking) [16]. | |
| Video Quality Metric (VQM) | Linear combination of several impairment parameters [17] | |
| Audio | PESQ (Perceptual Evaluation of Speech Quality) | It is an audio quality assessment model standardized as the ITU-T recommendation P.862 [18] |
| ViSQOL (Virtual Speech Quality Objective Listener) | FR model for audio quality assessment modeling the human speech quality perception using a spectro-temporal measure of similarity [19] | |
| POLQA (Perceptual Objective Listening Quality Analysis) | The successor of PESQ, standardized as the ITU-T recommendation P.863 [20] |
| Ref. | Title | Assessment Type |
|---|---|---|
| [27] | A congestion avoidance mechanism for WebRTC interactive video sessions in LTE networks | QoS: Packet delay, end-to-end delay, bandwidth, throughput, packet loss, jitter, bitrate |
| [28] | Optimization framework for uplink video transmission in HetNets | Objective QoE (VQM) |
| [29] | VoIP-based calibration of the DQX model | QoS: Jitter, latency, packet loss, bandwidth. Subjective QoE (MOS) |
| [30] | The impact of mobile device factors on QoE for multi-party video conferencing via WebRTC | Subjective QoE (MOS) |
| [31] | On-demand, dynamic, and at-the-edge VNF deployment model application to web real-time communications | QoS: Call setup time, end-to-end delay, jitter |
| [32] | A black box analysis of WebRTC mouth-to-ear delays | QoS: End-to-end delay, bitrate, jitter |
| [33] | A performance evaluation of WebRTC over LTE | QoS: Throughput, jitter, packet loss |
| [34] | Video QoE killer and performance statistics in WebRTC-based video communication | QoS: Throughput, bandwidth, packet loss, bitrate, picture loss indication, bucket delay. Subjective QoE |
| [35] | Implementation and analysis of real-time streaming protocols | QoS: Call setup time, end-to-end delay |
| [36] | Integrating HEC with circuit breakers and multipath RTP to improve RTC media quality | Objective QoE (PESQ and PEVQ) |
| [37] | A comparison of QoS parameters of WebRTC video conference with conference bridge placed in private and public cloud | QoS: Throughput, end-to-end delay, error rate |
| [38] | VR video conferencing over named data networks | QoS: End-to-end delay |
| [39] | WebRTC testing: Challenges and practical solutions | QoS: End-to-end delay. Objective QoE (PESQ, SSIM, and PSNR) |
| [40] | WebNSM: A novel scalable WebRTC signalling mechanism for many-to-many video conferencing | QoS: Bandwidth. Subjective QoE |
| [41] | QoS analysis for WebRTC video conference on bandwidth-limited network | QoS: Bandwidth, jitter, bitrate, frame rate, packet rate, packet loss, latency, packet delay |
| MOS | ||||
|---|---|---|---|---|
| Interview with Packet Loss | Interview with Jitter | Game with Packet Loss | Game with Jitter | |
| VMAF | r = 0.991 | r = 0.938 | r = 0.983 | r = 0.966 |
| p = 0.009 | p = 0.062 | p = 0.017 | p = 0.034 | |
| VIFp | r = 0.992 | r = 0.954 | r = 0.987 | r = 0.953 |
| p = 0.010 | p = 0.046 | p = 0.013 | p = 0.047 | |
| SSIM | r = 0.981 | r = 0.952 | r = 0.951 | r = 0.957 |
| p = 0.007 | p = 0.048 | p = 0.049 | p = 0.043 | |
| MS-SSIM | r = 0.998 | r = 0.925 | r = 0.943 | r = 0.962 |
| p = 0.006 | p = 0.075 | p = 0.057 | p = 0.038 | |
| PSNR | r = 0.988 | r = 0.946 | r = 0.977 | r = 0.974 |
| p = 0.012 | p = 0.054 | p = 0.023 | p = 0.026 | |
| PSNR-HVS | r = 0.987 | r = 0.951 | r = 0.979 | r = 0.975 |
| p = 0.013 | p = 0.049 | p = 0.021 | p = 0.025 | |
| PSNR-HVS-M | r = 0.987 | r = 0.953 | r = 0.980 | r = 0.976 |
| p = 0.013 | p = 0.047 | p = 0.020 | p = 0.024 | |
| PESQ | r = 0.989 | r = 0.445 | r = 0.970 | r = 0.671 |
| p = 0.006 | p = 0.555 | p = 0.030 | p = 0.329 | |
| ViSQOL | r = 0.973 | r = −0.160 | r = 0.981 | r = 0.602 |
| p = 0.027 | p = 0.840 | p = 0.019 | p = 0.398 | |
| POLQA | r = 0.993 | r = 0.227 | r = 0.959 | r = 0.500 |
| p = 0.007 | p = 0.773 | p = 0.041 | p = 0.500 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
García, B.; Gortázar, F.; Gallego, M.; Hines, A. Assessment of QoE for Video and Audio in WebRTC Applications Using Full-Reference Models. Electronics 2020, 9, 462. https://doi.org/10.3390/electronics9030462
García B, Gortázar F, Gallego M, Hines A. Assessment of QoE for Video and Audio in WebRTC Applications Using Full-Reference Models. Electronics. 2020; 9(3):462. https://doi.org/10.3390/electronics9030462
Chicago/Turabian StyleGarcía, Boni, Francisco Gortázar, Micael Gallego, and Andrew Hines. 2020. "Assessment of QoE for Video and Audio in WebRTC Applications Using Full-Reference Models" Electronics 9, no. 3: 462. https://doi.org/10.3390/electronics9030462
APA StyleGarcía, B., Gortázar, F., Gallego, M., & Hines, A. (2020). Assessment of QoE for Video and Audio in WebRTC Applications Using Full-Reference Models. Electronics, 9(3), 462. https://doi.org/10.3390/electronics9030462