Towards Near-Real-Time Intrusion Detection for IoT Devices using Supervised Learning and Apache Spark


Abstract
1. Introduction
- -
- to value the performances of several machine learning algorithms in identifying SYN-DOS attacks to IoT systems in a Cloud environment, both in terms of application performances, and in training/application times. Namely, we use several general-purpose machine learning algorithms included in the MLlib library of Apache Spark [22], one of the most interesting and used technologies in the big data field, available with an open source license and present in the cloud computing facilities of the main world players [23].
- -
- by using the previous results, to propose a strategy for the sustainable implementation of machine learning algorithms for the detection of SYN-DOS cyber-attacks on IOT devices. Our purpose is to create a hybrid architecture that realizes the training of machine learning models for protecting against DDOS attacks on the cloud and the application of the obtained models directly on the IOT devices.
2. Materials and Methods
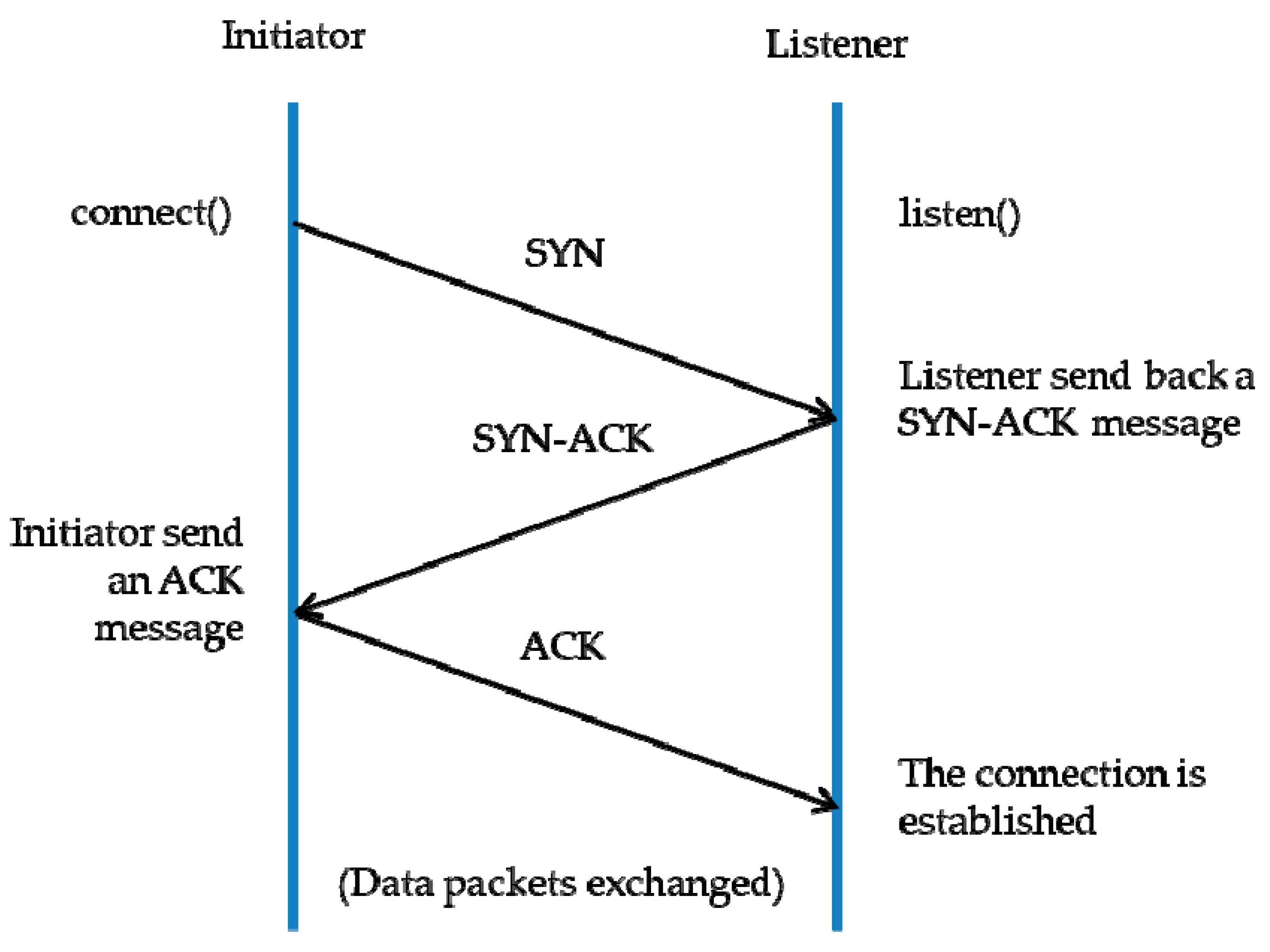
2.1. Brief Description of a SYN-DOS Attack
- Client requests connection by sending SYN (synchronize) message to the server.
- Server acknowledges by sending SYN-ACK (synchronize-acknowledge) message back to the client.
- Client responds with an ACK (acknowledge) message, and the connection is established.
2.2. Attack Data
2.3. Apache Spark
2.4. Machine learning algorithms
3. Experiments and Results
3.1. Execution Environment
- 8 cores (shared)
- 6 GB RAM
- Apache Spark 2.4.0, Scala 2.11
3.2. Datasets
3.3. Evaluation Parameters
- (1)
- The Accuracy on the testing set (ACC):where TP (True Positive) is the number of malicious packets correctly identified, TN (True Negative) is the number of normal instances correctly identified, FP (False Positive) are normal instances incorrectly identified, FN (False Negative) is the number of undetected malicious packets.ACC = (TP + TN)/(P + N) = (TP + TN)/(TP + TN + FP + FN)
- (2)
- The Error Rate on the testing set (ERR):ERR = 1 − ACC
- (3)
- The Total number of errors on the testing set.
- (4)
- The Training time, i.e., the time in seconds required to train each machine learning method (Logistic Regression (LR); Decision Tree (DT); Random Forest (RF); Linear Support Vector Machine (SVM); Gradient Boosted Tree (GBT])) in the selected execution environment (3.1).
- (5)
- The application time, in seconds, of the rule/solution obtained from each method on the testing set in the selected execution environment (see Section 3.1).
3.4. Classification Performance Evaluation
3.5. Results
3.6. Hybrid Architecture
4. Discussion
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Lee, I.; Lee, K. The Internet of Things (IoT): Applications, investments, and challenges for enterprises. Bus. Horizons 2015, 58, 431–440. [Google Scholar] [CrossRef]
- Gartner Says the Internet of Things Will Transform the Data Center. Available online: https://www.gartner.com/en/newsroom/press-releases/2014-05-01-gartner-says-iot-security-requirements-will-reshape-and-expand-over-half-of-global-enterprise-it-security-programs-by-2020 (accessed on 19 December 2019).
- Internet of Things (Iot) Connected Devices Installed Base Worldwide From 2015 to 2025 (In Billions). Available online: https://www.statista.com/statistics/471264/iot-number-of-connected-devices-worldwide/ (accessed on 19 December 2019).
- Liu, G.; Jiang, D. 5G: Vision and Requirements for Mobile Communication System towards Year 2020. Chin. J. Eng. 2016, 2016, 5974586. [Google Scholar] [CrossRef]
- HP Study Reveals 70 Percent of Internet of Things Devices Vulnerable to Attack. Available online: http://www8.hp.com/us/en/hp-news/press-release.html?id=1744676#.VOTykPnF-ok (accessed on 10 November 2019).
- Radanliev, P.; De Roure, C.; Cannady, S.; Montalvo, R.M.; Nicolescu, R.; Huth, M. Economic impact of IoT cyber risk-analysing past and present to predict the future developments in IoT risk analysis and IoT cyber insurance. In Living in the Internet of Things: Cybersecurity of the IoT; Institution of Engineering and Technology: London, UK, 2018. [Google Scholar] [CrossRef]
- Irdeto Global Connected Industries Cybersecurity Survey-Full Report. Available online: https://go.irdeto.com/thank-you-download-connected-industries-survey-report/ (accessed on 10 November 2019).
- Gartner Says Worldwide IoT Security Spending Will Reach $1.5 Billion in 2018. Available online: https://www.gartner.com/en/newsroom/press-releases/2018-03-21-gartner-says-worldwide-iot-security-spending-will-reach-1-point-5-billion-in-2018 (accessed on 13 September 2019).
- Cisco Cybersecurity Reports. 2018. Available online: https://www.cisco.com/c/en/us/products/security/security-reports.html (accessed on 24 August 2019).
- Defenses Against TCP SYN Flooding Attacks-The Internet Protocol Journal-Volume 9, Number 4. Available online: https://www.cisco.com/c/en/us/about/press/internet-protocol-journal/back-issues/table-contents-34/syn-flooding-attacks.html (accessed on 24 August 2019).
- Ngo, D.-M.; Pham-Quoc, C.; Thinh, T.N. An Efficient High-Throughput and Low-Latency SYN Flood Defender for High-Speed Networks. Secur. Commun. Networks 2018, 2018, 9562801. [Google Scholar] [CrossRef]
- García-Teodoro, P.; Diaz-Verdejo, J.; Maciá-Fernández, G.; Vázquez, E. Anomaly-based network intrusion detection: Techniques, systems and challenges. Comput. Secur. 2009, 28, 18–28. [Google Scholar] [CrossRef]
- Harjinder, K.; Gurpreet, S.; Jaspreet, M. A review of machine learning based anomaly detection techniques. arXiv 2013, arXiv:1307.7286. [Google Scholar]
- Buczak, A.L.; Guven, E. A Survey of Data Mining and Machine Learning Methods for Cyber Security Intrusion Detection. IEEE Commun. Surv. Tutor. 2015, 18, 1153–1176. [Google Scholar] [CrossRef]
- Xiao, L.; Wan, X.; Lu, X.; Zhang, Y.; Wu, D. IoT Security Techniques Based on Machine Learning: How Do IoT Devices Use AI to Enhance Security? IEEE Signal Process. Mag. 2018, 35, 41–49. [Google Scholar] [CrossRef]
- Machaka, P.; Nelwamondo, F. Data mining techniques for distributed denial of service attacks detection in the internet of things: A research survey. In Securing the Internet of Things: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2020; pp. 561–608. [Google Scholar]
- Nooribakhsh, M.; MollaMotalebi, M. A review on statistical approaches for anomaly detection in DDoS attacks. Inf. Secur. J. 2020, 29, 118–133. [Google Scholar] [CrossRef]
- D’Angelo, G.; Palmieri, F.; Ficco, M.; Rampone, S. An uncertainty-managing batch relevance-based approach to network anomaly detection. Appl. Soft Comput. 2015, 36, 408–418. [Google Scholar] [CrossRef]
- Rampone, S.; Russo, C. A fuzzified BRAIN algorithm for learning DNF from incomplete data. Electron. J. Appl. Stat. Anal. (EJASA) 2012, 5, 256–270. [Google Scholar]
- Hasan, M.; Islam, M.M.; Zarif, M.I.I.; Hashem, M.M.A. Attack and anomaly detection in IoT sensors in IoT sites using machine learning approaches. Internet Things 2019, 7. [Google Scholar] [CrossRef]
- L’Heureux, A.; Grolinger, K.; Elyamany, H.F.; Capretz, M.A.M. Machine learning With Big Data: Challenges and approaches. IEEE Access 2017, 5, 7776–7797. [Google Scholar] [CrossRef]
- Apache Spark Home Page. Available online: http://spark.apache.org/ (accessed on 13 December 2019).
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Ghodsi, A. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Chang, T.Y.; Hsieh, C.J. Detection and Analysis of Distributed Denial-of-service in Internet of Things—Employing Artificial Neural Network and Apache Spark Platform. Sens. Mater. 2018, 30, 857–867. [Google Scholar]
- Pallaprolu, S.C.; Sankineni, R.; Thevar, M.; Karabatis, G.; Wang, J. Zero-day attack identification in streaming data using semantics and Spark. In Proceedings of the 2017 IEEE International Congress on Big Data (BigData Congress), Honolulu, HI, USA, 25–30 June 2017; pp. 121–128. [Google Scholar]
- Gupta, G.P.; Kulariya, M. A Framework for Fast and Efficient Cyber Security Network Intrusion Detection Using Apache Spark. Procedia Comput. Sci. 2016, 93, 824–831. [Google Scholar] [CrossRef]
- Hafsa, M.; Jemili, F. Comparative Study between Big Data Analysis Techniques in Intrusion Detection. Big Data Cogn. Comput. 2018, 3, 1. [Google Scholar] [CrossRef]
- Manzoor, M.A.; Morgan, Y. Real-time support vector machine based network intrusion detection system using Apache Storm. In Proceedings of the 2016 IEEE 7th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 13–15 October 2016; pp. 1–5. [Google Scholar]
- Abusitta, A.; Bellaiche, M.; Dagenais, M.; Halabi, T. A deep learning approach for proactive multi-cloud cooperative intrusion detection system. Futur. Gener. Comput. Syst. 2019, 98, 308–318. [Google Scholar] [CrossRef]
- Mirsky, Y.; Doitshman, T.; Elovici, Y.; Shabtai, A. Kitsune: An Ensemble of Autoencoders for Online Network Intrusion Detection. arXiv 2018, arXiv:1802.09089. [Google Scholar]
- What is a SYN Flood Attack. Available online: https://www.imperva.com/learn/application-security/syn-flood/ (accessed on 24 August 2019).
- Karau, H.; Warren, R. High Performance Spark: Best Practices for Scaling and Optimizing Apache Spark, 1st ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017; pp. 10–19. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Safavian, S.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Scholkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Friedman, H.J. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Chambers, B.; Zaharia, M. Spark: The Definitive Guide: Big Data Processing Made Simple; O’Reilly Media, Inc.: New York, NY, USA, 2018. [Google Scholar]
- Apache Spark, Classification and Regression. Available online: https://spark.apache.org/docs/latest/ml-classification-regression.html (accessed on 22 February 2019).
- Apache Spark, Decision Tree. Available online: https://spark.apache.org/docs/latest/mllib-decision-tree.html (accessed on 22 February 2019).
- Apache Spark, Ensembles-RDD-based API. Available online: https://spark.apache.org/docs/latest/mllib-ensembles.html (accessed on 22 February 2019).
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; pp. 417–421. [Google Scholar]
- Apache Spark, MLlib-Linear Methods. Available online: https://spark.apache.org/docs/1.0.0/mllib-linear-methods.html (accessed on 22 February 2019).
- Databricks Home Page. Available online: https://databricks.com/ (accessed on 18 December 2019).
- Yahalom, R.; Steren, A.; Nameri, Y.; Roytman, M. Small versions of the extracted features datasets for 9 attacks on IP camera and IoT networks generated by Mirskey et al. (2018). Mendeley Data v1 2018. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning, 1st ed.; McGraw-Hill, Inc.: New York, NY, USA, 1997. [Google Scholar]
- Apache Spark, ML Tuning: Model Selection and Hyperparameter Tuning. Available online: https://spark.apache.org/docs/latest/ml-tuning.html (accessed on 22 February 2019).
- Othman, S.M.; Ba-Alwi, F.M.; Alsohybe, N.T.; Al-Hashida, A.Y. Intrusion detection model using machine learning algorithm on Big Data environment. J. Big Data 2018, 5, 34. [Google Scholar] [CrossRef]
- Belouch, M.; El Hadaj, S.; Idhammad, M. Performance evaluation of intrusion detection based on machine learning using Apache Spark. Procedia Comput. Sci. 2018, 127, 1–6. [Google Scholar] [CrossRef]
- Key Trends from the Iot Developer Survey. 2018. Available online: https://blog.benjamin-cabe.com/2018/04/17/key-trends-iot-developer-survey-2018 (accessed on 20 February 2019).




{kind=link}
{kind=link}
{kind=link}
| Dataset name | Dim (Gbyte) | Training Instances | Testing Instances | Total Instances | Normal/Malicious Instances |
|---|---|---|---|---|---|
| SYNDOS10K | 0.0317 | 7698 | 3302 | 11,000 | 10,000/1000 |
| SYNDOS100K | 0.266 | 67,871 | 29,167 | 97,038 | 90,000/7038 |
| SYNDOS300K | 0.825 | 210,245 | 89,793 | 300,038 | 293,000/7038 |
| SYNDOS1M | 2.68 | 700,192 | 299,846 | 1,000,038 | 993,000/7038 |
| SYNDOS2M | 5.39 | 1,405,057 | 601,981 | 2,007,038 | 2,000,000/7038 |
| ACC | |||||
|---|---|---|---|---|---|
| Dataset | LR | DT | RF | GBT | SVM |
| SYNDOS10K | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| SYNDOS100K | 1.0000 | 0.9998 | 1.0000 | 1.0000 | 0.9999 |
| SYNDOS300K | 1.0000 | 1.0000 | 1.0000 | 0.9999 | 0.9800 |
| SYNDO1M | 0.9999 | 0.9999 | 1.0000 | 0.9999 | 0.9945 |
| SYNDOS2M | 0.9973 | 0.9999 | 1.0000 | 0.9999 | 0.9999 |
| ERR | |||||
|---|---|---|---|---|---|
| Dataset | LR | DT | RF | GBT | SVM |
| SYNDOS10K | 0 | 0 | 0 | 0 | 0 |
| SYNDOS100K | 0 | 0.0002 | 0 | 0 | 0.0001 |
| SYNDOS300K | 0 | 0 | 0 | 0.0001 | 0.0200 |
| SYNDO1M | 0.0001 | 0.0001 | 0 | 0.0001 | 0.0055 |
| SYNDOS2M | 0.0027 | 0.0001 | 0 | 0.0001 | 0.0001 |
| TOTAL ERRORS | |||||
|---|---|---|---|---|---|
| Dataset | LR | DT | RF | GBT | SVM |
| SYNDOS10K | 0 | 0 | 0 | 0 | 0 |
| SYNDOS100K | 0 | 4 | 0 | 0 | 1 |
| SYNDOS300K | 0 | 0 | 0 | 2 | 1635 |
| SYNDO1M | 1540 | 2 | 0 | 1 | 1646 |
| SYNDOS2M | 1601 | 3 | 0 | 1 | 1655 |
| TRAINING TIME | |||||
|---|---|---|---|---|---|
| Dataset | LR | DT | RF | GBT | SVM |
| SYNDOS10K | 6.54 | 1.65 | 2.31 | 23.34 | 4.41 |
| SYNDOS100K | 8.09 | 2.65 | 10.27 | 29.15 | 72.46 |
| SYNDOS300K | 20.10 | 8.07 | 30.45 | 41.96 | 179.83 |
| SYNDO1M | 94.66 | 10.57 | 92.88 | 144.83 | 705.54 |
| SYNDOS2M | 118.64 | 23.22 | 215.82 | 212.76 | 1412.29 |
| APPLICATION TIME | |||||
|---|---|---|---|---|---|
| Dataset | LR | DT | RF | GBT | SVM |
| SYNDOS10K | 0.05 | 0.09 | 0.10 | 0.09 | 0.09 |
| SYNDOS100K | 0.05 | 0.09 | 0.10 | 0.09 | 0.09 |
| SYNDOS300K | 0.06 | 0.11 | 0.11 | 0.09 | 0.10 |
| SYNDO1M | 0.06 | 0.11 | 0.11 | 0.11 | 0.13 |
| SYNDOS2M | 0.06 | 0.12 | 0.13 | 0.14 | 0.14 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morfino, V.; Rampone, S. Towards Near-Real-Time Intrusion Detection for IoT Devices using Supervised Learning and Apache Spark. Electronics 2020, 9, 444. https://doi.org/10.3390/electronics9030444
Morfino V, Rampone S. Towards Near-Real-Time Intrusion Detection for IoT Devices using Supervised Learning and Apache Spark. Electronics. 2020; 9(3):444. https://doi.org/10.3390/electronics9030444
Chicago/Turabian StyleMorfino, Valerio, and Salvatore Rampone. 2020. "Towards Near-Real-Time Intrusion Detection for IoT Devices using Supervised Learning and Apache Spark" Electronics 9, no. 3: 444. https://doi.org/10.3390/electronics9030444
APA StyleMorfino, V., & Rampone, S. (2020). Towards Near-Real-Time Intrusion Detection for IoT Devices using Supervised Learning and Apache Spark. Electronics, 9(3), 444. https://doi.org/10.3390/electronics9030444