1. Introduction
Entering the Fourth Industrial Revolution era in recent years, researchers are conducting various studies with core technologies of the Fourth Industrial Revolution, including big data, artificial intelligence, and the Internet of Things, across a range of various fields [
1,
2].
Ref. [
3] proposed an idea of increasing the reliability of the agriculture journal by saving the data of product conditions and controlled environments automatically and entering the multimedia data of products. It consisted of soil sensors for the cultivation plot, internal and external sensors for the cultivation field, a database of cultivation environments, a middle layer encompassing videos, sensors, and server management, and a management layer providing users with a Graphical User Interface(GUI). A farming journal was designed to record pests and diseases predictions as well as general work and check the data inserted in videos, voices, texts, and images. Ref. [
4] proposed a system to manage and monitor the growth and development environment of a crop to increase its yield. The proposed monitoring system used sensors to check the states of crops and control their environment artificially. Related environmental sensors proposed in the study covered EC, pH, temperature, humidity, intensity of illumination, and CO
2. The sensor nodes were mostly in a streamlined shape, and the system was in the RS485 format. The ZigBee-based USN technology was applied for wireless arrangement. The control system encompassed crop cultivation, environments, nutrient solutions, and light sources. Data collected from sensors and sink nodes was transmitted to the server of a local gate to monitor the states of crops in real time. An independent gateway was set to monitor and control sensors and energy. Ref. [
5] analyzed problems with the management of an Acer mono sap system and proposed an improved system. It proposed a module to evaluate the areas of collection by managing Acer mono and its sap collectors and introducing a database, GIS system, and practical Acer mono sap management system with built-in user interface for convenience. The proposed system comprised of a sap collection management model, analysis model of cost and profit for sap production, and assessment model in the area of sap collection. The sap collection management model covered all the information needed to manage Acer mono trees and their collectors. The cost and profit analysis model for the production of Acer mono sap analyzed costs needed to produce sap and profit from the sap. The assessment model for the collection zones of Acer mono sap classified upper, middle and lower groups according to sap production and management conditions. Ref. [
6] proposed a U-IT-based farm management system to manage producing areas and forest products. It proposed an IoT-based water supply system to promote the growth of forest products. A total detection system with radar sensors measured temperature, humidity, and wind direction. A database was proposed to analyze the growth and development environment based on information collected from the monitoring system connected to all the sensors and management system.
Active research has been carried out on various monitoring systems combined with the ubiquitous computer paradigm that was in the spotlight between the early and late 2000s. Entering the mid 2010s, big data emerged with great importance. Research is underway on the fusion of agriculture and state-of-the-art IT in the era of the Fourth Industrial Revolution. Today, the Republic of Korea faces a problem of sharp population decline. In agricultural areas, they have a difficult time securing labor force due to population aging as well as population decline, unlike in urban areas. These issues are found in the field of forestry as well as agriculture. In the field of forestry, research efforts have been concentrated mainly on the monitoring systems to prevent risks, including fires, forest disasters such as pests and diseases, and climate changes. To overcome these issues, the present study focused on an integrated monitoring system to combine data and analysis monitoring beyond a simple monitoring system. The integrated monitoring system encompasses control monitoring to reduce labor force and prediction monitoring for production timing and outputs as well as prevention of risks. In the field of forestry, the government-led smart forestry projects are attracting huge attention by incorporating technologies of the Fourth Industrial Revolution [
7,
8]. The most important goal in the fusion of agriculture and the Fourth Industrial Revolution is to increase outputs [
9,
10]. Timely measures are needed throughout the process from seed planting to harvesting to increase outputs, but most farming today is done based on an accumulation of experiences rather than quantitative data. In other words, farmers depend on their know-how and accordingly have a difficult time figuring out the exact causes of failure in farming. Of all agricultural products, forest products are cultivated in deep mountains or alpine zones, in most cases. Such extreme geographical conditions make it difficult to apply forest products to smart forestry. Acer mono sap is collected from February, when it starts to get warmer, to April. It is difficult to collect data influencing Acer mono sap outputs due to the conditions mentioned before. In previous studies on connections between Acer mono sap outputs and environmental information, data were collected with manual measurements, which means that such data lacked both reliability and size for analysis. Attempts were made to solve these problems, including lead storage batteries and data loggers. These approaches to big data collection, however, would not record data in extreme mid-winter weather when batteries would be drained earlier than the calculations [
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25]. There are many limitations with equipment installed in alpine zones to collect accurate data. Recent climate changes are also adding more unusual local weather events. In its AIB scenario, the National Institute of Meteorological Research anticipates that temperatures will rise by 4 °C across the Korean Peninsula in the end of the 22nd century and starting from the end of the 21st century and that daily lows will rise more than daily highs with the annual range dropping by 1.7 °C. It is also predicted that precipitation will increase by 17% across all the regions of the peninsula. Such weather changes will likely have enormous impacts on agriculture and forestry on the peninsula. Forest products with the most unfavorable cultivation conditions will be the most vulnerable to such weather changes. If it is feasible to obtain accurate information about the supporting capacity of production-based elements and the major factors of cultivation management to reinforce the productive competitive edge of forest products, it will be possible to predict outputs according to the major cultivation conditions of trees in forestry, including changing weather conditions and unusual weather events based on the alteration of statistical outputs. In the Republic of Korea, Acer mono is an important tree species to collect sap from. Acer mono is a broadleaf tree in the family of Aceraceae and called the maple tree in North America. In the Republic of Korea, major producing areas of Acer mono sap include Inje, Gwangyang, and Sancheong that are usually in alpine zones 500 m above sea level. Given the characteristics of Acer mono found in rugged mountains where its management is difficult, the work of managing the tree species and collecting its sap require substantial labor force and is accompanied by accident risk. Despite its unfavorable conditions, however, Acer mono sap holds a big part in farmers’ income in the Jeonnam region and is managed for research purposes. The old management system, however, demands that people should check and record Acer mono sap exudation in person, thus having a couple of disadvantages, including the inaccuracy of recorded information and difficulty with the efficient use of the information. And various fields have conducted research on energy collection with various new renewable energy sources including thermal, piezoelectric and vibration with regard to energy harvesting. In recent years, IoT and various devices require energy supply and raise a need for energy self-sufficient IoT devices capable of self-supply of energy. Research is underway on energy collection devices combined with IoT devices [
1,
2,
7]. Forest products in deep mountains or alpine zones pose many limits due to their extreme geographical conditions. For data analysis, data should be collected in such alpine zones where there is no smooth supply of electricity. When batteries are used, they are drained quickly due to low temperature, which make it difficult to collect data normally. These problems can be solved with a self-sufficient supply of energy in big data collection devices.
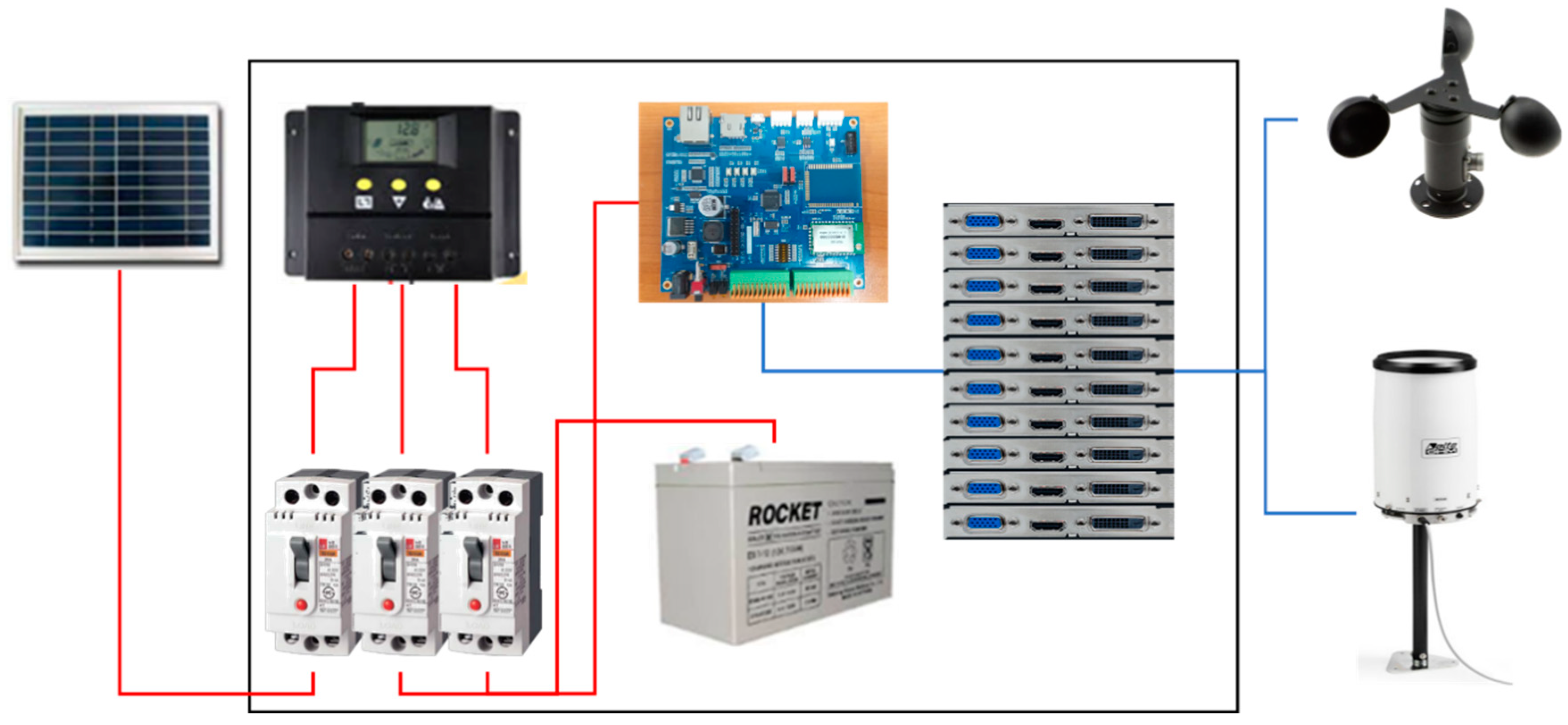
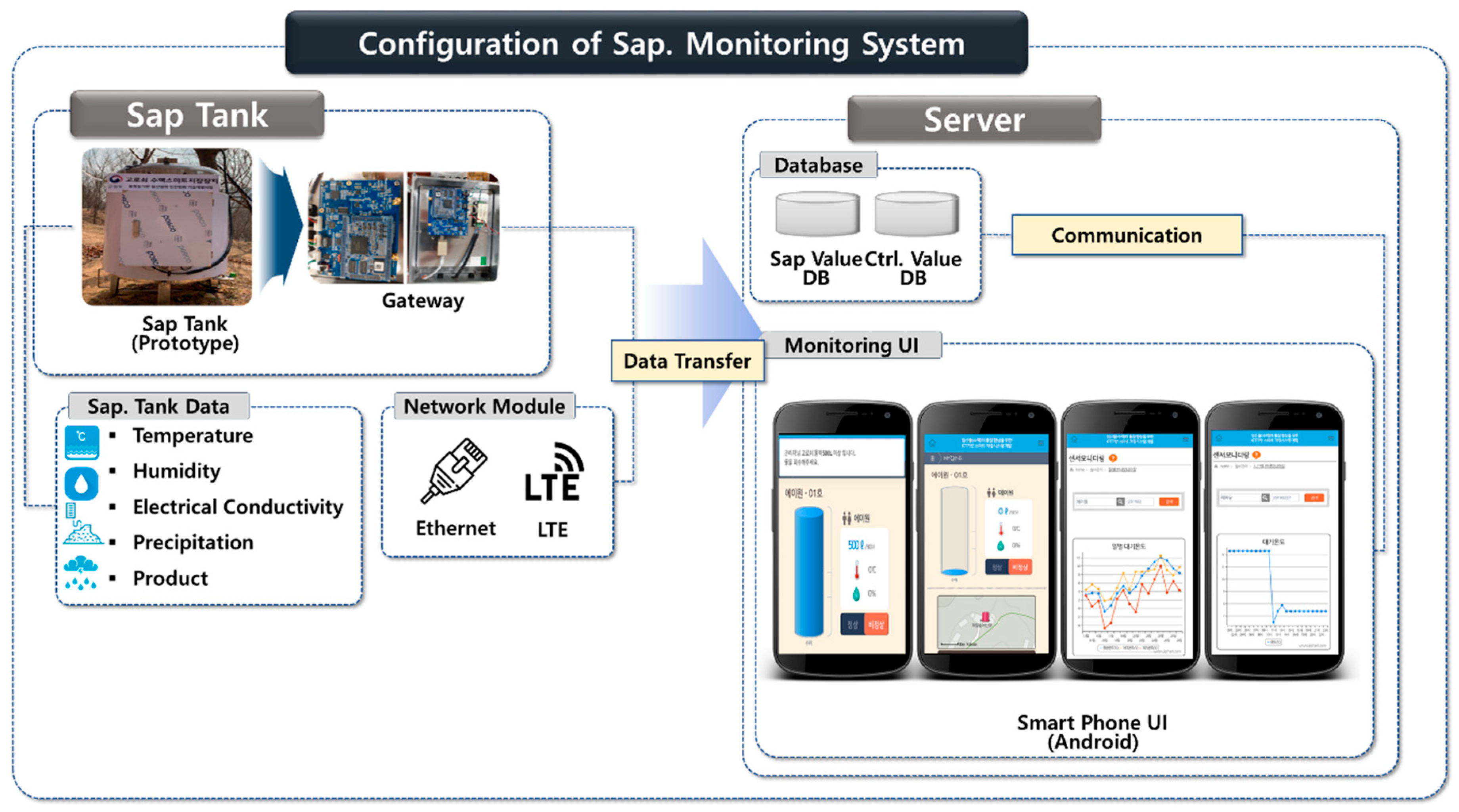
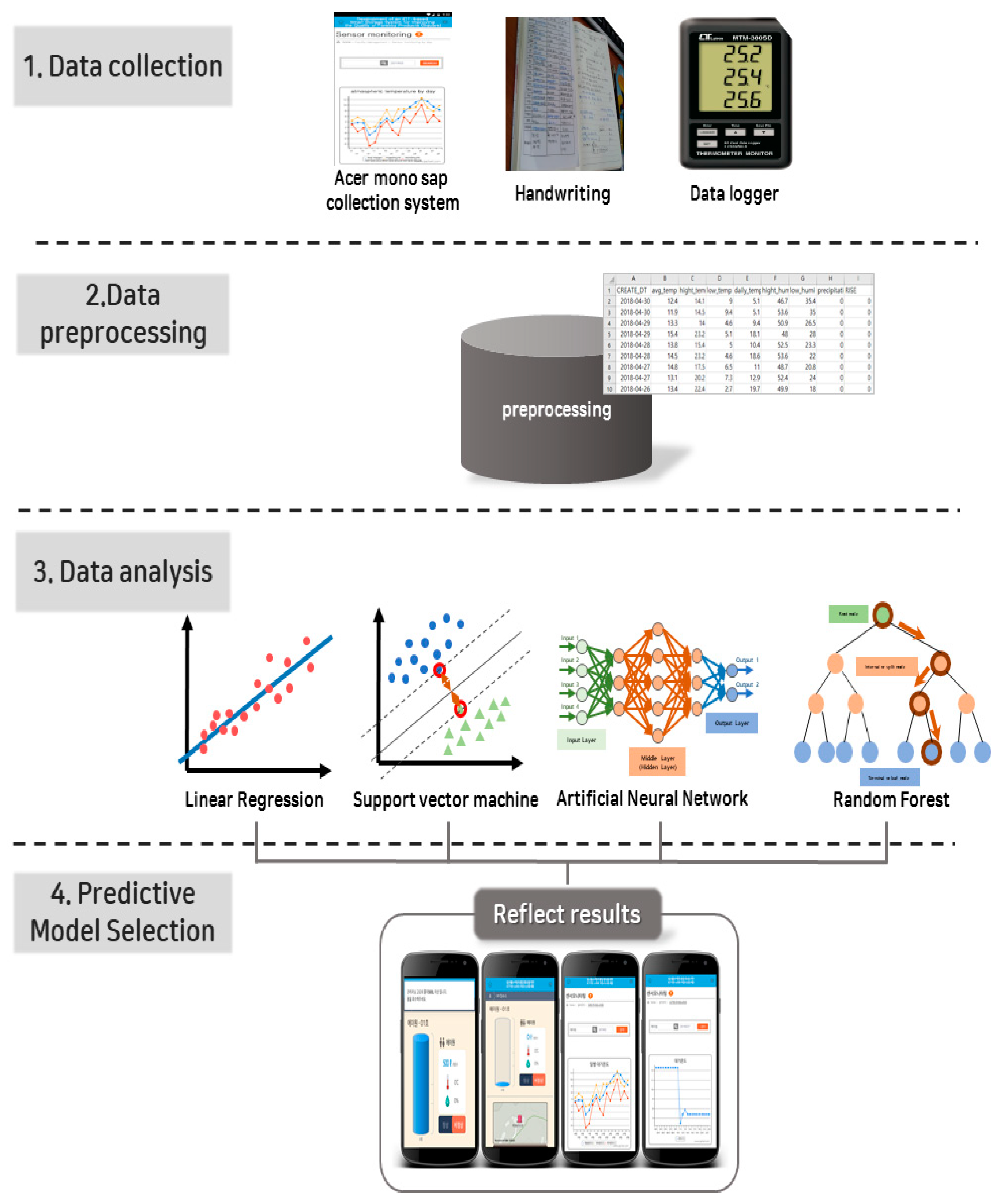
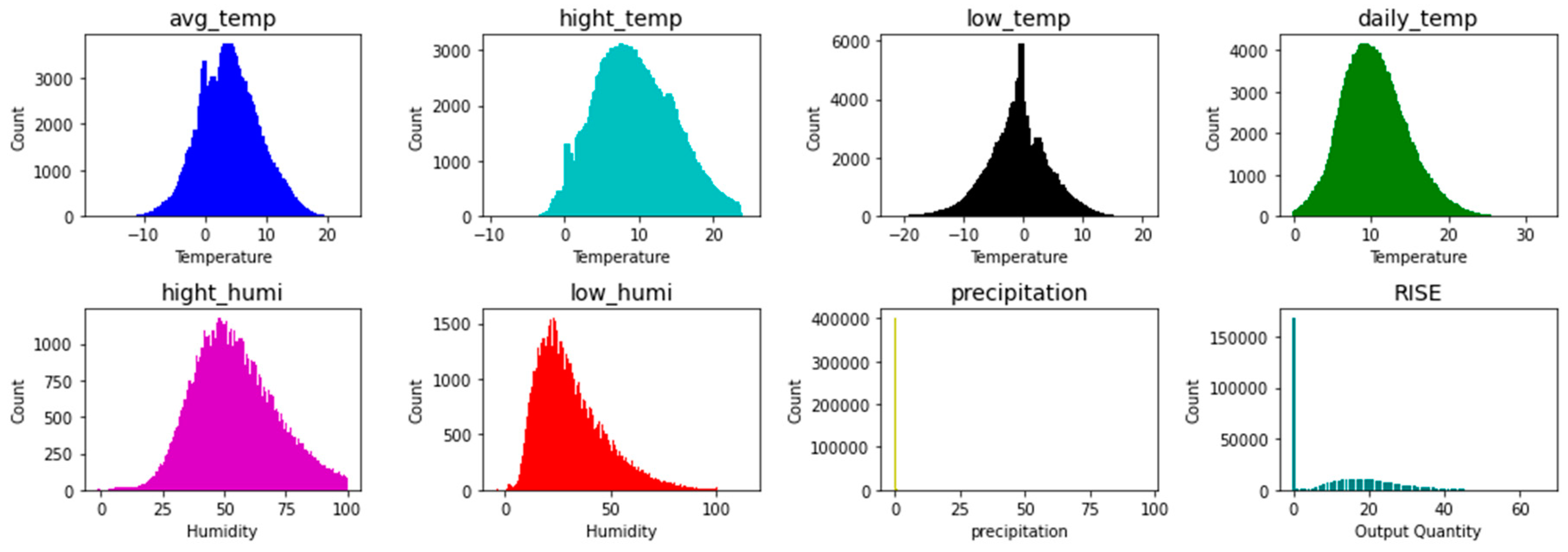
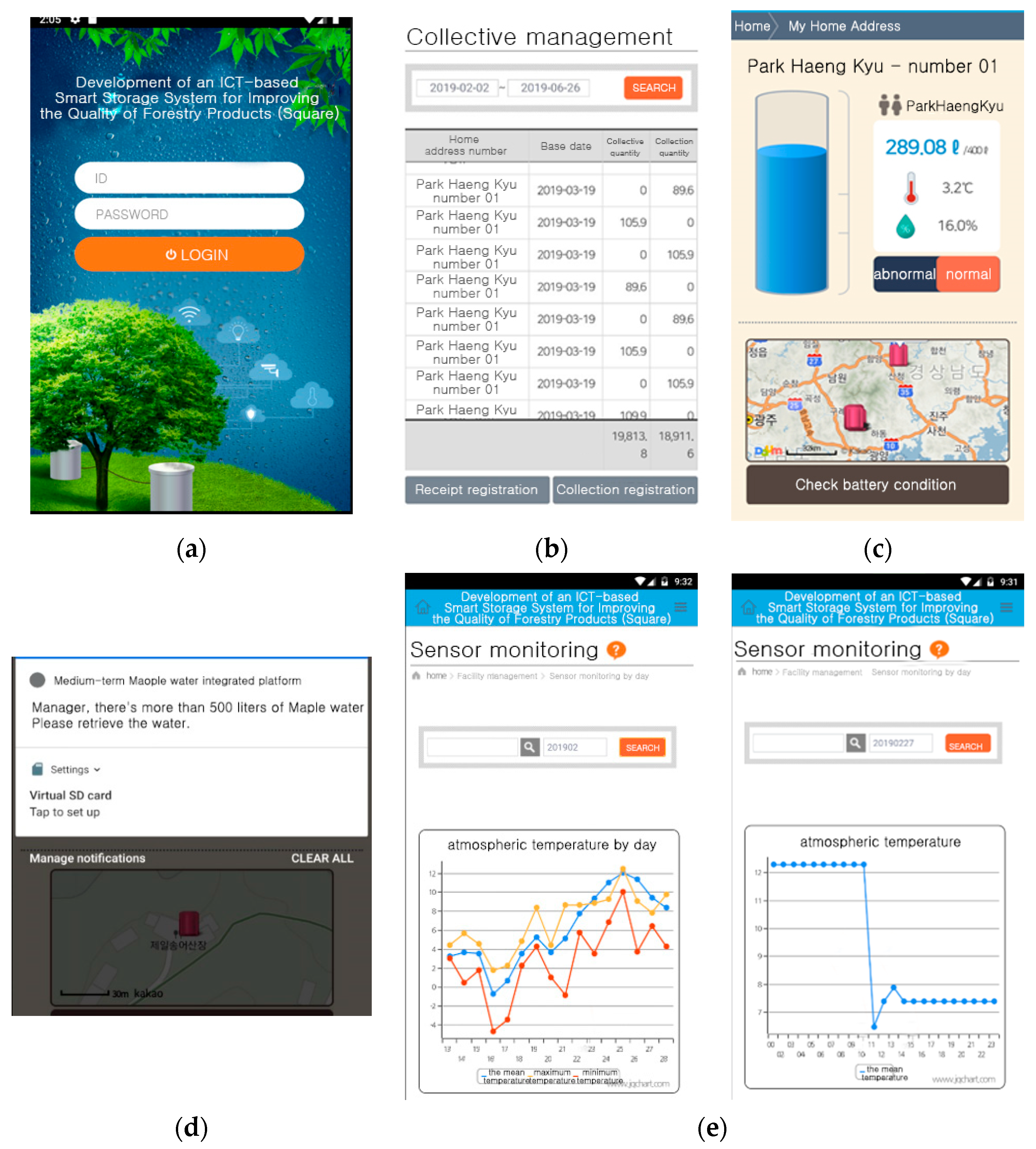
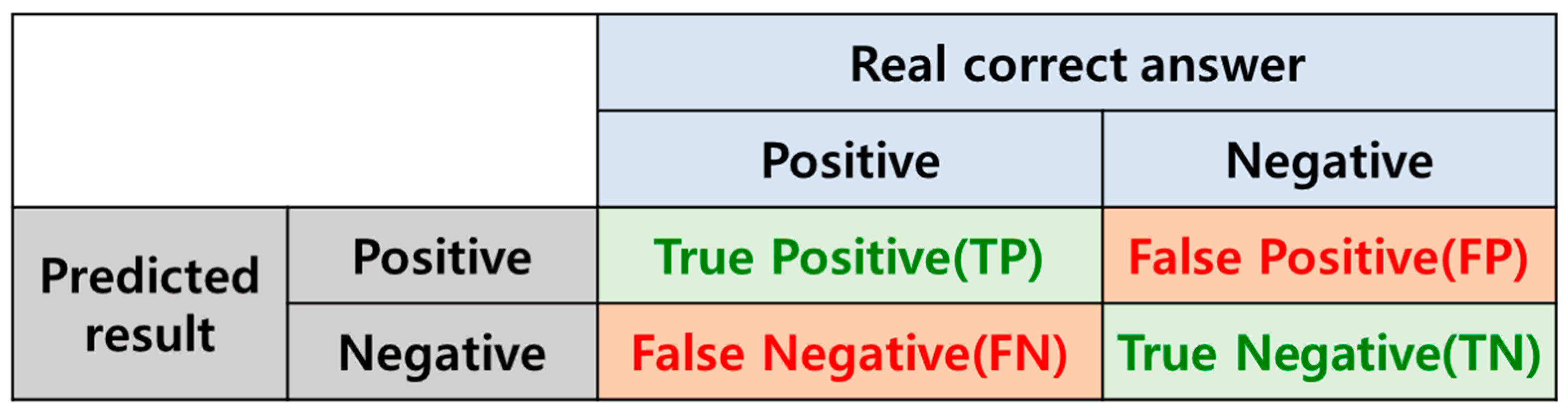
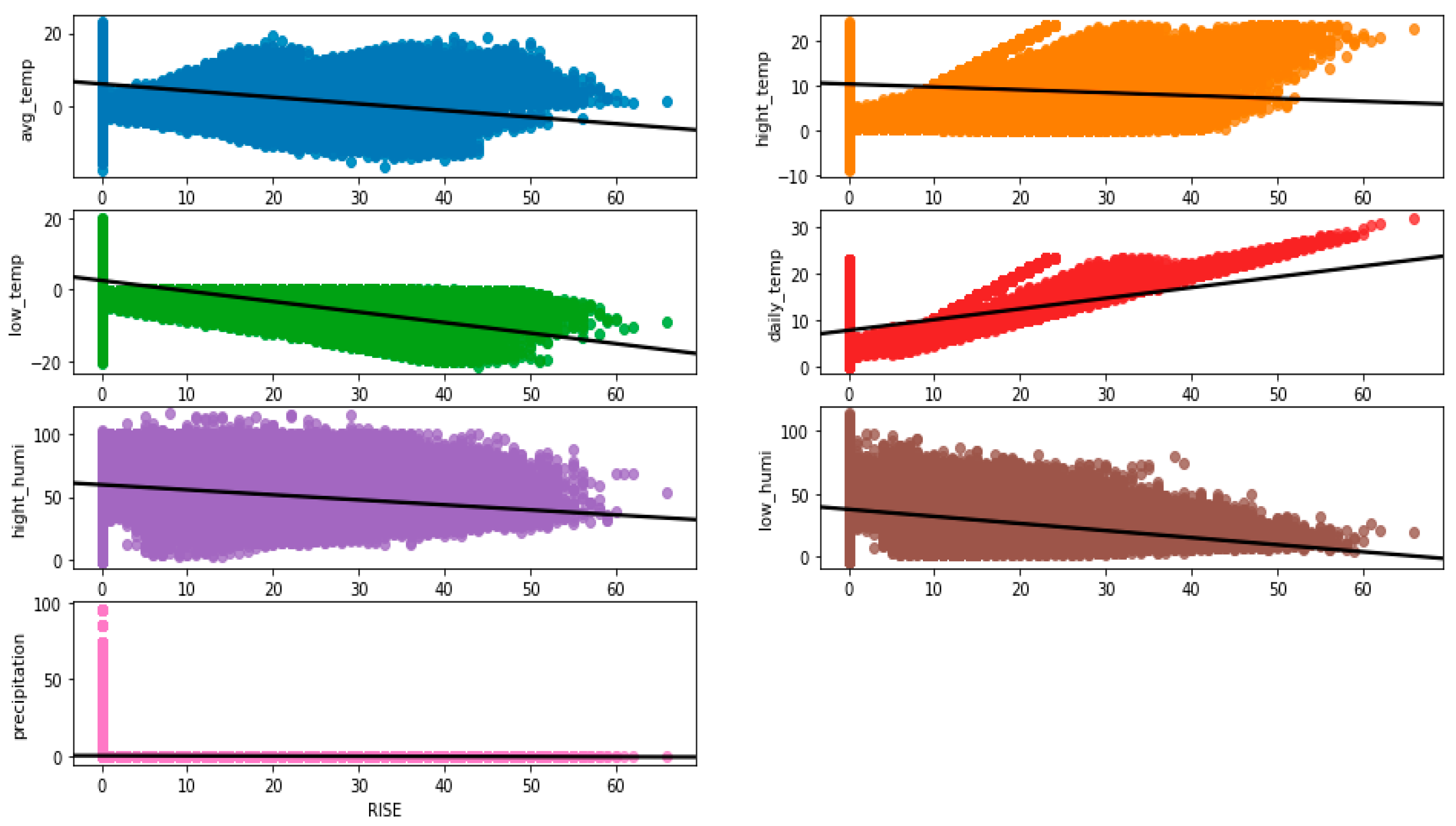
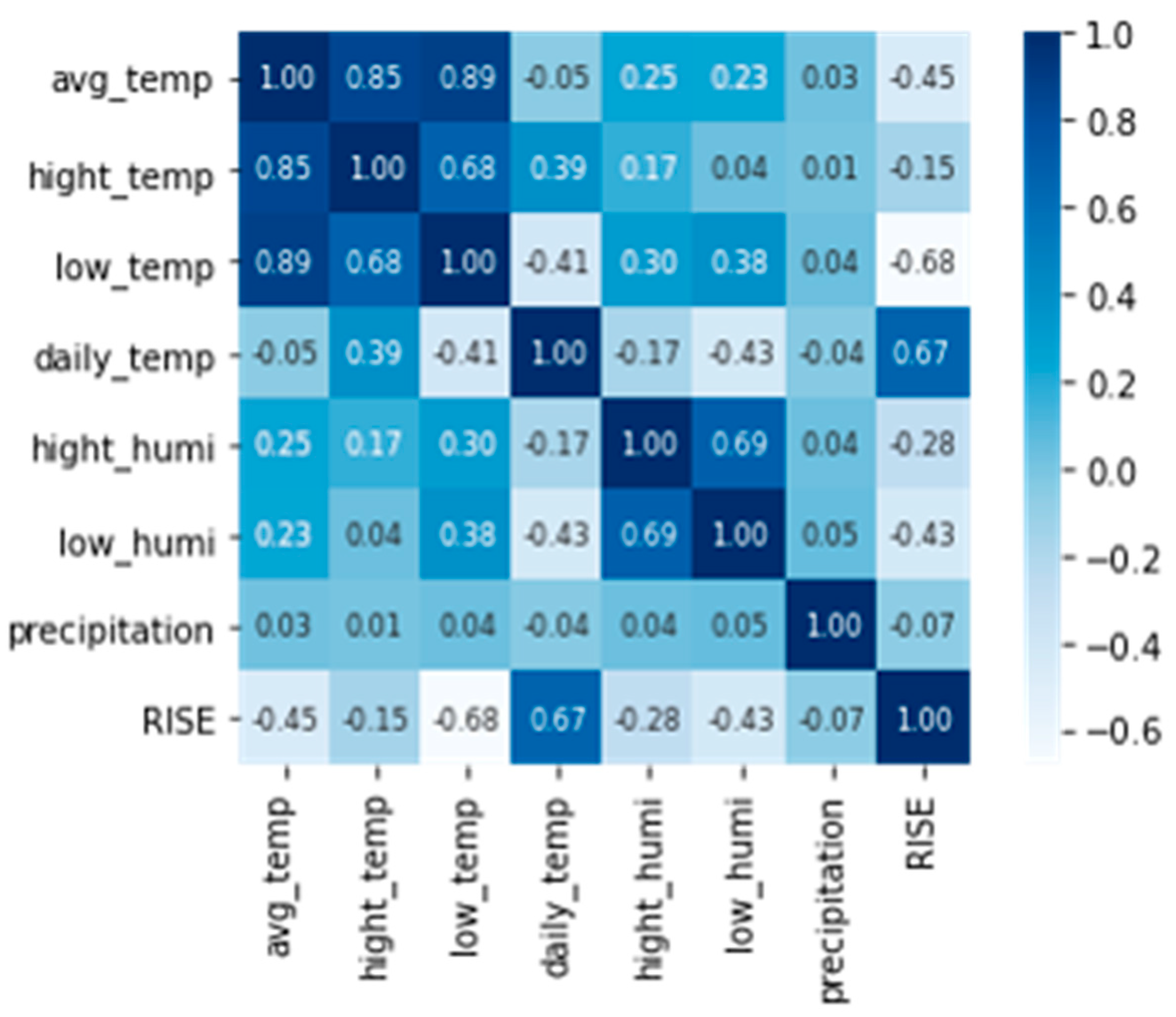
The present study decided to apply the energy harvesting technology to solve these problems. And this study thus set out to develop an ICT-based smart Acer mono sap collection device to promote the efficient utilization of labor force and reduce accident risk by cutting down unnecessary activities, including the manual recording of sap exudation in previous studies, collecting eight factors of environmental data and sap exudation within an hour. Based on farmers’ experiences to suggest close connections between environmental information and Acer mono sap exudation, the study analyzed correlations between them with linear regression, SVM, ANN and random forest and tested a hypothesis with a prediction model for Acer mono sap outputs by the algorithm. Of these prediction models embodied in the study, one was selected for its great availability for a mobile app based on learning hours, prediction hours, and prediction accuracy to provide such data via a mobile app along with environmental information collected with a smart collection device.
4. Conclusions
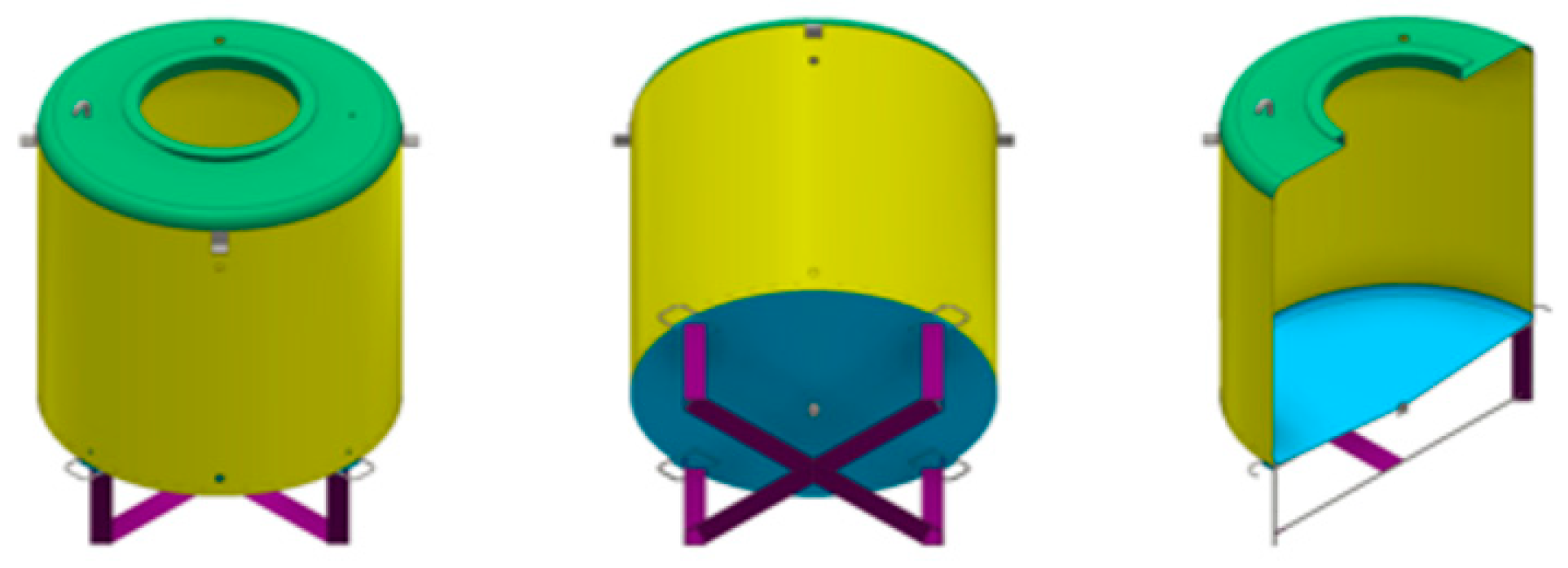
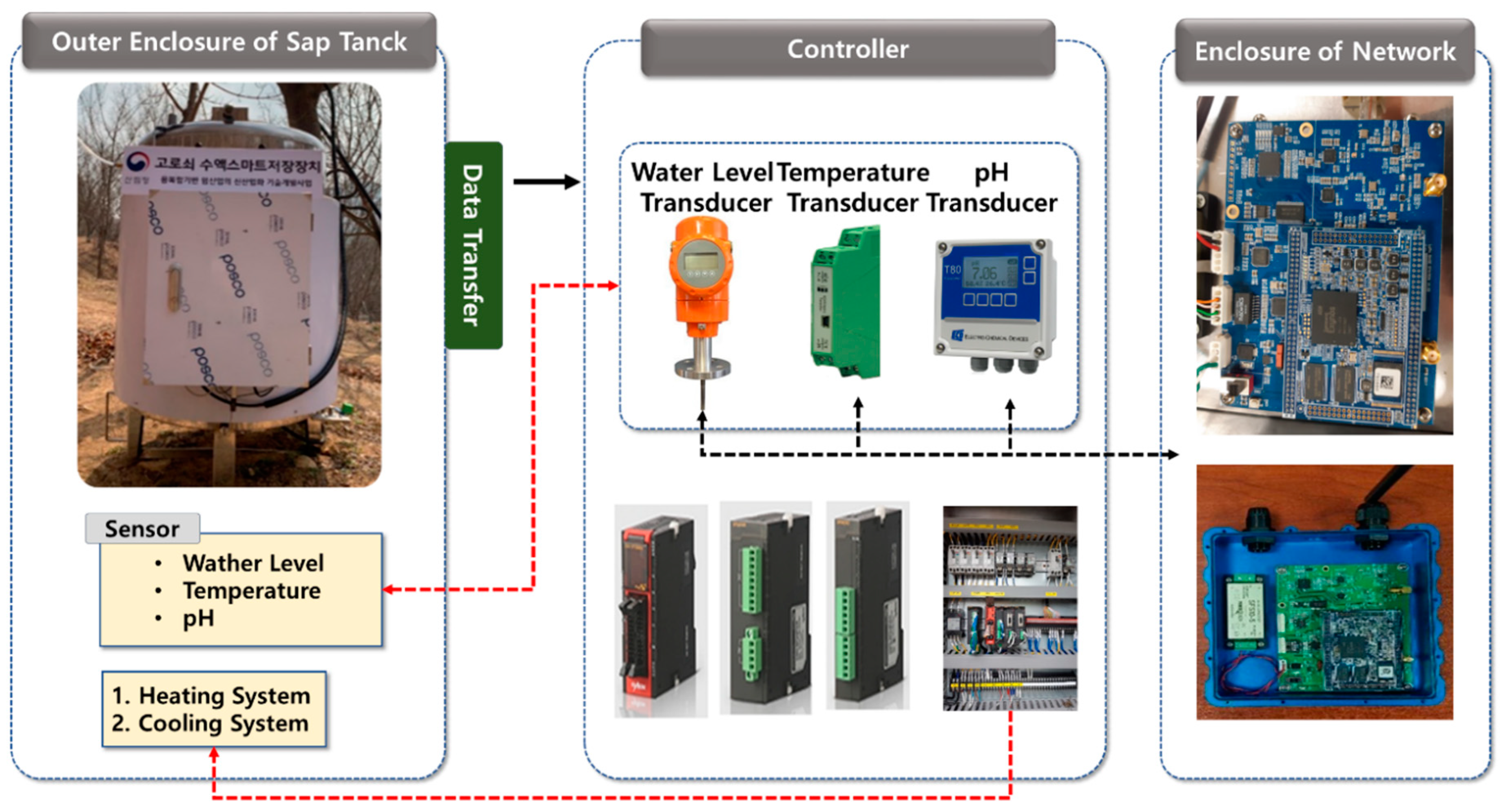
The present study made an Acer mono sap collection device and invented a mobile app for farm managers to check predicted Acer mono sap exudation in real time based on the analysis of data about environmental factors including exudation, outdoor temperature, humidity, conductivity, and wind direction and velocity collected from such a device.
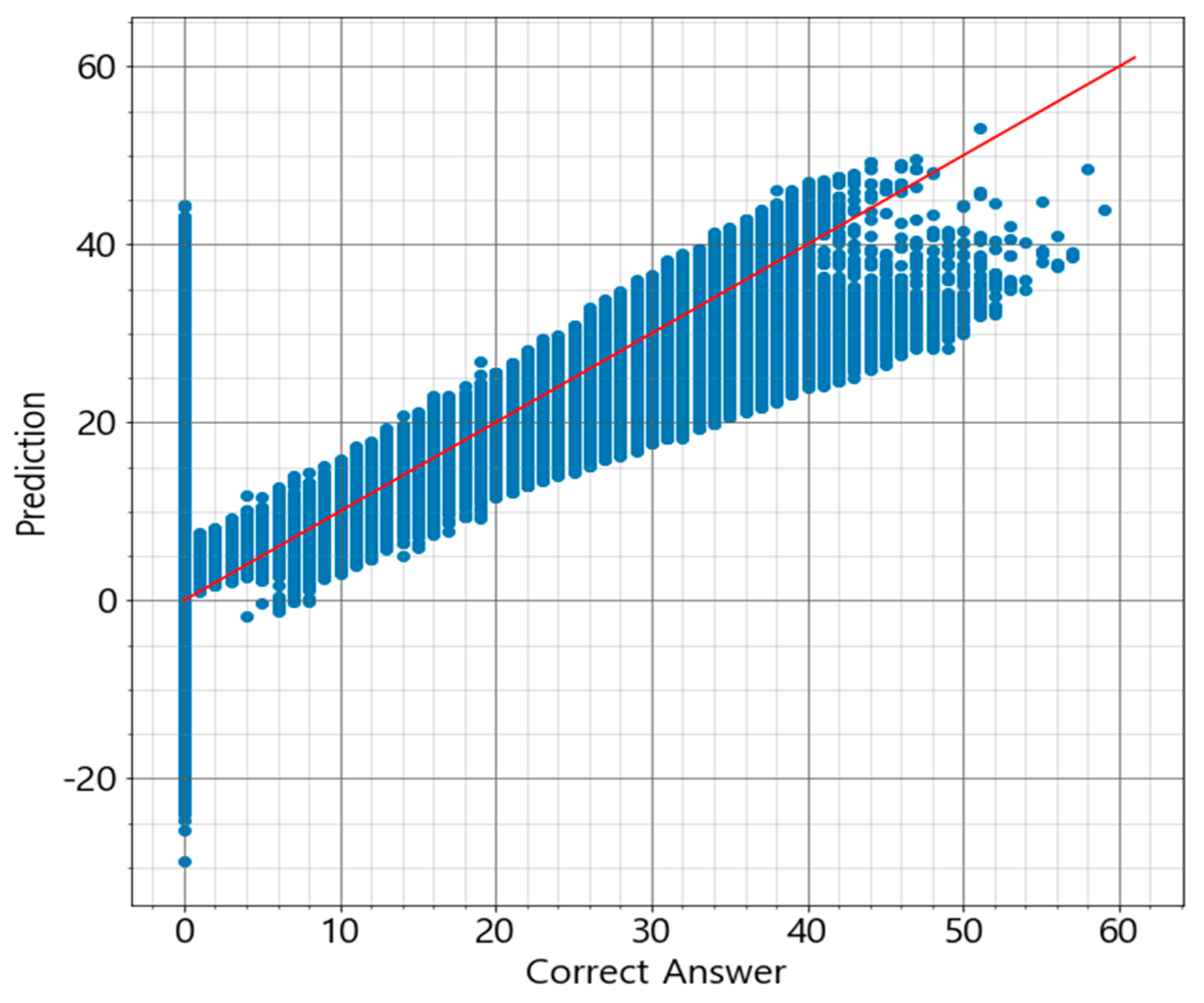
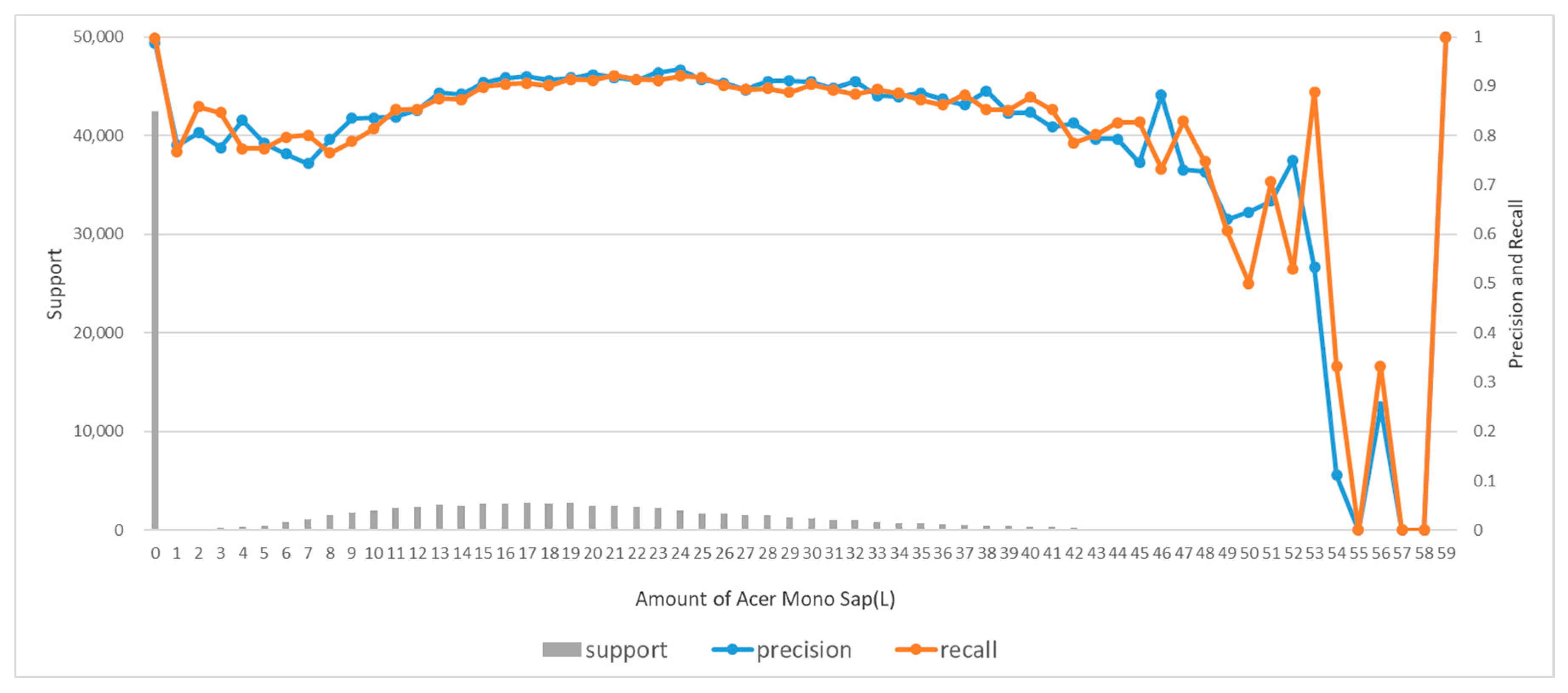
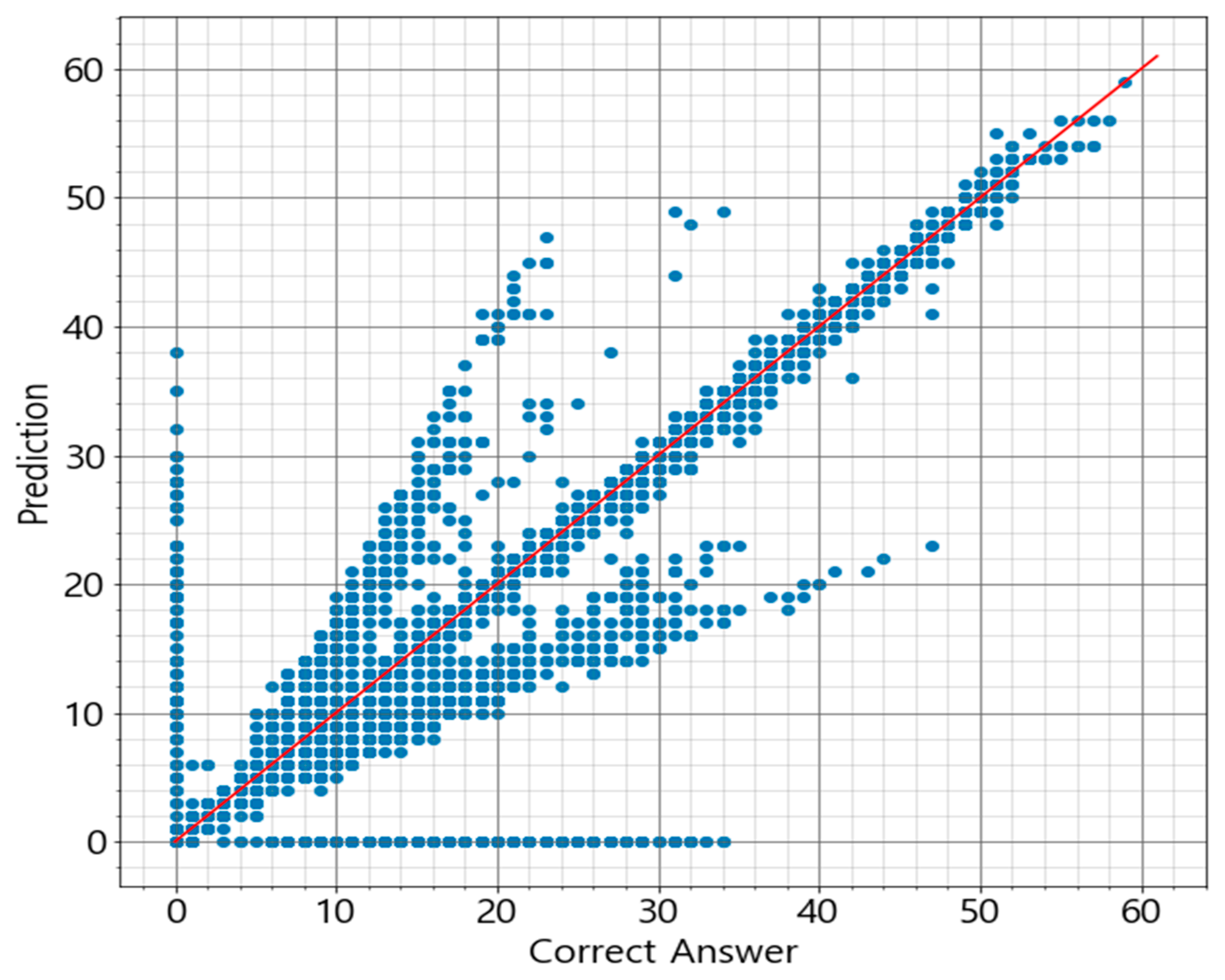
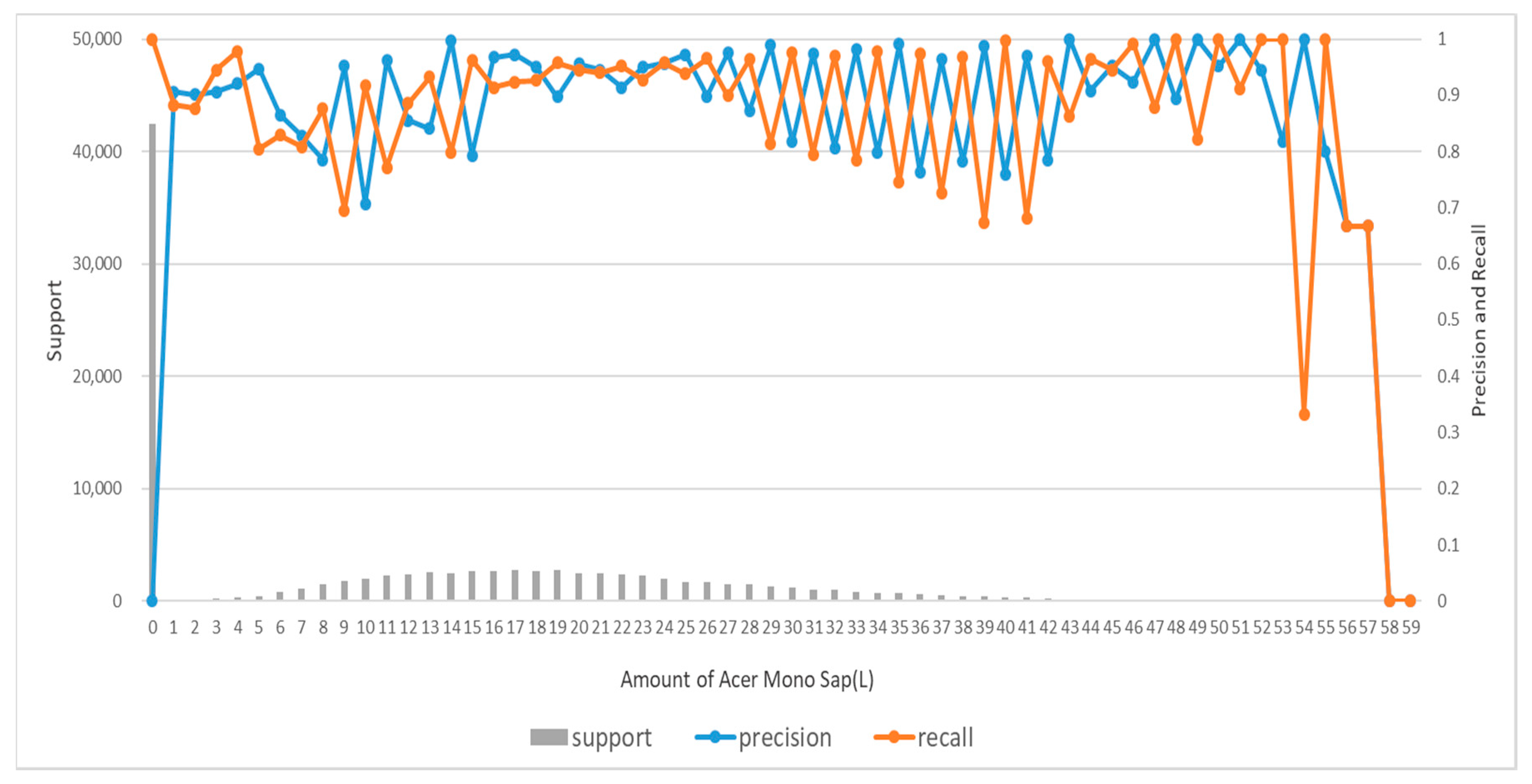
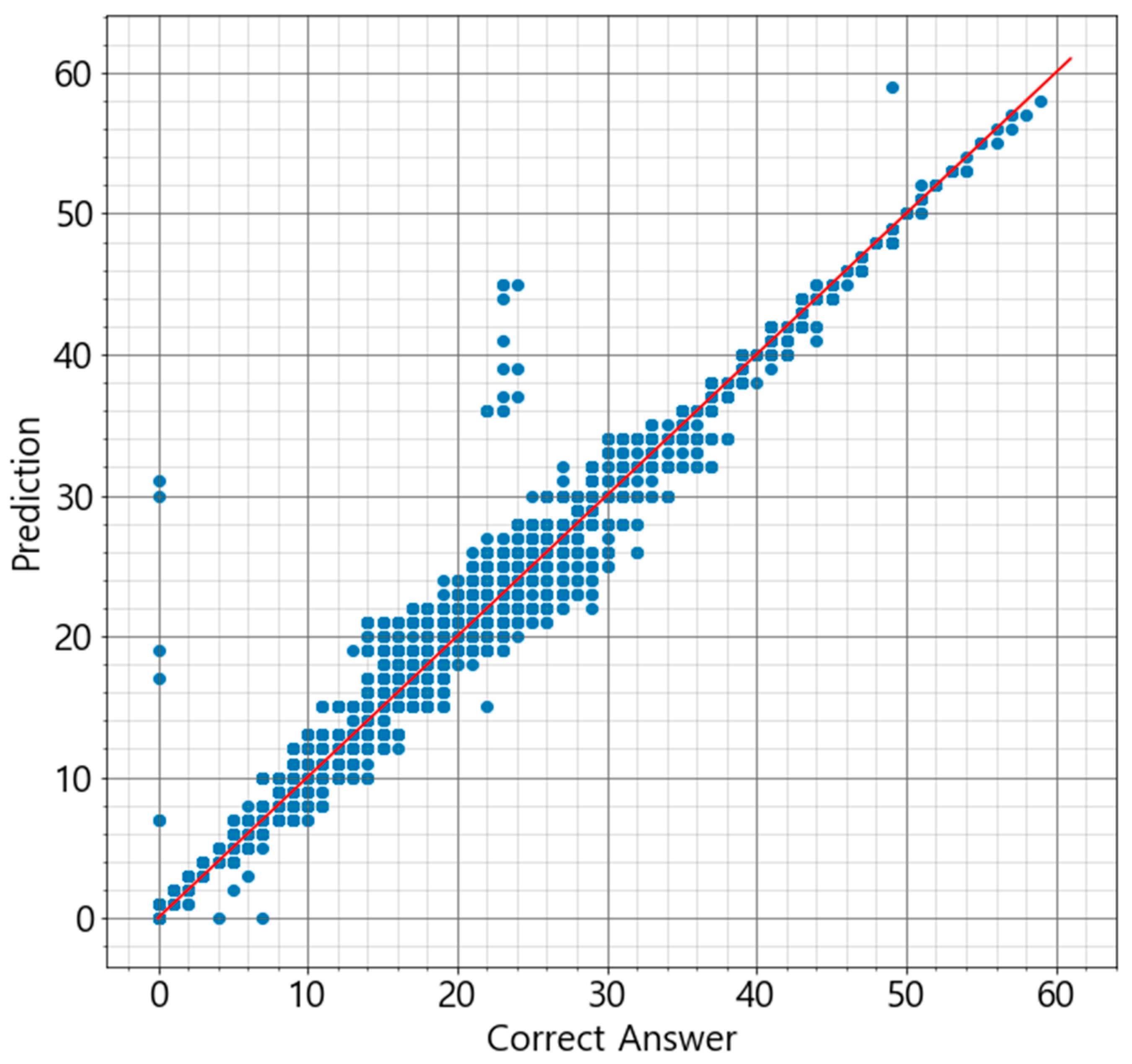
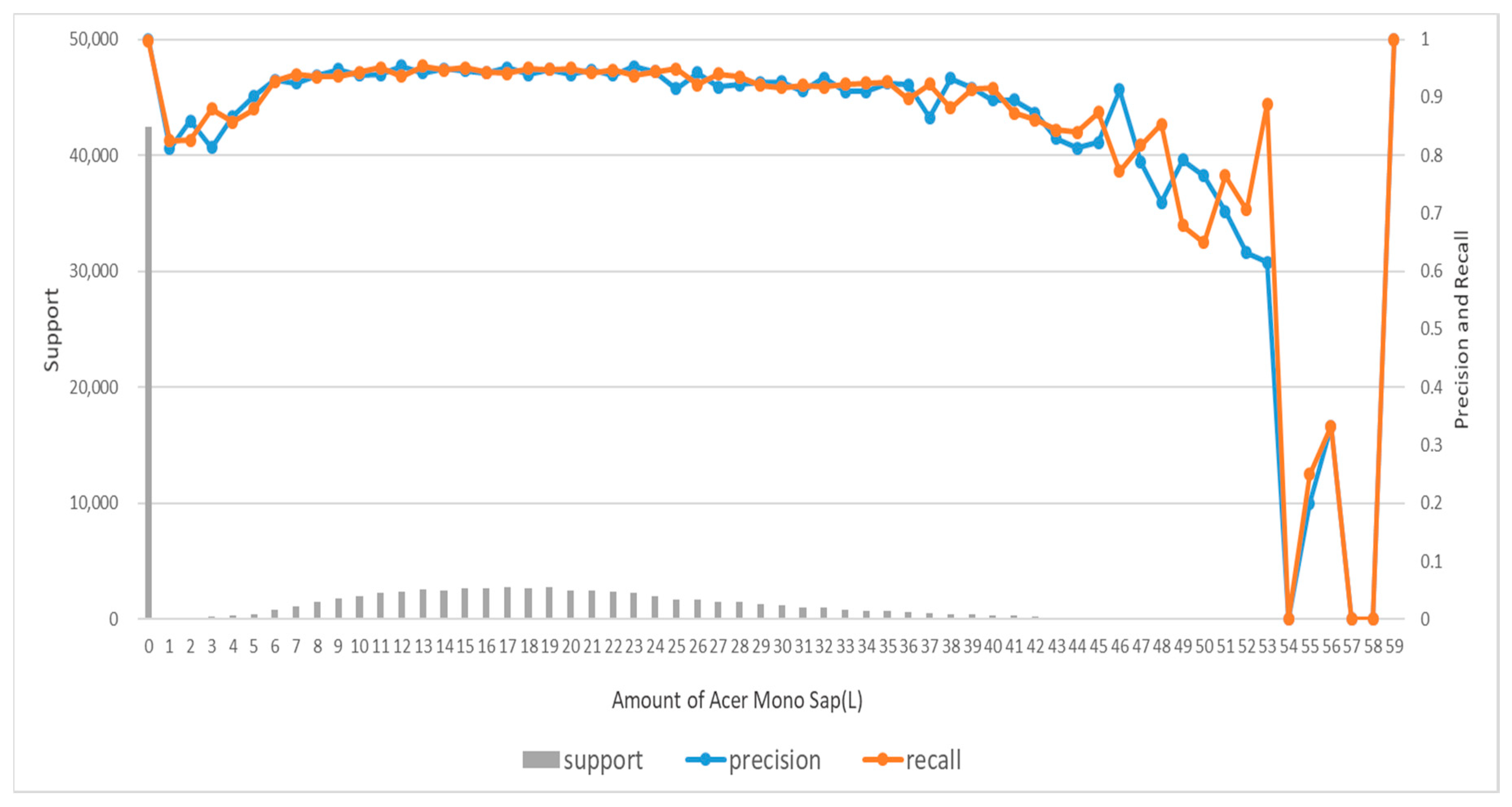
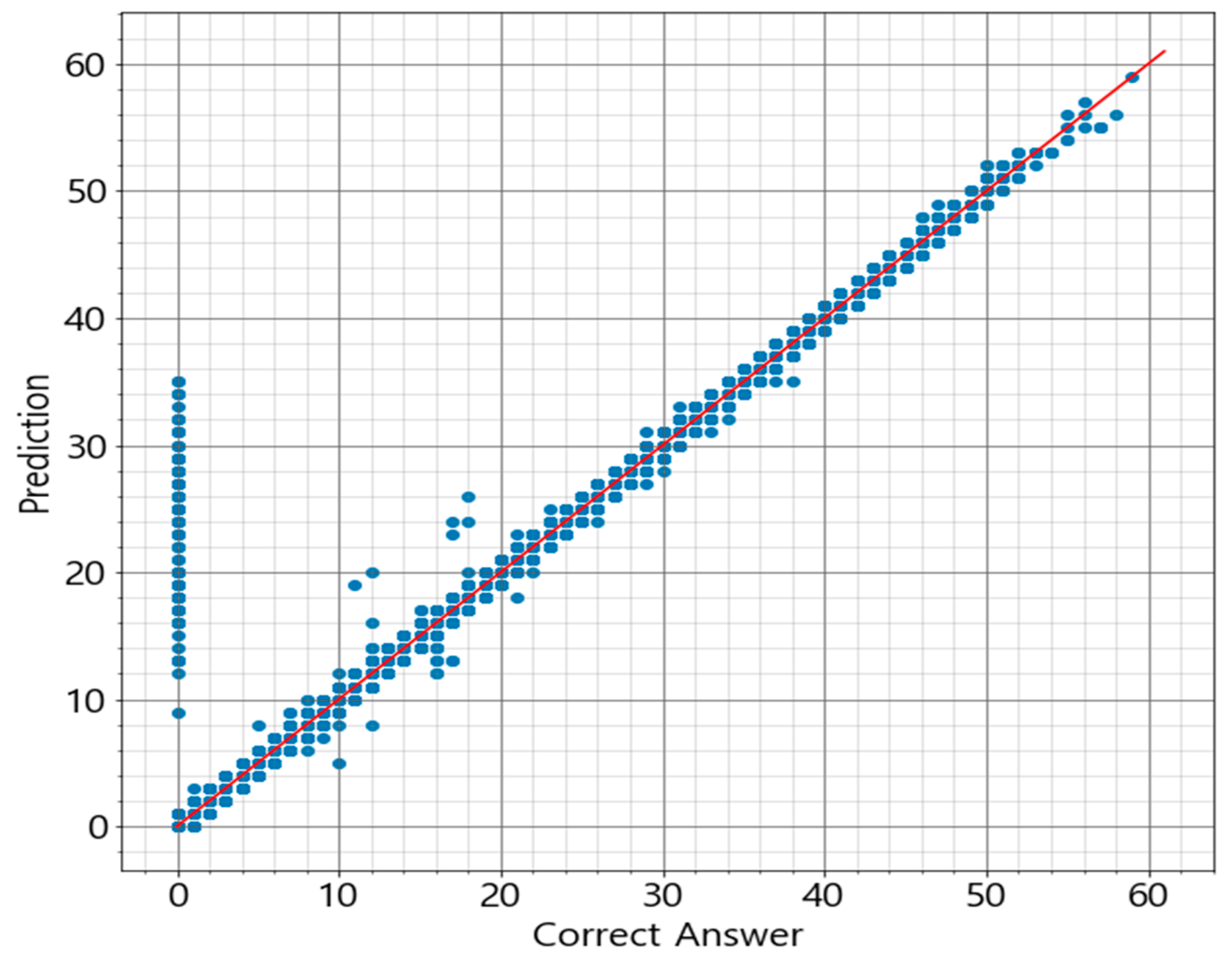
Based on the assumption that Acer mono sap exudation would depend on the environment of Acer mono trees, the study designed prediction models for Acer mono sap exudation with linear regression, SVM, ANN, and random forest algorithms. All the algorithms recorded high prediction accuracy except for linear regression, which confirms the assumption that Acer mono sap exudation would be determined by the surrounding environment. These models were also compared in learning time, prediction time, and accuracy, and the random forest model was chosen to be applicable for a mobile app.
A follow-up study will examine clearer correlations between Acer mono sap exudation and environmental information and design a new algorithm by gathering more data based on the findings of the present study and resolving the data imbalance issue. If the data imbalance issue is not resolved due to climate characteristics, a new approach will be proposed to combine ANN and random forest in an ensemble technique and address the overfitting issue of ANN and the error numbers at 0 L of random forest with the disadvantages of the two algorithms supplemented.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}