1. Introduction
Video compression standard technologies are increasingly becoming more efficient and complex. With continuous development of display resolution and type along with enormous demand for high quality video contents, video coding also plays a key role in display and content industries. After standardizing H.264/AVC [
1] and H.265/HEVC [
2] successfully, Versatile Video Coding (VVC) [
3] is being standardized by the Joint Video Exploration Team (JVET) of ITU-T Video Coding Experts Group (VCEG) and ISO/IEC Moving Picture Experts Group (MPEG). Obviously, the HEVC is a reliable video compression standard. Nevertheless, more efficient video coding scheme is required for higher-resolution and the newest services such as UHD and VR.
To develop the video compression technologies beyond HEVC, experts in JVET have been actively conducting much research. VVC provides a reference software model called as VVC Test Model (VTM) [
4]. At the 11th JVET meeting, VTM2 [
5] was established with the inclusion of a group of new coding features as well as some of HEVC coding elements.
The basic framework of VVC is the same as HEVC, which consists of block partitioning, intra and inter prediction, transform, loop filter and entropy coding. Inter prediction, which aims to obtain a similar block in the reference frames in order to reduce the temporal redundancy, is an essential part in video coding. The main tools for inter prediction are motion estimation (ME) and motion compensation (MC). Finding precise correlation between consecutive frames is important to final coding performance. Block matching based ME and MC have been implemented in the reference software model of the previous video compression standards such as H.264/AVC and H.265/HEVC. The fundamental motion model of the conventional block-based MC is a translational motion model. In the early research, a translational motion model-based MC cannot address complex motions in natural videos such as rotation and zooming. Such being the case, during the development of the video coding standards, further elaborate models are required to handle non-translational motions.
Non-translational motion model-based studies have also been presented in the early research on video coding. Seferidis [
6] and Lee [
7] proposed deformable block based ME algorithms, in which all motion vectors (MVs) at any position inside a block can be calculated by using control points (CPs). Besides, Cheung and Siu [
8] proposed to use the neighboring block’s MVs to estimate the affine motion transformation parameters and added an affine mode. After those, affine motion compensation (AMC) has begun to attract attention. A local zoom motion estimation method was proposed to achieve more coding gain by Kim et al. [
9]. In this method, they used to estimate some zoom-in/out cases of the object or background part. However they dealt with just zoom motion cases using the H.264/AVC standard.
Later, Narroschke and Swoboda [
10] proposed an adjusted AMC to HEVC coding structure by investigates the use of an affine motion model with analyzing variable block size. Huang et al. [
11] extended the work in [
8] for HEVC and included the affine skip/direct mode to improve coding efficiency. Also, Heithausen and Vorwerk [
12] investigated different kinds of higher order motion models. Moreover, Chen et al. [
13] proposed the affine skip and merge mode. In addition, Heithausen [
14] developed a block-to-block translational shift compensation (BBTSC) technique which related to the advanced motion vector prediction (AMVP) [
15] and improved the BBTSC algorithm by applying the translational motion vector field (TMVF) in [
16]. Li [
17] proposed the six-parameter affine motion model and extended by simplifying model to four-parameter and adding gradient-based fast affine ME algorithm in [
18]. Because the trade-off between the complexity and coding performance is attractive, the scheme in [
18] was proposed to JVET [
19] and was accepted as one of the core modules of Joint Exploration Model (JEM) [
20,
21]. After that, Zhang [
22] proposed a multi model AMC approach. At the 11th JVET meeting in July 2018, modified AMC of JEM was integrated into VVC and Test Model 2 (VTM2) [
5] based on [
22].
Although AMC has significantly improved performance over the conventional translational MC, there is still a limit to finding complex motion accurately. Affine transformation is a model that maintains parallelism based on the 2D plane, and thus cannot work efficiently for some sequences containing object distortions. In actual videos, motion by a non-affine transformation appears more generally than by an affine transformation with such restriction.
Figure 1 shows an example of a non-affine transformation in nature video. When a part of an object is represented by a rectangle, the four vertices must operate independently of each other to illustrate the deformation of the object most similarly. Even though different frames have the same object, if the depth or viewpoint information changes, the motion can not be completely estimated by affine transformation model. For this reason, more flexible motion model is desired for new coding tool to raise the encoding quality.
The method using basic warping transformation model results in high computational complexity and bit overhead because of the large number of parameters. Therefore, it is necessary to apply a model that is not greatly increased for bit overhead compared to the existing AMC and has flexibility enough to replace the warping transformation model.
In this paper, we propose a perspective affine motion compensation (PAMC) method which improve coding efficiency compared with the AMC method of VVC. Compared to prior-arts, this paper presents two practical contributions to AMC. First, a perspective transformation model is designed in the form of MVs so that it can be used in AMC. It is an eight parameter based motion model that requires four CPMVs. Second, we propose a multi-motion model switch approach based framework to operate adaptively with AMC. In other words, six and four parameter model-based AMC and eight parameter-based perspective ME/MC are performed to select the best coding mode adaptively.
This paper is organized as follows. In
Section 2, we first present AMC in VVC briefly. The proposed perspective affine motion compensation (PAMC) is introduced in
Section 3. The experimental results are shown in
Section 4. Finally,
Section 5 concludes this paper.
3. Proposed Perspective Affine Motion Estimation/Compensation
Affine motion estimation in the VVC is applied since it is more efficient than translational motion compensation. The coding gain can be increased by delicately estimating motion on the video sequence in which complex motion is included. However, still it has a limit to accurately find all motions in the natural video.
Affine transformation model has properties to maintain parallelism based on the 2D plane, and thus cannot work efficiently for some sequences containing object distortions or dynamic motions such as shear and 3D affine transformation. In real world, numerous moving objects have irregular motions rather than regular translational, rotation and scaling motions. So, more elaborated motion model is needed for video coding tool to estimate motion delicately.
The basic warping transformation model can estimate motion more accurately, but this method is not suitable because of its high computational complexity and bit overhead by the large number of parameters. For these reasons, we propose a perspective affine motion compensation (PAMC) method which improve coding efficiency compared with the existing AMC method of the VVC. The perspective transformation model-based algorithm adds one more CPMV, which gives degree of freedom to all four corner vertices of the block for more precise motion vector. Furthermore, the proposed algorithm is integrated while maintaining the AMC structure. Therefore, it is possible to adopt an optimal mode between the existing encoding mode and the proposed encoding mode.
3.1. Perspective Motion Model for Motion Estimation
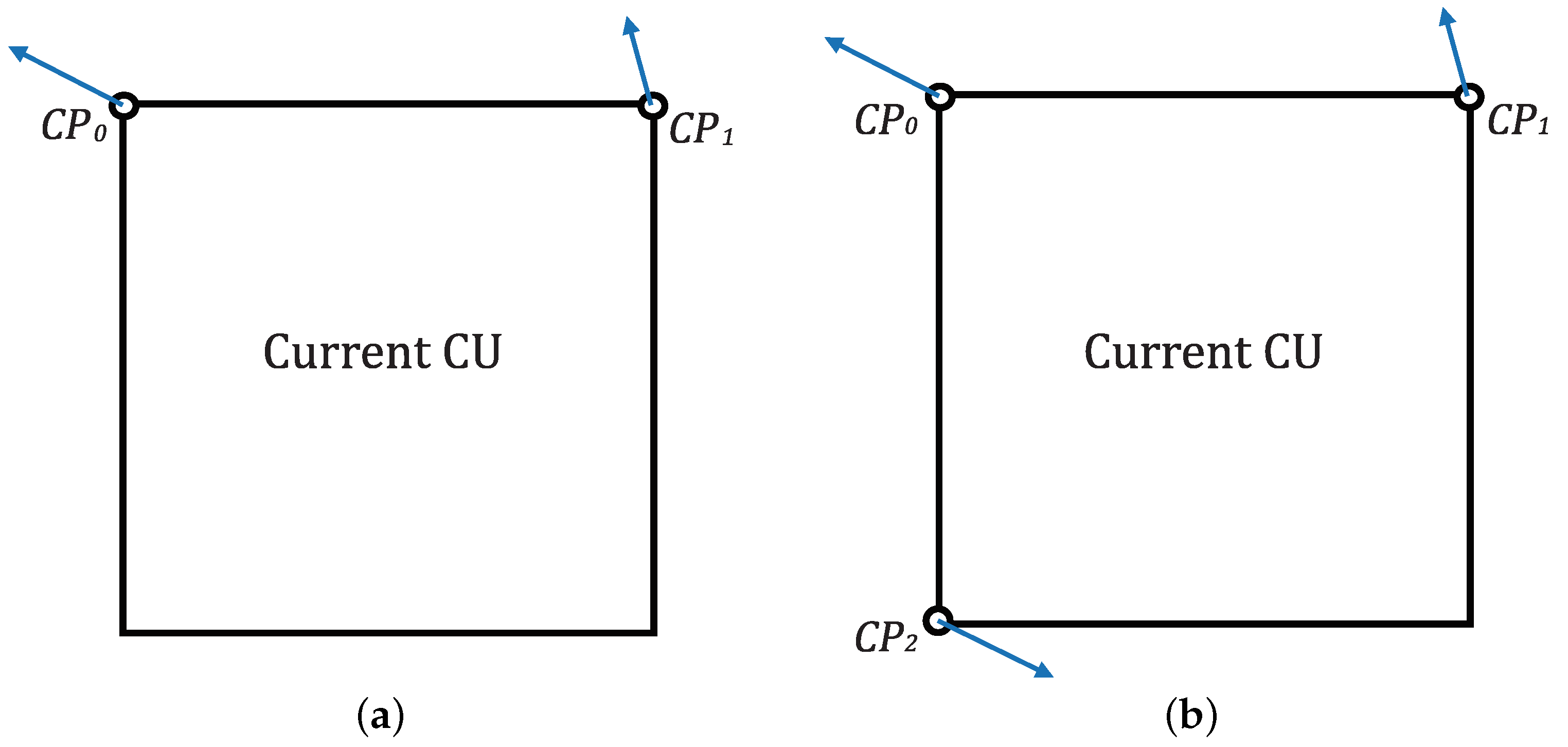
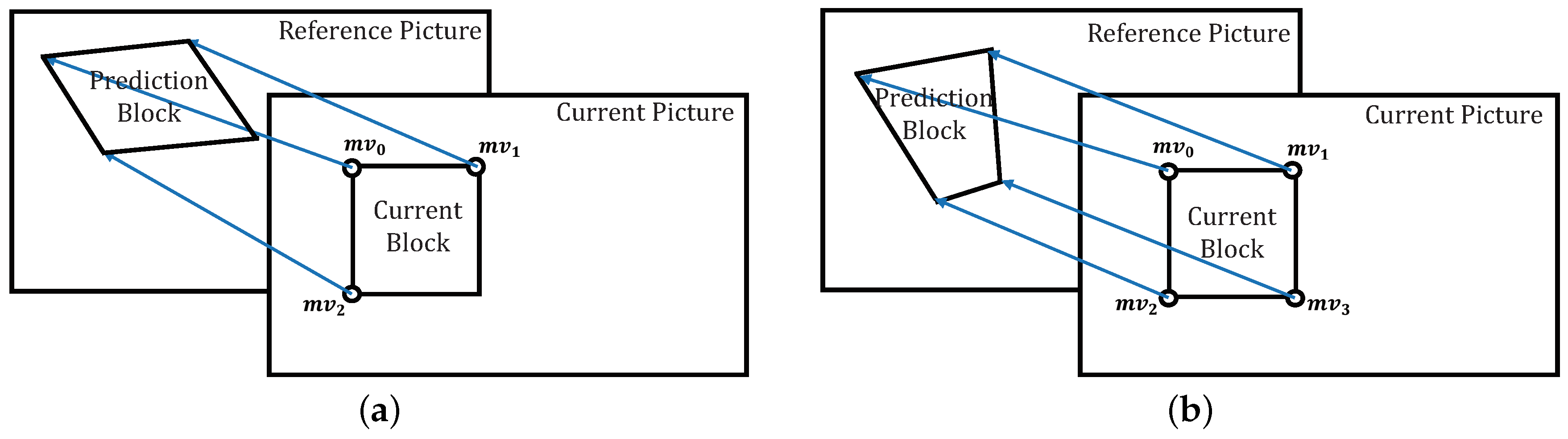
Figure 6 shows that the proposed perspective model with four CPs (b) can estimate motion more flexible compared with the affine model with three CPs (a). Affine motion model-based MVF of a current block is described by three CPs which are matched to
in illustration. On the other hand, one more field is added for perspective motion model-based MVF. It is composed of four CPs which are matched to
. As can be seen from
Figure 6, one vertex of the block can be used additionally, so that motion estimation can be performed on various types of rectangular bases. Each side of the prediction block obtained through motion estimation based on the perspective motion model has various lengths and does not has to be parallel. The typical eight-parameter perspective motion model can be described as:
where
,
,
,
,
,
,
and
are eight perspective model parameters. Among them, parameters
and
serve to give the perspective to motion model. With this characteristic, as though it is a conversion in the 2D plane, it is possible to obtain an effect that the surface on which the object is projected is changed.
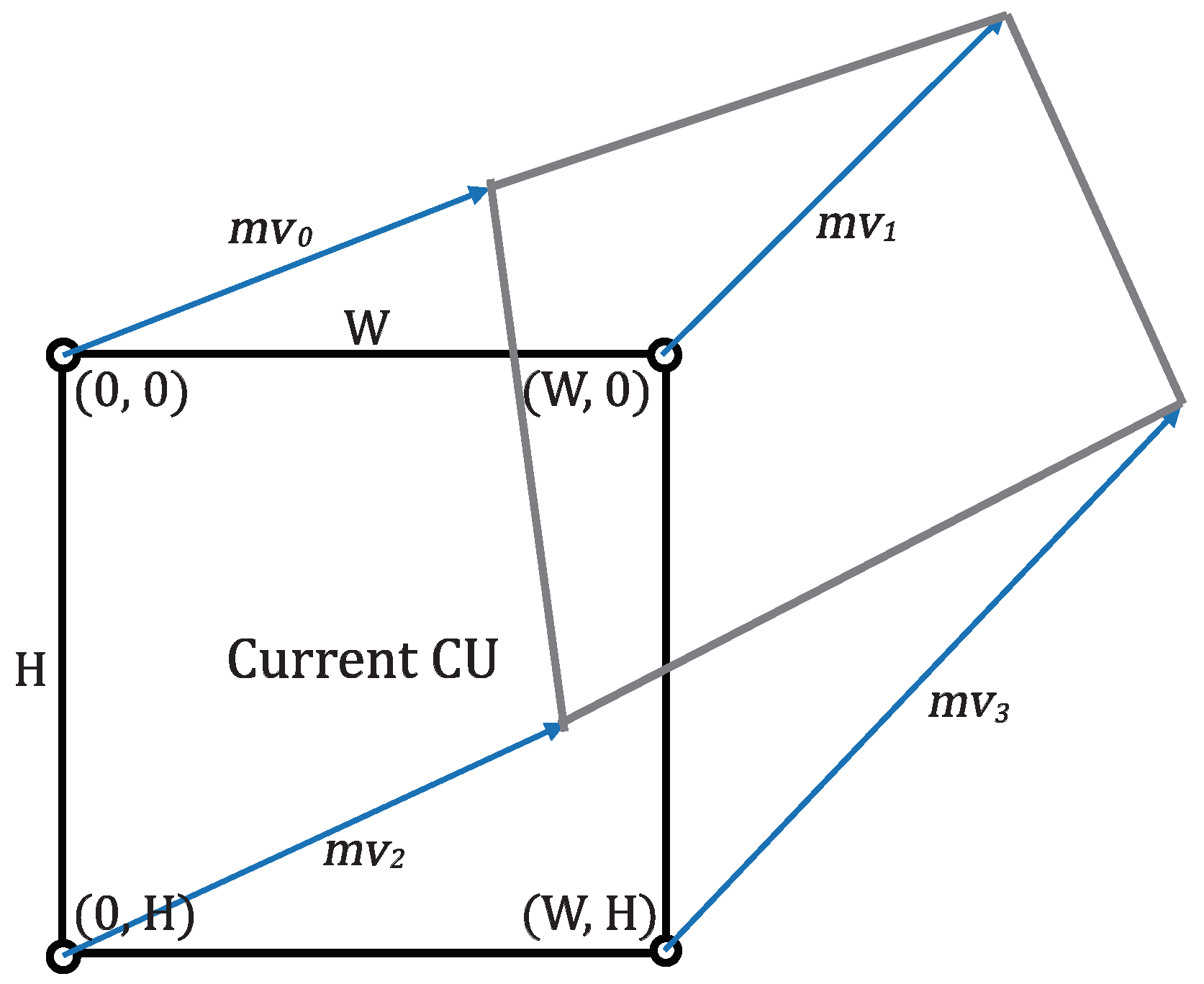
Instead of these eight parameters, we used four MVs to equivalently represent the perspective transformation model like the technique applied to AMC of the existing VTM. In video codecs, using MV is more efficient in terms of coding structure and flag bits. Those four MVs can be chosen at any location of the current block. However, in this paper, we choose the points at the top left, top right, bottom left and bottom right for convenience of model definition. In a
W x
H block as shown in
Figure 7, we denote the MVs of
,
,
, and
pixel as
,
,
and
. Moreover, we replace
and
with
and
to simplify the formula. The six parameters
,
,
,
,
and
of model can solved as following Equation (
4):
In addition,
and
can solved as Equation (
5):
Based on Equations (
4) and (
5), we can derive MV at sample position
in a CU by following Equation (
6):
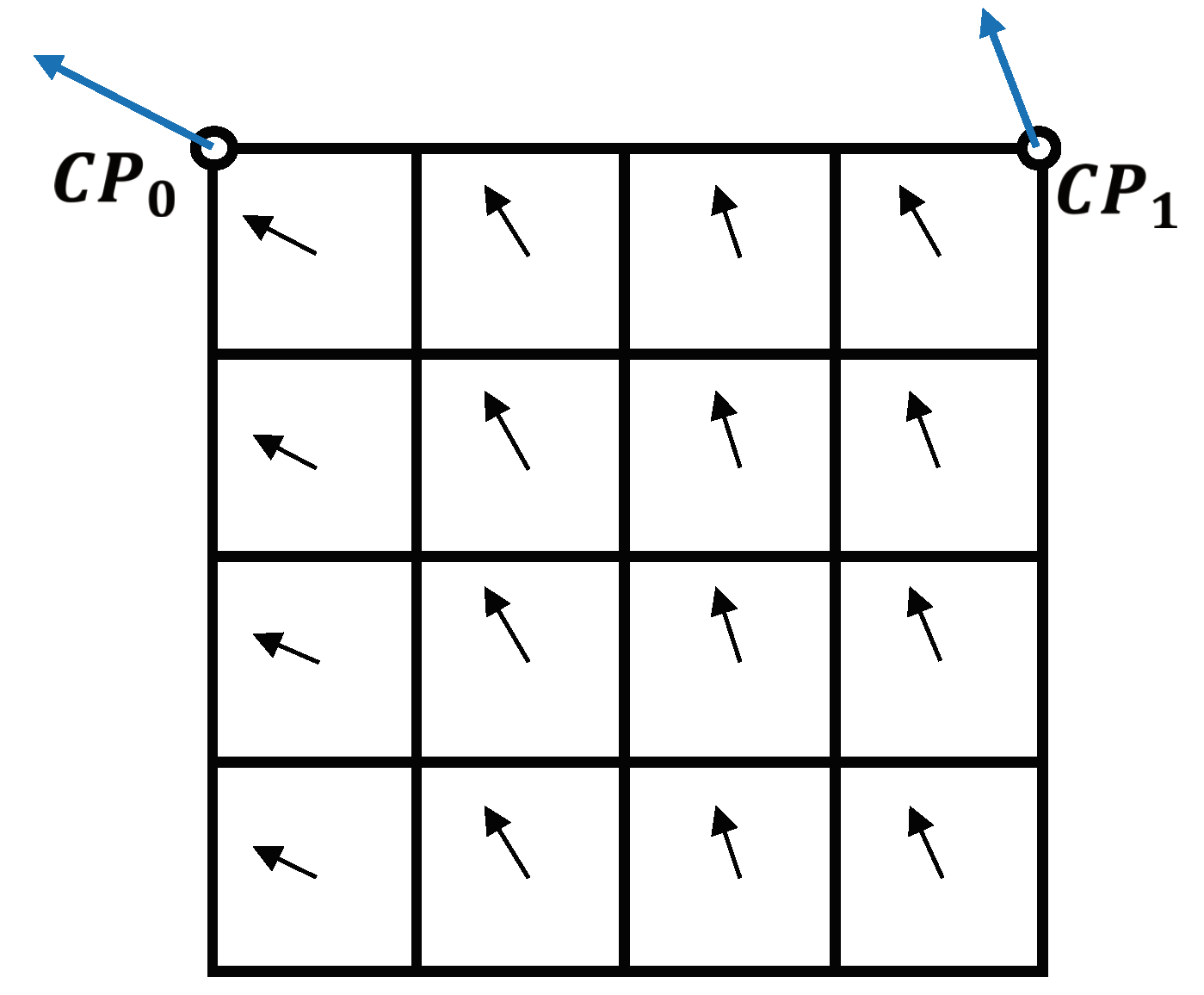
With the AMC, the designed perspective motion compensation also is also applied by 4 × 4 sub block-based MV derivation in a CU. Similarly, the motion compensation interpolation filters are used to generate the prediction block.
3.2. Perspective Affine Motion Compensation
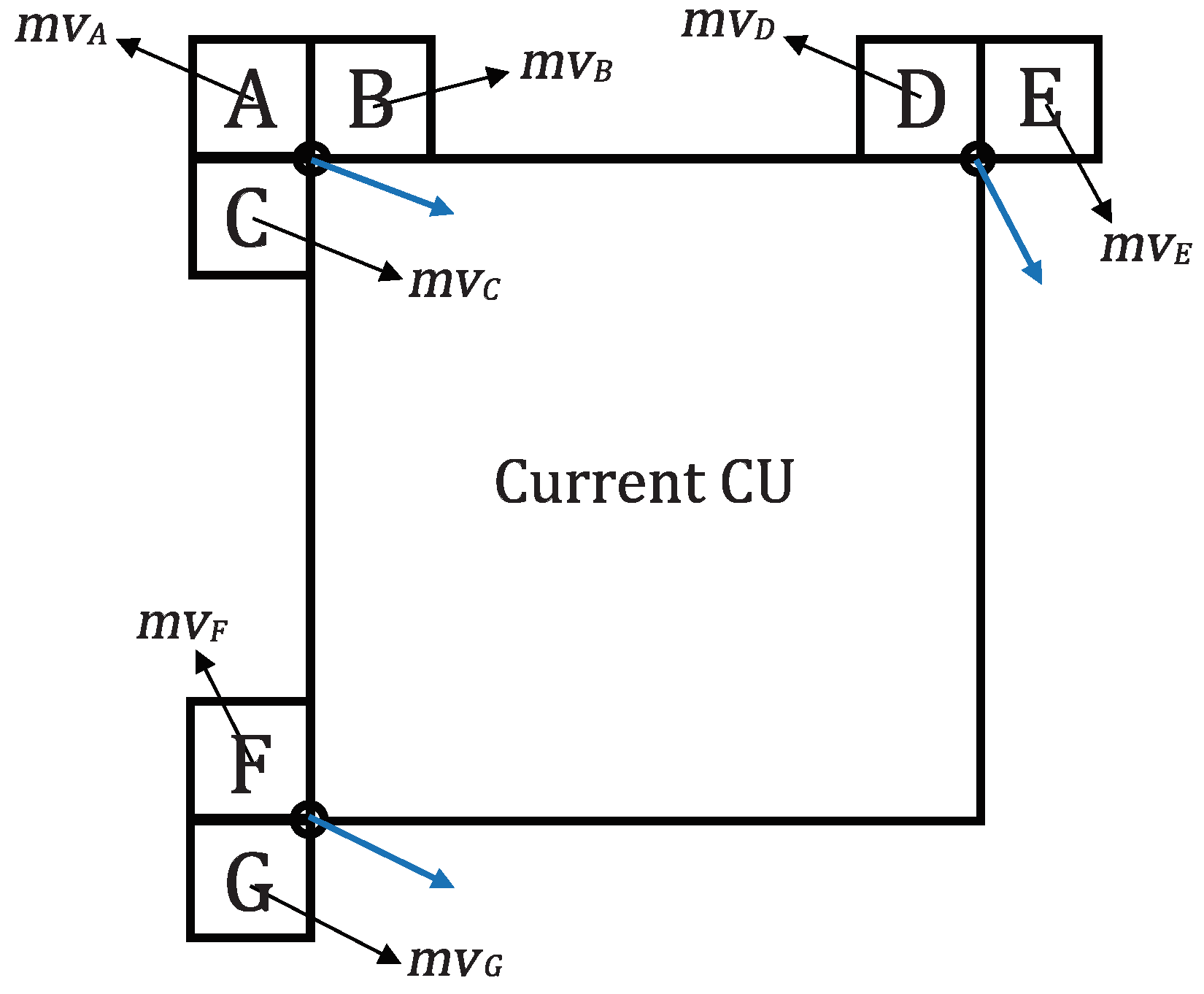
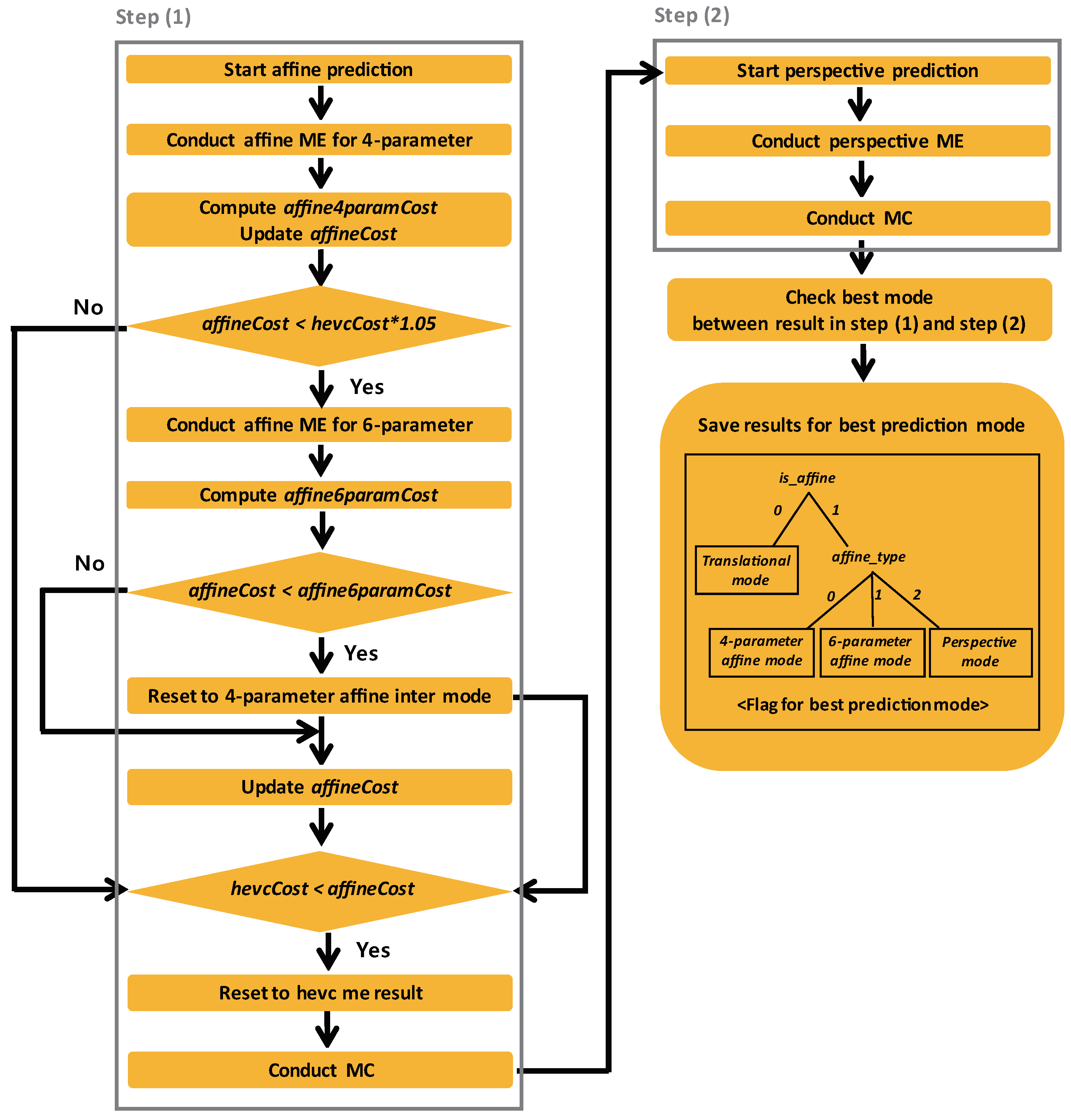
Based on the aforementioned perspective motion model, the proposed algorithm is integrated into the existing AMC. A flowchart of the proposed algorithm is shown in
Figure 8. Each motion model has its own strength. As the number of parameters increases, the precision of generating a prediction block increases. So at the same time, more bit signaling for CPMVs is required. It is effective to use the perspective motion model with four MVs is appropriate for reliability. On the other hand, if only two or three MVs are sufficient, it may be excessive to use four MVs. To take advantage of each motion model, we propose an adaptive multi-motion model-based technique.
After performing fundamental translational ME and MC as in HEVC, the 4-parameter and 6-parameter affine prediction process is conducted first in step (1). Then, the proposed perspective prediction process is performed as step (2). After that, we check the best mode between result in step (1) and step (2) by RD cost check process in a current CU. Once the best mode is determined, the flag for prediction mode are signaled in the bitstream. At this time, two flags are required: affine flag and affine type flag. If the current CU is finally determined in affine mode, the affine flag is true and false otherwise. In other words, if the affine flag is false, only translational motion is used for ME. An affine type flag is signaled for a CU when its affine flag is true. When an affine type flag is 0, 4-parameter affine motion model is used for a CU. If an affine type flag is 1, 6-parameter affine motion model-based mode is used. Finally, when an affine type flag is 2, it means that the current CU is coded in the perspective mode.
4. Experimental Results
To evaluate the performance of the proposed PAMC module, the proposed algorithm was implemented on VTM 2.0 [
24]. The 14 test sequences used in the experiments were from class A to class F specified in the JVET common test conditions (CTC) [
25]. Experiments are conducted under random access (RA) and low delay P (LDP) configurations and four base layer quantization parameters (QP) values of 22, 27, 32 and 37. We used 50 frames in each test sequence. The objective coding performance comparison was evaluated by the Bjontegaard-Delta Rate (BD-Rate) measurement [
26]. The BD-Rate was calculated by using piece-wise cubic interpolation.
Table 1 shows the overall experimental results of the proposed algorithm for each test sequence compared with VTM 2.0 baseline. Compared with the VTM anchor, we can see that proposed PAMC algorithm can bring about 0.07% and 0.12% BD-Rate gain on average Y component in RA and LDP cases respectively, and besides it can be up to 0.45% and 0.30% on Y component for random access (RA) and low delay P (LDP) configurations, respectively. Especially in LDP, shows better gain averagely. Compared to the RA, which allow bi-directional coding schemes so have two or more prediction blocks, LDP has one predication block. For the inter prediction algorithm, the coding performance depends on the number of reference frames. For these reason, when the novel algorithm is applied to the existing encoder, the coding efficiency is higher in the LDP configuration.
Although there were a small BD-rate losses of chroma components, the chroma components are usually less sensitive to the perception of human eye for recognition. So the luminance component is more important to measure the performance. The proposed algorithm achieved up to 0.45% and in the most of sequences, the coding gain was obtained in Y component (luminance component) although they were small value in some sequences such as BasketballDrill, PartyScene, and BQsquare with RA configuration. For RaceHorse, SlideEditing, and FourPeople sequences in LDP configuration, 0.25%, 0.28%, and 0.45% of DB-rate savings of Y component were observed in
Table 1.
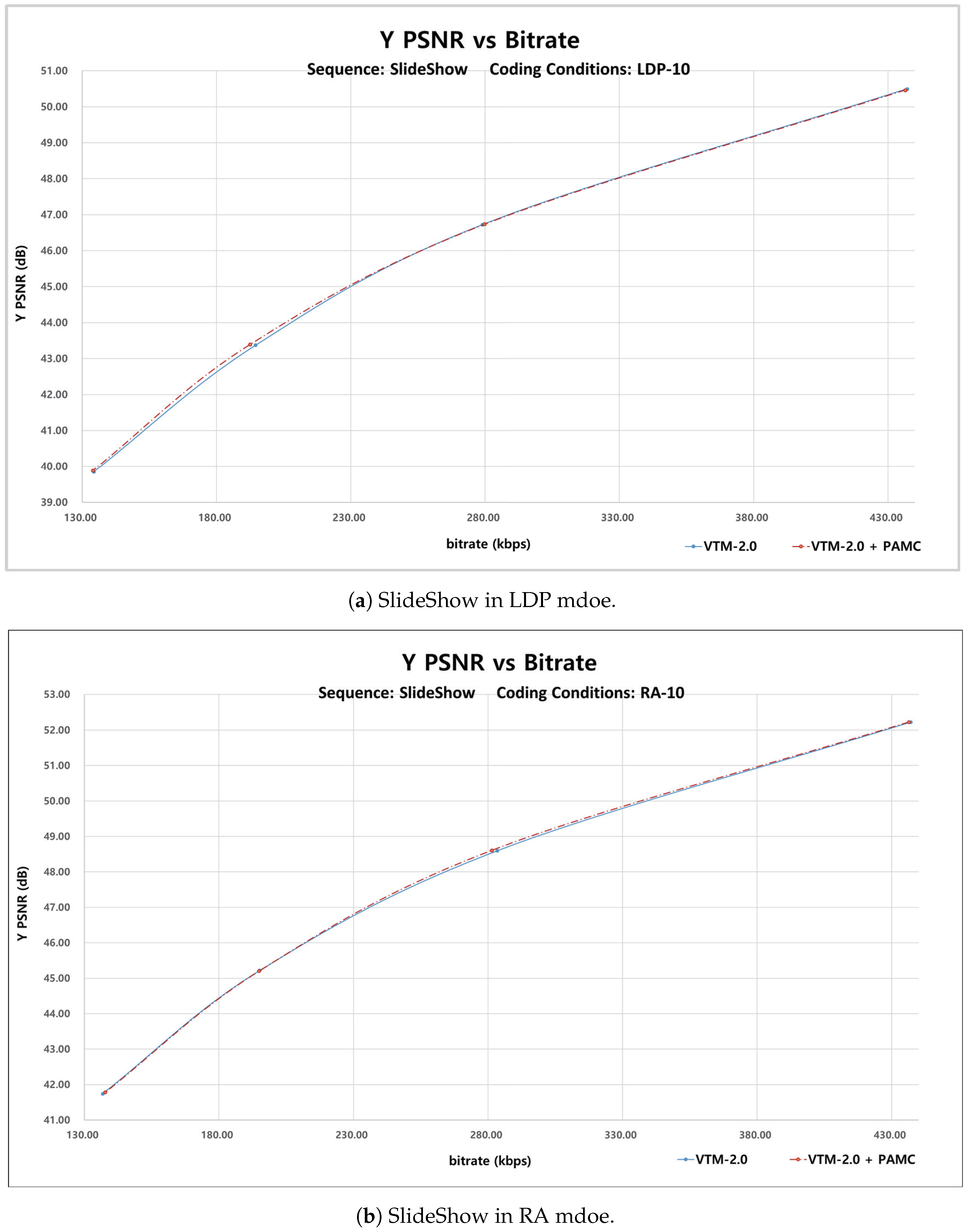
Some examples of rate-distortion (R-D) curves are shown in
Figure 9. The R-D curves also verify that the proposed perspective affine MC can achieve better coding performance compared with the VTM baseline. It can be seen from
Figure 9 that the proposed algorithm works more efficiently than the existing affine MC algorithm in both the LDP and RA configurations. For LDP coding condition, it is more efficient in
= 32 and
= 37 cases and for RA coding condition, it seems to have an effect on
= 22 and
= 27.
To improve the coding efficiency through the proposed algorithm, the test sequence have to contain irregular object distortions or dynamic rapid motions.
Figure 10 shows the examples of perspective motion area in test sequences.
Figure 10a–c present the examples of sequence “Campfire”, “CatRobot1” and “BQTerrace”, respectively. The class A sequence “Campfire” contains a bonfire that moves inconsistently and steadily. Also “CatRobot1” contains a lot of flapping scarves and a flipped book, and class B sequence “BQTerrace” involves the ripples on the surface of the water. All of such moving objects commonly include object distortions whose shape changes. Because of this, those sequences can be compressed more efficiently by the proposed framework. The results of “Campfire” and “CatRobot1” sequences show that proposed PAMC achieves 0.09% and 0.10% BD-Rate savings respectively on Y component in RA. The result of “BQTerrace” sequence shows a coding gain of 0.08% on Y component for both RA and LDP.
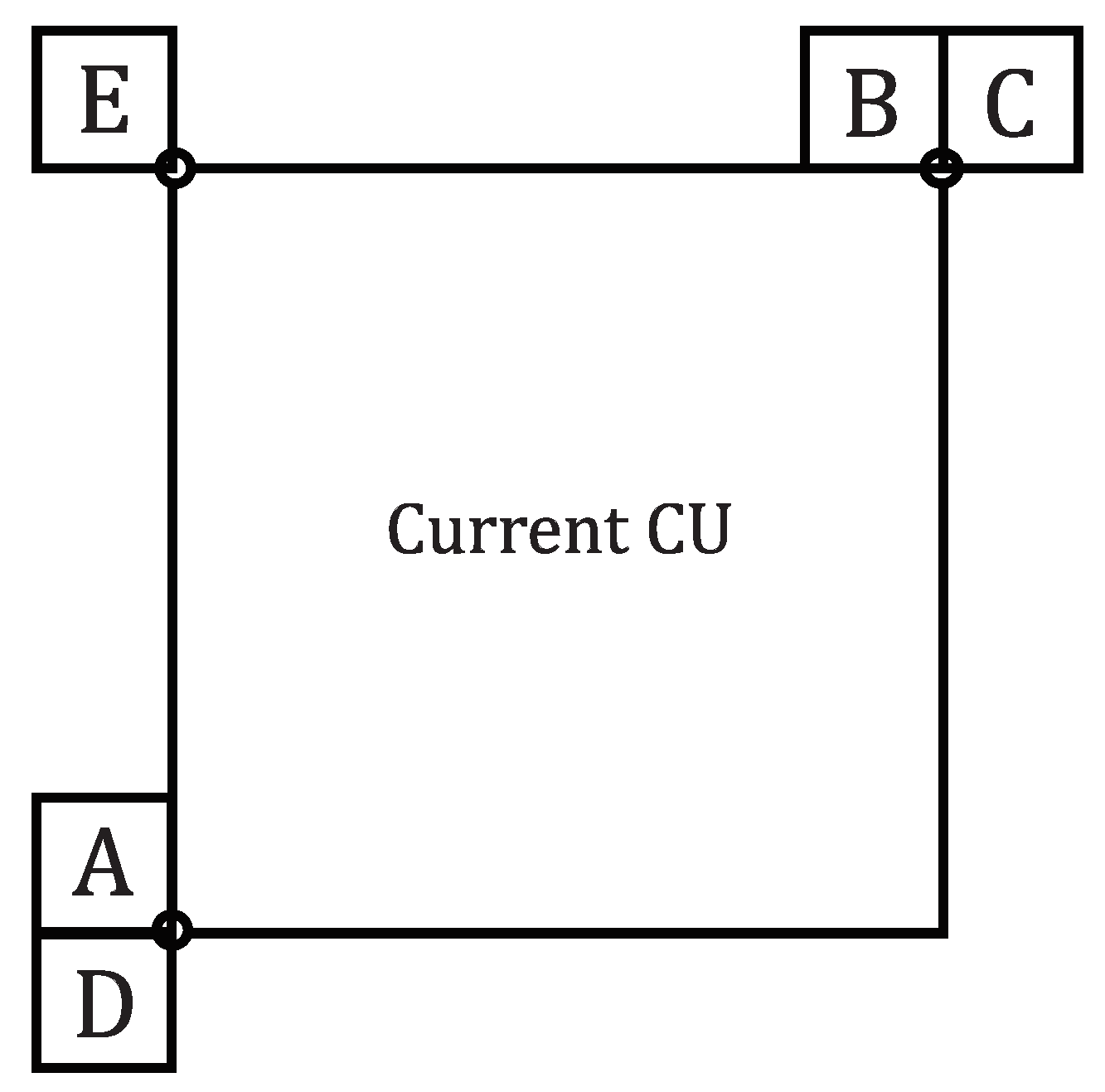
Figure 11 shows an example of comparing AMC in VVC and the proposed PAMC using “CatRobot1” sequence. It is a result for POC 24 encoded by setting QP 22 in RA.
Figure 11a presents the coded CU with affine mode in VVC baseline and
Figure 11b shows the coded CU with affine and perspective mode in the proposed framework. If the unfilled rectangles imply the CUs coded in affine mode and the filled rectangles imply the CUs coded in perspective mode, in
Figure 11b, some filled rectangles can be found on scarves and on the pages of a book. The class B sequences “RitualDance” and “BasketballDrive” and class C sequence “BasketballDrill”, which contain dynamic fast movements, can also be seen to bring coding gains in both RA and LDP configurations. For the three sequences mentioned above, performance result shows that proposed PAMC results in 0.04%, 0.14%, and 0.09% BD-Rate savings respectively on Y component in RA. In LDP configuration, BD-Rate gains are 0.06%, 0.06% and 0.02% respectively on Y component.
In class F which has the screen content sequences, rapid long range motions as large as half a frame often happen like browsing and document editing. Even in this case, the proposed PAMC algorithm can bring BD-Rate gain. In particular, the “SlideShow” sequence gives the largest coding gain resulting in 0.30% and 0.45% BD-Rate savings on Y component in RA and LDP respectively. Besides, on U component in LDP, it brings 1.39% of BD-Rate gain.
When the resolution of sequence is too small such as class D, the sequence contains a small amount of textures and object content. Therefore, it is possible to estimate the motion accurately with only using further enhanced configuration. For that reason, it can be seen from the result of class D that proposed algorithm contributes to overall coding gain in LDP but not in RA. The result of “BQSquare” sequence shows that proposed PAMC achieves 0.03%, 0.42% and 1.87% BD-Rate savings on Y, U and V components respectively in LDP. For “RaceHorces” sequence, the result shows 0.25% of BD-Rate gain on Y component in LDP.
As the proposed algorithm is designed to better describe the motion with distortion of object shape, some equirectangular projection (ERP) format sequences [
27] are selected to verify the performance of the proposed algorithm.
Figure 12 shows an example of ERP sequence.
Figure 12a presents a frame of the “Broadway” sequence and
Figure 12b shows a enlarged specific area of the frame.
Figure 12c shows a picture in posterior frame for the same area. The ERP produces significant deformation, especially in the pole area. It can be obviously seen from
Figure 12 that the distortion of the building object occurs. Perspective motion model can take such deformation into account when compressing the planar video of panoramic content.
The R-D performance of the proposed algorithm for the ERP test sequences is illustrated in
Table 2. From
Table 2, we can see that the proposed framework can be up to 0.15% on Y component for low delay P (LDP) configuration. The experimental results obviously demonstrate that the proposed perspective affine motion model can well represent the motion with distortion of object shape.
As shown in some video coding research [
28,
29], the results show 0.07% and 0.12% BD-Rate gain on average, respectively. Furthermore, several advanced affine motion estimation algorithms in JVET meeting documents [
30,
31,
32], the results show 0.09%, 0.09% and 0.13% BD-Rate gain on average Y component. Compared with these results, the performance of the proposed algorithm is also competitive. Moreover, our proposed method contributes in that the encoder can be more robust in natural videos by proposing a flexible motion model for affine ME, one of the main inter prediction tools of the existing VTM codec.
From experimental results, the designed PAMC achieved better coding gain compared to VTM 2.0 Baseline. It means that the proposed PAMC scheme can be applied for providing better video quality in terms of a limited network bandwidth environment.
5. Conclusions
In this paper, an efficient perspective affine motion compensation framework was proposed to estimate further complex motions beyond the affine motion. Affine motion model has properties which maintains parallelism, and thus cannot work efficiently for some sequences containing object distortions or rapid dynamic motions. In the proposed algorithm, an eight-parameter perspective motion model was first defined and analyzed. Like the technique applied to AMC of existing VTM, we designed four MVs based motion model instead of using eight parameters. Then the perspective motion model-based motion compensation algorithm was proposed. To take advantage of each affine and perspective motion model, we proposed an adaptive multi-motion model-based technique. The proposed framework was implemented in the reference software of VVC. We experimented with two kinds of sequences. In addition to experimenting with JVET common test condition sequences, we demonstrated the effectiveness of the proposed algorithm by showing the results for the equirectangular projection format sequences. The experimental results showed that the proposed perspective affine motion compensation framework could achieve much better BD-Rate performance compared with the VVC baseline especially for sequences that contain irregular object distortions or dynamic rapid motions.
Although the proposed algorithm improved the inter-prediction of the VVC video standard technology, there is still room for further improvement. For future studies, the higher-order motion models should be investigated and applied for three-dimensional modeling of motion. Higher-order models can improve the accuracy of irregular motion, but they can result in an increase in the number of bits, as these parameters must be sent together. Considering these points, an approximation model should also be conducted to be compatible for the VVC standard.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}