Ensemble Bagged Tree Based Classification for Reducing Non-Technical Losses in Multan Electric Power Company of Pakistan

 ,
,
Abstract
1. Introduction
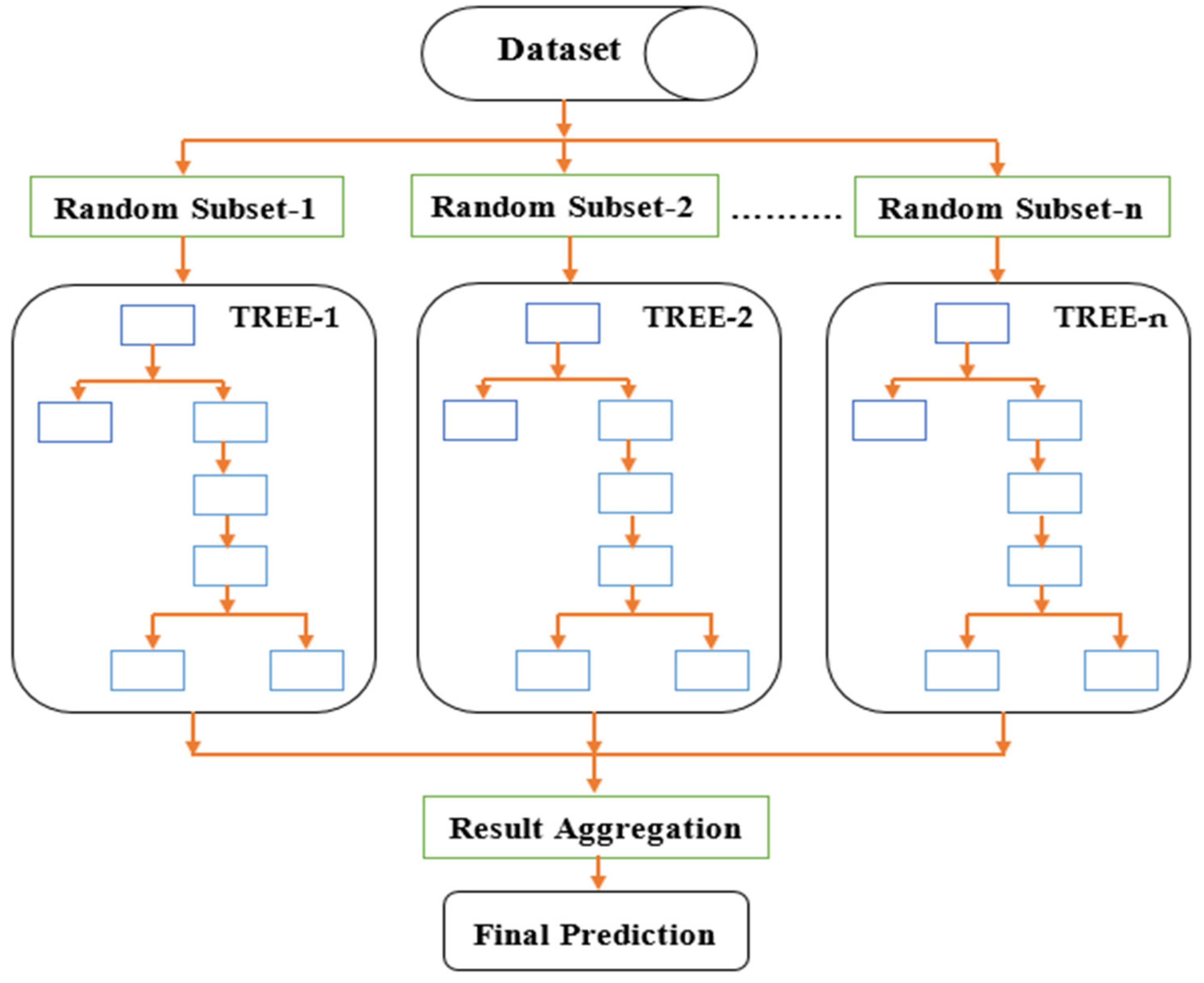
2. Classification Using Ensemble Bagged Tree
3. Methodology
3.1. Data Acquisition
3.2. Consumption Pattern of Fraudulent and Honest Consumers
3.3. Customer Filtering and Selection
- All those consumers whose entire 36 months consumption data was not available or those who were not using electricity due to change of residence or any other reason.
- All consumers who were registered after May 2015.
- All healthy consumers who were charged an average i.e., whose metering equipment became defective during the studied time period.
3.4. Studied Classification Methods
3.4.1. Decision Trees
3.4.2. Support Vector Machines (SVM)
3.4.3. K-Nearest Neighbor
3.4.4. Ensemble Classification
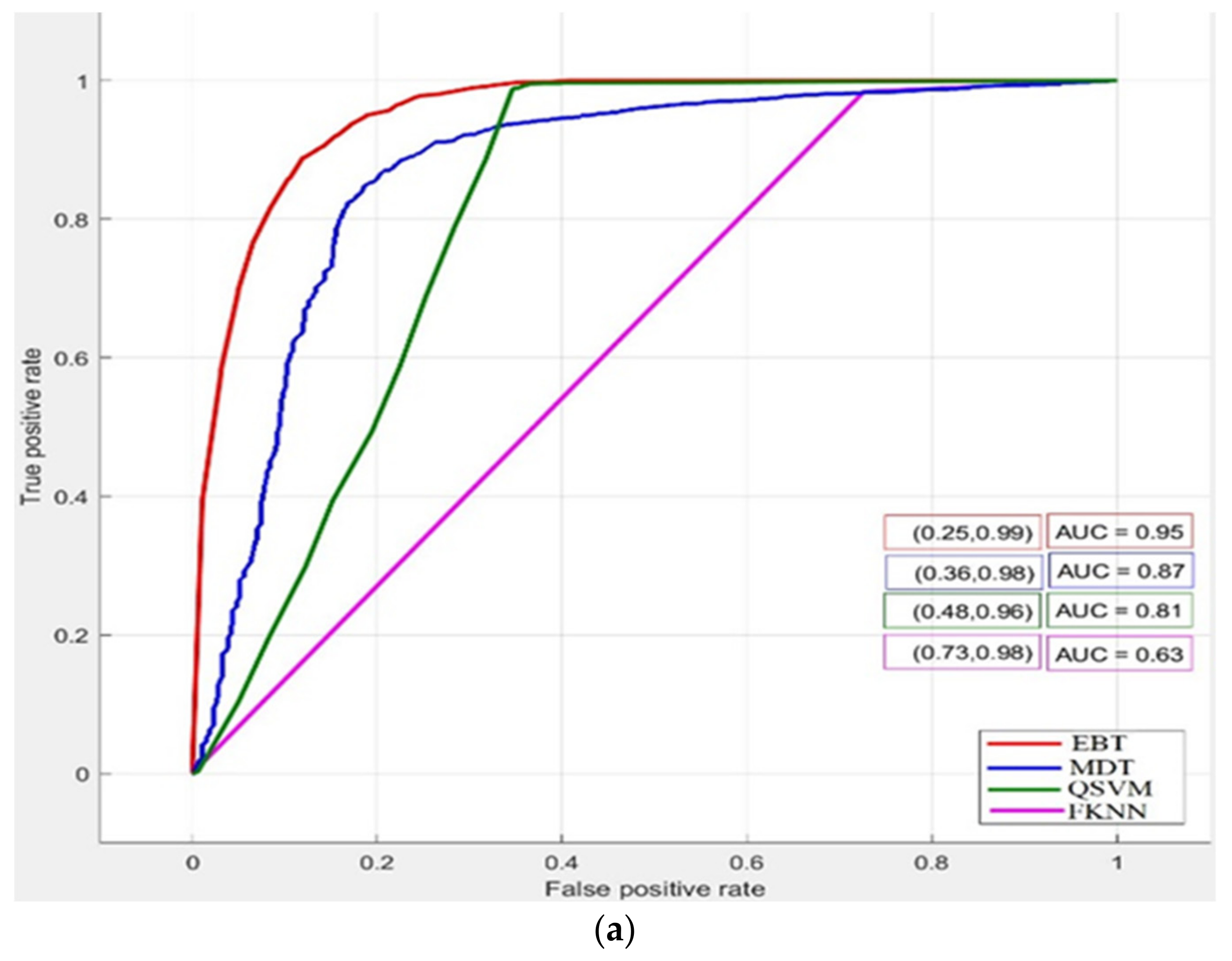
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Depuru, S.S.S.R.; Wang, V.; Devabhaktuni, V.; Nelapati, P. A hybrid neural network model and encoding technique for enhanced classification of energy consumption data. In Proceedings of the 2011 IEEE Power and Energy Society General Meeting, San Diego, CA, USA, 24–29 July 2011; pp. 1–8. [Google Scholar]
- Costa, B.C.; Alberto, B.L.A.; Portela, A.M.; Maduro, W.; Eler, E.O. Fraud Detection in Electric Power Distribution Networks using an Ann-Based Knowledge-Discovery Process. Int. J. Artif. Intell. Appl. 2013, 4, 17–23. [Google Scholar] [CrossRef]
- Regulators, E.E.; Saint-michel, C. CEER Report on Power Losses; Arrondissement judiciaire de Bruxelles: Brussels, Belgium, 2017. [Google Scholar]
- Messinis, G.M.; Hatziargyriou, N.D. Review of non-technical loss detection methods. Electr. Power Syst. Res. 2018, 158, 250–266. [Google Scholar] [CrossRef]
- Sharma, T.; Pandey, K.K.; Punia, D.K.; Rao, J. Of pilferers and poachers: Combating electricity theft in India. Energy Res. Soc. Sci. 2016, 11, 40–52. [Google Scholar] [CrossRef]
- Sahoo, S.; Nikovski, D.; Muso, T.; Tsuru, K. Electricity theft detection using smart meter data. In Proceedings of the 2015 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference ISGT, Washington, DC, USA, 18–20 February 2015; pp. 1–5. [Google Scholar]
- Viegas, J.L.; Esteves, P.R.; Melício, R.; Mendes, V.M.F.; Vieira, S.M. Solutions for detection of non-technical losses in the electricity grid: A review. Renew. Sustain. Energy Rev. 2017, 80, 1256–1268. [Google Scholar] [CrossRef]
- Kessides, I.N. Chaos in power: Pakistan’s electricity crisis. Energy Policy. 2013, 55, 271–285. [Google Scholar] [CrossRef]
- Guerrero, J.I.; Monedero, I.; Biscarri, F.; Biscarri, J.; Millan, R.; Leon, C. Non-Technical Losses Reduction by Improving the Inspections Accuracy in a Power Utility. IEEE Trans. Power Syst. 2018, 33, 1209–1218. [Google Scholar] [CrossRef]
- Depuru, S.S.S.R.; Wang, L.; Devabhaktuni, V. Smart meters for power grid: Challenges, issues, advantages and status. Renew. Sustain. Energy Rev. 2011, 15, 2736–2742. [Google Scholar] [CrossRef]
- Singh, S.K.; Bose, R.; Joshi, A. Energy Theft Detection in Advanced Metering Infrastructure. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018; pp. 529–534. [Google Scholar]
- Jiang, R.; Lu, R.; Wang, Y.; Luo, J.; Shen, C.; Shen, X. Energy-theft detection issues for advanced metering infrastructure in smart grid. Tsinghua Sci. Technol. 2014, 19, 105–120. [Google Scholar] [CrossRef]
- Jokar, P. Detection of Malicious Activities Against Advanced Metering Infrastructure in Smart Grid. Ph.D. Thesis, University of British Columbia, Vancouver, BC, Canada, December 2015. [Google Scholar]
- Cardenas, A.A.; Amin, S.; Schwartz, G.; Dong, R.; Sastry, S. A game theory model for electricity theft detection and privacy-aware control in AMI systems. In Proceedings of the 2012 50th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 1–5 October 2012; pp. 1830–1837. [Google Scholar]
- Jokar, P.; Arianpoo, N.; Leung, V.C.M. Electricity theft detection in AMI using customers’ consumption patterns. IEEE Trans. Smart Grid 2016, 7, 216–226. [Google Scholar] [CrossRef]
- Muniz, C.; Figueiredo, K.; Vellasco, M.; Chavez, G.; Pacheco, M. Irregularity detection on low tension electric installations by neural network ensembles. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 2176–2182. [Google Scholar]
- Angelos, E.W.S.D.; Saavedra, O.R.; Cortés, O.A.C.; de Souza, A.N. Detection and identification of abnormalities in customer consumptions in power distribution systems. IEEE Trans. Power Deliv. 2011, 26, 2436–2442. [Google Scholar] [CrossRef]
- Spirić, J.V.; Stanković, S.S.; Dočić, M.B.; Popović, T.D. Using the rough set theory to detect fraud committed by electricity customers. Int. J. Electr. Power Energy Syst. 2014, 62, 727–734. [Google Scholar] [CrossRef]
- McLaughlin, S.; Holbert, B.; Fawaz, A.; Berthier, R.; Zonouz, S. A multi-sensor energy theft detection framework for advanced metering infrastructures. IEEE J. Sel. Areas Commun. 2013, 31, 1319–1330. [Google Scholar] [CrossRef]
- Mohammad, N.; Barua, A.; Arafat, M.A. A smart prepaid energy metering system to control electricity theft. In Proceedings of the 2013 International Conference on Power, Energy and Control (ICPEC), Sri Rangalatchum Dindigul, India, 6–8 February 2013; no. ATmega 32. pp. 562–565. [Google Scholar]
- Nagi, J.; Mohammad, A.M.; Yap, K.S.; Tiong, S.K.; Ahmed, S.K. Nontechnical loss detection for metered consumers in power utility using support vector machines. IEEE Trans. Power Deliv. 2010, 25, 1162–1171. [Google Scholar] [CrossRef]
- Nagi, J.; Yap, K.S.; Tiong, S.K.; Ahmed, S.K.; Nagi, F. Improving SVM-based nontechnical loss detection in power utility using the fuzzy inference system. IEEE Trans. Power Deliv. 2011, 26, 1284–1285. [Google Scholar] [CrossRef]
- Chebrolu, S.; Abraham, A.; Thomas, J.P. Feature deduction and ensemble design of intrusion detection systems. Comput. Secur. 2005, 24, 295–307. [Google Scholar] [CrossRef]
- Kim, M.J.; Kang, D.K. Classifiers selection in ensembles using genetic algorithms for bankruptcy prediction. Expert Syst. Appl. 2012, 39, 9308–9314. [Google Scholar] [CrossRef]
- Cruz, R.M.O.; Sabourin, R.; Cavalcanti, G.D.C. Dynamic classifier selection: Recent advances and perspectives. Inf. Fusion 2018, 41, 195–216. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Lecture Notes in Computer Science, Proceedings of the International Workshop on Multiple Classifier Systems, Cagliari, Italy, 21–23 June 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar]
- Soares, S.G.; Araújo, R. A dynamic and on-line ensemble regression for changing environments. Expert Syst. Appl. 2015, 42, 2935–2948. [Google Scholar] [CrossRef]
- Krawczyk, B.; Minku, L.L.; Gama, J.; Stefanowski, J.; Woźniak, M. Ensemble learning for data stream analysis: A survey. Inf. Fusion 2017, 37, 132–156. [Google Scholar] [CrossRef]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Xiao, H.; Xiao, Z.; Wang, Y. Ensemble classification based on supervised clustering for credit scoring. Appl. Soft Comput. J. 2016, 43, 73–86. [Google Scholar] [CrossRef]
- Mousavi, R.; Eftekhari, M. A new ensemble learning methodology based on hybridization of classifier ensemble selection approaches. Appl. Soft Comput. J. 2015, 37, 652–666. [Google Scholar] [CrossRef]
- Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 21–44. [Google Scholar] [CrossRef]
- Muhlbaier, M.; Topalis, A.; Polikar, R. Ensemble Confidence Estimates Posterior Probability. In Lecture Notes in Computer Science, Proceedings of the International Workshop on Multiple Classifier Systems, Seaside, CA, USA, 13–15 June 2005; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3541, pp. 326–335. [Google Scholar]
- Mishra, P.K.; Yadav, A.; Pazoki, M. A Novel Fault Classification Scheme for Series Capacitor Compensated Transmission Line Based on Bagged Tree Ensemble Classifier. IEEE Access 2018, 6, 27373–27382. [Google Scholar] [CrossRef]
- Choudhury, S.; Chaudhuri, A.; Patra, D. An ensemble approach for the detection and classification of mixed pixels of remotely sensed images. In Proceedings of the 2018 4th International Conference on Recent Advances in Information Technology (RAIT), Dhanbad, India, 15–17 March 2018; pp. 1–5. [Google Scholar]
- Zhang, L.; Xiong, J.; Zhao, H.; Hong, H.; Zhu, X.; Li, C. Sleep stages classification by CW Doppler radar using bagged trees algorithm. In Proceedings of the 2017 IEEE Radar Conference (RadarConf), Seattle, WA, USA, 8–12 May 2017; pp. 0788–0791. [Google Scholar]
- León, C.; Biscarri, F.; Monedero, I.; Guerrero, J.I.; Biscarri, J.; Millán, R. Variability and trend-based generalized rule induction model to NTL detection in power companies. IEEE Trans. Power Syst. 2011, 26, 1798–1807. [Google Scholar] [CrossRef]
- Coma-Puig, B.; Carmona, J.; Gavalda, R.; Alcoverro, S.; Martin, V. Fraud detection in energy consumption: A supervised approach. In Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; pp. 120–129. [Google Scholar]
- Kosut, J.P.; Santomauro, F.; Jorysz, A.; Fernández, A.; Lecumberry, F.; Rodriguez, F. Abnormal consumption analysis for fraud detection: UTE-UDELAR joint efforts. In Proceedings of the 2015 IEEE PES Innovative Smart Grid Technologies Latin America (ISGT LATAM), Montevideo, Uruguay, 5–7 October 2015; pp. 887–892. [Google Scholar]
- Shekara, S.; Reddy, S.; Wang, L.; Devabhaktuni, V. Classification for Detection of Electricity Theft. In Proceedings of the 2011 IEEE/PES Power Systems Conference and Exposition, Phoenix, AZ, USA, 20–23 March 2011; pp. 1–8. [Google Scholar]
- Jindal, A.; Dua, A.; Kaur, K.; Singh, M.; Kumar, N.; Mishra, S. Decision Tree and SVM-Based Data Analytics for Theft Detection in Smart Grid. IEEE Trans. Ind. Inform. 2016, 12, 1005–1016. [Google Scholar] [CrossRef]
- Nagi, J.; Yap, K.S.; Tiong, S.K.; Ahmed, S.K.; Mohammad, A.M. Detection of abnormalities and electricity theft using genetic support vector machines. In Proceedings of the TENCON 2008—2008 IEEE Region 10 Conference, Hyderabad, India, 19–21 November 2008; pp. 1–6. [Google Scholar]
- Pereira, D.R.; Pereira, D.R.; Pazoti, M.A.; Pereira, L.A.M.; Rodrigues, D.; Ramos, C.O.; Souza, A.N.; Papa, J.P. Social-Spider Optimization-based Support Vector Machines applied for energy theft detection. Comput. Electr. Eng. 2016, 49, 25–38. [Google Scholar] [CrossRef]
- Ramos, C.C.O.; Souza, A.N.; Chiachia, G.; Falcão, A.X.; Papa, J.P. A novel algorithm for feature selection using Harmony Search and its application for non-technical losses detection. Comput. Electr. Eng. 2011, 37, 886–894. [Google Scholar] [CrossRef]
- No, J.; Han, S.Y.; Joo, Y.; Shin, J.-H. Conditional abnormality detection based on AMI data mining. IET Gener. Transm. Distrib. 2016, 10, 3010–3016. [Google Scholar]
- Ramos, C.C.O.; de Sousa, A.N.; Papa, J.P.; Falcão, A.X. A new approach for nontechnical losses detection based on optimum-path forest. IEEE Trans. Power Syst. 2011, 26, 181–189. [Google Scholar] [CrossRef]
- Glauner, P.; Boechat, A.; Dolberg, L.; State, R.; Bettinger, F.; Rangoni, Y. Large-scale detection of non-technical losses in imbalanced data sets. In Proceedings of the 2016 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Minneapolis, MN, USA, 6–9 September 2016; pp. 1–5. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Maximum Number of Splits | Split Criterion |
|---|---|---|
| Fine Tree | 100 | Gini’s diversity index |
| Medium Tree | 20 | Gini’s diversity index |
| Coarse Tree | 4 | Gini’s diversity index |
| Model | Kernel Function | Kernel Scale |
|---|---|---|
| Linear SVM | Linear | 1 |
| Quadratic SVM | Quadratic | 1 |
| Cubic SVM | Cubic | 1 |
| Fine Gaussian SVM | Gaussian | 1.5 |
| Medium Gaussian SVM | Gaussian | 6 |
| Coarse Gaussian SVM | Gaussian | 24 |
| Model | Distance Metric | Number of Neighbors |
|---|---|---|
| Fine KNN | Euclidean | 1 |
| Medium KNN | Euclidean | 10 |
| Coarse KNN | Euclidean | 100 |
| Cosine KNN | Cosine | 10 |
| Cubic KNN | Minkowski | 10 |
| Weighted KNN | Euclidean | 10 |
| Ensemble Models | Ensemble Method | Learner Type | Max. Number of Splits | Number of Learners |
|---|---|---|---|---|
| Boosted Trees | AdaBoost | Decision tree | 20 | 30 |
| Bagged Trees | Bag | Decision tree | 20 | 30 |
| Subspace KNN | Subspace | Nearest neighbors | 20 | 30 |
| RUSBoosted Trees | RUSBoost Bag | Decision tree | 20 | 30 |
| Random Forest | RUSBoost Bag | Decision tree | 20 | 30 |
| Model | Accuracy | Sensitivity | Specificity | F1 Score | FPR |
|---|---|---|---|---|---|
| Decision Trees | |||||
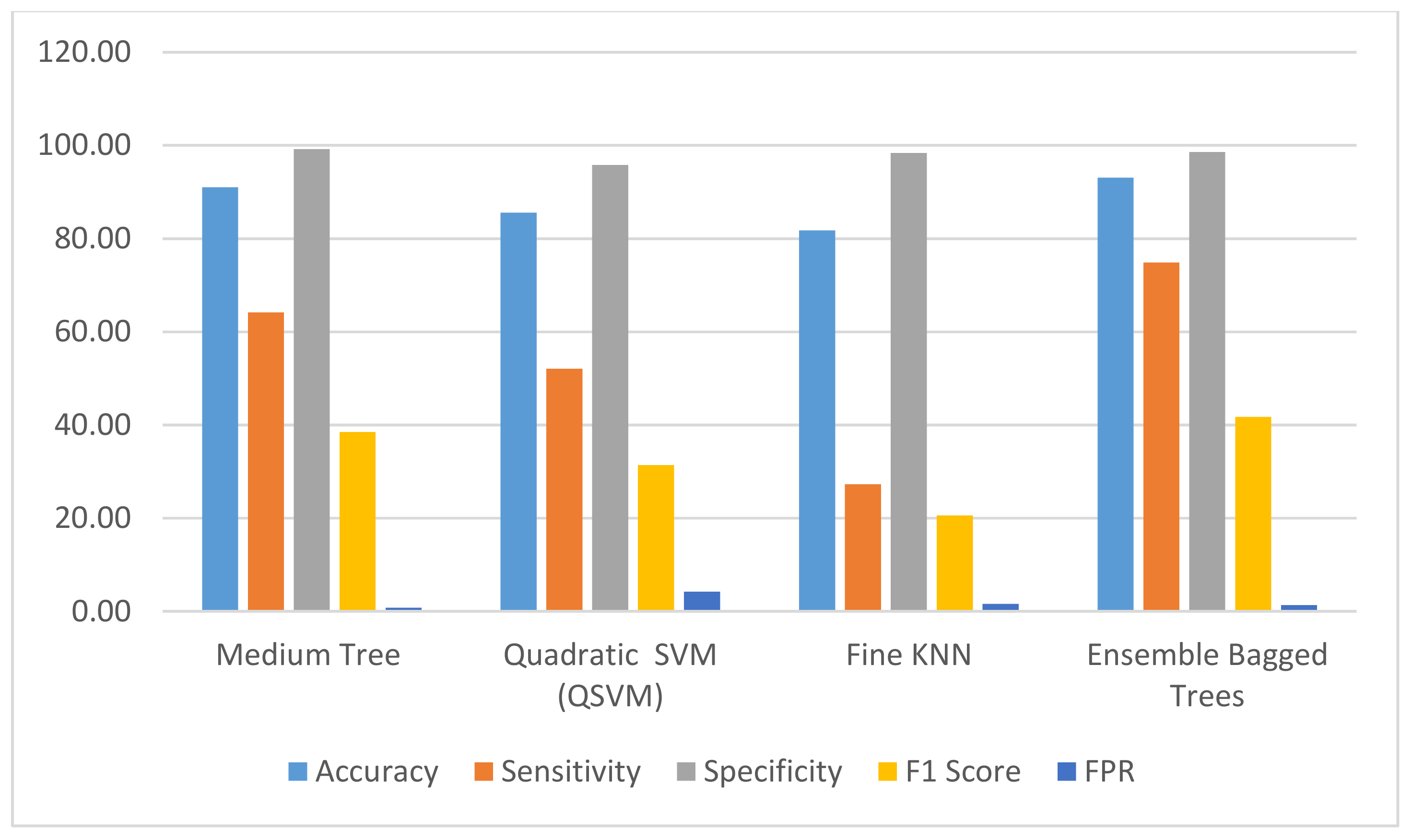
| Fine Tree | 85.84 | 42.33 | 99.10 | 29.14 | 0.90 |
| Medium Tree | 91.02 | 64.19 | 99.20 | 38.48 | 0.80 |
| Coarse Tree | 86.35 | 43.41 | 99.43 | 29.88 | 0.57 |
| Support Vector Machines | |||||
| Linear SVM (LSVM) | 79.54 | 16.43 | 98.77 | 13.64 | 1.23 |
| Quadratic SVM (QSVM) | 85.59 | 52.09 | 95.80 | 31.40 | 4.20 |
| Cubic SVM (CSVM) | 52.32 | 58.14 | 50.54 | 18.14 | 49.46 |
| Fine Gaussian SVM | 85.01 | 63.88 | 91.45 | 33.28 | 8.55 |
| Medium Gaussian SVM | 81.54 | 28.53 | 97.69 | 20.96 | 2.31 |
| Coarse Gaussian SVM | 76.94 | 1.86 | 99.81 | 1.82 | 0.19 |
| K-Nearest Neighbours | |||||
| Fine KNN | 81.79 | 27.29 | 98.39 | 20.58 | 1.61 |
| Medium KNN | 79.58 | 13.49 | 99.72 | 11.79 | 0.28 |
| Coarse KNN | 76.65 | 0.00 | 100.00 | 0.00 | |
| Cosine KNN | 78.20 | 20.00 | 95.94 | 15.00 | 4.06 |
| Cubic KNN | 78.96 | 11.01 | 99.67 | 9.82 | 0.33 |
| Weighted KNN | 79.33 | 12.40 | 99.72 | 10.94 | 0.28 |
| Ensemble Classification | |||||
| Boosted Trees | 90.66 | 61.55 | 99.53 | 37.74 | 0.47 |
| Bagged Trees | 93.08 | 74.88 | 98.63 | 41.75 | 1.37 |
| Subspace Discriminant | 77.23 | 2.79 | 99.91 | 2.71 | 0.09 |
| Subspace KNN | 82.80 | 29.61 | 99.01 | 22.29 | 0.99 |
| RUSBoosted Tree | 89.03 | 66.51 | 95.89 | 36.95 | 4.11 |
| Random Forest | 90.03 | 67.51 | 96.89 | 37.71 | 3.11 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saeed, M.S.; Mustafa, M.W.; Sheikh, U.U.; Jumani, T.A.; Mirjat, N.H. Ensemble Bagged Tree Based Classification for Reducing Non-Technical Losses in Multan Electric Power Company of Pakistan. Electronics 2019, 8, 860. https://doi.org/10.3390/electronics8080860
Saeed MS, Mustafa MW, Sheikh UU, Jumani TA, Mirjat NH. Ensemble Bagged Tree Based Classification for Reducing Non-Technical Losses in Multan Electric Power Company of Pakistan. Electronics. 2019; 8(8):860. https://doi.org/10.3390/electronics8080860
Chicago/Turabian StyleSaeed, Muhammad Salman, Mohd Wazir Mustafa, Usman Ullah Sheikh, Touqeer Ahmed Jumani, and Nayyar Hussain Mirjat. 2019. "Ensemble Bagged Tree Based Classification for Reducing Non-Technical Losses in Multan Electric Power Company of Pakistan" Electronics 8, no. 8: 860. https://doi.org/10.3390/electronics8080860
APA StyleSaeed, M. S., Mustafa, M. W., Sheikh, U. U., Jumani, T. A., & Mirjat, N. H. (2019). Ensemble Bagged Tree Based Classification for Reducing Non-Technical Losses in Multan Electric Power Company of Pakistan. Electronics, 8(8), 860. https://doi.org/10.3390/electronics8080860