Challenges in NoSQL-Based Distributed Data Storage: A Systematic Literature Review


Abstract
:1. Introduction
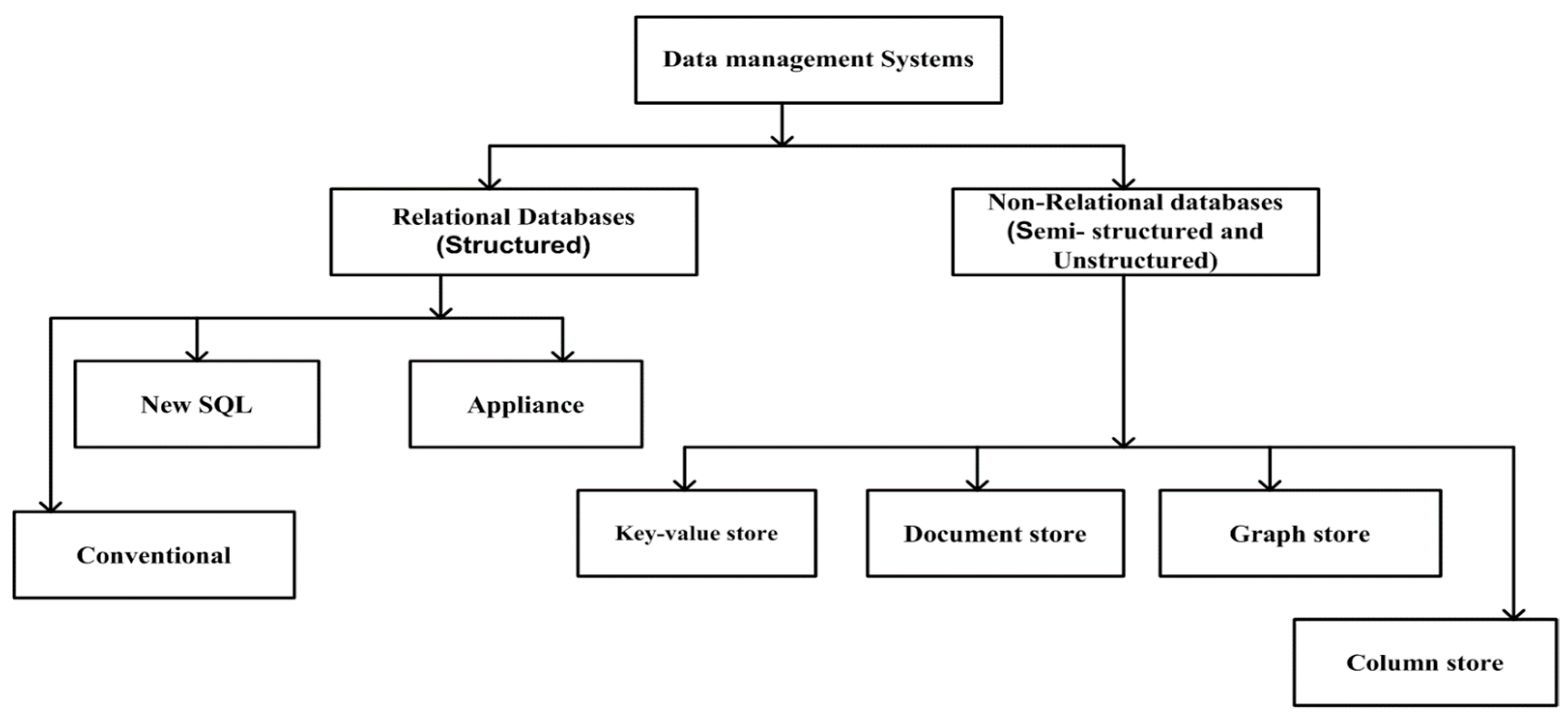
1.1. NoSQL Databases
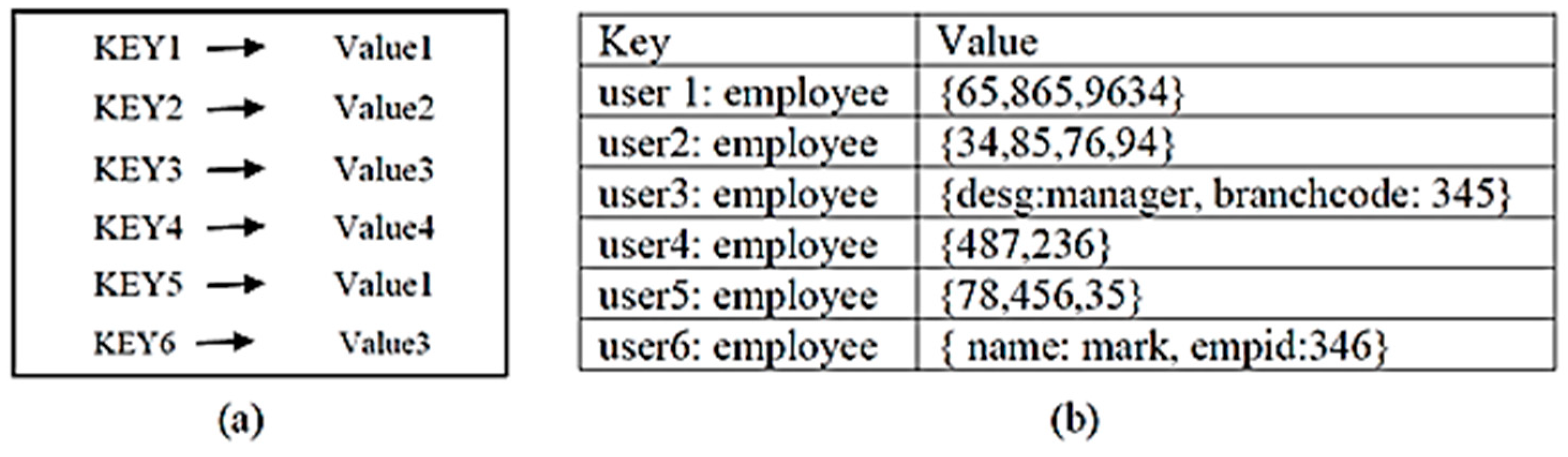
1.2. Key-Value Store
2. Related Work
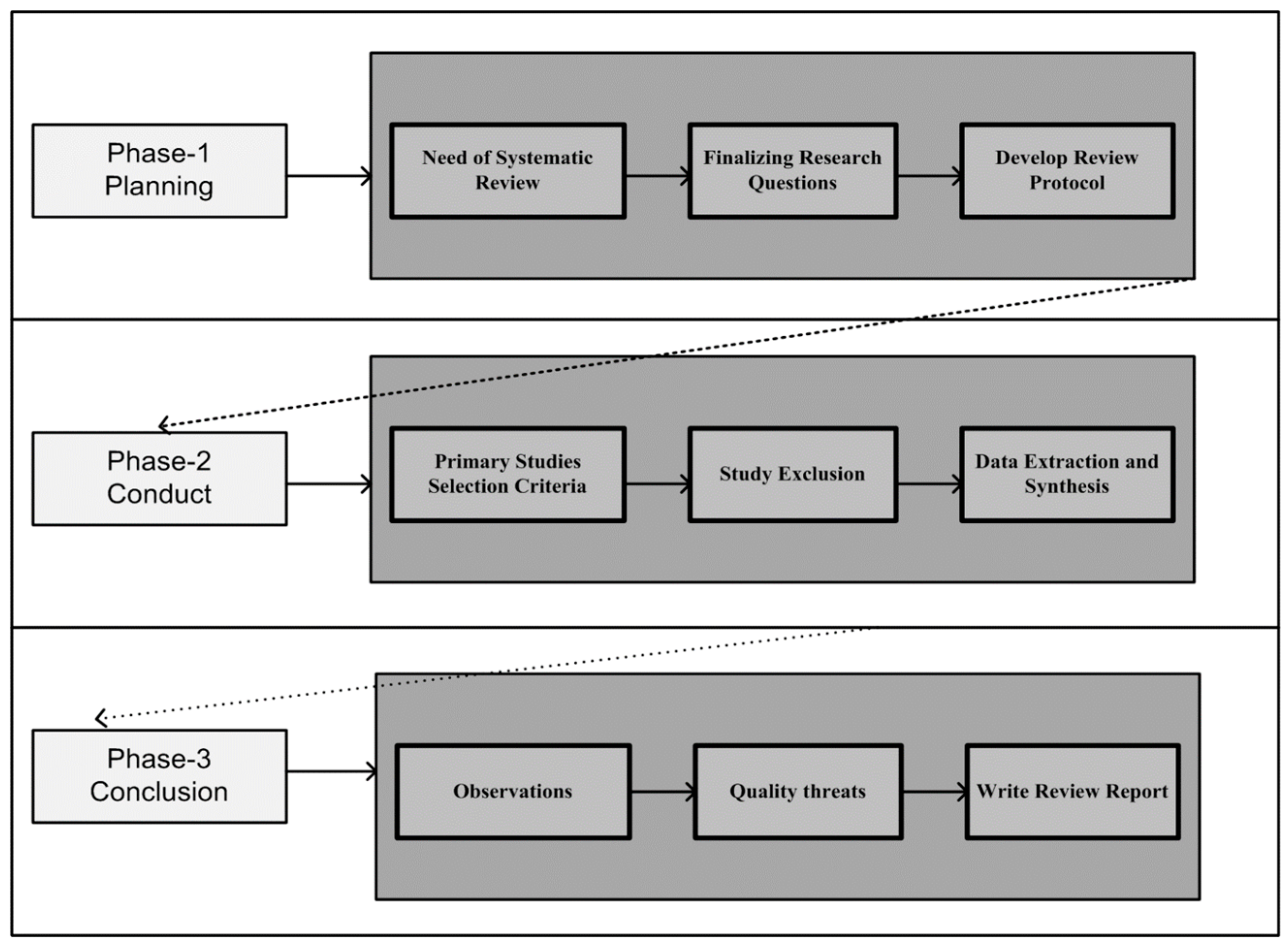
3. Systematic Literature Review (SLR)
3.1. Research Questions
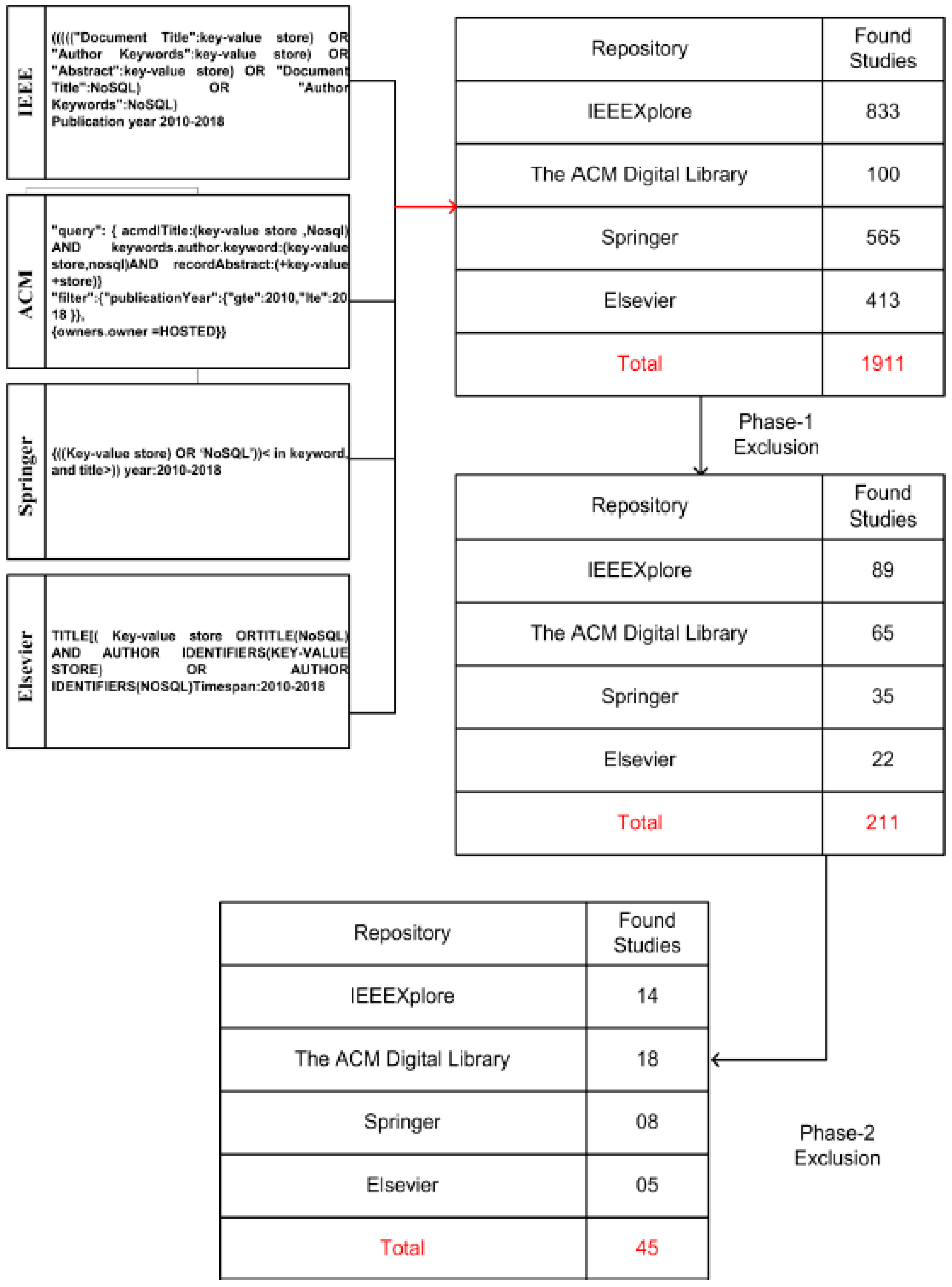
3.2. Searching Strategy
- (1)
- Selection of data sources
- (2)
- Identification of search terms
- (3)
- Scrutiny of studies based on inclusion or exclusion criteria
3.3. Data Sources
3.4. Identification of Search Terms
- On the basis of selected terms that are derived from formulated research questions.
- Try alternative terms, if relevant data on selected terms is not found.
- Search through target databases with the use of Boolean operators; “OR” and “AND” and “NOT” link the selected terms.
3.5. Inclusion and Exclusion Criteria for Study Selection:
- (1)
- Initially, studies were selected on the basis of title and abstracts.
- (2)
- Selection on the basis of reading the abstract.
- (3)
- Further selection based on reading the text of the article.
- Selected material that addresses the quality attribute challenges of the key-value store.
- All articles from peer-reviewed publication forums.
- Highly relevant papers that were published from 2010 to 2018.
- Research papers that are in the English language.
- Material that is not related to research questions.
- PhD dissertations, technical reports, posters, and studies that had less than five pages were excluded. The aim of this study is to extract data from peer-reviewed studies that have sufficient technical details.
- Articles that were not from peer-reviewed publication forums.
- Papers that do not have information related to the publication date, such as issue and volume number, were excluded.
- Research papers that were not in the English language.
- Duplicates were included; we selected the best one that was more recent, complete, and improved. The other was excluded.
- All articles that could answer at least one research question
3.6. Data Extraction
4. Results and Discussions
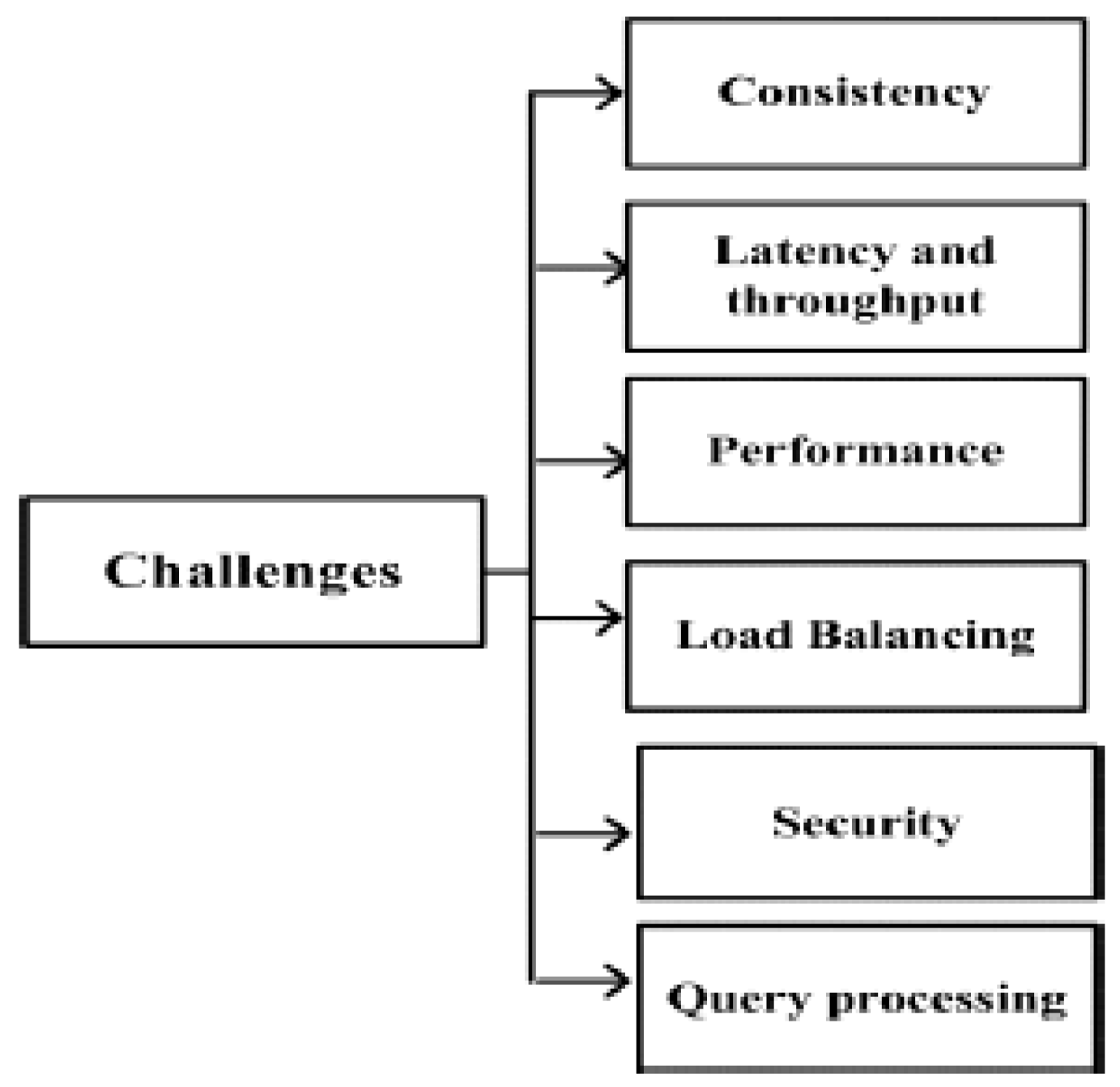
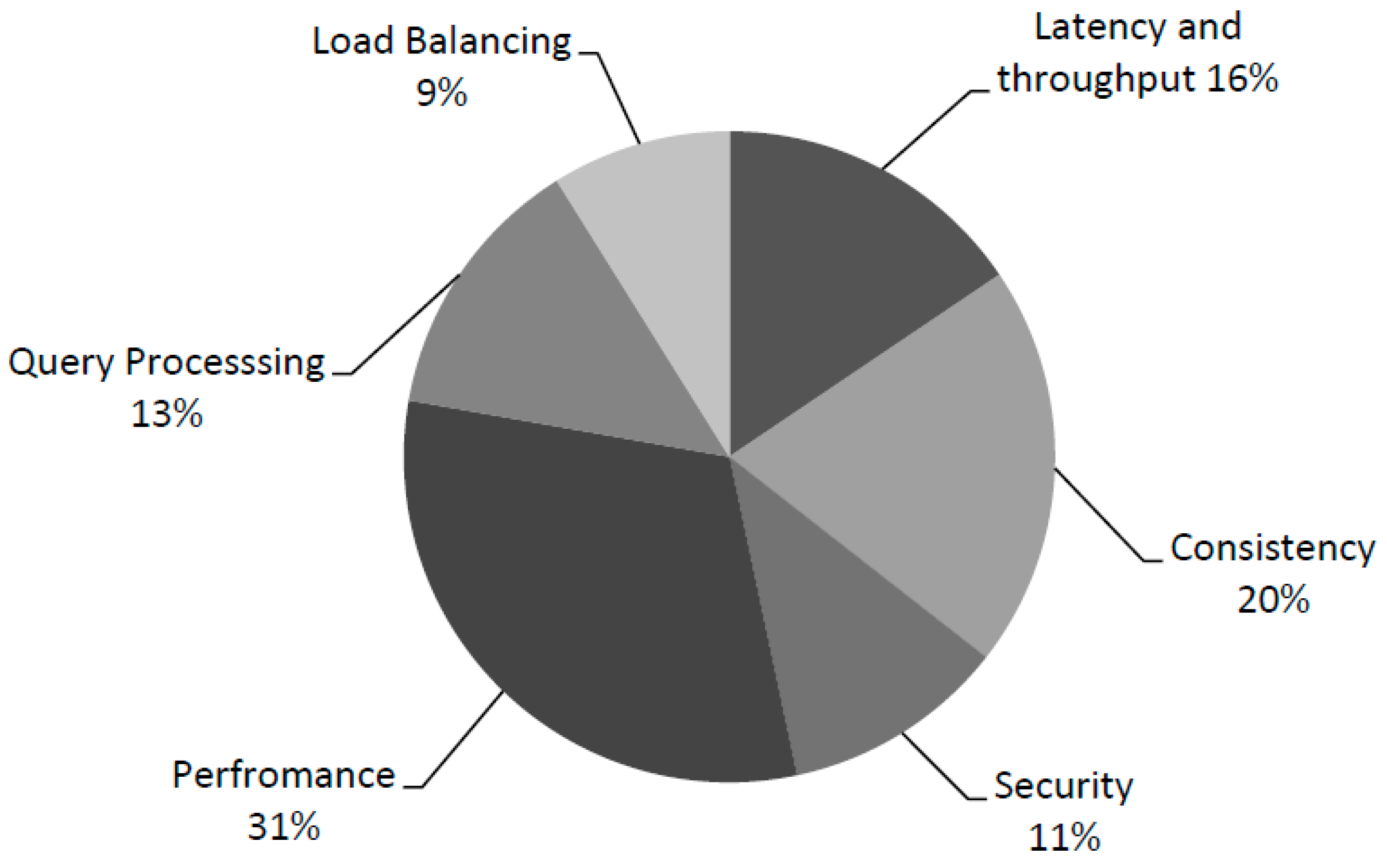
4.1. RQ 1: What Are the Main Challenges Faced by Key-Value Store, and What Are Their Solutions?
4.1.1. Challenges:
4.1.2. Solutions
4.2. RQ2: Which Models and Techniques are Deployed for the Execution and Assessment of the Presented Solutions?
4.2.1. Models and Techniques for Execution
4.2.2. Algorithm-Based Solutions
4.2.3. Techniques for Assessment
4.3. RQ3: What Is the Reliability Status of the Presented Approaches, And What Is the Quality Status of the Included Publications?
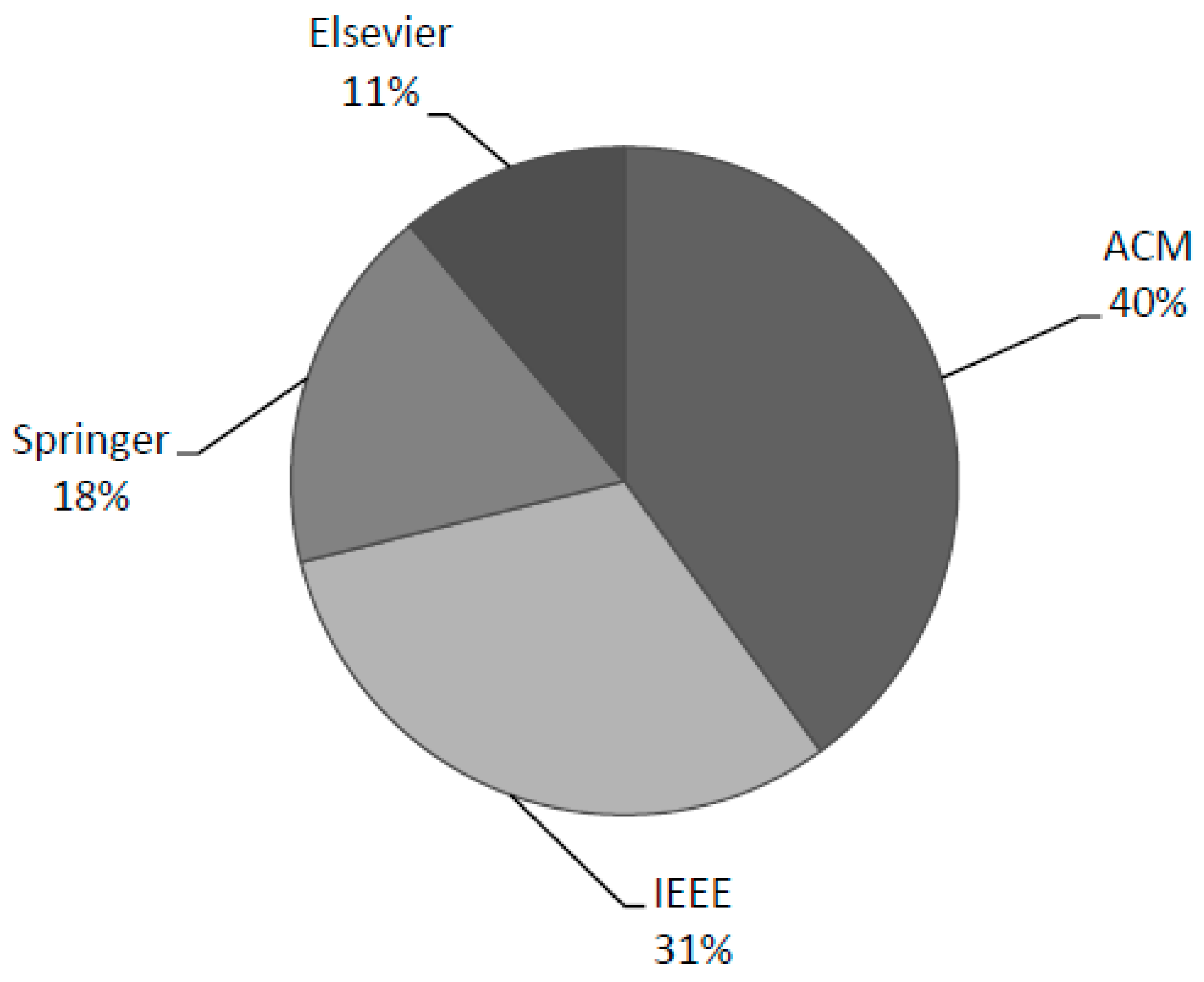
4.4. RQ4: What Are the Forums of Publication and Line of Development in Studies on the Key-Value Store?
4.4.1. Overview of Studies
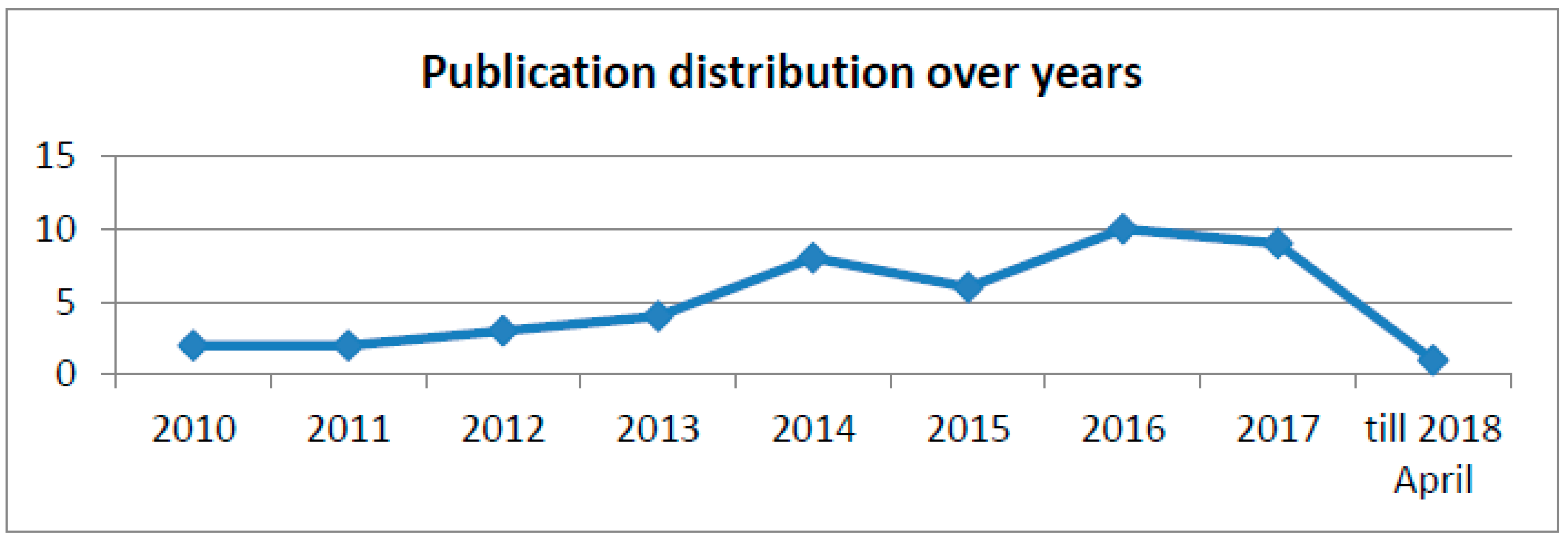
4.4.2. Publication Over Years
5. Discussion
6. Threats to Validity
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
- [S01].
- Bailey, K.A.; Hornyack, P.; Ceze, L.; Gribble, S.D.; Levy, H.M. Exploring storage class memory with key value stores. In Proceedings of the 1st Workshop on Interactions of NVM/FLASH with Operating Systems and Workloads, Farmington, PA, USA, 3 November 2013; p. 4.
- [S02].
- Garefalakis, P.; Papadopoulos, P.; Magoutis, K. Acazoo: A Distributed key-value store based on replicated lsm-trees. In Proceedings of the 2014 IEEE 33rd International Symposium on Reliable Distributed Systems (SRDS), Nara, Japan, 6–9 October 2014; pp. 211–220).
- [S03].
- Yuan, X.; Guo, Y.; Wang, X.; Wang, C.; Li, B.; Jia, X. Enckv: An encrypted KVS with rich queries. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 423–435.
- [S04].
- Qin, X.; Wang, W.; Zhang, W.; Wei, J.; Zhao, X.; Huang, T. Elasticat: A load rebalancing framework for cloud-based KVSs. In Proceedings of the 2012 19th International Conference on High Performance Computing (HiPC), Pune, India, 18–21 December 2012; pp. 1–10.
- [S05].
- Rahman, M.R.; Tseng, L.; Nguyen, S.; Gupta, I.; Vaidya, N. Characterizingand adapting the consistency-latency tradeoff in distributed KVSs. ACM Trans. Auton. Adapt. Syst. (TAAS), 2017, 11, 20.
- [S06].
- Raju, P.; Kadekodi, R.; Chidambaram, V.; Abraham, I. PebblesDB: Building KVSs using Fragmented Log-Structured Merge Trees. In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28 October 2017; pp. 497–514.
- [S07].
- Lemire, D.; Rupp, C. Upscaledb: Efficient integer-key compression in a KVS using SIMD instructions. Inf. Syst. 2017, 66, 13–23.
- [S08].
- Tang, Y.; Wang, T.; Liu, L.; Hu, X.; Jang, J. Lightweight authentication of freshness in outsourced KVSs. In Proceedings of the 30th Annual Computer Security Applications Conference, Los Angeles, CA, USA, 7–11 December 2014; pp. 176–185.
- [S09].
- Lim, H.; Fan, B.; Andersen, D.G.; Kaminsky, M. SILT: A memoryefficient, high- performance KVS. In Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles, Cascais, Portugal, 23–26 October 2011; pp. 1–13).
- [S010].
- Thongprasit, S.; Visoottiviseth, V.; Takano, R. Toward fast and scalable KVSs based on user space TCP/ip stack. In Proceedings of the Asian Internet Engineering Conference, Bangkok, Thailand, 18–20 November 2015; pp. 40–47.
- [S011].
- Debnath, B.; Sengupta, S.; Li, J. FlashStore: High throughput persistent KVS. Proc. VLDB Endow. 2010, 3, 1414–1425.
- [S012].
- Zhang, W.; Xu, Y.; Li, Y.; Li, D. Improving Write Performance of LSMT-Based KeyValueStore. In Proceedings of the 2016 IEEE 22nd International Conference on Parallel and Distributed Systems (ICPADS), Wuhan, China, 13–16 December 2016; pp. 553–560).
- [S013].
- Trajano, A.F.; Fernandez, M.P. Two-phase load balancing of In-Memor Key-Value Storages using Network Functions Virtualization (NFV). J. Netw. Comput. Appl. 2016, 69, 1–13.
- [S014].
- Xu, C.; Sharaf, M.A.; Zhou, X.; Zhou, A. Quality-aware schedulers for weak consistency key-value data stores. Distrib. Parallel Databases 2014, 32, 535–581.
- [S015].
- Wang, L.; Chen, G.; Wang, K. Research of Massive Data Caching Strategy Based on Key-Value Storage Model. In Proceedings of the International Conference on Intelligent Science and Big Data Engineering, Suzhou, China, 14–16 June 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 443–453.
- [S016].
- Cho, J.M.; Choi, K. An FPGA implementation of high-throughput KVS using Bloom filter. In Proceedings of the 2014 International Symposium on VLSI Design, Automation and Test (VLSI-DAT), Hsinchu, Taiwan, 25–27 April 2014; pp. 1–4.
- [S017].
- Pattuk, E.; Kantarcioglu, M.; Khadilkar, V.; Ulusoy, H.; Mehrotra, S. Bigsecret: A secure data management framework for KVSs. In Proceedings of the 2013 IEEE Sixth International Conference on Cloud Computing (CLOUD), Santa Clara, CA, USA, 28 June–3 July 2013; pp. 147–154.
- [S018].
- Zhou, J.; Shen, Y.; Li, S.; Huang, L. NVHT: An efficient key-value storage library for non-volatile memory. In Proceedings of the 3rd IEEE/ACM International Conference on Big Data Computing, Applications and Technologies, Shanghai, China, 6–9 December 2016; pp. 227–236.
- [S019].
- Shim, H. PHash: A memory-efficient, high-performance KVS for large-scale data intensive applications. J. Syst. Softw. 2017, 123, 33–44.
- [S020].
- Waye, L.; Buiras, P.; Arden, O.; Russo, A.; Chong, S. Cryptographically Secure Information Flow Control on KVSs. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1893–1907.
- [S021].
- Tan, Z.; Dang, Y.; Sun, J.; Zhou, W.; Feng, D. PaxStore: A Distributed Key Value Storage System. In Proceedings of the IFIP International Conference on Network and Parallel Computing, Ilan, Taiwan, 18–20 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 471–484.
- [S022].
- Yue, Y.; He, B.; Li, Y.; Wang, W. Building an Efficient Put-Intensive KVS with Skip-tree. IEEE Trans. Parallel Distrib. Syst. 2016, 28, 961–973.
- [S023].
- Son, Y.; Kang, H.; Han, H.; Yeom, H.Y. Improving Performance of Cloud Key-Value Storage Using Flushing Optimization. In Proceedings of the IEEE International Workshops on Foundations and Applications of Self* Systems, Augsburg, Germany, 12–16 September 2016; pp. 42–47).
- [S024].
- Gavrielatos, V.; Katsarakis, A.; Joshi, A.; Oswald, N.; Grot, B.; Nagarajan, V. Scale-out ccNUMA: Exploiting skew with strongly consistent caching. In Proceedings of the Thirteenth EuroSys Conference, Porto, Portugal, 21–23 April 2018, p. 21.
- [S025].
- Zaki, A.K.; Indiramma, M. A novel redis security extension for NoSQL database using authentication and encryption. In Proceedings of the 2015 IEEE International Conference on Electrical, Computer and Communication Technologies (ICECCT), Coimbatore, India, 5–7 March 2015; pp. 1–6.
- [S026].
- Taranov, K.; Alonso, G.; Hoefler, T. Fast and strongly-consistent per-item resilience in KVSs. In Proceedings of the Thirteenth EuroSys Conference, Porto, Portugal, 23–26 April 2018; p. 39.
- [S027].
- Escriva, R.; Wong, B.; Sirer, E.G. HyperDex: A distributed, searchable key-value store. In Proceedings of the ACM SIGCOMM 2012 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, Helsinki, Finland, 13–17 August 2012; pp. 25–36.
- [S028].
- Jin, X.; Li, X.; Zhang, H.; Soulé; R; Lee, J.; Foster, N.; Stoica, I. NetCache: Balancing KVSs with Fast In-Network Caching. In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28 October 2017; pp. 121–136.
- [S029].
- Li, B.; Ruan, Z.; Xiao, W.; Lu, Y.; Xiong, Y.; Putnam, A.; Zhang, L. KV-Direct: High-Performance In-Memory KVS with Programmable NIC. In In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28 October 2017; pp. 137–152.
- [S030].
- Najaran, M.T.; Hutchinson, N.C. Innesto: A searchable key/value store for highly dimensional data. In Proceedings of the 2013 IEEE 5th International Conference on Cloud Computing Technology and Science (CloudCom), Bristol, UK, 2–5 December 2013; Volume 1, pp. 411–420.
- [S031].
- Li, S.; Lim, H.; Lee, V.W.; Ahn, J.H.; Kalia, A.; Kaminsky, M.; Dubey, P. Full-Stack Architecting to Achieve a Billion-Requests-Per-Second Throughput on a Single KVS Server Platform. ACM Trans. Comput. Syst. (TOCS) 2016, 34, 5.
- [S032].
- Zhang, K.; Wang, K.; Yuan, Y.; Guo, L.; Lee, R.; Zhang, X. Mega-KV: A case for GPUs to maximize the throughput of in-memory KVSs. Proc. VLDB Endow. 2015, 8, 1226–1237.
- [S033].
- Garefalakis, P.; Papadopoulos, P.; Manousakis, I.; Magoutis, K. Strengthening consistency in the cassandra distributed KVS. In Proceedings of the IFIP International Conference on Distributed Applications and Interoperable Systems, June 2013; Springe: Berlin/Heidelberg, Germany, 2013; pp. 193–198.
- [S034].
- Glendenning, L.; Beschastnikh, I.; Krishnamurthy, A.; Anderson, T. Scalable consistency in Scatter. In Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles, Cascais, Portugal, 23–26 October 2011; pp. 15–28.
- [S035].
- Takeuchi, S.; Shinomiya, J.; Shiraki, T.; Ishi, Y.; Teranishi, Y.; Yoshida, M.; Shimojo, S. A large scale KVS based on range-key skip graph and its applications. In Proceedings of the International Conference on Database Systems for Advanced Applications, Tsukuba, Japan, 1–4 April 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 432–435.
- [S036].
- Hong, B.; Kwon, Y.; Ahn, J.H.; Kim, J. Adaptive and flexible KVSs through soft data partitioning. In Proceedings of the 2016 IEEE 34th International Conference on Computer Design (ICCD), Phoenix, AZ, USA, 3–5 October 2016; pp. 296–303.
- [S037].
- Hu, H.; Xu, J.; Xu, X.; Pei, K.; Choi, B.; Zhou, S. Private searchon KVSs with hierarchical indexes. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering (ICDE), Chicago, IL, USA, 31 March–4 April 2014; pp. 628–639.
- [S038].
- Chang, D.; Zhang, Y.; Yu, G. MaiterStore: A Hot-Aware, High- Performance KVS for Graph Processing. In Proceedings of the International Conference on Database Systems for Advanced Applications, Bali, Indonesia, 21–24 April 2014; Springer: Berlin/Heidelberg, Germany; 2014; pp. 117–131.
- [S039].
- Li, T.; Wang, K.; Zhao, D.; Qiao, K.; Sadooghi, I.; Zhou, X.; Raicu, I. A flexible qos fortified distributed key-value storage system for the cloud. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 515–522.
- [S040].
- Ge, W.; Huang, Y.; Zhao, D.; Luo, S.; Yuan, C.; Zhou, W.; Zhou, J. Cinhba: A secondary index with hotscore caching policy on key-value data store. In Proceedings of the International Conference on Advanced Data Mining and Applications, December 2014; Springer: Berlin/Heidelberg, Germany, pp. 602–615.
- [S041].
- Wu, H.J.; Lu, K.; Li, G. Design and Implementation of Distributed Stage DB: A High Performance Distributed Key-Value Database. In Proceedings of the 6th International Asia Conference on Industrial Engineering and Management Innovation; Atlantis Press: Paris, France, 2016; pp. 189–198.
- [S042].
- Zhao, D.; Wang, K.; Qiao, K.; Li, T.; Sadooghi, I.; Raicu, I. Toward high-performance KVSs through GPU encoding and locality-aware encoding. J. Parallel Distrib. Comput. 2016, 96, 27–37.
- [S043].
- Sun, H.; Tang, Y.; Wang, Q.; Liu, X. Handling multi-dimensional complex queries in key-value data stores. Inf. Syst. 2017, 66, 82–96.
- [S044].
- Ahn, J.S.; Seo, C.; Mayuram, R.; Yaseen, R.; Kim, J.S.; Maeng, S. ForestDB: A fast key-value storage system for variable-length string keys. IEEE Trans. Comput. 2016, 65, 902–915.
- [S045].
- Lu, L.; Pillai, T.S.; Gopalakrishnan, H.; Arpaci-Dusseau, A.C.; Arpaci-Dusseau, R.H. WiscKey: Separating keys from values in SSD-conscious storage. ACM Trans. Storage (TOS) 2017, 13, 5.
References
- Codd, E.F. Relational database: A practical foundation for productivity. In Readings in Artificial Intelligence and Databases; Elsevier: Amsterdam, The Netherlands, 1988; pp. 60–68. [Google Scholar]
- Strozzi, C. Nosql-a relational database management system. Lainattu 1998, 5, 2014. [Google Scholar]
- Moniruzzaman, A.; Hossain, S.A. Nosql database: New era of databases for big data analytics-classification, characteristics and comparison. arXiv 2013, arXiv:1307.0191. [Google Scholar]
- Lith, A.; Mattsson, J. Investigating Storage Solutions for Large Data—A Comparison of Well Performing and Scalable Data Storage Solutions for Real Time Extraction and Batch Insertion of Data; Chalmers University Of Technology: Göteborg, Sweden, 2010. [Google Scholar]
- Sharma, V.; Dave, M. Sql and nosql databases. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2012, 2, 20–27. [Google Scholar]
- Cattell, R. Scalable sql and nosql data stores. ACM SIGMOD Rec. 2011, 39, 12–27. [Google Scholar] [CrossRef]
- Leavitt, N. Will nosql databases live up to their promise? Computer 2010, 43, 12–14. [Google Scholar] [CrossRef]
- Schram, A.; Anderson, K.M. MySQL to NoSQL: Data modeling challenges in supporting scalability. In Proceedings of the 3rd Annual Conference on Systems, Programming, and Applications: Software for Humanity, Tucson, AR, USA, 19–26 October 2012. [Google Scholar]
- Orend, K. Analysis and classification of nosql databases and evaluation of their ability to replace an object-relational persistence layer. Architecture 2010, 1. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.184.483&rep=rep1&type=pdf (accessed on 29 April 2019).
- Kuznetsov, S.D.; Poskonin, A.V. Nosql Data Management Systems. Program. Comput. Softw. 2014, 40, 323–332. [Google Scholar] [CrossRef]
- Bell, G.; Hey, T.; Szalay, A. Beyond the data deluge. Science 2009, 323, 1297–1298. [Google Scholar] [CrossRef]
- Almassabi, A.; Bawazeer, O.; Adam, S. Top NewSQL Databases and Features Classification. Int. J. Database Manag. Syst. 2018, 10, 11–31. [Google Scholar] [CrossRef]
- McAfee, A.; Brynjolfsson, E.; Davenport, T.H.; Patil, D.; Barton, D. Big data: The management revolution. Harv. Bus. Rev. 2012, 90, 60–68. [Google Scholar]
- Gomez, A.; Ouanouki, R.; April, A.; Abran, A. Building an experiment baseline in migration process from sql database to column oriented no-sql databases. J. Inf. Technol. Softw. Eng. 2014, 4, 137. [Google Scholar]
- Hecht, R.; Jablonski, S. Nosql evaluation: A use case oriented survey. In Proceedings of the 2011 International Conference on Cloud and Service Computing (CSC), Hong Kong, China, 12–14 December 2011; pp. 336–341. [Google Scholar]
- DeCandia, G.; Hastorun, D.; Jampani, M.; Kakulapati, G.; Lakshman, A.; Pilchin, A.; Sivasubramanian, S.; Vosshall, P.; Vogels, W. Dynamo: Amazon’s highly available key-value store. ACM SIGOPS Oper. Syst. Rev. 2007, 41, 205–220. [Google Scholar] [CrossRef]
- Wylie, B.; Dunlavy, D.; Davis, W.; Baumes, J. Using nosql databases for streaming network analysis. In Proceedings of the 2012 IEEE Symposium on Large Data Analysis and Visualization (LDAV), Seattle, WA, USA, 14–15 October 2012; pp. 121–124. [Google Scholar]
- Chang, F.; Dean, J.; Ghemawat, S.; Hsieh, W.C.; Wallach, D.A.; Burrows, M.; Chandra, T.; Fikes, A.; Gruber, R.E. Bigtable: A distributed storage system for structured data. ACM Trans. Comput. Syst. 2008, 26, 4. [Google Scholar] [CrossRef]
- Cooper, B.F.; Ramakrishnan, R.; Srivastava, U.; Silberstein, A.; Bohannon, P.; Jacobsen, H.-A.; Puz, N.; Weaver, D.; Yerneni, R. Pnuts: Yahoo!’S hosted data serving platform. Proc. VLDB Endow. 2008, 1, 1277–1288. [Google Scholar] [CrossRef]
- Marston, S.; Li, Z.; Bandyopadhyay, S.; Zhang, J.; Ghalsasi, A. Cloud computing—The business perspective. Decis.Supp. Syst. 2011, 51, 176–189. [Google Scholar] [CrossRef]
- Lourenço, J.R.; Cabral, B.; Carreiro, P.; Vieira, M.; Bernardino, J. Choosing the right nosql database for the job: A quality attribute evaluation. J. Big Data 2015, 2, 18. [Google Scholar] [CrossRef]
- Horie, H.; Asahara, M.; Yamada, H.; Kono, K. Pangaea: A single key space, inter-datacenter key-value store. In Proceedings of the 2013 International Conference on Parallel and Distributed Systems (ICPADS), Seoul, Korea, 15–18 December 2013; pp. 434–435. [Google Scholar]
- Davoudian, A.; Chen, L.; Liu, M. A survey on nosql stores. ACM Comput. Surv. (CSUR) 2018, 51, 40. [Google Scholar] [CrossRef]
- Fitzpatrick, B.; Vorobey, A. Memcached: A Distributed Memory Object Caching System. 2011. Available online: http://memcached.org/ (accessed on 4 January 2019).
- Jang, J.; Cho, Y.; Jung, J.; Jeon, G. Enhancing lookup performance of key-value stores using cuckoo hashing. In Proceedings of the 2013 Research in Adaptive and Convergent Systems, Montreal, QC, Canada, 1–4 October 2013; pp. 487–489. [Google Scholar]
- Iwazume, M.; Iwase, T.; Tanaka, K.; Fujii, H.; Hijiya, M.; Haraguchi, H. Big data in memory: Benchimarking in memory database using the distributed key-value store for machine to machine communication. In Proceedings of the 2014 15th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Las Vegas, NV, USA, 30 June–2 July 2014; pp. 1–7. [Google Scholar]
- Cronin, D. A Survey of Modern Key-Value Stores; Cal Poly Computer Science Department Labs: San Luis Obispo, CA, USA, 2012. [Google Scholar]
- Grolinger, K.; Higashino, W.A.; Tiwari, A.; Capretz, M.A. Data management in cloud environments: Nosql and newsql data stores. J. Cloud Comput. Adv. Syst. Appl. 2013, 2, 49. [Google Scholar] [CrossRef]
- Gajendran, S.K. A Survey on Nosql Databases; University of Illinois: Champaign, IL, USA, 2012. [Google Scholar]
- Gessert, F.; Wingerath, W.; Friedrich, S.; Ritter, N. Nosql database systems: A survey and decision guidance. Comput. Sci. Res. Dev. 2017, 32, 353–365. [Google Scholar] [CrossRef]
- Brereton, P.; Kitchenham, B.A.; Budgen, D.; Turner, M.; Khalil, M. Lessons from applying the systematic literature review process within the software engineering domain. J. Syst. Softw. 2007, 80, 571–583. [Google Scholar] [CrossRef]
- Dieste, O.; Grimán, A.; Juristo, N. Developing search strategies for detecting relevant experiments. Empir. Softw. Eng. 2009, 14, 513–539. [Google Scholar] [CrossRef]
- Debnath, B.; Sengupta, S.; Li, J. Skimpystash: Ram space skimpy key-value store on flash-based storage. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; pp. 25–36. [Google Scholar]
- Liu, S.; Nguyen, S.; Ganhotra, J.; Rahman, M.R.; Gupta, I.; Meseguer, J. Quantitative analysis of consistency in nosql key-value stores. In Proceedings of the International Conference on Quantitative Evaluation of Systems, Madrid, Spain, 1–3 September 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 228–243. [Google Scholar]
- Mohamed, M.A.; Altrafi, O.G.; Ismail, M.O. Relational vs. Nosql databases: A survey. Int. J. Comput. Inf. Technol. 2014, 3, 598–601. [Google Scholar]
- Fiebig, T.; Feldmann, A.; Petschick, M. A one-year perspective on exposed in-memory key-value stores. In Proceedings of the 2016 ACM Workshop on Automated Decision Making for Active Cyber Defense, Vienna, Austria, 24 October 2016; pp. 17–22. [Google Scholar]
- Lamport, L. Paxos made simple. ACM Sigact News 2001, 32, 18–25. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Study Reference | Study Objective | Publication Year |
|---|---|---|---|
| Survey | [27] | A Survey of Modern KVSs | 2012 |
| Survey | [21] | NoSQL Quality Attribute Evaluation | 2015 |
| Survey | [28] | NoSQL and NewSQL | 2013 |
| Survey | [23] | Challenges in developing NoSQL | 2018 |
| Survey | [29] | Evolution of NoSQL | 2012 |
| Survey | [30] | NoSQL Databases | 2017 |
| No | Research Questions | Bases |
|---|---|---|
| RQ1 | What are the main quality attribute challenges faced by key-value store, and what are their solutions? | This question determines the major challenges for key-value store and their solutions from the literature studied in this review. |
| RQ2 | Which models and techniques are deployed for the execution and assessment of the presented solutions? | The main objective of this question is to play up the models and techniques applied by researches for the execution and testing of their proposed solutions. |
| RQ3 | What is the reliability status of the presented approaches, and what is the quality status of included publications? | This question finds out the reliability and quality of the selected publications. |
| RQ4 | What are the forums of publication and line of development in studies on the key-value store? | The main objective of this research question is to identify trends of publication and publication forums. |
| Data Origins | Web Sites |
|---|---|
| IEEE Xplore | http://ieeexplore.ieee.org/Xplore/ |
| The ACM Digital Library | http://dl.acm.org/ |
| Springer | http://www.springerlink.com/ |
| Elsevier | http://www.elsevier.com/ |
| Term | Explanation |
|---|---|
| Study Area | The focus of the study. |
| Date of Review | Data collection date |
| Aims | Objective of the study |
| Impetus | Motivation for the study. |
| Algorithm | The algorithm presented in the study as a solution. |
| Problem | The issue addressed by the study. |
| Solutions | The approach presented to solve problem. |
| Improvements | Research directions for future work in the area of study. |
| Research Classes and Relevant Research Papers | |
|---|---|
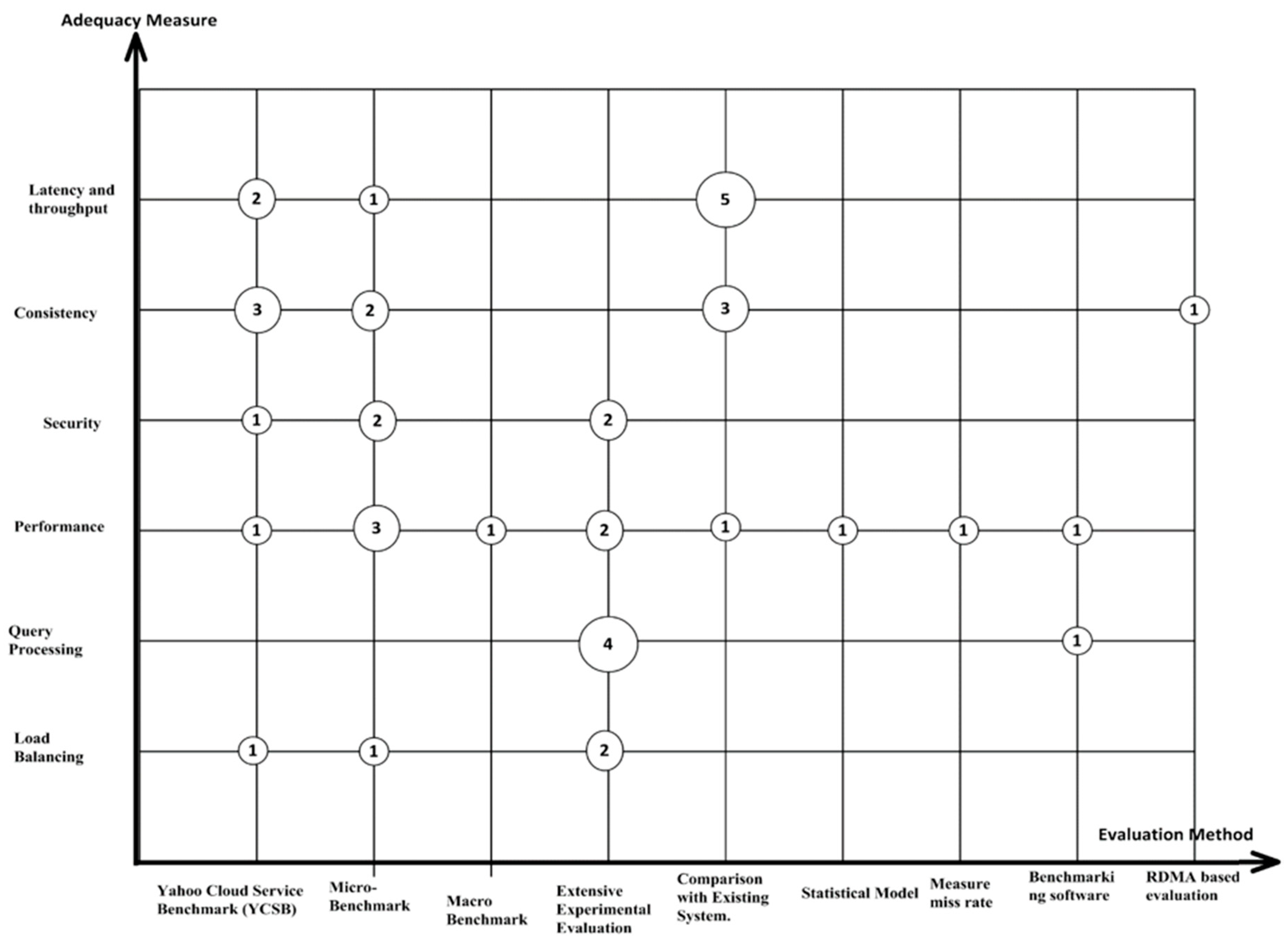
| Latency and Throughput | [S06][S11][16][S22][S31][S32][S39] |
| Consistency | [S01] [S02][S05][S14][S18][S21][S26] [S33][S34] |
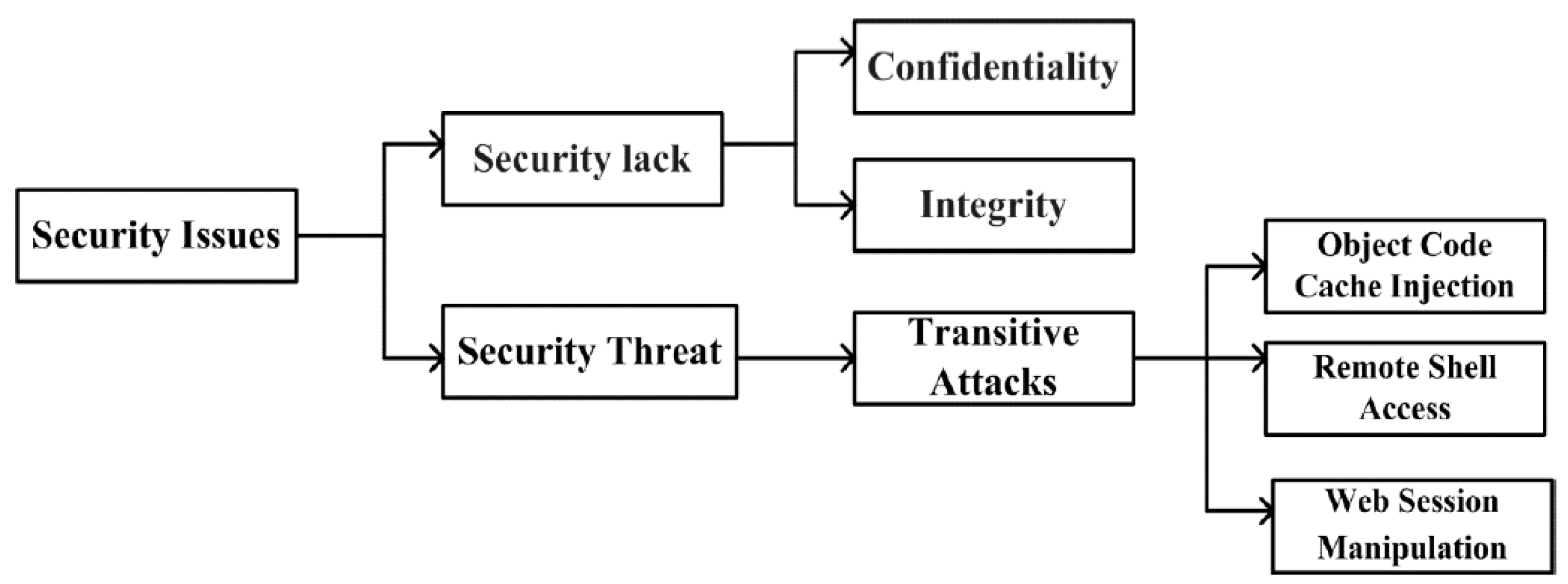
| Security | [S03][S08][S17][S20][S25] |
| Performance | [S07][S09][S10][S12][S15][S19][S23] [S29][S36][S38][S41][S42][S44][S45] |
| Query Processing | [S27][S30][S35][S37][S40][S43] |
| Load Balancing | [S04][S13] [S24][S28] |
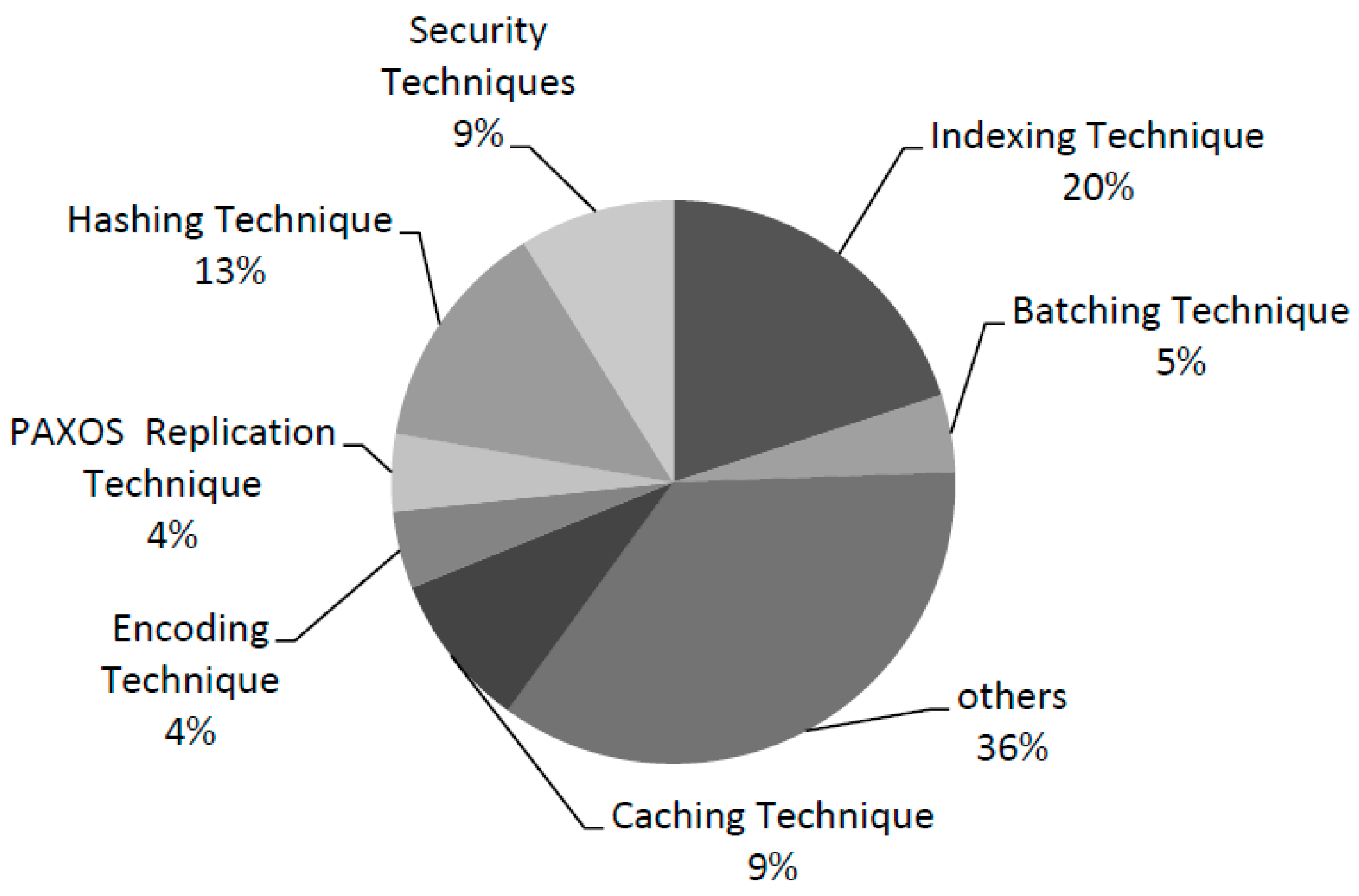
| Technique/Strategy | Description | Study ID |
|---|---|---|
| Batching technique | Batching strategies are used to combine similar tasks together to make a group. | [S31][S39] |
| Hashing technique | “A randomized algorithm that selects a hashing function from a list of hash functions, so that the collision probability between two distinct keys is 1/n, where n is the number of distinct hash values desired independently of the two keys.” | [S11][S16][S19][S27] [S32][S41] |
| Indexing technique | Indexing scheme is a technique of data structure to improve the data retrieval speed. | [S02][S06][S09][S22] [S36][S40][S43][S44] |
| Security techniques | These techniques are used to secure data of KVSs that are publicly accessible. | [S03][S17][S20][S25] |
| Caching technique | Caching is a technique that helps achieve performance, affordability and scalability against data accuracy and consistency. | [S15][S24][S28][S38] |
| Paxos technique | Paxos protocol and Paxos algorithm. They are replication techniques. They based on consensus; they elect one node to select a value, send it to all the nodes, and a decision is made by consensus. | [S21][S34] |
| Encoding technique | Encoding techniques are used to encode information into signals. | [S26][S42] |
| Algorithm | Study ID |
|---|---|
| Secure Data Partition Algorithm | [S03] |
| Cost-Aware Rebalancing Algorithm | [S04] |
| Control Loop Algorithm | [S05] |
| Pointer-Free Buddy Allocator (PFBA). | [S18] |
| Modified Earliest-Deadline First (EDF) Algorithm. | [S39] |
| Hotscore Algorithm | [S40] |
| Evaluation Technique | Description | Study ID |
|---|---|---|
| Yahoo Cloud Serving Benchmark (YCSB) | YCSB is the standard used to evaluate the performance of NoSQL databases. It is a suite that evaluates the retrieval as well as maintenance performance of NoSQL databases for a set of desired workloads | [S02][S04][S06] [S08][S14][S19] [S27][S33] |
| Microbenchmark | It is a tiny routine to evaluate the performance of language feature or specific hardware. | [S05][S10][S20] [S23][S25][S28] [S29][S34][S39] [S45] |
| Extensive experimental evaluation | The extensive experiments performed to evaluate the proposed system. | [S03][S13][S17] [S24][S30][S37] [S38][S40][S42] [S43] |
| Comparison with existing system. | Performance of the proposed system is compared with the performance of an already existing system. | [S01][S11][S12] [S16][S18][S21] [S22][S31][S32] |
| Statistical model. | The system is evaluated by a statistical model of user behavior. It is concluded by Facebook for key-value storage. | [S41] |
| Measure miss rate | The system performance is evaluated in terms of the miss rate over six different reuse patterns. | [S36] |
| Benchmarking software | They compile benchmarking software for system evaluation. | [S07][S35] |
| RDMA-based evaluation | The proposed approach is evaluated on an RDMA network. | [S26] |
| Test-based benchmark | Benchmark for testing is the access time in milliseconds. | [S15] |
| Assessment Criteria | |
|---|---|
| C1 | Has the study included formal research, or was it just based upon the judgment of expert? |
| C2 | Are the research aims clearly depicted and addressed in the studies? |
| C3 | Does the paper mention the limitations for future work? |
| C4 | Is there any description about the evaluation of the proposed solution? |
| C5 | Were the experiments performed on adequate datasets? |
| Assessment Scores of Reviewed Literature | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Paper ID | Formal Research C1 | Objectives C2 | Limitations C3 | Findings C4 | Experiment C5 | Total Score | Paper ID | Formal Research C1 | Objectives C2 | Limitations C3 | Findings C4 | Experiment C5 | Total Score |
| [S02] | 1 | 1 | 1 | 1 | 1 | 5 | [S23] | 1 | 1 | 1 | 1 | 1 | 5 |
| [S07] | 1 | 1 | 1 | 1 | 1 | 5 | [S33] | 1 | 1 | 1 | 1 | 1 | 5 |
| [S13] | 1 | 1 | 1 | 1 | 1 | 5 | [S39] | 1 | 1 | 1 | 1 | 1 | 5 |
| [S16] | 1 | 1 | 1 | 1 | 1 | 5 | [S40] | 1 | 1 | 1 | 1 | 1 | 5 |
| [S17] | 1 | 1 | 1 | 1 | 1 | 5 | [S43] | 1 | 1 | 1 | 1 | 1 | 5 |
| [S10] | 1 | 1 | 0.5 | 1 | 1 | 4.5 | [S42] | 1 | 1 | 0.5 | 1 | 1 | 4.5 |
| [S04] | 1 | 1 | 0.5 | 1 | 1 | 4.5 | [S24] | 1 | 1 | 0.5 | 1 | 1 | 4.5 |
| [S31] | 1 | 1 | 0.5 | 1 | 1 | 4.5 | [S36] | 1 | 1 | 0.5 | 1 | 1 | 4.5 |
| [S37] | 1 | 1 | 0.5 | 1 | 1 | 4.5 | [S44] | 1 | 1 | 1 | 1 | 0.5 | 4.5 |
| [S03] | 1 | 1 | 0 | 1 | 1 | 4 | [S41] | 1 | 1 | 0 | 1 | 1 | 4 |
| [S01] | 1 | 1 | 0 | 1 | 1 | 4 | [S38] | 1 | 1 | 0 | 1 | 1 | 4 |
| [S05] | 1 | 1 | 0 | 1 | 1 | 4 | [S32] | 1 | 1 | 0 | 1 | 1 | 4 |
| [S08] | 1 | 1 | 0 | 1 | 1 | 4 | [S06] | 1 | 1 | 0 | 1 | 1 | 4 |
| [S09] | 1 | 1 | 0 | 1 | 1 | 4 | [S26] | 1 | 1 | 0 | 1 | 1 | 4 |
| [S11] | 1 | 1 | 0 | 1 | 1 | 4 | [S28] | 1 | 1 | 0 | 1 | 1 | 4 |
| [S14] | 1 | 1 | 0 | 1 | 1 | 4 | [S34] | 1 | 1 | 0 | 1 | 1 | 4 |
| [S15] | 1 | 1 | 0 | 1 | 1 | 4 | [S21] | 1 | 1 | 0 | 1 | 1 | 4 |
| [S18] | 1 | 1 | 0 | 1 | 1 | 4 | [S22] | 1 | 1 | 0 | 1 | 1 | 4 |
| [S19] | 1 | 1 | 0 | 1 | 1 | 4 | [S27] | 1 | 1 | 0 | 1 | 1 | 4 |
| [S30] | 1 | 1 | 0 | 1 | 1 | 4 | [S45] | 1 | 1 | 0 | 1 | 1 | 4 |
| [S12] | 1 | 1 | 0 | 1 | 0.5 | 3.5 | [S29] | 1 | 1 | 0 | 1 | 0.5 | 3.5 |
| [S25] | 1 | 1 | 0.5 | 0 | 1 | 3.5 | [S20] | 1 | 1 | 0 | 0 | 1 | 3 |
| [S35] | 1 | 1 | 0 | 0 | 0.5 | 2.5 | |||||||
| Formal Research C1 | Objectives C2 | Limitations C3 | Findings C4 | Experiment C5 | Total Score | |
|---|---|---|---|---|---|---|
| Average | 1 | 1 | 0.3 | 0.95 | 0.95 | 4.2 |
| Study ID | Publication Year | Publication Type | Publication Venue |
|---|---|---|---|
| [05] | 2017 | Journal | ACM Transactions on Autonomous and Adaptive Systems |
| [07] | 2017 | Journal | Information Systems |
| [13] | 2016 | Journal | ACM |
| [14] | 2014 | Journal | Distributed and Parallel Databases |
| [19] | 2017 | Journal | Journal of Systems and Software |
| [22] | 2016 | Journal | IEEE on Parallel and Distributed Systems |
| [31] | 2016 | Journal | ACM Transactions on Computer Systems (TOCS), 34(2), 5. |
| [42] | 2016 | Journal | Journal of Parallel and Distributed Computing, |
| [43] | 2017 | Journal | Information Systems, Elsevier |
| [44] | 2016 | Journal | IEEE transaction |
| [45] | 2017 | Journal | ACM transaction on storage. |
| [03] | 2017 | Conference | ACM on Asia Conference on Computer and Communications Security |
| [04] | 2012 | Conference | Cluster Computing Workshops (CLUSTER WORKSHOPS), EEE International Conference |
| [06] | 2012 | Conference | Mass Storage Systems and Technologies (MSST), IEEE Symposium |
| [08] | 2014 | Conference | Concepts, Theory and Applications (ICAICTA), International Conference |
| [10] | 2015 | Conference | In Cluster, Cloud and Grid Computing (CCGrid), 2015 15th IEEE/ACM International Symposium IEEE. |
| [12] | 2016 | Conference | Parallel and Distributed Systems (ICPADS), EEE International Conference |
| [15] | 2015 | Conference | International Conference on Intelligent Science and Big Data Engineering, Springer |
| [17] | 2013 | Conference | Cloud computing (CLOUD), IEEE international Conference. |
| [18] | 2016 | Conference | International Conference on Big Data Computing, Applications and Technologies ACM |
| [20] | 2017 | Conference | Workshop on Automated Decision Making for Active Cyber Defense. |
| [21] | 2014 | Conference | IFIP International Conference on Network and Parallel Computing, Springer Berlin Heidelberg |
| [24] | 2015 | Conference | Trustcom/BigDataSE/I SPA, 2016 IEEE (pp. 1660-1667). IEEE |
| [25] | 2015 | Conference | Electrical, Computer and Communication Technologies (ICECCT), 2015 IEEE International Conference |
| [26] | 2018 | Conference | ACM SIGPLAN workshop on ERLANG. |
| [27] | 2012 | Conference | ACM SIGCOMM conference on Applications, technologies, architectures, and protocols for computer communication Computer Communication Review |
| [30] | 2013 | Conference | Concurrency and Computation: Practice and Experience, |
| [33] | 2013 | Conference | International Conference on Distributed Applications and Interoperable Systems Springer. |
| [35] | 2010 | Conference | In Proceedings of the 19th international conference on World wide web (pp. 1193-1194). ACM. |
| [36] | 2016 | Conference | Computer Design (ICCD), International Conference, IEEE. |
| [37] | 2014 | Conference | Data Engineering (ICDE), International Conference on (pp. 628-639). IEEE. |
| [38] | 2014 | Conference | International Conference on Database Systems for Advanced Applications, Springer. |
| [39] | 2015 | Conference | In Big Data (Big Data), IEEE International Conference. IEEE. |
| [40] | 2014 | Conference | International Conference on Advanced Data Mining and Applications, Springer. |
| [41] | 2016 | Conference | International Asia Conference on Industrial Engineering and Management Innovation, Atlantis Press. |
| [23] | 2016 | Workshop | Foundations and Applications of Self* Systems, IEEE International Workshops. |
| [28] | 2017 | Workshop | Symposium on Operating Systems Principles, ACM. |
| [01] | 2013 | Workshop | Workshop on Interactions of NVM/FLASH with Operating Systems and Workloads |
| [29] | 2017 | Symposium | Annual ACM Symposium on Applied Computing (pp. 2072-2074). ACM. |
| [34] | 2011 | Symposium | Symposium on Operating Systems Principles ACM. |
| [02] | 2014 | Symposium | Reliable Distributed Systems (SRDS), IEEE International Symposium. |
| [09] | 2011 | Symposium | ACM Symposium on Operating Systems Principles |
| [16] | 2014 | Symposium | VLSI Design, Automation and Test (VLSI-DAT), International Symposium, IEEE. |
| [11] | 2010 | VLDB Endowment | ACM |
| [32] | 2015 | VLDB Endowment | ACM |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramzan, S.; Bajwa, I.S.; Kazmi, R.; Amna. Challenges in NoSQL-Based Distributed Data Storage: A Systematic Literature Review. Electronics 2019, 8, 488. https://doi.org/10.3390/electronics8050488
Ramzan S, Bajwa IS, Kazmi R, Amna. Challenges in NoSQL-Based Distributed Data Storage: A Systematic Literature Review. Electronics. 2019; 8(5):488. https://doi.org/10.3390/electronics8050488
Chicago/Turabian StyleRamzan, Shabana, Imran Sarwar Bajwa, Rafaqut Kazmi, and Amna. 2019. "Challenges in NoSQL-Based Distributed Data Storage: A Systematic Literature Review" Electronics 8, no. 5: 488. https://doi.org/10.3390/electronics8050488
APA StyleRamzan, S., Bajwa, I. S., Kazmi, R., & Amna. (2019). Challenges in NoSQL-Based Distributed Data Storage: A Systematic Literature Review. Electronics, 8(5), 488. https://doi.org/10.3390/electronics8050488