TLS-VaD: A New Tool for Developing Centralized Link-Scheduling Algorithms on the IEEE802.15.4e TSCH Network



Abstract
1. Introduction
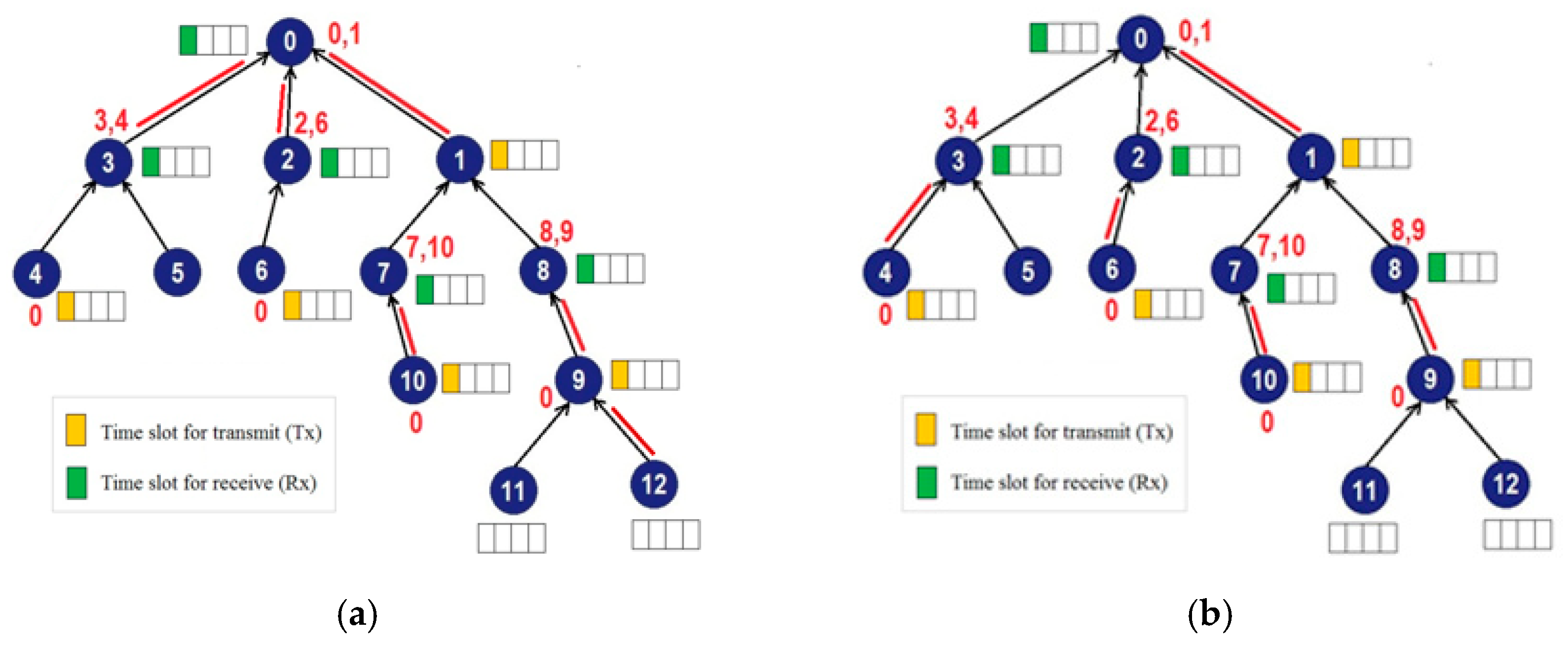
- (a)
- The server knows the overall network conditions, such as the network topology, the number of nodes in the network, and the number of packets waiting in the queue of each network node.
- (b)
- Each node can synchronize itself to the network and know the schedule to transmit, receive, and sleep, based on information sent by the server.
- (c)
- At the beginning of each slotframe, each node generates one packet of data regularly to be sent to the master node.
- (d)
- Each node will do a bursty transmission when it gets its turn to transmit, so that after the transmit process, the queue in the node becomes empty.
- (e)
- There is no interference and packet loss.
2. Related Works
3. Underlying Theories
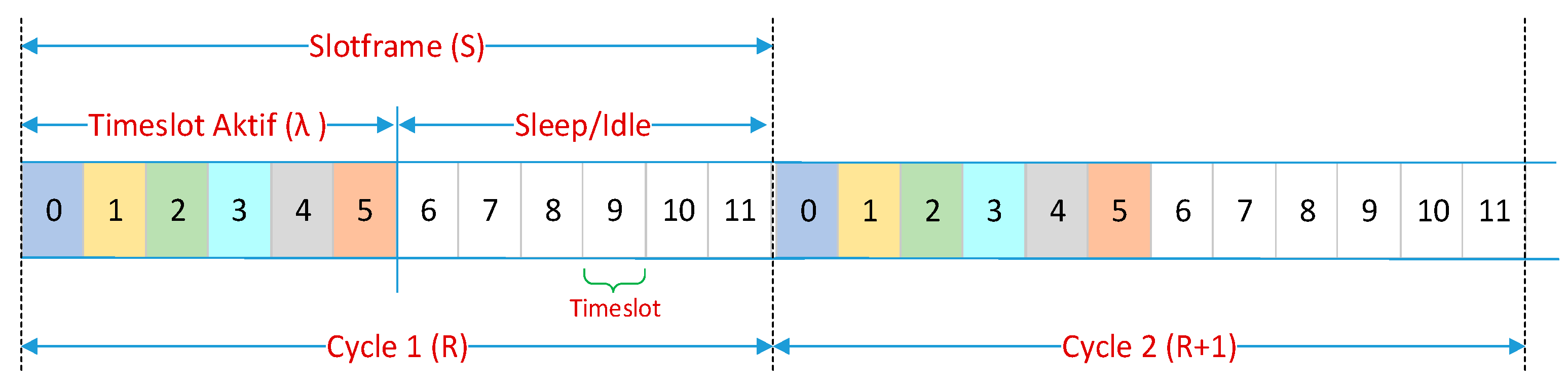
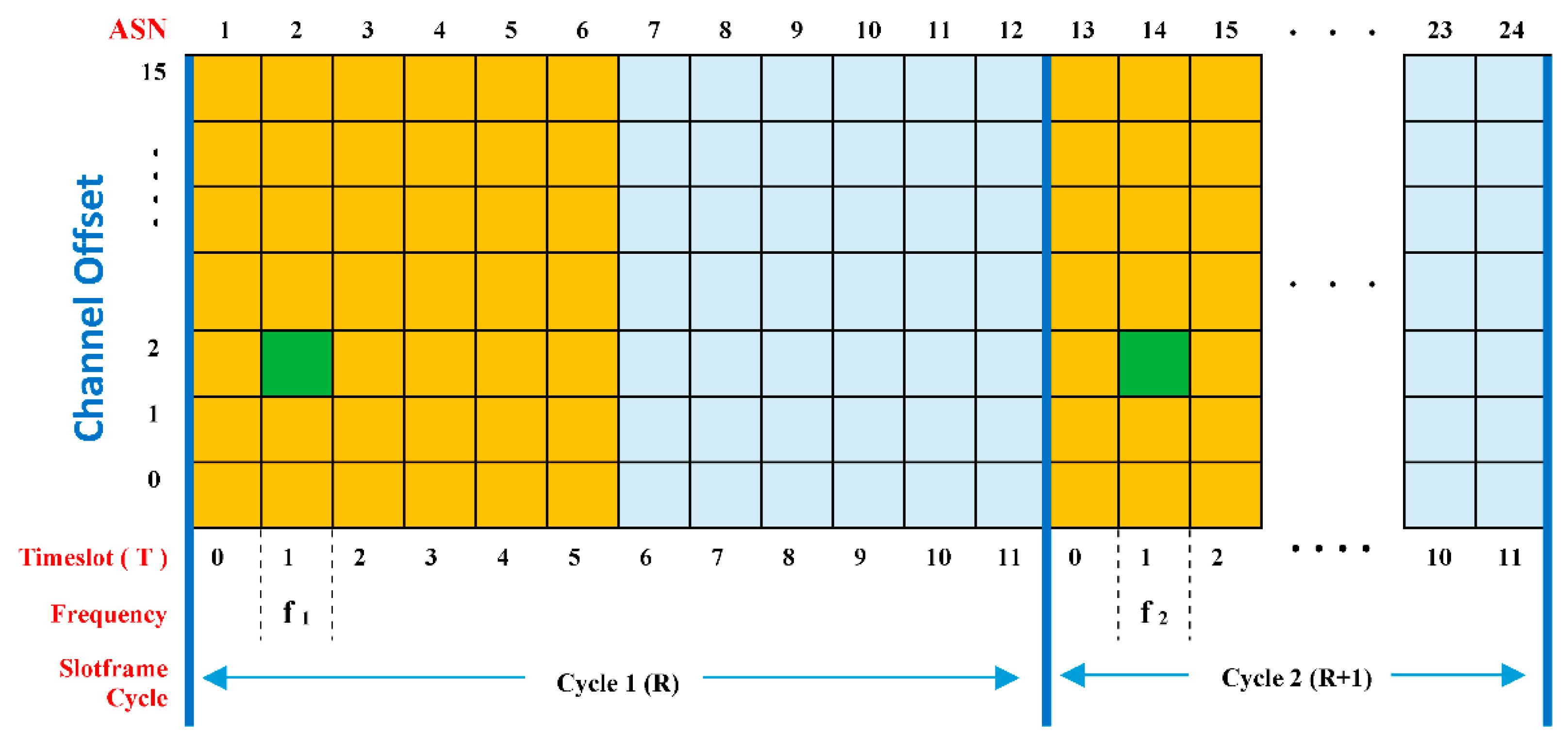
3.1. IEEE802.15.4 Standards
3.2. IEEE802.15.4e TSCH
3.3. Link Scheduling
4. Centralized Scheduling Algorithm for the IEEE802.15.4e TSCH Network
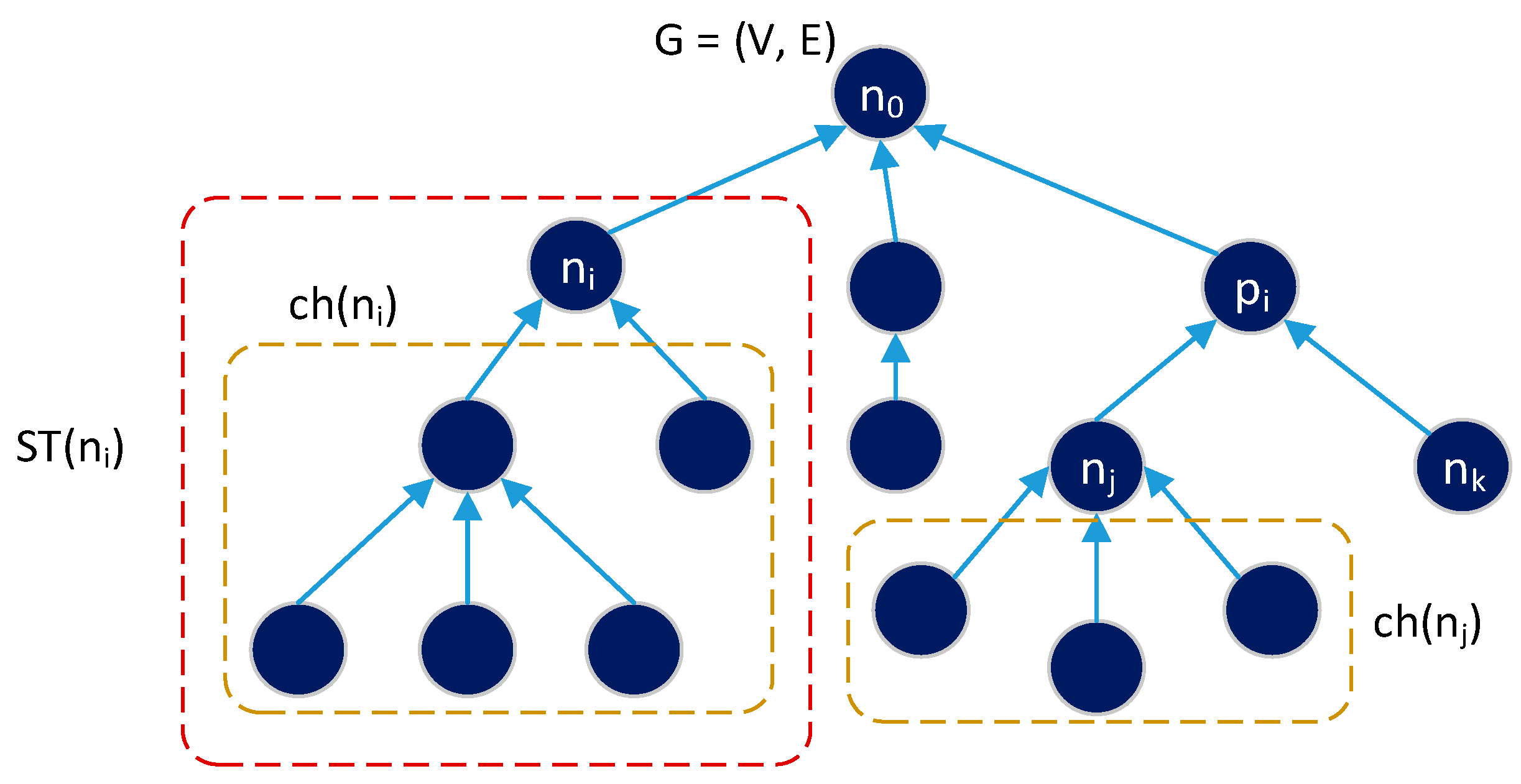
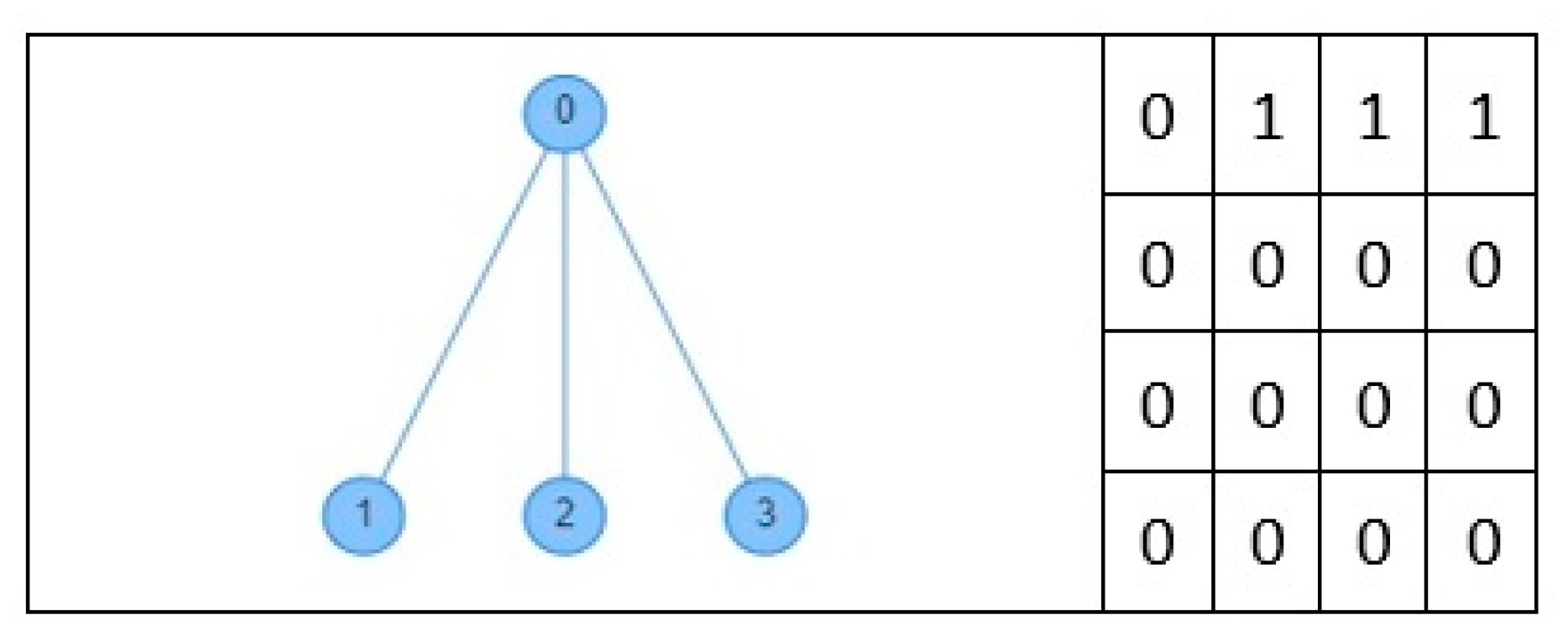
4.1. Network Models
4.2. Maximal Matching Algorithm
4.3. Network Traffic and the Duty Cycle
4.4. Deepening of the Observed Scheduling Algorithm
4.4.1. IRByTSA
- 1
- 2
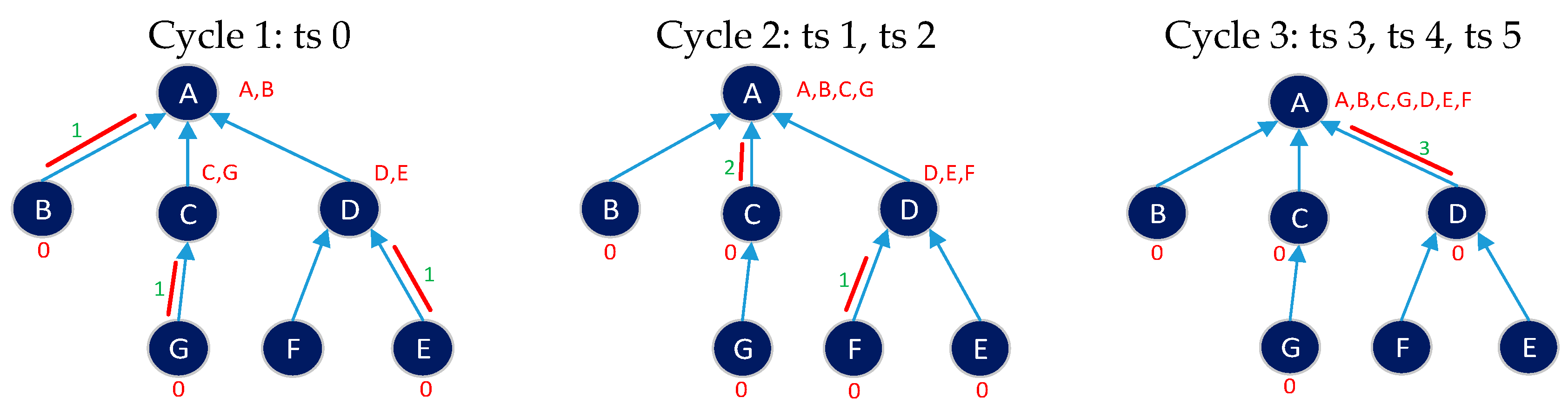
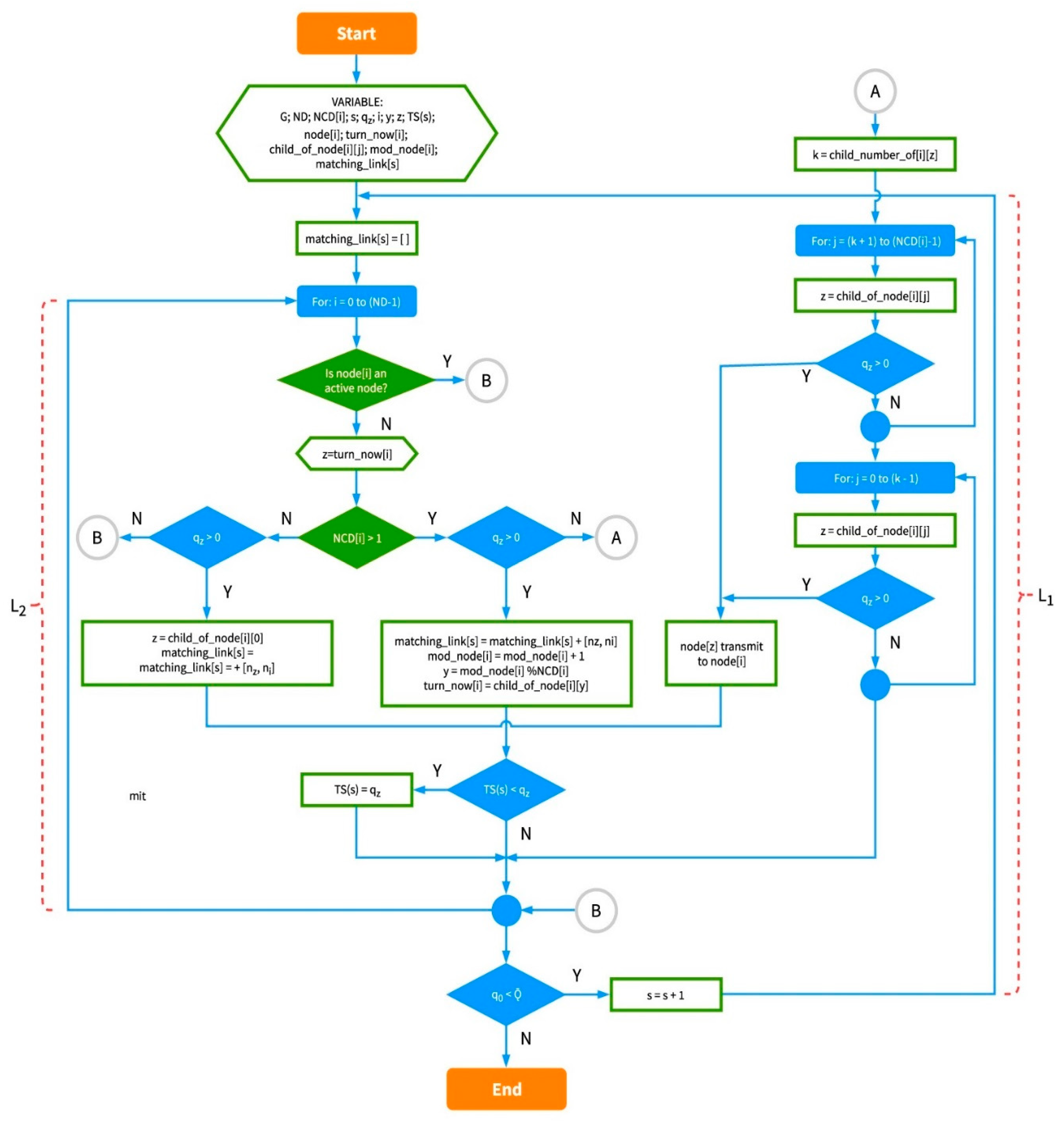
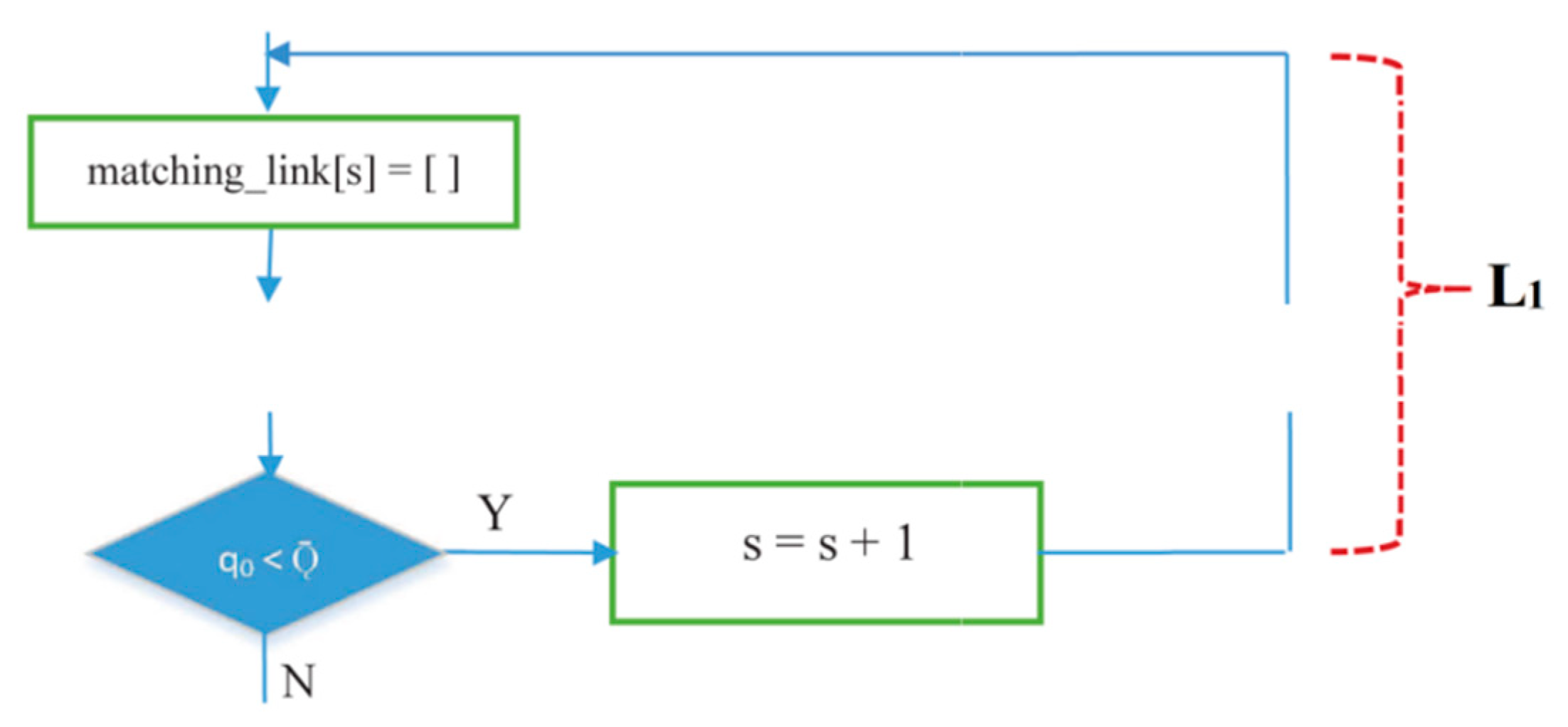
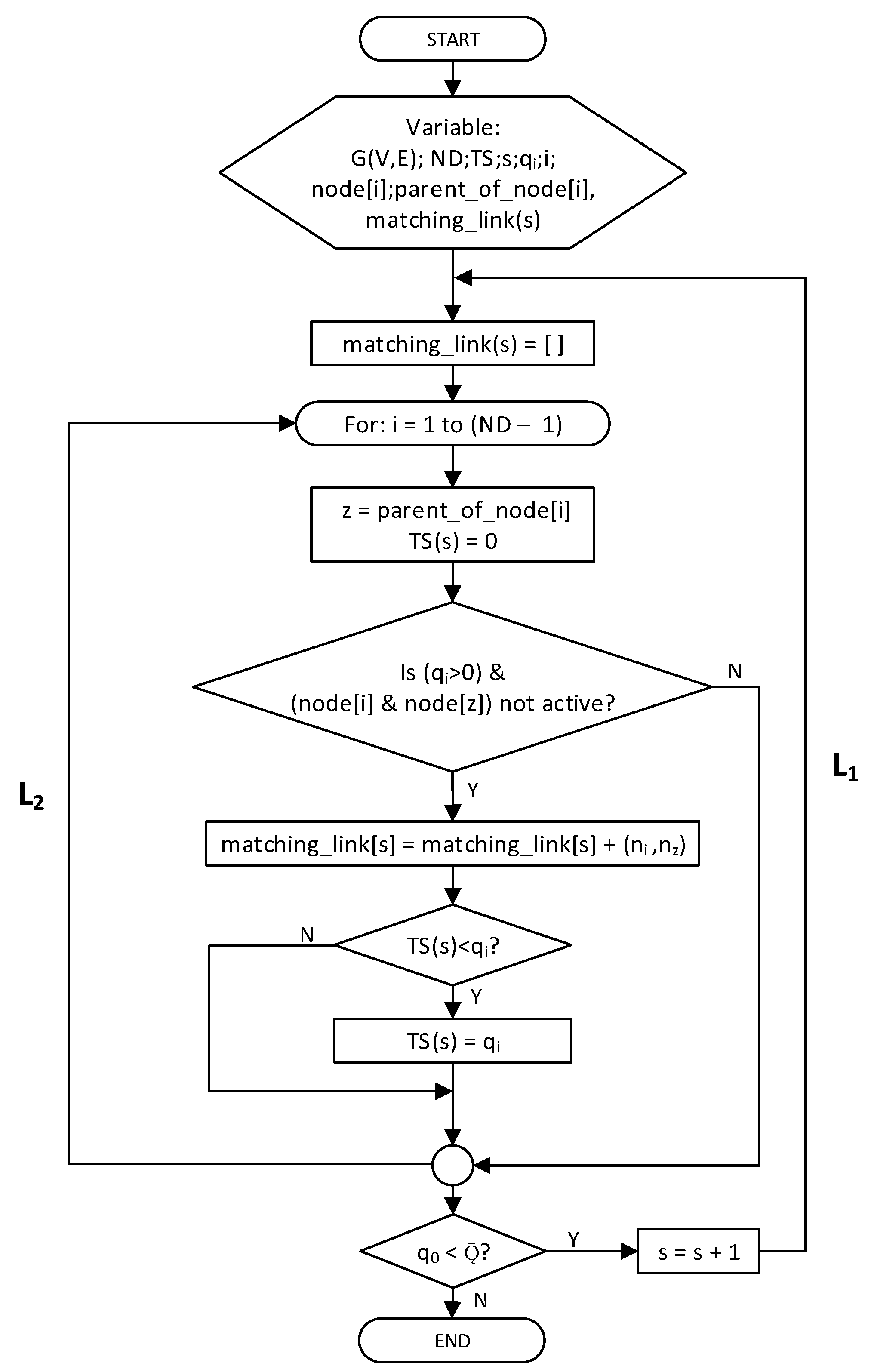
- IRByTSA contains two loops/iterations, L1 and L2, where L2 is inside L1. The continuity of the looping process in L1 is determined by the condition q0 < , as shown in Figure 12.
- 3
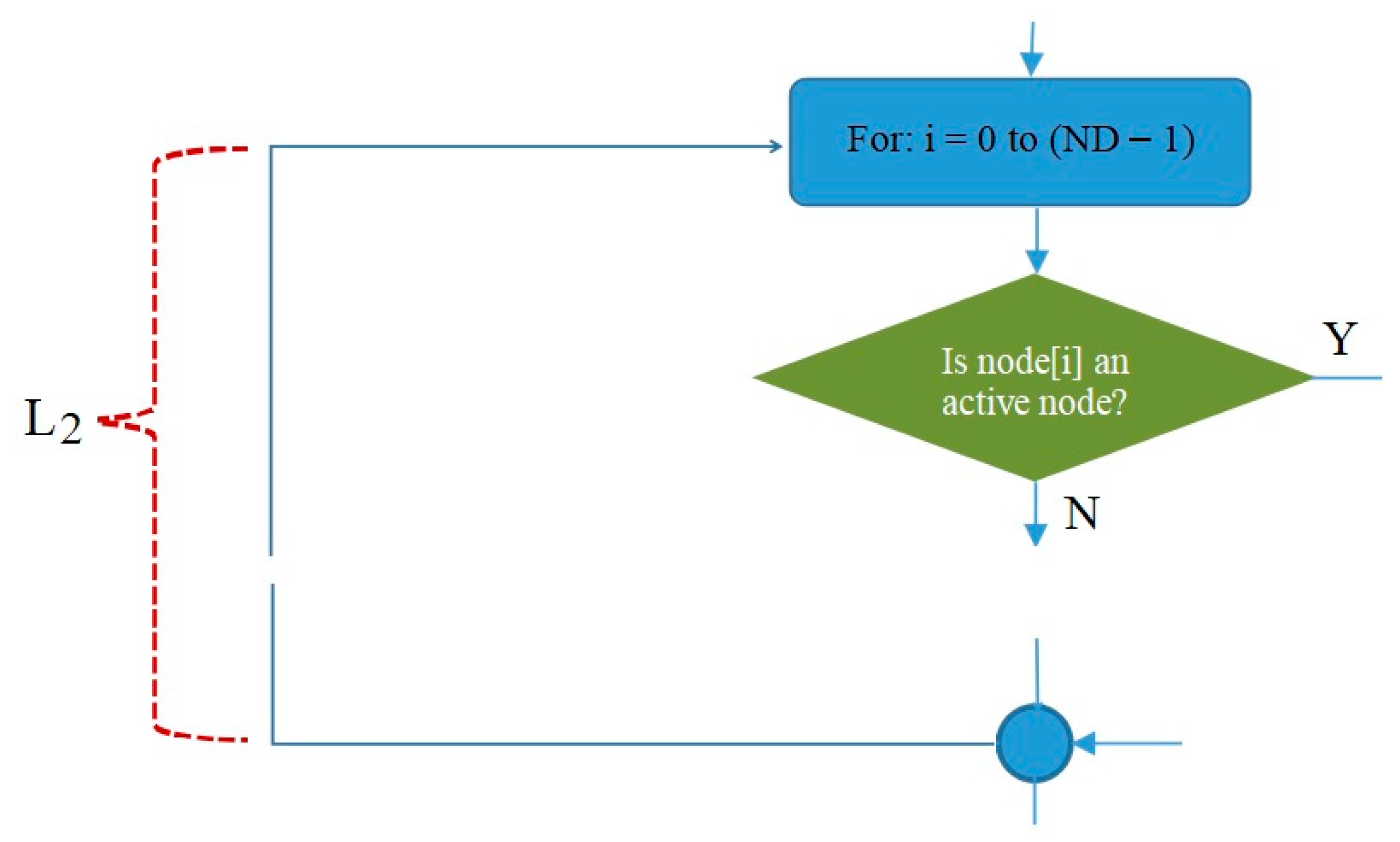
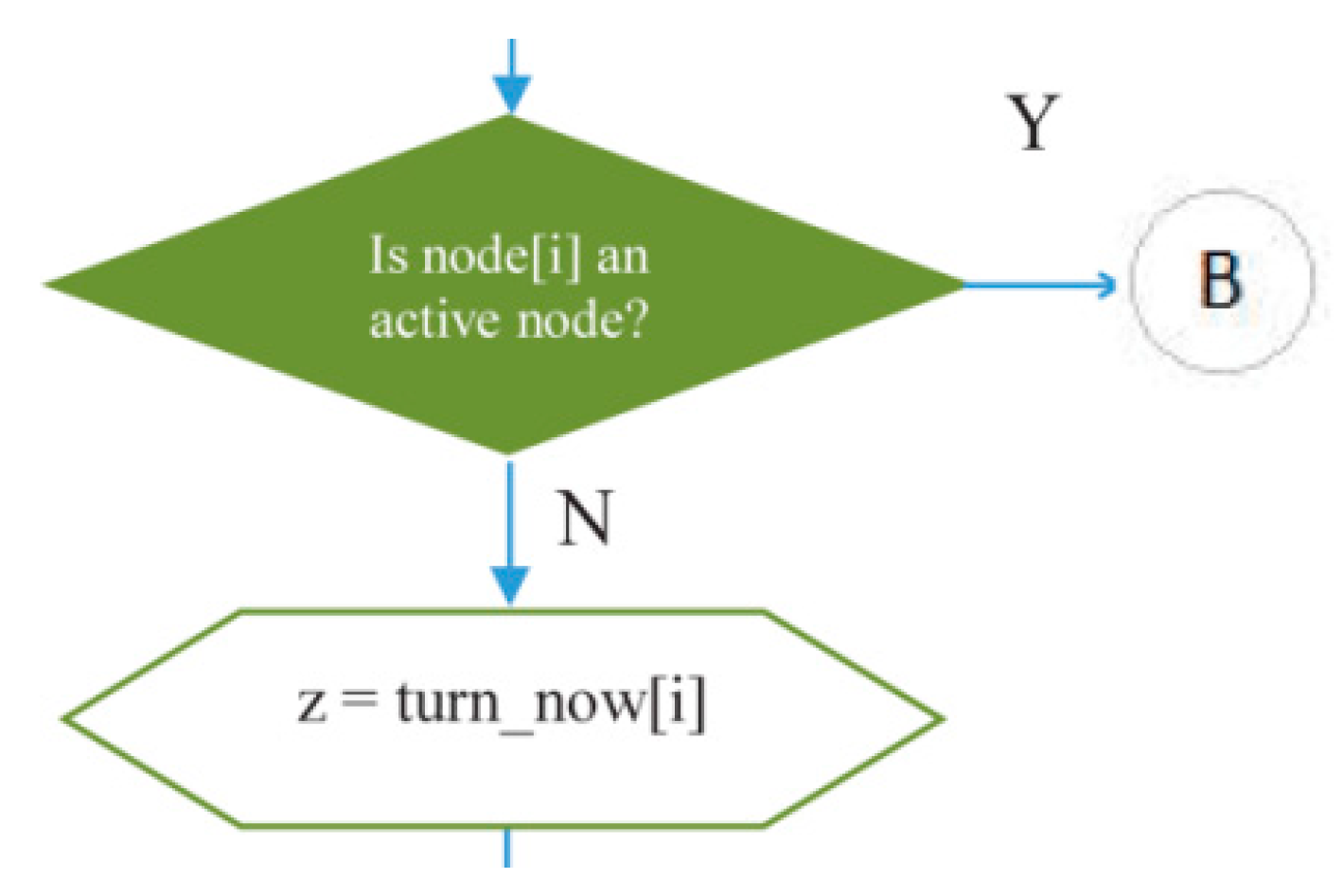
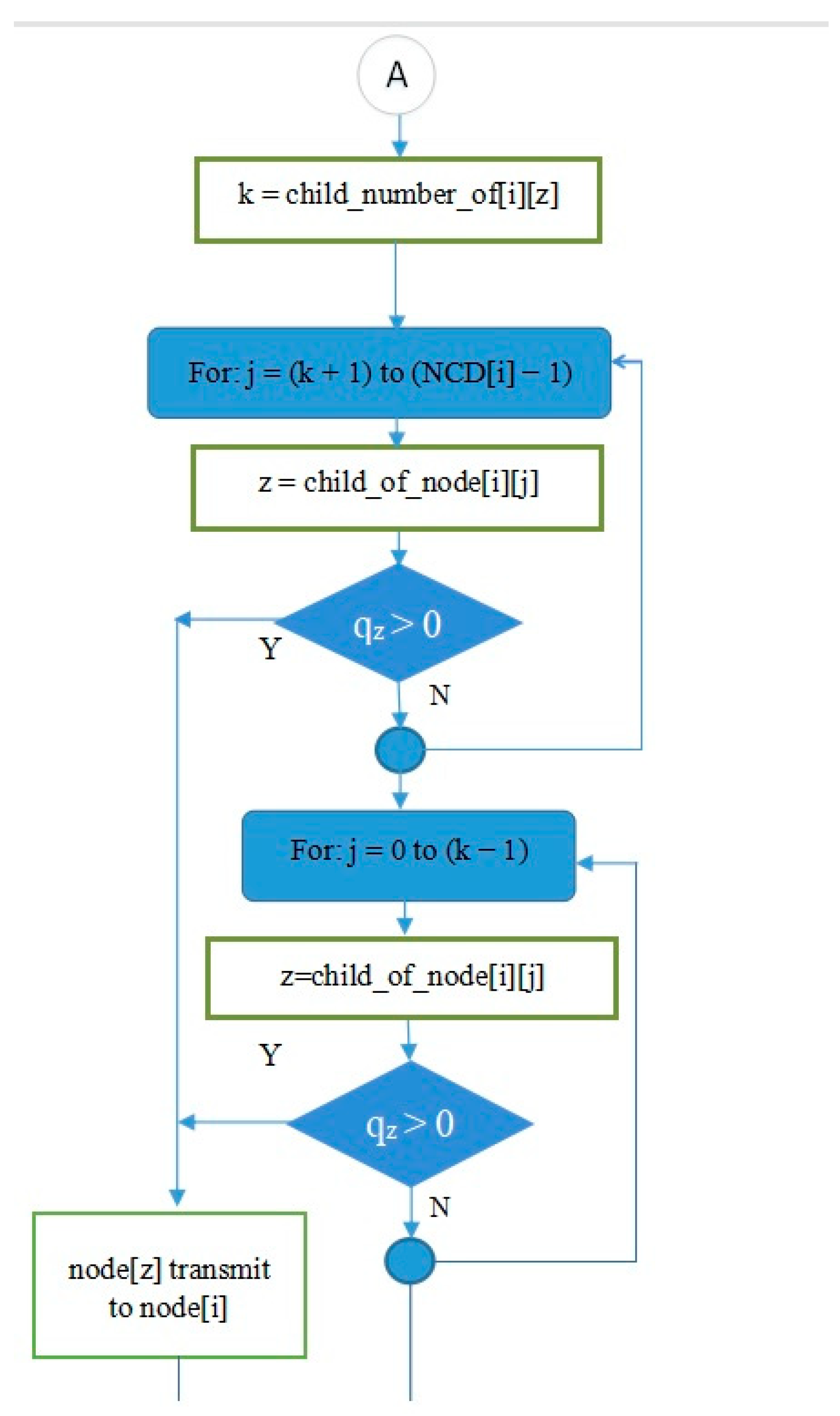
- The decision-making symbol in Figure 14 is used to indicate that if at a certain cycle/iteration node i is not active (because it has not had a turn to transmit or receive), one of the children of node i will get a turn to transmit. Meanwhile, if node i is active, the iteration in L2 will continue to node (i + 1) until all inactive nodes in the network get a turn to transmit or receive. In this way, the principle of graph matching will be realized in this scheduling algorithm.
- 4
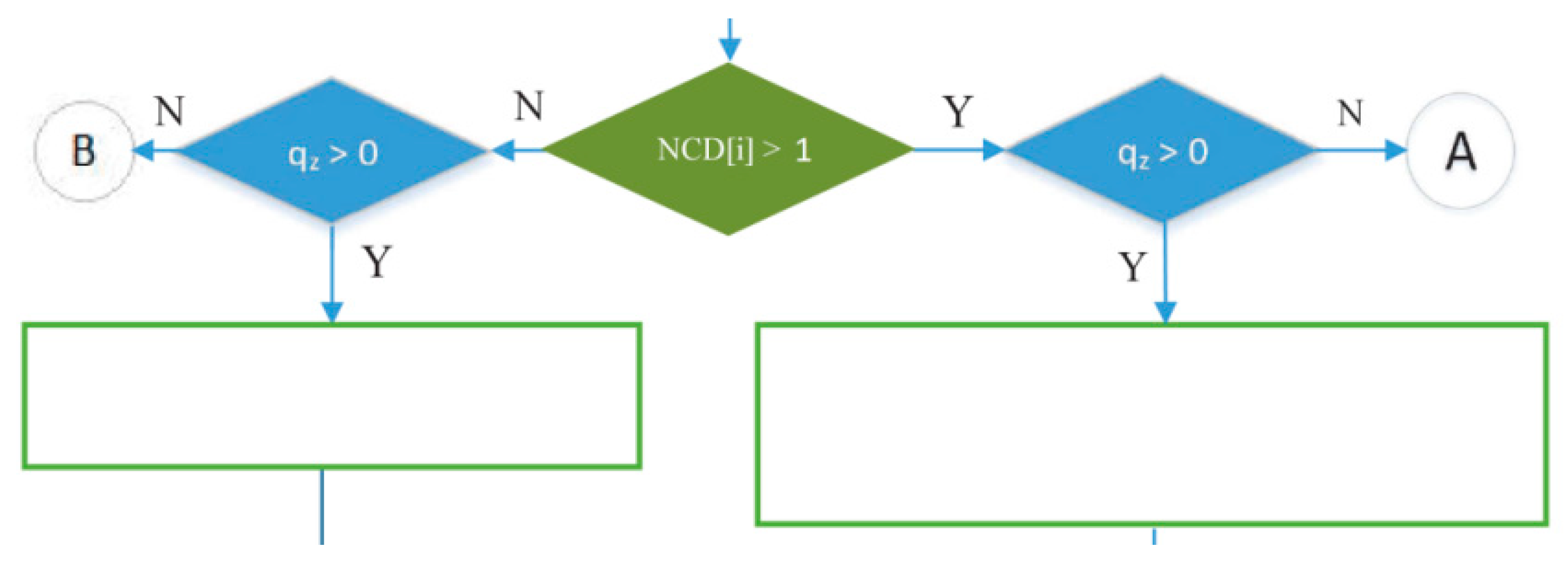
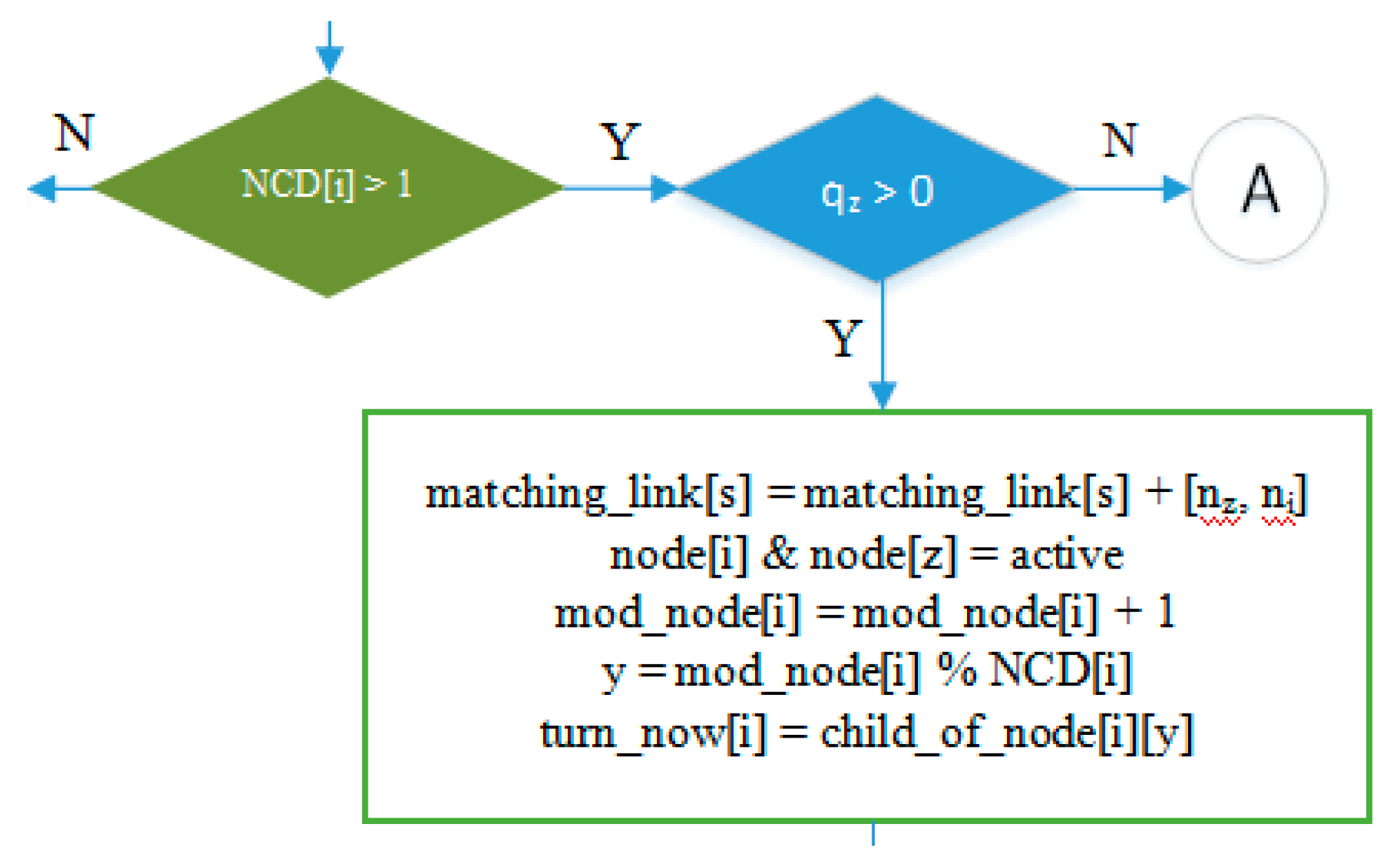
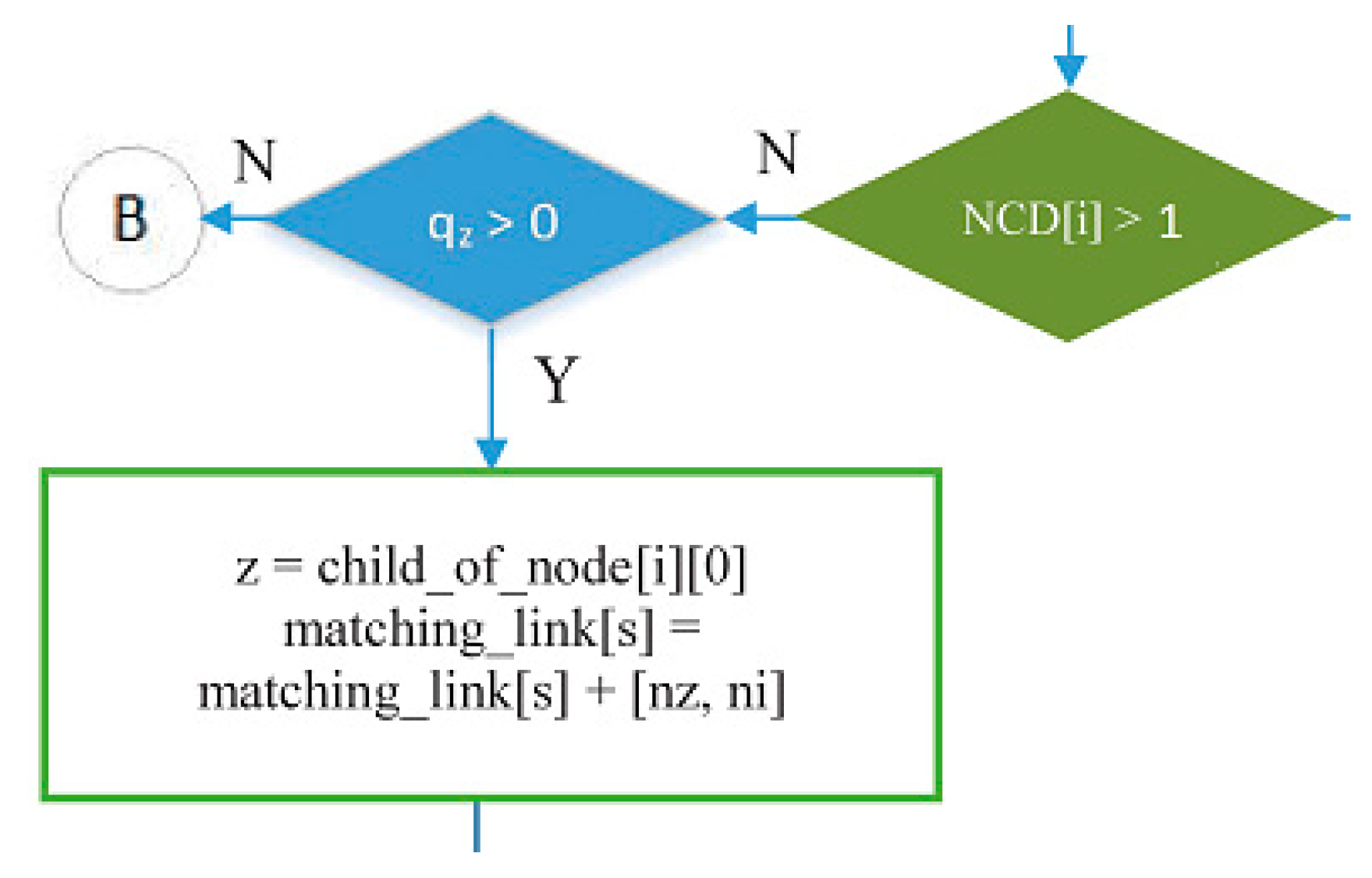
- The green decision symbol in Figure 15 is used to indicate whether node i has more than one child or not. If node i has more than one child, it will proceed to the blue decision symbol on the right, and if it only has one child, it will proceed to the left. Meanwhile, the two blue decision symbols are used to determine whether the queue is empty at the child node of node i.
- 5
- Part of the IRByTSA flowchart in Figure 16 states that if node i has more than one child (NCD [i] > 1) and the child of node i has a transmit turn (node z) and its queue is not empty (qz > 0), then node z is given the opportunity to transmit to node i, as indicated by the command line matching_link[s] = matching_link[s] + [nz,ni].
- 6
- If node i only has one child node and it has data to send, the child node (nz) will be scheduled to transmit data to its parent (ni), indicated by the command line matching_link[s] = matching_link[s] + [nz,ni]. Figure 18 shows the part of flowchart that illustrates that step.
- 7
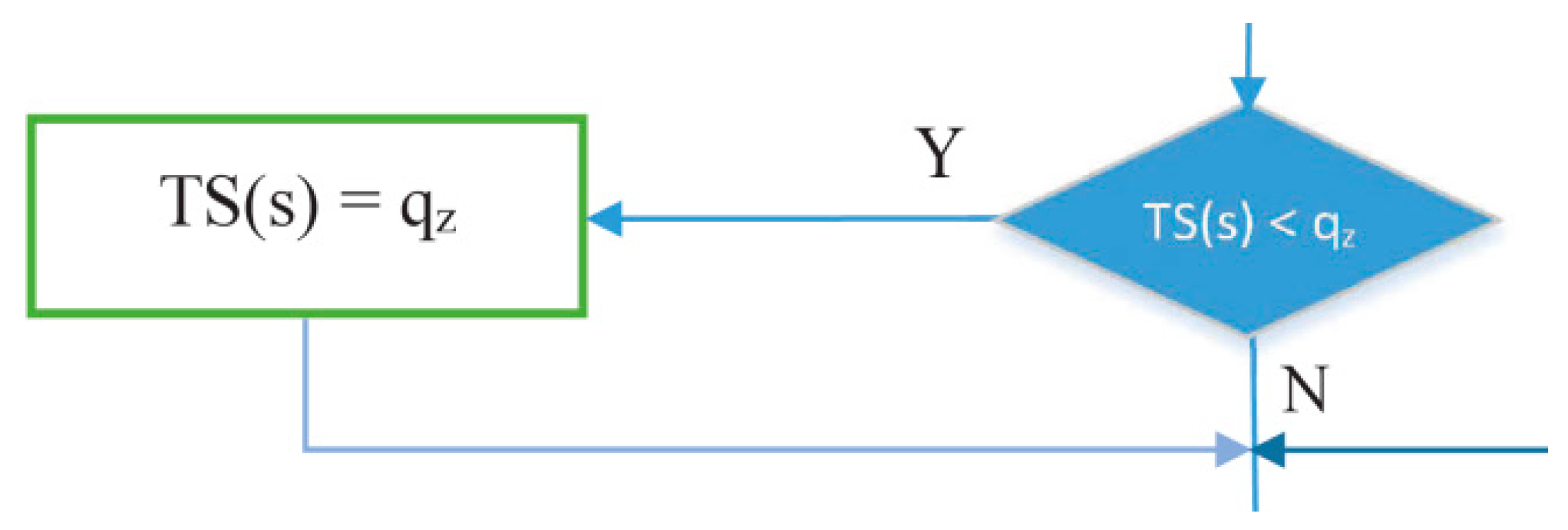
- The part of the flowchart in Figure 19 is used to find the node that has largest number of packets to be sent in a cycle (s), since the number of packets indicates the number of timeslots needed. IRByTSA looks for the largest timeslot value required by active nodes in each cycle (s) to ensure that the number of timeslots allocated meets the transmission needs of all active nodes.
- ◆
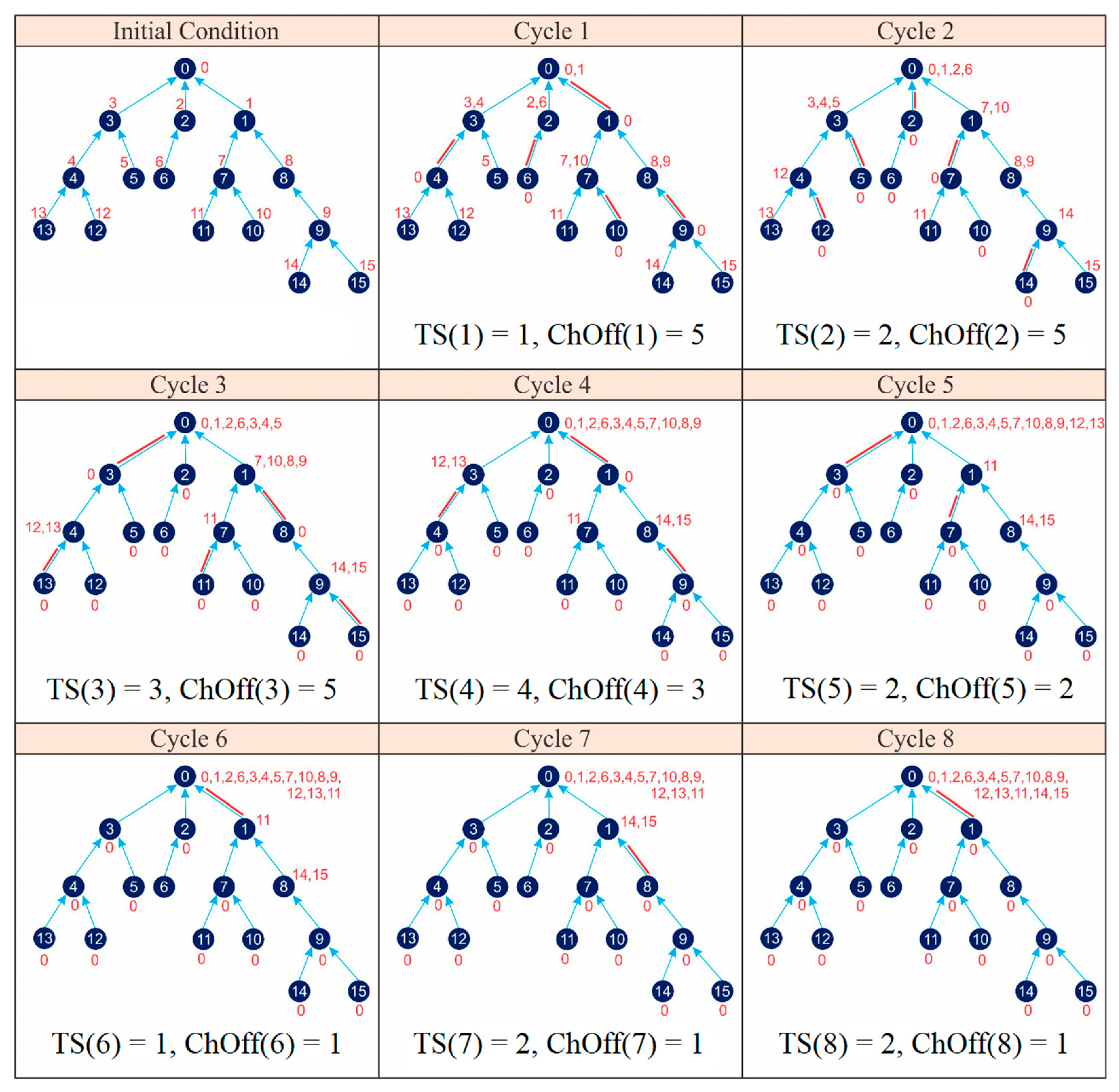
- CIRByTSA = 8 cycles;
- ◆
- = ChOff(1) + ChOff(2) + ChOff(3) + ChOff(4) + ChOff(5) + ChOff(6) + ChOff(7) + ChOff(8) = 5 + 5 + 5 + 3 + 2 + 1 + 1 + 1 = 23 ChOffs;
- ◆
- = TS(1) + TS(2) + TS(3) + TS(4) + TS(5) + TS(6) + TS(7) + TS(8) = 1 + 2 + 3 + 4 + 2 + 1 + 2 + 2 = 17 timeslots.
4.4.2. FTSA
- ◆
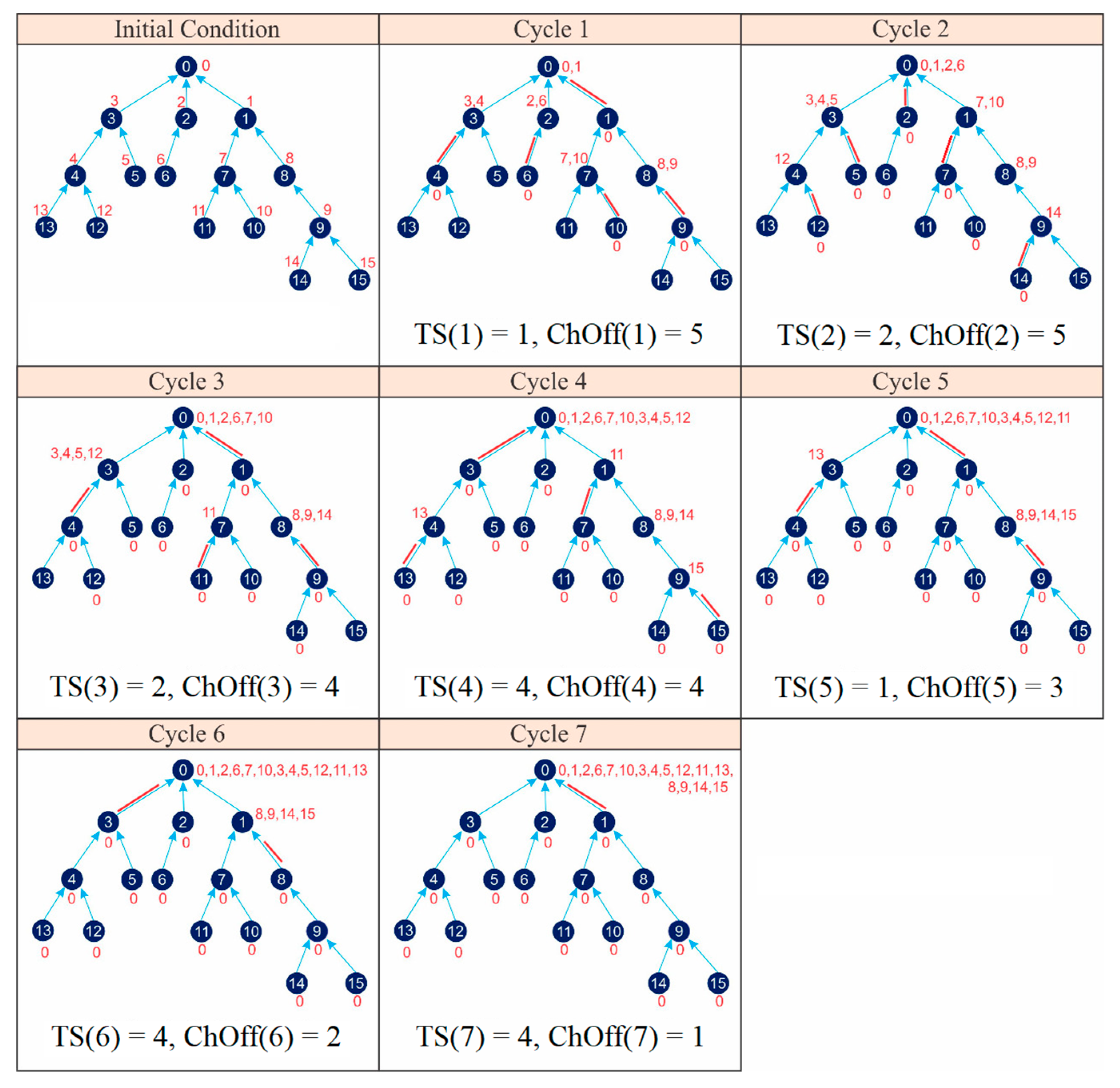
- CFTSA = 7 cycles;
- ◆
- = ChOff(1) + ChOff(2) + ChOff(3) + ChOff(4) + ChOffS(5) + ChOff(6) + ChOff(7) = 5 + 5 + 4 + 4 + 3 + 2 + 1 = 24 ChOffs;
- ◆
- = TS(1) + TS(2) + TS(3) + TS(4) + TS(5) + TS(6) + TS(7) = 1 + 2 + 2 + 4 + 1 + 4 + 4 = 18 timeslots.
4.4.3. FLSA
- ◆
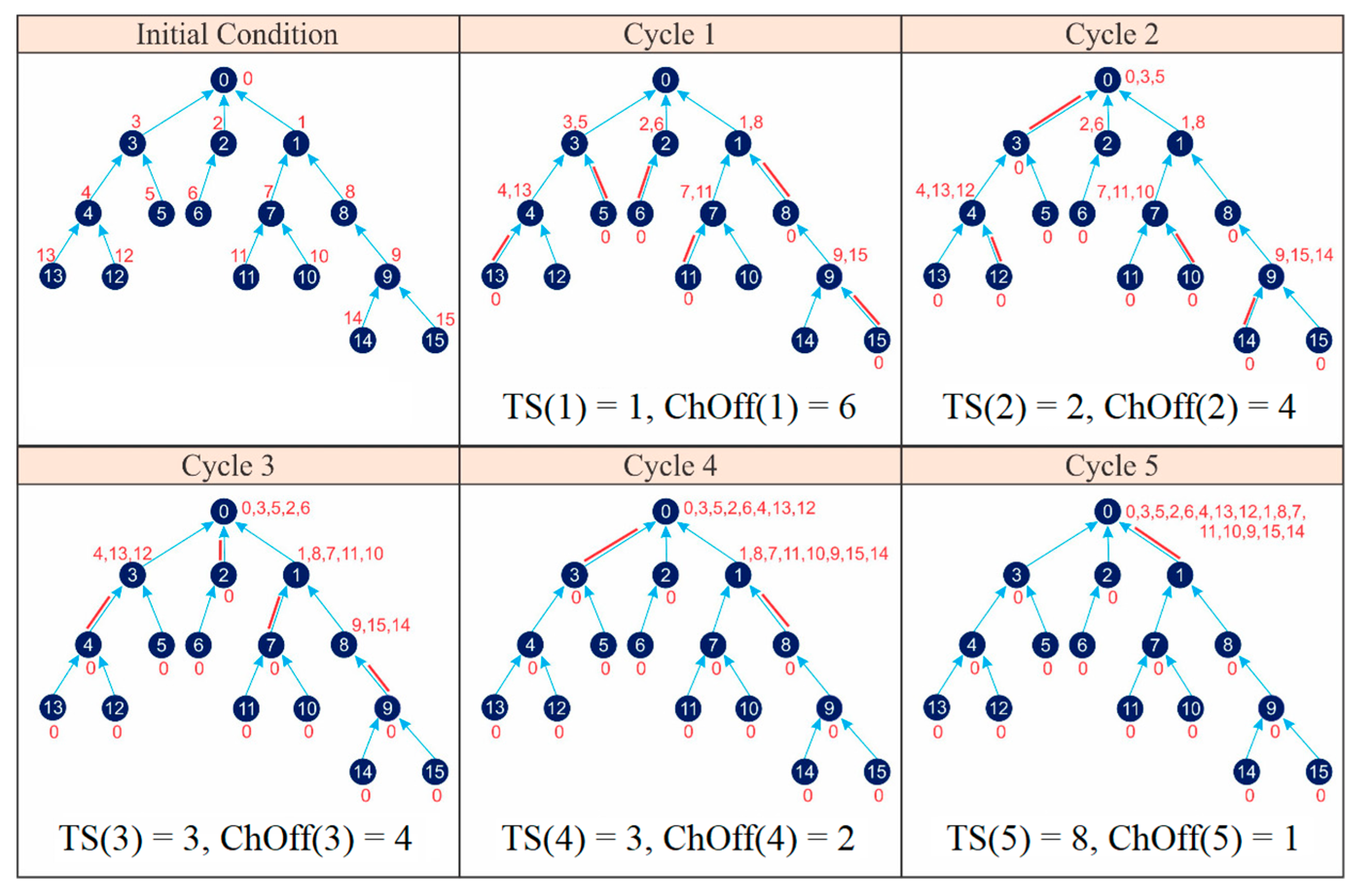
- CFLSA = 5 cycles;
- ◆
- = 6 + 4 + 4 + 2 + 1 = 17 ChOffs;
- ◆
- = TS(1) + TS(2) + TS(3) + TS(4) + TS(5) = 1 + 2 + 3 + 3 + 8 = 17 timeslots.
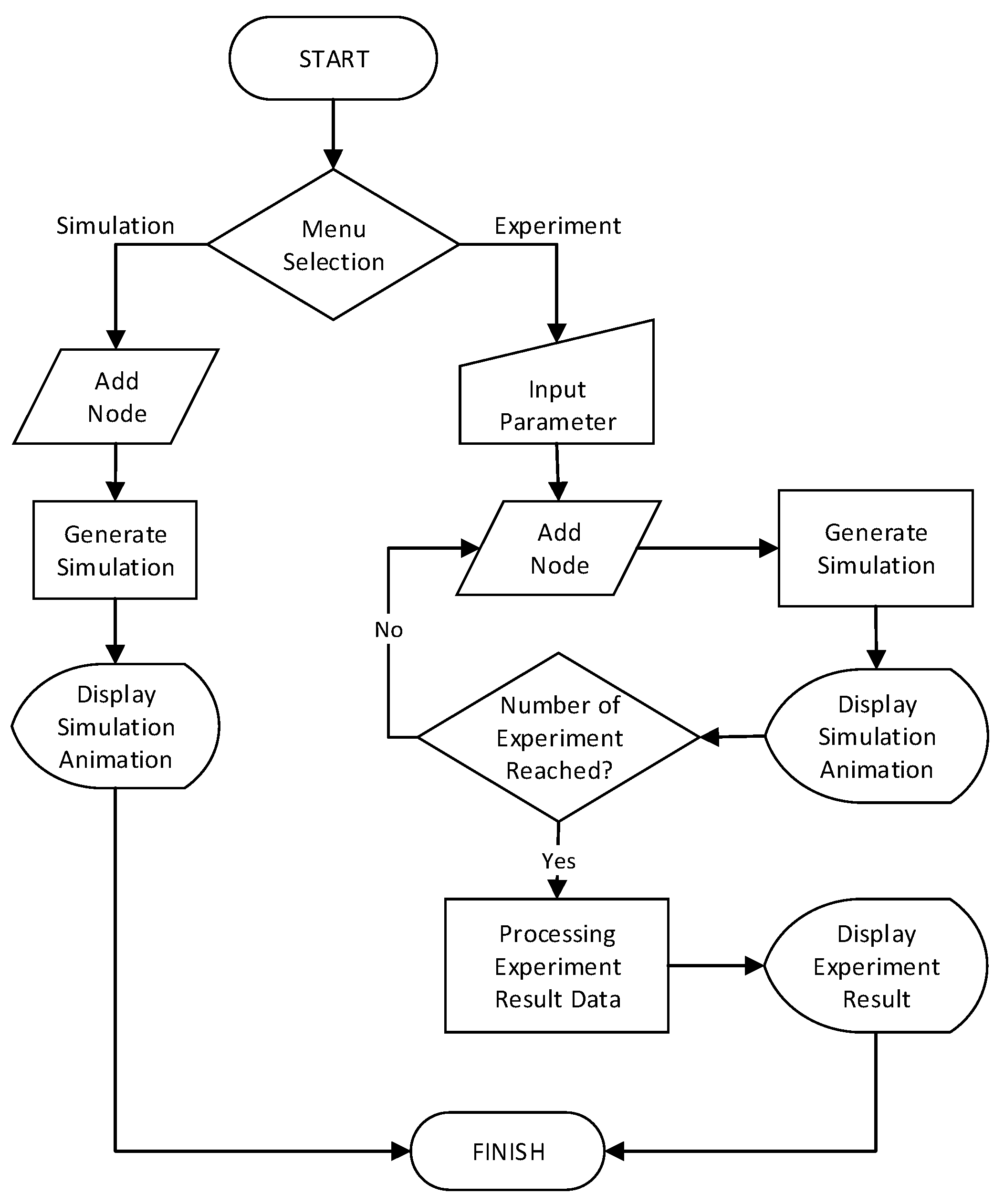
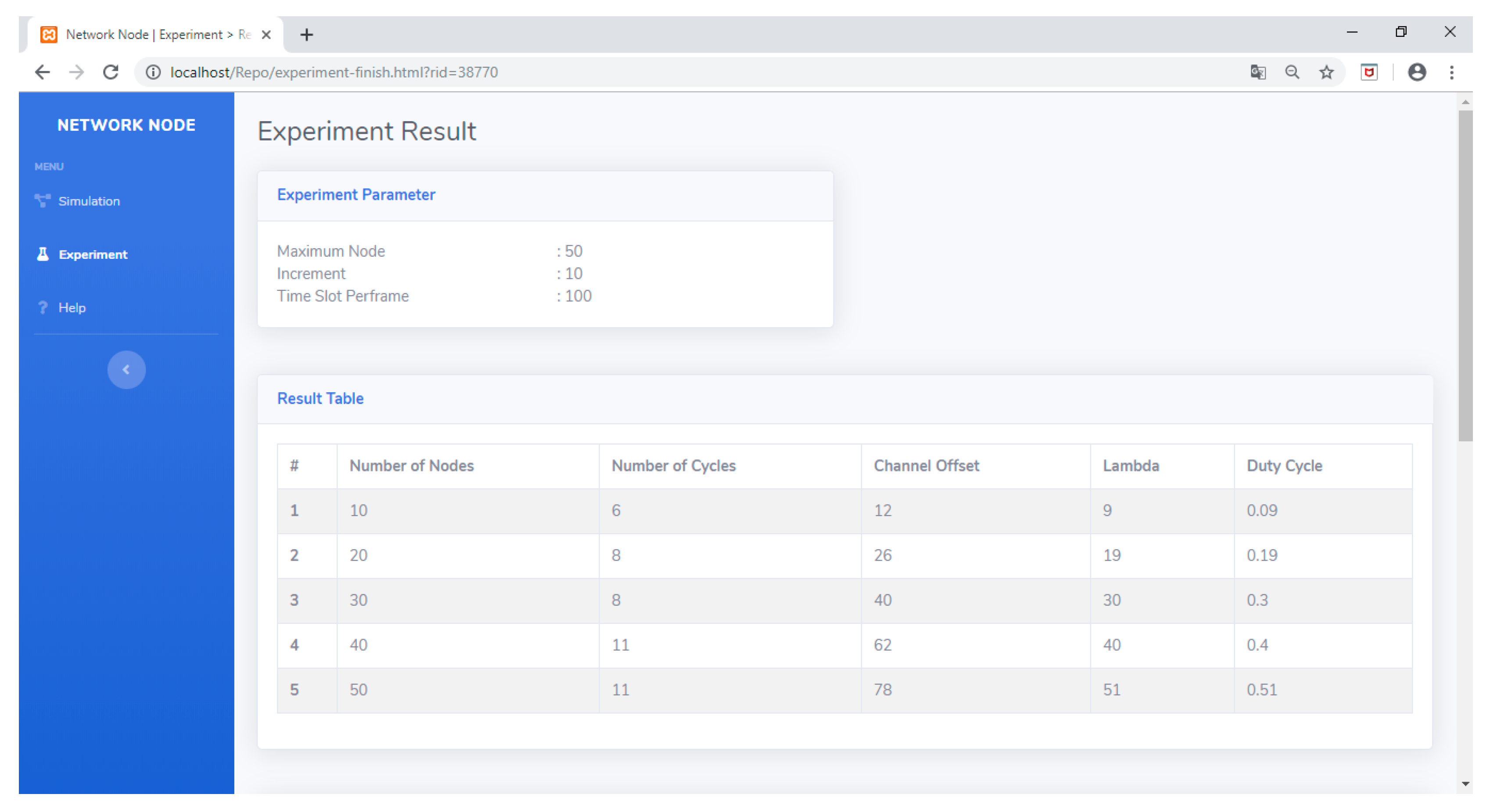
5. TSCH Link Scheduling Visualization and Data Processing
- ❖
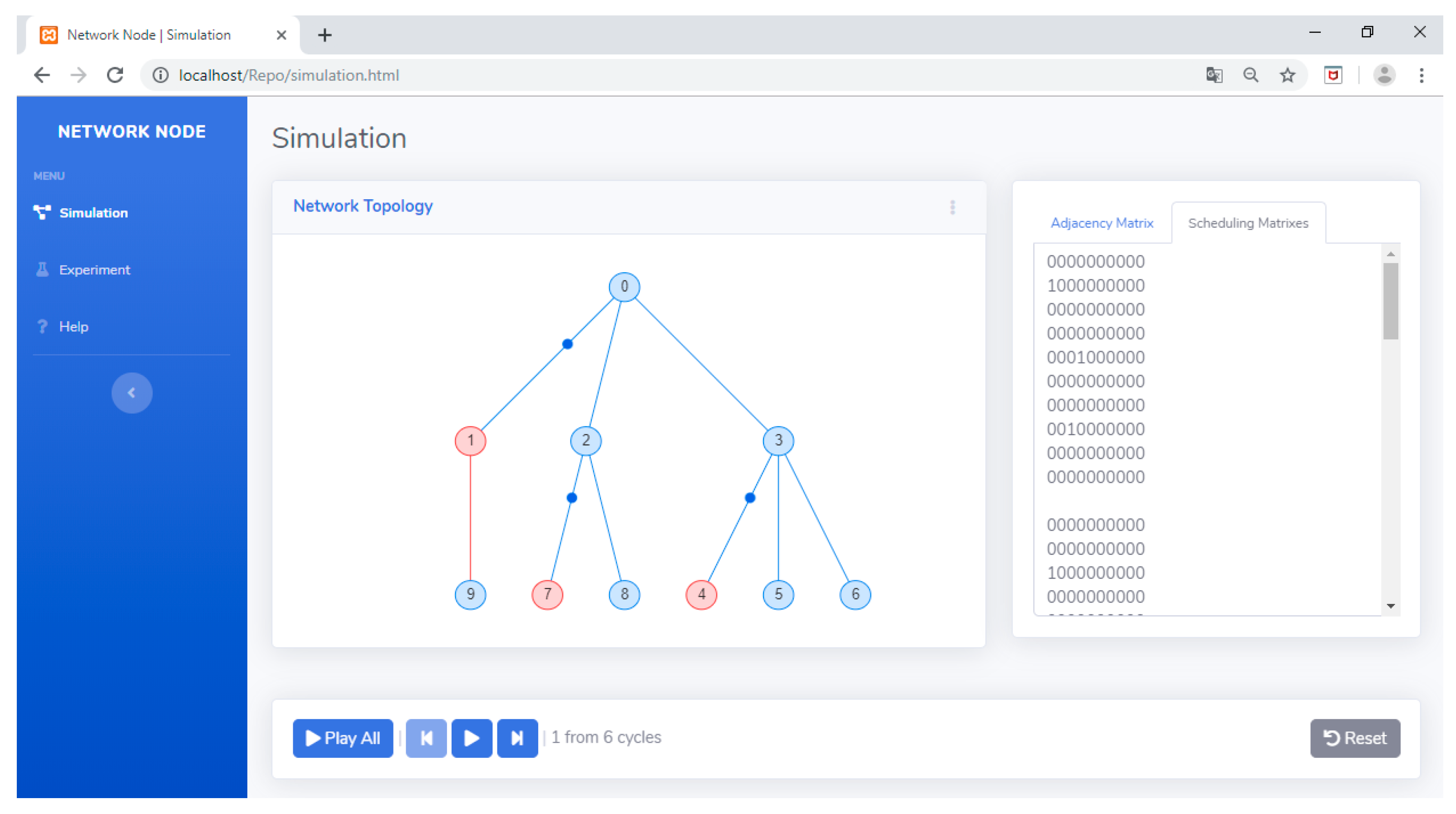
- It visualizes the transmit and receive processes between nodes in a network in a number of cycles. The data in the nodes of each cycle will move toward the master node gradually. Information on which nodes are active in each round is determined by the schedule matrices generated by the scheduling algorithm. With this visualization, researchers can determine whether the developed scheduling algorithm is in accordance with the plan or not.
- ❖
- It provides data output that shows the performance of the developed scheduling algorithm: number of active timeslots per slotframe (λ), number of cycles (C) and duty cycles (DC), and number of required channel offsets (ChOffs). The output of this tool will show the following performance:
- ■
- Number of active timeslots per slotframe (λ): the fewer active timeslots, the shorter the on time of network nodes, thereby saving on the amount of energy used.
- ■
- Number of cycles: indicates the speed of the scheduling algorithm in generating schedules. The smaller the number of cycles, the faster the algorithm can create a schedule. In terms of centralized network management, the faster the schedule, the better, because the resources to create the schedule can be used to serve other networks.
- ■
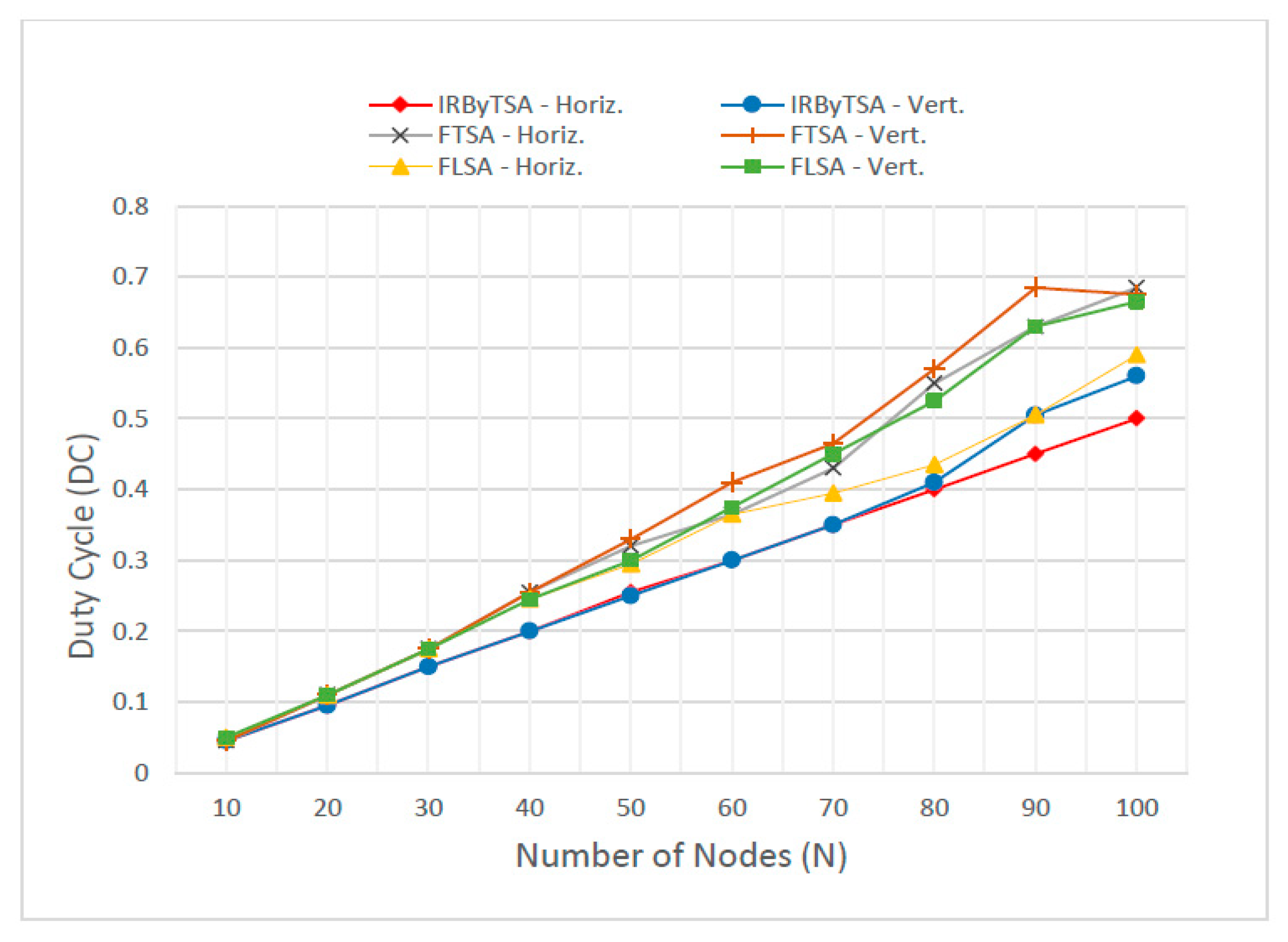
- Duty cycle: number of active timeslots when connected to the size of the slotframe. At the same slotframe size, the smaller the duty cycle, the better, because it indicates a network condition that is increasingly energy-efficient.
- ■
- Required channel offset: used to get the channel offset per cycle (ChOff/C) parameter. ChOff/C shows the average number of channel offsets used in each cycle. Since the 802.15.4e standard only provides 16 channel offsets, the ChOff/C value should be smaller than 16. The smaller the ChOff/C value, the better, because it will reduce the possibility of interference with other nodes that are active at the same time/cycle. Even though this research assumes there is no interference, it is still important to note ChOff/C data as preliminary information for researchers who want to include interference problems as a parameter to consider.
- ❖
- It provides a platform for researchers in the field of centralized link-scheduling algorithms to test the performance level of developed algorithms. A scheduling algorithm has good performance if all output data released from TLS-VaD has a minimum value. If we want to improve the performance of the algorithm, it can be repaired separately, because in order to use TLS-VaD, researchers can simply create an executable (exe) file from the developed algorithm and embed the file on TLS-VaD. Since TLS-VaD only requires exe files, researchers do not need to be bound to one particular programming language; they only need to create an exe file capable of processing input in the form of an adjacency matrix and producing schedule matrices as output. These schedule matrices will then be processed by TLS-VaD to produce animations and data output. A description of the relationship between TLS-VaD and the exe file of the scheduling algorithm is presented in Figure 25.
5.1. The Design of TLS-VaD
5.1.1. System Design
5.1.2. Implementation
- Native PHP (hypertext processor): A technology for creating basic scripts that are widely used for website-based applications.
- C ++: the programming language used in this software for processing input data in the form of a matrix that is transformed into the software using a multi-dimensional array.
- Javascript: a high-level programming language that runs on the client-side like a browser. Here, it was used to create animations/visualizations.
- HTML (hypertext markup language): a markup language that is used to make the main structure of the display of web-based software.
- Bootstrap: a CSS framework that is used for HTML styling so that the software display becomes neater and more attractive.
- Animate traffic: this library, which was created using Javascript, displays animation from input data in the form of arrays. Here, it was used as a library to display animation/visualization.
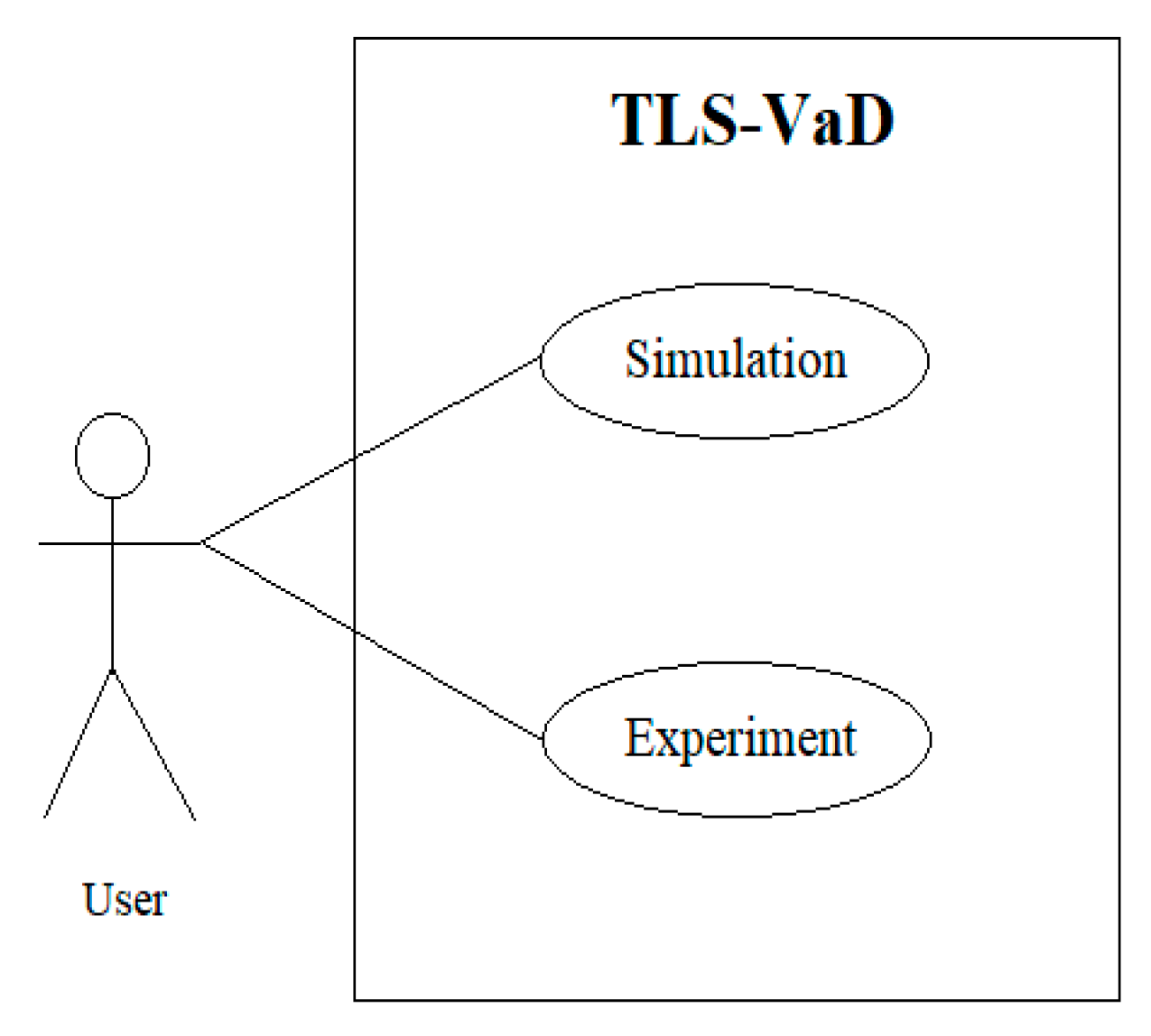
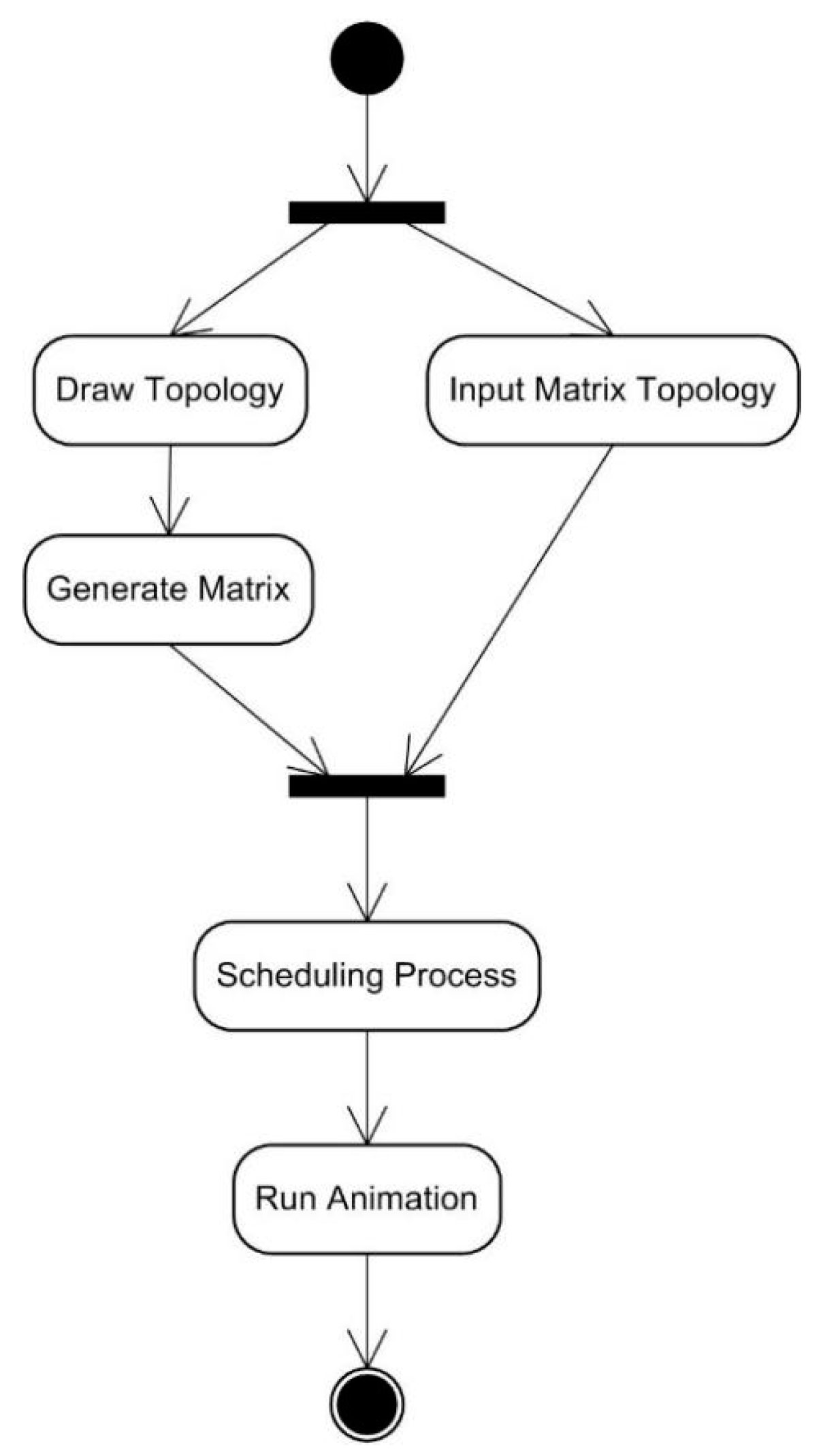
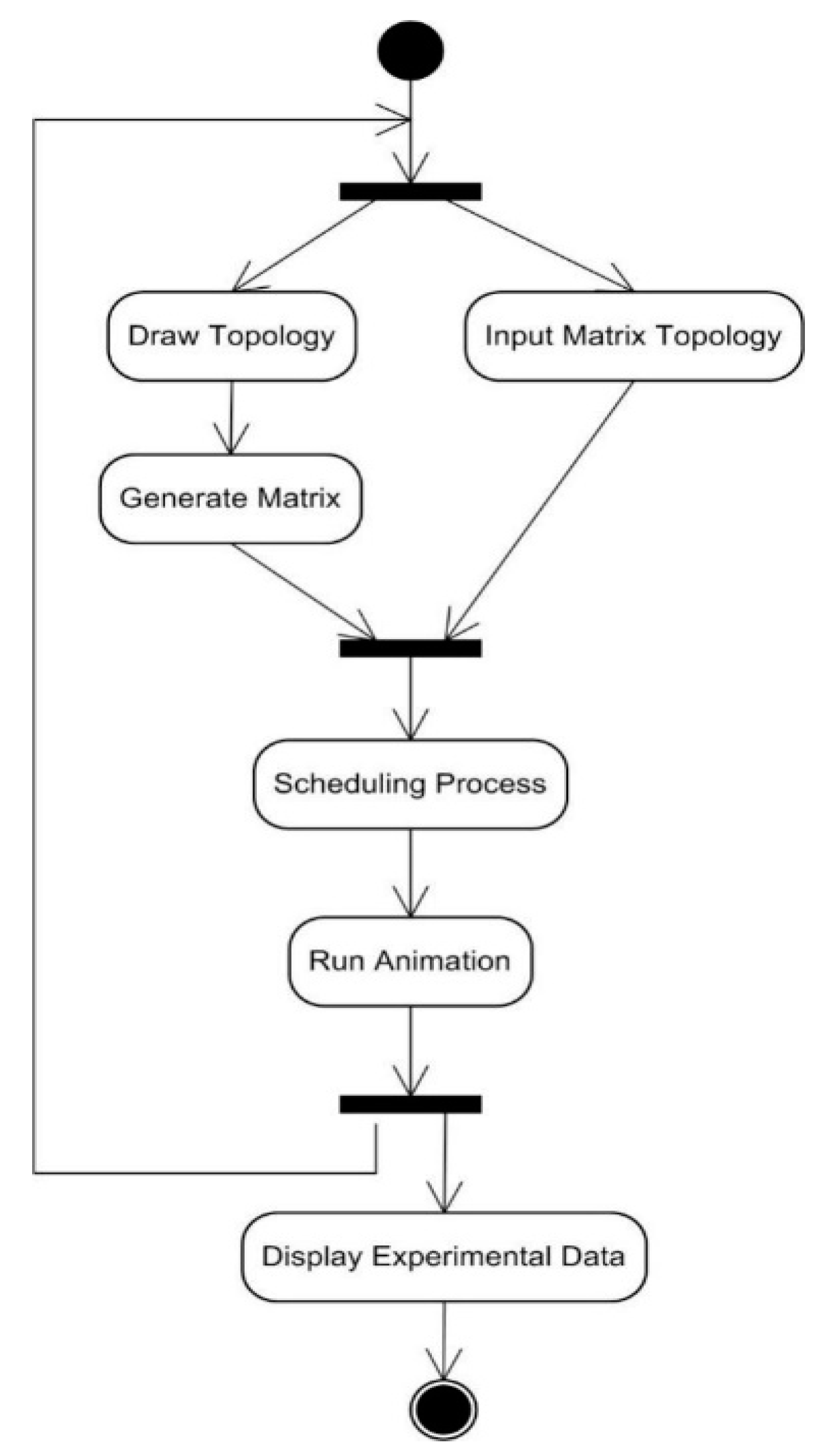
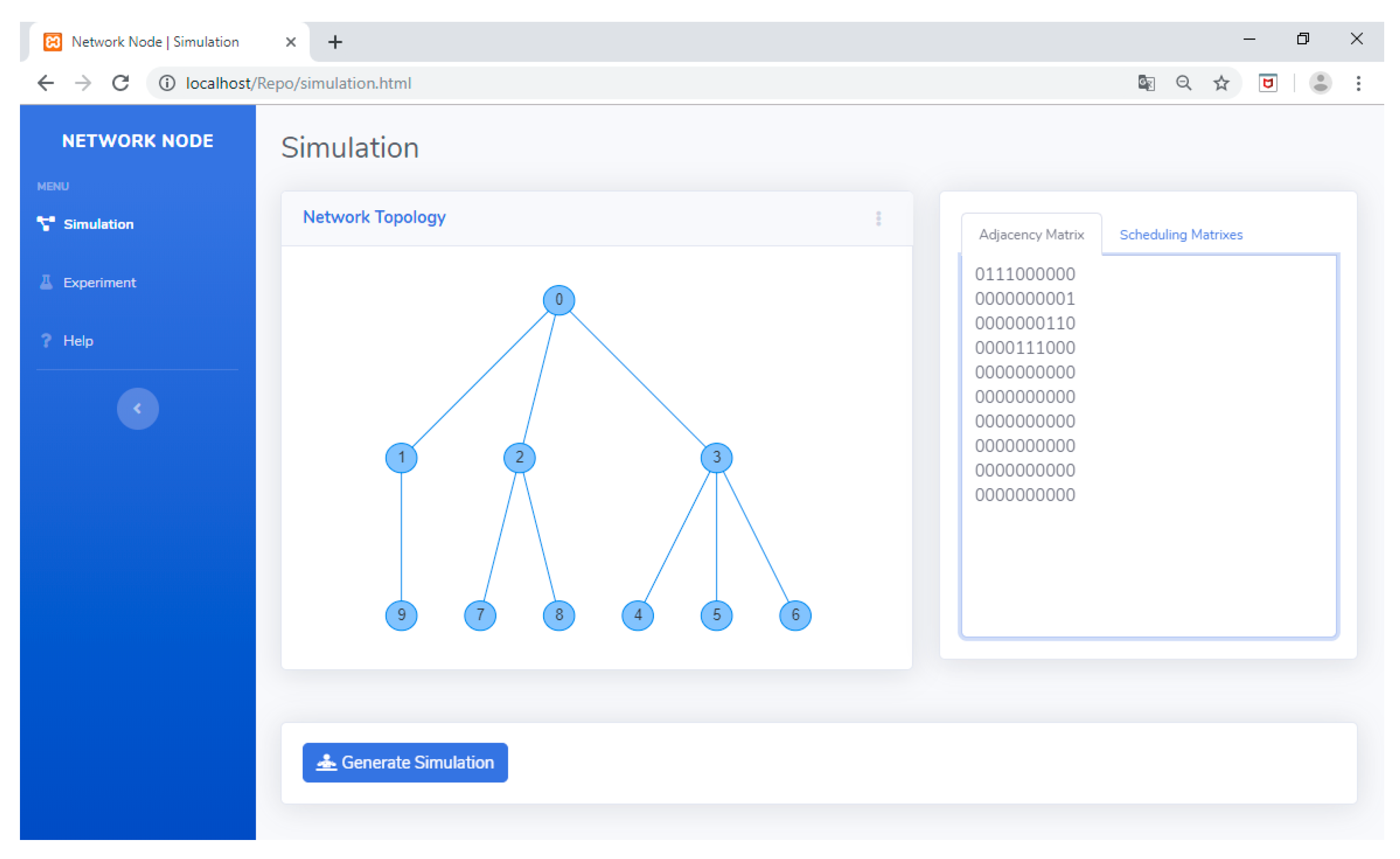
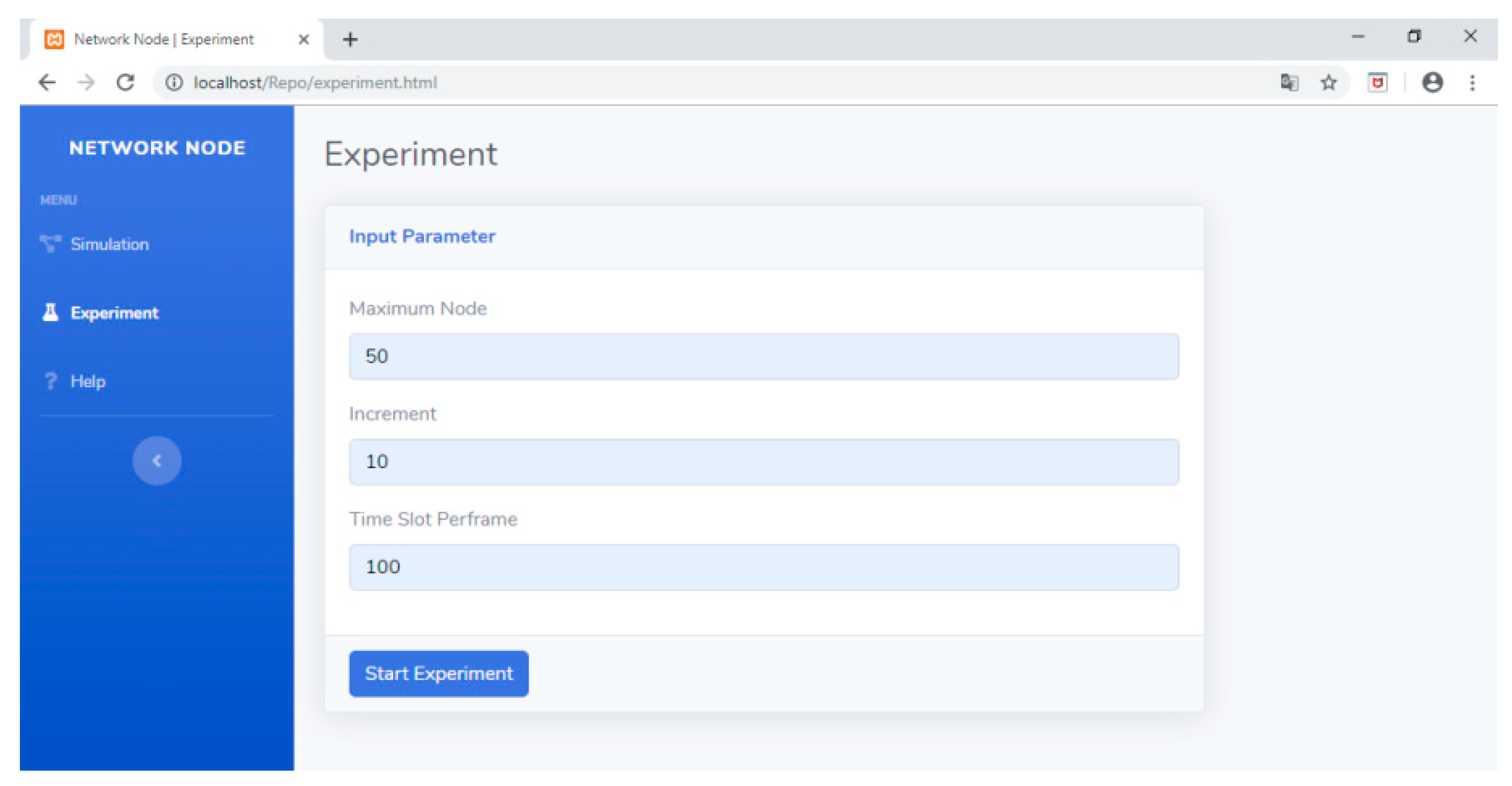
5.2. Using the TLS-VaD
6. Scheduling Algorithm Performance Test Using TLS-VaD
- (a)
- It results in minimum values for active timeslots (λ) and duty cycles (D).
- (b)
- It is quick at generating scheduling decisions that are marked by a minimum cycle (C) value.
6.1. Hypotheses on the Performance of Scheduling Algorithms
- (a)
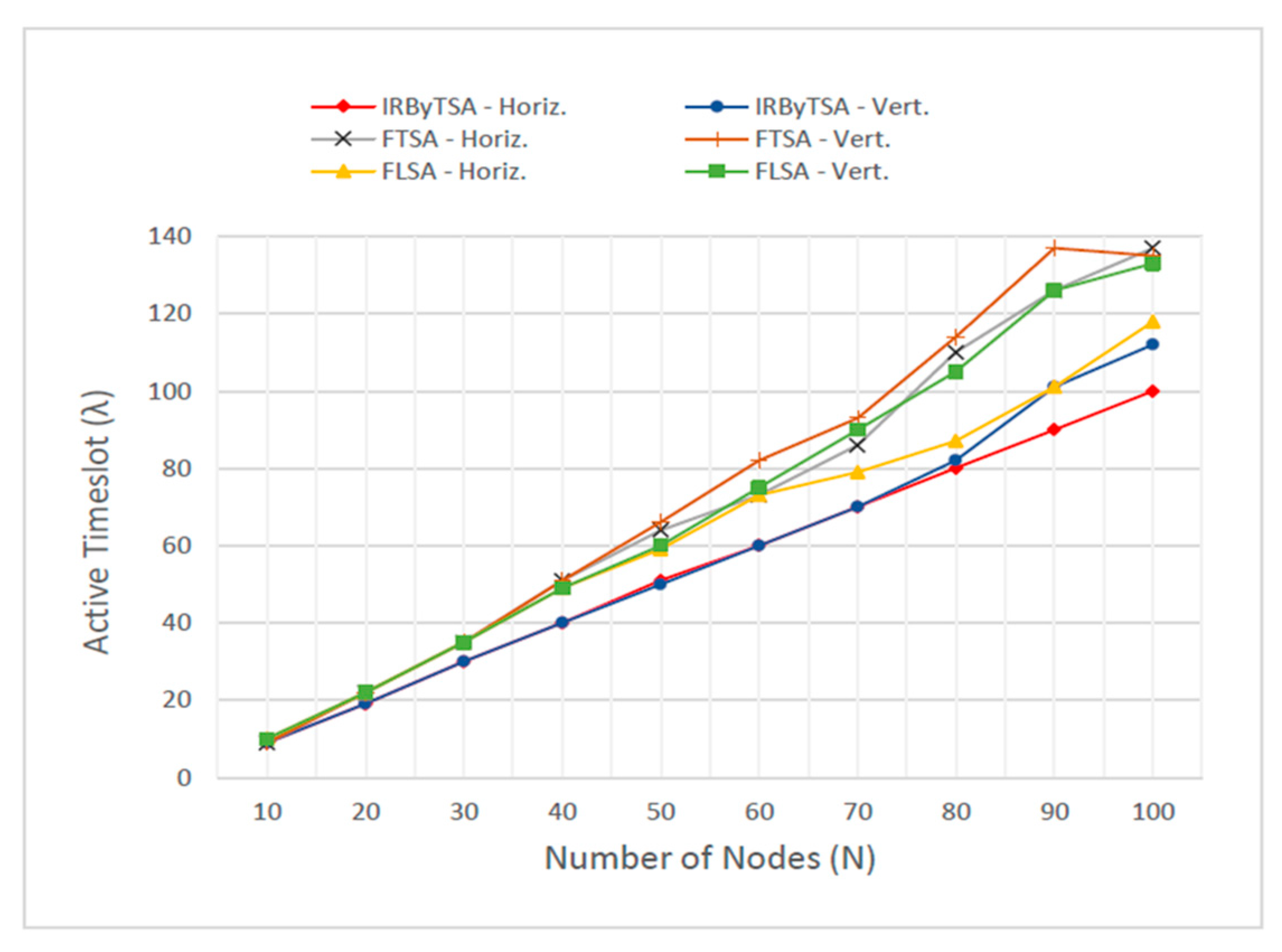
- In producing minimum λ, IRByTSA will outperform FTSA and FLSA. This is estimated because IRByTSA prioritizes transmission at higher-rank nodes. By prioritizing higher-rank nodes, data packets will arrive at the master node faster, which decreases the number of timeslots needed to send data along the passing of cycles. The decreased need for timeslots in each cycle will produce the minimum λ value.
- (b)
- In producing the minimum number of cycles, FLSA will outperform IRByTSA and FTSA. This can occur because FLSA gives priority to transmission at leaf nodes that will give more links to the DCFL(s) than the algorithm that prioritizes transmission at higher nodes. With more links on DCFL(s), network data will reach the master node faster. Faster arrival of data at the master node on a network that uses FLSA will be reflected in fewer cycles than a network that uses IRByTSA or FTSA.
- (c)
- In producing a minimum λ, FTSA will not perform as well as IRByTSA, because in FTSA, the opportunity to transmit from the child node to its parent is not done in rotation, resulting in a buildup of data at certain nodes, leading to increased λ value generated by the algorithm.
- (d)
- In producing a minimum number of cycles, FTSA will not perform as well as FLSA because of two factors: (i) transmission priority is given to higher nodes. Algorithms that give priority to transmission at higher nodes will not be able to provide more DCFLs than algorithms that give priority to transmission at leaf nodes. Thus, what happens to IRByTSA will also happen to FTSA. (ii) The process of transmitting from a child node to its parent always starts from the first child node, not based on turns. As long as the child nodes have data, even if only one data packet, the node will be given the opportunity to transmit. This will result in data reaching the master node slowly, so the number of cycles needed to collect all data at the master node will be greater than the number of cycles in IRByTSA and FLSA.
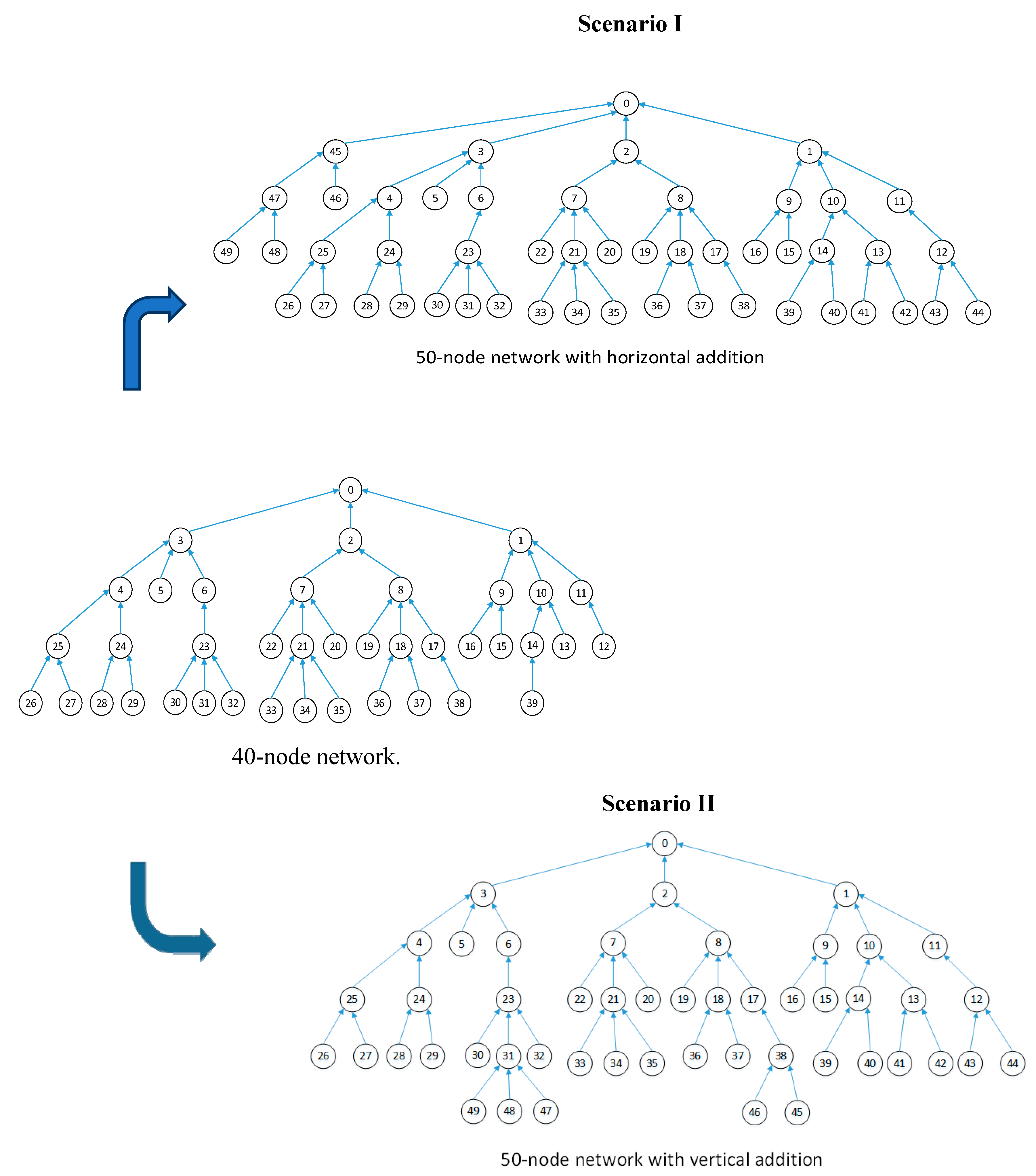
6.2. Experimental Scenarios
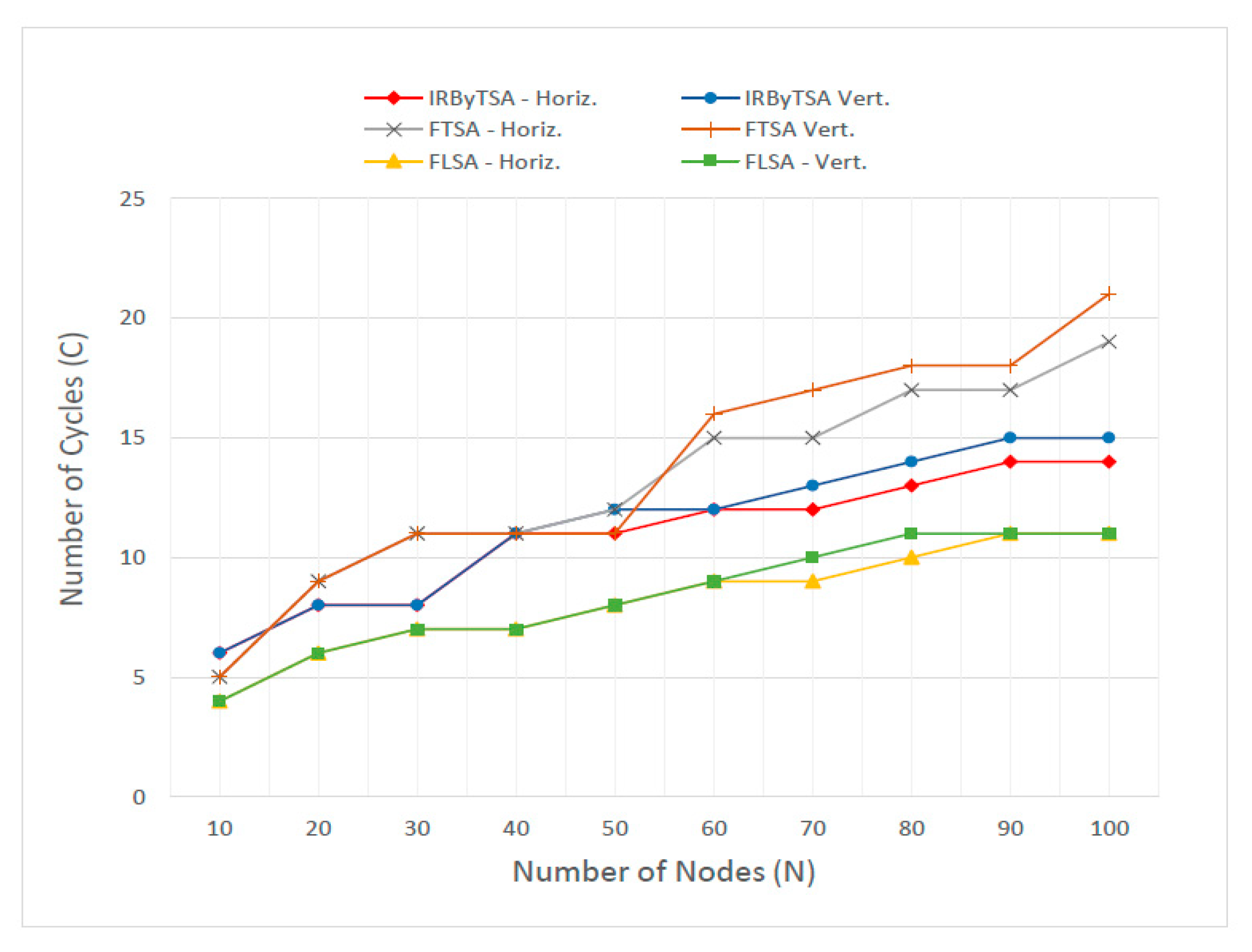
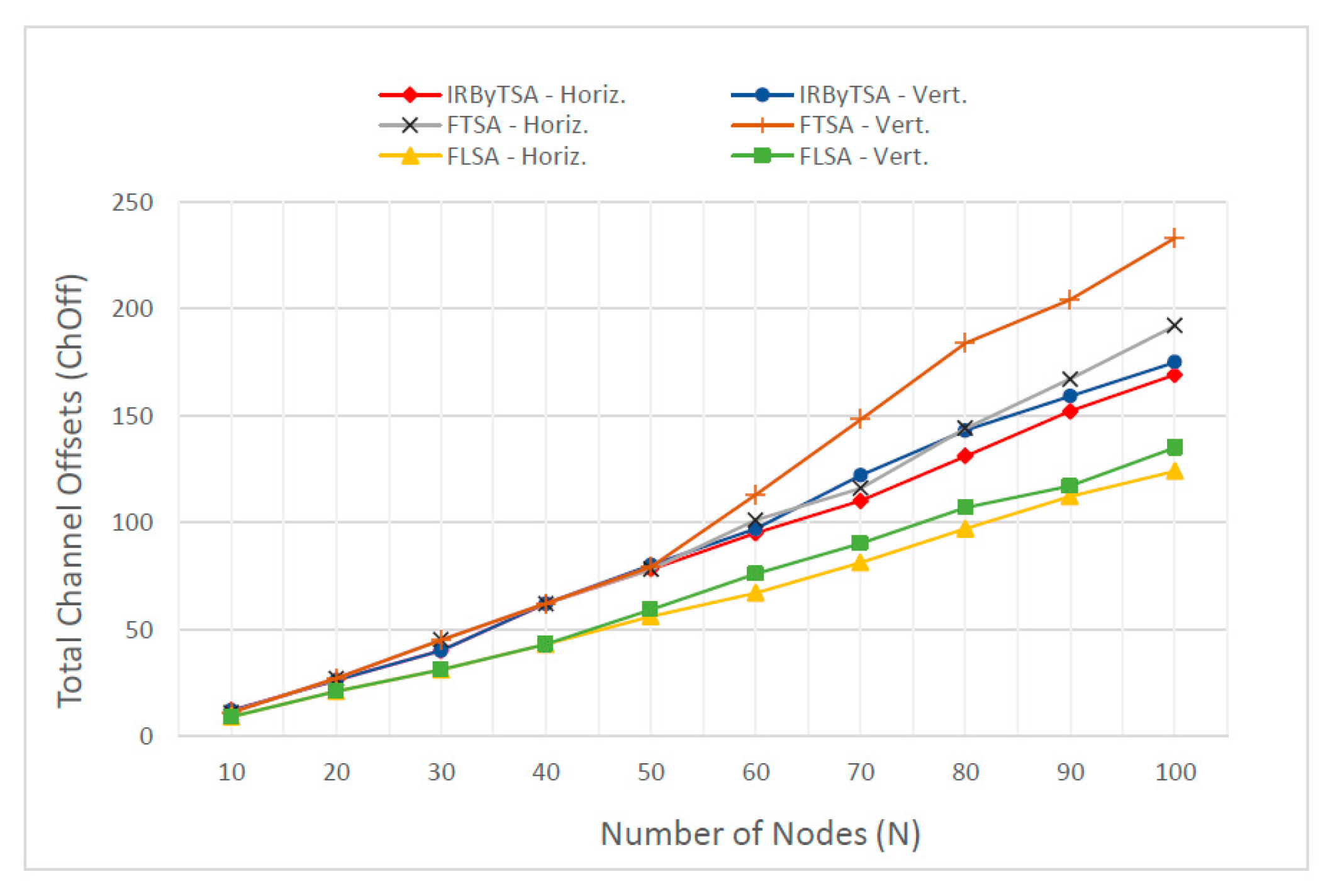
6.3. Results and Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Atzori, L.; Iera, A.; Morabito, G. Understanding the Internet of Things: Definition, potentials, and societal role of a fast evolving paradigm. Ad Hoc Netw. 2017, 56, 122–140. [Google Scholar] [CrossRef]
- Li, S.; Da Xu, L.; Zhao, S. The internet of things: A survey. Inf. Syst. Front. 2015, 17, 243–259. [Google Scholar] [CrossRef]
- Bizanis, N.; Kuipers, F.A. SDN and virtualization solutions for the Internet of Things: A survey. IEEE Access 2016, 4, 5591–5606. [Google Scholar] [CrossRef]
- Chen, Y.; Han, F.; Yang, Y.H.; Ma, H.; Han, Y.; Jiang, C.; Lai, H.-Q.; Claffey, D.; Liu, K.R. Time-reversal wireless paradigm for green Internet of Things: An overview. IEEE Internet Things J. 2014, 1, 81–98. [Google Scholar] [CrossRef]
- Palattella, M.R.; Thubert, P.; Vilajosana, X.; Watteyne, T.; Wang, Q.; Engel, T. 6tisch wireless industrial networks: Determinism meets ipv6. In Internet of Things; Springer: Cham, Switzerland, 2014; pp. 111–141. [Google Scholar]
- Thubert, P.; Palattella, M.R.; Engel, T. 6TiSCH centralized scheduling: When SDN meet IoT. In Proceedings of the 2015 IEEE Conference onStandards for Communications and Networking (CSCN), Tokyo, Japan, 28–30 October 2015; pp. 42–47. [Google Scholar]
- Bera, S.; Misra, S.; Vasilakos, A.V. Software-defined networking for internet of things: A survey. IEEE Internet Things J. 2017, 4, 1994–2008. [Google Scholar] [CrossRef]
- Thubert, P. An Architecture for IPv6 over the TSCH mode of IEEE 802.15. 4. Working Draft. Available online: https://tools.ietf.org/id/draft-ietf-6tisch-architecture-15.html (accessed on 14 December 2019).
- Palattella, M.R.; Accettura, N.; Grieco, L.A.; Boggia, G.; Dohler, M.; Engel, T. On optimal scheduling in duty-cycled industrial IoT applications using IEEE802. 15.4 e TSCH. IEEE Sens. J. 2013, 13, 3655–3666. [Google Scholar] [CrossRef]
- Palattella, M.R.; Accettura, N.; Dohler, M.; Grieco, L.A.; Boggia, G. Traffic aware scheduling algorithm for reliable low-power multi-hop IEEE 802.15. 4e networks. In Proceedings of the 2012 IEEE 23rd International Symposium on Personal Indoor and Mobile Radio Communications (PIMRC), Sydney, Australia, 9–12 September 2012; pp. 327–332. [Google Scholar]
- Palattella, M.R.; Accettura, N.; Dohler, M.; Grieco, L.A.; Boggia, G. Traffic-aware time-critical scheduling in heavily duty-cycled IEEE 802.15. 4e for an industrial IoT. Proc. IEEE Sens. 2012, 2012, 1–4. [Google Scholar]
- Santoso, I.H.; Ramli, K. IRByTSA: A Novel link-scheduling algorithm for IEEE802.15.4e TSCH Network. J. Theor. Appl. Inf. Technol. 2019, 97, 2725–2738. [Google Scholar] [CrossRef]
- Santoso, I.H.; Ramli, K. Speed improvement of centralized scheduling algorithm on IEEE 802.15. 4e TSCH netwok using heuristic method. J. Commun. 2017, 12, 661–667. [Google Scholar] [CrossRef]
- Meng, M.; Yujun, Z.; Dadong, Z.; Fan, C. Scheduling for Data Transmission in Multi-Hop IEEE 802.15. 4e TSCH Networks. Mob. Netw. Appl. 2018, 23, 119–125. [Google Scholar] [CrossRef]
- Ojo, M.; Giordano, S.; Portaluri, G.; Adami, D.; Pagano, M. An energy efficient centralized scheduling scheme in TSCH networks. In Proceedings of the 2017 IEEE International Conference on Communications Workshops (ICC Workshops), Paris, France, 21–25 May 2017; pp. 570–575. [Google Scholar]
- Chen, T.S.; Kuo, S.Y.; Kuo, C.H. Scheduling for data collection in multi-hop IEEE 802.15. 4e TSCH networks. In Proceedings of the 2016 International Conference on Networking and Network Applications (NaNA), Hakodate, Japan, 23–25 July 2016; pp. 218–222. [Google Scholar]
- Choi, K.H.; Chung, S.H. A new centralized link scheduling for 6TiSCH wireless industrial networks. In Internet of Things, Smart Spaces, and Next Generation Networks and Systems; Springer: Cham, Switzerland, 2016; pp. 360–371. [Google Scholar]
- Livolant, E.; Minet, P.; Watteyne, T. The cost of installing a 6tisch schedule. In International Conference on Ad-Hoc Networks and Wireless; Springer: Cham, Switzerland, 2016; pp. 17–31. [Google Scholar]
- Shreedhar, M.; Varghese, G. Efficient fair queuing using deficit round-robin. IEEE/ACM Trans. Netw. 1996, 3, 375–385. [Google Scholar] [CrossRef]
- Sayenko, A.; Alanen, O.; Karhula, J.; Hämäläinen, T. Ensuring the QoS requirements in 802.16 scheduling. In Proceedings of the 9th ACM International Symposium on Modeling Analysis and Simulation of Wireless and Mobile Systems, Torremolinos, Spain, 2–6 October 2006; pp. 108–117. [Google Scholar]
- Khoufi, I.; Minet, P.; Livolant, E.; Rmili, B. Building an IEEE 802.15. 4e TSCH network. In Proceedings of the 2016 IEEE 35th International Performance Computing and Communications Conference (IPCCC), Las Vegas, NV, USA, 9–11 December 2016; pp. 1–2. [Google Scholar]
- Felicetti, L.; Femminella, M.; Reali, G. A simulation tool for nanoscale biological networks. Nano Commun. Netw. 2012, 3, 2–18. [Google Scholar] [CrossRef]
- Beshay, J.D.; Subramani, K.S.; Mahabeleshwar, N.; Nourbakhsh, E.; McMillin, B.; Banerjee, B.; Prakash, R.; Du, Y.; Huang, P.; Xi, T.; et al. Wireless networking testbed and emulator (winetester). Comput. Commun. 2016, 73, 99–107. [Google Scholar] [CrossRef]
- De Guglielmo, D.; Brienza, S.; Anastasi, G. IEEE 802.15. 4e: A survey. Comput. Commun. 2016, 88, 1–24. [Google Scholar] [CrossRef]
- Zheng, J.; Lee, M.J. A Comprehensive Performance Study of IEEE 802.15.4. Sens. Netw. Oper. 2004, pp. 218–237. Available online: https://sites.google.com/site/jzhengresearch/papers/paper1_wpan_performance.pdf (accessed on 17 December 2019).
- 802.15.4e-2012: IEEE Standard for Local and Metropolitan Area Networks—Part 15.4: Low-Rate Wireless Personal Area Networks (LRWPANs) Amendment 1: MAC Sublayer; Institute of Electrical and Electronics Engineers Std. IEEE Computer Society: New York, NY, USA, 2012.
- Palattella, M.R.; Accettura, N.; Vilajosana, X.; Watteyne, T.; Grieco, L.A.; Boggia, G.; Dohler, M. Standardized protocol stack for the internet of (important) things. IEEE Commun. Surv. Tutor 2013, 15, 1389–1406. [Google Scholar] [CrossRef]
- Watteyne, T.; Palattella, M.R.; Grieco, L. Using IEEE 802.15. 4e Time-Slotted Channel Hopping (TSCH) in the Internet of Things (IoT): Problem Statement. Available online: https://tools.ietf.org/html/rfc7554 (accessed on 14 December 2019).
- NS3. Current Development. 7 July 2019. Available online: https://www.nsnam.org/wiki/Current_Development (accessed on 3 November 2018).
- Atlassian Inc. The 6TiSCH Simulator. Available online: https://bitbucket.org/6tisch/simulator (accessed on 16 April 2019).









































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Item | IRByTSA | FTSA | FLSA |
|---|---|---|---|---|
| 1 | Process of generating scheduling decisions is done on/for each timeslot | No | No | No |
| 2 | Bursty transmission | Yes | Yes | Yes |
| 3 | Transmission priority on the network | From higher-rank node | From higher-rank node | From leaf node |
| 4 | Transmission priority based on queue size of a node | No | No | No |
| 5 | Transmission priority based on number of child nodes | No | No | No |
| 6 | Resource allocation is only given to nodes with qn ≠ 0 | Yes | Yes | Yes |
| 7 | Chance to transmit from child to parent node based on turn | Yes | No | No |
| Variables | Description |
|---|---|
| G | Graph representation |
| ND | Total number of nodes in the network |
| NCD[i] | Number of child nodes of node [i] |
| TS(s) | Number of timeslots needed for each cycle (s) |
| Total number of packets in network nodes waiting to be sent to master node within 1 slotframe duration | |
| i | Node number |
| y | Turns |
| s | Cycle/iteration |
| qz | Queue size in node z |
| turn_now[i] | Refers to one child of node i that gets a transmission turn at a particular cycle/iteration |
| child_of_node[i][j] | j-th child node of node i |
| child_number_of[i][z] | The function that will produce a number showing the sequence number of node z as a child node of node i. |
| mod_node[i] | Value used for modulus operations on node i, used to enable child nodes to send data to node i alternately (no priority) |
| Matching_link[s] | Variable that stores the set of active links in each cycle/iteration (s) |
| Scheduling Algorithm | Active Timeslots (λ) | Cycles (C) | Total Channel Offsets (ChOff) |
|---|---|---|---|
| IRByTSA | 17 | 8 | 23 |
| FTSA | 18 | 7 | 24 |
| FLSA | 17 | 5 | 17 |
| Number of Nodes | IRByTSA | FTSA | FLSA | |||
|---|---|---|---|---|---|---|
| Horiz. | Vert. | Horiz. | Vert. | Horiz. | Vert. | |
| 10 | 9 | 9 | 9 | 9 | 10 | 10 |
| 20 | 19 | 19 | 22 | 22 | 22 | 22 |
| 30 | 30 | 30 | 35 | 35 | 35 | 35 |
| 40 | 40 | 40 | 51 | 51 | 49 | 49 |
| 50 | 51 | 50 | 64 | 66 | 59 | 60 |
| 60 | 60 | 60 | 73 | 82 | 73 | 75 |
| 70 | 70 | 70 | 86 | 93 | 79 | 90 |
| 80 | 80 | 82 | 110 | 114 | 87 | 105 |
| 90 | 90 | 101 | 126 | 137 | 101 | 126 |
| 100 | 100 | 112 | 137 | 135 | 118 | 133 |
| Number of Nodes | IRByTSA | FTSA | FLSA | |||
|---|---|---|---|---|---|---|
| Horiz. | Vert. | Horiz. | Vert. | Horiz. | Vert. | |
| 10 | 0.045 | 0.045 | 0.045 | 0.045 | 0.050 | 0.050 |
| 20 | 0.095 | 0.095 | 0.110 | 0.110 | 0.110 | 0.110 |
| 30 | 0.150 | 0.150 | 0.175 | 0.175 | 0.175 | 0.175 |
| 40 | 0.200 | 0.200 | 0.255 | 0.255 | 0.245 | 0.245 |
| 50 | 0.255 | 0.250 | 0.320 | 0.330 | 0.295 | 0.300 |
| 60 | 0.300 | 0.300 | 0.365 | 0.410 | 0.365 | 0.375 |
| 70 | 0.350 | 0.350 | 0.430 | 0.465 | 0.395 | 0.450 |
| 80 | 0.400 | 0.410 | 0.550 | 0.570 | 0.435 | 0.525 |
| 90 | 0.450 | 0.505 | 0.630 | 0.685 | 0.505 | 0.630 |
| 100 | 0.500 | 0.560 | 0.685 | 0.675 | 0.590 | 0.665 |
| Number of Nodes | IRByTSA | FTSA | FLSA | |||
|---|---|---|---|---|---|---|
| Horiz. | Vert. | Horiz. | Vert. | Horiz. | Vert. | |
| 10 | 6 | 6 | 5 | 5 | 4 | 4 |
| 20 | 8 | 8 | 9 | 9 | 6 | 6 |
| 30 | 8 | 8 | 11 | 11 | 7 | 7 |
| 40 | 11 | 11 | 11 | 11 | 7 | 7 |
| 50 | 11 | 12 | 12 | 11 | 8 | 8 |
| 60 | 12 | 12 | 15 | 16 | 9 | 9 |
| 70 | 12 | 13 | 15 | 17 | 9 | 10 |
| 80 | 13 | 14 | 17 | 18 | 10 | 11 |
| 90 | 14 | 15 | 17 | 18 | 11 | 11 |
| 100 | 14 | 15 | 19 | 21 | 11 | 11 |
| Number of Nodes | IRByTSA | FTSA | FLSA | |||
|---|---|---|---|---|---|---|
| Horiz. | Vert. | Horiz. | Vert. | Horiz. | Vert. | |
| 10 | 12 | 12 | 11 | 11 | 9 | 9 |
| 20 | 26 | 26 | 27 | 27 | 21 | 21 |
| 30 | 40 | 40 | 45 | 45 | 31 | 31 |
| 40 | 62 | 62 | 62 | 62 | 43 | 43 |
| 50 | 78 | 80 | 78 | 79 | 56 | 59 |
| 60 | 95 | 97 | 101 | 113 | 67 | 76 |
| 70 | 110 | 122 | 116 | 148 | 81 | 90 |
| 80 | 131 | 143 | 144 | 184 | 97 | 107 |
| 90 | 152 | 159 | 167 | 204 | 112 | 117 |
| 100 | 169 | 175 | 192 | 233 | 124 | 135 |
| Number of Nodes | (λIRByTSA − λFTSA) | (λIRByTSA − λFLSA) | ||
|---|---|---|---|---|
| Horiz. | Vert. | Horiz. | Vert. | |
| 10 | 0 | 0 | 1 | 1 |
| 20 | 3 | 3 | 3 | 3 |
| 30 | 5 | 5 | 5 | 5 |
| 40 | 11 | 11 | 9 | 9 |
| 50 | 13 | 16 | 8 | 10 |
| 60 | 13 | 22 | 13 | 15 |
| 70 | 16 | 23 | 9 | 20 |
| 80 | 30 | 32 | 7 | 23 |
| 90 | 36 | 36 | 11 | 25 |
| 100 | 37 | 23 | 18 | 21 |
| Number of Nodes | |CFLSA − CIRByTSA| | |CFLSA − CFTSA| | ||
|---|---|---|---|---|
| Horiz. | Vert. | Horiz. | Vert. | |
| 10 | 2 | 2 | 1 | 1 |
| 20 | 2 | 2 | 3 | 3 |
| 30 | 1 | 1 | 4 | 4 |
| 40 | 4 | 4 | 4 | 4 |
| 50 | 3 | 4 | 4 | 3 |
| 60 | 3 | 3 | 6 | 7 |
| 70 | 3 | 3 | 6 | 7 |
| 80 | 3 | 3 | 7 | 7 |
| 90 | 3 | 4 | 6 | 7 |
| 100 | 3 | 4 | 8 | 10 |
| Number of Nodes | IRByTSA | FTSA | FLSA | |||
|---|---|---|---|---|---|---|
| Horiz. | Vert. | Horiz. | Vert. | Horiz | Vert. | |
| 10 | 2 | 2 | 2 | 2 | 2 | 2 |
| 20 | 3 | 3 | 3 | 3 | 4 | 4 |
| 30 | 5 | 5 | 4 | 4 | 4 | 4 |
| 40 | 6 | 6 | 6 | 6 | 6 | 6 |
| 50 | 7 | 7 | 7 | 7 | 7 | 7 |
| 60 | 8 | 8 | 7 | 7 | 7 | 8 |
| 70 | 9 | 9 | 8 | 9 | 9 | 9 |
| 80 | 10 | 10 | 8 | 10 | 10 | 10 |
| 90 | 11 | 11 | 10 | 11 | 10 | 11 |
| 100 | 12 | 12 | 10 | 11 | 11 | 12 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santoso, I.H.; Ramli, K.; M.T., S. TLS-VaD: A New Tool for Developing Centralized Link-Scheduling Algorithms on the IEEE802.15.4e TSCH Network. Electronics 2019, 8, 1555. https://doi.org/10.3390/electronics8121555
Santoso IH, Ramli K, M.T. S. TLS-VaD: A New Tool for Developing Centralized Link-Scheduling Algorithms on the IEEE802.15.4e TSCH Network. Electronics. 2019; 8(12):1555. https://doi.org/10.3390/electronics8121555
Chicago/Turabian StyleSantoso, Iman Hedi, Kalamullah Ramli, and Suryadi M.T. 2019. "TLS-VaD: A New Tool for Developing Centralized Link-Scheduling Algorithms on the IEEE802.15.4e TSCH Network" Electronics 8, no. 12: 1555. https://doi.org/10.3390/electronics8121555
APA StyleSantoso, I. H., Ramli, K., & M.T., S. (2019). TLS-VaD: A New Tool for Developing Centralized Link-Scheduling Algorithms on the IEEE802.15.4e TSCH Network. Electronics, 8(12), 1555. https://doi.org/10.3390/electronics8121555