Performance Profiling of Embedded ConvNets under Thermal-Aware DVFS



Abstract
:1. Introduction
- Quantify the thermal headroom of ConvNets deployed for continuous inference. Our analysis identifies applications that can be critical for power constrained devices.
- Assess the performance of ConvNets under thermal-aware DVFS. The experiments cover two control policies, namely reactive and proactive.
- Identify the optimal operating points of voltage scaled ConvNets. The analysis provides useful guidelines to develop smarter control policies specialized for ConvNets.
- Demonstrate that the thermal profile of ConvNets depends on the network topology. The collected results reveal the need for new optimization techniques for training thermal-aware ConvNets.
2. Related Works
3. Background
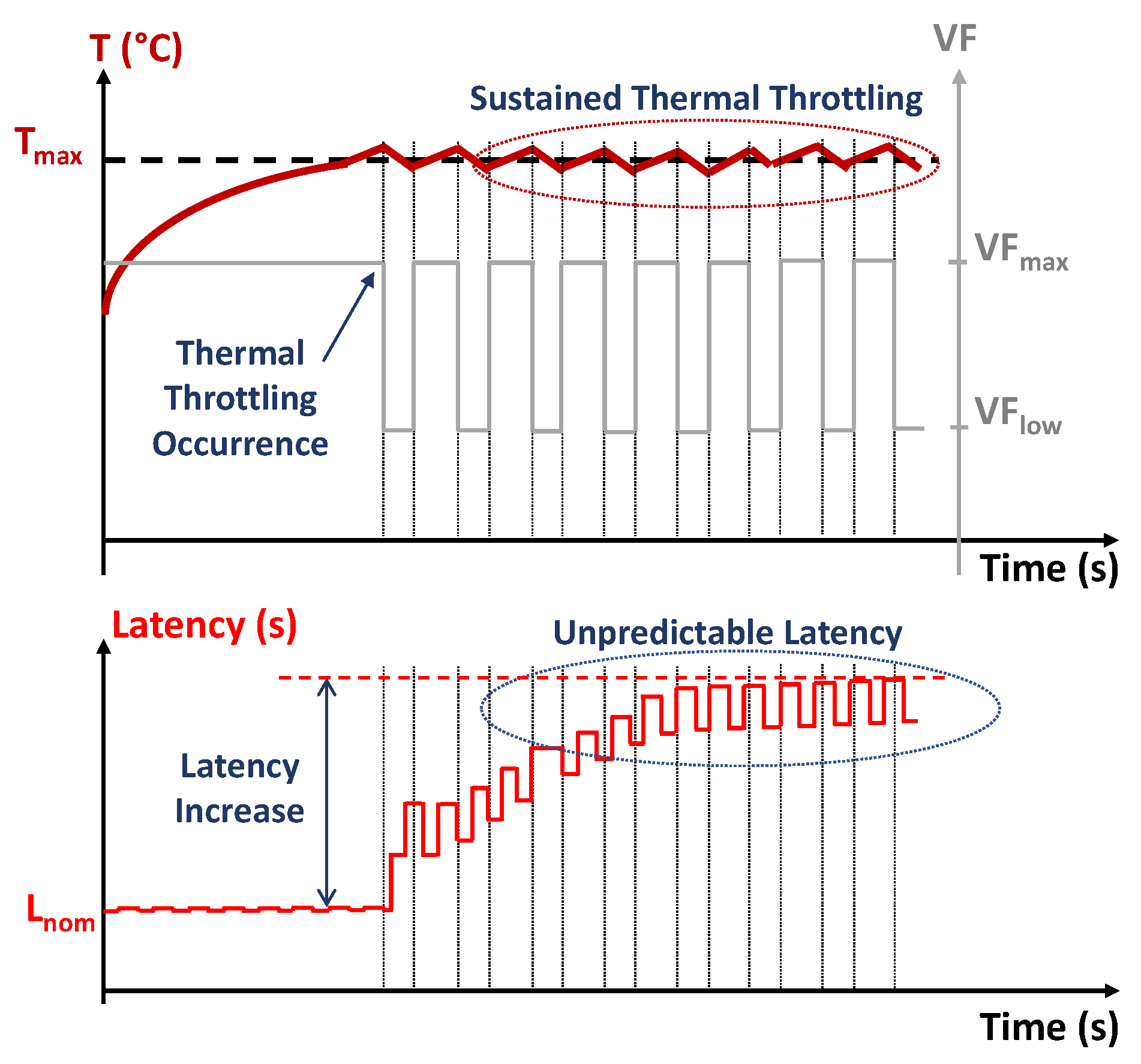
3.1. Thermal Management Strategies
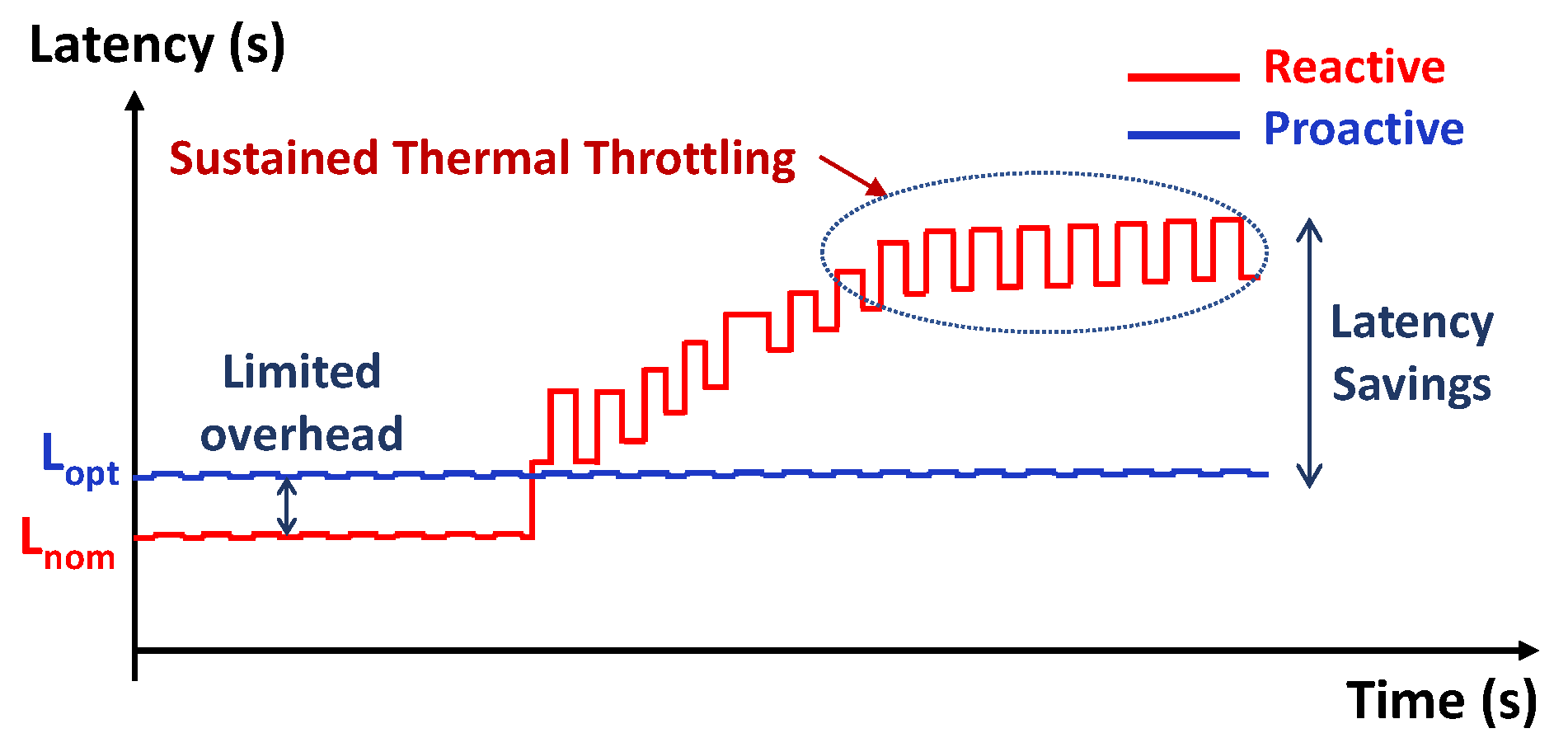
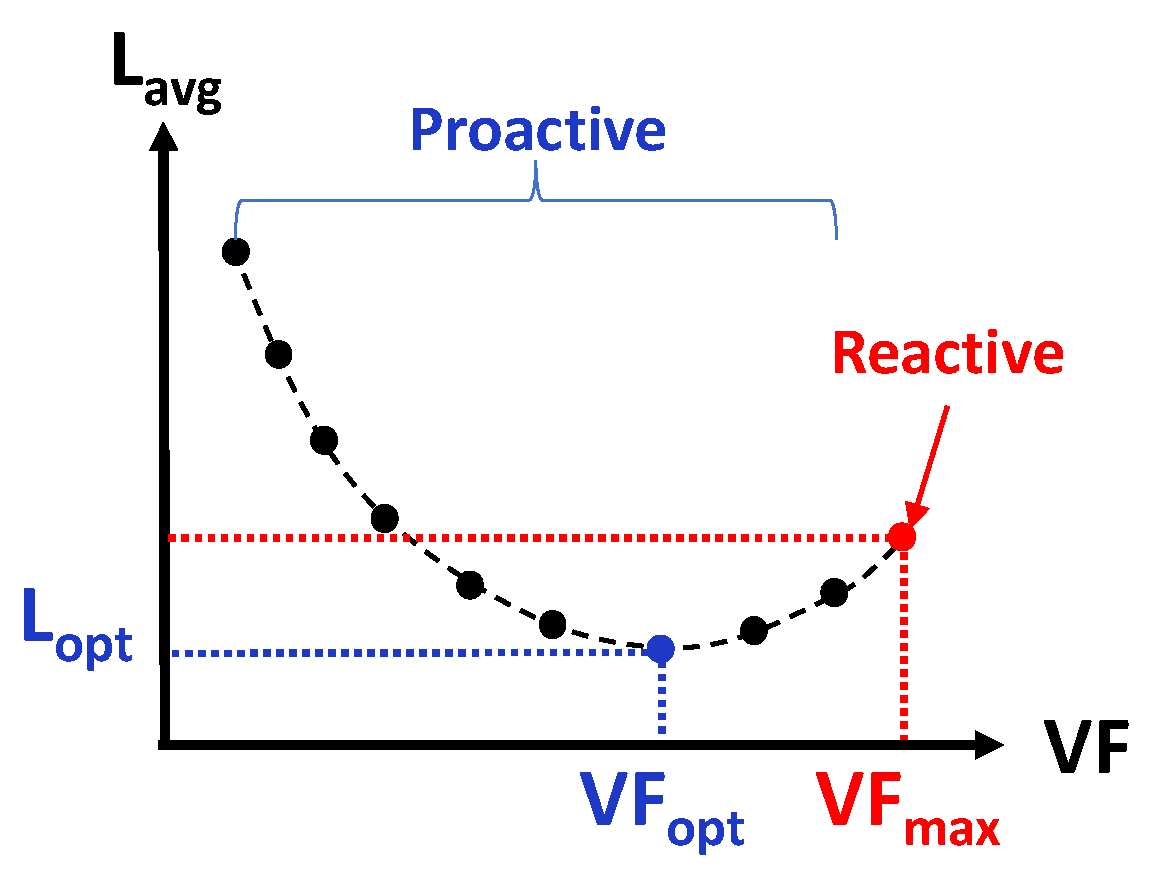
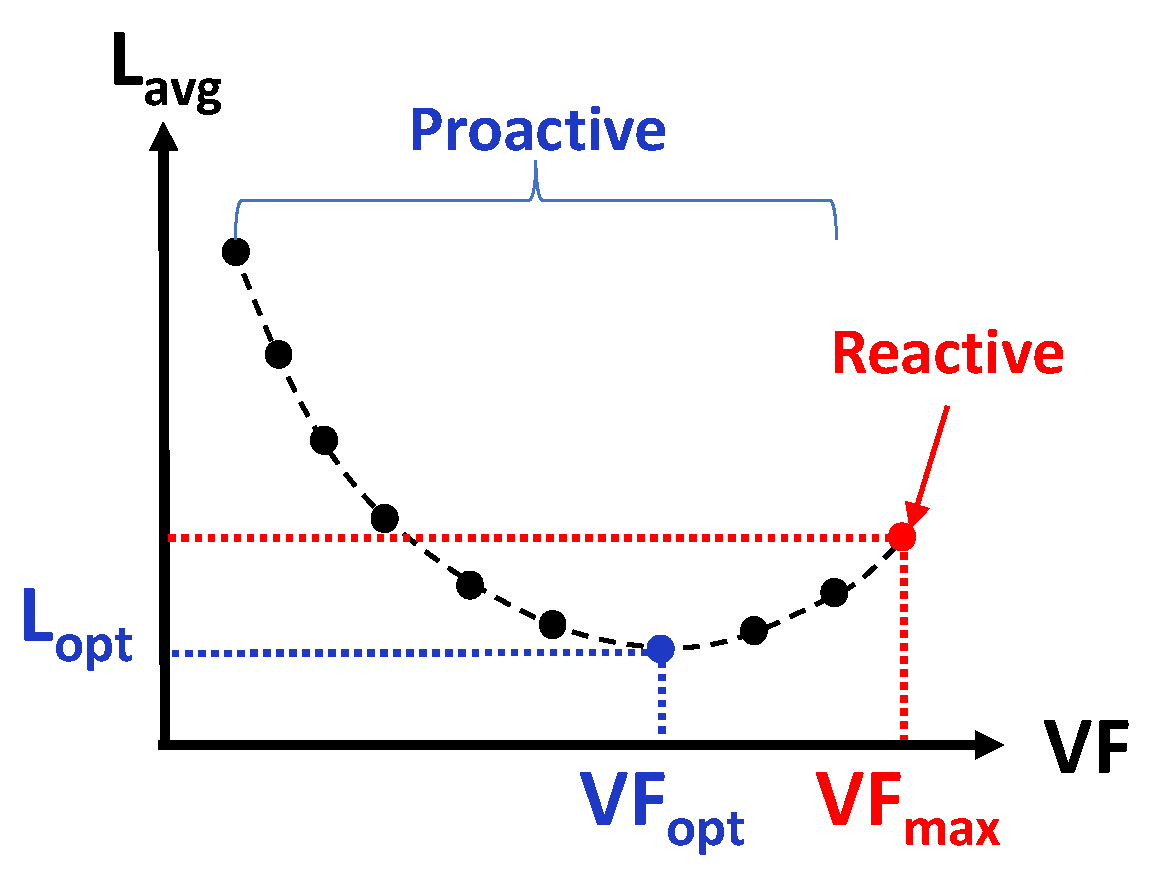
3.2. Optimal Trade-Off
3.3. Proactive Control Policies
4. Thermal-Aware Performance Optimization and Characterization Framework
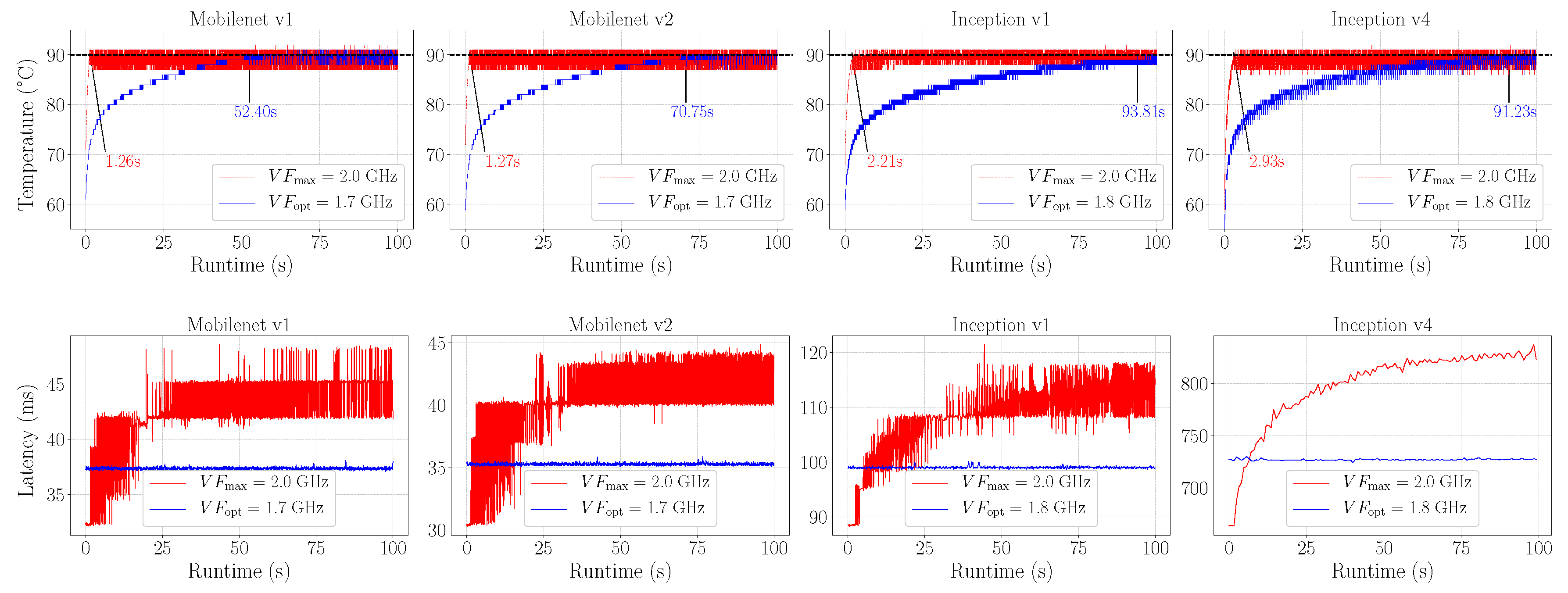
5. Experimental Setup and Results
5.1. Hardware Platform and Software Configurations
5.2. ConvNet Benchmarks
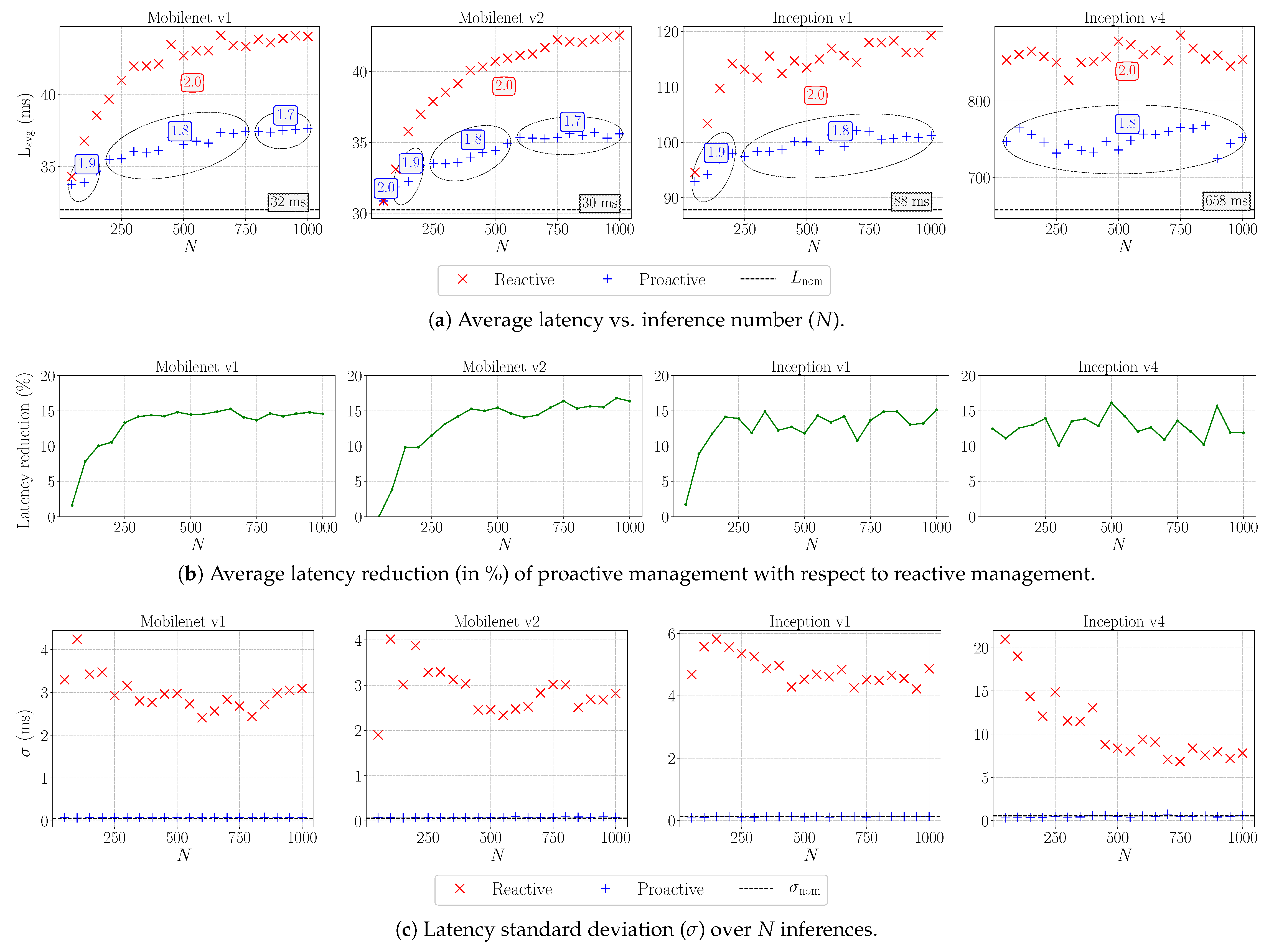
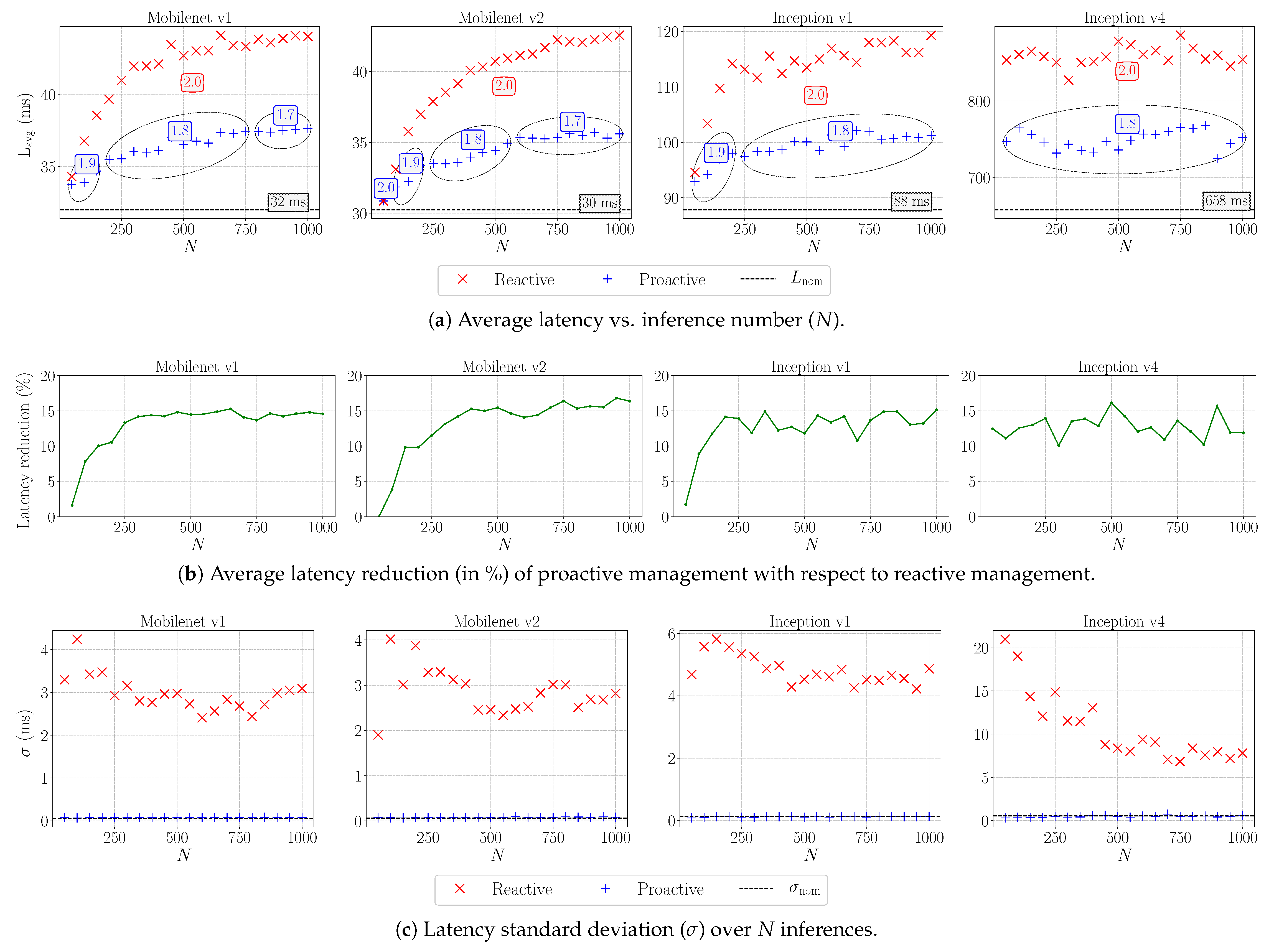
5.3. Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- LiKamWa, R.; Priyantha, B.; Philipose, M.; Zhong, L.; Bahl, P. Energy characterization and optimization of image sensing toward continuous mobile vision. In Proceedings of the 11th Annual International Conference on Mobile Systems, Applications, and Services, Taipei, Taiwan, 25–28 June 2013; ACM: New York, NY, USA, 2013; pp. 69–82. [Google Scholar]
- Seidenari, L.; Baecchi, C.; Uricchio, T.; Ferracani, A.; Bertini, M.; Bimbo, A.D. Deep artwork detection and retrieval for automatic context-aware audio guides. ACM Trans. Multimedia Comput. Commun. Appl. 2017, 13, 35. [Google Scholar] [CrossRef]
- Wang, A.; Chen, G.; Yang, J.; Zhao, S.; Chang, C.Y. A comparative study on human activity recognition using inertial sensors in a smartphone. IEEE Sens. J. 2016, 16, 4566–4578. [Google Scholar] [CrossRef]
- Yao, S.; Hu, S.; Zhao, Y.; Zhang, A.; Abdelzaher, T. Deepsense: A unified deep learning framework for time-series mobile sensing data processing. In Proceedings of the 26th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, Perth, Australia, 3–7 April 2017; pp. 351–360. [Google Scholar]
- Wu, C.J.; Brooks, D.; Chen, K.; Chen, D.; Choudhury, S.; Dukhan, M.; Hazelwood, K.; Isaac, E.; Jia, Y.; Jia, B.; et al. Machine learning at facebook: Understanding inference at the edge. In Proceedings of the 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA), Washington, DC, USA, 16–20 February 2019; pp. 331–344. [Google Scholar]
- Exynos 5 Octa 5422 Processor: Specs, Features. Available online: https://www.samsung.com/semiconductor/minisite/exynos/products/mobileprocessor/exynos-5-octa-5422/ (accessed on 8 November 2019).
- Jang, M.; Kim, K.; Kim, K. The performance analysis of ARM NEON technology for mobile platforms. In Proceedings of the 2011 ACM Symposium on Research in Applied Computation, Miami, FL, USA, 2–5 November 2011; ACM: New York, NY, USA, 2011; pp. 104–106. [Google Scholar]
- Cheng, A.C.; Dong, J.D.; Hsu, C.H.; Chang, S.H.; Sun, M.; Chang, S.C.; Pan, J.Y.; Chen, Y.T.; Wei, W.; Juan, D.C. Searching toward pareto-optimal device-aware neural architectures. In Proceedings of the International Conference on Computer-Aided Design, San Diego, CA, USA, 5–8 November 2018; ACM: New York, NY, USA, 2018; p. 136. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the 4th International Conference on Learning Representations (ICLR 2016), San Juan, Puerto Rico, 2–4 May 2016. Conference Track Proceedings. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Grimaldi, M.; Peluso, V.; Calimera, A. Optimality Assessment of Memory-Bounded ConvNets Deployed on Resource-Constrained RISC Cores. IEEE Access 2019, 7, 152599–152611. [Google Scholar] [CrossRef]
- Peluso, V.; Cipolletta, A.; Calimera, A.; Poggi, M.; Tosi, F.; Mattoccia, S. Enabling energy-efficient unsupervised monocular depth estimation on armv7-based platforms. In Proceedings of the IEEE 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 25–29 March 2019; pp. 1703–1708. [Google Scholar]
- Brooks, D.; Dick, R.P.; Joseph, R.; Shang, L. Power, thermal, and reliability modeling in nanometer-scale microprocessors. IEEE Micro 2007, 27, 49–62. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Kim, Y.G.; Kong, J.; Chung, S.W. A survey on recent OS-level energy management techniques for mobile processing units. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 2388–2401. [Google Scholar] [CrossRef]
- Hardkernel. Odroid-XU4 User Manual. Available online: https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=2ahUKEwi7y4Sn94vmAhXayYsBHb7kCb0QFjAAegQIARAC&url=https%3A%2F%2Fmagazine.odroid.com%2Fwp-content%2Fuploads%2Fodroid-xu4-user-manual.pdf&usg=AOvVaw0iPReYKQAm-qcHwvYU8mde (accessed on 8 November 2019).
- Zhang, X.; Wang, Y.; Shi, W. pcamp: Performance comparison of machine learning packages on the edges. In Proceedings of the USENIX Workshop on Hot Topics in Edge Computing (HotEdge 18), Boston, MA, USA, 10 July 2018. [Google Scholar]
- Xia, C.; Zhao, J.; Cui, H.; Feng, X. Characterizing DNN Models for Edge-Cloud Computing. In Proceedings of the 2018 IEEE International Symposium on Workload Characterization (IISWC), Raleigh, NC, USA, 30 September–2 October 2018; pp. 82–83. [Google Scholar]
- Ignatov, A.; Timofte, R.; Chou, W.; Wang, K.; Wu, M.; Hartley, T.; Van Gool, L. Ai benchmark: Running deep neural networks on android smartphones. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Almeida, M.; Laskaridis, S.; Leontiadis, I.; Venieris, S.I.; Lane, N.D. EmBench: Quantifying Performance Variations of Deep Neural Networks across Modern Commodity Devices. In Proceedings of the 3rd International Workshop on Deep Learning for Mobile Systems and Applications, Seoul, Korea, 21 June 2019; ACM: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Hanhirova, J.; Kämäräinen, T.; Seppälä, S.; Siekkinen, M.; Hirvisalo, V.; Ylä-Jääski, A. Latency and throughput characterization of convolutional neural networks for mobile computer vision. In Proceedings of the 9th ACM Multimedia Systems Conference, Amsterdam, The Netherlands, 12–15 June 2018; ACM: New York, NY, USA, 2018; pp. 204–215. [Google Scholar]
- Yang, T.J.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Sze, V.; Adam, H. Netadapt: Platform-aware neural network adaptation for mobile applications. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 285–300. [Google Scholar]
- Cai, H.; Zhu, L.; Han, S. ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Peluso, V.; Rizzo, R.G.; Calimera, A.; Macii, E.; Alioto, M. Beyond ideal DVFS through ultra-fine grain vdd-hopping. In Proceedings of the IFIP/IEEE International Conference on Very Large Scale Integration-System on a Chip, Tallinn, Estonia, 26–28 September 2016; Springer: Cham, Switzerland, 2016; pp. 152–172. [Google Scholar]
- Sahin, O.; Varghese, P.T.; Coskun, A.K. Just enough is more: Achieving sustainable performance in mobile devices under thermal limitations. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design, Austin, TX, USA, 2–6 November 2015; pp. 839–846. [Google Scholar]
- Isuwa, S.; Dey, S.; Singh, A.K.; McDonald-Maier, K. TEEM: Online Thermal-and Energy-Efficiency Management on CPU-GPU MPSoCs. In Proceedings of the IEEE 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 25–29 March 2019; pp. 438–443. [Google Scholar]
- Bhat, G.; Singla, G.; Unver, A.K.; Ogras, U.Y. Algorithmic optimization of thermal and power management for heterogeneous mobile platforms. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2017, 26, 544–557. [Google Scholar] [CrossRef]
- Dey, S.; Guajardo, E.Z.; Basireddy, K.R.; Wang, X.; Singh, A.K.; McDonald-Maier, K. Edgecoolingmode: An agent based thermal management mechanism for dvfs enabled heterogeneous mpsocs. In Proceedings of the IEEE 2019 32nd International Conference on VLSI Design and 2019 18th International Conference on Embedded Systems (VLSID), Delhi, India, 5–9 January 2019; pp. 19–24. [Google Scholar]
- Linaro Toolchain. Available online: https://www.linaro.org/downloads/ (accessed on 8 November 2019).
- TensorFlow Lite Hosted Models. Available online: https://www.tensorflow.org/lite/guide/hosted_models (accessed on 8 November 2019).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ConvNet | Memory (MB) | Top-1 (%) | (ms) | (ms) |
|---|---|---|---|---|
| MobileNet v1 | 4.3 | 70.0 | 31.99 | 0.06 |
| MobileNet v2 | 3.4 | 70.8 | 30.24 | 0.06 |
| Inception v1 | 6.4 | 70.1 | 87.84 | 0.13 |
| Inception v4 | 41.0 | 79.5 | 658.06 | 0.57 |
| ConvNet | (s) | |
|---|---|---|
| MobileNet v1 | 39 | 1.26 |
| MobileNet v2 | 42 | 1.27 |
| Inception v1 | 25 | 2.21 |
| Inception v4 | 4 | 2.93 |
| ConvNet | Lnom-3 (ms) | Lopt-wc (ms) |
|---|---|---|
| MobileNet v1 | 41 | 38 |
| MobileNet v2 | 38 | 36 |
| Inception v1 | 103 | 102 |
| Inception v4 | 770 | 768 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peluso, V.; Rizzo, R.G.; Calimera, A. Performance Profiling of Embedded ConvNets under Thermal-Aware DVFS. Electronics 2019, 8, 1423. https://doi.org/10.3390/electronics8121423
Peluso V, Rizzo RG, Calimera A. Performance Profiling of Embedded ConvNets under Thermal-Aware DVFS. Electronics. 2019; 8(12):1423. https://doi.org/10.3390/electronics8121423
Chicago/Turabian StylePeluso, Valentino, Roberto Giorgio Rizzo, and Andrea Calimera. 2019. "Performance Profiling of Embedded ConvNets under Thermal-Aware DVFS" Electronics 8, no. 12: 1423. https://doi.org/10.3390/electronics8121423
APA StylePeluso, V., Rizzo, R. G., & Calimera, A. (2019). Performance Profiling of Embedded ConvNets under Thermal-Aware DVFS. Electronics, 8(12), 1423. https://doi.org/10.3390/electronics8121423