Semi-Supervised Deep Time-Delay Embedded Clustering for Stress Speech Analysis




Abstract
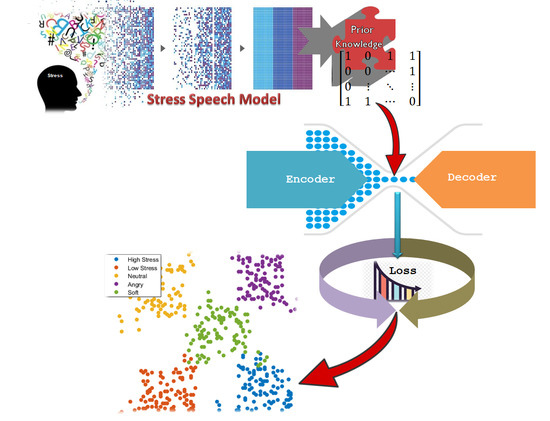
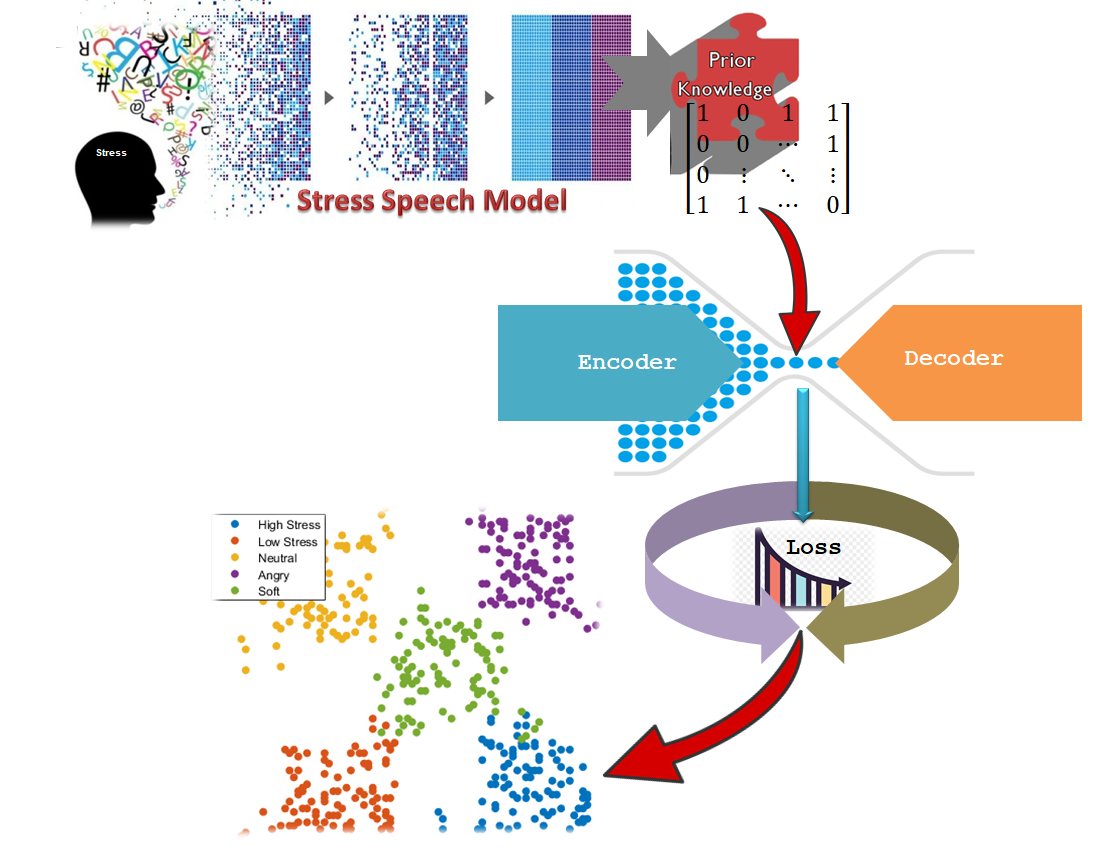
1. Introduction
2. Related Works
- K-means is the fastest clustering method but becomes ineffective in high dimensional data. Thus, to overcome this limitedness, most clustering methods reduce the data dimension before performing a clustering assignment.
- Spectral and self-organizing clustering methods reduce a high-dimensional input into a lower-dimensional space using DNN, and then applying the clustering assignment on this space.
- Unlike the previous methods, a deep clustering (DEC, DTEC, and SDTEC) uses a DNN-based autoencoder to parameterize the input with nonlinear mapping to embedding space that simultaneously optimizes the feature representation and the clustering assignment.
- The main difference between DEC and our methods (DTEC and SDTEC) is the type of DNN used in the autoencoder structure. DEC uses original DNN while our methods use TDNN. Moreover, our methods added a discriminatory approach to the clustering objective.
- Since DTEC’s clustering objective cannot be confirmed yet as to whether the output class corresponds to informational classes, a semi-supervised framework of DTEC is proposed by incorporating prior information from model-based pairwise constraints to guide the clustering procedures.
3. Semi-Supervised Deep Time-Delay Embedded Clustering
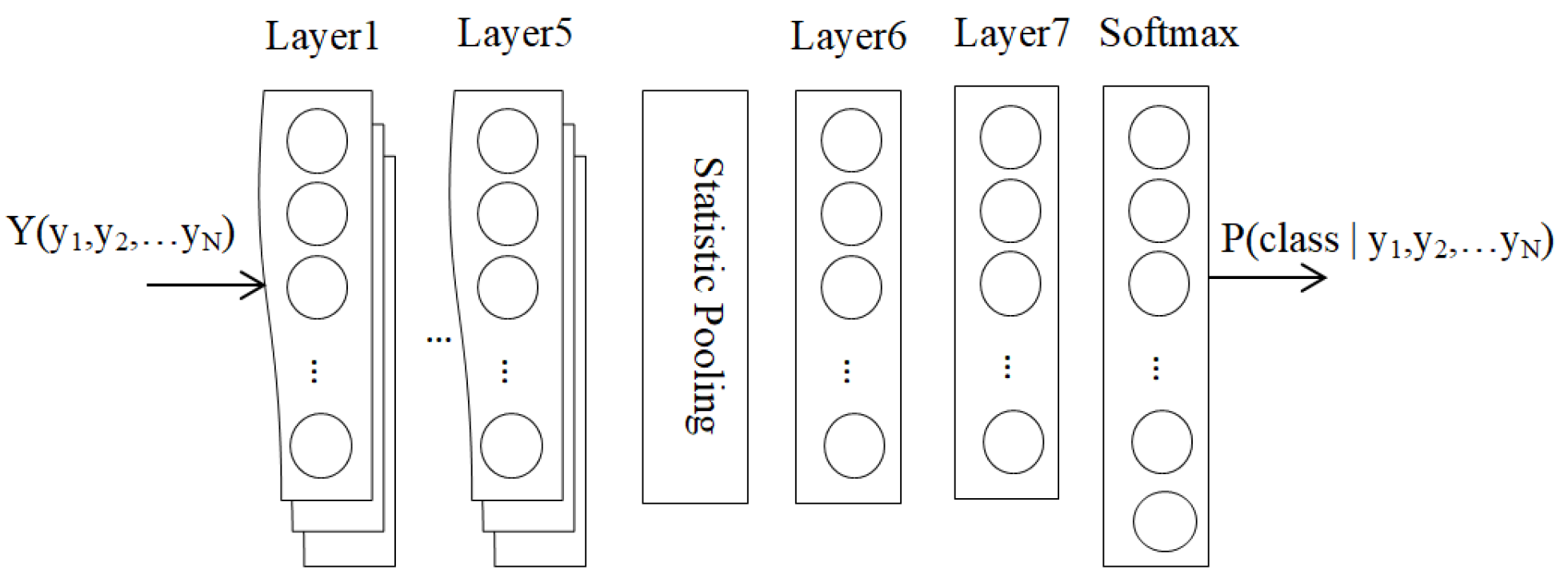
3.1. Nonlinear Transformation
3.2. Stress Speech Recognition Model Based Pairwise Constraints
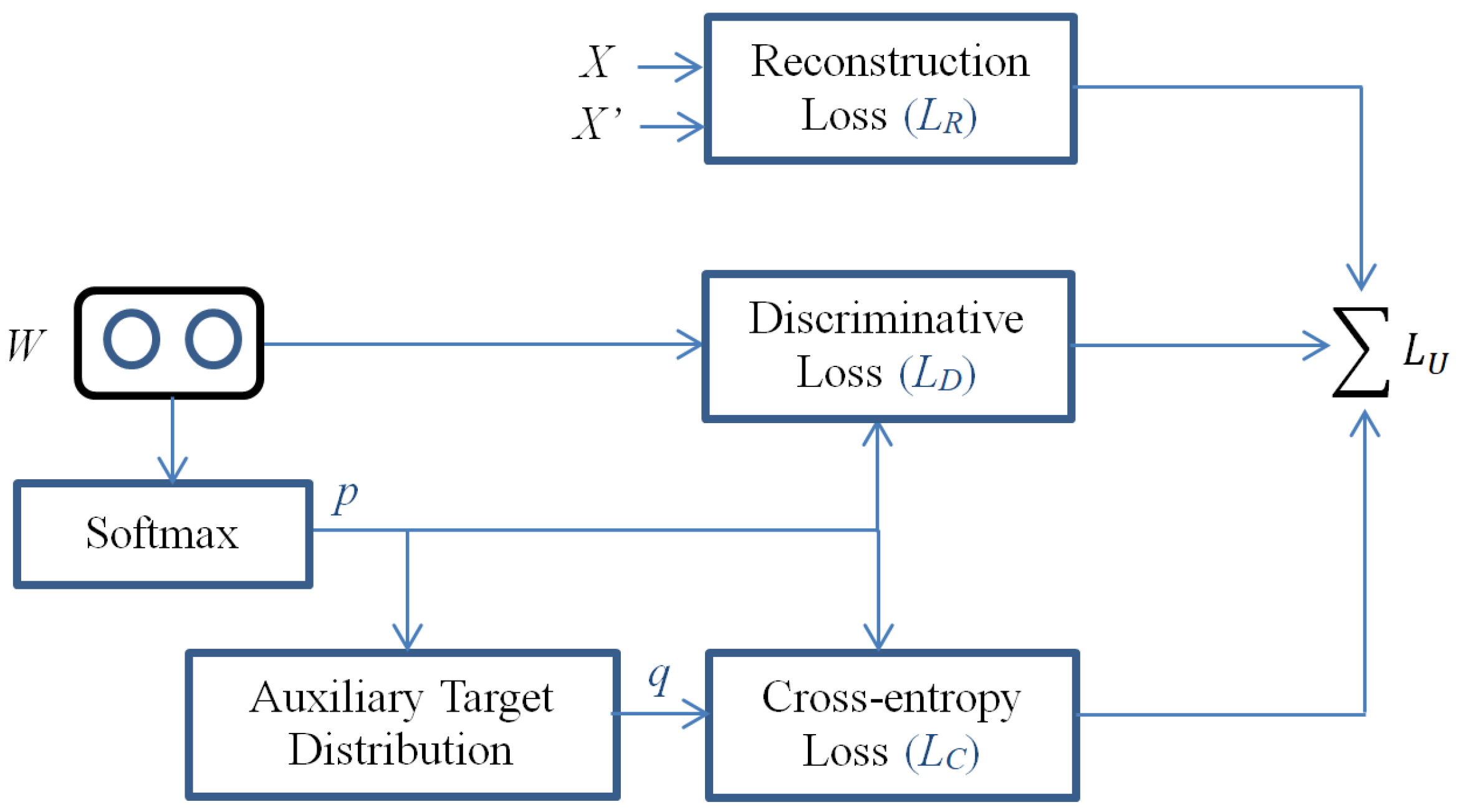
3.3. Objective Function of the Network
4. Experimental Setup
4.1. Dataset
4.2. Experiment Settings
4.3. Baseline Clustering Methods
| Km: | apply k-means clustering [8] in X space |
| Km+PC: | apply k-means with pairwise constraints from SSR model (Equation (1)) in X space |
| Km+AE: | perform TDNN-based autoencoder [20] then apply k-means in Z space |
| Km+AE+PC: | perform TDNN-based autoencoder [20] then apply k-means with pairwise constraints from SSR model (Equation (1)) in Z space |
| SOTA: | perform a full system of SOTA [29] |
| DEC: | perform a full system of DEC [32] |
| DTEC: | apply a full system of DTEC [20] |
5. Results and Discussion
5.1. Evaluation Result
5.2. Ablation Study
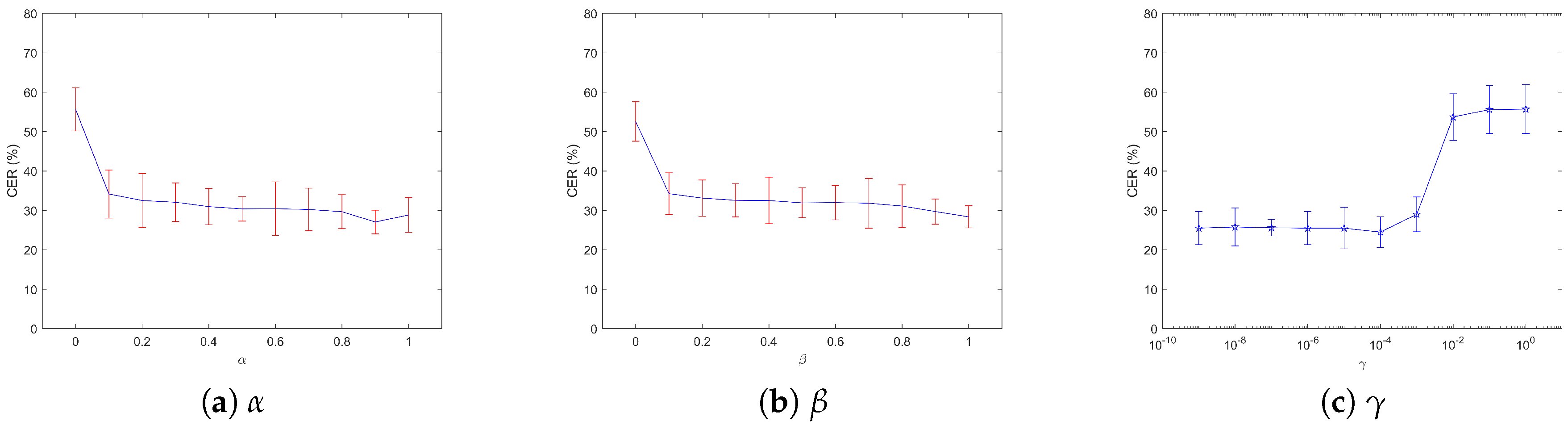
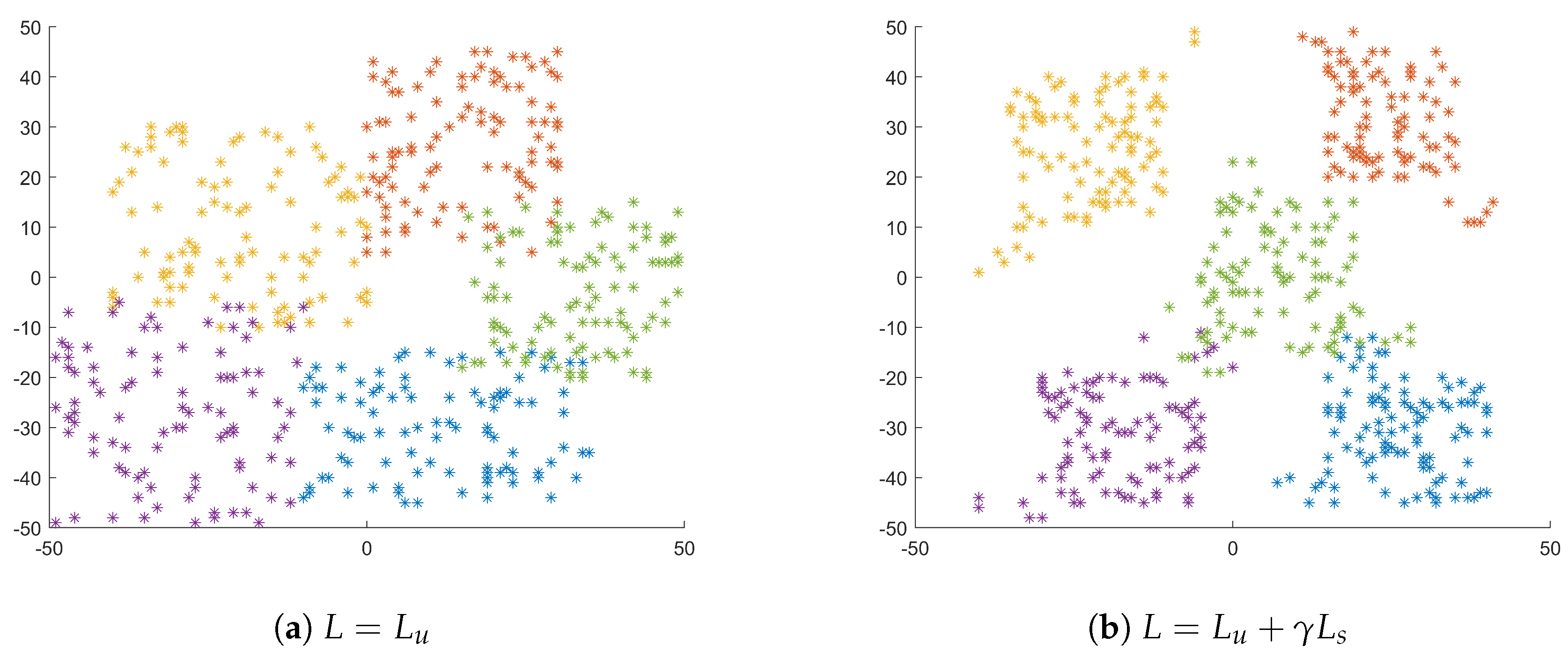
5.2.1. The Effect of Losses
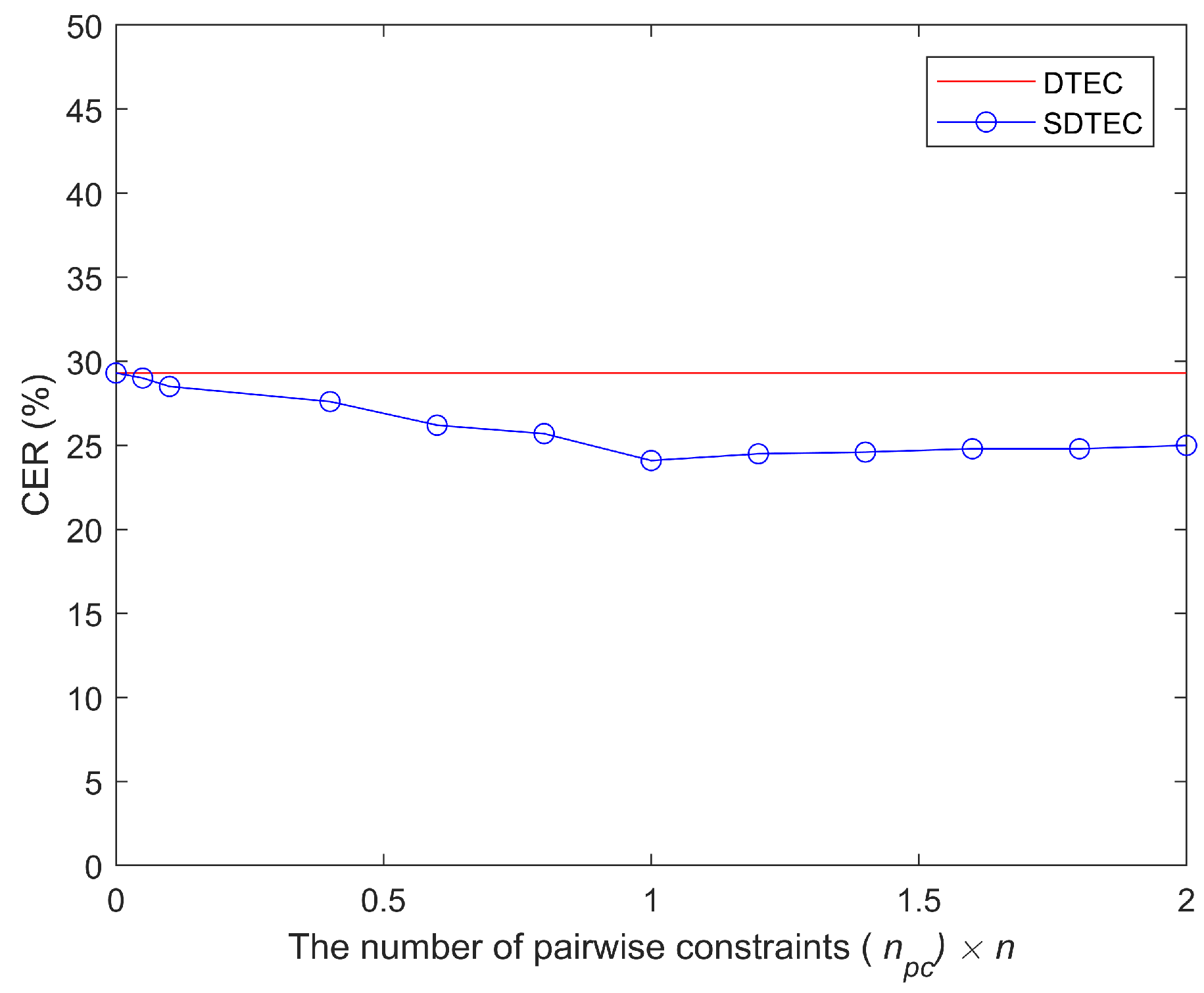
5.2.2. The Effect of the Number of Constraints
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ACC | Accuracy |
| ASR | Automatic Speech Recognition |
| CER | Clustering Error Rate |
| DEC | Deep Embedded Clustering |
| DNN | Deep Neural Network |
| DTEC | Deep Time-delay Embedded Clustering |
| LDC | Linguistic Data Consortium |
| MFCC | Mel-Frequency Cepstral Coefficient |
| MSE | Mean Squared Error |
| NMI | Normalized Mutual Information |
| ReLU | Rectified Linear Unit |
| SDTEC | Semi-supervised Deep Time-delay Embedded Clustering |
| SGD | Stochastic Gradient Descent |
| SOM | Self-Organizing Map |
| SOTA | Self-Organizing Tree Algorithm |
| SSR | Stress Speech Recognition |
| SUSAS | Speech Under Simulated and Actual Stress |
| TDNN | Time-delay Neural Network |
| t-SNE | t-Distributed Stochastic Neighbor Embedding |
| UBM | Universal Background Model |
References
- Smith, R.; Lane, R.D. Unconscious emotion: A cognitive neuroscientific perspective. Neurosci. Biobehav. Rev. 2016, 69, 216–238. [Google Scholar] [CrossRef] [PubMed]
- Gordan, R.; Gwathmey, J.K.; Xie, L.-H. Autonomic and endocrine control of cardiovascular function. World J. Cardiol. 2015, 7, 204–214. [Google Scholar] [CrossRef] [PubMed]
- Hansen, J.H.L.; Patil, S. Speech Under Stress: Analysis, Modeling and Recognition. In Speaker Classification I. Lecture Notes in Computer Science; Müller, C., Ed.; Springer: Berlin, Germany, 2007; Volume 4343, pp. 108–137. [Google Scholar]
- Zhang, Z. Mechanics of human voice production and control. J. Acoust. Soc. Am. 2016, 140, 2614–2635. [Google Scholar] [CrossRef] [PubMed]
- Tomba, K.; Dumoulin, J.; Mugellini, E.; Khaled, O.A.; Hawila, S. Stress Detection Through Speech Analysis. In Proceedings of the International Joint Conference on e-Business and Telecommunications (ICETE), Porto, Portugal, 26–28 July 2018; pp. 394–398. [Google Scholar]
- Prasetio, B.H.; Tamura, H.; Tanno, K. Ensemble Support Vector Machine and Neural Network Method for Speech Stress Recognition. In Proceedings of the International Workshop on Big Data and Information Security (IWBIS), Jakarta, Indonesia, 12–13 May 2018; pp. 57–62. [Google Scholar]
- Joels, M.; Baram, T.Z. The neuro-symphony of stress. Nat. Rev. Neurosci. 2009, 10, 459–466. [Google Scholar] [CrossRef] [PubMed]
- Moungsri, D.; Koriyama, T.; Kobayashi, T. HMM-based Thai speech synthesis using unsupervised stress context labeling. In Proceedings of the Signal and Information Processing Association Annual Summit and Conference (APSIPA), Siem Reap, Cambodia, 9–12 December 2014; pp. 1–4. [Google Scholar]
- Moungsri, D.; Koriyama, T.; Kobayashi, T. Unsupervised Stress Information Labeling Using Gaussian Process Latent Variable Model for Statistical Speech Synthesis. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), San Francisco, CA, USA, 8–12 September 2016; pp. 1517–1521. [Google Scholar]
- Morales, M.R.; Levitan, R. Mitigating Confounding Factors in Depression Detection Using an Unsupervised Clustering Approach. In Proceedings of the Computing and Mental Health Workshop (CHI), San Jose, CA, USA, 7–12 May 2016; pp. 1–4. [Google Scholar]
- Kamper, H.; Livescu, K.; Goldwater, S. An embedded segmental K-means model for unsupervised segmentation and clustering of speech. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 719–726. [Google Scholar]
- Xu, D.; Tian, Y. A Comprehensive Survey of Clustering Algorithms. Ann. Data Sci. 2015, 2, 165–193. [Google Scholar] [CrossRef]
- Wong, K. A Short Survey on Data Clustering Algorithms. In Proceedings of the International Conference on Soft Computing and Machine Intelligence (ISCMI), Hong Kong, China, 23–24 November 2015; pp. 64–68. [Google Scholar]
- Shirkhorshidi, A.S.; Aghabozorgi, S.; Wah, T.Y. A Comparison Study on Similarity and Dissimilarity Measures in Clustering Continuous Data. PLoS ONE 2015, 10, e0144059. [Google Scholar] [CrossRef] [PubMed]
- Bouveyron, C.; Girard, S.; Schimid, C. High-Dimensional Data Clustering. Elsevier Comput. Stat. Data Anal. 2007, 52, 502–519. [Google Scholar] [CrossRef]
- Min, E.; Guo, X.; Liu, Q.; Zhang, G.; Cui, J.; Long, J. A Survey of Clustering With Deep Learning: From the Perspective of Network Architecture. IEEE Access 2018, 6, 39501–39512. [Google Scholar] [CrossRef]
- Jang, G.; Kim, H.; Oh, Y. Audio Source Separation Using a Deep Autoencoder. arXiv 2014, arXiv:1412.7193. [Google Scholar]
- Chorowski, J.; Weiss, R.J.; Bengio, S.; Oord, A. Unsupervised speech representation learning using WaveNet autoencoders. arXiv 2019, arXiv:1901.08810. [Google Scholar] [CrossRef]
- Zion Golumbic, E.M.; Poeppel, D.; Schroeder, C.E. Temporal context in speech processing and attentional stream selection: A behavioral and neural perspective. Brain Lang 2012, 122, 151–161. [Google Scholar] [CrossRef] [PubMed]
- Prasetio, B.H.; Tamura, H.; Tanno, K. A Deep Time-delay Embedded Algorithm for Unsupervised Stress Speech Clustering. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Bari, Italy, 6–9 October 2019. [Google Scholar]
- Chapelle, O.; Scholkopf, B.; Sien, A. Semi-Supervised Learning; The MIT Press: London, UK, 2007. [Google Scholar]
- Davidson, I.; Basu, S. A Survey of Clustering with Instance Level Constraints. ACM Trans. Knowl. Discov. Data 2007, 1, 1–41. [Google Scholar]
- Wagstaff, K.; Cardie, C. Clustering with Instance-level Constraints. In Proceedings of the 17th International Conference on Machine Learning (ICML), Stanford, CA, USA, 29 June–2 July 2000; pp. 1103–1110. [Google Scholar]
- Xu, G.; Zong, Y.; Yang, Z. Constraint-based Clustering Algorithm. In Applied Data Mining; CRC Press: Boca Raton, FL, USA, 2013; pp. 89–92. [Google Scholar]
- Peng, X.; Xiao, S.; Feng, J.; Yau, W.; Yi, Z. Deep Subspace Clustering with Sparsity Prior. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI), New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Yang, Y.; Xu, D.; Nie, F.; Yan, S.; Zhuang, Y. Image clustering using local discriminant models and global integration. IEEE Trans. Image Process. 2010, 19, 2761–2773. [Google Scholar] [CrossRef] [PubMed]
- Nie, F.; Zeng, Z.; Tsang, I.W.; Xu, D.; Zhang, C. Spectral embedded clustering: A framework for in-sample and out-of-sample spectral clustering. IEEE Trans. Neural Netw. 2011, 22, 1796–1808. [Google Scholar]
- Peng, X.; Feng, J.; Xiao, S.; Yau, W.; Zhou, J.T.; Yang, S. Structured AutoEncoders for Subspace Clustering. IEEE Trans. Image Process. 2018, 27, 5076–5086. [Google Scholar] [CrossRef] [PubMed]
- Suarez Gomez, S.L.; Santos Rodriguez, J.D.; Iglesias Rodriguez, F.J.; De Cos Juez, F. Analysis of the Temporal Structure Evolution of Physical Systems with the Self-Organising Tree Algorithm (SOTA): Application for Validating Neural Network Systems on Adaptive Optics Data before On-Sky Implementation. Entropy 2017, 19, 103. [Google Scholar] [CrossRef]
- Yin, L.; Huang, C.; Ni, J. Clustering of gene expression data: Performance and similarity analysis. BMC Bioinformat. 2006, 7, S19. [Google Scholar] [CrossRef] [PubMed]
- Mateos, A.; Herrero, J.; Tamames, J.; Dopazo, J. Supervised Neural Networks for Clustering Conditions in DNA Array Data After Reducing Noise by Clustering Gene Expression Profiles. In Methods of Microarray Data Analysis II; Lin, S.M., Johnson, K.F., Eds.; Springer: Boston, MA, USA, 2002; pp. 91–103. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the 33rd International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Graf, S.; Herbig, T.; Buck, M.; Schmidt, G. Features for voice activity detection: A comparative analysis. EURASIP J. Adv. Signal Process. 2015, 91, 1–15. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks, 2nd ed.; Arbib, M.A., Ed.; The MIT Press: Cambridge, MA, USA, 1995; pp. 276–278. [Google Scholar]
- Peddinti, V.; Povey, D.; Khudanpur, S. A Time Delay Neural Network Architecture for Efficient Modeling of Long Temporal Contexts. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Prasetio, B.H.; Tamura, H.; Tanno, K. Generalized Discriminant Methods for Improved X-Vector Back-end Based Speech Stress Recognition. IEEJ Trans. Electron. Inf. Syst. 2019, 139, 1341–1347. [Google Scholar] [CrossRef]
- Hansen, J.H.L. Composer. SUSAS LDC99S78. Web Download. In Sound Recording; Linguistic Data Consortium: Philadelphia, PA, USA, 1999. [Google Scholar]
- Hansen, J.H.L. Composer. SUSAS Transcript LDC99T33. In Sound Recording; Linguistic Data Consortium: Philadelphia, PA, USA, 1999. [Google Scholar]
- Ibrahim, N.S.; Ramli, D.A. I-vector Extraction for Speaker Recognition Based on Dimensionality Reduction. In Proceedings of the International Conference on Knowledge-Based and Intelligent Information & Engineering Systems (KES), Belgrade, Serbia, 3–5 September 2018. [Google Scholar]
- Peddinti, V.; Chen, G.; Povey, D.; Khudanpur, S. Reverberation robust acoustic modeling using i-vectors with time delay neural networks. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Feng, X.; Zhang, Y.; Glass, J. Speech Feature Denoising and Dereverberation via Deep Autoencoders for Noisy Reverberant Speech Recognition. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Hidden Layer | Context |
|---|---|---|
| Layer-1 | {−4,+4} | |
| Encoder | Layer-2 | {−3,+3} |
| Layer-3 | {−6,+2} | |
| Feature space | Embedding | {0} |
| Layer- | {−6,+2} | |
| Decoder | Layer- | {−3,+3} |
| Layer- | {−4,+4} |
| Method | Clustering Error Rate (% CER) |
|---|---|
| Km | 55.79 |
| Km+PC | 58.95 |
| Km+AE | 36.17 |
| Km+AE+PC | 34.55 |
| SOTA | 31.28 |
| DEC | 30.14 |
| DTEC | 29.93 |
| Proposed SDTEC | 24.22 |
| Cluster | DTEC | SDTEC |
|---|---|---|
| 1 | 26.08 | 23.91 |
| 2 | 34.37 | 23.43 |
| 3 | 25.51 | 22.44 |
| 4 | 36.43 | 23.51 |
| 5 | 27.27 | 24.79 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prasetio, B.H.; Tamura, H.; Tanno, K. Semi-Supervised Deep Time-Delay Embedded Clustering for Stress Speech Analysis. Electronics 2019, 8, 1263. https://doi.org/10.3390/electronics8111263
Prasetio BH, Tamura H, Tanno K. Semi-Supervised Deep Time-Delay Embedded Clustering for Stress Speech Analysis. Electronics. 2019; 8(11):1263. https://doi.org/10.3390/electronics8111263
Chicago/Turabian StylePrasetio, Barlian Henryranu, Hiroki Tamura, and Koichi Tanno. 2019. "Semi-Supervised Deep Time-Delay Embedded Clustering for Stress Speech Analysis" Electronics 8, no. 11: 1263. https://doi.org/10.3390/electronics8111263
APA StylePrasetio, B. H., Tamura, H., & Tanno, K. (2019). Semi-Supervised Deep Time-Delay Embedded Clustering for Stress Speech Analysis. Electronics, 8(11), 1263. https://doi.org/10.3390/electronics8111263