Memory Optimization for Bit-Vector-Based Packet Classification on FPGA




Abstract
1. Introduction
- Heterogeneous Two-dimensional Pipeline for matching rules, WeeTP. WeeTP converts some standard PEs (proposed in [15]) with the memory storing BV and lookup logic to wildcard PEs. A wildcard PE integrates only registers and fixed logic wires while the SRAM memory is eliminated.
- Optimized heuristic Maximum Covering algorithm for searching wildcards to be removed, WeeMC. WeeMC tries to find the wildcard groups as much as possible by adjusting the order of the rules, where each group occupies a whole SRAM block to be removed. The search space is extremely large and the search problem is NP-hard. WeeMC utilizes a greedy idea for a near-optimal solution.
- Dynamic Sink-Update strategy, WeeSU. WeeSU is proposed to support dynamic updates function for WeeBV. Furthermore, it utilizes the dynamically reconfigurable feature of the state-of-the-art FPGA for accommodating drastic updates.
2. Background and Motivations
2.1. BV-Based Approaches and Challenges
2.2. Motivation
3. Architecture and Algorithms
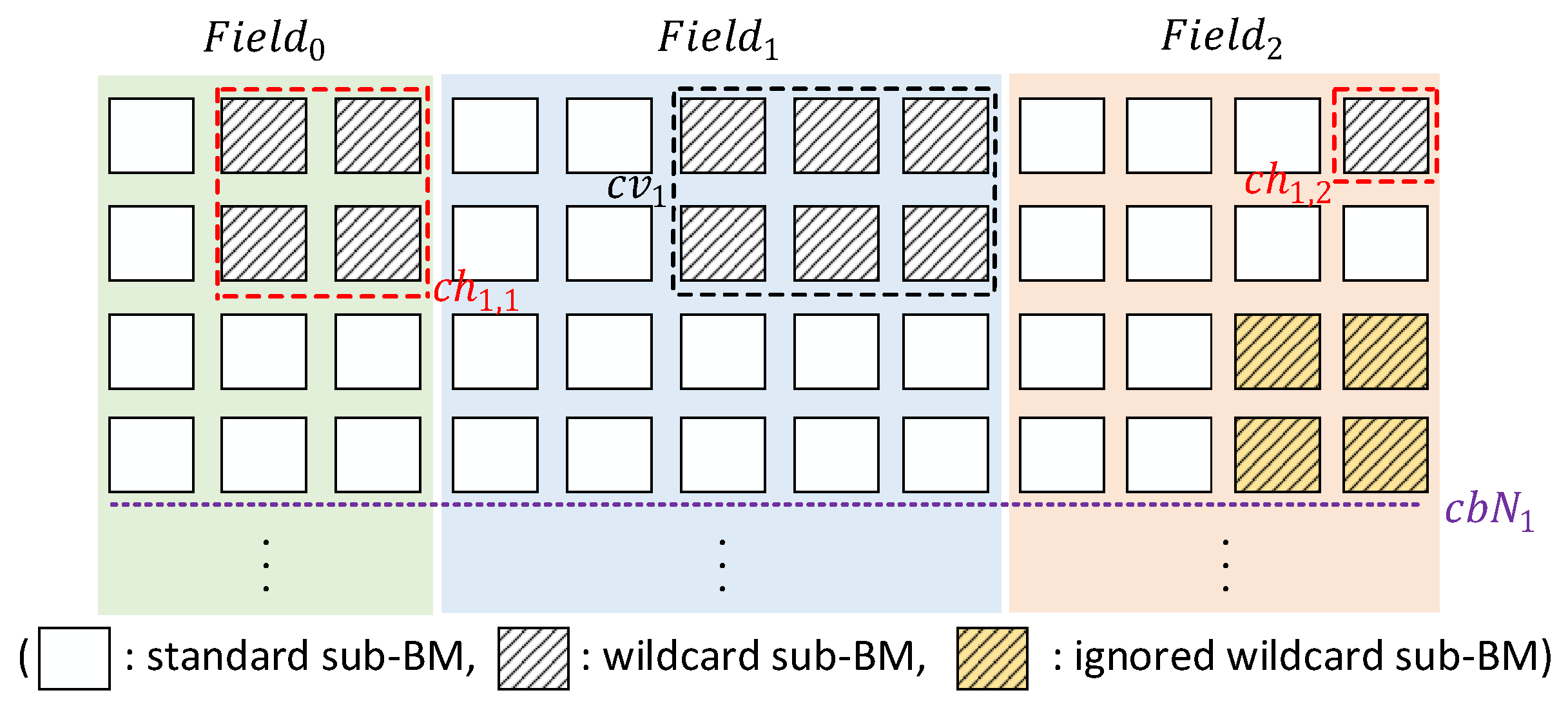
3.1. WeeTP Design
- (1)
- how to find as many standard PE as possible that can be converted into wildcard PE;
- (2)
- a wildcard PE cannot support dynamic update effectively without memory of the BV table.
3.2. WeeMC Algorithm
3.2.1. Problem Definition
3.2.2. Core Function of WeeMC
| Algorithm 1 GreedySearch |
| Input: The set of fields for searching, ; The set of rules for searching, ; The length of stride, s; The number of cluster, n; Output: The set of remaining fields after searching, ; The set of selected rules, ; Other helpful extra information, ;
|
3.2.3. Combination Searching of WeeMC
- (1)
- all rules have been covered;
- (2)
- no wildcard BM can be found in the remaining rules;
- (3)
- the number of iterations reaches .
- (1)
- no wildcard BM can be found in the remaining rules;
- (2)
- the number of iterations reaches .
| Algorithm 2 WeeMC |
| Input: The set of rules, ; The number of combinations, ; The length of stride, s; The number of cluster, n; Output: An arrangement of the ruleset with maximum compression, ;
|
3.3. WeeSU Strategy
- (1)
- Update bit in standard PE: The Controller component can well support delete, add and modify these three operations.
- (2)
- Update bit in wildcard PE: The Controller component can still support the delete operation. For inserts and modifications, we use a strategy called Wildcard-removed Sink-Update (WeeSU). For each , the wildcard sub-BMs are congregated above the same field by the greedy strategy. For a bit position, there will always be a standard PE below. Therefore, the insert and modify operations first perform a delete operation in the original location. WeeSU will then search a standard PE with unoccupied location (indexed by valid-bit) and perform an insert operation. Therefore, the sink processing includes a deletion above, a downward searching and a renewedly insertion.
4. Optimization Techniques
4.1. MaxPadding Technique
4.2. UpstreamRule Technique
5. Evaluation
5.1. Experimental Setup
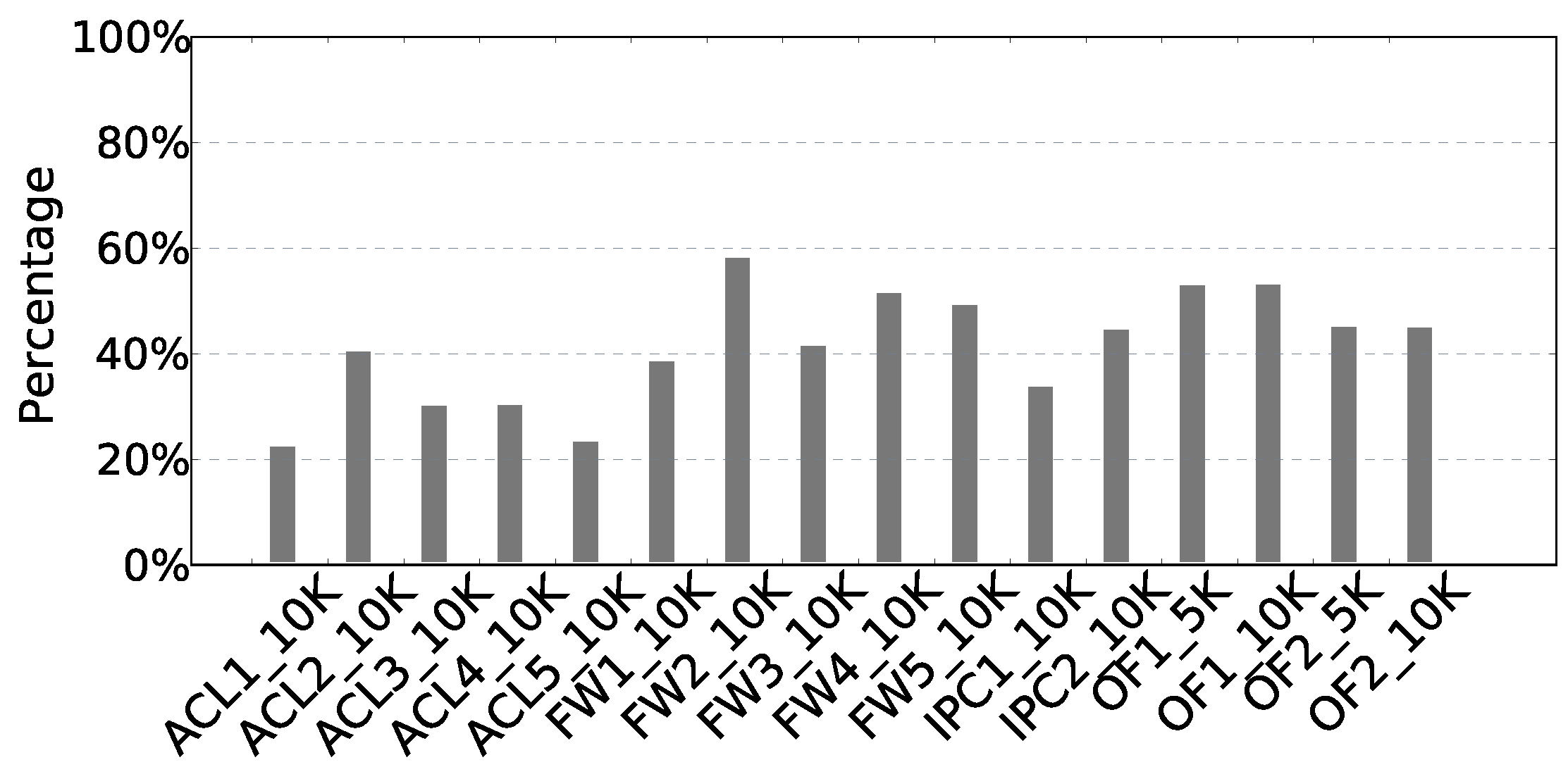
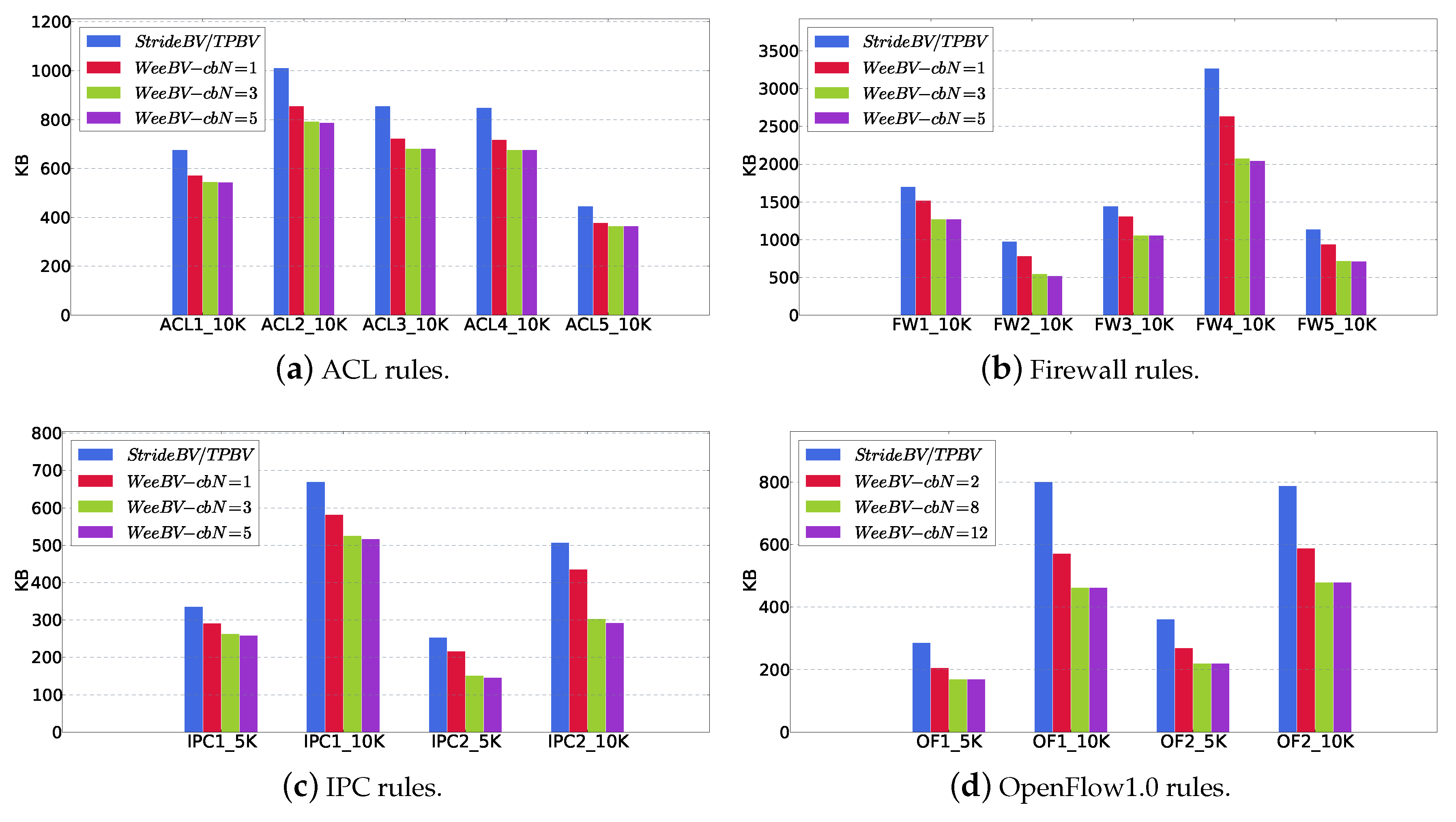
5.2. cbN for WeeMC
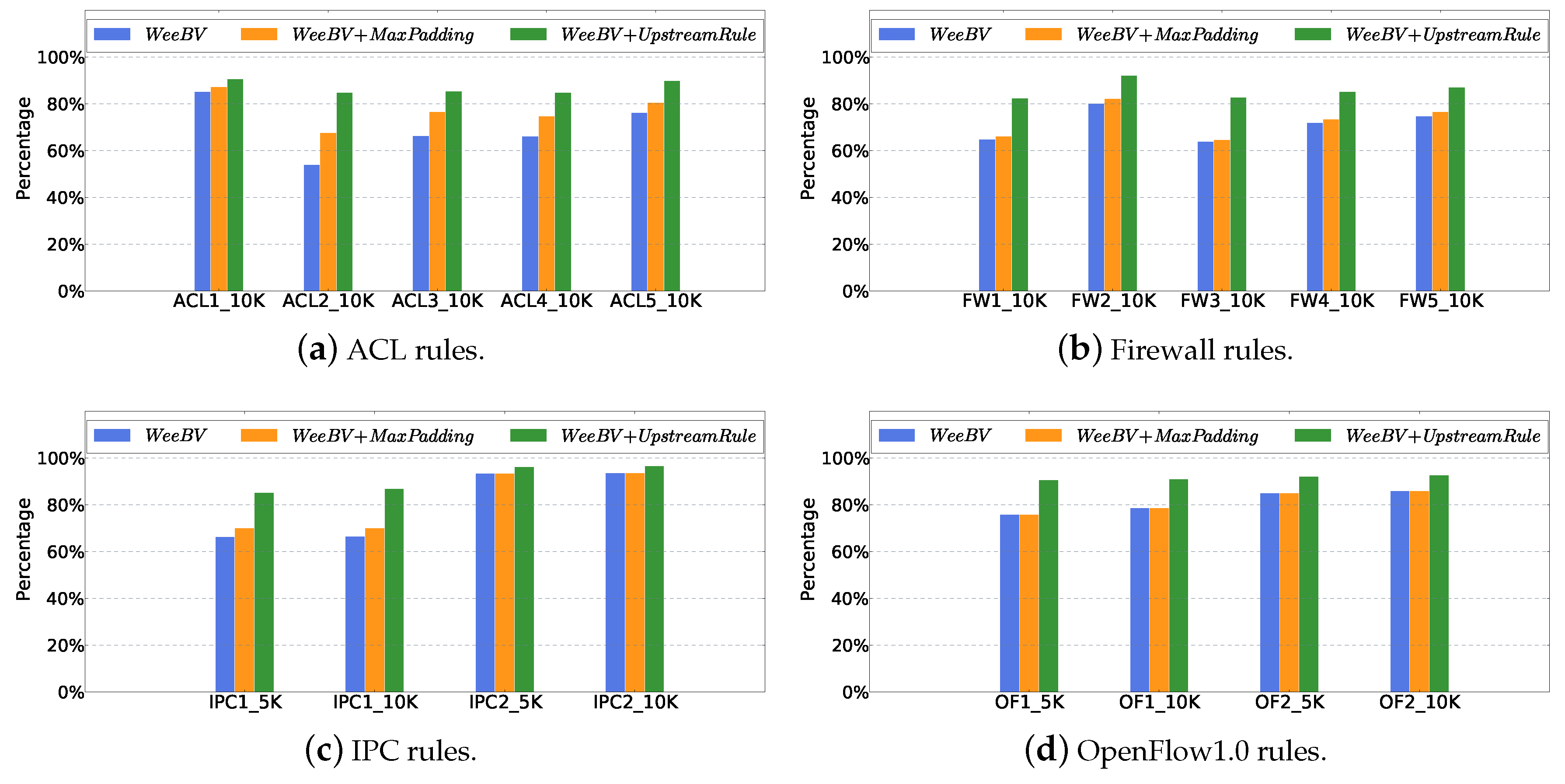
5.3. Compression with MaxPadding and UpstreamRule
5.4. Resource and Throughput
6. Related Works
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- ONF. OpenFlow Switch Specification. Available online: https://www.opennetworking.org/software-defined-standards/specifications/ (accessed on 8 October 2019).
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.M.; Peterson, L.L.; Rexford, J.; Shenker, S.; Turner, J.S. OpenFlow: Enabling innovation in campus networks. SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Pfaff, B.; Pettit, J.; Koponen, T.; Jackson, E.J.; Zhou, A.; Rajahalme, J.; Gross, J.; Wang, A.; Stringer, J.; Shelar, P.; et al. The Design and Implementation of Open vSwitch. In Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15), Oakland, CA, USA, 4–6 May 2015; pp. 117–130. [Google Scholar]
- Singh, S.; Baboescu, F.; Varghese, G.; Wang, J. Packet classification using multidimensional cutting. In Proceedings of the ACM SIGCOMM 2003 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, Karlsruhe, Germany, 25–29 August 2003; pp. 213–224. [Google Scholar] [CrossRef]
- Vamanan, B.; Voskuilen, G.; Vijaykumar, T.N. EffiCuts: Optimizing packet classification for memory and throughput. In Proceedings of the ACM SIGCOMM 2010 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, New Delhi, India, 30 August–3 September 2010; pp. 207–218. [Google Scholar] [CrossRef]
- Srinivasan, V.; Suri, S.; Varghese, G. Packet Classification Using Tuple Space Search. In Proceedings of the SIGCOMM ’99 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, Cambridge, MA, USA, 30 August–3 September 1999; pp. 135–146. [Google Scholar] [CrossRef]
- Lakshminarayanan, K.; Rangarajan, A.; Venkatachary, S. Algorithms for advanced packet classification with ternary CAMs. In Proceedings of the ACM SIGCOMM 2005 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Philadelphia, PA, USA, 22–26 August 2005; pp. 193–204. [Google Scholar] [CrossRef]
- Ma, Y.; Banerjee, S. A smart pre-classifier to reduce power consumption of TCAMs for multi-dimensional packet classification. In Proceedings of the ACM SIGCOMM 2012 Conference, Helsinki, Finland, 13–17 August 2012; pp. 335–346. [Google Scholar] [CrossRef]
- Li, B.; Tan, K.; Luo, L.L.; Peng, Y.; Luo, R.; Xu, N.; Xiong, Y.; Cheng, P. ClickNP: Highly flexible and High-performance Network Processing with Reconfigurable Hardware. In Proceedings of the ACM SIGCOMM 2016 Conference, Florianopolis, Brazil, 22–26 August 2016; pp. 1–14. [Google Scholar] [CrossRef]
- Fu, W.; Li, T.; Sun, Z. FAS: Using FPGA to Accelerate and Secure SDN Software Switches. Secur. Commun. Netw. 2018, 2018, 5650205. [Google Scholar] [CrossRef]
- Zhao, T.; Li, T.; Han, B.; Sun, Z.; Huang, J. Design and implementation of Software Defined Hardware Counters for SDN. Comput. Netw. 2016, 102, 129–144. [Google Scholar] [CrossRef]
- Lakshman, T.V.; Stiliadis, D. High-Speed Policy-Based Packet Forwarding Using Efficient Multi-Dimensional Range Matching. In Proceedings of the ACM SIGCOMM ’98 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, Vancouver, BC, Canada, 31 August–4 September 1998; pp. 203–214. [Google Scholar] [CrossRef]
- Jiang, W.; Prasanna, V.K. Field-split parallel architecture for high performance multi-match packet classification using FPGAs. In Proceedings of the SPAA 2009: 21st Annual ACM Symposium on Parallelism in Algorithms and Architectures, Calgary, AB, Canada, 11–13 August 2009; pp. 188–196. [Google Scholar] [CrossRef]
- Ganegedara, T.; Jiang, W.; Prasanna, V.K. A Scalable and Modular Architecture for High-Performance Packet Classification. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 1135–1144. [Google Scholar] [CrossRef]
- Qu, Y.R.; Prasanna, V.K. High-Performance and Dynamically Updatable Packet Classification Engine on FPGA. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 197–209. [Google Scholar] [CrossRef]
- Taylor, D.E.; Turner, J.S. ClassBench: A packet classification benchmark. IEEE/ACM Trans. Netw. 2007, 15, 499–511. [Google Scholar] [CrossRef]
- Matouvsek, J.; Antichi, G.; Lucansky, A.; Moore, A.W.; Korenek, J. ClassBench-ng: Recasting ClassBench after a Decade of Network Evolution. In Proceedings of the ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS 2017), Beijing, China, 18–19 May 2017; pp. 204–216. [Google Scholar] [CrossRef]
- Kogan, K.; Nikolenko, S.I.; Rottenstreich, O.; Culhane, W.; Eugster, P. SAX-PAC (Scalable And eXpressive PAcket Classification). In Proceedings of the ACM SIGCOMM 2014 Conference, Chicago, IL, USA, 17–22 August 2014; pp. 15–26. [Google Scholar] [CrossRef]
- Hsieh, C.; Weng, N. Many-Field Packet Classification for Software-Defined Networking Switches. In Proceedings of the 2016 Symposium on Architectures for Networking and Communications Systems (ANCS 2016), Santa Clara, CA, USA, 17–18 March 2016; pp. 13–24. [Google Scholar] [CrossRef]
- Dantzig, G.B.; Fulkerson, D.R.; Johnson, S.M. Solution of a Large-Scale Traveling-Salesman Problem. Oper. Res. 1954, 2, 393–410. [Google Scholar] [CrossRef]
- Abel, N. Design and Implementation of an Object-Oriented Framework for Dynamic Partial Reconfiguration. In Proceedings of the International Conference on Field Programmable Logic and Applications (FPL 2010), Milano, Italy, 31 August–2 September 2010; pp. 240–243. [Google Scholar] [CrossRef]
- Kalb, T.; Göhringer, D. Enabling dynamic and partial reconfiguration in Xilinx SDSoC. In Proceedings of the International Conference on ReConFigurable Computing and FPGAs (ReConFig 2016), Cancun, Mexico, 30 November–2 December 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Li, C. Open-Source of WeeBV Prototypeon on FPGA. Available online: https://github.com/LCLinVictory/WeeBV (accessed on 8 October 2019).
- Intel. Intel STRATIX V GS FPGAs. Available online: https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/pt/stratix-v-product-table.pdf (accessed on 8 October 2019).
- Taylor, D.E. Survey and taxonomy of packet classification techniques. ACM Comput. Surv. 2005, 37, 238–275. [Google Scholar] [CrossRef]
- Yang, T.; Liu, A.X.; Shen, Y.; Fu, Q.; Li, D.; Li, X. Fast OpenFlow Table Lookup with Fast Update. In Proceedings of the 2018 IEEE Conference on Computer Communications (INFOCOM 2018), Honolulu, HI, USA, 16–19 April 2018; pp. 2636–2644. [Google Scholar] [CrossRef]
- Bremler-Barr, A.; Hendler, D. Space-Efficient TCAM-Based Classification Using Gray Coding. IEEE Trans. Comput. 2012, 61, 18–30. [Google Scholar] [CrossRef]
- Bremler-Barr, A.; Hay, D.; Hendler, D. Layered interval codes for TCAM-based classification. Comput. Netw. 2012, 56, 3023–3039. [Google Scholar] [CrossRef][Green Version]
- Baboescu, F.; Varghese, G. Scalable Packet Classification. In Proceedings of the 2001 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications (SIGCOMM ’01), San Diego, CA, USA, 27–31 August 2001; pp. 199–210. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RuleSet Type | Rule Number | Block Memory | ALMs | Registers | Clock Rate | ||||
|---|---|---|---|---|---|---|---|---|---|
| (KB) | Number | Number | (MHz) | ||||||
| TPBV | WeeBV | TPBV | WeeBV | TPBV | WeeBV | TPBV | WeeBV | ||
| ACL | 128 | 120 | 95 | 2690 | 2126 | 4221 | 3335 | 160.03 | 153.66 |
| 256 | 210 | 166 | 4492 | 3549 | 7085 | 5598 | 155.45 | 149.95 | |
| 512 | 390 | 309 | 8015 | 6332 | 12,607 | 9960 | 151.54 | 142.80 | |
| 1024 | 780 | 617 | 15,605 | 12,328 | 24,470 | 19,332 | 145.33 | 138.25 | |
| FW | 128 | 120 | 65 | 2690 | 1453 | 4221 | 2280 | 160.03 | 153.13 |
| 256 | 210 | 114 | 4492 | 2426 | 7085 | 3826 | 155.45 | 149.43 | |
| 512 | 390 | 211 | 8015 | 4329 | 12,607 | 6808 | 151.54 | 140.68 | |
| 1024 | 780 | 422 | 15,605 | 8427 | 24,470 | 13,214 | 145.33 | 136.41 | |
| IPC | 128 | 120 | 71 | 2690 | 1588 | 4221 | 2491 | 160.03 | 153.36 |
| 256 | 210 | 124 | 4492 | 2651 | 7085 | 4181 | 155.45 | 149.38 | |
| 512 | 390 | 231 | 8015 | 4729 | 12,607 | 7439 | 151.54 | 141.29 | |
| 1024 | 780 | 461 | 15,605 | 9207 | 24,470 | 14,438 | 145.33 | 136.29 | |
| OpenFlow1.0 | 128 | 320 | 192 | 5684 | 3411 | 8202 | 4922 | 153.14 | 149.28 |
| 256 | 560 | 336 | 9635 | 5782 | 13,860 | 8316 | 151.58 | 147.38 | |
| 512 | 1040 | 624 | 17,537 | 10,523 | 25,176 | 15106 | 150.2 | 145.67 | |
| 1024 | 2080 | 1248 | 34,658 | 20,795 | 49,694 | 29,817 | 147.71 | 144.01 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Li, T.; Li, J.; Li, D.; Yang, H.; Wang, B. Memory Optimization for Bit-Vector-Based Packet Classification on FPGA. Electronics 2019, 8, 1159. https://doi.org/10.3390/electronics8101159
Li C, Li T, Li J, Li D, Yang H, Wang B. Memory Optimization for Bit-Vector-Based Packet Classification on FPGA. Electronics. 2019; 8(10):1159. https://doi.org/10.3390/electronics8101159
Chicago/Turabian StyleLi, Chenglong, Tao Li, Junnan Li, Dagang Li, Hui Yang, and Baosheng Wang. 2019. "Memory Optimization for Bit-Vector-Based Packet Classification on FPGA" Electronics 8, no. 10: 1159. https://doi.org/10.3390/electronics8101159
APA StyleLi, C., Li, T., Li, J., Li, D., Yang, H., & Wang, B. (2019). Memory Optimization for Bit-Vector-Based Packet Classification on FPGA. Electronics, 8(10), 1159. https://doi.org/10.3390/electronics8101159