A Deep Feature Extraction Method for HEp-2 Cell Image Classification


Abstract
1. Introduction
2. Proposed Cell Classification Method
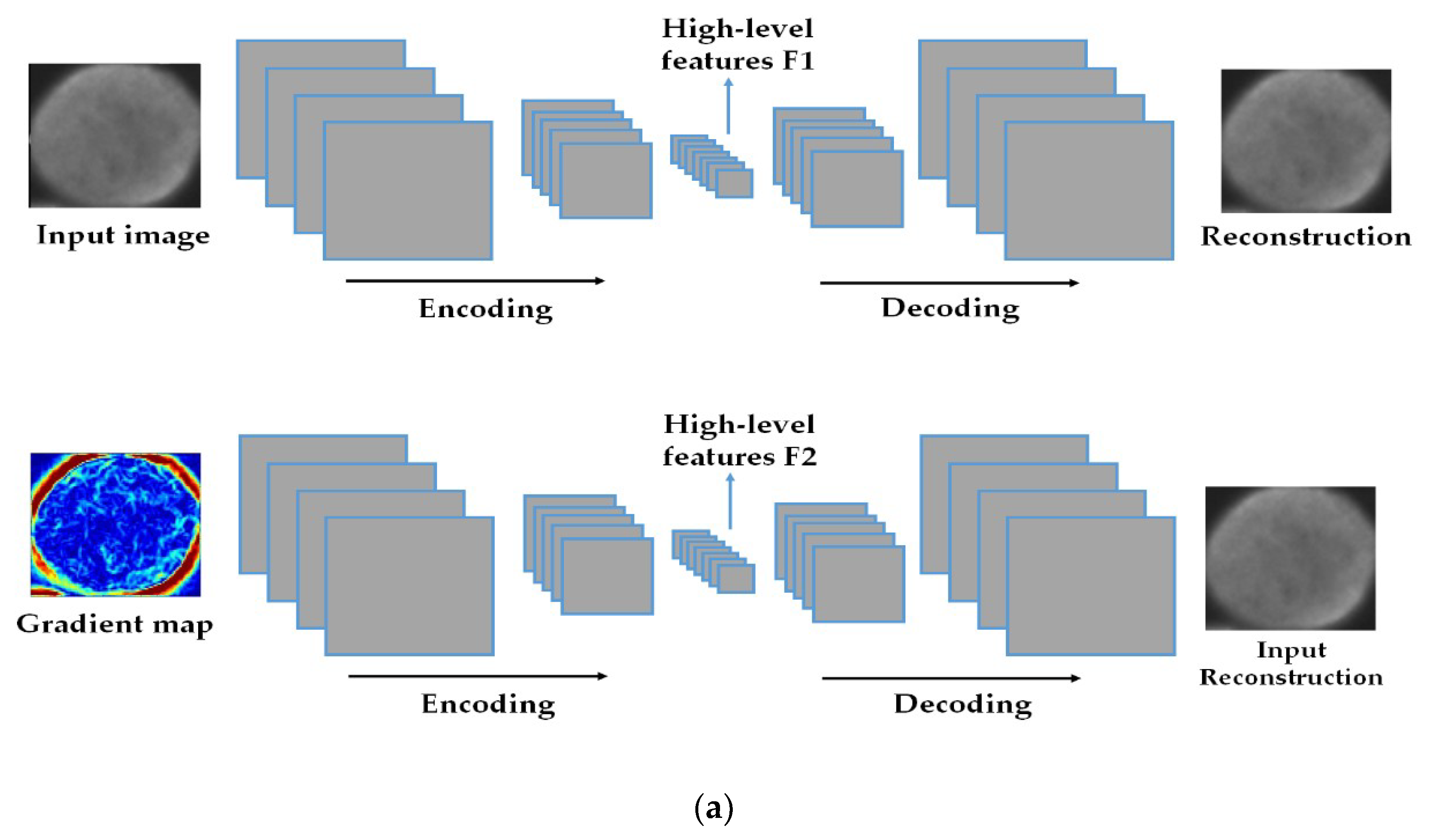
2.1. Feature Learning and Extraction using Two Levels of a Convolutional Auto-Encoder
2.2. Classification Using a Nonlinear Classifier
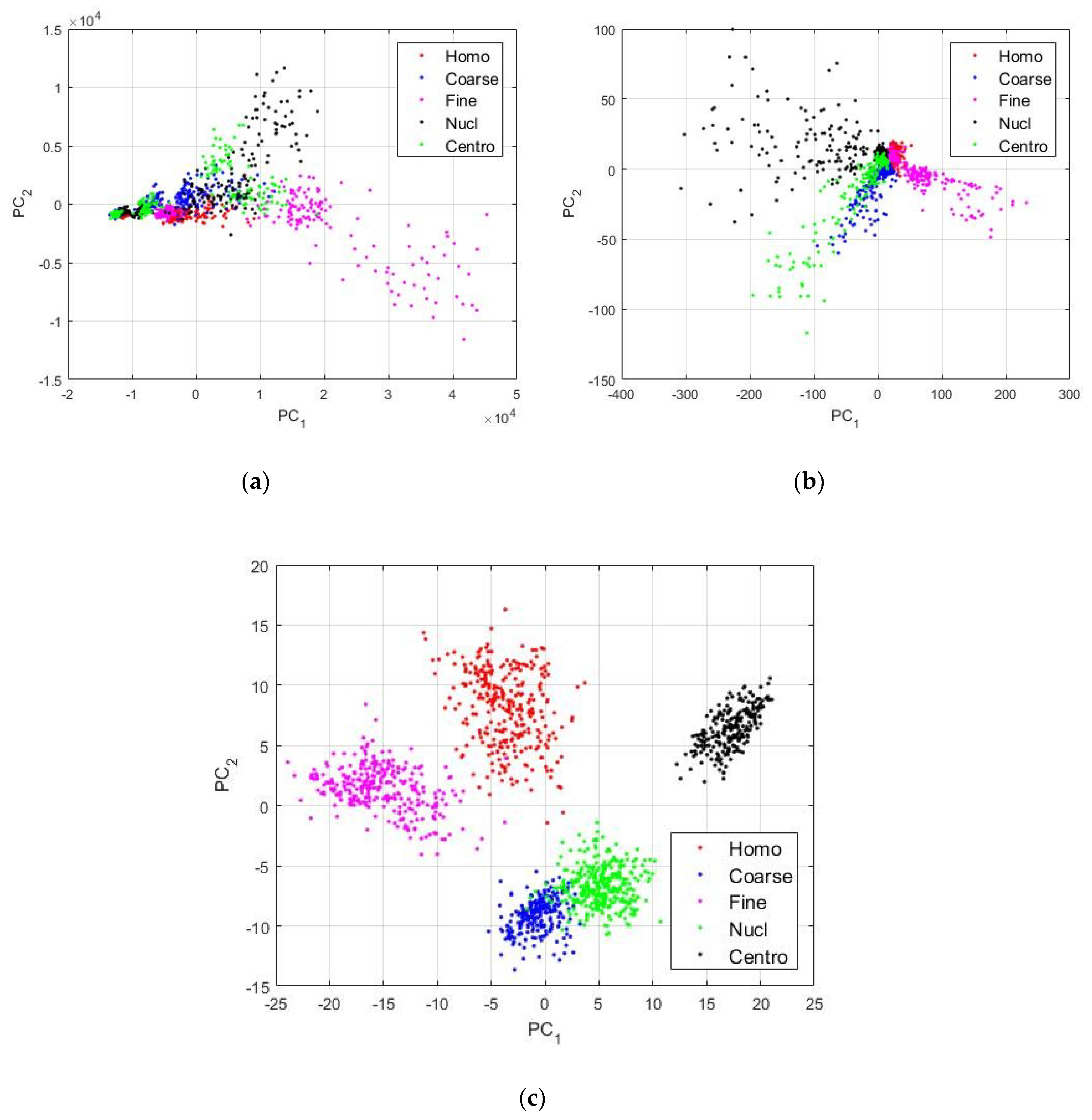
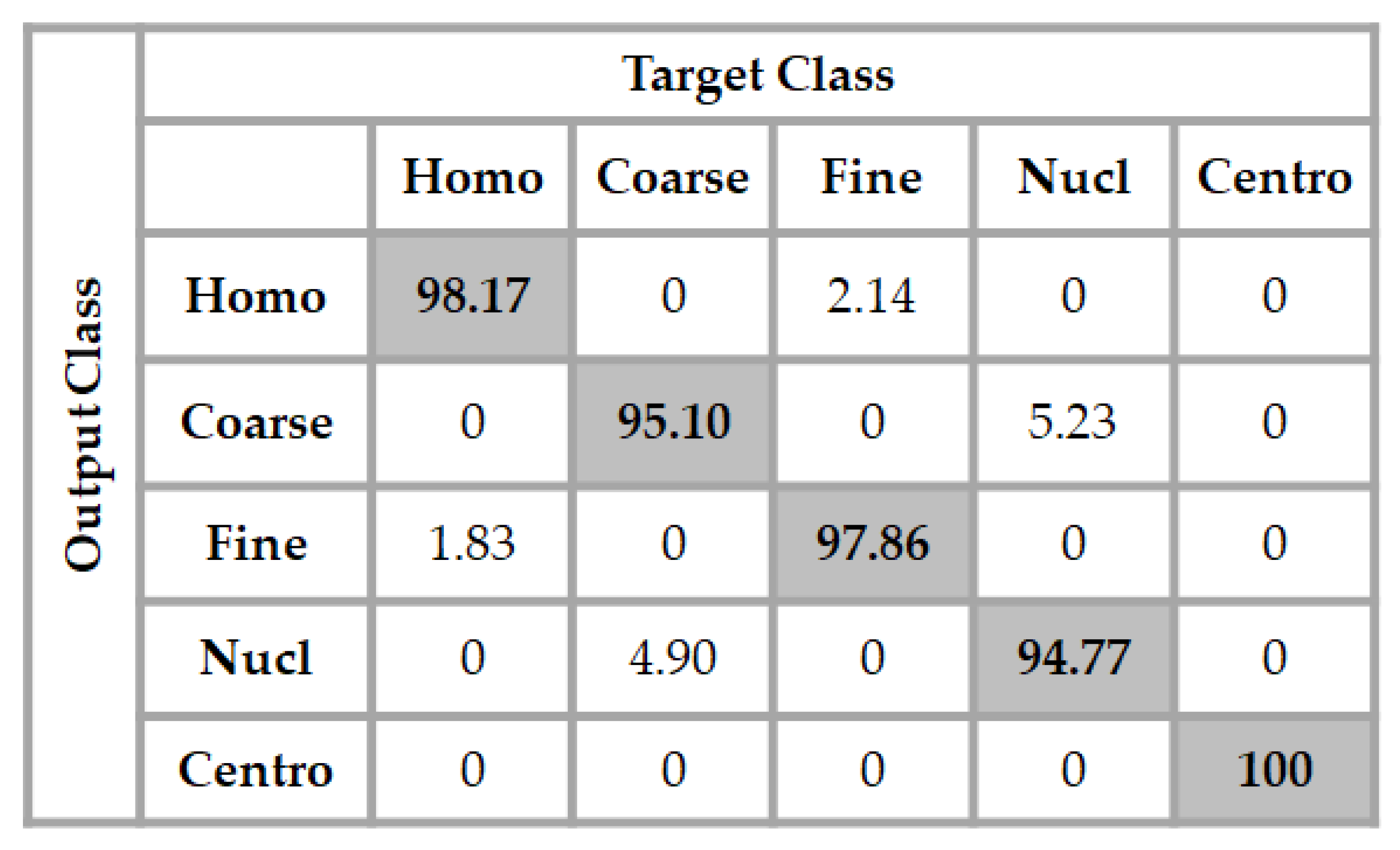
3. Results
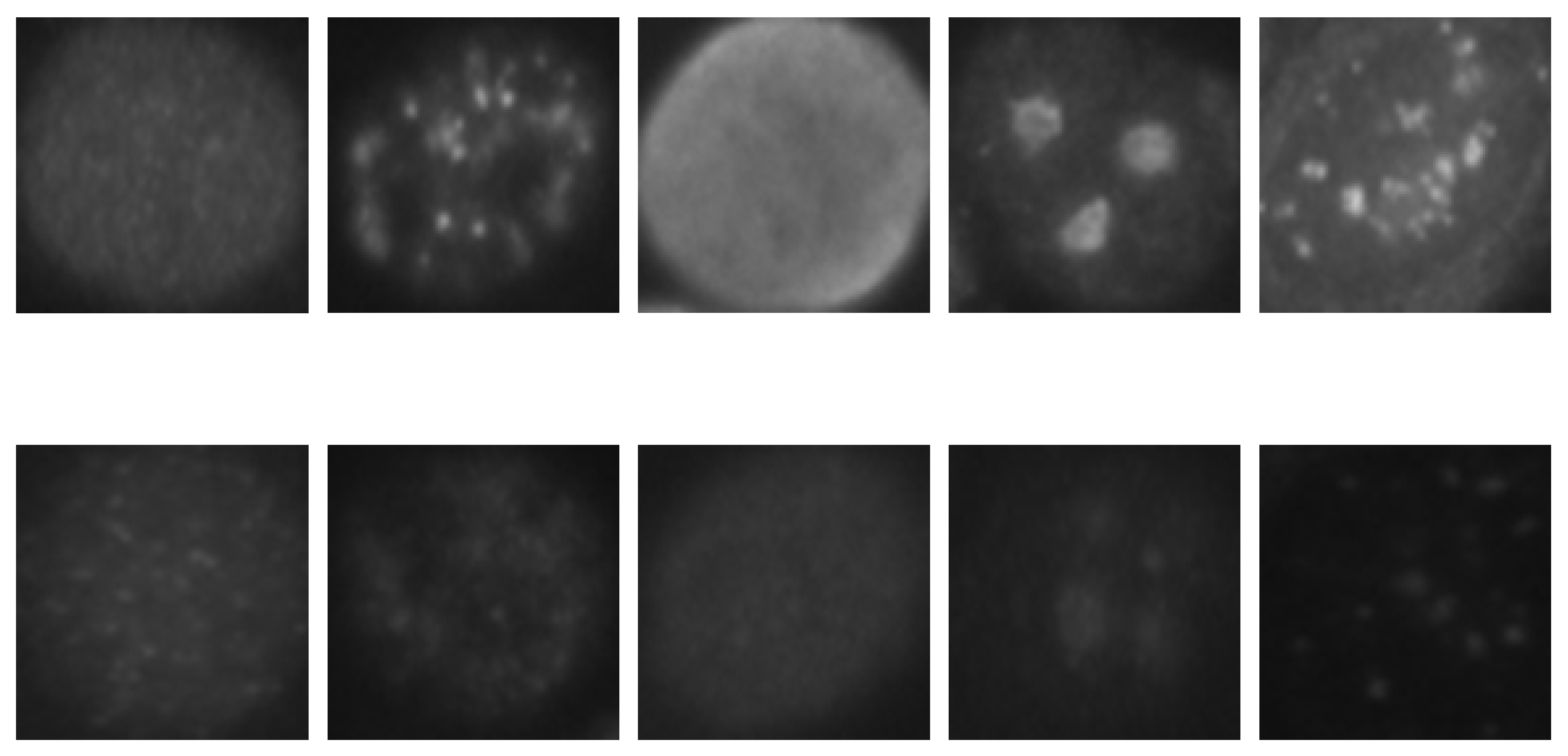
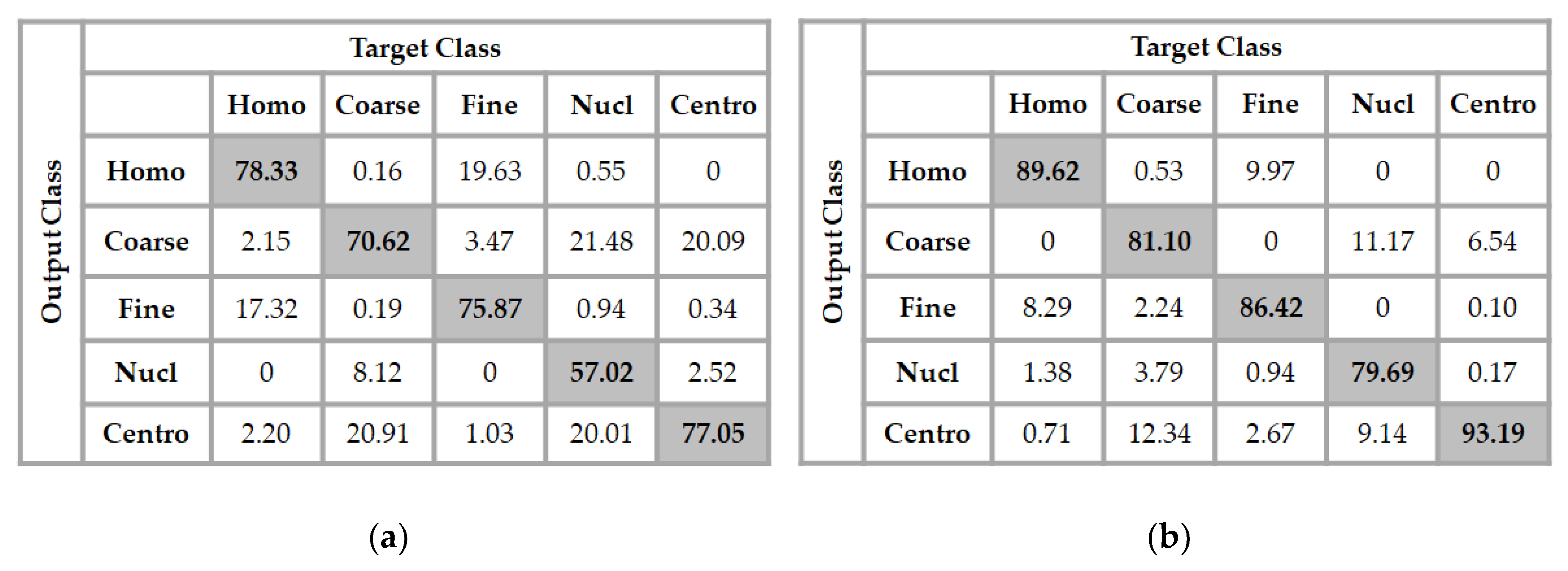
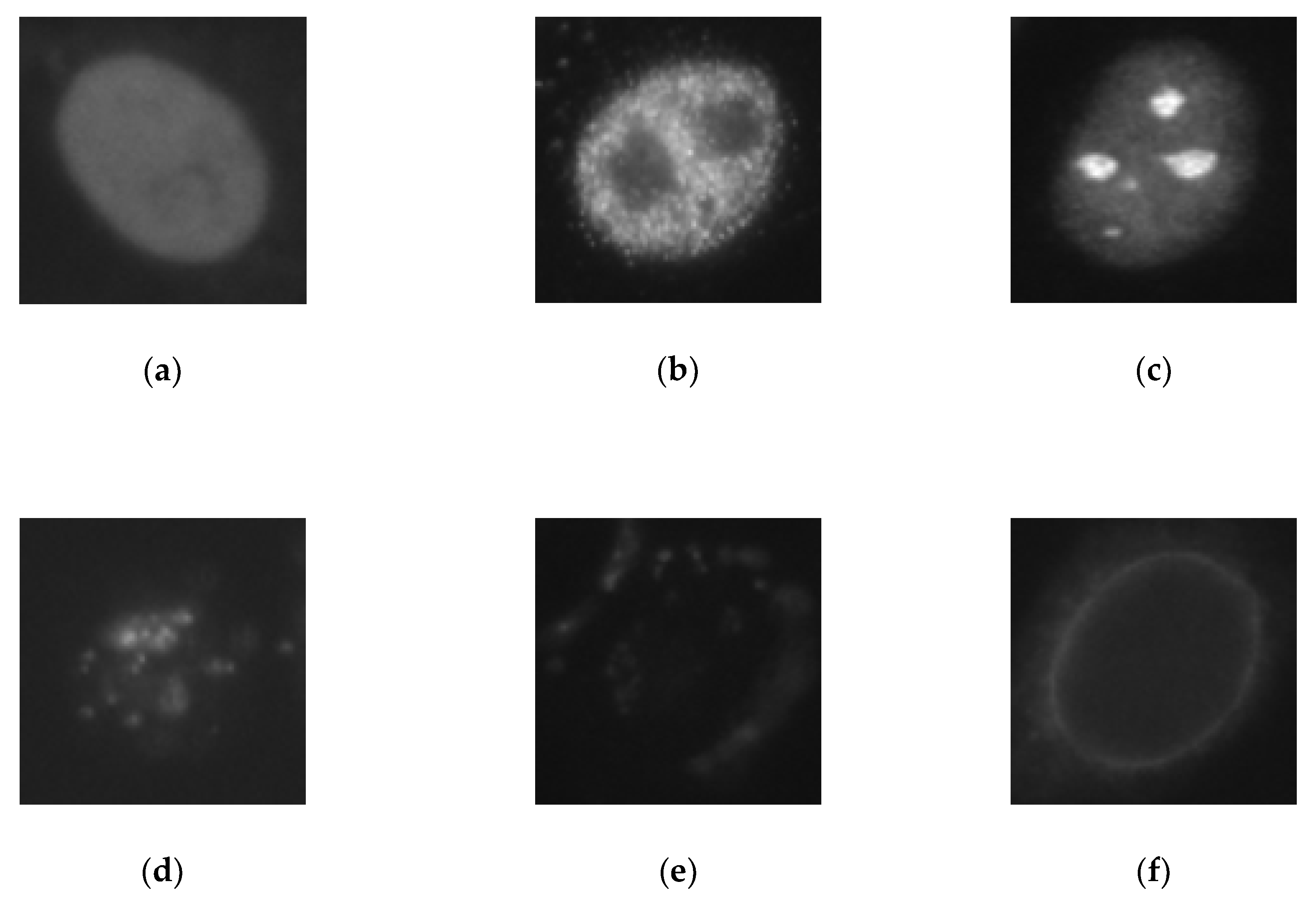
3.1. SNPHEp-2 Dataset
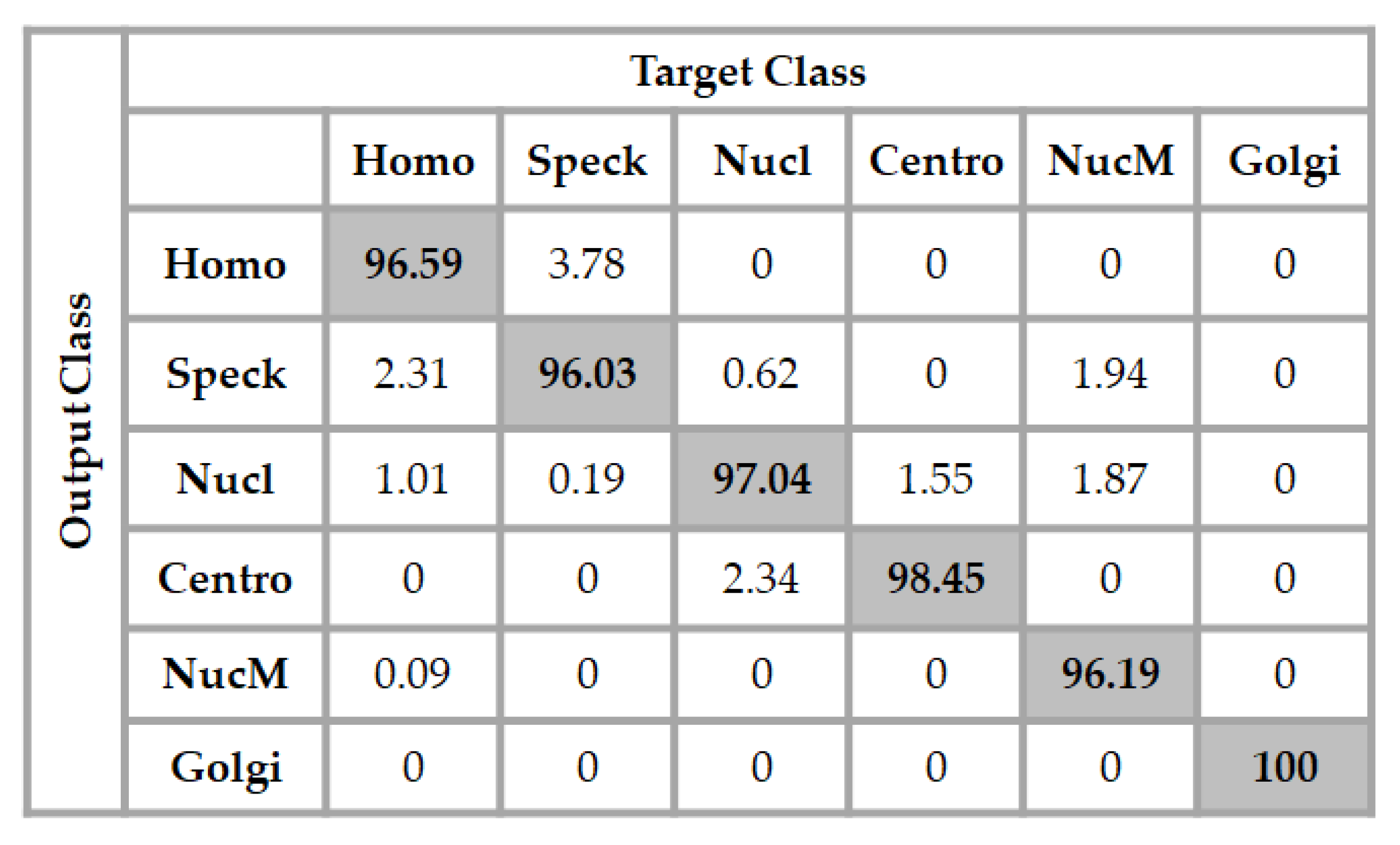
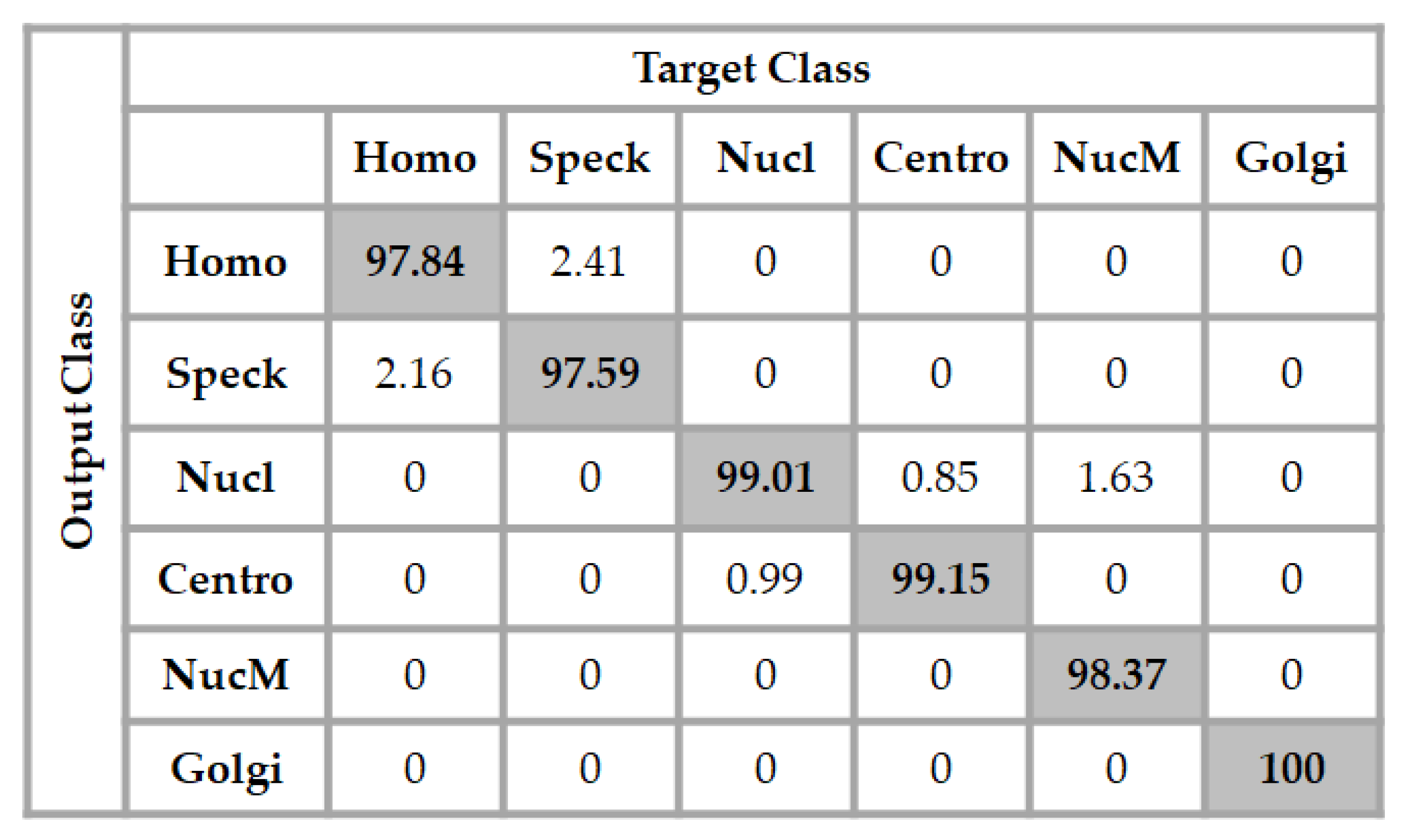
3.2. ICPR 2016 Dataset
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rigon, A.; Soda, P.; Zennaro, D.; Iannello, G.; Afeltra, A. Indirect immunofluorescence in autoimmune diseases: Assessment of digital images for diagnostic purpose. Cytom. B Clin. Cytom. 2007, 72, 472–477. [Google Scholar] [CrossRef]
- Foggia, P.; Percannella, G.; Soda, P.; Vento, M. Benchmarking hep-2 cells classification methods. IEEE Trans. Med. Imaging 2013, 32, 1878–1889. [Google Scholar] [CrossRef] [PubMed]
- Foggia, P.; Percannella, G.; Saggese, A.; Vento, M. Pattern recognition in stained hep-2 cells: Where are we now? Pattern Recognit. 2014, 47, 2305–2314. [Google Scholar] [CrossRef]
- Cataldo, S.D.; Bottino, A.; Ficarra, E.; Macii, E. Applying textural features to the classification of HEp-2 cell patterns in IIF images. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 689–694. [Google Scholar]
- Wiliem, A.; Wong, Y.; Sanderson, C.; Hobson, P.; Chen, S.; Lovell, B.C. Classification of human epithelial type 2 cell indirect immunofluorescence images via codebook based descriptors. In Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision (WACV), Tampa, FL, USA, 15–17 January 2013; pp. 95–102. [Google Scholar] [CrossRef]
- Nosaka, R.; Fukui, K. Hep-2 cell classification using rotation invariant co-occurrence among local binary patterns. Pattern Recognit. 2014, 47, 2428–2436. [Google Scholar] [CrossRef]
- Huang, Y.C.; Hsieh, T.Y.; Chang, C.Y.; Cheng, W.T.; Lin, Y.C.; Huang, Y.L. HEp-2 cell images classification based on textural and statistic features using self-organizing map. In Proceedings of the 4th Asian Conference on Intelligent Information and Database Systems, Part II, Kaohsiung, Taiwan, 19–21 March 2012; pp. 529–538. [Google Scholar]
- Thibault, G.; Angulo, J.; Meyer, F. Advanced statistical matrices for texture characterization: Application to cell classification. IEEE Trans. Biomed. Eng. 2014, 61, 630–637. [Google Scholar] [CrossRef] [PubMed]
- Wiliem, A.; Sanderson, C.; Wong, Y.; Hobson, P.; Minchin, R.F.; Lovell, B.C. Automatic classification of human epithelial type 2 cell indirect immunofluorescence images using cell pyramid matching. Pattern Recognit. 2014, 47, 2315–2324. [Google Scholar] [CrossRef]
- Xu, X.; Lin, F.; Ng, C.; Leong, K.P. Automated classification for HEp-2 cells based on linear local distance coding framework. J. Image Video Proc. 2015, 2015, 1–13. [Google Scholar] [CrossRef]
- Cataldo, S.D.; Bottino, A.; Islam, I.U.; Vieira, T.F.; Ficarra, E. Subclass discriminant analysis of morphological and textural features for hep-2 staining pattern classification. Pattern Recognit. 2014, 47, 2389–2399. [Google Scholar] [CrossRef]
- Bianconi, F.; Fernández, A.; Mancini, A. Assessment of rotation-invariant texture classification through Gabor filters and discrete Fourier transform. In Proceedings of the 20th International Congress on Graphical Engineering (XX INGEGRAF), Valencia, Spain, 4–6 June 2008. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Nosaka, R.; Ohkawa, Y.; Fukui, K. Feature extraction based on co-occurrence of adjacent local binary patterns. In Proceedings of the 5th Pacific Rim Symposium on Advances in Image and Video Technology, Part II, Gwangju, Korea, 20–23 November 2012; pp. 82–91. [Google Scholar]
- Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar] [CrossRef]
- Theodorakopoulos, I.; Kastaniotis, D.; Economou, G.; Fotopoulos, S. Hep-2cells classification via sparse representation of textural features fused into dissimilarity space. Pattern Recognit. 2014, 47, 2367–2378. [Google Scholar] [CrossRef]
- Ponomarev, G.V.; Arlazarov, V.L.; Gelfand, M.S.; Kazanov, M.D. ANA hep-2 cells image classification using number, size, shape and localization of targeted cell regions. Pattern Recognit. 2014, 47, 2360–2366. [Google Scholar] [CrossRef]
- Shen, L.; Lin, J.; Wu, S.; Yu, S. Hep-2 image classification using intensity order pooling based features and bag of words. Pattern Recognit. 2014, 47, 2419–2427. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Huang, F.J.; Bottou, L. Learning methods for generic object recognition with invariance to pose and lighting. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’04), Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS’12), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Gao, Z.; Wang, L.; Zhou, L.; Zhang, J. Hep-2 cell image classification with deep convolutional neural networks. IEEE J. Biomed. Health Inf. 2017, 21, 416–428. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Shen, L. A deep residual inception network for HEp-2 cell classification. In Proceedings of the 3rd International Workshop on Deep Learning in Medical Image Analysis (DLMIA 2017), Québec City, QC, Canada, 14 September 2017; pp. 12–20. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Phan, H.T.H.; Kumar, A.; Kim, J.; Feng, D. Transfer learning of a convolutional neural network for HEp-2 cell image classification. In Proceedings of the 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), Prague, Czech Republic, 13–16 June 2016; pp. 1208–1211. [Google Scholar]
- Lei, H.; Han, T.; Zhou, F.; Yu, Z.; Qin, J.; Elazab, A.; Lei, B. A deeply supervised residual network for HEp-2 cell classification via cross-modal transfer learning. Pattern Recognit. 2018, 79, 290–302. [Google Scholar] [CrossRef]
- Shen, L.; Jia, X.; Li, Y. Deep cross residual network for HEp-2 cell staining pattern classification. Pattern Recognit. 2018, 82, 68–78. [Google Scholar] [CrossRef]
- Bayramoglu, N.; Kannala, J.; Heikkilä, J. Human epithelial type 2 cell classification with convolutional neural networks. In Proceedings of the IEEE 15th International Conference on Bioinformatics and Bioengineering (BIBE), Belgrade, Serbia, 2–4 November 2015; pp. 1–6. [Google Scholar]
- Xi, J.; Linlin, S.; Xiande, Z.; Shiqi, Y. Deep convolutional neural network based HEp-2 cell classification. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 77–80. [Google Scholar]
- Nigam, I.; Agrawal, S.; Singh, R.; Vatsa, M. Revisiting HEp-2 cell classification. IEEE Access 2015, 3, 3102–3113. [Google Scholar] [CrossRef]
- Lovell, B.C.; Percannella, G.; Saggese, A.; Vento, M.; Wiliem, A. International contest on pattern recognition techniques for indirect immunofluorescence images analysis. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 74–76. [Google Scholar]
- Bengio, Y. Learning deep architecture for AI. Foundat. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of the data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. A very deep convolutional networks for large-scale image recognition. In Proceedings of the 2015 International Conference on Learning Representation (ICLR15), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICAAI 2015), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayana, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Filter size | #Feature Maps | Stride | Padding | Output |
|---|---|---|---|---|---|
| Input | - | - | - | - | 112 × 112 |
| Conv 1 | 3 × 3 | 32 | 1 | 1 | 112 × 112 |
| Pool 1 | 2 × 2 | 32 | 2 | 0 | 56 × 56 |
| Conv 2 | 3 × 3 | 64 | 1 | 1 | 56 × 56 |
| Pool 2 | 2 × 2 | 64 | 2 | 0 | 28 × 28 |
| Conv 3 | 3 × 3 | 128 | 1 | 1 | 28 × 28 |
| Pool 3 | 2 × 2 | 128 | 2 | 0 | 14 × 14 |
| Conv 4 | 3 × 3 | 256 | 1 | 1 | 14 × 14 |
| Pool 4 | 2 × 2 | 256 | 2 | 0 | 7 × 7 |
| Conv 5 | 7 × 7 | 512 | 1 | 1 | 1 × 1 |
| Deconv 5 | 7 × 7 | 256 | 1 | 0 | 7 × 7 |
| Unpool 4 | 2 × 2 | 256 | 2 | 0 | 14 × 14 |
| Deconv 4 | 3 × 3 | 128 | 1 | 1 | 14 × 14 |
| Unpool 3 | 2 × 2 | 128 | 2 | 0 | 28 × 28 |
| Deconv 3 | 3 × 3 | 64 | 1 | 1 | 28 × 28 |
| Unpool 2 | 2 × 2 | 64 | 2 | 0 | 56 × 56 |
| Deconv 2 | 3 × 3 | 32 | 1 | 1 | 56 × 56 |
| Unpool 1 | 2 × 2 | 32 | 2 | 0 | 112 × 112 |
| Deconv 1 | 3 × 3 | 1 | 1 | 1 | 112 × 112 |
| Method | Authors | Description | Accuracy |
|---|---|---|---|
| Hand-crafted features | Nigam et al. [31] | Texture features + SVM | 80.90% |
| Wiliem et al. [5] | DCT features + SIFT + SVM | 82.50% | |
| Nosaka et el. [6] | LPB + SVM | 85.71% | |
| Deep Learning | Gao et al. [22] | 5 layers CNN | 86.20% |
| Bayramoglu et al. [29] | 4 layers CNN | 88.37% | |
| Li et al. [23] | Deep Residual Inception Model | 95.61% | |
| Lei et al. [27] | Cross-modal transfer learning | 95.99% | |
| Shen et al. [28] | Use of a Deep-Cross Residual Module | 96.26% | |
| Proposed method | Double DCAEs feature extraction + ANN 1 | 97.18% |
| Method | Authors | Description | Accuracy |
|---|---|---|---|
| Hand-crafted features | Nigam et al. [31] | Texture features + SVM | 71.63% |
| Wiliem et al. [5] | DCT features + SIFT + SVM | 74.91% | |
| Nosaka et el. [6] | LPB + SVM | 79.44% | |
| Deep Learning | Gao et al. [22] | 5 layers CNN | 96.76% |
| This work | Double DCAE feature extraction + ANN-1024-100-6 | 97.38% | |
| Xi et al. [29] | VGG-like network | 98.26% | |
| Li et al. [23] | Deep Residual Inception Model | 98.37% | |
| Lei et al. [27] | Cross-modal transfer learning | 98.42% | |
| Shen et al. [28] | Use of a Deep-Cross Residual Module | 98.62% | |
| This work | Double DCAE feature extraction + ANN-1024-200-20-6 | 98.66% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vununu, C.; Lee, S.-H.; Kwon, K.-R. A Deep Feature Extraction Method for HEp-2 Cell Image Classification. Electronics 2019, 8, 20. https://doi.org/10.3390/electronics8010020
Vununu C, Lee S-H, Kwon K-R. A Deep Feature Extraction Method for HEp-2 Cell Image Classification. Electronics. 2019; 8(1):20. https://doi.org/10.3390/electronics8010020
Chicago/Turabian StyleVununu, Caleb, Suk-Hwan Lee, and Ki-Ryong Kwon. 2019. "A Deep Feature Extraction Method for HEp-2 Cell Image Classification" Electronics 8, no. 1: 20. https://doi.org/10.3390/electronics8010020
APA StyleVununu, C., Lee, S.-H., & Kwon, K.-R. (2019). A Deep Feature Extraction Method for HEp-2 Cell Image Classification. Electronics, 8(1), 20. https://doi.org/10.3390/electronics8010020