2. Problem Formulation
We consider a ride-sharing system consisting of an order matcher that assigns passenger requests to vehicles and a repositioning policy that moves idle vehicles across a spatial grid. The interaction between these components determines service quality, vehicle efficiency, and overall system performance.
Figure 1 illustrates the grid environment and an example trajectory that includes repositioning, pickup, and drop-off movement. Shaded blocks represent demand zones 1–3. Zones 1–3 are three example zones in order to illustrate repositioning and pickup/dropoff trips. Zone 1 is a 4 × 4 central block in the middle of the grid. Zones 2 and 3 are two smaller 2 × 2 regions located near opposite corners of the grid. The simulator itself generates requests on the full grid according to the Poisson–diurnal model without any special zone-specific differences. The dashed blue line indicates a repositioning move, and the red arrows show one served request (pickup and drop-off).
The simulation takes place on a grid G with time step s, cell size km, and horizon steps (10 h). A fleet of single-capacity vehicles operates on this grid. Passenger requests arrive according to a Poisson process whose rate is modulated by a diurnal function, creating realistic temporal demand variation. To simulate different request levels, we use a diurnal function with two peaks around the morning and evening periods and relatively lower intensity in the middle of the day. Internally, the simulator scales the Poisson arrival rate up during the peaks and down during off-peak times, so that the instantaneous request intensity varies between roughly 0.6 and 2.2 on a normalized scale, with the busiest times being a bit more than twice as busy as the quietest period. The spatial distribution of demand is homogeneous across the grid. At each step t, the total number of new requests is drawn from the time-varying Poisson process, and each request independently samples an origin and a destination uniformly over the 10 × 10 grid. Arrival-scale parameters represent different load regimes and are used throughout the evaluation.
With
cells, the vehicle density is
representing a medium-load operating environment. When scaling the grid size (e.g.,
), the fleet size is increased proportionally (e.g.,
) in order to maintain the same density. Conversely, varying the density at a fixed grid size (e.g.,
on
) enables controlled experiments on operational capacity. The 0.5 km cell resolution and
area approximate a small urban district. These default settings provide a reproducible medium-scale environment; scalability experiments vary the grid size and fleet density accordingly.
Each request is defined by its origin, destination, and arrival time. Newly generated requests enter a queue, and a FIFO–nearest matching rule assigns requests to feasible idle vehicles subject to both a maximum-wait threshold and a radius bound . This rule reflects operational practice and avoids over-concentration of vehicles. Ablation experiments additionally evaluate alternative matching rules, including greedy insertion and random assignment.
Vehicles move on the grid using Manhattan distance [
26]. Idle vehicles follow repositioning decisions from a learned policy, while vehicles with assigned passengers follow precomputed shortest paths for pickup and drop-off. At each step, the environment updates vehicle states, request queues, travel statistics, and performance metrics such as served rate, wait time, cruising time, and empty miles.
The system is modeled as a discounted episodic Markov Decision Process (MDP)
In the ride-sharing repositioning problem, relocation decisions have long-term effects on vehicle availability and request coverage over time steps. A high discount factor makes the agent care about rewards many steps in the future, so it values the long-term effects of repositioning vehicles toward demand instead of only improving the immediate match. A state
encodes (i) the spatial distribution and occupancy of vehicles, (ii) request queues across grid cells, (iii) time-of-day indicators, and (iv) a short-term pickup heatmap summarizing recent demand patterns. Each idle vehicle selects an action
corresponding to dwelling or moving one cell north, south, west, or east. State transitions
result from the combined effects of vehicle motion, order assignment, and service completion.
The goal is to learn a repositioning policy that reflects human preferences over key service metrics rather than relying on handcrafted proxy rewards. Each trajectory
is summarized by a feature vector
The served rate is defined as the fraction of requests that are successfully served, the empty-mile ratio is the fraction of vehicle-miles traveled without passengers over the total vehicle-miles, the cruising hours measure the total time that vehicles spend idling while waiting for requests, and the movement cost aggregates the distance traveled by repositioning moves. Together, these four features summarize each trajectory in terms of service quality (served rate), passenger experience (cruising hours), and operational efficiency (empty-mile ratio and movement cost).
Pairwise preference comparisons over trajectories are fitted using a Bradley–Terry model, producing preference weights
w that define a shaped per-step reward,
The scalars
,
,
, and
are the preference weights learned by the Bradley–Terry model. Intuitively, a larger
increases the value of trajectories that serve more requests, whereas larger
and
penalize unnecessary empty travel and long cruising time. The reward term
plays the role of an operational regularizer on repositioning distance. At each upper-level update, the preference model produces an updated per-step reward
. This provides a connection between human preferences at the trajectory level and the per-step reward used by the lower-level RL algorithms.
The resulting trajectory-level reward is
The preference-aligned policy optimization problem is
where the expectation is taken over trajectories generated by policy
under the environment dynamics. To promote stable learning, particularly during early training when the reward model is still being refined, we incorporate an imitation regularizer that encourages
to remain close to a reference policy
obtained from the Stage-1 warm start.
During the PPO-RLHF stage, policy optimization proceeds through a KL-regularized objective of the form
where
is an adaptive coefficient automatically tuned to maintain a target KL divergence between the current policy and the reference policy, following standard practice in RLHF [
14,
21]. This KL term prevents rapid policy drift, stabilizes optimization, and ensures that preference-updated rewards do not induce abrupt, undesirable behavior.
Our simulation relies on the following modeling assumptions:
- 1.
Customer requests follow a Poisson process with a fixed diurnal function on a 10 × 10 grid.
- 2.
Travel time between two cells is proportional to the Manhattan distance [
26] with a constant speed (no congestion model).
- 3.
All vehicles are homogeneous and centrally controlled. Drivers always follow the repositioning decisions.
- 4.
The preference model evaluates policies only through three metrics: wait time, served rate, and empty-mile ratio.
Let
be the total number of generated requests in a period and
be the number of requests that are successfully served. Served rate (dimensionless) is defined as
Wait time (minutes) is defined as
where we record the number of simulation steps between request creation and pickup for each served request with a step length of
s.
Empty-mile ratio (dimensionless) is defined as
In Equation (
11), VMT =
, where
and
denote the total empty and loaded distances traveled by all vehicles in an episode.
3. Two-Stage Bilevel RLHF Framework
This section presents the proposed two-stage bilevel RLHF framework for preference-aligned vehicle repositioning. The framework consists of a value-based warm start stage based on Double DQN and a policy-gradient stage based on PPO with KL regularization. Both stages interact with a learned preference-based reward model, which is updated from pairwise trajectory comparisons.
The two stages are tightly coupled rather than independent. Stage 1 learns an initial preference-aligned reward model and a stable reference policy using a Double DQN RLHF procedure with FIFO-nearest matching. Stage 2 starts from and the learned reward model from Stage 1 in the initial round. Later on, it uses the reward model from the previous round and fine-tunes a stochastic policy via PPO-RLHF with action masking and KL regularization. Overall, Stage 1 shapes the reward model and provides a safe starting point, while Stage 2 performs policy improvement under KL regularization starting from the initial model learned by Stage 1. Two coordination schemes are considered: a purely alternating outer loop and a k-step style alternating loop.
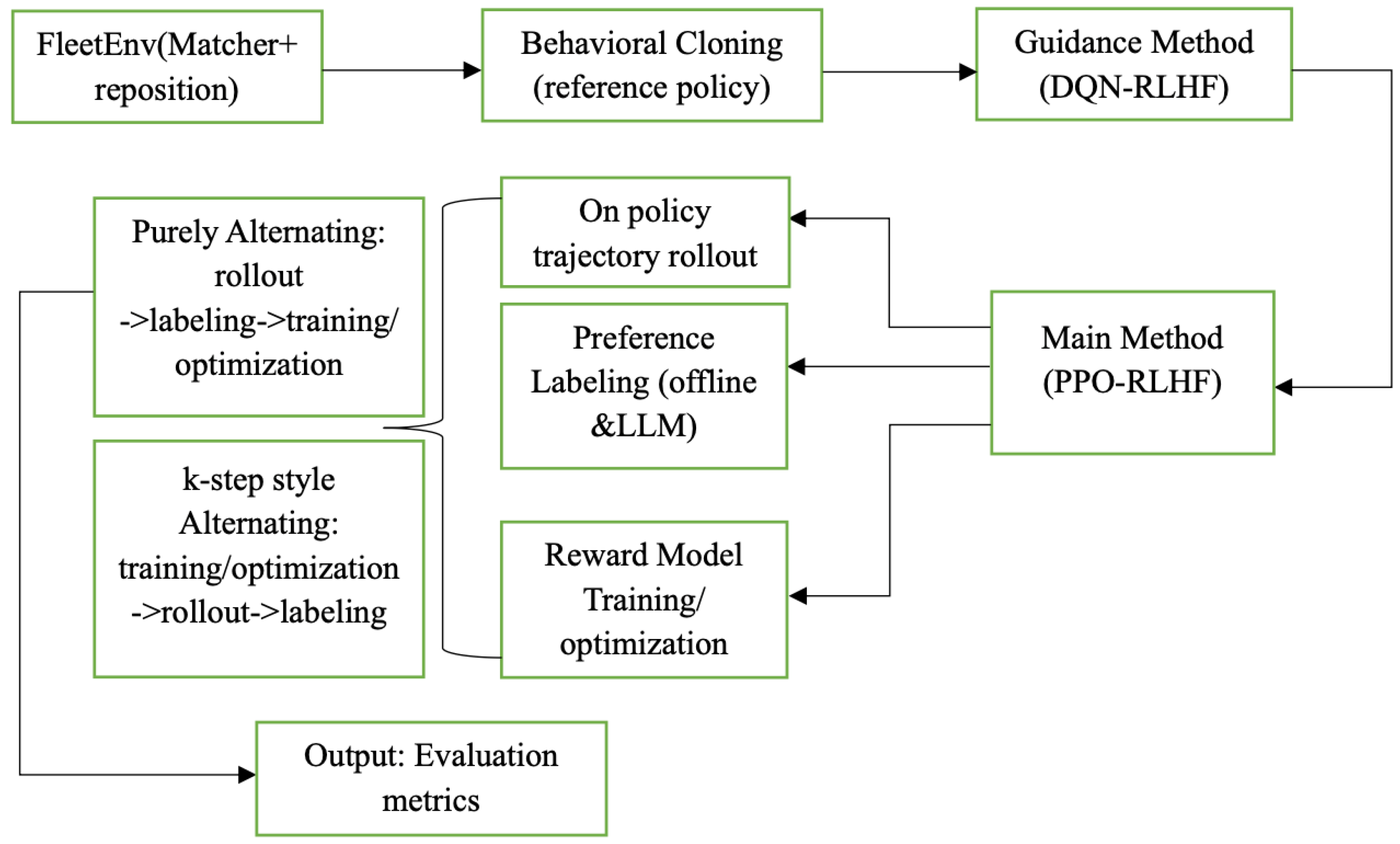
Figure 2 summarizes the two-stage bilevel RLHF framework. Requests generated by FleetEnv (Matcher + reposition) are used to train a Behavioral Cloning policy at first and then the guidance method (DQN-RLHF). After obtaining the initial weight and reward function, the main method (PPO-RLHF) produces on-policy trajectories. These trajectory preferences are labeled through a combination of an offline rubric and LLM assistance. Then, they will enter the lower-level loop to complete reward model training and optimization. The main method follows either a purely alternating scheme (rollout → labeling → training/optimization) or a
k-step alternating scheme (training/optimization → rollout → labeling).
3.1. Action Masking
At each decision step, an idle vehicle at grid location
may move toward a target location
or remain in place. The Manhattan distance between these locations is
Two distance thresholds are used to restrict the available actions:
and
. For a state
s and corresponding distance
to the nearest relevant target (for example, a demand hotspot or previously chosen goal), the feasible action set
is defined as
where st = stay, 1-step = move one step toward target, and
= moves that decrease distance.
For each state–action pair
we define a mask
which is added to the action logits
before the softmax. The resulting masked policy is
Action masking ensures that invalid or operationally undesirable movements have zero probability, reduces oscillatory behavior, and suppresses unnecessary empty travel. To maintain exploration within the feasible set, we define a masked entropy term
which is added to the PPO objective with an entropy coefficient in Stage 2.
3.2. Preference-Based Reward Learning
The preference model operates at the upper level of the bilevel RLHF framework. At each round
K, the current policy
is used to generate pairs of trajectories
. Each trajectory is summarized by a feature vector capturing key service metrics, such as wait time, served rate, and empty-mile ratio. For a trajectory pair, the feature difference is
Here,
denote the differences in average wait time, served rate, and empty-mile ratio between trajectories
A preference label
is assigned to each pair
using either rubric-based rules or LLM-assisted comparisons, where
indicates that
is preferred to
. The preference probability is modeled by a Bradley–Terry formulation [
13],
where
is the logistic function and
is the trajectory-level score produced by a reward network with parameters
.
Given a batch of
N labeled pairs, the Bradley–Terry loss [
13] is
where
are optional importance weights. Minimizing
yields an updated parameter vector
, which is mapped to a normalized weight vector
and induces a shaped per-step reward
The corresponding trajectory-level reward is
which is then used by the lower-level RL algorithm in both stages, determining whether the algorithm prioritizes serving more requests while reducing waiting time and empty travel at each step through the shaped reward
.
3.3. Stage 1: DQN-RLHF Warm Start
The first stage uses a Double DQN agent trained with the preference-aligned shaped reward and action masking. This stage serves two purposes. First, it learns a stable value-based repositioning policy in the many-to-many environment. Second, it produces a preference-aligned reward model that can be used to warm-start the PPO stage. Algorithm 1 summarizes the Stage-1 DQN-RLHF warm start procedure, including trajectory pairs generation, preference fitting, reward model, reference policy, weight updates, and Q-networks.
Let
denote the online Q network and
the target network. At state
, the agent selects an action
using an
-greedy policy over
, and observes reward
and next state
. The target action is
The one-step target
is
where
is the episode termination indicator. The temporal-difference error is
. A Huber loss [
27]
is used to stabilize training, and the DQN objective is
An additional imitation term can be included to nudge the DQN policy toward a simple baseline policy
(for example, a rule that moves vehicles toward high-demand regions), with loss
. The total loss is
and the target parameters are updated via
After several rounds of alternation between preference fitting and DQN updates, Stage 1 outputs a reference policy
derived from
and a reward model with parameters
(or equivalently
), which are used to initialize Stage 2.
| Algorithm 1 Stage 1: DQN-RLHF Warm Start |
- 1:
Initialize Q networks , , reward model parameters , and reference policy . - 2:
for do - 3:
Generate trajectory pairs using current policy and action masking. - 4:
Fit preference model by minimizing and obtain weights . - 5:
Define shaped reward using . - 6:
for each DQN update step do - 7:
Collect transitions . - 8:
Compute target and TD error . - 9:
Update using . - 10:
Soft-update target parameters . - 11:
end for - 12:
Update reference policy from . - 13:
end for - 14:
return , .
|
3.4. Stage 2: PPO-RLHF with KL Regularization
Stage 2 starts from the reference policy and the initial reward model learned in Stage 1. The goal is to refine a stochastic policy under the preference-aligned reward while maintaining stability via KL regularization and action masking.
3.4.1. PPO Objective
Let
denote the value function. For each transition, the advantage estimate is
which is standardized to
to reduce variance. The PPO importance ratio is defined using the masked policy,
The clipped PPO loss is
The value-function loss is
where
is the return computed from the shaped rewards, and the entropy regularization term using masked entropy is
The combined PPO loss is
3.4.2. KL Regularization
To prevent large deviations from the reference policy, we add a KL regularizer between the current policy
and a fixed reference policy
. The KL divergence is computed using unmasked action distributions obtained via temperature-scaled softmax,
for mini-batch observations
, where
controls the sharpness of the distributions.
The forward and reverse KL divergences are
An alternating schedule switches between forward and reverse KL every fixed number of steps. Early in training, reverse KL promotes exploration, while forward KL later in training encourages convergence toward the reference policy.
The KL regularization loss is
where
is adapted to maintain a target KL level
by increasing
when the observed KL exceeds
and decreasing
when it falls significantly below this threshold. The total Stage 2 loss is
3.4.3. Alternating Coordination Schemes
The bilevel nature of PPO-RLHF allows different coordination schemes between the upper-level reward updates and the lower-level policy updates. We consider two schemes.
PPO-Alternating
In the purely alternating scheme, training proceeds in outer rounds indexed by K. At round K, the algorithm achieves the following:
- 1.
Fixes the current policy and generates trajectory pairs using action masking.
- 2.
Updates the reward model to obtain weights and shaped rewards by minimizing .
- 3.
Fixes and optimizes the policy using PPO with KL regularization and action masking, yielding an updated policy .
The reference policy
used in KL regularization is updated once per round, typically by setting
. In practice, a small number of outer rounds (for example, two) suffices. The overall training loop is summarized in Algorithm 2.
| Algorithm 2 PPO-Alternating Bilevel RLHF |
- 1:
Initialize policy , reference policy , and reward model. - 2:
for do - 3:
Set . - 4:
Generate trajectory pairs using and action masking. - 5:
Fit reward model to obtain weights and shaped rewards . - 6:
for each PPO update step do - 7:
Collect rollouts under current policy (initialized from ) with action masking. - 8:
Compute advantages and PPO loss with KL regularization. - 9:
Update policy parameters to obtain . - 10:
end for - 11:
end for - 12:
return final policy .
|
PPO-k-Step
Algorithm 3 indicates the PPO-k-step procedures. In the k-step alternating scheme, preference learning and policy optimization are interleaved more frequently. Each training round is partitioned into chunks indexed by . Within chunk c, the algorithm achieves the following:
- 1.
Fixes the reward model from the previous update and reference policy .
- 2.
Performs several PPO update steps using this fixed reward model and KL regularization, yielding an updated policy .
- 3.
Uses to generate new trajectory pairs and updates the reward model to obtain .
Compared with PPO-Alternating, PPO-
k-step refreshes both the reward model and the reference policy more frequently, which can reduce lag between preference learning and policy behavior, at the cost of increased sensitivity to short-term fluctuations.
| Algorithm 3 k-step Bilevel PPO-RLHF |
- 1:
Initialize policy , reference policy , and reward model. - 2:
for do - 3:
Fix current reward model and set . - 4:
for each PPO update step in chunk c do - 5:
Collect rollouts under current policy (initialized from ) with action masking. - 6:
Compute advantages and PPO loss with KL regularization. - 7:
Update policy parameters to obtain . - 8:
end for - 9:
Generate new trajectory pairs using and update reward model to obtain . - 10:
end for - 11:
return final policy .
|
Both coordination schemes share the same building blocks: preference fitting at the upper level, PPO-RLHF with action masking and KL regularization at the lower level, and an adaptive KL coefficient that keeps the policy close to a reference behavior while still allowing exploration.
4. Simulation and Evaluation
This section evaluates the proposed two-stage bilevel RLHF framework across a variety of demand conditions, labeling modes, and fleet configurations. Our experiments are designed to answer five questions: (i) how the two PPO-RLHF methods perform across arrival scales relative to no-repositioning and the classical baseline (heuristic), (ii) whether LLM-assisted and offline rubric-based labeling yield consistent improvements, (iii) how performance changes with increased fleet density, (iv) whether the two PPO variants differ meaningfully in practice, and (v) whether the DQN-RLHF warm start is necessary.
4.1. Experimental Setup
All experiments take place in a grid with cell size, a fleet of single-capacity vehicles (unless otherwise stated), and episode length at s. Vehicles execute actions in under action masking. Order arrivals follow a Poisson process whose rate is scaled by a diurnal multiplier to simulate morning and evening peaks.
To explore different demand regimes, we vary the arrival scale , . The request rejection radius is set to 6 km for lower scales (0.60, 0.75) and increased to km for to accommodate higher demand. To avoid over-concentration during repositioning, only a fraction of vehicles are allowed to move; this fraction increases gradually from at low scales to at scale .
Preference models use both offline rubric-based labeling and LLM-assisted labeling. In all runs we use 256 trajectory pairs per upper-level update and six rollouts per training epoch. KL regularization begins at
with a target value of
. Reported confidence intervals correspond to
CIs,
In addition to 95% CIs, we also conduct Wilcoxon signed-rank tests. Both PPO-based policies are trained to improve over the no-repositioning baseline, so we test a directional hypothesis that they do not perform worse than no rep.
Table 1 shows that their average performance is slightly better than no rep, which is consistent with this hypothesis. We therefore report one-sided Wilcoxon signed-rank tests (and also provide the corresponding two-sided
p-values for completeness). Detailed discussion is in
Appendix E Table A4.
We compare four methods: no-reposition (baseline), heuristic (classical baseline), PPO-Alternating, and PPO-k-step.
4.2. Results Across Arrival Scales
We first examine how policy performance varies with demand level under LLM-assisted labeling on a fleet of 90 vehicles. Lower arrival scales correspond to lighter workloads, where vehicles are more likely to be located near pickup points. As a result, wait time and empty-mile ratio are naturally lower, and the served rate is close to one. As demand increases, vehicles must travel farther to reach requests, which increases wait and empty-mile ratios and lowers the served rate. At the highest scale (), the system becomes nearly saturated, and both PPO methods reduce repositioning frequency to maintain feasibility, which incidentally lowers the empty-mile ratio.
Table 1 and
Figure 3,
Figure 4 and
Figure 5 show that both PPO methods offer small but consistent improvements over no-reposition in all three metrics across all arrival scales. Confidence intervals for PPO-Alternating and PPO-
k-step are tighter than those for the baseline, indicating more stable behavior under preference-aligned training. Importantly, improvements do not come at the expense of trade-offs among the three sectors; both PPO methods jointly reduce wait and empty-mile ratio while maintaining or slightly improving served rate.
Besides the no-reposition baseline, we also compare it with the classical baseline heuristic. We implement a hand-crafted repositioning policy that greedily chases recent demand. At each decision step, the policy collects the most frequent K = 3 recent pickup cells from the simulator log and treats them as temporary demand hotspots. It then selects idle vehicles that are closest to these hotspots and moves roughly 30 % of them one grid step toward the corresponding target cell if their Manhattan distance is larger than two, with all other vehicles remaining idle. The results are reported in
Table 1. Across all arrival scales except
, the heuristic achieves the lowest average wait time and the highest served rate but results in a higher empty-mile ratio than no rep, which indicates the heuristic baseline is making trade-offs among the three sectors. In contrast, both PPO-Alternating and PPO-k-Step keep wait time and served rate very close to the heuristic while maintaining some empty-mile ratio improvements against the no-reposition baseline, which demonstrates that the PPO-RLHF policies avoid trade-offs and provide a more balanced solution across wait time, empty-mile ratio, and served rate.
Figure A7 and
Figure A8 analyze the spatial behavior of the learned policies under arrival scale
. Even though passenger requests are generated with a spatially homogeneous distribution over the 10 × 10 grid, the PPO-RLHF policies learn to avoid over-concentration. The heat maps show a higher occupancy near the middle of the service area and gradually lower density towards the corners, reflecting how the policies coordinate vehicles under the action constraints to balance coverage and travel distance.
4.3. Effect of Labeling Mode
We next compare LLM-assisted labeling against offline rubric-based labeling for all three policies. Both modes outperform no-reposition across arrival scales and metrics, confirming the robustness of the preference-fitting procedure.
Figure 6 shows the wait time comparison: after aligning scales by horizontal normalization, both labeling modes exhibit nearly identical trends with small absolute differences. Similar consistency holds for served rate and empty ratio, demonstrating that the choice of labeling mode does not qualitatively affect conclusions.
4.4. Increased Fleet Density
To assess robustness to larger fleets, we increase vehicle count from 90 to 110 and run five seeds under moderate (0.85) and high (1.0) demand. Increasing fleet density reduces wait time and increases served rate, as more vehicles remain idle and can be dispatched quickly. At moderate demand, the empty-mile ratio decreases as more vehicles dwell waiting for requests. At high demand, however, additional vehicles create more opportunities for repositioning and slightly increase the empty ratio.
Table A2 and
Figure 7 show that both PPO policies continue to outperform no-reposition at
with LLM-assisted labeling. The magnitude of improvement is similar to the
setting, indicating scalability of the RLHF methods.
4.5. Comparing PPO-Alternating and PPO-k-Step
Across all experiments, PPO-Alternating and PPO-
k-step produce remarkably similar performance. For wait time under LLM labeling, the paired difference
oscillates around zero, and their
confidence intervals almost perfectly overlap. Under offline labeling, PPO-Alternating achieves slightly lower wait times and empty-mile ratios, though the differences remain small. Served-rate differences are negligible across all settings.
Figure 8,
Figure 9 and
Figure 10 confirm that both algorithms track nearly identical Pareto-efficient performance curves across demand levels. In summary, the two variants behave comparably in practice, with PPO-Alternating exhibiting marginal advantages under offline labeling.
4.6. Ablation: Removing the Warm Start
We evaluate both PPO variants without the DQN-RLHF warm start at
using ten seeds. Although both achieve comparable served rates to no-reposition, they exhibit higher wait times and empty-mile ratios: their wait time increases (1.864–1.869 vs. 1.859) and empty-mile ratios rise (0.25383–0.25386 vs. 0.2528) (
Table A3). The results highlight the coupling between the two stages: without the Stage 1 warm start, the Stage 2 PPO-RLHF optimization no longer benefits from a well-aligned reference policy and reward. This supports the hypothesis that the warm start reduces noise in the preference-fitting stage and provides a better initialization for PPO-RLHF, stabilizing learning and reducing variance.
4.7. Training Dynamics
Figure 11 illustrates the evolution of KL divergence and the adaptive regularization coefficient
for PPO-
k-step over six epochs. The KL divergence decreases steadily from
to
in epoch 1 and remains within
throughout training, while
saturates at its cap when tighter regularization is required. This behavior shows that adaptive KL regularization effectively controls policy drift under frequent reward-model updates, ensuring stable bilevel optimization.
Figure 12 shows analogous stabilization behavior for the PPO-Alternating scheme. In round 1, KL decreases steadily from
to
under strong regularization. Round 2 begins with a small KL increase following the reward-model update, after which KL decays smoothly to
. Together,
Figure 11 and
Figure 12 demonstrate that both coordination schemes maintain controlled policy updates despite differing reward–policy synchronization schedules.
For DQN-RLHF,
Figure 13 reports the reward-model training loss, which decreases from
to
over four epochs with only a minor rebound at epoch 5. This indicates stable convergence of the preference model and supports the role of the warm start in producing smooth, informative rewards for subsequent PPO-RLHF training.
Additionally, we record the wall-clock training time of each method to quantify computational cost. On a single CPU-only machine (24 GB RAM), the DQN-RLHF requires 0.28 h, while our two PPO-RLHF policies are more expensive: PPO-Alternating requires 1.95 h and PPO-k-step requires 2.32 h under LLM-assisted labeling for one full run.
4.8. Economic Considerations
We evaluate the economic implications of the proposed policies. Under offline labeling, both PPO methods yield higher profits than the no-reposition baseline (
Figure 14). Under LLM-assisted labeling, PPO policies outperform no-reposition at moderate and high arrival scales, but not at the lightest scales (
and
), where the economic signal is weak due to the abundance of idle vehicles (
Figure 15). Overall, RLHF-based repositioning offers both service quality and economic benefits under realistic load conditions.
4.9. Limitations
Our simulation abstracts away several real-world factors such as traffic congestion, speed limits, driver cancellations, pricing dynamics, and weather. The reward model uses a linear Bradley–Terry structure that may not capture nonlinear regional or temporal effects. We apply a single weight vector across the entire episode, ignoring spatial and temporal heterogeneity. Preference noise remains a concern due to the limited number of labeled pairs. Additionally, our experiment lacks comparisons against strong state-of-the-art RL-based algorithms. Since the experiment is mainly a simulation environment, it may face challenges when converting to real-world scenarios. Finally, the alternating KL schedule may introduce sensitivity to hyperparameters.
4.10. Discussion and Summary
Despite these simplifications stated in the previous subsection, the empirical results provide the following practical takeaways:
- (i)
Role of the warm start: The DQN-RLHF warm start is beneficial under medium and high arrival scales, where it stabilizes the reference policy and reduces variance via providing a starting reward model, as confirmed by the ablation in
Section 4.6.
- (ii)
Alternating vs. k-step: In our experiment, the two PPO-RLHF variants have similar performance and deliver almost identical Pareto fronts. Both PPO-RLHF versions show a small gain over the no-reposition baseline.
- (iii)
Labeling modes and cost: Both LLM-assisted and offline rubric labeling achieve similar results in wait time, served rate and empty-mile ratio, but the offline rubric does not generate API cost at the expense of reduced flexibility.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






















