1. Introduction
The rapid advancement of generative artificial intelligence has enabled impressive progress in multimodal storytelling. Systems such as TaleBrush [
1], which integrates sketch-based interaction for story co-creation, StoryDALL·E [
2], which adapts pretrained text-to-image transformers for narrative continuation, and commercial platforms like Midjourney [
3], which provide visually striking illustrations from text prompts, exemplify the potential of AI-assisted narrative generation.
However, these advances have primarily focused on generic or Western-centric corpora, often overlooking the cultural distinctiveness embedded in traditional narratives. Folktales, as repositories of symbolic systems, moral frameworks, and oral performance traditions, remain a particularly challenging and underexplored domain for AI-driven contents generation. Preserving these narratives requires not only multimodal fluency but also cultural fidelity, a property that current systems struggle to achieve.
To systematically address this challenge, it is necessary to clarify how cultural fidelity is conceptualized in multimodal generative systems. In this work, we define cultural bias as a model’s tendency to default to dominant-cultural representations or to inadequately localize culturally specific narrative elements during cross-cultural adaptation. In addition, cultural coherence refers to the semantic and stylistic consistency of culturally grounded elements maintained throughout narrative structure and across modalities, including text, visual illustration, and storytelling audio.
These concepts emphasize cultural grounding beyond superficial stylistic imitation, focusing on whether generated content preserves symbolic meanings, narrative conventions, and expressive characteristics inherent to the target culture. Based on these definitions, MELT treats cultural context as a foundational generative constraint that informs both system design and evaluation throughout the framework.
Existing research highlights several limitations that our work seeks to address. First, most multimodal story generation frameworks are bi-modal at best (typically text–image), lacking a cohesive integration of narration, which is central to the oral tradition of folktales. Second, when cultural elements are considered, they are often treated as superficial stylistic add-ons (e.g., prompt keywords or surface-level translations) rather than as structural principles that guide narrative form, visual symbolism, and prosody. This results in outputs that may appear visually appealing but fail to capture the symbolic depth or performative conventions of the target culture. Third, state-of-the-art adaptation methods often rely on computationally expensive full fine-tuning or require large-scale culture-specific datasets, which are unavailable for many underrepresented traditions. These gaps limit the ability of current generative AI to serve as tools for cultural preservation and dissemination.
In this context, we propose
MELT (Multimodal Engine for Localized Tales), a unified framework for culturally adaptive folktale generation across text, illustration, and storytelling audio. As illustrated in
Figure 1, MELT takes an English-written foreign folktale as input and produces a target localized folktale, generates culturally styled illustrations to enrich the narrative, and synthesizes storytelling audio in the target language, thereby creating a fully multimodal folktale. MELT embeds cultural context as a foundational generative constraint, rather than a superficial modifier, and ensures alignment across text, illustration, and audio narration. Specifically, MELT comprises three components:
A Localized Folktale Generation module, which adapts foreign narratives into target cultural conventions through structured prompting with cultural context injection, name reference lists, and CoT (chain-of-thought) reasoning;
An Illustration Generation module, which ensures cultural aesthetics and character identity preservation via a novel Tri-Stage LoRA pipeline;
A Storytelling Audio Generation module, which synthesizes expressive narration aligned with cultural prosody and oral performance traditions.
MELT addresses the broader research challenge of achieving culturally faithful multimodal generation in low-resource settings. By leveraging parameter-efficient fine-tuning and structured prompting, the framework reduces dependence on costly retraining while maintaining cultural fidelity.
The contributions of this work are as follows:
We present the first tri-modal cultural adaptation framework that unifies text, image, and audio generation in folktale storytelling, enabling consistent cultural fidelity across modalities.
We propose lightweight, data-efficient strategies such as structured prompting and parameter-efficient LoRA [
4] adaptation that enable cultural transfer without the need for full model retraining.
We validate MELT through case studies in Korean and Bengali folktales, demonstrating superior cultural coherence and multimodal integration compared to baselines, supported by both human and automated evaluations.
Figure 1.
Overall architecture and data flow of MELT.
Figure 1.
Overall architecture and data flow of MELT.
By positioning culture as a central design principle, MELT offers a pathway for AI-driven storytelling systems to serve as tools of cultural preservation, education, and creative dissemination, particularly for underrepresented traditions.
2. Related Work
While generative AI has made significant strides in creating multimodal content, its ability to faithfully represent diverse cultural contexts remains a critical weakness. Research in this area has tackled cultural adaptation in text, images, and multimodal systems, but fundamental challenges like cross-modal coherence and deep-seated model biases persist. This section reviews these efforts and their limitations, and situates our framework, MELT, within this evolving landscape. A comparative summary of representative frameworks is presented in
Table 1.
2.1. Cultural Adaptation and Bias in Language Models
Early efforts in cultural adaptation have primarily focused on text generation. KAHANI [
5] combined GPT-4 [
19] Turbo with SDXL [
20], relying on Chain-of-Thought (CoT) [
21] reasoning and text-to-image prompting to produce non-Western narratives. While this prompt-based approach offered low adaptation cost, it could not ensure scene-level cultural consistency. Other strategies include intralingual adaptation across regions [
22] and methods like CultureLLM [
6], which demonstrated textual alignment by fine-tuning language models on survey data. However, such approaches are constrained by their reliance on costly full-model training and their restriction to the text modality.
A more fundamental challenge lies in the inherent biases of the foundational models these methods rely on. Analyses of GPT-3, GPT-3.5-turbo, GPT-4, GPT-4-turbo, and GPT-4o reveal strong alignment with Western liberal values such as self-expression and secular–rational orientations, effectively treating these perspectives as cultural “defaults” [
23]. Psychological profiling further confirms traits aligned with Western liberal discourse, suggesting that current LLMs implicitly reinforce dominant cultural norms [
24,
25]. Collectively, these challenges underscore the need for a multimodal, data-efficient framework that can actively steer generation toward faithful cultural representation.
Crucially, cultural biases are deeply intertwined with model uncertainty. Underrepresented concepts often trigger high latent uncertainty, causing generative models to produce overconfident, stereotyped, or Western-centric outputs [
14]. Mitigating these persistent geo-cultural biases typically requires robust interventions like cross-modal adapters [
15]. While recent studies propose explicitly penalizing dependence under uncertainty via mathematical regularizers [
13], applying such statistical constraints across complex multimodal pipelines is computationally restrictive. Consequently, there is a critical need for structural approaches combining targeted adapter conditioning with precise prompt constraints to directly bound generative ambiguity during inference.
2.2. Cultural Awareness in Image Generation Models
Numerous benchmarks have revealed persistent cultural biases in text-to-image models. CUBE and TIBET highlight systematic failures in capturing culturally specific content, especially beyond highly represented regions [
26,
27]. ViSAGe further demonstrates stereotyped portrayals across 135 nationalities [
28], while recent studies show that models like Stable Diffusion and SDXL frequently default to Western-centric representations and homogenized appearances [
29,
30,
31]. These biases persist even in data-dominant cultures such as Korea and Japan, and are exacerbated in underrepresented regions [
32,
33].
On the generative side, full fine-tuning of diffusion models has been used to capture cultural motifs [
34], but remains resource-intensive. Parameter-efficient methods like LoRA offer promising alternatives for low-data adaptation, with success in cultural art forms such as paper-cutting [
35,
36,
37,
38]. Aether Weaver introduces dynamic scene graphs for improved cultural alignment [
12], but most approaches still treat culture as a stylistic layer rather than a core narrative constraint.
To avoid the prohibitive costs of full fine-tuning, recent literature emphasizes parameter-efficient fine-tuning (PEFT) and structured prompting. For instance, Singular Value Fine-tuning [
18] demonstrates robust few-shot adaptation with minimal parameters. Moreover, explicit content-style decoupling [
16] and multi-group text-visual prompts [
17] have proven highly effective for personalized, style-consistent image generation. Inspired by these advancements, MELT integrates a Tri-Stage LoRA architecture with explicit content-style prompt decoupling. This computationally efficient approach specifically targets multimodal cultural localization, ensuring target aesthetics are faithfully rendered without distorting the core narrative.
2.3. Limitations in Multimodal Story Generation
Although recent work has advanced multimodal story generation, cultural conditioning and speech integration remain limited. SEED-Story employs a multimodal large language model (MLLM) to generate long-form text–image narratives [
7], but it does not extend to speech output. Similarly, benchmarks such as SoS have linked narrative text to background sound, yet these evaluations focus on contextual alignment rather than cultural fidelity [
39,
40,
41].
Other frameworks, such as the audio-only Multi-Agent AI Framework [
10] and the bi-modal Multi-Modal Story Framework [
11], either fail to target cultural adaptation or offer only superficial support for it. Within the speech modality, StoryTTS introduces a storytelling-oriented dataset for expressivity [
8], while MultiVerse demonstrates zero-shot multi-task TTS [
9]. However, most systems lack full tri-modal (text–image–audio) integration and rely on computationally expensive training.
MELT addresses these limitations by achieving consistent tri-modal cultural alignment through culture-specific constraints embedded across all modalities via structured prompting and parameter-efficient LoRA adaptation.
3. Methodology
MELT is a style-adaptive, tri-modal framework designed to generate culturally coherent folktales across text, illustration, and audio. Rather than relying on joint cross-modal training, MELT adopts a text-first strategy in which the culturally adapted narrative serves as the semantic anchor for downstream modules. Scene-level prompts extracted from the Localized Folktale Generation module are passed to the Illustration Generation module, while the same narrative also conditions the Storytelling Audio Generation module. This design enables lightweight yet coherent transfer of cultural features across modalities, reducing the need for extensive multimodal alignment. This modular architecture was intentionally adopted to support parameter-efficient adaptation in low-resource cultural settings, where fully joint multimodal optimization would require substantially larger aligned datasets and computational resources. This design is directly informed by our definitions of cultural bias and cultural coherence: by anchoring all downstream modules to a culturally adapted narrative base, MELT minimizes dominant-culture defaulting and promotes semantic and stylistic consistency across modalities.
As illustrated in the top, center, and bottom sections of
Figure 2, the modules are vertically interconnected to enable smooth cross-modal flow. The Localized Folktale Generation Module (top) produces both culturally adapted text and structured prompts that guide subsequent modules. These outputs are then utilized by the Illustration Generation Module (center) to construct visually coherent scenes through a three-stage LoRA-based process, ensuring both stylistic and character consistency. Finally, the Storytelling Audio Generation Module (bottom) employs the same narrative context to synthesize culturally aligned speech, completing the multimodal storytelling pipeline. By grounding each modality in a shared narrative base, MELT promotes consistent expression of culture-specific semantics throughout the system.
While MELT automates multimodal generation through LLM inference, diffusion-based illustration, and neural TTS synthesis, certain upstream steps, such as cultural reference selection, prompt template design, and dataset curation, require structured human configuration. The downstream generation processes are executed under fixed training settings and disclosed hyperparameters to support reproducibility.
As illustrated in the top, center, and bottom sections of
Figure 2, the modules are vertically interconnected to enable smooth cross-modal flow. The Localized Folktale Generation Module (top) produces both culturally adapted text and structured prompts that guide subsequent modules. These outputs are then utilized by the Illustration Generation Module (center) to construct visually coherent scenes through a three-stage LoRA-based process, ensuring both stylistic and character consistency. Finally, the Storytelling Audio Generation Module (bottom) employs the same narrative context to synthesize culturally aligned speech, completing the multimodal storytelling pipeline. By grounding each modality in a shared narrative base, MELT promotes consistent expression of culture-specific semantics throughout the system. While MELT automates multimodal generation through LLM inference, diffusion-based illustration, and neural TTS synthesis, certain upstream steps, such as cultural reference selection, prompt template design, and dataset curation, require structured human configuration. The downstream generation processes are executed under fixed training settings and disclosed hyperparameters to support reproducibility.
3.1. Localized Folktale Generation Module
The Localized Folktale Generation Module (see upper section of
Figure 2) transforms the content and structure of foreign folktales to align with the narrative conventions of a target culture. This is achieved by prompting the LLM using structured inputs and step-by-step reasoning inspired by the CoT approach.
This section outlines the module’s two core components: (1) a prompt construction strategy and (2) a three-stage inference process for culturally faithful folktale transformation (see
Appendix A for detailed prompt templates).
3.1.1. Prompt Construction Strategy for LLM Control
To ensure culturally faithful adaptation, the LLM must be guided through structured reasoning grounded in cultural context. We achieve this through a prompt design that incorporates three key elements: cultural context, name references, and example reasoning.
Cultural Context Injection. To enhance authenticity, culturally grounded knowledge such as social customs, religion, rituals, and literary forms is retrieved from external sources and embedded into the prompt using Retrieval-Augmented Generation (RAG) [
42]. This allows the LLM to supplement its static training with real-time cultural context.
Name References. A culture’s identity is often encoded in its naming conventions. The prompt includes a curated list of character names, kinship-based titles, and culturally appropriate occupations commonly found in the target culture’s folktales. These references support both archetypal character construction and stylistic consistency.
Example Reasoning. To help the LLM execute the transformation in a structured manner, the prompt includes an explicit example of step-by-step reasoning based on the CoT principle. The reasoning process follows three main steps:
Identify culturally specific items (CSIs) in the source text;
Find culturally appropriate equivalents in the target culture;
Rewrite the sentence to match the narrative style of the target folktale tradition.
This encourages the model to go beyond surface-level rewriting and perform deeper reasoning that integrates analysis, adaptation, and generation.
3.1.2. Three-Step Inference Process for Style Adaptive Folktale Generation
Based on the structured prompt template, the LLM follows a three-step process to transform the input text into the traditional folktale style of the target culture.
Step 1. CSIs Identification. In this initial analytical step, the model identifies CSIs present in the source text. These include vocabulary, concepts, and customs that are culturally incompatible with, or entirely absent from, the traditional folktales of the target culture.
Step 2. Cultural Adaptation. The second step focuses on replacing each CSIs identified in Step 1 with a traditional equivalent drawn from the target culture. To ensure both accuracy and cultural appropriateness, the model references the Cultural Context variable and predefined Name References.
Step 3. Folktale-Style Generation. In the final step, the model generates the output text based on the adaptation plan constructed in the previous steps. This process follows the Example Reasoning pattern defined in the Prompt Construction Strategy and must adhere to all specified constraints.
3.1.3. T2I Prompt Generation
Building on the cultural adaptation from the previous stage, a prompt engineering strategy is designed to automatically generate T2I prompts. This process consists of character extraction and scene-level prompt generation, with templates provided in
Appendix A.
3.2. Illustration Generation Module
As shown in
Figure 3, the Illustration Generation Module employs a tri-stage LoRA pipeline to capture cultural style and maintain character consistency. The Cultural Base LoRA (CBL) stage captures cultural aesthetics, the Character Image Construction (CIC) stage generates identity-consistent character images, and the Cultural Illustration LoRA (CIL) stage integrates both elements for coherent scene-level illustration generation. Because the CIL stage relies on culturally adapted character datasets produced in the preceding stages, these components form a hierarchical dependency, and reordering them would disrupt the cultural grounding pipeline.
3.3. Storytelling Audio Generation Module
The storytelling audio generation module uses a high-quality Text-to-Speech (TTS) model to convert culturally localized folktales into speech. A reference voice clip controls speaker identity, while additional parameters regulate prosody and expressive style. The synthesized waveform constitutes the final audio output of the storytelling module.
4. Case Studies: Culturally Adaptive Multimodal Generation in Korean and Bengali Folktales
We evaluate MELT in two underrepresented domains: Korean and Bengali folktales. Korean visual motifs are often misrepresented as generic East Asian elements [
45], while Bengali art, especially the Kalighat style, is frequently generalized [
46]. Due to their oral origins and lack of aligned resources, these traditions serve as ideal testbeds for few-shot adaptation. These case studies demonstrate MELT’s ability to preserve cultural fidelity and cross-modal coherence in low-resource, culturally specific settings.
4.1. Localized Folktale Generation Module Process
4.1.1. Localization of the Filipino Folktale “The Terrible Tic-Balan”
To demonstrate the practical application of our methodology, we conducted a case study on the Filipino folktale “The Terrible Tic-balan.” The source text was obtained from the Folk Tales Dataset on Kaggle [
47]. This excerpt contains multiple CSIs, including the mythical creature “Tic-balan,” the sacred “Balete tree,” the ritual phrase “Tabi,” and religious symbols such as the rosary and crucifix. These elements serve as the primary targets for the cultural adaptation process.
The prompt for this case study was constructed following the strategy outlined in
Section 3.1.1 and
Appendix A (
Table A1). Rather than redefining the general procedure, we adapted the prompt components with culture-specific data relevant to the Korean and Bengali contexts:
Cultural Context: Wikipedia-derived knowledge on society, religion, rituals, and literary conventions dynamically retrieved and injected as the Cultural Context variable [
48].
Name References: Traditional names, kinship-based titles, and occupational roles compiled from Korean folktales available through the National Library for Children and Young Adults and the Korea Copyright Commission [
49,
50], as well as Bengali sources such as TagoreWeb, the Internet Archive folk narrative collection, and Thakurmar Jhuli [
51,
52,
53].
Example Reasoning: A step-by-step reasoning pattern based on the CoT principle, including representative examples drawn from Korean and Bengali folktales [
49,
53] to ensure cultural authenticity.
Guided by this prompt, GPT-4.1 [
19] executed the three-step inference process described in
Section 3.1.2, comprising CSIs Identification, Cultural Adaptation, and Folktale-style Generation.
In adapting “The Terrible Tic-balan” to distinct cultural contexts, key narrative elements were culturally reinterpreted rather than directly translated. The original creature Tic-balan was replaced with a Dokkaebi (Korean goblin) and a Mecho Petni (Bengali ghost), aligning with each culture’s mythological taxonomy. Similarly, the Balete tree was localized as a Zelkova in Korean folklore and a Banyan in Bengali mythology, while ritual elements were recontextualized through instruments such as the janggu and dhak. These transformations illustrate how cultural adaptation within multimodal generation preserves symbolic coherence and stylistic authenticity across traditions.
In adapting “The Terrible Tic-balan” across cultures, key narrative elements were reinterpreted through a style-adaptive generation process. The original creature Tic-balan was transformed into a Dokkaebi (Korean goblin) and a Mecho Petni (Bengali ghost), aligning with each culture’s mythological archetypes and stylistic conventions. Likewise, the sacred Balete tree was localized as a Zelkova in the Korean version and a Banyan in the Bengali version, reflecting symbolic continuity within distinct cultural ecosystems.
Figure 4 demonstrate MELT’s ability to generate culturally adaptive folktale adaptations. The table outlines how key symbolic elements in the Filipino folktale “The Terrible Tic-balan” were localized into culturally coherent forms in Korean and Bengali contexts, while the figure illustrates that MELT retains the narrative structure and stylistic integrity of the original story. The examples presented are representative excerpts selected for comparison rather than complete style-adaptive outputs.
4.1.2. T2I Prompt Generation of the Filipino Folktale “The Terrible Tic-Balan”
Following the methodology described in
Section 3.1.3, this case study applies the proposed T2I prompt generation framework to the culturally adapted folktale described in
Section 4.1.1.
Character and Appearance Descriptions. Each cultural version reflected traditional aesthetics through distinctive visual attributes. The Korean adaptation incorporated Joseon-era clothing (jeogori, chima, durumagi, and gat) and traditional hairstyles, depicting the Dokkaebi with horse-like features and Soon-yi as the main girl wearing a hanbok. The Bengali version emphasized regional identity using jamdani sari, floral ornaments, alta, and shankha, portraying Petni as a water demon and Chandra as the main girl adorned with flowers. These adaptations reflect distinct aesthetic conventions, including traditional Korean ink-wash motifs inspired by the Joseon dynasty and the Kalighat folk art style of West Bengal, while maintaining consistency between narrative and illustration.
Scene-Level Prompts. The narrative was divided into three units (Introduction, Body, Conclusion, ), each mapped to a corresponding visual scene. For the Korean folktale, the prompts incorporated visual elements evoking late Joseon aesthetics, such as zelkova trees, thatched cottages, jangseung (village totems), and hanok walls, while the Bengali version featured rural Bengal landscapes including the Ganges riverbank, banyan trees, clay huts, and paddy fields. We define culture-specific stylistic keywords, including “Kimhongdo style”, “Joseon Dynasty”, and “ink wash painting” for Korean, and “Kalighat Painting”, “Bengal Folk Art”, and “Bold Outlines” for Bengali, as aesthetic anchors that guide the diffusion model toward culturally coherent image generation.
This example is illustrated in
Figure 5, while detailed prompt templates are provided in
Appendix A. These adaptations demonstrate how the proposed design concretizes cultural visual codes and aesthetic traditions at the prompt level.
4.2. Illustration Generation Module Process
For the Korean and Bengali case studies, we selected representative traditional styles to ensure cultural fidelity: the works of the well-known Korean artist Kim Hong-do and the Kalighat painting tradition from Bengal.
4.2.1. Construction of the Style Dataset
We collected culturally representative artworks from copyright-free public-domain sources, including Kim Hong-do’s paintings [
54] for Korean folktales and Kalighat paintings [
55,
56] for Bengali folktales, to construct the Style Datasets. Each dataset used for training consists of 500 images, comprising both original artworks and cropped augmentation samples derived from them. To capture stylistic features, the datasets include both original full-scene images and cropped variants focusing on upper bodies, full figures, and distinctive objects (see
Figure 6). Each image was paired with a caption following the standardized prompt structure ([subject], [activity/context], [stylistic keywords]) defined in
Section 4.1.2, and representative examples for both domains are shown in
Table A2 in
Appendix B.
4.2.2. Fine-Tuning for the Cultural Base LoRA (CBL)
To efficiently adapt the SDXL backbone to the stylistic features of the target culture, we trained the Cultural Base LoRA (CBL) using the
kohya_ss toolkit [
57,
58,
59,
60,
61]. Training was conducted on the 500 image dataset.
Data Processing. All images were resized to 1024 × 1024. The model was trained for 10 epochs, with image repeats set to 2, effectively exposing the model to each image twice per epoch. Tag shuffling was applied to improve prompt diversity, and a standardized activation tag was prepended to each caption.
Learning Configuration. The UNet and text encoder were fine-tuned with learning rates of
and
, respectively, under a cosine restart schedule with warmup [
62] to stabilize convergence. Minimum-SNR weighting [
63] and multi-noise augmentation were enabled to improve training stability.
Network Structure. LoRA adapters were applied only to cross-attention layers, following the Style LoCon configuration [
64]. This significantly reduced the number of trainable parameters compared to full fine-tuning. Training was performed with a batch size of 4,
bf16 precision, and latent caching for memory efficiency.
Optimization. The model was optimized using AdamW8bit with weight decay regularization. A fixed random seed was set to ensure reproducibility.
4.2.3. Construction of the Character Dataset
To construct the culturally adapted Character Dataset, we first generated 30 base portraits per character using DALL·E 3 [
65] to ensure consistent character identity and appearance across all illustrations. The generation was conditioned on character appearance prompts extracted from the text module and varied across multiple viewpoints and expressions to establish a consistent character identity. These base portraits were subsequently adapted to the target cultural style via i2i transfer using pretrained CBL models (see
Figure 7). The resulting culturally stylized images, paired with their corresponding captions, form a parallel Character Dataset used in subsequent training.
4.2.4. Fine-Tuning with Merged Dataset: Cultural Illustration LoRA (CIL Training and Inference)
In the CIL stage, we merged the Style Dataset from CBL (see
Section 4.2.1) with the Character Dataset from CIC (see
Section 4.2.3), creating a dataset that encodes both cultural features and character identity. The CIL was fine-tuned with the same configuration as CBL (see
Section 4.2.2), inserting LoRA adapters into the UNet cross-attention layers. This enables CIL to generate illustrations from structured text prompts while simultaneously preserving character identity and capturing the target culture’s stylistic features.
Applied to both Korean and Bengali domains, the CIL stage produced culturally faithful and identity-consistent illustrations. As shown in
Figure 8, the model successfully transformed folktale prompts into coherent scene-level illustrations that align narrative content with cultural aesthetics.
4.3. Storytelling Audio Generation Process
This case study evaluates the proposed storytelling audio generation pipeline in Korean and Bengali folktale contexts, focusing on its ability to reproduce culturally appropriate speech styles with limited reference voice data. Using a multi-speaker configuration, distinct tone and manner conditions were assigned to each role to reflect cultural expressiveness and narrative immersion.
Input Text. Localized Korean and Bengali folktales generated by MELT (
Section 3.1) served as textual input for speech synthesis. The Korean narration was synthesized using the Zonos model [
66], while the Bengali narration employed the ElevenLabs v3 model [
67], which supports emotion-tagged TTS generation.
Reference Voices. Multiple reference voice clips were used for each culture to capture stylistic variation between narration and character speech. For Korean, a 56 s narrator sample and a 31 s male peasant clip were obtained from the folktale “Shinseonbawi Ddongbawi” [
68] provided by the National Library for Children and Young Adults. For Bengali, a 40 s professional narration and four character samples (young girl, woman, man, and ghost voice; each over 15 s) were collected from open-source Bengali storytelling archives [
52,
53].
Speech Control. In the Korean synthesis, LLM-based parameter recommendations were used to set the emotional tone, speaking rate, and pitch for each role. The narrator’s speech employed moderate emotional and prosodic values to create a neutral yet warm tone, while the goblin (Dokkaebi) was configured with higher fear, faster rate, and elevated pitch to convey tension. For Bengali synthesis, emotional tags were embedded directly into the text (e.g., [calmly], [cheerfully], [dramatically], [sadly], [desperately], [shouting], [suspensefully]) following emotion-tagging strategies [
67].
The proposed pipeline successfully distinguished narrator and character tones, reproduced emotional variation, and maintained cultural consistency in both Korean and Bengali storytelling. These findings confirm that even with limited reference voice data, AI-based multimodal generation systems can achieve expressive and culturally faithful audio synthesis, demonstrating the effectiveness of the proposed storytelling audio generation module.
5. Results
To assess the performance of MELT, we conducted a series of evaluations targeting different aspects of multimodal cultural adaptation. First, a human evaluation of multimodal narratives was performed to assess the overall quality and cultural consistency of the generated text, illustrations, and audio. Participants rated each sample in terms of overall quality, cultural adaptation, and cross-modal cultural coherence.
Second, the Localized Folktale Generation module was evaluated to examine MELT’s effectiveness in culturally adaptive storytelling. Three complementary evaluation protocols were employed: human evaluation, LLM-based judge evaluation, and automatic quantitative metrics, focusing on narrative coherence, stylistic fidelity, and cultural grounding.
Finally, the Illustration Generation module was evaluated to analyze artistic style similarity, character consistency, and the impact of dataset size on cultural adaptation performance. Together, these evaluations validate the effectiveness of MELT in preserving cultural semantics and stylistic coherence across modalities.
To ensure transparency, detailed information on participant recruitment, evaluation instructions, rating criteria, and quality control procedures is provided in
Appendix D. Native-level speakers were recruited for both Korean and Bengali evaluations through platform-appropriate channels, and identical evaluation criteria were applied across cultures to ensure methodological consistency.
5.1. Evaluation Measures for Cultural Bias and Coherence
Based on the conceptual definitions introduced in
Section 1, we operationalize cultural bias and cultural coherence through a set of complementary quantitative and qualitative evaluation measures. Cultural bias is evaluated by examining the degree to which generated outputs successfully localize culturally specific narrative elements rather than reverting to dominant-cultural representations. To measure this property, we employ Cultural Adaptation scores obtained through human evaluation, Folktale Style ratings assessed using LLM-based evaluation, and stylistic similarity metrics (StyleSim) computed against curated cultural reference corpora. Cultural coherence is assessed as the consistency of culturally grounded semantics and stylistic elements across narrative components and modalities. This property is measured using Cultural Coherence ratings in multimodal human evaluation, Narrative Coherence and Cultural Appropriateness scores in text evaluation, and cross-modal alignment metrics, including CLIP-T and CLIP-I, for illustration assessment. Together, these evaluation measures enable systematic analysis of whether generated outputs achieve genuine cultural localization while maintaining multimodal consistency, rather than exhibiting superficial stylistic resemblance.
5.2. Human Evaluation of Multimodal Narratives
To assess MELT’s effectiveness in achieving culturally faithful and cross-modally coherent folktale generation, we conducted a comparative human evaluation against a baseline system. A direct comparison with the multimodal and culture-aware frameworks reviewed in
Section 2 was not feasible due to differences in data accessibility, modality coverage, and implementation availability. Most prior approaches are either limited to a single modality or rely on full model fine-tuning, making fair multimodal benchmarking impractical. Furthermore, recent systems such as SEED-Story [
7] and MultiVerse [
9] primarily emphasize narrative expressivity and stylistic transfer rather than style-adaptive and culturally grounded generation, which diverges from the MELT objective of achieving explicit and faithful cultural representation.
Accordingly, the baseline used in this study was designed to represent a typical multimodal generation pipeline without any culture-specific fine-tuning. Specifically, GPT-4.1 was employed for text generation, SDXL for illustration generation, and Zonos (for Korea) and ElevenLabs (for Bengal) were used for audio.
A total of 21 adult Korean participants, recruited through an online Google Form, and 18 Bengali-speaking participants, recruited via Prolific [
69], evaluated aligned pairs of folktales (Baseline vs. MELT) on a five-point Likert scale (1 = lowest, 5 = highest). Each narrative pair was rated on three dimensions: Overall Quality, Cultural Adaptation, and Cultural Coherence, selected to evaluate not only general narrative fluency but also MELT’s primary objective of achieving culturally faithful and cross-modal alignment across text, image, and audio outputs. Paired
t-tests revealed statistically significant improvements across all metrics in the Korean group (t = 4.318–8.401,
p ≤ 0.0003). In the Bengali group, Cultural Adaptation and Cultural Coherence showed significant differences (t = 2.298–3.949,
p≤ 0.031), whereas Overall Quality did not (
p = 0.136). Inter-rater reliability (ICC(3,k)) was high for the Korean group (0.946–0.986) and moderate for the Bengali group (0.412–0.541).
Each criterion was explicitly defined to promote consistent evaluation: Overall Quality measured the holistic quality and naturalness of multimodal outputs; Cultural Adaptation assessed how effectively the system localized culturally specific symbols and narrative cues across modalities; and Cultural Coherence evaluated the semantic and stylistic harmony among text, image, and audio components within each folktale. As shown in
Table 2, MELT consistently achieved higher scores across all criteria, demonstrating the effectiveness of its style-adaptive and culturally grounded design in multimodal folktale generation.
While human evaluation provides valuable qualitative insights, relying solely on subjective ratings limits the reproducibility and scalability of the assessment. Future work should therefore explore complementary automated metrics to more objectively evaluate cross-modal alignment and cultural fidelity.
5.3. Localized Folktale Generation Module Evaluation
To evaluate the effectiveness of MELT in localized folktale generation, we employed three complementary protocols: (1) human evaluation, (2) evaluation using large language models, and (3) quantitative comparison based on automatic metrics. Each method was designed to assess different aspects of the system’s performance, including narrative coherence, stylistic fidelity, and cultural grounding. For fair comparison, the Base model was configured using the same system instruction as MELT, as described in
Appendix A.
5.3.1. Human Evaluation
We collected responses from 17 Korean and 18 Bengali native speakers, who rated the generated folktales on a five-point Likert scale across three evaluation dimensions: Narrative Coherence, Style Transfer Accuracy, and Cultural Appropriateness. Participant recruitment followed the same platforms used in the multimodal evaluation.
Following the same statistical procedure used in the multimodal evaluation, we examined the differences in the text-based results. Statistically significant differences were observed across all metrics in both the Korean and Bengali groups (), indicating that MELT’s performance improvements were not due to random variation but reflected a consistent trend. Inter-rater reliability was also high in the Korean group (ICC = 0.992–0.994) and moderate to high in the Bengali group (ICC = 0.552–0.752), suggesting that the observed differences were supported by stable agreement among evaluators.
Each criterion was explicitly defined to promote consistent rating: Narrative Coherence assessed structural clarity and content consistency; Style Transfer Accuracy evaluated the presence of culturally characteristic elements such as formulaic openings and oral-style closings; and Cultural Appropriateness measured naturalness in honorific usage, substitutions, and value alignment.
As shown in
Table 3, MELT received consistently higher scores than the Base model across all criteria in both languages. These results suggest that MELT may provide improved cultural alignment and stylistic fluency in localized folktale generation.
5.3.2. LLM Judge Evaluation
We conducted an LLM-based evaluation using three state-of the art models, GPT-4o, Claude Opus 4-1 [
70], and Gemini 2.5 Pro [
71], as automated judges. To ensure the stability and reproducibility of the automated assessments, each evaluation was executed across three independent runs with a low generation temperature (
). The reported scores represent the average of these runs, with standard deviations confirming high intra-model consistency. Furthermore, to address potential concerns regarding the models’ capacity to act as cultural “experts,” we calibrated the LLM-as-a-judge framework against our human evaluations. A correlation analysis on a subset of manually annotated samples revealed a strong positive alignment between the aggregated LLM ratings and human judgments for Naturalness and Folktale Style. This calibration evidence demonstrates that our LLM evaluation framework provides a reliable, well-grounded proxy for scalable cultural and stylistic assessment. Each folktale output from the MELT and Base models was rated on three evaluation dimensions: Naturalness, Folktale Style, and Content Preservation to assess linguistic fluency, genre conformity, and narrative fidelity.
As shown in
Table 4, MELT consistently received higher scores than the Base model in both Naturalness and Folktale Style across the Korean and Bengali datasets, while the Base model demonstrated relatively stronger performance in Content Preservation. These results suggest that MELT offers improved stylistic and cultural alignment in localized folktale generation, albeit with a moderate trade-off in content fidelity. It is important to note that Content Preservation reflects a nuanced balance: higher values indicate closer adherence to the original narrative but may imply insufficient cultural transformation, whereas lower values suggest stronger adaptation yet risk excessive deviation from core narrative structures. Thus, optimal performance in this dimension involves maintaining a balance between narrative fidelity and cultural reinterpretation.
Importantly, a reduction in Content Preservation does not necessarily imply a loss of core narrative structure. In cross-cultural folktale adaptation, certain surface-level elements—such as symbolic motifs, character roles, or setting-specific attributes—may be recontextualized to better align with the target cultural framework. When the fundamental narrative arc and causal relationships remain intact, such transformations can be interpreted as culturally grounded reinterpretation rather than structural degradation.
We used KoGPT2 [
72] and Bengali GPT-2 [
73], implemented via publicly available HuggingFace and GitHub repositories, as language models to compute PPL for fluency evaluation. PPL is a language-model-based uncertainty metric derived from word prediction probabilities, where lower values indicate greater confidence and fluency in text generation. In general, a PPL below 50 is considered indicative of a well-trained language model with stable linguistic generation. Across both Korean and Bengali datasets, MELT produced outputs with lower PPL scores than the Base model-approximately 10–15% lower on average-demonstrating more fluent narrative generation.
5.3.3. Quantitative Evaluation
We conducted a quantitative evaluation of the Korean and Bengali folktales generated by the MELT model using two metrics: stylistic consistency, and fluency, as shown in
Table 5.
Stylistic Consistency (StyleSim) measures stylistic consistency by computing the cosine similarity between a generated sentence embedding and the mean embedding of reference folktale sentences. Embeddings were computed using SimCSE and Ko-SimCSE models [
74,
75,
76]:
Reference sentences were selected from a curated set of traditional folktales (see
Section 4.1.1). MELT demonstrated higher stylistic similarity than the Base model, with particularly strong results for Bengali outputs.
Perplexity (PPL) measures the fluency of generated text based on the likelihood of word predictions and is computed as:
5.4. Illustration Generation Module Evaluation
To evaluate the cultural alignment of generated images, we constructed a set of culture-specific visual references (
Figure 6) that served as comparative anchors for both human and automated evaluation. A total of 30 participants conducted human evaluations by judging the generated images against these references, focusing on perceived cultural fidelity within each cultural domain.
CLIP-I [
77] measures visual similarity between a generated image
x and a culturally relevant reference image
y using the cosine similarity of their CLIP image encoder representations
and
:
CLIP-T measures image–text alignment by computing the cosine similarity between the CLIP text encoder representation
of the input prompt
p and the CLIP image encoder representation
of the generated image:
DINOv2 [
78] measures visual similarity between a generated image
x and a reference image
y by computing the cosine similarity between their feature representations
and
extracted from the DINOv2 visual encoder:
LLM-as-a-Judge is an evaluation framework where a large language model (LLM) rates the style faithfulness of generated outputs on a ten-point Likert scale (1 = lowest, 10 = highest). Specifically, we utilized GPT-4o with visual input capabilities as the judge model. To prevent the overstatement of the LLM’s cultural expertise and ensure score stability, all inferences were repeated three times at a temperature of
, yielding highly consistent scores with average standard deviations of less than 0.5 points. Calibration against human visual preference ratings on a validation subset showed a robust Kendall rank correlation justifying the model’s reliability in assessing target stylistic fidelity without hallucinating cultural expertise. The prompt format and evaluation setup are provided in
Table A6 in
Appendix C.
Human Evaluation was conducted through a forced-choice protocol in which participants were presented with pairs of illustrations generated by different models. They were asked to select the image they considered superior with respect to stylistic fidelity and character consistency. The results are reported as the percentage of participants preferring each model’s output.
5.4.1. Style Similarity Evaluation
We evaluated each model’s ability to reproduce cultural painting styles using identical prompts. As summarized in
Table 6 and
Figure 9, MELT consistently outperformed both SDXL and DALL·E 3 in reproducing the Korean (Kim Hong-do) and Bengali (Kalighat) styles. Qualitative comparisons further demonstrate that MELT more faithfully captures region-specific visual characteristics, including brush texture, traditional clothing forms, and compositional balance, compared to baseline models. Averaged across three prompt pairs, MELT was selected most frequently (100% for the Korean style and 90% for the Bengali style), indicating a clear preference for MELT in terms of cultural style reproduction. Chi-square tests confirm statistically significant differences in human preference among the models for both the Korean (
) and Bengali (
) groups. Notably, while Korean evaluators reached complete consensus (100% preference for MELT), Bengali evaluators exhibited a lower level of inter-rater reliability (Fleiss’
), reflecting the extreme preference distribution toward our proposed model across both cultural contexts.
5.4.2. Character Consistency Evaluation
In illustrated folktales, maintaining consistent character identity and appearance across multiple scenes is essential to preserve narrative coherence and visual continuity. Although standardized automatic metrics for character consistency are not yet established, we conducted evaluations using both human judgment and the LLM-as-a-Judge framework to ensure a reliable assessment of model performance. In the human evaluation, participants were presented with pairs of illustrations generated using identical character keywords (e.g., main-girl, main-woman). One set was produced by MELT-CBL, which focuses on cultural style adaptation, while the other was generated by MELT-CIL, which incorporates character-level learning to preserve identity consistency across scenes. As shown in
Figure 10 and
Table 7, MELT-CIL consistently outperformed MELT-CBL, achieving higher identity preservation while maintaining cultural style. Chi-square tests indicate significant differences in human preference between MELT-CBL and MELT-CIL in both Korean (
,
) and Bengali (
,
) datasets. The low Kappa values are not due to a lack of consensus among evaluators, but rather the ’Paradox of Unanimity,’ where an overwhelming preference for our model reduces statistical variance. Given the highly significant Chi-square results (
), these values do not undermine reliability but rather provide evidence for the decisive superiority of our model.
5.4.3. Effect of Dataset Size
We further analyzed the impact of dataset size under identical hyperparameters to examine how data availability influences model performance in low-resource cultural settings. Since underrepresented cultures often lack sufficient training data, this experiment aims t;o identify the minimum data scale required for effective few-shot fine-tuning. Outputs generated with only 20 images resembled the base SDXL with minimal cultural adaptation, while 50–100 images markedly improved CLIP-I scores, with saturation observed thereafter. Larger sets (300–500 images) did not further raise scores but improved stability, diversity, and brushwork fidelity. As detailed in
Table 8 and
Figure 11, these findings demonstrate that MELT achieves faithful cultural style adaptation in a few-shot setting, enabling practical application to underrepresented domains with limited cultural data.
5.5. Failure Case—Fundamental Limitations of the SDXL Model
Although MELT improves cultural style fidelity, it remains subject to limitations inherited from the underlying SDXL backbone with respect to prompt faithfulness. In particular, later prompt elements, such as emotional cues and spatial details, are occasionally underrepresented. As shown in
Table 9 and
Figure 12, DALL·E 3 achieved higher prompt faithfulness scores according to LLM-based evaluation.
DALL·E 3 is included as a closed-source upper-bound reference rather than a directly comparable model under identical training constraints. These findings suggest that part of the prompt fidelity gap may be associated with the representational characteristics of the SDXL backbone under low-resource adaptation settings. However, disentangling architectural constraints from prompt-level effects (e.g., prompt decomposition or iterative refinement) requires further investigation and is left for future work.
5.5.1. Prompt Component Ablation
To determine whether this limitation arises from prompt composition or from backbone-level constraints, we conducted a controlled ablation study isolating components of the prompting pipeline. Using the same folktale ending and textual description, we generated images under four configurations: (1) Base SDXL, (2) MELT with full conditioning, (3) MELT without stylistic keywords, and (4) MELT without character-specific references. As shown in
Figure 13, the visually complex attribute (e.g., “holding a gleaming”) was not consistently rendered across any configuration. The failure persisted regardless of stylistic conditioning or character grounding. These results indicate that the issue cannot be directly attributed to MELT’s prompt structure or architectural design.
5.5.2. Guidance Scale Sensitivity Analysis
We further examined whether insufficient text-conditioning strength contributes to this limitation by varying the
guidance_scale parameter (7.5–20) while keeping other settings fixed. As illustrated in
Figure 14, increasing the guidance scale to enforce stronger textual adherence did not resolve the visual underrepresentation of the target attribute. The failure remained consistent across guidance levels.
Overall, the evidence indicates that the limitation arises from the SDXL backbone’s representational capacity, rather than from prompt design or MELT’s architecture.
6. Conclusions
This paper presented MELT, a tri-modal framework for culturally adaptive folktale generation that integrates text, illustration, and audio to support the coherent representation of narrative traditions from underrepresented cultures. By combining structured cultural prompting with parameter-efficient LoRA-based fine-tuning, MELT enables consistent cultural expression across modalities while remaining feasible in low-resource settings without relying on large-scale retraining or extensive domain-specific corpora.
MELT contributes to the field in three key aspects. First, it introduces a unified and modular architecture that explicitly incorporates cultural context as a core generative constraint rather than a surface-level prompt feature. Considering that existing state-of-the-art models are primarily limited to single modalities and do not directly align with the tri-modal evaluation metrics for minority cultural storytelling, this highlights MELT’s unique approach. Second, it demonstrates that lightweight adaptation strategies can effectively achieve stylistic transfer and character identity consistency across scenes and modalities. Third, through comprehensive evaluation using automatic metrics, human judgment, and an LLM-as-a-Judge framework, MELT shows consistent improvements in narrative fluency, cultural fidelity, and cross-modal alignment, validated on Korean and Bengali folktale datasets.
Beyond its technical contributions, MELT provides a practical framework for culturally faithful storybook creation, the preservation of endangered narrative traditions, and applications in education and cultural heritage. These findings demonstrate that multimodal generative models can meaningfully engage with culture-specific aesthetics and narrative structures, highlighting a promising direction for the development of culturally inclusive and adaptive AI storytelling systems.
6.1. Limitations
Despite its contributions, MELT has several limitations. First, its independent modular architecture hinders fine-grained cross-modal alignment. Second, the reliance on manual upstream processes such as cultural reference selection, prompt design, and dataset curation constrains scalability and end-to-end reproducibility. This reliance also risks essentializing dynamic cultural traditions by reducing them to fixed stylistic anchors. Third, the Character-Infused LoRA (CIL) stage presents overfitting risks when reusing synthetic data in low-resource settings. Finally, the absence of standardized, culture-aware evaluation metrics to capture multimodal coherence and stylistic nuance remains an open challenge.
6.2. Future Work
Future work will explore unified multimodal optimization strategies, such as shared latent spaces, to move beyond the current sequential architecture and enable tighter cross-modal semantic alignment. To enhance scalability and reproducibility, we will investigate automated cultural reference extraction and data-driven anchor selection, minimizing human in the loop dependencies. Additionally, controlled experiments on prompt decomposition will be conducted to better separate architectural constraints from prompt fidelity. We also plan to expand MELT across more diverse artistic lineages and temporally evolving cultural forms. Lastly, we will explicitly engage with ethical considerations through participatory evaluation frameworks to mitigate cultural oversimplification and support socially responsible AI storytelling.
6.3. Data and Code Availability
The source code, system prompts, and training configurations for the MELT framework are publicly available at
https://github.com/egggbeee-dev/MELT (accessed on 8 March 2026). Due to licensing constraints on certain cultural artwork datasets, only reproducible components and representative subsets are released, along with instructions for dataset reconstruction and training replication.
Author Contributions
Conceptualization, H.C. and Y.K.; methodology, H.C., Y.K., D.K. and H.S.; software, H.C., Y.K., D.K. and H.S.; validation, H.C., Y.K., D.K. and H.S.; formal analysis, H.C., Y.K., D.K. and H.S.; investigation, H.C., Y.K., D.K. and H.S.; data curation, H.C., Y.K., D.K. and H.S.; writing—original draft preparation, H.C. and Y.K.; writing—review and editing, H.C., Y.K., D.K., H.S. and M.L.; visualization, H.C., Y.K., D.K. and H.S.; project administration, M.L.; supervision, M.L.; funding acquisition, M.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partly supported by the IITP (RS-2022-II220951-LBA/50%) and NRF (RS-2024-00358416-AutoRL/50%) grant funded by the Korean government.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
During the preparation of this manuscript, the authors utilized ChatGPT (version 5.2) and Gemini (version 2.5) to assist with language editing and proofreading. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Localized Folktale Generation and T2I Generation LLM Prompt Templates
Table A1.
Prompt Templates for Localized Folktale Generation (
Section 3.1).
Table A1.
Prompt Templates for Localized Folktale Generation (
Section 3.1).
| A. Localized Folktale Generation (Section 3.1.1) | System Prompt
You are an AI storyteller who recrafts global folktales for children into the rhythmic, and oral tradition of {target culture}.
Original Narrative
At the edge of a village stood a great tree. Villagers whispered that after sunset strange sounds came from there. One evening two friends walked by, and a ghostly figure warned, “Leave this place, or you too will be bound to this tree forever!”
Culturally Specific Items (CSI)
- Tree species (foreign sacred tree motif)
- Crop fields (foreign staple crop)
- Foreign personal names
- Priest/landlord (foreign social roles)
- Holy ritual (foreign exorcism practice)
Replacements (Target Culture Localized)
- Replace tree with target culture folklore tree
- Replace crop with local staple crop
- Replace names with target culture folktale names
- Replace priest/landlord with local elder/landlord figure
- Replace ritual with target culture traditional ritual
Result
[Final narrative retold in target culture folktale style]
Key Parameters
Generation model = GPT-4.1 [19], Temperature = 0.7, Chunk size = 500, Overlap = 50, Embedding model = text-embedding-3-small |
| B. T2I Prompt Generation (Section 3.1.3) | Character Extraction & Replacement
- Extract main character and represent as JSON: { “character_name”: [“reference_name”, “appearance description”]
}
- Infer missing appearance details from traditional
[target_culture] style
- Replace all mentions (including pronouns) with the reference name
Narrative Segmentation
- Divide the story into {n} parts (background → development → conflict → resolution)
Scene Prompt Generation
- One scene per character
- Format entities as: “[reference_name] [attributes]. [Position.]”
- Add background elements ([target_culture_elements]) with positions
- Length: 30–40 words; vivid and compact (like a painting frame) - Use only simple English phrases (e.g., Standing, Holding)
- Order: main character → objects → background → stylistic keywords
- Ensure no overlap between characters and background
Result
- Final T2I description combining extracted characters and segmented narrative
Key Parameters
Generation model = GPT-4o [19], Temperature = 0.7, Tokenizer = cl100k_base (tiktoken), Output length = 30–40 words per scene |
Appendix B. Illustration Generation Prompts
Table A2.
Examples of captions used in the Style Dataset. Stylistic keywords are marked with an asterisk (*).
Table A2.
Examples of captions used in the Style Dataset. Stylistic keywords are marked with an asterisk (*).
| Domain | Caption Examples |
|---|
| Korean | korean men practicing archery with bows and arrows, *kimhongdo style, *ink wash painting, *joseon dynasty |
| Bengali | a multi-armed, dark-blue goddess, standing over a small, kneeling figure who is looking up at her, *Kalighat Painting, *Indian Folk Art, *Bold Outlines |
Table A3.
Examples of captions used in the Character Dataset. Stylistic keywords are marked with an asterisk (*).
Table A3.
Examples of captions used in the Character Dataset. Stylistic keywords are marked with an asterisk (*).
| Domain | Caption Examples |
|---|
| Korean | a main-girl with long black hair neatly braided and tied with a ribbon, Her facial expression is calm and quiet, she is wearing a white sleeveless top, and she is facing forward. Front-facing upper body portrait, centered in the frame, *kimhongdo style, *ink wash painting, *joseon dynasty |
| Bengali | main-woman with long black hair, wearing red blouse, gold earrings and necklace, facing forward, portrait, plain background *Kalighat Painting, *Indian Folk Art, *Bold Outlines |
Table A4.
Character Consistency Comparison Prompts (
Figure 10). Stylistic keywords are marked with an asterisk (*).
Table A4.
Character Consistency Comparison Prompts (
Figure 10). Stylistic keywords are marked with an asterisk (*).
| Domain | Prompts |
|---|
| Korean | main-girl, a young girl with long black hair braided to one side, smiling gently while sitting cross-legged on the floor, *kimhongdo style, *Joseon Dynasty, *ink wash painting. |
| | main-girl, a young girl with long black hair braided to one side, holding a small brush and writing on paper, slightly leaning forward, *kimhongdo style, *Joseon Dynasty, *ink wash painting. |
| | main-girl, a young girl with long black hair braided to one side, sitting by a low wooden table, folding paper, focused expression, *kimhongdo style, *Joseon Dynasty, *ink wash painting. |
| | negative prompt: text, bright colors, saturated tones, golden embroidery, digital art, anime, cartoon, 3D render, fantasy, glossy finish, distorted face, blurry face, extra limbs. |
| Bengali | main-woman with long black hair, wearing red blouse, gold earrings and necklace, writing with a quill pen on parchment paper, by a desk. *Kalighat Painting, *Indian Folk Art, *Bold Outlines. |
| | main-woman with long black hair, wearing red blouse, gold earrings and necklace, shaping clay on a potter’s wheel, focused expression. *Kalighat Painting, *Indian Folk Art, *Bold Outlines. |
| | main-woman with long black hair, wearing red blouse, gold earrings and necklace, reading a book to a small child sitting beside her. *Kalighat Painting, *Indian Folk Art, *Bold Outlines. |
| | negative prompt: photorealistic, realistic, 3D, blurry, deformed, disfigured, poor anatomy, bad hands, extra limbs, watermark, text, signature, modern, digital painting. |
Appendix C. LLM-as-a-Judge Prompts
Table A5.
Localized Folktale Generation Module Evaluation Prompts (
Table 4).
Table A5.
Localized Folktale Generation Module Evaluation Prompts (
Table 4).
| Content Preservation | You are an AI system tasked with evaluating the degree of content preservation between two folktale passages.The first passage (S1) represents the original folktale, while the second passage (S2) represents the converted or translated version. Assess how well S2 maintains the key events, character traits, and overall setting of S1 using a five-point scale,
where
1 = completely different content,
3 = somewhat similar but partially altered or incomplete,
5 = identical or nearly identical in content.
Return only a single final score as a number between 1 and 5. |
Folktale
Appropriateness | You are an expert in [target_culture] folktales.
Examples:
Story: """example_story1""" → Score: 5
Story: """example_story2""" → Score: 3
Story: """example_story3""" → Score: 1.
Now evaluate the following story: """story""".
Evaluation criteria: Narrative tone and storytelling style typical of [target_culture] folktales; Characters, settings, values, and cultural elements consistent with [target_culture] traditions; Folktale structure (introduction–development–conclusion).
Scoring scale:
1 = Not a [target_culture] folktale,
3 = Some elements but awkward/inconsistent,
5 = Strongly resembles a traditional [target_culture] folktale.
Return only a single final score as a number between 1 and 5. |
| Naturalness | You are a strict evaluator of the style and linguistic quality of [target_culture] folktales.
Examples:
"""example_story1""" → 5,
"""example_story2""" → 3,
"""example_story3""" → 1.
Now evaluate: """story""".
Criteria: grammar and accuracy, logical flow, tone and rhythm, cultural references.
Scoring:
1 = awkward with errors,
3 = somewhat unnatural,
5 = fluent and natural.
Output only a single number between 1 and 5. |
Table A6.
Illustration Generation Module Evaluation Prompts (
Table 6 and
Table 7).
Table A6.
Illustration Generation Module Evaluation Prompts (
Table 6 and
Table 7).
| Style Similarity Evaluation (Table 6) | You will be
given three images in target culture. Your task is to evaluate which image most closely matches the target style based on five criteria. Each criterion should be scored from 0 to 10, and the average score should be calculated for each image.
Evaluation Criteria: Coloring, Character Depiction, Composition, Linework, Background Rendering.
Instructions: Assign a score for each criterion, calculate the average, and present results in JSON format. |
| Character Consistency Evaluation (Table 7) | You will be given a set of reference images showing the target main character, followed by image sets generated by two models (Model A, Model B). Study the references to internalize key features (facial structure, hairstyle, clothing, accessories, proportions). Do not score or describe references. After reviewing, evaluate how consistently the same character appears across images.
Scope: Ignore background, rendering quality, and style; focus only on character identity.
Evaluation:
0 = no resemblance,
5 = partial/inconsistent resemblance,
10 = strong consistent resemblance.
Instructions: Assign one consistency score (0–10) per model. |
Table A7.
Failure Case Evaluation Prompts (
Table 9).
Table A7.
Failure Case Evaluation Prompts (
Table 9).
Failure Cases
– Fundamental Limitations of the Base SDXL Model (Table 9) | You are an AI system tasked with evaluating image generation failures caused by the fundamental limitations of the Base SDXL model. Your goal is to assess prompt faithfulness and clarity while ignoring style, technique, or aesthetic quality. The evaluation should follow the instructions below:
Role: The LLM acts as an image evaluator and must strictly follow the given rules.
Objective: Focus solely on prompt faithfulness and clarity, excluding any stylistic or artistic assessment.
Input: The textual prompt and images generated by Model A, Model B, and Model C.
Evaluation Criteria:
– Prompt Faithfulness (0–10): entity count, attributes, spatial relations, emotional alignment.
– Expressivity (0–10): clarity of emotions and actions, readability of emphasized elements, absence of clutter.
Notes: Do not judge cultural or garment names (e.g., hanbok/kimono). Use only explicit attributes from the prompt. Stylistic aspects must be ignored. |
Appendix D. Human Evaluation Guidelines
Table A8.
Participant Recruitment and Quality Control Protocol.
Table A8.
Participant Recruitment and Quality Control Protocol.
| Category | Korean Evaluation | Bengali Evaluation |
|---|
| Recruitment Platform | Google Forms | Prolific |
| Participant Criteria | Native Korean speakers with high linguistic proficiency and cultural familiarity | Native Bengali speakers with native-level fluency (platform pre-screening filters applied) |
| Language Verification | Self-reported native status | Platform-verified native language status |
| Attention Checks | No platform-automated checks; responses reviewed manually | Automated attention checks implemented via Prolific |
| Response Screening | Manual inspection for abnormal response patterns | Automated filtering for outlier response times |
| Straight-Lining Control | Manual detection of uniform response patterns (e.g., identical ratings across items) | Automated exclusion of straight-lining responses |
| Bias Mitigation Strategy | Cultural familiarity screening and manual response review | Pre-screening filters and automated quality control procedures |
Table A9.
Multimodal Human Evaluation Instructions.
Table A9.
Multimodal Human Evaluation Instructions.
| Multimodal Evaluation | In this section, you will evaluate folktales presented in a multimodal format (text, image, and audio).
Multimodal Components:
Text: A culturally adapted folktale that includes traditional elements, characters, and oral-style expressions of the {target culture}.
Images: Illustrations reflecting the representative painting style of the {target culture}, corresponding to the introduction, body, and conclusion of the story.
Audio: Storytelling recordings with multiple narrators, designed to capture the features of traditional folktale narration in the {target culture}.
Instruction: Please evaluate each folktale by considering all three modalities together. We kindly ask you to judge each item independently and carefully, without bias across criteria.
Rating Scale (5-point Likert):
1 point: Very Low; 2 points: Low; 3 points: Neutral; 4 points: High; 5 points: Very High. |
| Criteria 1: Overall Quality and Immersion | The extent to which the story feels smooth, engaging, and immersive when considering text, imagery, and audio together. |
| Criteria 2: Reflection of Cultural Elements | The degree to which cultural characteristics of the {target culture} folktale tradition are expressed through setting, vocabulary, visual style, and storytelling manner. |
| Criteria 3: Cultural Coherence | The extent to which text, imagery, and audio consistently maintain the cultural expressions, style, and atmosphere of the {target culture} tradition. |
Table A10.
Text-Only Human Evaluation Instructions.
Table A10.
Text-Only Human Evaluation Instructions.
| Text Evaluation | Please read the provided stories and freely evaluate how much each one feels like a folktale of the {target culture}.
Rating Scale (5-point Likert):
1 point: Very Low; 2 points: Low; 3 points: Neutral; 4 points: High; 5 points: Very High. |
| Criterion 1: Narrative Coherence | Was the narrative flow of the story smooth and natural, with clear causal relationships? |
| Criterion 2: Style Transfer Accuracy | Did the story successfully reflect the unique style of the {target culture} folktale tradition? |
| Criterion 3: Cultural Appropriateness | Did the themes and expressions of the story fit well with the cultural background and sentiment of the {target culture} folktale tradition? |
Table A11.
Image Human Evaluation Instructions.
Table A11.
Image Human Evaluation Instructions.
| Image Evaluation | You will evaluate images generated by different models under controlled prompts. Before the evaluation, you will be shown representative reference artworks of the {target culture} painting style to calibrate stylistic judgment. |
| Task 1: Style Similarity (Forced Choice) | Compare image outputs generated under identical prompts (e.g., SDXL, DALL·E 3, and the LoRA-tuned model) and select the image that most closely matches the representative painting style of the {target culture}. |
| Task 2: Character Consistency (Forced Choice) | Compare image sets generated from the same character prompt and select the model that most consistently preserves character identity across scenes (i.e., the same character appears repeatedly). |
Appendix E. Full Folktale Input and Generated Outputs
Figure A1.
Example of culturally adapted folktale generation results produced by the MELT framework. The top panel shows the original input folktale in English. The lower panels present the culturally localized outputs generated by MELT, including Korean (left) and Bengali (right) versions of the same narrative. Each output consists of culturally adapted text and corresponding illustrations that reflect the visual aesthetics and narrative elements of the target culture. The Korean and Bengali texts shown in the figure illustrate localized storytelling styles, while the accompanying images demonstrate culture-specific artistic characteristics generated through the proposed style-transfer framework.
Figure A1.
Example of culturally adapted folktale generation results produced by the MELT framework. The top panel shows the original input folktale in English. The lower panels present the culturally localized outputs generated by MELT, including Korean (left) and Bengali (right) versions of the same narrative. Each output consists of culturally adapted text and corresponding illustrations that reflect the visual aesthetics and narrative elements of the target culture. The Korean and Bengali texts shown in the figure illustrate localized storytelling styles, while the accompanying images demonstrate culture-specific artistic characteristics generated through the proposed style-transfer framework.
References
- Chung, J.J.Y.; Kim, W.; Yoo, K.M.; Lee, H.; Adar, E.; Chang, M. TaleBrush: Sketching stories with generative pretrained language models. In Proceedings of the CHI Conference on Human Factors in Computing Systems (CHI ’22), New Orleans, LA, USA, 29 April–5 May 2022; pp. 1–19. [Google Scholar] [CrossRef]
- Maharana, A.; Hannan, D.; Bansal, M. StoryDALL-E: Adapting pretrained text-to-image transformers for story continuation. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 70–87. [Google Scholar] [CrossRef]
- Midjourney. Available online: https://www.midjourney.com/ (accessed on 15 October 2025).
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-rank adaptation of large language models. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 25–29 April 2022. [Google Scholar] [CrossRef]
- Hamna; Sudharsan, D.; Seth, A.; Budhiraja, R.; Khullar, D.; Jain, V.; Bali, K.; Vashistha, A.; Segal, S. Kahani: Culturally-nuanced visual storytelling tool for non-Western cultures. In Proceedings of the ACM SIGCAS/SIGCHI Conference on Computing and Sustainable Societies (COMPASS ’25), Sydney, NSW, Australia, 22–25 July 2025; pp. 379–400. [Google Scholar] [CrossRef]
- Li, C.; Chen, M.; Wang, J.; Sitaram, S.; Xie, X. CultureLLM: Incorporating cultural differences into large language models. In Proceedings of the 38th International Conference on Neural Information Processing Systems (NeurIPS ’24), Vancouver, BC, Canada, 9–15 December 2024; pp. 84799–84838. [Google Scholar]
- Yang, S.; Ge, Y.; Li, Y.; Chen, Y.; Ge, Y.; Shan, Y.; Chen, Y. SEED-Story: Multimodal long story generation with large language model. arXiv 2024, arXiv:2407.08683. [Google Scholar] [CrossRef]
- Liu, S.; Guo, Y.; Chen, X.; Yu, K. StoryTTS: A highly expressive text-to-speech dataset with rich textual expressiveness annotations. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 11521–11525. [Google Scholar] [CrossRef]
- Bak, T.; Eom, Y.; Choi, S.; Joo, Y.S. MultiVerse: Efficient and expressive zero-shot multi-task text-to-speech. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; pp. 9130–9147. [Google Scholar] [CrossRef]
- Selvamani, S.A.; Ganapathy, N.D. A multi-agent AI framework for immersive audiobook production through spatial audio and neural narration. arXiv 2025, arXiv:2505.04885. [Google Scholar] [CrossRef]
- Kim, J.; Heo, Y.; Yu, H.; Nang, J. A multi-modal story generation framework with AI-driven storyline guidance. Electronics 2023, 12, 1289. [Google Scholar] [CrossRef]
- Ghorbani, S. Aether weaver: Multimodal affective narrative co-generation with dynamic scene graphs. arXiv 2025, arXiv:2507.21893. [Google Scholar] [CrossRef]
- Incremona, A.; Pozzi, A.; Guiscardi, A.; Tessera, D. A differentiable and uncertainty-aware mutual information regularizer for bias mitigation. Neurocomputing 2025, 669, 132498. [Google Scholar] [CrossRef]
- Seo, H.; Choi, S.; Hong, M.; Zhou, Y.; Kim, J.; Ismaila, L.; Etori, N.; Agarwal, M.; Liu, Z.; Kim, J.; et al. Exposing blindspots: Cultural bias evaluation in generative image models. arXiv 2025, arXiv:2510.20042. [Google Scholar] [CrossRef]
- Zhou, Z.; Xi, Y.; Xing, S.; Chen, Y. Cultural bias mitigation in vision-language models for digital heritage documentation: A comparative analysis of debiasing techniques. Artif. Intell. Mach. Learn. Rev. 2024, 5, 28–40. [Google Scholar] [CrossRef]
- Xing, P.; Wang, H.; Sun, Y.; Wang, Q.; Bai, X.; Ai, H.; Huang, R.; Li, Z. CSGO: Content-Style Composition in Text-to-Image Generation. arXiv 2024, arXiv:2408.16766. [Google Scholar] [CrossRef]
- Bo, W.; Sun, Y.; Wang, Y.; Zhang, X.; Li, Z. FedMGP: Personalized Federated Learning with Multi-Group Text-Visual Prompts. arXiv 2025, arXiv:2511.00480. [Google Scholar] [CrossRef]
- Sun, Y.; Chen, Q.; He, X.; Wang, J.; Feng, H.; Han, J.; Ding, E.; Cheng, J.; Li, Z.; Wang, J. Singular value fine-tuning: Few-shot segmentation requires few-parameters fine-tuning. Adv. Neural Inf. Process. Syst. 2022, 35, 37484–37496. [Google Scholar]
- OpenAI. GPT Technical Report. 2024. Available online: https://openai.com/research (accessed on 22 September 2025).
- Podell, D.; English, Z.; Lacey, K.; Blattmann, A.; Dockhorn, T.; Müller, J.; Penna, J.; Rombach, R. SDXL: Improving latent diffusion models for high-resolution image synthesis. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 7–11 May 2024. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.H.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NeurIPS ’22), New Orleans, LA, USA, 28 November–9 December 2022; pp. 24824–24837. [Google Scholar]
- Singh, P.; Patidar, M.; Vig, L. Translating across cultures: LLMs for intralingual cultural adaptation. In Proceedings of the 28th Conference on Computational Natural Language Learning (CoNLL ’24), Miami, FL, USA, 7–8 November 2024; pp. 400–418. [Google Scholar] [CrossRef]
- Tao, Y.; Viberg, O.; Baker, R.S.; Kizilcec, R.F. Cultural bias and cultural alignment of large language models. PNAS Nexus 2024, 3, 346. [Google Scholar] [CrossRef] [PubMed]
- Yuan, H.; Che, Z.; Li, S.; Zhang, Y.; Hu, X.; Luo, S. The high dimensional psychological profile and cultural bias of ChatGPT. Sci. China Inf. Sci. 2025, 68, 2934. [Google Scholar] [CrossRef]
- AlKhamissi, B.; EINokrashy, M.; AlKhamissi, M.; Diab, M. Investigating cultural alignment of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024), Bangkok, Thailand, 11–16 August 2024; pp. 12404–12422. [Google Scholar] [CrossRef]
- Kannen, N.; Ahmad, A.; Andreetto, M.; Prabhakaran, V.; Prabhu, U.; Dieng, A.B.; Bhattacharyya, P.; Dave, S. Beyond aesthetics: Cultural competence in text-to-image models. arXiv 2025, arXiv:2407.06863. [Google Scholar] [CrossRef]
- Chinchure, A.; Shukla, P.; Bhatt, G.; Salij, K.; Hosanagar, K.; Sigal, L.; Turk, M. TIBET: Identifying and evaluating biases in text-to-image generative models. In Proceedings of the European Conference on Computer Vision (ECCV ’24), Milan, Italy, 29 September–4 October 2024; pp. 429–446. [Google Scholar] [CrossRef]
- Jha, A.; Prabhakaran, V.; Denton, R.; Laszlo, S.; Dave, S.; Qadri, R.; Reddy, C.K.; Dev, S. ViSAGe: A global-scale analysis of visual stereotypes in text-to-image generation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), Bangkok, Thailand, 11–16 August 2024; pp. 12333–12347. [Google Scholar] [CrossRef]
- Ghosh, S.; Caliskan, A. ‘Person’ == light-skinned, Western man, and sexualization of women of color: Stereotypes in Stable Diffusion. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 6971–6985. [Google Scholar] [CrossRef]
- Nouar, N.; Rahwan, T.; Zaki, Y. AI-generated faces influence gender stereotypes and racial homogenization. Sci. Rep. 2025, 15, 14449. [Google Scholar] [CrossRef] [PubMed]
- Malakouti, S.; Kovashka, A. Role bias in text-to-image diffusion models: Diagnosing and mitigating compositional failures through intermediate decomposition. arXiv 2025, arXiv:2503.10037. [Google Scholar]
- Bayramli, Z.; Suleymanzade, A.; An, N.M.; Ahmad, H.; Kim, E.; Park, J.; Thorne, J.; Oh, A. Diffusion models through a global lens: Are they culturally inclusive? In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL ’25), Vienna, Austria, 27 July–1 August 2025; pp. 31137–31155. [Google Scholar] [CrossRef]
- DIVA Portal. Community Reports on Midjourney: Misrepresentation of Korean Cultural Elements. Available online: https://www.diva-portal.org/smash/get/diva2:1833416/FULLTEXT01.pdf (accessed on 2 October 2025).
- Zhou, Y.; Liu, Y.; Shao, Y.; Chen, J. Fine-tuning diffusion model to generate new kite designs for the revitalization and innovation of intangible cultural heritage. Sci. Rep. 2025, 15, 7519. [Google Scholar] [CrossRef] [PubMed]
- Zhou, M.; Bai, Y.; Yang, Q.; Zhao, T. StyleInject: Parameter-efficient tuning of text-to-image diffusion models. ACM Trans. Multimed. Comput. Commun. Appl. 2025, 21, 152. [Google Scholar] [CrossRef]
- Yeh, S.Y.; Hsieh, Y.G.; Gao, Z.; Yang, B.B.W.; Oh, G.; Gong, Y. Navigating text-to-image customization: From LyCORIS fine-tuning to model evaluation. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 7–11 May 2024. [Google Scholar] [CrossRef]
- Dai, M.; Feng, Y.; Wang, R.; Jung, J. Enhancing the digital inheritance and development of Chinese intangible cultural heritage paper-cutting through Stable Diffusion LoRA models. Appl. Sci. 2024, 14, 11032. [Google Scholar] [CrossRef]
- Ruiz, N.; Li, Y.; Jampani, V.; Aberman, A.; Huang, J.B.; Pritch, Y. DreamBooth: Fine-tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 22500–22510. [Google Scholar]
- Bae, J.; Jeong, S.; Kang, S.; Han, N.; Lee, J.-Y.; Kim, H.; Kim, T. Sound of story: Multi-modal storytelling with audio. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 13467–13479. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), Online, 5–10 July 2020; pp. 8440–8451. [Google Scholar] [CrossRef]
- FacebookAI. XLM-RoBERTa (xlm-roberta-base). HuggingFace Model Hub. 2020. Available online: https://huggingface.co/FacebookAI/xlm-roberta-base (accessed on 22 September 2025).
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.-T.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 6–12 December 2020; pp. 9459–9474. [Google Scholar]
- Liu, V.; Chilton, L.B. Design guidelines for prompt engineering text-to-image generative models. In Proceedings of the CHI Conference on Human Factors in Computing Systems (CHI ’22), New Orleans, LA, USA, 29 April–5 May 2022; pp. 1–23. [Google Scholar] [CrossRef]
- Segmind. How to Engineer the Perfect Stable Diffusion Prompt. Automagically by Segmind. Available online: https://blog.segmind.com/guide-to-prompt-engineering-for-stable-diffusion/ (accessed on 17 February 2025).
- Lee, H.; Park, Y. A comparative study on patterns in traditional palaces of Korea, China, and Japan. In Proceedings of the Design Research Society International Conference (DRS), Melbourne, Australia, 17–21 November 2004. [Google Scholar] [CrossRef]
- Pandey, N. Negotiating Performativity and Commodification: The Artistic Shift from Pattachitra to Kalighat Paintings. Dialog 2024, 44, 234–250. [Google Scholar]
- Panczenko, A. Folk Tales Dataset. Kaggle. 2021. Available online: https://www.kaggle.com/datasets/andrzejpanczenko/folk-tales-dataset (accessed on 2 October 2025).
- Wikipedia Contributors. Wikipedia: The Free Encyclopedia. Available online: https://www.wikipedia.org/ (accessed on 2 October 2025).
- National Library for Children and Young Adults. Multilingual Folktale Contents. Available online: https://www.nlcy.go.kr/NLCY/contents/C10503010000.do?cmd=kor&schFld=ko (accessed on 2 October 2025).
- Korea Copyright Commission. Korean Public Domain Repository. Available online: https://gongu.copyright.or.kr/gongu/wrt/wrtCl/listWrtText.do?menuNo=200019 (accessed on 2 October 2025).
- TagoreWeb. TagoreWeb Folklore Archive. Available online: https://www.tagoreweb.in/ (accessed on 2 October 2025).
- Internet Archive. Tajik Folktales in Bengali: Free Download, Borrow, and Streaming. Available online: https://archive.org/details/tajik-folktales-tajik-lokkahini_202309/page/16/mode/2up (accessed on 2 October 2025).
- Dhakeshwari Foundation. Thakurmar Jhuli. Available online: http://dhakeshwari.com/thakurmarjhuli.pdf (accessed on 2 October 2025).
- Korea Copyright Commission. Gongu: Public Domain Works Service. Available online: https://gongu.copyright.or.kr/gongu/main/main.do (accessed on 24 September 2025).
- Victoria and Albert Museum. Kalighat Painting. Available online: https://www.vam.ac.uk/articles/kalighat-painting (accessed on 29 September 2025).
- Wikipedia. Kalighat Painting. Available online: https://en.wikipedia.org/wiki/Kalighat_painting (accessed on 24 September 2025).
- hollowstrawberry. Kohya-Colab. GitHub Repository. Available online: https://github.com/hollowstrawberry/kohya-colab (accessed on 22 September 2025).
- kohya_ss. sd-scripts. GitHub Repository. Available online: https://github.com/kohya-ss/sd-scripts (accessed on 22 September 2025).
- Derrian-Distro. LoRA_Easy_Training_scripts_Backend. GitHub Repository. Available online: https://github.com/derrian-distro/LoRA_Easy_Training_scripts_Backend/ (accessed on 22 September 2025).
- Linaqruf. Kohya-Trainer. GitHub Repository. Available online: https://github.com/Linaqruf/kohya-trainer (accessed on 22 September 2025).
- Jelosus2. LoRA_Easy_Training_Colab. GitHub Repository. Available online: https://github.com/Jelosus2/LoRA_Easy_Training_Colab (accessed on 22 September 2025).
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Hang, T.; Gu, S.; Li, C.; Bao, J.; Chen, D.; Hu, H.; Geng, X.; Guo, B. Efficient Diffusion Training via Min-SNR Weighting Strategy. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 7446–7456. [Google Scholar] [CrossRef]
- Zhou, M.; Bai, Y.; Yang, Q.; Zhao, T. StyleInject: Parameter Efficient Tuning of Text-to-Image Diffusion Models. arXiv 2024, arXiv:2401.13942. [Google Scholar] [CrossRef]
- OpenAI. DALL-E 3 System Card. OpenAI Blog. Available online: https://openai.com/research/dall-e-3 (accessed on 22 September 2025).
- Zyphra. Zonos: Open-Weight Text-to-Speech Model. GitHub Repository. 2025. Available online: https://github.com/Zyphra/Zonos (accessed on 22 September 2025).
- ElevenLabs. Eleven Multilingual v3. 2025. Available online: https://elevenlabs.io/v3 (accessed on 22 September 2025).
- National Library for Children and Young Adults (NLCY). Shinseonbawi Ddongbawi. Multilingual Folktale Contents. Available online: https://nlcy.go.kr/NLCY/contents/C10503010000.do?schFld=ko&schM=view&cmd=kor&langCodeType=ko&storySeq=343 (accessed on 22 September 2025).
- Prolific. Available online: https://www.prolific.com/ (accessed on 24 September 2025).
- Anthropic. Claude Opus 4.1 System Card Addendum. Technical Report, August 2025. Available online: https://assets.anthropic.com/m/4c024b86c698d3d4/original/Claude-4-1-System-Card.pdf (accessed on 22 September 2025).
- Comanici, G.; Bieber, E.; Schaekermann, M.; Pasupat, I.; Sachdeva, N.; Dhillon, I.; Blistein, M.; Ram, O.; Zhang, D.; Rosen, E.; et al. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities. Google DeepMind. 2025. Available online: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf (accessed on 8 March 2026).
- SK Telecom. KoGPT2 (skt/kogpt2-base-v2). GitHub Repository. 2021. Available online: https://github.com/SKT-AI/KoGPT2 (accessed on 22 September 2025).
- Flax Community. Bengali GPT-2. HuggingFace Model Hub. 2021. Available online: https://huggingface.co/flax-community/gpt2-bengali (accessed on 22 September 2025).
- BM-K. Ko-SimCSE-roberta. HuggingFace Model Hub. 2021. Available online: https://huggingface.co/BM-K/KoSimCSE-roberta (accessed on 22 September 2025).
- princeton-nlp. sup-simcse-roberta-base. HuggingFace Model Hub. 2021. Available online: https://huggingface.co/princeton-nlp/sup-simcse-roberta-base (accessed on 22 September 2025).
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple contrastive learning of sentence embeddings. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual Event, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 6894–6910. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the International Conference on Machine Learning (ICML), Online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. DINOv2: Learning robust visual features without supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 14948–14958. [Google Scholar]
Figure 2.
Architecture of MELT, a style-adaptive multimodal folktale generation framework. The Korean text shown in the “Output Folktale” box represents an example of a localized Korean folktale-style narrative generated by the proposed system.
Figure 2.
Architecture of MELT, a style-adaptive multimodal folktale generation framework. The Korean text shown in the “Output Folktale” box represents an example of a localized Korean folktale-style narrative generated by the proposed system.
Figure 3.
Illustration Generation Module with a tri-stage process (CBL, CIC, and CIL).
Figure 3.
Illustration Generation Module with a tri-stage process (CBL, CIC, and CIL).
Figure 4.
Examples of style-transfer folktale generation outputs: Korea (left) and Bengal (right) versions of the Filipino folktale “The Terrible Tic-balan.” The Korean and Bengali texts illustrate culturally localized folktale narratives generated by MELT. English translations provided in parentheses explain culture-specific entities, places, and traditional elements appearing in each localized story.
Figure 4.
Examples of style-transfer folktale generation outputs: Korea (left) and Bengal (right) versions of the Filipino folktale “The Terrible Tic-balan.” The Korean and Bengali texts illustrate culturally localized folktale narratives generated by MELT. English translations provided in parentheses explain culture-specific entities, places, and traditional elements appearing in each localized story.
Figure 5.
Character extraction and scene-level prompt generation for Korean and Bengali folktales.
Figure 5.
Character extraction and scene-level prompt generation for Korean and Bengali folktales.
Figure 6.
Examples of training images from the Korean (Kim Hong-do) and Bengali (Kalighat) datasets.
Figure 6.
Examples of training images from the Korean (Kim Hong-do) and Bengali (Kalighat) datasets.
Figure 7.
Base character images generation using DALL·E 3 and culturally stylized results after i2i transfer using MELT-CBL.
Figure 7.
Base character images generation using DALL·E 3 and culturally stylized results after i2i transfer using MELT-CBL.
Figure 8.
Example of folktale-to-illustration generation using the Cultural illustration LoRA (CIL) model.
Figure 8.
Example of folktale-to-illustration generation using the Cultural illustration LoRA (CIL) model.
Figure 9.
Qualitative comparison of outputs generated from identical prompts by SDXL, DALL·E 3, and MELT-CBL.
Figure 9.
Qualitative comparison of outputs generated from identical prompts by SDXL, DALL·E 3, and MELT-CBL.
Figure 10.
Character consistency comparison: MELT-CBL vs. MELT-CIL.
Figure 10.
Character consistency comparison: MELT-CBL vs. MELT-CIL.
Figure 11.
Outputs generated with increasing dataset sizes (20–500 images).
Figure 11.
Outputs generated with increasing dataset sizes (20–500 images).
Figure 12.
Comparison of MELT, Base SDXL, and DALL·E 3 for prompts with rich descriptions (top) and emotional expressions (bottom).
Figure 12.
Comparison of MELT, Base SDXL, and DALL·E 3 for prompts with rich descriptions (top) and emotional expressions (bottom).
Figure 13.
Prompt component ablation results.
Figure 13.
Prompt component ablation results.
Figure 14.
Guidance scale sensitivity analysis.
Figure 14.
Guidance scale sensitivity analysis.
Table 1.
Comparative overview of representative systems and frameworks for multimodal storytelling and cultural adaptation. Training cost denotes prompt-based (Low), parameter-efficient (Moderate), and full fine-tuning (High) approaches. Cultural adaptation is marked as O (explicit), Δ (partial, e.g., stylistic transfer only), or X (none).
Table 1.
Comparative overview of representative systems and frameworks for multimodal storytelling and cultural adaptation. Training cost denotes prompt-based (Low), parameter-efficient (Moderate), and full fine-tuning (High) approaches. Cultural adaptation is marked as O (explicit), Δ (partial, e.g., stylistic transfer only), or X (none).
| System/Framework | Modalities | Cost | Multimodal Integration | Adapt. | Method |
|---|
| KAHANI [5] | Text + Image | Low | Bi-modal only | O | Prompt (CoT, T2I) |
| CultureLLM [6] | Text | High | No | O | Fine-tuning |
| SEED-Story [7] | Text + Image | High | Bi-modal, no audio | Δ | Multimodal LLM |
| StoryTTS [8,9] | Audio (TTS) | Mod.–High | Audio only | X | Expressive TTS/Zero-shot |
| Multi-Agent [10] | Audio | Mod. | Audio only | X | Spatial audio + neural narration |
| Multi-Modal [11] | Text + Image | Mod. | Bi-modal | Δ | Diffusion-based storyline guidance |
| Aether Weaver [12] | Text + Image | High | Bi-modal | Δ | Dynamic scene graph |
| UA-MIR [13] | Agnostic | High | No | O | Uncertainty Regularizer |
| Blindspots [14] | Image | N/A | No | X | Bias Evaluation |
| CBM-VLM [15] | Text + Image | Mod. | Bi-modal | O | Cross-modal Adapters |
| CSGO [16] | Text + Image | Mod.–High | Bi-modal | O | Content-Style Decoupling |
| FedMGP [17] | Text + Image | Mod. | Bi-modal | O | Multi-Group Prompts |
| SVF [18] | Image | Low | No | Δ | Singular Value Fine-tuning |
| MELT (ours) | T + I + A | Low–Mod. | Full tri-modal | O | Structured prompting + Tri-Stage LoRA |
Table 2.
Human evaluation results for multimodal folktale narratives in Korean and Bengali traditions. * ; *** .
Table 2.
Human evaluation results for multimodal folktale narratives in Korean and Bengali traditions. * ; *** .
| Metric | Korean | Bengali |
|---|
| Base | MELT | Base | MELT |
|---|
| Overall Quality | | | | |
| t, p | t = 4.318, p = 0.0003 *** | t = 1.543, p = 0.136 |
| ICC (3, k) | 0.946 [0.69, 1.00] | 0.412 [−0.05, 0.71] |
| Cultural Adaptation | | | | |
| t, p | t = 8.401, p < 0.001 *** | t = 2.298, p = 0.031 * |
| ICC (3, k) | 0.986 [0.92, 1.00] | 0.541 [0.18, 0.78] |
| Cultural Coherence | | | | |
| t, p | t = 6.473, p < 0.001 *** | t = 3.949, p = 0.0006 *** |
| ICC (3, k) | 0.976 [0.86, 1.00] | 0.462 [0.04, 0.74] |
Table 3.
Human evaluation results for localized folktale texts. *** .
Table 3.
Human evaluation results for localized folktale texts. *** .
| Metric | Korean | Bengali |
|---|
| Base | MELT | Base | MELT |
|---|
| Narrative Coherence | | | | |
| t, p | t = 10.926, p < 0.001 *** | t = 3.643, p = 0.0014 *** |
| ICC (3,k) | 0.992 [0.95, 1.00] | 0.752 [0.57, 0.88] |
| Style Transfer Accuracy | | | | |
| t, p | t = 13.191, p < 0.001 *** | t = 3.927, p = 0.0007 *** |
| ICC (3,k) | 0.994 [0.96, 1.00] | 0.552 [0.23, 0.78] |
| Cultural Appropriateness | | | | |
| t, p | t = 11.671, p < 0.001 *** | t = 4.360, p = 0.0002 *** |
| ICC (3,k) | 0.993 [0.95, 1.00] | 0.600 [0.31, 0.80] |
Table 4.
LLM judge evaluation of folktale generation.
Table 4.
LLM judge evaluation of folktale generation.
| | | Korean | Bengali |
|---|
| Model | Metrics | BASE | MELT | BASE | MELT |
|---|
| GPT | Naturalness | 2.40 ± 0.97 | 5.00 ± 0.00 | 3.00 ± 1.26 | 5.00 ± 0.00 |
| Folktale Style | 2.10 ± 0.99 | 4.70 ± 0.48 | 2.33 ± 1.51 | 4.83 ± 0.41 |
| Preservation | 4.50 ± 0.53 | 3.70 ± 0.67 | 4.00 ± 1.67 | 3.17 ± 1.17 |
| Gemini | Naturalness | 3.60 ± 0.52 | 4.30 ± 0.48 | 3.40 ± 0.89 | 4.00 ± 0.00 |
| Folktale Style | 2.30 ± 1.06 | 4.80 ± 0.42 | 3.00 ± 1.41 | 4.80 ± 0.45 |
| Preservation | 4.20 ± 0.79 | 3.60 ± 0.52 | 4.40 ± 0.55 | 3.80 ± 0.84 |
| Claude | Naturalness | 2.10 ± 0.32 | 4.70 ± 0.67 | 2.80 ± 0.98 | 3.20 ± 0.98 |
| Folktale Style | 1.80 ± 0.63 | 4.80 ± 0.42 | 2.20 ± 1.17 | 4.20 ± 0.45 |
| Preservation | 4.60 ± 0.52 | 4.70 ± 0.48 | 4.60 ± 0.55 | 4.20 ± 1.10 |
| Average | Naturalness | 2.70 ± 0.60 | 4.67 ± 0.38 | 3.07 ± 1.04 | 4.07 ± 0.33 |
| Folktale Style | 2.07 ± 0.89 | 4.77 ± 0.44 | 2.51 ± 1.36 | 4.61 ± 0.44 |
| Preservation | 4.43 ± 0.61 | 4.00 ± 0.56 | 4.33 ± 0.92 | 3.72 ± 1.04 |
Table 5.
Quantitative evaluation results for the generated Korean and Bengali folktales.
Table 5.
Quantitative evaluation results for the generated Korean and Bengali folktales.
| Metric | Korean | Bengali |
|---|
| Base | MELT | Base | MELT |
|---|
| StyleSim | 0.35 ± 0.07 | 0.42 ± 0.12 | 0.64 ± 0.02 | 0.94 ± 0.01 |
| PPL | 45.48 ± 14.66 | 32.48 ± 6.75 | 10.29 ± 0.76 | 4.26 ± 0.37 |
Table 6.
Style similarity performance and statistical analysis of MELT, SDXL, and DALL·E 3 on Korean and Bengali datasets.
Table 6.
Style similarity performance and statistical analysis of MELT, SDXL, and DALL·E 3 on Korean and Bengali datasets.
| Metric | Korean | Bengali |
|---|
| Base SDXL | DALL·E 3 | MELT | Base SDXL | DALL·E 3 | MELT |
|---|
| CLIP-I | 0.68 ± 0.04 | 0.73 ± 0.02 | 0.79 ± 0.02 | 0.72 ± 0.01 | 0.72 ± 0.04 | 0.77 ± 0.04 |
| CLIP-T | 0.36 ± 0.03 | 0.37 ± 0.03 | 0.35 ± 0.02 | 0.34 ± 0.02 | 0.33 ± 0.02 | 0.32 ± 0.02 |
| DINOv2 | 0.58 ± 0.09 | 0.66 ± 0.04 | 0.67 ± 0.05 | 0.56 ± 0.08 | 0.60 ± 0.09 | 0.66 ± 0.22 |
| LLM-Judge | 6.73 ± 0.38 | 5.87 ± 0.34 | 8.73 ± 0.09 | 5.00 ± 1.22 | 6.80 ± 1.48 | 7.80 ± 0.45 |
| Human (%) | 0 | 0 | 100 | 5.0 ± 2.4 | 6.7 ± 0.0 | 90.0 ± 3.3 |
| Chi-square () | 112.00 | 43.53 |
| p-value | <0.001 | <0.001 |
| Fleiss’ Kappa () | N/A (100% agreement) | −0.026 |
Table 7.
Our evaluation of character consistency across Korean and Bengali datasets reveals statistically significant performance gains.
Table 7.
Our evaluation of character consistency across Korean and Bengali datasets reveals statistically significant performance gains.
| Metric | Korean | Bengali |
|---|
| MELT-CBL | MELT-CIL | MELT-CBL | MELT-CIL |
|---|
| LLM-Judge | | | | |
| Human (%) | | | | |
| Chi-square () | | |
| p-value | | |
| Fleiss’ Kappa () | | |
Table 8.
Effect of dataset size on style and identity preservation for Korean and Bengali cases.
Table 8.
Effect of dataset size on style and identity preservation for Korean and Bengali cases.
| Size | Korean | Bengali |
|---|
| CLIP-I | CLIP-T | DINOv2 | CLIP-I | CLIP-T | DINOv2 |
|---|
| Base | 0.67 ± 0.04 | 0.35 ± 0.03 | 0.54 ± 0.06 | 0.72 ± 0.01 | 0.34 ± 0.08 | 0.56 ± 0.08 |
| 20 | 0.72 ± 0.03 | 0.35 ± 0.03 | 0.65 ± 0.03 | 0.75 ± 0.03 | 0.33 ± 0.03 | 0.69 ± 0.03 |
| 50 | 0.76 ± 0.01 | 0.34 ± 0.04 | 0.66 ± 0.02 | 0.77 ± 0.01 | 0.34 ± 0.02 | 0.72 ± 0.03 |
| 100 | 0.79 ± 0.01 | 0.33 ± 0.03 | 0.67 ± 0.03 | 0.80 ± 0.02 | 0.31 ± 0.02 | 0.77 ± 0.03 |
| 300 | 0.77 ± 0.01 | 0.33 ± 0.03 | 0.69 ± 0.02 | 0.80 ± 0.01 | 0.33 ± 0.01 | 0.82 ± 0.03 |
| 500 | 0.79 ± 0.01 | 0.35 ± 0.03 | 0.69 ± 0.02 | 0.78 ± 0.04 | 0.31 ± 0.02 | 0.78 ± 0.03 |
Table 9.
Prompt faithfulness comparison of MELT, SDXL, and DALL·E 3.
Table 9.
Prompt faithfulness comparison of MELT, SDXL, and DALL·E 3.
| | Korean | Bengali |
|---|
| Metric | SDXL | DALL-E | MELT | SDXL | DALL-E | MELT |
|---|
| CLIP-T | 0.35 ± 0.01 | 0.36 ± 0.02 | 0.36 ± 0.01 | 0.33 ± 0.01 | 0.34 ± 0.01 | 0.36 ± 0.01 |
| LLM-Judge | 5.00 ± 1.75 | 9.00 ± 0.00 | 4.38 ± 1.88 | 5.75 ± 1.26 | 9.50 ± 0.58 | 3.75 ± 1.50 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |



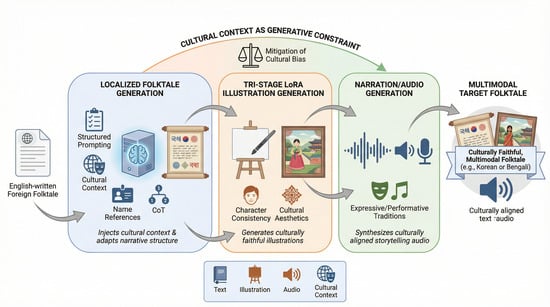


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













