1. Introduction
Detecting container corner castings is crucial for port automation, as these structural components ensure the safe lifting and transportation of shipping containers. Failures in detection can lead to serious safety risks and operational inefficiencies [
1]. In port automation systems, robotics gantry arms are commonly employed to handle containers efficiently, further emphasizing the importance of precise corner casting detection. With the increasing adoption of edge devices for intelligent perception and control in robotics, platforms like Raspberry Pi and Nvidia Jetson have gained popularity due to their open-source nature and developer-friendly features. Additionally, there is a rising trend of deploying real-time computational models on edge devices such as Raspberry Pi for various applications, including microscopy [
2], drone operations [
3], and detection-based counting systems [
4]. Raspberry Pi, in particular, has been widely recognized for its suitability in resource-constrained edge computing environments, supporting real-time and low-cost applications in IoT and industrial monitoring [
5,
6].
Object detection in AI is a tool in intelligent perception and it can be categorized into single-shot detection (SSD) models and region proposal networks (RPNs). RPN-based models, like Faster R-CNN [
7], employ a two-stage process that, while accurate, tends to be slower than single-stage SSD models such as MobileNet-V2 [
8] and EfficientDet [
9]. Given their efficiency, SSD models are commonly used for corner casting detection. However, these models rely on supervised learning and suffer from data limitations [
10], making zero-shot detection (ZSD) a promising alternative. ZSD models, such as Grounded Language-Image Pre-Training (GLIP) [
11] and Grounding DINO [
12], leverage large language models (LLMs) to recognize objects without prior training [
13], making them particularly useful for detecting specialized objects like corner castings.
Grounding DINO uses self-supervised training to learn representations from unlabeled data, reducing the need for manual annotation. It allows open-set detection, which enables the model to detect objects belonging to classes that are not present in the training data. Open-set detection is integrated with Referring Expression Comprehension (REC) [
14], allowing the model to localize objects in images based on descriptions provided by natural language.
Building on our previous studies [
15,
16] in single-shot object detection, our works extend the comparison to zero-shot detection on edge devices. Specifically, we evaluate Grounding DINO’s zero-shot detection against three SSD models: SSD320 MobileNetV2 FPNLite, MobileNetV2, and EfficientDet-Lite0. By comparing these models, we assess their efficiency and effectiveness in lightweight object detection. SSD MobileNetV2 FPNLite offers optimized feature extraction, MobileNetV2 serves as a baseline, and EfficientDet-Lite0 is designed for resource-constrained environments. This study provides a comprehensive analysis of lightweight detection architectures and validates the potential of zero-shot models in edge computing applications.
Research on container corner casting detection spans four key areas: 3D vision, LiDAR-based cameras, machine vision, and artificial intelligence. Zhang et al. [
17] introduced a 3D vision-based method for detecting container positions, aiding stacker spreader adjustments. However, the need for depth camera calibration makes this approach time-consuming. Similarly, Zhang et al. [
18] leveraged LiDAR for container positioning and trajectory planning, integrating a fuzzy adaptive PID control algorithm for crane positioning. While LiDAR is robust to environmental factors, its high cost and limited accuracy pose significant drawbacks [
19].
Machine vision techniques have also been explored for corner casting detection. Diao et al. [
20] combined hybrid machine vision with a multi-class support vector machine, while Shen et al. [
21] applied image processing techniques such as HSV color space analysis and Hough Transform. However, these methods require parameter adjustments for different container sizes, making them less adaptable. Lee et al. [
22] used recurrent neural networks (RNNs) and long short-term memory (LSTM) for detection, yet traditional machine vision methods remain sensitive to environmental variations like container color and contamination. In AI-based approaches, Zhang et al. [
1] employed a modified Single-Shot Multibox Detector with a Programmable Logic Controller (PLC) for automated rail-mounted gantry (ARMG) control, achieving high accuracy but requiring specialized PLC knowledge and infrastructure, making it impractical for SMEs.
Zero-shot detection (ZSD) offers a promising alternative, though its adoption in engineering applications remains relatively limited. Researchers have harnessed CLIP’s capabilities to develop zero-shot object detection methods aimed at improving order accuracy in food packing [
23]. Son et al. [
24] demonstrated the feasibility of ZSD by utilizing Grounding DINO for auto-labeling CCTV and smartphone footage, significantly reducing costs. Building upon the potential of ZSD and Grounding DINO, this study aims to integrate zero-shot detection into automated corner casting detection, with a focus on cost-effective implementation through object detection in intelligent perception and robotic controls.
Our main contributions are as follows:
Introducing a new prompt engineering framework based on Referring Expression Compression (REC) and Additional Feature Keywords (AFKs) to improve model implementation and deployment;
Conducting a detailed analysis of zero-shot detection and single-shot detection (SSD) models for detecting shipping containers and corner castings;
Evaluating the feasibility and efficiency of these detection models when deployed on edge devices, considering factors like mean Average Precision (mAP) and detection score.
2. Materials and Methods for Zero-Shot Detection
As shown in
Figure 1, Grounding DINO begins by extracting fundamental image and text features using dedicated image and text backbones. These features are then processed through a feature enhancer network, which facilitates cross-modal fusion between image and text representations. Next, a language-guided query selection module identifies relevant cross-modality queries from the extracted image features. These queries are then fed into a cross-modality decoder, which refines and adapts them to extract meaningful bimodal features. This step ensures that the model effectively links textual descriptions with corresponding visual elements. Finally, the model generates object proposals for each detected object in the natural language input. These proposals incorporate diverse features such as color, shape, and texture, leveraging Grounding DINO’s extensive pre-training on datasets like O365, GoldG, Cap4M, and COCO, ensuring robust and accurate object detection.
Figure 2 illustrates the comparison of workflow utilizing conventional object detection techniques with single-shot detection and zero-shot detection. The workflow for zero-shot detection is notably shorter, thanks to the absence of dataset preparation and training prerequisites, rendering the entire process significantly faster and easier to implement. Upon successful detection of the shipping container by the model in Raspberry Pi, the next step involves pinpointing the locations of the corner casting holes using machine vision. Once the hole locations are determined, the Raspberry Pi transmits a signal to the Programmable Logic Controller (PLC) to commence the lowering of spreader procedure. This signal transmission occurs through the General-Purpose Input/Output (GPIO) pins on the Raspberry Pi, which are directly connected to the PLC. The conical top is then lowered into the corner casting hole and rotated to secure the container in place.
Grounding DINO is classified into three main tasks based on text type: open-vocabulary detection, phrase grounding, and Referring Expression Comprehension (REC). The model processes an (image, text) pair by generating multiple object box and noun phrase pairs, effectively linking visual elements to textual descriptions. As illustrated in
Figure 3, the model identifies key objects, such as a shipping container and a corner casting hole, within an input image. It then extracts corresponding class labels, recognizing “container” and “hole” from the input text. This capability highlights Grounding DINO’s strength in associating textual prompts with visual features, facilitating precise object detection. This process leverages Natural Language Processing (NLP) to interpret and understand the textual input, enhancing the model’s ability to accurately detect and classify objects based on the provided descriptions.
Our primary goal is to detect corner casting holes located on the top of shipping containers using a two-step approach. First, we identify the shipping container, followed by the detection of corner casting holes. This sequential method enhances accuracy by initially detecting the larger, more distinguishable container before narrowing focus to the smaller, intricate corner castings. This process is an integral part of intelligent perception and control in robotics, facilitating automated systems to interpret and interact with their environment effectively. To achieve this, we harness the capabilities of Large Language Models (LLMs) and employ Grounding DINO for object identification based on textual prompts. The model distinguishes key elements within a phrase, such as recognizing “container” and “corner hole” as separate entities in “container with corner hole.” Similarly, in “corner hole on the roof of container”, it identifies “corner hole” and “roof” as distinct objects, ensuring precise localization. As shown in
Figure 4, we enhance detection accuracy by incorporating Additional Feature Keywords (AFKs)—descriptive terms that provide supplementary contextual information beyond standard class labels. Examples of AFKs include “extreme”, “roof”, and “top”, which help refine object identification and improve model performance in detecting corner castings in complex scenarios.
As depicted in
Figure 5, the first step involves confirming the object classes with predefined categories. This involves comparing the detection results with known classes specified in the ground truth annotations. The ground truth annotations of custom dataset is provided in
Supplementary Material S2. If the model encounters difficulties in detecting less common classes, such as the ‘corner casting hole,’ which may not be readily recognized due to its uncommon usage, it can lead to challenges in accurately identifying and localizing these specific objects. To address this issue, we revise prompt engineering to incorporate more commonly used phrases such as ‘corner hole’ or ‘extreme corner’. Once the model successfully detects both classes, with the assistance of Referring Expression Comprehension (REC) intervention, a control command will be transmitted to the gantry motor through the Raspberry Pi’s GPIO pins.
Our study focuses on detecting corner casting holes on container roofs, which are essential for securing spreaders. Using Grounding DINO’s zero-shot detection, we test three open-source images as shown in
Figure 6, featuring containers from different perspectives—left, right, and center—within the camera’s field of view. Each container presents unique challenges. Container 1 has a white body that blends with the background, making detection difficult, and corner casting hole 1A is less visible. Container 2 is partially visible, but its corner casting hole 2A is clearly distinguishable. Container 3 offers a distinct test case, featuring two visible corner castings (3A and 3B) in a full front view. By analyzing these varying conditions—including occlusion, color similarity, and different viewing angles—we evaluate the model’s ability to accurately detect corner casting holes, ensuring robust performance in real-world applications. This is part of our broader effort in intelligent perception, aiming to enhance the model’s capability to interpret and understand complex visual environments.
2.1. Box and Text Thresholds
Grounding DINO processes an image–text pair and generates 900 object boxes with confidence scores. Each box is evaluated using two thresholds: (1) box_threshold, which filters out low-confidence detections, and (2) text_threshold, which selects words with high similarity scores to the detected objects. For Container 1, we focus on corner casting C1A at the extreme front right, as the front left corner is harder to detect due to distance. For Container 2, C2A on the front left is used as the primary reference, while C2B, another clearly visible corner casting, is also included as ground truth. Container 3 has two front-facing corner castings (C3A and C3B) that serve as reference points due to their clear visibility. The final evaluation involves calculating the average successful detections of corner castings across all test cases, assessing the model’s accuracy and reliability in detecting these crucial structural elements.
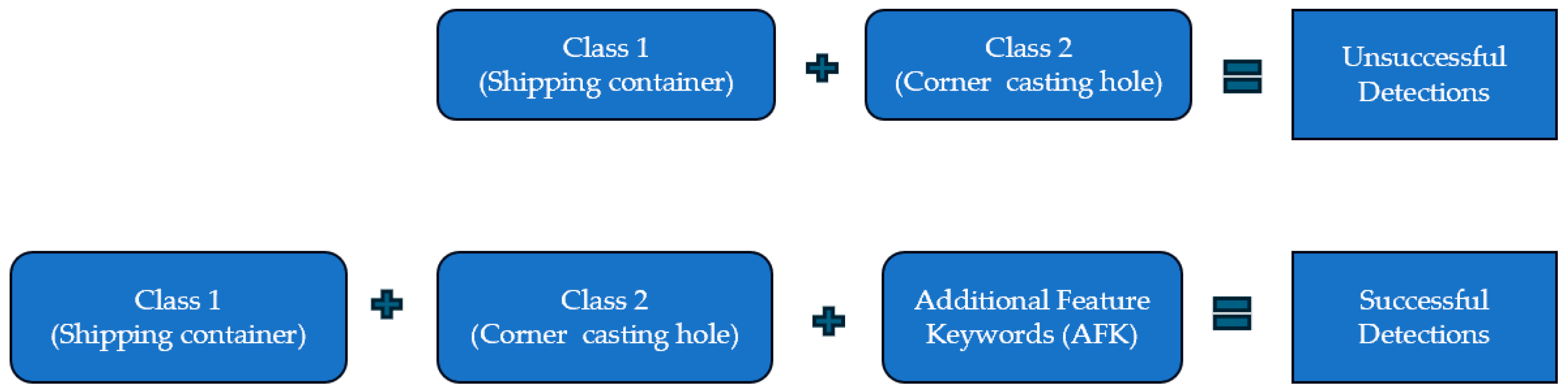
2.2. REC with AFKs
Table 1 shows the evaluation method using prompt phase with REC. In total, there are 8 evaluation test cases with two classes, “shipping container” and “corner hole”. Our initial test involves applying Grounding DINO to simple text prompts such as ‘corner casting hole’ and ‘corner hole.’ This test aims to assess the system’s effectiveness in detecting straightforward prompts before proceeding to evaluate its performance with various Additional Feature Keywords (AFKs) in the REC.
In our research, we employ the careful selection of keywords as it is vital for accurate detection. For example, the terms like “top” and “roof” have distinct meanings: “top” refers to a point above the container, while “roof” specifies the surface directly above the container. The term “only” helps narrow the focus, ensuring that the model considers only the specified area, excluding other potential locations.
The AFKs are denoted by bold formatting for clarity:
REC1: “Corner casting hole on top only”
REC2: “Corner hole on top only”
REC3: “Hole on extreme corner only”
REC4: “Hole on extreme top corner”
REC5: “Corner hole on roof of shipping container”
REC6: “Corner hole located on roof of shipping container only”
2.3. Prompt Engineering Based on Zero-Shot Detection
As detailed in
Table 1, eight evaluation test cases were designed using prompt phases with REC to systematically assess detection performance. For improved clarity, enlarged and clearer versions of the ZSD prompt engineering results corresponding to these test cases are provided in
Supplementary Material S1.
2.3.1. Prompt 1: “Corner Casting Hole”
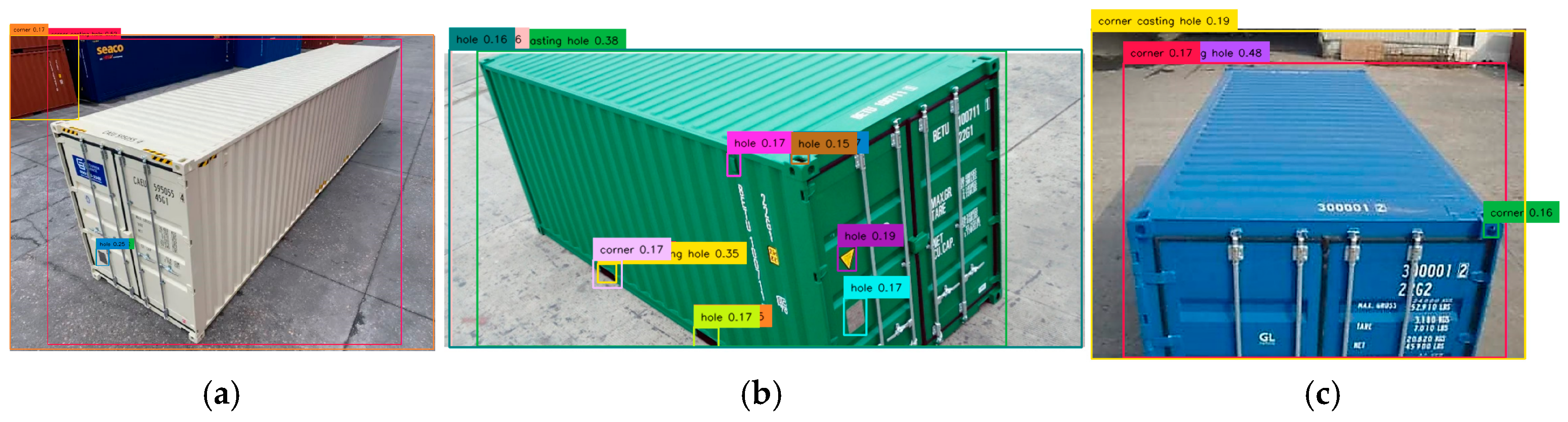
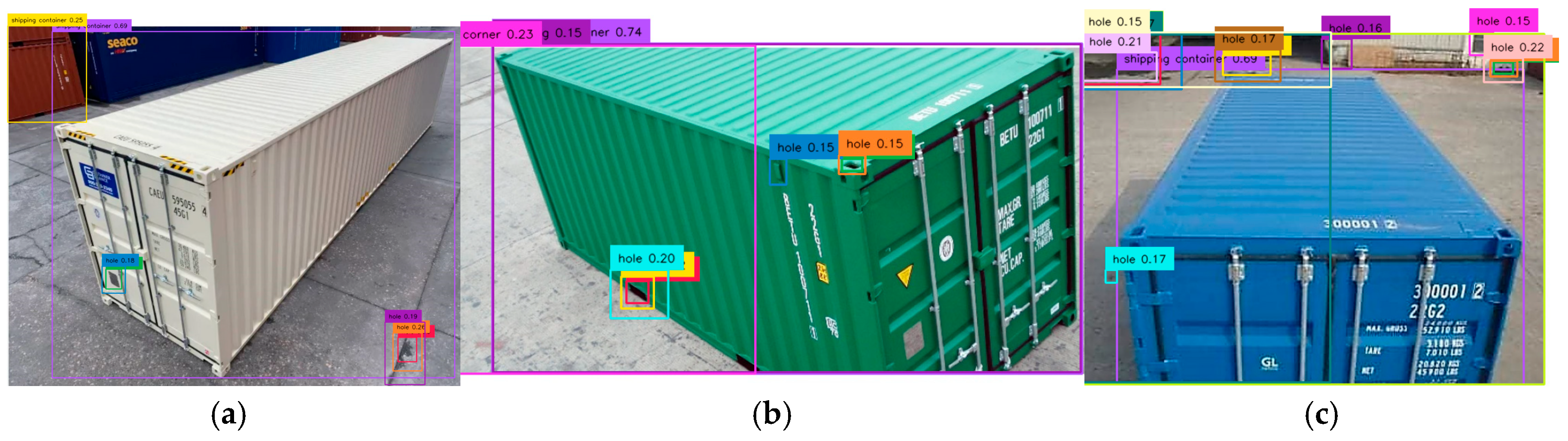
The prompt “corner casting hole” was used to detect corner castings on three containers, as shown in
Figure 7. No positive detections were found for Containers 1 and 3, while Container 2 had a 15% detection for corner casting C2A, though the text detected was “hole” instead of “corner casting hole.” Another detection for Container 2 correctly identified “corner casting hole” but was mislocated at the bottom with a 35% confidence level. Additionally, entire container bodies were mistakenly detected as corner casting holes with high confidence levels (52% for Container 1, 38% for Container 2, and 46% for Container 3), indicating a possible misalignment of the term “casting” with the Grounding DINO training dataset. No shipping containers were detected, as they were not mentioned in the prompt.
2.3.2. Prompt 2: “Corner Hole”
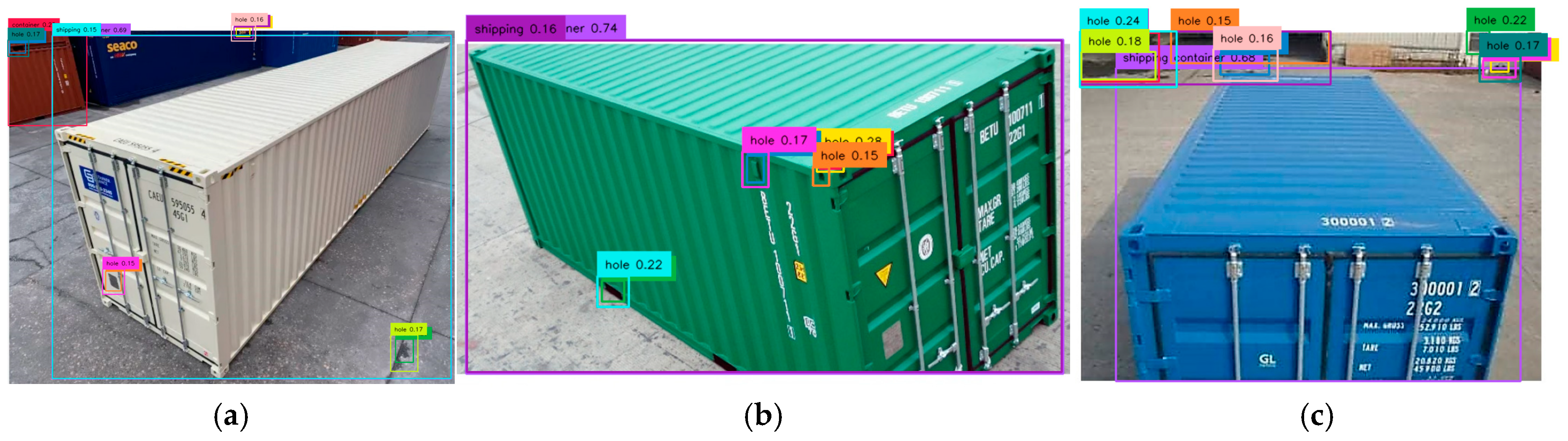
After analyzing the misdetections, we simplify the terminology in the prompt to “corner hole” by removing the less familiar term “casting.” As shown in
Figure 8, only Container 2 exhibited a positive detection for the corner hole, while no detections were observed for Container 1 and Container 3. Misdetections persisted for Containers 1 and 2, where either the entire container or background holes were incorrectly identified as corner holes. For Container 2, a single detection was recorded for corner casting C2A, with a confidence level of 16% (orange).
2.3.3. Prompt 3: “Shipping Container. Corner Casting Hole on Top Only”
To prevent misclassification of the container as a corner hole, the prompt “shipping container” was introduced, along with the Additional Feature Keywords (AFKs) “on top only” to refine positioning. These constraints shifted all detections upward, eliminating unwanted hole detections at the bottom of Containers 1 and 2, but also rendered corner casting 3A undetectable, as shown in
Figure 9. The shipping container was detected with high confidence levels—71% for Container 1, 70% for Container 2, and 64% for Container 3—indicated by purple boxes. These results suggest the model can generalize well to the “shipping container” object, despite not being explicitly trained on it.
2.3.4. Prompt 4: “Shipping Container. Corner Hole on Top Only”
To improve detection, we removed the word “casting”, and, as shown in
Figure 10, Prompt 4 restored the detection of corner casting 2A (brown box) on Container 2 with a 20% confidence level. It also enabled the detection of corner casting 3A (brown, 18%) and corner casting 3B (cyan, 16%) on Container 3. However, Grounding DINO still failed to detect the corner casting on Container 1. Consistent with previous prompts, the shipping container was detected with high confidence levels—69% for Container 1, 74% for Container 2, and 66% for Container 3—indicated by purple boxes.
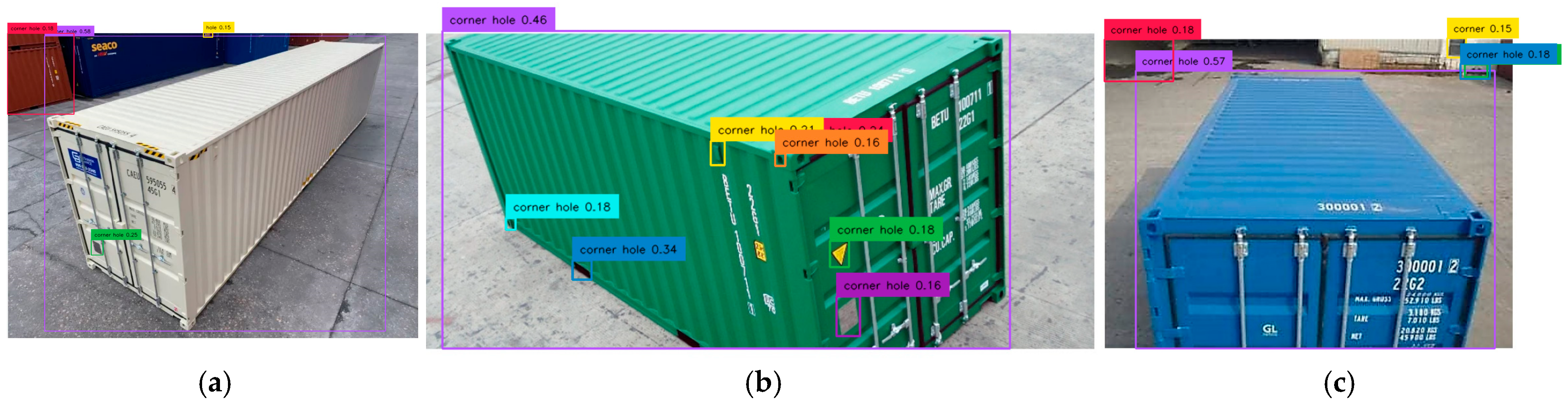
2.3.5. Prompt 5: “Shipping Container. Hole on Extreme Corner”
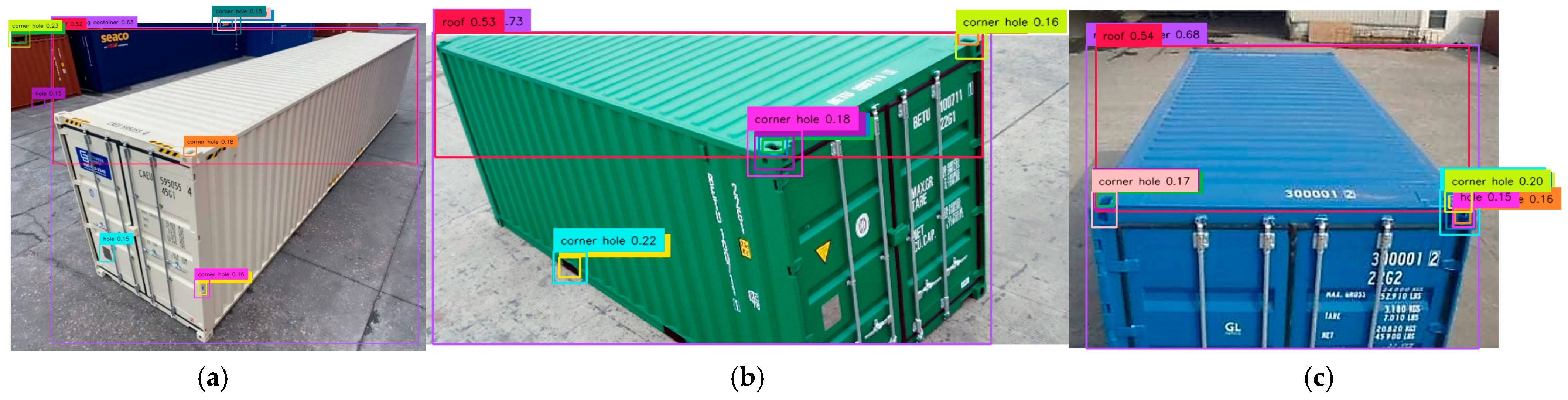
To reduce false detections of holes at the lower part of the container, Prompt 5 was designed using two Additional Feature Keywords (AFKs): “extreme” and “corner.” The AFK “extreme” helps the model focus on holes at the extreme edges. As shown in
Figure 11, two damp patches on the extreme right bottom of the image were mistakenly detected as holes (purple and brown boxes). Container 2 correctly detected corner casting 2A (brown, 15%), while Container 3 had multiple false detections of background holes and one ground hole (cyan, 17%).
2.3.6. Prompt 6: “Shipping Container. Hole on Extreme Top Corner”
To reduce false detections on the holes at the lower part of the container, we engineered Prompt 6 as a combination of three AFKs: “extreme”, “top”, and “corner”. It is similar to Prompt 5, except it has an additional AFK “top”. This helped to remove one of the ground detections on Container 1 and ground hole on Container 3, as shown in
Figure 12. For Container 2, there was an accurate detection for corner casting 2A (yellow, 28%). The level of confidence was 13% higher than Prompt 5. As for the shipping container, it was detected with a 69% confidence level for Container 1, 74% for Container 2, and 68% for Container 3. All the detections are indicated with a purple box. Only Container 3 had a slight drop of 1% compared to Prompt 5.
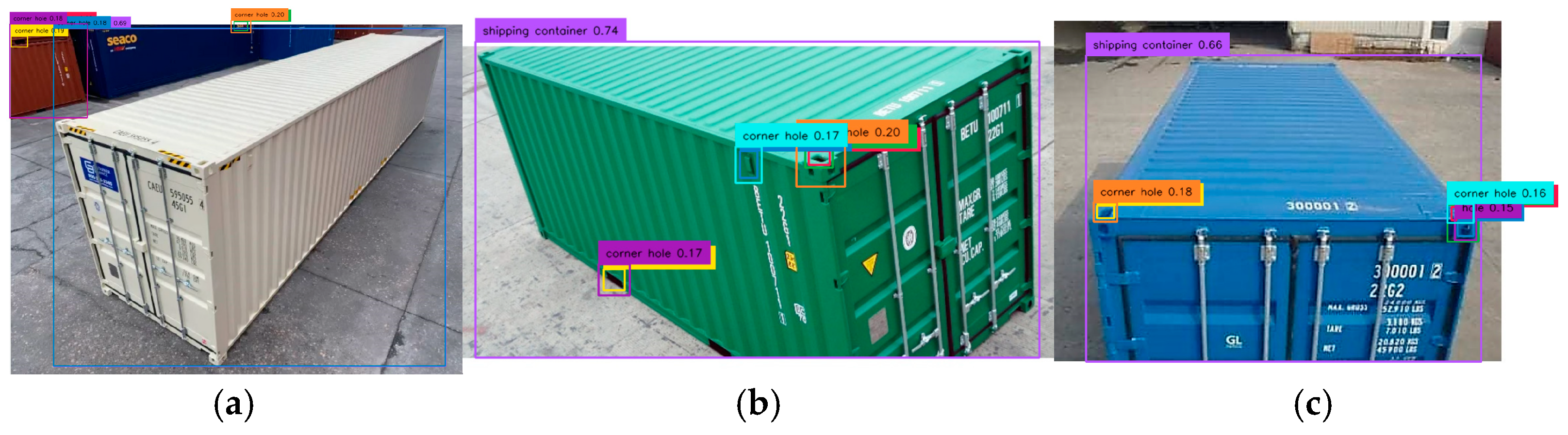
2.3.7. Prompt 7: “Corner Hole on Roof of Shipping Container Only”
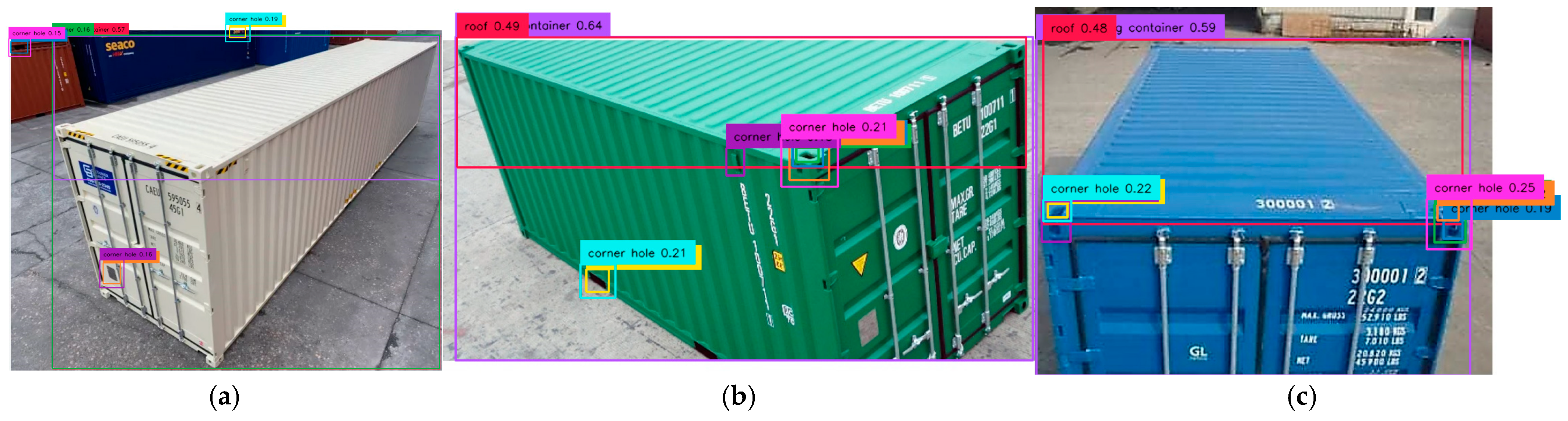
Prompt 7 introduced the AFK “roof” to improve corner hole detection accuracy, successfully identifying corner castings across all containers. As shown in
Figure 13, there were detections for Container 1’s corner casting 1A (18%) and Container 2’s corner castings 2A (18%) and 2B (16%)—the first detection of 2B. There were also identifications of Container 3’s corner castings 3A (17%) and 3B (20%). The prompt also enabled roof detection with confidence levels of 52% (Container 1), 53% (Container 2), and 54% (Container 3), marked by red boxes. Shipping container detection remained high at 63% (Container 1), 73% (Container 2), and 68% (Container 3), with only a slight 3% confidence drop for Container 1 compared to Prompt 6.
2.3.8. Prompt 8: “Corner Hole Located on Roof of Shipping Container Only”
Adding the keywords “located” and “only” to REC6 aimed to improve detection but led to the loss of corner casting 1A for Container 1, as shown in
Figure 14. Detection was maintained for Container 2’s corner casting 2A at 18% confidence and Container 3’s corner hole 3A (16%) and corner casting 3B (16%), though both saw slight confidence drops of 1% and 4%, respectively, compared to Prompt 7. Shipping container detection also declined, with confidence levels of 57% (Container 1), 64% (Container 2), and 59% (Container 3), reflecting drops of 8%, 13%, and 12%. This suggests that the verbosity of REC6 may have negatively impacted accuracy, highlighting the need for simpler terms.
2.4. Detection Score of Corner Castings
Table 2 presents a summary of detections for corner castings, detailing the number of corner castings detected and highlighting the highest detection score among the identified corner castings. Clearly, the text prompt “corner hole on roof of shipping container” yielded the most favorable results. Our analysis suggests that Grounding DINO exhibits enhanced detection capabilities when the AFK “roof” is employed. As Test Case 7 exhibited the highest detection rate (5 out of 6) and the highest average detection confidence, it served as the basis for calculating the sustainability score of ZSD. The use of AFKs such as ‘extreme’ and ‘only’ improved detection accuracy. ‘Only’ restricted the focus to targeted areas and ‘extreme’ guided the model towards boundary features, resulting in more precise corner casting localization.
2.5. Detection Scores of Shipping Containers
Table 3 shows that explicitly mentioning “shipping container” significantly improved detection confidence, with scores exceeding 71% when it was labeled as a separate prompt. Test Case 6 achieved the highest average detection score at 70.67%. The model’s ability to exclude detections when the prompt is unrelated (as seen in Test Cases 1 and 2) demonstrates strong language understanding.
2.6. Average Precision of Corner Casting
The Average Precision (AP) metric evaluates the model’s performance in corner casting detection by measuring precision and recall. Using a 0.15 box threshold and 0.15 text threshold yielded the highest number of positive detections. Prompt 7 was selected to generate detection scores for the three images, with a focus on corner castings rather than shipping containers due to their smaller size and detection difficulty. The mean Average Precision (mAP) serves as a benchmark to compare zero-shot detection (ZSD) and supervised object detection (SSD). The ground truth annotations, illustrated in
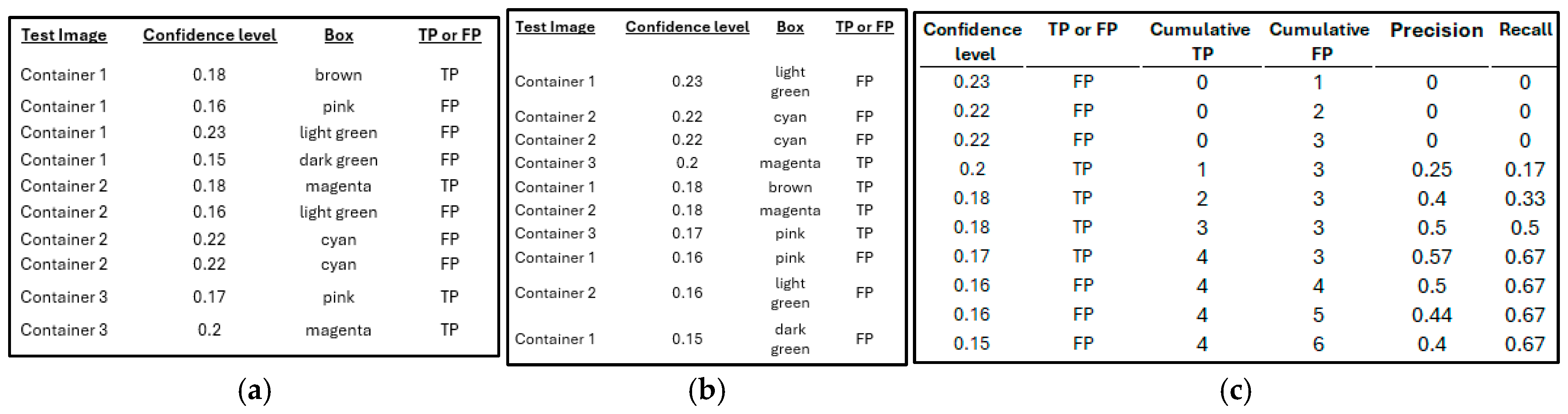
Figure 15, serve as a benchmark for evaluating detection performance. Precision and recall are computed manually from the sorted textual output scores, leveraging true positives (TPs) and false positives (FPs) to quantify detection accuracy for both corner castings and shipping containers.
As shown in
Figure 16, predictions are sorted by descending confidence levels, and cumulative true positives and false positives are tabulated to calculate precision and recall. The precision–recall curve is summarized using the Average Precision (AP), which is calculated as the area under the curve using Simpson’s numerical integration method. Simpson’s rule, preferred for its accuracy over the trapezoidal rule, uses a quadratic polynomial approximation. The formula for Simpson’s rule is given below, where a quadratic polynomial passes through the points (
x0,
f0); (
x1,
f1); (
x2,
f2), where
f1 =
f(
x1).
The formula for Simpson’s rule is provided and the mean Average Precision for Grounding DINO is calculated as 24.398%. The formulas for precision and recall for the manual calculation of mAP are below:
Recall indicates the model’s ability to correctly identify all relevant instances. The denominator for recall is always 6, representing the number of ground truths (specifically, six corner castings).
5. Discussion and Statistical Analysis
The observed performance gap underscores the inherent trade-offs between supervised and self-supervised learning approaches. Supervised models, such as SSD320 FPNLite, EfficientDet-Lite0, and MobileNetV2, benefit from large, annotated datasets, enabling higher accuracy. In contrast, self-supervised models like Grounding DINO excel in scenarios with limited labeled data but exhibit lower precision, as reflected by a mean Average Precision (mAP) of 24.4%. Nevertheless, Grounding DINO achieved a 7.14% higher detection score than the SSD models, highlighting its effectiveness despite the absence of training.
To further strengthen the analysis of Grounding DINO’s detection performance compared to the SSD models, an approximation of Cohen’s d [
26] analysis was performed. The standard deviation of the SSD models was computed as 2.52 and the resulting effect size was 2.2, indicating a significant difference in detection performance. Cohen’s d is given by
where M
2 represents the detection score of Grounding DINO, M
1 is the average detection score of the SSD models, and SD
2 is the standard deviation of the SSD models.
The results demonstrate that Grounding DINO outperforms the SSD models, achieving a mean detection score of 17.8%, compared to 10.66% for the SSD models. This substantial difference highlights Grounding DINO’s superior ability to detect corner castings without prior training, leveraging Referring Expression Comprehension (REC) and Additional Feature Keywords (AFKs). The large effect size (Cohen’s d = 2.2) further reinforces the magnitude of this performance gap, emphasizing Grounding DINO’s enhanced detection capability compared to traditional SSD models. The improvement in detection accuracy achieved by Grounding DINO, despite a lower mAP, demonstrates practical relevance for applications in resource-constrained environments.
The large effect size (Cohen’s d = 2.2) observed in this study indicates that the performance difference compared to SSD models is both statistically and practically significant, supporting the effectiveness of prompt engineering in zero-shot detection. Similar use of effect size analysis in object detection, such as by Jung et al. [
27], has highlighted the value of quantifying such differences to assess real-world impact. Moreover, improvements in detection accuracy have been shown to enhance operational efficiency and reliability in various industrial contexts, including defect detection in manufacturing [
28] and real-time object recognition in intelligent transport systems [
29]. These findings suggest that the performance gains achieved by Grounding DINO can contribute to more efficient and scalable automation solutions.
7. Conclusions
In this work, we demonstrated the potential of the Grounding DINO model on a Raspberry Pi to effectively detect holes in shipping containers from images. By utilizing zero-shot detection in the automated corner casting detection, we were able to prioritize cost-effectiveness in development. This is part of our broader effort in intelligent perception and automated rail-mounted gantry control, enhancing the model’s capability to interpret and understand complex visual environments.
We introduced an innovative NLP-framework combining Referring Expression Comprehension (REC) and Additional Feature Keywords (AFKs) to achieve successful detection on the Raspberry Pi without any model training. Additionally, we provided a comparison between zero-shot detection (ZSD) and single-shot detection (SSD). Grounding DINO was selected for the automated container lifting system due to its high detection accuracy, detecting objects and assigning scores that activated the Raspberry Pi’s GPIO pins once scores exceeded a set threshold. This controlled the twist lock mechanism, ensuring precise and reliable container handling.
Our work highlighted that supervised models, such as SSD320 FPNLite, EfficientDet-Lite0, and MobileNetV2, benefit from large, annotated datasets, resulting in higher accuracy. In contrast, Grounding DINO, despite offering large language model (LLM) capabilities to auto-annotate objects, lagged in precision, as evidenced by its lower mAP but higher detection score, leading to a high effect size (Cohen’s d = 2.2). For validation, we demonstrated that the mAP of our SSD models exceeded that of the COCO2017 dataset.
In summary, this study demonstrates the effective application of Grounding DINO for detecting shipping container corner castings on a Raspberry Pi, leveraging zero-shot detection as a cost-efficient solution. While Grounding DINO showcased significant potential, supervised models like SSD320 FPNLite exhibited higher precision. Given the critical importance of high detection accuracy in mitigating safety risks, future research will aim to optimize inference timing for real-time detection, further enhancing intelligent perception and automated rail-mounted gantry control systems through zero-shot detection.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}