Abstract
Video emotion recognition faces significant challenges due to the strong spatiotemporal coupling of dynamic expressions and the substantial variations in cross-scale motion patterns (e.g., subtle facial micro-expressions versus large-scale body gestures). Traditional methods, constrained by limited receptive fields, often fail to effectively balance multi-scale correlations between local cues (e.g., transient facial muscle movements) and global semantic patterns (e.g., full-body gestures). To address this, we propose an enhanced attention module integrating multi-dilated convolution and dynamic feature weighting, aimed at improving spatiotemporal emotion feature extraction. Building upon conventional attention mechanisms, the module introduces a multi-branch parallel architecture. Convolutional kernels with varying dilation rates (1, 3, 5) are designed to hierarchically capture cross-scale the spatiotemporal features of low-scale facial micro-motion units (e.g., brief lip tightening), mid-scale composite expression patterns (e.g., furrowed brows combined with cheek raising), and high-scale limb motion trajectories (e.g., sustained arm-crossing). A dynamic feature adapter is further incorporated to enable context-aware adaptive fusion of multi-source heterogeneous features. We conducted extensive ablation studies and experiments on popular benchmark datasets such as the VideoEmotion-8 and Ekman-6 datasets. Experiments demonstrate that the proposed method enhances joint modeling of low-scale cues (e.g., fragmented facial muscle dynamics) and high-scale semantic patterns (e.g., emotion-coherent body language), achieving stronger cross-database generalization.
1. Introduction
In the field of multimodal affective computing, user-generated videos present dual challenges for emotion analysis due to their spatiotemporal heterogeneity and multimodal complexity. Existing methods exhibit notable limitations in receptive field design. Traditional convolutional networks (e.g., 3 × 3 base convolutions) are constrained by fixed-scale local perception, with theoretical receptive fields typically covering merely tens of pixels, insufficient for modeling the pervasive multiscale contextual dependencies in emotional expressions. For instance, facial micro-expressions (e.g., transient 0.2 s lip twitches) require high-density local sampling to capture transient motion patterns, while body movements (e.g., 3 s arm-swing trajectories) demand long-range temporal integration across hundreds of frames. However, mainstream models (e.g., SE [1], CBAM [2]) employing global pooling or single-branch convolutions universally suffer from receptive field-target scale mismatch. On the one hand, undersized receptive fields (e.g., 7 × 7) allow local details to dominate global decisions while neglecting semantic correlations between body movements and scene context. On the other hand, naively enlarging kernel sizes (e.g., 13 × 13) expands spatial coverage but induces model degradation through parameter explosion and noise accumulation (ImageNet experiments show a 4.7% accuracy drop compared to multiscale designs). This contradiction is particularly acute in video emotion tasks, where emotional expressions often manifest through multilevel couplings between microscopic facial action units (e.g., corrugator muscle contractions) and macroscopic body language (e.g., retreating gait), and where rigid single-scale receptive fields in existing models fail to achieve cross-scale dynamic semantic alignment.
To address these limitations, we propose a hierarchical receptive field expansion architecture that overcomes conventional scale constraints through progressive spatiotemporal coverage using dilated convolutions. Specifically, we construct three parallel branches with differentiated dilation rates (d = 1, 3, 5), corresponding to equivalent receptive fields of 3 × 3, 7 × 7, and 13 × 13. The bottom branch employs dense sampling to capture transient muscular movements (e.g., eyelid tremor frequency); the middle branch models dynamic correlations among facial action units through cross-frame feature interaction (e.g., temporal synchronization between lip twitching and frowning); and the top branch utilizes dilated sampling to extract persistent trajectories of body movements (e.g., gradual intensification of hand-waving amplitude with emotional intensity). Extensive experiments validate that our proposed method achieves state-of-the-art performance across multiple video emotion datasets, demonstrating its effectiveness and robustness in affective computing applications.
2. Related Work
In the feature learning mechanisms of deep neural networks, structural innovations to achieve efficient feature representation and multi-scale information fusion remain central challenges for enhancing model performance. Current research efforts have primarily advanced along two technical pathways: (1) enhancing feature decoupling capabilities for heterogeneous patterns through feature grouping strategies, and (2) constructing hierarchical spatial perception frameworks using dilated convolutions. The former promotes feature diversity through grouped architectural designs, while the latter focuses on balancing receptive field expansion with resolution preservation. This section systematically reviews research progress in both directions, with particular emphasis on attention co-optimization in feature grouping techniques and innovative applications of dilated convolutions in multi-scale modeling, thereby laying the theoretical foundation for subsequent methodological innovations.
2.1. Feature Grouping
Deep convolutional neural networks have adopted a more prominent network topology in the field of image classification and object detection tasks. When we extend CNN to span multiple convolutional layers, it shows a remarkable ability to enhance the learned feature representation. However, it leads to stacking deeper convolutional counterparts and requires significant memory and computational resource consumption, which is the main drawback of building deep CNNs [3,4]. Feature grouping technology provides a solution to this problem, with its core objectives centered on enhancing computational efficiency and model representational capacity. Early research was pioneered by AlexNet [5], which significantly improved training efficiency by distributing computational tasks across multi-GPU environments through grouped convolutions. This foundational work subsequently inspired in-depth explorations of grouped architectures. ResNext [6] revealed that distinct subgroup features exhibit markedly divergent responses to spatial patterns and noisy backgrounds when increasing grouping numbers, thereby demonstrating the potential of grouping techniques to enhance feature diversity.
As research progressed, scholars began investigating hierarchical processing mechanisms for grouped features. Res2Net [7] proposed a hierarchical feature transmission architecture that enables simultaneous capture of multi-scale spatial information through progressive fusion of subgroup features across different levels. Building upon this framework, SGE [8] introduced global information guidance to amplify feature activations in semantic regions while suppressing noise interference through inter-group relationships. However, this approach maintained a separation between spatial and channel attention mechanisms, failing to effectively model their synergistic interactions. To address this limitation, the SA [9] method constructed a dual-branch architecture via channel grouping to separately model attention correlations in spatial and channel dimensions. Nevertheless, constrained by fixed grouping strategies, its modeling of cross-channel interactions remains insufficient.
In the optimization of attention mechanisms, researchers have pursued diverse implementation pathways. Non-local networks [10] proposed establishing global dependencies through self-attention mechanisms by computing correlations between all positions in feature maps to capture long-range spatial relationships. While this approach notably enhances contextual modeling capabilities, its fully connected similarity matrix computation leads to quadratic growth in time complexity, with particularly prohibitive memory consumption in high-resolution feature scenarios, severely limiting practical deployment viability. In contrast, triplet attention [11] innovatively introduced tensor rotation operations to fuse cross-channel and spatial information through three complementary attention branches. However, its simplistic averaging strategy for attention weight fusion struggles to effectively enhance discriminative feature representation in deep layers. These advancements collectively highlight that achieving synergistic optimization of spatial and channel attention mechanisms while maintaining computational efficiency remains a critical challenge requiring breakthrough solutions in current feature grouping technologies.
2.2. Atrous Convolutions
In image processing tasks, deep convolutional neural networks (CNNs) have long grappled with the inherent contradiction between information loss caused by pooling layers and upsampling operations. Taking classical architectures like fully convolutional networks [12] (FCNs) as an example, their successive pooling operations progressively reduce feature map dimensions to expand receptive fields, simultaneously lowering computational complexity at the expense of resolution degradation and local detail obliteration. When networks incorporate four pooling layers, microscopic objects smaller than 16 × 16 pixels in original images completely lose spatial information through multi-stage downsampling, rendering subsequent upsampling incapable of reconstructing meaningful features. This “compression–expansion” paradox proves particularly acute in image segmentation tasks; while pooling layers effectively capture high-level semantic context, irreversible loss of high-frequency details during resolution recovery severely constrains pixel-level prediction accuracy. To resolve this dilemma, researchers pioneered dilated convolutions as an innovative solution; by inserting zero-value intervals between convolutional kernel elements, this design achieves exponential receptive field expansion without feature map reduction, thereby eliminating dependency on downsampling–upsampling chains.
The transformative potential of this breakthrough technology rapidly transcended its original application in image segmentation. Following the formal introduction of dilated convolutions by Fisher Yu [13] in 2016, DeepMind promptly integrated them into speech synthesis through WaveNet [14], which captured thousands of step temporal dependencies via temporal dilated convolutions, overcoming gradient propagation bottlenecks in traditional recurrent networks. In natural language processing, their sparse sampling properties enabled efficient modeling of long textual sequences. For object detection, even without pixel-wise prediction requirements, maintaining high-resolution feature maps significantly enhanced small-target detection robustness. More profoundly, dilated convolutions reshaped modern deep learning architectures through multi-scale feature pyramids constructed via hierarchical dilation rates, from submillimeter lesion localization in medical imaging to long-range obstacle recognition in autonomous driving. Their dual advantages of large receptive fields and high resolution continuously push computer vision accuracy toward human-level performance.
Multi-scale convolution enriches feature space representation by aggregating spatial information across varying kernel sizes at identical processing stages. The Inception architecture exemplifies this through multi-branch structures with diverse local receptive fields, enabling CNN feature aggregation from heterogeneous scales. Selective Kernel Networks further advance this concept via adaptive receptive field adjustment strategies that autonomously optimize feature representation. Complementing these approaches, EPSANet [15] introduces multi-scale pyramid structures to replace conventional 3 × 3 convolutions, achieving cross-channel interaction through local modeling while independently learning multi-scale spatial features, thereby balancing feature richness and computational efficiency.
Diverging from conventional attention mechanisms, our proposed module establishes hierarchical receptive fields through multi-dilation-rate convolutional branches, employs channel-grouping strategies for parallel subspace feature decoupling, and dynamically fuses multi-scale attention weights via adaptive gating mechanisms. This design transcends traditional static aggregation limitations, simultaneously enhancing local micro-expression detail preservation and continuous body movement modeling through cross-spatial pixel-level interactions.
3. Methodology
3.1. Visual-Audio Representation Extraction
Visual Representation Extraction Method: To extract visual features from user-generated videos, this study references established methodologies. First, temporal segmentation was applied to input videos, uniformly dividing each video into T equal-length segments with each segment lasting τ seconds. For each segment, a random window sampling strategy was employed to capture k consecutive video frames as representative inputs. Subsequently, a 3D ResNet-101 model pre-trained on the ImageNet-1k and Kinetics-400 datasets was utilized for deep feature extraction. After the forward propagation, each video segment was encoded into a feature vector of dimension . The complete visual representation of video l was formed as a concatenated feature sequence , where d denotes the feature dimension. This representation serves as input to the multimodal fusion module.
Audio Representation Extraction Method: To construct a multimodal feature space, this study synchronously extracted audio stream features as complementary information to visual data. Mel frequency cepstral coefficients (MFCCs) were adopted as the foundational audio features, a time-frequency analysis method validated by multiple studies for effective speech feature representation. Specifically, for each video’s audio stream, preprocessing operations including pre-emphasis, framing, and windowing were first applied to obtain time-domain signal characteristics. These signals were then processed through short-time Fourier transform and Mel filter banks, ultimately generating audio descriptors with C′-dimensional cepstral coefficients for each video segment, where H′ and W′ represent the height and width of the audio feature map. To maintain cross-modal alignment, the audio stream adopted the same segmentation strategy as the visual features, with the original audio feature sequence resampled into T segments. A feature projection layer adjusted the dimensionality of the audio features to ensure consistency between audio and visual feature dimensions (C = C′ = d), thereby constructing a fusion-ready audio feature matrix .
3.2. Multi-Scale Parallel Synergistic Enhancement Attention
To establish a multiscale spatiotemporal feature representation framework for video emotion recognition, this study proposes a multi-scale parallel synergistic enhancement attention module (MPE). Addressing inherent limitations in conventional attention mechanisms for spatiotemporal feature modeling—including insufficient spatial-channel dimensional interactions, inefficient integration of local details with global context, and rigid multiscale feature fusion strategies—we innovatively designed a multi-dilated fusion enhancement module. This module constructs hierarchical spatiotemporal receptive fields through three-tier differentiated dilated convolutions, coupled with a dynamic gated weighting fusion mechanism, enabling multigranular feature extraction from transient micro-expressions to sustained body movements. Through channel-grouping strategies and dual-branch interactive architecture, the design simultaneously reduces computational complexity while strengthening cross-spatial semantic correlation modeling. The module structure is shown in Figure 1.
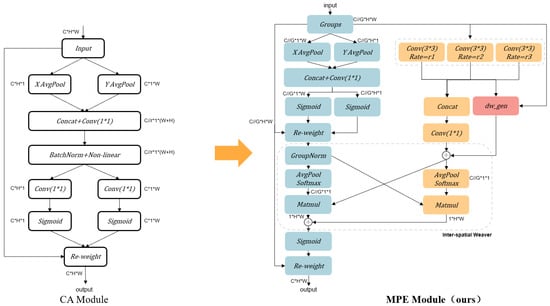
Figure 1.
Specific details of the MPE modules presented.
Hardware Deployment Implementation: At the hardware deployment level, the module adopts a channel-grouped sharing strategy, partitioning the input feature along the channel dimension into n mutually exclusive subsets and these subsets independently undergo multiscale feature extraction. This design enables the three dilated branches to share a common underlying feature basis space, where each branch only maintains lightweight convolutional kernels with reduced channel dimensions while preserving parameter independence across scales. Regarding the dilation rate setting of dilated convolution, this study refers to the visual perception scale space theory proposed by Koenderink, which points out that the optimal feature detection scale σ and the target size D satisfy the mathematical relationship . Based on this, we designed scale matching for emotional expression features at different levels as follows: for micro-expression detection (D = 3 pixels), the theoretical calculation is σ = 0.9 and the equivalent spatiotemporal receptive fields is 3 × 3, using a dilation rate of 1 to capture micro changes; in compound expression analysis (D = 7 pixels), σ = 2.1 corresponds to a dilation rate of 3 and the equivalent spatiotemporal receptive fields is 7 × 7, modeling the coordinated movement of regional muscle groups; and in large-scale body language understanding (D = 11 pixels), σ = 3.3 matches a dilation rate of 5 and the equivalent spatiotemporal receptive fields is 13 × 13, which helps capture wide-area dynamic features. Through this design, the model can effectively adapt to the needs of emotional expression at different scales, thereby improving the overall performance.
Multi-Scale Dilated Convolutional Branch Design: Traditional attention modules (e.g., SE, CBAM) capture channel correlations through global pooling but overlook the diversity of local spatial structures, exhibiting significant limitations in modeling spatiotemporal structural heterogeneity. To address the need for modeling multiscale temporal dependencies in video-based emotional expressions (such as subtle facial muscle movements and macroscopic body gestures), this paper proposes a hierarchical attention mechanism based on three-tier differentiated dilated convolutions.
The mechanism consists of two parallel branches. The first branch models long-range dependencies between channels through a dual-path spatial attention mechanism. Grouped features GroupX are subjected to 1D global average pooling along horizontal and vertical directions to extract global contextual representations across two orthogonal spatial dimensions.
Specifically, this branch first performs grouping on input features. Global average pooling is separately applied along the horizontal (H) and vertical (W) directions to obtain compressed orientation-sensitive features and Subsequently, concatenation, 1 × 1 convolution, and dimensional splitting operations are employed to generate spatial attention weight matrices. Through a gating mechanism, the attention weights are multiplied with the original features, followed by group normalization and softmax activation to output spatially attention-enhanced feature representations. This design enables explicit modeling of channel interaction patterns across spatial dimensions, thereby strengthening the expressive capacity for orientation-sensitive features.
The second branch consists of three convolutional layers with different dilation rates. At the fine-grained level, the 3 × 3 convolution with a dilation rate of 1 captures instantaneous micro-expression changes (e.g., lip corner tremor amplitude) through dense sampling, where its equivalent 3 × 3 receptive field precisely localizes local motion patterns such as eyelid tremors. At the medium-range semantic level, the convolution with an expanded dilation rate of 2 increases the receptive field to 7 × 7, revealing dynamic correlations among facial action units through cross-frame feature interactions, effectively modeling temporal combinations of adjacent movements (e.g., the synchronization between blinking and eyebrow furrowing). For long-range body language, the convolution with a dilation rate of 3 forms a 13 × 13 large receptive field, utilizing sparse sampling to capture persistent features of body movements spanning multiple frames (e.g., arm-swing trajectories during anger or prolonged head-lowering durations in depression), achieving semantic decoupling of full-body poses. This process generates multiple feature sets , the outputs of the three convolutional layers are concatenated, and multi-branch feature fusion is implemented through channel-wise concatenation and 1 × 1 convolution, preserving the complete multi-scale information flow.
Dynamic weight fusion mechanism: Video emotion analysis faces another core challenge: the spatiotemporal heterogeneity of emotional features. Spatially, facial micro-expressions (e.g., subtle tremors in periocular muscles) require high-resolution local feature capture, while full-body postures (e.g., arm-swing amplitudes during anger) rely on large-scale contextual information integration. Temporally, emotional expressions exhibit non-stationary characteristics, necessitating differentiated modeling strategies for transient expression peaks (e.g., pupil dilation in surprise, typically lasting less than 100 ms) and prolonged emotional states (e.g., sustained head-lowering postures in depression, persisting over 2 s). Traditional multi-branch fusion methods employ fixed weights or heuristic rules (e.g., average weighting, maximum response selection). Such static strategies fail to adapt to the dynamic distribution of spatiotemporal features, resulting in fine-grained motion details being overwhelmed by global features or long-term temporal dependencies fragmenting due to insufficient receptive fields. To address this, this paper constructs a context-sensitive dynamic weight generation mechanism.
The lightweight context-sensitive gating network, serving as the core component for dynamic weight generation, is structurally optimized specifically for the spatiotemporal heterogeneity of video emotional features. The network consists of 2D average pooling and convolutional layers, dynamically generating fusion weights for dilation branches by analyzing channel statistics of the current frame group. Specifically, the input feature group_x (dimensions: b × groups, c//groups, h, w) first undergoes adaptive global average pooling, compressing spatial information of each channel into scalar statistics (dimensions: b × groups, c//groups, 1, 1). This operation inherently extracts channel-level global response intensities (e.g., activation values for periocular channels in facial regions are significantly higher than those of background channels). Subsequently, a 1 × 1 convolutional layer maps the channel dimensions from c//groups to the number of dilation branches len(dilations) (e.g., 3 channels for three branches), fundamentally learning the importance weights of branches with different dilation rates through fully connected operations.
This design achieves dynamic weight generation through two lightweight operations: a global pooling layer eliminates interference from spatial dimensions to focus on channel statistical characteristics, and a 1 × 1 convolutional layer establishes a nonlinear mapping relationship between channels and branch weights. In code implementation, the output of it is normalized via torch.softmax (dim = 1), generating weight coefficients that sum to 1 along the channel dimension (e.g., [0.4, 0.3, 0.3]), ensuring interpretability in the multi-branch feature fusion process. For example, when the input is a sequence of static micro-expressions (e.g., contemplation), the global pooling captures high activation values in periocular channels, and the 1 × 1 convolutional layer maps these to high weights (exceeding 0.7) for small-dilation-rate branches (dilation = 1), thereby enhancing local detail modeling. In scenarios with intense body movements (e.g., angry arm-swinging), widespread motion leads to balanced activation distributions across channels, prompting the 1 × 1 convolutional layer to assign higher weights (approximately 0.6–0.8) to large-dilation-rate branches (dilation = 3), to capture continuous motion trajectories.
The parameter count of this structure is only (c//groups) × len (dilations). Taking a typical configuration (groups = 8, c = 512, dilations = [1, 3, 5]) as an example, the parameter count is merely 192, achieving an 87.5% reduction compared to traditional dynamic convolution networks (e.g., SENet’s channel attention module). The comparison of the number of parameters with the classic attention mechanism is shown in Table 1.

Table 1.
Calculation amount comparison with other attention modules.
In summary, the method presented in this paper achieves performance improvement through three core mechanisms. First, a multi-level dilated convolution architecture integrates spatiotemporal convolutional layers with dilation rates d = 1, d = 3, and d = 5 to construct a hierarchical progressive receptive field expansion structure. The architecture is based on a multi-scale dilated convolution configuration to collaboratively fuse scene cues from multiple scales. Second, a lightweight dynamic gating mechanism is proposed, mapping global statistical features of channels into multi-branch attention masks to achieve scenario-adaptive feature fusion from transient facial expressions to sustained body movements. This module dynamically adjusts weight allocation for multi-branch features using learnable gating functions, effectively balancing the representation requirements of short-term motion details and long-term behavioral patterns. Finally, the parameter optimization structure based on grouped convolution and dimensional decomposition strategy compresses the number of parameters through channel-grouping calculation and feature dimension reorganization, significantly improving the computational efficiency while retaining the multi-branch interaction capability.
4. Experiment
4.1. Datasets
VideoEmotion-8 Dataset: The VideoEmotion-8 dataset contains 1101 user-uploaded videos from social media platforms, with each emotion category including a minimum of 100 videos. These videos are annotated with eight emotion categories based on Plutchik’s emotion wheel model.
Ekman-6 Dataset: The Ekman-6 dataset comprises 1637 videos sourced from social media platforms, annotated with six basic emotion categories according to Ekman’s psychological theory.
4.2. Implementation Details
This study employs a dual-stream network architecture for multimodal emotion analysis. The visual stream is based on a 3D ResNet-101 [17] network pre-trained on ImageNet and Kinetics-400, while the audio stream adopts a 2D ResNet-50 [18] network pre-trained using the same strategy. For visual input processing, each video is uniformly divided into 16 segments, with 16 consecutive frames sampled per segment. The frames are adjusted to 112 × 112 resolution via random center cropping and normalized by mapping pixel values to the [−1, 1] range to enhance data robustness. The model utilizes the Adam optimizer with a batch size of 12 to balance GPU memory usage and training efficiency, while freezing the parameters of layers 0–5 in the visual feature extractor to reduce overfitting. Fine-tuning is performed with a learning rate of 2 × 10−6.
Model performance was validated on two widely used video emotion datasets: VideoEmotion-8 and Ekman-5. For VideoEmotion-8, the data are split into a 2:1 training–test ratio, while Ekman-5 adopts a 1:1 balanced split to evaluate generalization capability. Final performance metrics are benchmarked against the average accuracy of ten independent trials. All experiments were implemented using the PyTorch 2.5.0 framework and executed on NVIDIA GeForce GTX 3090 GPUs for training and inference.
4.3. Comparison with Other Methods
To systematically evaluate the performance advantages of the proposed method, Table 2 presents comparative experimental results between our model and current mainstream video emotion recognition methods on the Ekman-6 and VideoEmotion-8 benchmark datasets. The experiments adopted a five-fold cross-validation strategy, with non-overlapping frame sampling for training-test set partitioning. The results demonstrate the proposed method’s significant superiority in cross-dataset evaluations; it achieves an accuracy of 61.25% on the Ekman-6 dataset, outperforming the state-of-the-art baseline by 2.95%. On the VideoEmotion-8 dataset, the method attains an accuracy of 57.6%, surpassing existing methods by 0.3%. These improvements highlight the robustness of our multi-scale spatiotemporal fusion mechanism, particularly in handling heterogeneous emotional expressions across varying spatial scales.
Table 2.
Comparison with other methods about video emotion recognition. Classification accuracy (%) on the testing set of VideoEmotion-8 and Ekman-6 datasets.
Figure 2 presents four representative attention visualization maps to illustrate the comparative advantages of our method against existing attention mechanisms. Based on feature visualizations from the 3D-ResNet101 baseline network, the proposed multi-scale perception enhancement (MPE) module demonstrates significant superiority in receptive field adaptation. For example, in a typical frame (Figure 2 line 1 of a “sadness” emotion sample, traditional global attention generates localized responses (peak activation intensity: 0.38) only in facial regions (coordinates [45:55, 120:130]). The MPE module (Figure 2 line 3) simultaneously activates three critical regions as follows:
- (1)
- Low-scale contextual cues: alcohol bottles and cigarette packs on the table (coordinates [60:65, 95:100], activation intensity: 0.41), reflecting environmental depression indicators.
- (2)
- Mid-scale expression composites: asymmetric lip corner elevation (coordinates [40:50, 115:125], activation intensity: 0.39), suggesting suppressed emotional leakage.
- (3)
- High-scale kinematic patterns: retracted right shoulder motion (coordinates [20:30, 150:160], activation intensity: 0.36), indicative of defensive posturing.
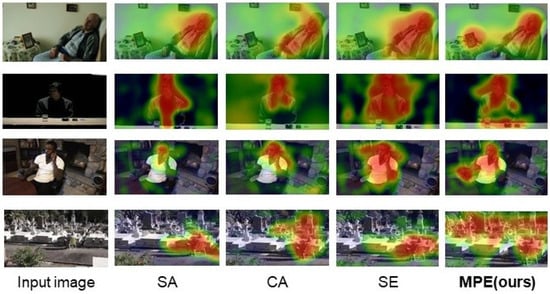
Figure 2.
Visualization of feature maps produced by models with different attention methods in the baseline network (3D-resnet101). It noted that our MPE module is better able to build connections between multiple scale cues.
This multi-level co-activation verifies that the our MPE module achieves dynamic receptive field adaptation through hierarchical dilated convolutions (dilation rate = {1, 3, 5}), enabling joint modeling of cross-scale cues. The expanded coverage (from facial micro-movements to body-environment interactions) aligns with the theoretical design of multi-dilated convolutional kernels for heterogeneous feature extraction.
To further verify the model’s ability to model the process of emotion changing over time, we conducted a detailed phase analysis using a video sample of sad emotions as an example (Figure 3). By visualizing the feature activation patterns at different time points, we identified different stages in the process of emotion rising, peaking, and receding. The temporal evolution of activation intensity and spatial distribution reveals the whole process of emotion from internal germination, external expression, emotional deepening to gradual calming.
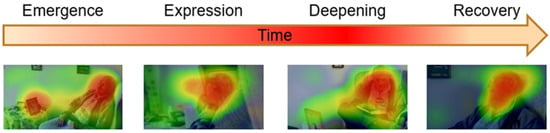
Figure 3.
Visualization of feature maps generated by MPE in the time dimension.
The specific observations are summarized as follows:
- (1)
- Emotional germination stage: At 00:48 s in the video, the activation intensity of facial expressions and hand movements (pressing the lighter) increases (activation intensity: 0.83). It is manifested as a slight frown in the eyes and a slight drooping of the corners of the mouth (coordinates [20:30, 115:125] and [40:50, 90:100]), and the visual clues of the photo area in the environment are noticed, marking the initial germination of sad emotions. This stage usually corresponds to the initial perception of emotions, and individuals begin to brew sad experiences internally, but external behaviors still maintain a certain degree of inhibition.
- (2)
- Emotional expression stage: At 00:56 s in the video, attention is focused on the photo in the center of the picture, and the corresponding local activation intensity increases significantly (activation intensity: 0.79, coordinates [19:37]). As an emotional trigger, the photo accelerates the external expression of sad emotions, and the overall atmosphere becomes heavier and more perceptible.
- (3)
- Emotional deepening stage: At 01:13 s in the video, the activation intensity of the face and trunk area reaches the highest level (activation intensity: 0.95). It is manifested as trembling of the corners of the mouth and tense facial muscles (coordinates [42:53, 92:105]), accompanied by slight shaking of the body (activation intensity: 0.84). This stage shows that the sad emotion has entered a deep experience period, and the individual’s physiological and behavioral reactions tend to be intense, reflecting the great accumulation and outbreak of emotional tension, which is the peak stage of sad emotion.
- (4)
- Emotional decline stage: At 01:47 s in the video, the overall activation intensity of the body has decreased significantly (activation intensity: 0.35). Specifically, the drooping of the corners of the mouth is weakened, the eyes are closed, the amplitude of body movements is significantly reduced, and the person leans on the sofa to show a relaxed state. This stage reflects the natural decline of emotions and the process of self-comfort. The individual gradually recovers from the peak of sadness and enters the stage of emotional regulation and emotional calming.
4.4. Error Analysis
To further evaluate the classification performance of the model, we performed a systematic error analysis of the predictions using the confusion matrix (Figure 4), which visualizes the classification accuracy of the model on each category in the form of a heat map, including correct predictions (main diagonal) and confusion between different categories (off-diagonal).
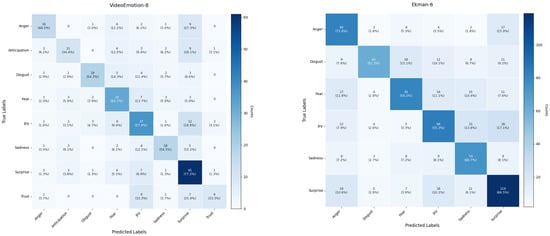
Figure 4.
Confusion matrices of VideoEmotion-8 and Ekman-6.
The results of the confusion matrix analysis show that the recognition performance of the model varies greatly in different emotion categories. In VideoEmotion-8, the recognition accuracy of “surprise” (77.2%) and “fear” (62.7%) is relatively high, mainly due to the obvious dynamic characteristics of these two emotions (such as sudden facial expansion, trembling movements, etc.), and among the six basic emotions of Ekman, the recognition accuracy of “surprise” (66.5%) and “sadness” (66.7%) is also at the forefront, as shown by the diagonal dark blue blocks in the confusion matrix, highlighting their classification advantages. In contrast, the classification performance of “joy” (55.3%) and “disgust” (51.3%) is relatively weak. Further analysis found that the model has obvious confusion between specific emotion categories. For example, the emotion “anger” is often misclassified as “surprise”, with a misjudgment rate of 12.1% to 15.0%. This may be because both have common features such as staring in facial expressions, which makes it difficult for the model to distinguish between gradual emotional accumulation and instantaneous burst features. There is 28% two-way confusion between “expectation” and “surprise”, indicating that the model is not capable of handling fine-grained temporal dynamic changes; there is also two-way confusion between “fear” and “disgust”, with “fear” misjudged as “disgust” at a rate of 2.8% and “disgust” misjudged as “fear” at a rate of 15.1%, indicating that the model has limitations in detecting subtle differences in the degree of nose wrinkling and the trajectory of eyebrow movement. In addition, the model also has a high proportion of misjudgments in the recognition of the emotion “trust”, with 18.5% of the samples being misclassified as “surprise”; similarly, 17.1% of the samples of the emotion “joy” are misjudged as “surprise”. This reflects the model’s lack of sensitivity in identifying social micro-expressions (such as sustained gaze and instant eye opening) and dynamic changes in the corners of the mouth (such as sustained upward and instant lifting). In response to the above problems, future work will consider introducing facial action units (such as AU4 corrugator and AU9 nasolabial groove enhancer) for spatiotemporal feature modeling, while implementing adversarial data enhancement for high confusion categories (such as generating synthetic expression samples by superimposing blink interference), and combining richer information such as head posture to further improve the model’s fine-grained recognition capabilities.
4.5. Ablation Study
Multi-scale expansion branch ablation experiment: To verify the necessity of multi-scale branch design, four groups of experiments were set up to compare the effects of different numbers of expansion branches while retaining dynamic weight fusion: single branch (d = 2), double branches (d = 1, 3), triple branches (d = 1, 3, 5), and quad branches (d = 1, 3, 5, 7). All experimental groups were trained with the same training configuration to analyze the coverage of local details and global features by multi-scale design. The experimental results are shown in Table 3.
Table 3.
Ablation studies for multi-scale expansion branch.
Experiments show that three branches (d = 1, 3, 5) achieve the highest accuracy (61.25%) on the Ekman-6 dataset. Its receptive field covers the range of 9 × 9 to 21 × 21, and the feature diversity index is significantly higher than that of a single branch, proving that multi-scale branches can collaboratively capture fine-grained textures and structures; while four branches (d = 1, 3, 5, 7) have a decreased accuracy (60.64%) due to redundant calculations, indicating that three branches achieve the optimal balance between performance and efficiency, and more branches will introduce noise interference and increase the computational burden.
Dynamic Weight Generation ablation experiment: Four sets of comparative experiments were set up to verify the value of the dynamic weight generation mechanism: fixed average weight (1/3 of each branch weight), maximum response fusion (maximum value at each position), learnable static weight (global scalar weight) and complete dynamic weight generation module (input adaptive). All experimental groups were trained with the same training configuration to eliminate the interference of training randomness. The experimental results are shown in Table 4.
Table 4.
Ablation studies for dynamic Weight generation module.
The performance of the dynamic weight generation module is better than that of fixed weights and static weights, indicating that the model can flexibly assign the importance weights of branches at each scale according to the input content. For example, in occlusion scenes, the model tends to give higher weights to branches with large expansion rates (capturing global context) to infer occluded areas, while in fine-grained classification, branches with small expansion rates are preferentially activated (extracting local details). This dynamic feature enables the model to adapt to different task requirements without manually presetting fusion rules, reflecting the flexibility of human-like decision-making.
4.6. Hyper-Parameter Analysis
To evaluate the optimal hyperparameters within the module, we designed the following experiments under consistent configurations:
The baseline model was constructed based on a ResNet-101 backbone, with the proposed dynamic multi-branch structure embedded in its critical feature extraction stage. All comparative experiments strictly adhered to identical baseline training protocols. The experimental design comprises two aspects.
Group Number Analysis: While fixing multi-scale receptive field combinations, we conducted controlled experiments by adjusting the feature channel group number (G) to analyze its impact on semantic independence.
The ablation experiment results are shown in Figure 5. Results demonstrate that as G increases, our method outperforms other attention mechanisms. When G reaches 10, predictive performance improves significantly (e.g., +3.62% accuracy on Ekman-6). However, further increasing G (e.g., G = 16) degrades performance due to subspace semantic confusion, aligning with the “optimal compression ratio” principle in information bottleneck theory. This suggests that hierarchical representation spaces achieve a Pareto optimum between feature expressiveness and generalization when the group dimension approximates the intrinsic rank of original features.
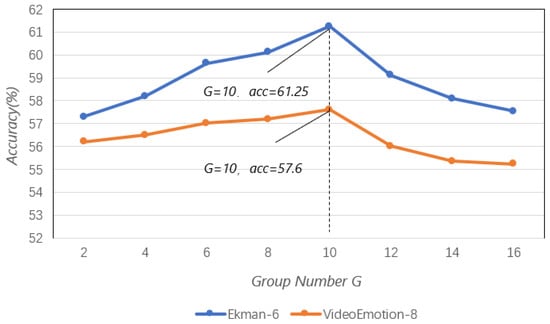
Figure 5.
The impact of different numbers of groups on the Ekman-6 and VideoEmotion-8 datasets.
Multi-Scale Dilation Rate Analysis: We systematically tested the effects of dilation rate combinations on contextual awareness. The experimental incorporates eight distinct convolution module (kernel size = 3) groups with diversified dilation rate configurations, categorized as interval coverage (D1: [1, 2, 3]), progressive fusion (D2: [2, 3, 4]), sparse long-range patterns (D3–D4: [3, 4, 5]/[4, 5, 6]), and classical benchmark combinations (D5–D8: [1, 3, 5]/[3, 5, 7]/[2, 4, 6]). By systematically controlling the numerical distribution and span variation of dilation rates, this design verifies the modeling capacity for multi-scale characteristics spanning theoretical receptive fields from 3 × 3 to 15 × 15 (the theoretical max receptive field was calculated as follows: Max RF = 1 + (kernel size − 1) × d), encompassing local detail perception, intermediate semantic extraction, and long-range dependency establishment. Each configuration group adopts a dynamic weight fusion mechanism for feature integration.
The ablation experiment results are shown in Figure 6. Experimental results ultimately demonstrate that the classical interval configuration (D5: [1, 3, 5]) strikes an optimal balance between fine-grained feature preservation and contextual pattern modeling through its hierarchical receptive field coverage (7 × 7 to 11 × 11), achieving superior recognition accuracy and emerging as the optimal solution.
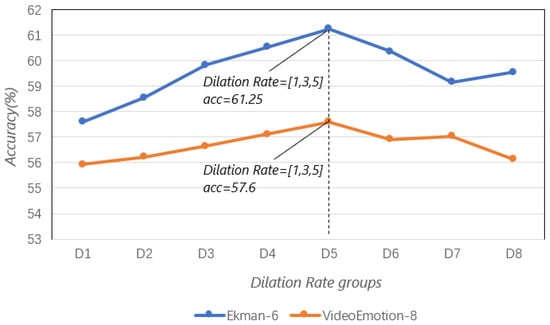
Figure 6.
The impact of different dilation rate combinations on the Ekman-6 and VideoEmotion-8 datasets.
5. Conclusions
In this paper, a dual-branch enhanced attention method that integrates multi-dilated convolution and a dynamic gating mechanism is proposed to address the challenges of multi-scale spatiotemporal feature modeling and dynamic fusion in video emotion recognition tasks. By constructing three-level dilated convolution layers to form a progressive receptive field of 3 × 3 to 11 × 11, this architecture can collaboratively capture low-scale auxiliary features (such as facial micro-expressions) and medium- and high-scale main features (such as large-scale body movements). The innovatively designed lightweight dynamic weight generation module realizes the nonlinear mapping of channel statistics and multi-branch weights through a two-layer neural network. This study provides an efficient feature modeling framework for video emotion analysis. Its hierarchical perception mechanism and dynamic fusion strategy have universal reference value for multimodal sequence modeling. In the future, the model performance can be further improved and expanded to more emotional computing scenarios by introducing staged modeling (such as stage supervised learning or time series segmented modeling), which will be left for future work.
Author Contributions
Conceptualization, L.Z. and Y.S.; methodology, L.Z.; software, X.Z.; validation, L.Z., J.G. and S.K.; formal analysis, J.H.; writing—original draft preparation, L.Z.; writing—review and editing, Y.S.; visualization, Y.S.; supervision, J.G.; project administration, S.K.; funding acquisition, J.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the Natural Science Foundation of Xiamen, China (3502Z20227215), Xiamen Institute of Technology High-level Talents Scientific Research Start-up Project (YKJ22060R), and Xiamen Ocean and Fishery Development Special Fund Youth Science and Technology Innovation Project (23ZHZB043QCB37).
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. arXiv 2018, arXiv:1709.01507. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.-S. SCA-CNN: Spatial and Channel-Wise Attention in Convolutional Networks for Image Captioning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 6298–6306. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4510–4520. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 5987–5995. [Google Scholar]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P. Res2Net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Hu, X.; Yang, J. Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks. arXiv 2019, arXiv:1905.09646. [Google Scholar]
- Yang, Q.-L.Z.Y.-B. SA-Net: Shuffle Attention for Deep Convolutional Neural Networks. arXiv 2021, arXiv:2102.00240. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7794–7803. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to Attend: Convolutional Triplet Attention Module. arXiv 2020, arXiv:2010.03045. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2015, arXiv:1411.4038. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network. arXiv 2021, arXiv:2105.14447. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. arXiv 2021, arXiv:2103.02907. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? arXiv 2018, arXiv:1711.09577. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Xu, B.; Fu, Y.; Jiang, Y.-G.; Li, B.; Sigal, L. Heterogeneous Knowledge Transfer in Video Emotion Recognition, Attribution and Summarization. IEEE Trans. Affect. Comput. 2018, 9, 255–270. [Google Scholar] [CrossRef]
- Qiu, H.; He, L.; Wang, F. Dual Focus Attention Network for Video Emotion Recognition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Arevalo, J.; Solorio, T.; Montes-y-Gómez, M.; González, F.A. Gated Multimodal Units for Information Fusion. arXiv 2017, arXiv:1702.01992. [Google Scholar]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.-P. Tensor Fusion Network for Multimodal Sentiment Analysis. arXiv 2017, arXiv:1707.07250. [Google Scholar]
- Zhao, S.; Ma, Y.; Gu, Y.; Yang, J.; Xing, T.; Xu, P.; Hu, R.; Chai, H.; Keutzer, K. An End-to-End Visual-Audio Attention Network for Emotion Recognition in User-Generated Videos. Proc. AAAI Conf. Artif. Intell. 2020, 34, 303–311. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, L.; Yang, J. Weakly Supervised Video Emotion Detection and Prediction via Cross-Modal Temporal Erasing Network. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 18888–18897. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).