1. Introduction
Data clustering or cluster analysis refers to the process of dividing a set of objects into groups or clusters such that objects in the same cluster are similar to each other and objects from different clusters are quite distinct [
1,
2,
3]. Data clustering has found applications in a wide range of areas [
4]. For example, data clustering is also used to sample insurance policies in order to build predictive models [
5].
In the recent decades, many clustering algorithms have been developed by researchers from different fields [
2,
3,
6]. Among these clustering algorithms, the
k-means algorithm is one of the oldest and most commonly used clustering algorithms [
7,
8]. The
k-means algorithm is also considered one of the top-ten algorithms in data mining [
9]. Given a set of
n data points
, the
k-means algorithm tries to divide the dataset into
k clusters by minimizing the following objective function:
where
is an
partition matrix,
is a set of cluster centers, and
is the
norm or Euclidean distance. The partition matrix
U satisfies the following conditions
In the
k-means algorithm,
k is the desired number of clusters specified by the user. The optimization problem of minimizing (
1) is NP-hard [
10]. To minimize the objective function, the
k-means algorithm starts from
k initial cluster centers selected randomly from the dataset and then keeps updating the partition matrix
U and updating the cluster centers
Z alternately until some criterion is met.
One drawback of the
k-means algorithm is that it does not have a built-in mechanism to detect outliers and its result is sensitive to outliers. Improving the
k-means algorithm to handle outliers and noise data has the following benefits. First, considering outliers in the clustering process can improve the clustering accuracy of the
k-means algorithm [
11]. Second, outlier detection is an important data analysis task in its own right and has important applications in intrusion detection and fraud detection [
12]. As a result, several clustering algorithms based on the
k-means algorithm have been developed to handle outliers. See, for example, [
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26].
The existing clustering algorithms for handling outliers can be divided into two categories: multi-stage algorithms and single-stage algorithms. As its name indicates, a multi-stage algorithm performs clustering and detects outliers at multiple stages. Examples of multi-stage algorithms include [
11,
13,
15,
16,
18,
20]. The Outlier Removal Clustering (ORC) algorithm [
11] is one of the earliest approaches proposed to enhance
k-means by addressing the impact of outliers. Unlike multi-stage algorithms, single-stage algorithms integrate outlier detection into the clustering process. Examples of single-stage algorithms include [
12,
14,
21,
22,
23,
24,
25,
26,
27].
Among the single-stage algorithms, the algorithms proposed in [
14,
27] are extensions of the fuzzy
c-means algorithm. Others are variants of the well-known
k-means algorithm. For example, the ODC (Outlier Detection and Clustering) algorithm [
12], the NEO-
k-means (non-exhaustive overlapping
k-means) algorithm [
22] and the
k-means algorithm [
21], and the KMOR (
k-means clustering with outlier removal) algorithm [
23] are extensions of the
k-means algorithm that can provide data clustering and outlier detection simultaneously. A major difference between the KMOR algorithm and the other
k-means variants (i.e., ODC, NEO-
k-means and
k-means) is that KMOR was based on the idea of an outlier cluster that was introduced by [
28]. In KMOR, every data point in the outlier cluster has a constant distance from all data points. The constant distance is chosen to be the scaled average of the squared distances between all normal data points and their corresponding cluster centers.
However, one drawback of the KMOR algorithm is that it requires two parameters to control the number of outliers. Setting values for these parameters poses some challenges for real-world applications. In this paper, we propose the KMOD (k-means clustering with outlier detection) algorithm, which removes the drawback of the KMOR algorithm. In the proposed KMOD algorithm, the scaled average squared distance is incorporated into the objective function in an elegant way. There are two major differences between the KMOD algorithm and the KMOR algorithm:
KMOD requires only one parameter to control the number of outliers, while KMOR requires two parameters to do this.
In KMOD, outliers are used to update cluster centers with lower weights, while in KMOR, outliers are not used to update cluster centers.
Similarly to ODC, NEO-k-means, k-means--, and KMOR, the KMOD algorithm can also provide data clustering and outlier detection simultaneously.
The remaining part of this paper is organized as follows. In
Section 2.1, we provide brief descriptions of some clustering algorithms that can conduct data clustering and outlier detection simultaneously. In
Section 3, we present the KMOD algorithm in detail. In
Section 4, we demonstrate the effectiveness of the KMOD algorithm using both synthetic data and real data. In
Section 5, we conclude the paper with some remarks.
2. Related Work
In this section, we provide a review of the clustering methods that can detect outliers during the clustering process. In particular, we review the ODC algorithm, the NEO-k-means algorithm, the k-means-- algorithm, and the KMOR algorithm.
2.1. The ODC Algorithm
The ODC (Outlier Detection and Clustering) algorithm proposed by [
12] is a modified version of the
k-means algorithm. In the ODC algorithm, a data point that is at least
times the average distance from its centroid is considered an outlier. At each iteration, the average distance is calculated as follows:
where
k is the desired number of clusters,
X is the dataset after outliers are removed,
is the Euclidean distance, and
is a set of cluster centers.
Although the ODC algorithm is a modified version of the
k-means algorithm, the ODC algorithm does not have an objective function that incorporates outliers explicitly. In fact, the ODC algorithm uses the following
ratio to measure the quality of the clustering results:
where
is the
lth cluster and
is the mean of all the points in
. For a fixed
k, a lower value of the ratio indicates a better result. Note that data points that are considered as outliers are excluded from the calculation of
.
In the ODC algorithm, outlier detection is not reversible in the sense that if a data point is considered an outlier at a particular iteration of the iterative process, then the data point cannot be changed back to be a normal point later.
2.2. The NEO-k-Means Algorithm
The NEO-
k-means (non-exhaustive overlapping
k-means) algorithm proposed by [
22] can identify outliers during the clustering process. Its objective function is defined as
where
k is the desired number of clusters,
is a set of cluster centers, and
is a binary partition matrix. The matrix
U satisfies the following conditions:
where Tr(·) is the trace of a matrix and
is an indicator function.
In addition to the desired number of clusters k, NEO-k-means requires another two parameters: and . The parameter controls the degree of overlap among clusters. The parameter controls the number of outliers. The maximum number of data points that can be considered outliers is . The objective function of the NEO-k-means algorithm is equivalent to that of the k-means algorithm when and .
The NEO-k-means algorithm minimizes the objective function iteratively. Given a fixed set of cluster centers, the algorithm first calculates the distances between every data point and its center. Then, it updates the binary matrix U by assigning the first data points to their closest centers. Then, it creates more assignments by taking the minimum distances from the distances. Given the binary matrix, the algorithm updates the cluster centers to the means of the clusters. The above process is repeated until some stopping criterion is met.
2.3. The k-Means-- Algorithm
The
k-means-- algorithm proposed by [
21] provides data clustering and outlier detection simultaneously. The objective function of this algorithm is defined as
where
X is the dataset,
L is the set of outliers,
Z is the set of cluster centers, and
Here, is a distance function. This algorithm requires two parameters, k and l, which specify the desired number of clusters and the desired number of top outliers, respectively.
In the k-means-- algorithm, an iterative procedure that is similar to k-means’ is used to minimize the objective function. In each iteration, the l top outliers are removed from the clusters before the cluster centers are updated. The l top outliers are defined to be the data points that have the l largest distances from their centers.
2.4. The KMOR Algorithm
Like the
k-mean-- algorithm, the KMOR (
k-means with outlier removal) algorithm proposed by [
23] can also conduct data clustering and outlier detection simultaneously. Let
k be the desired number of clusters. Motivated by the fuzzy clustering algorithm proposed by [
27], the KMOR algorithm divides a dataset into
groups, including
k clusters and a group of outliers.
Mathematically, KMOR aims to minimize the following objective function:
subject to the following condition:
where
and
are parameters,
is the
norm,
,
, …,
is a set of cluster centers, and
is a
binary partition matrix (i.e.,
) such that
and
The two parameters and work together to control the number of outliers. The maximum number of data points that can be considered outliers is . When , then the number of outliers produced by the algorithm will be . When is large, then the number of outliers will be 0. As a result, the objective function of KMOR will be equivalent to that of k-means when or .
The KMOR algorithm iteratively minimizes the objective function. Given a binary matrix U, the cluster centers are updated to be the means of the clusters. Given a set of cluster centers, the data points are assigned to clusters and the group of outliers as follows. If a data point’s distance to its center is greater than , the point will be considered an outlier. If the number of such points is more than , then the points that are furthest from their centers will be assigned to the group of outliers. If a data point’s distance to its center is not greater than , then the data point will be assigned to its nearest cluster. This process is repeated until some stopping criterion is met.
3. The KMOD Algorithm
In this section, we present the KMOD (k-means with outlier detection) algorithm, which is an extension of the KMOR algorithm described in the previous section.
Let
be a dataset containing
n data points, each of which is described by
d numerical attributes. Let
k be the desired number of clusters. Let
is a
binary partition matrix, such that
The binary matrix U has columns. The last column of U is used to indicate whether a data point is an outlier; that is, if is an outlier and if otherwise. If , then for some , where l is the index of the cluster to which belongs. The binary matrix U divides the dataset X into groups, which include k clusters and one group of outliers.
Let
is an
binary matrix such that
Unlike U, the binary matrix V has k columns. The binary matrix V is a partition matrix that assigns all data points in X into the k clusters. If , then the data point is assigned to the lth cluster.
The objective function of the KMOD algorithm is defined as
where
is a parameter,
is a set of cluster centers,
is the
norm, and
is the scaled average squared distance between all data points and their corresponding cluster centers, i.e.,
After some algebraic manipulation, we can write the objective function (
12) as follows:
where
that is,
is the proportion of outliers. From Equation (
14), we can see the following. If
is not an outlier, then
for some
and the contribution of
to the objective function is
If
is an outlier, then
for all
and
for some
. In this case, the contribution of
to the objective function is
Thus, we can rewrite the objective function as
where
is the index of the center to which
is closest, and
and
are the index sets of normal points and outliers, respectively. From Equation (
15), we can see that a point will be considered an outlier if the reduction in the first term is higher than the increase in the second term.
The goal of the KMOD algorithm is to find
, and
Z, such that the objective function defined in Equation (
12) is minimized. Like the
k-means algorithm, the KMOD algorithm starts with a set of
k initial cluster centers and then keeps updating
U,
V, and
Z alternatively until some stopping criterion is met. The rules used to update
U,
V, and
Z are summarized in the following three theorems.
Theorem 1. Let and be fixed. If at least one data point is an outlier, i.e., for some i, then the binary matrix V that minimizes the objective function (
12)
is given as follows:for and . If no data points are outliers, i.e., for all , then the objective function (
12)
is independent of V. Proof. When
and
, the objective function (
12) becomes
If
for all
, then the objective function is independent of
V. If
for some
i, then the objective function is minimized if the following function
is minimized. Since the rows of
V are independent of each other,
is minimized if
is minimized for all
. Since
, the above equation is minimized if
This proves the theorem. □
Theorem 2. Let and be fixed. Then, the partition matrix U that minimizes the objective function (12) is established as follows:for and , where For , we have .
Proof. Since
and
are fixed and the rows of the partition matrix
U are independent of each other, the objective function
is minimized if, for each
, the following function
is minimized. Note that
for
and
Equation (
18) is minimized if
for
. This completes the proof. □
Theorem 3. Let and be fixed. Then, the cluster centers Z that minimize the objective function (
12)
are derived as follows:for and . Proof. When
and
, the objective function (
12) becomes
The above equation is minimized if its derivative with respect to
is equal to zero for all
and
; that is,
which leads to Equation (
19). This completes the proof. □
Note that we can also use Equation (
14) to prove Theorem 3 and we can write Equation (
19) as follows:
where
is the proportion of outliers found in the dataset. From the above equation, we see that the center of a cluster is calculated as the weighted average of the data points that are closest to the center of the cluster. However, a normal point has a weight of
and an outlier is given a weight of
. Thus, the impact of outliers on cluster centers is also reduced in the KMOD algorithm.
The pseudo-code of the KMOD algorithm is shown in Algorithm 1. The KMOD algorithm requires four parameters:
k,
,
, and
. Parameter
k is the desired number of clusters for a particular dataset. Parameter
is a positive real number used to control the number of outliers. In general, a smaller value for
will result in more outliers. If
is close to zero, then all data points will be assigned to the outlier group. The last two parameters,
and
, are used to terminate the iterative process. Some default values of
,
, and
are shown in
Table 1.
The difference between KMOD and KMOR is that the former uses outliers with low weights to update the cluster centers but the latter does not use outliers to update centers. In addition, KMOD does not require users to set a maximum number of outliers. Instead, the number of outliers is controlled by parameter
.
| Algorithm 1: The KMOD Algorithm |
![Electronics 14 01723 i001]() |
4. Numerical Experiments
In this section, we conduct numerical experiments based on both synthetic data and real data to show the effectiveness of the KMOD algorithm. All algorithms were implemented in Java and the source code is available at
https://github.com/ganml/jclust, accessed on 21 April 2025.
4.1. Validation Measures
In our experiments, we used the following validation measures to measure the accuracy of the clustering results: the adjusted Rand index (ARI) [
29], the normalized mutual information (NMI) [
30], and the classifier distance [
12]. The first two measures are commonly used to measure the accuracy of clustering algorithms when the labels of a dataset are known. The classifier distance is used to measure the accuracy of outlier detection when outlier information is provided.
Let
,
, …,
be a partition found by a clustering algorithm and let
be the true partition. Let
,
,
, and
n be the total number of data points. Then, the adjusted Rand index is defined as follows:
It can be seen that the value of R ranges from −1 to 1. A higher ARI value indicates a more accurate result.
The normalized mutual information is defined as follows:
where
denotes the entropy of a partition and
denotes the mutual information score between two partitions. Mathematically, they are defined as
and
The NMI has a value in the range . Similar to the ARI, a higher value of the NMI indicates a more accurate result.
The classifier distance is defined as the Euclidean distance between a binary classifier on the Receiver Operating Curve graph and the perfect classifier:
where
Here, , , , and denote the number of data points in the categories of true positive, false positive, false negative, and true negative, respectively. The notion of true or false indicates whether a point was presented as an outlier while the notion of positive or negative indicates whether a point was found to be an outlier. A lower value for the classifier distance indicates a more accurate result.
4.2. Experimental Setup
We compared the performance of KMOD with other four similar algorithms described in
Section 2.1. All of these algorithms require some major parameters, such as the number of outliers and the distance threshold, to determine outliers. For KMOD, KMOR, and ODC, the distance threshold is required. For KMOR,
k-means--, and NEO-
k-means, the number of outliers is required.
Table 2 shows six configurations of the parameters for these algorithms, denoted by bold letters from
A to
F. For example, the distance threshold was set to integers from 2 to 7. The number of outliers was set as a percentage of the total number of data points, which ranges from 0% to 20%. These parameter values cover a wide range, which allows us to see the performance of the algorithms in different settings. Note that, for the NEO-
k-means algorithm, we set
because we did not allow clusters to overlap in our experiments.
Since all the algorithms start with initial cluster centers randomly selected from the dataset, we ran each algorithm 100 times with different sets of initial cluster centers. In all runs, we set the desired number of clusters to the true number of clusters.
4.3. Results on Synthetic Data
We created two synthetic datasets to test the performance of the KMOD algorithm. The two synthetic datasets are shown in
Figure 1. The first dataset has two clusters and six outliers. The two clusters in this dataset contain 40 and 60 points, respectively. The second dataset has eight clusters and sixteen outliers. Each cluster in the second dataset contains 100 data points.
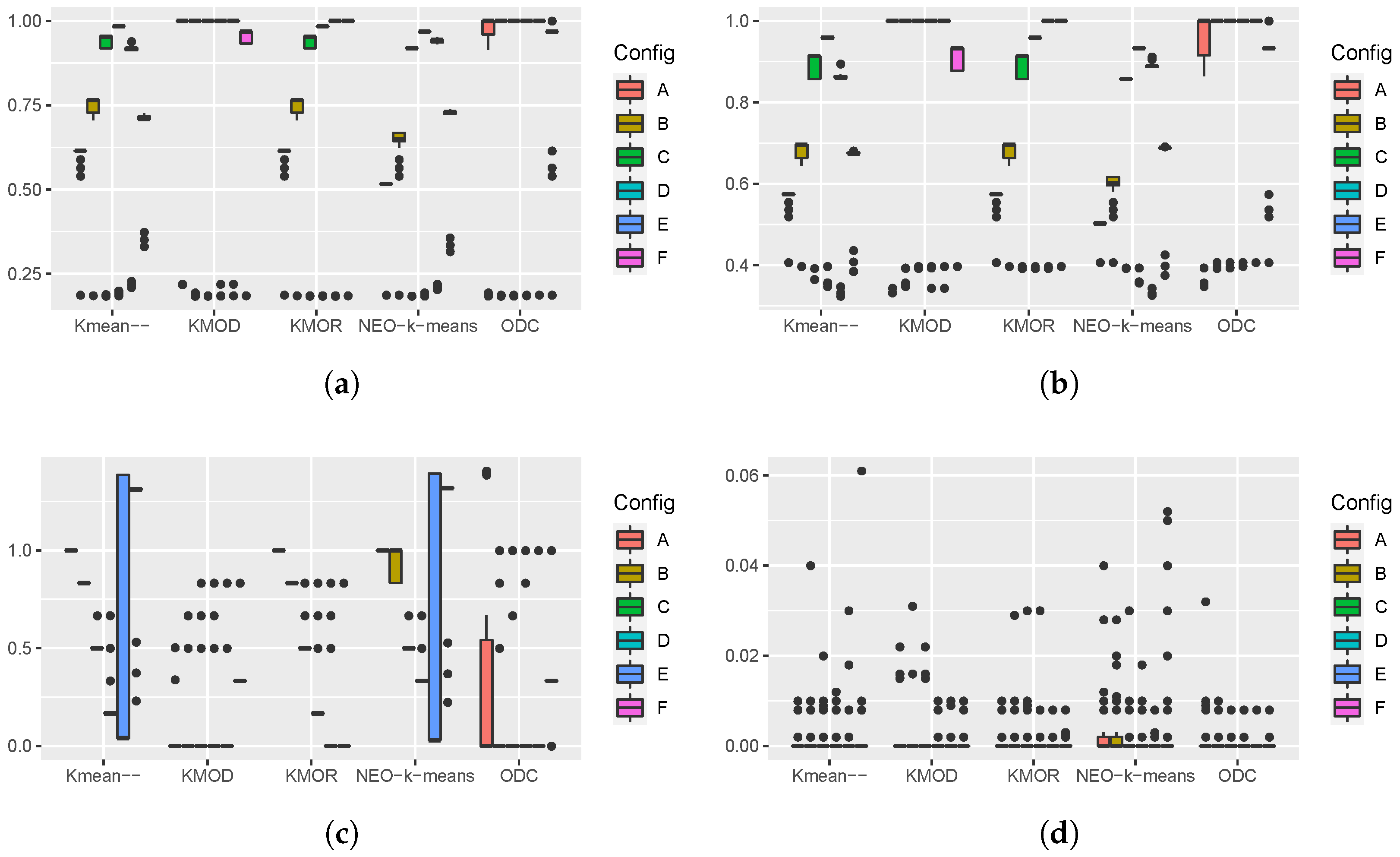
Figure 2 shows the boxplots of the performance measures produced by 100 runs of the five algorithms on the first synthetic dataset. The parameter configurations are shown in
Table 2. From the boxplots of the ARI and the NMI, we can see that the KMOD algorithm and the ODC algorithm produced 100% accurate clusters most of the time. The other three algorithms produced many partially accurate clusters. Looking at the boxplots of the classifier distance, we see that the KMOD algorithm performed the best among the five algorithms. In most cases, KMOD produced a classifier distance of zero. The
k-means--, NEO-
k-means, and ODC produced volatile results for some parameter configurations. Since this synthetic dataset contains only 106 data points, all algorithms converged pretty quickly in most cases.
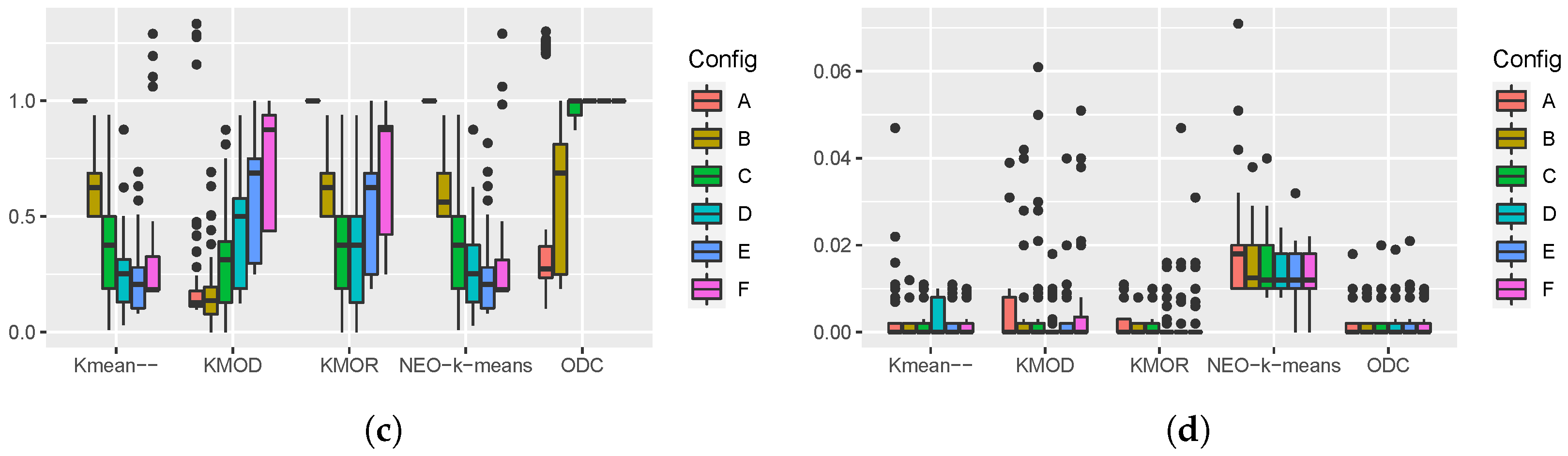
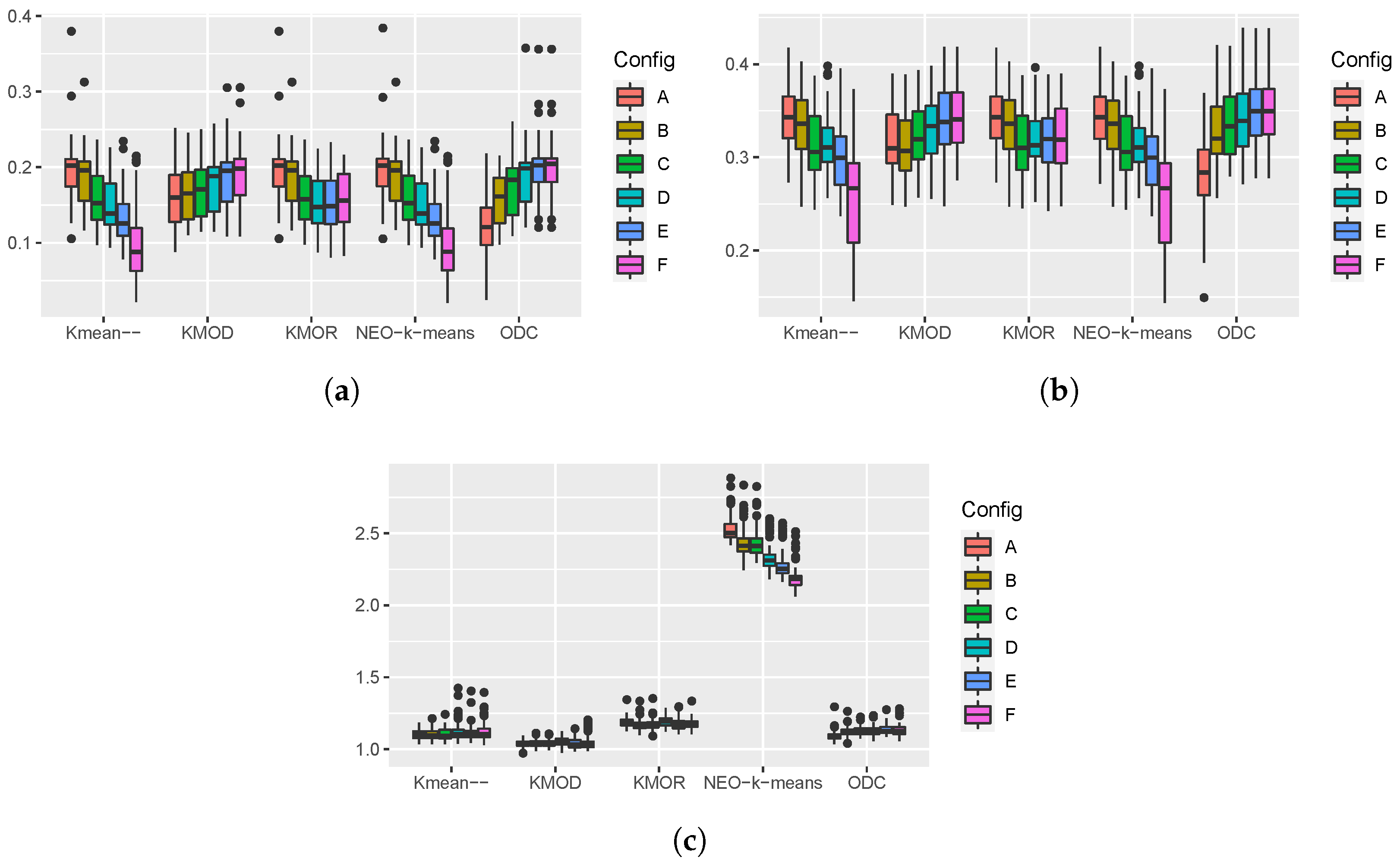
Figure 3 shows the boxplots of the performance measures obtained from 100 runs of the five algorithms on the second synthetic dataset. The boxplots of the AIR and the NMI show that the five algorithms have a similar median performance in most cases. For parameter configuration
A, the KMOD algorithm obtained the best performance and the ODC had the worst performance. The boxplots of the classifier distance show that, for parameter configurations
A and
B, the KMOD algorithm achieved the best performance. From the boxplots of the runtime, we can see that NEO-
k-means is the slowest algorithm. The other four algorithms have similar runtimes.
From the boxplots of the classifier distances shown in
Figure 3c, we can see some interesting patterns regarding the performance of these algorithms in terms of outlier detection. The
k-means-- algorithm and the NEO-
k-means algorithm use a percentage of the total number of data points to control the number of outliers. From parameter configurations
A to
B, the percentage increases from 0% to 20%. We can see that the median classifier distance of
k-means-- and NEO-
k-means decreases from the parameter configuration
A to
B. This pattern indicates that a large percentage parameter value is needed to include the outliers. The pattern of KMOR is not monotonic because the number of outliers is controlled by the interaction between two parameters. The pattern of ODC shows jumps and does not change gradually because the data points identified as outliers in ODC cannot become normal points anymore. The pattern of KMOD shows gradual changes when parameter
increases from 2 to 7. The median classifier distance was the lowest when
was set to 2. The experiment on the second synthetic data shows that using
as the default parameter value is a good choice.
4.4. Results on Real Data
We obtained several real datasets from the UCI machine learning Repository [
31] to compare the performance of the KMOD algorithm and the other four algorithms.
Table 3 presents some information about these real datasets. The real datasets have different sizes and different dimensionalities.
The wine dataset contains records from three different origins, which can be used as classes for the purpose of cluster analysis. The gesture phase dataset contains records extracted from videos of people gesticulating. The anuran calls dataset contain records created by segmenting 60 audio records that belong to four different families, eight genera, and ten species. In our experiments, we divided the dataset into 10 clusters, each of which represents a species. The shuttle dataset is a relatively large dataset that contains 58,000 records. The shuttle dataset consists of a training set and a test set. In our experiments, we used the training set that contains 43,500 records from seven classes.
Since the real datasets do not have labels for outliers, we assigned the outliers found by the clustering algorithms to their nearest cluster centers before calculating the two performance measures: the ARI and the NMI. As a result, we did not calculate the classifier distances for real datasets.
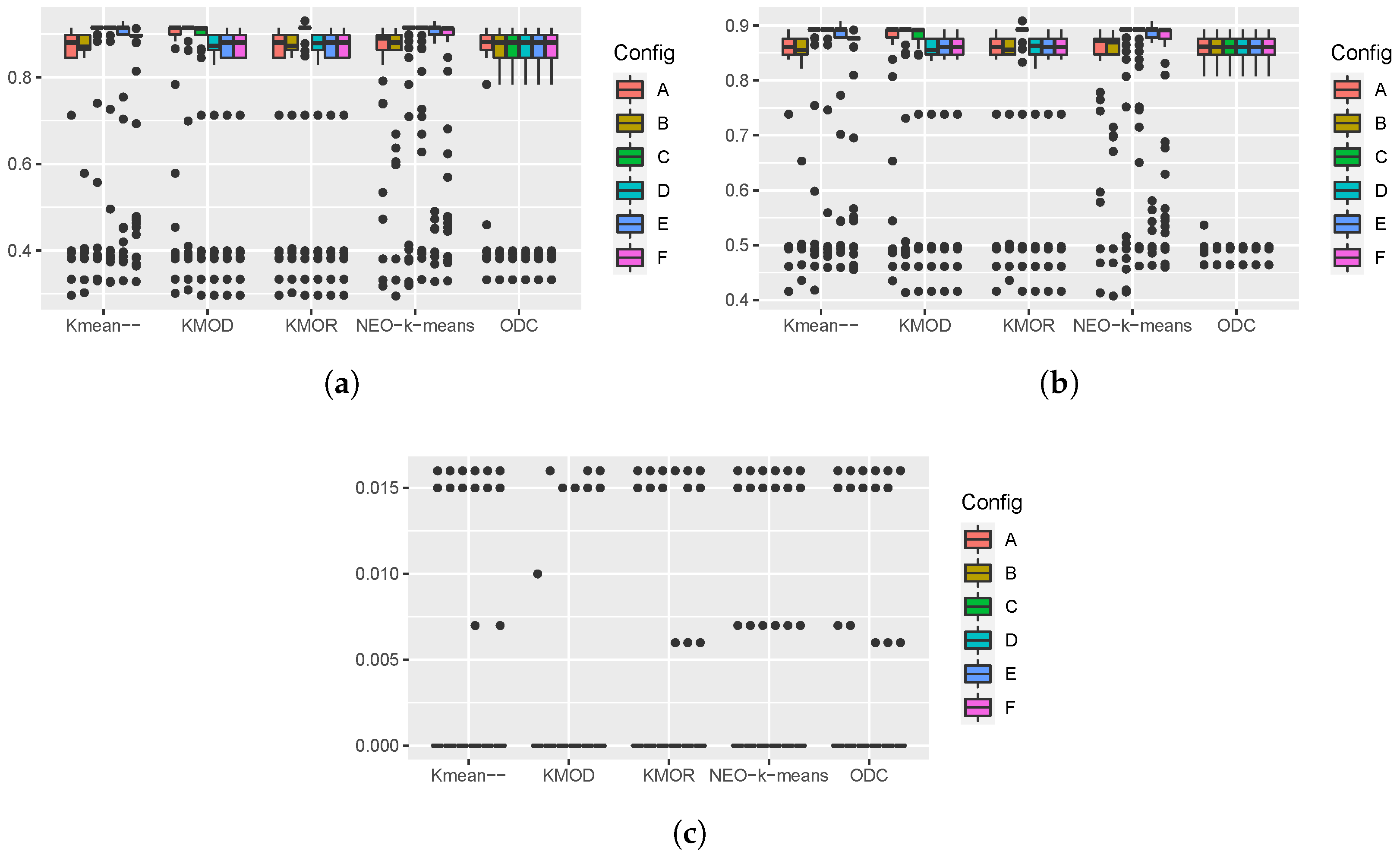
Figure 4 shows the boxplots of the performance measures produced by 100 runs of the five algorithms on the wine dataset. The boxplots of the ARI and the NMI show that the KMOD algorithm and the KMOR algorithm had a similar performance on the wine dataset. However, the KMOD algorithm outperformed the KMOR algorithm when parameter configurations
A to
C were used. Since the wine dataset is small, all algorithms converged quickly in most cases.
Figure 5 shows the boxplots of the performance measures obtained from 100 runs of the five algorithms on the gesture phase dataset. From the boxplots of the ARI and the NMI, we see that all five algorithms achieved a similar performance on this dataset in terms of accuracy. Since the gesture phase dataset is relatively large, we can see the runtime differences in the boxplots of the runtime. The NEO-
k-means algorithm was the slowest of the five algorithms. If we look at the median runtime, we can see that the KMOD algorithm was the fastest of the five algorithms.
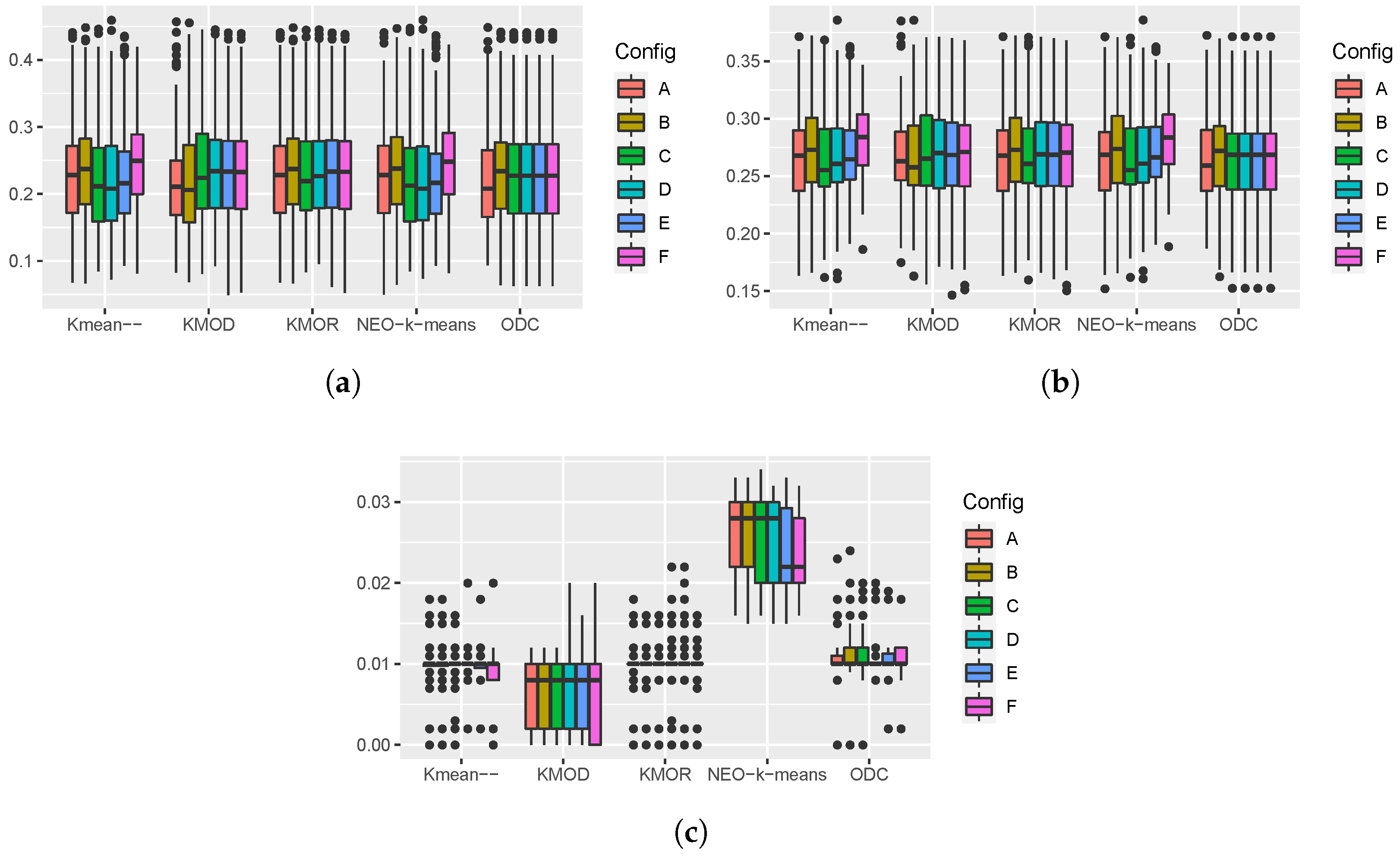
Figure 6 shows the boxplots of the performance measures produced by 100 runs of the five algorithms on the anuran calls dataset. From the boxplots of the ARI and the NMI, we see that the KMOD algorithm and the KMOR algorithm have a similar average performance. When the parameter configuration
F was used, the average accuracy of the
k-means-- algorithm and the NEO-
k-means algorithm decreased. The boxplots of the runtime shows that the NEO-
k-means algorithm was the slowest algorithm. The average runtime was similar for the other four algorithms.
Figure 7 shows the boxplots of the performance measures produced by 100 runs of the five algorithms on the shuttle dataset. From the boxplots of the ARI and the NMI, we can see that the KMOD algorithm achieved the best overall performance across the different parameter configurations. The performance of
k-means--, NEO-
k-means, and ODC varied a lot across different parameter configurations.
From the boxplots of the runtime, we can see that the KMOD algorithm was the fastest of the five algorithms when applied to this dataset, which is a relatively large dataset. We expect the KMOD algorithm to be faster than the KMOR algorithm because the latter sorts distances to find outliers to satisfy the constraints imposed by the algorithm. In the KMOD algorithm, distance sorting is not required.
In summary, the experiments on synthetic data showed that the KMOD algorithm is able to cluster data and detect outliers simultaneously. The experiments on real data showed that the KMOD algorithm is able to achieve a better overall performance and is faster than other algorithms. The experiments on real data also showed that the KMOD algorithm is not sensitive to the parameter used to control the number of outliers.
5. Conclusions
In this paper, we proposed a KMOD algorithm that is able to perform data clustering and outlier detection simultaneously. In the KMOD algorithm, outlier detection is a natural part of the clustering process. This is achieved by introducing an “outlier” cluster that contains all the points that are considered outliers. The KMOD algorithm produces two partition matrices: one partition matrix divides a dataset into k clusters and an “outlier” cluster and the other partition matrix divides a dataset into k clusters without labeling outliers. As a result, the KMOD algorithm can be used to detect outliers and can also be used like a normal clustering algorithm.
An advantage of the KMOD algorithm is that it requires only one parameter to control the number of outliers. This parameter is intuitive in that it is a distance threshold to determine whether a data point is an outlier. As a result, setting a value for this parameter is straightforward for any dataset.
We compared the KMOD algorithm with other four similar algorithms (i.e., k-means--, KMOR, NEO-k-means, and ODC) using both synthetic datasets and real datasets. The test results have shown that the KMOD algorithm outperformed the other algorithms in terms of accuracy and speed. In particular, the KMOD algorithm was less sensitive to the parameter used to control the number of outliers than other algorithms.
The KMOD algorithm is a variant of the
k-means algorithm. As a result, the KMOD algorithm inherits the advantages as well as the disadvantages of the
k-means algorithm. The KMOD algorithm is simple to implement and can be used in applications where the
k-means algorithm is used. Like the
k-means algorithm, the KMOD algorithm is also sensitive to initial cluster centers. Other efficient cluster center initialization methods [
32] can be used to improve the KMOD algorithm.
It is worth mentioning that outliers can also be handled before clustering algorithms are applied. For example, Fränti and Yang [
33] proposed a data cleaning procedure that employs a medoid shift to reduce noise in the data prior to clustering. This method processes each data point by computing its
k-nearest neighbors (k-NN) and replacing the point with the medoid of its neighborhood. Another example in this line of research is the mean-shift outlier detection method proposed by Yang et al. [
34].









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}