1. Introduction
In the context of global digital transformation, intellectual property has become a core resource for promoting scientific and technological innovation and industrial development. An effective IPR certification mechanism not only helps to establish ownership and combat infringement but also plays a key role in enhancing regional innovation capacity and building market trust mechanisms. For a long time, intellectual property certification has relied on a centralized third-party institution to complete the work of confirming rights and depositing evidence, which has certain credibility but also has significant structural drawbacks, specifically manifested as follows: First, the centralized authentication platform faces data tampering, system paralysis, and other security threats, such as DDoS attacks and witch attacks [
1] on the authentication of data integrity and usability challenges; second, the confirmation of rights and rights process usually involves multi-party coordination; there is a process of cumbersome, high cost, long cycle, and other issues; and third, under the participation of multi-stakeholder subjects, the transparency and traceability of the authentication and certification process is insufficient, which may easily lead to a trust crisis [
2].
In recent years, blockchain technology has been widely regarded as a potential technical solution for reconstructing the intellectual property certification system due to its decentralization, tamperability, openness, and transparency [
3]. By storing intellectual property data on the chain through the blockchain ledger, the security and traceability of property rights data can be effectively guaranteed so that the subject of property rights can no longer rely on third-party organizations to complete the original proof of ownership and the process of defending rights. In addition, infringement acts can be permanently recorded on the chain and shared across the network, thus increasing the cost of infringement and realizing a strong deterrent effect.
However, building a high-performance, scalable, and secure blockchain IPR authentication system still faces core challenges, among which the efficiency and stability of the consensus mechanism are the key factors restricting the system’s landing. The PBFT consensus algorithm, which is currently widely used in coalition chain scenarios, has strong fault tolerance and fast convergence speed [
4], but when the node scale is expanded, the communication complexity rises exponentially, which leads to serious limitations on system throughput and makes it difficult to meet the needs of large-scale intellectual property data high concurrent authentication and depository needs [
5].
Although some researchers have tried to improve PBFT by lightweighting or hierarchizing to reduce the communication overhead, most of these methods have not been optimized for the actual characteristics of high data value, node heterogeneity, and high-security requirements in intellectual property rights authentication systems, and they are still deficient in resisting the malicious nodes and guaranteeing the consensus trustworthiness. Therefore, there is a need to design an improved consensus mechanism that takes into account performance, scalability, and security to adapt to large-scale, dynamic, multi-node collaborative intellectual property certification scenarios. The data in the IPR authentication system are of high value and sensitivity [
6], so the consensus algorithm needs to cope with potential malicious node attacks, data tampering, and other security issues to ensure the system’s anti-attack capability and data integrity. And as the scale of the system expands, the number of nodes increases, which puts higher requirements on the performance of the consensus algorithm. Specifically, the PBFT algorithm has exponential growth in communication complexity when the number of nodes increases, and the communication overhead will increase rapidly, which may cause limitations on large-scale deployment of the intellectual property authentication system. Reducing communication complexity to minimize resource consumption while ensuring the accuracy of consensus results is one of the core issues.
The innovativeness of this paper lies in the following: The blockchain-based MBFT (improved PBFT) consensus algorithm is proposed, and combined with the distributed storage system IPFS, it effectively solves the problem of increasing communication complexity faced by the traditional PBFT algorithm when the node scale is expanded. Different from the simplified or hierarchical treatment of PBFT in existing research, the MBFT algorithm introduces a node scoring mechanism based on the Fibonacci series, a classification consensus layer, and a dynamic node updating strategy to improve the consensus efficiency and enhance the system’s anti-attack capability and carries out the PBFT consensus in the classification consensus and the consensus confirmation layer, respectively, thus ensuring the accuracy and reliability of the consensus results. In addition, the MBFT algorithm significantly reduces the global communication requirements through the design of a layered consensus structure and a small number of global consensus nodes, thus significantly improving the performance and scalability of the system.
The main work of this paper is as follows:
- (1)
Design a fair and intuitive node stratification mechanism, divide the nodes into a classification consensus layer, consensus confirmation layer, and supervision layer with an evaluation system, and divide the work in each layer to improve the consensus efficiency and ensure the consensus accuracy.
- (2)
Design a category-based consensus strategy, using the Maglev algorithm to generate a lookup table to divide the nodes in the classification consensus layer into four groups. The grouping results can be quickly obtained by the lookup table operation with time complexity O (1), and at the same time, the characteristics of consistency hash are used to ensure the balanced distribution of nodes in each group.
- (3)
Optimize the consistency protocol and carry out PBFT consensus once in each of the classification consensus layers and the consensus confirmation layer, according to the consensus situation and to achieve the dynamic update of nodes, to ensure the accuracy and reliability of the consensus.
- (4)
Combine blockchain with distributed database IPFS to reduce the pressure of intellectual property data storage in blockchain and improve operational efficiency.
The next pages are organized as follows:
Section 2 is an introduction to the related work,
Section 3 describes the detailed design scheme of MBFT,
Section 4 compares and analyses the improved algorithm with the existing commonly used consensus algorithms,
Section 5 conducts an experimental analysis of the performance of the improved algorithm, and
Section 6 concludes this paper.
2. Related Work
System solutions for intellectual property authentication at home and abroad generally adopt the model of manual combined with central agency management. Under this traditional model, the system is vulnerable to DDOS attacks and witch attacks by malicious users, resulting in data loss and system failure. At the same time, multiple parties with mutually compromising interests may be able to tamper with the data. Blockchain technology brings a new solution to the pain points that exist in traditional intellectual property authentication. Because of its decentralization, distribution and sharing, non-tampering, openness, and other characteristics, it can well solve the problems of falsification of property rights certificates, difficulty in tracing ownership, and high cost of defending rights that exist in the traditional protection mode.
Regarding the application scheme of blockchain in intellectual property protection and management, the literature [
7] studies the risk problems brought by blockchain-enabled intellectual property protection, identifies the legal risk, information risk, regulatory risk, and intellectual property risk, analyzes the technological causes of these risks, and proposes that a risk-avoidance mechanism combining legal norms, policy monitoring, and technological self-governance should be constructed so as to enhance the intellectual property protection’s intellectualization level and efficiency. Literature [
8] explores the application of blockchain in intellectual property management, analyzes the potential of blockchain in governance and enforcement, summarizes the practical applications and insights in the white paper of the World Intellectual Property Organization, and discusses the advantages, limitations, and implementation challenges of blockchain in intellectual property protection. Literature [
9] explores the potential of blockchain in intellectual property protection, emphasizing that blockchain improves security, combats piracy, and protects creators’ rights through transparent ledgers and smart contracts. Literature [
10] studies the application of blockchain in intellectual property management, analyzes 120 cases to explore the role of blockchain in the life cycle of intellectual property, and proposes strategic guidance to promote blockchain innovation.
For the blockchain and related technologies in intellectual property anti-infringement application schemes, literature [
11] uses timestamp technology as a means of electronic evidence forensics authentication, and the electronic certificates provided by the Joint Trust Timestamp Service Center are deposited and fixed. Literature [
12] proposes an intellectual property management scheme based on blockchain and smart contracts, using non-homogenized tokens to represent intellectual property rights, and automatically executing licensing, transferring, and royalty distribution through smart contracts. Literature [
13] proposes a blockchain-based framework to protect architectural design intellectual property rights in the architecture, engineering, and construction industry, utilizing tamper-evident tokens, distributed ledgers, and cryptographic algorithms to improve the efficiency of intellectual property protection, reduce costs, and enhance transparency and security. Literature [
14] proposes a digital management method for intellectual property rights based on non-homogenized tokens to achieve a strong binding of on-chain and off-chain property rights authentication so that the proof of property rights has a safe and reliable unique identification and on-chain corroboration. Literature [
15] proposes a privacy-preserving intellectual property authentication scheme based on Ethernet blockchain, which realizes selective encryption of user information by combining elliptic curve encryption and digital signatures and adopts zero-knowledge proof to complete intellectual property ownership authentication. Literature [
16] utilizes big data mining technology to proactively provide online intellectual property infringement matching services to meet the needs of original authentication and depositing of innovation results of innovation subjects, which launches a positive exploration for the application in the field of property rights protection. Literature [
17] proposes a blockchain-based intellectual property protection platform that solves the problems of property right confirmation, infringement monitoring, and evidence collection. The accuracy of copyright infringement detection is improved by improving the SimHash algorithm.
Regarding the research on the application of blockchain and related technologies in intellectual property rights deposit, literature [
18] constructed a medical property rights platform based on blockchain technology, aiming to ensure security and transparency in the process of sharing medical property rights. The platform incentivizes innovative behavior and promotes multi-party collaboration through pledged tokens while effectively reducing R&D costs. Literature [
19] designed a data storage incentive model combining a storage platform and blockchain technology, which utilizes the secure storage characteristics of the storage platform and the public trust mechanism of the blockchain to classify users into different categories, thus effectively incentivizing users to expand their storage space and promoting the development of the intellectual property rights service and protection platform for digital economy based on blockchain technology. Literature [
20] proposes an agricultural intellectual property rights confirmation model based on a coalition chain, which realizes the automated confirmation and transfer process of agricultural intellectual property rights by presetting the smart contract mechanism of intellectual property rights registration and rights transfer. The intellectual property protection system is constructed to realize the credible confirmation and traceability of agricultural intellectual property rights. Literature [
4] proposes a blockchain-based digital copyright protection scheme that uses improved locally sensitive hashing technology to realize feature extraction and originality verification of textual digital content, effectively preventing the uploading and depositing of infringing works. Literature [
21] proposes a digital platform based on blockchain and patent watermarking technology to protect the intellectual property rights of 3D printing digital assets. The platform provides encryption, authentication, and transaction services to enhance intellectual property protection and promote the standardization and internationalization of the 3D printing industry. Literature [
22] proposes a blockchain-based code copyright management system to construct a code originality verification model based on abstract syntax trees, and a peer-to-peer blockchain network aims to store the copyright information of the original code. Literature [
23] proposes a blockchain-based intellectual property protection framework for music, which improves security, reduces tampering risk, and simplifies the intellectual property protection process through blockchain storage and continuity judgment.
In summary, the potential of blockchain technology in intellectual property protection has been partially discussed, but there are still fewer studies that closely integrate blockchain consensus algorithms with intellectual property scenarios. Most of the existing research mainly focuses on how the basic features of blockchain, such as tampering and timestamping mechanisms, can be applied to the aspects of intellectual property rights authentication and authorization management. Research on how to design consensus algorithms suitable for IP authentication and transaction scenarios, such as optimizing their performance and reducing communication overhead, is still limited. Optimizing the consensus mechanism can avoid the performance degradation of the system due to excessive computation and communication overhead in order to improve the processing power of the system.
3. Overall Design of the D-PBFT Algorithm
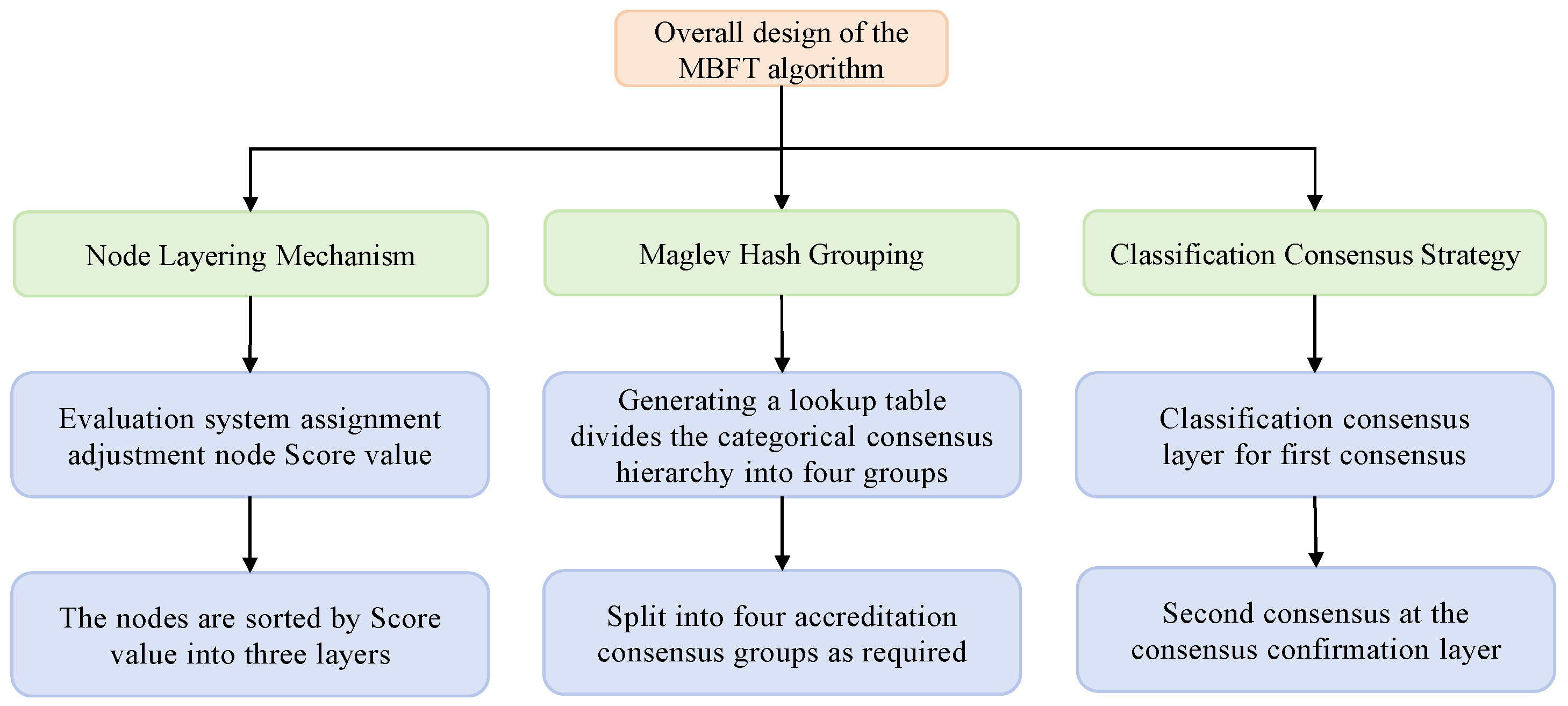
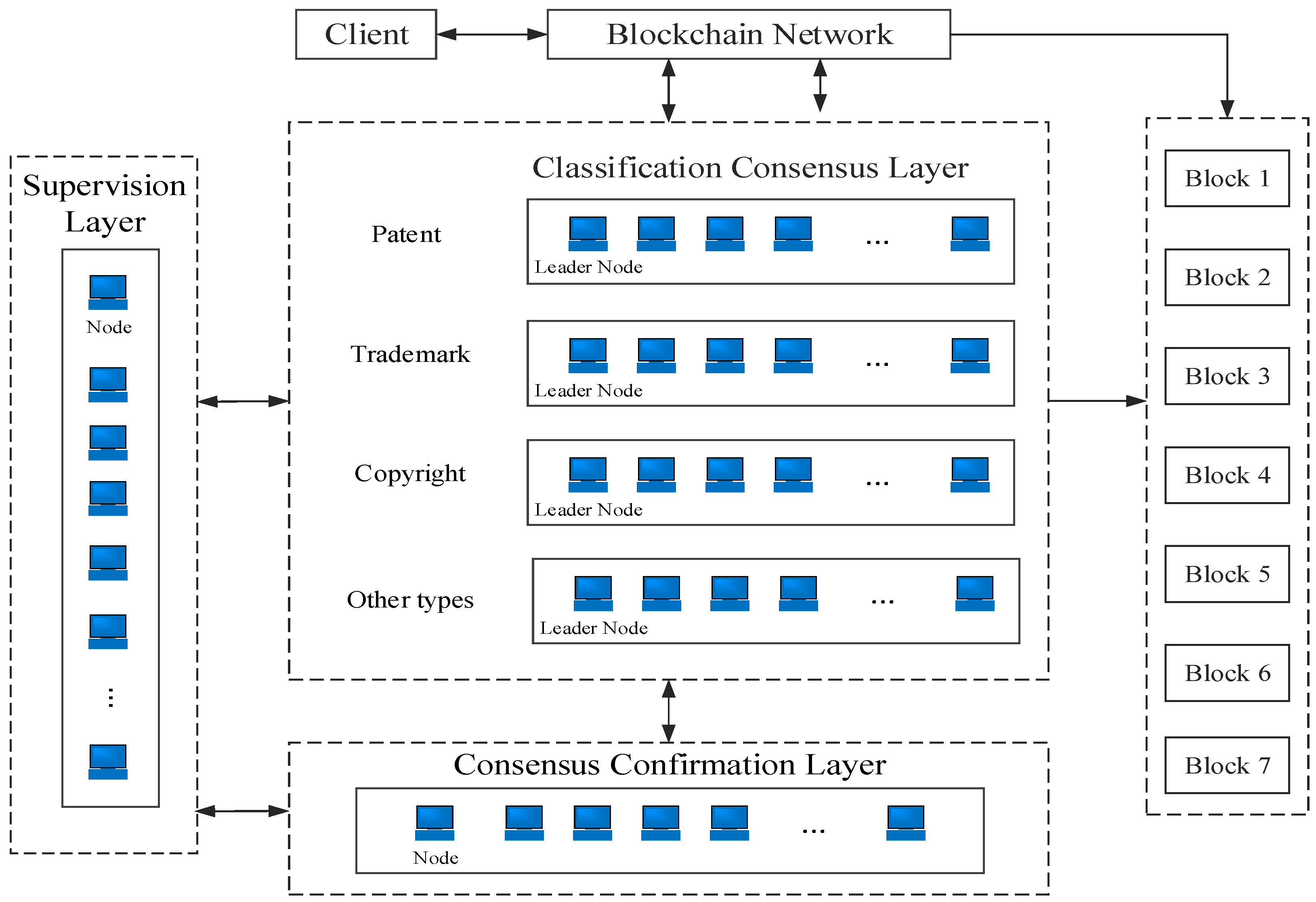
The MBFT consensus algorithm in the intellectual property authentication scenario consists of three parts: the node layering mechanism, Maglev hash grouping, and classification consensus strategy. The layering mechanism divides the nodes into the classification consensus layer, the consensus confirmation layer, and the supervision layer, and each layer divides the work to improve the consensus efficiency. The nodes are also encouraged to maintain correct behavior to ensure consensus accuracy. The Maglev algorithm divides the nodes of the classification consensus layer into four groups by generating a lookup table. The grouping results can be quickly obtained by a lookup table operation with time complexity O (1), while the property of consistent hashing is used to ensure a balanced distribution of nodes in each group. In the classification consensus strategy, in order to improve consensus efficiency, according to the type of intellectual property authentication, the four groups of nodes in the categorized consensus layer are divided into four consensus groups, which are required for intellectual property authentication, and each authentication consensus group verifies the corresponding type of intellectual property authentication request initiated by the client, and each authentication consensus group works independently in parallel. The overall design of the MBFT algorithm is shown in
Figure 1.
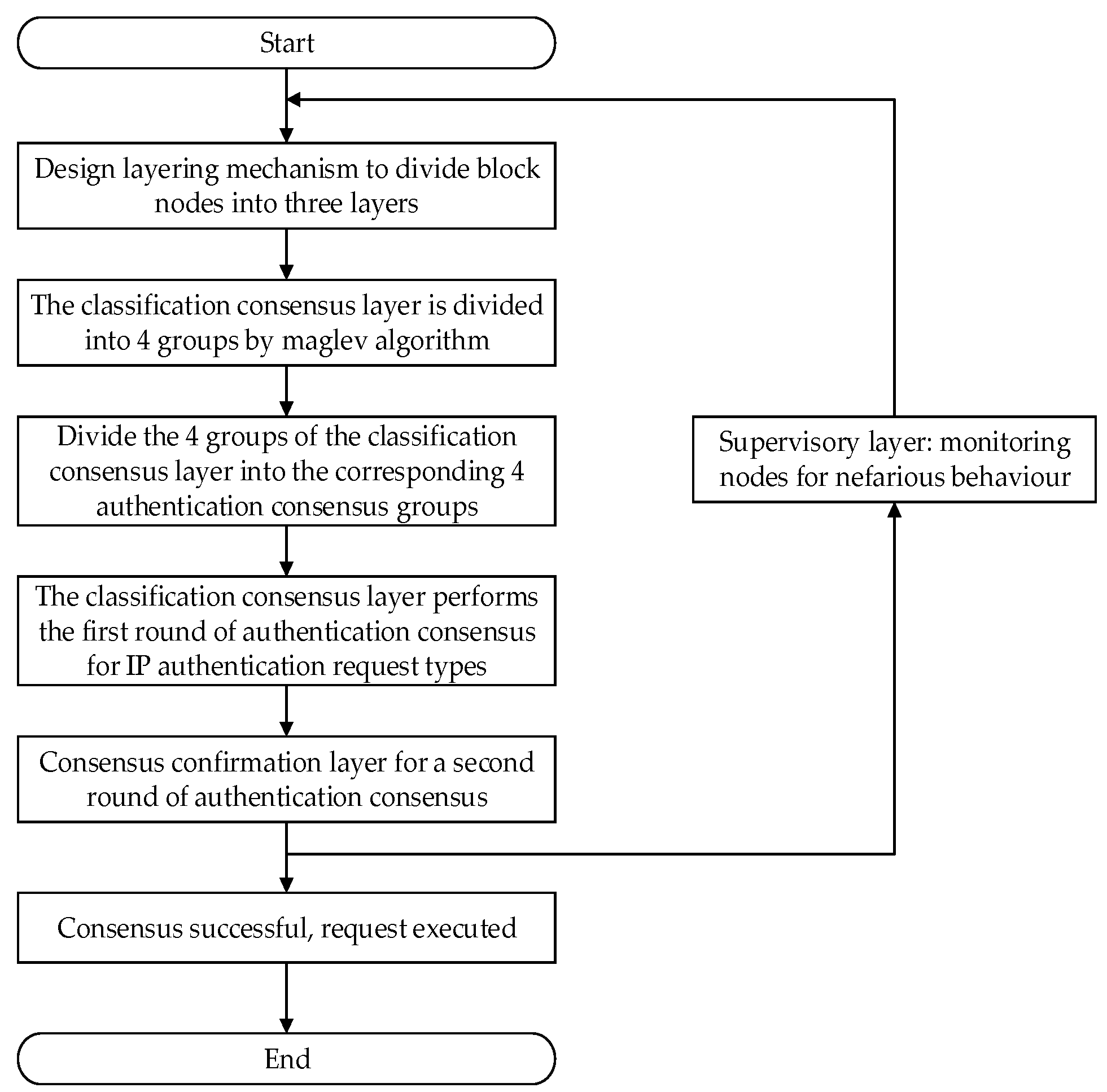
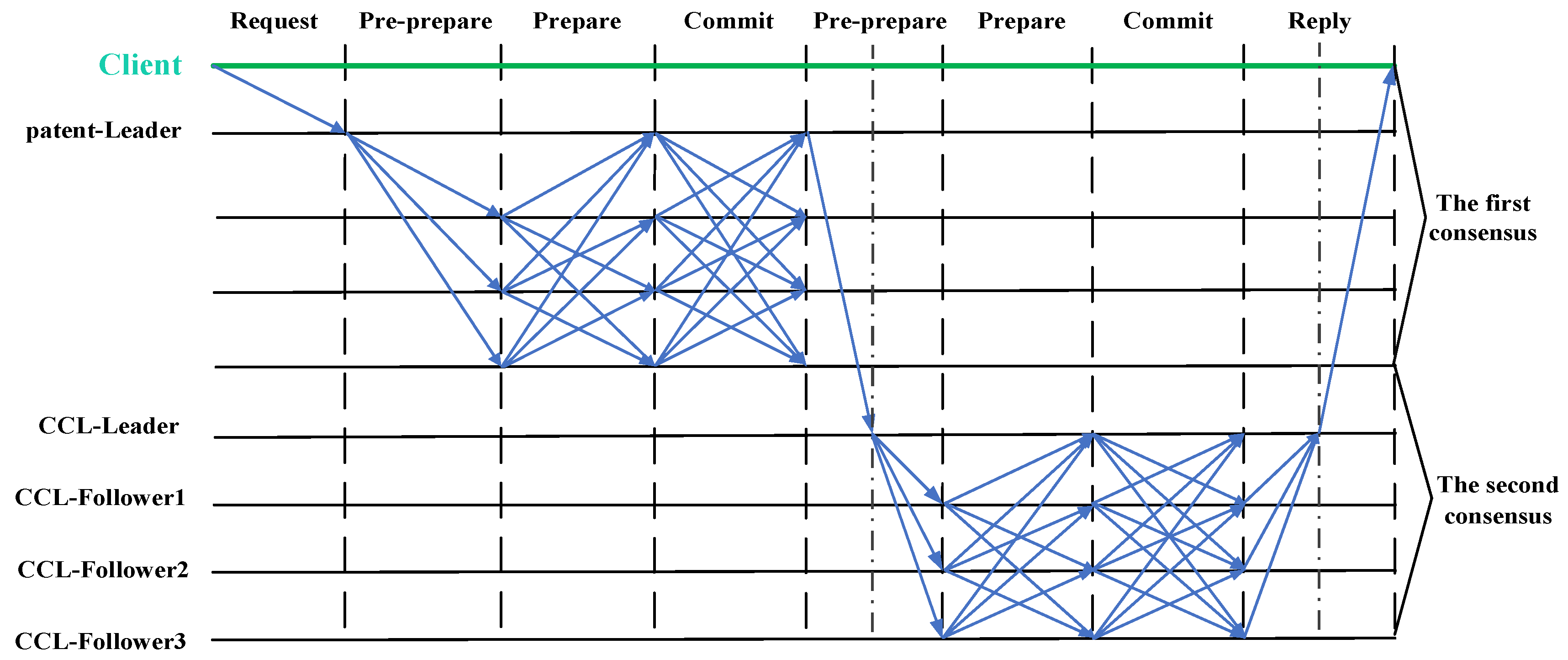
The overall process of the MBFT algorithm is illustrated in
Figure 2. First of all, the nodes are divided into three layers by the layering mechanism: the classification consensus layer, consensus confirmation layer, and supervision layer. The Maglev algorithm generates a lookup table to divide the nodes of the classification consensus layer into four groups in a balanced way. According to the type of intellectual property authentication needs, the four groups of nodes are set into patent, trademark, copyright, and other types of authentication consensus groups in turn. When there is an authentication request in the intellectual property authentication system, according to the classification of intellectual property, the request will be sent to the corresponding authentication consensus group, the group for the first PBFT consensus, if the first PBFT consensus is successful, the consensus confirmation layer for the second PBFT consensus, the consensus is successful after the successful end of the entire transaction consensus process, that is, the success of the intellectual property authentication. In case the consensus fails to meet the requirements, the Byzantine node will be replaced, and the appropriate penalty will be enforced. Subsequently, the authentication consensus process will restart based on the evaluation system within the layering mechanism.
Nodes are categorized based on their historical performance, frequency of participation in consensus, and their role in the system. To ensure the flexibility and robustness of the system, roles are dynamically assigned based on the Score value of the nodes, and nodes with excellent performance are given more critical roles, such as leader nodes or supervisory nodes, while nodes with poor performance are demoted. Thresholds are set based on the Score value or historical behavior of the nodes to ensure that each node is in the right role. In terms of consensus thresholds, the system should clearly define which node behaviors meet the criteria of “correctly participating in the consensus”. Only when a node responds correctly in a certain round of consensus and passes the consistency verification with other nodes is it considered to have participated in a valid consensus. For different levels of consensus, different criteria can be set; only when each consensus node receives 2f + 1 identical messages from other nodes and verifies them successfully, the consensus is considered successful.
For the handling of malicious nodes, it is necessary to clarify which behaviors are considered malicious behaviors, such as intentionally sending wrong messages, refusing to participate in the consensus, or creating confusion in the consensus. In order to deal with this situation, the system sets up a specialized detection mechanism, and after discovering the malicious node, timely punitive measures are taken, and the Score value of the malicious node will be cleared or even kicked out of the system. At the same time, it adopts graded punishment measures to determine the intensity of punishment according to the severity of malicious behavior. The supervisory layer will monitor the whole consensus process, and when inconsistent behavior is found, it can be verified by collecting evidence and deciding whether to punish the malicious node through the voting mechanism. Dynamic adjustment is the key to ensuring the long-term stable operation of the system. The Score value of a node should be dynamically adjusted according to its participation, and nodes that continuously perform well can be rewarded, while nodes that do not participate in the consensus will be punished. Through this mechanism, nodes can be incentivized to maintain a positive participation attitude, while ensuring system decentralization. In addition, the role allocation of nodes should be dynamic to ensure that the system can timely elect new key nodes and leader nodes according to the performance of nodes in new consensus rounds so as to ensure the stability and flexibility of the system. These assumptions and mechanisms are designed to ensure that the system can still maintain a high degree of reliability and robustness in the face of different types of node behaviors, especially in the face of malicious nodes, which can be effectively prevented from disrupting the normal operation of the system.
The user submits factual identity information to the intellectual property authentication platform for account registration, including the user’s real name, gender, and specific documents that can prove identity information. The administrator node checks the user’s identity. After passing the verification, the system will establish an account model for the user consisting of the main account, the property rights account, and the contract account. The main account is the user’s real identity information account, which is convenient for the system administrator node to confirm the user’s identity and management, as well as for other users to know the basic identity information when they conduct transactions with the user; the property rights account is the user’s intellectual property information account, including the user’s current intellectual property information and intellectual property information that has been traded; the contract account is the user’s smart contract information account; based on the classification and characteristics of the intellectual property rights and the construction of a specific and applicable intellectual property rights transaction smart contract, the user will generate a contract record in the subsequent intellectual property rights transaction.
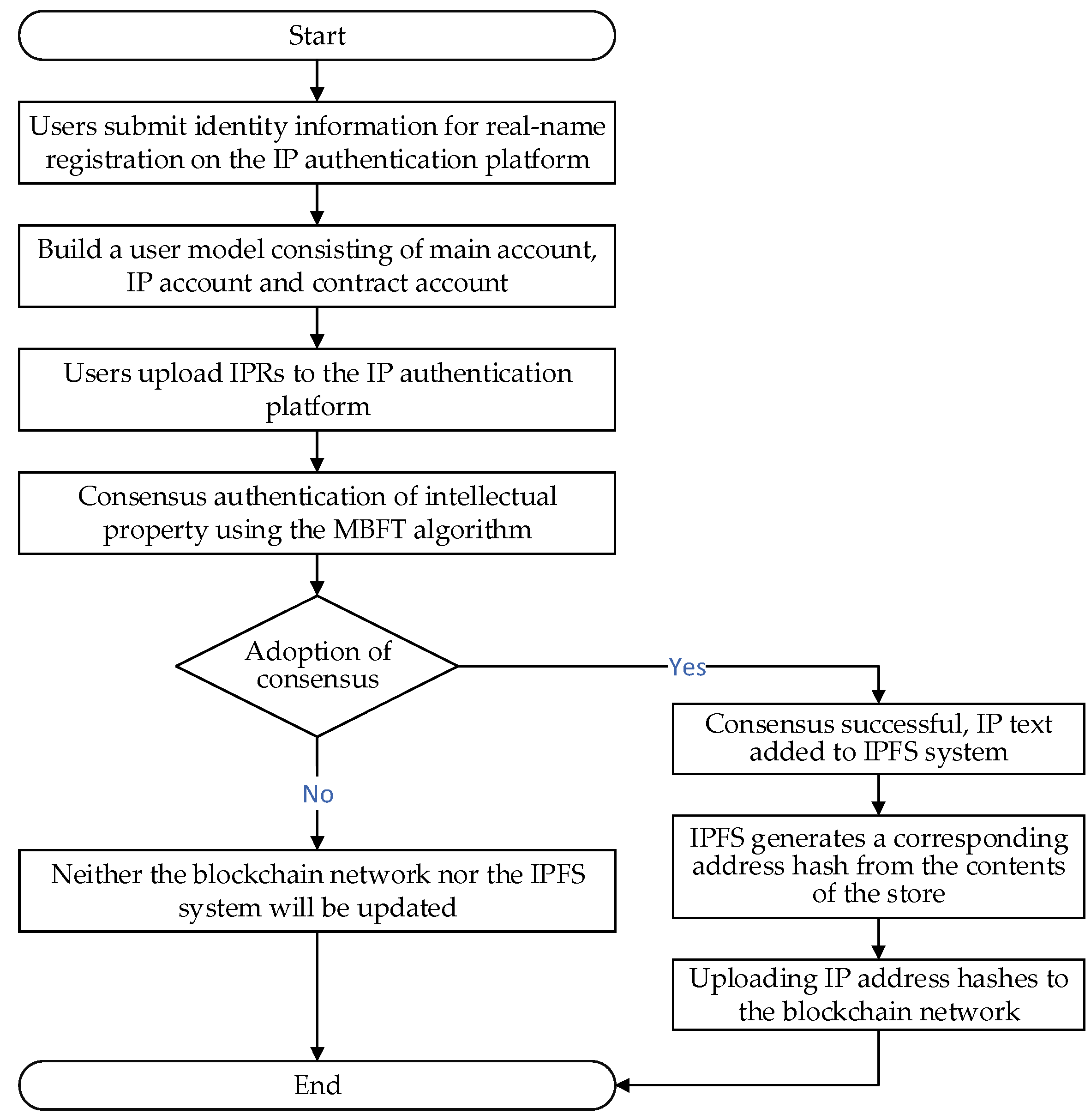
The process of IP authentication is depicted in
Figure 3. The user uploads the intellectual property certificate to the intellectual property authentication platform, and the content of the certificate contains detailed information such as the specific intellectual property typology, the name of the intellectual property, the timestamp, etc. The MBFT algorithm carries out a consensus on intellectual property. If the consensus is successful, the blockchain consensus mechanism is responsible for storing the intellectual property authentication information in the blockchain ledger for the notarization of the whole network. The certificate file and the IP authentication information are stored in IPFS, which generates the corresponding address hash from the stored content and stores the hash and user information in the blockchain.
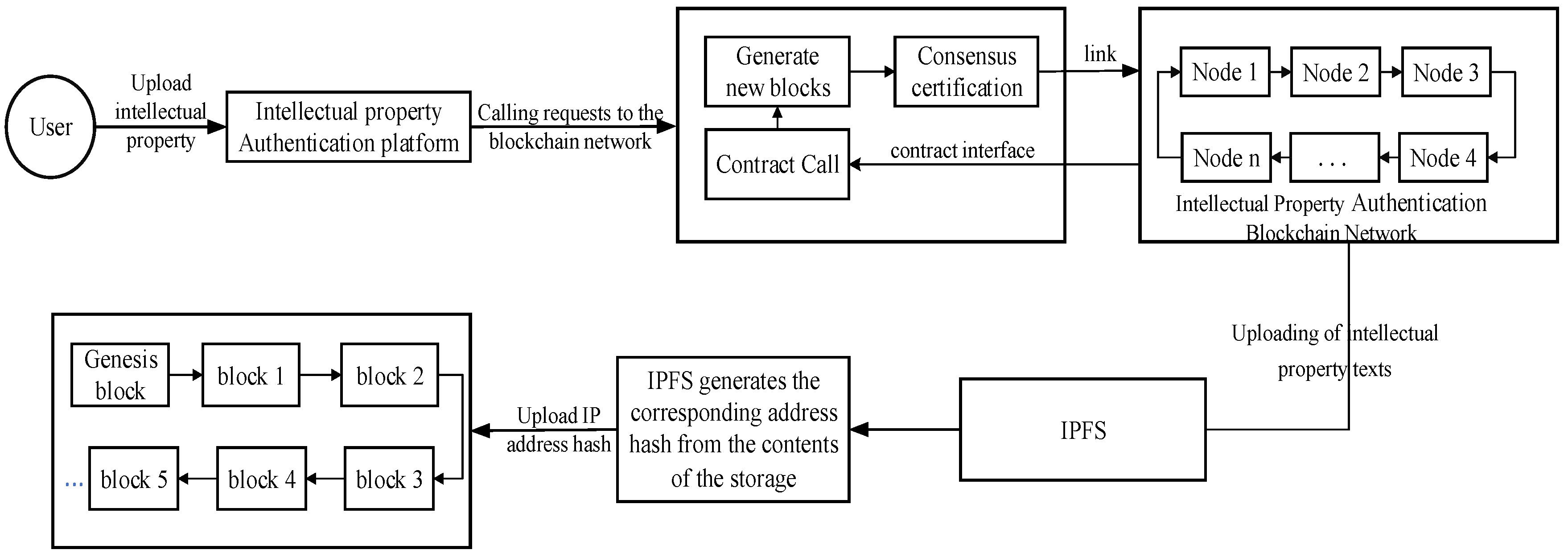
The user side uploads its own works in the intellectual property authentication system and initiates a request to the user side to the intellectual property authentication blockchain network, calls the intellectual property authentication blockchain network interface, executes the already deployed property rights authentication contract, broadcasts the data to the whole network through the improved PBFT consensus mechanism, reaches a consensus and then connects the new block to the chain, and then stores the complete content of the work in the IPFS, and the IPFS generates the corresponding address hash through the stored content and writes the address hash value of the work into the new data block. The data entered into the chain cannot be tampered with. Additionally, each block within the blockchain includes a timestamp, which serves as robust evidence of intellectual property ownership and mitigates issues related to property disputes. The structure of the intellectual property authentication model is illustrated in
Figure 4.
3.1. Node Layering Mechanism
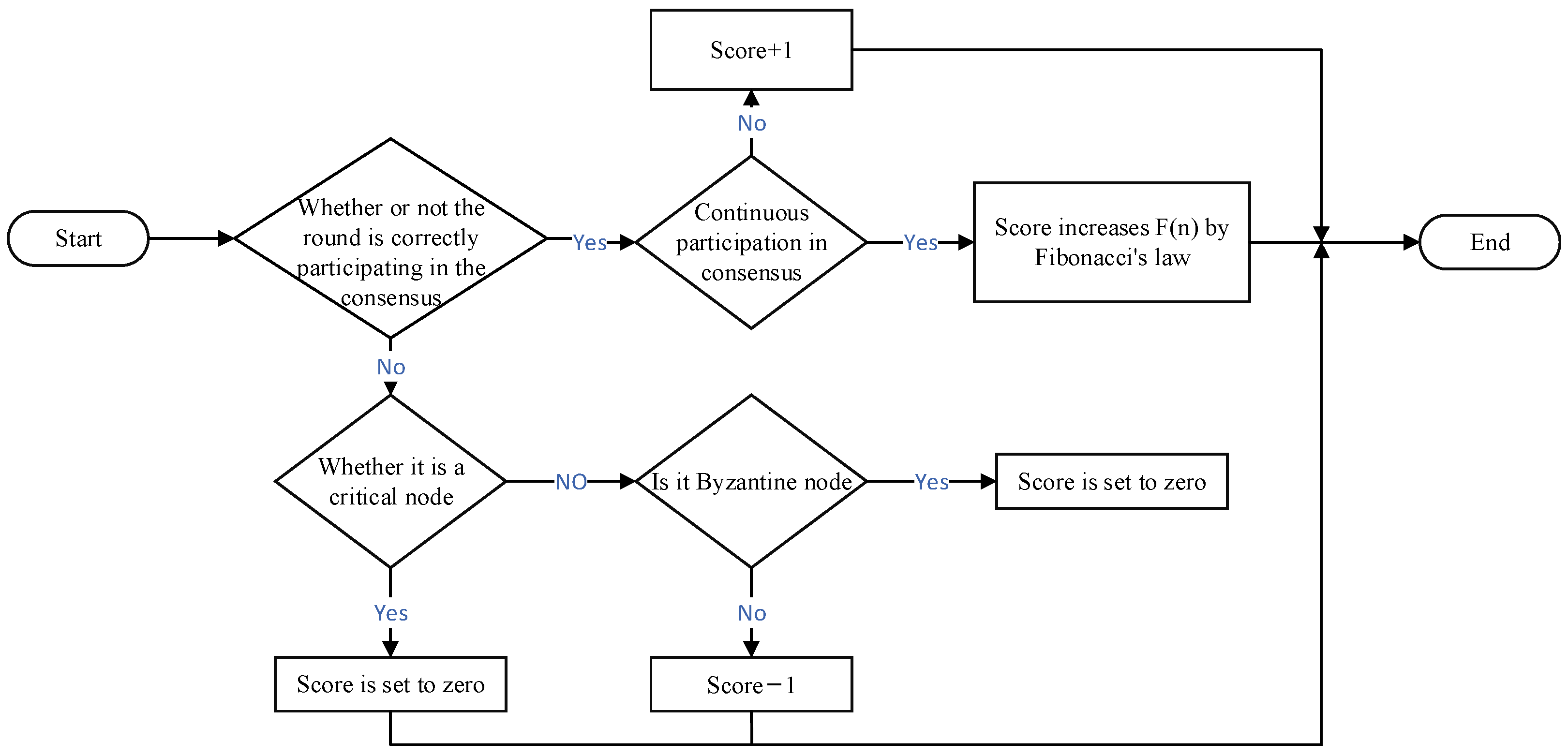
The hierarchical mechanism divides the nodes into a categorical consensus layer, consensus confirmation layer, and supervision layer. If the leader nodes and supervisory nodes are Byzantine nodes, they are likely to fail to fulfill their obligations, leading to the interruption of the consensus process. In order to make the elected nodes as reliable as possible, an evaluation system is introduced in the hierarchical mechanism, which scores the consensus credit of each node according to its behavioral status in a round of consensus. The evaluation system aims to dynamically assess the reliability of a node based on its performance during the consensus process and to motivate the node to continuously participate in the consensus by adjusting the Score value. The system encourages nodes to maintain stable and reliable behavior by introducing the Fibonacci series incremental law, which gives higher rewards to nodes when they participate in consensus correctly and continuously. The Score value of a node is increased or decreased according to its performance in participating in consensus, and in the initial state, the Score value of each node is 0. When a round of consensus is over, the Score value of each node will be adjusted.
For all nodes, the Score value increases as follows:
- (1)
If a node participates correctly in the consensus in this round but did not participate correctly in the consensus in the previous round, the Score value increases by 1;
- (2)
If the node correctly participates in the consensus for n consecutive rounds, the Score value increases according to the Fibonacci series with an increase in F(n) as shown in Equation (1).
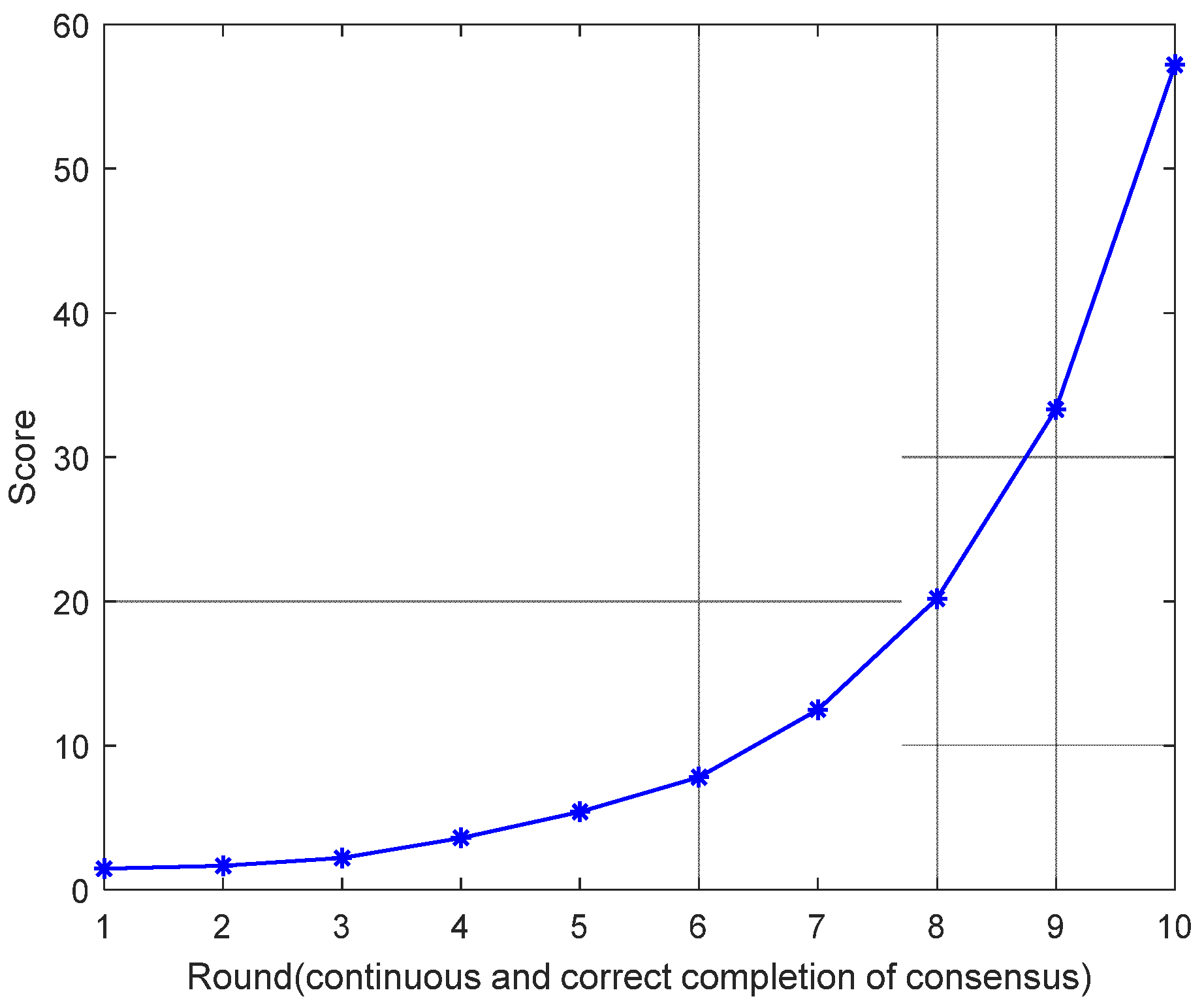
The growth trend of the Score value of a node for n consecutive rounds of correct participation in consensus is shown in
Figure 5. From the figure, it can be seen that as the number of consecutive rounds of correct participation of nodes in consensus increases, the Score value of nodes also grows faster and faster. And the more the number of consecutive correct participations of a node in a consensus round, the higher the growth rate of its corresponding Score value. By assigning higher Score values to nodes that operate correctly consecutively, the system is able to encourage nodes to maintain correct behavior. For IP authentication systems, ensuring that nodes perform consensus operations accurately and correctly is critical to the reliability of the system. This mechanism can encourage nodes to maintain stability and consistency, which is conducive to the security and stability of the authentication system. Through this incentive mechanism, nodes can be inclined to actively participate in each round of consensus. Especially for Byzantine fault-tolerant scenarios, by increasing the reward for correct participation, it can increase the nodes’ willingness to participate and reduce malicious behavior. Since the Score value only increases by 1 when a node does not participate consecutively, even if a node makes an occasional mistake, it can still make up the score through subsequent consecutive participation. This provides nodes with a certain amount of fault-tolerant space, which makes the consensus system still work properly when a few nodes make mistakes.
All nodes in the consensus confirmation layer, the supervisory layer, and the leader node in the categorical consensus layer are critical nodes, and the remaining nodes are regular nodes. For nodes that cannot participate in consensus stably and continuously, the probability of becoming a key node should be reduced to ensure the system’s activity. For the node that does not correctly participate in the consensus, the Score value is directly reduced to 0 if the node is a key node. If the node is an ordinary node, the node is evaluated to determine if it is a Byzantine node. If identified as a Byzantine node, the Score value is directly placed at 0. If the node fails to participate in the consensus correctly in the current round due to network and other reasons and is not judged to be a Byzantine node, the Score value is reduced by 1. The scoring logic of the evaluation system is shown in
Figure 6.
In the scenario of intellectual property authentication with n nodes, the nodes are ranked according to their Score value. Among the nodes with Score value ranked in the top n/3, the nodes with odd rankings are assigned to the consensus confirmation layer, the ones with even rankings are assigned to the supervision layer, and the remaining 2n/3 nodes are assigned to the classification consensus layer, which guarantees the nodes’ reliability across the consensus confirmation layer and the supervision layer. The leader nodes of the consensus confirmation layer and the supervision layer are the nodes with the highest Score value within the layer.
The classification consensus layer carries out the first round of authentication consensus for the IP authentication request sent by the client. Upon successful consensus, the consensus confirmation layer proceeds with a second round of authentication consensus to validate the accuracy of the consensus result. The role of the supervision layer is to prevent the Byzantine nodes from generating evil behaviors when performing consensus; when it is found that the information sent by a consensus node is different from that sent by other consensus nodes, it can be determined that the node is a malicious node, and evidence, i is sent to the nodes of the other layers, where evidence is the evidence of the node’s evil behavior, and i is the node’s label number. After collecting more than half of the votes, the supervisory node reduces the Score value of the node and restricts it from acting as a master node. If the Score value of a node drops to 0 twice, it kicks the node out. The supervisory layer nodes do not participate in consensus voting to ensure fairness but must maintain the consensus result.
3.2. Maglev Hash Algorithm Grouping
Since the scheme proposed in this paper requires grouping the nodes in the classification consensus layer using network slicing techniques, the existing network slicing mainly includes slicing according to geographical location [
24] and protocol-based slicing [
25]. The former may be subject to human control, and the latter is prone to uneven computational grouping. Subsequent studies have found that the uniformity and efficiency of consistent algorithms can be applied to network sharding. The current consistent hashing algorithms are the hash ring method [
26], the jump consistent hashing method [
27], and the Maglev hashing algorithm. Since the first two of these algorithms have high time complexity and are not very uniform, this paper adopts the Maglev hash algorithm to group the blockchain nodes.
The purpose of the Maglev hash algorithm is to divide the nodes of the classification consensus layer into four groups in a balanced way. The overall idea is to look up the table, hash the input values first, and then take the remainder; the result is mapped to the lookup table slots. The process of generating the lookup table is as follows: First, create an empty table entry of size M; each slot generates a sequence of size M, and the numbers in the sequence are installed in random order, after which each slot is filled in turn with the lookup table when a new value is inserted into a slot; first, determine whether the position is occupied; if it is not occupied, directly insert the location of the label; otherwise, it searches downward in sequence order until it finds a free marker. The sequence generation of slots is generated by two unrelated hash functions
and
. Assuming that the name of a slot is
b,
o and
s are computed by the functions Equation (2) [
28] and Equation (3) [
28].
In Equations (2) and (3),
o and
s are both offsets for generating the sequence of slots; % denotes a modulo operation on
that ensures that the generated offsets are within the range of
M. For each
j, the sequence is computed, Equation (4) [
26].
The above Equation shows that a quadratic hash-like approach is used to reduce the probability of collision of the mapping results. The mapping of this hashing algorithm is very well balanced, and checking the table has a time complexity of O (1) since it is in the form of building a table.
The detailed pseudo-code is presented in Algorithm 1.
| Algorithm 1 Node Grouping Algorithm |
Input:
Total number of slots N, Length of slot sequence M.
Output:
Search table entry
1: for each i < N do next [i] ← 0;
2: for each j < M do entry [j] ← −1;
3: n ← 0;
4: while true do
5: for each i < N do
6: c ← permutation [i] [next [j]];
7: while entry [c] ≥ 0 do
8: next [i] ← next [i] + 1;
9: c ← permutation [i] [next [j]];
10: next end while
11: entry [c] ← i;
12: next [i] ← next [i] + 1;
13: n ←n + 1 //next [i] ←
14: if n = M then return
15: end if
16: end for
17: end while
18: end for
19: end for |
The particular grouping process is depicted in
Figure 7. Twelve nodes are distributed among four groups; firstly, the first position in the sequence of group A corresponds to an empty position in the lookup table and is identified as 3, so node 3 is assigned to group A; group B is the same as above; group C, because position 3 in the lookup table is occupied, looks for the position that is not yet occupied in accordance with the sequence, position 4, so node 4 is assigned to group C; and node 1 is assigned to group B. After assigning a node to each group, the second round is started until the nodes are assigned. After one node is assigned to each group, the second round is started until the nodes are assigned. Through the above process, it can be found that only the time complexity O (1) lookup table can obtain the grouping results, and the nature of the consistency hash can also ensure the balance of the grouping.
Traditional PBFTs face network burden and performance bottlenecks when the node size increases. The Maglev hashing algorithm is able to effectively reduce conflicts and uneven loads among nodes in large-scale systems through an efficient and balanced node allocation mechanism. The lookup table approach of the Maglev algorithm ensures that the time complexity of the node allocation operation is O (1), which is essential for improving the throughput, and the ability to handle large-scale nodes is essential. Compared to the traditional PBFT algorithm, the grouping approach of the Maglev hashing algorithm better handles the dynamic changes of nodes and ensures that the load balancing and performance of the network remain stable even when nodes join or leave frequently. Especially in Byzantine fault-tolerant scenarios, the balanced grouping provided by the Maglev hash algorithm helps to reduce the risk of a single point of failure and improve the fault tolerance of the entire system. By combining the Maglev hash algorithm and the credit scoring mechanism of the nodes, the fault tolerance of the system is improved, the consensus process is optimized, and the resilience, throughput, and scalability of the blockchain network are improved. In the case of node instability, the system is still able to maintain an efficient and reliable consensus process through reasonable grouping and scoring mechanisms.
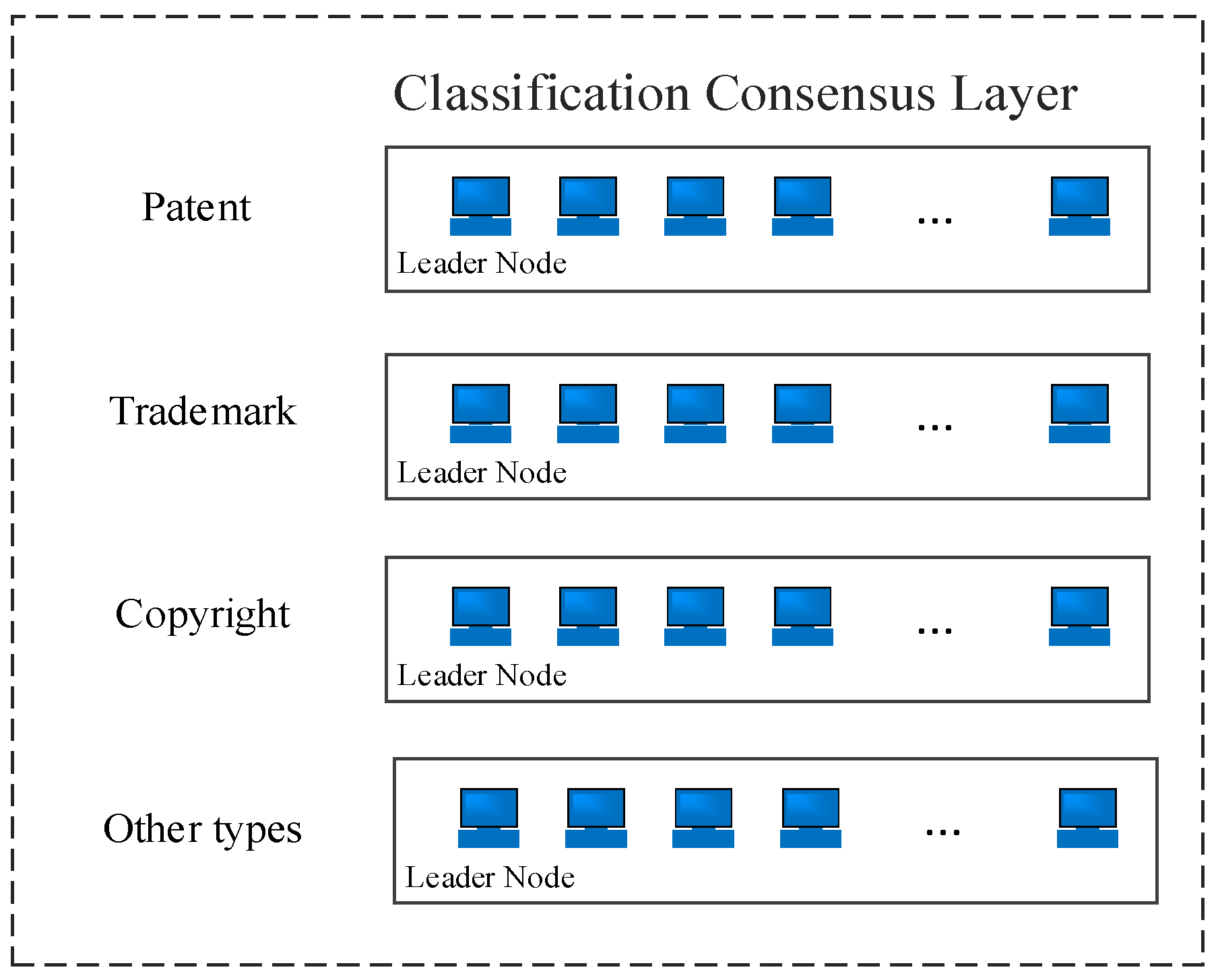
3.3. Category Consensus Strategy
Maglev algorithm grouping has a balanced and efficient classification consensus layer; in order to improve the consensus efficiency, according to the type of intellectual property authentication, the Maglev algorithm is divided into four groups: the patent authentication consensus group, trademark authentication consensus group, copyright authentication consensus group, other types of authentication consensus group. Each authentication consensus group verifies the corresponding type of intellectual property authentication request initiated by the client, and each authentication consensus group works independently in parallel. The leader node of each group is the node with the highest Score value in the group. The category consensus strategy is shown in
Figure 8.
Figure 9 depicts the consensus process of the MBFT algorithm for intellectual property authentication within the blockchain network. First, the client utilizes the intellectual property authentication system, constructs an intellectual property authentication request, and sends the intellectual property authentication request to the blockchain network. The blockchain network receives the client’s request for intellectual property authentication and forwards it to the relevant authentication consensus group within the classification consensus layer based on the type of intellectual property authentication requested by the client. The leader node of the authentication consensus group will initiate the consensus of the authentication content within the group after receiving the client’s request and send the successful result of its consensus to the leader node of the consensus confirmation layer; a second consensus within the tier is initiated by it. After the consensus is successful, the leader node of the categorized consensus layer sorts and packages the object to generate a block with the successful consensus of the authentication and sends the block to the other layers for broadcasting to ensure the consistency of the block ledger of each node.
The nodes in the supervision layer do not contribute to reaching consensus but are required to store the consensus results. Supervisory layer nodes supervise the consensus process throughout the process when the classification consensus layer and the consensus confirmation layer carry out the consensus; the digital signature mechanism is introduced each time the leader node sends log information and signatures to the replica nodes, as well as the replica nodes of each layer and each group, and gives feedback on the received information; it firstly sends the information with the digital signature to the supervisory nodes, and the supervisory nodes aggregate the collected digital signatures one by one and carry out the validation. When it is found that information sent by a consensus node is different from the information sent by other consensus nodes, it can be decided that the node is a malicious node and sends <evidence, i> to the nodes in other layers, where evidence is the evidence that the node is evil, and i is the label of the node. After collecting more than half of the votes, the supervisory layer node reduces the Score value of the node and restricts it from acting as a leader node. If the Score value of a node is reduced to 0 twice, the node is kicked out.
After each round of consensus, the Score values of all nodes will be updated. In order to avoid over-centralization, when starting a new round of consensus, the nodes in the classification consensus layer, consensus confirmation layer, and supervision layer will be re-elected, and each leader node will be updated to ensure the decentralization of the scheme.
3.4. Consistency Agreements
In the IPR authentication scenario, the MBFT consensus algorithm employs two consensus phases to ensure the system’s consistency and reliability. The first consensus ensures the validity of the request and coordination among nodes, and the second consensus aims to further verify and confirm the validity of the patent authentication and its final approval.
Figure 10 illustrates the interaction flow of the consistency protocol for the algorithm, which clearly demonstrates the interaction and information transfer between the stages, thus guaranteeing the integrity and correctness of the whole authentication process.
Consensus implementation phase:
The first classification consensus layer consensus:
Request phase: The client initiates an IPR authentication request and sends the request to the corresponding authentication consensus group of the classification consensus layer according to the type of IPR. For instance, if a client initiates a trademark right authentication request, it sends the request to the corresponding trademark right authentication consensus group.
Pre-preparation phase: The leader node of the corresponding authentication consensus group assigns a unique sequence number to the client request, encapsulates the request into a pre-preparation message, and broadcasts the message to all consensus nodes in the group.
Preparation phase: After receiving the authentication request message from the leader node, all the consensus nodes in the group will validate the message, and after passing the validation, they will generate a preparation message to broadcast to the other consensus nodes in the group. After receiving the ready message from most (at least 2f + 1 nodes) of the consensus nodes in the group, it enters the ready state, where f is the number of Byzantine nodes, the same as below.
Commit phase: When the consensus node in the group receives a sufficient number of ready messages, it broadcasts a commit message to all nodes in the group. The commit message contains the node’s final confirmation of the request, indicating that the node is ready to execute the request. Each consensus node confirms the success of the first consensus when it receives the same commit message from the majority (at least 2f + 1 nodes) of the consensus nodes in the group.
Second consensus confirmation layer consensus:
Pre-preparation phase: After the first consensus is successful, the leader node of the corresponding authentication consensus group broadcasts the authentication request message to the leader node of the consensus confirmation layer. The leader node of the consensus confirmation layer verifies the validity of the message and encapsulates the request into a pre-preparation message after successful verification, broadcasting the message to all consensus nodes in the layer.
Preparation phase: After receiving the pre-prepared message from the leader node, all consensus nodes in the layer validate the message, and after passing the validation, generate a prepared message and broadcast it to other consensus nodes in the layer. After receiving the ready message from most (at least 2f + 1 nodes) of the consensus nodes in the layer, it enters the ready state.
Commit phase: When a consensus node in the layer receives a sufficient number of ready messages, it broadcasts a commit message to all nodes in the layer. Each consensus node confirms the success of the second consensus when it receives the same commit message from the majority (at least 2f + 1 nodes) of the consensus nodes in the layer.
Response phase: execution of the client request after the second consensus success. The execution result is broadcast so that all consensus nodes perform the same operation and reach a consensus state. Finally, the result is returned to the client, and synchronized updating of the entire network ledger is started to ensure that the data remain consistent, and the IP authentication process is completed.
In the blockchain network, when a new node wishes to join, the system will assign the node to the appropriate tier based on its initial Score value if the authentication consensus has not yet been performed.
4. Comparative Analysis of the Proposed Scheme with Existing Consensus Algorithms
The proposed improved PBFT algorithm has optimization and enhancement in many aspects compared with the traditional PBFT and other consensus algorithms, especially in terms of communication complexity, which has significant advantages. Comparative analysis of the improved PBFT algorithm and other existing commonly used consensus algorithms through the following dimensions can show their respective advantages and disadvantages and applicable scenarios more clearly. The results are shown in
Table 1.
Comparing the ability of the improved PBFT algorithm and the other algorithms in dealing with Byzantine faulty nodes. The PBFT algorithm is inherently Byzantine fault-tolerant and can tolerate malicious behaviors from up to 1/3 of the nodes in the system, and thus performs well in environments where potential attacks or untrustworthy nodes need to be guarded against. In contrast, Raft is a crash-tolerant algorithm that can only handle node crash failures and cannot cope with Byzantine behavior. The PoS algorithm, Hotstuff algorithm, CBBFT algorithm, and MBFT algorithm proposed in this paper are all capable of dealing with Byzantine node capabilities.
Fault tolerance is a measure of the upper limit of what a consensus algorithm can tolerate in case of network node failures. PBFT is able to tolerate up to 1/3 of the nodes in the system to be Byzantine nodes, HotStuff and CBBFT have the same fault tolerance, and PoS and Raft have a fault tolerance of 1/2; however, Raft cannot tolerate Byzantine failures and can only keep the system up and running in the event of a node crash or loss of connectivity. The MBFT algorithm proposed in this paper makes the fault tolerance rate larger than the traditional PBFT through the node layering mechanism, and the category consensus strategy and can tolerate more than 1/3 of the nodes in the system to be Byzantine nodes.
Different algorithms show their applicability in different application environments. PoS is mainly used in public blockchains due to its decentralization and anti-attack ability. PBFT has higher communication complexity, so it is more suitable for consortium blockchains with smaller node sizes and the need for strong consistency. Raft is usually suitable for consortium blockchain due to its simple and low overhead design. HotStuff is more suitable for private blockchains of medium size with certain scaling needs due to linear communication complexity. The CBBFT algorithm and MBFT algorithm proposed in this paper are improved algorithms of PBFT, which are also suitable for consortium blockchain.
The communication complexity of a consensus algorithm measures the amount of resources required by the algorithm to communicate between nodes, which usually has a direct impact on the algorithm’s scalability, performance, and applicability scenarios. Different consensus algorithms vary widely in communication complexity. PBFT’s communication complexity maintains good efficiency with fewer nodes, but the communication overhead increases significantly as the scale increases. HotStuff’s linear communication complexity makes it more suitable for large-scale application environments and can maintain a good balance between scalability and efficiency. Raft has relatively low communication overhead and is suitable for use in simple crash tolerance scenarios. The PoS algorithm participates in consensus through equity locking, which is suitable for decentralized public chains, and can reduce energy consumption and improve efficiency. The CBBFT algorithm and MBFT algorithm proposed in this paper are improved algorithms for PBFT, which have reduced communication complexity compared to the traditional PBFT algorithm, and the communication complexity of the MBFT algorithm is much smaller than that of PBFT and CBBFT; the specific experiments are described in detail below.
Intellectual property authentication scenarios have specific requirements for the characteristics of consensus algorithms to ensure data security, accuracy, and efficiency. Intellectual property authentication requires consensus algorithms to be applicable to the consortium blockchain to ensure that multiple participants work together to verify and maintain the trustworthiness of the data in a controlled permission environment, safeguard the privacy and non-tamperability of the information, and, at the same time, enhance the efficiency and security of the authentication process. The consensus algorithm needs to have the ability to tolerate Byzantine nodes to prevent data tampering or malicious behavior during the authentication process. Particularly in consortium blockchain, Byzantine fault tolerance ensures that the system remains stable even if a portion of the nodes fail or act maliciously. The IPR authentication process requires high efficiency, so the selected algorithm should have low communication complexity to reduce the network burden and speed up the authentication process.
By analyzing and comparing the above key aspects, it is possible to gain a more comprehensive understanding of the advantages of the MBFT algorithm and its applicability in IPR authentication systems. It is able to show how MBFT can meet the data consistency, low communication overhead, and fast processing capability required for IPR authentication while ensuring system security and high efficiency so as to achieve reliable data authentication in a multi-party participatory federation chain environment.
5. Experimental Analysis
Intellectual property rights include papers, softwritings, trademarks, etc. Here, we take trademark right authentication as a case study to explore the consensus process of intellectual property authentication in blockchain networks. Comparative analysis of communication complexity, transaction processing capacity, and execution time of IPFS operations is performed. The experiments compare the proposed MBFT with the existing commonly used consensus algorithms by comparing the experimental results by adjusting the number of nodes.
5.1. Consensus Mechanism Deployment and Configuration
- (1)
Operating environment
The IPR verification system based on the federation chain builds the underlying federation chain network based on the open-source Hyperledger Fabric federation chain framework and uses the Golang language to realize the IPR-related business logic code. The process of launching the blockchain Fabric platform requires the appropriate version configuration to be selected in order to ensure that the software components are compatible with each other, as shown in
Table 2.
- (2)
Hyperledger Fabric Network Deployment
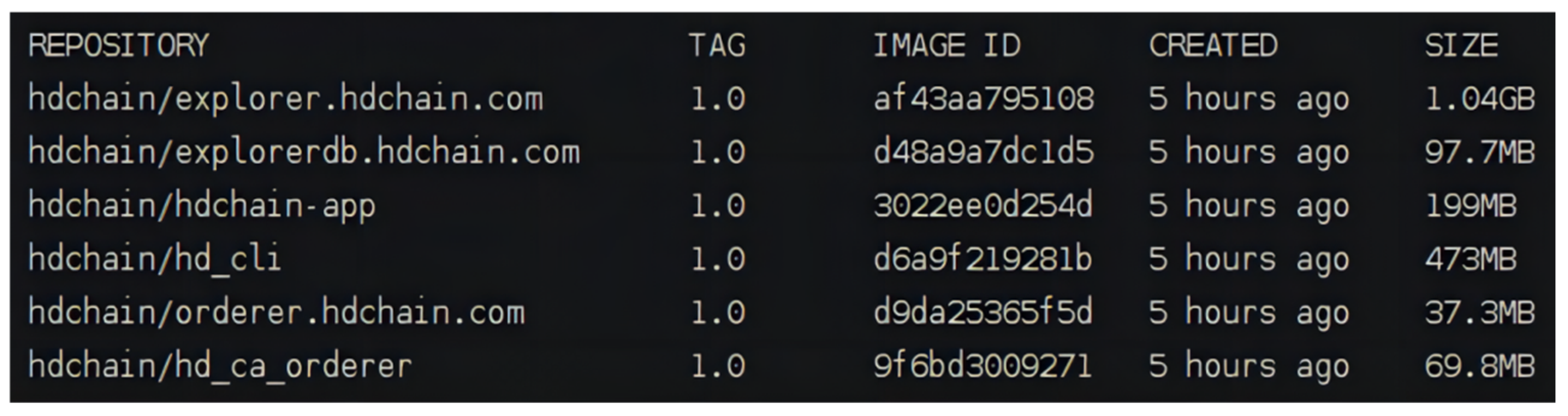
On the Ubuntu operating system, first, install the Docker environment and configure the relevant dependencies and create the directory of files required by Hyperledger Fabric. Pull the source code for Hyperledger Fabric version V1.4.4 and start the network by executing the byfn.sh script. The system will automatically download the required related images. After the installation is complete, use the command ‘docker images|grep Hyperledger’ to check if the images were successfully downloaded and installed. The result of the relevant image check is shown in
Figure 11.
Use the certificate generation tool provided by the Fabric platform to create the node certificate files required to access the blockchain platform, combined with the Fabric configuration tool to generate the genesis block and channel configuration files, which will ensure that the various nodes in the network can securely communicate and exchange data. After generating the relevant files, the network configuration can be completed by writing the docker-comp-ose.yaml configuration file, which defines the nodes in the network and their interrelationships. According to the network configuration information to start the blockchain network, the nodes will be added to the channel to ensure that the nodes in the network can effectively access and share the blockchain data. The fabric network node startup interface is shown in
Figure 12.
- (3)
IPFS deployment
In order to realize efficient interoperability between IP blockchain and IPFS, go to the IPFS official website on the virtual machine to download and install the go-ipfs installation package. Initialize IPFS by executing the ‘ipfs init’ command to create a brand new IPFS repository and generate a unique identifier for the repository to ensure its independence and uniqueness in the network. Successfully add other nodes in the private network to the Bootstrap list. Create a private network node using a fixed public IP address in the private network environment as a basis for connecting to other nodes to ensure the stability and reliability of the network. The IPFS startup process is shown in
Figure 13.
- (4)
Consensus mechanism code configuration
In the Fabric Alliance Chain open-source framework, the scalable consensus algorithm is supported. The implementation code of the consensus algorithm is placed in the fabrics/fabric/consensus directory, and its configuration information is added to the fabrics/fabric/consensus/consensus.json file. The corresponding image file will be generated after compiling the source code. The MBFT algorithm configuration is shown in
Figure 14.
5.2. Consensus Testing
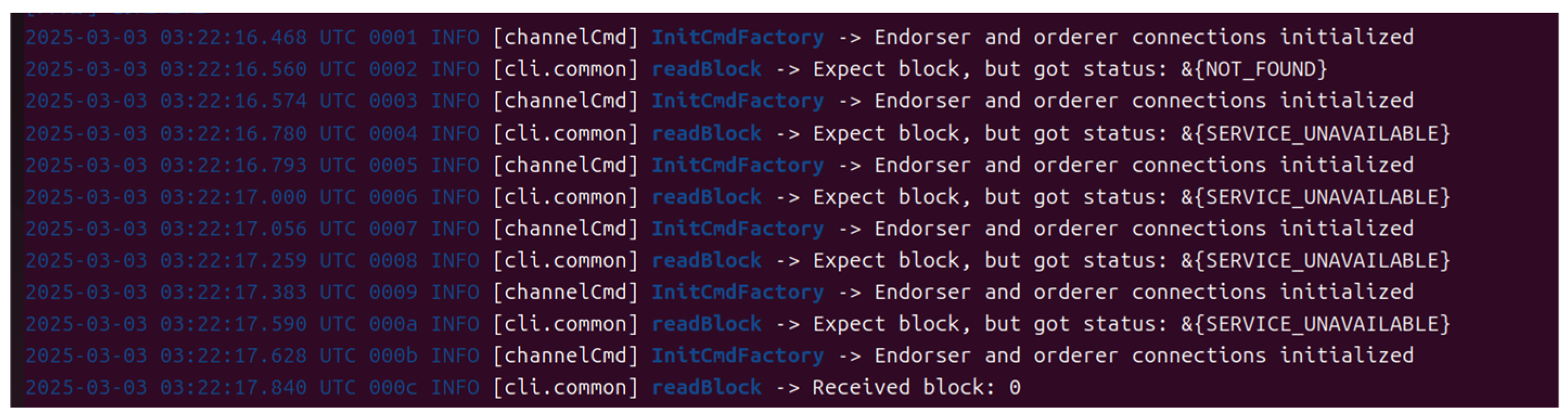
The process of joining the channel by each organization node in the Hyperledger Fabric federation chain network is shown in
Figure 15. The log records show that the organization nodes (Org1Peer, Org2Peer, and Org3Peer) sequentially perform the channel join operation, including initializing the connection (InitCmdFactory) of the Endorser node (Endorser) and the Orderer node (Orderer) and successfully submitting the proposal to join the channel (executeJoin). From the timestamp information, the joining process of each node was completed within 0–1 s without any exception or error. After the nodes join the channel, consensus processing can be performed in that channel.
On the IPR authentication page, users are required to fill in relevant information and click on registration according to the prompts. After the authentication request is submitted to the consensus node by the client, the MBFT algorithm is triggered for consensus processing. If consensus is reached, the authentication information will be written into the blockchain ledger. Users can query the underlying block data and view the latest completed IPR certification through the blockchain browser, as shown in
Figure 16.
5.3. Communications Complexity Analysis
Communication complexity is the number of messages exchanged between nodes during the process of reaching a conformance agreement. Communication complexity is usually measured and computationally compared through the three phases of a consensus algorithm. These stages involve the frequency of message exchange and transmission between different nodes, and the communication complexity of different consensus algorithms can be quantified by analyzing the communication requirements of each stage. This analysis method can clearly reflect the performance of the algorithms under different numbers of nodes, thus providing a basis for the applicability of the consensus mechanism in specific application scenarios. Let there be n nodes in the consensus system for intellectual property authentication. Assuming that a trademark is authenticated once, the three-stage communication complexity comparison between PBFT and MBFT in this paper and the CBBFT algorithm in literature [
28] is performed, and the results are shown in
Table 3.
In trademark right authentication consensus, the experiment is conducted with the number of nodes as the independent variable. The experiments set the number of nodes as 20, 25, 30, 35, 40, 45, and 50 and kept the number of consensus nodes in MBFT, CBBFT, and PBFT consistent. The effect of the change in the number of nodes on the communication complexity of the three algorithms in the process of trademark right authentication is analyzed, and the final experimental results are presented in
Figure 17.
In distributed systems, frequent communication is required between nodes in order to reach an agreement, and lower communication complexity usually means higher system efficiency and a faster response time. As the number of nodes in the network increases, the communication complexity of different algorithms exhibits significant differences. The PBFT algorithm and the CBBFT algorithm show an exponential growth in communication complexity, which means that the amount of communication increases drastically when the number of nodes increases, leading to a significant degradation of the system performance, and may even result in network congestion, which affects the consensus efficiency. In contrast, the pairwise communication complexity of the MBFT algorithm grows linearly with the increase in the number of nodes. This linear growth ensures that the MBFT algorithm maintains a low communication overhead and high processing efficiency even when the number of nodes is high. This optimization is particularly important for IPR authentication environments, where there are usually multiple participants working together to maintain data consistency and where a reduction in communication complexity can directly improve the speed of the authentication process and the scalability of the system. The proposed improved MBFT algorithm can therefore effectively address the needs of IP authentication systems by reducing the amount of communication, thereby reducing the authentication time and increasing the overall throughput of the system.
5.4. Fault Tolerance Analysis
Fault tolerance represents the maximum number of error nodes that can be tolerated in the IP authentication system. It is related to the total number of nodes in the IPR authentication system; if the number of error nodes exceeds the maximum number of nodes that can be tolerated by the current system, the authentication consensus will not be successful. The ability of the PBFT algorithm to tolerate error nodes is f = (n − 1)/3; N is the total number of nodes in the system, and f is the number of faulty or malicious nodes. When there are enough nodes within the IP authentication system, more error nodes are tolerated, and when the number of error nodes in the system exceeds the maximum value of f, the authentication consensus process cannot continue, and the system is paralyzed. In fact, the node stratification mechanism and the category consensus strategy can help to form a good node distribution; i.e., highly reliable nodes participate in the consensus to play a leading role, and faulty nodes do not participate in the consensus to produce a smaller impact. Since the MBFT algorithm is based on the evaluation system to select the master node, the nodes participating in the consensus are nodes with a certain credit guarantee, so the possibility of encountering forged node attacks is extremely small; compared to the PBFT algorithm, its resistance to forged node attacks is stronger preventive, which makes the intellectual property rights authentication more secure and reliable. That is, in the case of the correct master node, the fault tolerance rate of MBFT will be greater than that of PBFT. As the consensus proceeds, the system will gradually remove malicious nodes and increase the reliability of the master node. At this point, the fault tolerance of the MBFT algorithm can be considered to be greater than 1/3.
5.5. Throughput Analysis
Throughput refers to the number of transactions or operations processed per unit of time and is one of the most important indicators of the efficiency of a consensus algorithm. The formula for throughput is [
33] as follows:
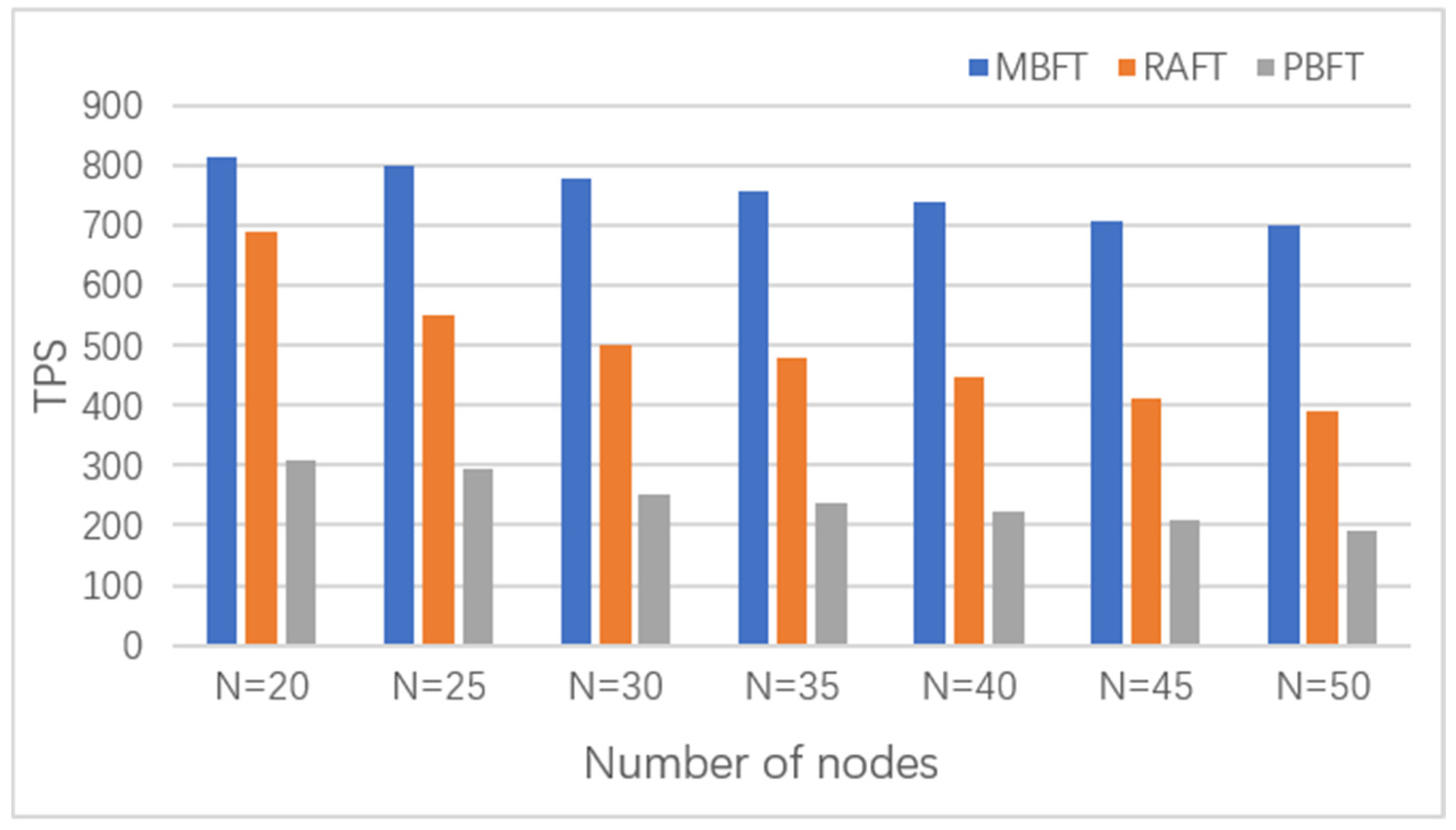
In this experiment, the client was set to send 2000 authentication requests and record the number of completed consensus per second. The number of nodes in the system was used as the independent variable in this experiment, and the number of nodes was gradually increased and set to 20, 25, 30, 35, 40, 45, and 50, respectively, and the number of consensus nodes in MBFT, CBBFT, and PBFT was always kept constant, and the throughput of the three algorithms (MBFT, PBFT, and RAFT) was compared. The ultimate experimental results are depicted in
Figure 18.
The high throughput of consensus algorithms can significantly improve the processing power of the system, especially important when facing a large number of verification requests. As the number of nodes increases, the throughput of MBFT, PBFT, and RAFT algorithms usually shows a decreasing trend. However, the MBFT algorithm consistently exhibits better throughput performance than the PBFT and RAFT algorithms in various scenarios. The comparison shows that MBFT has significantly higher TPS than PBFT and RAFT under multiple node counts. The performance improvement of MBFT indicates that it is able to handle highly concurrent tasks more efficiently, improving the throughput and responsiveness of the system in real applications. The high TPS and stability demonstrated by MBFT make it suitable for highly concurrent transaction processing environments, such as IP authentication systems. In IP verification systems, real-time processing and high throughput are critical, and MBFT can effectively provide both. Therefore, MBFT can be used in systems that require large-scale distributed verification, especially in blockchain or distributed ledger systems, to provide security and consistency guarantees. For intellectual property authentication systems, high throughput means that the system can operate efficiently, handle a large number of requests in a timely manner, and ensure fast response and stability of the service, thus improving the overall efficiency. Compared to PBFT and RAFT algorithms, the MBFT algorithm has higher throughput under the same number of nodes, which is better suited for IP authentication scenarios.
5.6. IPFS Operation Execution Time
Combining distributed database IPFS with blockchain has better security and, at the same time, can solve the problem of blockchain storage space limitation. Simply upload the intellectual property file to IPFS and get the unique hash address corresponding to the file to save it in the blockchain. Since the execution time of each operation varies due to multiple factors, the median of the execution times of ten identical operations is taken as the final result.
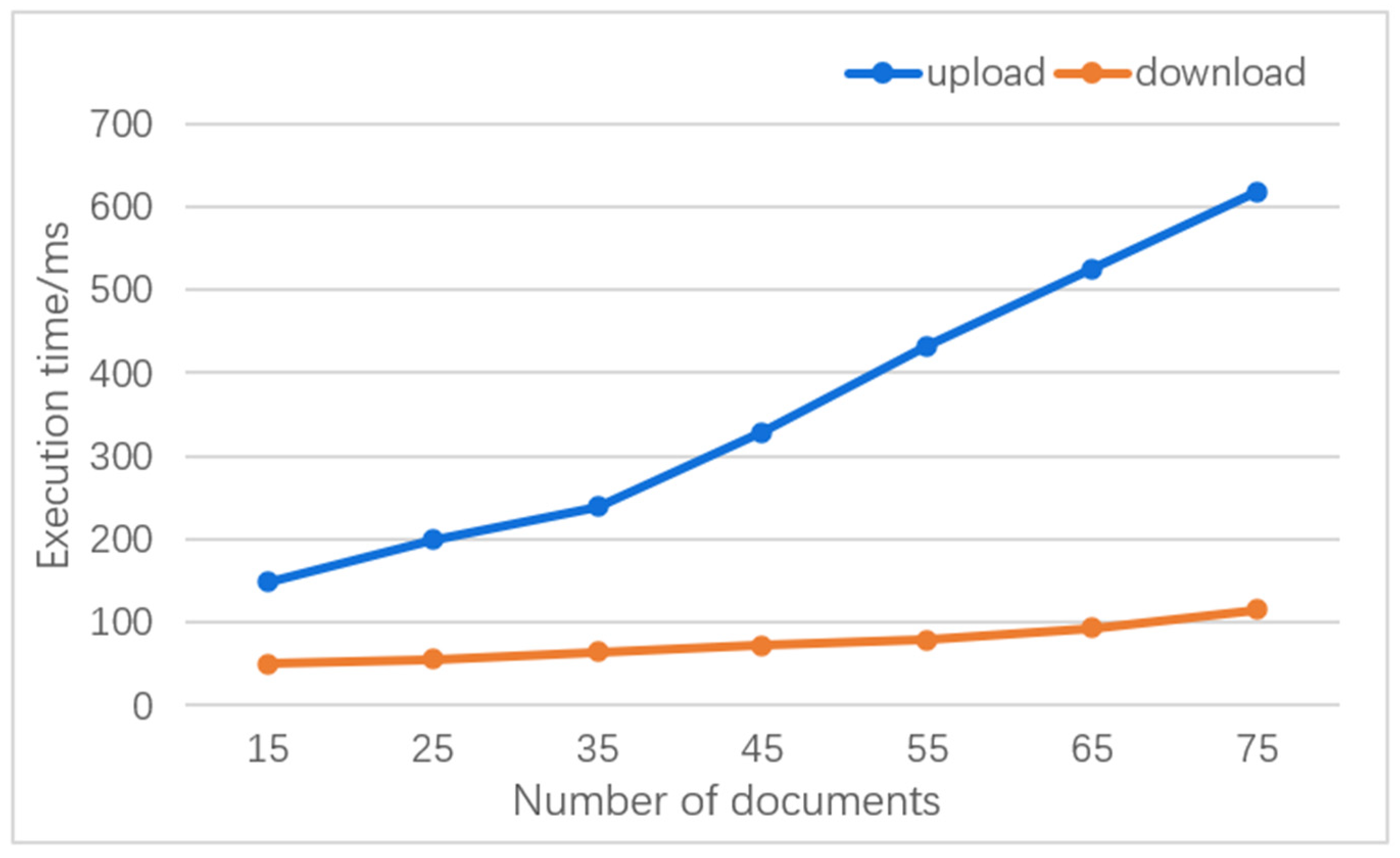
Figure 19 shows the execution time for uploading and downloading different numbers and sizes of files using IPFS (off-chain storage). It can be seen that the execution time gradually increases with the number and size of files, but the overall performance still meets the actual demand and can accurately obtain the required files.
The experimental graphs show the trend of the execution time of the upload and download operations with the number of documents, especially the time of the upload operation increases exponentially with the increase in the data volume, while the time of the download operation remains relatively stable. The increase in upload operation time is mainly affected by network bandwidth, data processing, and preprocessing, and the transmission and processing overhead rises as the number of documents increases. In contrast, the stability of the download operation time reflects the efficiency of the system in reading existing data, possibly thanks to the optimized and efficient transmission protocol. In addition, because IPFS in the creation of a data object to be written, it will be divided into a series of small pieces and hash and then connected in hash value order to form a Merkle tree, with the root hash value of the Merkle tree as the unique identifier of the data object. When accessing the data, you only need to use the identifier to find the object of each small piece and then download and reassemble it into a complete data object, so the upload operation consumes more time and speed than the download operation.
The above experimental results show that with the increase in the number of nodes, MBFT can maintain a better performance in processing concurrent requests, especially when the number of nodes is greater than a certain threshold and shows a significant improvement and a smoother performance growth in the case of different sizes of nodes, implying that it is still able to maintain a more stable performance in a highly concurrent and high load environment. In real IP verification systems, system efficiency and throughput are crucial, and MBFT maintains better performance under high load, which is critical for processing large numbers of transactions in real-time, reducing verification time, and improving system responsiveness. MBFT’s ability to provide high throughput and low latency in a distributed verification system makes it an ideal choice for handling large numbers of IP verification requests.
Although MBFT exhibits smoother TPS growth at larger node counts, it may still face scalability bottlenecks in very large-scale systems. After the number of nodes increases, the system still encounters bottlenecks in terms of communication overhead and computational burden. This is due to the fact that the MBFT protocol is still characterized by the need for frequent synchronization of states among multiple nodes, and when the number of nodes is further increased, the delay in message delivery and computational complexity will have an impact on system performance. Therefore, when deploying MBFT, how to optimize the network topology, reduce the synchronization frequency, and optimize the data flow will be the key to improve its scalability and performance.
6. Summary and Outlook
In this paper, an improved MBFT algorithm is proposed, aiming to solve the problems of high communication overhead and low efficiency faced by traditional PBFT algorithms in intellectual property authentication. By introducing a layering mechanism and Fibonacci series to update the node scores, the nodes are effectively divided into a classification consensus layer, a consensus confirmation layer, and a supervision layer, and each layer performs a PBFT consensus, which significantly improves the consensus efficiency and accuracy. In addition, node grouping is balanced with the help of the Maglev algorithm, and different types of authentication requests (e.g., patents, trademarks, copyrights, etc.) are processed independently, which further reduces the communication complexity and optimizes the processing speed. Combined with blockchain and IPFS technologies, the improved MBFT algorithm not only reduces the storage pressure but also improves the efficiency and scalability of the authentication process. Experimental results show that MBFT has significant advantages in communication complexity and throughput compared with the traditional PBFT algorithm. Although the IPFS execution time gradually increases with the number and size of files, the algorithm is still able to effectively meet the performance requirements and ensure that the required files can be accurately and quickly obtained in practical applications.
The research in this paper not only improves the efficiency of the intellectual property certification system but also enhances its credibility and security. Through the blockchain’s property right confirmation mechanism, it effectively prevents the risk of false authentication and misappropriation of property rights, ensures the consistency between intellectual property rights and property rights holders, and thus promotes credible authentication and reliable transactions of intellectual property rights.
In future work, we will further optimize the algorithm, especially for its adaptability in IP application scenarios. Future research will focus on the improvement of the evaluation and selection mechanism in the algorithm, exploring the optimization scheme based on aggregated signatures, as well as enhancing the dynamic join and exit functions of nodes. These improvements will help to solve the efficiency problem when a large number of network nodes participate in consensus, further promote the performance of the IPR authentication system, facilitate the realization of the value of IPR and mobility enhancement, and provide more efficient, secure, and reliable technical support for related fields.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}