
FasterGDSF-DETR: A Faster End-to-End Real-Time Fire Detection Model via the Gather-and-Distribute Mechanism



Abstract
1. Introduction
- To our knowledge, FasterGDSF-DETR is the first real-time detection model based on the RT-DETR that is designed for fire detection scenarios. It enables rapid and precise detection in complex fire environments, offering outstanding performance in terms of detection accuracy, model size, and computational efficiency.
- In order to enhance the accuracy of detection while ensuring the lightweightness of the model, we developed a novel backbone network, FasterDBBNet. Moreover, comparative experiments and visualizations were conducted on it with the objective of enhancing the interpretability of FasterDBBNet.
- The AIFI intra-scale interaction mechanism was retained and the fusion architecture was redesigned when introducing the AIFI-GDSF hybrid encoder. By incorporating the enhanced Gather-and-Distribute mechanism [19] and the SSFF [20] module, we further strengthened the model’s intra-scale and cross-scale feature interaction capabilities, preventing information loss during feature fusion.
- Based on an open source fire dataset, we manually collected and annotated fire images, creating a more comprehensive dataset that covers a wide range of fire scenarios. Furthermore, WIoU [21] was introduced as a more appropriate loss function, given the characteristics of the dataset.
2. Related Work
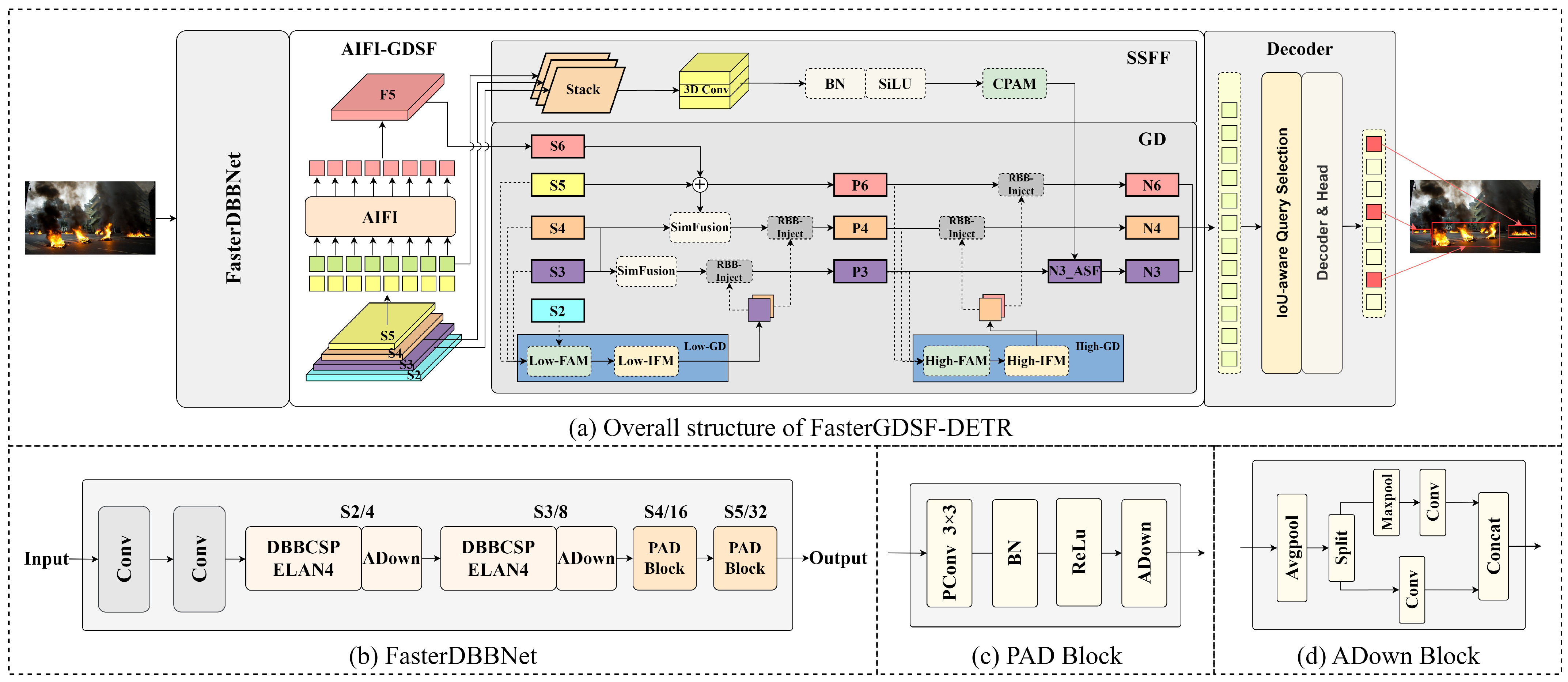
3. Method
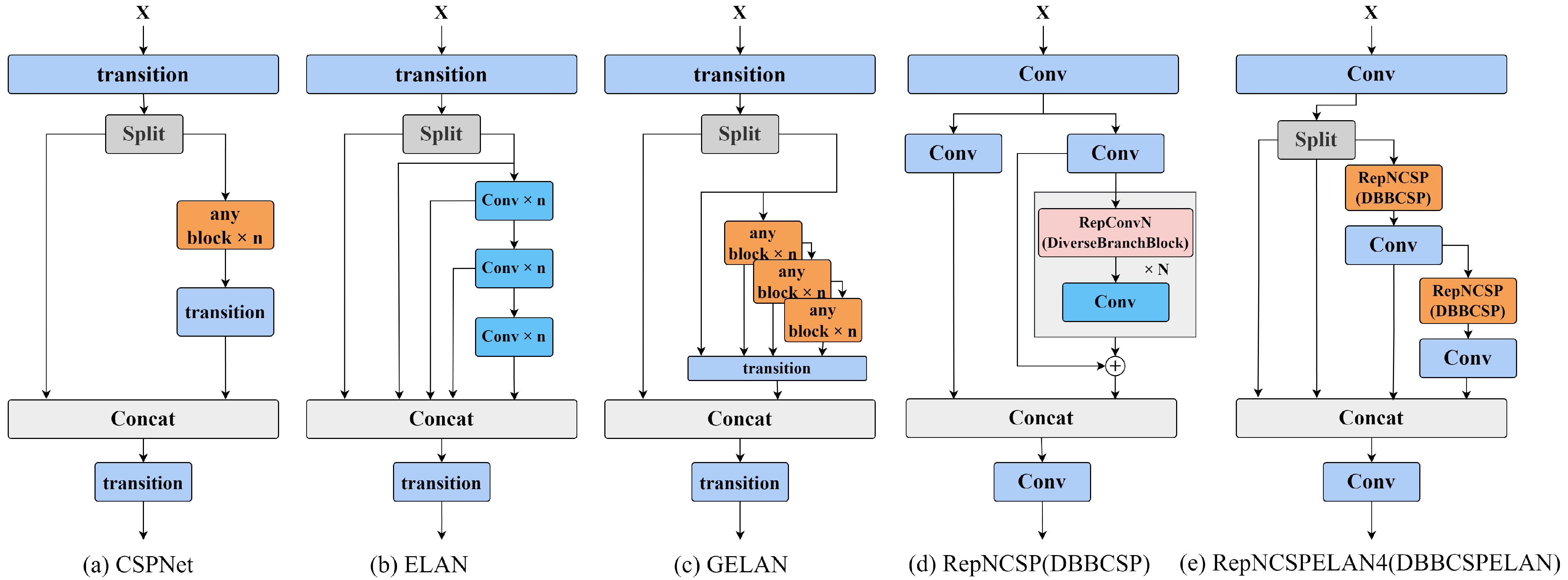
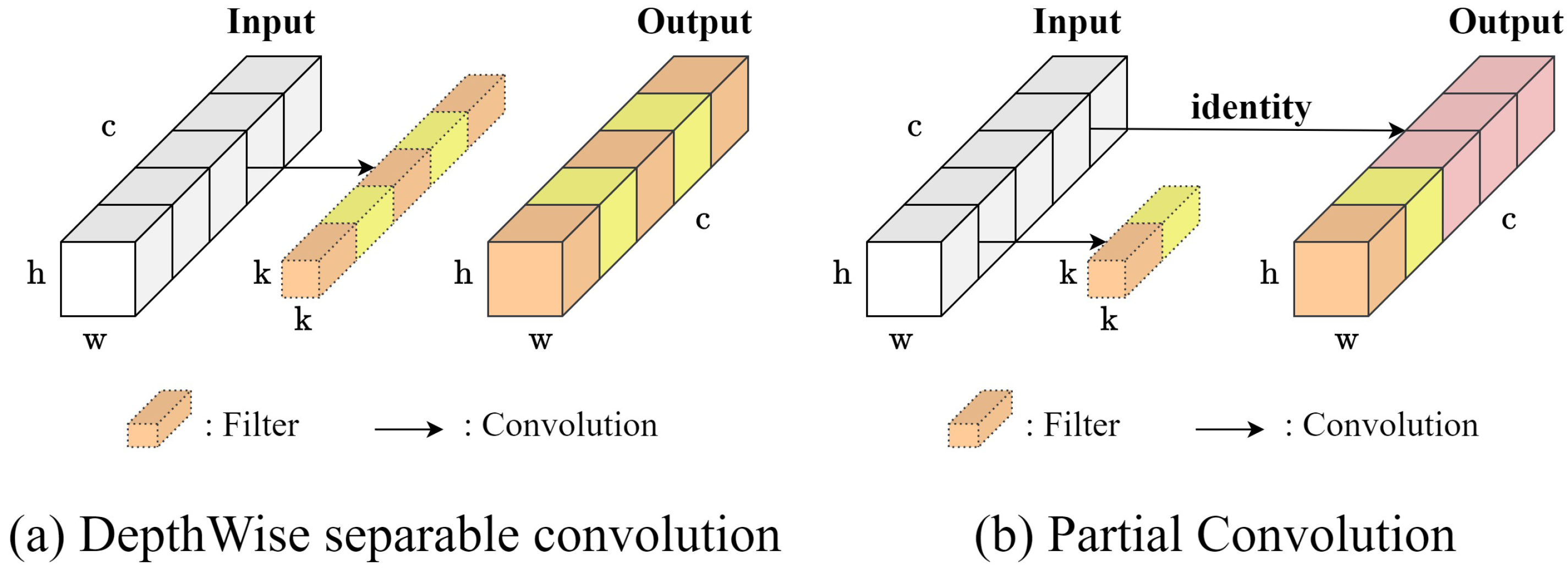
3.1. Backbone
3.1.1. DBBCSPELAN
3.1.2. PAD
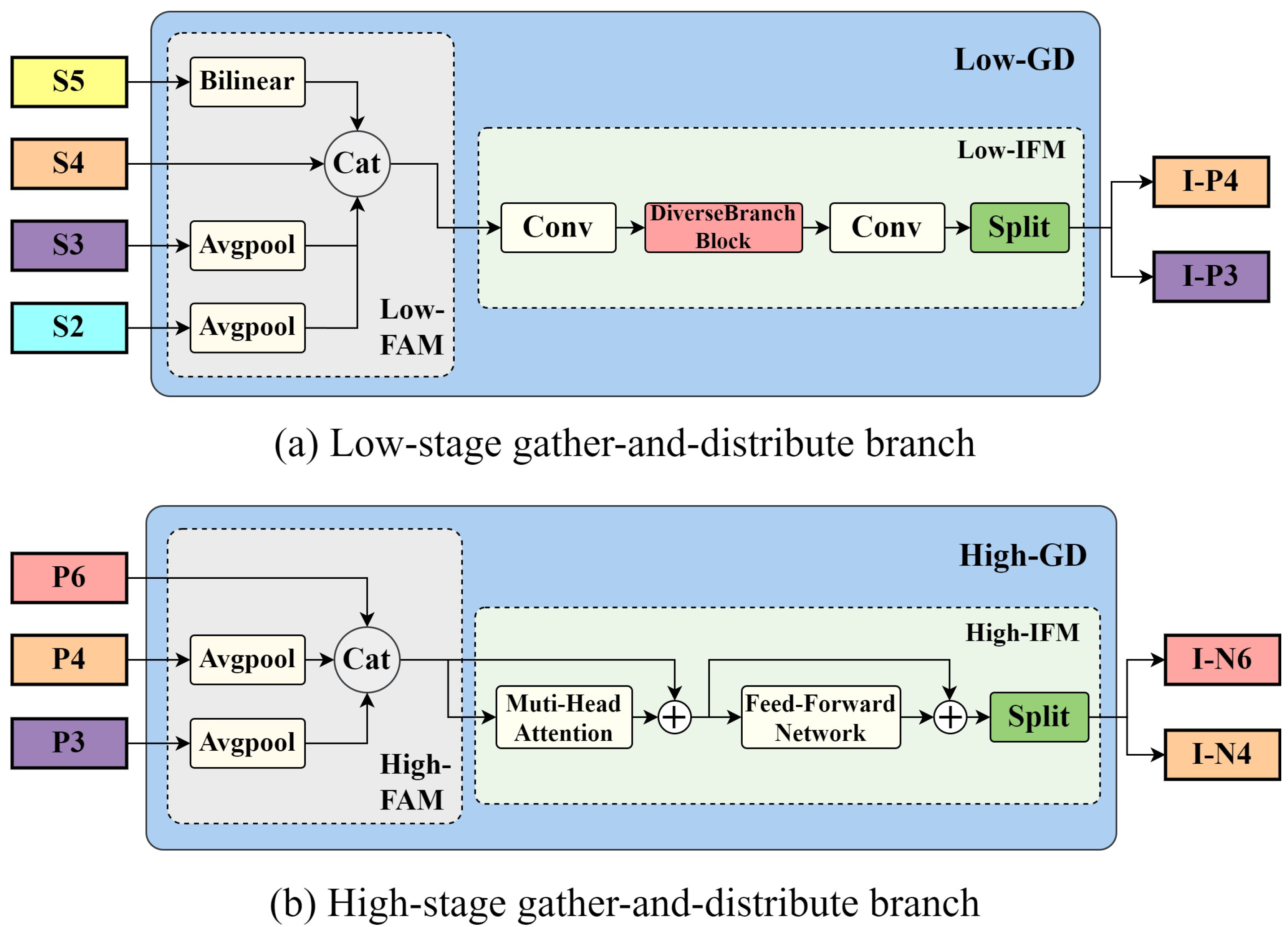
3.2. AIFI-GDSF Hybrid Encoder
3.2.1. Gather-and-Distribute Branch
3.2.2. Scale Sequence Feature Fusion Module
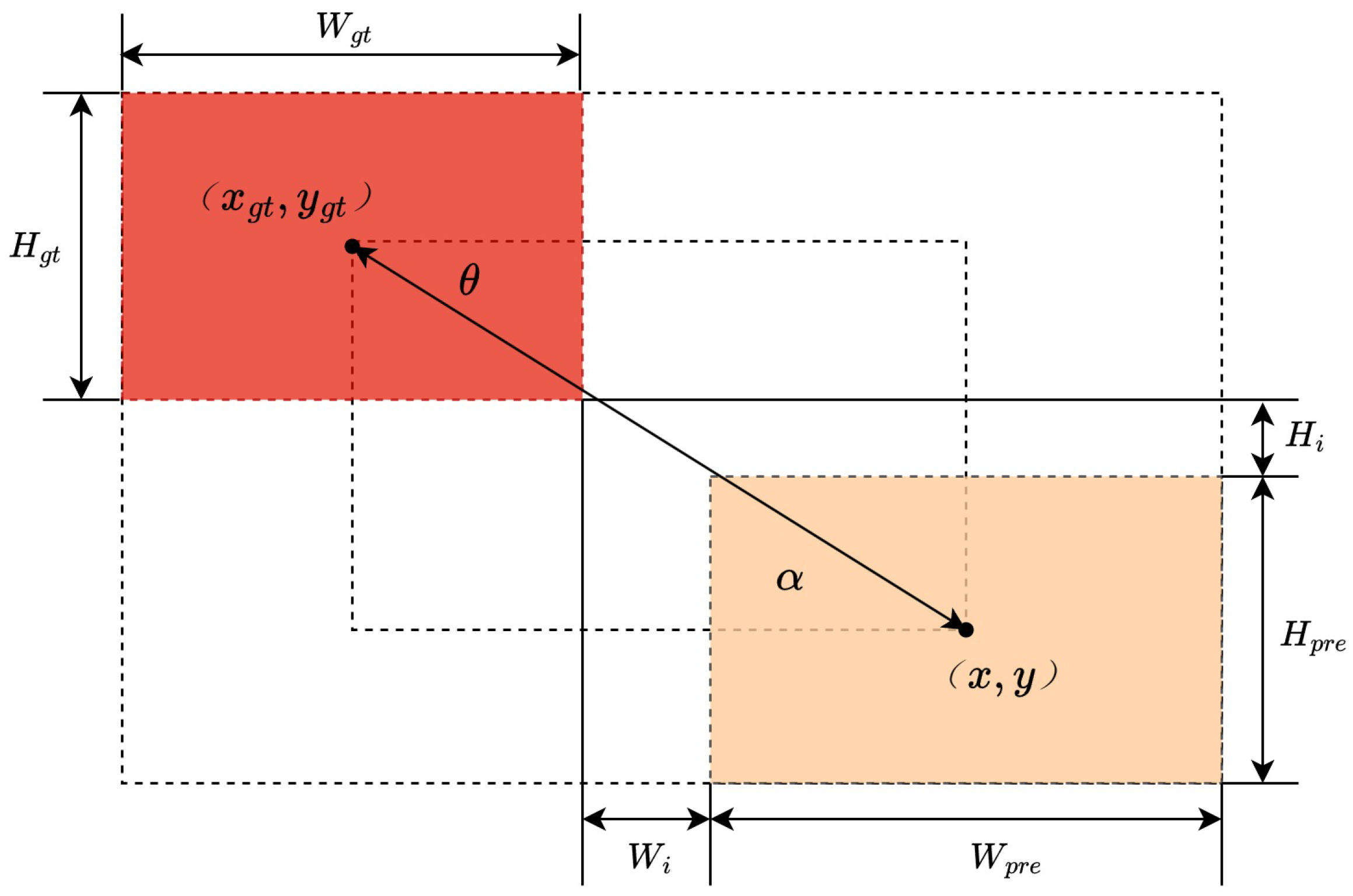
3.3. Loss Function
4. Results and Discussion
4.1. Implementation Details
4.2. Dataset
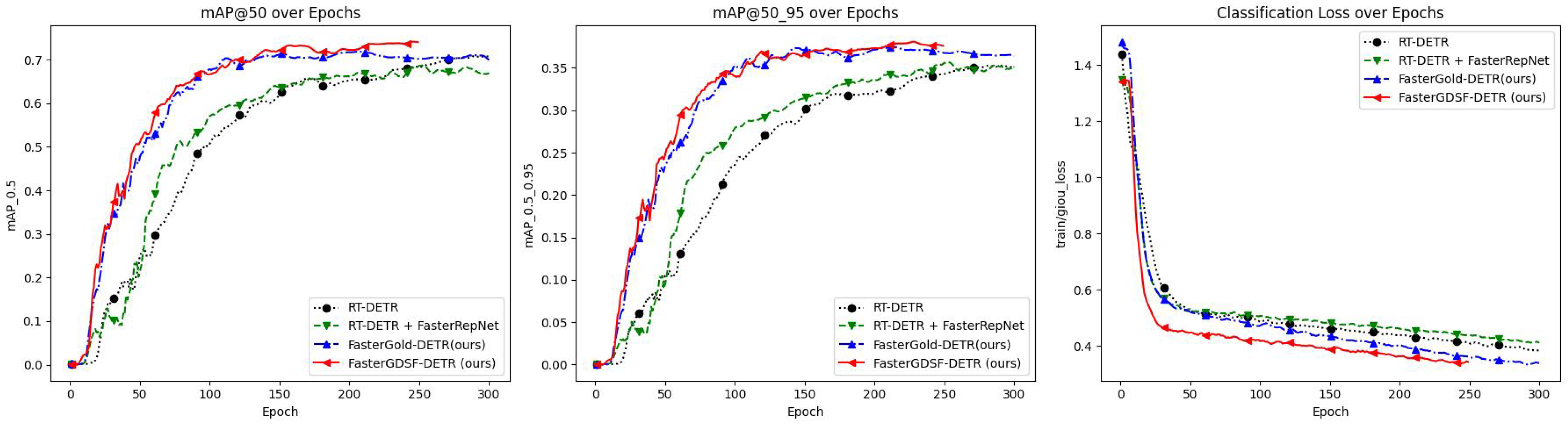
4.3. Ablation Experiments
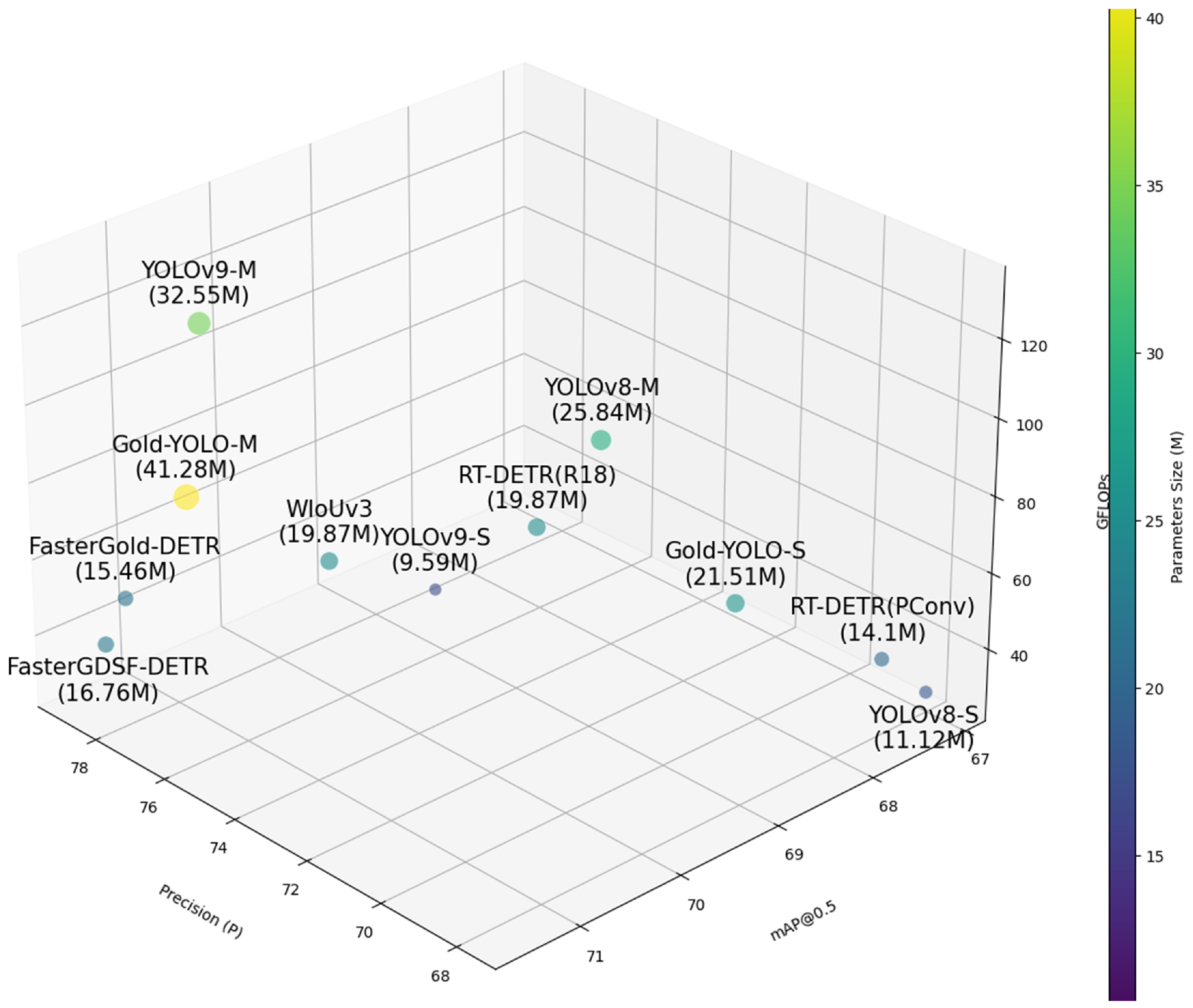
4.4. Comparison with the State-of-the-Art Detectors
4.5. Visualisation and Analysis
4.5.1. Effective Receptive Field (ERF) Visualization
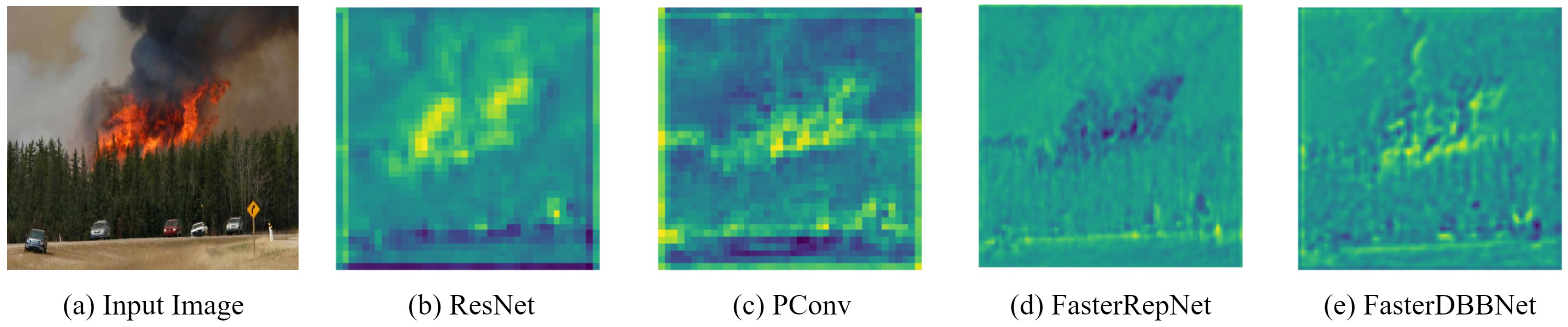
4.5.2. Feature Visualization of the Backbone Network
4.5.3. Heatmap Visualization of the Feature Fusion Layer
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ya’acob, N.; Najib, M.S.M.; Tajudin, N.; Yusof, A.L.; Kassim, M. Image Processing Based Forest Fire Detection using Infrared Camera. J. Phys. Conf. Ser. 2021, 1768, 012014. [Google Scholar] [CrossRef]
- Yang, S.; Huang, Q.; Yu, M. Advancements in remote sensing for active fire detection: A review of datasets and methods. Sci. Total Environ. 2024, 943, 173273. [Google Scholar] [CrossRef] [PubMed]
- Li, N.; Hu, X.; Lu, Y.; Li, Y.; Ren, M.; Luo, X.; Ji, Y.; Chen, Q.; Sui, X. Wavelength-Selective Near-Infrared Organic Upconversion Detectors for Miniaturized Light Detection and Visualization. Adv. Funct. Mater. 2024, 34, 2411626. [Google Scholar] [CrossRef]
- Wei, H.; Wang, N.; Liu, Y.; Ma, P.; Pang, D.; Sui, X.; Chen, Q. Spatio-Temporal Feature Fusion and Guide Aggregation Network for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–16. [Google Scholar] [CrossRef]
- Sui, X.; Chen, Q.; Bai, L. Detection algorithm of targets for infrared search system based on area infrared focal plane array under complicated background. Optik 2012, 123, 235–239. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.-E. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. DN-DETR: Accelerate DETR Training by Introducing Query DeNoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 13619–13627. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Zhu, M.; Kong, E. Multi-Scale Fusion Uncrewed Aerial Vehicle Detection Based on RT-DETR. Electronics 2024, 13, 1489. [Google Scholar] [CrossRef]
- Ge, Q.; Yuan, H.; Zhang, Q.; Hou, Y.; Zang, C.; Li, J.; Liang, B.; Jiang, X. Hyper-Progressive Real-Time Detection Transformer (HPRT-DETR) algorithm for defect detection on metal bipolar plates. Int. J. Hydrog. Energy 2024, 74, 49–55. [Google Scholar] [CrossRef]
- Cheng, Y.; Liu, D. AdIn-DETR: Adapting Detection Transformer for End-to-End Real-Time Power Line Insulator Defect Detection. IEEE Trans. Instrum. Meas. 2024, 73, 1–11. [Google Scholar] [CrossRef]
- Zheng, H.; Wang, G.; Xiao, D.; Liu, H.; Hu, X. FTA-DETR: An efficient and precise fire detection framework based on an end-to-end architecture applicable to embedded platforms. Expert Syst. Appl. 2024, 248, 123394. [Google Scholar] [CrossRef]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; Han, K. Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; Curran Associates, Inc.: Sydney, Australia, 2023; Volume 36, pp. 51094–51112. [Google Scholar]
- Kang, M.; Ting, C.M.; Ting, F.F.; Phan, R.C.W. ASF-YOLO: A novel YOLO model with attentional scale sequence fusion for cell instance segmentation. Image Vis. Comput. 2024, 147, 105057. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Sharma, A.; Kumar, R.; Kansal, I.; Popli, R.; Khullar, V.; Verma, J.; Kumar, S. Fire Detection in Urban Areas Using Multimodal Data and Federated Learning. Fire 2024, 7, 104. [Google Scholar] [CrossRef]
- Vorwerk, P.; Kelleter, J.; Müller, S.; Krause, U. Classification in Early Fire Detection Using Multi-Sensor Nodes—A Transfer Learning Approach. Sensors 2024, 24, 1428. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Dimitropoulos, K.; Kaza, K.; Grammalidis, N. Fire Detection from Images Using Faster R-CNN and Multidimensional Texture Analysis. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8301–8305. [Google Scholar] [CrossRef]
- Chaoxia, C.; Shang, W.; Zhang, F. Information-Guided Flame Detection Based on Faster R-CNN. IEEE Access 2020, 8, 58923–58932. [Google Scholar] [CrossRef]
- Pan, J.; Ou, X.; Xu, L. A Collaborative Region Detection and Grading Framework for Forest Fire Smoke Using Weakly Supervised Fine Segmentation and Lightweight Faster-RCNN. Forests 2021, 12, 768. [Google Scholar] [CrossRef]
- Duan, K.; Xie, L.; Qi, H.; Bai, S.; Huang, Q.; Tian, Q. Corner Proposal Network for Anchor-Free, Two-Stage Object Detection. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 399–416. [Google Scholar]
- Zheng, H.; Duan, J.; Dong, Y.; Liu, Y. Real-time fire detection algorithms running on small embedded devices based on MobileNetV3 and YOLOv4. Fire Ecol. 2023, 19, 31. [Google Scholar] [CrossRef]
- Zheng, H.; Dembélé, S.; Wu, Y.; Liu, Y.; Chen, H.; Zhang, Q. A lightweight algorithm capable of accurately identifying forest fires from UAV remote sensing imagery. Front. For. Glob. Chang. 2023, 6, 1134942. [Google Scholar] [CrossRef]
- Ren, D.; Zhang, Y.; Wang, L.; Sun, H.; Ren, S.; Gu, J. FCLGYOLO: Feature Constraint and Local Guided Global Feature for Fire Detection in Unmanned Aerial Vehicle Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 5864–5875. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, W.; Liu, Y.; Jing, R.; Liu, C. An efficient fire and smoke detection algorithm based on an end-to-end structured network. Eng. Appl. Artif. Intell. 2022, 116, 105492. [Google Scholar] [CrossRef]
- Liang, T.; Zeng, G. FSH-DETR: An Efficient End-to-End Fire Smoke and Human Detection Based on a Deformable DEtection TRansformer (DETR). Sensors 2024, 24, 4077. [Google Scholar] [CrossRef]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in Resnet: Generalizing Residual Architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar] [CrossRef]
- Wang, C.Y.; Yeh, I.H.; Liao, H. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wang, C.Y.; Liao, H.; Yeh, I.H. Designing Network Design Strategies Through Gradient Path Analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse Branch Block: Building a Convolution as an Inception-Like Unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10886–10895. [Google Scholar]
- Chen, J.; Kao, S.h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Do not Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, G.; Li, H.; Li, P.; Lang, X.; Feng, Y.; Ding, Z.; Xie, S. M4SFWD: A Multi-Faceted synthetic dataset for remote sensing forest wildfires detection. Expert Syst. Appl. 2024, 248, 123489. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, K.; Lin, W.; See, J.; Yu, H.; Ke, Y.; Yang, C. PIoU Loss: Towards Accurate Oriented Object Detection in Complex Environments. arXiv 2020, arXiv:2007.09584. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, C.; Zhang, S. Inner-IoU: More Effective Intersection over Union Loss with Auxiliary Bounding Box. arXiv 2023, arXiv:2311.02877. [Google Scholar] [CrossRef]
- Pan, Z.; Cai, J.; Zhuang, B. Fast Vision Transformers with HiLo Attention. arXiv 2023, arXiv:2205.13213. [Google Scholar] [CrossRef]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Sydney, Australia, 2016; Volume 29. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Zhang, J.; Li, X.; Li, J.; Liu, L.; Xue, Z.; Zhang, B.; Jiang, Z.; Huang, T.; Wang, Y.; Wang, C. Rethinking Mobile Block for Efficient Attention-based Models. arXiv 2023, arXiv:2301.01146. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations From Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Encoder | Evaluation Metrics | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PConv | FasterRepNet | FasterDBBNet | AIFI-GD | AIFI-GDSF | WIoUv3 | mAP@0.5 | Params (M) | GFLOPs | ||||
| Single Structure Verification | ||||||||||||
| 1 (RT-DETR, Baseline) | - | - | - | - | - | - | 68.6 | 19.87 | 56.9 | |||
| 2 | ✓ | - | - | - | - | - | 67.6 | 14.10 | 43.2 | |||
| 3 | - | - | - | ✓ | - | - | 70.8 | 22.25 | 59.9 | |||
| 4 | - | - | - | - | - | ✓ | 70.1 | 19.87 | 56.9 | |||
| 5 | ✓ | - | - | - | - | 68.4 | 8.56 | 23.7 | ||||
| 6 | ✓ | - | - | - | 68.7 | 10.68 | 19.5 | |||||
| Multi Structure Verification | ||||||||||||
| 7 | ✓ | - | ✓ | - | - | 70.7 | 15.46 | 46.6 | ||||
| 8 | - | - | - | ✓ | - | ✓ | 71.4 | 22.25 | 59.9 | |||
| 9 | ✓ | - | ✓ | ✓ | 71.4 | 15.71 | 49.8 | |||||
| 10 (FasterGold-DETR, Ours) | ✓ | - | ✓ | - | ✓ | 71.2 | 15.46 | 46.6 | ||||
| 11 (FasterGDSF-DETR, Ours) | ✓ | ✓ | ✓ | 71.5 | 16.76 | 39.4 | ||||||
| Model | mAP@0.5 | mAP@0.5:0.95 | Params (M) | GFLOPs |
|---|---|---|---|---|
| ResNet-18 | 68.6 | 35.5 | 19.87 | 56.9 |
| PConv | 67.6 | 35.2 | 14.10 | 43.2 |
| Unireplknet | 68.5 | 35.6 | 12.71 | 33.4 |
| EfficientViT | 68.2 | 35.3 | 10.70 | 27.2 |
| MobileNet v3 | 64.7 | 32.8 | 9.54 | 23.6 |
| RepNCSPELAN | 68.0 | 35.2 | 9.05 | 26.5 |
| FasterRepNet (ours) | 68.4 | 35.4 | 8.56 | 23.7 |
| FasterDBBNet (ours) | 68.7 | 35.7 | 10.68 | 19.5 |
| Model | mAP@0.5 | mAP@0.5:0.95 | Params (M) | GFLOPs | FPS |
|---|---|---|---|---|---|
| S and M Models of YOLO Detectors | |||||
| YOLOv8-S | 67.1 | 34.4 | 11.12 | 28.4 | 150.2 |
| YOLOv8-M | 68.2 | 35.7 | 25.84 | 78.7 | 102.7 |
| GoldYOLO-S | 67.9 | 33.6 | 21.51 | 46.1 | 143.5 |
| GoldYOLO-M | 71.4 | 37.8 | 41.28 | 87.3 | 112.3 |
| YOLOv9-S | 69.1 | 37.2 | 9.59 | 38.7 | 170.5 |
| YOLOv9-M | 71.3 | 38.1 | 32.55 | 130.7 | 130.8 |
| RT-DETR Detectors | |||||
| RT-DETR (R18) | 68.6 | 35.5 | 19.87 | 56.9 | 66.3 |
| RT-DETR (R34) | 69.8 | 37.1 | 31.11 | 88.8 | 60.1 |
| FasterGold-DETR (ours) | 71.2 | 37.9 | 15.46 | 46.6 | 75.5 |
| FasterGDSF-DETR (ours) | 71.5 | 38.1 | 16.76 | 39.4 | 72.1 |
| Model | mAP@0.5 | mAP@0.5:0.95 | Params (M) | GFLOPs | FPS |
|---|---|---|---|---|---|
| S and M Models of YOLO Detectors | |||||
| YOLOv8-S | 86.0 | 49.6 | 11.12 | 28.4 | 155.7 |
| YOLOv8-M | 86.6 | 50.2 | 25.84 | 78.7 | 107.2 |
| GoldYOLO-S | 85.1 | 45.9 | 21.51 | 46.1 | 149.6 |
| GoldYOLO-M | 87.3 | 50.8 | 41.28 | 87.3 | 115.4 |
| YOLOv9-S | 87.2 | 50.6 | 9.59 | 38.7 | 169.5 |
| YOLOv9-M | 89.1 | 51.2 | 32.55 | 130.7 | 122.8 |
| RT-DETR Detectors | |||||
| RT-DETR (R18) | 87.5 | 50.5 | 19.87 | 56.9 | 69.5 |
| RT-DETR (R34) | 88.3 | 51.0 | 31.11 | 88.8 | 62.9 |
| FasterGold-DETR (ours) | 88.1 | 50.9 | 15.46 | 46.6 | 77.2 |
| FasterGDSF-DETR (ours) | 89.3 | 51.4 | 16.76 | 39.4 | 73.4 |
| Model | t = 20% | t = 30% | t = 50% | t = 99% |
|---|---|---|---|---|
| ResNet-18 | 1.23% | 2.02% | 4.18% | 25.15% |
| PConv | 0.45% | 0.73% | 1.52% | 14.89% |
| iRMB [49] | 0.05% | 1.29% | 30.07% | 81.84% |
| RepNCSPELAN [34] | 1.23% | 2.20% | 5.42% | 47.05% |
| Unireplknet | 4.85% | 10.46% | 26.74% | 95.06% |
| FasterRepNet(ours) | 0.79% | 1.37% | 3.08% | 36.56% |
| FasterDBBNet(ours) | 2.39% | 4.58% | 11.71% | 89.95% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Wu, F.; Shi, L. FasterGDSF-DETR: A Faster End-to-End Real-Time Fire Detection Model via the Gather-and-Distribute Mechanism. Electronics 2025, 14, 1472. https://doi.org/10.3390/electronics14071472
Liu C, Wu F, Shi L. FasterGDSF-DETR: A Faster End-to-End Real-Time Fire Detection Model via the Gather-and-Distribute Mechanism. Electronics. 2025; 14(7):1472. https://doi.org/10.3390/electronics14071472
Chicago/Turabian StyleLiu, Chengming, Fan Wu, and Lei Shi. 2025. "FasterGDSF-DETR: A Faster End-to-End Real-Time Fire Detection Model via the Gather-and-Distribute Mechanism" Electronics 14, no. 7: 1472. https://doi.org/10.3390/electronics14071472
APA StyleLiu, C., Wu, F., & Shi, L. (2025). FasterGDSF-DETR: A Faster End-to-End Real-Time Fire Detection Model via the Gather-and-Distribute Mechanism. Electronics, 14(7), 1472. https://doi.org/10.3390/electronics14071472