
A CLIP-Based Framework to Enhance Order Accuracy in Food Packaging




Abstract
1. Introduction
- Introduced a novel CLIP-based framework that employs zero-shot learning to accurately recognize and validate food items in food packaging, improving order accuracy.
- Achieved high precision (92.92%) and recall 76.65% in identifying food items from images, showcasing the model’s robust image-to-text matching capabilities.
- Demonstrated an overall order accuracy of 85.86% in ensuring food packages match customer orders, highlighting the framework’s potential.
2. Related Work
3. Material and Method
3.1. Food Segmentation
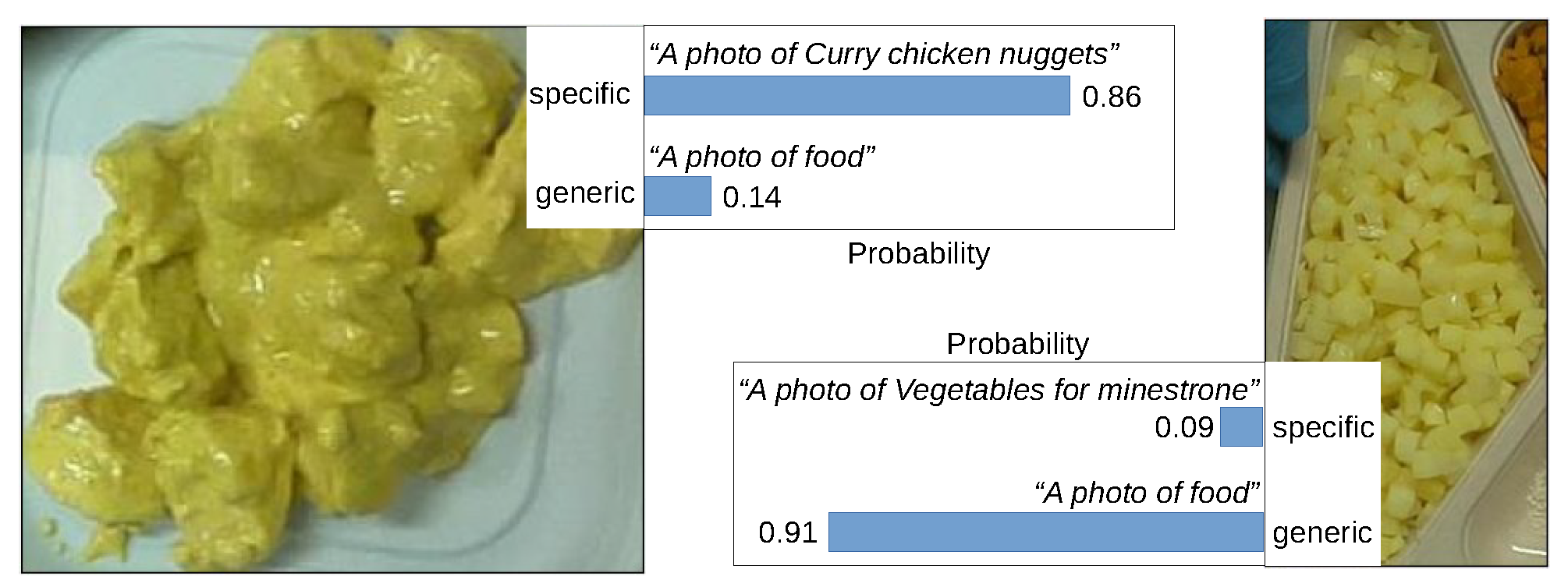
3.2. Contrastive Language-Image Pre-Training (CLIP)
3.3. CLIP for Food Recognition
| Algorithm 1 Order validation algorithm |
|
3.4. Dataset
4. Experiments
5. Results and Analysis
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mentzer, J.T.; Flint, D.J.; Kent, J.L. Developing a logistics service quality scale. J. Bus. Logist. 1999, 20, 9. [Google Scholar]
- Gallo, I.; Rehman, A.U.; Dehkordi, R.H.; Landro, N.; La Grassa, R.; Boschetti, M. Deep object detection of crop weeds: Performance of YOLOv7 on a real case dataset from UAV images. Remote Sens. 2023, 15, 539. [Google Scholar] [CrossRef]
- Rehman, A.U.; Gallo, I. Cross-pollination of knowledge for object detection in domain adaptation for industrial automation. Int. J. Intell. Robot. Appl. 2024, 1–19. [Google Scholar] [CrossRef]
- Rehman, A.U.; Gallo, I.; Lorenzo, P. A Food Package Recognition Framework for Enhancing Efficiency Leveraging the Object Detection Model. In Proceedings of the 28th International Conference on Automation and Computing (ICAC), IEEE, Birmingham, UK, 30 August 2023–1 September 2023; pp. 1–6. [Google Scholar]
- Junyong, X.; Kangyu, W.; Hongdi, Z. Food packaging defect detection by improved network model of Faster R-CNN. Food Mach. 2023, 39, 131–136. [Google Scholar]
- Selvam, P.; Koilraj, J.A.S. A deep learning framework for grocery product detection and recognition. Food Anal. Methods 2022, 15, 3498–3522. [Google Scholar] [CrossRef]
- Aguilar, E.; Remeseiro, B.; Bolaños, M.; Radeva, P. Grab, pay, and eat: Semantic food detection for smart restaurants. IEEE Trans. Multimed. 2018, 20, 3266–3275. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Wang, W. Advanced Auto Labeling Solution with Added Features. 2023. Available online: https://github.com/CVHub520/X-AnyLabeling (accessed on 1 February 2025).
- Chaurasia, G.J.A.; Qiu, J. YOLOv8 Instance Segmentation. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 1 February 2025).
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Kagaya, H.; Aizawa, K.; Ogawa, M. Food Detection and Recognition Using Convolutional Neural Network. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 1085–1088. [Google Scholar]
- Subhi, M.A.; Ali, S. A Deep Convolutional Neural Network for Food Detection and Recognition. In Proceedings of the 2018 IEEE-EMBS Conference on Biomedical Engineering and Sciences (IECBES), Sarawak, Malaysia, 3–6 December 2018; pp. 284–287. [Google Scholar] [CrossRef]
- Khan, S.; Ahmad, K.; Ahmad, T.; Ahmad, N. Food items detection and recognition via multiple deep models. J. Electron. Imaging 2019, 28, 013020. [Google Scholar] [CrossRef]
- Bretti, C.; Mettes, P. Zero-shot action recognition from diverse object-scene compositions. arXiv 2021, arXiv:2110.13479. [Google Scholar]
- Thong, W.; Snoek, C.G. Bias-awareness for zero-shot learning the seen and unseen. arXiv 2020, arXiv:2008.11185. [Google Scholar]
- Huang, H.; Chen, Y.; Tang, W.; Zheng, W.; Chen, Q.G.; Hu, Y.; Yu, P. Multi-label zero-shot classification by learning to transfer from external knowledge. arXiv 2020, arXiv:2007.15610. [Google Scholar]
- Chen, J.; Pan, L.; Wei, Z.; Wang, X.; Ngo, C.W.; Chua, T.S. Zero-Shot Ingredient Recognition by Multi-Relational Graph Convolutional Network. Proc. AAAI Conf. Artif. Intell. 2020, 34, 10542–10550. [Google Scholar] [CrossRef]
- Li, G.; Li, Y.; Liu, J.; Guo, W.; Tang, W.; Liu, Y. ESE-GAN: Zero-Shot Food Image Classification Based on Low Dimensional Embedding of Visual Features. IEEE Trans. Multimed. 2024, 1–11. [Google Scholar] [CrossRef]
- Zhou, P.; Min, W.; Zhang, Y.; Song, J.; Jin, Y.; Jiang, S. SeeDS: Semantic Separable Diffusion Synthesizer for Zero-shot Food Detection. In Proceedings of the 31st ACM International Conference on Multimedia, ACM, Ottawa, ON, Canada, 29 October 2023–3 November 2023. [Google Scholar] [CrossRef]
- Zhou, P.; Min, W.; Song, J.; Zhang, Y.; Jiang, S. Synthesizing Knowledge-enhanced Features for Real-world Zero-shot Food Detection. IEEE Trans. Image Process. 2024, 33, 1285–1298. [Google Scholar] [PubMed]
- Ogrinc, M.; Koroušić Seljak, B.; Eftimov, T. Zero-shot evaluation of ChatGPT for food named-entity recognition and linking. Front. Nutr. 2024, 11, 1429259. [Google Scholar] [CrossRef] [PubMed]
- Tran-Anh, D.; Huu, Q.N.; Bui-Quoc, B.; Hoang, N.D.; Quoc, T.N. Integrative zero-shot learning for fruit recognition. Multimed. Tools Appl. 2024, 83, 73191–73213. [Google Scholar] [CrossRef]
- Bossard, L.; Guillaumin, M.; Van Gool, L. Food-101—Mining Discriminative Components with Random Forests. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June 2016; pp. 770–778. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Carlsson, F.; Eisen, P.; Rekathati, F.; Sahlgren, M. Cross-lingual and Multilingual CLIP. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 25 June 2022; pp. 6848–6854. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Images | Labels | P | R | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|---|
| YOLOv8 | 250 | food | 99.00% | 98.90% | 98.90% | 95.90% |
| Mask R-CNN | 250 | food | 98.20% | 84.00% | 84.40% | 84.30% |
| Dataset | Model | Images | Accuracy | Precision | Recall |
|---|---|---|---|---|---|
| Food101 | CLIP | 25,250 | 95.40% | 96.31% | 94.43% |
| FR (EN) | CLIP | 3850 | 85.40% | 92.92% | 76.65% |
| FR (IT) | CLIP | 3850 | 71.40% | 69.64% | 75.87% |
| Dataset | Model | Containers | Accuracy |
|---|---|---|---|
| FR (EN) | YOLO + CLIP | 1000 | 85.86% |
| FR (IT) | YOLO + CLIP | 1000 | 58.71% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gatti, M.; Rehman, A.U.; Gallo, I. A CLIP-Based Framework to Enhance Order Accuracy in Food Packaging. Electronics 2025, 14, 1420. https://doi.org/10.3390/electronics14071420
Gatti M, Rehman AU, Gallo I. A CLIP-Based Framework to Enhance Order Accuracy in Food Packaging. Electronics. 2025; 14(7):1420. https://doi.org/10.3390/electronics14071420
Chicago/Turabian StyleGatti, Mattia, Anwar Ur Rehman, and Ignazio Gallo. 2025. "A CLIP-Based Framework to Enhance Order Accuracy in Food Packaging" Electronics 14, no. 7: 1420. https://doi.org/10.3390/electronics14071420
APA StyleGatti, M., Rehman, A. U., & Gallo, I. (2025). A CLIP-Based Framework to Enhance Order Accuracy in Food Packaging. Electronics, 14(7), 1420. https://doi.org/10.3390/electronics14071420