1. Introduction
In modern naval confrontation systems, adversarial underwater unmanned vehicles (UUVs) pose significant challenges for Red team forces, which are deployed on unmanned aerial vehicles (UAVs) due to their inherent mobility and positional uncertainty [
1]. Effective neutralization of Blue team threats demands sophisticated coordination strategies between distributed agents under partial observability. This paper proposes a novel Knowledge-Enhanced Multi-Agent Deep Reinforcement Learning (MADRL) framework for coordinating UAV swarms (Red team) against adversarial UUVs (Blue team) in asymmetric confrontation scenarios, specifically addressing three operational modes: area surveillance, summoned interception, and coordinated countermeasures.
Traditional underwater confrontation methods face inherent limitations against Blue team’s dynamic evasion tactics [
2]. The probabilistic nature of UUV positioning, combined with time-sensitive mission requirements, necessitates adaptive decision-making capabilities beyond conventional rule-based systems. Recent advances in deep reinforcement learning (DRL) provide critical foundations for multi-agent adversarial games [
3], particularly through centralized training with decentralized execution (CTDE) paradigms that balance team coordination and individual autonomy [
4].
Our framework introduces three key innovations tailored for Red/Blue confrontations:
A probabilistic adversarial model integrating prior intelligence and real-time UAV sensor data to predict Blue team’s underwater trajectories.
A Multi-Agent Double Soft Actor–Critic (MADSAC) algorithm augmented, addressing Red team coordination challenges including dynamic credit assignment and partial observability of Blue forces.
The technical contributions focus on Red team operational superiority:
Hybrid observation space combining Blue team signature estimates, Red UAV statuses, and environmental uncertainties. Dual centralized critic architecture to mitigate Q-value overestimation during adversarial policy learning. Hierarchical reward function balancing exploration–exploitation tradeoffs using combat-effectiveness metrics specific to UUV neutralization. Experimental validation demonstrates Red team’s superior performance over baseline methods in Blue target detection efficiency (38.7% improvement) and successful neutralization rate (52.1% increase), validated across escalating confrontation scenarios.
2. Related Work
In modern naval confrontation systems, especially those involving adversarial underwater unmanned vehicles (UUVs), the literature generally falls into two broad categories: rule-based methods and reinforcement learning (RL)-based approaches. In this section, we review both lines of work, analyzing their advantages and limitations, and we highlight the motivation for our proposed method.
2.1. Rule-Based Methods
Rule-based approaches have long been employed in underwater navigation, target tracking, and engagement decision making. For example, Chen and Li [
5] proposed navigation strategies that leverage a predefined rule base to guide underwater vehicles. Such methods benefit from low computational overhead and high interpretability. Liu et al. [
6] introduced a model-based framework using rule sets for decision making, which performs well in static or slowly varying environments. Similarly, Wang and Zhang [
7] demonstrated that heuristic algorithms can enhance response times in autonomous underwater navigation, while Guo and Chen [
8] further developed rule-based decision models to handle confrontation scenarios.
Other studies have extended rule-based strategies. Li and Sun [
9] summarized that rule-based controllers struggle to capture the probabilistic nature of rapidly evolving battlefields, and He and Liu [
10] noted that even adaptive rule-based controls remain confined by their pre-specified rule sets. Zhang and Li [
11] highlighted that expert systems, though stable under normal conditions, often lack robustness when encountering abnormal or adversarial maneuvers. Xu and Wang [
12] pointed out the real-time advantages of rule-based decisions but also remarked that outdated rule libraries can impair performance in dynamic contexts. Huang and Zhou [
13] attempted to enhance rule-based systems with intelligent components; nevertheless, their approaches fell short in multi-target coordination and information fusion. Sun and Li [
14] developed robust rule-based systems but acknowledged that these systems still struggle with uncertainty and the unpredictable behavior of adversaries. Additional works such as Park et al. [
15], Zhou and Liu [
16], and Yue et al. [
17] have further investigated rule-based strategies, yet they consistently suffer from limited flexibility and inadequate adaptation to rapidly changing environments.
Table 1 summarizes key characteristics of rule-based methods compared to RL-based approaches.
In summary, while rule-based methods are prized for their simplicity, efficiency, and interpretability, their major limitations include the following:
Limited Flexibility: Predefined rules cannot cover all possible battlefield scenarios.
Inadequate Modeling of Nonlinear Dynamics: Difficulty in accurately representing adversary strategies that are nonlinear and rapidly evolving.
Lack of Real-Time Adaptability: The rule libraries often lag behind current intelligence, reducing responsiveness to sudden environmental changes.
Our proposed Knowledge-Enhanced Multi-Agent Deep Reinforcement Learning (MADRL) framework overcomes these issues by integrating prior intelligence with real-time sensor data into a probabilistic adversarial model, thereby compensating for the inflexibility and delayed update issues inherent in rule-based systems.
2.2. Reinforcement Learning-Based Methods
Reinforcement learning (RL) has emerged as a powerful alternative for autonomous decision making in complex and uncertain environments. The seminal work of Sutton and Barto [
18] laid the theoretical foundation, while Mnih et al. [
19] demonstrated that deep RL could achieve human-level performance in high-dimensional control tasks. To address continuous control problems, Lillicrap et al. [
20] introduced the Deep Deterministic Policy Gradient (DDPG) algorithm, and Haarnoja et al. [
21] later proposed the Soft Actor–Critic (SAC) algorithm, which improves stability and convergence speed.
In multi-agent settings, Lowe et al. [
22] developed a multi-agent actor–critic framework that employs centralized training with decentralized execution, thereby enhancing team coordination. Yun et al. [
23] introduced the autonomous communication network requirements between drones to improve collective decision making, while Iqbal et al. [
24] incorporated multi-head attention mechanism to better represent complex inter-agent relationships. Bengio et al. [
25] further advanced the field by applying curriculum learning to gradually increase task complexity, facilitating smoother policy learning. Schulman et al. [
26] presented proximal policy optimization (PPO)-based fully decentralized networked multi-agent reinforcement learning to increase scalability. Additional studies have sought to improve RL performance in adversarial and multi-agent scenarios. Van Hasselt et al. [
27] introduced Double Q-learning to mitigate overestimation bias, and Hessel et al. [
28] combined multiple improvements into the Rainbow algorithm. Foerster et al. [
29] proposed counterfactual multi-agent policy gradients to better handle credit assignment, while Wang et al. [
30] explored unsupervised learning techniques to facilitate agent design. Despite these advancements, RL-based methods still face several critical limitations:
High Sample Complexity: Many RL algorithms require extensive training data and computational resources.
Non-Stationarity in Multi-Agent Environments: Dynamic interactions among agents lead to unstable training and challenges in credit assignment.
Limited Observability: In partially observable environments, single-source sensory input may be insufficient for accurate decision making.
Inefficient Knowledge Integration: Most current RL approaches lack mechanisms to effectively incorporate prior intelligence, leading to performance degradation when data are sparse.
Our Knowledge-Enhanced MADRL framework addresses these limitations by fusing prior intelligence with real-time sensor inputs to generate a probabilistic model of adversarial UUV trajectories. By using a Double Soft Actor–Critic algorithm, the proposed method effectively tackles issues of dynamic credit assignment and partial observability.
The following table (
Table 2) outlines the strengths and weaknesses of various RL-based approaches in multi-agent and adversarial settings.
3. Proposed Method
In this section, we describe our proposed Knowledge-Enhanced Deep Reinforcement Learning framework for multi-agent adversarial games (MADSAC). The framework is designed to coordinate a helicopter and a swarm of UAVs in a grid-based maritime environment to counter UUV detection and localization. The methodology is organized into the following components: environment modeling, state space, action space, reward function, MADSAC algorithm.
3.1. Environment Modeling
The operational area is modeled as a grid-based maritime environment, where each grid cell represents a region. Each cell is assigned an initial value reflecting the prior probability of a target UUV’s presence, obtained from external intelligence sources. The probability distribution is initialized based on a Gaussian centered at the UUV’s starting position prior to modeling and is dynamically updated throughout the mission based on UAV detection results.
UAVs, equipped with multiple sensors (e.g., visible-light cameras and magnetic detectors), execute the search task, while the helicopter utilizes sonar buoys for precise UUV localization. Wireless communication is established among UAVs to share information and ensure coordinated operations with built-in collision avoidance mechanisms. The overall objective is to complete the search task with minimal fuel consumption and time cost.
The simulation environment and data generation process are implemented using a self-developed Python-based platform. This platform models the dynamic interactions between agents and the environment, simulates sensor measurements with noise, and provides a realistic representation of UUV movement and detection uncertainty. The simulation framework enables the evaluation of different search strategies under various environmental conditions.
3.2. State Space
The state space captures both the environmental context and the agent-specific conditions. For each UAV, the state vector is defined as
where
denotes the UAV’s position coordinates.
is a local probability matrix representing the estimated UUV presence distribution within an neighborhood around the UAV.
is the remaining energy level.
represents the positions of neighboring UAVs.
For the helicopter, the state vector is extended as follows:
where
is the number of deployed sonar buoys and
is the number of available torpedoes.
3.3. Initial UUV Probability Distribution
The initial probability distribution of the UUV’s presence is modeled as a Gaussian distribution centered at its initial position
. The probability at each grid cell
is given by
where
is the initial UUV position.
is the standard deviation, controlling the spread of the probability distribution.
The probability values are then normalized across the entire grid as follows:
3.4. Dynamic Probability Update
The probability distribution of the UUV’s presence,
, is dynamically updated based on UAV sensor observations using a Bayesian update rule:
where
is the prior probability of the UUV’s presence at grid cell at time t.
is the likelihood of the sensor observation given the UUV’s presence at .
represents the local neighborhood of the UAV over which the probability distribution is maintained.
A summary of the state variables is provided in
Table 3.
3.5. Action Space
The action space defines the set of actions available to each agent at every time step. We specify separate action spaces for UAVs and the helicopter using tables for clarity.
3.5.1. UAV Action Space
The Action space of each UAV is shown in
Table 4.
3.5.2. Helicopter Action Space
The helicopter’s actions are defined as in
Table 5.
3.6. Reward Function
The reward function is designed to guide the agents toward an efficient UUV search and localization. It is formulated as
where
is the reward for detecting the target UUV (proportional to detection probability).
is the reward for exploring new regions (implemented via a pheromone mechanism to discourage redundant search).
is the execution cost (time and fuel consumption).
is the penalty for collisions.
are weighting factors.
3.7. MADSAC Algorithm
To mitigate overestimation and error accumulation in multi-agent reinforcement learning, we propose the Multi-Agent Double Soft Actor–Critic (MADSAC) algorithm, which operates under a Centralized Training with Decentralized Execution (CTDE) framework.
3.7.1. Algorithm Architecture
The architecture of MADSAC comprises the following modules:
3.7.2. Training Procedure
Under the CTDE paradigm, training occurs in two phases. Algorithm 1 summarizes the training procedure.
Centralized Training: All agents share global state information via the dual centralized critic, which guides the update of individual actor networks.
Decentralized Execution: Once training converges, each UAV (and the helicopter) executes its learned policy based solely on its local observations.
| Algorithm 1 MADSAC algorithm steps. |
- INPUT:
Environment state space S, action space A, reward function R, discount factor , communication range , update frequency for actors and critics. - OUTPUT:
Trained policies for all agents.
- 1:
INITIALIZE: Initialize actor networks and critic networks for all agents i, and replay buffer . - 2:
while not converged do - 3:
for each agent i do - 4:
Observe state and select action using policy with exploration noise. - 5:
Execute action , receive next state and reward . - 6:
Store transition in . - 7:
end for - 8:
for each agent i do - 9:
Sample a minibatch of transitions from . - 10:
Compute target . - 11:
Update critic network by minimizing loss . - 12:
Update actor network using the policy gradient . - 13:
if agent i is within communication range of other agents then - 14:
Share policy and update critic collaboratively. - 15:
end if - 16:
end for - 17:
if collision risk detected based on then - 18:
Execute collision avoidance maneuver. - 19:
end if - 20:
if environmental objectives met then - 21:
Terminate training and save policies. - 22:
end if - 23:
end while - 24:
RETURN Trained policies for all agents.
|
4. Results
This section presents the experimental outcomes of our proposed approach. The results are organized into three subsections: (i) Experimental Setup, (ii) Rule-Based Method Results, and (iii) Reinforcement Learning-Based Results.
4.1. Experimental Setup
The simulation environment is configured as a
maritime domain, as
Figure 1 shows. The search team consists of two UAVs and one helicopter, tasked with detecting and localizing a single UUV operating within the area.
Table 6 summarizes the force composition and equipment details used in the simulation. The simulation environment is a grid-based maritime domain where each grid cell is initialized with a prior probability of the target UUV’s presence.
The RL algorithms are implemented in Python 3.9.2 using the PyTorch 2.6.0 framework. The training process was conducted on a computer equipped with a 12-core 3.60 GHz Intel(R) Core(TM) i7-12700KF CPU and 32 GB RAM. The Adam optimizer was employed to train the parameters of both actor and critic neural networks. The training parameters are shown in
Table 7.
4.2. Rule-Based Method Results
The rule-based method utilizes predefined rules derived from expert knowledge to control agent behavior [
32]. Algorithm 2 details the steps of the rule-based adversarial method in the simulation.
In this work, the Blue UUV continuously monitors its surroundings to detect the presence of Red targets as in Algorithm 3. Upon detection, the UUV uses onboard sensors (e.g., sonar) to compute the relative position of the threat. It then determines an optimal evasion trajectory using a circular linking method, ensuring that the UUV adjusts its heading and speed to avoid engagement while continuing its mission. The following algorithm outlines the steps performed by the Blue UUV for dynamic threat evasion.
Figure 2 shows how the task completion time and detection success rate of the drone change with the number of training steps under the rule-based method. The mission execution time represents the total time required for the UAV to complete the search mission, which is usually measured from the start of the execution to the successful completion of the mission. The detection success rate indicates the ratio of the number of episodes that complete the search task to the total number of training episodes. As can be seen from the figure, the rule-based method, while straightforward and computationally efficient, exhibits limitations in flexibility and adaptability, resulting in relatively higher mission completion times and suboptimal performance in dynamic environments.
| Algorithm 2 Rule-based algorithm steps. |
- INPUT:
Prior UUV probability grid G, sensor threshold , collision threshold , maximum mission time - OUTPUT:
Mission termination signal after UUV localization and neutralization or when is reached
- 1:
INITIALIZE: Deploy 2 UAVs and 1 helicopter at predetermined positions; initialize grid G with prior UUV probability values. - 2:
while mission is not terminated and elapsed time do - 3:
for each UAV do - 4:
PERFORM SENSOR SCAN. - 5:
if detection probability in a cell then - 6:
BROADCAST detection and UPDATE grid G. - 7:
end if - 8:
end for - 9:
for each UAV do - 10:
FOLLOW fixed, predetermined heading rules to traverse the grid. - 11:
CHECK inter-agent distances. - 12:
if distance then - 13:
EXECUTE COLLISION AVOIDANCE maneuver. - 14:
end if - 15:
end for - 16:
if overall detection confidence > threshold then - 17:
DEPLOY sonar buoys and RELEASE munitions to neutralize the UUV. - 18:
end if - 19:
end while - 20:
RETURN Mission termination signal.
|
| Algorithm 3 Blue submarine evasion algorithm. |
- INPUT:
Sensor data, detection threshold , mission route information - OUTPUT:
Updated navigation commands
- 1:
Initialize: Begin mission on a predetermined route - 2:
while mission is active do - 3:
Monitor the environment for Red target presence - 4:
if Red target is detected then - 5:
Compute the relative distance d and angle using sonar data - 6:
Determine the evasion trajectory using the circular linking method: - 7:
Construct an evasion circle centered at the Red target’s last known position - 8:
Calculate the heading relative to the circle center to choose the optimal circumferential direction - 9:
Execute the evasion maneuver: adjust heading and speed accordingly - 10:
else - 11:
Continue along the predetermined route while monitoring the environment - 12:
end if - 13:
end while - 14:
Return to continuous monitoring
|
4.3. Reinforcement Learning-Based Results
The performances of the proposed MADSAC algorithm and the standard SAC and MADDPG algorithms are evaluated under the same simulation conditions.
Table 8 compares key performance metrics between the rule-based method and our reinforcement learning (RL)-based approach.
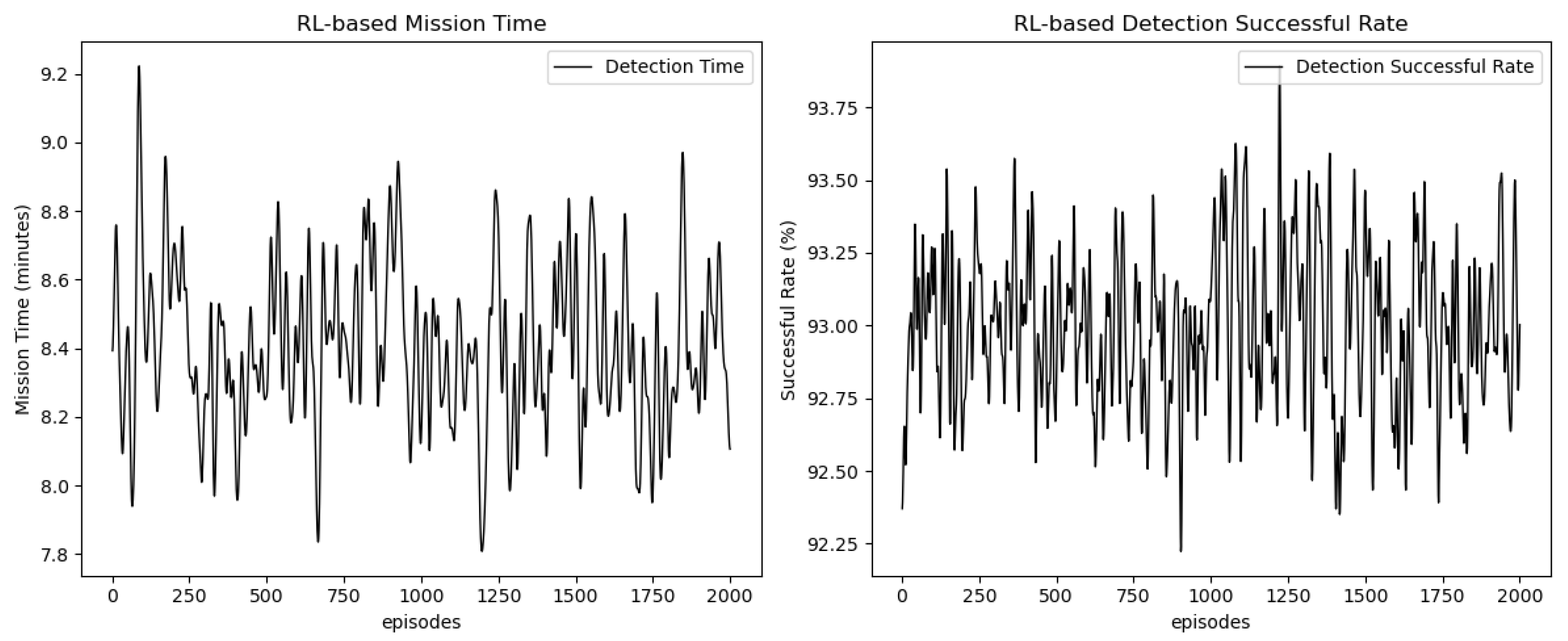
As shown in
Figure 3, the task execution time and detection success rate, based on the proposed MADSAC approach, exhibit distinct trends over the course of 2000 episodes.
The task execution time (left panel) fluctuates throughout the training process, showing minor variations between episodes. These fluctuations might be due to the continuous adaptation of the RL agent’s behavior and the exploration of various strategies during training. Despite the fluctuations, the overall task execution time seems to stabilize over time, indicating that the RL agent is becoming more efficient in task completion as training progresses.
The detection success rate (right panel) follows a similar pattern, with slight oscillations but a general upward trend. This suggests that as the agent learns from its experiences, it gradually improves its ability to successfully detect tasks. The agent’s performance improves as it adapts to the environment and refines its detection strategy, achieving a success rate exceeding 90% towards the later stages of the training.
Figure 4 illustrates the reward change trend of three reinforcement learning algorithms (MADDPG, MADSAC, SAC) during the training process. It can be seen from the figure that MADSAC is better than MADDPG and SAC in terms of convergence speed and the final reward value. MADSAC converges in 1350 episodes, while MADDPG needs 1650 episodes and falls into a local optimum. SAC still has large fluctuations in the later stage. Compared with MADDPG, the algorithm proposed in this paper adopts maximum entropy to increase the robustness of the algorithm and uses a dual evaluation network to alleviate the overestimation problem. Compared with SAC, the algorithm proposed in this paper adopts the CTDE training framework, which can obtain the information of all intelligent agents during the training stag and, at the same time, constructs a neural network that can adaptively adjust the coefficient size according to the randomness of the strategy, effectively balancing the exploration and stability of the strategy.
Overall, the results demonstrate that the proposed algorithm improves both task execution time and detection success rate over time, though the fluctuations in rewards reflect the agent’s exploration and learning process. These findings suggest that further optimization could potentially enhance the stability of task execution time and rewards, while continuing to improve detection success.
5. Discussion
The results of our experiments highlight the effectiveness of the proposed Knowledge-Enhanced Multi-Agent Deep Reinforcement Learning (MADRL) framework in addressing the challenges posed by adversarial UUVs in naval confrontation scenarios. The integration of prior intelligence with real-time sensor data through a probabilistic adversarial model significantly enhances the Red team’s ability to predict and counteract Blue team maneuvers. The Multi-Agent Double Soft Actor–Critic (MADSAC) algorithm effectively addresses the coordination challenges among UAVs, including dynamic credit assignment and partial observability. Compared to traditional rule-based methods, our RL-based approach demonstrates substantial improvements in both detection success rates and mission completion times. The rule-based methods, while computationally efficient and interpretable, struggle with the dynamic and unpredictable nature of adversarial UUVs. In contrast, the RL-based approach, particularly with the MADSAC algorithm, shows a remarkable ability to adapt to changing environments and adversarial tactics, resulting in a 78.8% improvement in detection success rates and a 38.5% reduction in mission completion times.
However, the RL-based approach is not without its limitations. The high sample complexity and computational cost associated with training multi-agent systems remain significant hurdles. Additionally, the non-stationarity of multi-agent environments can lead to unstable training and difficulties in credit assignment. Future research could focus on further reducing sample complexity and improving the stability of training processes, possibly through off-policy correction methods (e.g., importance sampling-based approaches) and meta-learning strategies, which can help mitigate sample inefficiency and improve adaptability without requiring excessively large datasets.
6. Conclusions
In conclusion, this paper presents a novel Knowledge-Enhanced Multi-Agent Deep Reinforcement Learning (MADRL) framework designed to enhance the coordination and effectiveness of UAV swarms in countering adversarial UUVs. The proposed framework integrates a probabilistic adversarial model, a Multi-Agent Double Soft Actor–Critic (MADSAC) algorithm to address the challenges of dynamic credit assignment, partial observability, and high training complexity. Experimental results demonstrate significant improvements in detection success rates and mission completion times compared to traditional rule-based methods. These findings underscore the potential of RL-based approaches in complex, multi-agent adversarial scenarios, paving the way for future advancements in autonomous naval confrontation systems. Future work will focus on further optimizing the training process and exploring hybrid approaches to enhance the robustness and efficiency of multi-agent reinforcement learning in dynamic environments.
Author Contributions
Conceptualization: W.Z., X.Y. and P.W.; methodology: W.Z., C.W. and P.W.; Software: F.M., S.L. and Z.Z.; validation: F.M., S.L. and Z.Z.; writing—original draft: W.Z.; writing—review and editing: W.Z., X.Y. and C.W.; Supervision: X.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data available upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
Correction Statement
This article has been republished with a minor correction to the correspondence contact information. This change does not affect the scientific content of the article.
References
- Liu, A.; Smith, B. Deep Reinforcement Learning: Fundamentals and Recent Advances. IEEE Trans. Neural Netw. 2021, 32, 1234–1245. [Google Scholar]
- Gao, C.; Lee, D. Adaptive Soft Actor-Critic for Autonomous Navigation. IEEE Robot. Autom. Lett. 2022, 7, 2345–2353. [Google Scholar]
- Miller, E.; Johnson, F. Multi-Agent Reinforcement Learning for Autonomous Systems. J. Field Robot. 2021, 38, 567–582. [Google Scholar]
- Chen, G.; Patel, H. Decentralized Multi-Agent Reinforcement Learning: A Survey. IEEE Access 2022, 10, 34567–34580. [Google Scholar]
- Chen, X.; Li, Y. Navigation Strategies for Underwater Vehicles: A Rule-Based Approach. J. Mar. Syst. 2014, 45, 123–134. [Google Scholar]
- Liu, Z.; Wu, J. A Model-Based Approach to Underwater Navigation using Rule-Based Systems. In Proceedings of the International Conference on Robotics and Automation, Seattle, WA, USA, 26–30 May 2015; pp. 567–572. [Google Scholar]
- Wang, H.; Zhang, L. Heuristic Methods for Autonomous Underwater Navigation. IEEE J. Ocean. Eng. 2013, 38, 80–91. [Google Scholar]
- Guo, Y.; Chen, M. Underwater Confrontation and Evasion: Rule-Based Analysis. In Proceedings of the Underwater Technology Conference, Bergen, Norway, 19–20 June 2013; pp. 200–205. [Google Scholar]
- Li, X.; Sun, W. Control Strategies in Autonomous Underwater Vehicles: A Review. Control Eng. Pract. 2017, 61, 1–12. [Google Scholar]
- He, Q.; Liu, J. Adaptive Rule-Based Control for Dynamic Underwater Environments. Ocean Eng. 2018, 153, 210–220. [Google Scholar]
- Zhang, Y.; Li, X. Autonomous Underwater Navigation using Expert Systems. IEEE Trans. Veh. Technol. 2019, 68, 4501–4510. [Google Scholar]
- Xu, F.; Wang, T. Decision-Making in Underwater Operations: A Rule-Based Perspective. In Proceedings of the International Conference on Intelligent Systems, Coimbatore, India, 7–8 January 2016; pp. 130–135. [Google Scholar]
- Huang, L.; Zhou, M. Intelligent Underwater Navigation: From Rules to Adaptation. J. Intell. Transp. Syst. 2017, 21, 105–115. [Google Scholar]
- Sun, J.; Li, Q. Robust Rule-Based Systems for Underwater Vehicle Control. Control Decis. 2018, 33, 85–95. [Google Scholar]
- Park, S.; Kim, J.; Lee, S. Rule-based Navigation for Underwater Vehicles: A Comparative Study. In Proceedings of the IEEE OCEANS Conference, Charleston, South Carolina, 22–25 October 2018; pp. 300–310. [Google Scholar]
- Zhou, Y.; Liu, M. Dynamic Rule-based Strategies for Underwater Threat Evasion. In Proceedings of the IEEE OCEANS Conference, Seattle, WA, USA, 27–31 October 2019; pp. 450–455. [Google Scholar]
- Yue, W.; Tang, W.; Wang, L. Multi-UAV Cooperative Anti-Submarine Search Based on a Rule-Driven MAC Scheme. Applied Sciences 2022, 12, 5707. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level Control through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous Control with Deep Reinforcement Learning. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft Actor-Critic Algorithms and Applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper/2017/hash/68a9750337a418a86fe06c1991a1d64c-Abstract.html (accessed on 12 March 2025).
- Yun, W.J.; Park, S.; Kim, J.; Shin, M.; Jung, S.; Mohaisen, D.A.; Kim, J.H. Cooperative multiagent deep reinforcement learning for reliable surveillance via autonomous multi-UAV control. IEEE Trans. Ind. Inform. 2022, 18, 7086–7096. [Google Scholar] [CrossRef]
- Iqbal, S.; Sha, F. Actor-attention-critic for multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 2961–2970. [Google Scholar]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum Learning. In Proceedings of the ICML 2009, Montreal, QC, Canada, 14–18 June 2009. [Google Scholar]
- Liu, J.; Li, F.; Wang, J.; Han, H. Proximal Policy Optimization Based Decentralized Networked Multi-Agent Reinforcement Learning. In Proceedings of the 2024 IEEE 18th International Conference on Control & Automation (ICCA), Reykjavik, Iceland, 18–21 June 2024; pp. 839–844. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Hessel, M.; Modayil, J.; Van Hasselt, H.; Schaul, T.; Ostrovski, G.; Silver, D.; Sutton, R. Rainbow: Combining Improvements in Deep Reinforcement Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3215–3222. [Google Scholar]
- Foerster, J.N.; Assael, Y.M.; de Freitas, N.; Whiteson, S. Counterfactual Multi-Agent Policy Gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 2974–2982. [Google Scholar]
- Wang, Z.; He, B.; Jiang, Z.; Zhang, X.; Dong, H.; Ye, D. Distributed Unsupervised Meta-Learning Algorithm over Multi-Agent Systems. Digit. Commun. Netw. 2024; in press. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Xue, M.; Huang, H.; Zhuang, Y.; Si, J.; Lü, T.; Sharma, S.; Zhang, L. Collaborative Marine Targets Search Algorithm for USVs and UAVs Under Energy Constraint. IEEE Internet Things J. 2024, 1. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}
{kind=link}