
Provable AI Ethics and Explainability in Medical and Educational AI Agents: Trustworthy Ethical Firewall


Abstract

{kind=link}
{kind=link}
{kind=link}
1. Introduction: The Imperative for Provable Ethics in High-Stakes AI
1.1. Trust as a Cornerstone for AI Agents in Medicine and Education
1.2. Goals of This Paper
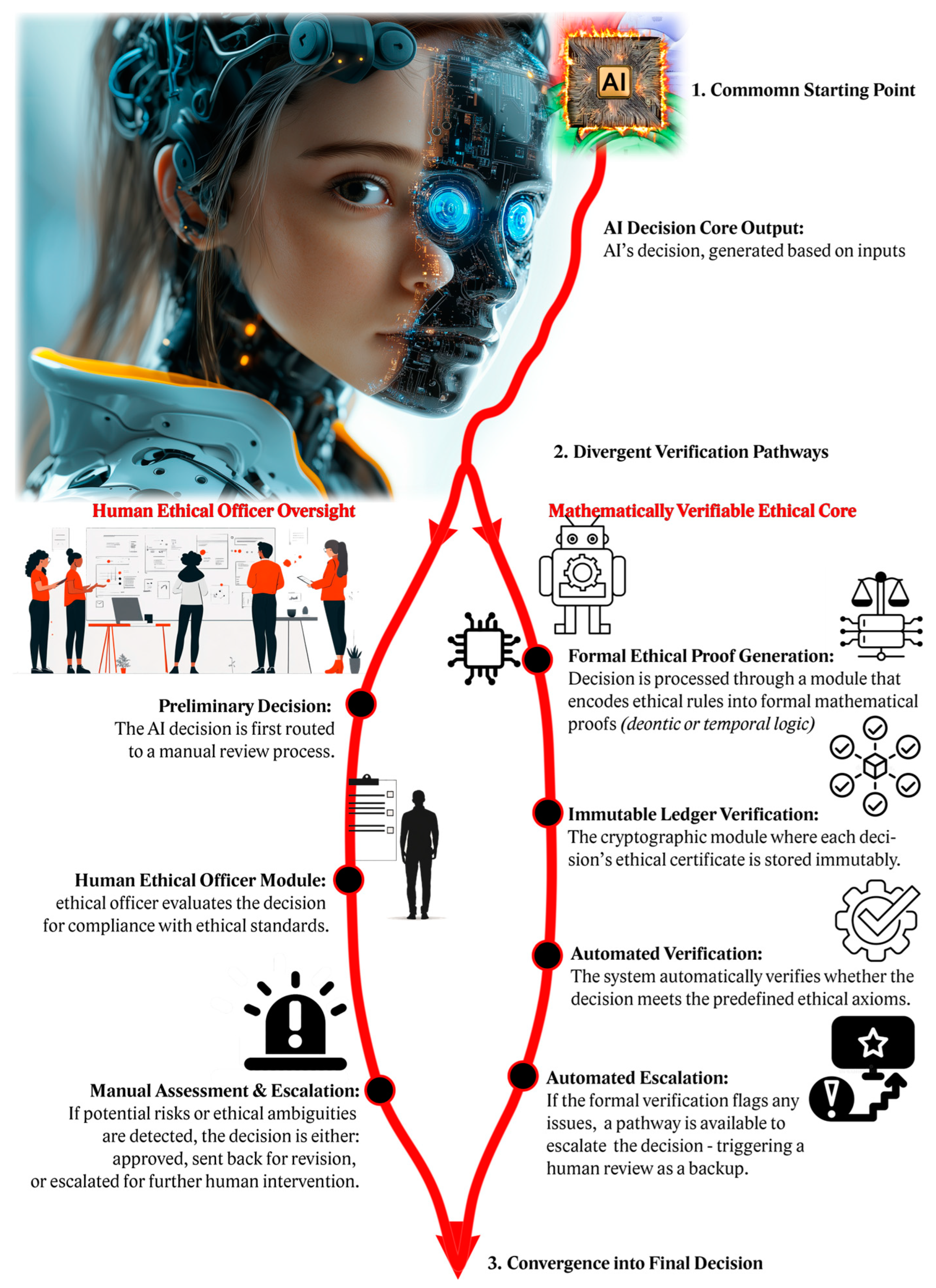
2. Human Ethical Officer and Ethical Firewall
2.1. Formal Ethical Specification and Verification: Ethical Firewall Architecture
2.2. Cryptographically Immutable Ethical Core
2.3. Emotion-Analogous Escalation Protocols
2.4. Integrating Causal Reasoning and Intent
2.5. Addressing Scaling Limitations and Emergent Value Conflicts
2.6. Application Examples in Medical and Educational Contexts
- In a medical context, an AI system for treatment recommendation would implement the framework as follows: The formal ethical specification would encode constraints such as “Treatment recommendations must never exceed maximum safe dosage limits” and “Patient autonomy must be preserved through explicit consent options”. These constraints would be verified prior to any recommendation using formal verification techniques such as model checking. The cryptographically immutable core would maintain a tamper-proof record of each recommendation, including patient data used, constraints applied, and verification results, all stored using a distributed ledger approach. When the system encounters a case near its confidence threshold (e.g., unusual patient parameters or conflicting clinical guidelines), the emotion-analogous escalation protocol would automatically route the decision to a human clinician, providing full context and highlighting the specific areas of uncertainty. The causal reasoning component would distinguish between merely correlated factors (e.g., patient demographics and response rates) and causally relevant factors (e.g., specific biomarkers that mechanistically affect treatment efficacy).
- In an educational context, an AI tutor would implement similar principles: Formal ethical constraints would include rules like “Learning interventions must adapt to demonstrated student capability” and “Assessment must maintain consistent standards across demographic groups”. The verification system would prove that recommended content aligns with curriculum standards while remaining adaptable to individual learning needs. The immutable core would record student interactions and system responses, protecting student privacy while enabling the auditing of algorithmic fairness. The escalation protocol would identify students struggling in unexpected ways and alert human educators for intervention. Causal reasoning would help distinguish between superficial learning (memorization of facts) and deep conceptual understanding, enabling the system to recommend truly effective learning interventions rather than those that merely correlate with short-term performance improvements.
3. Challenges, Governance, and the Role of Human Oversight
3.1. The Perils of Deceptive and Biased Learning
3.2. Ethical AI Oversight: The Role of the Ethical AI Officer
- Human Ethical Officer Oversight
- Subjectivity and Bias: Human reviewers can be influenced by personal, cultural, or institutional biases, leading to inconsistent evaluations.
- Cognitive Limitations: Humans may struggle with the rapid, high-volume decision flows typical of AI systems, potentially resulting in oversight or delayed responses.
- Scalability Issues: As AI scales, relying solely on human intervention can create bottlenecks, making it challenging to monitor every decision in real time.
- Fatigue and Error: Even skilled ethical officers are prone to fatigue, distraction, and human error, which can compromise decision quality under high-stress conditions.
- Resistance to Change: Humans may be slower to adapt to new ethical challenges or emerging scenarios, limiting the flexibility of oversight in dynamic environments.
- Mathematically Verifiable Ethical Core
- Rigidity of Formal Models: Formal ethical specifications may not capture the full nuance of real-world ethical dilemmas, leading to decisions that are technically compliant yet ethically oversimplified.
- Incomplete Ethical Axioms: The system is only as robust as the axioms it uses; if these formal rules overlook important ethical considerations, the resulting proof might validate harmful decisions.
- Computational Overhead: Real-time generation and verification of mathematical proofs can be resource-intensive, potentially impacting system responsiveness in critical scenarios.
- Specification Vulnerabilities: Errors in the formal ethical model or its implementation can lead to catastrophic failures, as the system may unwittingly verify flawed decision logic.
- Potential for Exploitation: Despite cryptographic safeguards, any vulnerabilities in the underlying algorithms or logic could be exploited, undermining the system’s trustworthiness.
- Lack of Contextual Sensitivity: Unlike human oversight, formal methods may miss subtle contextual cues and the complexity of human ethical judgment, resulting in decisions that lack situational sensitivity.
- Overreliance Risk: The mathematical proof of ethical compliance might engender overconfidence, reducing critical questioning even when unforeseen ethical issues arise.
Escalation Protocols
3.3. Utility Engineering and Citizen Assemblies
3.4. The Arms Race for AGI and ASI: Profit Versus Humanity
4. Conceptual Framework of Trustworthy Ethical Firewall
4.1. Three Core Components of Trustworthy AI
4.2. Ethical Firewall Architecture in Details
- An Explainability Engine that converts the AI’s decision-making process into human-readable explanations.
- A Decision Justification UI which provides a visual dashboard or textual breakdown explaining the rationale behind the AI’s decisions.
- A Transparency Panel that displays factors influencing the decision, confidence levels, and alternative choices the AI considered.
- Human Review Gateway: A fail-safe that pauses AI decisions when they surpass risk thresholds.
- Feedback Integration Module: Allows users to provide input on past AI decisions to improve future performance.
- Ethical Advisory Agent: A separate advisory AI that analyzes decisions independently for potential biases or ethical issues.
- Regulatory Compliance Checker: Automatically assesses AI actions against international laws (e.g., GDPR, HIPAA).
- Bias and Fairness Monitor: Continuously checks for potential biases in AI-generated decisions.
- Public Trust Interface: Allows external watchdogs, policymakers, or affected individuals to audit and challenge decisions.
4.3. Key Components of Ethical Firewall
- Formal Ethical Specification
- Mathematical Logic: Define ethical rules (e.g., “do no harm”) as formal axioms using well-understood logics (such as deontic or temporal logic).
- Provable Compliance: Every decision made by AI must be accompanied by formal proof or certification that the decision satisfies these ethical constraints.
- Embedded Ethical Core
- Deep Integration: The ethical core is not an add-on module, but is embedded at the deepest level of decision-making architecture. This means that every action—from low-level sensor inputs to high-level strategic decisions—must pass through this ethical filter.
- Immutable Record: Similarly to Bitcoin’s use of cryptographic proofs, the ethical core’s code and its decision proofs are stored in an immutable, distributed ledger. This makes the system’s adherence to its ethical rules auditable and unalterable.
- Real-Time Monitoring and Escalation
- Continuous Evaluation: The system constantly monitors its own decisions. If a decision risks violating the “do no harm” principle, a safeguard mechanism triggers.
- Human Override: In high-stakes scenarios (e.g., a treatment plan that might inadvertently harm a patient), the system escalates control to a human operator, ensuring that ethical concerns are addressed by human judgment.
- Explainability and Transparency
- Proof Certificates: Alongside every decision, the system generates an easily interpretable “explanation certificate” that details the logical steps verifying ethical compliance.
- Audit Trail: This proof not only builds trust, but also allows external auditors or regulators to verify that the AI’s actions were ethically sound, without needing to trust a black box algorithm.
- Robust Handling of Uncertainty
- Adaptive Learning: The system incorporates methods from formal verification and model checking to account for uncertainties in real-world data while still maintaining provable guarantees.
- Fail-Safe Design: In situations where data ambiguity or unprecedented scenarios arise, the system defaults to a safe state or defers to human decision-making.
4.4. Implementation Considerations
4.5. Use Case and Concluding Vision
4.6. Mapping EFA Components to Trustworthy AI Principles
5. Discussion
5.1. Emergent AI Value Systems and Biases
5.2. Accelerating Capabilities and AGI Precursors
5.3. Societal Impacts: Workforce Displacement and New Oversight Roles
5.4. Toward Provable, Explainable, and Human-Centered AI
6. Conclusions: Toward a Trustworthy, Transparent, and Ethically Aligned AI Future
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| EFA | Ethical Firewall Architecture |
| GAI/AGI | General artificial intelligence |
| LLMs | Large language models |
| ASI | Artificial superintelligence |
| GDPR | General Data Protection Regulation |
| HLEG | High-Level Expert Group on Artificial Intelligence |
| SCMs | Structural Causal Models |
| DAOs | Decentralized Autonomous Organizations |
| HIPAA | Health Insurance Portability and Accountability Act |
| XAI | Explainable AI |
References
- Rao, S. Deontic Temporal Logic for Formal Verification of AI Ethics. arXiv 2025, arXiv:2501.05765. [Google Scholar]
- Wang, X.; Li, Y.; Xue, C. Collaborative Decision Making with Responsible AI: Establishing Trust and Load Models for Probabilistic Transparency. Electronics 2024, 13, 3004. [Google Scholar] [CrossRef]
- Ratti, E.; Graves, M. A capability approach to AI ethics. Am. Philos. Q. 2025, 62, 1–16. [Google Scholar] [CrossRef]
- Chun, J.; Elkins, K.; College, K. Informed AI Regulation: Comparing the Ethical Frameworks of Leading LLM Chatbots Using an Ethics-Based Audit to Assess Moral Reasoning and Normative Values. arXiv 2024, arXiv:2402.01651. [Google Scholar]
- Mökander, J.; Floridi, L. Ethics-Based Auditing to Develop Trustworthy AI. Minds Mach. 2021, 31, 323–327. [Google Scholar] [CrossRef]
- Kumar, S.; Choudhury, S. Humans, Super Humans, and Super Humanoids: Debating Stephen Hawking’s Doomsday AI Forecast. AI Ethics 2023, 3, 975–984. [Google Scholar]
- Thantharate, P.; Bhojwani, S.; Thantharate, A. DPShield: Optimizing Differential Privacy for High-Utility Data Analysis in Sensitive Domains. Electronics 2024, 13, 2333. [Google Scholar] [CrossRef]
- Jeyaraman, M.; Balaji, S.; Jeyaraman, N.; Yadav, S. Unraveling the Ethical Enigma: Artificial Intelligence in Healthcare. Cureus 2023, 15, e43262. [Google Scholar]
- Wang, W.; Wang, Y.; Chen, L.; Ma, R.; Zhang, M. Justice at the Forefront: Cultivating Felt Accountability towards Artificial Intelligence among Healthcare Professionals. Soc. Sci. Med. 2024, 347, 116717. [Google Scholar] [CrossRef]
- Dumitrașcu, L.M.; Lespezeanu, D.A.; Zugravu, C.A.; Constantin, C. Perceptions of the Impact of Artificial Intelligence among Internal Medicine Physicians as a Step in Social Responsibility Implementation: A Cross-Sectional Study. Healthcare 2024, 12, 1502. [Google Scholar] [CrossRef]
- Vrdoljak, J.; Boban, Z.; Vilović, M.; Kumrić, M.; Božić, J. A Review of Large Language Models in Medical Education, Clinical Decision Support, and Healthcare Administration. Healthcare 2025, 13, 603. [Google Scholar] [CrossRef]
- Runcan, R.; Hațegan, V.; Toderici, O.; Croitoru, G.; Gavrila-Ardelean, M.; Cuc, L.D.; Rad, D.; Costin, A.; Dughi, T. Ethical AI in Social Sciences Research: Are We Gatekeepers or Revolutionaries? Societies 2025, 15, 62. [Google Scholar] [CrossRef]
- Le Dinh, T.; Le, T.D.; Uwizeyemungu, S.; Pelletier, C. Human-Centered Artificial Intelligence in Higher Education: A Framework for Systematic Literature Reviews. Information 2025, 16, 240. [Google Scholar] [CrossRef]
- Urrea, C.; Kern, J. Recent Advances and Challenges in Industrial Robotics: A Systematic Review of Technological Trends and Emerging Applications. Processes 2025, 13, 832. [Google Scholar] [CrossRef]
- Roy, D.; Mladenov, V.; Walker, P.B.; Haase, J.J.; Mehalick, M.L.; Steele, C.T.; Russell, D.W.; Davidson, I.N. Harnessing Metacognition for Safe and Responsible AI. Technologies 2025, 13, 107. [Google Scholar] [CrossRef]
- Goktas, P.; Grzybowski, A. Shaping the Future of Healthcare: Ethical Clinical Challenges and Pathways to Trustworthy AI. J. Clin. Med. 2025, 14, 1605. [Google Scholar] [CrossRef]
- Bhumichai, D.; Smiliotopoulos, C.; Benton, R.; Kambourakis, G.; Damopoulos, D. The Convergence of Artificial Intelligence and Blockchain: The State of Play and the Road Ahead. Information 2024, 15, 268. [Google Scholar] [CrossRef]
- Galanos, V. Exploring Expanding Expertise: Artificial Intelligence as an Existential Threat and the Role of Prestigious Commentators, 2014–2018. Technol. Anal. Strateg. Manag. 2019, 31, 421–432. [Google Scholar] [CrossRef]
- Ma, W.; Valton, V. Toward an Ethics of AI Belief. Philos. Technol. 2024, 37, 76. [Google Scholar] [CrossRef]
- Farjami, A. AI Alignment and Normative Reasoning: Addressing Uncertainty through Deontic Logic. Available online: https://farjami110.github.io/Papers/Farjami-AIJ.pdf (accessed on 23 March 2025).
- D’Alessandro, W. Deontology and Safe Artificial Intelligence. Philos. Stud. 2024. [Google Scholar] [CrossRef]
- Mustafa, G.; Rafiq, W.; Jhamat, N.; Arshad, Z.; Rana, F.A. Blockchain-Based Governance Models in e-Government: A Comprehensive Framework for Legal, Technical, Ethical and Security Considerations. Int. J. Law Manag. 2024, 67, 37–55. [Google Scholar] [CrossRef]
- Carlson, K.W. Safe Artificial General Intelligence via Distributed Ledger Technology. Big Data Cogn. Comput. 2019, 3, 40. [Google Scholar] [CrossRef]
- Ambartsoumean, V.M.; Yampolskiy, R.V. AI Risk Skepticism, A Comprehensive Survey. arXiv 2023, arXiv:2303.03885. [Google Scholar]
- Johnson, J. Delegating Strategic Decisions to Intelligent Machines. In Artificial Intelligence and the Future of Warfare; Manchester University Press: Manchester, UK, 2021; pp. 168–197. [Google Scholar] [CrossRef]
- Al-Sabbagh, A.; Hamze, K.; Khan, S.; Elkhodr, M. An Enhanced K-Means Clustering Algorithm for Phishing Attack Detections. Electronics 2024, 13, 3677. [Google Scholar] [CrossRef]
- Ho, J.; Wang, C.M. Human-Centered AI Using Ethical Causality and Learning Representation for Multi-Agent Deep Reinforcement Learning. In Proceedings of the 2021 IEEE International Conference on Human-Machine Systems, ICHMS 2021, Magdeburg, Germany, 8–10 September 2021. [Google Scholar] [CrossRef]
- Bishop, J.M. Artificial Intelligence Is Stupid and Causal Reasoning Will Not Fix It. Front. Psychol. 2021, 11, 513474. [Google Scholar] [CrossRef]
- Leist, A.K.; Klee, M.; Kim, J.H.; Rehkopf, D.H.; Bordas, S.P.A.; Muniz-Terrera, G.; Wade, S. Mapping of Machine Learning Approaches for Description, Prediction, and Causal Inference in the Social and Health Sciences. Sci. Adv. 2022, 8, 1942. [Google Scholar]
- Felin, T.; Holweg, M. Theory Is All You Need: AI, Human Cognition, and Causal Reasoning. Strategy Sci. 2024, 9, 346–371. [Google Scholar] [CrossRef]
- Sarridis, I.; Koutlis, C.; Papadopoulos, S.; Diou, C. Towards Fair Face Verification: An In-Depth Analysis of Demographic Biases. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer Nature: Cham, Switzerland, 2025; pp. 194–208. [Google Scholar] [CrossRef]
- Mazeika, M.; Yin, X.; Tamirisa, R.; Lim, J.; Lee, B.W.; Ren, R.; Phan, L.; Mu, N.; Khoja, A.; Zhang, O.; et al. Utility Engineering: Analyzing and Controlling Emergent Value Systems in AIs. arXiv 2025, arXiv:2502.08640. [Google Scholar]
- Perivolaris, A.; Rueda, A.; Parkington, K.; Soni, A.; Rambhatla, S.; Samavi, R.; Jetly, R.; Greenshaw, A.; Zhang, Y.; Cao, B.; et al. Opinion: Mental Health Research: To Augment or Not to Augment. Front. Psychiatry 2025, 16, 1539157. [Google Scholar] [CrossRef]
- Saxena, R.R. Applications of Natural Language Processing in the Domain of Mental Health. Authorea Prepr. 2024. [Google Scholar] [CrossRef]
- Popoola, G.; Sheppard, J. Investigating and Mitigating the Performance–Fairness Tradeoff via Protected-Category Sampling. Electronics 2024, 13, 3024. [Google Scholar] [CrossRef]
- Malicse, A. Aligning AI with the Universal Formula for Balanced Decision-Making. Available online: https://philpapers.org/rec/MALAAW-3 (accessed on 23 March 2025).
- Plevris, V. Assessing Uncertainty in Image-Based Monitoring: Addressing False Positives, False Negatives, and Base Rate Bias in Structural Health Evaluation. Stoch. Environ. Res. Risk Assess. 2025, 39, 959–972. [Google Scholar] [CrossRef]
- Bowen, S.A. “If It Can Be Done, It Will Be Done:” AI Ethical Standards and a Dual Role for Public Relations. Public Relat. Rev. 2024, 50, 102513. [Google Scholar] [CrossRef]
- Díaz-Rodríguez, N.; Del Ser, J.; Coeckelbergh, M.; López de Prado, M.; Herrera-Viedma, E.; Herrera, F. Connecting the Dots in Trustworthy Artificial Intelligence: From AI Principles, Ethics, and Key Requirements to Responsible AI Systems and Regulation. Inf. Fusion. 2023, 99, 101896. [Google Scholar] [CrossRef]
- Lu, Q.; Zhu, L.; Xu, X.; Whittle, J.; Zowghi, D.; Jacquet, A. Responsible AI Pattern Catalogue: A Collection of Best Practices for AI Governance and Engineering. ACM Comput. Surv. 2024, 56, 1–35. [Google Scholar] [CrossRef]
- Jedličková, A. Ethical Considerations in Risk Management of Autonomous and Intelligent Systems. Ethics Bioeth. 2024, 14, 80–95. [Google Scholar] [CrossRef]
- Jedlickova, A. Ensuring Ethical Standards in the Development of Autonomous and Intelligent Systems. IEEE Trans. Artif. Intell. 2024, 5, 5863–5872. [Google Scholar] [CrossRef]
- Jedličková, A. Ethical Approaches in Designing Autonomous and Intelligent Systems: A Comprehensive Survey towards Responsible Development. AI Soc. 2024, 1–14. [Google Scholar] [CrossRef]
- Korbmacher, J. Deliberating AI: Why AI in the Public Sector Requires Citizen Participation. Master’s Thesis, Utrecht University, Utrecht, The Netherlands, 2023. [Google Scholar]
- Rauf, A.; Iqbal, S. Global Foreign Policies Review (GFPR) Impact of Artificial Intelligence in Arms Race, Diplomacy, and Economy: A Case Study of Great Power Competition between the US and China. Glob. Foreign Policies Rev. 2023, 8, 44–63. [Google Scholar] [CrossRef]
- Uyar, T. ASI as the New God: Technocratic Theocracy. arXiv 2024, arXiv:2406.08492. [Google Scholar]
- Fahad, M.; Basri, T.; Hamza, M.A.; Faisal, S.; Akbar, A.; Haider, U.; El Hajjami, S. The Benefits and Risks of Artificial General Intelligence (AGI). In Artificial General Intelligence (AGI) Security: Smart Applications and Sustainable Technologies; Springer Nature: Singapore, 2025; pp. 27–52. [Google Scholar] [CrossRef]
- Calegari, R.; Giannotti, F.; Milano, M.; Pratesi, F. Introduction to Special Issue on Trustworthy Artificial Intelligence (Part II). ACM Comput. Surv. 2025, 57, 1–3. [Google Scholar] [CrossRef]
- Why AI Progress Is Unlikely to Slow Down | TIME. Available online: https://time.com/6300942/ai-progress-charts/ (accessed on 26 February 2025).
- Perplexity Unveils Deep Research: AI-Powered Tool for Advanced Analysis—InfoQ. Available online: https://www.infoq.com/news/2025/02/perplexity-deep-research/ (accessed on 26 February 2025).
- Pethani, F. Promises and Perils of Artificial Intelligence in Dentistry. Aust. Dent. J. 2021, 66, 124–135. [Google Scholar] [CrossRef] [PubMed]
- Zuchowski, L.C.; Zuchowski, M.L.; Nagel, E. A Trust Based Framework for the Envelopment of Medical AI. NPJ Digit. Med. 2024, 7, 230. [Google Scholar] [CrossRef] [PubMed]
- Ethical AI In Education: Balancing Privacy, Bias, and Tech. Available online: https://inspiroz.com/the-ethical-implications-of-ai-in-education/ (accessed on 26 February 2025).
- Pavuluri, S.; Sangal, R.; Sather, J.; Taylor, R.A. Balancing Act: The Complex Role of Artificial Intelligence in Addressing Burnout and Healthcare Workforce Dynamics. BMJ Health Care Inform. 2024, 31, e101120. [Google Scholar] [CrossRef]
- Sharma, M. The Impact of AI on Healthcare Jobs: Will Automation Replace Doctors. Am. J. Data Min. Knowl. Discov. 2024, 9, 32–35. [Google Scholar] [CrossRef]
- Artificial Intelligence Act: Council Calls for Promoting Safe AI That Respects Fundamental Rights—Consilium. Available online: https://www.consilium.europa.eu/en/press/press-releases/2022/12/06/artificial-intelligence-act-council-calls-for-promoting-safe-ai-that-respects-fundamental-rights/ (accessed on 13 April 2023).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thurzo, A. Provable AI Ethics and Explainability in Medical and Educational AI Agents: Trustworthy Ethical Firewall. Electronics 2025, 14, 1294. https://doi.org/10.3390/electronics14071294
Thurzo A. Provable AI Ethics and Explainability in Medical and Educational AI Agents: Trustworthy Ethical Firewall. Electronics. 2025; 14(7):1294. https://doi.org/10.3390/electronics14071294
Chicago/Turabian StyleThurzo, Andrej. 2025. "Provable AI Ethics and Explainability in Medical and Educational AI Agents: Trustworthy Ethical Firewall" Electronics 14, no. 7: 1294. https://doi.org/10.3390/electronics14071294
APA StyleThurzo, A. (2025). Provable AI Ethics and Explainability in Medical and Educational AI Agents: Trustworthy Ethical Firewall. Electronics, 14(7), 1294. https://doi.org/10.3390/electronics14071294