1. Introduction
As 5G technology has been developing rapidly, 3D capture techniques have made progress, and the utilization of 3D devices has been on the rise, real-world scenes can currently be digitized into 3D forms effectively by means of point clouds. These point clouds describe object shapes and properties through their 3D spatial topology, providing users with unprecedented visual experiences. Furthermore, 3D point clouds can be applied in a wide range of different fields, such as the preservation of cultural heritage, autonomous driving, robotics, and virtual reality, augmented reality, and mixed reality (VR/AR/MR) [
1,
2].
Three-dimensional point clouds are mainly classified into three types: static point clouds, dynamic point clouds, and dynamic collection point clouds [
3]. To achieve the effective compression of point cloud data, the Moving Picture Experts Group (MPEG) has formulated two standards regarding point cloud compression, namely geometry-based point cloud compression (G-PCC) and video-based point cloud compression (V-PCC). V-PCC, mainly concentrating on the compression of dynamic point clouds, maps 3D point clouds onto 2D video frames and makes use of the available video codecs to reduce the geometry and texture data of dynamic point clouds. This approach helps to reduce the development cycle [
4]. Enhancing the 2D video coding process within V-PCC can significantly improve the overall performance of 3D point cloud compression [
5]. Therefore, investigating fast coding techniques for 2D projection videos in combination with V-PCC is essential to further accelerate its implementation.
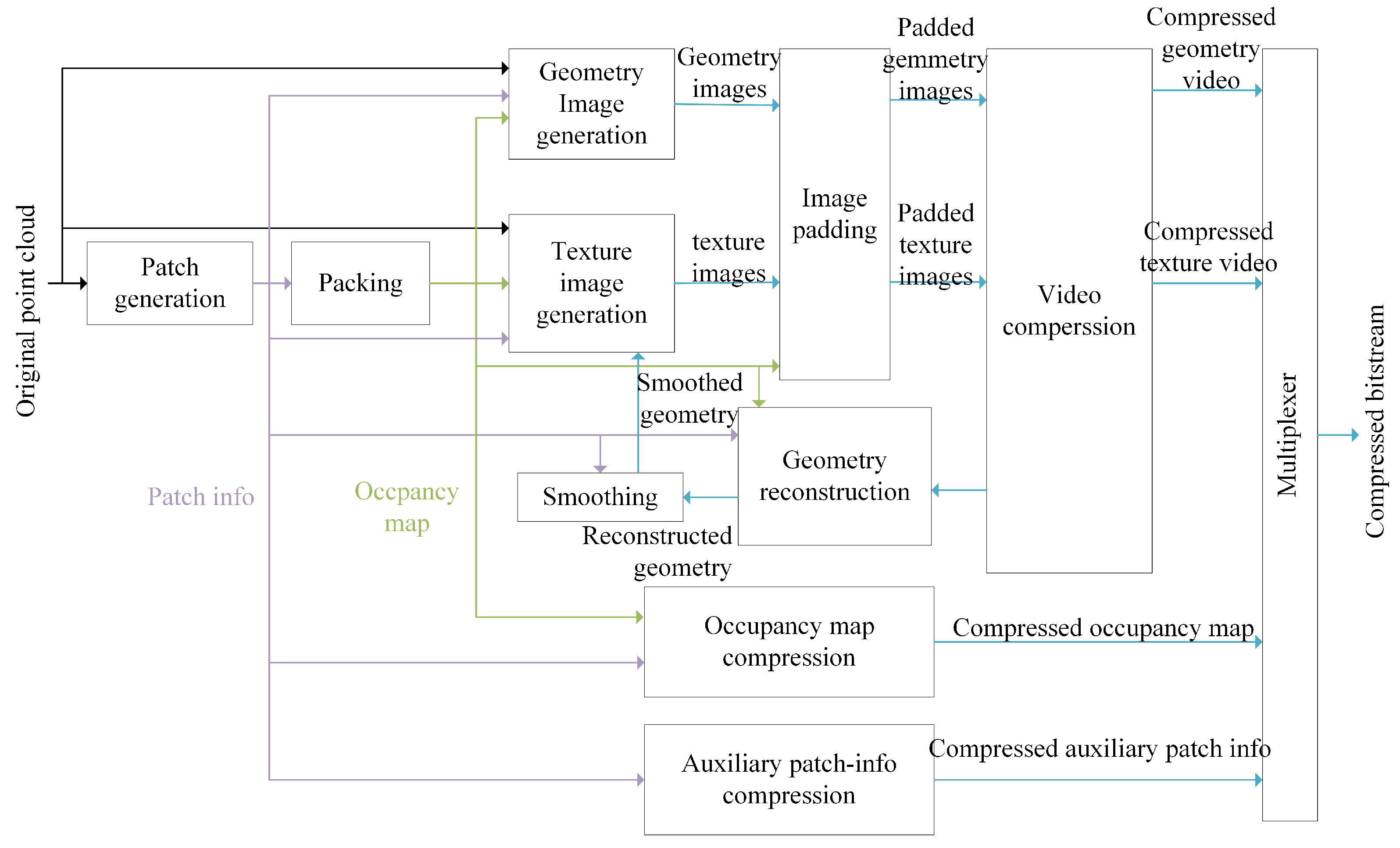
During the V-PCC procedure, the point cloud is initially split into small three-dimensional patches [
6]. After that, these 3D patches are projected onto a two-dimensional surface and arranged to form geometry videos and attribute videos. Following this, the vacant areas in both the geometry videos and the attribute videos are filled up to guarantee spatial continuity and enhance the efficiency of video compression. Ultimately, High-Efficiency Video Coding (HEVC) is utilized to carry out the compression of the geometry and attribute videos [
7]. Among them, the traditional sequential method follows a “prediction–transform” architecture, where the input frame is divided into blocks of equal size. The motion vector between the current frame and the previous reconstructed frame is calculated through motion estimation and compensation steps, thereby generating a prediction frame. Subsequently, the residual between the original frame and the prediction frame is transformed and quantized. The entire framework of the V-PCC encoding procedure is illustrated in
Figure 1.
In the V-PCC reference software TMC2v18.0 [
8,
9], HEVC serves as the 2D video encoder, with coding unit (CU) partitioning as its initial stage. In the course of this process, every frame is split into coding tree units (CTUs) with a size of 64 × 64 [
10]. Each CTU then recursively explores permitted partitioning patterns, including quadtree (QT) and non-split configurations; the procedure goes on until the smallest size of 8 × 8 is reached or the best partitioning plan is determined. The selection of segmentation modes is driven by the rate-distortion optimization (RDO) strategy [
11]. This strategy necessitates that the encoder assesses all potential options and conducts subsequent operations, including prediction, quantization, and transformation, to identify the mode that has the minimum rate-distortion (RD) cost [
12]. As a result, this process entails a high computational complexity. Predicting CU partitioning can reduce the RDO overhead in HEVC and accelerate V-PCC. However, although the CU partitioning method of HEVC performs well in natural video coding, it faces many challenges in V-PCC. First, V-PCC deals with data resulting from the projection of 3D point clouds onto 2D videos. When projected onto a 2D plane, point cloud data generate a large number of empty regions, which are rarely seen in natural videos. The CU partitioning method of HEVC typically attempts to encode these empty regions, leading to a waste of computational resources. Second, there are distinct sparse and dense regions in point cloud data. Sparse regions require fewer encoding resources, while dense regions need more refined encoding strategies. The CU partitioning method of HEVC lacks flexibility in handling such differences. Finally, V-PCC needs to encode both geometry and attribute information simultaneously, whereas the CU partitioning method of HEVC is mainly designed for single-type video content and is difficult to use in order to optimize the encoding efficiency of both geometry and attributes at the same time. Therefore, directly applying the CU partitioning method of HEVC in V-PCC may result in low encoding efficiency or degraded coding quality.
To meet the specific needs of V-PCC, this paper proposes an adaptive CU partitioning method combining occupancy maps, convolutional neural networks (CNNs), and Bayesian optimization [
13], specifically targeting the coding complexity of dynamic 3D point clouds. The innovation of this paper lies in proposing an adaptive CU partitioning method that combines CNNs and Bayesian optimization, specifically targeting the coding complexity of dynamic 3D point clouds in V-PCC. This method introduces occupancy map information to classify coding units (CUs) into dense and sparse regions. It then uses CNNs for preliminary partitioning decisions and employs Bayesian optimization to fine-tune regions with low confidence. Compared with existing methods, this strategy, which integrates deep learning and Bayesian optimization, not only significantly reduces coding complexity but also maintains high coding quality, offering a new solution for the practical application of V-PCC.
The main contributions of this paper are as follows:
Adaptive CU Partitioning Based on Occupancy Graph and CNN Framework: By calculating the occupancy rate R of the CUs, the regions are classified into dense areas, sparse areas, and complex composite areas. The partitioning is then adaptively adjusted according to the characteristics of each region.
Bayesian Optimization to Improve Classification Accuracy in Low-Confidence Regions: In regions where the CNN outputs low confidence, Bayesian optimization is further employed to make adjustments, thereby improving the accuracy of partitioning and encoding efficiency.
Adaptive Strategy for Optimizing Coding Efficiency and Quality: The proposed algorithm dynamically adjusts the partitioning depth based on the occupancy rate and spatial features of the CUs. It achieves adaptive partitioning for different regions, significantly enhancing the compression efficiency of V-PCC geometry image coding. Meanwhile, it ensures a low bit rate and high coding quality.
The structure of the paper is as follows.
Section 2 reviews current research on CU partitioning, with a focus on existing algorithms developed to reduce video coding complexity.
Section 3 details the proposed CU partitioning algorithm. The experimental results are presented in
Section 4. Ultimately,
Section 5 wraps up by summarizing the performance and contributions of the algorithm.
2. Research Background and Overview
This paper investigates the compression process of geometry videos, attribute videos, occupancy videos, and metadata generated by V-PCC via the default scheme of TMC2v18.0 reference software and HEVC.
2.1. Reducing the Coding Complexity of HEVC
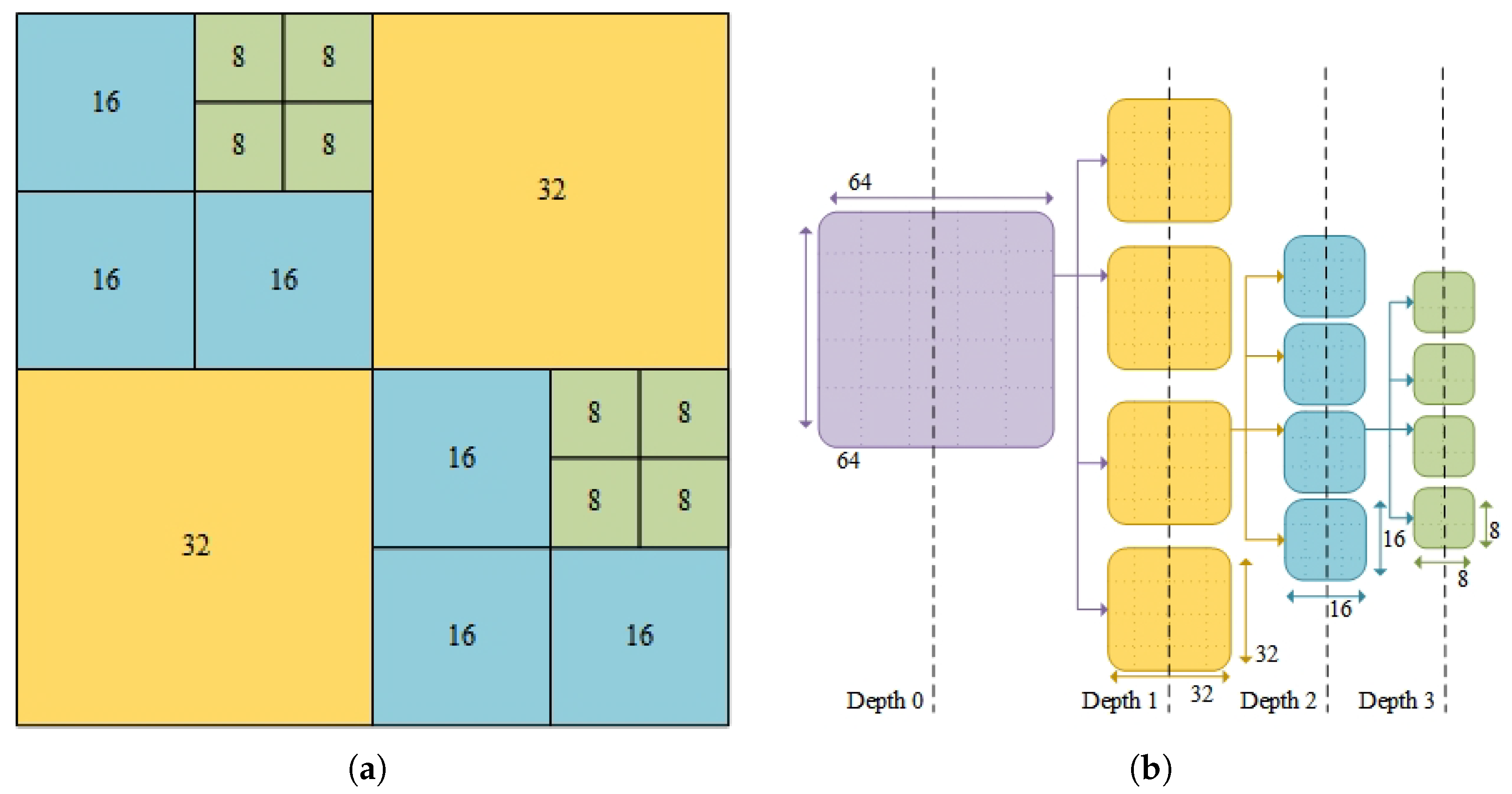
The CU partitioning process in HEVC involves significant computational complexity. It begins with a quadtree-based recursive partitioning structure that determines the size and depth of each CU based on the minimum RD cost. The procedure begins with a CTU 64 × 64 in size at depth 0 [
14]. This CTU is successively divided in a recursive way into smaller CUs (with a size of 32 × 32 at depth 1 and 16 × 16 at depth 2), until the minimum CU size of 8 × 8 is achieved at depth 3 [
15]. Finally, the minimum RD cost is calculated, and the partitioning is trimmed bottom-up based on the lowest RD cost. The process is illustrated in
Figure 2.
When studying the CU division of HEVC, Xu et al. [
16] proposed a deep learning-based method for reducing HEVC complexity by establishing a large-scale CU partitioning database and employing the ETH CNN and ETH LSTM networks to predict CU division. This approach replaces traditional brute-force search RDO, effectively reducing coding complexity. Li et al. [
17] introduced a fast CU partitioning method that leverages spatial correlation and RD cost characteristics. By predicting the CU depth range and applying an adaptive threshold, they terminated partitioning early, reducing the coding time. Specifically, when the RD cost of a CU falls below the threshold, quadtree partitioning can be halted. Kuo et al. [
18] developed a fast CU size decision algorithm based on spatiotemporal features, which reduces HEVC coding complexity through adaptive depth prediction, DBF boundary checking, and smooth region detection. Zhang et al. [
19] utilized a CNN-based acceleration scheme for texture classification to predict division patterns in each CU layer of heterogeneous CTUs, thus reducing the complexity of internal coding in HEVC.
2.2. Reducing the V-PCC Coding Complexity
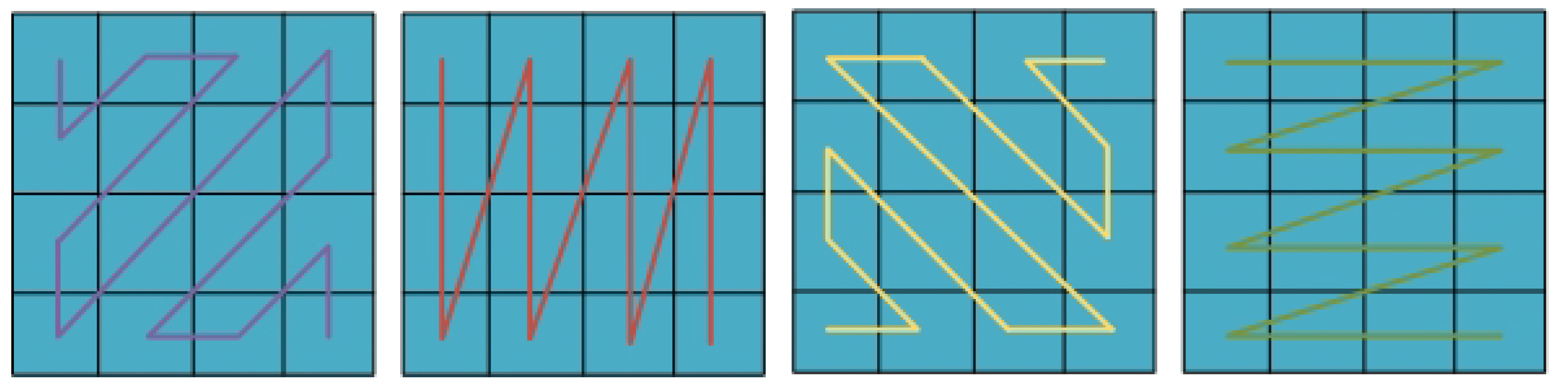
During the V-PCC encoding procedure, at the image generation phase, a 3D-to-2D mapping method is employed to encode the geometric and texture details of the point cloud into images [
20], as illustrated in
Figure 3.
Building upon the generated geometry and texture maps, the occupancy map is introduced. In V-PCC, the occupancy graph is a binary map that represents the distribution of point cloud data in 3D space on a 2D plane. Defined with a precision of
B × B blocks, the occupancy graph distinguishes between occupied and non-occupied areas of the point cloud data (where
B is a defined parameter). For lossless coding,
B is set to 1. Each
B × B block is classified as full or empty based on a binary value that indicates whether it contains at least one non-empty pixel. During processing, each
T × T block (Patch) is further subdivided into smaller
B × B subblocks for more granular data management. The subblock traversal strategy involves the encoder selecting a specific order to traverse these
B × B subblocks, with an explicit signal representing their index in the bitstream. This strategy enables the encoder to sort the binary values of the subblocks according to the selected traversal order and compress them using the stroke-length algorithm, thus optimizing the encoding process of the entire
T × T block [
21]. The subblock traversal is illustrated in
Figure 4.
The existing research on V-PCC methods can be categorized into two main areas. First, the optimization of the process for converting point cloud data from 3D to 2D, which includes patch generation, packaging, efficient filling, and rate control, ensures that the generated images are better suited for 2D video encoders. Second, the 2D video encoder is optimized to handle the projected 2D images more effectively, involving coding unit division, quantization parameter selection, rate-distortion optimization, and image filling, among other techniques.
In addressing traditional fast CU partitioning algorithms for dynamic point cloud compression, Lin et al. [
22] introduced the concept of block occupancy markers based on the occupancy graph and designed a fast CU decision method that leverages 2D/3D spatial homogeneity to terminate unnecessary CU partitioning early. Xiong et al. [
23] investigated the relationship between predictive coding and block complexity using a local linear image gradient model, analyzed the complexity of different occupancy CU types, and proposed a fast coding approach guided by the occupancy graph. This method effectively reduced the computational complexity of V-PCC while maintaining coding quality. Liu et al. [
24] proposed a coarse-to-fine rate control method that divides the 3D point cloud into distinct regions and applies different compression strategies to each, thereby improving compression efficiency and achieving better results. Yuan et al. [
5] developed a rate-distortion-guided learning method based on cross-projection information. This approach determined the CU partitioning scheme by combining occupancy, geometry, and attribute characteristics, thereby reducing coding loss caused by CU partition misprediction.
With the widespread use of 3D point cloud data in various applications, high-quality point cloud data are crucial for fields such as cultural heritage preservation, autonomous driving, robotics, and virtual reality. In recent years, many studies have focused on developing effective point cloud quality assessment methods. For example, Zhou et al. [
25] proposed a novel objective point cloud quality index with structure-guided resampling (SGR) to automatically evaluate the perceptual visual quality of dense 3D point clouds. This method leverages both geometric and attribute information of point clouds, achieving accurate quality assessments through regional preprocessing and quality-aware feature extraction. Additionally, Shan et al. [
26] introduced a novel contrastive pre-training framework tailored for point cloud quality assessments (PCQAs), called CoPA. This framework combines contrastive pre-training with multi-view fusion, integrating deep learning and multi-view information to further enhance the performance of no-reference point cloud quality assessments. These methods provide new ideas and tools for the objective assessment of point cloud quality.
In this study, we integrate these advanced point cloud quality assessment methods with our encoding optimization strategies. By leveraging point cloud quality assessments to dynamically adjust the encoding parameters, we further enhance the encoding efficiency and quality, thereby achieving higher overall performance.
2.3. Application of Threshold-Based Partitioning in Video Coding
In video coding, threshold-based partitioning is a technique that determines the division of CUs based on specific decision criteria, aiming to reduce computational complexity and improve coding efficiency. Since different regions of a frame exhibit varying texture complexities, applying a uniform partitioning strategy across all regions can lead to redundant encoding and inefficient resource utilization. To address this issue, this study leverages occupancy maps and neural networks to analyze voxel distribution density, setting adaptive thresholds to determine whether finer CU partitioning is required. Furthermore, CNNs are combined with Bayesian optimization to fine-tune model hyperparameters, enhancing encoding decision accuracy and reducing redundant computations.
Several studies have explored threshold-based partitioning in video coding. Li et al. [
3] proposed a fast CU size decision method for geometric video encoding, leveraging unsupervised learning. Considering that geometric videos are characterized by distinct sharp edges and multi-scale areas, the researchers devised a hierarchical clustering method to determine the most suitable CU size. Additionally, they integrated an adaptable linkage threshold within the clustering procedure, which makes adjustments based on the changing quantization parameters and CU dimensions. Tariq et al. [
27] developed a novel early termination mechanism based on the duration problem, incorporating dynamic thresholds to minimize computational costs. Their model outperformed most existing approaches in computation efficiency and optimal decision adjustment. Bukit et al. [
28] introduced an efficient depth decision algorithm utilizing spatial homogeneity and thresholding modification techniques. By utilizing uniform region characteristics and CU partitioning types, their approach effectively reduced the encoding time and overall computational complexity.
3. Research on Adaptive CU Partitioning for Efficient V-PCC Coding
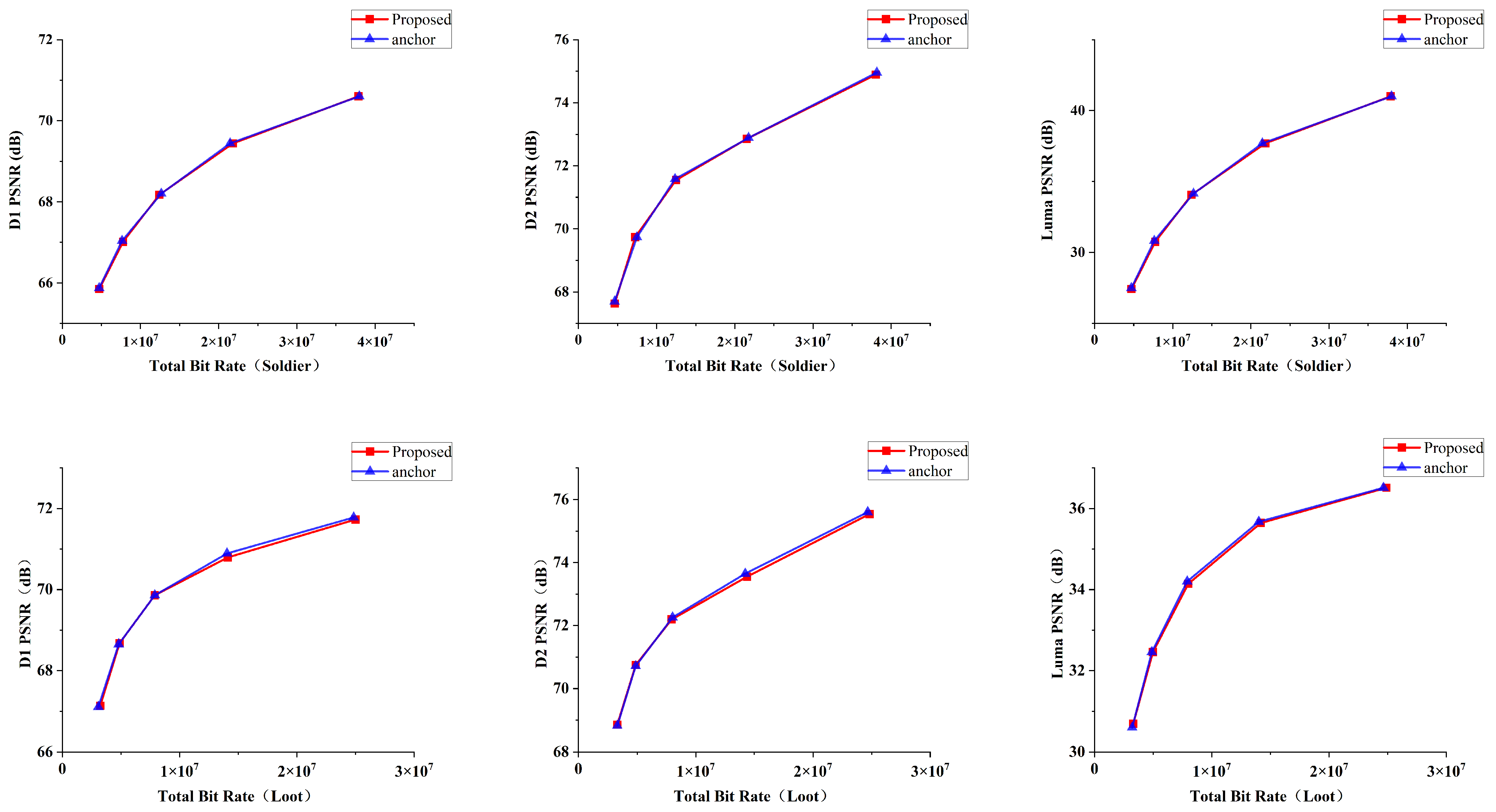
This paper proposes a method for encoding geometric video using HEVC in V-PCC. While numerous fast CU partitioning methods exist for HEVC, these approaches are unable to take into consideration the distinctive features of point clouds. As a result, their efficiency diminishes when directly applied to V-PCC. Specifically, projecting a 3D point cloud onto a 2D image through patch generation often results in a significant number of empty pixels. Furthermore, the spatiotemporal correlation is lower than that of natural images. To address the complexity of geometry coding in V-PCC, we propose a fast coding method that integrates occupancy graphs, CNNs, and Bayesian optimization. By integrating deep learning techniques, improvements have been achieved in traditional sequential methods, and thus, this approach significantly enhances both coding efficiency and quality.
First, the occupancy rate R of every CU is computed according to the V-PCC occupancy graph, which indicates the ratio of the occupied voxels within the CU. Depending on the occupancy rate, the CUs are divided into three different types of regions: sparse regions, dense regions, and complex composite regions. Next, different CU sizes are input into the designed CNN framework to determine whether further division is necessary. The CNN generates partitioning decisions for each region by extracting features from the CU occupancy graph and other geometric information. For dense regions, the CNN generates deeper partitioning strategies to preserve more geometric details. For sparse regions, shallower division is employed to reduce the computation and bit rate. For the complex composite regions, we employ a hybrid strategy: First, we utilize a CNN framework to analyze the features within the region and identify the distribution of high-occupancy and low-occupancy pixels. Then, based on this distribution, we dynamically adjust the partitioning depth. Specifically, for the high-occupancy parts, we adopt the same partitioning strategy as for the dense regions; for the low-occupancy parts, we apply the same strategy as for the sparse regions. Through this hybrid approach, we are able to better handle the details of complex composite regions while maintaining coding efficiency.
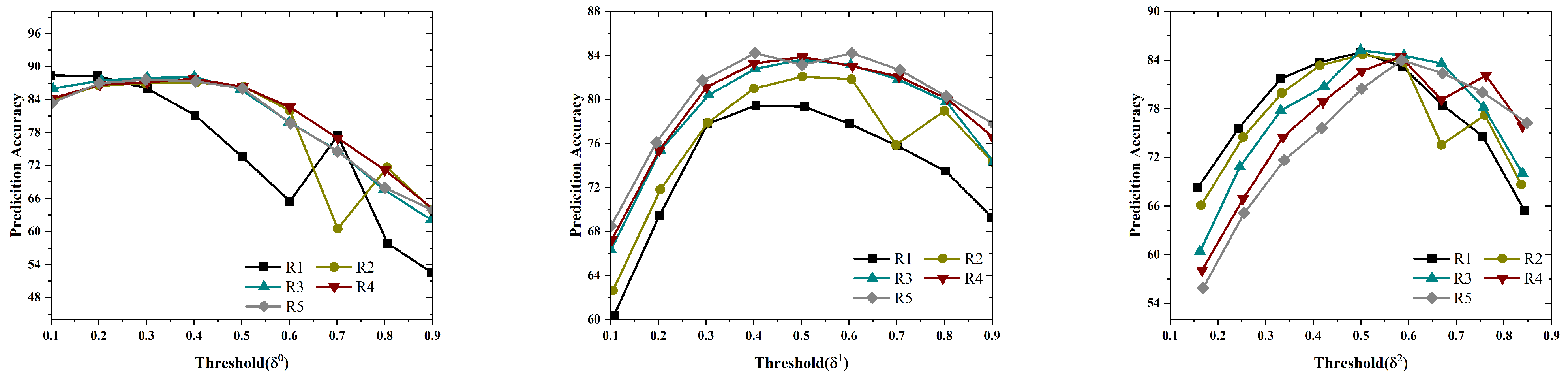
The CNN’s output is the confidence value Conf(x), indicating whether further division is needed. If the confidence value exceeds a set threshold, the current partitioning result is finalized. Otherwise, the process moves to the next stage of Bayesian optimization. Finally, for low-confidence regions, Bayesian optimization adjusts the partitioning strategy by refining the proxy model based on the CNN’s partitioning results and the region’s occupancy information. This further optimization improves coding efficiency, reduces the bit rate, and maintains coding quality.
3.1. An Adaptive CU Partitioning Method Based on Occupancy Maps and CNN Framework
When coding is optimized via an occupancy graph, the first step is to divide it into occupied and unoccupied blocks. In V-PCC, the occupancy graph plays a crucial role in encoding the spatial distribution of 3D point cloud data. The 3D data are mapped to a 2D occupancy graph, where each pixel value represents whether the corresponding 3D voxel is occupied by a point cloud. Based on the binary values in the occupancy graph, the geometry is divided into occupied and unoccupied blocks, considering the equilibrium between the time efficiency and coding performance. To expedite CU partitioning, the occupancy graph is defined as O(x,y), where O(x,y) = 1 indicates that the corresponding area is occupied by the point cloud and O(x,y) = 0 indicates that it is not.
To increase coding efficiency, the occupancy graph is segmented into multiple CUs of uniform size, resulting in several subblocks. Each CU has a size of
N × N. The occupancy rate
R for each CU is then calculated using the following formula:
Herein, the occupancy rate R represents the proportion of occupied pixels within a sub-block, with a range of . Based on the occupancy rate, CUs are classified into three categories: dense regions , where the point cloud data are complex and rich in detail, potentially requiring deeper partitioning to preserve more details; sparse regions , where the point cloud data are sparse, allowing for reduced partitioning depth to enhance coding efficiency; and complex composite regions , which contain a mixture of high-occupancy and low-occupancy pixels, necessitating a specialized processing strategy. Among them, a higher CU occupancy rate indicates a denser point cloud and more complex geometric information, necessitating additional partitioning layers to retain the details. Conversely, CUs with low occupancy typically correspond to sparse regions, where the point cloud data are minimal and a shallower partition depth suffices, thereby improving compression efficiency.
This paper presents an adaptive CU partitioning strategy based on the binary index value and occupancy characteristics of the occupancy graph. In this study, ResNet-18 is selected as the backbone CNN network for CU partitioning decisions, aiming to minimize the computational complexity during the CU partitioning process. Specifically, three different CNN network structures are designed for CUs of various sizes, including 64 × 64, 32 × 32, 16 × 16, and 8 × 8. Each architecture comprises 17 convolutional layers, succeeded by a fully connected (FC) layer activated via the Softmax function, as illustrated in
Figure 5.
To further enhance the generalization ability of ResNet-18 on occupancy maps, we employed dynamic point cloud data from the V-PCC reference software TMC2v18.0 as the training set to fine-tune ResNet-18. This process enabled the network to better adapt to the sparsity and binary structure of occupancy maps. To improve model robustness, data augmentation techniques were applied during training. Specifically, random cropping, rotation, and flipping operations were performed on the occupancy maps to generate more diverse training samples, thereby enhancing the model’s adaptability to different occupancy map structures. By continuing to train on occupancy map data and adjusting the network weights, the model was able to better capture local features and spatial relationships within the occupancy maps.
After the CU occupancy rate is calculated, the CU is input into the designed CNN framework, where the CNN extracts the features of the input CU. Each CNN network outputs a partition confidence value, denoted as , where . If (the threshold for CNN confidence), the partition decision generated by the CNN is directly adopted. If , the CU enters the Bayesian optimization module for further evaluation.
Specifically, the frame that corresponds to the occupancy map is retrieved from the point cloud video sequence meant for encoding, and subsequently, it is split into 64 × 64 CTUs. Each CTU is initially treated as a CU with a depth of 0 and input into the first-level CNN of the CNN framework. Based on the occupancy rate and regional features, the first-level CNN outputs a confidence value, Conf64, to determine whether further partitioning is required for the current CU. If the model predicts no need for further division, the CU partitioning process is halted, and the RDO mechanism in V-PCC is utilized to finalize the encoding. If the prediction indicates the need for partitioning, the 64 × 64 CU is divided into four 32 × 32 child CUs, which are then input into the next-level CNN for further decision-making. This process is repeated for each 32 × 32 child CU, and, if partitioning is needed, it is further divided into four 16 × 16 child CUs and evaluated by the next-level CNN. Similarly, for each 16 × 16 child CU, the same decision process is applied, leading to further division into four 8 × 8 child CUs, followed by another CNN decision. When the CU attains the smallest partition size of 8 × 8, the CNN decision terminates, and the coding phase begins.
In this study, the CNN pipeline employs a multi-stage processing approach (64 × 64 → 32 × 32 → 16 × 16 → 8 × 8). This hierarchical structure may lead to the accumulation of errors in deeper layers. To mitigate the impact of error propagation, a feedback mechanism is introduced. Specifically, the output of each CNN stage is not only used for partitioning decisions at the current stage but is also fed back to the previous stage to correct errors. If the CNN output at a certain stage has low confidence, the output is fed back to the previous stage, where it is combined with the features from the previous stage to re-make partitioning decisions, as illustrated in the figure. Through this approach, errors can be corrected in a timely manner, reducing the accumulation of errors in subsequent stages. Additionally, the Bayesian optimization module further adjusts the partitioning strategy for low-confidence regions, thereby minimizing the impact of error accumulation, as illustrated in
Figure 6.
In this paper, TMC2v18.0 with the HEVC encoder is employed to encode the generated video, and the proposed framework is developed in two stages: the training stage and the testing stage. During the training phase, the CNN determines whether to split each CU on the basis of the given dataset, which includes labeled data indicating whether a split is required for each CU. Upon the completion of the training process, the CNN model that has been trained is integrated into the V-PCC encoder, replacing the traditional recursive CU partitioning procedure.
By incorporating the occupancy feature and the CNN framework, this partitioning strategy enables the adaptive partitioning of the occupancy graph area, allowing for the more detailed processing of dense and complex boundary regions. Simultaneously, it avoids redundant calculations in unoccupied and sparse areas, significantly improving encoding efficiency and compression performance. This method not only enhances the coding efficiency and shortens the encoding time, but also maintains high video quality and strengthens the robustness of the prediction.
3.2. Bayesian Optimization Improves the Accuracy of Low-Confidence Region Partitioning
In V-PCC, based on the definition of occupancy maps, this method combines occupancy rate R and a designed multi-stage CNN framework with Bayesian optimization (BO) for adaptive adjustment of geometric CU partitioning. In high-occupancy regions, the CNN framework directly determines the need for partitioning, followed by the fine-tuning of the partition strategy through Bayesian optimization. In low-occupancy regions, the CNN model may directly output a decision of no partitioning. The Bayesian optimization module will then further adjust the partitioning strategy. Through Gaussian process modeling and active sampling, it dynamically adjusts the partitioning parameters and optimizes the partitioning strategy, thereby reducing the impact of accumulated errors. Specifically, Bayesian optimization dynamically adjusts the partitioning strategy based on the current partitioning results from the CNN and the occupancy information of the region, ensuring minimal reconstruction distortion while maintaining a low bit rate.
For CU partition optimization in low-confidence regions, Bayesian optimization minimizes the rate-distortion cost by integrating Gaussian process (GP) modeling and active sampling. The objective is to minimize the following rate-distortion cost function:
where
x represents the parameterized vector of CU partitioning modes, including quadtree depth, partition flags, and other discrete or continuous parameters.
is the encoding bitrate,
is the reconstruction distortion, and
is the Lagrange multiplier. Minimizing this objective function effectively reduces encoding redundancy and improves efficiency. The parameter space X for CU partitioning modes is defined by parameter vectors
, such as the quadtree depth
(0 for no partition and 1–3 for partition levels) and the partition direction
(horizontal or vertical).
To make the objective function adaptable to different content complexities and point cloud densities, we propose a method for dynamically selecting the Lagrange multiplier
, which is adjusted based on the occupancy rate
R and texture complexity of the current CU. For regions with high occupancy rates, i.e.,
, the point cloud data are complex and rich in detail, requiring higher encoding precision. Therefore, a smaller
value is chosen to focus more on optimizing the distortion
. For regions with low occupancy rates, i.e.,
, the point cloud data are sparse, and it is possible to increase the bit rate to improve the encoding efficiency. Therefore, a larger
value is chosen to focus more on optimizing the bit rate
. For boundary regions or regions with complex textures, we further adjust
by analyzing the spatial features
T of the CU. If a region has high texture complexity, we appropriately reduce
to minimize reconstruction distortion. Conversely, if the texture complexity is low, we appropriately increase
to reduce the encoding bit rate. This dynamic selection mechanism allows
to be adaptively adjusted based on the occupancy rate and texture complexity of the CU. The formula for
is defined as follows:
Herein, is the initial Lagrange multiplier, R is the occupancy rate of the current CU, T is the spatial feature complexity of the current CU, and and are adjustment parameters.
Bayesian optimization uses a Gaussian process to probabilistically model the objective function
, capturing performance variations across different CU partitioning modes. Specifically, the objective function is modeled as a Gaussian process:
where the mean function
is typically set to a constant and the covariance function
uses the Squared Exponential (SE) Kernel:
Here,
is the signal variance and
l is the length scale parameter. Bayesian optimization approximates the objective function using the GP model and selects the optimal parameter combination based on the acquisition function. The acquisition function employs the Expected Improvement (EI) strategy:
where
is the current best objective value,
and
are the predicted mean and standard deviation from the GP
, and
and
are the CDF and PDF of the standard normal distribution.
By maximizing the acquisition function, Bayesian optimization iteratively updates the parameter set, selecting the optimal solution as follows:
Low-confidence regions benefit from BO by balancing exploration and exploitation through Gaussian process modeling and active sampling. This allows the approach to approximate the global optimum partition mode within a limited number of evaluations. In each iteration, parameters like and the parameterized vector x are dynamically adjusted to optimize partitioning strategies for complex and uncertain regions, thus improving the balance between encoding efficiency and reconstruction quality.
During V-PCC encoding, Bayesian optimization continuously adjusts partition parameters (e.g., CU size, partition density) and gradually refines the partition strategy through a feedback mechanism, ensuring a balance between encoding efficiency and reconstruction quality. In each iteration, a new sampling point is selected based on the current surrogate model and the acquisition function, and the surrogate model is updated. The optimization is terminated when the predefined objective is achieved. The integration of Bayesian optimization with the CNN framework enables the system to flexibly adjust partition strategies based on the varying characteristics of point cloud data, further reducing redundant data encoding and optimizing computational overhead.
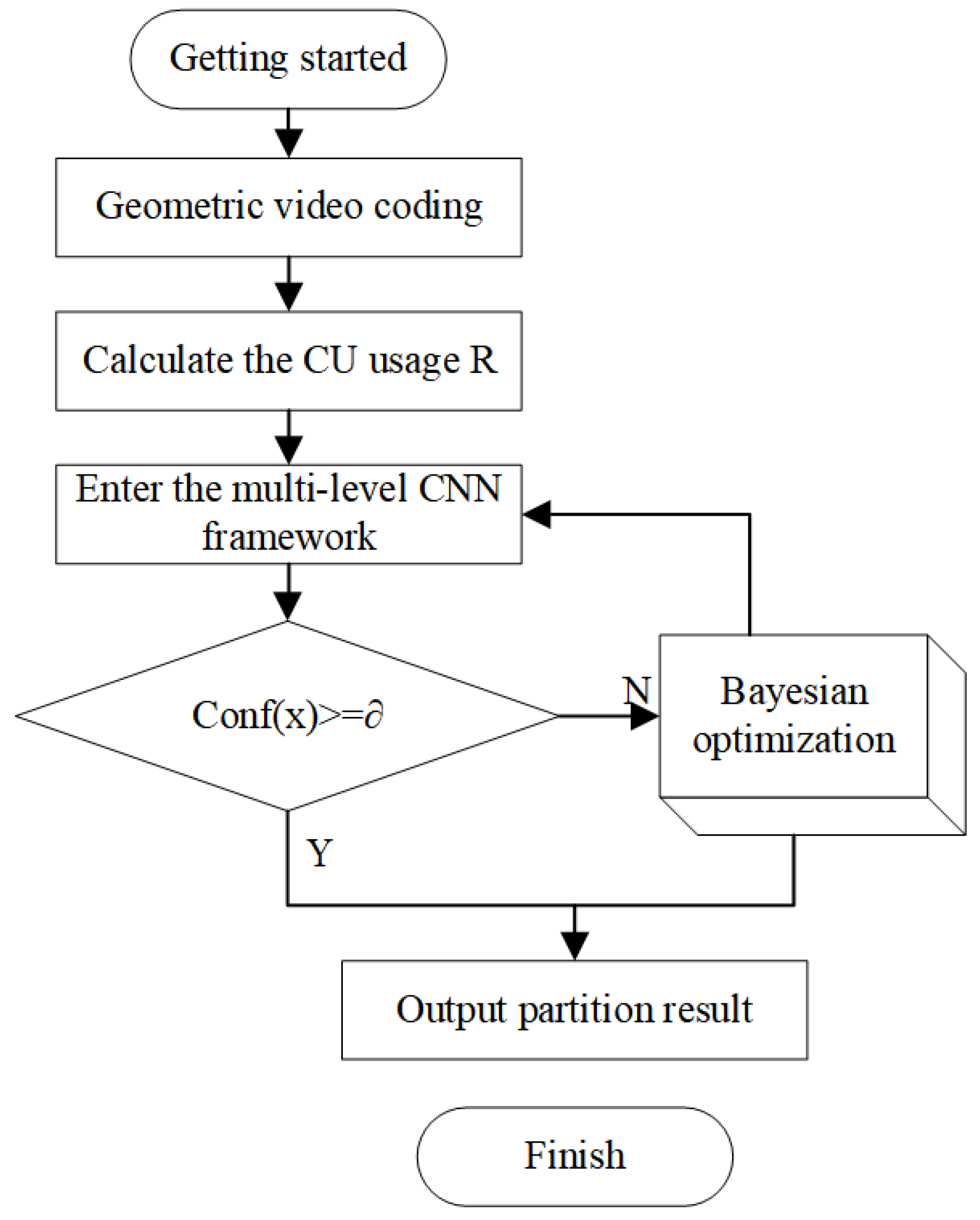
3.3. Algorithm Process
This algorithm integrates the definition of the V-PCC occupancy graph, occupancy information, CNN framework, and Bayesian optimization techniques to optimize the CU partitioning decision in point cloud video coding. This method effectively performs adaptive CU partitioning for different types of regions by combining multi-level recursive decisions based on occupancy information and the CNN framework with Bayesian optimization. For high-confidence regions, the partition results are directly output. For low-confidence regions, Bayesian optimization is applied to further increase the accuracy and efficiency of partitioning, ultimately optimizing the coding effect and improving both the compression performance and the quality of point cloud video coding. The specific algorithm flow is shown in Algorithm 1 below.
| Algorithm 1: The proposed algorithm |
| 1 | Prepare the training data and preprocess the V-PCC data. |
| 2 | Calculate the occupancy rate R of each CU, which represents the proportion of occupied voxels in the CU. Based on the occupancy rate, divide the CU into three categories: dense regions, sparse regions, and complex composite regions. |
| 3 | Use the multilevel CNN framework to make partitioning decisions based on the regional occupancy information. |
| 4 | A multi-level recursive decision-making process is employed, where each CU is evaluated layer by layer through multiple stages of CNNs and outputs a confidence threshold. If the confidence output by the CNN is low, it is fed back to the previous stage. |
| 5 | For regions with low-confidence CNN outputs, apply Bayesian optimization to further refine the partitioning decision. |
| 6 | Output the partition results. For high-confidence regions, directly output the partitioning results and proceed to the subsequent coding stage. For low-confidence regions, after Bayesian optimization adjustments, output the final partitioning strategy and encode. |
According to the above algorithm steps, the overall process of the two algorithms can be obtained as shown in
Figure 7.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}