1. Introduction
In this era of rapid multimedia content growth, people are exposed daily to a vast array of visual media. Content centered around human characters, such as product advertisements, action movies, dance videos, and animations, is particularly prevalent and plays a pivotal role. Producing multimedia with high-quality visual representation usually consumes substantial human effort and time. In particular, when modifications or improvements are necessary, the process often involves expensive and complex reshoots or productions.
To address these challenges, the development of pose transfer technology has emerged as a viable solution. This field, which has been extensively researched in academia for many years, shows great application potential. By simply providing a model with a basic human skeleton, it is possible to generate diverse human poses, thereby enabling the supplementation or correction of existing media content without the need for reshoots. This technology can also leverage past materials for new content creation through AI models, significantly saving time and costs while opening new possibilities in visual media production.
Since Ma et al. [
1] first introduced the task of human pose transfer, this research area has rapidly developed in the field of image processing. Initially, GAN-based methods with a coarse-to-fine approach were used, but these often led to feature misalignment issues. To address this, Esser et al. [
2] integrated Variational Autoencoders (VAEs) with a U-net architecture, resulting in more natural pose transfers and improved accuracy. Following this, a flow-based strategy [
3] was introduced, which used global flow fields and occlusion masks to finely adjust local image regions, enhancing the precision and detail quality of pose transfers.
In recent years, the field of image generation has made significant strides, particularly with the appearance of diffusion models [
4]. Researchers have achieved substantial results with De-noising Diffusion Probabilistic Models (DDPMs) [
5], which perform comparably to traditional Generative Adversarial Networks (GANs) in terms of performance metrics. However, typical diffusion models operate at the pixel level and require significant computational resources. Due to the intensive processing complexity needed for fine-grained data, they are often inaccessible to researchers with limited resources. For example, the state-of-the-art Person Image Diffusion Model (PIDM) [
6] requires up to eight A100 GPUs to produce high-quality generative results.
In light of this, the aim of this study is to explore how to achieve high-quality image generation with limited computational resources. In order to achieve efficient and accurate performance in pose transformation tasks, we propose a new architecture based on the latent diffusion model (LDM) [
7], incorporating methods including the ControlNet [
8] module, a multi-scale feature module, and a semantic extraction filter. The goal of this paper is to lower the hardware requirements by leveraging the advantages of the latent diffusion model. The proposed model is able to maintain or enhance the quality of the generated images and provide a feasible solution for scholars with limited computational resources. Therefore, this paper’s contributions can be summarized as follows:
A training strategy is proposed that allows the model to achieve state-of-the-art (SOTA) results using only an RTX-4090 GPU.
By combining multi-scale feature extraction modules and semantic extraction filters, we apply the latent diffusion model that can successfully accomplish the pose transfer task and focus the model on important features within the image.
Taking advantage of the ability of the ControlNet module to learn human skeletons, the proposed model accurately controls human poses and fully leverages the pre-trained weights of Stable Diffusion [
7], leading to faster convergence.
2. Proposed Pose Transfer Model
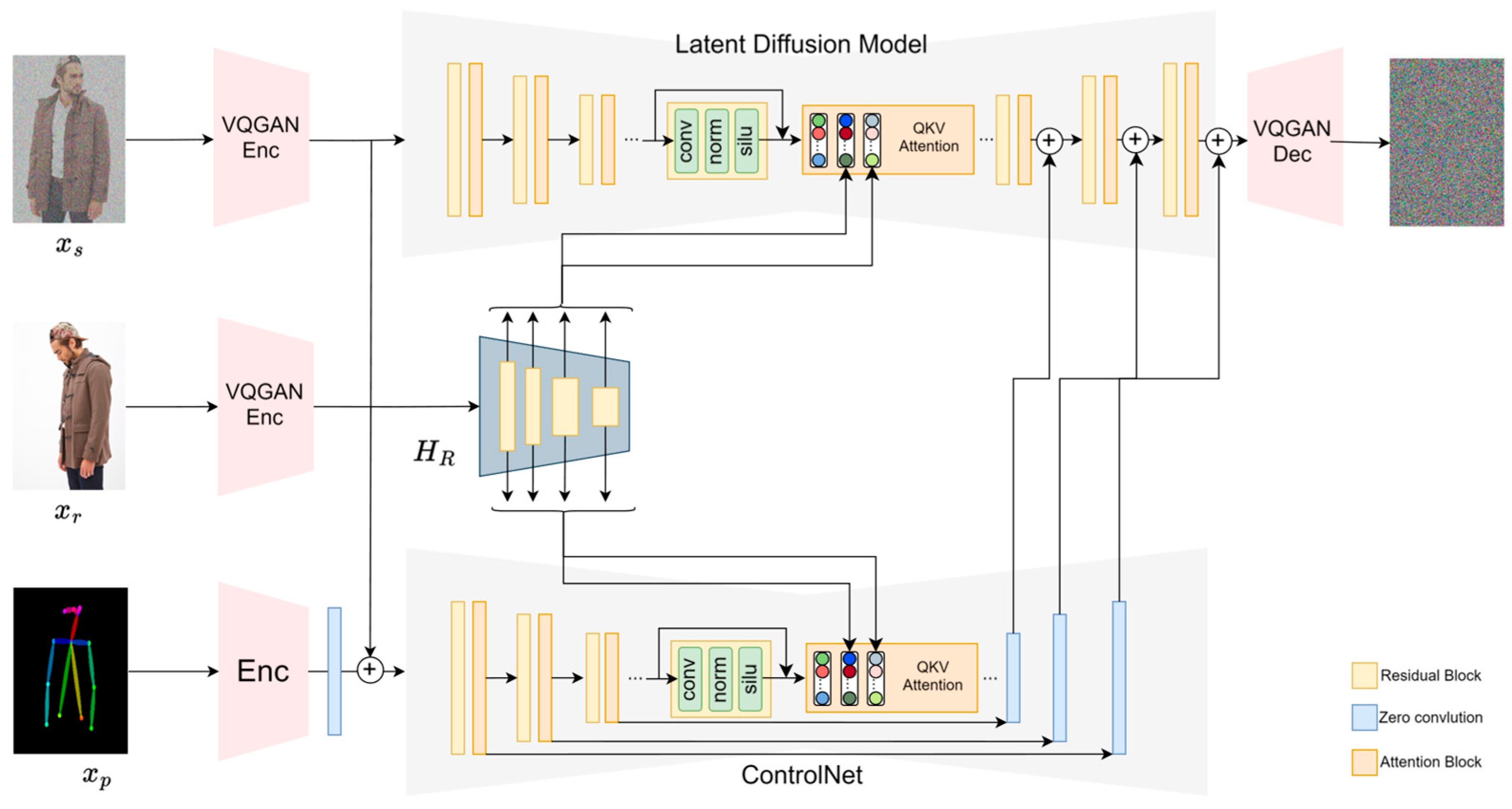
The overall architecture of the proposed model is illustrated in
Figure 1. The model architecture in this paper is divided into the latent diffusion model, ControlNet, and a multi-scale feature extraction module
. The LDM consists of 12 layers of Encoder, 1 middle layer, and 12 layers of Decoder, each layer being composed of multiple residual blocks and attention mechanisms. The Encoder for ControlNet is the same as LDM, while its decoder consists of several layers of zero convolution. The feature extraction Encoder
is made up of multiple residuals, matching the dimensions of each layer in LDM. It allows distinct features to be learned at various layers during training.
This chapter is divided into several sections.
Section 2.1 explains the latent diffusion model.
Section 2.2 introduces how to precisely control human poses using the ControlNet module.
Section 2.3 describes the design of the multi-scale feature extraction network, which enables the attention neural network layer in the latent diffusion model to learn features at different scales through feature maps at various layers. This also ensures that the model can accurately learn the features of the given reference image.
Section 2.4 explains how to optimize computational load and model focus points using semantic extraction filters. These filters effectively make the attention map weights sparser by focusing the model on important features.
Section 2.5 elaborates on the use of classifier-free guidance techniques in our task. The model can learn both unconditional and conditional generation. During inference, adjusting the weights allows control over the generated image to better match the specified condition. Additionally, different classifier-free guidance sampling strategies are employed to enhance the accuracy of pose transfer.
Compared to other existing models, the proposed model fine-tunes the weights of Stable Diffusion and trains only the attention neural networks within the latent diffusion model, leveraging the de-noising capability learned by Stable Diffusion on the LAION 5B dataset [
9]. This transfer learning preserves the quality and diversity of the generated images, enabling the model to converge more quickly and achieve the pose transfer task with satisfactory results.
2.1. Latent Diffusion Model
The primary goal of generative models is to determine a set of model parameters that enable the generation of images based on those parameters. The main objective is to minimize the difference between the generated image distribution and the true image distribution . In other words, this process involves maximizing the likelihood as much as possible. Likelihood serves as a key indicator of how accurately a model represents a distribution, with more similar distributions receiving higher scores. We first define the training objectives and then iteratively adjust the model parameters based on the results produced by the generative model. This progressive optimization refines the generated outputs, making them increasingly similar to the actual images.
As mentioned in the previous section, the latent diffusion model was proposed to reduce the high computational cost of the diffusion model while preserving its ability to generate high-resolution images. It integrates the diffusion model with a VQGAN model [
10], leveraging the technique of mapping the image space to a latent space. This approach ensures perceptual alignment between the latent space and the image space. It significantly reduces the required computational costs. Additionally, this architecture introduces a cross-attention-based conditional mechanism that allows the model to undergo multimodal training. It successfully implements training for models based on category conditions, as well as text-to-image and layout-to-image transformations. The following two subsections will detail the methodologies and technical principles underlying the latent diffusion model.
2.1.1. Vector-Quantized Generative Adversarial Network (VQGAN)
VQGAN is a model similar to the VAE [
11] architecture. It is initially trained independently to allow it to learn a latent space that perceptually corresponds to the image space. This training is augmented with perceptual loss calculations [
12] and patch-based [
13] adversarial learning to better restore the details of the images and prevent blurring. Consequently, images are compressed into a smaller-dimensional space where they can be accurately restored through the decoder to their original image space, achieving significant reductions in computational resources. To minimize excessive variability in the latent space, two methods, Kullback–Leibler (KL) regularization and Vector Quantization-based (VQ) regularization, can be used to stabilize the training of the model.
2.1.2. De-Noising Diffusion Probabilistic Models (DDPMs)
The diffusion model proposed by Sohl-Dickstein et al. is a probabilistic model that has recently been proven to have the capability to generate high-quality images. It also possesses stable training objectives and is easily scalable. This means that the model can produce a wide and varied range of samples. These samples are better visually and statistically. They also approximate the real-world data distribution more closely.
The training process can be divided into two parts: forward pass and backward pass. In the forward pass, which is a Markov chain, noises are gradually added to the image
using the set of variances
. After adding noise
t times,
approximately becomes a Gaussian noise, which we can denote using Equation (1):
In this context,
(
|
represents
after
t steps of random noise addition, and
represents a Gaussian distribution. The term
represents the noise strength added at each time step, controlling the amount of noise introduced into the data during the diffusion process. Conversely,
represents the proportion of the original data retained at each time step. We can further simplify the equation as follows: if
and
, then the equation can be simplified as Equation (2):
The backward pass is a reverse de-noising process, where the model progressively predicts and removes noise from
~
(0, I). By continually de-noising
, where
T represents the total number of time steps, the model learns how to step-by-step restore the image from the Gaussian-distributed noise. After
T iterations of de-noising, it comprehensively captures the data distribution of the real image.
Equation (3) represents the probability distribution for restoring
from the image
, which is assumed to be a Gaussian distribution. Here,
is the mean of the noise predicted by the model based on the noise-added image
, and
) is the assumed variance. Thus, the loss function can be written as follows:
However, further research has found that instead of letting the model predict the mean, directly predicting the noise actually yields better results. Therefore, the noise model prediction, denoted as
, can be expressed by the following formula:
Redefining the training objectives of the model, the loss function can be written as follows:
It can be simplified as follows:
Here, is the noise added during the forward pass step, and is the noise outcome predicted by the model, with the L2 norm used as the loss function.
2.1.3. Training Objective
The latent diffusion model combines the advantages of both VQGAN and diffusion models by compressing images into a latent space and learning through a gradual process of adding and removing noise targeted at the objective. Compared to pixel-level diffusion models, it not only effectively reduces computational costs but also efficiently focuses the diffusion model on learning the most important features in the images. The training objective can be expressed as follows:
where
is the image compressed by the VQGAN,
is the noise added during the forward pass step, and
is the noise predicted by the model. After multiple noise removals,
is restored to the original image through the VQGAN decoder.
Furthermore, the latent diffusion model introduces a mechanism based on cross-attention, which can use data such as text and images as references to control the model’s output. For example, if we input text into a BERT tokenizer [
14] and then map it to the model’s Cross-Attention Layer to compute the relevance between the text and the image, the calculation results directly influence the image generated by the model, enabling applications like text-to-image generation. However, in the pose transfer task, there is no textual information available. Therefore, our proposed method attempts to use images to control the generation of human features.
Unlike PIDM, LDM does not operate directly at the pixel level. Instead, it maps images to a latent space via VQGAN and then trains the model to predict the noises. The images are encoded by the pre-trained VQGAN model’s Encoder
where the latent code
z is continuously added with noise through the forward pass. Subsequently, the model gradually de-noises the images and finally restores them via the VQGAN model’s Decoder
, as shown in
Figure 1. The reference image is first encoded by VQGAN’s Encoder
, and then different scale feature maps are learned and extracted through the multi-scale feature extraction module
. Furthermore, Query, Value, and Key are utilized in the attention neural networks within LDM and ControlNet to learn the relationship between the noise image and the reference image following the concept proposed by Vision Transformer [
15,
16]. Finally, the Pose ControlNet module learns the pose features using human skeleton images. And its output is added to the output of LDM’s decoder, thereby influencing the model’s output to achieve pose transformation. The training objective of the model can thus be expressed as follows:
In this context,
represents the noise added during the forward pass step. The term
refers to the noise predicted by the model, where
is the latent code of the input image after being processed by the VQGAN encoder. The variable
indicates the number of noise additions applied to the image up to that point, which also represents the intensity of the added noise. The term
represents the feature map of the reference image, and
is the human skeleton image detected by OpenPose [
17]. The L2 norm is used as the loss function.
During the training stage, the model randomly initializes to determine the noise intensity added to each image, resulting in varying noise levels for each image. Consequently, the model learns to de-noise and restore the image to its previous state across different noise intensities. During the inference stage, the model has learned how to restore the current noisy image to its previous state. Therefore, the input will be a randomly initialized noisy image, which the model will gradually de-noise while using the given condition image to generate the final output.
2.2. ControlNet Module
The ControlNet model demonstrates outstanding performance in the domain of image generation without modifying any LDM architecture and altering the original weights. It can utilize various forms of images, such as Canny edge detection maps, human skeleton maps generated by OpenPose, and depth maps, to precisely control the details of the generated images. Thanks to the precise control of human movements by the ControlNet model, it can accomplish pose transfer tasks very effectively.
However, while ControlNet can take multiple condition images as input to control the generated textures or pose features, it is fundamentally designed as a text-to-image model, using textual descriptions to control the style of the generated characters. Due to the inherent randomness of generative models, the characters generated may differ each time. Therefore, this paper combines the ControlNet module with the multi-scale feature module to control various features of the generated images, enabling the model to generate specific characters from images rather than relying on textual descriptions. Additionally, ControlNet is used to control the poses of the characters. This design not only broadens the application scope of the model but also opens new pathways for the development of image generation technology.
The idea behind ControlNet is based on duplicating an already trained neural network within the existing model architecture, denoted as
, where
is the trained neural network and
refers to the model parameters. It can map the feature map
x to another space
y.
As shown in
Figure 2,
c represents a hint conditional input used to subsequently affect the output of the LDM. Through the use of zero convolution, the output of ControlNet can initially be set to zero during model training, ensuring it does not affect the outputs of the hidden layers of the model. Since the convolution weights are initially set to zero, this also prevents the randomness of weight initialization from affecting the gradient calculation of the model. In this paper, the condition
c represents a human skeleton diagram, used to control the character’s movements. The process can be expressed as follows:
where
represents the trained neural network,
stands for zero convolution, and
denotes the neural network parameters. Moreover,
and
represent the first and second layers of zero convolution, respectively, and
represents the copied neural network.
Taking latent diffusion as an example, ControlNet duplicates a U-net feature extraction network as a down-sampling encoder. In the decoder part, multiple 1 × 1 zero convolutions are used as a decoder. In pose transfer tasks, we use OpenPose to obtain human skeletal diagrams, allowing the model to learn movements. Some pose transfer models based on the diffusion model would concatenate the noise image with the human skeleton during the de-noising stage [
6,
18]. However, applying this method in LDM changes the dimensions of the first layer of the model and makes it unfeasible to use the pre-trained weights for this layer. This forces the rest of the model to relearn how to adjust these weights to effectively handle the new input data structure. According to our research, we have found that this can cause the model to converge more slowly.
Therefore, this paper utilizes the ControlNet module to learn the features of the human skeleton. The LDM first processes the image through the VQGAN encoder, compressing a 256 × 256 image into a 32 × 32 feature map. To ensure that the output feature map size of each layer in ControlNet matches that of LDM, the conditional image
is first passed through an encoder denoted by ε. The encoder involves a convolution with a 3 × 3 kernel size and the SiLU [
19] activation function. It encodes
into
.
The vector is used as the input to ControlNet. Subsequently, the output from ControlNet is added at the pixel level to the output from the decoder of the latent diffusion model. This method not only preserves the complete weights of the residual blocks in the latent diffusion model but also enables ControlNet to accurately learn the transitions in poses.
2.3. Multi-Scale Feature Module
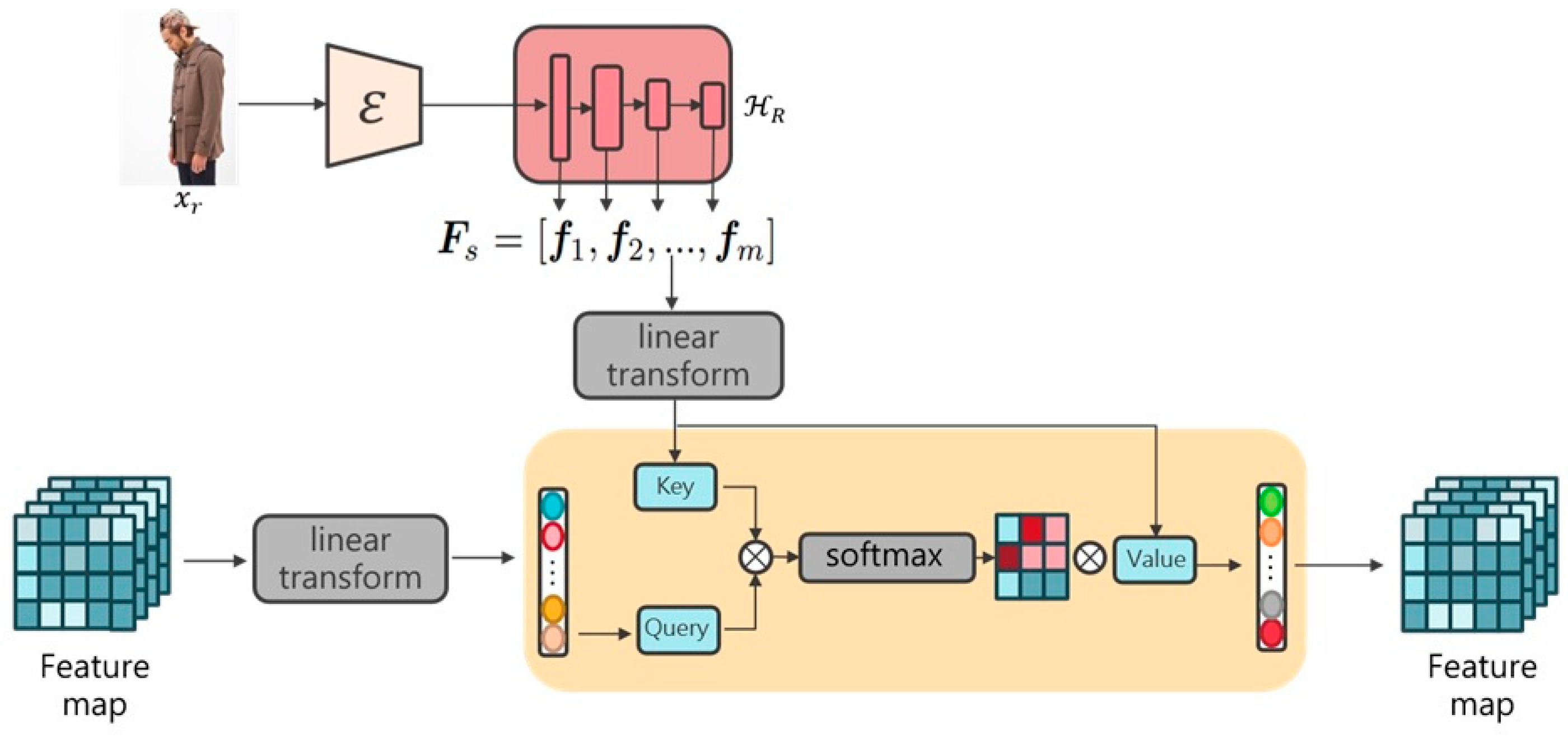
In the original LDM, text descriptions are used to control the images generated by the model. The text is converted into vectors via a text encoder, and these text vectors are then correlated with the noise image in the attention neural network layer to generate the final image. In this paper, we attempt to utilize reference images to influence the features of the generated characters. The reference images are used as conditional information, and by employing the Query, Key, and Value mechanism proposed by Vision Transformer, calculating the correlation between the image and the noise image in the attention neural network layer. Through this approach, the model can generate the same character based on the reference image and achieve the task of pose transfer.
PIDM proposed a multi-scale feature extraction method that helps LDM learn image features at different levels of the neural network layers. This method does not require additional data preprocessing for the model to learn [
20,
21], and it effectively achieves the task of pose transfer. Inspired by PIDM, this paper designs a model architecture compatible with the latent diffusion model, employing an encoder
that extracts multi-scale features. Since the latent diffusion model is a U-Net architecture,
continuously down-samples while retaining features at each layer.
The encoder comprises four layers, with each layer containing three, three, three, and two residual blocks, respectively. In addition, a residual block is applied to the features before entering the multi-scale feature extraction module, resulting in a total of 12 residual blocks. For simplicity, we refer to these residual blocks as layers, represented as , and features are represented as , where . Each layer provides feature maps of different scales. These features are used in the corresponding attention neural network layers of the LDM to calculate the correlation between the reference image features and the noise image, thereby controlling the characteristics of the generated character.
To integrate the features of the reference image when predicting noises, this paper employs a cross-attention mechanism to calculate the dependency between the current noise image and feature map . By computing the correlation between and , the similarity between the output and the target is enhanced. This allows the model to more accurately predict the subsequent noise and generate the target pose and features. During the inference stage, the model can gradually produce images that closely resemble the target data distribution.
The attention mechanism is shown in
Figure 3. The query
Q comes from the noise feature map of the previous layer of the U-Net, while the key K and value V are derived from the feature maps
of
. The attention modules at different layers learn features at various scales, which can be expressed as follows:
For the terms , the subscripts q, k, and v represent the linear transformation layers of , , and , respectively, with the superscript indicating the current neural network layer.
The attention score is calculated by multiplying the
and
matrices. Afterwards, the output is passed through a softmax function before being multiplied with the
matrix:
is the linear transformation layer. It transforms the feature map calculated by the attention mechanism into the final output feature map . Here, represents the current layer and denotes the output layer.
Figure 3.
Overview of the multi-scale feature module. The Query is the noise feature map. The Key and Value correspond to , representing the multi-scale features of .
Figure 3.
Overview of the multi-scale feature module. The Query is the noise feature map. The Key and Value correspond to , representing the multi-scale features of .
2.4. Semantic Extraction Filter
Typically, in an attention mechanism, the Query interacts with all Keys to compute relevance. However, in pose transfer tasks, if the pose transformation is substantial, it is unnecessary to focus on all Keys. For instance, when a frontal portrait is provided and the corresponding skeletal diagram indicates a side or back view, many features in the frontal portrait are irrelevant because local features from the side and back are not visible. This would increase unnecessary computational load and may cause the model to focus on irrelevant features during prediction.
In order to improve this method, a strategy called extraction then distribution on the attention map can be adopted [
18,
22]. Here, we refer to it as the semantic extraction filter. It would assign greater weights to more important features. This allows the model to recognize which features should be focused on. In practice, a learnable parameter, denoted as weight
W, is defined to identify which features in the attention map are important. The model learns to assign weights to enhance critical features based on both the reference image and the skeletal diagram, while diminishing relatively irrelevant information. Furthermore, the model focuses on features corresponding to specific viewing angles or clothing details to improve the quality of pose transfer, concurrently reducing the importance attributed to background elements or features unrelated to the target pose.
More specifically, the weights
, are applied to Query and Key before performing matrix multiplication of the Query and the Key, as shown in Equation (15). The superscript
represents the current neural network layer, and the subscripts
q and
k indicate the weights applied to the Query and Key, respectively. In our approach, the key and value features exhibit varying channel sizes across different levels (320, 640, 1280, etc.). To accommodate these differences, the learnable weight W adjusts the cross-attention feature shape from
to
. Since
n is much smaller than both
and
, this modification reduces the computational complexity from
to
, thereby lowering the computational cost.
In Equation (15),
and
represent the softmax function, and
denotes the filtered Attention map, as shown in
Figure 4. We perform preprocessing on the feature maps of the Query and Key through a single-layer filter to reduce the number of Keys each Query needs to focus on. The attention map generated by this method has a more sparsely distributed weight compared to the original attention mechanism, indicating that the model focuses more on important regional features.
2.5. Classifier-Free Guidance
In traditional diffusion model studies, it is common to train a classifier to guide the generative model, thereby controlling the category of the generated images. This method is known as classifier guidance [
23], which involves training classifiers on noise-added images. However, most pre-trained models are trained on noise-free datasets, limiting the possibility of integrating these pre-trained models during training and complicating the entire training process.
To overcome these limitations, Jonathan Ho [
24] proposed an alternative method called Classifier-Free Diffusion Guidance (CFG). During training, this method involves setting the conditional information to null (represented as
). Thus, it trains the model to handle both conditional and unconditional generation tasks. During the inference stage, by adjusting weights, the distribution of the generated images can be fine-tuned to match a specific conditional or unconditional distribution more closely, as shown in Equation (16). This approach not only achieves effects similar to classifier guidance but also reduces the complexity of training and makes implementation more straightforward.
where
represents the unconditional image generation, and
represents the conditional image generation.
PIDM proposes the use of disentangled guidance, which further refines the generation conditions of the human skeleton and reference images, as shown in Equations (17)–(19). This allows the model to adjust the generated image distribution to be closer to either condition using two weights,
and
. However, it was found that this method does not effectively control the pose. Since
does not include the human skeleton image, it affects the precision of the pose transfer and is not suitable for our pose transfer task. Therefore, this paper employs the cumulative CFG [
25] method, represented by the following formulas.
In the disentangled guidance approach adopted in PIDM, and contain only pose and style information, respectively, with pose information obtained from human skeleton images and style information derived from reference images. In contrast, Equations (20) and (21) in this paper incorporate additional pose information into . This modification enables the model to capture the target pose across all conditions. As a result, both and incorporate the human skeleton images. Therefore, the accuracy of the pose transfer can be increased.
3. Experimental Results
This chapter includes several subsections.
Section 3.1 describes the datasets we used.
Section 3.2 provides the implementation details.
Section 3.3 and
Section 3.4 discuss the qualitative and quantitative experiments conducted to test the model.
Section 3.5 conducts ablation experiments on proposed method.
Section 3.6 applies our proposed model to the appearance control task.
3.1. Dataset
This paper utilizes the DeepFashion dataset, specifically the In-shop Clothes Retrieval Benchmark. This dataset comprises a total of 7982 items, each modeled by a model wearing the clothing. It includes multiple angles such as front, side, back, and full body, with 52,712 photographs in total.
3.2. Implementation Details
The model was trained for a total of 200 epochs. The mean-square error (MSE) was used as the loss function during the training phase, with optimization performed using the AdamW optimizer. The learning rate followed a progressive decay, starting at 1 × 10
−5 and decreasing to 2.5 × 10
−7 after 100 epochs. The LDM loaded weights released officially by Stable Diffusion except for the attention neural network layers. Only the weights of the attention layers were updated during training. Because the sampling method of DDPM is too slow, this paper utilized DDIM [
26] with a reduced number of sampling steps to accelerate the generation process during inference. The sampling step was set to 50, meaning that noise was removed 50 times when generating an image.
3.3. Qualitative Results
As shown in
Figure 5, compared to PIDM, our proposed model can generate the desired poses and characters more precisely based on the features provided by the reference image. Also, the proposed method is less likely to produce unnecessary accessories or features. From the first row and the second row in
Figure 5, it is evident that PIDM is unable to adequately focus on the corresponding regional features provided by the reference image. In contrast, our model can generate the appropriate features and accessories more accurately based on the reference image. Through the method of ControlNet, the model can generate poses that are closer to the actual human skeleton, as seen in the fifth row of
Figure 5, where the poses generated by our model more closely resemble real data, with better representations of the hands and legs.
3.4. Quantitative Results
As shown in
Table 1, the proposed model achieves the best scores on SSIM and LPIPS metrics, slightly surpassing PIDM [
6] and PoCoLD [
18]. However, it does not outperform some of the methods on the FID metric. However, experimental results show that the FID metric calculated using the ground truth images of the test dataset is 7.68. It means that there might be some differences in data distribution between the training and testing datasets. In a sense, we can regard the value of 7.68 as the lower bound for FID. Therefore, generated images with FID scores lower than 7.68 are satisfactory results.
The main drawback of PIDM is that this method is time-consuming and requires significant memory space to achieve good generative results. Our model not only matches PIDM in quantitative evaluations but also achieves scores that outperforms other SOTA with limited computational resources, making it a viable research direction for scholars with limited resources. Although the architecture of the proposed method is larger, we do not update the entire weights of the model. Instead, we only update the weights of the attention blocks. Moreover, benefiting from the LDM architecture, the memory requirement of the proposed model is reduced. Also, the speed of sampling an image remains superior to PIDM.
3.5. Selection of Null Condition Probability
Experiments show that the probability of setting the condition to null in classifier-free guidance affects the convergence of the model. As shown in
Table 2, experiments with null condition probabilities of 4%, 8%, and 15% exhibit different performance metrics. When we train the model, only the weights of the attention neural network layers are updated, and the entire model is not fully updated. Therefore, when the null condition probability is too high, the model takes more time to achieve better performance. When we reduce the null condition probability, the model learns faster and performs better in evaluation metrics. But if the null condition probability is too low, the model’s ability to learn unconditional generation is affected, leading to inferior performance in evaluation metrics. Thus, an appropriate ratio must be found for the model to balance between conditional and unconditional generation.
3.6. Computational Resources and Training Speed
This paper presents experiments under conditions of limited resources. The PIDM utilized eight A100 GPUs for training, with the batch size set to 8 and training parallelized across the GPUs, effectively making the batch size equivalent to 64. Consequently, they can achieve high scores on quantitative evaluation. However, not all scholars have access to such computational resources to train models, making the availability of computational resources a significant factor in academic research.
As shown in
Table 3, the performance of PIDM on evaluation metrics is not impressive under limited computational resources when the batch size can only be set to 4. In contrast, under the conditions of an RTX 4090 GPU with 24 GB of VRAM, our model can set the batch size to 10. In terms of quantitative evaluation, our model surpasses PIDM by approximately 17% on the LPIPS and about 7% on the SSIM if both models use an RTX 4090 GPU. As shown in
Table 3, the proposed method saves about 0.7 G of GPU memory, resulting in faster training speed and more efficient resource usage compared to the methods described in the PIDM paper. The training speed of the proposed method is approximately 52% faster compared to PIDM, which is equivalent to halving the computation time required.
3.7. Ablation Study
In this subsection, we present two parts of ablation studies on the model we proposed. The first one is whether the ControlNet module surpasses the method of concatenating noise images with human skeletons in learning human poses and skeletons. The second part is whether the semantic extraction filter method allows the model to better learn its features.
3.7.1. Ablation Study on the ControlNet Module
When using pre-trained neural network models for pose transformation tasks, a common strategy is to concatenate additional input information (such as target pose data) with the original input data. However, this approach often affects the weights of the initial layers, which are trained on the original input data and do not account for the added input information. This prevents the initial neural network weights from being directly applied to the modified input, forcing the model to relearn how to adjust these weights to effectively handle the new input data structure. This not only adds an extra training burden but may also require additional data and time to optimize parameters for accurate pose transformation.
However, with the proposed architecture that includes the ControlNet module, it is possible to fully leverage the advantages of the pre-trained model, achieving better results in learning human skeletal structures. As shown in
Table 4, under the same number of training epochs, the proposed model with ControlNet achieves better scores across three evaluation metrics, and the task is learned more quickly. As illustrated in
Figure 6, the loss function curve reaches convergence more rapidly. As seen in
Figure 7, the visual results demonstrate that using the ControlNet module to learn poses would generate outcomes that match the provided human skeletal more closely.
3.7.2. Ablation Study on Semantic Extraction Filter
As shown in
Table 5, it is evident that the model using a semantic extraction filter is better able to identify important features and reduce attention to unnecessary ones. It also optimizes sampling time. In terms of quantitative evaluation, the model with a semantic extraction filter demonstrates better SSIM and LPIPS scores.
As illustrated in
Figure 8, it is clear that models using semantic extraction filters can generate better clothing textures and accurately learn the correct features at the right locations, without overly focusing on other unimportant areas. This prevents the model from generating irrelevant features or missing important features.
In
Figure 9, we visualize the weights from one layer of the attention neural network. Without semantic filters, the attention map focuses on many unnecessary parts, potentially confusing the model about which body parts should be prioritized during feature learning. With semantic filters, the weights of the attention map appear sparser, indicating that it focuses attention on crucial features and areas. Therefore, it can enhance the ability of the model to learn features more effectively and better accomplish the task of pose transformation.
3.8. Experiments on More Diverse Poses
To test if the proposed model architecture can be applied to transfer more diverse poses in addition to the standing poses in the DeepFashion dataset, we also apply the proposed method on the poseDataset [
27] to demonstrate the generalization ability of the proposed model. We utilize model weights already trained on the DeepFashion dataset and fine-tune them to adapt to the dance-oriented poseDataset. This approach allows the model to leverage the weights learned from DeepFashion without needing to be trained from scratch. It not only speeds up convergence on the new dataset but also enhances the handling of large motion pose transformations. This strategy significantly improves the model’s ability to accurately capture movements even with substantial pose changes, enhancing its generalization capabilities. As shown in
Figure 10, it is evident that if the model is trained on datasets with large pose transformations, it can successfully perform pose transformations in test datasets with large movements.
To validate the effectiveness of the proposed model, we conducted a series of experiments, including swapping actions between characters. This experimental design aims to explore whether training characters on datasets with a greater variety of poses can enhance the character’s capability for pose transformation. As shown in
Figure 11, the results indicate that the character can adapt to wide-ranging pose changes during the inference stage. This demonstrates that even if a specific dancer has not learned certain specific dance movements during training, the character can still successfully capture these movements and perform effective dance pose transformations.
4. Discussion and Future Work
Due to the use of a pre-trained VQGAN model, the images are compressed in the latent space from the original dimensions of 256 × 256 to a much smaller size of 32 × 32. At this reduced scale, some details of the features may be lost, leading to incomplete capture of complex textural patterns and detailed features in images such as intricate clothing patterns, facial features, and hand details.
Figure 12 illustrates this limitation, with the top row showing the ground truth and the bottom row displaying the generated images. We can see that the details of the faces in the bottom row of
Figure 12 exhibit some distortions and incompleteness. Due to the inherent mechanics of the diffusion model, it cannot independently learn detailed features such as those of the faces. Since the diffusion models do not generate images during training, it prevents the models from calculating explicit loss functions on facial features. We believe that the most significant factor affecting the results lies in mapping images to the latent space. To enhance overall model efficiency, a pre-trained VQGAN was employed; however, this approach resulted in feature loss during the mapping process for large-scale images, which substantially impacted the representation of complex textures, such as intricate clothing details or facial features. Regarding the other model components (e.g., the multi-scale feature module, semantic extraction filter, etc.), we believe that if the feature mapping issue with VQGAN can be resolved or more efficient mapping methods can be developed, the model would still demonstrate excellent performance.
These experimental results highlight the need for future research to enhance the model’s ability to capture details in large pose transformations. Also, since the null condition probability of classifier-free guidance affects the performance of the model, it would be helpful to develop a model that could dynamically adjust the weight based on pose complexity or confidence scores. Future studies could design adaptive CFG weight tuning to prevent the trade-off between pose accuracy and generalization. Furthermore, future studies could explore further optimizations of the model, such as fine-tuning the VQGAN to prevent the loss of small part features, designing alternative loss functions to ensure feature preservation, or using higher-resolution training datasets to improve the model’s ability to generate details. Additionally, incorporating a wider variety of dance styles and increasing data diversity could further expand the model’s generalization capabilities and practical application potential.
5. Conclusions
Inspired by the latent diffusion model and ControlNet, this paper trains a model capable of competing with the state-of-the-art pose transfer works using only a single RTX 4090 GPU. This study examines the advantages and performance of the model and compares it to existing models in the literature. The proposed architecture utilizes a multi-scale feature extraction module to learn the external features of reference images, combined with the ControlNet module to learn pose variations, and preserves the original input layer weights of Stable Diffusion to generate the target pose. Additionally, the use of a semantic extraction filter allows the proposed model to focus on critical features during learning. By leveraging the characteristics of latent diffusion, the computational resources required are significantly reduced. Compared to PIDM, which uses eight A100 GPUs, our method achieves better results on SSIM and LPIPS metrics with just a single RTX-4090. It also demonstrates faster speed during training and inference phases with less memory required.
Experimental validation confirms that this paper adopts a resource-efficient strategy, updating only the attention layers within the model. By utilizing the feature maps of the attention mechanism and the latent space vectors, the model directly learns the external feature of characters. ControlNet is used for learning pose transformations, precisely controlling the characters’ movements. This method maintains the diversity and image quality learned by Stable Diffusion on the LAION-5B dataset, demonstrating excellent generalization and transfer learning capabilities of the pre-trained Stable Diffusion model weights. The experimental results and analysis highlight several advantages:
Observations from the experiments show that the focus of Stable Diffusion lies in the attention mechanism network. By training only this network, computational costs are minimized, achieving results comparable to SOTA with just one RTX-4090.
The use of a multi-scale feature extraction module and semantic learning filters enables the model to accurately capture and emphasize critical features of characters across different scales.
The results indicate that learning human skeletal pose transformations with the ControlNet module provides superior performance and results in faster convergence by retaining the input layer weights of Stable Diffusion.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}