1. Introduction
In recent years, many leading technology companies have introduced “Machine Learning as a Service” (MLaaS) platforms, such as Amazon SageMaker, Microsoft Azure Machine Learning, Google Cloud AI Platform, Alibaba Cloud Platform of Artificial Intelligence, and Tencent Cloud TI Platform. These platforms provide users with easy access to pre-trained neural network models through simple API calls, without requiring a deep understanding of the underlying technical details. As a result, users can quickly perform inference tasks using their own data. This approach has significantly lowered the barrier to using neural network technologies, making it possible for more businesses and individuals to benefit from the advantages of neural network models.
However, behind the convenience of these services lies a significant risk of privacy leakage and challenges that cannot be ignored. On one hand, when users’ data are uploaded to cloud servers for processing, there exists the risk of these private data being leaked or misused. For example, in 2023, the short-video platform TikTok faced widespread privacy concerns globally due to its data-collection and -processing practices. Governments and regulatory authorities in multiple countries have investigated its data-handling methods, fearing that user private data might be employed for improper purposes. On the other hand, when users employ machine learning models provided by service providers for inference tasks, there is a risk of leakage of model parameters and training data. Malicious users can potentially reverse-engineer model parameters and even deduce parts of the training dataset content through repeated access to the model. This poses a significant threat to enterprises that rely on highly confidential data to train their models. Therefore, ensuring the privacy of both users’ input data and neural network models during the model inference phase has become one of the current research hotspots.
Secure Multi-Party Computation (MPC) allows multiple data owners to perform arbitrary computational tasks without revealing their private data. This technology provides an effective method for addressing the challenges. Current research on privacy-preserving deep neural network inference using MPC primarily focuses on convolutional neural networks (CNNs) that handle spatially distributed data [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12]; these efforts have advanced secure inference for image and grid-structured tasks. With the rapid development of large language models in recent years, models that can handle sequence problems have become a focus of research. Recurrent Neural Networks (RNNs) is an architecture specifically designed for time series such as speech signals, physiological time series, and financial transaction flows, while there are relatively limited works on RNNs [
13,
14,
15]. RNNs are more complex in structure compared to CNNs, particularly due to the inclusion of complex nonlinear activation functions (e.g., sigmoid/Tanh function). On one hand, existing work for RNNs only supports secure inference between two parties, without considering the high communication overhead associated with involving multiple parties. On the other hand, existing methods often use piecewise linear functions for approximate computations, which can result in lower accuracy. To address these issues, we propose a communication-efficient secure three-party RNN inference method. In summary, we made the following contributions:
- (1)
We construct novel three-party secret-sharing-based digit decomposition, B2A conversion protocols.These protocols complement the existing three-party secret-sharing scheme, effectively reducing the communication overhead in the online phase.
- (2)
We propose the lookup table-based secure three-party protocol by utilizing the inherent mathematical properties of binary lookup tables, and the communication complexity of the LUT protocol is only related to the output bit width.
- (3)
We propose the lookup table-based secure three-party protocols for RNN inference, including key functions in RNNs, such as matrix multiplication, sigmoid and Tanh function, and achieving lower online communication overhead compared to current SOTA-SIRNN.
The rest of this paper is organized as follows:
Section 2 describes work related to this work.
Section 3 introduces the preliminaries of the secret sharing scheme and lookup table.
Section 4 provides the protocol constructions, including the system model, conversions of secret sharing, and the lookup table-based 3PC protocol.
Section 5 gives the basic building blocks of RNN based on the secure protocols of
Section 4.
Section 6 provide the security analysis.
Section 7 provides performance analysis from theoretical and experimental perspectives, and
Section 8 summarizes the conclusions.
2. Related Work
In recent years, privacy preservation has become a crucial concern across various domains, reflecting the growing need to protect sensitive data in increasingly interconnected environments. In cloud computing, significant advancements have been made in enabling secure and verifiable machine learning model training [
16], as well as in developing efficient frameworks for privacy-preserving neural network training and inference [
17]. In the realm of path planning, researchers have introduced techniques to manage complex multi-task assignments while maintaining data privacy [
18]. Additionally, the blockchain sector has progressed in privacy governance by ensuring data integrity and controlling access within decentralized databases [
19]. Despite these diverse applications, there remains a critical need to specifically address the security issues of sensitive data and privacy models in neural network computation.
There are already many works aimed at CNNs in the privacy-preserving machine learning field, designing secure computing protocols for specific structures in CNNs. For works only focusing on two parties involving secure neural network computations, many of them use different techniques to evaluate secure inference [
1,
2,
3,
4,
5,
6,
7,
8,
9]. Some work ignores nonlinear mathematical functions [
1,
6,
10,
11], since whether a monotonic mathematical function is used or not does not affect the inference result in some cases. In 2PC settings, some works use higher-degree polynomials to approximate nonlinear mathematical functions [
12] to ensure accuracy. Some previous works use ad hoc approximations to approximate nonlinear functions, but this may cause a loss in model accuracy while achieving higher computational efficiency [
3,
9]. Rathee et al. [
13] utilized a lookup table for some complex nonlinear math functions and the model accuracy was improved to a certain extent. Flute et al. [
20] utilized a lookup table for some complex nonlinear math functions, and the model accuracy of nonlinear math functions was improved under 2PC settings.
In order to improve the performance of two-party secure neural network computations, many works introduce a third party to provide randomness during the offline phase to assist computation or involve computations. Similar to the previous work under 2PC settings, 3PC works still use polynomial approximation to compute nonlinear math functions [
21,
22,
23,
24]. Chameleon et al. [
21] utilized a semi-honest third-party server to assist in generating correlated random numbers during the offline phase and Yao’s Garbled Circuits for nonlinear functions. To reduce the expensive computing operations caused by garbled circuits, some work (e.g., [
25]) used ad hoc approximations instead of GC to calculate nonlinear functions, such as maxpool, ReLU, and so on. Moreover, ref. [
26] proposed improved replication secret sharing that improved the online communication efficiency. In addition, some multi-party works focus on application scenarios where malicious adversaries exist, thus requiring more communication and computation overhead [
27,
28,
29,
30].
However, in many practical scenarios, such as those involving sequential data, Recurrent Neural Networks (RNNs) are essential for effective computation. Early efforts in secure inference of RNNs include ref. [
13] addressing SIRNN, which used lookup tables to calculate commonly used nonlinear activation functions like sigmoid and tanh in RNNs. This approach enabled high accuracy with a two-server setup, making it a significant step forward in secure RNN inference, particularly for speech and time series sensor data. Building on this, Zheng et al. [
14] introduced a three-party secure computation protocol to handle nonlinear activation functions and their derivatives in RNNs, leveraging Fourier series approximations to balance precision and computation efficiency.
RNNs still face significant challenges in secure computation, particularly in real-world applications. One major issue is the high communication overhead associated with secure RNN inference, which is caused by the complexity of nonlinear activation functions and the recurrent structure of RNNs. Our work focuses on designing secure computation protocols for complex nonlinear functions in RNNs to reduce online communication.
3. Preliminaries
This section provides the fundamental theory required by our method. We introduce the related 3PC secret sharing scheme for the whole framework of our works, and the lookup table technology for nonlinear layers. The notations used in this work are listed in
Table 1.
3.1. Secret Sharing
In this paper, we utilize the optimized 3PC secret sharing scheme provided in Meteor [
26] to calculate the linear layer of the RNN, which can accelerate fixed-point multiplication of two inputs and integer multiplication of N inputs, and this scheme can be easily extended to more party settings. The scheme is executed with three parties
over a Boolean ring
(or arithmetic ring
, where
l is the bit width). Given two private bits
, Boolean sharing refers to the secret sharing scheme of bit size
and with logical AND, XOR, NOT operations, denoting
, respectively.
3.1.1. -Sharing
For -sharing over Boolean ring , any Boolean value is secret shared by three random values , , , and holds its share , such that .
For -sharing over arithmetic ring , any arithmetic value is secret shared by three random values , , , and holds its share , such that .
3.1.2. -Sharing
-Sharing is similar to -sharing, but it is the three-party 2-out-of-3 replicated secret sharing scheme.
For -sharing over Boolean ring , any Boolean value is secret shared by three random values , , , where . holds , such that any two parties can construct the secret value v.
For -sharing over arithmetic ring , any arithmetic value is secret shared by three random values , , , where . Also, holds , such that any two parties can construct the secret value v.
Linear Operation: For secret shared Boolean values and , three parties can compute value , where are public constant bits. In the Boolean ring , each party can locally compute its secret shares , such that any two parities of can recover the secret value z. It is similar for arithmetic rings , by replacing the XOR operation ⊕ with the ADD operation +, and taking the modulus of for the result.
AND Operation: For secret shared Boolean values
and
, three parties
can compute the secret shared value
as follows: (a) each party
locally computes
; (b) each party
locally computes
, where
(for random number generation, please refer to
Appendix A); (c) all three parties together perform re-sharing to obtain the sharing of
by sending
to
so that each
holds
.
Multiplication: For secret shared arithmetic values
and
, three parties
can compute the secret shared value
as follows: (a) each party
locally computes
; (b) each party
computes
, where
(for generation of
, please refer to
Appendix A); (c) all three parties together perform re-sharing so that each party
holds its own secret share
.
3.2. Secret Sharing Semantics of This Work
In order to improve the computational efficiency of the
-sharing and
-sharing, we provide the novel and efficient three-party secret sharing scheme denoted as
-sharing inspired by the scheme in [
9,
26]. With the aid of using
-sharing, we further divide the computation into online and offline phases.
For -sharing over Boolean ring , any Boolean value is secret shared with a mask value and the -sharing of a random value , holds , where is known to all three parties, .
For -sharing over arithmetic ring , any arithmetic value is secret shared with a mask value and the -sharing of a random value , holds , where is known to all three parties, . In addition, the complement of v can be computed as by setting .
Linear operation: This pattern is linear for both Boolean and arithmetic rings. For example, for Boolean sharing, assume are public constant bits, are two secret-shared values, and , then each party can compute its share locally by setting and , for .
Secret share operation: Secret share operation enables a privacy data owner (assume
is the data owner) to generate
-sharing of its private input
x. In the offline phase, all parties jointly invoke
in
Appendix A to sample random values
, where privacy data owner
knows
clearly. In the online phase,
computes and reveals
in a Boolean ring and
in an arithmetic ring. The above process can be carried out using
function.
Reconstruct operation: can reconstruct x by invoking first to obtain , and then parties can locally compute in a Boolean ring and in an arithmetic ring.
AND operation: With the functionality
AND two Boolean secret value
, and output
, where
, we have:
As shown in Equation (
1), all terms except for
can be computed locally since
is known to all parties. Therefore, the main difficulty becomes calculating
given
and
. Since
and
is input-independent,
can be computed in the offline phase using
. In the offline phase, parties interactively generate the randomness
using the method in
Appendix A, and in the online phase, each party
computes
. The protocols of function
are shown in Algorithm 1.
| Algorithm 1 : two-input AND in boolean ring
|
|
Multi-input AND operation: For multi-input AND gates,
takes the
N Boolean value
as input, and output
, then we have:
So as the procedure of the two-input AND gate, parties compute the input-independent
-sharing of
by invoking
in a tree-like combinatorial manner in the offline phase.
Two-input multiplication: the multiplication of two numbers in an arithmetic ring
is similar to that in Boolean sharing, simply replacing the OR operation in Boolean sharing with addition and the AND operation with multiplication. The multiplication of two numbers under arithmetic sharing is depicted in Equation (
3):
Similarly, the shares of
can be calculated using
in
Section 3.1.2. As introduced in
Section 3.3, the calculation of secure inference uses fixed-point representation in
; after precise multiplication, the decimal part of the result will double its original size, i.e.,
. Therefore, we should truncate the last
d bits of the product to obtain an approximate result. In a secret sharing scheme, truncation takes into account two types of probability errors: a small error caused by carry bit error and a large error caused by overflow during multiplication calculation. And the shares of output that make
hold a probability of 1 are called faithful truncation. We use faithful truncation methods from [
9,
26]: In the offline phase, parties mutually generate the
-sharing of
and
where
. During the online phase, all parties
locally compute
and reveal
, and then parties set
. The protocols of
are shown in the Algorithm 2.
| Algorithm 2 : two-input multiplication in arithmetic ring |
|
Multi-input multiplication: Similar to the multi-input AND operation under Boolean sharing, multiplication of multiple numbers under arithmetic sharing is shown in Equation (
4):
3.3. Fixed-Point Representation
Practical applications such as machine learning and mathematical statistics usually require the floating-point numbers for calculations. While in MPC, it is generally calculated in finite rings or fields, so it is necessary to encode floating-point numbers as fixed-point numbers [
3,
11,
21,
24,
31]. The conversion relationship between floating-point numbers and fixed-point numbers is as follows: given a floating-point number
, its corresponding fixed-point number
, where
l is bit width and
d is precision. We use
and
to represent positive and negative numbers, respectively.
3.4. Lookup Table
The lookup table (LUT) structure is used to pre-compute and store the inputs and corresponding results of the function. The corresponding results can be found by looking up the input in the table, without the need to calculate again.
The lookup table of a function in this paper refers to the set of all inputs and their corresponding outputs within a certain range, i.e.,
[
32], where
and
are bit width of input and output, respectively. Using this representation, any function can construct its corresponding lookup table within a certain range, and the computational complexity of the lookup table is related to its size. Therefore, logically complex lookup tables are theoretically more suitable to computing using lookup tables.
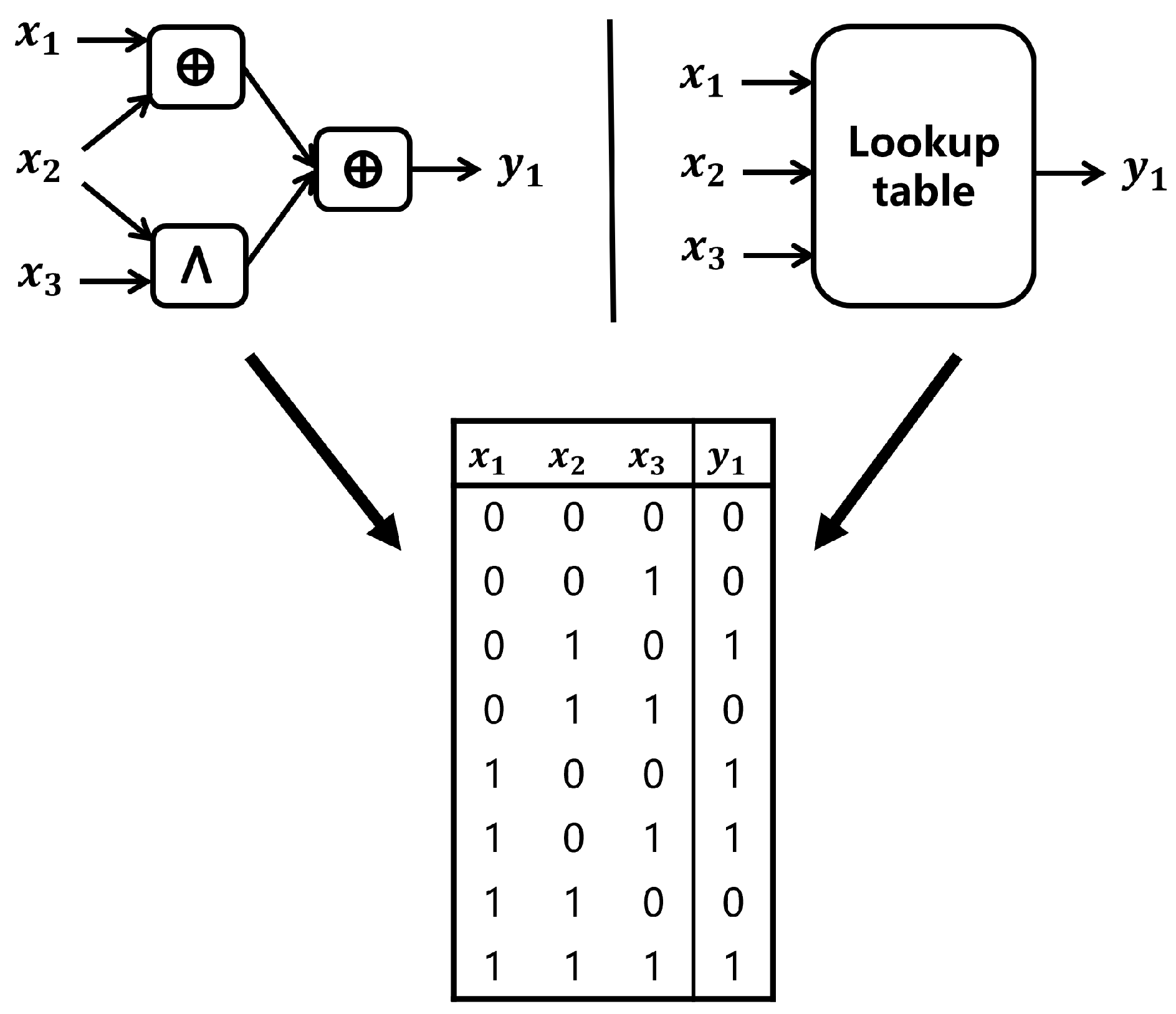
An instance of an LUT is demonstrated in
Figure 1. In this work,
is the input column of the table and
is the output column, where each length is
, for example,
is 00110011 and
is 00101101. In practical scenarios, the bit width design of lookup tables (LUTs) requires a balance between computational efficiency and numerical accuracy requirements. Our lookup table (LUT) selects 12 bit input/12 bit output precision, achieving a balance between the actual deployability of RNNs and model accuracy. In latency-critical scenarios like real-time ECG anomaly detection (sampling rates ≤ 250 Hz), 12-bit input limits LUT size to 4 KB. For applications such as speech recognition that are not sensitive to real-time efficiency, 12-bit can also ensure good accuracy. However, if users want to use a look-up table for models with large numbers or high accuracy requirements, they need to optimize the look-up table structure by using an automation toolchain to reduce the level of look-up table circuits and achieve higher performance.
4. Protocol Constructions
In this section, to provide a clearer exposition of the protocol we have constructed, we first present the system model in this paper. Then, we provide the digit decomposition, B2A and Bit2A conversion protocols based on the -sharing. Finally, we proposed a lookup table-based secure three-party protocol.
4.1. System Model
Consider a computing scenario with three servers that are independent of each other. We execute a secure computing protocol under a semi-honest model, As shown in
Figure 2, there are three roles in a system model: model owner, data owner, and computation participants.
- (1)
Model owner: This is the model’s architecture and parameters, typically having a machine learning model that has been trained or needs to be trained. In the initial stage of computation, the model owner must send the model parameters to the computation participants in the form of secret shares, but does not receive the computation results.
- (2)
Data owner: This has real data and aims to conduct joint inference without exposing data privacy. The data owner sends the secret shares of private data to the computation participants at the beginning of the calculation, and receives the result shares sent by the computation participants after the secure computation is completed.
- (3)
Computation participants: These act as the actual “computing executors” within the secure computation protocol, typically serving as third-party platforms, service providers, or distributed nodes with multi-party secure computation capabilities. In the context of this paper, the computation participant servers are three servers that initially receive the model shares from the model owner and the data shares from the data owner. After executing the secure computation protocol, three servers send their result shares back to the data owner, respectively.
To demonstrate this system model’s practical applicability, we take the healthcare field as an example. Some medical institutions utilize speech-recognition technology to develop electronic medical record (EMR)-management platforms, which enables physicians to complete clinical documentation through voice dictation, significantly reducing documentation burdens and improving workflow efficiency. Concurrently, the technology assists clinicians in rapidly retrieving patients’ historical medical records, thereby providing robust support for accurate diagnosis. However, as patient medical information involves sensitive personal privacy, the system model in this work can be used. For this case, the model owner as in
Figure 2 is the medical institution, it can train the model locally or via other methods using relevant datasets, and then the model parameters are distributed to three servers through secret sharing. The data owner is a physician (or patient); they can split their private personal data into secret shares and transmit them to the same three servers. Following secure computation protocols, the servers return the result shares to the physician. This process effectively prevents leakage of both the medical institution’s model parameters and the patient’s private information.
4.2. Conversions of Sharing
In the lookup table protocol, the inputs are
-shares of every
bit. Therefore, a secure digit decomposition function
under a 3PC
-sharing scheme is required before each invoking of a lookup table protocol. In this protocol, the wrap function and the 3PC private-compare function (the same as the protocol in [
31]) under the
-sharing scheme will be invoked. The following describes the protocol in detail.
4.2.1. Wrap Function
The wrap function
calculates the carry bit when the secret shares held by three parties are added together, and the output may be 0, 1 or 2, i.e., assume three secret shares are
, and
is:
But since the operands in the lookup table protocol are all bits, the wrap function defined here is modulo 2 on the original result, i.e.,
. The details of the secure wrap protocol can refer to [
31].
4.2.2. Private Compare
In the digit decomposition protocol, the operation should obtain the bit shares of comparison results of secret value
x and a public number
r. The 3PC private compare function
can be realized in [
31].
4.2.3. Digit Decomposition
converts secret shares in arithmetic ring into shares in Boolean ring . Given private input , output , where is the jth bit of x (i.e., ). For ease of calculation, each party locally decomposes value , then obtains public bits , where . Next, each party interactively converts the -shares into Boolean shares.
The challenge of the three-party decomposition protocol under
-sharing lies in how to construct a specific
on the basis of an existing arithmetic ring
. Based on the mathematical observation, we propose a three-party decomposition protocol under
-sharing, enabling most calculations to be completed offline for decomposition. Below, we describe the mathematical observation and the corresponding protocol in detail. Given the secret sharing
, where
, suppose
, then the
-sharing follows Formula (
5):
where
is the carry bit of
, i.e.,
.
Similarly, suppose there is
,
,
. The secret sharing
satisfies:
where
is the carry bit of
, i.e.,
. However, in actual computation,
is encrypted, so
cannot be directly computed. By observation, we can deduce
Since
is a public value, this term can be moved to the right side of the inequality, i.e.,
. Since
can be computed locally, there is no online communication. The protocols of the
are described in Algorithm 3.
| Algorithm 3 : 3PC digit decomposition |
Input: -shares of x, where . Output: -shares of , where . Offline Phase: - 1.
Each party locally converts the shares into bits and computes locally, where ; - 2.
Each party invokes the function to obtain ; - 3.
Each party locally computes .
Online Phase: - 1.
Each party locally converts the shares into bits ; - 2.
Each party invokes the function to obtain ; - 3.
Each party locally computes . The final share after bit conversion is .
|
4.2.4. B2A Conversion
Boolean to arithmetic function
is the inverse operation of digit decomposition. It converts the bit shares
to value
, such that
. We can first convert
to the arithmetic ring, and then use the linear property of
-sharing to calculate. Then, for secret
in
-sharing that
, we can derive the following mathematical properties:
; so we have:
We have
, and assume that the arithmetic value in
is
, respectively. Therefore, we can derive the mathematical equation in Equation (
7) in the same way. All items except for
can be computed locally, but we can have one of the participants
locally compute
, and then securely compute
using the Du-Atallah protocol [
21].
4.3. Lookup Table-Based 3PC Protocol
We assume that the function to be evaluated is represented as a lookup table, and the LUT is public that all parties can know the input encoding
and output encoding
, and the parties have Boolean secret sharing of the private input. In secure two-party computation, there are several approaches to compute a lookup table. The most widely applied are One Time True Table (OTTT) [
33], Online-LUT (OP-LUT) [
32], and Setup-LUT (SP-LUT) [
32]. But in the 3PC scenario, there are no efficient computation schemes. In order to increase the efficiency of the online phase, we proposed a 3PC lookup table protocol, expanding the application scenarios of Flute [
20] from 2PC to 3PC settings.
This approach converts the lookup process of the lookup table into a computing function that is related to the private input representing the inner product. The previous lookup table method enumerated all inputs [
32,
33] or all outputs [
32] and then obtained the final lookup table output by utilizing the obvious transfer (OT). This is regular but the complexity of computation and communication are too high because the whole table will be sent to the other party. Therefore, we only require part of the lookup table to be evaluated rather than an entire table. There are four steps involved in this conversion, and the specific steps are shown below.
(1) The first step: compute the fully disjunctive normal form of the input. When evaluating a Boolean
-to-
lookup table, we only need to focus on the rows where the result is 1, then the output of LUT can be represented as the full disjunctive normal form (DNF) of the corresponding input for those rows. Taking a lookup table with output 1 as an example in
Figure 1, assuming there are
rows whose results are 1, then for each
, we compute all terms
, where
if
in the LUT and
if
for all
, and then connect all terms using the OR operation, output
.
Using the lookup table depicted in
Figure 1 as an illustration, the output of the third, fifth, sixth rows is 1, i.e.,
, and assuming the input is
, the output of LUT is 0. And then we calculate the formula; then, we can exactly obtain the output result
.
(2) The second step: replace the OR operation with the XOR operation. Evaluating the above DNF expression requires
AND and OR operations, which costs high online communication. However, We remove OR operations with the following significant properties: Given the input
, in the above DNF equation
, at most one term can result in 1 [
20], which means that it is impossible for any two different terms to each result in 1. Based on this property, we can obtain the following Equation (
8):
Still taking the lookup table in
Figure 1 as an example,
, and assuming the input is
, the output of LUT is 0. Then, compute the improved formula to obtain
.
(3) The third step: replace the previous formula with an equivalent inner product computation. The purpose of this step is to transform the equation from the previous step into a more easily computable and efficient form. When
, the equation is
, which can be seen as multi-input AND gate in
Section 3.2. When
, the transformed equation is
, which is equivalent to the vector inner product operation over a Boolean ring. Therefore, we use the aforementioned protocols to calculate the inner product and the multi-input AND gate, inspired by [
9,
20]. Finally, the equation is as follows in Equation (
9)
where ⨀ denotes an inner product operation like the form in vector. Assume
, and the input is
; the output of LUT is 0. Then, compute the improved formula to obtain
, and we can see that the result is correct.
4.3.1. Mathematical Expression of Multi-Input LUT
Consider a
input vector
and 1-bit output, the dimension of each component
is represented as
d where
. Based on the above conclusion, we need to calculate
. Let
be a set of the
jth element of each
. As we mentioned in
Section 3.2, the secret value
x is
-sharing in this work, so we have:
In Equation (
10), it is easy to derive the equations for the first three lines from
Section 4, while in the fourth step,
is the expansion of
, which follows the distribution law, and its expension has
items in total, power set
means all the expanded items, and
is one of a subset in
, and
means difference set, where
, i.e.,
. Although the expression contains
AND gates, these AND gates can be locally calculated to obtain the shares of each term leading to low online communication since
can be computed by
locally and
is clear to all parties.
4.3.2. Lookup Table Protocol
Given a
-to-
LUT T, we calculate the lookup table results bit by bit, so the goal is to compute
as mentioned in Equation (
10), where
is the number of rows that output 1. To filter out rows with output 1, we can multiply this expression by the output encoding of LUT
, so the rows with output 0 will be deleted. Since the lookup table is public, the output encoding is also public, so no additional communication is required to obtain all rows with output 1 as in Equation (
11).
In Equation (
11), we also need to handle the mapping relationship between the input vector
and vector
for
. We can see from
Section 4.3 that
if
and
if
for all
. Since the lookup table is public, we can also obtain the input encoding
, so we can obtain
as Equation (
12):
where
,
. Because the input encoding
is public and the secret sharing scheme we used in
Section 3.2 is linear, no additional communication is required for this step of processing.
Furthermore, in our secret sharing scheme, calculating the complement
only needs to compute the complement of
z, but
remains unchanged, such that
. Thus, we can observe that the term
for all
in Equation (
13) is the same for each row with input vector
, so the same random number
can be used. Therefore, we can obtain the following derivation formula as Equation (
13):
where
denotes the output encoding of LUT for all
,
denotes a set replacing each
with
,
and
is the secret shares of
for
, and
is the shares of each
where
is replaced with
, and
stays the same. The third to fourth lines follow the law of distribution, and since it is observed that
and
are public parameters, these two items are combined for computation. And then according to Equation (
9), the final equation, Equation (
13), can be obtained.
Because are reused, in the offline phase, we just need to invoke the times.
The protocol details are shown in Protocol 4. In the second step of the online phase in Algorithm 4, to prevent parties repeat calculating the
, we move this term in the fourth step for calculation.
| Algorithm 4 : protocol of LUT |
Input: a public -to- LUT T with input encoding and output encoding , and -shares of input vector . Output: , where . Offline Phase: - 1.
Each party sample random values using for , . - 2.
Each party interactively generates for by invoking .
Online Phase: - 1.
All parties locally set in Equation ( 12) for . - 2.
Each Party locally computes: - 3.
All parties renconstruct by exchanging and computing . - 4.
All parties locally compute .
|
5. The 3PC Protocols of Secure RNNs Operators
In this section, we will introduce secure matrix multiplication and secure activation functions of nonlinear layers commonly used in RNNs, such as sigmoid, and tanh as shown in
Table 2. In computers, only finite numbers can be represented; complex mathematical functions cannot be accurately represented. Therefore, floating-point numbers are usually used to approximate infinite numbers [
34].
5.1. Matrix Multiplication
The linear part of the model is usually matrix computation. The protocol for matrix multiplication is similar to
. An
matrix
is multiplied by an
matrix
, then we obtain matrix
and matrix
. In the offline phase, all parties
mutually generate
by invoking
, and then in the online phase, all parties
reveal
and compute
locally. The details are shown in Algorithm 5.
| Algorithm 5 Matrix multiplication |
|
5.2. Exponential
Consider the following exponential function:
. Due to the properties of exponential functions, this can be equivalent to
, where
x of length
l is divided into
k parts, each with a length of
d [
13], where this can be easily computed by invoking
in
Section 3 first, and then invoking the lookup table protocols separately in Algorithm 4. To reduce communication and computing costs as well as memory usage, the private inputs from the larger arithmetic ring are decomposed into smaller one
. The details are in Algorithm 6.
| Algorithm 6 Functionality of exponential |
|
5.3. Sigmoid
The sigmoid function can be simply assumed to be composed of an exponential function
and a reciprocal
. Therefore, we sequentially calculate the exponential function and the reciprocal to obtain the result of the sigmoid function. For exponential function
, we can use
and obtain the accurate approximate results (the accuracy depends on the size of the lookup table). Then, for reciprocal
, we use the Goldschmidt iteration method (similar to the method in [
13]); this method’s accuracy largely depends on the initial iteration value. In order to obtain a closer initial value, we construct a lookup table to obtain a more reliable approximation of the reciprocal function, and then continuously iterate on this basis to improve accuracy. The details are in Algorithm 7.
| Algorithm 7 Functionality of exponential |
|
5.4. Tanh
The hyperbolic tangent (tanh) has many application scenarios in neural networks, mainly as activation functions for hidden layers. It is a variant of the sigmoid function. The tanh function maps the input value to a continuous value in the range of −1 to 1. According to the definition, the following equation holds: tanh sigmoid; thus, it can be computed by invoking the sigmoid function.
6. Security Analysis
We prove security protocols under both real world execution and ideal world simulation paradigms, and consider the security in the semi-honest model with all three parties following the protocol exactly.
Proof: assume is a semi-honest adversary in the real world that cannot corrupt more than one party at the same time, and is a simulator of the ideal world. In the real world, all parties involved execute the protocol in the presence of adversary ; in an ideal world, all parties send their inputs to the simulator and have execute the protocol honestly. Any knowledge that adversary can obtain in the real world can also be obtained by simulator in the ideal world, so the real world and the ideal world are indistinguishable.
Security for
,
,
,
,,
,
,
,
,
,
. Since we use the 3PC protocol of [
26] as our secret sharing primitiveness, the security of these protocols in this paper are inherited from [
26].
Security for : let corrupt during the protocol , and it is symmetric to . In the offline phase, each party invokes to generate correlation randomness and invokes to obtain the multi-input dot inner product, so security is guaranteed by these two functions. In both real and ideal protocols, the only key information obtained by the corrupt party from the honest party is a bit . Whether in real or ideal execution, this bit is masked by a random number selected by the honest party, which is invisible for , making it a random bit that follows a uniform distribution in view. Since this is the only mask message that can observe, from its perspective, the execution of the real world and the simulation of the ideal world are indistinguishable.
Security for : let corrupt during the protocol , and let it be symmetric to . The interaction between the parties only occurs when invoking protocol and , and all other calculations are completed locally. Therefore, this protocol’s security is guaranteed by the security of and .
7. Evaluation
This chapter provides experimental results and corresponding experimental settings for the proposed protocol.
Experiment setting: The experiment was run on an Intel(R) Xeon(R) Platinum 8176 M CPU @ 2.10 GHz and 48 GB RAM and was conducted on a single threaded LAN and WAN, and we created three docker containers representing three servers in Ubuntu 20.04. The bandwidth in the LAN was approximately 1 GB/s and round-trip time (RTT) was 1ms, while the bandwidth in the WAN was 40 MB/s and RTT was 70 ms. The code implementation written in C++ programming language.
For our work’s benchmark, we compared the state-of-the-art SIRNN [
13] in current RNN secure inference. In theoretical analysis, we compared the complexity of online communication and online communication rounds. Then, we compared the running time respectively under LAN and WAN, and communication volume of key building blocks. Finally, we applied our sigmoid and tanh protocols to end-to-end RNN secure inference and compared it with SIRNN [
13] under the same setting. We simulated the fastGRNN [
35] model on the Speech Command dataset [
36], which identified keywords in short speech (such as digits, simple command, or directions). Its primary goal is to provide a way to build and test models that detect when a single word is spoken, from a set of ten target words, and the datasize size is 8.17 GiB. The FastGRNN model contains 99 sigmoid and 99 tanh layers; each layers has 100 instances.
7.1. Comparison of Theoretical Communication Cost on Building Blocks
As shown in
Table 3 and
Table 4, we compared the online communication complexity and communication rounds of basic building blocks of our 3PC work with the previous current optimal RNN work [
13]. Note that the sigmoid and tanh functions of SIRNN is in 2PC setting. Moreover, we also compared with the typical three-party computation (3PC) framework ABY3 [
24] and SecureNN [
25], which are not specifically designed for RNNs, to obtain more comprehensive comparison results. For
, compared to SIRNN with a communication complexity of
, our method reduces the communication complexity by an order of magnitude to
l, and the communication rounds are reduced from 4 to 1. Our work reduces the online communication complexity by 10 times and 4 times compared to ABY3 and SecureNN, respectively, while also decreasing the number of communication rounds by one round compared to SecureNN, maintaining the same number of communication rounds as ABY3. For
, the online communication complexity and communication rounds of basic building blocks of our work are not much different from ref. [
13]. For
, SIRNN and SecureNN do not implement
. Although the communication complexity of our work is slightly lower than that of ABY3, the communication rounds are reduced from
to 1. For
, the communication complexity of our work was reduced so that it was only related to the output bit width
, and the communication round was reduced to only one round.
7.2. Online Cost of RNN Building Blocks and End-to-End Inference
We tested the basic building blocks of RNN, including matrix multiplication, sigmoid, and tanh. It should be noted that our work focused on reducing online communication overhead, so the communication cost and runtime we provide are obtained during the online phase. Similarly, we also evaluated the online communication overhead and runtime for SIRNN. However, since SIRNN does not strictly divide the calculation into online/offline phases, all computations are related to the privacy input. Therefore, we took the total communication cost and runtime of SIRNN as online communication cost and online runtime. Compared with SIRNN [
13], the online communication of RNN key building blocks matrix multiplication, sigmoid, and tanh in our research work was reduced by 27.56%, 80.39%, and 79.94%, respectively, as shown in
Table 5. The results of online runtime for RNN’s building blocks under LAN and WAN are shown in
Table 6. In the LAN setting, for the sigmoid and tanh functions, the online runtime of our work is similar to that of SIRNN. However, in the WAN setting, for the sigmoid function, our work is 8% faster than SIRNN in terms of online runtime, and for the tanh function, our scheme is 3% faster than SIRNN. Also, we conducted end-to-end RNN secure inference using the Google-30 dataset [
36] on fastGRNN [
35]. As shown in
Table 7, although our work is slightly slower than SIRNN in terms of online communication time (LAN: SIRNN 10.29s vs. Ours 10.31s; WAN: SIRNN 522.07 s vs. Ours 598.10 s), our online communication overhead is reduced by 39.45% compared to SIRNN.
8. Conclusions
In this work, we introduce an innovative protocol to improve the efficiency of three-party secret sharing and secure inference in recurrent neural networks (RNNs). The experimental results show that compared with SIRNN, the online communication of the core building blocks of the RNN model is significantly reduced (matmul, 27.56%; sigmoid, 80.39%; tanh, 79.94%), making our protocol available for delay-sensitive applications, such as real-time healthcare diagnosis, motion detection, financial risk control detection, and smart voice assistants.
However, it is important to acknowledge potential limitations. When our protocol is applied to RNN models with more layers or more complex structures, it may lead to a linear increase in the total/online communication overhead. In addition, although our lookup table protocol requires only one round of online communication, the performance of our method in a distributed environment may be affected by network latency, which may affect the communication time of the online phase in real deployment.
In summary, this research presents significant advancements in reducing communication costs for secure three-party computations in RNNs, but it also highlights areas for further improvement. Future work will focus on integrating these protocols into real-world model inference tasks, addressing scalability and latency challenges, and enhancing the privacy and security of lookup tables. Considering the balance of communication efficiency and security, our work only supports semi-honest security. We plan to improve the work further to support malicious security in the future. In addition, multi-valued logic (MVL) may work in reducing the communication overhead of the lookup table in theory, so future research will consider improvements with MVL. By exploring these methods, we aim to broaden the utility and robustness of secure computation protocols in practical applications.







{kind=link}
{kind=link}