
Efficient Adversarial Training for Federated Image Systems: Crafting Client-Specific Defenses with Robust Trimmed Aggregation



Abstract
1. Introduction
- Client-Specific Adversarial Generation: We introduce a novel mechanism that customizes adversarial example generation based on local data statistics, ensuring that the adversarial examples are appropriately scaled and effectively challenge the model.
- Robust Trimmed Aggregation: We propose a robust aggregation strategy that uses the trimmed mean to mitigate the effects of malicious or low-quality updates during global model aggregation. This protects the global model from adversarial interference.
- Comprehensive Evaluation: We evaluate our framework through experiments on widely used datasets like CIFAR-10 and MNIST. Our results show significant improvements in adversarial robustness, with the model maintaining high performance on clean data as well.
2. Related Works and Preliminary
2.1. Federated Learning
2.2. Adversarial Training in Centralized and Distributed Settings
2.3. Robust Aggregation Techniques
2.4. Client-Specific Strategies
2.5. Integration of Robust Aggregation and Client-Specific Adversarial Training
3. Methodology
3.1. Client-Specific Adversarial Generation
3.2. Robust Trimmed Aggregation
3.3. Federated Training Procedure
| Algorithm 1 Federated image adversarial training with client-specific generation and robust trimmed aggregation |
|
4. Experiments
4.1. Experimental Setup
4.2. Results
4.2.1. Parameter Analysis
4.2.2. Ablation Studies
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ma, C.; Li, J.; Shi, L.; Ding, M.; Wang, T.; Han, Z.; Poor, H.V. When federated learning meets blockchain: A new distributed learning paradigm. IEEE Comput. Intell. Mag. 2022, 17, 26–33. [Google Scholar] [CrossRef]
- Rauniyar, A.; Hagos, D.H.; Jha, D.; Håkegård, J.E.; Bagci, U.; Rawat, D.B.; Vlassov, V. Federated learning for medical applications: A taxonomy, current trends, challenges, and future research directions. IEEE Internet Things J. 2023, 11, 7374–7398. [Google Scholar] [CrossRef]
- Lu, Z.; Pan, H.; Dai, Y.; Si, X.; Zhang, Y. Federated learning with non-iid data: A survey. IEEE Internet Things J. 2024, 11, 19188–19209. [Google Scholar] [CrossRef]
- Kumar, K.N.; Mohan, C.K.; Cenkeramaddi, L.R. The impact of adversarial attacks on federated learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 2672–2691. [Google Scholar] [CrossRef] [PubMed]
- Amini, S.; Ghaemmaghami, S. Towards improving robustness of deep neural networks to adversarial perturbations. IEEE Trans. Multimed. 2020, 22, 1889–1903. [Google Scholar] [CrossRef]
- Rodríguez-Barroso, N.; Jiménez-López, D.; Luzón, M.V.; Herrera, F.; Martínez-Cámara, E. Survey on federated learning threats: Concepts, taxonomy on attacks and defences, experimental study and challenges. Inf. Fusion 2023, 90, 148–173. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the convergence of fedavg on non-iid data. arXiv 2019, arXiv:1907.02189. [Google Scholar]
- Konečnỳ, J. Federated Learning: Strategies for Improving Communication Efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Xiang, M.; Ioannidis, S.; Yeh, E.; Joe-Wong, C.; Su, L. Efficient federated learning against heterogeneous and non-stationary client unavailability. arXiv 2024, arXiv:2409.17446. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Pan, Z.; Ying, Z.; Wang, Y.; Zhang, C.; Zhang, W.; Zhou, W.; Zhu, L. Feature-Based Machine Unlearning for Vertical Federated Learning in IoT Networks. IEEE Trans. Mob. Comput. 2025, 1–14. [Google Scholar] [CrossRef]
- Morris, J.X.; Lifland, E.; Yoo, J.Y.; Grigsby, J.; Jin, D.; Qi, Y. Textattack: A framework for adversarial attacks, data augmentation, and adversarial training in nlp. arXiv 2020, arXiv:2005.05909. [Google Scholar]
- Beltrán, E.T.M.; Pérez, M.Q.; Sánchez, P.M.S.; Bernal, S.L.; Bovet, G.; Pérez, M.G.; Pérez, G.M.; Celdrán, A.H. Decentralized federated learning: Fundamentals, state of the art, frameworks, trends, and challenges. IEEE Commun. Surv. Tutorials 2023, 25, 2983–3013. [Google Scholar] [CrossRef]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Online, 26–28 August 2020; pp. 2938–2948. [Google Scholar]
- Lyu, L.; Yu, H.; Ma, X.; Chen, C.; Sun, L.; Zhao, J.; Yang, Q.; Philip, S.Y. Privacy and robustness in federated learning: Attacks and defenses. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 8726–8746. [Google Scholar] [CrossRef]
- Qi, P.; Chiaro, D.; Guzzo, A.; Ianni, M.; Fortino, G.; Piccialli, F. Model aggregation techniques in federated learning: A comprehensive survey. Future Gener. Comput. Syst. 2024, 150, 272–293. [Google Scholar] [CrossRef]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5650–5659. [Google Scholar]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Li, Y.; Sani, A.S.; Yuan, D.; Bao, W. Enhancing federated learning robustness through clustering non-IID features. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 41–55. [Google Scholar]
- Gallus, S. Federated Learning in Practice: Addressing Efficiency, Heterogeneity, and Privacy. TechRxiv 2025. [Google Scholar] [CrossRef]
- Smith, V.; Chiang, C.K.; Sanjabi, M.; Talwalkar, A.S. Federated multi-task learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4427–4437. [Google Scholar]
- Fallah, A.; Mokhtari, A.; Ozdaglar, A. Personalized federated learning: A meta-learning approach. arXiv 2020, arXiv:2002.07948. [Google Scholar]
- Tang, J.; Du, X.; He, X.; Yuan, F.; Tian, Q.; Chua, T.S. Adversarial training towards robust multimedia recommender system. IEEE Trans. Knowl. Data Eng. 2019, 32, 855–867. [Google Scholar] [CrossRef]
- Kim, T.; Singh, S.; Madaan, N.; Joe-Wong, C. Characterizing internal evasion attacks in federated learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Valencia, Spain, 25–27 April 2023; pp. 907–921. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features From Tiny Images. 2009. Available online: https://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 8 April 2025).
- Deng, L. The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading digits in natural images with unsupervised feature learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 12–17 December 2011; Volume 2011, p. 4. [Google Scholar]
- Tang, M.; Wang, Y.; Zhang, J.; DiValentin, L.; Ding, A.; Hass, A.; Chen, Y.; Li, H. FedProphet: Memory-Efficient Federated Adversarial Training via Theoretic-Robustness and Low-Inconsistency Cascade Learning. arXiv 2024, arXiv:2409.08372. [Google Scholar]
- Li, Q.; He, B.; Song, D. Model-contrastive federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10713–10722. [Google Scholar]
- Chen, L.; Zhao, D.; Tao, L.; Wang, K.; Qiao, S.; Zeng, X.; Tan, C.W. A credible and fair federated learning framework based on blockchain. IEEE Trans. Artif. Intell. 2024, 6, 301–316. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Huynh, T.T.; Ren, Z.; Nguyen, P.L.; Liew, A.W.C.; Yin, H.; Nguyen, Q.V.H. A survey of machine unlearning. arXiv 2022, arXiv:2209.02299. [Google Scholar]
- Jiang, Y.; Shen, J.; Liu, Z.; Tan, C.W.; Lam, K.Y. Towards efficient and certified recovery from poisoning attacks in federated learning. IEEE Trans. Inf. Forensics Secur. 2025, 20, 2632–2647. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Dataset | Total Samples | Training Samples | Testing Samples | Image Size (Channels) |
|---|---|---|---|---|
| CIFAR-10 | 60,000 | 50,000 | 10,000 | 32 × 32 (RGB) |
| CIFAR-100 | 60,000 | 50,000 | 10,000 | 32 × 32 (RGB) |
| MNIST | 70,000 | 60,000 | 10,000 | 28 × 28 (Grayscale) |
| SVHN | 99,000 | 73,257 | 26,032 | 32 × 32 (RGB) |
| Fashion-MNIST | 70,000 | 60,000 | 10,000 | 28 × 28 (Grayscale) |
| EMNIST | 131,600 | 112,800 | 18,800 | 28 × 28 (Grayscale) |
| STL-10 | 13,000 | 5000 | 8000 | 96 × 96 (RGB) |
| Dataset | Method | Clean Acc. (%) | Adv. Acc. (%) | Robustness Gain (%) |
|---|---|---|---|---|
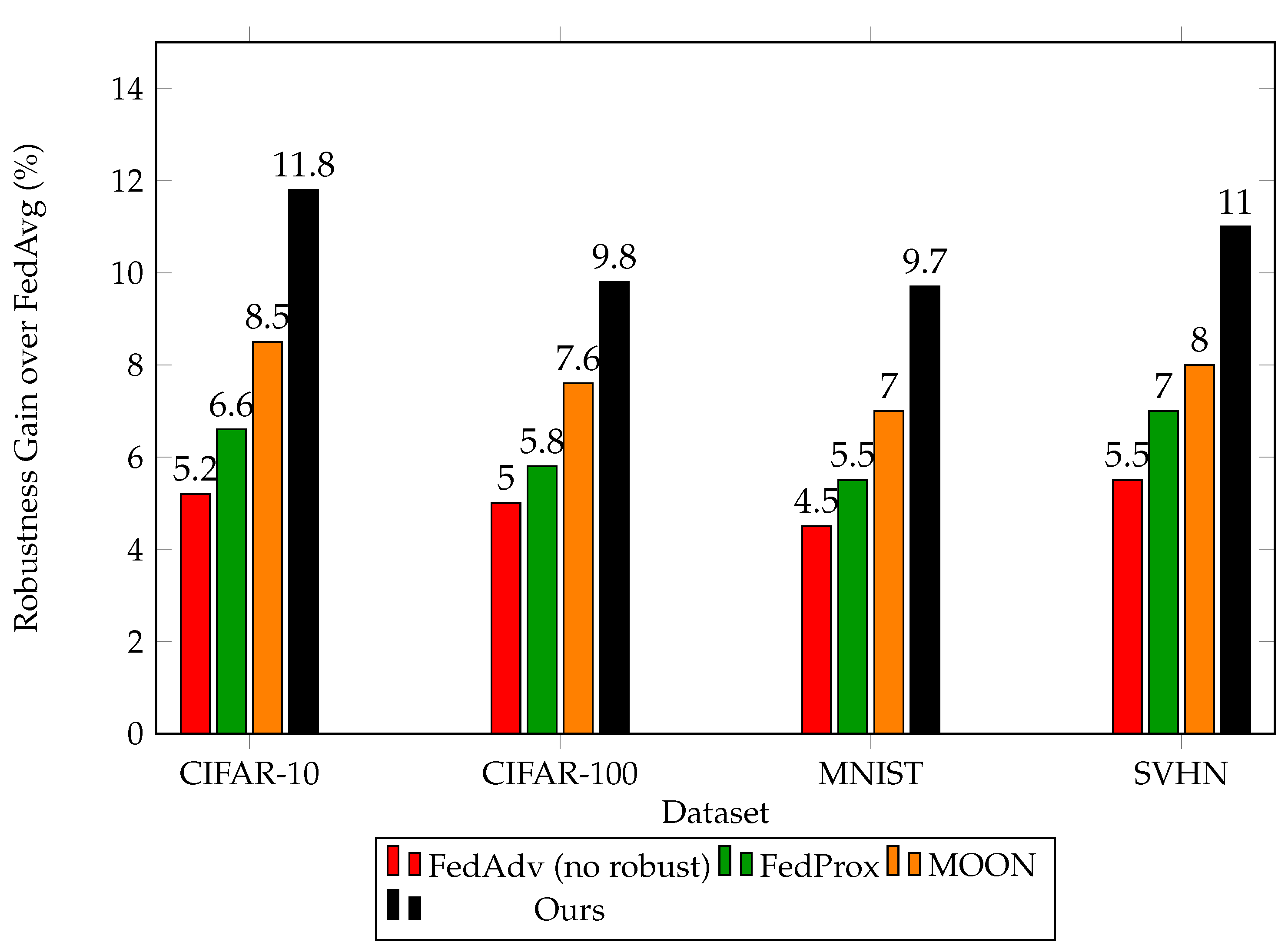
| CIFAR-10 | FedAvg | 85.2 | 43.5 | - |
| FedAdv (no robust) | 83.0 | 48.7 | +5.2 | |
| FedProx | 84.0 | 50.1 | +6.1 | |
| MOON | 83.5 | 52.0 | +8.5 | |
| Ours | 82.5 | 55.3 | +11.8 | |
| CIFAR-100 | FedAvg | 60.0 | 30.2 | - |
| FedAdv (no robust) | 58.0 | 35.1 | +5.0 | |
| FedProx | 59.0 | 36.0 | +6.0 | |
| MOON | 58.5 | 37.8 | +7.8 | |
| Ours | 57.0 | 40.0 | +9.8 | |
| MNIST | FedAvg | 99.0 | 70.5 | - |
| FedAdv (no robust) | 98.5 | 75.0 | +4.5 | |
| FedProx | 98.8 | 76.0 | +5.5 | |
| MOON | 98.7 | 77.5 | +7.0 | |
| Ours | 98.0 | 80.2 | +9.7 | |
| SVHN | FedAvg | 92.0 | 55.0 | - |
| FedAdv (no robust) | 91.0 | 60.5 | +5.5 | |
| FedProx | 91.5 | 62.0 | +6.0 | |
| MOON | 91.0 | 63.0 | +7.0 | |
| Ours | 90.5 | 66.0 | +11.0 |
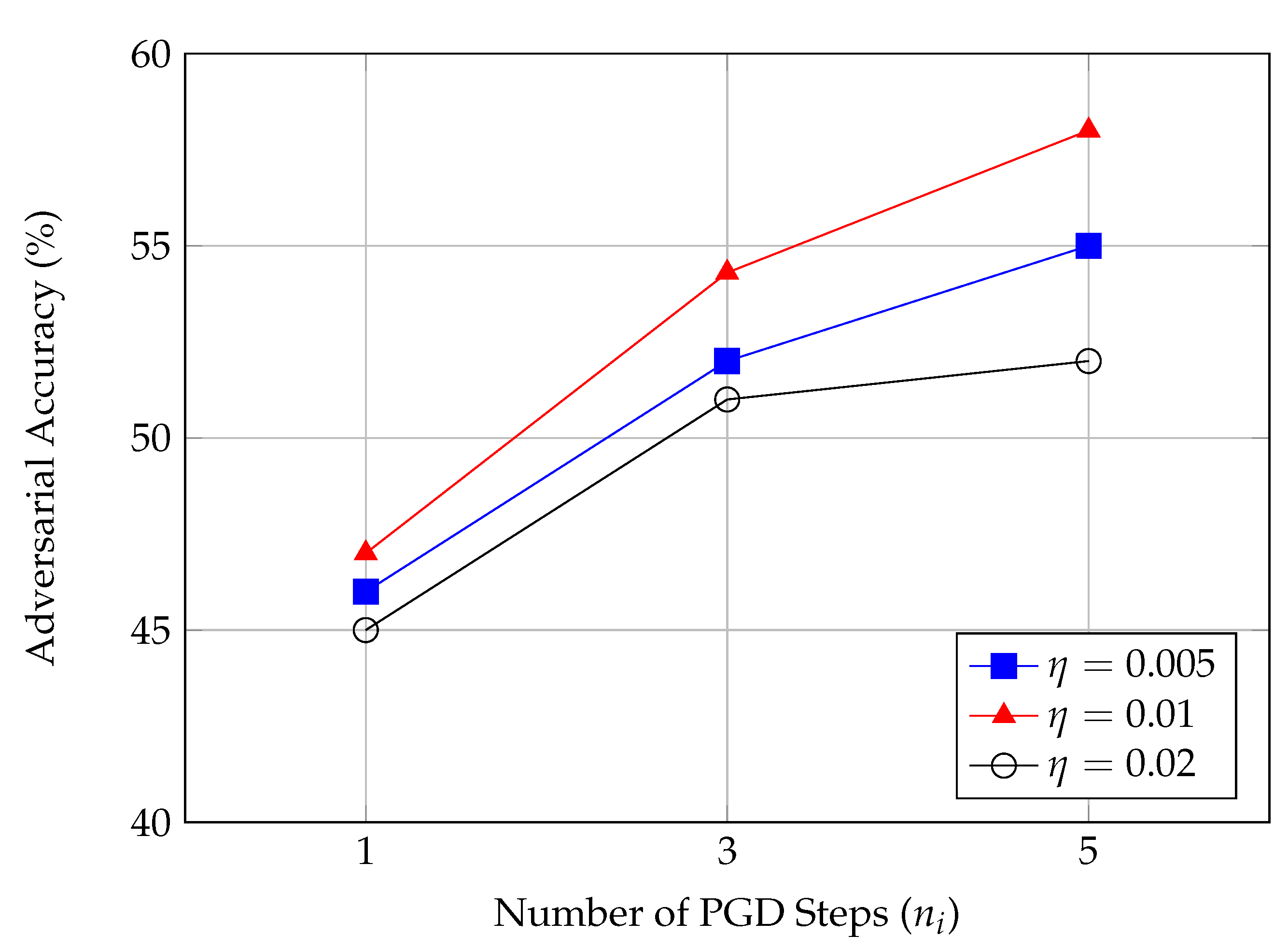
| Clean Accuracy (%) | Adversarial Accuracy (%) | Robustness Gain (%) | |
|---|---|---|---|
| 1 | 84.5 | 47.0 | +2.5 |
| 3 | 82.5 | 55.3 | +11.8 |
| 5 | 81.0 | 56.0 | +12.5 |
| Configuration | Adversarial Accuracy (%) | Robustness Gain (%) |
|---|---|---|
| Full Model (Ours) | 55.3 | +11.8 |
| Without Robust Aggregation | 49.1 | +5.6 |
| Without Client-Specific Adv. Generation | 50.3 | +6.8 |
| Without Both Components | 45.0 | +2.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, S.; Zheng, X.; Chen, J. Efficient Adversarial Training for Federated Image Systems: Crafting Client-Specific Defenses with Robust Trimmed Aggregation. Electronics 2025, 14, 1541. https://doi.org/10.3390/electronics14081541
Zhao S, Zheng X, Chen J. Efficient Adversarial Training for Federated Image Systems: Crafting Client-Specific Defenses with Robust Trimmed Aggregation. Electronics. 2025; 14(8):1541. https://doi.org/10.3390/electronics14081541
Chicago/Turabian StyleZhao, Siyuan, Xiaodong Zheng, and Junming Chen. 2025. "Efficient Adversarial Training for Federated Image Systems: Crafting Client-Specific Defenses with Robust Trimmed Aggregation" Electronics 14, no. 8: 1541. https://doi.org/10.3390/electronics14081541
APA StyleZhao, S., Zheng, X., & Chen, J. (2025). Efficient Adversarial Training for Federated Image Systems: Crafting Client-Specific Defenses with Robust Trimmed Aggregation. Electronics, 14(8), 1541. https://doi.org/10.3390/electronics14081541