
Collision Avoidance in Autonomous Vehicles Using the Control Lyapunov Function–Control Barrier Function–Quadratic Programming Approach with Deep Reinforcement Learning Decision-Making



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
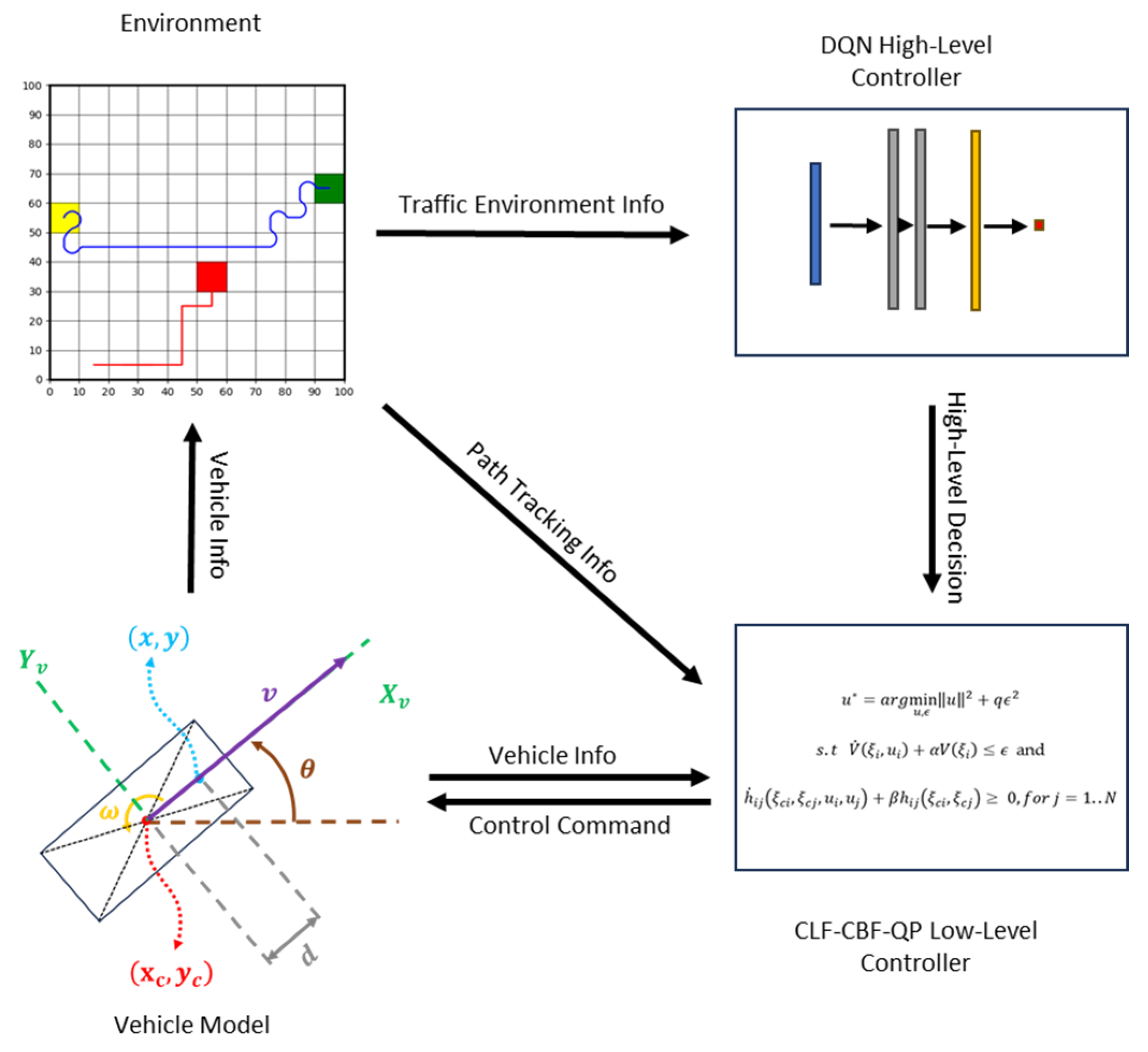
- The proposed control system enables precise path tracking when no potential collisions are detected and performs effective collision avoidance when obstacles are nearby.
- To achieve this, we first applied the CLF-CBF-QP approach to design an optimization-based path-tracking controller. The CLF constraint in the optimization ensures the stability and accurate path tracking of the autonomous vehicle, while the CBF constraint guarantees safety by preventing potential collisions between the vehicle and obstacles.
- Building on this foundation, we integrated the traditional CLF-CBF-based control with a deep reinforcement learning algorithm for path planning.
- The DRL algorithm generates a rough sketch of the optimal path, which the proposed optimization-based control then refines and executes.
- To further enhance computational efficiency, a lookup table is incorporated into the CLF-CBF optimization framework, significantly accelerating the calculation process.
- This hybrid approach leverages the strengths of both traditional control theory and modern machine learning to achieve robust, safe, and efficient autonomous vehicle operation.
2. Methodology
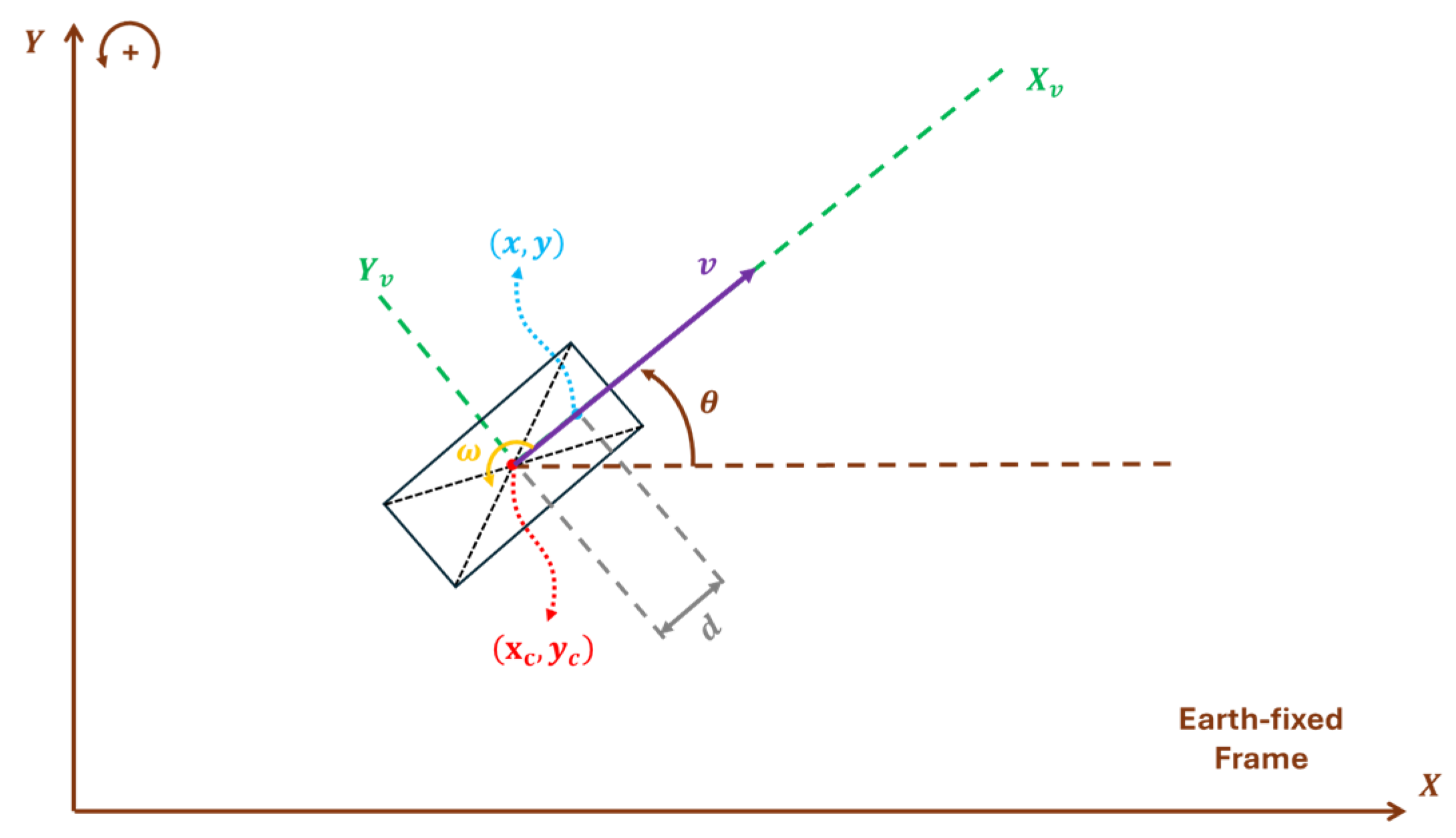
2.1. Unicycle Vehicle Dynamics
2.2. Control Lyapunov Functions and Control Barrier Functions
2.2.1. Control Lyapunov Functions’ Principle and Design
- (1)
- Positive definiteness:
- (2)
- Sublevel set boundedness: For a given constant, , the sublevel set is bounded. This ensures that defines a meaningful region of attraction (ROA) around .
- (3)
- Stability: there exists a control input, , such that the derivative of along the trajectory of the system satisfies
2.2.2. Control Barrier Functions’ Principle and Design
2.2.3. CLF-CBF-QP Formulation
2.3. Deep Reinforcement Learning
| Algorithm 1: DQN algorithm flowchart. |
| 1: Initialize replay memory |
| 2: Initialize target network and Online Network with random weights |
| 3: for each episode do |
| 4: Initialize traffic environment |
| 5: for t = 1 to T do |
| 6: With probability select a random action |
| 7: Otherwise select |
| 8: Execute in CARLA and extract reward and next state |
| 9: Store transition (, , , ) in |
| 10: if t mod training frequency == 0 then |
| 11: Sample random minibatch of transitions (, , , )) from D |
| 12: Set |
| 13: for non-terminal |
| 14: or for terminal |
| 15: Perform a gradient descent step to update |
| 16: Every N steps reset = |
| 17: end if |
| 18: Set = |
| 19: end for |
| 20: end for |
3. Results
3.1. CLF-CBF-Based Optimization Controller
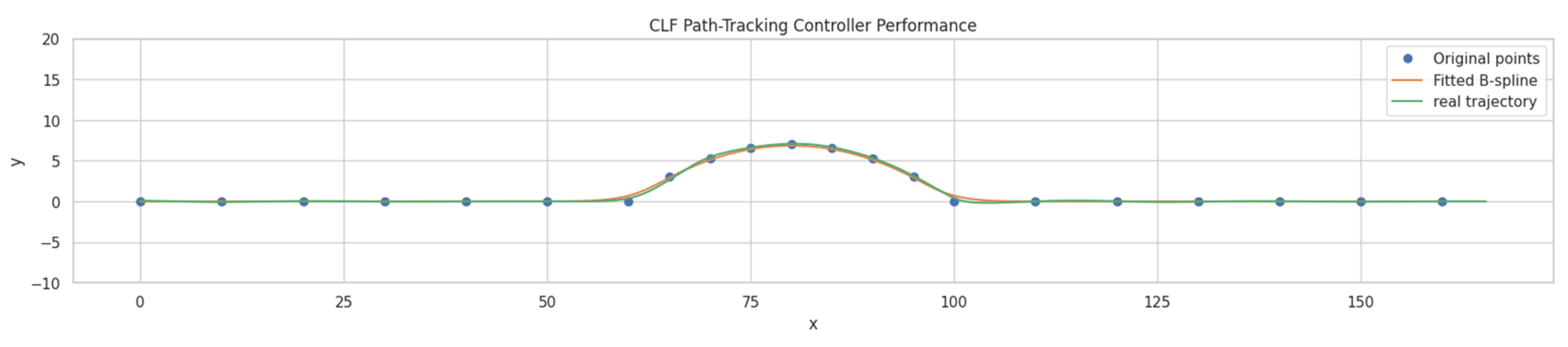
3.1.1. CLF-Based Path-Tracking Controller
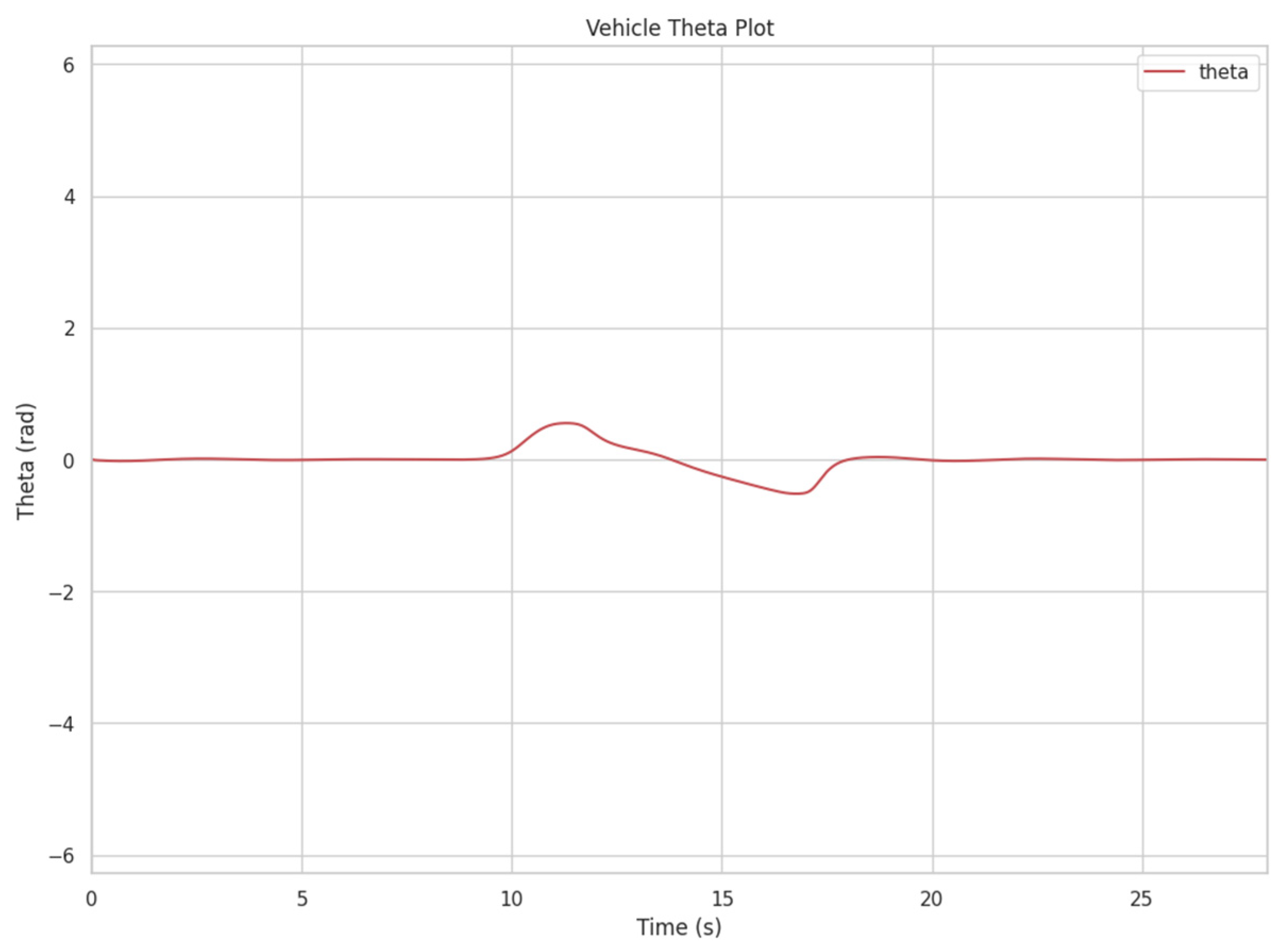
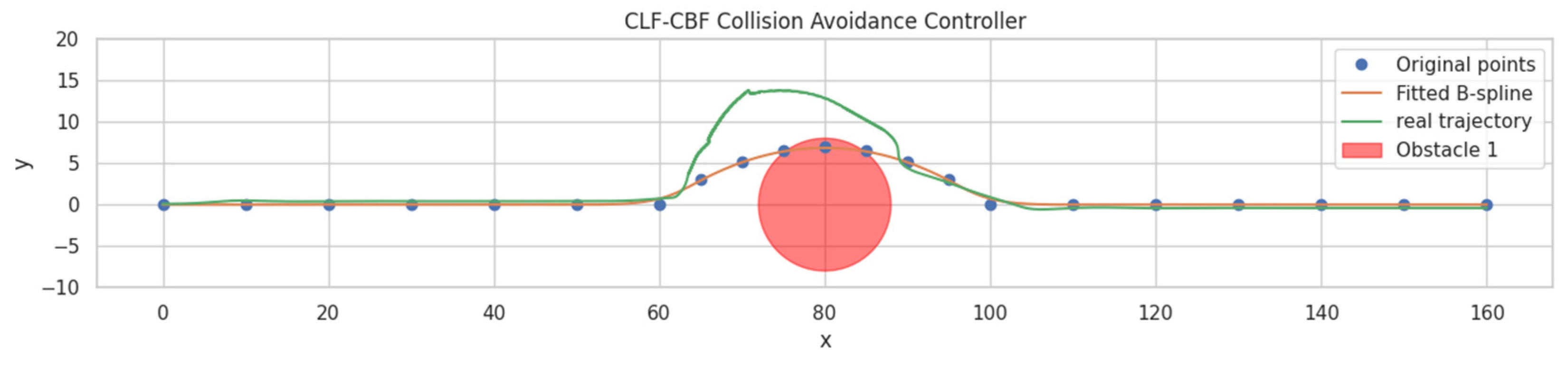
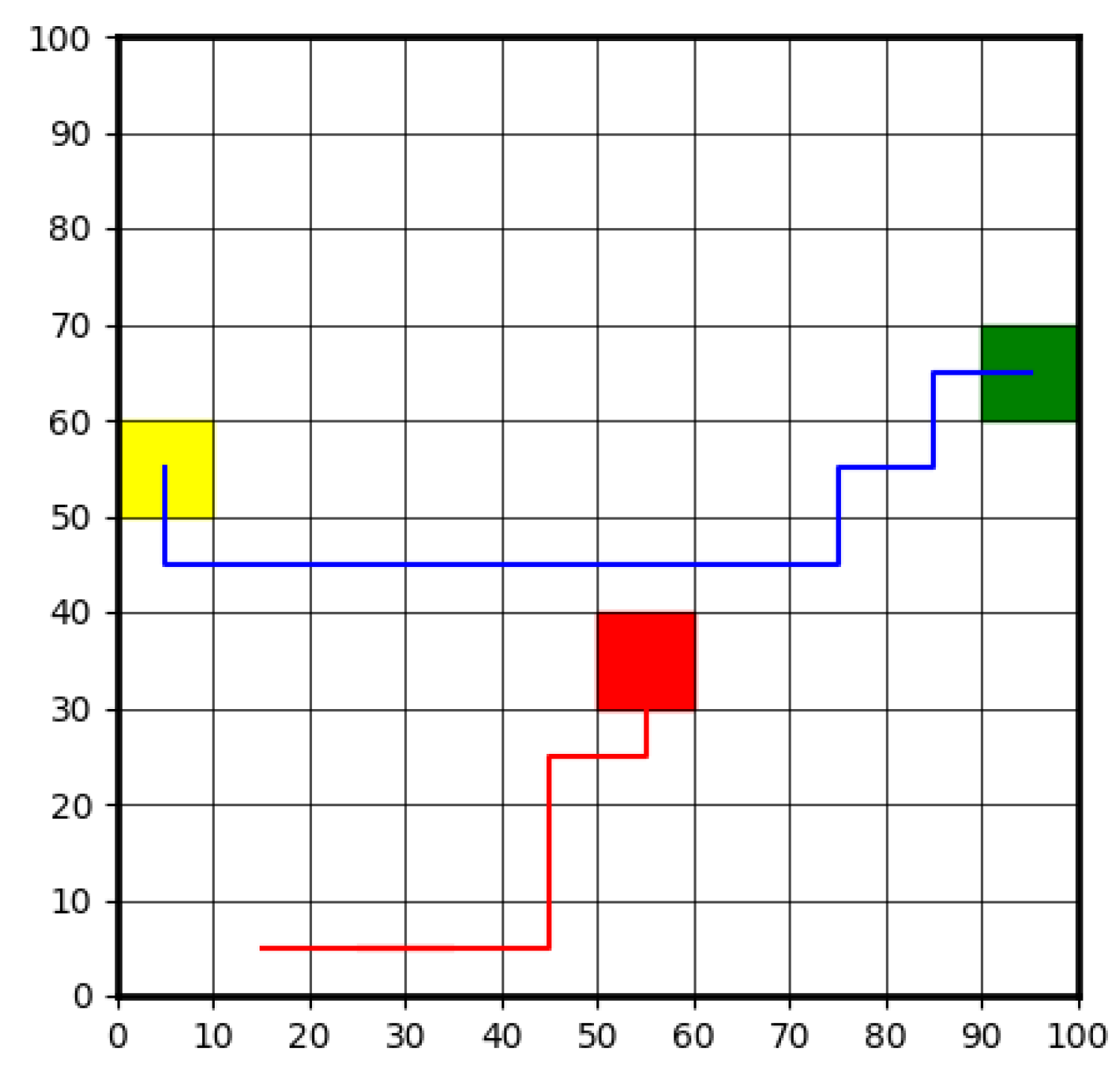
3.1.2. CLF-CBF-Based Autonomous Driving Controller for Static Obstacle
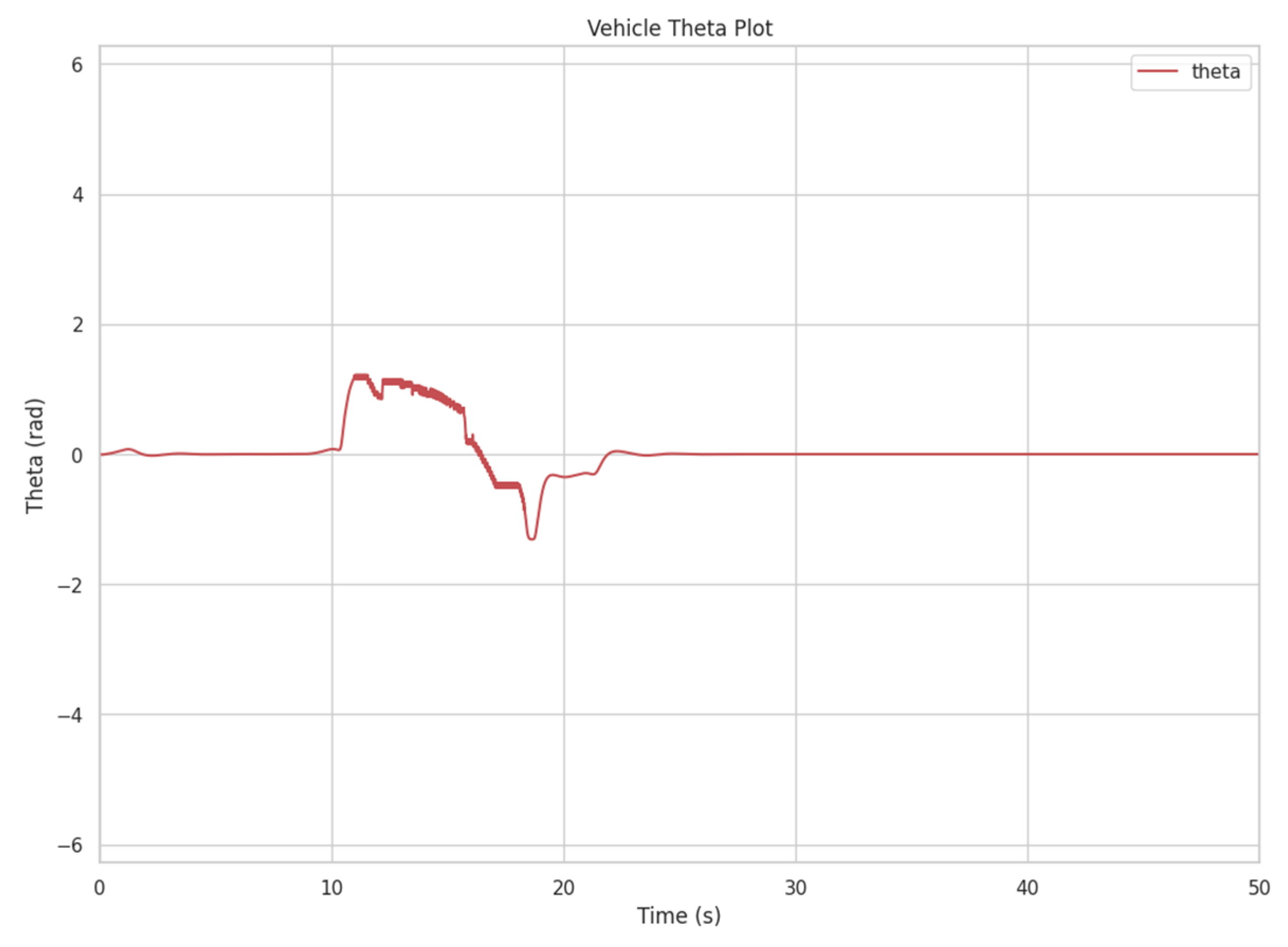
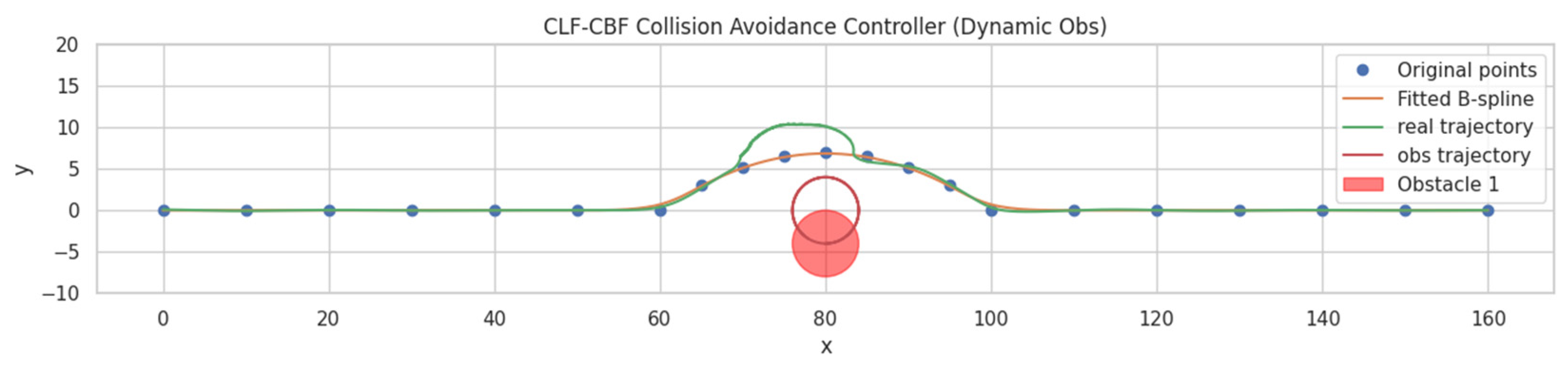
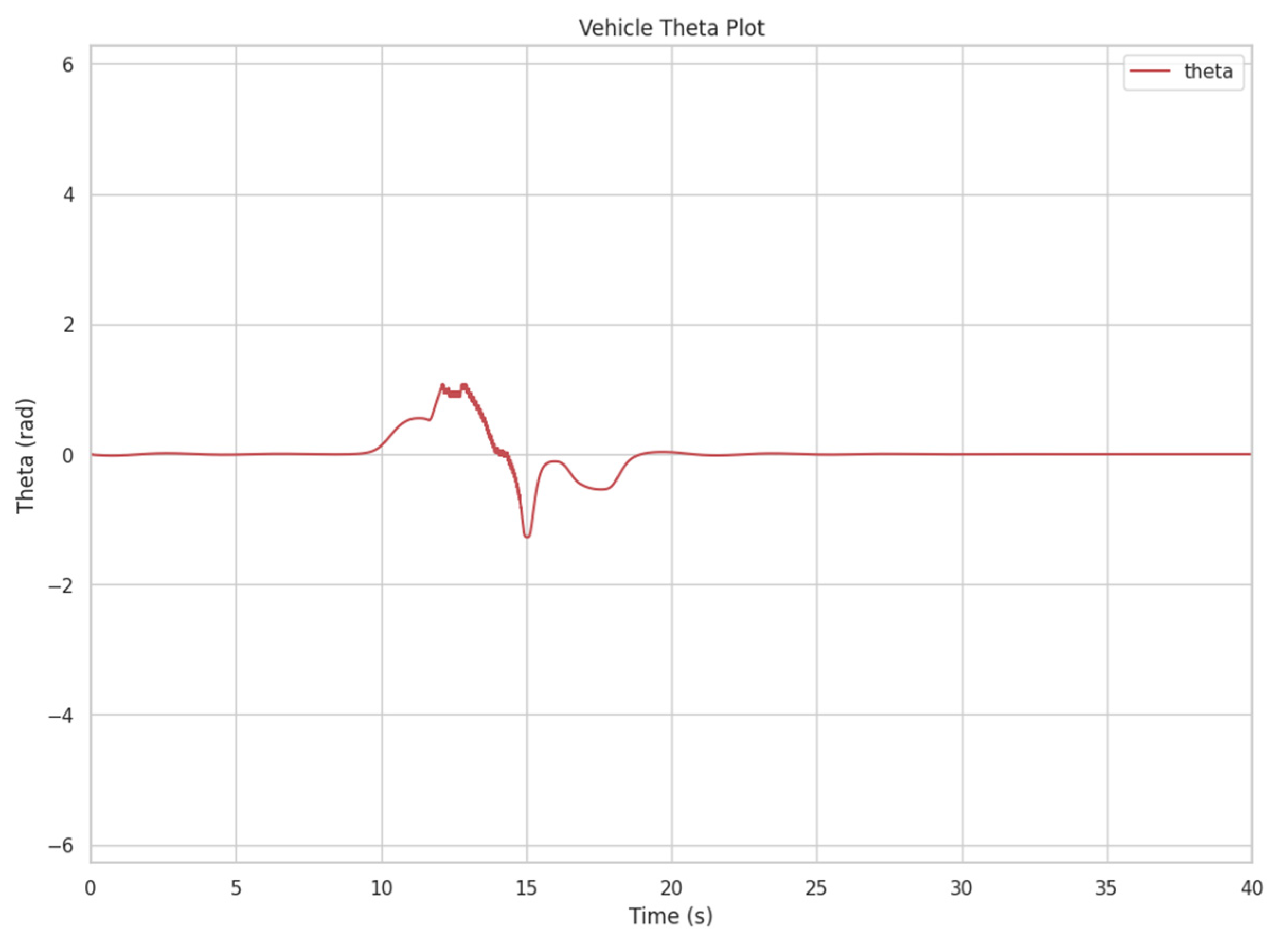
3.1.3. CLF-CBF-Based Autonomous Driving Controller for Dynamic Obstacle
3.2. Hybrid DRL- and CLF-CBF-Based Controller
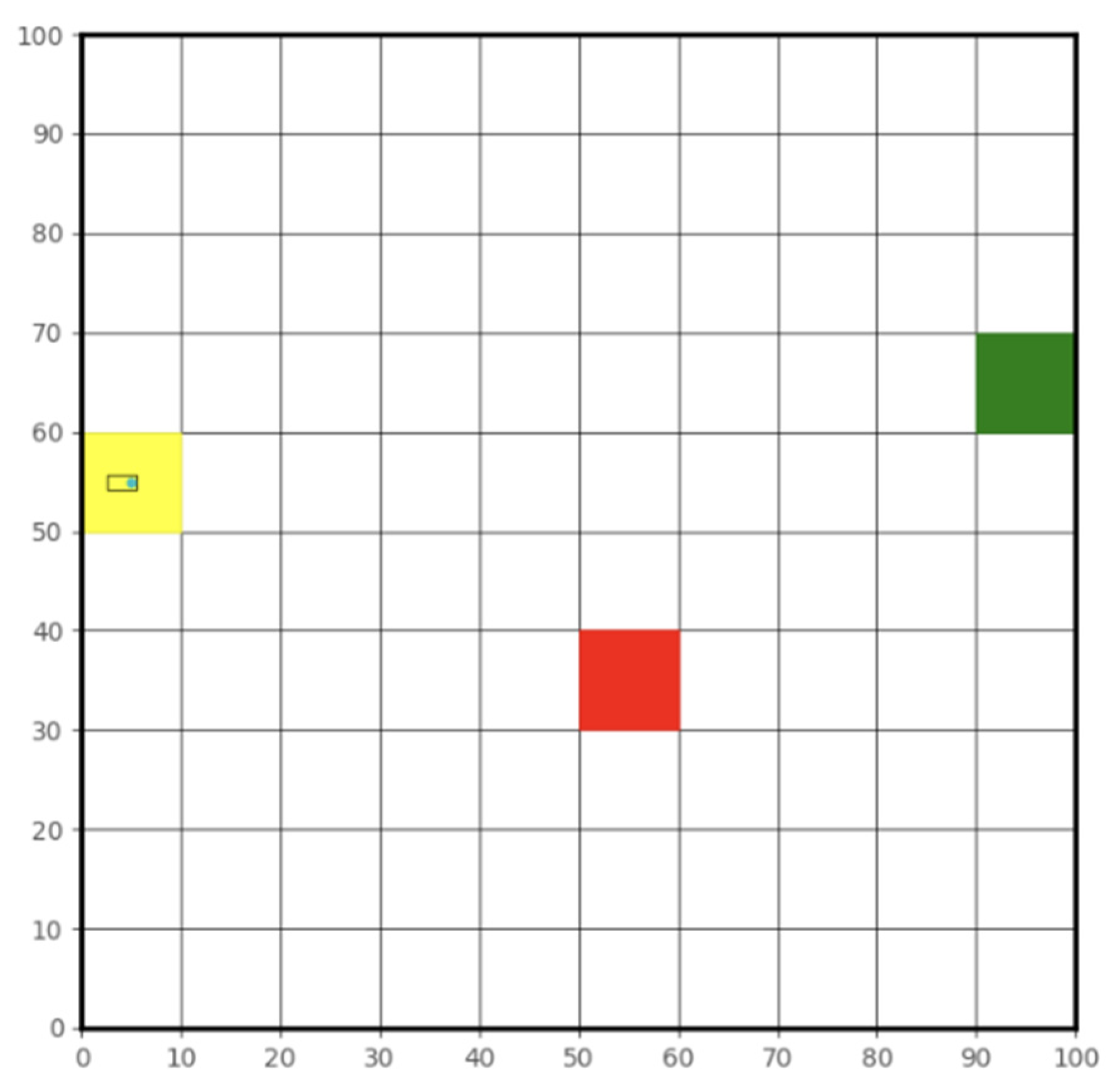
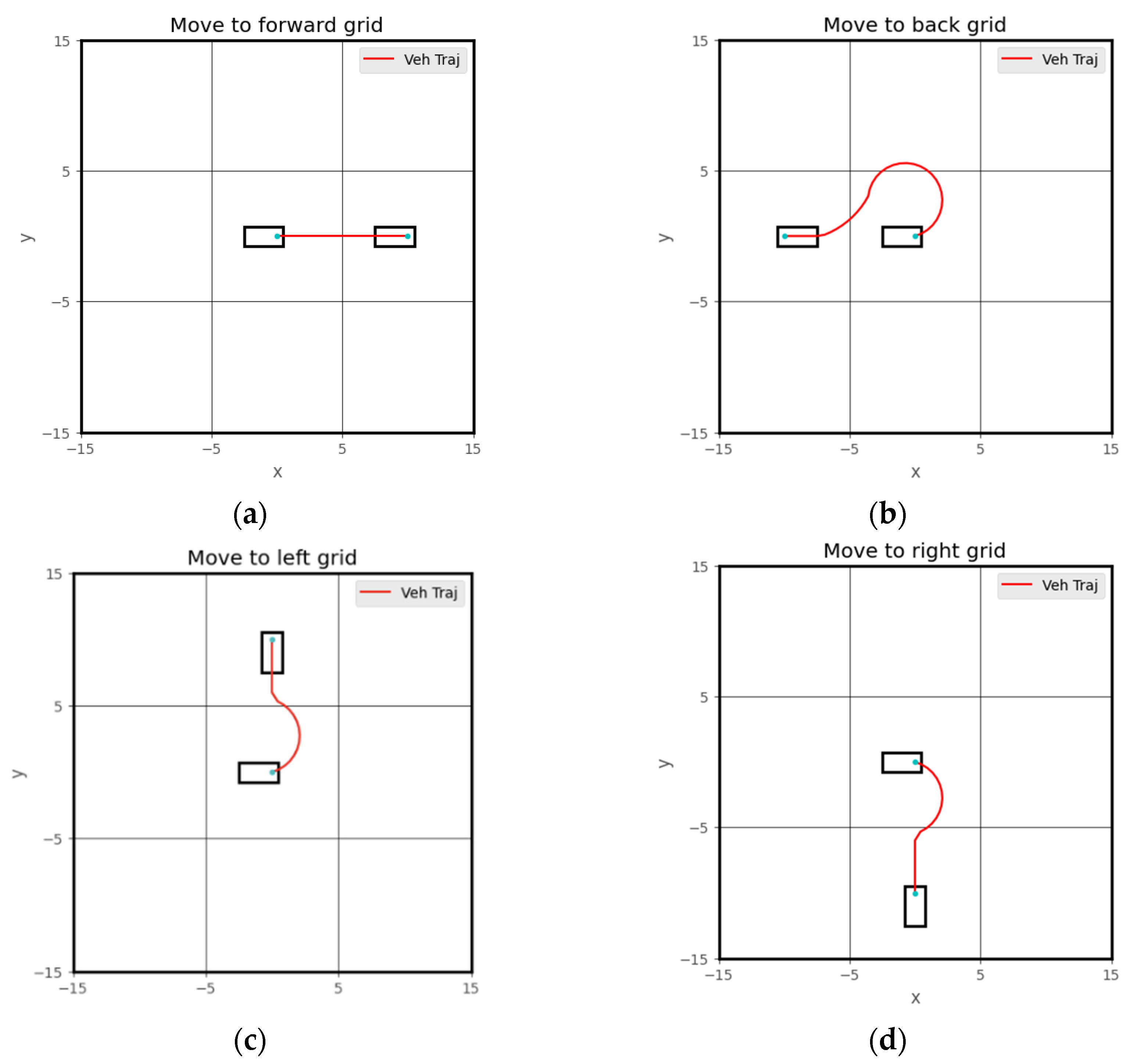
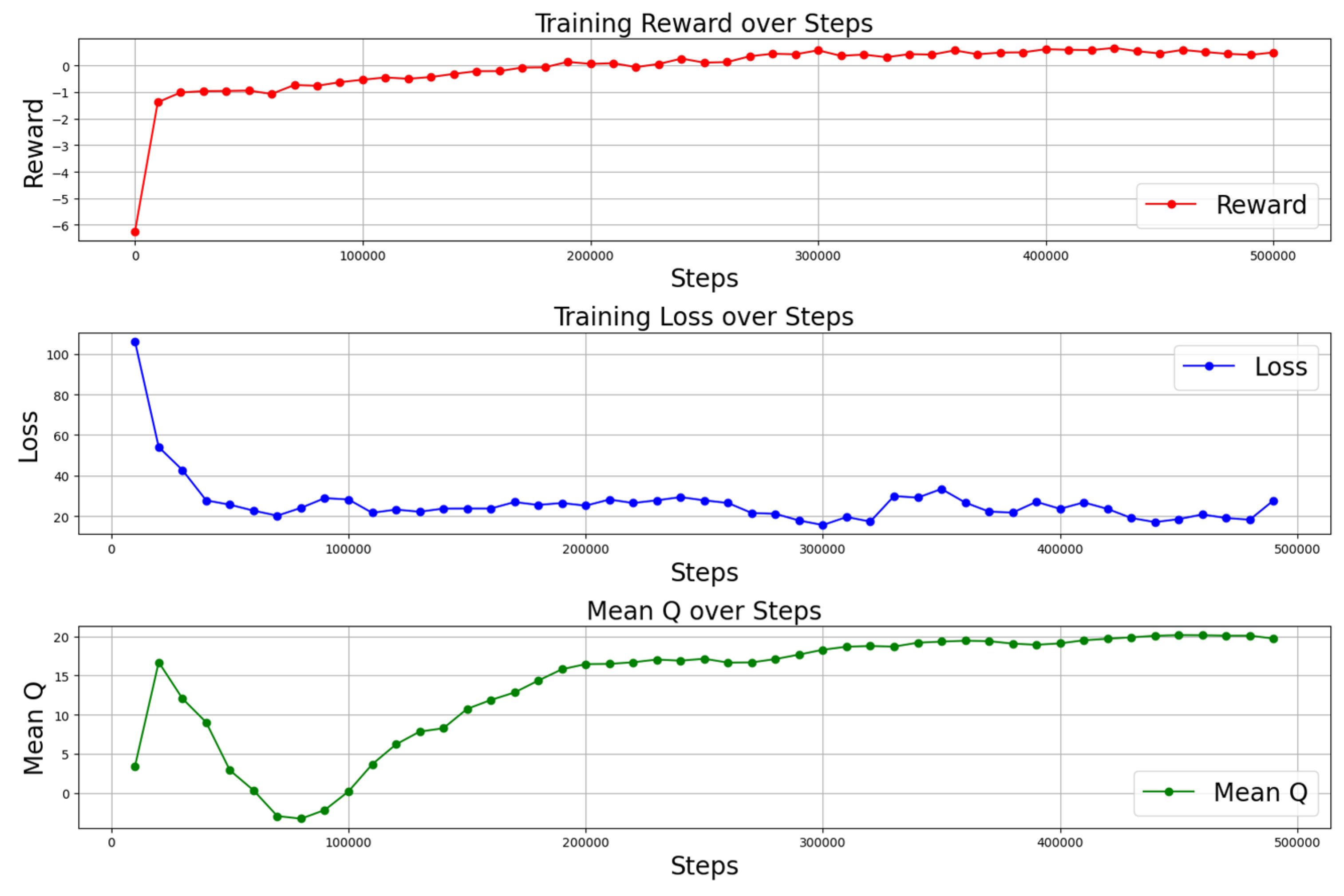
3.2.1. DRL High-Level Decision-Making Agent
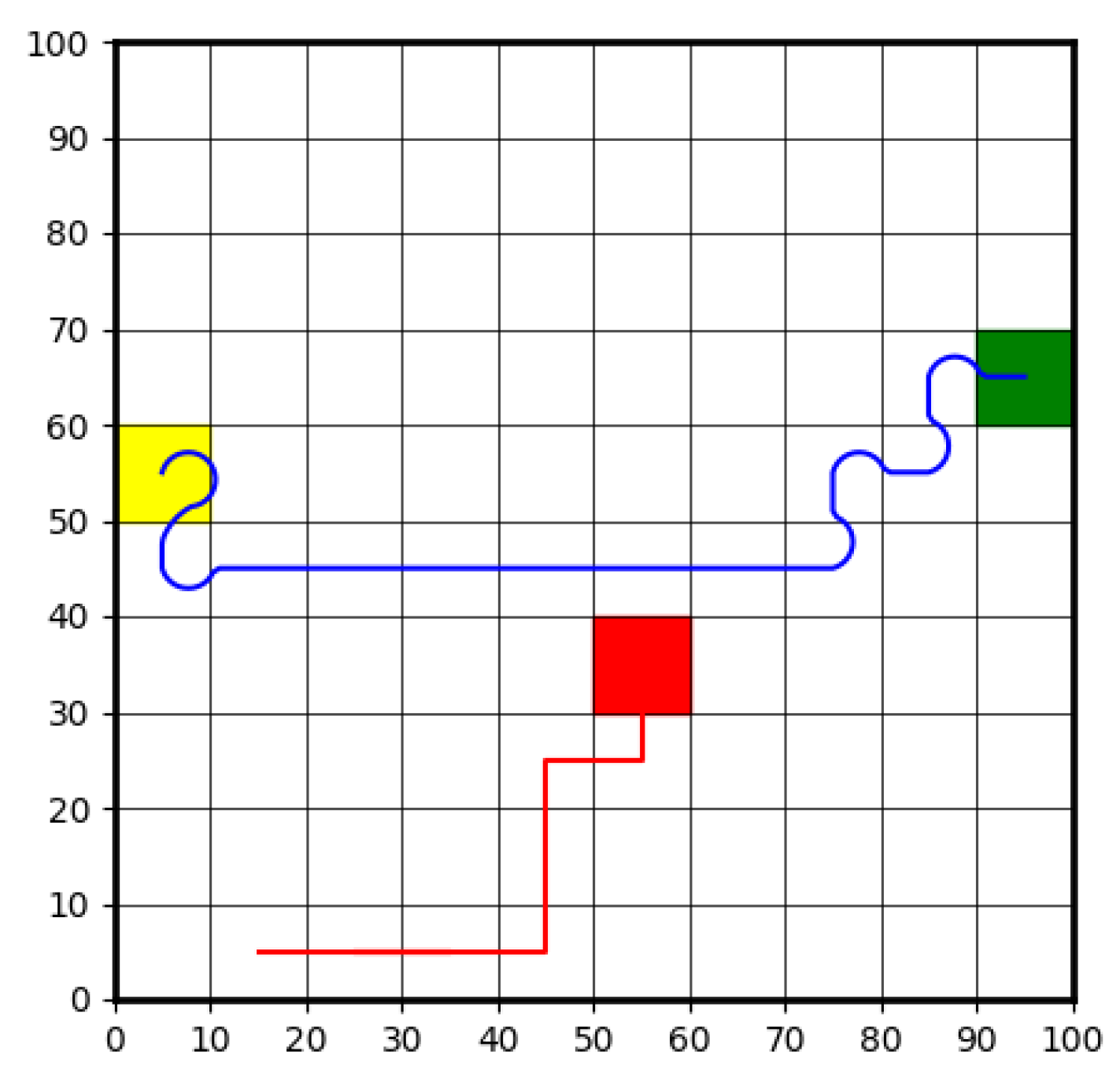
3.2.2. Hybrid DRL and CLF-CBF Controller
4. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wen, B.; Gelbal, S.; Aksun-Guvenc, B.; Guvenc, L. Localization and Perception for Control and Decision Making of a Low Speed Autonomous Shuttle in a Campus Pilot Deployment. SAE Int. J. Connect. Autom. Veh. 2018, 1, 53–66. [Google Scholar] [CrossRef]
- Gelbal, S.Y.; Guvenc, B.A.; Guvenc, L. SmartShuttle: A unified, scalable and replicable approach to connected and automated driving in a smart city. In Proceedings of the 2nd International Workshop on Science of Smart City Operations and Platforms Engineering, in SCOPE ’17, Pittsburgh, PA, USA, 11–12 November 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 57–62. [Google Scholar] [CrossRef]
- Autonomous Road Vehicle Path Planning and Tracking Control|IEEE eBooks|IEEE Xplore. Available online: https://ieeexplore.ieee.org/book/9645932 (accessed on 24 October 2023).
- Emirler, M.T.; Wang, H.; Güvenç, B. Socially Acceptable Collision Avoidance System for Vulnerable Road Users. IFAC-PapersOnLine 2016, 49, 436–441. [Google Scholar] [CrossRef]
- Chen, H.; Cao, X.; Guvenc, L.; Aksun-Guvenc, B. Deep-Reinforcement-Learning-Based Collision Avoidance of Autonomous Driving System for Vulnerable Road User Safety. Electronics 2024, 13, 1952. [Google Scholar] [CrossRef]
- Cao, X.; Chen, H.; Gelbal, S.Y.; Aksun-Guvenc, B.; Guvenc, L. Vehicle-in-Virtual-Environment (VVE) Method for Autonomous Driving System Development, Evaluation and Demonstration. Sensors 2023, 23, 5088. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y.; Zhong, H.; Qian, Y.; Wang, L.; Xie, Y. Lane-Change Collision Avoidance Control for Automated Vehicles with Control Barrier Functions. Int. J. Automot. Technol. 2023, 24, 739–748. [Google Scholar] [CrossRef]
- Jang, I.; Kim, H.J. Safe Control for Navigation in Cluttered Space Using Multiple Lyapunov-Based Control Barrier Functions. IEEE Robot. Autom. Lett. 2024, 9, 2056–2063. [Google Scholar] [CrossRef]
- Nasab, A.A.; Asemani, M.H. Control of Mobile Robots Using Control Barrier Functions in Presence of Fault. In Proceedings of the 2023 9th International Conference on Control, Instrumentation and Automation (ICCIA), Tehran, Iran, 20–21 December 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Alan, A.; Taylor, A.J.; He, C.R.; Ames, A.D.; Orosz, G. Control Barrier Functions and Input-to-State Safety With Application to Automated Vehicles. IEEE Trans. Control Syst. Technol. 2023, 31, 2744–2759. [Google Scholar] [CrossRef]
- Ames, A.D.; Grizzle, J.W.; Tabuada, P. Control barrier function based quadratic programs with application to adaptive cruise control. In Proceedings of the 53rd IEEE Conference on Decision and Control, Los Angeles, CA, USA, 15–17 December 2014; pp. 6271–6278. [Google Scholar] [CrossRef]
- Ames, A.D.; Xu, X.; Grizzle, J.W.; Tabuada, P. Control Barrier Function Based Quadratic Programs for Safety Critical Systems. IEEE Trans. Autom. Control 2017, 62, 3861–3876. [Google Scholar] [CrossRef]
- Ames, A.D.; Coogan, S.; Egerstedt, M.; Notomista, G.; Sreenath, K.; Tabuada, P. Control Barrier Functions: Theory and Applications. In Proceedings of the 2019 18th European Control Conference (ECC), Naples, Italy, 25–28 June 2019; pp. 3420–3431. [Google Scholar] [CrossRef]
- He, S.; Zeng, J.; Zhang, B.; Sreenath, K. Rule-Based Safety-Critical Control Design using Control Barrier Functions with Application to Autonomous Lane Change. arXiv 2021, arXiv:2103.12382. [Google Scholar] [CrossRef]
- Wang, L.; Ames, A.D.; Egerstedt, M. Safety Barrier Certificates for Collisions-Free Multirobot Systems. IEEE Trans. Robot. 2017, 33, 661–674. [Google Scholar] [CrossRef]
- Liu, M.; Kolmanovsky, I.; Tseng, H.E.; Huang, S.; Filev, D.; Girard, A. Potential Game-Based Decision-Making for Autonomous Driving. arXiv 2023, arXiv:2201.06157. [Google Scholar] [CrossRef]
- Reis, M.F.; Andrade, G.A.; Aguiar, A.P. Safe Autonomous Multi-vehicle Navigation Using Path Following Control and Spline-Based Barrier Functions. In Proceedings of the Robot 2023: Sixth Iberian Robotics Conference, Coimbra, Portugal, 22–24 November 2023; Marques, L., Santos, C., Lima, J.L., Tardioli, D., Ferre, M., Eds.; Springer Nature: Cham, Switzerland, 2024; pp. 297–309. [Google Scholar] [CrossRef]
- Desai, M.; Ghaffari, A. CLF-CBF Based Quadratic Programs for Safe Motion Control of Nonholonomic Mobile Robots in Presence of Moving Obstacles. In Proceedings of the 2022 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Hokkaido, Japan, 11–15 July 2022; pp. 16–21. [Google Scholar] [CrossRef]
- Long, K.; Yi, Y.; Cortes, J.; Atanasov, N. Distributionally Robust Lyapunov Function Search Under Uncertainty. arXiv 2024, arXiv:2212.01554. [Google Scholar] [CrossRef]
- Chang, Y.-C.; Roohi, N.; Gao, S. Neural Lyapunov Control. arXiv 2022, arXiv:2005.00611. [Google Scholar] [CrossRef]
- Knox, W.B.; Allievi, A.; Banzhaf, H.; Schmitt, F.; Stone, P. Reward (Mis)design for autonomous driving. Artif. Intell. 2023, 316, 103829. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.; Pérez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 4909–4926. [Google Scholar] [CrossRef]
- Ye, F.; Zhang, S.; Wang, P.; Chan, C.-Y. A Survey of Deep Reinforcement Learning Algorithms for Motion Planning and Control of Autonomous Vehicles. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 1073–1080. [Google Scholar] [CrossRef]
- Zhu, Z.; Zhao, H. A Survey of Deep RL and IL for Autonomous Driving Policy Learning. IEEE Trans. Intell. Transp. Syst. 2022, 23, 14043–14065. [Google Scholar] [CrossRef]
- Wang, H.; Tota, A.; Aksun-Guvenc, B.; Guvenc, L. Real time implementation of socially acceptable collision avoidance of a low speed autonomous shuttle using the elastic band method. Mechatronics 2018, 50, 341–355. [Google Scholar] [CrossRef]
- Lu, S.; Xu, R.; Li, Z.; Wang, B.; Zhao, Z. Lunar Rover Collaborated Path Planning with Artificial Potential Field-Based Heuristic on Deep Reinforcement Learning. Aerospace 2024, 11, 253. [Google Scholar] [CrossRef]
- Morsali, M.; Frisk, E.; Åslund, J. Spatio-Temporal Planning in Multi-Vehicle Scenarios for Autonomous Vehicle Using Support Vector Machines. IEEE Trans. Intell. Veh. 2021, 6, 611–621. [Google Scholar] [CrossRef]
- Zhu, S. Path Planning and Robust Control of Autonomous Vehicles. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA, 2020. Available online: https://www.proquest.com/docview/2612075055/abstract/73982D6BAE3D419APQ/1 (accessed on 24 October 2023).
- Chen, G.; Yao, J.; Gao, Z.; Gao, Z.; Zhao, X.; Xu, N.; Hua, M. Emergency Obstacle Avoidance Trajectory Planning Method of Intelligent Vehicles Based on Improved Hybrid A*. SAE Int. J. Veh. Dyn. Stab. NVH 2023, 8, 3–19. [Google Scholar] [CrossRef]
- Kendall, A.; Hawke, J.; Janz, D.; Mazur, P.; Reda, D.; Allen, J.-M.; Lam, V.-D.; Bewley, A.; Shah, A. Learning to Drive in a Day. arXiv 2018, arXiv:1807.00412. [Google Scholar] [CrossRef]
- Yurtsever, E.; Capito, L.; Redmill, K.; Ozguner, U. Integrating Deep Reinforcement Learning with Model-based Path Planners for Automated Driving. arXiv 2020, arXiv:2002.00434. [Google Scholar] [CrossRef]
- Dinh, L.; Quang, P.T.A.; Leguay, J. Towards Safe Load Balancing based on Control Barrier Functions and Deep Reinforcement Learning. arXiv 2024, arXiv:2401.05525. [Google Scholar] [CrossRef]
- Ashwin, S.H.; Naveen Raj, R. Deep reinforcement learning for autonomous vehicles: Lane keep and overtaking scenarios with collision avoidance. Int. J. Inf. Technol. 2023, 15, 3541–3553. [Google Scholar] [CrossRef]
- Muzahid, A.J.M.; Kamarulzaman, S.F.; Rahman, M.A.; Alenezi, A.H. Deep Reinforcement Learning-Based Driving Strategy for Avoidance of Chain Collisions and Its Safety Efficiency Analysis in Autonomous Vehicles. IEEE Access 2022, 10, 43303–43319. [Google Scholar] [CrossRef]
- Emuna, R.; Borowsky, A.; Biess, A. Deep Reinforcement Learning for Human-Like Driving Policies in Collision Avoidance Tasks of Self-Driving Cars. arXiv 2020, arXiv:2006.04218. [Google Scholar] [CrossRef]
- Albarella, N.; Lui, D.G.; Petrillo, A.; Santini, S. A Hybrid Deep Reinforcement Learning and Optimal Control Architecture for Autonomous Highway Driving. Energies 2023, 16, 3490. [Google Scholar] [CrossRef]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep Reinforcement Learning framework for Autonomous Driving. EI 2017, 29, 70–76. [Google Scholar] [CrossRef]
- Kavas-Torris, O.; Gelbal, S.Y.; Cantas, M.R.; Aksun Guvenc, B.; Guvenc, L. V2X Communication between Connected and Automated Vehicles (CAVs) and Unmanned Aerial Vehicles (UAVs). Sensors 2022, 22, 8941. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Zhang, F.; Aksun-Guvenc, B. Collision Avoidance in Autonomous Vehicles Using the Control Lyapunov Function–Control Barrier Function–Quadratic Programming Approach with Deep Reinforcement Learning Decision-Making. Electronics 2025, 14, 557. https://doi.org/10.3390/electronics14030557
Chen H, Zhang F, Aksun-Guvenc B. Collision Avoidance in Autonomous Vehicles Using the Control Lyapunov Function–Control Barrier Function–Quadratic Programming Approach with Deep Reinforcement Learning Decision-Making. Electronics. 2025; 14(3):557. https://doi.org/10.3390/electronics14030557
Chicago/Turabian StyleChen, Haochong, Fengrui Zhang, and Bilin Aksun-Guvenc. 2025. "Collision Avoidance in Autonomous Vehicles Using the Control Lyapunov Function–Control Barrier Function–Quadratic Programming Approach with Deep Reinforcement Learning Decision-Making" Electronics 14, no. 3: 557. https://doi.org/10.3390/electronics14030557
APA StyleChen, H., Zhang, F., & Aksun-Guvenc, B. (2025). Collision Avoidance in Autonomous Vehicles Using the Control Lyapunov Function–Control Barrier Function–Quadratic Programming Approach with Deep Reinforcement Learning Decision-Making. Electronics, 14(3), 557. https://doi.org/10.3390/electronics14030557