Abstract
This study evaluates the performance of seven large language models (LLMs) in generating context-aware recommendations. The system is built on a collection of PDF documents (brochures) describing local events and activities, which are embedded into an FAISS vector store to support semantic retrieval. Synthetic user profiles are defined to simulate diverse preferences, while static weather conditions are incorporated to enhance the contextual relevance of recommendations. To further improve output quality, a reranking step, utilizing Cohere’s API, is used to refine the top retrieved results before passing them to the LLMs for final response generation. This allows better semantic organization of relevant content in line with user context. The main aim of this research is to identify which models best integrate multimodal inputs, such as user intent, profile attributes, environmental context and how these insights can inform the development of adaptive, personalized recommendation systems. The main contribution of this study is a structured comparative analysis of 7 LLMs, applied to a tourism-specific RAG framework, providing practical insights into how effectively different models integrate contextual factors to produce personalized recommendations. The evaluation revealed notable differences in model performance, with Qwen and Phi emerging as the strongest performers, whereas LLaMA frequently produced irrelevant recommendations. Moreover, many models favored gastronomy-related venues over other types of attractions. These findings indicate that although the RAG framework provides a solid foundation, the selection of underlying models plays an important role in achieving high quality recommendations.
1. Introduction
The growing volume of digital information has transformed the tourism industry, making recommendation systems essential for managing choice overload [1]. These systems aim to reduce information overload by offering personalized suggestions for points of interest (POIs), events, and activities [2]. While traditional recommendation approaches have evolved over time [3], the emergence of Large Language Models (LLMs) marks a paradigm shift, providing new capabilities for interpreting context-rich queries and generating human-like text [4]. Moreover, their ability to process diverse inputs and large text datasets has led to increasing use in domain-specific applications, including tourism, where specialized implementations can offer more relevant and personalized experiences [5]. Primary challenge in modern recommendation engines is the delivery of personalized and context-aware suggestions [6] because effective personalization requires integration of both static user preferences and dynamic contextual inputs, such as, environmental factors (e.g., weather conditions) or temporary user interests. Integrating multiple sources of context is essential for building a complete user model that supports meaningful personalization. Moreover, grounding the recommendation process in a reliable and domain-specific information base helps minimize hallucinations and ensures that suggestions remain both useful and accurate. To address these challenges, this study evaluates the performance of seven distinct large language models in a context-aware recommendation setting. The models are run locally, using Ollama and providing a consistent and controlled evaluation environment. The system follows a Retrieval-Augmented Generation (RAG) approach, using a collection of PDF brochures, detailing local activities and events, as the knowledge base for semantic retrieval. These documents are embedded into an FAISS vector store, allowing relevant content to be retrieved based on user queries. A reranking step, conducted using Cohere, is applied to refine the top retrieved chunks, which helps prioritize semantically relevant results aligned with the user’s context. This setup simulates a realistic recommendation workflow where multiple sources of context are combined to tailor suggestions to individual users, and the models are evaluated based on their ability to deliver personalized and contextually appropriate suggestions across a range of user scenarios. The recommendation process combines two main contextual inputs: manually defined user profiles and fixed (static) weather conditions, simulating realistic but diverse situations. Through evaluation of these models within a defined, domain-specific scenario, the main contribution of this work lies in a systematic, comparative evaluation of 7 LLMs within a controlled, tourism-oriented RAG environment, emphasizing their capabilities and limitations in integrating multimodal context for personalized recommendations.
2. Background and Related Work
Previous research has shown that general-purpose language models often lack domain-specific knowledge required to generate accurate tourism recommendations, whereas integrating organized, domain-focused resources has been demonstrated to reduce errors and improve contextual relevance. This view is consistent with findings of Arefieva et al. (2022) [5], who introduced TourBERT, a BERT-based model trained on tourism corpora from over 20 countries which resulted in capturing domain-specific vocabulary and nuances that generic models often miss, thereby improving tasks such as review understanding and semantic alignment in tourism. Moreover, Wei et al. (2024) [7] developed TourLLM, a fine-tuned large language model trained on a specialized tourism corpus, which substantially improved the detail and accuracy of trip plans compared to baseline LLMs. Similar to this, Lee et al. (2024) [8] propose a Learning to Reduce framework that segments and condenses long structured contexts, enhancing both the precision and efficiency of QA tasks, which can be leveraged to improve the detail and accuracy of tourism recommendations. Furthermore, Nguyen (2024) [1] introduced the OurSCARA framework, which integrates sustainability and cultural awareness into tourism recommendation services. By considering real-time weather, events, and user sentiment cues, the system aligns recommendations with both user satisfaction and socio-cultural responsibility. Flórez et al. (2023) [9] extend this perspective with a hybrid recommendation system that combines deep learning with an ontology of attractions and conservation rules. Their evaluations show that the system can deliver personalized itineraries aligned with local environmental goals, ensuring that tourism recommendations are not only relevant but also sustainable. In their research, Song et al. (2024) [10] present TravelRAG, a system that automatically constructs a multilayer tourism knowledge graph from user-generated travel blogs to support retrieval-augmented generation (RAG). Their approach demonstrates significantly improved answer accuracy and a substantial reduction in hallucinations compared to standard RAG baselines. Similar to this, Banerjee et al. (2024) [11] propose a sustainability-augmented RAG (SAR) pipeline, which incorporates domain-specific objectives, such as promoting less-crowded destinations, into both retrieval and reranking stages, resulting in maintained relevance and approximately a one-third reduction in hallucination rates. In parallel, tourism recommendation systems have long leveraged context-aware data, user preferences, temporal factors, and environmental conditions to personalize suggestions. For example, Smajić et al. (2025) [12] propose a modular architecture that enriches product recommendation systems with real-time contextual inputs such as weather conditions. The approach demonstrates how aligning AI-driven recommendations with environmental data can significantly enhance user relevance and satisfaction. Similarly, Liu et al. (2024) [13] tackle challenges in POI recommendation (user modeling, timing, and trajectory complexity) by capturing dynamic user interests via latent topic modeling and predicting arrival times through a self-attention mechanism, resulting in more accurate, time-sensitive itineraries. Based on this, the following research hypothesis is formulated:
- Systems that integrate domain-specific textual resources into the retrieval process, such as in a tourism recommendation engine, will provide more accurate and contextually relevant recommendations than systems relying solely on general-purpose knowledge.
Another concern in adopting LLMs for tourism recommendation systems lies in reliability and factual accuracy. Due to training on static and general-purpose corpora, LLMs are prone to generating “hallucinated” or inaccurate responses, particularly for specialized knowledge. To address this, Wu et al. (2024) [14] present RecSys Arena, an LLM-based evaluation framework that simulates user feedback by generating profiles and performing pairwise comparisons of recommendation outputs. Their approach shows improved alignment with real-world A/B testing and greater sensitivity to subtle model differences, offering a richer alternative to traditional offline evaluation metrics. Similarly, Qi et al. (2024) [15] apply a retrieval-augmented generation (RAG) framework to a Tibetan tourism assistant, showing that integrating external knowledge effectively mitigates hallucinations and improves fluency, accuracy, and relevance compared to a pure LLM baseline. Moreover, Ahmed et al. (2025) [16] develop an evaluation framework for a tourism-specific RAG system. Their experiments reveal that retrieval components preserve factual accuracy, whereas high randomness can reduce response quality by up to 64%. Meng et al. (2024) [17] directly address hallucinations by introducing KERAG_R, a knowledge-enhanced RAG model that incorporates external knowledge graphs into the retrieval-augmented generation process. Their results demonstrate significant improvements in retrieval accuracy and factual grounding, mitigating one of the most pressing issues in generative recommendation systems. Based on these findings, the following research hypothesis is formulated:
- LLM-based recommendation systems that integrate external retrieval mechanisms and evaluation frameworks achieve higher accuracy and alignment with human evaluations compared to generative models based on static information.
Recent works highlight that large language models substantially differ in their ability to generate accurate and personalized recommendations, depending on both their internal architecture and the way they are adapted to domain-specific tasks. Xu et al. (2025) [18] introduce a comprehensive framework for analyzing how LLM characteristics, such as parameter size, fine-tuning strategies, and prompt engineering choices, impact recommendation performance. Their empirical findings show that not all models respond equally to the same prompting strategies. Moreover, Zhang et al. (2023) [19] present a new paradigm with their InstructRec model, which presents the recommendation process as an instruction following task. By aligning recommendations more closely with explicit user intentions, InstructRec significantly outperforms strong baselines across multiple benchmarks. Similarly, Liu et al. (2024) [13] propose RecPrompt, a framework that iteratively refines prompt templates to better capture user preferences in the news domain. Through systematic adjustments of prompt length, keyword emphasis, and instruction framing, their approach improves both coherence and personalization in generated suggestions. Other studies, like the one from Ghiani et al. (2024) [20], take a different angle by combining LLMs with optimization algorithms, enabling semi-structured decision-making that balances machine recommendations with human preferences while reducing cognitive load. To summarize, these studies emphasize that effective recommendation performance cannot be expected from general-purpose LLMs without careful adaptation. Performance gains are consistently achieved through approaches such as prompt refinement and instruction tuning alongside optimization methods. In line with these findings, Kozhipuram et al. (2025) [21] emphasize that pre-trained LLMs are limited by the static nature of their training data, which do not reflect recent events, and that their memorization capabilities are constrained when dealing with less frequent topics. Empirical evidence supports these observations. Liu et al. (2025) [22] found that instruction-tuned and domain-optimized LLMs achieved considerably higher recommendation accuracy, with up to 43% improvement over zero-shot models and more than 5% compared to conventional recommenders, confirming the decisive role of adaptation strategies in enhancing model performance. This further supports the argument that effective recommendation performance cannot be expected from general-purpose LLMs without careful adaptation. Performance gains are consistently achieved through approaches such as prompt refinement and instruction tuning alongside optimization methods. Based on this, the following research hypothesis is formulated:
- Different LLM architectures and adaptation strategies, such as prompt refinement and instruction tuning achieve significantly different levels of recommendation quality, with tuned and domain-adapted models outperforming general-purpose LLMs.
In the light of the advances stated above, our work builds on these ideas by combining them into a unified approach. To specify, a context-aware tourism recommendation system that combines semantic retrieval with augmented LLM generation is examined.
3. Methodology
This section outlines the methodological framework used to design, implement, and evaluate the context-aware tourism recommendation system. The approach is structured to ensure reproducibility and transparency, moving step by step from data preparation to evaluation. First, the relevant data sources are collected, processed, and transformed into usable formats. Next, the prompting strategy and retrieval-augmented generation (RAG) pipeline are described, followed by details on the inference environment where all models were tested under identical conditions. Finally, the evaluation metrics and analysis methods are presented, which together provide a comprehensive basis for comparing the performance of seven large language models.
3.1. Data Preparation
The system is built upon a knowledge base and contextual data sources to enable context-aware tourism recommendations. All available online tourist brochures were first collected and then filtered by relevance, with any document not pertaining to Lošinj excluded. Second, a collection of local tourism brochures in PDF format (attractions descriptions, events, and activities) was processed and embedded into a vector database using the FAISS library for similarity search [23]. Each PDF document was segmented into semantically coherent chunks and encoded as high-dimensional embeddings, allowing relevant content to be retrieved via semantic queries. Alongside the document corpus, 100 user profiles were synthetically created to simulate diverse traveler preferences and constraints. User parameters are static preferences which serve as a personalized context for recommendations. Table 1 summarizes and generalizes this diversity into the following unified attributes:

Table 1.
Overview of user profile variables used for contextual recommendation generation.
In addition, static weather data was defined for each scenario to represent environmental context (e.g., sunny, mostly cloudy, rainy, windy, and humid). The combination of user profiles and weather conditions provides a rich context that the recommendation generation must account for. By preparing these three data components:
- An embedded brochure knowledge base
- Representative user profiles
- Fixed weather context
the foundation for a contextual retrieval-augmented recommendation system is established.
3.2. Prompt Construction and Query Design
A prompting strategy to effectively incorporate the above context into each model’s input is designed. When a user query is issued, for example:
- Where can I have inventive vegan sweets for lunch on Lošinj?
the system first formulates an internal retrieval query based on the user’s intent. This involves using the semantic embedding of the user’s query (enhanced with user profile and weather context) to search the vector store for relevant brochure content. The top retrieved passages (e.g., descriptions of nearby local restaurants aligned with the user’s dietary preferences, attractions matching the user’s interests, etc.) are then compiled into a context snippet. Next, a structured prompt template, coded as system_message, is constructed for the LLM based on the extended guidance prompting strategy [24]. The following prompt includes:
- A summary of the user’s profile—e.g., “User is a vegan, loves plant-based desserts and enjoys outdoor activities such as hiking”
- A note on current weather conditions—e.g., “Weather: sunny, temperature 25 °C, Wind 10 km/h”
- The relevant local information retrieved as knowledge snippets (chunks) from brochures
Finally, the user’s original query is appended and the model is instructed to generate a recommendation. The prompt is structured in such a way to guide the model to utilize the provided context—for instance, by prefacing with a system message like:
- “You are an intelligent tourism assistant.You recommend personalized activities to tourists based on (⋯)”
This approach to prompt construction ensures that each model receives the same relevant information and contextual cues, guiding it to produce answers grounded in the knowledge base and aligned with user-specific needs. The query wording and format were also standardized across models to ensure consistency in task presentation and reduce potential differences arising from prompt sensitivity [25].
3.3. RAG Pipeline
The recommendation system follows a Retrieval-Augmented Generation (RAG) pipeline which combines information retrieval with LLM response generation to embed outputs within the retrieved context. The pipeline shown in Figure 1 operates in several stages:
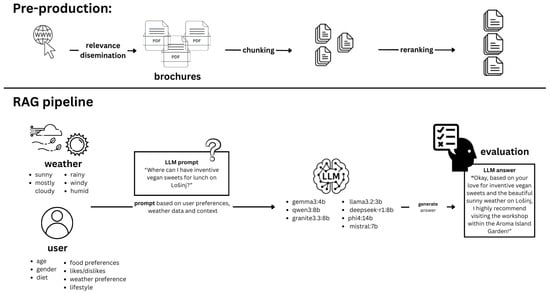
Figure 1.
Retrieval-Augmented Generation (RAG) pipeline for the recommender system based on the Lošinj dataset (Lošinj, Croatia), authors’ work.
- Semantic Retrieval: Given a user’s query and context, a semantic search is performed against the FAISS index of brochure embeddings. This provides the top-k most relevant document chunks (e.g., descriptions of attractions, events, or services pertinent to the query). In the experiment, an initial retrieval of 10 passages was performed using FAISS and the top five were subsequently reranked with Cohere to balance relevance with prompt-length constraints. A reranking step is then applied: using a secondary relevance model (in this case, the Cohere re-ranker) to reorder the retrieved chunks by contextual relevance. This retrieval stage with reranker improves the precision of retrieved passages by reordering candidates based on contextual relevance, thereby filtering out less pertinent information before prompt construction.
- Contextual Prompt Assembly: The highest-ranked textual snippets from retrieval are concatenated with the user’s profile and weather context into a single prompt, as described above. Each snippet is typically cited or separated (e.g., with headings or quotes) to clearly outline knowledge base content. This gives the LLM explicit evidence to draw from, reducing the chance of hallucination and providing factual grounding in the tourism domain.
- LLM Generation: The assembled prompt is passed to the language model which generates a response in the form of recommended activities or itineraries. Because the model’s generative process is conditioned on the retrieved facts and context, the output is expected to remain relevant to the query, personalized to the user profile, and contextually appropriate (e.g., suggesting indoor activities on a rainy day). The system prompt is configured to instruct the model as follows:
- “Respond in a friendly and informative tone.Your output should be a short and clear activity recommendation,followed by a brief explanation if needed.”
This setup ensures that a conversational style is adopted, with each recommendation accompanied by an explanation and relevant context references. No additional fine-tuning was performed on the models; instead, retrieval augmentation was employed to inject domain-specific knowledge at query time, following the paradigm demonstrated in prior knowledge-intensive LLM applications [7]. - Post-processing: The generated outputs from each LLM are captured without additional fine-tuning and only minimal post-processing is applied, limited to formatting corrections to preserve the authenticity of model behavior. This supports fair and transparent evaluation by retaining each model’s native response characteristics. Although stricter output constraints could be enforced in production settings, this study prioritizes the analysis of unaltered model capabilities. The RAG-based architecture ensures consistent access to the same context, combining accurate retrieval with consistent response generation. In other words, this system reduces hallucination risks and improves relevance in personalized tourism recommendations by grounding generation in brochure-derived knowledge.
3.4. Model Inference Environment
Seven large language models were evaluated within the above framework to compare their performance under identical conditions. The models LLaMA 3.2, Gemma 3, Mistral, Qwen 3, Granite 3.3, DeepSeek-R1, and Phi-4 were chosen to represent a mix of model architectures and parameter scales ranging from roughly 3 billion to 14 billion parameters as seen in Table 2.
Table 2.
LLM models and their parameter sizes.
All models were run locally on the same workstation using the Ollama LLM engine, thereby ensuring a controlled and consistent inference environment. Both methods used their default parameters and settings as given in their documentation [33]. By deploying each model on a local server, external sources of variability, such as network latency and reliance on third-party APIs, were eliminated. The use of Ollama provided a sandboxed inference environment, allowing seamless switching between models while maintaining all other conditions constant. Such uniformity is essential for a fair and unbiased comparative analysis, as it ensures that any observed differences in output can be attributed solely to the intrinsic behavior of the models, rather than to external or environmental factors. All evaluations were conducted on a single high-performance workstation equipped with GPU acceleration, ensuring adequate computational resources for all models during generation. This rigorously controlled setup allowed for a direct comparison of how each of the seven large language models interprets identical prompts and contextual information, thereby highlighting differences in their ability in integrating user profile and context data into recommendations.
3.5. Evaluation Metrics
Building upon the controlled inference setup described above, each model’s recommendation quality was subsequently evaluated through a unified assessment framework that combined structured logging with expert human annotations. This framework systematically captured each model’s generated output in response to standardized query scenarios, along with the contextual and profile information provided during inference. By preserving identical input conditions across all evaluations, the resulting outputs could be directly compared across models. Seven large language models (LLMs) were assessed under these uniform conditions, with their responses evaluated along three primary dimensions:
- relevance (the degree to which the recommendation addressed the user’s query and contextual cues)
- personalization (the extent to which the output aligned with the simulated user’s preferences and constraints) and
- factual accuracy (the correctness of specific details included in the response).
By integrating these dimensions, the evaluation provided a comprehensive perspective on each model’s capacity to generate contextually appropriate, personalized, and factually sound tourism recommendations within a consistent testing environment. Although attention visualization and internal token-level behavior analysis were outside the scope of this study, these remain promising directions for future evaluation frameworks in retrieval-augmented recommendation systems.
3.6. Relevance Ratings
Relevance was assessed using a three-point ordinal scale, where ratings were assigned as follows: −1 for recommendations deemed irrelevant to the user query or context, 0 for partially relevant or neutral responses, and 1 for highly relevant suggestions that directly addressed the user’s needs. This scale enabled a structured and interpretable evaluation of each model’s ability to generate contextually appropriate outputs.
3.7. Cohen’s Kappa
To assess the consistency of relevance judgments across different models, pairwise inter-model agreement was computed using Cohen’s kappa coefficient (). This statistic quantifies the level of agreement between two raters (in this case, models), correcting for agreement expected by chance. Formally, is defined as:
where represents agreement and the expected agreement due to chance. values range from −1 (complete disagreement) to 1 (perfect agreement), with 0 indicating agreement no better than chance. Each model was treated as an “independent rater” assigning relevance labels (−1, 0, 1) to each recommendation. Higher values indicate greater alignment between models in terms of their relevance judgments. Therefore, this analysis complements the human-evaluated personalization and factual accuracy dimensions.
3.8. Results and Discussion
Using relevance annotations across all test cases, scores are computed for all unique model pairs. The resulting pairwise values are visualized as a symmetric heatmap in Figure 2. In this matrix, each cell indicates the agreement between a pair of models, with values ranging from approximately 0.05 to 0.41. Diagonal entries are set to 1 by definition, representing perfect self-agreement. The color intensity corresponds to the magnitude of : darker (warmer) shades indicate stronger inter-model agreement, while lighter (cooler) shades reflect weaker agreement.
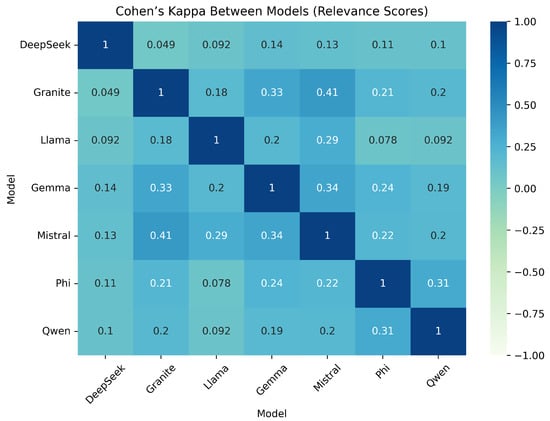
Figure 2.
Inter-model agreement on relevance judgments, measured using Cohen’s .
To complement the inter-model agreement analysis, a comprehensive breakdown of relevance score distributions, based on heatmap, is provided in Table 3. This presents a detailed overview, highlighting notable contrast in relevance quality across models.
Table 3.
Summary of Model Relevance Score.
Based on the available values, the strongest agreement was observed between Granite and Mistral ( ≈ 0.41), indicating that these two mid-performing models frequently made similar relevance judgments. Other pairs with relatively high agreement include Granite–Gemma ( ≈ 0.33) and Gemma–Mistral ( ≈ 0.34), suggesting a moderate degree of alignment among models within the same performance tier. In contrast, low scores were found in several mismatched pairs comprising dissimilar models. For instance, DeepSeek–Granite ( ≈ 0.05), DeepSeek–LLaMA ( ≈ 0.09), and LLaMA–Phi ( ≈ 0.08) demonstrated minimal agreement, indicating that these models often diverged in their assessments of relevance. Notably, agreement tended to be higher between models of similar performance, regardless of whether they were strong or weak. For example, the stronger-performing Phi and Qwen models achieved moderate agreement (≈ 0.31), while LLaMA, the weakest model overall, exhibited consistently low alignment with all others—reinforcing the view that correlates with overall model quality. This pattern suggests that models with comparable capabilities tend to succeed or fail on similar subsets of queries, resulting in higher scores. Conversely, pairings between strong and weak models approach chance-level agreement, likely due to differences in how they interpret and prioritize relevance. Figure 2 visualizes these patterns, revealing clusters of behavioral similarity: Gemma, Granite, and Mistral form a mid-tier group with moderate mutual agreement, while Phi and Qwen share patterns typical of top-performing models. The isolated position of LLaMA reflects its inconsistent and often misaligned judgments compared to all other systems.
To contextualize the observed scores, the raw relevance label was further analyzed for distributions for individual models. As shown in Figure 3, the models receiving the highest number of positive relevance scores (+1) were DeepSeek (), followed by Qwen () and Phi (). These models consistently generated outputs deemed relevant across a large number of prompts. This high incidence of positive labels aligns with their strong agreement in the kappa heatmap (e.g., ≈ 0.31 for Qwen–Phi), indicating not only good standalone performance but also consistency with one another in relevance judgments.
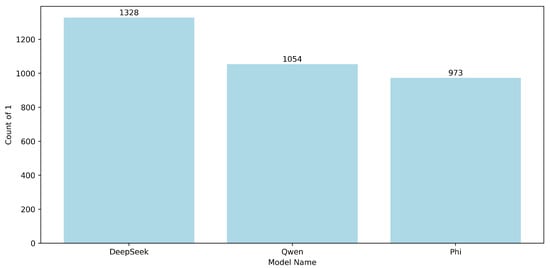
Figure 3.
Distribution of positive relevance scores (+1) for top-performing models.
Neutral judgments (i.e., relevance score = 0) were infrequent across the dataset, indicating that models typically produced outputs judged as clearly relevant or clearly irrelevant. As shown in Figure 4, the models with the lowest number of neutral scores were Granite (), Gemma (), and DeepSeek (). This scarcity of neutral ratings suggests that these models made more decisive relevance predictions, either generating clearly relevant or clearly irrelevant responses. For DeepSeek in particular, this reinforces its profile as a confident and assertive model, rarely producing borderline or ambiguous outputs—possibly contributing to its relatively polarized agreement scores with models of different performance tiers.
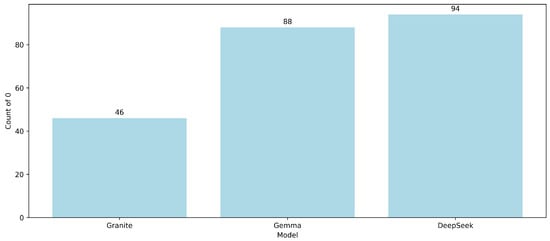
Figure 4.
Models with the lowest number of neutral relevance judgments (score = 0).
At the other end of the spectrum, Figure 5 displays the distribution of negative relevance scores (−1). The top three models receiving the most negative “feedback” were LLaMA (), Mistral (), and Granite (). This pattern reinforces the interpretation that these models struggled more often with generating relevant responses. It also provides a possible explanation for their relatively high inter-agreement (e.g., Mistral–Granite ≈ 0.41), as these models may have failed in tandem on similar queries, resulting in consistent but suboptimal performance.
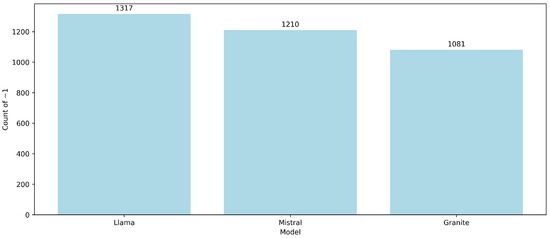
Figure 5.
Distribution of negative relevance scores (−1) among the lowest-performing models.
A deeper inspection of DeepSeek, the model with the highest total count of +1 labels (see Figure 6), confirms its position as a top performer in terms of relevance. With 1328 positively rated outputs, it not only outperformed others in terms of volume but also demonstrated strong relevance consistency across cases. Although DeepSeek’s agreement with models like Qwen ( ≈ 0.10) or Phi ( ≈ 0.11) remained modest, its high positive output count suggests strong overall alignment with human-judged relevance. Its elevated neutral score count further hints at a nuanced behavior, potentially reflecting its ability to attempt answers even in borderline cases where other models failed outright.
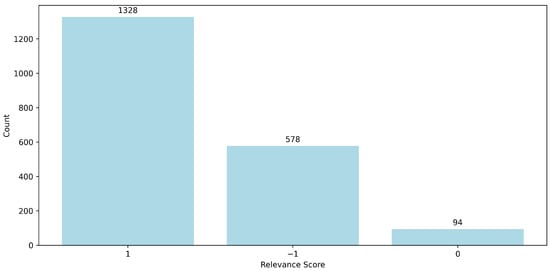
Figure 6.
Distribution of DeepSeek’s relevance scores across the evaluation dataset.
While relevance scores reflect how well a model responds to user queries, examining the semantic content of those responses, specifically, the categories of venues or activities suggested, provides a complementary lens for understanding model intent and topical accuracy.
To further contextualize model performance, external benchmark evaluations offer an additional, quantitative perspective on general reasoning and instruction-following capabilities. Figure 7 presents the comparative performance of Qwen3-8B and LLaMA 3.2-3B based on the BEYONDBENCH evaluation framework by Srivastava et al. (2025) [34]. This benchmark assesses models across a diverse set of reasoning, comprehension, and instruction-following tasks, providing an external validation of their general capabilities relevant to context-aware recommendation generation. Qwen3-8B achieves an overall accuracy of 59.70%, substantially outperforming LLaMA 3.2-3B, which reaches only 21.07%. Notably, the figure also illustrates that Qwen3-8B performs better on instruction-following tasks, which aligns with its tendency to generate recommendations concentrated in core categories. In contrast, LLaMA 3.2 produced a more dispersed set of outputs, with a significant number of recommendations falling outside expected categories, reflecting weaker adherence to instructions and lower contextual alignment.
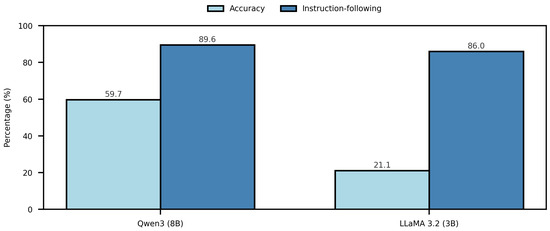
Figure 7.
Comparative results for Qwen3-8B and LLaMA 3.2-3B, showing accuracy and instruction-following rates. Data taken from Srivastava et al. (2025) [34].
Qwen3-8B’s advantage can be attributed to its larger model scale, comprising eight billion parameters, and the Strong-to-Weak Distillation training pipeline, which enhances representational efficiency and reasoning precision while maintaining computational efficiency [Qwen3 Tech Doc]. The correspondence between BEYONDBENCH results and recommendation patterns confirms that Qwen3-8B’s higher accuracy and stronger instruction-following contribute to more focused, semantically aligned outputs.
3.9. Category Label Distribution per Model
In addition to rating the relevance of model outputs, each recommendation was annotated with a category label indicating the type of venue or activity recommended (e.g., Gastronomy, Nature, Sport, Cafeteria, or Other). This labeling enabled a structured analysis of thematic tendencies across models. Figure 8 provides an illustrative example for the LLaMA model, showing the frequency distribution of category assignments.
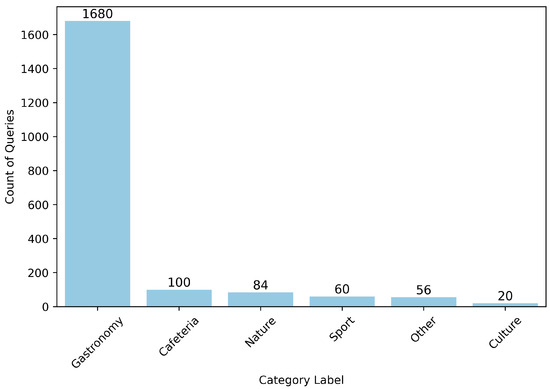
Figure 8.
Distribution of output categories for LLaMA-generated venue recommendations.
- Across all models, Gastronomy, which includes food-related venues such as restaurants or cafés, was the most common category of recommendation, counting 420, or 1680 for all four reviewers. This aligns with the query set, which frequently involved food- or drink-based requests
- In contrast, categories such as Cafeteria (25), Nature (21), Sport (15), and Culture (5) appeared only sporadically. The “Other” (16) label, which captures off-topic or hallucinated content, was used selectively but serves as a critical diagnostic signal.
Notably, higher-performing models such as Qwen and Phi tended to generate recommendations concentrated in core categories, especially Gastronomy, and rarely triggered the Other label. Conversely, weaker models like LLaMA, Granite, Mistral, and Gemma showed a greater dispersion of outputs, including a significant number of recommendations that fell outside expected categories. This trend directly mirrors their higher irrelevance rates discussed earlier—suggesting a tight coupling between category fidelity and relevance. In essence, strong models not only provided relevant answers but also understood the domain of the user query, whereas weaker models often hallucinated or misclassified venue types.
While Figure 8 illustrates the category distribution for LLaMA, separate plots for the remaining models are not included, as they follow the same categorical structure and offer no additional visual insight.
4. Conclusions
This work provides a systematic evaluation of seven large language models within the setting of a context-aware tourism recommendation system. The comparative analysis revealed considerable performance variability across models, demonstrating that not all architectures are equally suited for tasks requiring domain adaptation and personalized outputs. In particular, some models consistently generated highly relevant recommendations while minimizing irrelevant content, whereas others struggled to achieve satisfactory accuracy.
The findings highlight the critical role of model selection when deploying recommendation systems in applied contexts. By illustrating how different models handle contextual cues, such as user preferences and external factors like weather conditions, the study underscores the added value of context integration in enhancing personalization. These insights extend beyond tourism, offering implications for other domains where tailored recommendations can significantly improve user experience and decision-making.
From a methodological perspective, the study contributes a reproducible framework for benchmarking large language models under uniform conditions. This framework may serve as a foundation for future evaluations, enabling systematic comparisons as new models continue to emerge. Moreover, the observed variability suggests that hybrid strategies, combining the strengths of multiple models or integrating symbolic reasoning components, could be a promising approach for mitigating weaknesses and further boosting reliability.
In addition to expanding range of contextual and environmental variables, future work may also investigate the underlying factors contributing to differences in model performance. Understanding why certain models generate more relevant or semantically aligned recommendations, including differences in architecture, training data, or reasoning capabilities, could provide deeper insights and guide the design of more effective recommendation systems. Looking ahead, future work could explore the inclusion of additional contextual dimensions, such as seasonal variations, evolving user preferences or cultural preferences, as well as the incorporation of multimodal data sources beyond text. Expanding evaluations to larger and more diverse datasets, alongside real-world user studies, can also be essential for validating the scalability and practical impact of these systems. While the current study focused on performance variation among LLMs in a RAG-based tourism recommendation setting, it did not include direct comparisons with traditional recommendation methods such as collaborative filtering or popularity-based rankings. This was a deliberate design choice, as our aim was to evaluate language model behavior within a controlled, context-based framework. However, this absence of baseline comparison limits broader claims about real-world superiority. Future work should consider benchmarking RAG-based LLMs against traditional systems to more clearly assess their practical added value, particularly in live deployment scenarios. Furthermore, comparisons between domain-specific and general-purpose LLMs were not conducted within this study, as it was based solely on the comparison of the specified LLMs. Claims regarding the benefits of domain adaptation are grounded in prior empirical research, a part of the section titled Background and related work of this paper, rather than statistical evidence. While the literature reports measurable improvements in accuracy and contextual relevance for tourism-adapted models, future work could include controlled statistical evaluations to directly quantify these differences within our experimental setup. By pursuing these directions, researchers can contribute to more robust, transparent, and user-centered recommendation technologies that bridge the gap between experimental results and operational deployment.
Author Contributions
Conceptualization, R.K., M.R. and A.S., methodology, R.K., M.R. and A.S.; software, R.K. and M.R.; validation, R.K., M.R., A.S. and L.S.; formal analysis, A.S.; investigation, R.K.; resources, R.K., M.R. and A.S.; data curation, R.K., M.R. and A.S.; writing—original draft preparation, R.K., M.R. and A.S.; writing—review and editing, M.R.; visualization, A.S.; supervision, I.L.; project administration, I.L.; funding acquisition, I.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research is (partly) supported by SPIN projects “INFOBIP Konverzacijski Order Management (IP.1.1.03.0120)”, “Projektiranje i razvoj nove generacije laboratorijskog informacijskog sustava (iLIS)” (IP.1.1.03.0158), “Istraživanje i razvoj inovativnog sustava preporuka za napredno gostoprimstvo u turizmu (InnovateStay)” (IP.1.1.03.0039), “European Digital Innovation Hub Adriatic Croatia (EDIH Adria) (project no. 101083838)” under the European Commission’s Digital Europe Programme and the FIPU project “Sustav za modeliranje i provedbu poslovnih procesa u heterogenom i decentraliziranom računalnom sustavu”.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| FAISS | Facebook AI Similarity Search |
| LLM | Large Language Model |
| POI | Point of Interest |
| RAG | Retrieval-augmented Generation |
References
- Nguyen, L.V. OurSCARA: Awareness-Based Recommendation Services for Sustainable Tourism. World 2024, 5, 471–482. [Google Scholar] [CrossRef]
- Jiang, S.; Song, H.; Lu, Y.; Zhang, Z. News Recommendation Method Based on Candidate-Aware Long-and Short-Term Preference Modeling. Appl. Sci. 2024, 15, 300. [Google Scholar] [CrossRef]
- Smajić, A.; Karlović, R.; Bobanović Dasko, M.; Lorencin, I. Large Language Models for Structured and Semi-Structured Data, Recommender Systems and Knowledge Base Engineering: A Survey of Recent Techniques and Architectures. Electronics 2025, 14, 3153. [Google Scholar] [CrossRef]
- Zheng, H.; Xu, Z.; Pan, Q.; Zhao, Z.; Kong, X. Plugging Small Models in Large Language Models for POI Recommendation in Smart Tourism. Algorithms 2025, 18, 376. [Google Scholar] [CrossRef]
- Arefieva, V.; Egger, R. TourBERT: A pretrained language model for the tourism industry. arXiv 2022, arXiv:2201.07449. [Google Scholar] [CrossRef]
- Liu, F.; Chen, J.; Yu, J.; Zhong, R. Next Point of Interest (POI) Recommendation System Driven by User Probabilistic Preferences and Temporal Regularities. Mathematics 2025, 13, 1232. [Google Scholar] [CrossRef]
- Wei, Q.; Yang, M.; Wang, J.; Mao, W.; Xu, J.; Ning, H. Tourllm: Enhancing llms with tourism knowledge. arXiv 2024, arXiv:2407.12791. [Google Scholar]
- Lee, Y.; Kim, S.; Rossi, R.A.; Yu, T.; Chen, X. Learning to Reduce: Towards Improving Performance of Large Language Models on Structured Data. arXiv 2024, arXiv:2407.02750. [Google Scholar] [CrossRef]
- Flórez, M.; Carrillo, E.; Mendes, F.; Carreño, J. A Context-Aware Tourism Recommender System Using a Hybrid Method Combining Deep Learning and Ontology-Based Knowledge. J. Theor. Appl. Electron. Commer. Res. 2025, 20, 194. [Google Scholar] [CrossRef]
- Song, S.; Yang, C.; Xu, L.; Shang, H.; Li, Z.; Chang, Y. TravelRAG: A Tourist Attraction Retrieval Framework Based on Multi-Layer Knowledge Graph. ISPRS Int. J. Geo-Inf. 2024, 13, 414. [Google Scholar] [CrossRef]
- Banerjee, A.; Satish, A.; Wörndl, W. Enhancing tourism recommender systems for sustainable city trips using retrieval-augmented generation. In Proceedings of the International Workshop on Recommender Systems for Sustainability and Social Good; Springer: Cham, Switzerland, 2024; pp. 19–34. [Google Scholar]
- Smajić, A.; Rovis, M.; Lorencin, I. Context-aware Product Recommendations Using Weather Data and AI Models. In Proceedings of the 7th International Conference on Human Systems Engineering and Design (IHSED 2025), Juraj Dobrila University of Pula, Pula, Croatia, 22–24 September 2025. [Google Scholar]
- Liu, D.; Yang, B.; Du, H.; Greene, D.; Hurley, N.; Lawlor, A.; Dong, R.; Li, I. RecPrompt: A Self-tuning Prompting Framework for News Recommendation Using Large Language Models. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, Boise, ID, USA, 21–25 October 2024; pp. 3902–3906. [Google Scholar]
- Wu, Z.; Jia, Q.; Wu, C.; Du, Z.; Wang, S.; Wang, Z.; Dong, Z. RecSys Arena: Pair-wise Recommender System Evaluation with Large Language Models. arXiv 2024, arXiv:2412.11068. [Google Scholar]
- Qi, J.; Yan, S.; Zhang, Y.; Zhang, W.; Jin, R.; Hu, Y.; Wang, K. Rag-optimized tibetan tourism llms: Enhancing accuracy and personalization. In Proceedings of the 2024 7th International Conference on Artificial Intelligence and Pattern Recognition, Xiamen, China, 20–22 September 2024; pp. 1185–1192. [Google Scholar]
- Ahmed, B.S.; Baader, L.O.; Bayram, F.; Jagstedt, S.; Magnusson, P. Quality Assurance for LLM-RAG Systems: Empirical Insights from Tourism Application Testing. In Proceedings of the 2025 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Naples, Italy, 31 March–4 April 2025; pp. 200–207. [Google Scholar]
- Meng, Z.; Yi, Z.; Ounis, I. KERAG_R: Knowledge-Enhanced Retrieval-Augmented Generation for Recommendation. arXiv 2025, arXiv:2507.05863. [Google Scholar]
- Xu, L.; Zhang, J.; Li, B.; Wang, J.; Chen, S.; Zhao, W.X.; Wen, J.R. Tapping the potential of large language models as recommender systems: A comprehensive framework and empirical analysis. ACM Trans. Knowl. Discov. Data 2025, 19, 105. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, R.; Hou, Y.; Zhao, W.X.; Lin, L.; Wen, J.R. Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach. arXiv 2023, arXiv:2305.07001. [Google Scholar] [CrossRef]
- Ghiani, G.; Solazzo, G.; Elia, G. Integrating Large Language Models and Optimization in Semi-Structured Decision Making: Methodology and a Case Study. Algorithms 2024, 17, 582. [Google Scholar] [CrossRef]
- Kozhipuram, A.; Shailendra, S.; Kadel, R. Retrieval-Augmented Generation vs. Baseline LLMs: A Multi-Metric Evaluation for Knowledge-Intensive Content. Information 2025, 16, 766. [Google Scholar] [CrossRef]
- Liu, Q.; Zhu, J.; Fan, L.; Wang, K.; Hu, H.; Guo, W.; Liu, Y.; Wu, X.M. Can LLMs Outshine Conventional Recommenders? A Comparative Evaluation. In Proceedings of the Thirty-Ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, San Diego, CA, USA, 2–7 December 2025. [Google Scholar]
- Johnson, J.; Douze, M.; Jégou, H. Billion-Scale Similarity Search with GPUs. IEEE Trans. Big Data 2021, 7, 535–547. [Google Scholar] [CrossRef]
- Karlović, R.; Lorencin, I. Large language models as Retail Cart Assistants: A Prompt-Based Evaluation. In Human Systems Engineering and Design (IHSED2025): Future Trends and Applications; AHFE Open Access: Pula, Croatia, 2025. [Google Scholar]
- Carvalho, I.; Ivanov, S. ChatGPT for tourism: Applications, benefits, and risks. Tour. Rev. 2024, 79, 290–303. [Google Scholar] [CrossRef]
- Liu, Z.; Zhao, C.; Fedorov, I.; Soran, B.; Choudhary, D.; Krishnamoorthi, R.; Chandra, V.; Tian, Y.; Blankevoort, T. Spinquant: Llm quantization with learned rotations. arXiv 2024, arXiv:2405.16406. [Google Scholar] [CrossRef]
- Team, G.; Kamath, A.; Ferret, J.; Pathak, S.; Vieillard, N.; Merhej, R.; Perrin, S.; Matejovicova, T.; Ramé, A.; Rivière, M.; et al. Gemma 3 technical report. arXiv 2025, arXiv:2503.19786. [Google Scholar] [CrossRef]
- Jiang, A.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.; de Las Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7b. arXiv 2023, arXiv:2310.06825. [Google Scholar] [CrossRef]
- Yang, A.; Li, A.; Yang, B.; Zhang, B.; Hui, B.; Zheng, B.; Yu, B.; Gao, C.; Huang, C.; Lv, C.; et al. Qwen3 technical report. arXiv 2025, arXiv:2505.09388. [Google Scholar] [CrossRef]
- Team, G.V.; Karlinsky, L.; Arbelle, A.; Daniels, A.; Nassar, A.; Alfassi, A.; Wu, B.; Schwartz, E.; Joshi, D.; Kondic, J.; et al. Granite Vision: A lightweight, open-source multimodal model for enterprise Intelligence. arXiv 2025, arXiv:2502.09927. [Google Scholar] [CrossRef]
- Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; Bi, X.; et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv 2025, arXiv:2501.12948. [Google Scholar]
- Abdin, M.; Aneja, J.; Behl, H.; Bubeck, S.; Eldan, R.; Gunasekar, S.; Harrison, M.; Hewett, R.J.; Javaheripi, M.; Kauffmann, P.; et al. Phi-4 Technical Report. arXiv 2024, arXiv:2412.08905. [Google Scholar]
- Huang, D.; Wang, Z. LLMs at the Edge: Performance and Efficiency Evaluation with Ollama on Diverse Hardware. In Proceedings of the 2025 International Joint Conference on Neural Networks (IJCNN), Rome, Italy, 30 June–5 July 2025; pp. 1–8. [Google Scholar]
- Srivastava, G.; Hussain, A.; Bi, Z.; Roy, S.; Pitre, P.; Lu, M.; Ziyadi, M.; Wang, X. BeyondBench: Benchmark-Free Evaluation of Reasoning in Language Models. arXiv 2025, arXiv:2509.24210. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).