Abstract
With the continuous growth of user reviews, identifying underlying sentiment across multi-source texts efficiently and accurately has become a significant challenge in NLP. Traditional single models in cross-domain sentiment analysis often exhibit insufficient stability, limited generalization capabilities, and sensitivity to class imbalance. Existing ensemble methods predominantly rely on static weighting or voting strategies among homogeneous models, failing to fully leverage the complementary advantages between models. To address these issues, this study proposes a heterogeneous ensemble sentiment classification model integrating multi-view features and dynamic weighting. At the feature learning layer, the model constructs three complementary base learners, a RoBERTa-FC for extracting global semantic features, a BERT-BiGRU for capturing temporal dependencies, and a TextCNN-Attention for focusing on local semantic features, thereby achieving multi-level text representation. At the decision layer, a meta-learner is used to fuse multi-view features, and dynamic uncertainty weighting and attention weighting strategies are employed to adaptively adjust outputs from different base learners. Experimental results across multiple domains demonstrate that the proposed model consistently outperforms single learners and comparison methods in terms of Accuracy, Precision, Recall, F1 Score, and Macro-AUC. On average, the ensemble model achieves a Macro-AUC of 0.9582 ± 0.023 across five datasets, with an Accuracy of 0.9423, an F1 Score of 0.9590, and a Macro-AUC of 0.9797 on the AlY_ds dataset. Moreover, in cross-dataset ranking evaluation based on equally weighted metrics, the model consistently ranks within the top two, confirming its superior cross-domain adaptability and robustness. These findings highlight the effectiveness of the proposed framework in enhancing sentiment classification performance and provide valuable insights for future research on lightweight dynamic ensembles, multilingual, and multimodal applications.
1. Introduction
With the widespread adoption of the internet and mobile devices, UGC continues to grow exponentially. As a quintessential form of unstructured data, reviews contain rich emotional and opinion-based information. Such reviews directly influence user decisions and provide crucial insights for intelligent recommendations, human–computer interaction, sentiment monitoring, and service optimization across diverse sectors including healthcare, e-commerce, hospitality, and entertainment. Consequently, efficiently and accurately identifying sentiment tendencies from large-scale, multi-source, and cross-domain reviews represents both a core challenge in NLP and intelligent computing and a critical requirement for engineering deployment [1].
Traditional sentiment analysis methods often rely on dictionaries or machine learning models based on shallow features, such as naive Bayes or SVM. Although effective for small-scale or single-domain data, their performance is limited in complex semantics and domain transfer scenarios. With the advancement of deep learning, CNNs, RNNs, LSTMs, and transformer-based pretrained models have been widely adopted, significantly enhancing feature representation and semantic modeling capabilities. However, single DL models still face limitations in cross-domain generalization and stability. To address this, researchers have introduced ensemble learning into text sentiment classification by integrating multiple base learners at both the feature extraction and decision-making levels to enhance prediction accuracy and robustness. However, the existing ensemble methods exhibit shortcomings: First, many studies rely on simple voting or weighted averaging of homogeneous models, which makes it difficult to fully integrate multidimensional features such as global semantics, local patterns, and temporal dependencies. Second, ensemble weights are often statically assigned and do not dynamically adapt to sample uncertainty. Third, while some deep ensemble frameworks achieve high accuracy, their computational cost remains prohibitively high, limiting their application in complex cross-domain scenarios [2,3]. Therefore, balancing performance with improved generalization and computational scalability remains an urgent research challenge.
To address these challenges, a heterogeneous ensemble sentiment classification model integrating multi-view features and dynamic weights is proposed. At the feature extraction layer, the model learns from three complementary perspectives: (1) global semantic features capture long-range dependencies and holistic meaning via RoBERTa-FC; (2) temporal dependency features depict contextual dynamics through BERT-BiGRU; and (3) TextCNN with attention mechanisms extracts key sentiment trigger words for local pattern features. At the decision layer, meta-learner is designed to fuse multi-view features. Dynamic uncertainty weighting and attention-based weighting mechanisms are employed to adaptively assign weights to base learners, thereby enhancing model stability and generalization capabilities across domains while maintaining computational efficiency. To validate the model’s effectiveness, experiments were conducted across five representative datasets spanning healthcare, hospitality, food delivery, e-commerce, and film/TV. The experimental results show that the proposed method achieves stable and superior performance across diverse domains, demonstrating its practical utility and scalability potential.
2. Related Work
In recent years, integrated learning methods for text sentiment analysis have gradually emerged, which can be mainly divided into three categories: voting and feature fusion methods, stacking multi-level frameworks, and deep learning and hybrid integration technology.
Voting integration and feature fusion methods, Zhou et al. [4] analyzed car reviews by fusing multiple classifiers based on the Evidential Reasoning Rule (ER Rule), and the Recall and F1 Score increased by 3.5%, but the TF-IDF feature extraction method was difficult to capture semantic associations. Liu et al. [5] combined SMOTE and Boosting technology to solve the class imbalance problem of review usefulness recognition, with an accuracy rate of over 89%, but its applicability is limited in scenarios with extreme data imbalance. Zhu, M. [6] proposed a character-level integration model based on CNN-BiGRU-Attention to improve the performance of short-text classification tasks. The F_micro and Accuracy indicators of this model on the hotel review dataset were 94.4% and 91.1%, respectively, and on the spam dataset Trec06c, they were 93.3% and 91.7%, respectively. Experimental results show that the model can effectively improve the classification accuracy, but its support for multilingual text is still insufficient. Huang, D. [7] optimized the Weibo sentiment analysis task by integrating the improved TF-IDF method with the multi-feature matrix. In the six-category sentiment classification task on the SMP2020 Weibo sentiment dataset, the accuracy of this method reached 77.5%, and the recognition performance was significantly better than that of the baseline model. However, its real-time processing capability still needs to be improved. Shuai [8] proposed a sequential three-branch decision model based on bias integration to process hotel reviews. The boundary domain processing strategy needs to be optimized at an accuracy of 86.75%. Kristína Machová’s team [9] used SVM combined with Bagging/RF to classify Slovak toxicity, achieving an accuracy of 0.89, but the sentiment granularity was rough. Vimala Balakrishnan [10] achieved an accuracy of 99.7% in identifying offensive content through unsupervised clustering analysis of Tamil comments, but it relied on specific cultural labeling standards. This type of method has advantages in maintaining model simplicity but has obvious limitations in deep feature expression and multilingual adaptability.
In terms of the stacking multi-level integration framework, Zheng et al. [11] proposed a Chinese short-text classification model that integrates BERT with heterogeneous neural networks (including TextCNN, DPCNN, and TextRNN). The study conducted experimental evaluations on multiple datasets: Sogou News THUCNews_data (10 categories), Sina Weibo simplifyweibo_moods (4 categories) and Jingdong comments Jingdong_data (3 categories). The experimental results show that the model achieved precision of 0.96, 0.91 and 0.90 on the three datasets, respectively, and achieved the best performance in all evaluation indicators, but its reasoning process had significant delay problems. Lin, P. [12] used a two-stage stacking model to analyze health community questions and answers and improved the accuracy by 11.3% in chronic disease comments, but lacked a dynamic update mechanism. Zi Ye’s team [13] used LSTM-GRU stacking to analyze social media sentiment and predict Bitcoin prices, achieving an 88.74% reduction in MAE, but delayed response to sudden public opinion. Ming Yin’s team [14] combined attention mechanisms to detect technical debt annotations, improving cross-project performance in 62,285 code reviews, but lacked generalization verification. This type of method significantly improved the expressiveness of the model, but generally faced problems such as high computing resource consumption and complex system architecture.
In terms of deep learning and hybrid integration methods, Jiang, Q. [15] applied stacking to fuse financial indicators and stock comments for risk warning, improving the accuracy by 9.3% in listed company data, but there are compliance risks in obtaining commercially sensitive data. Cao [16] constructed a BERT-BiGRU multimodal system to analyze food safety public opinion, with good visualization of the entire process, but insufficient ability to identify emerging network terms. Alireza Ghorbanali [17] expanded the Dempster-Shafer theory to fuse multimodal features, achieving an accuracy of 0.9689 on the MVSA/T4SA dataset, but the complex structure resulted in slow reasoning. Nassera Habbat’s team [18] combined XLNet with a neural topic model to process multilingual hotel reviews, improving the accuracy by 0.975, but performance in mixed language scenarios declined. Devika [19] integrated BERT with a hybrid neural network (LSTM/BiLSTM/GRU/CNN) to analyze book reviews, achieving an F1 Score of 98.21%, but high computing requirements affected the real-time performance. Arup Baruah [20] constructed the Khasi language dataset KALD and integrated it with XGBoost/SVM, achieving an F1 Score of 0.918, but relied on the quality of manual annotation. S. Abarna [21] integrated BERT/ELMO to detect online harassment, with an F1 Score of 92.04%, but its applicability on multiple platforms was insufficiently verified. Ahmed Cherif Mazari [22] combined BERT with Bi-LSTM/Bi-GRU to detect hate speech, with an ROC-AUC index of 98.63%, but cross-scenario verification needs to be strengthened. Soheyla Eyvazi-Abdoljabbar [23] analyzed Persian comments based on Word2Vec and deep model integration, and the voting integration accuracy reached 72.337%, but there is significant room for improvement. Achyut Shankar [24] developed a recommendation system based on ensemble learning to improve recommendation accuracy in customer review processing, but the research on interpretability is insufficient. Rana Husni Al Mahmoud [25] integrated K-means and EM algorithms to process imbalanced data, but the computational efficiency needs to be optimized. This type of method has made breakthrough progress in semantic understanding and cross-modal analysis, but generally faces the problems of high computing resource requirements and weak interpretability.
3. Methodology
3.1. Construction of the Base Classifier
To fully exploit the multidimensional features of Lung Food delivery reviews and ensure accurate and robust sentiment analysis, we selected three complementary base learners: RoBERTa-FC, BERT-BiGRU, and TextCNN-Att. These models, respectively, focus on capturing global semantics, multi-scale sequence dependencies, and local feature information, providing rich high-dimensional feature representations for subsequent ensemble learning. The following describes the construction details of each base learner.
3.1.1. Base Classifier 1: RoBERTa-FC
The RoBERTa-FC model uses the Chinese RoBERTa pre-trained model (chinese-roberta-wwm-ext) as its core encoder, emphasizing the global semantic modeling of the text. This pre-trained model was trained by the Harbin Institute of Technology and iFlytek Joint Laboratory based on a large-scale, high-quality Chinese corpus. Building on BERT, it incorporates RoBERTa’s optimization strategies and the whole word masking mechanism, emphasizing the global semantic modeling of text. Based on thether parametersters trained on the large-scale corpus, the model maps the input review text into a high-dimensional vector space and captures the long-range dependencies between words through the transformer layers.
The construction process is as follows:
- (1)
- Text vectorization: Use the RoBERTa tokenizer to perform subword segmentation, ensuring uniform input length (sequence length is fixed at 128, short texts are padded, and long texts are truncated). Convert the text to token idsx and input it into RoBERTa to obtain the last -layer hidden state set . The CLS vectors of the layers are .
- (2)
- Feature extraction: Extract vectors from the last three hidden states of RoBERTa and concatenate them:Here, represents the hidden state of the th layer of RoBERTa. This not only preserves deep semantic information but also integrates mid-level representations, avoiding overfitting or loss of semantic information in single-layer representations.
- (3)
- Regularization and Classification: The concatenated vector is fed into a Dropout layer (p = 0.3) for regularization and then fed into a fully connected layer to predict sentiment probabilities. In the RoBERTaFC implementation, it outputs logits for two categories, denoted as . If only the probability of the positive class (label = 1) is of interest, the logit corresponding to the positive class is taken and a Sigmoid is applied:Implementation: AutoModel.from_pretrained (model_path,output_hidden_states = True) returns out.hidden_states; concatenate and perform three linear mappings to get logits; the code uses torch.sigmoid() to obtain the positive class probability .
- (4)
- Training Configuration: The AdamW optimizer (implemented in torch.optim.AdamW), a native component of PyTorch, was employed with a learning rate of and a weight decay of 0.01. A linear warm-up learning rate scheduler was adopted to stabilize the early stages of training. The batch size was set to 16, and the maximum number of training epochs was 20. To improve computational efficiency and prevent gradient explosion, mixed-precision training (AMP) and gradient clipping (maximum norm of 1.0) were applied during optimization.
RoBERTa-FC focuses on modeling global semantic consistency and is suitable for capturing implicit long-range dependencies in review text, providing a stable semantic foundation for sentiment judgment.
3.1.2. Base Classifier 2: BERT-BiGRU
To enhance the model’s temporal modeling capabilities, this study introduces the BiGRU (Bidirectional Gated Recurrent Unit) based on BERT’s contextual feature representation. This structure captures the global semantics of a sentence while more sensitively modeling the implicit sequential dependencies within the text. It is particularly well-suited for processing the sentiment differences caused by word order in Chinese reviews.
The construction process is as follows:
- (1)
- Text Encoding: The comments are tokenized using the BERT Tokenizer, provided by the Hugging Face Transformers library. Specifically, the bert-base-chinese model developed by Google Research is used. This is a pre-trained Chinese BERT model trained on a large-scale Chinese corpus including Chinese Wikipedia and news datasets. It supports tokenization for Chinese characters and subwords, thereby effectively encoding subtle differences in semantics and syntax. Each comment is tokenized and padded to a uniform sequence length of 128 bytes.
- (2)
- Contextual Feature Extraction: Contextual sequence vectors are extracted using the BERT-base.
- (3)
- Sequence Dependency Modeling: BERT output is fed into a bidirectional GRU (with 256 hidden units). The BiGRU simultaneously models left-to-right and right-to-left semantic dependencies, generating dynamic temporal features. The sequence S is fed into the BiGRU (with hidden dimension h), resulting in the bidirectional GRU output sequence . Symbolically,
- (4)
- Sentence Vector Representation: The first and last hidden states of the BiGRU are concatenated to form a sentence-level vector:Note: pooled = torch.cat([gru_out[:,0,:], gru_out[:,−1,:]], dim = 1) in the code corresponds to this formula.
- (5)
- Classification prediction: Input the fully connected layer to generate the binary classification output:
Training configuration: Batch size 32, learning rate , cross-entropy loss function, and early stopping to prevent overfitting.
BERT-BiGRU enhances the ability to model temporal semantic patterns, complementing the global semantic focus of RoBERTa-FC.
3.1.3. Base Classifier 3: TextCNN-Att (Feature-Level Fusion)
The TextCNN-Att model aims to efficiently identify sentiment in text by integrating local n-gram features with key emotional information captured by an attention mechanism through feature-level fusion. This design leverages the convolutional network’s sensitivity to local patterns and uses the attention mechanism to highlight key emotional segments, eliminating the need to rely on the global semantic representation generated by the Transformer.
The construction process is as follows:
- (1)
- Text Encoding and Sequence Input
The text undergoes standard Chinese word segmentation and embedding, mapping each word to a fixed-dimensional vector. The sequence output of the Embedding layer is denoted as .
The sequence length is uniformly set to 128, with any missing lengths padded and any excess length truncated.
- (2)
- TextCNN Branch
Local n-gram features were extracted using 1D convolutions with kernel sizes of 3, 4, and 5.
Each convolution kernel has 128 channels, and after convolution, a fixed-length vector is obtained using max pooling.
The pooled vectors from different convolution kernels are concatenated to form a 384-dimensional local feature vector. Dropout regularization is used to reduce the risk of overfitting. One-dimensional convolution is performed on with several convolution kernels of size ϵ {3, 4, 5} (in the time dimension). The convolution output is then max-pooled to obtain the pooled vector for each kernel, which is then concatenated:
where ( in the code, so ).
- (3)
- Attention Branch
Weighted summation of the word vectors in the text sequence is performed to obtain a weighted semantic vector.
Note: In the code, self.w = nn.Linear(hidden_size,1), scores = self.w(hidden_states).squeeze(−1), and attn = torch.softmax(scores,dim = 1).
Attention weights were generated through linear transformations and combined with masks to ensure numerical stability.
- (4)
- Feature Fusion and Classification
The vectors from the TextCNN branch and the attention branch are concatenated to form a final 384 + 768 = 1152-dimensional feature vector (adjustable based on the actual dimensions).
Attention vector , TextCNN vector , then:
Note: In the code, cnn_out of TextCNN-Att is equivalent to , and att_out is equivalent to . After concatenation, they are linearly mapped to output logits.
This is fed into a fully connected layer, and after dropout, the binary classification result is output.
- (5)
- Training Configuration
The optimizer used was AdamW (learning rate , weight decay 0.01), there was a batch size of 16, 20 training epochs, and dropout of 0.5.
Mixed precision training (FP16 + GradScaler) was used, combined with gradient clipping and early stopping to ensure training stability.
This model uses convolution to extract local sentiment patterns and employs an attention mechanism to highlight key sentiment terms, making it highly adaptable to both long and short sentences. Compared to models relying on Transformers, this architecture is more lightweight and computationally efficient, while still capturing the key sentiment information in the text.
The three models complement each other in terms of semantic understanding, temporal dependency modeling, and local segment extraction, providing a solid feature foundation for subsequent integration with Meta Learner. By leveraging multi-model collaboration, this research achieved higher accuracy and robustness in the sentiment classification task of reviews.
3.2. A Multi-Model Integration Framework Based on Dynamic Uncertainty Is Weighted
To fully leverage the multi-level representation capabilities of different deep learning models for text features and improve the accuracy and robustness of the sentiment analysis of reviews, this study designed a Meta Learner that integrates and adjusts the outputs of various base models using a dynamic uncertainty weighting mechanism. The core idea of this framework is to combine multiple complementary base learners to fuse their feature representations. Furthermore, during the prediction phase, the output probabilities of each model were dynamically weighted to reduce the impact of individual model bias and uncertainty on the final prediction results. This design mitigates the impact of individual model bias and uncertainty while highlighting stable models, thereby ensuring the reliability and generalization of the overall prediction.
3.2.1. Feature Splicing and Dynamic Uncertainty Is Weighting
In the integration phase, the feature vectors extracted by the three types of base learners are first concatenated at the dimension level to obtain a unified high-dimensional representation:
Among them,. After concatenation, they obtain a unified . During this process, linear projection and normalization strategies are used to align feature scales. Specifically, each branch output is mapped to a uniform dimension via an independent linear transformation layer (nn.Linear(d_i, 512)). Layer normalization (LayerNorm) is then used to eliminate scale differences before concatenating them into a unified fused feature . This process not only ensures feature comparability and gradient stability, but also avoids the problem of high-dimensional features dominating training during the fusion phase.
To account for the potential bias and uncertainty in the prediction process of different base models, this study further introduces a learnable temperature parameter to smooth the prediction probabilities of each base model:
Here, controls the degree of smoothing: larger corresponds to higher uncertainty, making the prediction distribution flatter and the weight assignment more conservative. Then, the dynamic weight of each model is calculated based on its uncertainty level:
This mechanism can automatically adjust the weight of each base model in the ensemble prediction, effectively suppressing the impact of highly uncertain models on the final result. The final ensemble prediction is then generated through the weighted summation:
Here, is a learnable parameter whose value automatically adjusts based on the uncertainty of each base model, thereby achieving dynamic weighting. This approach ensures that the ensemble model maintains reliable and robust predictions even when faced with unstable or noisy outputs from individual models.
3.2.2. Attention Weighting and Residual Connections
After obtaining the splicing features, to further highlight the key features important for sentiment discrimination, this study adopts the following linear attention mechanism:
Here, is the attention weight vector, which has the same dimension as the concatenated features (1536). In the experiment, a low-dimensional learnable vector with an implicit dimension of 256 is used for projection to highlight key sentiment words or text fragments. Furthermore, to prevent the loss of original semantic information during attention selection, this study introduces a residual connection between the attention-enhanced features and the original concatenated features:
This residual design ensures that the model retains the complete expression of the original multi-view semantics while focusing on discriminative features.
To further explore the complementary relationships between different base models and perform the final feature fusion and classification decision, an Attention-based Feedforward Network (AFFN) is employed as a meta-learner. This module structurally expands the expressive power of the aforementioned linear attention mechanism, enabling it to model nonlinear correlations and hierarchical dependencies between cross-model features.
The meta-learner first performs a nonlinear mapping on the residual-enhanced high-dimensional features to extract the fused latent semantic vector:
Then, the feature importance weights of each dimension are calculated through a learnable attention layer:
Finally, the attention-weighted representation is input into the output layer to generate emotion prediction probability:
Here, is the input projection matrix, is the attention weight matrix, is the output layer parameter, represents element-wise weighting, and is the Sigmoid activation function.
This mechanism forms a multi-layer feature integration framework of “linear attention enhancement—residual preservation—nonlinear fusion.” The residual term not only preserves semantic consistency during the local feature enhancement stage but also continues to influence the final fusion process through transmission to the meta-learner input, achieving a dynamic balance between global features and local discriminative signals, effectively improving the model’s robustness and generalization performance.
3.2.3. Training Strategy and Optimization
In order to ensure training stability and improve the performance of the ensemble model, this study adopts the following strategies during the training phase:
- (1)
- Freezing of base model features: During the ensemble training phase, all base learner parameters are fixed, and only the meta-learner and weighting parameters are optimized to avoid base feature perturbations caused by training instability.
- (2)
- Batch training: In each training batch, the base model extracts features and prediction probabilities, inputs them into the meta-learner, and generates the final prediction after attention weighting and dynamic uncertainty weighting, thus achieving end-to-end training.
- (3)
- Loss function: The model error is calculated using binary cross entropy:
- (4)
- Training Optimization: Combined with mixed-precision training (GradScaler), the stability and computational efficiency of large model training are ensured. Gradient clipping and strict early stopping mechanisms are introduced. When the F1 Score on the validation set does not improve after several consecutive rounds, training is stopped and the optimal model parameters are saved. This effectively prevents the ensemble model from being overly dependent on the training data, thereby improving the generalization ability on unseen data.
- (5)
- Robustness and Sensitivity Analysis: To verify the robustness of the dynamic uncertainty weighting mechanism to hyperparameter changes, this study conducted a system sensitivity experiment. The specific settings are as follows:Learning rate: [1 × 10−4, 2 × 10−4, 3 × 10−4, 4 × 10−4, 5 × 10−4].
Initial value of the temperature parameter : 0.5, 1.0, 1.5, and 2.0 were tried for each base model.
Meta-learner weighted layer implicit dimension: 128, 256, 384, and 512 were tried.
Number of replicates: Each hyperparameter combination was trained three times, and the average F1 Score on the validation set was taken to ensure statistical reliability.
The experimental results show that the performance fluctuation of the dynamic weighted ensemble model under the aforementioned hyperparameter perturbations is less than ±0.8%, with no significant performance degradation.
In summary, the dynamic uncertainty weighting mechanism maintains stable performance under different hyperparameter settings, demonstrating its high robustness and engineering transferability. It can reduce the cost of hyperparameter tuning in large-scale application scenarios and ensure the reliability and stability of predictions.
Figure 1 shows a schematic of the multi-model ensemble framework based on the dynamic uncertainty weighting proposed in this study. This framework consists of three modules: feature-level fusion, attention enhancement and residual preservation, and dynamic uncertainty weighting. It aims to achieve high-precision and robust sentiment classification of the review text.
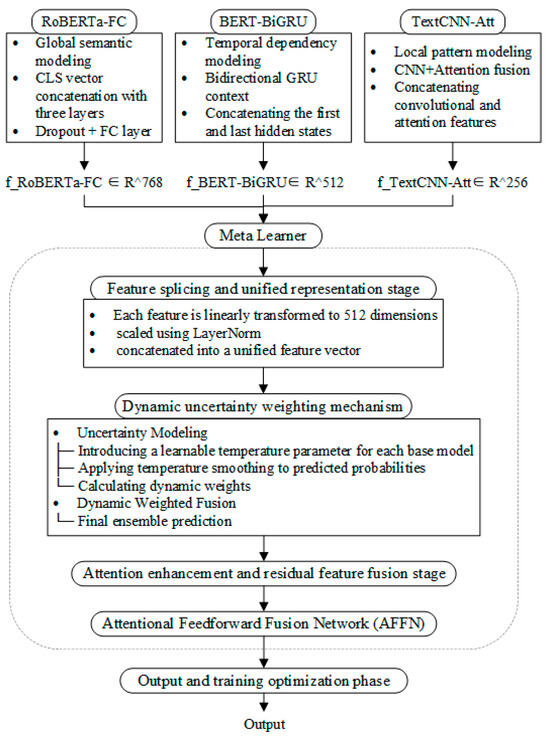
Figure 1.
Integrated learning model construction diagram.
4. Experimental Results
4.1. Data Acquisition and Preprocessing
To comprehensively evaluate the performance and generalization capabilities of the proposed multi-source, multi-domain ensemble learning sentiment analysis model, we selected five representative datasets covering a variety of typical scenarios, including food delivery, hotels, film and television, e-commerce, and medical reviews. These datasets vary significantly in scale, source, and text features, ensuring a diverse data source while highlighting the complexity and challenges of cross-domain sentiment analysis.
- (1)
- Waimai_10k Takeaway Review Dataset: This dataset contains a large number of real user reviews of food and beverage takeaways, with an original size of 11,987, including 4000 positive reviews and 7987 negative reviews. This study obtained this dataset from the ChineseNlpCorpus repository on GitHub (URL: https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/waimai_10k/waimai_10k.csv(accessed on 23 April 2025)). To improve the data quality, a systematic cleaning process was further performed, including removing invalid reviews, duplicate text, and redundant symbols. After processing, 11,604 valid reviews (3824 positive reviews and 7780 negative reviews) were retained, providing a reliable data foundation for the model’s sentiment recognition in the food and beverage consumption scenario.
- (2)
- ChnSentiCorp_htl_all Hotel Review Dataset: This dataset contains approximately 7766 hotel user reviews, with a distribution of 5322 positive reviews and 2444 negative reviews. It is a classic corpus in Chinese sentiment analysis research. These data, compiled by Professor Tan Songboon on the basis of Ctrip reviews, are available on ChineseNlpCorpus (URL: https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv (accessed on 23 April 2025)). To ensure the validity of the experiment, we cleaned the raw data by removing HTML tags, redundant spaces, duplicate comments, and excessively short text. The resulting dataset contained 7758 high-quality reviews (5318 positive and 2440 negative), providing data support for validating the cross-domain sentiment model’s applicability to the travel and service industries.
- (3)
- Douban Movie Short Comments: This dataset is large in scale, with more than 2.12 million original comments, covering a variety of semantic expressions and language styles. It is publicly released on the Kaggle community under the name “Douban Movie Short Comments” and can be retrieved and downloaded on the platform (URL: https://www.kaggle.com/datasets/utmhikari/doubanmovieshortcomments?select=DMSC.csv (accessed on 4 October 2025)). To ensure the balance of the binary classification experiment, this paper randomly selected reviews with a rating of 5 stars and 1 star as positive and negative samples, and after cleaning and screening, finally obtained 20,000 high-quality short comments. This dataset is highly representative in terms of sentiment polarity and language differences, providing an ideal scenario for evaluating the generalization ability of the model in large-scale unstructured text.
- (4)
- Alibaba Cloud Tianchi Multi-Domain Comment Dataset (ALY_ds): This dataset was sourced from the Alibaba Cloud Tianchi competition platform. It encompasses four distinct product domains: mobile phones, cars, cameras, and notebooks, characterized by their cross-product and multi-context nature. The corpus for this study was acquired by querying the platform using the keywords “ALY_ds” and “Multi-Domain Comment Data,” followed by the integration of the corresponding datasets from these four domains. The dataset for each of the four domains (mobile phones, cars, cameras, and notebooks) comprises two separate files: one containing the raw review texts and the other containing the corresponding sentiment labels. Therefore, the complete dataset consists of eight files (4 domains × 2 file types). The mapping between the file numbers (S1–S8) in the Supplementary Materials and the specific files is as follows: S1 (mobile_phone_sentence), S2 (mobile_phone_label), S3 (car_sentence), S4 (car_label), S5 (camera_sentence), S6 (camera_label), S7 (notebook_sentence), and S8 (notebook_label). To ensure data integrity, this study conducted systematic preprocessing, including text cleaning, deduplication, and invalid comment filtering. Ultimately, 6582 comments were retained. Their multi-domain attributes provide experimental support for exploring the performance of multi-source sentiment analysis models in domain transfer and feature fusion.
- (5)
- Chinese Medical Review Dataset (Lung_ds, self-constructed): This dataset was independently constructed by this study and aims to evaluate the performance of sentiment analysis models in the medical field, especially in scenarios related to lung diseases. Specifically, based on the keyword screening method, the research team extracted 2796 Q&A records related to lung diseases from the CHIP2020 medical question-and-answer dataset (URL: https://ai-studio-online.bj.bcebos.com/v1/2e0a232cfa4b4ef6bfcbdd4d82f2e12bae914019263e4b71afdd5c48ed6105bb?responseContentDisposition=attachment%3Bfilename%3DRAG-%E7%B2%BE%E9%80%89%E5%8C%BB%E7%96%97%E9%97%AE%E7%AD%94_onecolumn_80k.csv (accessed on 5 October 2025)) and collected 2171 real user reviews from the respiratory medicine and thoracic surgery pages of the “Good Doctor Online” platform. After manual cleaning, deduplication, and invalid text removal, 3337 medical review texts were finally obtained. To cope with the large number of professional terms in medical texts, this paper uses the pause medical field word segmentation model for segmentation and combines it with a self-constructed medical term dictionary for vocabulary normalization. In terms of sentiment annotation, multi-source dictionaries such as NTUSD, HowNet, and Dalian University of Technology Sentiment Vocabulary Ontology were integrated, and sentiment polarity and intensity were combined for binary classification annotation, resulting in 2370 positive reviews and 967 negative reviews. The dataset was split into training and test sets in a 4:1 ratio to ensure the scientific nature and reproducibility of the experiments.
To ensure fair and reproducible experimental results, this study adopted a consistent partitioning and usage strategy across all datasets. Specifically, the five datasets (Waimai_10k, ChnSentiCorp_htl_all, Douban Movie Short Comments, ALY_ds, and Lung_ds) were all split in a training:test ratio of 8:2. A 10% portion of the training set was randomly allocated as a validation set for early stopping.
Given that this study focuses on Chinese corpora, the datasets used are all Chinese review texts. The goal is to delve into the feature distribution and model generalization performance of multi-source and multi-domain sentiment analysis in the Chinese context. It is worth noting that Chinese differs significantly from other languages (such as English and French) in terms of lexical structure, word segmentation, and emotional expression. Direct cross-language transfer often leads to semantic drift and feature mismatch. Therefore, this paper focuses on cross-domain generalization within the same language system, rather than cross-language adaptation. Although no direct cross-language experiments were conducted at this stage, the proposed ensemble learning framework has strong scalability.
To ensure the reproducibility and computational stability of the experimental results, this study completed all model training and evaluation on the AutoDL cloud server platform (URL: https://www.autodl.com/market/list (accessed on 18 January 2025)), which provides GPU-based deep learning environments. The software and hardware configurations used in the experiment are shown in Table 1:

Table 1.
Experimental environment configuration.
All neural network modules (including RoBERTa-FC, BERT-BiGRU, TextCNN-Att, and the attention-based meta-learner), as well as the comparison models in Section 4.2.2 and the ablation experiments in Section 4.3, were implemented using the PyTorch 1.9.0 framework (URL: https://pytorch.org/, accessed on 18 January 2025). The models were constructed with the torch.nn and Transformers libraries (v4.30.2, URL: https://huggingface.co/transformers/, accessed on 18 January 2025) for parameter management and contextual feature encoding.The AdamW optimizer (implemented in torch.optim.AdamW), a native component of PyTorch, was employed for model optimization. Learning rate scheduling and gradient updates were managed using the mixed-precision training mechanism (torch.cuda.amp). The entire model training process was visualized and monitored via TensorBoard (v2.14.0, URL: https://www.tensorflow.org/tensorboard, accessed on 18 January 2025).To ensure consistency and comparability across experiments, all random processes use the same random seed (42) and the random number generator state is fixed.
4.2. Experimental Results Analysis
4.2.1. Performance Comparison Between the Single-Base Classifier and the Ensemble Model
To validate the effectiveness of the proposed ensemble learning framework, we compared the performance of three base classifiers (RoBERTa-FC, BERT-BiGRU, and TextCNN-Att) with the ensemble model on five sentiment classification datasets from different sources: Waimai, Chn_hot, disc, AlY_ds, and Lung_ds. Table 2 shows the experimental results of each model on five metrics: Accuracy, Precision, Recall, F1 Score, and Macro-AUC.
Table 2.
Performance comparison between the single-base classifier and the ensemble model.
Overall, the ensemble model outperformed the single-base classifiers on all datasets, with a steady and significant improvement.
On the Waimai dataset, the ensemble model achieved an Accuracy of 0.9259, an improvement of approximately 0.0112 over the best single model, RoBERTa-FC (0.9147). It also achieved an F1 Score improvement of 0.0148 and a Recall improvement of 0.0105. This demonstrates that in the relatively regularized context of e-commerce reviews, model fusion can better integrate the strengths of different classifiers and improve the overall recognition capabilities.
On the Chn_hot dataset, the ensemble model achieved an F1 Score of 0.9353, an improvement of 0.0278 over the best single model, BERT-BiGRU (0.9075). Furthermore, it achieved an Accuracy of 0.9111 and a Recall of 0.9379, both of which outperformed the single models. The integrated model demonstrates stronger robustness in discerning complex contexts by combining the global semantic modeling of RoBERTa-FC and the temporal feature capture of BiGRU.
On the dmsc dataset, the ensemble model achieved an Accuracy of 0.9071, significantly outperforming the single-model BERT-BiGRU (0.8706). Its F1 Score reached 0.9069, a 0.0283 improvement over RoBERTa-FC’s 0.8786. Its Macro-AUC also improved from 0.9417 for the best single-model BERT-BiGRU to 0.9724, demonstrating that the ensemble strategy can significantly enhance the model’s discrimination and generalization capabilities in multi-category and diverse corpus contexts.
On the AlY_ds dataset, the ensemble model achieved the best performance across all metrics, with an F1 Score of 0.9590, a 0.0292 improvement over the best single-model BERT-BiGRU (0.9298). Its Macro-AUC reached 0.9797, representing the largest improvement. The results show that in cross-domain data scenarios, the integrated model can effectively alleviate the overfitting and underfitting problems that may occur in the migration process of a single model.
Lung_ds Medical Review Dataset: This dataset features sparse samples, imbalanced categories, and specialized terminology. While the performance of the individual models varied significantly (Macro-AUC ranged from 0.6169 to 0.8027), the ensemble model achieved a Macro-AUC of 0.9238, a 0.1211 improvement over the best single model, TextCNN-Att. Accuracy, Precision, and F1 Score improved by 0.1309, 0.1578, and 0.0702, respectively, demonstrating that model fusion can effectively improve the recognition of minority and difficult-to-class samples in the medical context.
Figure 2 plots the F1 Score comparisons of various models on the five datasets. It is clear from Figure 2 that the ensemble model achieves significantly higher F1 Scores than a single-base classifier on all five datasets. This result demonstrates that ensemble learning can fully integrate the strengths of different models, demonstrating enhanced stability and generalization in sentiment classification tasks.
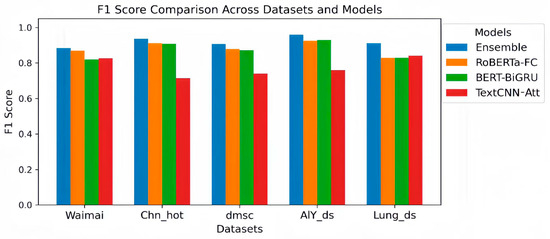
Figure 2.
F1 Score Comparison Across Datasets and Models.
Specifically, on the Waimai dataset, the ensemble achieved an F1 Score of 0.8844, an improvement of approximately 1.48% over the top-performing single model, RoBERTa-FC, which achieved a score of 0.8696. On the Chn_hot dataset, the ensemble achieved an F1 Score of 0.9353, a 2.36% improvement over RoBERTa-FC’s score of 0.9117 and far exceeding TextCNN-Att’s score of 0.7135, demonstrating the effectiveness of ensemble strategies in suppressing the negative effects of weak models. On the disc dataset, the ensemble achieved an F1 Score of 0.9069, surpassing both RoBERTa-FC and BERT-BiGRU, further demonstrating its robustness to diverse text distributions. On the AlY_ds dataset, the ensemble’s F1 Score reached 0.9590, significantly exceeding the top single-model BERT-BiGRU’s score of 0.9298. This demonstrates that even with complex datasets, ensemble models can leverage the complementary strengths of multiple models to improve the overall prediction accuracy. Even on datasets like Lung_ds, which have a smaller sample size or uneven class distribution, the ensemble achieved an F1 Score of 0.9115, a 7–8% improvement compared to the individual models’ scores, which fluctuated between 0.8281 and 0.8413. This demonstrates that ensemble strategies can effectively mitigate the overfitting problem of individual models on small or imbalanced datasets.
Analysis of single models shows that RoBERTa-FC performs well on most datasets, especially on Waimai, Chn_hot, and dmsc, where its F1 Score approaches that of the ensemble. However, its performance on Lung_ds drops significantly, indicating its limited adaptability to small or noisy data. BERT-BiGRU slightly outperforms RoBERTa-FC in F1 Score on AlY_ds and Lung_ds, reflecting the potential of recurrent networks in handling sequential dependencies and the semantics of long texts. However, it falls slightly short on the Waimai dataset. TextCNN-Att’s performance is relatively unstable, with an F1 Score significantly lower than other models on most datasets, particularly on the Chn_hot dataset, where it only reaches 0.7135. However, it slightly outperforms RoBERTa-FC on Lung_ds, demonstrating that convolutional networks have some advantages in extracting local features but struggle to capture complex semantics and long-range dependencies. In summary, by fusing the predictions of multiple base learners, the ensemble model not only combines the strengths of each model but also effectively reduces the bias and instability of individual models, achieving robust performance across multiple datasets and text distributions. Its generally leading performance and robustness to extreme conditions give it a significant advantage in sentiment analysis tasks, making it particularly suitable for complex, noisy, or unevenly distributed data scenarios, providing a reliable and highly generalizable solution for practical applications.
4.2.2. Comparative Analysis of the Existing Integrated Learning Strategies
To validate the effectiveness of the proposed multi-model ensemble framework based on dynamic uncertainty weighting for multi-domain text sentiment classification, we selected six representative ensemble learning strategies for comparison (see Table 3). These strategies include: heterogeneous classifiers + fuzzy integral weighting, stacking-BERT multi-base model, voting ensemble of adaptive NB and optimized SVM, BERT-BiGRU perturbation + voting, and regression ensemble of heterogeneous classifiers. Comparison metrics include Accuracy, Precision, Recall, F1 Score, and Macro-AUC. All methods were evaluated on five datasets: Waimai, Chn_hot, dmsc, AlY_ds, and Lung_ds. These datasets cover a variety of scenarios, including food delivery, e-commerce/hotels, film reviews, and medical reviews, effectively demonstrating cross-domain generalization capabilities.
Table 3.
Performance comparison table of the ensemble model and the existing ensemble learning strategies.
- (1)
- Heterogeneous integration model by Zhong et al. [26]: This method aims to improve the ability of sentence-level text sentiment classification and designs a multi-element integration framework based on heterogeneous classifiers. Its base classifiers include three categories: bidirectional long short-term memory network (BiLSTM) based on the self-attention mechanism, convolutional neural network (CNN) based on word embedding, and naive Bayes (NB) based on text information entropy. In the integration stage, this method uses a fuzzy integral algorithm to dynamically determine the weight of each classifier, thereby maximizing the complementarity and prediction effect between the different classifiers.
- (2)
- Stacking-BERT multi-base model [11]: In response to the limitations of traditional static word vectors (such as word2vec, GloVe) in semantic expression and the problem of insufficient generalization ability of single deep models, this method proposes a multi-base model framework based on BERT. First, the BERT pre-trained model is used to extract deep feature representations of text. Then, a heterogeneous classifier is constructed by combining multiple neural networks such as TextCNN, DPCNN, TextRNN, and TextRCNN. Finally, the stacking method is used to fuse them, and support vector machines (SVM) are used as meta-classifiers for training and prediction, thereby enhancing the adaptability and robustness of the model in different scenarios.
- (3)
- Voting ensemble method by Miao, P. et al. [27]: This method improves the naive Bayes into an adaptive version and optimizes the parameters of the support vector machine to construct multiple classifiers with differentiated performance. Subsequently, the SVM was used as the core base classifier and combined with the bagging strategy to form an integrated component. Finally, the results of multiple classifiers are fused through the voting mechanism to improve the overall classification performance.
- (4)
- BERT-BiGRU ensemble model by You, L. et al. [28]: To overcome the problem that traditional sentiment recognition models rely only on shallow semantics and have insufficient generalization ability, this method uses the BERT pre-trained model to obtain the contextual semantic features of the comments, and then combines BiGRU to extract deep nonlinear features, thereby obtaining the optimal performance under a single model. In the integration stage, by perturbing the training results of multiple BERT series models and fusing the voting strategy, the deep features of different classifiers are complemented, thereby enhancing the stability and overall performance of the model.
- (5)
- The heterogeneous classifier ensemble method proposed by Li, D. et al. [29]: This method focuses on integrating different feature extraction and classification methods, combining three mainstream models: long short-term memory network (LSTM) based on word embedding, convolutional neural network (CNN) based on word embedding, and logistic regression (LR) based on TF-IDF. In response to the problem that traditional hard voting methods are single and soft voting is difficult to directly apply to heterogeneous classifiers, this method proposes an ensemble strategy based on regression learning. By performing regression modeling on the outputs of multiple classifiers, the model’s ability to recognize emotional color is effectively improved.
In terms of overall performance, the ensemble model demonstrated high robustness and generalization across the five datasets. Its strengths are evident not only in F1 Score but also in the balance of multiple metrics, including Accuracy, Precision, Recall, and Macro-AUC.
On the Waimai dataset, the ensemble achieved Accuracy, Precision, F1 Score, Recall, and Macro-AUC of 0.9147, 0.8777, 0.8696, 0.8616, and 0.9478, respectively. While its F1 Score was slightly lower than Comparison-Model 2 (0.8883), its Accuracy, Precision, and Macro-AUC were higher than those of most individual models, but slightly lower than Comparison-Model 4 (0.9088) and Macro-AUC (0.9671). This phenomenon suggests that a single model may have a stronger fit for local features, such as oversensitivity to certain categories of samples, causing these metrics to peak for specific models. However, the ensemble’s F1 Score and Recall are closer to the overall optimal, indicating that it balances predictions for all categories while suppressing single-model bias and improving overall balance and robustness.
On the Chn_hot dataset, the ensemble achieved an F1 Score of 0.9353, with both precision (0.9327) and recall (0.9379) exceeding all other comparison models, demonstrating its significant advantage in handling data with complex category distributions or imbalanced sentiment. Some comparison models performed slightly higher or lower in accuracy or F1 Score. For example, Comparison-Model 2 achieved an accuracy of 0.9188, but its F1 Score and recall were inferior to those of the ensemble. This suggests that while individual models are strong in capturing local patterns, their overall prediction balance and generalization capabilities are insufficient. The ensemble model, through multi-model fusion, integrates the prediction results of each model, smooths local fluctuations, and achieves stable recognition of different sentiment categories. On the disc dataset, the ensemble achieved an F1 Score of 0.9069, which was slightly lower than Comparison-Model 2 (0.9086) and slightly lower Accuracy (0.9071) than Comparison-Model 2 (0.9105). However, its Macro-AUC (0.9724) was significantly higher than the other single models. This demonstrates that while the ensemble model does not pursue extreme values for individual metrics, by fusing the predictions of each model, it reduces sensitivity to noisy samples or extreme features, achieving a robust improvement in the overall performance. The slightly lower local metrics are due to the weighted or averaging strategy used in the ensemble model during fusion. This smooths out local peaks in individual models, but at the expense of overall generalization and cross-category balance.
On the AlY_ds dataset, the ensemble leads across all metrics, achieving an F1 Score of 0.9590 and the highest precision (0.9487), recall (0.9694), and macro-AUC (0.9797), fully demonstrating the effectiveness of multi-model complementarity on complex data. Even though some individual models are similar in terms of local metrics, such as Comparison-Model 2 with an F1 Score of 0.9338, their recall and macro-AUC are inferior to the ensemble. This suggests that individual models tend to overfit certain local features. By fusing the outputs of each model, the ensemble model balances predictions across categories, improving overall robustness and consistency and avoiding bias caused by local overfitting. On the Lung_ds dataset, the ensemble achieved an F1 Score of 0.9115, which was higher than most of the compared models. Its Precision (0.9053) was slightly lower than Comparison-Model 4 (0.9167), but its Recall (0.9177) and Macro-AUC (0.9238) were at the highest levels. Meanwhile, the ensemble’s Recall was slightly lower than that of Comparison-Model 3 (0.9367), reflecting the model’s aggressive discrimination of specific categories. While local metrics showed high peaks, the overall prediction was lacking in balance. In contrast, the ensemble model, through multi-model probability weighting, achieved a more balanced performance across different categories, thereby improving the overall accuracy and robustness.
Overall, the advantage of ensemble models lies in their ability to steadily improve multiple metrics by fusing predictions from multiple models, mitigate the impact of outliers, and enhance adaptability to diverse datasets. Even when a few metrics were slightly lower than those of the individual models, their overall accuracy, precision, recall, F1 Score, Macro-AUC, and consistency of prediction output remained significantly better than those of the individual models. This fully demonstrates the reliability and high generalization capabilities of the ensemble strategies for multi-dataset, multi-metric tasks. Slightly lower local metrics are often the result of the ensemble model’s smoothing strategy, which sacrifices local peaks in individual models to achieve global prediction stability, balance, and consistency, thereby optimizing the overall performance.
4.2.3. Model Complexity and Computational Efficiency Analysis
While verifying the model’s performance, this paper further compared the computational resource consumption of different models to evaluate the feasibility and efficiency of the proposed dynamic weighted integration mechanism in engineering implementation. The comparison results are shown in Table 4.
Table 4.
Model complexity and computational efficiency analysis table.
The table shows significant differences in model size and computational load among the three base classifiers:
TextCNN-Att, due to its lightweight structure and minimal parameters (approximately 72 MB), boasts the fastest training and inference speeds. BERT-BiGRU, while introducing recurrent layers, slightly increases computational load, but remains superior in semantic modeling. RoBERTa-FC, a representative Transformer architecture, boasts the strongest contextual modeling capabilities, but also carries a higher computational cost.
Compared to a single model, static weighted ensemble simultaneously activates multiple sub-models to achieve feature fusion, increasing training time to approximately 6.7 min per epoch and GPU usage to 7.8 GB. Dynamic weighted ensemble builds on this by introducing uncertainty-based adaptive weight allocation and an attention fusion module, resulting in a slight increase in training time (+6%) to 7.1 min, approximately 3% higher GPU usage, and approximately 10% higher inference latency. This additional overhead primarily stems from the dynamic weight calculation and attention mapping processes, but is relatively minor compared to the overall computational load of the Transformer backbone.
In terms of performance, the dynamic ensemble model achieves an average F1 Score improvement of approximately 0.5–2% compared to the static approach, with no performance degradation across all datasets, demonstrating improved stability and generalization. This demonstrates that, while the dynamic ensemble mechanism slightly increases training cost, the performance gains and improved robustness it brings offer a more cost-effective solution in practical applications.
Overall, the proposed dynamic weighted ensemble model achieves a good balance between performance and resource consumption: the structural diversity of lightweight sub-models provides feature complementarity; the dynamic fusion mechanism enhances adaptability to cross-domain tasks; and the computational cost is manageable, with the overall number of parameters and computation time only slightly increasing compared to static ensemble.
4.3. Ablation Experiments
To further quantify the contributions of each base learner and ensemble strategy to the overall framework, this paper designed and conducted systematic ablation experiments. These experiments focused on three types of base learners: the global semantic view (RoBERTa-FC), the time series view (BERT-BiGRU), and the local feature view (TextCNN-Att). The independent impact of residual connections, dynamic uncertainty weighting, and the attention fusion mechanism were also examined. Table 5 summarizes the F1 Scores for each dataset under different ablation conditions. Specifically, the experimental scheme includes:
Table 5.
Ablation Experiment Results (F1 Score).
- (1)
- Base learner ablation: remove RoBERTa-FC, BERT-BiGRU and TextCNN-Att, respectively, to evaluate the independent contribution of single semantic, sequence and local features to the ensemble performance;
- (2)
- Residual connection ablation: remove the residual path in the meta learner to analyze its impact on gradient transfer and feature stability fusion;
- (3)
- Dynamic weighting ablation: remove dynamic uncertainty weighting and only retain feature splicing to explore its robustness under the interference of weak classifiers;
- (4)
- Attention fusion ablation: remove the Attention Fusion module and only perform simple splicing to evaluate the applicability of the attention mechanism under different data complexities;
- (5)
- Combination view comparison: retain two base learner combinations (such as RoBERTa-FC + TextCNN-Att), respectively, to analyze the complementarity between views and the impact of single view loss.
- (6)
- Analysis of the independent contributions of dynamic weight and attention: New experiments include “Dynamic Weight Only” and “Attention Only” to further distinguish the independent contributions of the two mechanisms in ensemble decision-making.
To intuitively present the impact of each ablation experiment, the data in Table 3 are visualized (as shown in Figure 3). The columns (blue, green, and red) in the figure represent the contributions of the three base learners (RoBERTa-FC, BERT-BiGRU, and TextCNN-Att). The height of each column represents the overall performance of the ensemble model. The broken lines correspond to different ablation experiment settings. Overall, the image as a whole demonstrates the importance of each module in the final performance.
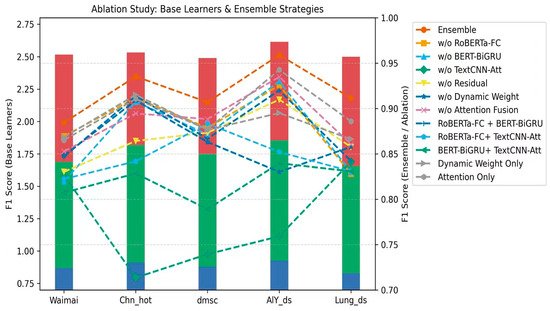
Figure 3.
Visualization of the base learner contribution and ablation strategy impact on the dataset.
Combining the table and the graph, we can further analyze the contribution of each base learner and the ensemble strategy to the overall performance.
- (1)
- Contribution of base learners to ensemble performance: The ensemble model performs best on all datasets (e.g., F1 = 0.8844 on the Waimai dataset), indicating that multi-view feature fusion has a significant complementary effect. Removing RoBERTa-FC (global semantic view) results in the most significant performance drop (e.g., Chn_hot drops from 0.9353 to 0.9117, a decrease of 2.36%), indicating that it plays a key role in capturing context and global semantic dependencies and is the core source of ensemble performance improvement. Removing BERT-BiGRU (time series view) reduces the F1 of the Waimai dataset from 0.8844 to 0.8197 (a decrease of 6.47%), indicating that it has important value in context sequence modeling and sequence dependency capture, and can make up for the shortcomings of static semantic features. The impact of TextCNN-Att (local feature view) varies significantly across datasets, especially in the Chn_hot dataset, where the drop is the largest (a decrease of 22.18%), indicating that local convolutional features are particularly important for emotional segment recognition and capturing high-frequency emotional words.
- (2)
- Analysis of inter-view complementarity: When only some base learners are retained, the overall performance decreases, further confirming the importance of multi-view fusion. When only RoBERTa-FC + BERT-BiGRU is retained, the average performance is relatively high (e.g., AlY_ds F1 Score = 0.9200), indicating that there is strong complementarity between semantic and temporal features. When only RoBERTa-FC + TextCNN-Att is retained, the performance decreases significantly (e.g., AlY_ds F1 Score = 0.8521), indicating that the model has difficulty capturing semantic transition information without temporal features. When only BERT-BiGRU + TextCNN-Att is retained, the overall performance is the lowest, proving that the lack of a global semantic view leads to a serious lack of contextual information, verifying the core role of the global semantic layer in sentiment modeling.
- (3)
- The role of residual connections: After removing the residual connections, the F1 Scores of all datasets decreased (e.g., AlY_ds dropped from 0.9590 to 0.9098), indicating that the residual mechanism effectively alleviated the problems of gradient vanishing and feature degradation during deep fusion, and helped improve the stability and convergence performance of the model.
- (4)
- The role of dynamic uncertainty weighting: After removing the dynamic weights, the performance of some datasets decreased significantly (e.g., AlY_ds F1 Score dropped from 0.9590 to 0.8301, a decrease of 12.89%), indicating that this mechanism can adaptively adjust the influence of weak classifiers in the ensemble decision, thereby improving the overall robustness. In particular, in the case of noise in multi-source heterogeneous features, dynamic weighting can effectively suppress the interference of local mismatches on the overall prediction.
- (5)
- Applicability of Attention Fusion: After removing attention fusion, performance slightly decreases (e.g., the AlY_ds F1 Score drops from 0.9590 to 0.9349, a decrease of 2.41%), indicating that attention weights may lead to local overfitting in data with sufficient complementary features. This result suggests that the fusion method should be flexibly selected under different data scales: the attention mechanism can bring benefits in large-scale and complex data, while simple splicing may be more robust in small and medium-sized datasets.
- (6)
- Independent effects of dynamic weight and attention mechanism: To further distinguish the effects of the two mechanisms, the “Dynamic Weight Only” and “Attention Only” experiments were added: Dynamic Weight Only: Attention Fusion was removed, and only the temperature parameter was retained for dynamic weighting. The results showed that high F1 (0.8684, 0.9151, 0.8765, 0.8661) was maintained on the Waimai, Chn_hot, dmsc, and Lung_ds datasets, indicating that dynamic weighting can effectively adjust the weights of each base learner and has a suppressive effect on the interference of weak classifiers. However, the F1 on the AlY_ds dataset was 0.8950, slightly lower than Attention Only (0.9426), suggesting that dynamic weighting alone is not enough to fully exploit local complementary information on large-scale datasets with fully complementary features. Attention Only: Dynamic weighting was removed, and only Attention Fusion was retained. The results show that the F1 Scores on the AlY_ds and Lung_ds datasets are 0.9426 and 0.8858, respectively, both exceeding those of the Dynamic Weight Only approach. This demonstrates that the attention mechanism can enhance the local complementarity of feature fusion, improving the ability to model complex semantic structures or sentiment patterns in long texts. However, on the Waimai, Chn_hot, and dmsc datasets, the F1 Scores are 0.8651, 0.9106, and 0.8769, respectively, slightly lower than those of the Dynamic Weight Only approach. This suggests that attention alone is insufficient to ensure robustness when noise levels are high or weak classifiers are interfering.
Combining the two, we can see that dynamic weights are more critical in suppressing weak classifier interference and ensuring model robustness, while the attention mechanism primarily improves feature fusion accuracy and local complementarity. Combining the two achieves both robustness and feature weighting efficiency, achieving optimal overall performance.
- (7)
- Analysis of the independent impact of multi-view feature deletion: In response to the problem that “multi-view feature integration is the key, but there is a lack of comprehensive ablation research”, the experimental results clearly reveal:
Deleting the global semantic view (RoBERTa-FC): The model loses the ability to model long-range dependencies and global sentiment transfer, and the F1 drops significantly, especially in semantically complex datasets (such as Chn_hot, AlY_ds);
Deleting the time series view (BERT-BiGRU): The model’s performance in modeling emotional transitions and context consistency degrades, indicating that time-dependent features are an important supplement to semantic continuity;
Deleting the local view (TextCNN-Att): The model has difficulty capturing phrase-level clues such as emotional words and modifiers, and the ability to recognize emotional polarity is significantly reduced, especially in short texts or high-noise corpora.
In summary, the collaborative integration of multi-view features is the key to improving overall performance. The global semantic structure provided by RoBERTa-FC is the basic core, BERT-BiGRU supplements the contextual dynamic dependency of the time series, and TextCNN-Att strengthens the emotion recognition ability of local segments. The three complement each other under the action of dynamic weighting and residual fusion mechanism, making the model show strong robustness and generalization ability under various corpus and task conditions.
4.4. Model Validation and Analysis
4.4.1. Statistical Significance Analysis
To verify the statistical significance of the performance improvement achieved by the proposed heterogeneous ensemble learning model on the multi-source, multi-domain sentiment classification task, we conducted paired t-tests and confidence interval (CI) analyses (see Table 6) on the experimental results in Table 2 and Table 3. Because the models on each dataset were independently trained and validated under the same conditions, this approach effectively controlled for the impact of inter-sample differences. The significance level was set at α = 0.05. Test metrics included the F1 Score and Macro-AUC, which comprehensively reflect the model’s overall classification ability and robustness to class imbalance.
Table 6.
Significance test results of the ensemble model and base classifier.
Let the null hypothesis be: There is no significant difference in the performance of the two models on the given dataset;
The alternative hypothesis is: The ensemble model significantly outperforms the comparison model.
The statistical definitions are as follows:
where is the mean of the performance differences between the two models on each dataset, is the standard deviation of the differences, and is the number of samples (i.e., the number of datasets). If p < 0.05, H_0 is rejected and the difference is considered statistically significant.
As shown in Table 4, the ensemble model achieved significant performance improvements on all base classifiers (p < 0.05), with F1 Score increases ranging from 3.7% to 14.3%, and none of the confidence intervals crossed zero, demonstrating robust and reliable performance. In particular, the TextCNN-Att -based model achieved the most significant improvement after ensemble (ΔF1 Score = 0.1435), demonstrating strong feature complementarity between this model and the other learners. These results confirm that the heterogeneous ensemble mechanism proposed in this paper can effectively combine the strengths of multiple models, significantly improving sentiment classification performance.
Table 7 shows that, with the exception of Comparison-Model 2, the performance differences between the other four comparison models and our method all reached statistically significant levels (p < 0.05). Among them, Comparison-Model 3 achieved the greatest improvement (ΔF1 Score = 0.1190), demonstrating that our proposed weighted ensemble framework possesses stronger optimization capabilities in terms of model fusion mechanisms.
Table 7.
Significance test results of the ensemble model and other ensemble strategies.
For Comparison-Model 2, the p-value is 0.3664, and the 95% confidence interval includes 0 ([−0.0088, 0.0279]), thus failing to reject the null hypothesis at an α < 0.05 level. The standard deviation of the differences inferred from the t-statistic is approximately 0.0209, resulting in a calculated pairwise effect size (Cohen’s d) of ≈0.46, which is considered a small-to-medium effect. This indicates that while the difference is not yet significant, there is a slight positive trend (ΔF1 Score 1 = +0.0095), indicating that the ensemble model performs slightly better overall. This type of “small but consistent” improvement reflects the robustness and generalization consistency of the model, especially in high-performance tasks (F1 Score > 0.90), where small improvements are still meaningful.
4.4.2. Stability Verification
To further evaluate the robustness and generalization ability of the proposed dynamic uncertainty weighted ensemble model under different data partitions, this study conducted a stability analysis using K = 5 cross-validation on five datasets. Table 8 shows the mean and within-fold standard deviation (mean ± std) of the F1 Score for different datasets and models under K = 5 cross-validation.
Table 8.
K = 5 cross-validation results (F1 Score, mean ± std).
Figure 4, corresponding to Table 4, presents the mean F1 Score and within-fold standard deviation (STD) of the four models on each dataset in the form of a grouped bar chart. The figure clearly shows that the ensemble’s mean bar is higher than that of most base learners on all datasets, and its error bars are shorter, indicating that the model significantly reduces the within-fold fluctuation under K = 5-fold cross-validation, demonstrating high stability. Comparing the error bar lengths, the ensemble significantly reduced the within-fold uncertainty on all five datasets, validating the conclusion that “ensembling reduces within-fold fluctuation.” On the Waimai dataset, the mean of a single-base model (TextCNN-Att) is close to that of the ensemble, but the ensemble’s mean is still slightly higher and its variance is smaller, demonstrating that the ensemble strategy can provide robust gains even in everyday scenarios with direct emotional expression and brief text. On the Chn_hot dataset, the mean of the ensemble is significantly higher than that of the three-base model, and the error bars almost do not overlap, demonstrating that in complex, long texts, information-intensive corpora with multiple emotional transitions, the integration mechanism can fully integrate the complementary features of the base models to achieve maximum performance improvement.
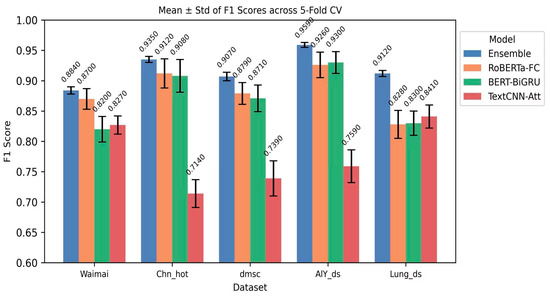
Figure 4.
Grouped histogram (mean ± std).
Figure 5 shows the performance trends of the models on different datasets using overlaid shading, with shading representing ±std. The analysis shows that the ensemble’s shading line consistently stays at the top and has a narrow shading band, indicating smoother and more stable performance across datasets. This not only supports the generalization advantage of ensemble methods for multi-source, multi-domain texts, but also reveals their robustness in the face of corpus differences. In particular, on the Chn_hot dataset, the vertical distance between the ensemble and the three-base model is the largest, intuitively reinforcing the phenomenon that ensembles yield the greatest benefits on complex, long texts. For short, everyday texts such as Waimai and dmsc, the shading lines are relatively close, indicating that the single-base model has achieved a good fit on these texts. However, the ensemble maintains its lead and has a smaller within-fold standard deviation, demonstrating that even with limited absolute improvement, its stability benefits are still significant.
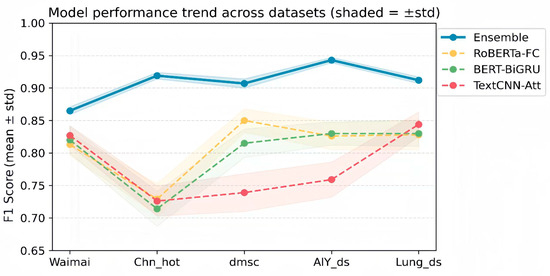
Figure 5.
Line Shaded Chart.
Further comparison of Figure 4 and Figure 5 reveals that the benefits of ensembling are not only reflected in an improvement in the mean, but also in a significant reduction in variance: the average standard deviation of the ensemble is significantly lower than that of the three-base model. This demonstrates that the ensemble approach, through dynamic uncertainty weighting, balances the bias between model outputs, resulting in consistently improved performance both within and across datasets. This stability is particularly important for practical industrial deployment and multi-round experimental validation, as it ensures the model’s repeatability and reliability under random data partitioning, while mitigating the risk of performance fluctuations caused by varying text feature distributions.
In summary, the K = 5 cross-validation results strongly demonstrate that the proposed dynamic uncertainty weighted ensemble model not only improves the average performance in multi-source, multi-domain sentiment analysis tasks but also significantly reduces within-fold fluctuations, achieving stable and universal performance improvements. Furthermore, the charts reveal the mechanism for the differential benefits across datasets: Ensembling yields the greatest gains on complex, long texts and cross-subdomain corpora, while maintaining stability on short, everyday texts, demonstrating the adaptability and robustness of the ensemble strategy across diverse corpora.
4.4.3. Analysis of the Model’s Cross-Domain Robustness and Comprehensive Advantages
To comprehensively evaluate the adaptability and overall advantages of the proposed integrated model in tasks in different fields, this study drew a radar chart based on five core indicators (Accuracy, Precision, F1 Score, Recall, and Macro-AUC) on five datasets (Waimai, Chn_hot, dmsc, AlY_ds, and Lung_ds) (as shown in Figure 6) and calculated the cross-dataset mean of each indicator (as shown in Table 9).
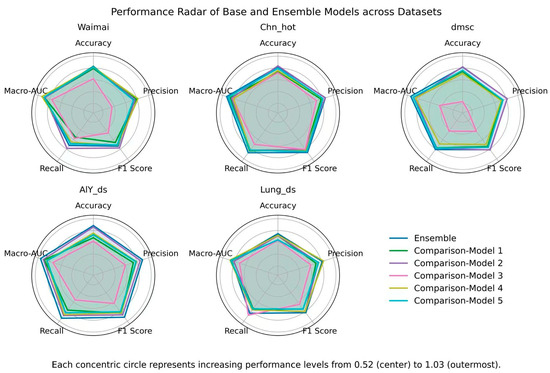
Figure 6.
Radar chart comparing multiple datasets and multiple indicators.
Table 9.
Cross-dataset mean table.
Statistical results show that the average performance of the ensemble model across the five datasets is Accuracy = 0.9097 ± 0.025, Precision = 0.9147 ± 0.027, Recall = 0.9183 ± 0.040, F1 Score = 0.9149 ± 0.033, and Macro-AUC = 0.9582 ± 0.023. The Macro-AUC consistently remained in the 0.92–0.98 range, demonstrating the model’s robust discriminative capabilities across different thresholds. Furthermore, Precision and F1 Score remained above 0.90 on most datasets, demonstrating the model’s superiority in class prediction balance and overall reliability. For example, the standard deviation of Accuracy for Comparison-Model 3 is as high as 0.096, while that of the ensemble model is only 0.025, demonstrating its lower fluctuation across different domain tasks. In particular, Macro-AUC has remained in the range of 0.92–0.98 for a long time, reflecting the model’s stable discrimination ability at different discrimination thresholds; Recall and F1 Score have both remained stable at around 0.91, indicating that its performance in balancing minority classes and overall categories is more reliable.
Combined with the radar chart in Figure 6, we can see that the ensemble model forms relatively full and stable coverage curves across all tasks, while the comparison models exhibit significant skewness: some models excel in Precision or Recall, but suffer from significant shortcomings in other metrics.
- (1)
- In the Waimai dataset (general scenario), the ensemble model achieves the best result in Accuracy (0.9147), but falls short in other individual metrics: Comparison-Model 4 leads in Precision (0.9088) and Macro-AUC (0.9671), while Comparison-Model 2 leads in F1 Score (0.8883), and also performs best in Recall (0.8930). This indicates that, in general review scenarios, individual comparison models often achieve advantages in specific metrics, but this advantage is often accompanied by significant declines in other metrics. For example, Comparison-Model 4 performs well in Precision and Macro-AUC, but its Recall (0.8277) is significantly lower than that of the ensemble model (0.8616), indicating a significant weakness in minority class recognition. While Comparison-Model 2 leads in F1 Score and Recall, its Accuracy and Macro-AUC are relatively low (0.9059 and 0.9396), limiting its overall discriminative ability. In contrast, the ensemble model’s distinguishing feature is not a single optimal metric, but rather a relatively balanced performance across all metrics: Accuracy and Recall are at relatively good levels, while Precision and F1 Score, while lower than the best model, remain within acceptable ranges (0.8777 and 0.8696), and Macro-AUC also remains high (0.9478). This coordination between metrics demonstrates that the ensemble strategy, by combining the discriminative strengths of different base learners, effectively mitigates biases in individual models due to threshold selection or overfitting, resulting in a more robust overall performance. Therefore, in general tasks, while the comparison model may outperform the ensemble model in some local dimensions, the ensemble model, thanks to its balanced approach across multiple metrics, demonstrates superior overall robustness and robustness.
- (2)
- In the Chn_hot dataset (cross-domain review scenario), the ensemble model achieved outstanding performance across multiple core metrics: Precision (0.9327), F1 Score (0.9353), Recall (0.9379), and Macro-AUC (0.9672) all achieved the best results, demonstrating strong overall discrimination and minority class recognition capabilities in cross-domain tasks. In comparison, while Accuracy (0.9111) was slightly lower than Comparison-Model 2 (0.9188), the gap was not significant. Further comparison reveals that Comparison-Model 2 achieved the best performance in Accuracy (0.9188), but its F1 Score (0.9015) and Recall (0.9117) lagged significantly behind the ensemble model. This suggests that while it leads in overall accuracy, it struggles to achieve a balanced classification performance. Overall, the ensemble model not only leads in core metrics such as Precision, F1 Score, Recall, and Macro-AUC but also maintains near-optimal accuracy, demonstrating comprehensive robustness through complementary advantages. This demonstrates that the cross-domain review task can effectively integrate the local strengths of different models to achieve a more representative overall lead.
- (3)
- On the dmsc (cross-domain social text) dataset, Comparison-Model 2 slightly outperformed the ensemble model (0.9071 and 0.9069) in Accuracy (0.9105) and F1 Score (0.9086), but the differences were only 0.34% and 0.17%, respectively, representing marginal advantages. In comparison, the ensemble model achieved the best results in Precision (0.9091), Recall (0.9048), and Macro-AUC (0.9724). The ensemble model achieved a 4% lead in Macro-AUC (0.9724 vs. 0.9323), demonstrating its superior discriminative ability under varying thresholds and sample distributions. Furthermore, the ensemble model’s Recall significantly outperformed Comparison-Model 2 (0.9048 vs. 0.8900), demonstrating its more comprehensive coverage of minority class samples. Overall, while individual models had slight advantages in Accuracy and F1 Score, the ensemble model, with its higher Recall and significantly higher Macro-AUC, demonstrated more robust overall performance in cross-domain noisy environments.
- (4)
- In the AlY_ds (multi-subdomain e-commerce data), the ensemble model leads across the board in Precision (0.9487), F1 Score (0.9590), Recall (0.9694), and Macro-AUC (0.9797), demonstrating strong discriminative ability and robustness in complex heterogeneous scenarios. In contrast, while Comparison-Model 2 achieves the best accuracy (0.9299), its Precision (0.9291), Recall (0.9409), and Macro-AUC (0.9554) lag significantly behind the ensemble model, indicating that its overall stability is insufficient. Notably, the ensemble model achieved a Recall score of 0.9694, significantly outperforming all the compared models, demonstrating its superior coverage of minority classes and marginal samples. Furthermore, the Macro-AUC reached a high of 0.9797, far exceeding the single model (which reached a maximum of only 0.9554) and demonstrating its robust discrimination capabilities across various thresholds. Overall, while not achieving an absolute advantage in accuracy, the ensemble model, with its comprehensive leadership across multiple metrics, achieved an optimal balance across diverse e-commerce sub-sectors, making it more suitable for addressing practical application needs in complex, multi-source environments.
- (5)
- On the Lung_ds (medical text) dataset, the ensemble model achieved the best results in Recall (0.9177) and F1 Score (0.9115), highlighting its stronger comprehensive recognition capabilities in complex medical semantic environments. In comparison, Comparison-Model 4 slightly outperformed the ensemble model in Precision (0.9167) and Macro-AUC (0.9379), but its Recall (0.8819) was significantly lower than the ensemble model, indicating insufficient coverage of minority class samples. Furthermore, while Comparison-Model 3 achieved the highest Recall (0.9367), its Precision and F1 Score were only 0.8056 and 0.8238, respectively, demonstrating a significant imbalance. In contrast, while the ensemble model did not achieve an overall lead in metrics such as Accuracy (0.8734), Precision (0.9053), and Macro-AUC (0.9238), it consistently maintained a high level, with a gap of only 1–1.5 percentage points from the best results. Overall, the ensemble model, through its advantages in Recall and F1 Score, balanced the recognition of minority classes with overall performance, meeting the need for “more detection and fewer omissions” in medical text scenarios and demonstrating greater practical value and robustness.
In addition, to avoid bias from a single metric, this study used an equally weighted ranking method based on the five metrics of Accuracy, Precision, Recall, F1 Score, and Macro-AUC to calculate the average ranking of each model across different datasets. The results show that the ensemble model achieved the lowest average ranking on dmsc and AlY_ds (both 1.25), 1.75 on Chn_hot, 2.25 on Waimai, and 2.00 on Lung_ds, respectively; the overall average ranking across datasets was 1.70. This demonstrates that regardless of the changing task scenarios, the ensemble model consistently maintains a top-two overall performance, often directly leading or on par with the best model.
In summary, while some comparison models may have advantages in terms of individual metrics or specific datasets, they often struggle to achieve consistent performance globally. In contrast, the ensemble model, leveraging the complementary nature of multi-base learners and its uncertainty weighting mechanism, effectively mitigates the bias and overfitting risks of individual models. It demonstrates stronger transferability and noise resistance in cross-domain tasks, achieving overall superiority across multiple metrics in multiple sub-domain tasks. Therefore, the proposed ensemble strategy not only demonstrates outstanding global performance but also possesses cross-domain robustness and practical deployment value.
5. Conclusions
With the explosive growth of text data across multiple domains, sentiment analysis tasks face significant challenges in cross-domain adaptability and model robustness. While existing single deep models perform well on specific datasets, their performance fluctuates significantly, making them incapable of addressing complex semantics, class imbalance, and cross-domain stability. Traditional ensemble methods often rely on homogeneous model voting or static weighting, lack the comprehensive integration of global semantics, local patterns, and temporal dependencies, and exhibit poor performance when processing noisy and class-skewed data.
To address these issues, this paper proposes a heterogeneous ensemble learning framework based on multi-view features. At the base learner level, this model combines RoBERTa-FC, BERT-BiGRU, and TextCNN-Att to achieve multi-level feature modeling from three dimensions: global semantics, temporal dependencies, and local patterns. At the decision layer, dynamic uncertainty weighting and attention enhancement mechanisms are introduced to adaptively assign weights based on sample prediction confidence, effectively improving the model’s robustness and generalization in cross-domain scenarios. The experimental results demonstrate that the proposed ensemble model outperfothe single-base learners and comparison models on five multi-domain datasets (Waimai, Chn_hot, dmsc, AlY_ds, and Lung_ds). In an equally weighted ranking of the five metrics—Accuracy, Precision, Recall, F1 Score, and Macro-AUC—the ensemble model achieved an average cross-dataset ranking of 1.70, consistently maintaining a top-two position and demonstrating a consistent, leading overall advantage. In particular, the Macro-AUC metric achieved scores of 0.9314 and 0.9724 on the Waimai and dmsc datasets, respectively, demonstrating its outstanding ability to distinguish between positive and negative samples. These results fully demonstrate the effectiveness and robustness of the proposed method for class imbalance, diverse text sentiment expression, and cross-domain tasks.
Although the proposed multi-view heterogeneous ensemble model demonstrates excellent robustness and generalization capabilities across multiple domains of sentiment analysis, it still has certain limitations. First, the model’s relatively complex structure, integrating multiple Transformer and recurrent network branches, results in high computational overhead during both training and inference. Particularly in environments with limited computing resources, the dynamic weight allocation and attention fusion modules further increase graphics memory usage and inference latency, impacting the model’s deployment efficiency. Second, the overall performance of the ensemble framework depends to a certain extent on the diversity and quality of the base learners. When some sub-models are underfit or overfit, their noisy predictions may interfere with the final ensemble results. Furthermore, in cases of small datasets or extreme class imbalance, the weight learning mechanism may struggle to fully capture the true uncertainty distribution, impacting the model’s stability and generalization performance.
In response to the above limitations, future research can be further expanded in the following directions: first, by combining more heterogeneous base learners with domain knowledge to improve the model’s adaptability in extreme category skew or low-resource scenarios; and second, by exploring lightweight dynamic integration strategies to reduce computational complexity while ensuring performance, balancing model accuracy and inference efficiency. This will promote the model’s application in online services and real-time analysis scenarios.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/electronics14214189/s1, S1 (mobile_phone_sentence), S2 (mobile_phone_label), S3 (car_sentence), S4 (car_label), S5 (camera_sentence), S6 (camera_label), S7 (notebook_sentence), and S8 (notebook_label).
Author Contributions
Conceptualization, S.Y. and J.X.; methodology, Z.D. and J.X.; software, J.X.; validation, Z.L. and Z.D.; formal analysis, J.X.; investigation, S.Y.; resources, Z.L.; data curation, J.X.; writing—original draft preparation, S.Y. and J.X.; writing—review and editing, S.Y., Z.L. and Z.D.; visualization, J.X.; supervision, S.Y.; project administration, S.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by 2017 Higher Education Research Project grant number 2017G04. The APC was funded by Dalian University of Foreign Languages.
Data Availability Statement
The original contributions presented in this study are included in the article/Supplementary Materials. For further inquiries, please contact the corresponding author(s).
Acknowledgments
During the preparation of this manuscript, the authors used DeepSeek R1 for the purposes of polishing. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhang, Z.; Xue, J.; Chen, G. Sentiment analysis of imbalanced data under deep learning framework. Mod. Inf. 2021, 41, 75–82. [Google Scholar]
- Azim, K.; Tahir, A.; Shahroz, M.; Karamti, H.; Vazquez, A.A.; Vistorte, A.R.; Ashraf, I. Ensemble stacked model for enhanced identification of sentiments from IMDB reviews. Sci. Rep. 2025, 15, 13405. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhu, Z.; Hua, Y. Research on the financial early warning models based on ensemble learning algorithms: Introducing MD&A and stock forum comments textual indicators. PLoS ONE 2025, 20, e0323737. [Google Scholar] [CrossRef]
- Zhou, M.; Zhou, Y.J.; He, Y.; Fang, B.H. Research on sentiment classification of automobile reviews using multiple classifiers based on ER Rule. Oper. Res. Manag. 2024, 33, 161–168. [Google Scholar]
- Liu, J.; Li, H.; Gu, Y.; Shi, Q.; Yang, X. Research on usefulness recognition of online reviews on imbalanced datasets. Inf. Sci. Theory Pract. 2023, 46, 119–125+153. [Google Scholar] [CrossRef]
- Zhu, M. Research on Short Text Classification Model Based on Deep Learning and Ensemble Learning. Master’s Thesis, Nanjing Audit University, Nanjing, China, 2023. [Google Scholar] [CrossRef]
- Huang, D. Sentiment Analysis of Weibo Comments Based on Ensemble Learning. Master’s Thesis, Dalian Jiaotong University, Dalian, China, 2023. [Google Scholar] [CrossRef]
- Shuai, C.; Qian, J.; Zhou, C. Sentiment classification based on weighted ensemble sequential three-way decision. J. Shanxi Univ. (Nat. Sci. Ed.) 2025, 48, 66–76. [Google Scholar] [CrossRef]
- Machová, K.; Mach, M.; Adamišín, K. Machine Learning and Lexicon Approach to Texts Processing in the Detection of Degrees of Toxicity in Online Discussions. Sensors 2022, 22, 6468. [Google Scholar] [CrossRef] [PubMed]
- Balakrishnan, V.; Govindan, V.; Govaichelvan, K.N. Tamil Offensive Language Detection: Supervised versus Unsupervised Learning Approaches. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 106. [Google Scholar] [CrossRef]
- Zheng, C.Y.; Wang, X.; Wang, T.; Yin, T.T.; Deng, Y.P. Chinese short text classification algorithm based on Stacking-BERT ensemble learning. Sci. Technol. Eng. 2022, 22, 4033–4038. [Google Scholar]
- Lin, P.; Lü, J. Research on information adoption recognition in online health communities based on Stacking ensemble learning. Inf. Sci. 2023, 41, 135–142. [Google Scholar] [CrossRef]
- Ye, Z.; Wu, Y.; Chen, H.; Pan, Y.; Jiang, Q. A Stacking Ensemble Deep Learning Model for Bitcoin Price Prediction Using Twitter Comments on Bitcoin. Mathematics 2022, 10, 1307. [Google Scholar] [CrossRef]
- Yin, M.; Zhu, K.; Xiao, H.; Zhu, D.; Jiang, J. Deep neural network ensembles for detecting self-admitted technical debt. J. Intell. Fuzzy Syst. 2022, 43, 93–105. [Google Scholar] [CrossRef]
- Jiang, Q.; Wang, C. Financial risk early warning of overseas mergers and acquisitions in Internet enterprises based on big data and Stacking ensemble learning. Technol. Econ. 2023, 42, 147–160. [Google Scholar]
- Cao, R.; Zhou, Y. Food safety public opinion analysis system based on BERT-BiGRU multimodal ensemble. Inf. Comput. (Theor. Ed.) 2022, 34, 94–97. [Google Scholar]
- Ghorbanali, A.; Sohrabi, M.K.; Yaghmaee, F. Ensemble transfer learning-based multimodal sentiment analysis using weighted convolutional neural networks. Inf. Process. Manag. 2022, 59, 102929. [Google Scholar] [CrossRef]
- Habbat, N.; Nouri, H. Unlocking travel narratives: A fusion of stacking ensemble deep learning and neural topic modeling for enhanced tourism comment analysis. Soc. Netw. Anal. Min. 2024, 14, 82. [Google Scholar] [CrossRef]
- Devika, P.; Milton, A. Book recommendation using sentiment analysis and ensembling hybrid deep learning models. Knowl. Inf. Syst. 2025, 67, 1131–1168. [Google Scholar] [CrossRef]
- Baruah, A.; Wahlang, L.; Jyrwa, F.; Shadap, F.; Barbhuiya, F.; Dey, K. Abusive language detection in Khasi social media comments. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2024; 1–32, accepted. [Google Scholar] [CrossRef]
- Abarna, S.; Sheeba, J.I.; Pradeep Devaneyan, S. A novel ensemble model for identification and classification of cyber harassment on social media platform. J. Intell. Fuzzy Syst. 2023, 45, 13–36. [Google Scholar] [CrossRef]
- Mazari, A.C.; Boudoukhani, N.; Djeffal, A. BERT-based ensemble learning for multi-aspect hate speech detection. Clust. Comput. 2024, 27, 325–339. [Google Scholar] [CrossRef]
- Eyvazi-Abdoljabbar, S.; Kim, S.; Feizi-Derakhshi, M.-R.; Farhadi, Z.; Mohammed, D.A. An Ensemble-Based Model for Sentiment Analysis of Persian Comments on Instagram Using Deep Learning Algorithms. IEEE Access 2024, 12, 151223–151235. [Google Scholar] [CrossRef]
- Shankar, A.; Perumal, P.; Subramanian, M.; Ramu, N.; Natesan, D.; Kulkarni, V.R.; Stephan, T. An intelligent recommendation system in e-commerce using ensemble learning. Multimed. Tools Appl. 2024, 83, 48521–48537. [Google Scholar] [CrossRef]
- Al Mahmoud, R.H.; Hammo, B.H.; Faris, H. Cluster-based ensemble learning model for improving sentiment classification of Arabic documents. Nat. Lang. Eng. 2024, 30, 1091–1129. [Google Scholar] [CrossRef]
- Zhong, Z.; Xiong, Y.; Huang, X. Research on multivariate text sentiment analysis based on heterogeneous ensemble learning. J. Nanjing Univ. (Nat. Sci.) 2023, 59, 471–482. [Google Scholar] [CrossRef]
- Miao, P.; Liu, Z.; Dai, X. Chinese review sentiment classification based on multi-classifier voting ensemble. Comput. Simul. 2025, 42, 494–500. [Google Scholar]
- You, L.; Zeng, H.; Han, F.Y.; Jin, H.; Cui, H.B.; Zhang, J.H. Sentiment semantic recognition based on BERT-BiGRU ensemble learning. Comput. Technol. Dev. 2023, 33, 159–166. [Google Scholar]
- Li, D.; Ji, C.; Liu, S. Research on sentiment classification method based on heterogeneous classifier ensemble learning. J. Wuhan Univ. (Eng. Ed.) 2021, 54, 975–982. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).