
Latency-Aware and Energy-Efficient Task Offloading in IoT and Cloud Systems with DQN Learning

 , and
, and
Abstract
1. Introduction
- A task offloading problem is formulated within a collaborative IoT–fog–cloud framework, accounting for real-world constraints such as device heterogeneity and fluctuating network conditions.
- An energy-efficient and latency-aware algorithm based on DQN learning is proposed to optimize task offloading decisions. The method provides a structured approach to assigning tasks across different layers of the computing hierarchy.
- The proposed model is evaluated and validated through comprehensive simulations, demonstrating its effectiveness in enhancing QoS metrics, particularly in reducing energy consumption and application latency when compared with existing approaches.
2. Related Works
2.1. Energy-Aware Task Offloading
2.2. Latency Aware Task Offloading
3. System Model and Problem Formulation
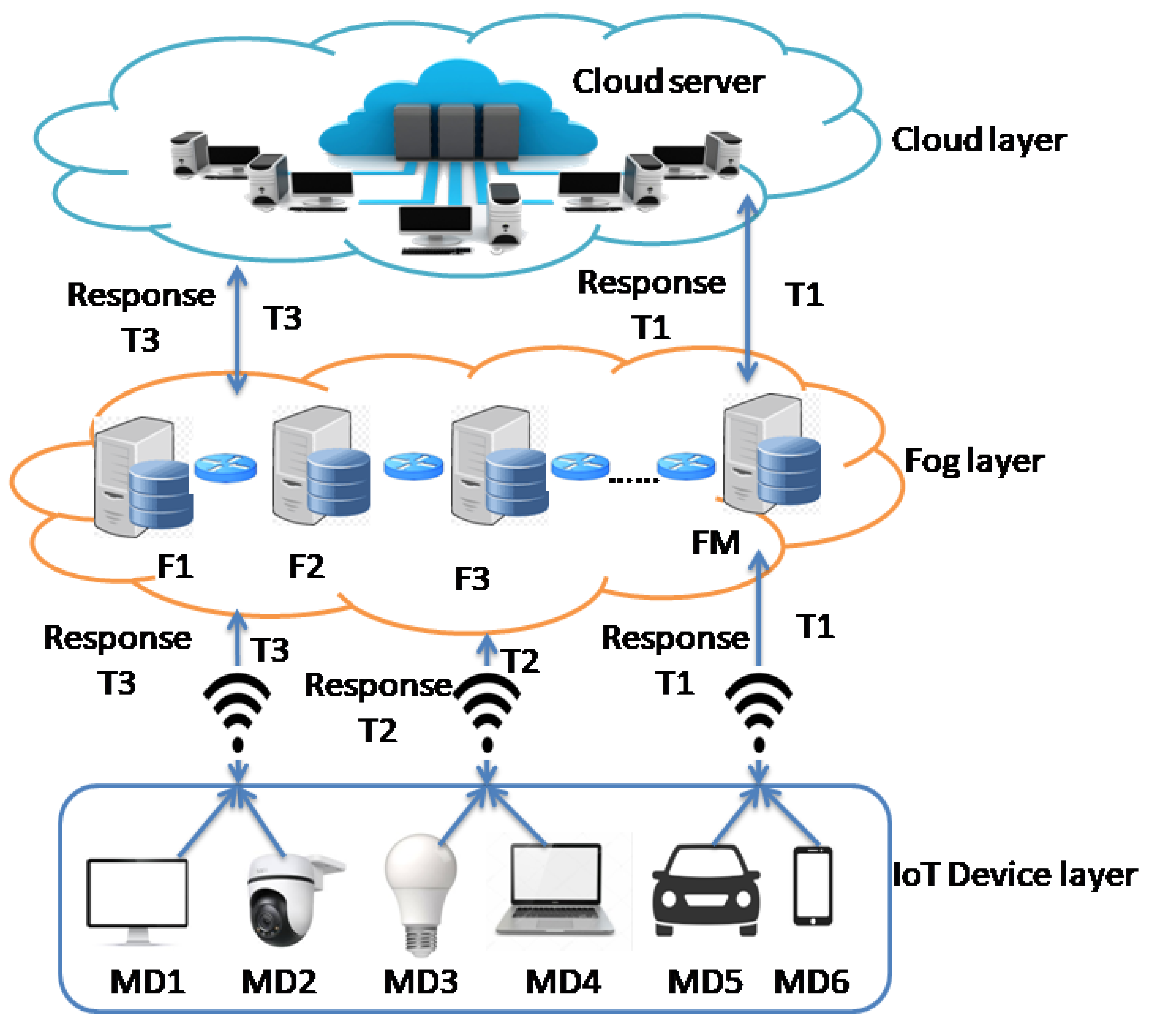
3.1. System Model
3.2. Task Offloading Model
3.3. The Three Variant Executions
3.3.1. Local Execution
3.3.2. Fog Execution
3.3.3. Cloud Execution
3.4. Problem Formulation
- C1:
- C2:
- C3:
- C4:
- C5:
- C6:
- C1, C2, and C3 denote that these decision variables are guaranteed to be binary through these three constraints.
- C4 indicates that there should only be one location in which each work is completed, so the choice location variable will be equal to 1.
- C5 ensures that the bandwidth assigned to the task must be positive.
- C6 indicates that the task latency must not exceed the maximum tolerable delay to execute task , whether in a local, fog, or cloud server.
4. Proposed Solution
4.1. Optimal Task Offloading Strategy
| Algorithm 1 Optimal task offloading strategy |
Input Mobile_devices MD, Fog_node F, Cloud_server C, Tasks T. Output Execution_Location EL, Min_Cost MC.
|
4.2. DQN-Based Task Offloading
| Algorithm 2 DQN-based task offloading strategy |
Input Tasks T, learning rate(), discount factor (). Output Optimal offloading decision and total cost.
|
5. Performance Analysis and Discussion
5.1. Simulation Model
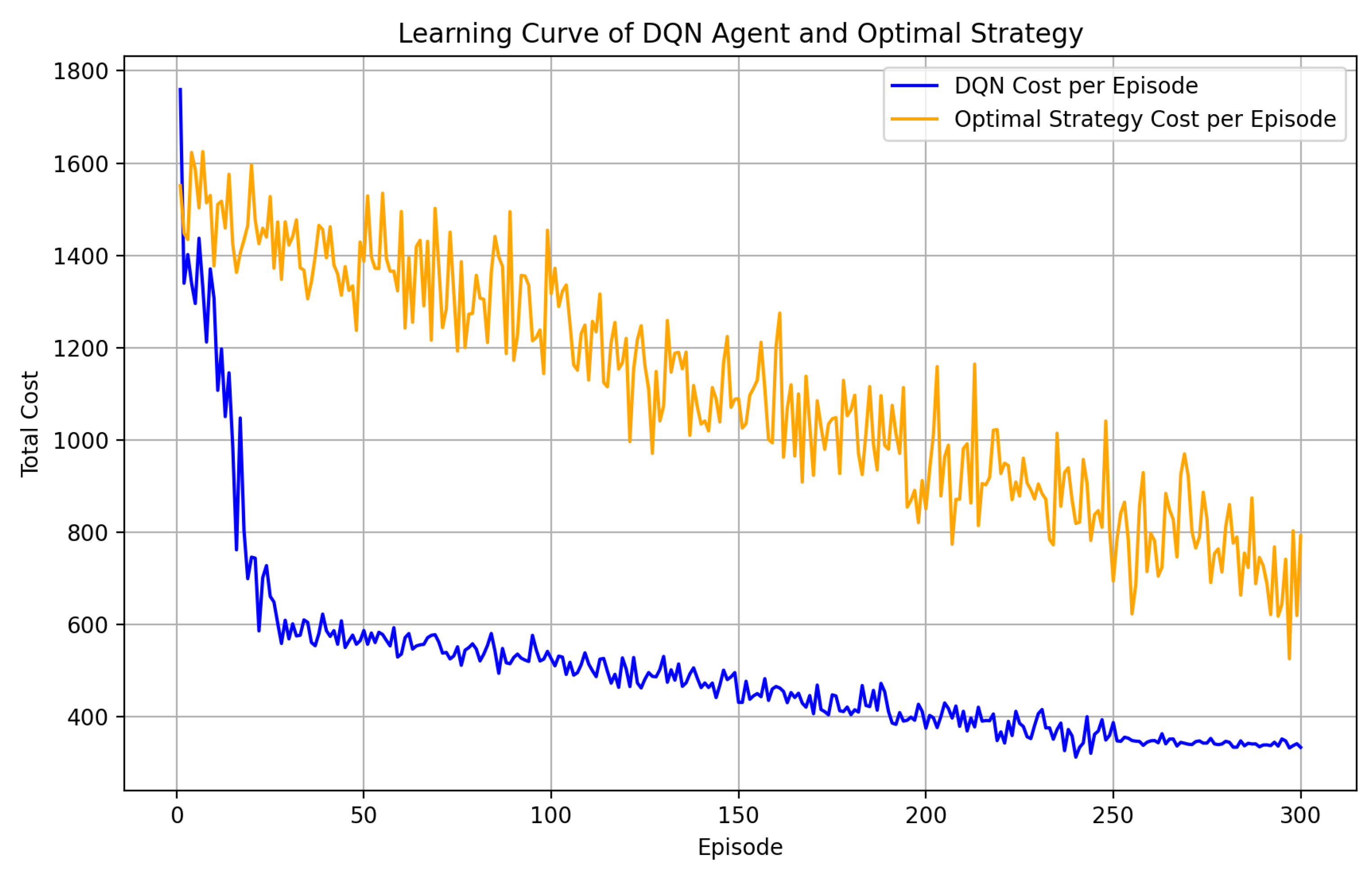
5.2. The Proposed Algorithm’s Convergence Analysis
5.3. The Proposed Algorithms Comparative Analysis
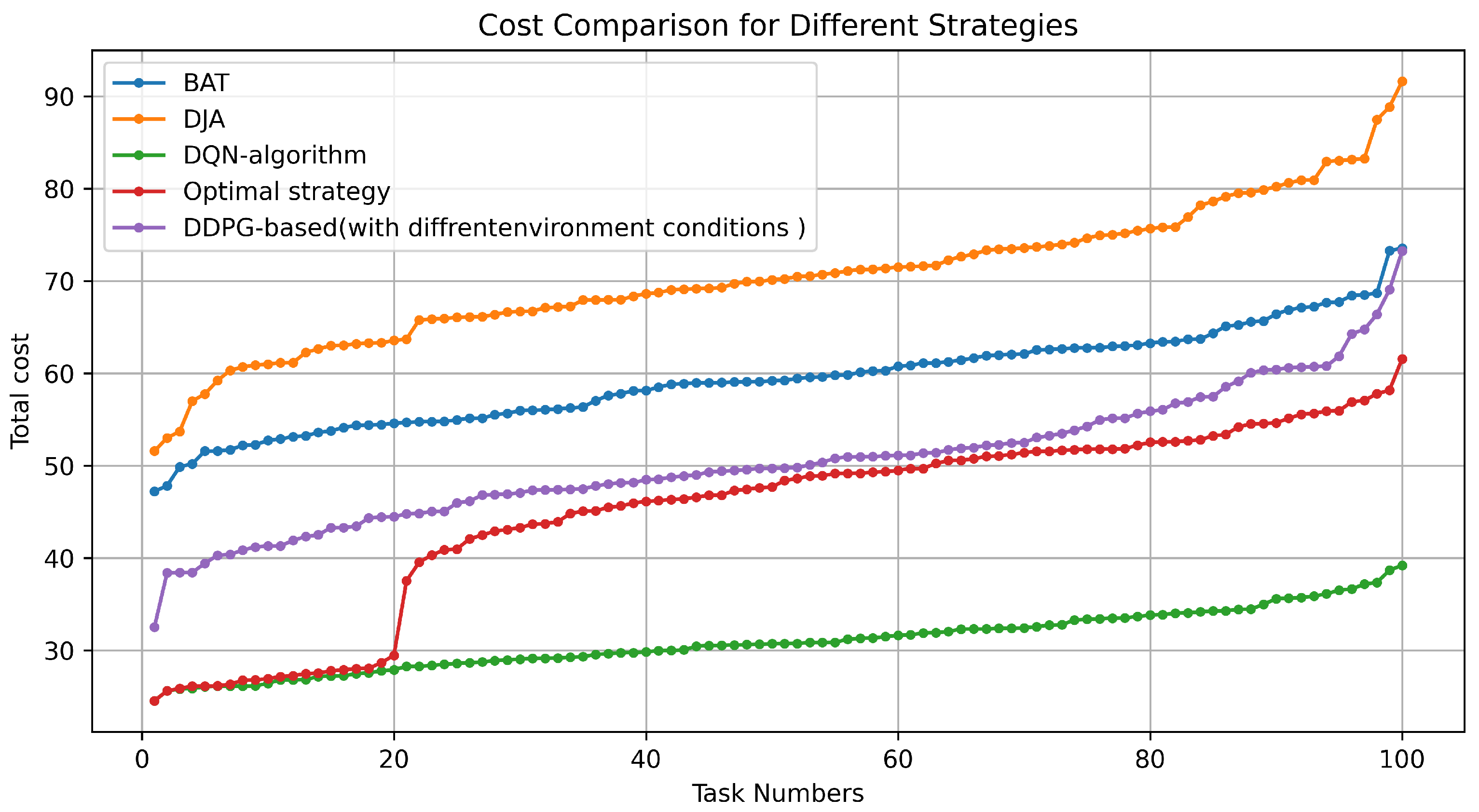
5.3.1. Energy Consumption
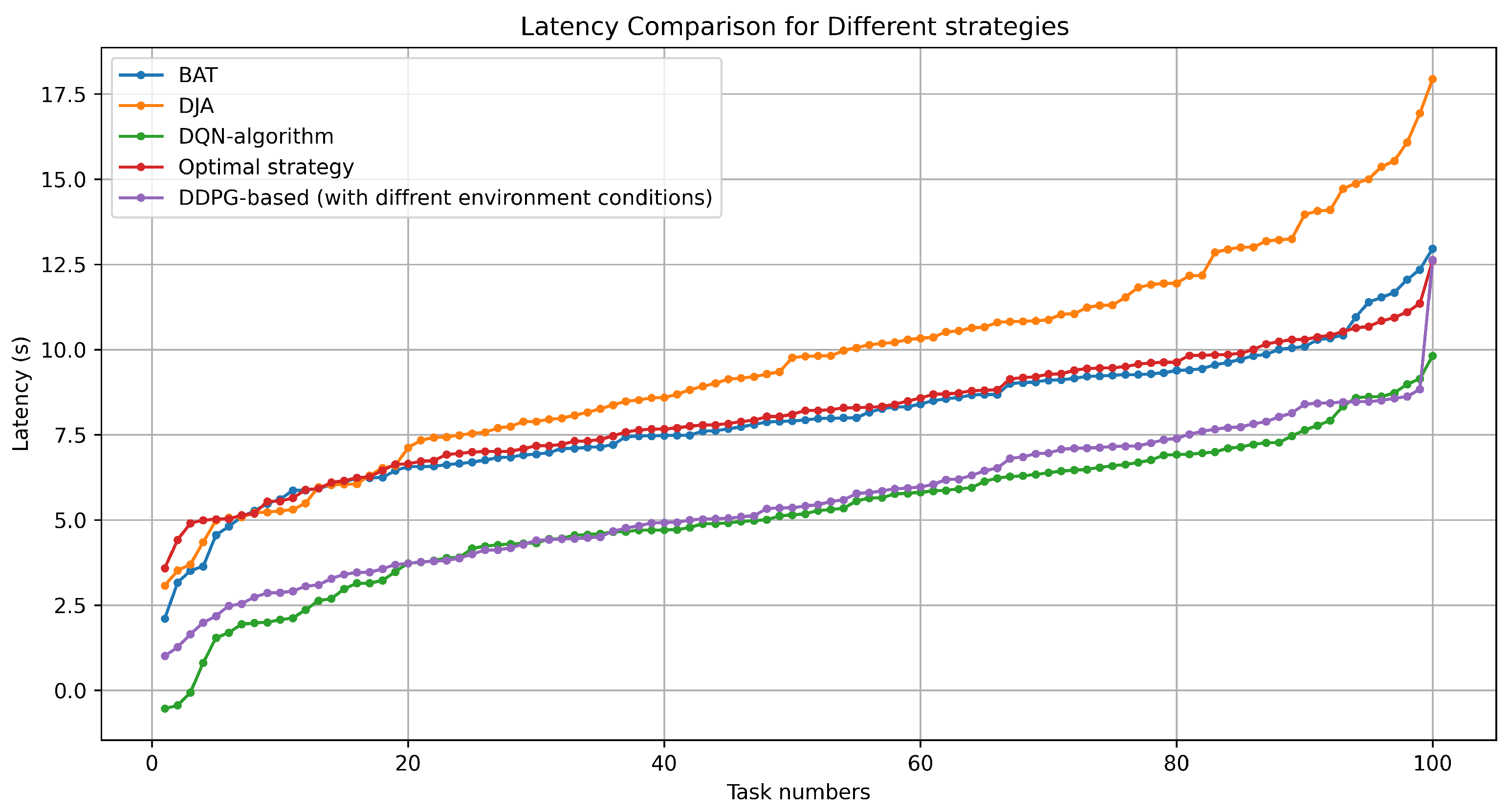
5.3.2. Latency
5.4. Compared Methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aknan, M.; Arya, R. AI and Blockchain Assisted Framework for Offloading and Resource Allocation in Fog Computing. J. Grid Comput. 2023, 21, 1–17. [Google Scholar] [CrossRef]
- Selim Demir, M.; Hossien, B.; Murat Uysal, E. Relay-Assisted Handover Technique for Vehicular VLC Networks. ITU J. Future Evol. Technol. 2022, 3, 11–19. [Google Scholar] [CrossRef]
- Safaei, B.; Mohammadsalehi, A.A.; Khoosani, K.T.; Zarbaf, S.; Monazzah, A.M.H.; Samie, F.; Bauer, L.; Henkel, J.; Ejlali, A. Impacts of Mobility Models on RPL-Based Mobile IoT Infrastructures: An Evaluative Comparison and Survey. IEEE Access 2020, 8, 167779–167829. [Google Scholar] [CrossRef]
- Goudarzi, M.; Wu, H.; Palaniswami, M.; Buyya, R. An Application Placement Technique for Concurrent IoT Applications in Edge and Fog Computing Environments. IEEE Trans. Mob. Comput. 2021, 20, 1298–1311. [Google Scholar] [CrossRef]
- Chow, C.-W. Recent Advances and Future Perspectives in Optical Wireless Communication, Free Space Optical Communication and Sensing for 6G. J. Light. Technol. 2024, 42, 3972–3980. [Google Scholar] [CrossRef]
- Alasmari, M.K.; Alwakeel, S.S.; Alohali, Y.A. A Multi-Classifier-Based Algorithm for Energy-Efficient Tasks Offloading in Fog Computing. Sensors 2023, 23, 7209. [Google Scholar] [CrossRef]
- Abdullah, S.; Jabir, A. A Lightweight Multi-Objective Task Offloading Optimization for Vehicular Fog Computing. Iraqi J. Electr. Electron. Eng. 2021, 17, 1–10. [Google Scholar] [CrossRef]
- Shi, J.; Du, J.; Wang, J.; Wang, J.; Yuan, J. Priority-Aware Task Offloading in Vehicular Fog Computing Based on Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2020, 69, 16067–16081. [Google Scholar] [CrossRef]
- Alharbi, H.A.; Aldossary, M.; Almutairi, J.; Elgendy, I.A. Energy-Aware and Secure Task Offloading for Multi-Tier Edge-Cloud Computing Systems. Sensors 2023, 23, 3254. [Google Scholar] [CrossRef]
- Kumar, M.; Sharma, S.C.; Goel, A.; Singh, S.P. A Comprehensive Survey for Scheduling Techniques in Cloud Computing. J. Netw. Comput. Appl. 2019, 143, 1–33. [Google Scholar] [CrossRef]
- Xin, J.; Li, X.; Zhang, L.; Zhang, Y.; Huang, S. Task Offloading in MEC Systems Interconnected by Metro Optical Networks: A Computing Load Balancing Solution. Opt. Fiber Technol. 2023, 81, 103543. [Google Scholar] [CrossRef]
- Jiang, Y.-L.; Chen, Y.-S.; Yang, S.-W.; Wu, C.-H. Energy-Efficient Task Offloading for Time-Sensitive Applications in Fog Computing. IEEE Syst. J. 2019, 13, 2930–2941. [Google Scholar] [CrossRef]
- Iftikhar, S.; Gill, S.S.; Song, C.; Xu, M.; Aslanpour, M.S.; Toosi, A.N.; Du, J.; Wu, H.; Ghosh, S.; Chowdhury, D.; et al. AI-Based Fog and Edge Computing: A Systematic Review, Taxonomy and Future Directions. Internet Things 2023, 21, 100674. [Google Scholar] [CrossRef]
- Lu, H.; He, X.; Zhang, D. Security-Aware Task Offloading Using Deep Reinforcement Learning in Mobile Edge Computing Systems. Electronics 2024, 13, 2933. [Google Scholar] [CrossRef]
- Samy, A.; Elgendy, I.A.; Yu, H.; Zhang, W.; Zhang, H. Secure Task Offloading in Blockchain-Enabled Mobile Edge Computing with Deep Reinforcement Learning. IEEE Trans. Netw. Serv. Manag. 2022, 19, 4872–4887. [Google Scholar] [CrossRef]
- Fang, J.; Qu, D.; Chen, H.; Liu, Y. Dependency-Aware Dynamic Task Offloading Based on Deep Reinforcement Learning in Mobile Edge Computing. IEEE Trans. Netw. Serv. Manag. 2023, 2, 1403–1415. [Google Scholar] [CrossRef]
- Wang, P.; Li, K.; Xiao, B.; Li, K. Multi-Objective Optimization for Joint Task Offloading, Power Assignment, and Resource Allocation in Mobile Edge Computing. IEEE Internet Things J. 2021, 9, 11737–11748. [Google Scholar] [CrossRef]
- Eldeeb, H.B.; Naser, S.; Bariah, L.; Muhaidat, S.; Uysal, M. Digital Twin-Assisted OWC: Towards Smart and Autonomous 6G Networks. IEEE Netw. 2024, 38, 153–162. [Google Scholar] [CrossRef]
- Zhou, R.; Zhang, X.; Qin, S.; Lui, J.C.S.; Zhou, Z.; Huang, H.; Li, Z. Online Task Offloading for 5G Small Cell Networks. IEEE Trans. Mob. Comput. 2022, 21, 2103–2115. [Google Scholar] [CrossRef]
- Eldeeb, H.B.; Selmy, H.A.I.; Elsayed, H.M.; Badr, R.I.; Uysal, M. Efficient Resource Allocation Scheme for Multi-User Hybrid VLC/IR Networks. In Proceedings of the 2022 IEEE Photonics Conference (IPC), Vancouver, BC, Canada, 13–17 November 2019; pp. 1–2. [Google Scholar] [CrossRef]
- Norsyafizan, W.; Mohd, S.; Dimyati, K.; Awais Javed, M.; Idris, A.; Mohd Ali, D.; Abdullah, E. Energy-Efficient Task Offloading in Fog Computing for 5G Cellular Network. Eng. Sci. Technol. Int. J. 2024, 50, 101628. [Google Scholar] [CrossRef]
- Kumar, D.; Baranwal, G.; Shankar, Y.; Vidyarthi, D.P. A Survey on Nature-Inspired Techniques for Computation Offloading and Service Placement in Emerging Edge Technologies. World Wide Web 2022, 25, 2049–2107. [Google Scholar] [CrossRef]
- Hosny, K.M.; Awad, A.I.; Khashaba, M.M.; Fouda, M.M.; Guizani, M.; Mohamed, E.R. Optimized Multi-User Dependent Tasks Offloading in Edge-Cloud Computing Using Refined Whale Optimization Algorithm. IEEE Trans. Sustain. Comput. 2024, 9, 14–30. [Google Scholar] [CrossRef]
- Song, F.; Xing, H.; Wang, X.; Luo, S.; Dai, P.; Li, K. Offloading Dependent Tasks in Multi-Access Edge Computing: A Multi-Objective Reinforcement Learning Approach. Future Gener. Comput. Syst. 2022, 128, 333–348. [Google Scholar] [CrossRef]
- Ma, S.; Song, S.; Yang, L.; Zhao, J.; Yang, F.; Zhai, L. Dependent Tasks Offloading Based on Particle Swarm Optimization Algorithm in Multi-Access Edge Computing. Appl. Soft Comput. 2021, 112, 107790. [Google Scholar] [CrossRef]
- Lin, C.-C.; Deng, D.-J.; Suwatcharachaitiwong, S.; Li, Y.-S. Dynamic Weighted Fog Computing Device Placement Using a Bat-Inspired Algorithm with Dynamic Local Search Selection. Mob. Netw. Appl. 2020, 25, 1805–1815. [Google Scholar] [CrossRef]
- Yan, P.; Choudhury, S. Deep Q-Learning Enabled Joint Optimization of Mobile Edge Computing Multi-Level Task Offloading. Comput. Commun. 2021, 180, 271–283. [Google Scholar] [CrossRef]
- Chiang, Y.; Hsu, C.-H.; Chen, G.-H.; Wei, H.-Y. Deep Q-Learning Based Dynamic Network Slicing and Task Offloading in Edge Network. IEEE Trans. Netw. Serv. Manag. 2022, 20, 369–384. [Google Scholar] [CrossRef]
- Tseng, C.-L.; Cheng, C.-S.; Shen, Y.-H. A Reinforcement Learning-Based Multi-Objective Bat Algorithm Applied to Edge Computing Task-Offloading Decision-Making. Appl. Sci. 2024, 14, 5088. [Google Scholar] [CrossRef]
- Hadi, M.U.; Abbasi, A.B. Optimizing UAV Computation Offloading via MEC with Deep Deterministic Policy Gradient. Trans. Emerg. Telecommun. Technol. 2023, 35, e4874. [Google Scholar] [CrossRef]
- Abdulazeez, D.H.; Askar, S.K. A Novel Offloading Mechanism Leveraging Fuzzy Logic and Deep Reinforcement Learning to Improve IoT Application Performance in a Three-Layer Architecture within the Fog-Cloud Environment. IEEE Access 2024, 12, 39936–39952. [Google Scholar] [CrossRef]
- Liu, Q.; Tian, Z.; Wang, N.; Lin, Y. DRL-Based Dependent Task Offloading with Delay-Energy Tradeoff in Medical Image Edge Computing. Complex Intell. Syst. 2024, 10, 3283–3304. [Google Scholar] [CrossRef]
- Zhang, S.; Tong, X.; Chi, K.; Gao, W.; Chen, X.; Shi, Z. Stackelberg Game-Based Multi-Agent Algorithm for Resource Allocation and Task Offloading in MEC-Enabled C-ITS. IEEE Trans. Intell. Transp. Syst. 2025, 1–12. [Google Scholar] [CrossRef]
- Gupta, H.; Vahid Dastjerdi, A.; Ghosh, S.K.; Buyya, R. IFogSim: A Toolkit for Modeling and Simulation of Resource Management Techniques in the Internet of Things, Edge and Fog Computing Environments. Software Pract. Exp. 2017, 47, 1275–1296. [Google Scholar] [CrossRef]
- Wu, M.; Song, Q.; Guo, L.; Lee, I. Energy-Efficient Secure Computation Offloading in Wireless Powered Mobile Edge Computing Systems. IEEE Trans. Veh. Technol. 2023, 72, 6907–6912. [Google Scholar] [CrossRef]
- Li, H.; Zhang, X.; Li, H.; Duan, X.; Xu, C. SLA-Based Task Offloading for Energy Consumption Constrained Workflows in Fog Computing. Future Gener. Comput. Syst. 2024, 156, 64–76. [Google Scholar] [CrossRef]
- Ale, L.; Zhang, N.; Fang, X.; Chen, X.; Wu, S.; Li, L. Delay-Aware and Energy-Efficient Computation Offloading in Mobile-Edge Computing Using Deep Reinforcement Learning. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 881–892. [Google Scholar] [CrossRef]
- Sabireen, H.; Venkataraman, N. A Hybrid and Light-Weight Metaheuristic Approach with Clustering for Multi-Objective Resource Scheduling and Application Placement in Fog Environment. Expert Syst. Appl. 2023, 223, 119895. [Google Scholar] [CrossRef]
- Ren, J.; Yu, G.; He, Y.; Li, G.Y. Collaborative Cloud and Edge Computing for Latency Minimization. IEEE Trans. Veh. Technol. 2019, 68, 5031–5044. [Google Scholar] [CrossRef]
- Chen, Y.; Li, W.; Huang, J.; Gao, H.; Deng, S. A Differential Evolution Offloading Strategy for Latency and Privacy Sensitive Tasks with Federated Local-Edge-Cloud Collaboration. ACM Trans. Sens. Netw. 2024, 20, 1–22. [Google Scholar] [CrossRef]
- Tang, M.; Wong, V.W.S. Deep Reinforcement Learning for Task Offloading in Mobile Edge Computing Systems. IEEE Trans. Mob. Comput. 2020, 21, 1985–1997. [Google Scholar] [CrossRef]
- Birhanie, H.M.; Adem, M.O. Optimized Task Offloading Strategy in IoT Edge Computing Network. J. King Saud Univ. Comput. Inf. Sci. 2024, 36, 101942. [Google Scholar] [CrossRef]
- Kumari, N.; Jana, P.K. A Metaheuristic-Based Task Offloading Scheme with a Trade-off between Delay and Resource Utilization in IoT Platform. Clust. Comput. 2023, 27, 4589–4603. [Google Scholar] [CrossRef]
- Ahmadi, K.; Serdijn, W.A. Advancements in Laser and LED-Based Optical Wireless Power Transfer for IoT Applications: A Comprehensive Review. IEEE Internet Things J. 2025, 12, 18887–18907. [Google Scholar] [CrossRef]
- Robles-Enciso, A.; Skarmeta, A.F. A Multi-Layer Guided Reinforcement Learning-Based Tasks Offloading in Edge Computing. Comput. Netw. 2023, 220, 109476. [Google Scholar] [CrossRef]
- Ma, L.; Wang, P.; Du, C.; Li, Y. Energy-Efficient Edge Caching and Task Deployment Algorithm Enabled by Deep Q-Learning for MEC. Electronics 2022, 11, 4121. [Google Scholar] [CrossRef]
- Penmetcha, M.; Min, B.-C. A Deep Reinforcement Learning-Based Dynamic Computational Offloading Method for Cloud Robotics. IEEE Access 2021, 9, 60265–60279. [Google Scholar] [CrossRef]
- Krishnamoorthy, A.; Safi, H.; Younus, O.; Kazemi, H.; Osahon, I.N.O.; Liu, M.; Liu, Y.; Babadi, S.; Ahmad, R.; Asim, I.; et al. Optical Wireless Communications: Enabling the next Generation Network of Networks. IEEE Veh. Technol. Mag. 2025, 20, 20–39. [Google Scholar] [CrossRef]
- Li, J.; Yang, Z.; Chen, K.; Ming, Z.; Cheng, L. Dependency-Aware Task Offloading Based on Deep Reinforcement Learning in Mobile Edge Computing Networks. Wirel. Netw. 2023, 30, 1–13. [Google Scholar] [CrossRef]
- Tu, Y.; Chen, H.; Yan, L.; Zhou, X. Task Offloading Based on LSTM Prediction and Deep Reinforcement Learning for Efficient Edge Computing in IoT. Future Internet 2022, 14, 30. [Google Scholar] [CrossRef]
- Zendebudi, A.; Choudhury, S. Designing a Deep Q-Learning Model with Edge-Level Training for Multi-Level Task Offloading in Edge Computing Networks. Appl. Sci. 2022, 12, 10664. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Q-Learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Chicone, C. Stability Theory of Ordinary Differential Equations. In Encyclopedia of Complexity and Systems Science; Springer: New York, NY, USA, 2009; pp. 8630–8649. [Google Scholar] [CrossRef]
- Sahmoud, S.; Topcuoglu, H.R. Dynamic multi-objective evolutionary algorithms in noisy environments. Inf. Sci. 2023, 634, 650–664. [Google Scholar] [CrossRef]
- Tema, E.Y.; Sahmoud, S.; Kiraz, B. Radar placement optimization based on adaptive multi-objective meta-heuristics. Expert Syst. Appl. 2024, 239, 122568. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Objectives | Proposed Solution | Executions Locations |
|---|---|---|---|
| [1] | Minimize network latency and energy | BAT-based | Local devices, fog, and cloud. |
| [6] | Minimize energy | MCEETO | local devices, fog, and cloud. |
| [34] | Minimize latency | Edge-ward | local devices, edge, fog, and cloud. |
| [35] | Minimize energy | SEE | local devices and MEC. |
| [29] | Minimize network latency and energy | MOBA-CV-SARSA | local device and edge server. |
| [23] | Minimize latency, energy and cost | RWOA | Local device, MEC, and cloud. |
| [36] | Minimize energy consumption | MSTEC and HREC | Local device, fog, and cloud. |
| [37] | Minimize energy consumption | DRL-based | Local device, fog, and cloud. |
| [38] | Minimize cost and latency | PSO | Local device, fog, and cloud. |
| [39] | Minimize latency | Collaborative cloud–edge scheme | Local device, edge, and cloud. |
| [40] | Minimize latency | federated learning-based | Local device, edge, cloud. |
| [11] | Minimize delay | TD-based CLB-TO and GA-based CLB-TO | Local device, edge servers connected by optical network |
| [17] | Minimize latency | Scheduling and queue management algorithms | Local device, edge, and cloud. |
| [27] | Minimize latency and energy | Deep Q-learnin | Local device and edge. |
| [41] | Minimize latency | LSTM and dual DQN | Local device and edge. |
| [28] | Minimize latency and energy | DRL-based | Local device and edge. |
| [30] | Minimize latency | DDPG-based | Local devices, fog, and cloud. |
| [31] | Minimize latency, energy consumption, network usage | fuzzy logic-based | Local devices, fog, and cloud. |
| [33] | Minimize latency, | RL-based | Local devices, fog, and cloud. |
| Our | Minimize latency, energy, and cost | DQN-based | Local device, fog, and cloud. |
| Notation | Description |
|---|---|
| MD | A set of mobile devices. |
| N | Number of tasks. |
| T | Set of tasks. |
| The task number i. | |
| Task data size. | |
| The maximum acceptable delay to execute task . | |
| CPU cycles required per bit of data. | |
| Total workload of the task . | |
| F | Set of fog node. |
| M | Number of fog nodes. |
| C | Cloud server. |
| Latency(execution time of task ). | |
| Decision offloading matrix of task from user i in the location k. | |
| CPU frequency of device d for a processing task. | |
| Q | The initial latency queue. |
| E | Energy consumption of the task. |
| Energy efficiency factor. | |
| Time processing of task locally. | |
| The total latency of processing task . | |
| Energy consumption of task that processing locally. | |
| Overall cost of task that processing locally. | |
| The transmission time of task to fog layer. | |
| The processing time of task in fog layer. | |
| The total latency of processing task in fog layer. | |
| The energy consumption of task that processing in fog layer. | |
| The MD and fog node communication bandwidth. | |
| The communication transmission power between MD and fog node. | |
| Cost of processing task over fog layer. | |
| The transmission time of task to cloud server. | |
| The processing time of task in cloud server. | |
| The total latency of processing task in cloud server. | |
| The communication bandwidth between fog node and cloud server. | |
| The communication transmission power between the cloud server and fog node. | |
| Cost of processing task over cloud server. |
| Parameter | Value |
|---|---|
| Learning rate () | 0.001 |
| Discount factor () | 0.99 |
| Batch size | 32 |
| Replay memory size | 100,000 |
| Initial exploration rate () | 1.0 |
| Maximum Episodes | 1000 |
| Maximum Steps per Episode | 200 |
| Latency Factor () | 0.18 |
| Energy Factor () | 0.82 |
| CPU Frequency of device () | 2.0 GHz |
| The CPU frequency of the fog node () | 2.5 GHz |
| The CPU frequency of the cloud server() | 3.0 GHz |
| Energy efficiency of the device () | 0.5 |
| Energy efficiency of the fog node () | 0.4 |
| Energy efficiency of the cloud server () | 0.3 |
| Device Queue latency | 5 ms |
| Fog layer Queue latency | 10 ms |
| Cloud Server Queue latency | 15 ms |
| Bandwidth between the MD and fog node () | 0.1 W |
| The bandwidth between the fog node and cloud server () | 0.05 W |
| Task data size () | [10–500] MB |
| Task Workload () | 500 MFLOPS |
| Strategy | Metrics | Mean | Standard Deviation |
|---|---|---|---|
| BAT | Cost | 58.7 | 0.024 |
| Energy consumption | 55.0 | 0.18 | |
| Latency | 8.7 | 0.07 | |
| DJA | Cost | 65.2 | 0.031 |
| Energy consumption | 70.3 | 0.25 | |
| Latency | 10.2 | 0.09 | |
| DQN-based algorithm | Cost | 28.0 | 0.012 |
| Energy consumption | 30.2 | 0.01 | |
| Latency | 5.1 | 0.04 | |
| Optimal strategy | Cost | 30.5 | 0.015 |
| Energy consumption | 35.0 | 0.13 | |
| Latency | 6.0 | 0.05 | |
| DDPG-based (with different environment constraints) | Cost | 45.3 | 0.029 |
| Energy consumption | 50.5 | 0.2 | |
| Latency | 4.5 | 0.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benaboura, A.; Bechar, R.; Kadri, W.; Ho, T.D.; Pan, Z.; Sahmoud, S. Latency-Aware and Energy-Efficient Task Offloading in IoT and Cloud Systems with DQN Learning. Electronics 2025, 14, 3090. https://doi.org/10.3390/electronics14153090
Benaboura A, Bechar R, Kadri W, Ho TD, Pan Z, Sahmoud S. Latency-Aware and Energy-Efficient Task Offloading in IoT and Cloud Systems with DQN Learning. Electronics. 2025; 14(15):3090. https://doi.org/10.3390/electronics14153090
Chicago/Turabian StyleBenaboura, Amina, Rachid Bechar, Walid Kadri, Tu Dac Ho, Zhenni Pan, and Shaaban Sahmoud. 2025. "Latency-Aware and Energy-Efficient Task Offloading in IoT and Cloud Systems with DQN Learning" Electronics 14, no. 15: 3090. https://doi.org/10.3390/electronics14153090
APA StyleBenaboura, A., Bechar, R., Kadri, W., Ho, T. D., Pan, Z., & Sahmoud, S. (2025). Latency-Aware and Energy-Efficient Task Offloading in IoT and Cloud Systems with DQN Learning. Electronics, 14(15), 3090. https://doi.org/10.3390/electronics14153090