
SDA-YOLO: Multi-Scale Dynamic Branching and Attention Fusion for Self-Explosion Defect Detection in Insulators
 , , , , ,
, , , , ,
Abstract
1. Introduction
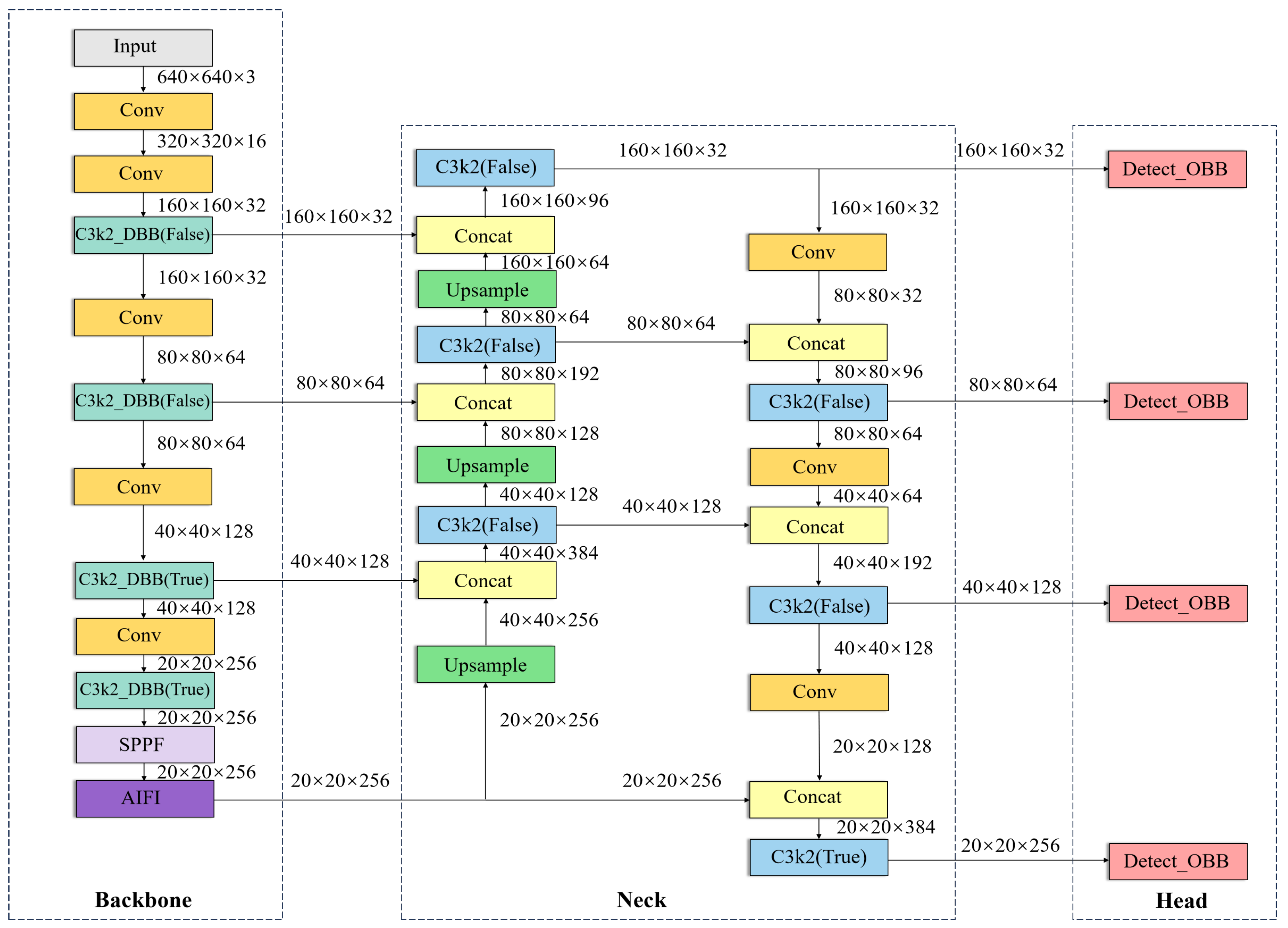
- To augment the model’s detection capability for diminutive targets, a supplementary small object detection layer (SODL) is incorporated into YOLOv11s, which amalgamates shallow and deep features to enhance the emphasis on small target characteristics. Additionally, the rotating target detection head (OBB) is devised in the HEAD section to refine detection efficacy for small-sized targets.
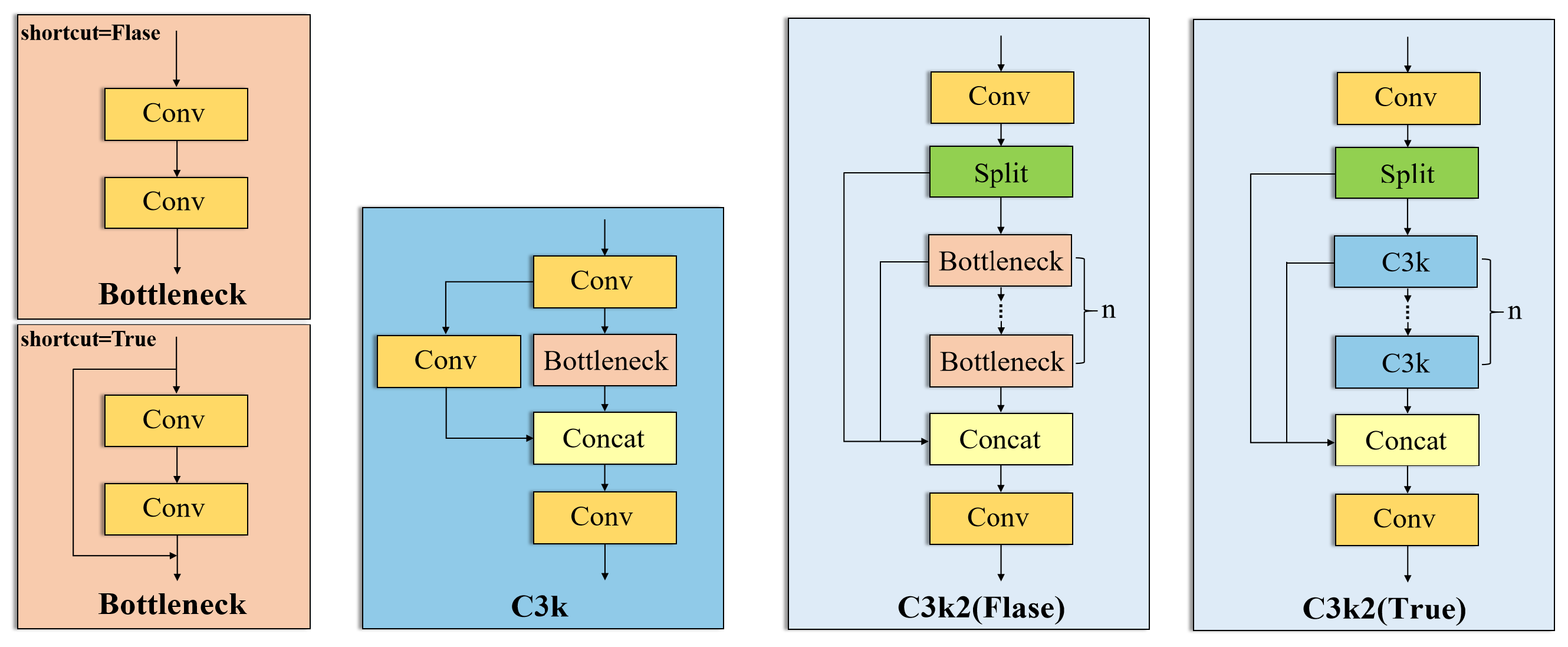
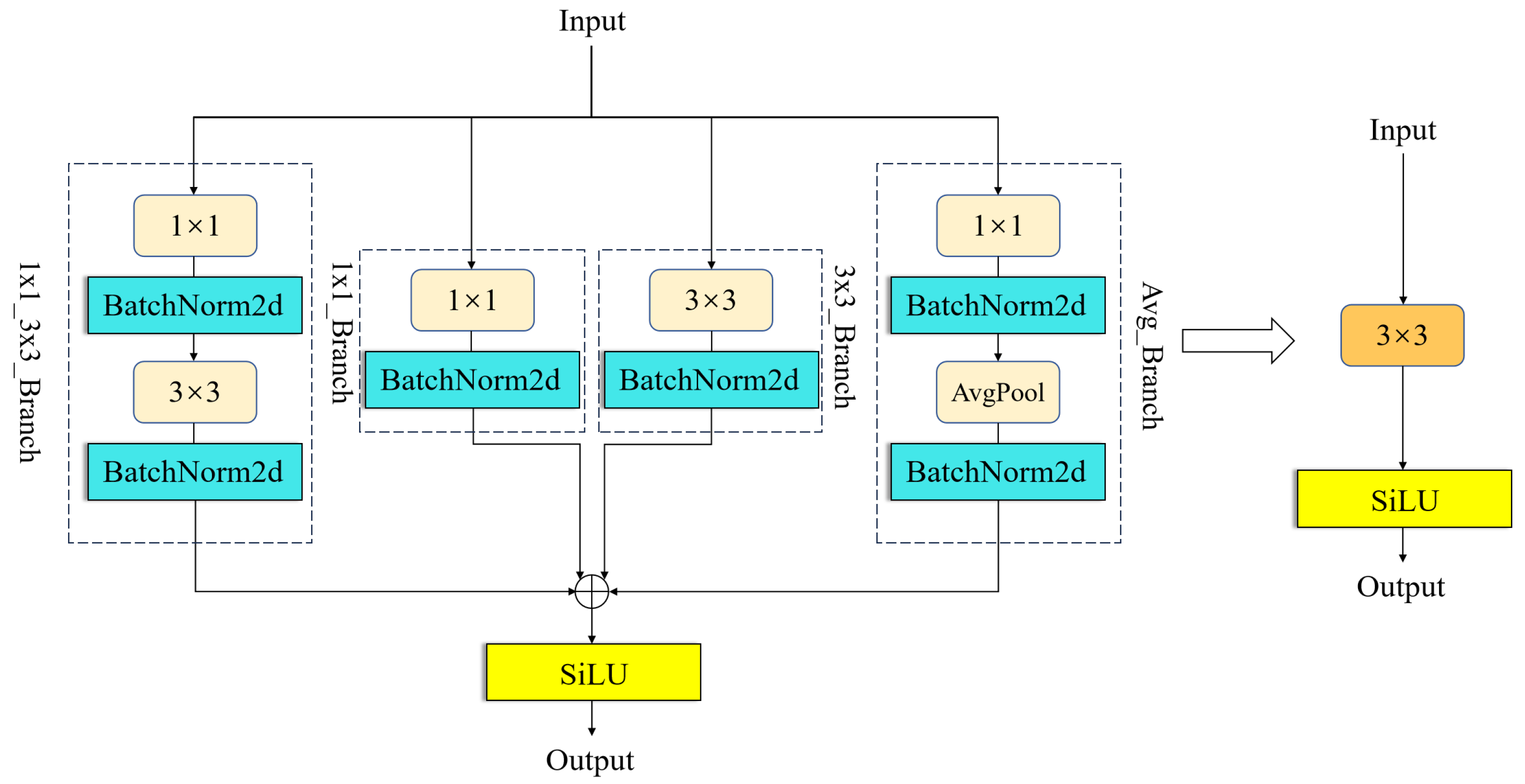
- Integrating the DBB module into the C3k2 module within the YOLOv11s model backbone enables feature extraction via a multi-branch parallel convolutional architecture, enhancing the model’s capacity to detect targets of varying scales and increasing detection accuracy in intricate environments.
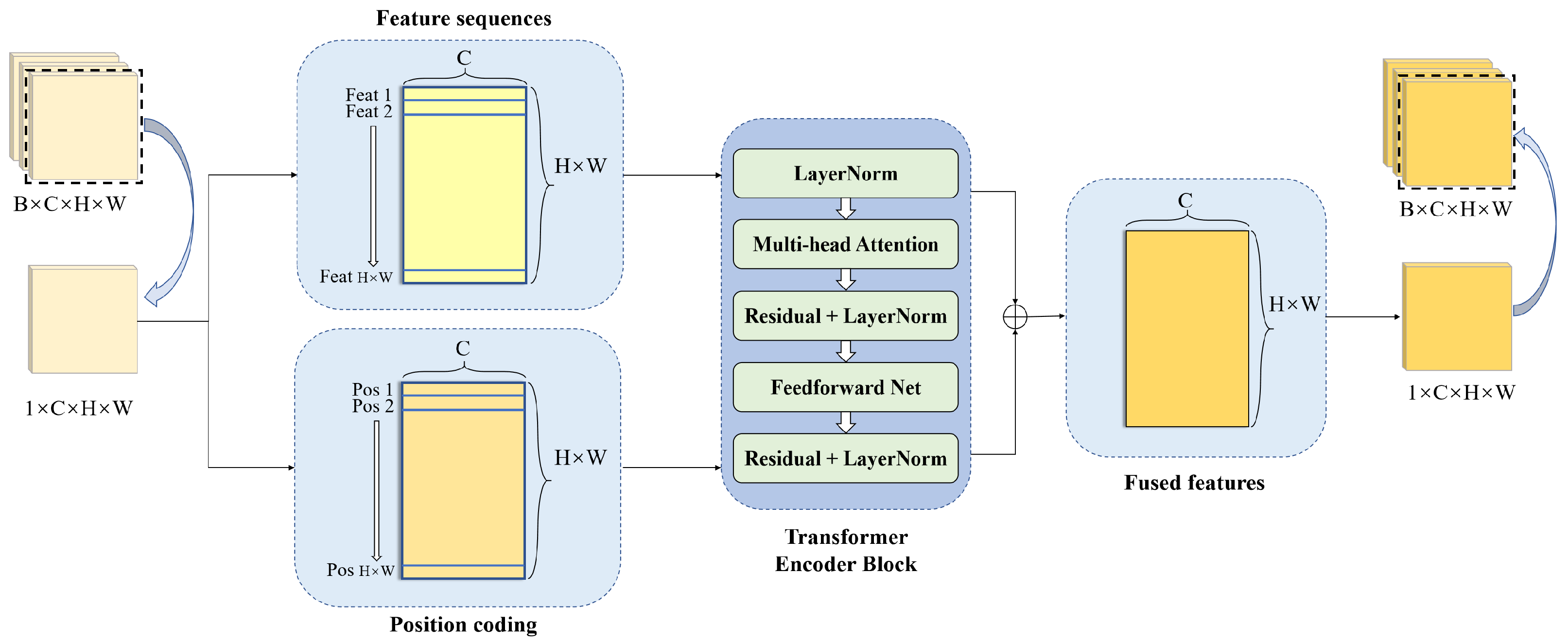
- The AIFI module is employed to substitute the C2PSA module in the YOLOv11s model backbone; this approach facilitates the guidance and aggregation of information across channels, thus enabling the model to concentrate on critical regions and diminish superfluous characteristics. It can significantly enhance detection accuracy and inference speed without altering the model’s computational requirements.
2. Related Work
2.1. YOLOv11 Algorithm
2.2. Oriented Bounding Box (OBB)
2.3. Small Object Detection Layer (SODL) [32]
2.4. Diverse Branch Block (DBB)
2.5. Adaptive Interaction Feature Integration (AIFI)
3. Model Improvement
4. Experiment
4.1. Dataset
4.2. Experimental Environment and Experimental Parameters
4.3. Evaluation Index
4.4. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Han, S.; Hao, R.; Lee, J. Inspection of insulators on high-voltage power transmission lines. IEEE Trans. Power Deliv. 2009, 24, 2319–2327. [Google Scholar] [CrossRef]
- Jenssen, R.; Roverso, D. Automatic autonomous vision-based power line inspection: A review of current status and the potential role of deep learning. Int. J. Electr. Power Energy Syst. 2018, 99, 107–120. [Google Scholar] [CrossRef]
- Ballard, D.H. Generalizing the Hough transform to detect arbitrary shapes. Pattern Recognit. 1981, 13, 111–122. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 2007, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for small object detection. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 214–230. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhao, W.; Xu, M.; Cheng, X.; Zhao, Z. An insulator in transmission lines recognition and fault detection model based on improved faster RCNN. IEEE Trans. Instrum. Meas. 2021, 70, 1–8. [Google Scholar] [CrossRef]
- Zhou, M.; Wang, J.; Li, B. ARG-Mask RCNN: An infrared insulator fault-detection network based on improved Mask RCNN. Sensors 2022, 22, 4720. [Google Scholar] [CrossRef]
- Lu, W.; Zhou, Z.; Ruan, X.; Yan, Z.; Cui, G. Insulator detection method based on improved Faster R-CNN with aerial images. In Proceedings of the 2021 2nd International Symposium on Computer Engineering and Intelligent Communications (ISCEIC), Nanjing, China, 6–8 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 417–420. [Google Scholar]
- Tang, J.; Wang, J.; Wang, H.; Wei, J.; Wei, Y.; Qin, M. Insulator defect detection based on improved faster R-CNN. In Proceedings of the 2022 4th Asia Energy and Electrical Engineering Symposium (AEEES), Chengdu, China, 25–28 March 2022; pp. 541–546. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Liu, C.; Wu, Y.; Liu, J.; Sun, Z. Improved YOLOv3 network for insulator detection in aerial images with diverse background interference. Electronics 2021, 10, 771. [Google Scholar] [CrossRef]
- Han, G.; He, M.; Zhao, F.; Xu, Z.; Zhang, M.; Qin, L. Insulator detection and damage identification based on improved lightweight YOLOv4 network. Energy Rep. 2021, 7, 187–197. [Google Scholar] [CrossRef]
- Wang, T.; Zhai, Y.; Li, Y.; Wang, W.; Ye, G.; Jin, S. Insulator defect detection based on ML-YOLOv5 algorithm. Sensors 2023, 24, 204. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Dou, Y.; Yang, K.; Song, X.; Wang, J.; Zhao, L. Insulator defect detection based on BaS-YOLOv5. Multimed. Syst. 2024, 30, 212. [Google Scholar] [CrossRef]
- He, M.; Qin, L.; Deng, X.; Liu, K. MFI-YOLO: Multi-fault insulator detection based on an improved YOLOv8. IEEE Trans. Power Deliv. 2024, 39, 168–179. [Google Scholar] [CrossRef]
- Zhang, L.; Li, B.; Cui, Y.; Lai, Y.; Gao, J. Research on improved YOLOv8 algorithm for insulator defect detection. J. Real-Time Image Proc. 2024, 21, 22. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8440–8449. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Wey, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Gottschalk, S.; Lin, M.C.; Manocha, D. OBBTree: A hierarchical structure for rapid interference detection. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 171–180. [Google Scholar]
- Wu, K.; Chen, Y.; Lu, Y.; Yang, Z.; Yuan, J.; Zheng, E. SOD-YOLO: A high-precision detection of small targets on high-voltage transmission lines. Electronics 2024, 13, 1371. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse branch block: Building a convolution as an inception-like unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2021; pp. 10886–10895. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 2002, 86, 2278–2324. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs beat YOLOs on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3Det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 19–21 May 2021; Volume 35, pp. 3163–3171. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Training Set | Validation Set | Test Set |
|---|---|---|---|
| Our dataset | 2073 | 296 | 593 |
| Model (OBB) | P (%) | R (%) | mAP@0.5 (%) | Params (M) | GFLOPs | FPS |
|---|---|---|---|---|---|---|
| YOLOv5n | 99.7 | 78.9 | 81.1 | 2.6 | 7.3 | 121.1 |
| YOLOv5s | 98.9 | 82.6 | 87.5 | 9.4 | 24.8 | 109.9 |
| YOLOv8n | 95.5 | 80.9 | 87.6 | 3.1 | 8.3 | 118.1 |
| YOLOv8s | 99.8 | 83.7 | 88.5 | 11.4 | 29.4 | 109.4 |
| YOLOv11n | 98.8 | 78.7 | 87.2 | 2.7 | 6.6 | 116.8 |
| YOLOv11s | 98.9 | 84.5 | 89.4 | 9.7 | 22.3 | 106.3 |
| SDA-YOLO | 98.1 | 92.3 | 96.0 | 10.9 | 30.3 | 93.6 |
| Model (OBB) | SODL | DBB | AIFI | mAP@0.5 (%) | Params (M) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv11s | ✗ | ✗ | ✗ | 89.4 | 9.7 | 22.3 | 106.3 |
| S-YOLO | ✓ | ✗ | ✗ | 91.9 | 9.8 | 30.2 | 79.3 |
| SD-YOLO | ✓ | ✓ | ✗ | 94.5 | 9.8 | 30.2 | 89.2 |
| SDA-YOLO | ✓ | ✓ | ✓ | 96.0 | 10.9 | 30.3 | 93.6 |
| Model (OBB) | Target Class (AP%) | mAP @0.5 (%) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PL | SH | ST | BD | TC | BC | GT | HA | BR | LV | SV | HE | RA | SB | SP | ||
| R3Det [40] | 70.9 | 46.8 | 42.1 | 48.8 | 80.7 | 26.3 | 38.7 | 41.3 | 26.0 | 42.5 | 19.6 | 7.3 | 40.1 | 24.4 | 29.0 | 39.0 |
| Oriented_RCNN [41] | 79.3 | 70.0 | 44.5 | 54.7 | 81.1 | 28.1 | 50.4 | 51.4 | 34.5 | 57.2 | 25.7 | 19.2 | 43.3 | 45.3 | 29.4 | 47.6 |
| YOLOv5n | 93.4 | 91.5 | 72.3 | 76.8 | 91.4 | 39.5 | 50.2 | 79.6 | 46.6 | 83.0 | 69.0 | 4.7 | 67.0 | 29.0 | 65.2 | 63.9 |
| YOLOv5s | 94.8 | 93.5 | 77.1 | 74.9 | 93.6 | 47.0 | 56.4 | 81.9 | 54.6 | 84.2 | 68.0 | 18.6 | 70.3 | 38.6 | 66.7 | 66.7 |
| YOLOv8n | 93.5 | 92.0 | 73.1 | 72.8 | 92.5 | 40.5 | 51.2 | 80.5 | 48.3 | 82.4 | 66.8 | 21.7 | 63.2 | 36.5 | 63.9 | 63.9 |
| YOLOv8s | 94.6 | 91.2 | 73.0 | 74.0 | 93.4 | 42.8 | 55.5 | 80.3 | 55.8 | 82.4 | 66.6 | 20.2 | 70.0 | 37.9 | 66.7 | 67.0 |
| YOLOv11n | 93.1 | 92.3 | 72.1 | 74.8 | 91.9 | 35.3 | 51.9 | 78.5 | 50.2 | 83.5 | 69.4 | 13.5 | 64.2 | 36.7 | 64.9 | 64.8 |
| YOLOv11s | 95.2 | 92.7 | 75.9 | 74.4 | 93.2 | 43.2 | 56.9 | 80.2 | 52.3 | 83.3 | 67.9 | 22.5 | 70.2 | 38.2 | 65.6 | 67.4 |
| SDA-YOLO | 95.0 | 93.9 | 81.6 | 74.3 | 92.5 | 45.3 | 59.6 | 81.8 | 61.0 | 84.3 | 71.7 | 30.3 | 72.4 | 41.2 | 71.1 | 70.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; Xu, W.; Chen, N.; Chen, Y.; Wu, K.; Xie, M.; Xu, H.; Zheng, E. SDA-YOLO: Multi-Scale Dynamic Branching and Attention Fusion for Self-Explosion Defect Detection in Insulators. Electronics 2025, 14, 3070. https://doi.org/10.3390/electronics14153070
Yang Z, Xu W, Chen N, Chen Y, Wu K, Xie M, Xu H, Zheng E. SDA-YOLO: Multi-Scale Dynamic Branching and Attention Fusion for Self-Explosion Defect Detection in Insulators. Electronics. 2025; 14(15):3070. https://doi.org/10.3390/electronics14153070
Chicago/Turabian StyleYang, Zhonghao, Wangping Xu, Nanxing Chen, Yifu Chen, Kaijun Wu, Min Xie, Hong Xu, and Enhui Zheng. 2025. "SDA-YOLO: Multi-Scale Dynamic Branching and Attention Fusion for Self-Explosion Defect Detection in Insulators" Electronics 14, no. 15: 3070. https://doi.org/10.3390/electronics14153070
APA StyleYang, Z., Xu, W., Chen, N., Chen, Y., Wu, K., Xie, M., Xu, H., & Zheng, E. (2025). SDA-YOLO: Multi-Scale Dynamic Branching and Attention Fusion for Self-Explosion Defect Detection in Insulators. Electronics, 14(15), 3070. https://doi.org/10.3390/electronics14153070