1. Introduction
In very recent times, transformer-based LVMs and LVLMs have seen some application in earth observation satellite imagery remote sensing, an unsurprising extension for the recent advancements in classic machine learning (ML)-based computer vision problems. Transformer-Architecture-based Large Language Models (LLMs) and Large Multi-Modal Models (LMMs) have seen outstanding achievements in Natural Language Processing (NLP) with extensive application and wide adoption in almost every sector, especially since the release of ChatGPT by OpenAI. These recorded successes have prompted more research in Vision Transformer Models (ViTs) that use self-attention algorithms to focus on the feature extraction of objects in remote-sensed scenes [
1,
2]. The recent application of LVMs and LVLMs to satellite images have focused on common objects and tasks including ship detection, melting icebergs, and car counting in parks [
1,
2,
3,
4] where reasonable amounts of labeled datasets already exist, even though they are still small when compared with the number of available datasets in classic computer vision tasks. For “uncommon” scenes and objects with limited representation in public datasets and complex visual characteristics that are difficult to describe textually, the application rate of LVLMs is very low owing to the lack of labeled datasets. One such “uncommon” object that this research paper focus on is the detection of cattle herds from satellite images in an attempt to create a digital twin of affected regions in Sub-Saharan Africa, where the effects of farmer–pastoralist clashes have devastated communities and threaten food security [
5,
6]. At the time of writing, some “uncommon” scenes or objects in satellite imagery based on available public datasets include peatlands and solar panel roof installs, to mention a few.
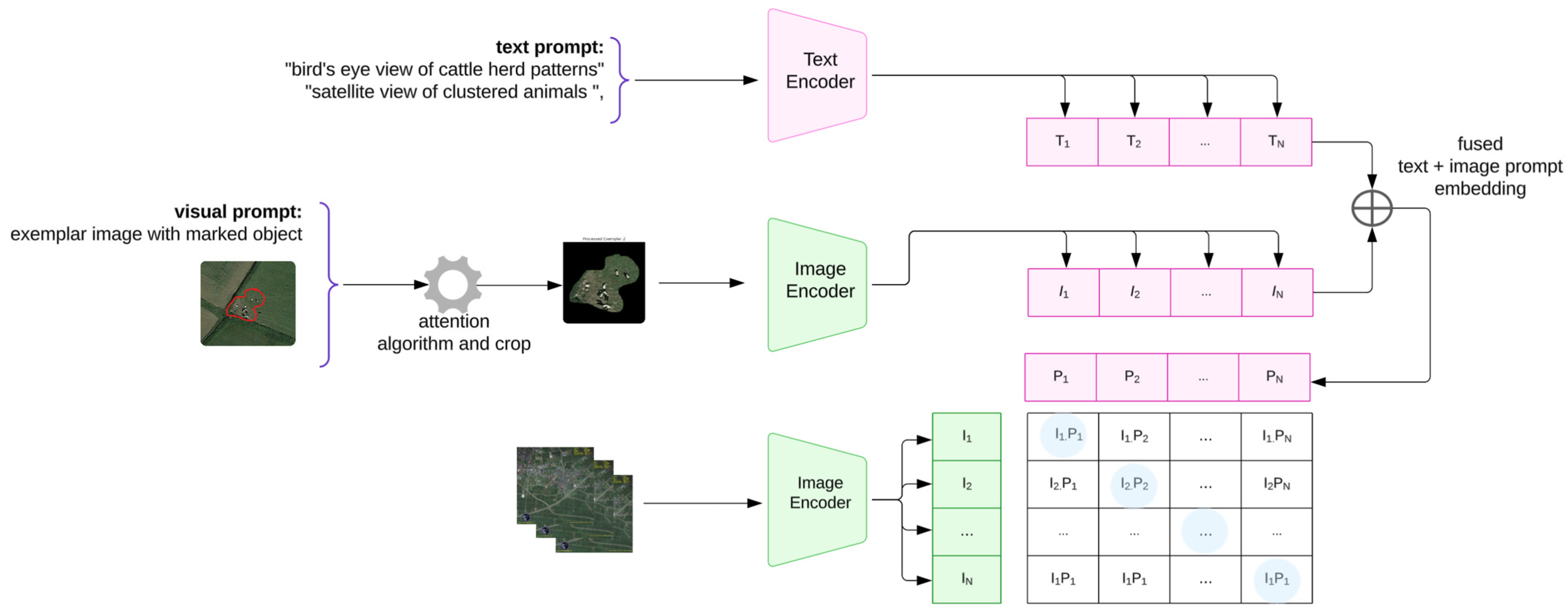
This paper explores the next frontier in deep learning approaches to satellite imagery remote sensing where LVLMs are applied. The diagram in
Figure 1 below depicts the key concept for CLIP, where images and text descriptions are mapped into a shared embedding space. A batch of images (e.g., satellite images of cattle herds) is processed by an image encoder to produce image embeddings {I
1, I
2, …, I
N}, while the text descriptions pass through a text encoder, yielding text embeddings {T
1, T
2, …, T
N}. Using contrastive loss, CLIP maximizes similarity for correct pairs (diagonal entries like I
1T
1, I
2T
2) and minimizes similarity for incorrect pairs (off-diagonal entries like I
1T
2). This cross-modal contrastive learning allows CLIP to generalize well across domains, including remote sensing.
In this paper, we propose an enhancement to CLIP when applied to remote sensing, an LVLM foundation model first proposed in [
3] where zero-shot remote-sensed scenes are classified using Remote Sensing CLIP (RS-CLIP). The enhancement extends the normal text prompting for CLIP shown in
Figure 1 to include curating a few sample objects as exemplar images, using these in conjunction with the text to create text-and-exemplar-image prompts for object detection. We apply this Enhanced-RSCLIP for cattle herd detection on remote-sensed non-temporal satellite images from Google Maps which are at zoom level 19 and are equivalent to temporal images at a Ground Sample Distance (GSD) between 1 and 1.5 m.
1.1. Problem Statement
Traditional LVLM approaches rely heavily on text prompting, which presents two critical limitations for remote sensing applications: (1) the complexity of accurately describing spatially distributed objects like cattle herds in satellite imagery; (2) the lack of sufficient labeled training data for specialized remote sensing tasks. These limitations significantly impact model performance when detecting objects that deviate from common computer vision scenarios.
1.2. Motivation and Application Context
Our research addresses cattle herd detection in satellite imagery—a critical application for monitoring pastoralist movements in Sub-Saharan Africa where farmer–herder conflicts threaten food security [
5,
6]. This represents a prototypical “uncommon object” detection challenge: cattle herds appear as sparse, small clusters in satellite imagery that are difficult to describe textually yet are visually distinct when proper exemplar images are provided.
1.3. Contributions
This paper makes three primary contributions:
Dual-Prompt Architecture: We introduce Enhanced-RSCLIP, combining traditional text prompts with preprocessed exemplar-image prompts for improved feature learning.
Exemplar Processing Algorithms: Two novel preprocessing methods (crop-based and attention-based) extract focused object features while preserving spatial relationships.
Cross-Domain Transfer Learning: Demonstration of effective knowledge transfer from data-rich (UK farmlands) to data-sparse (Nigerian settlements) environments through exemplar augmentation
The remainder of this paper is structured as follows:
Section 2 reviews related work,
Section 3 details our Enhanced-RSCLIP methodology,
Section 4 presents experimental setup and datasets,
Section 5 analyzes our results, and
Section 6 concludes with future directions.
2. Literature Review
While current deep learning methods struggle to extract semantic relationships, LVLMs have been known to thrive in scene reasoning where both visual and textual description contribute to inferencing. We were inspired by the work in [
4] where a few-shot architecture was applied to a self-guided SAM (Segment Anything Model) for a remote sensing task.
The remote sensing of objects or features from satellite imagery has seen an increased focus lately as there are more high-resolution images available and better performance is possible using deep learning. Thorsten Hoeser et al. [
7,
8] and John E. Ball et al. [
9] present comprehensive evolutions of and trends in deep learning approaches to satellite imagery remote sensing, both for object detection and land use classification. The application of deep learning-based object detection and counting to satellite images was explored in [
10] for whale counting, [
11] for counting albatrosses from space, pack-ice seals in [
12], and detecting mammals in UAV images in [
13]. Ahmad Mansour et al. [
14] present a deep learning approach for small-object detection in high-resolution satellite imagery.
2.1. Recent LVLM Approaches in Remote Sensing
Alec et al. [
15] defined Contrastive Language Image Pre-training (CLIP) as a Large Vision Language Model (LVLM) that learns under the supervision of Natural Language Processing (NLP). Like the GPT model family, it learns to perform various tasks during training enabling task generalization, including OCR, action recognition, geolocation, and many more using the contrastive learning process, a curriculum-based training method where the model is fed with batches of images and text, jointly training image and text encoders while minimizing the cosine similarities of the extracted image and text embeddings in each batch.
Xiang Li et al. [
3] conducted a thorough review of Vision Language Models (VLMs), highlighting advancements in framework architectures, challenges, and future implications across remote sensing applications, including Image Captioning, Visual Question Answering (VQA), and Terrestrial-Based Image Retrieval (TBIR). While current deep learning approaches often struggle with semantic understanding in satellite imagery remote sensing, Vision Language Models demonstrate superior capabilities by enhancing the interpretation of scene relationships, constructing reasoned analysis, and integrating textual descriptors to improve inference. Central to these models are foundation models (FMs), large, task-agnostic neural networks pre-trained on vast datasets that enable their versatile application across diverse fields. Notable FMs such as ViT (Vision Transformer), OpenAI’s GPT variants, and BERT (Bidirectional Encoder Representations from Transformers) and its extensions, like ALBRET, MacBERT, and VisualBERT, were referenced. The study also evaluates well-known VLMs for tasks including Remote Sensing Image Classification, Image Generation, scene classification, object detection, and semantic segmentation.
A zero-shot curriculum-based strategy for remote sensing using CLIP was introduced in [
3], where rather than extracting features using shallow networks in the inner loop of the ML setup, intensive CLIP was used for deeper feature extraction. This method achieved impressive zero-shot performances of over 85% and 95% in some tasks on the AID 30 (a 100-image collection of 30 remote-sensed scene categories at 600 × 600 pixels), UCM-21 (a 100-image collection of 21 remote-sensed scene classes at 256 × 256 pixels), and WHU-RS19 (image collection of 19 scene categories at 600 × 600 pixels) datasets. Their work is based on a pseudo-labeling curriculum learning process that generates pseudo-samples of unlabeled data for training. Both the initial and the further training of the hyperparameters were guided by text prompts. The study concluded that the construction of representations which are semantic-aware using the joint feature learning of vision and their semantic relationships made RS-CLIP achieve impressive results in comparison with other zero-shot models.
Fan Liu et al. [
16] introduced the RemoteCLIP framework, built upon the Contrastive Language Image Pre-training (CLIP) foundation model. This framework effectively captures rich visual–semantic relationships by learning robust features from remote sensing images while producing accurate text representations of their corresponding visual concepts. Through extensive data scaling, the framework utilized datasets 12 times larger than those available in open-source repositories. These datasets were drawn from various base layers, including ResNet-50, ViT-B/32, and ViT-Large-4. The training process took approximately 230 h on a single node equipped with four NVIDIA A100 GPUs (quad-NVIDIA-A100). The framework was evaluated on tasks such as object counting, cross-modal retrieval, zero-shot image classification, and few-shot classification. The authors demonstrated the effectiveness of their framework by introducing a foundation model with 304 million parameters in its visual feature extraction layer.
Xiyu et al. [
4] proposed a novel framework for few-shot semantic segmentation using the Segment Anything Model (SAM) enhanced with automatic prompt learning, deriving pixel-wise prompts from prior guide masks to automate the prompting process of Large Vision models. This model was evaluated on a Dense Labeling Remote Sensing Dataset (DLD), consisting of a multi-label classification task involving 17 predefined categories. The framework leveraged various Vision Language Models (VLMs), including SAM, CLIP, and GPT, to facilitate text-based prompting for segmentation tasks. The prior-guided masks were generated using a Prior-Guided Metric Learning Module, which incorporated a SAM ViT-Huge feature encoder–decoder algorithm. Training was conducted over 1000 epochs on a single node with two RTX 3900 GPUs. The model demonstrated superior performance in few-shot learning scenarios, outperforming other state-of-the-art architectures for one-shot and five-shot experiments, using mIOU as the evaluation metric.
Kartik Kuckreja et al. [
17] reported that even with high-resolution satellite imagery containing numerous small objects and categories, region-level reasoning is essential to achieve higher accuracy in remote sensing analysis. Their study introduced GeoChat, a multitask conversational model designed for high-resolution remote sensing images. This model enables users to query image-level information while addressing regional conversations based on the spatial coordinates of ground objects within the imagery. The foundation of their model was built upon a fine-tuned LLaVA (Large Language and Vision Assistant) framework which incorporates LoRA (low-rank adaptation). This approach consists of two stages: a pre-training phase that focuses on adapting the image encoder to work with the language decoder, followed by a fine-tuning stage optimized for remote sensing applications. In [
18], Yakoub Bazi et al. explored RS-LLaVA for Joint Captioning and Visual Question Answering (VQA), attempting to extend the success of the foundation model in remote sensing.
Jieneng Chen et al. [
2] proposed an innovative framework as an alternative to widely used ViT foundation models in most Large Language Models (LLMs) and Vision Language Models (CLIP). This new architecture offers differentiable performance, allowing LLMs to operate effectively without relying on the base layer being ViT. Among their proposed models, the largest variant, referred to as ViTamin-XL, achieved an impressive 82.9% zero-shot ImageNet performance, outperforming the ViT-L by 2.0%, demonstrating exceptional adaptability and generalization capabilities.
2.2. Challenges with Current Approaches and Research Gap
Our review of LVLMs in recent studies shows three focus areas [
19,
20] of contrastive- image scene classification and RS-foundation models, i.e., RemoteCLIP, conversational—Visual Question Answering, GeoChat—and generative—creating remote-sensed images from descriptive text, e.g., CRS-Diff [
21]. Current RS scene classification and object detection architectures primarily focus on handling tasks involving aerial remote-sensed images or very high-resolution satellite imagery. These models excel in detecting straightforward objects, such as planes, ships, and road networks which have a large amount of labeled datasets for machine learning training; these objects also have visual features that are distinct and easily describable. However, the existing approaches struggle when the objects have little or no labeled data, like with peatlands and smallholder farmlands, where farms and farmland features are sparsely spatially spaced and are only 1–2 hectares large, or when detecting herds based on the spatial relationship of sparsely distributed objects in satellite imagery.
Contrastive approaches relying on text prompting for such “uncommon” objects face significant limitations due to the data scarcity and overfitting biases inherent in these methods. The construction of the appropriate text to describe the object feature also becomes an activity that needs to be optimized in the object detection pipeline, hence further hindering the adoption of LVLMs in scarce object detection and labeling tasks.
This research addresses these challenges by introducing an enhanced CLIP framework that incorporates exemplar-image prompting, a preprocessing technique designed to improve feature extraction from exemplars before integrating them with text prompts within the foundation model. By doing so, this study aims to overcome existing limitations and advance satellite imagery analysis for complex scenarios, thereby contributing novel solutions to gaps in the current research.
We further extended the application of the enhanced-CLIP framework, augmenting the exemplar images from source regions where satellite imagery of the scenes or objects of interest is easily observable, to train models, thereby creating a transfer learning process. The trained model was successfully applied to challenging target regions where the scenes or objects were sparsely spatially spaced, resulting in a reduced spatial relationship.
2.3. Comparative Analysis with Existing RS-VLMs
To position our work within the current landscape, we provide comparisons with closely related approaches:
Remote-CLIP vs. Enhanced-RSCLIP:
- -
Remote-CLIP [
16] focuses on creating foundation models for zero-shot scene classification using large-scale remote sensing datasets (12× larger than open-source repositories). Our approach (Enhanced-RSCLIP) specifically targets object detection with exemplar-guided prompting for uncommon objects while using a foundation model. This aims to improve performance metrics when applied to real-world problems where labeled data is very scarce or does not exist.
- -
Key difference: Remote-CLIP relies solely on text–image contrastive learning, while we introduce visual exemplar processing. While Remote-CLIP addresses general scene classification, we focus on specific object detection with limited labeled data.
GeoChat vs. Enhanced-RSCLIP:
- -
While GeoChat [
17] enables conversational interaction with regional coordinate-based queries, our method provides exemplar-based visual guidance for object detection tasks.
- -
Architecture difference: GeoChat uses the LLaVA framework with LoRA adaptation to facilitate human–AI interaction (Vision Question Answering). This study introduces dual-stream CLIP with custom adapters that enable automated detection with minimal supervision.
Recent comparative studies reveal significant performance variations among Vision Language Models when applied to resource-constrained remote sensing scenarios. Li et al. [
3] demonstrated that RS-CLIP achieved impressive zero-shot performance exceeding 85% accuracy on scene classification tasks—a single label for an entire image. More granular tasks like identifying objects with pixel-wise masks for each instance prove substantially more challenging. Huang et al. [
22] reported that ZoRI, designed for zero-shot instance segmentation, achieved 9.30% mAP on unseen classes in the iSAID dataset, highlighting the increased difficulty of pixel-level precision tasks compared to scene-level classification. Liu et al. [
16] showed that RemoteCLIP, utilizing datasets 12 times larger than open-source alternatives, achieved superior performance in few-shot scenarios but required extensive computational resources (230 h on quad-NVIDIA-A100 setup). Our proposed Enhanced-RSCLIP provides a lightweight approach, demonstrating that exemplar-image prompting can achieve competitive performance (56.2% accuracy on cross-domain transfer) with significantly reduced computational requirements (single RTX3090) on our custom dataset.
3. Proposed Enhanced-RSCLIP Methodology
Traditional CLIP architectures rely solely on text prompting for zero-shot classification, which presents fundamental limitations for remote sensing applications where objects like cattle herds are (1) spatially distributed with complex geometric patterns, (2) difficult to describe comprehensively in text, (3) visually distinctive when proper exemplars are provided. Utkarsh Mall et al. [
23] highlighted this challenge and proposed Ground Remote Alignment for Training (GRAFT), which used ground images from Flickr to construct VLMs without textual annotations. Our proposed Enhanced-RSCLIP addresses these limitations through a dual-prompt architecture that combines textual descriptions with pre-processed exemplar images which are manually annotated with a red outline focusing on reference objects.
Manual annotation is similar to the process of creating a labeled dataset but it instead requires one person and reviewer, thereby requiring less time compared to detailed annotation. For example, Celine Robinson et al. [
24] detailed a process of creating a remote sensing dataset where about 22 research assistants and over 2300 h were needed.
By employing attention mechanisms and cropping techniques, the training focuses more effectively on particular object features within these exemplar images. Both methods—the original text prompting and enhanced visual prompt methods —were tested in our research, with results demonstrating a notable improvement in model performance.
Figure 2 below depicts the dual-prompt-stream approach.
3.1. Problem Formalization
The enhanced-CLIP object identification problem is structured as below:
Let be a set of satellite image slices where each , and let be a very small set of exemplar images with manual annotations indicating target objects or scenes.
Our objective is to learn a function
that maps the input images to binary classifications, such that
where T represents textual prompts describing the target objects.
The dual-prompt-stream architecture processes three input modalities:
Text-Prompt Stream:
RS Image Stream:
Exemplar-Image Stream Prompt: ).
The contrastive learning process then follows:
3.2. Dual-Prompt Architecture Design
Our enhance-CLIP architecture dual-prompt components are constructed as follows:
Text Prompting Component: Based on standard CLIP methodology, we construct textual descriptions of target objects:
- -
“aerial view of scattered small elongate spots on grass field, range land or barren land”;
- -
“satellite view of clustered animals from above”;
- -
“bird’s eye view of cattle herd patterns”.
Exemplar-Image Component: This comprises a proposed visual prompting using pre-processed exemplar images that provides direct visual references for target objects. This manual annotation of the reference object is similar to the process of creating labeled data but it is far less time-consuming because it only requires between three and five exemplar images. This component addresses the semantic gap between textual descriptions and visual appearances in satellite imagery. It also increases the applicability of LVLMs to real-world problems where objects of interest might not have any representation in the public datasets for training AI models.
3.3. Exemplar-Image Processing Algorithms
In order to focus the extracted object features on the exemplar images, we introduced two complementary approaches for the image preprocessing.
Crop-Based Processing: These extracts focused object regions manually annotated with red outline while preserving spatial scale and relationships.
Let be an exemplar image with red outline annotations. The crop-based processing performs the following steps:
- 1.
- 2.
- 3.
Mask Cleaning (Outline Removal):
where
K is a 3 × 3 morphological kernel.
- 4.
Cropping with Mask Application:
where ⊙ denotes element-wise multiplication and the bounding coordinates are
- 5.
Scale-Preserving Resizing:
Attention-Based Processing: This applies spatial attention weighting to emphasize target regions while maintaining contextual information. Our attention mechanism draws inspiration from spatial attention in computer vision [
25]. The process is expressed as follows:
- 1.
Attention Weight Generation:
where
is the feature dimesion scaling factor.
- 2.
Context-Aware Weighting:
where
controls the balance between focused attention and context preservation, and 1 represents uniform weighting.
- 3.
Spatial Normalization:
where μ and σ are the spatial mean and standard deviation, and
prevents division by zero.
3.4. Enhanced-CLIP Loss with Dual Streams
Our approach builds upon CLIP’s contrastive learning objective. For a batch of N image-text pairs, the CLIP loss function is
where
represents the cosine similarity between image embedding
and text embedding
, and
is the temperature parameter controlling the sharpness of the probability distribution
The proposed Enhanced-RSCLIP extends the standard CLIP loss to incorporate exemplar features. This can be expressed as follows:
where
Exemplar Contrastive Loss:
4. Experimental Setup and Datasets
4.1. Dataset Description
This research utilized a combination of high-resolution non-temporal images from Google Maps at zoom level 19. Although the study started with the use of Planet Labs’ PlanetScope API high–medium-resolution images with a ground sample size (GSD) of 3.0, these images proved to be inadequate due to difficulty in manually annotating the reference object, i.e., cattle herds.
The PlanetScope images that were available under the Research Program License were equivalent to Google Maps images at zoom level 15, while the Planet Labs’ SkySat images, available only with a business subscription, had images with a GSD of 0.8–1.0 m, equivalent to the Google Maps images at zoom level 19 used in this study. Under these conditions, individual cattle appeared as two-to-three-pixel clusters, providing optimal balance between object detectability and spatial coverage.
Our dataset comprised 260 high-resolution satellite images collected from two geographically distinct regions:
- -
Source Domain (UK): 130 images from British farmlands.
- -
Target Domain (Nigeria): 130 images from Sub-Saharan settlements.
- -
Resolution: Google Maps zoom level 19 (≈0.5–1 m Ground Sample Distance).
- -
Class Distribution: Balanced binary classification (50% cattle-present, 50% cattle-absent).
The source domain, characterized by well-established cattle herds on UK farmland, provided a region with relatively clear and consistent environmental conditions. In contrast, the target domain in Sub-Saharan Africa presented a more challenging environment with the sparse spatial features of pastoralist movements, potentially due to diverse vegetation cover or human activity patterns that complicate labeling.
The challenges in this research included handling class imbalance between images with and without cattle herds. Techniques such as oversampling the minority class or data augmentation on positive examples may be employed to address this issue. Additionally, evaluating different object detection algorithms or using a specific model suited for satellite imagery could enhance the study’s effectiveness.
Overall, this approach aims to develop a robust detector capable of identifying cattle herds in diverse satellite imagery by training on a limited dataset from two distinct regions. The focus is on leveraging both spatial and temporal data while addressing challenges related to environmental variability and limited labeled data. The
Table 1 below shows some of the geolocation of the observed cattle herds with the extracted images:
The
Table 2 below depicts satellite imagery with challenging cattle herd scenes in the target region, Nigeria. These features are much less discernible than those observed in the source region depicted in
Table 1, above.
4.2. Experimental Setup
The initial experimental setup utilized the CLIP foundation model augmented with text prompting. The pre-trained parameters from ViT-B/32 were loaded, fixed, and employed to train the model on a cattle herd dataset using crafted text prompts that described focused objects in satellite imagery.
Among these descriptions were specific examples such as
“aerial view of scattered small elongate spots on grass field, ranging land or barren land” and “satellite view of clustered animals from above.”
While this approach provided a foundation for leveraging CLIP’s pre-trained model to address remote sensing tasks and understand visual–text relationships, it exhibited limitations. These were primarily evident in the manual construction of precise text prompts that accurately described focused objects within challenging satellite images, and the significant disparity between using CLIP for such specialized tasks versus more straightforward computer vision scenarios where object descriptions are easier with text alone. Additionally, the method fell short in capturing the nuanced visual characteristics of cattle herds in satellite imagery.
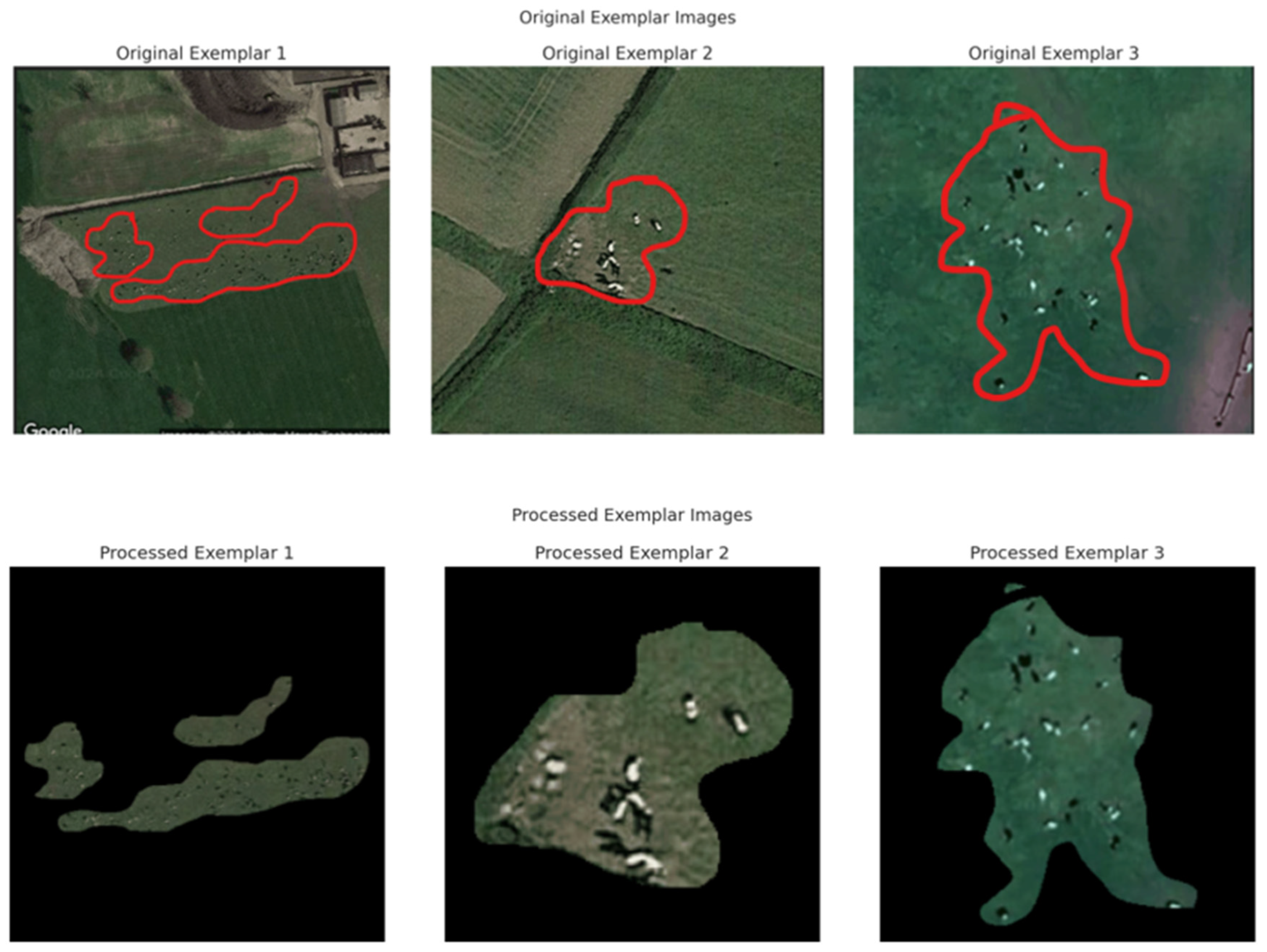
To overcome these limitations, and enhance the model’s ability to extract relevant feature embedding from focused objects, a dual-stream approach was integrated into the CLIP architecture by incorporating visual exemplar images alongside text prompts. These exemplars were selected from the dataset and explicitly marked with red outlines to highlight the focal areas while excluding extraneous elements through simple cropping or attention-based algorithms. The processed visual exemplars, combined with carefully crafted text prompts that provided concrete references of cattle patterns in satellite imagery, enabled the model to leverage extracted features from both the vision and text description effectively to improve performance and make the approach more accessible. The images in the
Figure 3 below show the exemplar images with red outlines for the interested objects and also a set of pre-processed exemplar images with cropped objects that focus on image feature prompts.
The dual-stream enhanced-CLIP architecture leverages both text-prompt features and cattle-specific exemplar features extracted using either crop-based or attention-based preprocessing, with both approaches evaluated for effectiveness. The training dataset itself was expanded through an augmentation process designed to simulate the visual conditions of the target domain. This augmentation specifically altered the background terrain (such as replacing green pasture with brown barren land) while preserving cattle appearance, ensuring the model learned to focus on cattle-relevant features rather than environmental context. By combining textual descriptions, e.g., “a satellite image of cattle herd visible as small black dots on grassland”, with visual exemplar features derived from red-outlined cattle regions, the model was trained to form a cattle-centric representation prioritizing shape, size, texture, and spatial clustering over background appearance. As a result, when the model was applied to Nigerian imagery, it could effectively identify cattle herds against unfamiliar terrain, even though its training began with UK-based pasture imagery. This exemplar-guided and text-prompted approach, combined with target-aware augmentation, forms the backbone of the cross-regional transfer learning strategy, enabling the model to generalize previously unseen geographic and visual conditions.
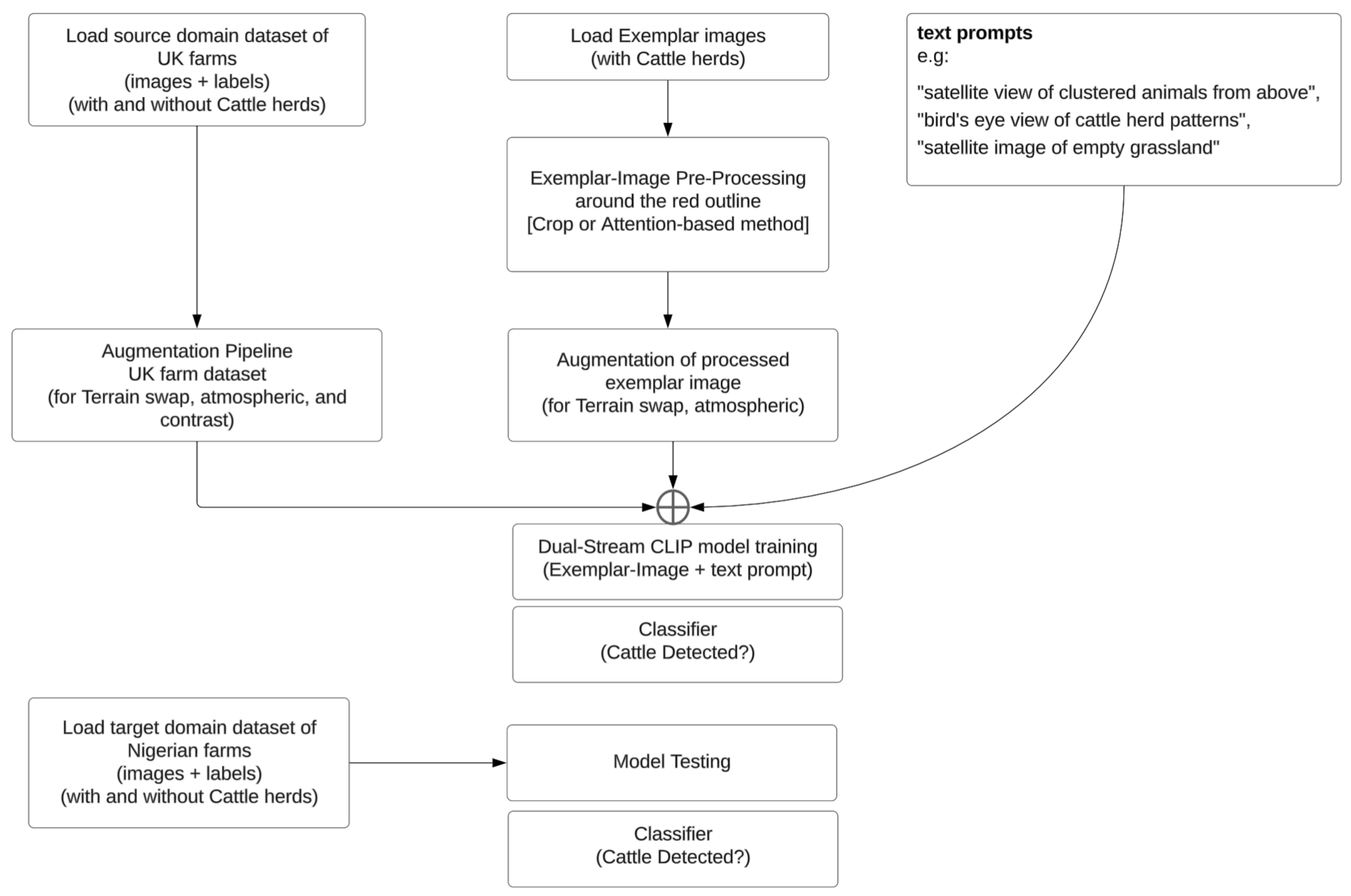
The
Figure 4 shows a flow diagram showing the processes that make up the enhanced-CLIP model.
Finally, the model training and evaluation were executed on a private cloud setup using a Rancher Kubernetes platform equipped with an NVIDIA RTX3090 multi-GPU configuration. The machine learning instance was based on Ubuntu 22.0 Linux, utilizing a container image with single-GPU pass-through capabilities for enhanced performance.
Table 3 shows a summary of the compute resources used in this study.
4.3. Enhanced-CLIP Exemplar Processing: Crop-Based and Attention-Based Methods
To further enhance cattle-focused feature extraction, the exemplar images (with manually annotated red-outlined cattle regions) underwent specialized exemplar processing, implemented using two complementary techniques: crop-based processing and attention-based processing.
4.3.1. Crop-Based Exemplar Processing
The crop-based approach directly leverages the red outline annotations to extract and isolate cattle-containing regions from the training images, as detailed in Algorithm 1. Each outlined region is treated as a cropping boundary, effectively removing background content and leaving only cattle and their immediate surroundings. By training on these focused crops, the model intensively learns the appearance, texture, and spatial distribution of cattle within the images. This technique enables the model to develop a concentrated understanding of cattle features such as white fur patches against green pastures or typical herd clustering patterns. However, its effectiveness is somewhat constrained by the quality and consistency of the manual annotations; the lack of contextual background may hinder generalization when the model is applied to new environments in which cattle appear in different settings (e.g., standing on dirt patches rather than grass).
| Algorithm 1. Scale-preserving crop processing. |
def process_image_crop (image_path, padding_ratio = 0.02):
# Load and convert to RGB
img = load_image(image_path). convert(‘RGB’)
# Create red outline mask
red_mask = (img[:,:,0] > 150) & (img[:,:,1] < 100) & (img[:,:,2] < 100)
# Extract bounding box with minimal padding
bbox = get_bounding_box (red_mask, padding_ratio)
# Create filled mask from contours
filled_mask = create_filled_mask(red_mask)
# Remove red outline artifacts
clean_mask = remove_outline_artifacts (filled_mask, red_mask)
# Apply mask and crop
masked_image = apply_mask(img, clean_mask)
cropped = crop_to_bbox (masked_image, bbox)
# Scale-preserving resize to target dimensions
return scale_preserve_resize (cropped, target_size = (224, 224)) |
4.3.2. Attention-Based Exemplar Processing
In contrast, the attention-based approach, detailed in Algorithm 2, takes a more holistic view of the exemplar images. Instead of cropping, it uses the red outlines to generate attention maps which assign higher importance weights to pixels within the outlined regions while retaining lower attention weights for the surrounding context. This allows the model to focus on cattle-specific visual features, such as clusters of small white dots indicative of cattle in satellite images, while maintaining spatial relationships with the environment. This context-aware approach ensures that the model does not entirely discard background information, thus enabling it to generalize better to novel landscapes where cattle may appear on different types of terrain or under variable lighting conditions.
The attention mechanism essentially teaches the model what to look for, rather than limiting it to what cattle look like in isolated crops. This distinction is particularly valuable in a cross-regional transfer learning setup, where background appearance varies dramatically between source (UK) and target (Nigeria) domains. By learning to focus on cattle while adapting to changing backdrops, the attention mechanism enhances the model’s robustness, making it more effective in detecting livestock across diverse agricultural landscapes.
| Algorithm 2. Context-aware attention processing. |
def process_image_attention(image_path):
# Similar preprocessing steps
img, clean_mask = preprocess_image(image_path)
# Generate attention weights
attention_weights = generate_spatial_attention(clean_mask)
# Apply attention while preserving context
attended_image = apply_attention_weighting (img, attention_weights)
return resize_with_context (attended_image, target_size = (224, 224)) |
4.4. Model Training and Augmented Exemplar-Image CLIP for Cross-Region Transfer Learning
Model testing across the different geographic domains, with the source domain being United Kingdom and the target domain being Nigeria, showed challenging model adaptation mainly due to the domain shift in visual characteristics, with the source domain showing cattle patterns on green grasslands while the target domain had cattle on varying terrain, including barren lands with brownish layouts.
Also, lighting conditions varied significantly between domains, impacting on the image quality across the domains. These issues were addressed by enhancing the augmentation process to include terrain variations, selective contrast adjustments, and atmospheric effects. The machine learning model was tested across two distinct geographic domains: the source domain (United Kingdom) and the target domain (Nigeria). The challenges presented by these domains stem from a significant difference in visual characteristics and environmental conditions, which collectively contributed to what is known as domain shift. In the United Kingdom, cattle are primarily found on green grasslands, whereas in Nigeria, the terrain varies widely, including barren lands with brownish layouts. Additionally, lighting conditions differ substantially between the two regions, further complicating the model’s ability to generalize its findings.
To address the domain shift between UK and Nigerian farms, a transfer learning approach was adopted in this study, employing a dual-pronged augmentation and domain adaptation strategy to bridge the visual disparity between the agricultural landscapes of both domains/regions. The core challenge arises from the significant environmental differences between these regions: the lush green pastures typical of UK farms contrast sharply with the drier, brownish terrain often observed in Nigerian farmland. To mitigate this domain gap, our approach applied enhanced terrain transformation augmentations to both the labeled training images and the exemplar reference images used to guide the model’s attention.
The labeled UK images underwent targeted augmentation using an implemented python class, Enhanced Cattle Augmenter detailed in Algorithm 3. The Enhanced Cattle Augmenter identifies and selectively converts grassland regions into brownish terrain while preserving the cattle features. This preservation is achieved by operating in the HSV color space, allowing the augmentation process to modify vegetation colors without distorting the bright-spot patterns associated with cattle (such as their white fur or dark shadows cast in the images). The resulting synthetic images simulate Nigerian visual conditions while retaining the critical cattle-specific visual cues necessary for detection. This creates a hybrid training set that blends original UK images with synthetic images mimicking Nigerian terrain, allowing the model to learn cattle detection in visually mixed contexts.
| Algorithm 3. Enhanced Cattle Augmenter for transfer learning. |
class EnhancedCattleAugmenter:
def convert_to_barren_land (self, image):
# Convert to HSV for selective color manipulation
hsv_image = cv2.cvtColor(image, cv2.COLOR_RGB2HSV)
# Detect and preserve bright spots (cattle features)
bright_spots = detect_bright_features(image)
# Create grass vegetation mask
grass_mask = create_vegetation_mask(hsv_image) & ~bright_spots
# Transform green to brown terrain colors
brown_terrain = generate_brown_terrain_colors ()
transformed = apply_color_transformation (image, grass_mask, brown_terrain)
# Preserve cattle features
final_image = preserve_cattle_features (transformed, bright_spots, image)
return add_terrain_texture(final_image) |
Also, for the exemplar images, which contain manually annotated cattle regions outlined in red, an image preprocessing and augmentation process was applied. These exemplars serve as visual references for the model during training. By applying the same terrain transformation augmentations to these exemplars, the model’s reference points are adapted to match the target domain characteristics, ensuring that the feature prototypes learned during training align with the visual conditions expected during deployment in Nigeria. This synchronized augmentation ensures that both the training images and exemplars evolve together to bridge the domain gap, enabling seamless transfer learning across geographies, as demonstrated in
Figure 5.
Despite these efforts, significant hurdles remain. The inherent differences in visual patterns between the source and target domains pose a challenge for the model’s generalization ability. Additionally, the complexity of domain adaptation techniques required to bridge this gap remains an active area of research.
5. Results and Analysis
The proposed frameworks of enhanced-CLIP with text and visual-exemplar prompting showed significant performance improvement compared with simply using text prompting. Applying the model trained using satellite images from a region with easily accessible datasets achieved an accuracy of 0.6 on the custom cattle-herd dataset for the target region, even though training was based solely on the dataset from the source region where cattle herds were easily deciphered from the satellite images. When applied to developed settings where the visual feature of a cattle herd had close similarities with the source domain, the model performed with 1.0 accuracy in detecting cattle herds.
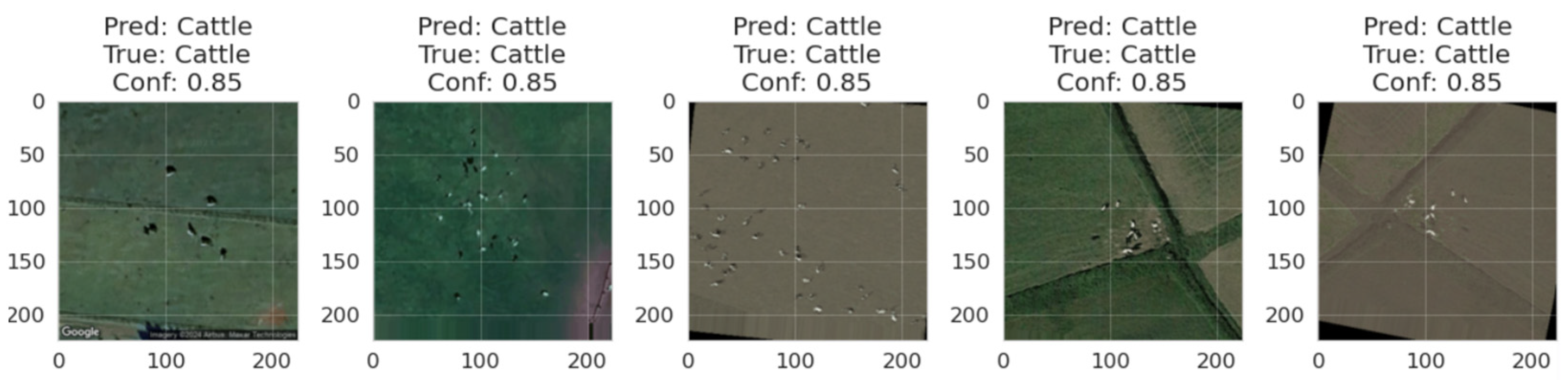
Some of the images visualizing the training and prediction process are shown in
Figure 6 below.
Evaluation of Enhanced-CLIP Performance
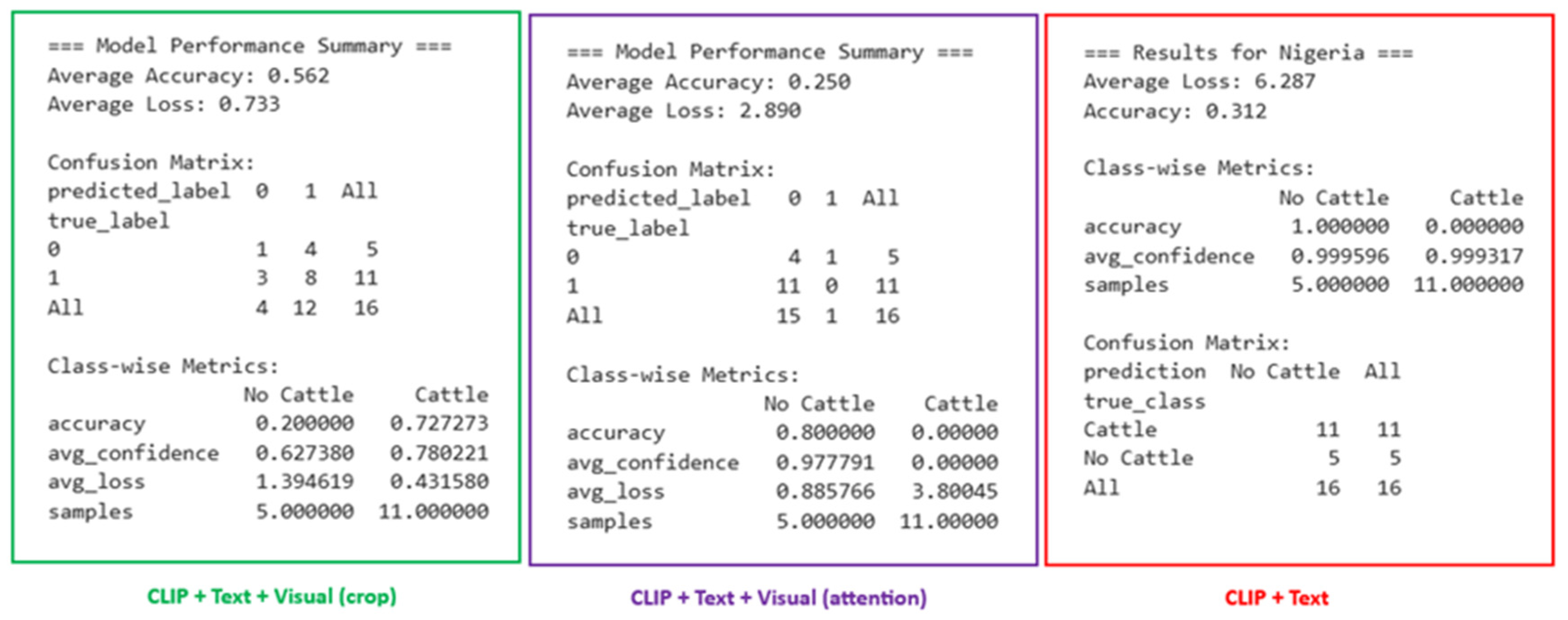
To systematically evaluate the model’s effectiveness,
Table 4 presents the performance metrics of the best models from the three CLIP variations used in the study, with detailed performance of model variants provided in
Table 5. The CLIP variations include the following:
The training epoch value was configured as 50 but stopped between 24 and 26 epochs. The testing on the target domain was performed on all 16 actual ground truth images collected of cattle-herd and non-cattle-herd images.
The CLIP + text prompt trained over just seven epochs with early stopping and introduced poor model generalization, which was reflected in the poor performance when applied to the target domain. It predicted only a single class (No Cattle) for all images. When applied to a random farm in the Netherlands with cattle herds, the model was not able to detect the cattle even though the test domain had similar features to the source domain where cattle herds were observed on green pastures or farmlands.
The CLIP + text + visual prompt, using an attention algorithm to preprocess exemplars, trained for just over 25 epochs with early stopping. Although performance on the target domain and cattle herd identification in the target domain was poor, the model identified two different classes (Cattle and No Cattle). With more tuning of the exemplar process, the performance might be improved.
When applied to a random farm in the Netherlands with cattle herds, the model correctly predicted the presence of cattle herds, hence showing encouraging results on test domains with similar features as the source domain where cattle herds were observed on green pastures or farmlands.
Figure 7 above shows some model performance metrics obtained during the evaluation of the CLIP variations.
The best performing model framework used cropping to preprocess the exemplar images for the CLIP + text + visual prompt architecture, producing predictions of both “Cattle” and “No-Cattle” classes, achieving an accuracy of 0.72 in predicting the presence of cattle and an overall accuracy of 0.562 for both-class prediction. When applied to a random farm in the Netherlands with cattle herds, the model also correctly predicted the presence of cattle, as shown in
Figure 8.
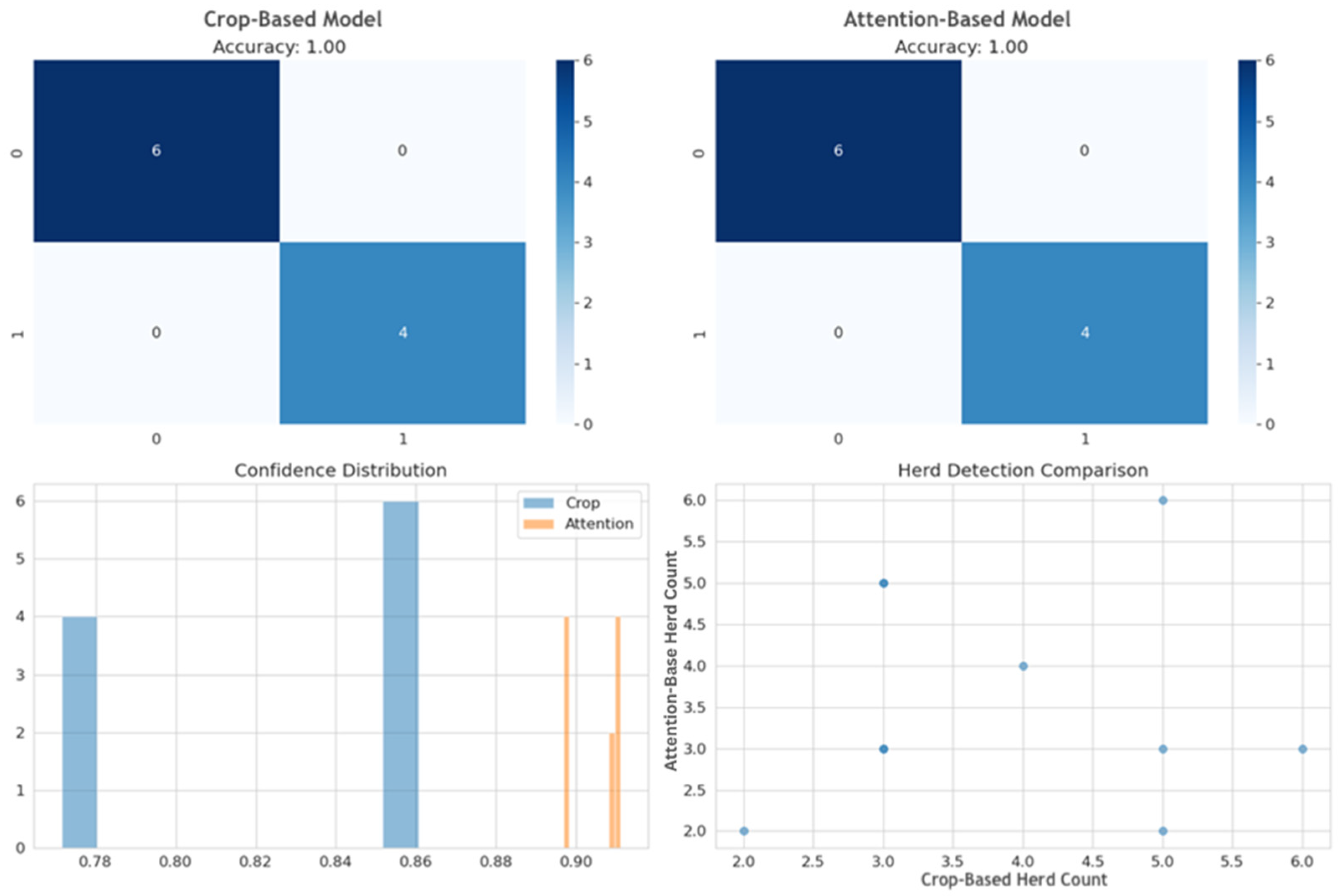
Figure 9, below, shows a comparison of various training metrics between the crop- and attention-based algorithms when applied to an exemplar image. Although both approaches showed similar accuracy and detection during training, the confidence intervals of prediction when exemplar images were pre-processed using attention algorithms have a narrow range and were slightly higher. This did not, however, translate to better prediction in the target domain when model knowledge was transferred. In contrast, the cropped algorithm, with wider-range confidence intervals during training, provided better generalization properties and performed significantly better when applied to the target domain.
Table 6, below, shows the model predictions for CLIP + text + visual prompt and the prediction confidence values for each of the images. Notably, the results reveal potential model overconfidence, particularly evident in cases where incorrect predictions are accompanied by high confidence scores. For example, third and fifth inline in
Table 6 had 84.3% and 72.6% confidence respectively for an incorrect prediction.
This overconfidence phenomenon suggests that while our dual-prompt architecture improves detection accuracy, the model may not adequately capture prediction uncertainty, particularly when generalizing across different geographic domains and terrain types.
Figure 10, shows prediction samples across different terrain types, the analysis includes true positives with varying confidence scores (0.79, 0.84) for successful cattle detection in rural and barren terrains. False positives were also recorded demonstrating overconfidence issues in urban environments. This limitation highlights a critical area for future investigation through meta-learning frameworks, as discussed in
Section 6. The enhanced-CLIP model integrated within the ProtoMAML (Prototypical Model-Agnostic) framework could potentially address this overconfidence issue by learning the optimal uncertainty quantification strategies across diverse geographic domains.
6. Conclusions and Future Work
While there has been laudable progress in the application of LVLMs like CLIP in computer vision and satellite imagery remote sensing where the object or scene is easily described and have had significant representation in public dataset albeit limited, applicability and adoption for detecting “uncommon” objects not represented in public datasets have been challenging. This research paper presents a framework using enhanced-CLIP with text and exemplar-image prompting, showing outstanding performance in object detection for this class of objects as compared to simply using text prompting.
Also, it shows that by augmenting some exemplar images, model transfer learning can be successfully applied to challenging regions even when the initial model is solely trained using satellite imagery data from regions where data is easily assessable and presented scenes that are easily decipherable. This provides an approach to increasing the application of LVLMs in more disciplines and challenging tasks where labeled data might not exist or are grossly underrepresented.
It is recommended that further investigation be carried out to compare our enhanced-CLIP approach with other Large Vision Language Models, particularly Vision Transformers (ViTs) and the Segment Anything Model (SAM) for uncommon object detection.
ViT’s self-attention mechanisms could potentially identify spatial relationships in cattle herd patterns more effectively, while SAM’s segmentation capabilities might provide superior exemplar processing compared to our crop-based and attention-based algorithms. A systematic comparison would evaluate computational efficiency, annotation requirements, and cross-domain transfer performance across these architectures.
An extension of the approach in a meta-learning framework can also be explored, which could compensate for the limited amount of labeled datasets. The most promising extension of our Enhanced-RSCLIP approach lies in meta-learning frameworks, specifically Prototypical Meta-Learning (ProtoMAML). Our preliminary investigations suggest that integrating our dual-prompt architecture with meta-learning could address the fundamental challenge of data scarcity in remote sensing applications and the overconfidence issues observed with enhanced-CLIP when used for transfer learning tasks. A CLIP-ProtoMAML framework would enable rapid adaptation to new geographic domains using only three to five exemplars per region, learning optimal exemplar processing strategies (crop-based vs. attention-based) automatically for different terrain types.
In order to provide an early warning signal for pastoralist–farmer clashes, further work can explore where the detection of an uncommon object, cattle, can be applied to a time-series of temporal satellite images to build a digital twin of an observed area. This digital twin can then be used to predict the positioning of the cattle herds in relation to detected farmlands some weeks ahead using high-resolution satellite imagery, thereby warning of potential farmer–herder clashes. This will give an opportunity for security agencies to curb or prevent such confrontations and can even provide evidence of damage to ensure adequate compensation if farmlands are destroyed.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















