1. Introduction
Energy is not only the foundation of economic development, but also plays an important role in addressing climate change and energy transition [
1,
2]. With the gradual depletion of fossil fuels and the growing call for environmental protection, the utilization of clean and renewable energy has become a global consensus [
3]. Among these energy sources, solar PV power generation is regarded as one of the key technologies in the future energy field. The application of PV energy is becoming increasingly widespread, and accurately predicting PV power generation has become particularly important [
4,
5]. However, PV power generation is susceptible to natural factors such as weather, season, and climate, and is characterized by volatility and uncertainty [
6,
7]. How to predict PV output efficiently has become a key issue in power grid dispatching. Therefore, accurate and reliable PV output prediction is of great value for the implementation of power grid dispatching and ensuring the stable and safe operation of PV power stations [
8].
In recent years, with the advancement of prediction technology, the scale of PV power generation projects has been continuously expanding, demonstrating a promising development prospect [
9]. At present, there have been relatively mature studies on PV power prediction methods, such as statistical methods [
10], which have simple principles and are easy to implement. However, when the sample data are relatively complex, the prediction effect is average. Another type of method is machine learning algorithms [
11], such as random forest (RF) [
12], extreme learning machine (ELM) [
13], and support vector machine (SVM) [
14]. However, single-layer neural network prediction models are difficult to meet the prediction requirements. Deep learning methods can effectively solve these problems. Deep learning networks such as long short-term memory (LSTM) [
15] and convolutional neural networks (CNNs) [
16] have gradually been applied in PV prediction. The features extracted by CNNs are used as the input of a recurrent neural network to achieve the prediction of PV power generation [
17]. More accurate PV power prediction is achieved by using LSTM autoencoders [
18]. However, a single model has difficulty handling complex data distributions and is prone to overfitting or underfitting during training.
Ensemble learning captures more patterns and rules by integrating the prediction results of multiple base learners and has a stronger generalization ability. The PV production forecast is generated by using the basic models of four different LSTM architectures [
19]. Two deep learning algorithms are utilized as the base learner, and the extreme gradient augmentation algorithm is used as the meta-learner to improve the accuracy of solar PV power generation prediction [
20]. The three machine learning algorithms are integrated using the baseline linear regression model to achieve PV prediction. The results show that the integrated model is superior to the individual model [
21]. A comparative analysis of the main features of various PV prediction technologies is shown in
Table 1. However, the traditional stacking method adopts a fixed learner and lacks dynamic adjustment, which limits the model performance and prediction accuracy when dealing with complex and variable PV prediction scenarios. Therefore, it is necessary to explore a dynamic adaptive ensemble learning framework to improve the model’s adaptability and generalization ability, which is of great significance for enhancing the performance of PV prediction models.
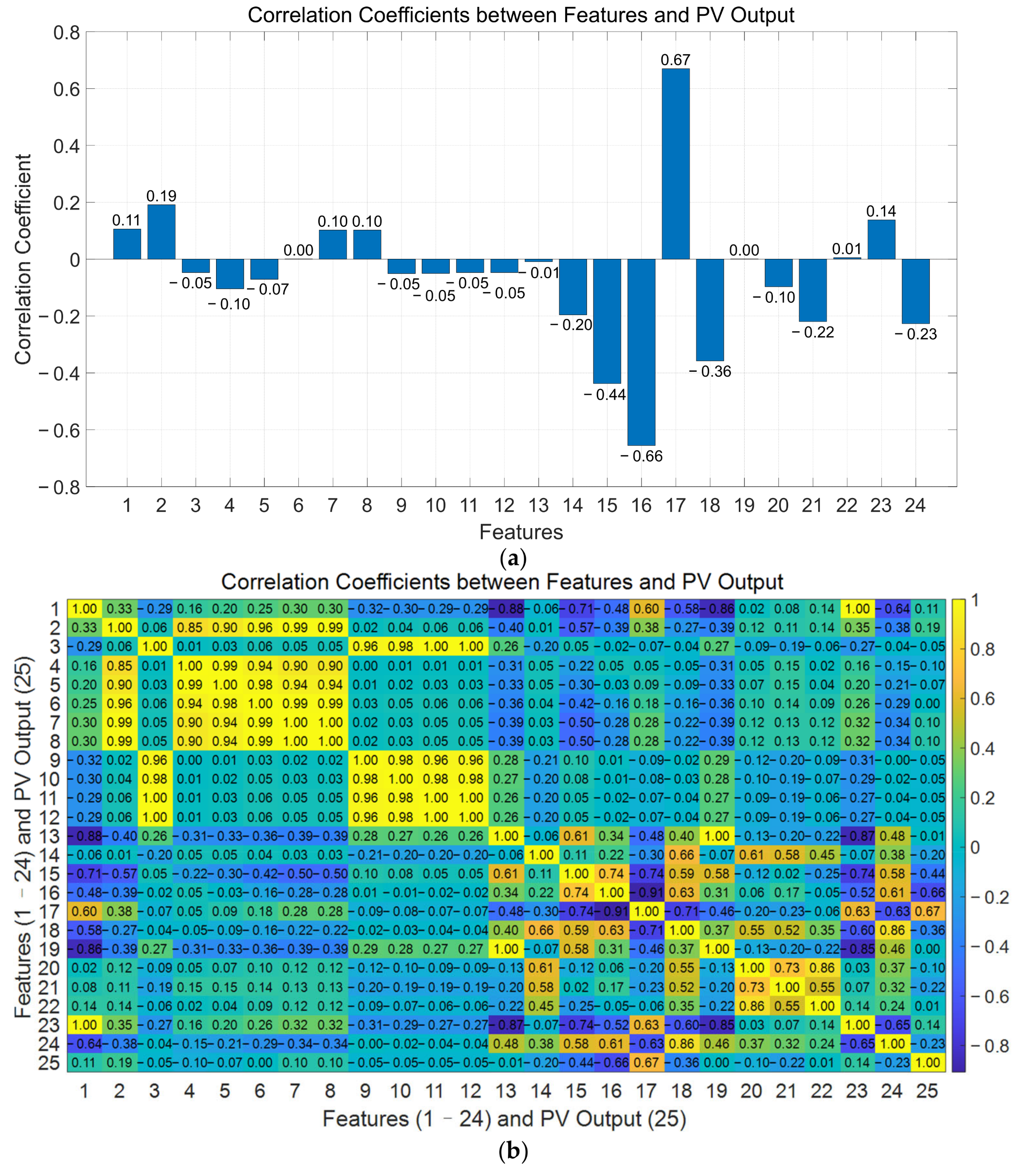
In addition, PV prediction includes multiple meteorological characteristics, such as solar radiation, temperature, wind speed, humidity, etc. PV power generation is significantly affected by meteorological conditions, and meteorological factors need to be comprehensively considered [
22]. However, meteorological characteristics have different influences on PV output. Considering all meteorological characteristics can affect the prediction accuracy of the model [
23]. Meteorological factors with low correlation should be analyzed and filtered to remove redundant features, thereby improving the prediction efficiency of the model.
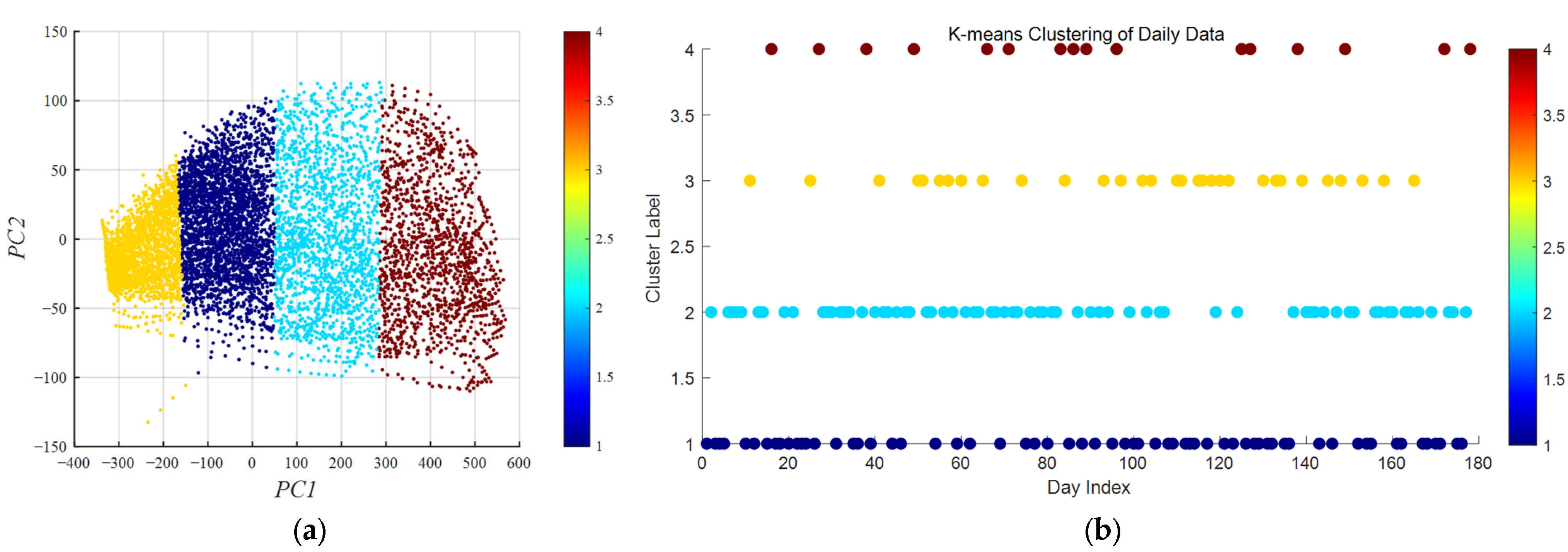
Moreover, for multi-level PV clusters, which contain multiple PV stations, due to the change of weather conditions, considering that the power mutation of sub-regional (low-level) station output is larger than that of large-scale regional (high-level) station output, high-level output can reflect the change trend of the power generation data of a period of time and a region as a whole, and establish the trend reference with high-level output to improve the prediction performance of low-level output. It can help low-level stations predict power generation more accurately. In traditional PV prediction methods, only single-level predictions are considered, and the correlations among multi-level PV outputs are not taken into account. Therefore, effective information mining of the relationship between multi-level PV data is a necessary condition for enhancing the precision of PV power forecasting.
The instability of PV power generation poses challenges to the dispatching decisions of energy storage systems [
24,
25]. Deterministic prediction cannot provide sufficient information to predict the actual fluctuations in power generation. Therefore, probabilistic prediction is needed to quantify the uncertainty of PV prediction and help energy managers make more flexible decisions [
26,
27]. The parameter estimation method combining the analytical method, the simulated annealing method, and the derived model is used to analyze the characteristics of solar PV [
28]. Parametric probabilistic prediction usually assumes that the data follow a specific distribution, such as the normal distribution and Poisson distribution. If the assumption does not hold true, the prediction result will be biased. Nonparametric probabilistic prediction effectively solves the problem of unknown distribution. A dual-branch deep learning quantile regression (QR) PV power prediction method is proposed to improve the prediction performance of the model [
29]. PV power prediction is carried out by using the least squares SVM and KDE, which realizes the combination of deterministic prediction and uncertain prediction [
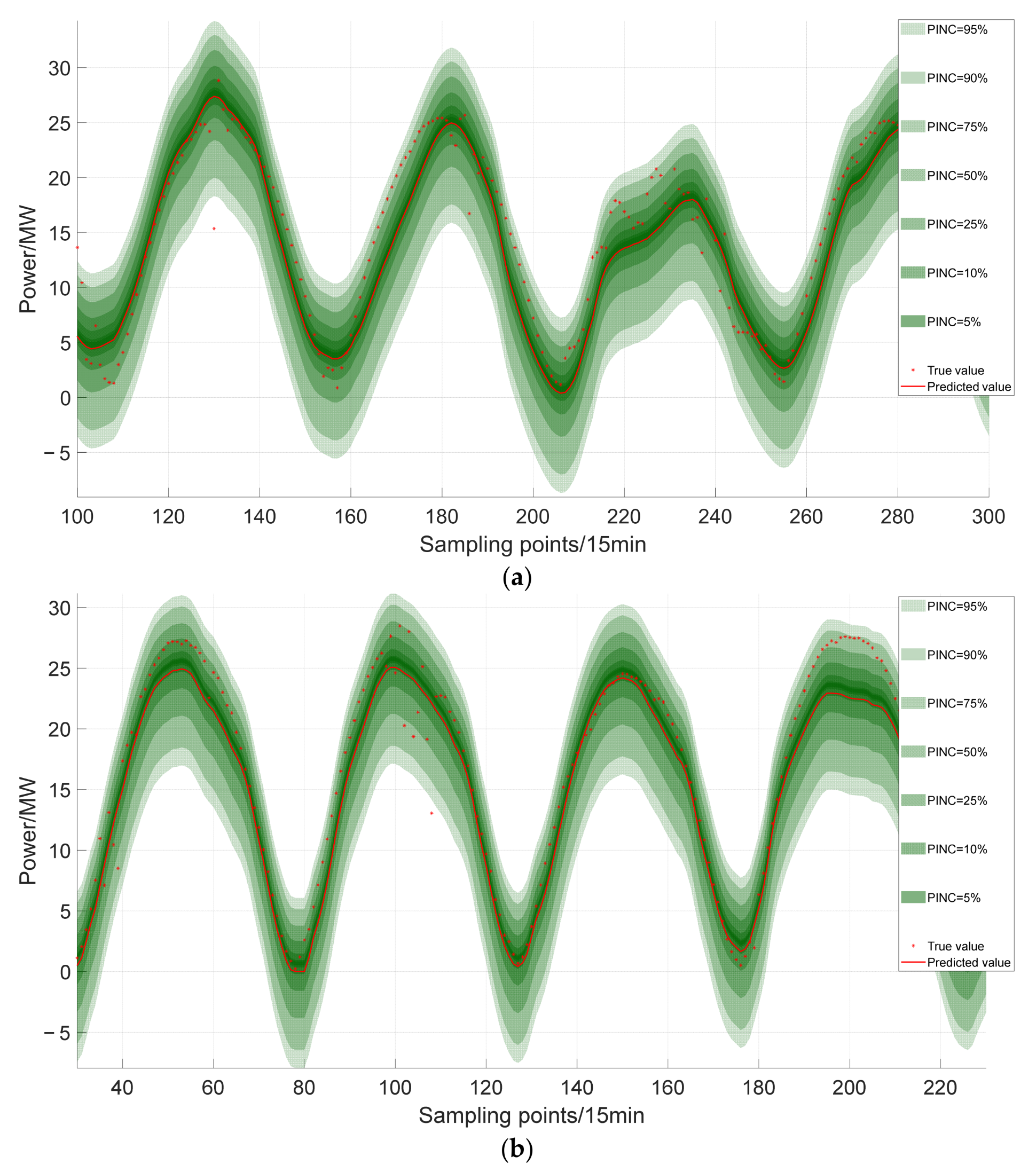
30]. However, in the traditional KDE, a fixed bandwidth is used, and the bandwidth parameter controls the width of the kernel function, which lacks the flexible processing of each data point estimation, thereby affecting the smoothness and accuracy of the estimation. Therefore, through an effective KDE strategy, a relatively reasonable PI can be determined to ensure the reliability of the interval.
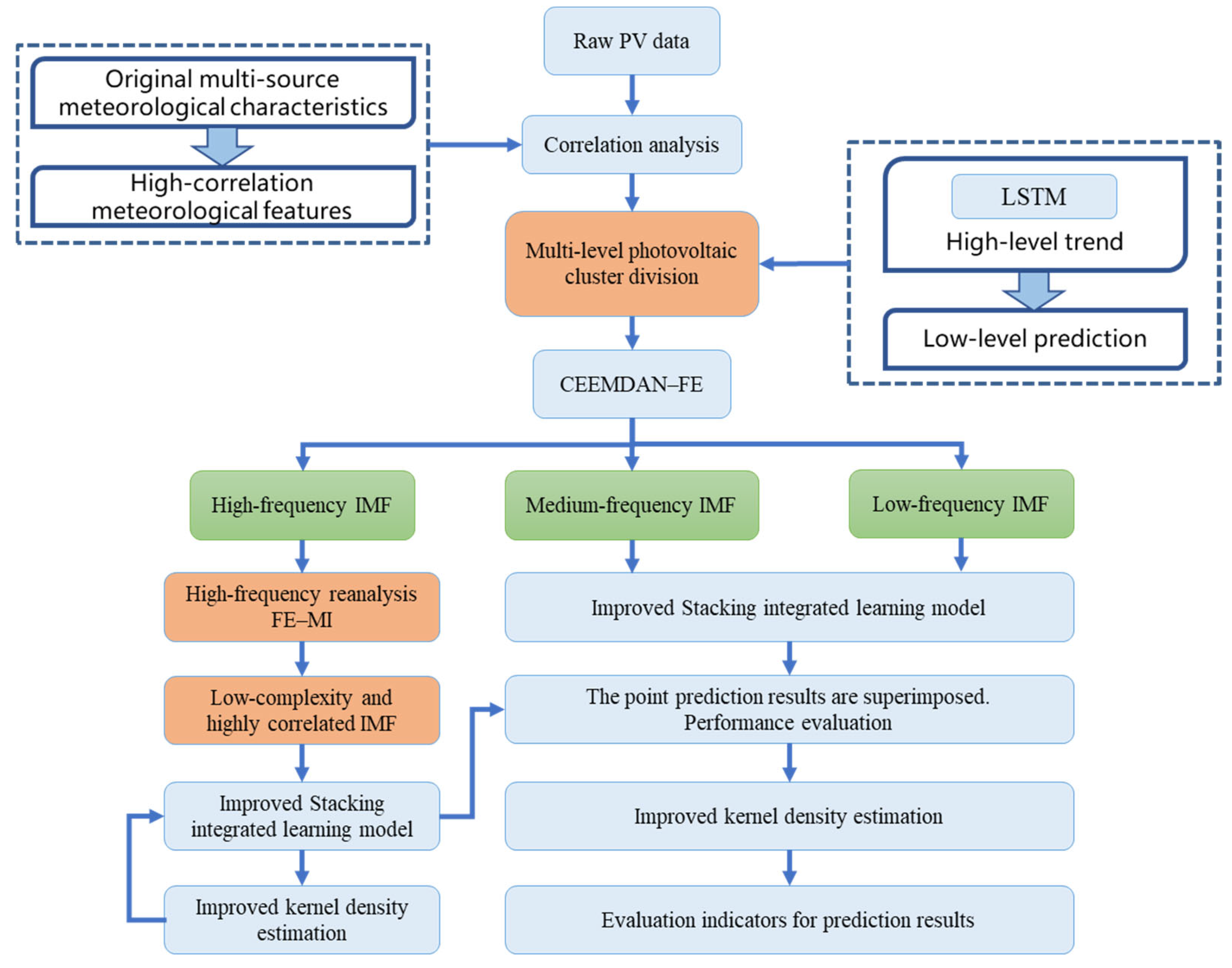
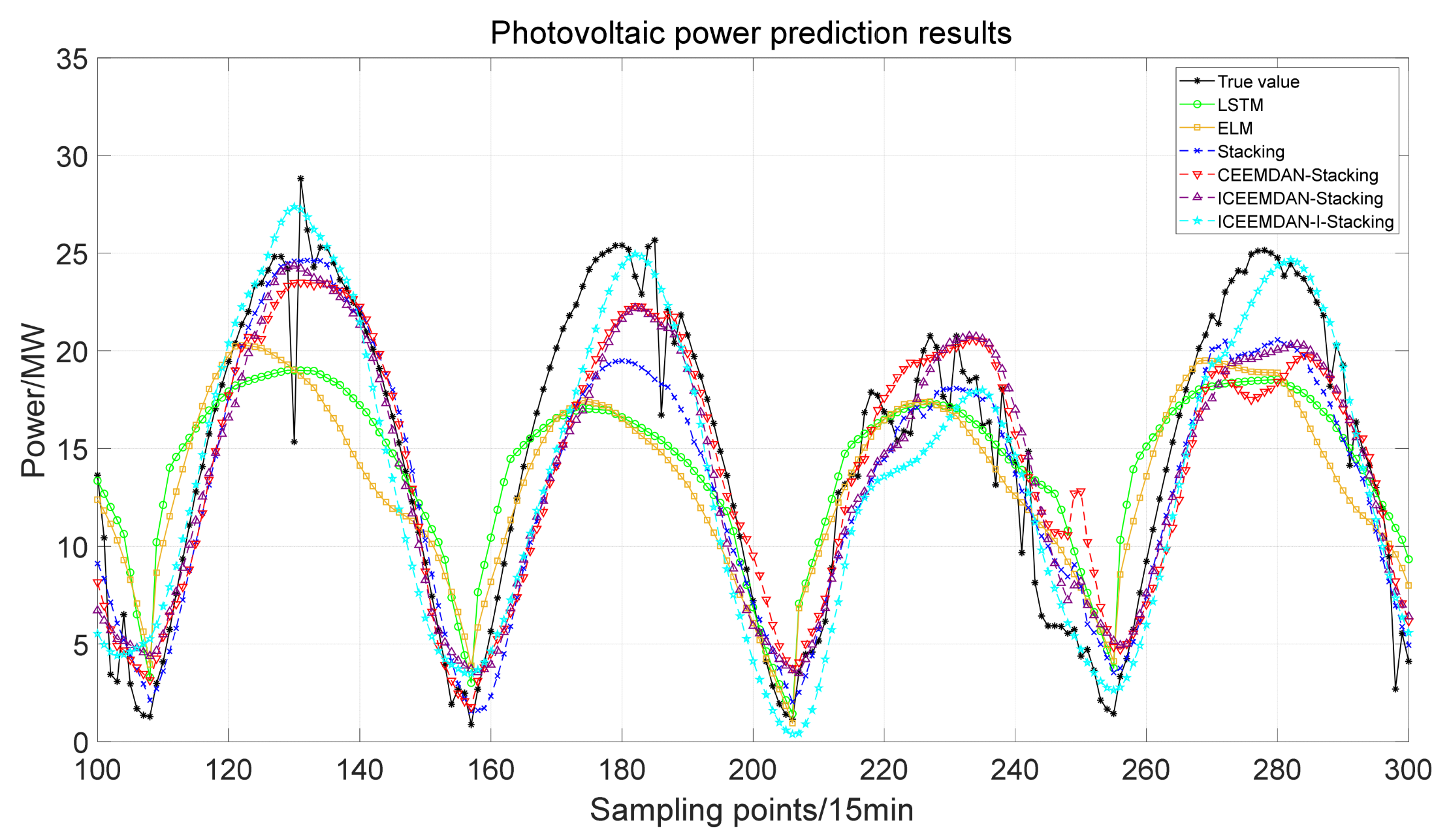
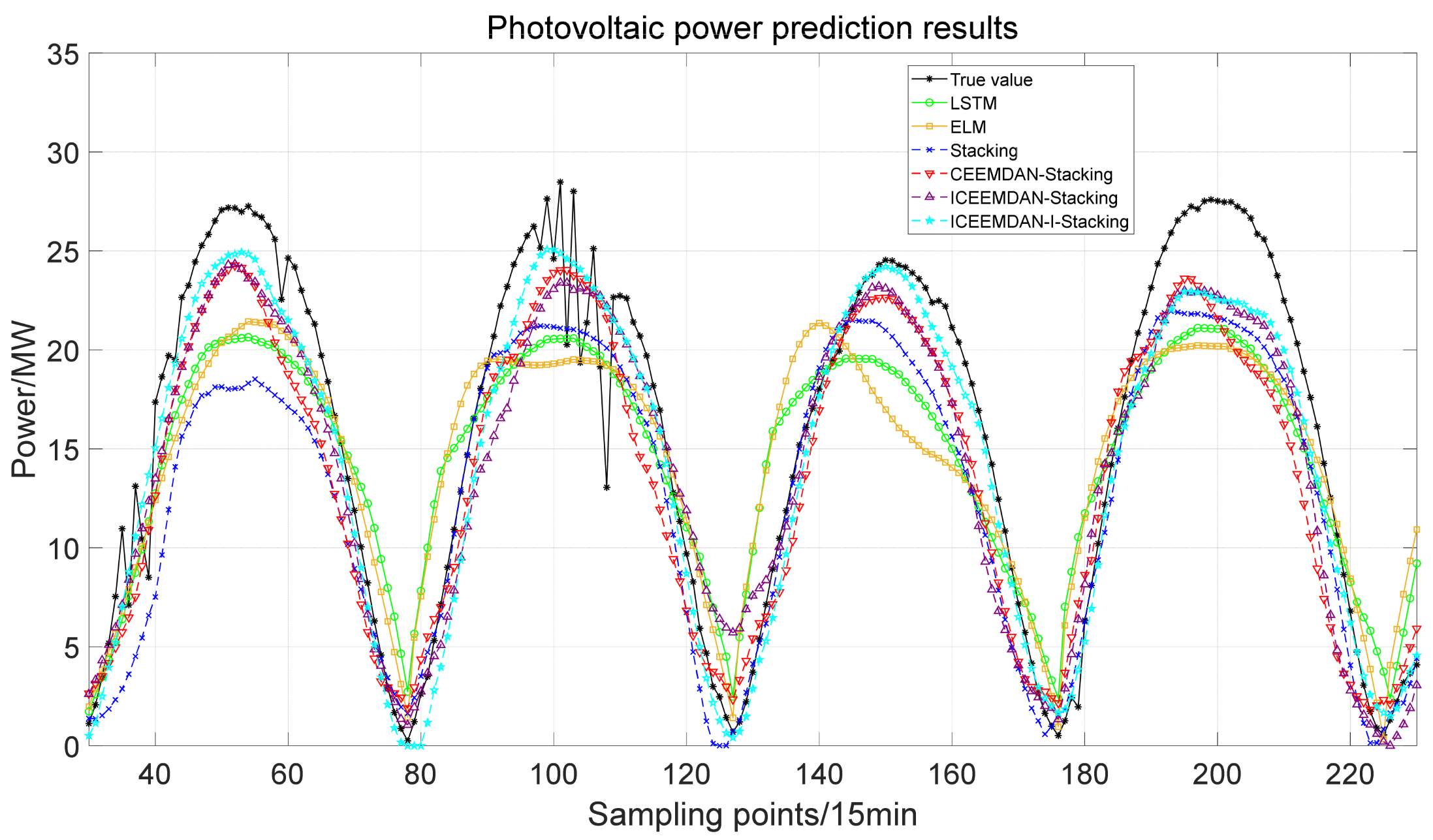
As a consequence, in this paper, a new short-term probabilistic forecasting model of PV power generation that utilizes multi-level adaptive dynamic integration is proposed. Firstly, the correlation between the high-level output and the low-level output within a PV region is analyzed to explore the potential relationship between multi-level PV outputs and the corresponding analysis results are introduced into the low-level output prediction model. Then, the PV data are decomposed by CEEMDAN and reconstructed with FE and MI (FE–MI). Then, the improved dual dynamic ensemble learning method is used to construct short-term PV power generation prediction models, and the high-frequency parts are analyzed and corrected. Finally, the adaptive KDE prediction error method is used to make interval predictions under different confidence levels to improve the overall performance of PIs. Compared with traditional PV forecasting models, the main contributions of this paper are as follows:
The potential information on multi-level PV outputs is explored. The correlation between high-level PV output and low-level PV output is analyzed, and the prediction accuracy of low-level output is improved with the trend of high-level output;
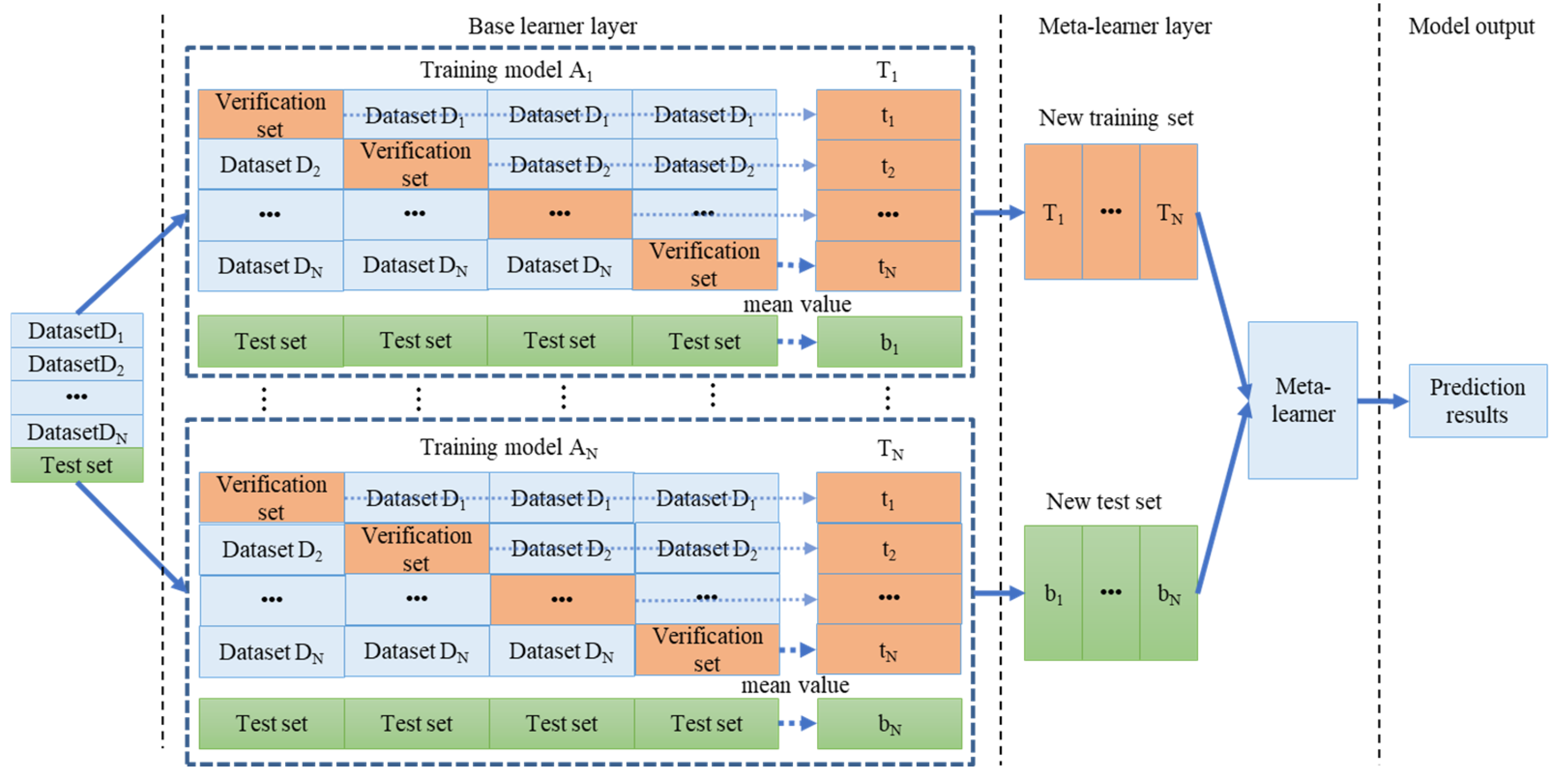
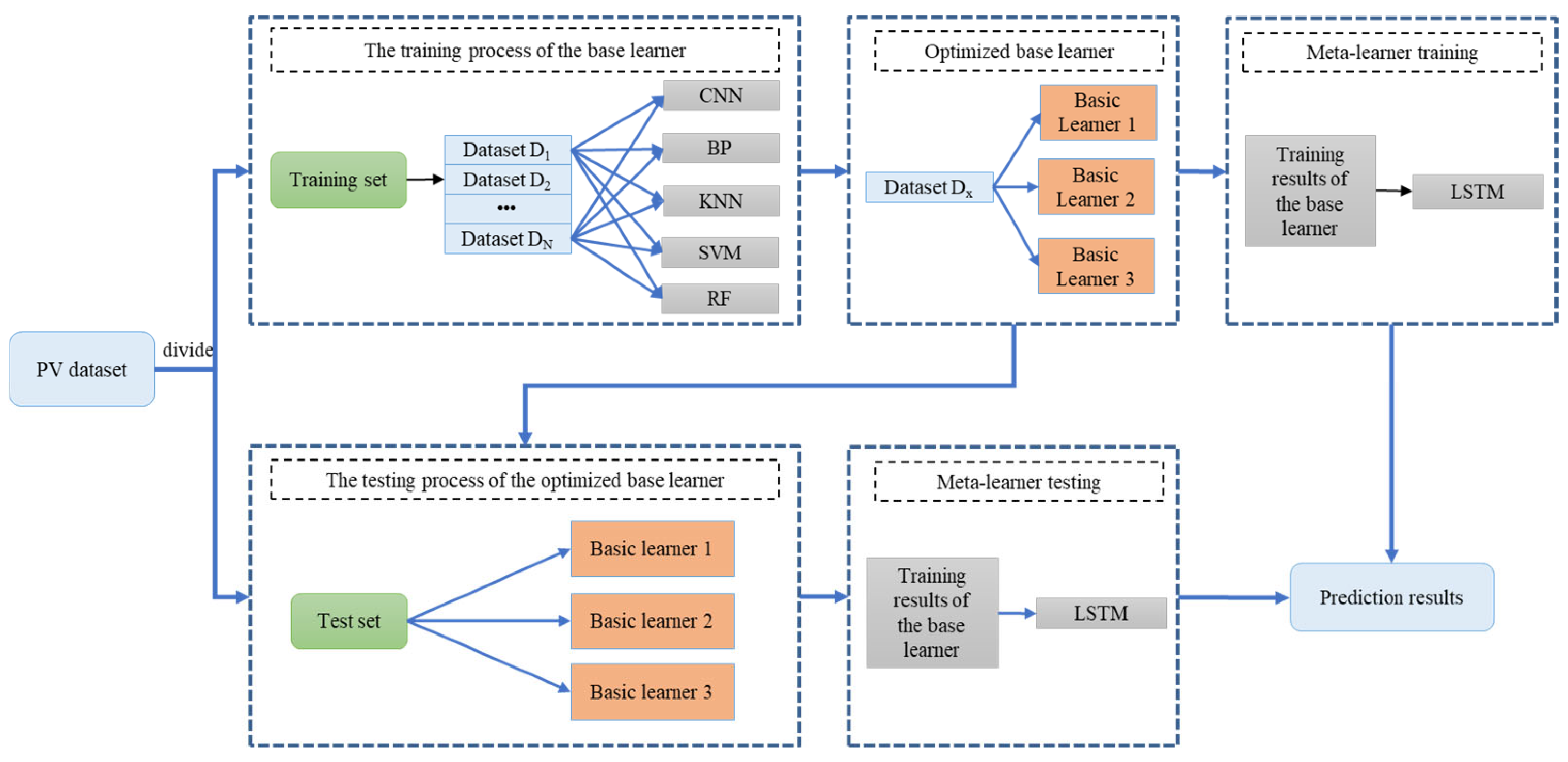
The proposed FE–MI method is used to reconstruct and analyze the PV data to extract the potential information, and the improved dual dynamic stacking model is used to make a deterministic prediction of PV power, thereby improving the accuracy of PV deterministic prediction;
The proposed adaptive KDE method is used to correct the point prediction error of the high-frequency time series and is used to predict the probability of PV power, thereby obtaining a more reliable PI and quantifying the uncertainty of PV power.
The rest of this paper is organized as follows:
Section 2 establishes theoretical methods and model structure;
Section 3 introduces the dataset and evaluation metrics; in
Section 4, the prediction results are given and analyzed;
Section 5 summarizes the paper.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}