
High-Throughput Post-Quantum Cryptographic System: CRYSTALS-Kyber with Computational Scheduling and Architecture Optimization

 , ,
, ,
Abstract
1. Introduction
- We propose a high-throughput scheduling for Kyber by parallelizing and pipelining the SHA-3 function, the sampling algorithm, and the NTT computations. The proposed scheduling reduces the time required to generate the necessary polynomial coefficients to just one-fourth of that required by the conventional software procedure.
- Due to the iterative and repetitive nature of hash operations in Kyber, pipeline bubbles are inevitable with both round-based and unrolled-pipeline architectures. Therefore, we propose an 8-stage pipelined architecture that effectively addresses feedback issues during the absorbing and squeezing phases of SHA-3 operations.
- We propose a multi-mode polynomial arithmetic module based on an unrolled-pipeline mixed-radix architecture, which can be configured into different modes for various polynomial computations in Kyber. Moreover, it employs resource-sharing techniques to maximize the utilization of each pipeline stage within a limited and reasonable hardware area.
2. Preliminaries
2.1. Symbol Definition
2.2. Auxiliary Functions in Kyber
- Hash function: The hash function used in Kyber is the SHA-3 algorithm. Four different SHA-3 modes are employed to increase randomness in Kyber: SHA3-256, SHA3-512, SHAKE128, and SHAKE256.
- Sampling function: The sampling functions in Kyber include SampleNTT and SamplePolyCBD. The former primarily samples coefficients from the NTT domain for the matrix , while the latter provides property with a centered binomial distribution (CBD) on . In this work, the hat on top, , represents a term in the NTT domain.
- Compress function: The compress function primarily serves two purposes: reducing the size of the ciphertext and creating an error tolerance gap for MLWE during decryption. The function compresses the input x into the range , , and then the result is rounded to the nearest integer, as shown below:However, if the compression module is directly implemented with (2), it would require 256 dividers for fully parallel processing. Therefore, we propose a hardware-friendly implementation to reduce its complexity.
2.3. Kyber KEM Algorithms
- Key-Generation: The key-generation algorithm produces a public key pk and a secret key sk. The function is derived from the MLWE-based construction in (1), where the secret vector and error vector are sampled from the centered binomial distribution (CBD), and the matrix is sampled uniformly in the NTT domain. The resulting pk consists of (, ), where is derived from SHA3-512 applied to a random seed d, and the secret key sk is the NTT form of . A simplified version of the key-generation process is listed as follows in Algorithm 1:
| Algorithm 1: K-PKE: Key Generation |
Output: Public key pk, Secret key sk
|
- Encapsulation: The encapsulation algorithm takes the public key pk and the message m as input to produce the ciphertext ct and a 32-byte shared secret key K. First, m is decompressed to generate an error tolerance gap, resulting in , where bit “0” maps to 0 and bit “1” maps to 1665. Next, the ciphertext components are computed as and . Finally, the shared key K is derived as the first 32 bytes of , and the ciphertext ct consists of (Compress (), Compress (v)). A simplified version of the encryption process is listed as follows in Algorithm 2:
| Algorithm 2: K-PKE: Encryption |
Input: Public key pk, Message m, Random coins r Output: Ciphertext c
|
- Decapsulation: The decapsulation algorithm takes dk and ct as input to produce the shared secret key K. Firstly, is computed as Compress(INTT()). Next, K is the first 32 bytes of SHA3-512(, h), where h is SHA3-256(ek). Finally, through re-encryption verification, the same K can be obtained. A simplified version of the decryption process is listed as follows in Algorithm 3:
| Algorithm 3: K-PKE: Decryption |
Input: Secret key sk, Ciphertext c Output: Message m
|
2.4. Mathematical Foundations of the Kyber Mixed Radix-2/4 NTT
- is the N-th primitive root of unity modulo q.
- is a scaling factor introduced to simplify reduction, where .
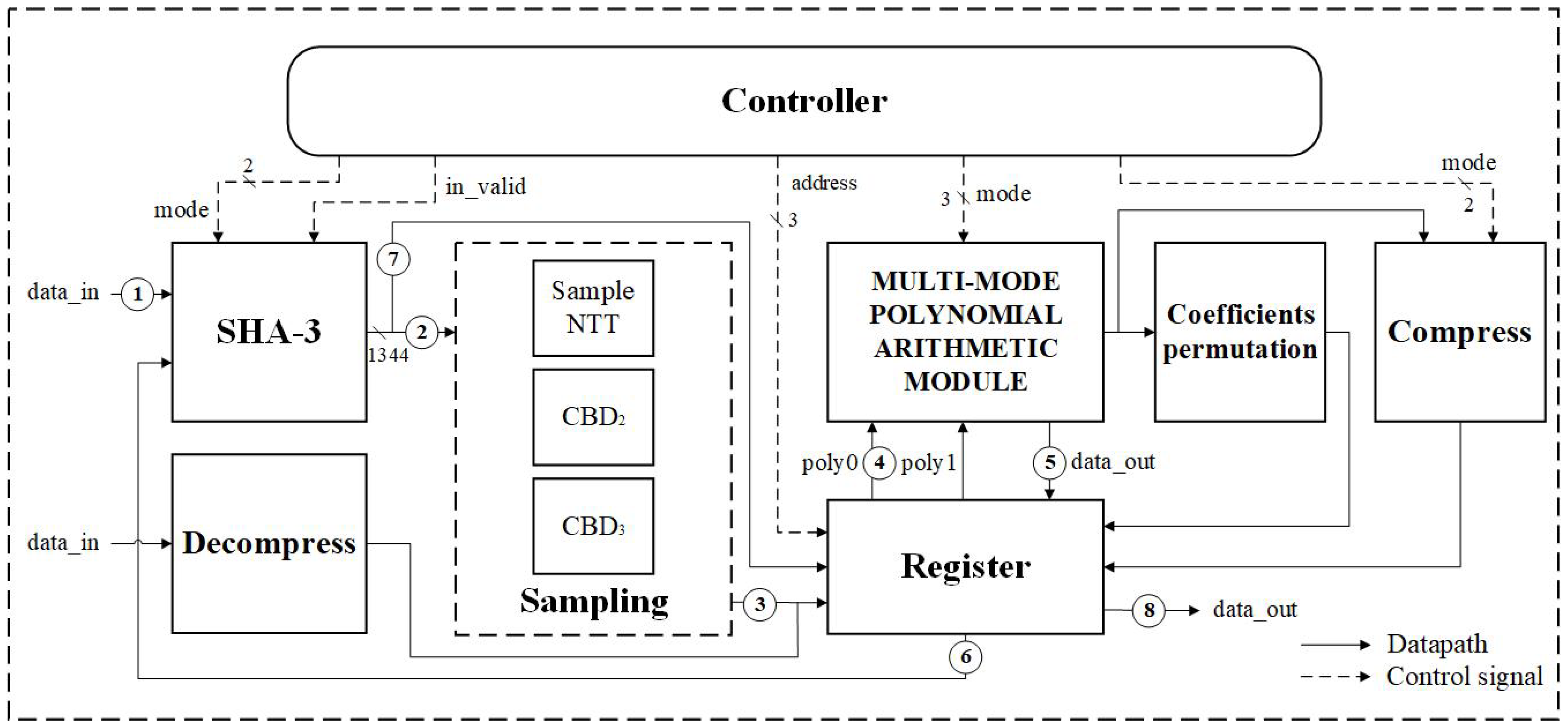
3. Proposed Hardware Architecture
3.1. Proposed Computational Scheduling
3.2. Proposed High-Speed Architecture
3.3. Multi-Mode Polynomial Arithmetic Module
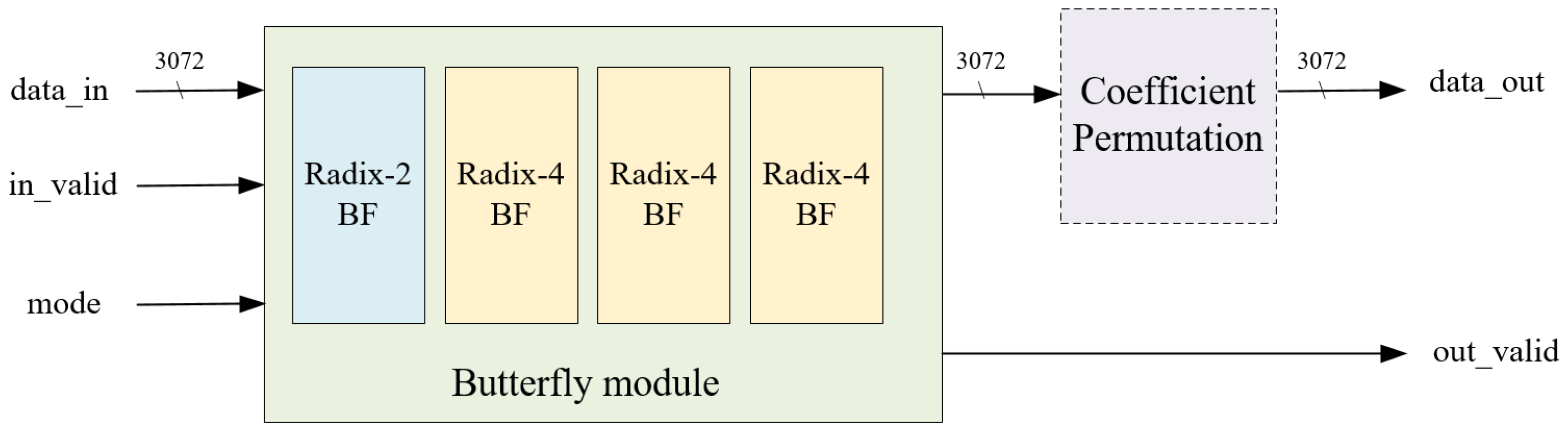
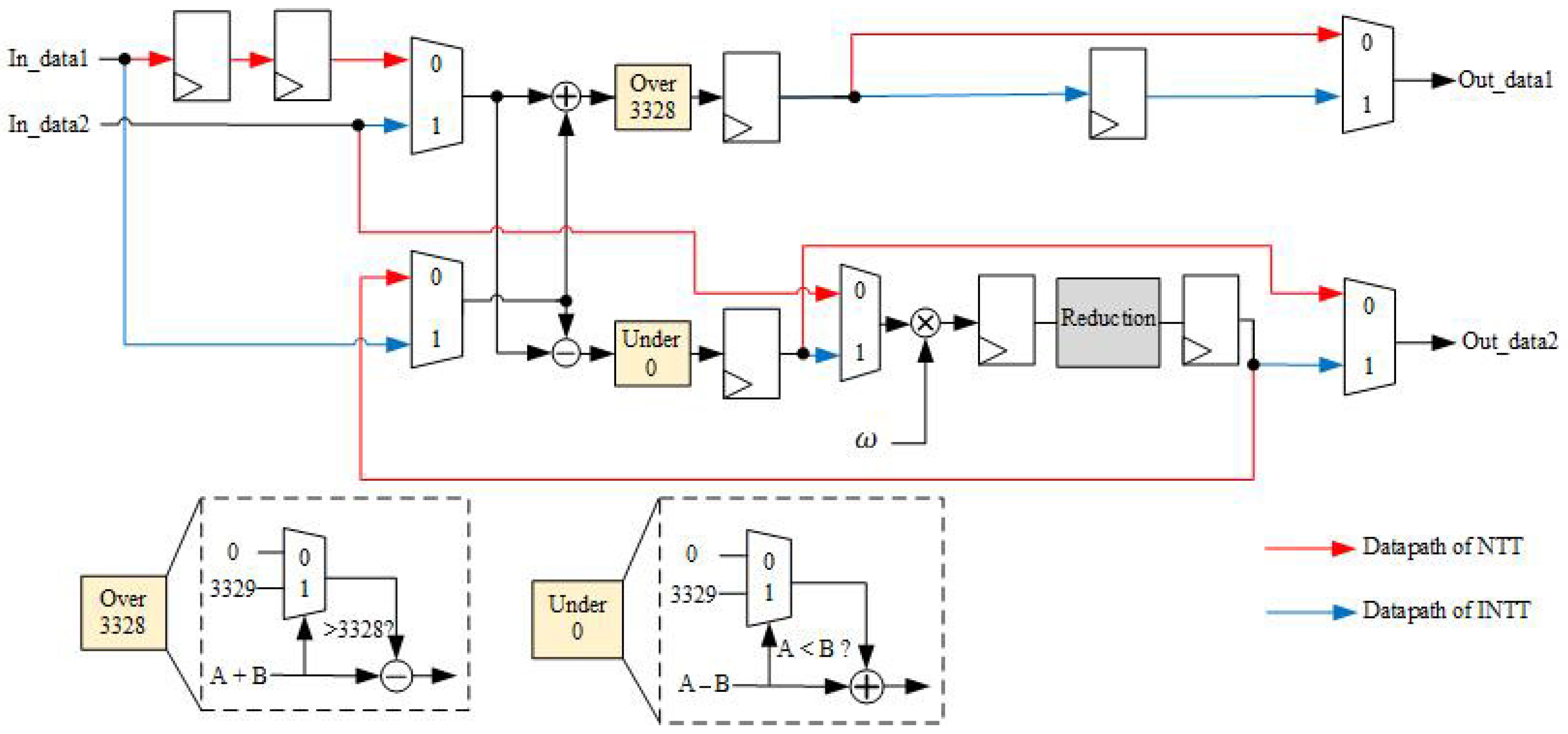
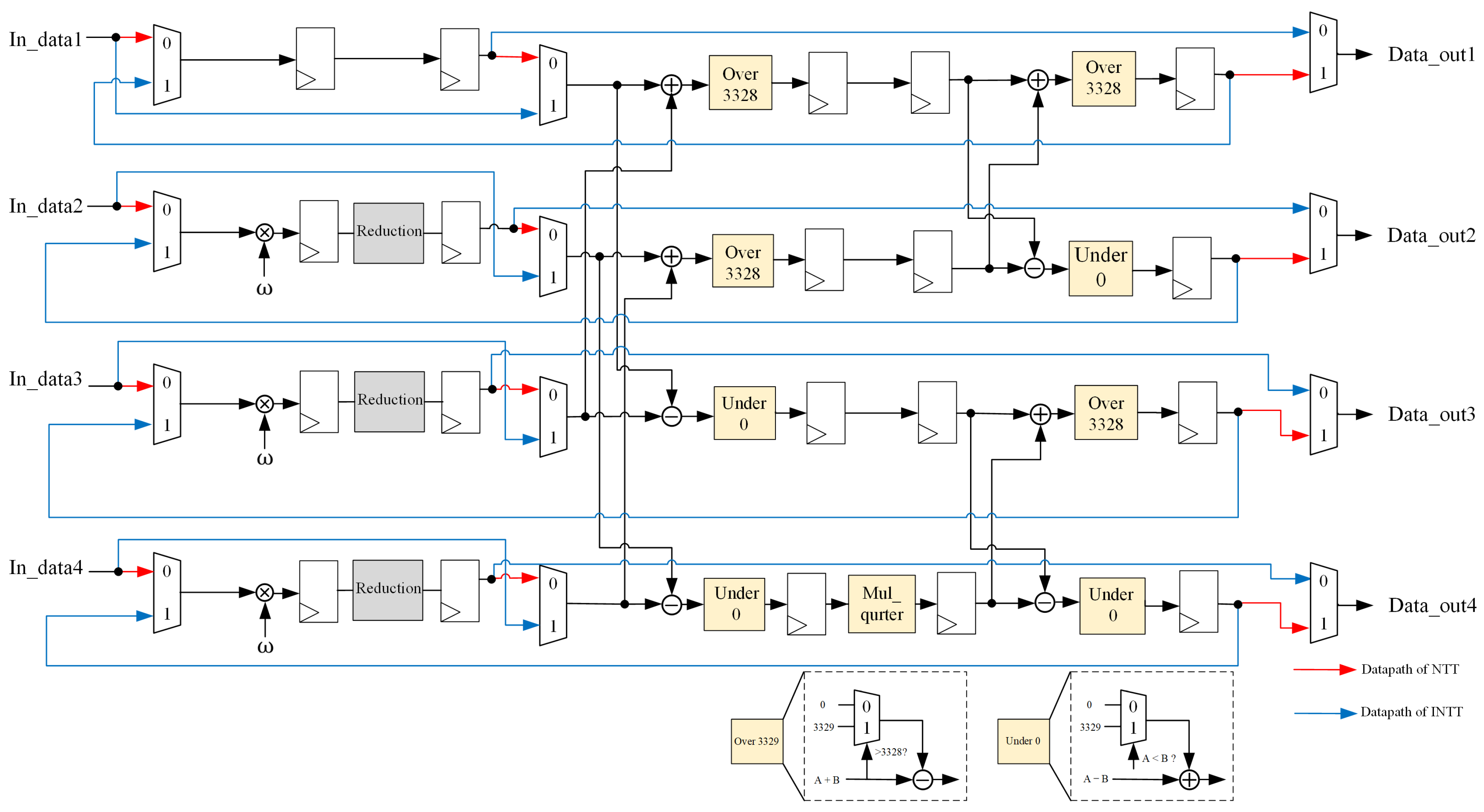
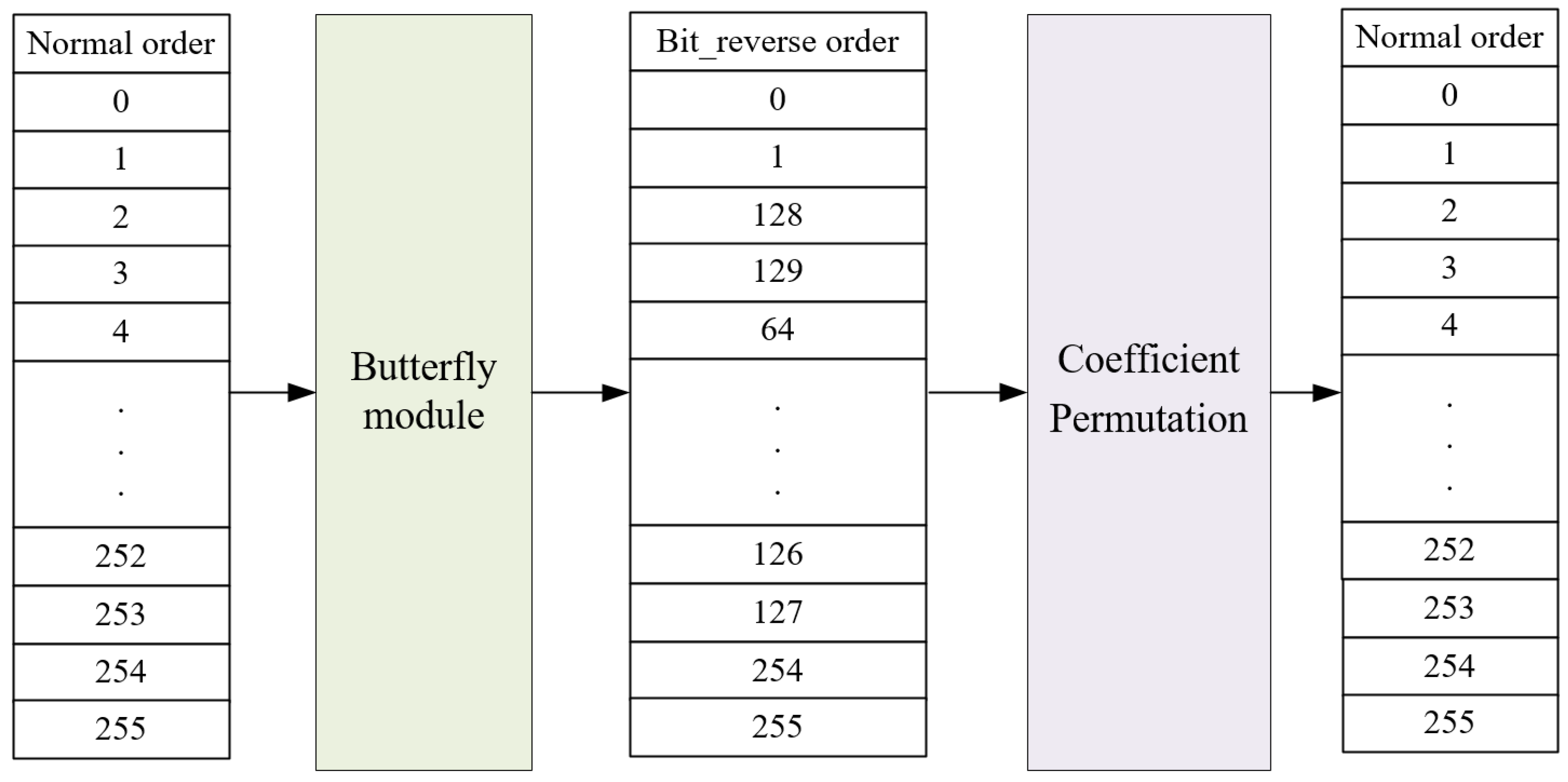
- Proposed Mixed-Radix Butterfly Architecture: we propose a mixed-radix architecture based on unrolled-pipeline techniques. Under this architecture, additional computational resources such as address generators or delay registers are not required to determine the input address for the next stage. Moreover, by fully unrolling the computation, polynomial operations are no longer the bottleneck in Kyber.Due to the mathematical background in Kyber, where the 512th primitive root cannot be found, it is unfeasible to perform a 256-point transformation for NTT/INTT, limiting the operation to 128 points. As a result of this factor, the polynomial must be divided into odd and even terms and transforming them using the same roots of unity in Kyber. Based on this characteristic, we design an 128-point mixed-radix NTT/INTT architecture to compute the 256-term polynomial NTT and INTT; the incoming 256-term polynomial needs to be divided into odd and even groups, and then input into the mixed-radix architecture sequentially. However, when performing pointwise multiplication, modular addition, and modular subtraction, the 256-term polynomial can be directly input into the mixed-radix architecture for computation. Figure 3 is the block diagram of the proposed mixed-radix architecture. In the proposed mixed-radix architecture, the first stage consists of 64 sets radix-2 butterfly, while each of the second to fourth stages consist of 32 sets radix-4 butterfly; the individual radix-2 and radix-4 butterfly units are shown in Figure 4 and Figure 5, respectively. The reordering module, required due to the shared architecture between the NTT and INTT, is shown in Figure 6. Since all modules are pipelined, the input interface of this module receives 256 polynomial coefficients simultaneously, with each coefficient represented in 12 bits, resulting in a total input width of 3072 bits. The output follows the same format. A control signal, mode, determines the operational behavior of the module.In the original algorithm, the output addresses of each stage in the NTT and INTT operations differ, resulting in distinct unfolded architectures. This design arises because, during NTT computation, the input is in normal order while the output is in bit-reversed order, whereas INTT operates in the opposite manner. To create a shared architecture capable of computing both NTT and INTT, adjustments are necessary. Thus, we designed a coefficient permutation module to ensure the correctness of the order after transformation. This module adjusts the output order from being bit-reversed to normal, as shown in Figure 6. Notably, due to the unroll-pipeline architecture, the permutation module only requires rewiring without needing any logic gates.
- Proposed Hardware Architecture of Radix-2 Butterfly: To achieve high throughput, we implement the radix-2 butterfly using a three-stage pipelined architecture, combined with modular adders, modular subtractors, and multipliers. Since the product may exceed q-1 after multiplication, we need to insert a modular reduction unit after the multipliers.The modular reduction unit in our design is based on [7], which proposes a hardware-friendly modular reduction algorithm tailored for Kyber’s mathematical background. The proposed reduction unit effectively simplifies the modular reduction operation for 24-bit products under . The proposed algorithm decomposes the 24-bit product into its upper 12 bits and lower 12 bits, and utilizes mathematical manipulations to simplify values that exceed 12 bits, thereby simplifying the modular reduction operation. The detailed implementation of the radix-2 butterfly is shown in Figure 4. The red datapath represents the three-stage pipelined architecture of the single-stage radix-2 NTT butterfly, including modular addition, subtraction, and multiplication.To reduce resource usage, arithmetic units are shared between the single-stage radix-2 NTT and INTT butterflies. The blue datapath illustrates the INTT butterfly that reuses the same computational resources.
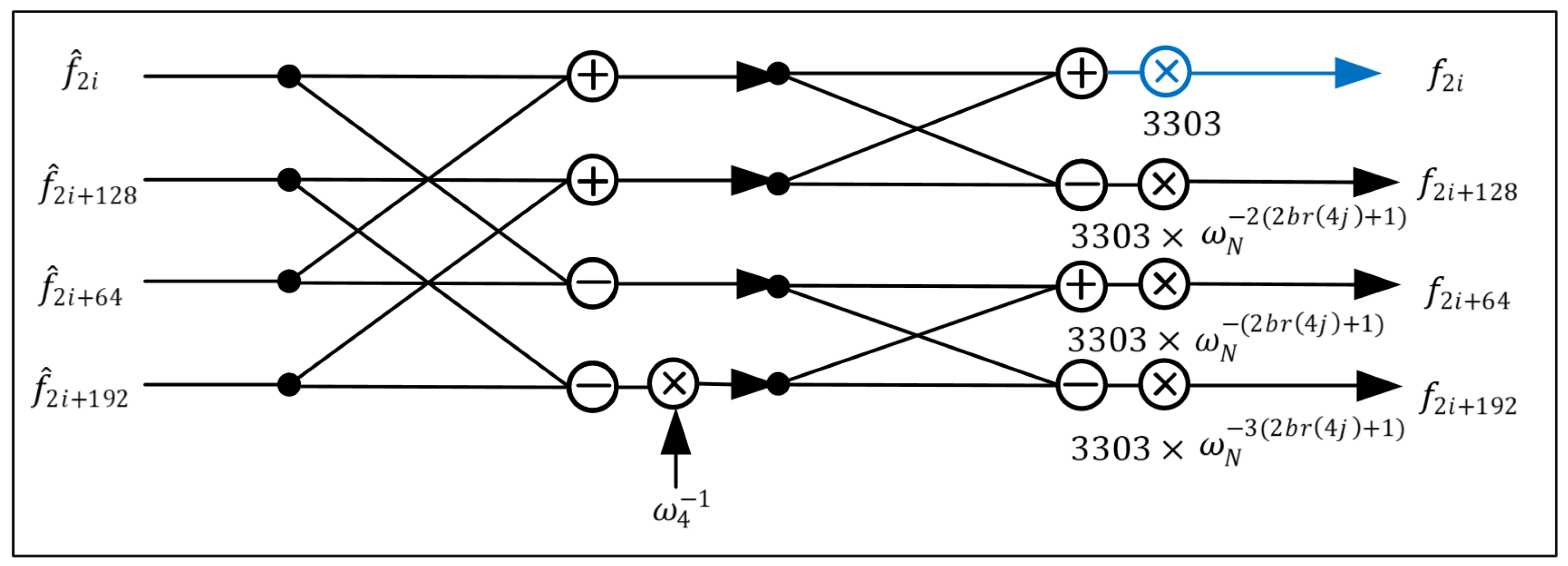
- Proposed Hardware Architecture of Radix-4 Butterfly: We implement the radix-4 butterfly in a five-stage pipelined architecture. The mul_quarter modules of NTT and INTT are constant multiplications designed for and , respectively. These modules adopt the same modular multiplication strategy as the radix-2 design, where the product is followed by a modular reduction to ensure correctness. The detailed implementation of the radix-4 butterfly is shown in Figure 5. The red datapath represents the five-stage pipelined architecture of a single-stage radix-4 NTT butterfly, which includes modular addition, subtraction, and multiplication. To minimize resource consumption, arithmetic units are shared between the radix-4 NTT and INTT butterflies. The blue datapath highlights the INTT computation, which reuses the same set of arithmetic units.When implementing the INTT, it is necessary to multiply all output coefficients by the modular inverse of the number of points used in the computation at the final stage. Our proposed approach preprocesses the roots of unity in the radix-4 butterfly at the final stage. Figure 7 represents the radix-4 INTT butterfly in the final stage. The blue multiplier denotes the additional multiplication for the modular inverse, while the black ones perform multiplication with the roots of unity after preprocessing in the original radix-4 INTT butterfly. Here, we preprocess the roots of unity and modular inverse offline; 3303 is the modular inverse of 128 in . Through this method, the mixed-radix INTT architecture can eliminate 75% of the computational workload at the final stage.
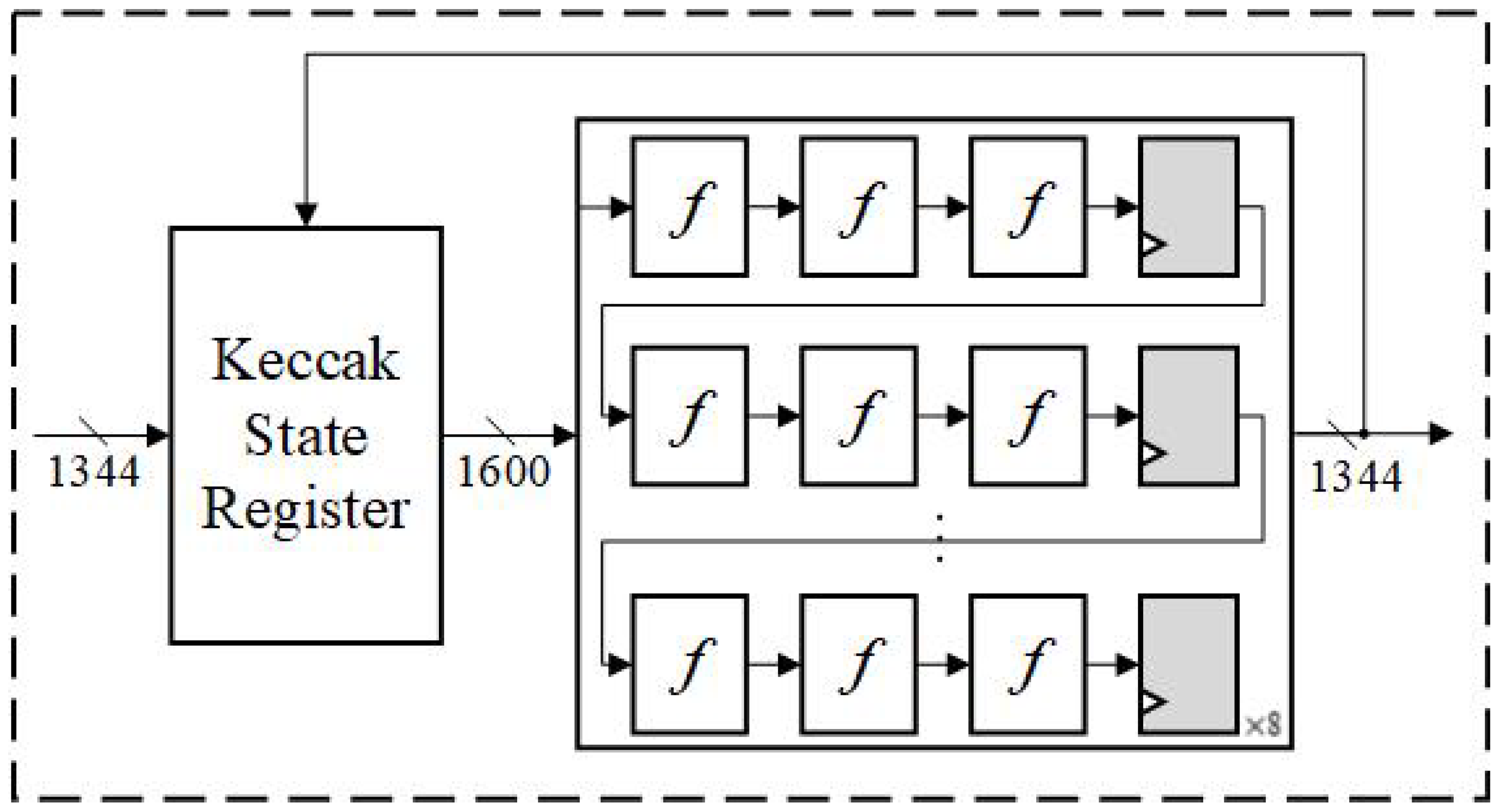
3.4. SHA-3 Module
3.5. Sampling Module
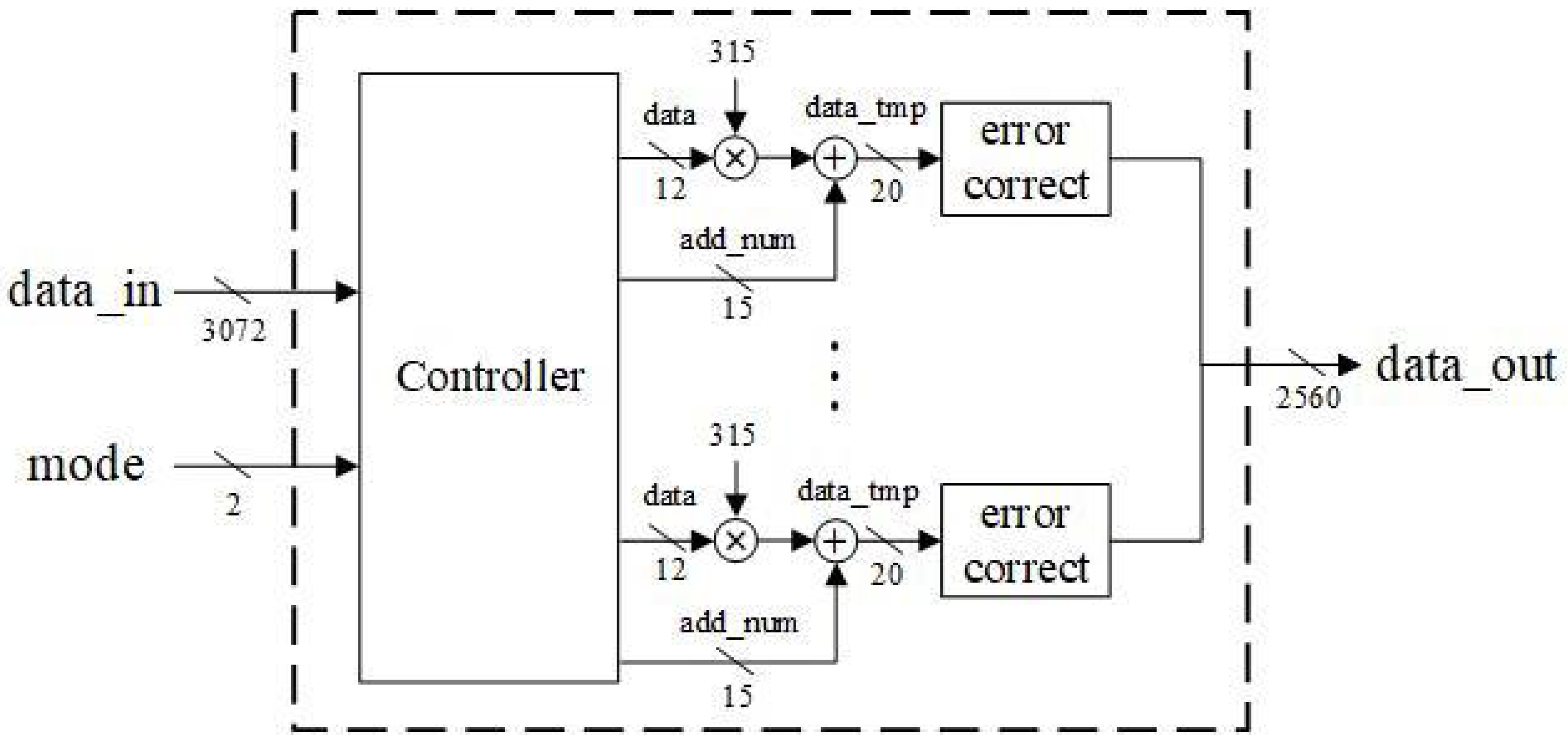
3.6. Compress Module
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CBD | Centered Binomial Distribution |
| ECC | Elliptic Curve Cryptography |
| HTTP | HyperText Transfer Protocol |
| INTT | Inverse Number Theoretic Transform |
| KEM | Key Encapsulation Mechanism |
| LWE | Learning With Errors |
| MLWE | Module Learning With Errors |
| NIST | National Institute of Standards and Technology |
| NTT | Number Theoretic Transform |
| PKE | Public-Key Encryption |
| PQC | Post-Quantum Cryptography |
| QUIC | Quick UDP Internet Connections |
| RLWE | Ring Learning With Errors |
| RSA | Rivest–Shamir–Adleman |
| SHA-3 | Secure Hash Algorithm 3 |
| TLS | Transport Layer Security |
| VPN | Virtual Private Network |
References
- Shor, P.W. Algorithms for Quantum Computation: Discrete Logarithms and Factoring. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science, Santa Fe, NM, USA, 20–22 November 1994; pp. 124–134. [Google Scholar]
- Avanzi, R.; Bos, J.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.M.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS-Kyber: Algorithm Specifications and Supporting Documentation; Version 3.01; NIST (National Institute of Standards and Technology): Gaithersburg, MD, USA, 2021.
- FIPS PUB203; Specification for the Module-Lattice-Based Key-Encapsulation Mechanism Standard. National Institute of Standards and Technology: Gaithersburg, MD, USA, 2023.
- Moody, D.; Alagic, G.; Apon, D.; Cooper, D.; Dang, Q.; Kelsey, J.; Liu, Y.; Miller, C.; Peralta, R.; Perlner, R.; et al. Status Report on the Second Round of the NIST Post-Quantum Cryptography Standardization Process; NIST Interagency/Internal Report (NISTIR) 8309; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2020.
- Nejatollahi, H.; Dutt, N.; Ray, S.; Regazzoni, F.; Banerjee, I.; Cammarota, R. Post-Quantum Lattice-Based Cryptography Implementations: A Survey. ACM Comput. Surv. 2019, 51, 129. [Google Scholar] [CrossRef]
- Bisheh-Niasar, M.; Azarderakhsh, R.; Mozaffari-Kermani, M. Instruction-Set Accelerated Implementation of CRYSTALS-Kyber. IEEE Trans. Circuits Syst. I Reg. Pap. 2021, 68, 4648–4659. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, S.; Sun, P.; Deng, D.; Sun, G. An Efficient and Low-Cost Design of Modular Reduction for CRYSTALS-Kyber. Electronics 2025, 14, 2309. [Google Scholar] [CrossRef]
- Xin, G.; Han, J.; Yin, T.; Zhou, Y.; Yang, J.; Cheng, X.; Zeng, X. VPQC: A Domain-Specific Vector Processor for Post-Quantum Cryptography Based on RISC-V Architecture. IEEE Trans. Circuits Syst. I Reg. Pap. 2020, 67, 2672–2684. [Google Scholar] [CrossRef]
- Chauhan, S.; Shrestha, R. Reconfigurable and Hardware-Efficient KECCAK Architecture with SHAKE Integration and Dynamic Input Processing for Post Quantum Cryptography. In Proceedings of the 2025 International VLSI Symposium on Technology, Systems and Applications (VLSI TSA), Hsinchu, Taiwan, 21–24 April 2025; pp. 1–4. [Google Scholar]
- Kieu-Do-Nguyen, B.; The Binh, N.; Pham-Quoc, C.; Nghi, H.P.; Tran, N.-T.; Hoang, T.-T.; Pham, C.-K. Compact and Low-Latency FPGA-Based Number Theoretic Transform Architecture for CRYSTALS-Kyber Postquantum Cryptography Scheme. Information 2024, 15, 400. [Google Scholar] [CrossRef]
- Li, A.; Lu, J.; Liu, D.; Yang, S.; Huang, T.; Zhang, J.; Xiong, S.; Yang, C.; Li, X. A 273 μW 0.34 mm2 Efficient CRYSTALS-KYBER Processor for PQC Towards Edge Computing. In Proceedings of the 2024 IEEE European Solid-State Electronics Research Conference (ESSERC), Bruges, Belgium, 9–12 September 2024; pp. 472–475. [Google Scholar]
- Li, A.; Lu, J.; Liu, D.; Li, X.; Yang, S.; Huang, T.; Zhang, J.; Xiong, S.; Yang, C. A 40 nm 2.76 μJ/Op Energy-Efficient Secure Post-Quantum Crypto-Processor for CRYSTALS-Kyber on Module-LWE. In Proceedings of the 2023 IEEE Asian Solid-State Circuits Conference (A-SSCC), Haikou, China, 5–8 November 2023; pp. 1–3. [Google Scholar] [CrossRef]
- Ni, Z.; Khalid, A.; Kundi, D.-S.; O’Neill, M.; Liu, W. HPKA: A High-Performance CRYSTALS-Kyber Accelerator Exploring Efficient Pipelining. IEEE Trans. Comput. 2023, 72, 3340–3353. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Kim, S.; Eom, Y.; Lee, H. Area-Time Efficient Hardware Architecture for CRYSTALS-Kyber. Appl. Sci. 2022, 12, 5305. [Google Scholar] [CrossRef]
- Shimada, T.; Ikeda, M. High-Speed and Energy-Efficient Crypto-Processor for Post-Quantum Cryptography CRYSTALS-Kyber. In Proceedings of the 2022 IEEE Asian Solid-State Circuits Conference (A-SSCC), Taipei, Taiwan, 6–9 November 2022; pp. 12–14. [Google Scholar]
- Sideris, A.; Dasygenis, M. Enhancing the Hardware Pipelining Optimization Technique of the SHA-3 via FPGA. Computation 2023, 11, 152. [Google Scholar] [CrossRef]
- Zhao, Y.; Xie, R.; Xin, G.; Han, J. A High-Performance Domain-Specific Processor with Matrix Extension of RISC-V for Module-LWE Applications. IEEE Trans. Circuits Syst. I Reg. Pap. 2022, 69, 2871–2884. [Google Scholar] [CrossRef]
- Bisheh-Niasar, M.; Azarderakhsh, R.; Mozaffari-Kermani, M. High-Speed NTT-Based Polynomial Multiplication Accelerator for CRYSTALS-Kyber Post-Quantum Cryptography. In Proceedings of the 2021 IEEE 28th Symposium on Computer Arithmetic (ARITH), Lyngby, Denmark, 14–16 June 2021; Paper 2021/563. [Google Scholar]
- FIPS PUB202; SHA-3 Standard: Permutation-Based Hash and Extendable-Output Functions. National Institute of Standards and Technology: Gaithersburg, MD, USA, 2015.
- Albrecht, M.R.; Deo, A. Large Modulus Ring-LWE ≥ Module-LWE. In International Conference on the Theory and Application of Cryptology and Information Security; Paper 2017/612; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar]
- Guo, W.; Li, S. Highly-Efficient Hardware Architecture for CRYSTALS-Kyber with a Novel Conflict-Free Memory Access Pattern. IEEE Trans. Circuits Syst. I Reg. Pap. 2023, 70, 4505–4515. [Google Scholar] [CrossRef]
- Zhang, N.; Yang, B.; Chen, C.; Yin, S.; Wei, S.; Liu, L. Highly Efficient Architecture of NewHope-NIST on FPGA using Low-Complexity NTT/INTT. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2, 49–72. [Google Scholar] [CrossRef]
- Duong-Ngoc, P.; Lee, H. Configurable Mixed-Radix Number Theoretic Transform Architecture for Lattice-Based Cryptography. IEEE Access 2022, 10, 12732–12741. [Google Scholar] [CrossRef]
- Nguyen, T.-H.; Nguyen, H.-D.; Chen, J.-Y.; Lin, Y.-H. An Area-Time Efficient Hardware Architecture for ML-KEM Post-Quantum Cryptography Standard. IEEE Access 2025, 13, 103834–103847. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Tech. (nm) | Freq. (MHz) | Logic Gates (kGE) b | Memory (kB) | Cycles a (kCCs) | Total Time a (s) | Throughput a (kOPS) | Area Eff. a (kOPS/kGE) | Power Eff. a (kOPS/W) |
|---|---|---|---|---|---|---|---|---|---|
| [8] | 28 | 300 | 979 | 12 | 144.5 | 482 | 2.074 | 0.002 | 78.13 |
| [17] | 28 | 540 | 697 | 24.75 | 72.2 | 134 | 7.462 | 0.011 | 900.01 |
| [6] | 65 | 200 | 95 | 80 | 21 | 105 | 9.523 | 0.091 | – |
| [17] c | 28 | 540 | 623 | 36.75 | 7.6 | 14 | 71.428 | 0.114 | – |
| [17] d | 28 | 540 | 623 | 36.75 | 6 | 11 | 90.909 | 0.146 | – |
| [15] | 65 | 336 | 1370 | – | 6.132 | 12.9 | 77.519 | 0.0566 | – |
| [24] | 180 | 93 | 160 | 7.37 | 7.7 | 82.8 | 12.077 | 0.075 | 156.25 |
| [12] | 40 | 115 | 532 | 14 | 12.245 | 106.49 | 9.391 | 0.018 | 362.32 |
| [11] | 40 | 270 | 253 | 7 | 21.143 | 78.31 | 12.270 | 0.051 | 1388.89 |
| This Work | 40 | 500 | 3183 | – | 0.57 | 1.14 | 877.192 | 0.276 | 2272.73 |
| Module | Logic Gates (kGE) | Area (%) |
|---|---|---|
| SHA-3 | 843.495 | 26.5% |
| Multi-mode Polynomial Arithmetic Unit | 1276.383 | 40.1% |
| CBD Sampler | 6.366 | 0.2% |
| Compression/Decompression | 159.15 | 5.0% |
| Others | 897.606 | 28.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chou, S.-H.; Yang, Y.-H.; Chin, W.-L.; Chen, C.; Tsao, C.-Y.; Tung, P.-L. High-Throughput Post-Quantum Cryptographic System: CRYSTALS-Kyber with Computational Scheduling and Architecture Optimization. Electronics 2025, 14, 2969. https://doi.org/10.3390/electronics14152969
Chou S-H, Yang Y-H, Chin W-L, Chen C, Tsao C-Y, Tung P-L. High-Throughput Post-Quantum Cryptographic System: CRYSTALS-Kyber with Computational Scheduling and Architecture Optimization. Electronics. 2025; 14(15):2969. https://doi.org/10.3390/electronics14152969
Chicago/Turabian StyleChou, Shih-Hsiang, Yu-Hua Yang, Wen-Long Chin, Ci Chen, Cheng-Yu Tsao, and Pin-Luen Tung. 2025. "High-Throughput Post-Quantum Cryptographic System: CRYSTALS-Kyber with Computational Scheduling and Architecture Optimization" Electronics 14, no. 15: 2969. https://doi.org/10.3390/electronics14152969
APA StyleChou, S.-H., Yang, Y.-H., Chin, W.-L., Chen, C., Tsao, C.-Y., & Tung, P.-L. (2025). High-Throughput Post-Quantum Cryptographic System: CRYSTALS-Kyber with Computational Scheduling and Architecture Optimization. Electronics, 14(15), 2969. https://doi.org/10.3390/electronics14152969