1. Introduction
In recent years, voice-based biometric authentication has become widely adopted across various domains, enabling identity verification through Automatic Speaker Verification (ASV) systems. These systems analyze speech signals to determine whether a speaker is who they claim to be, supporting applications ranging from customer service authentication to secure access control. A wide array of deep learning models have been proposed for ASV, varying in both architectural design and complexity [
1,
2,
3,
4].
However, despite their strong performance, ASV systems remain vulnerable to audio deepfakes, i.e., synthetic speech signals generated using deep learning techniques that closely mimic the voice of a target speaker while producing arbitrary content. The proliferation of user-friendly speech synthesis tools, combined with the public availability of voice samples on social media, has significantly lowered the barrier to generating realistic synthetic audio, posing serious security and privacy risks. Malicious use of speech deepfakes has already been documented in cases of election interference, financial fraud, and social engineering attacks [
5].
To address these threats, the multimedia forensics community has developed a range of countermeasures aimed at distinguishing real from synthetic audio [
6,
7]. As generative AI becomes increasingly accessible, concerns about its role in spreading misinformation across text, image, and audio domains have intensified [
8]. In response, major platforms now rely on AI-based moderation tools, underscoring the need for systems that remain robust against adversarial manipulation. Within this broader effort, fact-checking approaches have also emerged [
9,
10], reflecting a growing convergence between speech forensics and misinformation detection. Our work situates itself in this wider context, focusing on the vulnerabilities of speech-based deepfake detectors and proposing strategies to improve their resilience.
Traditional approaches for this task typically involve extracting handcrafted features (e.g., spectral or cepstral coefficients) followed by classification modules [
11], while state-of-the-art models leverage more complex architectures, such as graph neural networks [
12] and transformers [
13], organized in an end-to-end fashion [
14,
15,
16]. However, the data-driven nature of these systems renders them vulnerable to Adversarial Attacks (AAs): perturbations in input signals designed to deceive machine learning models without being perceived by a listener.
AAs against speech deepfake detection systems can be broadly categorized into two categories, white-box and black-box attacks, depending on the attacker’s knowledge of the target model. White-box attacks assume complete transparency of the target model, granting the attacker full access to its architecture, parameters, and gradients, and allowing for them to craft more effective AAs [
17]. In contrast, in black-box settings, none of this information is available, making them more reflective of real-world scenarios. For these reasons, black-box AAs are generally more challenging to implement and computationally expensive.
One of the most crucial aspects to consider when studying AAs is transferability, i.e., the ability of adversarial examples generated to deceive one model to mislead other systems [
18]. This property has been explored in the context of sound classification [
19], with ensemble-based approaches proposed to enhance cross-model attack effectiveness [
20]. Nevertheless, important open questions remain regarding the consistency and robustness of such attacks across diverse input domains and model architectures.
In this work, we conduct a systematic investigation into AAs against speech deepfake detectors, deepening our understanding in several aspects. First, we analyze whether attacks are more effective when conducted in the time or frequency domain, and assess their ability to transfer across these representations. Then, we examine the transferability of the considered attacks using four different state-of-the-art deepfake detection models with distinct architectural and representational characteristics. Finally, we propose a novel gradient aggregation strategy for an ensemble-based AA integrating the Basic Iterative Method (BIM) framework. The method is designed to achieve balanced effectiveness across all models in the ensemble, while potentially enhancing transferability. We evaluate our approach in both white-box and black-box settings, measuring attack success across multiple state-of-the-art deepfake detection models.
Our findings contribute to a deeper understanding of adversarial vulnerabilities in speech deepfake detection systems and offer valuable guidance for building more robust detectors. While ensemble-based adversarial attacks—where gradients from multiple models are fused—have been studied extensively in the broader adversarial machine learning literature [
21,
22,
23], their application to speech deepfake detection remains underexplored. In particular, BIM-based ensemble strategies have received little attention, despite their suitability for evaluating white-box threat scenarios in this domain. Moreover, existing methods typically aggregate gradients uniformly, ignoring the varying robustness of individual models within the ensemble. Our proposed approach addresses this gap by dynamically weighting each model’s gradient contribution based on its resistance to perturbation, enabling more balanced attack performance and enhancing the transferability of adversarial examples across diverse model architectures and input representations.
The key contributions of our work are the following:
Cross-Domain Transferability: We analyze the relative effectiveness of adversarial perturbations generated in the time and frequency domains and examine their transferability across representations.
Comprehensive Evaluation: We conduct a large-scale empirical study assessing the performance of AAs in both white-box and black-box settings across four diverse deepfake detection models.
Ensemble Gradient Aggregation: We introduce a novel ensemble-based attack method that combines gradients from multiple models to generate adversarial examples that are effective against multiple detectors.
The rest of the paper is structured as follows:
Section 2 reviews related work in speech deepfake detection and AAs against deep learning models.
Section 3 formally defines the problem we aim to address and details the method we propose.
Section 4 presents the experimental setup used in our experiments.
Section 5 presents the results we achieved and discusses the implications of our findings. Finally,
Section 6 concludes the paper and suggests directions for future works.
2. State of the Art
In this section, we provide an overview of the current landscape of speech deepfake detection, summarizing the strategies employed by state-of-the-art systems. Then, we discuss how these systems can be compromised by AAs, revealing their vulnerabilities.
2.1. Speech Deepfake Detection
The rapid advancement of synthetic speech generation has led to growing interest in developing reliable detection methods for speech deepfakes. In the last few years, the research community has proposed a variety of techniques based on diverse detection paradigms [
6,
24,
25]. These methods can be broadly classified into two categories based on the features they utilize for detection. The first category analyzes low-level features, identifying artifacts introduced by speech generators at the signal level. The second category focuses on higher-level features, capturing more complex characteristics, such as semantic information.
An example of an artifacts-based approach is presented in [
26], where channel pattern noise analysis is used to secure ASV systems against physical attacks. The authors of [
27] exploit bicoherence features based on the assumption that a genuine recording has more significant non-linearity than a fake one. End-to-end approaches have also emerged, such as [
28], which leverages deep neural networks to learn discriminative speech representations, and [
29], which employs Mel-Frequency Cepstral Coefficient (MFCC) features coupled with a Support Vector Machine (SVM) classifier. Finally, new approaches aim to improve the practicality of existing detectors in real-world scenarios [
30,
31,
32,
33] and study the biases they may have [
34,
35].
Semantic-feature-based methods, on the other hand, operate under the assumption that current speech synthesis models, while proficient at replicating acoustic features, struggle to emulate complex high-level semantics. Based on this idea, they analyze such semantic aspects to discriminate between real and fake signals. For instance, the authors of [
36] utilized classical features from the Music Information Retrieval (MIR) domain to perform the task, while [
37] analyzed affective cues to discriminate between real and generated voices.
Recent trends in the speech deepfake detection field also include the exploration of Explainable AI (XAI) methodologies [
38,
39,
40,
41,
42,
43], the study of singing-voice deepfakes [
44,
45], and the integration of pre-trained self-supervised models. These models, originally designed for Automatic Speech Recognition, are repurposed as feature extractors to create embeddings from input speech, which are subsequently used by synthetic speech detectors [
46,
47].
2.2. Adversarial Attacks
An AA is a technique that aims to mislead neural network classifiers by introducing small, often imperceptible, perturbations into input data [
48,
49]. These attacks can target any type of classifier, ranging from those used in computer vision, natural language processing, and video classification to the ones adopted in audio and speech processing, such as the speech deepfake detectors we consider in this work.
The most effective attacks are those performed under white-box conditions, where the attacker has complete knowledge of the model under attack, including its architecture, parameters, loss function, and gradients [
50]. This transparency allows for the design of highly effective adversarial perturbations. Among white-box attacks, we can distinguish two categories: gradient-based and optimization-based methods. The most common gradient-based attacks include Fast Gradient Sign Method (FGSM) and BIM [
51,
52], while among optimization-based attacks, we acknowledge the Carlini & Wagner (C&W) attack and AdvPulse, which can also operate in real-time [
53,
54].
Despite the effectiveness of these attacks, white-box assumptions rarely hold in practice, especially for proprietary or security-critical systems. In more realistic black-box settings, attackers lack access to internal model details and can only observe outputs or class predictions. In this case, query-based attacks can be employed, which attempt to infer model behavior through repeated interactions, leveraging strategies such as gradient estimation or evolutionary algorithms [
55]. These methods, while effective, are often limited by high computational costs and query rate restrictions. To circumvent these challenges, attackers frequently exploit transferability: the ability of adversarial examples generated for one model to remain effective against others, regardless of architectural or parameter differences [
18,
56].
A crucial technique for enhancing adversarial transferability is the use of an ensemble attack, which generates perturbations by simultaneously targeting multiple surrogate models, which typically differ in architecture, training data, or input pre-processing. The final goal is to produce an adversarial sample capable of deceiving all the models together, following the underlying idea that if an attacked signal can deceive several diverse models, it is more likely to transfer successfully to an unseen target system.
In practice, ensemble attacks aggregate gradient or output information across the ensemble to optimize a unified adversarial objective, as we illustrate later in this Section. A common strategy is to average gradients or losses across models to guide perturbation updates. However, simple averaging can dilute important model-specific features that contribute to transferability [
21]. Advanced ensemble methods, therefore, employ adaptive weighting or optimization techniques to preserve diverse gradients and amplify the components most likely to generalize [
57].
In the context of audio-based attacks, it is also important to consider where and how perturbations are applied. Adversarial modifications can be introduced either in the frequency domain or directly in the time domain, depending on the input representation used by the target models. Many speech deepfake detectors operate on spectrogram-based features such as log-spectrograms, Mel spectrograms, or MFCCs [
58,
59,
60]. Consequently, several white-box attacks manipulate these representations using techniques adapted from image processing. However, converting a perturbed spectrogram back into a valid waveform often introduces artifacts and degrades perceptual quality. To mitigate these issues, alternative strategies target the time domain, directly modifying raw audio waveforms. Time-domain attacks like FGSM and BIM can maintain a high signal-to-noise ratio (SNR), preserving the perceptual fidelity of adversarial examples. Nonetheless, these perturbations may still be visible in spectrograms and tend to localize in low-salience regions, potentially making them detectable [
61]. Recent findings in music classification suggest that frequency–domain perturbations can transfer effectively to the time domain and maintain cross-model generalizability [
62]. Inspired by this, our work seeks to determine whether similar transferability holds for adversarial examples targeting speech deepfake detection systems.
3. Problem Formulation and Proposed Method
In this paper, we investigate Basic Iterative Method (BIM)-based Adversarial Attacks (AAs) in the context of speech deepfake detection, with a particular focus on the challenges associated with crafting effective and transferable adversarial examples. Given a speech signal and a deepfake detection model that correctly classifies it as real or fake, our objective is to modify the input signal by generating an adversarial example that alters the output of the detector.
We assess the performance of AAs across a variety of detection models and under different conditions, including both inter-domain (e.g., time vs. frequency representations) and inter-model transferability. Furthermore, we introduce a novel ensemble-based attack strategy that integrates the BIM algorithm, with an explicit emphasis on achieving balanced effectiveness across all models in the ensemble. By preventing the perturbation from overfitting to a single model, this approach also enhances the likelihood of successful black-box transfer.
Although more advanced attacks, such as Projected Gradient Descent (PGD) [
63] and Carlini & Wagner (C&W) [
53], can produce more powerful or imperceptible perturbations, in this paper, we focus on BIM-based attacks due to their simplicity, efficiency, and strong compatibility with our ensemble-based gradient manipulation strategy. The iterative nature of BIM attacks is particularly well-suited to our goal of balancing adversarial impact within ensembles, without introducing the additional complexity of optimization-based or confidence-targeting objectives.
The following sections formally define the task at hand and introduce our proposed methodology.
3.1. Problem Formulation
The speech deepfake detection task is formally defined as follows: Let
be a discrete-time input speech signal, sampled with a sampling frequency
. We associate
with a label
, which indicates whether the signal is real (
) or has been synthetically generated (
). The goal of speech deepfake detection is to develop a detection model
that takes
as input and outputs an estimate of its class:
where
is a continuous value in the range
representing the likelihood that the signal
is fake.
In this context, an AA consists of modifying the input signal by introducing a small perturbation
, resulting in an adversarial sample
that can induce misclassification in the detector
while remaining imperceptible to human listeners. The attack is successful if the model’s output is different from the actual label
y, such as
where
is typically bounded by a norm constraint
to ensure perceptual similarity between
and
.
An ensemble attack extends the adversarial objective by simultaneously targeting multiple deepfake detection models
, which can differ in architecture, training setup, or in another way. The goal is to construct a single adversarial example
that successfully deceives all models in the ensemble:
As in the single-model attack, the perturbation must remain imperceptible while simultaneously causing misclassification across all, or a majority of, the ensemble models.
Ensemble-based AAs are commonly utilized to improve transferability, allowing for adversarial examples to remain effective even against black-box models that are not explicitly included in the ensemble. In this work, we propose the design of ensemble attacks that are not only optimized for high efficacy against a predefined set of target detectors, but that also exhibit enhanced transferability. This dual focus serves as a foundation for future investigations into broader black-box generalization and transferability across diverse detection models.
3.2. Proposed Method
Our proposed method comprises two primary stages, each designed to explore the distinct aspects of AAs targeting speech deepfake detection systems.
In the first stage, we investigate the most effective domain in which to apply adversarial perturbations: either the time or frequency domain. To this end, we generate adversarial speech samples using distinct strategies, aiming to attack a set of victim models in a white-box setting, where full knowledge of the model parameters and architecture is assumed. Across all experiments, we adopt BIM as the underlying AA algorithm. After generating the adversarial samples, we perform a systematic evaluation of their effectiveness and transferability, considering different domains and model architectures, in both white- and black-box settings.
Adversarial examples are generated by backpropagating the loss gradient with respect to a specific model output. The point within the network at which the gradient is computed determines the domain of the perturbation. In frequency–domain attacks, the gradient is computed with respect to intermediate acoustic features, i.e., spectrograms, resulting in 2D perturbations that are applied to the spectrogram of the input track. In time–domain attacks, the gradient is propagated back to the raw audio waveform, yielding 1D perturbations that can be directly added to the original audio signal.
Figure 1 shows the gradient backpropagation strategies employed in both domains. Comprehensive descriptions of the domain-specific methodologies and BIM attack strategies are provided in the following sections.
3.2.1. Frequency–Domain Attacks
In frequency–domain attacks, adversarial perturbations are introduced in the spectrogram space. Specifically, the loss gradient is computed with respect to the input spectrogram, and the resulting perturbations are added to form an adversarial spectrogram. To convert this perturbed spectrogram back into an audio waveform, we perform spectrogram inversion using the original phase information, following the approach described in [
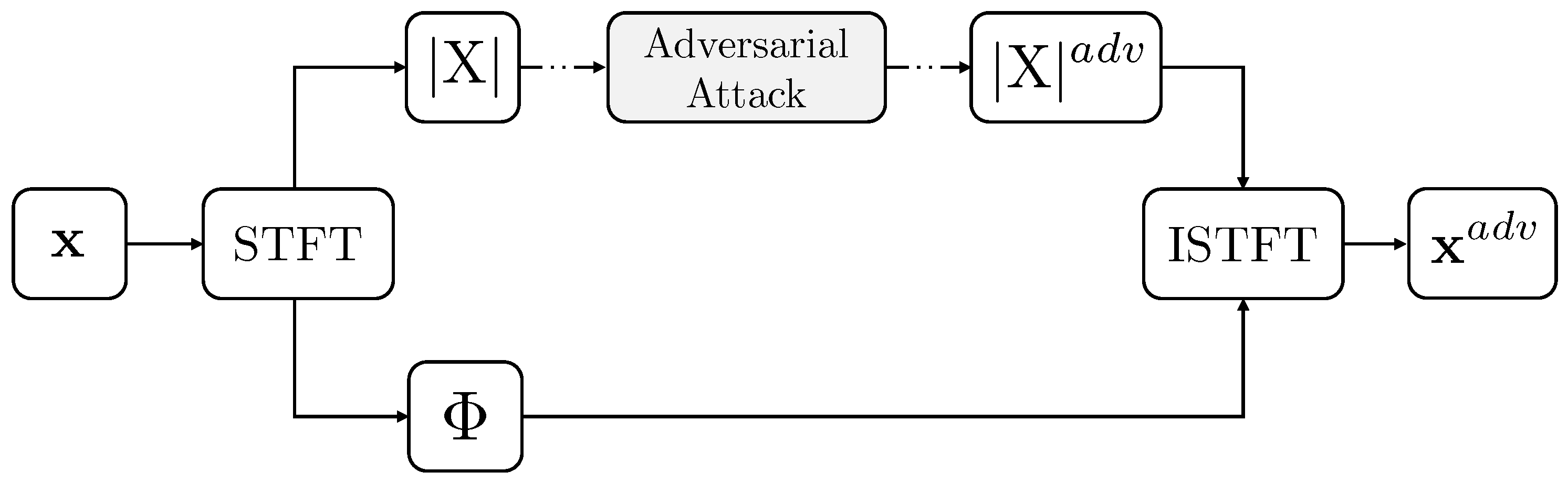
62]. This reconstruction process ensures (1) perceptual consistency with the original signal, including preservation of temporal structure, symmetry, and phase, and (2) retention of adversarial effectiveness through inverse transformations, ensuring that the perturbations remain impactful even after re-encoding into the waveform domain.
Figure 2 shows the full frequency–domain attack pipeline, including spectrogram manipulation and audio reconstruction. To maintain audio quality, we ensure consistency between the Short-Time Fourier Transform (STFT) and Inverse Short-Time Fourier Transform (ISTFT) and apply normalization parameters derived from the original audio to stabilize the dynamic range. The final output is an adversarial audio signal that remains acoustically similar to the clean sample, but is capable of deceiving the target detector.
3.2.2. Time–Domain Attacks
In contrast to the frequency–domain approach, time–domain attacks operate directly on the raw audio waveform. To do so, the adversarial gradient is propagated all the way back to the input waveform. This results in a 1D perturbation that matches the dimensionality of the original signal and can be directly added without requiring further transformation. A key advantage of time–domain attacks is the elimination of the reconstruction step required in frequency–domain approaches, simplifying the pipeline and reducing potential sources of distortion. Despite this simplicity, time–domain perturbations can be highly effective, depending on the structure and sensitivity of the target model.
3.2.3. Basic Iterative Method (BIM)
BIM [
51] is a widely used technique for generating adversarial examples. It was introduced as an enhancement of the Fast Gradient Sign Method (FGSM) [
52], aiming to improve attack effectiveness by applying multiple iterative perturbations instead of a single gradient step. We chose to adopt BIM in our experiments because it offers a good trade-off between computational efficiency and attack strength, making it well-suited for scenarios where fast, white-box attacks are needed without the overhead of full optimization-based methods.
In the context of adversarial machine learning, the goal is to craft an input
that is perceptually similar to the input
, yet induces incorrect predictions from a target detector
, as formally introduced in
Section 3.1.
Given a model
, its associated loss function
and the gradient
, the adversarial perturbation
(cf. Equation (
2)) can be computed as
where
controls the maximum allowable perturbation and
y is the true label. This single-step approach corresponds to the FGSM attack. However, this strategy may not fully exploit the vulnerability of the target model, especially in complex or high-dimensional input spaces.
To address this limitation, BIM applies the same gradient-based perturbation iteratively using a reduced step size
, allowing for finer-grained optimization of the adversarial example. The BIM update rule is defined as
where
ensures that the perturbed sample remains within the
-bounded neighborhood of the original input and respects the input domain constraints.
In our implementation, we perform M iterations and set the step size . This configuration guarantees that the total perturbation does not exceed the threshold, which allows us to omit the clipping operation in practice while ensuring compliance with the attack constraints. BIM has been demonstrated to produce more effective and transferable adversarial examples than FGSM, particularly in applications involving deep neural networks. For these reasons, it serves as the foundational attack strategy throughout our experiments on adversarial speech deepfake detection.
The second stage of our investigation focuses on the development of an ensemble-based AA strategy. This approach aims to craft adversarial audio examples that are optimized to deceive a set of target models under a white-box threat model. The goal of this attack is to improve not only the effectiveness against the ensemble systems themselves, but also to enhance transferability to unseen, black-box models. To this end, our method explicitly emphasizes balanced effectiveness across the ensemble, ensuring that no single model dominates the perturbation direction. The underlying intuition is that, by avoiding overfitting to any individual model, the resulting adversarial examples are more likely to generalize across architectures and domains. As a result, these examples may generalize better and be capable of deceiving multiple classifiers, even those not explicitly included during the attack generation process.
Similar to the single-model case, the ensemble attack is built upon the BIM framework. However, we introduce a novel dynamic gradient aggregation mechanism that adaptively integrates gradient signals from the ensemble members at each iteration. This mechanism follows the general gradient-based ensemble approach illustrated in
Figure 3. However, differently from conventional ensemble strategies that average gradients uniformly across models, our method assigns adaptive weights to each model’s gradient contribution during each iteration of the attack optimization.
This adaptive weighting scheme enables the attack to prioritize gradient contributions from models that are currently more resistant to perturbation, thereby focusing optimization on the most challenging components of the ensemble. By dynamically balancing these contributions, the method promotes faster convergence and stronger attack efficacy, particularly when dealing with heterogeneous architectures or divergent gradient landscapes. Unlike uniform fusion approaches that may dilute critical adversarial directions, our method explicitly modulates the influence of each model to generate perturbations that remain consistently effective across the ensemble. This makes it especially suitable for threat scenarios in which an adversary has full white-box access to a diverse set of models with distinct decision boundaries.
4. Experimental Setup
In this section, we provide the reader with some insights regarding the experimental setup used across our experiments. We begin by defining the metrics used to evaluate both the effectiveness of the attacks and the perceptual quality of the resulting adversarial examples. Then, we describe the datasets and training protocols used for the target detection models. Finally, we detail the Adversarial Attack (AA) strategies, beginning with Basic Iterative Method (BIM)-based attacks on individual models and extending to the proposed ensemble-based approach.
4.1. Evaluation Metrics
To assess the impact of the AAs, we evaluate both their classification effectiveness and their perceptual imperceptibility.
The goal of an AA is to induce misclassification in the target detector. To quantify this, we compute multiple metrics: the Receiver Operating Characteristic (ROC) curve and the associated Area Under the Curve (AUC), the Equal Error Rate (EER), and the Balanced Accuracy (BA).
Ideally, a successful attack should decrease the AUC and BA values from near 100% to 0% and increase the EER from 0% to 100%, indicating that all adversarial samples cause misclassification. To compute the balanced accuracy BA score, we first determine the optimal decision threshold from the ROC curve generated using clean (non-adversarial) validation data. This threshold is then applied to both clean and adversarial examples to ensure the fair and consistent evaluation of classifier performance. This choice reflects the assumption that the behavior of the detector on clean speech is known, and that its optimal operating point can be established.
Finally, we also evaluate how much the adversarial perturbation can be perceived in terms of noise after it is applied. To do so, we compute the SNR between each original audio signal and its adversarial counterpart. A higher SNR indicates less perceptible perturbation, which is desirable for attacks that aim to remain undetected by human listeners.
4.2. Speech Deepfake Detectors
In our experiments, we evaluate AAs against four state-of-the-art speech deepfake detectors: ResNet [
58], SENet [
64], LCNN [
65], and RawNet2 [
28].
The first three models operate on log-magnitude spectrograms as their input features. These leverage Convolutional Neural Network (CNN)-based architectures designed to capture time–frequency patterns indicative of synthetic speech. RawNet2, in contrast, operates on raw audio waveforms and employs SincConv layers for learnable band-pass filtering, allowing for it to extract relevant acoustic features directly from the time–domain signal. We refer the reader to the respective papers for more details regarding each model.
4.3. Considered Dataset
For training, evaluation, and testing of our speech deepfake detection models, we use the ASVspoof 2019 dataset [
66], a widely recognized benchmark for synthetic speech detection. The dataset is built upon the VCTK corpus [
67] and contains both real and synthetic audio samples from a total of 78 speakers (33 male and 45 female). It was originally released as part of a challenge on ASV, with a focus on assessing countermeasures against spoofing attacks.
Our experiments are conducted using the Logical Access (LA) partition of the dataset, which contains deepfake audio generated using both Text-to-Speech (TTS) and Voice Conversion (VC) techniques. The LA partition is split into three subsets: training, validation, and evaluation. The training set includes 2580 real and 22,800 synthetic utterances, generated using four TTS and two VC algorithms. The validation set comprises 2548 real and 22,296 fake audio samples, created with the same algorithms as the training set, but featuring different speakers. The evaluation set contains 7355 real and 63,882 synthetic utterances, produced using a broader set of seven TTS and six VC algorithms.
This open-set configuration enables robust evaluation of generalization capabilities, allowing us to assess model performance on unseen synthesis techniques. Notably, the dataset exhibits a substantial class imbalance, with synthetic audio samples significantly outnumbering genuine ones. This imbalance must be carefully considered during model training to prevent biased learning behavior. All AAs are conducted on the evaluation partition of the ASVspoof 2019 dataset.
4.4. Training Strategy
All models are trained using a unified strategy to ensure fair comparison. Specifically, we train each model for a maximum of 100 epochs, monitoring performance on the validation set using the Negative Log-Likelihood (NLL) loss function. Optimization is performed using the Adam optimizer with an initial learning rate of 10−4, which is adaptively reduced upon performance plateaus. We employ early stopping with a patience of 10 epochs to prevent overfitting, and use a batch size of 64. Input features are linearly normalized to the range between 0 and 1 to ensure consistency and stability across different models and training conditions.
For models operating on log-magnitude spectrograms, we compute the time–frequency representation using the STFT with an FFT size of 2048, a hop length of 512 samples, and a window size of 2048 samples. To enable precise spectrogram inversion during both training and AA phases, all input audio signals are standardized to a fixed length of 47,104 samples. This length corresponds to the closest possible approximation to 3 at a sampling rate of , which ensures full coverage by the STFT windowing process without discarding any samples. Specifically, this represents the maximum input length that can be entirely covered by the STFT windowing scheme without discarding samples or requiring zero padding. This alignment guarantees that the entire signal is fully processed during the time–frequency transformation and can be accurately reconstructed back into the time domain after applying adversarial perturbations. Longer audio samples are truncated, while shorter samples are repeated to match the required length. Additionally, phase information is preserved throughout the process to ensure faithful audio reconstruction in later stages, particularly for frequency–domain AAs.
All experiments were conducted on an Ubuntu-based system with an Intel i9-9980XE CPU, 126 GB RAM (Intel Corporation, Santa Clara, CA, USA), and an NVIDIA Titan RTX GPU (Nvidia Corporation, Santa Clara, CA, USA).
4.5. Adversarial Attacks
As anticipated in the previous sections, in the following experiments, we consider two categories of AAs: single-model attacks and ensemble-based attacks.
4.5.1. Single-Model Attacks
For attacks targeting individual models, we employ the BIM in both the time and frequency domains, using ResNet and SENet as white-box models. The implementation details follow the procedure outlined in
Section 3.2. Each of the two models is attacked independently in both domains, resulting in two distinct adversarial clones of the ASVspoof 2019 evaluation set: one perturbed in the time domain, the other in the frequency domain.
We evaluate the effectiveness of these attacks in two scenarios. White-box evaluation: adversarial examples are tested on the same model used during attack generation (ResNet or SENet). Black-box evaluation: adversarial examples are tested on unseen models (LCNN and RawNet2) to assess transferability.
When performing these attacks, BIM is applied over
iterations. Given a maximum perturbation constraint
, the step size at each iteration is set to
. At every step, the gradient of the NLL loss with respect to the input (either spectrogram or waveform) is computed and used to update the input in the direction of the sign of the gradient, as defined in Equation (
5).
4.5.2. Ensemble-Based Attacks
To simultaneously target multiple models, we propose a novel ensemble AA method, called Weighted Random Gradient Ensemble (WRGE). For clarity, we describe the procedure for an ensemble comprising two classifiers, denoted and , although the approach can be readily extended to larger ensembles.
We operate on mini-batches and apply adversarial perturbations over BIM iterations. The increased number of iterations (relative to single-model attacks) is necessary to effectively converge toward perturbations that are simultaneously effective across models with potentially divergent gradients.
At each iteration,
The current batch is passed through both and .
Independent gradients of the NLL loss with respect to the input waveform are computed for each model.
These gradients are fused using a loss-adaptive, randomized element-wise sampling strategy: the loss values determine the scalar weights that control how many gradient elements to draw from each model, and a randomized permutation selects which specific elements are used. This encourages contributions from the more robust model while maintaining diversity across iterations.
The heuristic operates as follows. Let and denote the gradients of the NLL loss with respect to the input waveform for classifiers and , respectively. These gradients are computed independently and flattened into one-dimensional vectors. The scalar NLL losses and for each model are used to derive inverse-proportional weights, assigning greater weight to the gradient of the model that is currently less fooled (i.e., has higher loss).
In the case of two models, we define the weight
as
where
p is the sharpness parameter (e.g.,
) that accentuates the relative difference in loss values. A higher loss from model
leads to a greater weight on gradient
, thereby prioritizing the contribution from the model that is currently harder to fool. This weight
determines how many components of the final ensemble gradient are selected from
, with the remaining components taken from
.
A random permutation of indices is generated, and the first entries are assigned to , while the remaining entries are taken from , where N is the total number of gradient elements. The selected values are merged into a single ensemble gradient, which is reshaped to the original input dimension and used in a BIM-style update step.
This approach biases the perturbation toward the gradient of the model that is currently harder to fool, while still integrating gradient information from both models. The random selection of gradient components adds variability, helping the attack to escape local minima that may be unique to each individual model’s loss surface.
This weighting strategy extends naturally to ensembles with three or more models:
. To give more influence to the most resilient models, we adopt an inverse-loss weighting scheme, defined as
with
used to sharpen the contrast between model contributions. This formulation not only accentuates the role of the most difficult-to-fool models, but also progressively downweights the influence of weaker models as the ensemble size increases. The result is a more focused perturbation strategy that targets the most robust decision boundaries within the ensemble.
We compare the performance of the proposed WRGE method with that of a simpler baseline, referred to as Random Gradient Ensemble (RGE), derived from the original optimization-based RGE algorithm in [
57]. The main difference between the baseline and WRGE is that, while both attacks begin by computing individual model gradients from the considered models, they differ in how these gradients are fused:
WRGE, during the attack iterations, takes into consideration the effect that the perturbation getting added have on each model participating in the ensemble. If a model is less affected by the attack, its gradient contribution on the ensemble-gradient is increased.
In RGE, the gradients from the models are combined randomly on a per-element basis using a simple binary mask. Each element of the adversarial gradient had an equal chance of getting sampled from any of the computed gradients.
Both the attacks are implemented in the time domain. For consistency, both methods use BIM iterations.
5. Results
In this section, we present and discuss the results of our experimental campaign. We assess each Adversarial Attack (AA) under both white-box and black-box settings, i.e., we measure its effectiveness against models it was specifically crafted for, as well as its transferability to unseen models. Additionally, we evaluate the perceptibility of the perturbations introduced by each attack. Finally, we present a novel ensemble AA technique and examine its effectiveness.
5.1. Adversarial Attacks Across Different Domains
In our first experiment, we aimed to investigate the effectiveness of AAs generated in different domains, specifically, we compare attacks conducted in the time domain (1D) and frequency domain (2D). The goal was to determine which representation yields more effective adversarial examples.
Table 1 and
Table 2 and
Figure 4 show the results of this analysis in terms of EER, BA, and ROC curves. For the ResNet model, adversarial examples generated in both domains exhibit comparable effectiveness: EER exceeds 99%, while BA falls below 5%. Although the 1D attack attack performs marginally better, the difference is negligible. In the case of SENet, both 1D and 2D attacks remain effective, although the 2D variant demonstrates slightly reduced performance. Nevertheless, both achieve strong results, with EER values above 70% and BA below 30%.
Regarding attack transferability, 1D attacks again show superior performance, producing an increase of 10–20% in EER and a 5–40% drop in BA on unseen (black-box) models. An exception is observed with the RawNet2 model, which appears highly robust to transferred attacks; its performance metrics show minimal variation, indicating limited vulnerability to adversarial perturbations generated for other models.
5.2. Perceptibility of Adversarial Perturbations
In addition to effectiveness, it is critical to evaluate the perceptibility of adversarial perturbations. For an attack to be practically viable, it must remain imperceptible to human listeners, thereby deceiving both automated detectors and human evaluators.
We assess perceptibility by comparing clean and perturbed audio samples using signal-to-noise ratio (SNR) as a metric.
Table 3 presents the results of this analysis. Across both ResNet and SENet models, the 1D attack produced significantly higher SNR values, approximately three times higher than the 2D attack, indicating that it is less perceptible.
To gain further insight into the behavior of the adversarial perturbations, we also visualize the modifications introduced by the 1D and 2D attacks on the same audio sample.
Figure 5 presents this comparison. Spectrogram analysis reveals that time–domain (1D) perturbations tend to concentrate in the silent or low-energy regions of the signal. In contrast, frequency–domain (2D) perturbations appear more uniformly distributed across the entire spectrogram. This observation also aligns with findings reported in the previous literature [
57].
In summary, 1D (time–domain) AAs outperform their 2D counterparts in both white-box and black-box settings, while also producing significantly less perceptible perturbations. This makes them a more effective and stealthy strategy overall.
5.3. Ensemble Adversarial Attacks
Our single-model experiments demonstrate that 1D time–domain AAs are generally more effective and less perceptible than their 2D, frequency–domain counterparts. However, their transferability remains inconsistent, especially to models based on raw-signal analysis like RawNet2. To address this limitation, we investigate ensemble-based attack strategies that optimize perturbations across multiple models simultaneously, with the goal of enhancing generalization over all of them and increasing black-box success.
In this context, we evaluate our proposed Weighted Random Gradient Ensemble (WRGE) method, which is specifically designed to balance attack effectiveness across diverse models. We compare WRGE against a baseline ensemble attack, Random Gradient Ensemble (RGE).
Table 4 and
Table 5 present the EER and BA values for clean and adversarial inputs generated using both methods. Unlike RGE, which often overfits to the most vulnerable model in the ensemble, WRGE promotes more uniform degradation across all white-box models. For instance, in the ResNet + RawNet2 ensemble, RGE causes a significant drop in BA for ResNet but only a marginal effect on RawNet2, indicating a bias toward ResNet. In contrast, WRGE induces similar levels of degradation in both models, reflecting a more balanced adversarial impact. This trend holds across other model combinations, where WRGE consistently produces EER and BA values that are more symmetric between the participating models.
A key enabler of this cross-model generalization is our extension of gradient backpropagation to the raw waveform domain. This approach allows for adversarial perturbations to be computed directly on audio signals, making it possible to attack both models that operate on acoustic features (e.g., spectrogram-based models like ResNet, SENet, and LCNN) and those that process raw audio (e.g., RawNet2) within a unified framework.
To further assess the capabilities of the proposed WRGE method, we considered a three-model ensemble comprising ResNet, SENet, and RawNet2.
Table 6 shows the results of this analysis, with high attack effectiveness across all models, although RawNet2 remains the most robust, exhibiting a lower EER and higher BA than the other two. This robustness likely stems from architectural similarities between ResNet and SENet, which dominate the gradient optimization and hinder the attack’s ability to align with RawNet2’s distinct decision boundaries.
This behavior can be seen in
Figure 6, which shows attack effectiveness measured as the misclassification rate, which corresponds to the proportion of adversarial examples for which the model’s predicted label differs from the ground truth (i.e., 1—accuracy), across BIM iterations. In particular,
Figure 6b indicates that ResNet and SENet respond similarly to the attack, diverging from RawNet2’s response. This not only reflects architectural similarity, but also suggests overlapping input sensitivities. The contrast is even clearer when comparing to the individual attack setting in
Figure 6a, where ResNet and SENet are attacked separately. These observations highlight the importance of architectural diversity within ensembles, not only for maximizing transferability, but also for ensuring that attacks do not disproportionately target specific models. Future work may explore incorporating even greater model heterogeneity to further balance adversarial effectiveness.
Finally,
Table 7 confirms that all ensemble attacks remain imperceptible, with SNR values well above perceptual thresholds. Interestingly, the highest SNR is observed in the ResNet + SENet attack, likely due to their similar architectures producing less conflicting gradients and more compact perturbations.
In conclusion, the WRGE strategy highlights that balancing adversarial impact across models, rather than merely maximizing it, can be critical for understanding vulnerabilities in ensemble-based detection systems. These findings underscore the need to develop deepfake detectors that are robust not only to individual attacks, but also to coordinated, transferable adversarial strategies that exploit weaknesses across multiple models.
6. Conclusions
In this paper, we investigate the effectiveness of Basic Iterative Method (BIM) Adversarial Attacks (AAs) against deepfake speech detectors, focusing on the generation and transferability of perturbations in both time and frequency domains. Our cross-domain analysis showed that while spectrogram-based perturbations can successfully transfer to the waveform domain, directly attacking the raw waveform yields adversarial examples that are not only more effective, but also substantially less perceptible. Despite this, transferability across detection models, particularly those based on different architectures, remains a significant challenge for attacks tailored to fool individual systems.
To mitigate this limitation, we proposed a novel ensemble-based BIM attack strategy called Weighted Random Gradient Ensemble (WRGE). This aggregates gradients from multiple models to produce perturbations with balanced effectiveness across all white-box detectors. Our experiments, conducted on four architecturally diverse models in both white-box and black-box settings, demonstrate that WRGE improves generalization and increases attack success rates on unseen models.
Our findings highlight the susceptibility of current deepfake detectors to well-crafted adversarial attacks and underscore the need for more robust, architecture-independent defense mechanisms.
Future works will expand in several directions to further advance both Adversarial Attack strategies and the robustness of deepfake detection systems. On the attack side, improving ensemble construction by strategically selecting models with maximally diverse architectures and input modalities could improve the generalizability and transferability of the perturbations. Additionally, incorporating more advanced attack techniques, such as Carlini & Wagner or PGD, would provide a stronger basis for evaluating detector resilience. Finally, assessing the robustness of adversarial examples under real-world conditions, including post-processing operations like lossy compression and additive noise, remains a critical step toward understanding the practical impact of these attacks. From a defense perspective, developing detection methods that are less sensitive to domain-specific perturbations is a key objective. Also, leveraging cross-domain features, such as combining time- and frequency-based representations, may improve resilience against attacks crafted in either domain. Finally, input preprocessing strategies that aim to suppress or remove adversarial noise from the audio signal represent a promising line of defense.
Author Contributions
Conceptualization, W.E.W. and D.S.; methodology, D.S.; software, W.E.W.; validation, W.E.W., D.S. and V.N.; formal analysis, W.E.W.; investigation, W.E.W. and V.N.; resources, D.U.L.; data curation, W.E.W.; writing—original draft preparation, W.E.W. and D.S.; writing—review and editing, V.N., D.U.L., P.B. and S.T.; supervision, P.B. and S.T.; project administration, P.B.; funding acquisition, S.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the FOSTERER project, funded by the Italian Ministry of Education, University, and Research within the PRIN 2022 program. This work was partially supported by the European Union—Next Generation EU under the Italian National Recovery and Resilience Plan (NRRP), Mission 4, Component 2, Investment 1.3, CUP D43C22003080001, partnership on “Telecommunications of the Future” (PE00000001—program “RESTART”) and “SEcurity and RIghts in the CyberSpace” (PE00000014—program “FF4ALL-SERICS”).
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Reynolds, D.A.; Quatieri, T.F.; Dunn, R.B. Speaker verification using adapted Gaussian mixture models. Digit. Signal Process. 2000, 10, 19–41. [Google Scholar] [CrossRef]
- Jung, J.W.; Kim, Y.J.; Heo, H.S.; Lee, B.J.; Kwon, Y.; Chung, J.S. Pushing the limits of raw waveform speaker recognition. arXiv 2022, arXiv:2203.08488. [Google Scholar] [CrossRef]
- Desplanques, B.; Thienpondt, J.; Demuynck, K. Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification. arXiv 2020, arXiv:2005.07143. [Google Scholar] [CrossRef]
- Chen, Y.; Zheng, S.; Wang, H.; Cheng, L.; Chen, Q.; Zhang, S.; Li, J. Eres2netv2: Boosting short-duration speaker verification performance with computational efficiency. arXiv 2024, arXiv:2406.02167. [Google Scholar]
- Schäfer, K.; Choi, J.E.; Zmudzinski, S. Explore the world of audio deepfakes: A guide to detection techniques for non-experts. In Proceedings of the 3rd ACM International Workshop on Multimedia AI against Disinformation, Phuket, Thailand, 10–14 June 2024; pp. 13–22. [Google Scholar]
- Cuccovillo, L.; Papastergiopoulos, C.; Vafeiadis, A.; Yaroshchuk, A.; Aichroth, P.; Votis, K.; Tzovaras, D. Open Challenges in Synthetic Speech Detection. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Shanghai, China, 12–16 December 2022. [Google Scholar]
- Amerini, I.; Barni, M.; Battiato, S.; Bestagini, P.; Boato, G.; Bruni, V.; Caldelli, R.; De Natale, F.; De Nicola, R.; Guarnera, L.; et al. Deepfake media forensics: Status and future challenges. J. Imaging 2025, 11, 73. [Google Scholar] [CrossRef] [PubMed]
- Saeidnia, H.R.; Hosseini, E.; Lund, B.; Tehrani, M.A.; Zaker, S.; Molaei, S. Artificial intelligence in the battle against disinformation and misinformation: A systematic review of challenges and approaches. Knowl. Inf. Syst. 2025, 67, 3139–3158. [Google Scholar] [CrossRef]
- Ma, J.; Hu, L.; Li, R.; Fu, W. Local: Logical and causal fact-checking with llm-based multi-agents. In Proceedings of the ACM on Web Conference 2025, Sydney, Australia, 28 April–2 May 2025; pp. 1614–1625. [Google Scholar]
- Hang, C.N.; Yu, P.D.; Tan, C.W. TrumorGPT: Graph-Based Retrieval-Augmented Large Language Model for Fact-Checking. IEEE Trans. Artif. Intell. 2025, 1–15. [Google Scholar] [CrossRef]
- Mari, D.; Salvi, D.; Bestagini, P.; Milani, S. All-for-One and One-For-All: Deep learning-based feature fusion for Synthetic Speech Detection. arXiv 2023, arXiv:2307.15555. [Google Scholar] [CrossRef]
- Jung, J.W.; Heo, H.S.; Tak, H.; Shim, H.j.; Chung, J.S.; Lee, B.J.; Yu, H.J.; Evans, N. Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 6367–6371. [Google Scholar]
- Zaman, K.; Samiul, I.J.; Sah, M.; Direkoglu, C.; Okada, S.; Unoki, M. Hybrid Transformer Architectures with Diverse Audio Features for Deepfake Speech Classification. IEEE Access 2024, 12, 149221–149237. [Google Scholar] [CrossRef]
- Mun, S.H.; Shim, H.j.; Tak, H.; Wang, X.; Liu, X.; Sahidullah, M.; Jeong, M.; Han, M.H.; Todisco, M.; Lee, K.A.; et al. Towards single integrated spoofing-aware speaker verification embeddings. arXiv 2023, arXiv:2305.19051. [Google Scholar] [CrossRef]
- Jung, J.w.; Wang, X.; Evans, N.; Watanabe, S.; Shim, H.j.; Tak, H.; Arora, S.; Yamagishi, J.; Chung, J.S. To what extent can ASV systems naturally defend against spoofing attacks? arXiv 2024, arXiv:2406.05339. [Google Scholar] [CrossRef]
- Salvi, D.; Negroni, V.; Bondi, L.; Bestagini, P.; Tubaro, S. Freeze and Learn: Continual Learning with Selective Freezing for Speech Deepfake Detection. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025. [Google Scholar]
- Kreuk, F.; Adi, Y.; Cisse, M.; Keshet, J. Fooling end-to-end speaker verification with adversarial examples. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1962–1966. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Subramanian, V.; Benetos, E.; Xu, N.; McDonald, S.; Sandler, M. Adversarial attacks in sound event classification. arXiv 2019, arXiv:1907.02477. [Google Scholar] [CrossRef]
- Chen, B.; Yin, J.; Chen, S.; Chen, B.; Liu, X. An adaptive model ensemble adversarial attack for boosting adversarial transferability. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 4489–4498. [Google Scholar]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into transferable adversarial examples and black-box attacks. arXiv 2016, arXiv:1611.02770. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Chen, Z.; Li, J.; Chen, C. Ensemble Adversarial Defenses and Attacks in Speaker Verification Systems. IEEE Internet Things J. 2024, 11, 32645–32655. [Google Scholar] [CrossRef]
- Rabhi, M.; Bakiras, S.; Di Pietro, R. Audio-deepfake detection: Adversarial attacks and countermeasures. Expert Syst. Appl. 2024, 250, 123941. [Google Scholar] [CrossRef]
- Li, M.; Ahmadiadli, Y.; Zhang, X.P. A Survey on Speech Deepfake Detection. ACM Comput. Surv. 2025, 57, 1–38. [Google Scholar] [CrossRef]
- Wang, Z.; Wei, G.; He, Q. Channel pattern noise based playback attack detection algorithm for speaker recognition. In Proceedings of the IEEE International Conference on Machine Learning and Cybernetics (ICMLC), Guilin, China, 10–13 July 2011. [Google Scholar]
- Malik, H. Securing voice-driven interfaces against fake (cloned) audio attacks. In Proceedings of the IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019. [Google Scholar]
- Tak, H.; Patino, J.; Todisco, M.; Nautsch, A.; Evans, N.; Larcher, A. End-to-end anti-spoofing with rawnet2. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6369–6373. [Google Scholar]
- Hamza, A.; Javed, A.R.; Iqbal, F.; Kryvinska, N.; Almadhor, A.S.; Jalil, Z.; Borghol, R. Deepfake Audio Detection via MFCC features using Machine Learning. IEEE Access 2022, 10, 134018–134028. [Google Scholar] [CrossRef]
- Salvi, D.; Bestagini, P.; Tubaro, S. Reliability Estimation for Synthetic Speech Detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar]
- Sivaraman, G.; Tak, H.; Khoury, E. Investigating voiced and unvoiced regions of speech for audio deepfake detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025. [Google Scholar]
- Negroni, V.; Salvi, D.; Mezza, A.I.; Bestagini, P.; Tubaro, S. Leveraging Mixture of Experts for Improved Speech Deepfake Detection. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025. [Google Scholar]
- Coletta, E.; Salvi, D.; Negroni, V.; Leonzio, D.U.; Bestagini, P. Anomaly detection and localization for speech deepfakes via feature pyramid matching. In Proceedings of the European Signal Processing Conference (EUSIPCO), Palermo, Italy, 8–12 September 2025. [Google Scholar]
- Estella, T.; Zahra, A.; Fung, W.K. Accessing Gender Bias in Speech Processing Using Machine Learning and Deep Learning with Gender Balanced Audio Deepfake Dataset. In Proceedings of the 2024 Ninth International Conference on Informatics and Computing (ICIC), Medan, Indonesia, 24–25 October 2024; pp. 1–6. [Google Scholar]
- Yadav, A.K.S.; Bhagtani, K.; Salvi, D.; Bestagini, P.; Delp, E.J. FairSSD: Understanding Bias in Synthetic Speech Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–18 June 2024. [Google Scholar]
- Sahidullah, M.; Kinnunen, T.; Hanilçi, C. A comparison of features for synthetic speech detection. In Proceedings of the Conference of the International Speech Communication Association (INTERSPEECH), Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. Emotions don’t lie: An audio-visual deepfake detection method using affective cues. In Proceedings of the ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Ge, W.; Todisco, M.; Evans, N. Explainable DeepFake and Spoofing Detection: An Attack Analysis Using SHapley Additive ExPlanations. In Proceedings of the International Speech Communication Association Conference (INTERSPEECH), Incheon, Republic of Korea, 18–22 September 2022. [Google Scholar]
- Ge, W.; Patino, J.; Todisco, M.; Evans, N. Explaining deep learning models for spoofing and deepfake detection with SHapley Additive exPlanations. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4768–4777. [Google Scholar]
- Halpern, B.M.; Kelly, F.; van Son, R.; Alexander, A. Residual networks for resisting noise: Analysis of an embeddings-based spoofing countermeasure. In Proceedings of the Speaker and Language Recognition Workshop (Odyssey), Tokyo, Japan, 2–5 November 2020. [Google Scholar]
- Salvi, D.; Bestagini, P.; Tubaro, S. Towards Frequency Band Explainability in Synthetic Speech Detection. In Proceedings of the 31st European Signal Processing Conference (EUSIPCO), Helsinki, Finland, 4–8 September 2023. [Google Scholar]
- Salvi, D.; Balcha, T.S.; Bestagini, P.; Tubaro, S. Listening between the lines: Synthetic speech detection disregarding verbal content. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024. [Google Scholar]
- Zang, Y.; Zhang, Y.; Heydari, M.; Duan, Z. Singfake: Singing voice deepfake detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024. [Google Scholar]
- Gohari, M.; Salvi, D.; Bestagini, P.; Adami, N. Audio Features Investigation for Singing Voice Deepfake Detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025. [Google Scholar]
- Kawa, P.; Plata, M.; Czuba, M.; Szymanski, P.; Syga, P. Improved DeepFake Detection Using Whisper Features. In Proceedings of the Conference of the International Speech Communication Association (INTERSPEECH), Dublin, Ireland, 20–24 August 2023. [Google Scholar]
- Guo, Y.; Huang, H.; Chen, X.; Zhao, H.; Wang, Y. Audio Deepfake Detection with Self-Supervised Wavlm and Multi-Fusion Attentive Classifier. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024. [Google Scholar]
- Bhanushali, A.R.; Mun, H.; Yun, J. Adversarial attacks on automatic speech recognition (ASR): A survey. IEEE Access 2024, 12, 88279–88302. [Google Scholar] [CrossRef]
- Hu, S.; Shang, X.; Qin, Z.; Li, M.; Wang, Q.; Wang, C. Adversarial examples for automatic speech recognition: Attacks and countermeasures. IEEE Commun. Mag. 2019, 57, 120–126. [Google Scholar] [CrossRef]
- Chakraborty, A.; Alam, M.; Dey, V.; Chattopadhyay, A.; Mukhopadhyay, D. A survey on adversarial attacks and defences. CAAI Trans. Intell. Technol. 2021, 6, 25–45. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (sp), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Li, Z.; Wu, Y.; Liu, J.; Chen, Y.; Yuan, B. Advpulse: Universal, synchronization-free, and targeted audio adversarial attacks via subsecond perturbations. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 9–13 November 2020; pp. 1121–1134. [Google Scholar]
- Taori, R.; Kamsetty, A.; Chu, B.; Vemuri, N. Targeted adversarial examples for black box audio systems. In Proceedings of the 2019 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 19–23 May 2019; pp. 15–20. [Google Scholar]
- Zhang, J.; Wu, W.; Huang, J.t.; Huang, Y.; Wang, W.; Su, Y.; Lyu, M.R. Improving adversarial transferability via neuron attribution-based attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14993–15002. [Google Scholar]
- Guo, F.; Sun, Z.; Chen, Y.; Ju, L. Towards the transferable audio adversarial attack via ensemble methods. Cybersecurity 2023, 6, 44. [Google Scholar] [CrossRef]
- Alzantot, M.; Wang, Z.; Srivastava, M.B. Deep residual neural networks for audio spoofing detection. arXiv 2019, arXiv:1907.00501. [Google Scholar] [CrossRef]
- Wu, Z.; Das, R.K.; Yang, J.; Li, H. Light convolutional neural network with feature genuinization for detection of synthetic speech attacks. arXiv 2020, arXiv:2009.09637. [Google Scholar] [CrossRef]
- Pham, L.; Lam, P.; Nguyen, T.; Nguyen, H.; Schindler, A. Deepfake audio detection using spectrogram-based feature and ensemble of deep learning models. In Proceedings of the 2024 IEEE 5th International Symposium on the Internet of Sounds (IS2), Erlangen, Germany, 30 September–2 October 2024; pp. 1–5. [Google Scholar]
- Tan, H.; Wang, L.; Zhang, H.; Zhang, J.; Shafiq, M.; Gu, Z. Adversarial attack and defense strategies of speaker recognition systems: A survey. Electronics 2022, 11, 2183. [Google Scholar] [CrossRef]
- Koerich, K.M.; Esmailpour, M.; Abdoli, S.; Britto, A.d.S.; Koerich, A.L. Cross-representation transferability of adversarial attacks: From spectrograms to audio waveforms. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wu, X.; He, R.; Sun, Z.; Tan, T. A light CNN for deep face representation with noisy labels. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2884–2896. [Google Scholar] [CrossRef]
- Wang, X.; Yamagishi, J.; Todisco, M.; Delgado, H.; Nautsch, A.; Evans, N.; Sahidullah, M.; Vestman, V.; Kinnunen, T.; Lee, K.A.; et al. ASVspoof 2019: A large-scale public database of synthesized, converted and replayed speech. Comput. Speech Lang. 2020, 64, 101114. [Google Scholar] [CrossRef]
- Veaux, C.; Yamagishi, J.; MacDonald, K. CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit. Univ. Edinburgh. Cent. Speech Technol. Res. (CSTR) 2017, 6, 15. [Google Scholar]
Figure 1.
Backpropagation with respect to a spectrogram representation of the audio input (top) and with respect to the input waveform (bottom). We refer to these as 2D and 1D attacks, respectively.
Figure 1.
Backpropagation with respect to a spectrogram representation of the audio input (top) and with respect to the input waveform (bottom). We refer to these as 2D and 1D attacks, respectively.
Figure 2.
Audio to spectrogram conversion pipeline.
Figure 2.
Audio to spectrogram conversion pipeline.
Figure 3.
Gradient-based ensemble attack.
Figure 3.
Gradient-based ensemble attack.
Figure 4.
ROC curves of each of the considered models tested against multiple AAs.
Figure 4.
ROC curves of each of the considered models tested against multiple AAs.
Figure 5.
Log-spectrograms of the Basic Iterative Method (BIM) adversarial noise injected in a test audio sample. Figure (a) displays the log-spectrogram of the original clean audio for reference, while (b,c) show the perturbations introduced by time–domain (1D) and frequency–domain (2D) attacks, respectively.
Figure 5.
Log-spectrograms of the Basic Iterative Method (BIM) adversarial noise injected in a test audio sample. Figure (a) displays the log-spectrogram of the original clean audio for reference, while (b,c) show the perturbations introduced by time–domain (1D) and frequency–domain (2D) attacks, respectively.
Figure 6.
Progression of attack success on the models included in the ensemble during BIM iterations, illustrating how effectiveness evolves over time.
Figure 6.
Progression of attack success on the models included in the ensemble during BIM iterations, illustrating how effectiveness evolves over time.
Table 1.
EER for clean and adversarial samples tested against different models. White-box AAs are highlighted in bold.
Table 1.
EER for clean and adversarial samples tested against different models. White-box AAs are highlighted in bold.
| EER [%] | ResNet | SENet |
|---|
| Test Model | Clean | 1D Attack | 2D Attack | 1D Attack | 2D Attack |
|---|
| ResNet | 6.83 | 99.99 | 99.95 | 15.40 | 7.90 |
| SENet | 6.32 | 22.61 | 13.13 | 99.73 | 71.27 |
| LCNN | 6.23 | 29.71 | 13.65 | 21.88 | 9.98 |
| RawNet2 | 12.17 | 12.03 | 13.38 | 12.10 | 12.85 |
Table 2.
BA for clean and adversarial samples tested against different models. White-box AAs are highlighted in bold.
Table 2.
BA for clean and adversarial samples tested against different models. White-box AAs are highlighted in bold.
| BA [%] | ResNet | SENet |
|---|
| Test Model | Clean | 1D Attack | 2D Attack | 1D Attack | 2D Attack |
|---|
| ResNet | 93.17 | 0.27 | 4.91 | 81.89 | 91.82 |
| SENet | 93.68 | 53.67 | 81.80 | 4.18 | 26.31 |
| LCNN | 93.77 | 48.19 | 69.46 | 50.38 | 83.19 |
| RawNet2 | 87.83 | 88.36 | 86.49 | 88.12 | 86.83 |
Table 3.
Average SNR [dB] values for adversarial examples generated using 1D and 2D attack methods against ResNet and SENet models, measured relative to their corresponding clean inputs.
Table 3.
Average SNR [dB] values for adversarial examples generated using 1D and 2D attack methods against ResNet and SENet models, measured relative to their corresponding clean inputs.
| SNR [dB] | 1D Attack | 2D Attack |
|---|
| ResNet | 45.20 | 14.32 |
| SENet | 46.27 | 15.12 |
Table 4.
EER for clean and adversarial samples computed with RGE and WRGE strategies tested against different models. White-box AAs are highlighted in bold.
Table 4.
EER for clean and adversarial samples computed with RGE and WRGE strategies tested against different models. White-box AAs are highlighted in bold.
| EER [%] | ResNet + SENet | ResNet + RawNet2 | SENet + RawNet2 |
|---|
| Test Model | Clean | RGE | WRGE | RGE | WRGE | RGE | WRGE |
|---|
| ResNet | 6.83 | 99.82 | 99.79 | 99.99 | 98.86 | 16.91 | 18.78 |
| SENet | 6.32 | 97.17 | 99.12 | 17.14 | 14.04 | 99.96 | 97.54 |
| LCNN | 6.23 | 17.24 | 17.73 | 22.19 | 18.34 | 19.36 | 17.97 |
| RawNet2 | 12.17 | 12.18 | 12.17 | 72.05 | 88.85 | 71.99 | 89.59 |
Table 5.
BA for clean and adversarial samples computed with RGE and WRGE strategies tested against different models. White-box AAs are highlighted in bold.
Table 5.
BA for clean and adversarial samples computed with RGE and WRGE strategies tested against different models. White-box AAs are highlighted in bold.
| BA [%] | ResNet + SENet | ResNet + RawNet2 | SENet + RawNet2 |
|---|
| Test Model | Clean | RGE | WRGE | RGE | WRGE | RGE | WRGE |
|---|
| ResNet | 93.17 | 11.05 | 11.40 | 1.99 | 16.67 | 78.55 | 73.20 |
| SENet | 93.68 | 27.05 | 19.55 | 71.37 | 76.79 | 5.11 | 26.30 |
| LCNN | 93.77 | 74.63 | 72.41 | 53.78 | 59.33 | 56.78 | 58.14 |
| RawNet2 | 87.83 | 87.86 | 87.88 | 25.07 | 14.93 | 25.11 | 14.40 |
Table 6.
EER and BA values for clean and adversarial samples computed with the WRGE ensemble strategy considering three white-box models (ResNet, SENet, RawNet2) and tested against different models. White-box AAs are highlighted in bold.
Table 6.
EER and BA values for clean and adversarial samples computed with the WRGE ensemble strategy considering three white-box models (ResNet, SENet, RawNet2) and tested against different models. White-box AAs are highlighted in bold.
| Test Model | EER [%] | BA [%] |
|---|
| Clean | WRGE | Clean | WRGE |
|---|
| ResNet | 6.83 | 87.71 | 93.17 | 21.79 |
| SENet | 6.32 | 93.42 | 93.68 | 34.46 |
| LCNN | 6.23 | 20.30 | 93.77 | 54.39 |
| RawNet2 | 12.17 | 57.87 | 87.83 | 16.34 |
Table 7.
Average SNR [dB] values for adversarial samples generated using WRGE strategies, including the ResNet, SENet and RawNet2 models, in different configurations.
Table 7.
Average SNR [dB] values for adversarial samples generated using WRGE strategies, including the ResNet, SENet and RawNet2 models, in different configurations.
| Ensemble Configuration | SNR [dB] |
|---|
| ResNet + SENet | 56.75 |
| ResNet + RawNet2 | 42.34 |
| SENet + RawNet2 | 42.13 |
| ResNet + SENet + RawNet2 | 42.89 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}