4.1.1. Datasets
To comprehensively validate the evolutionary binary decision framework (EBDF), we conduct experiments on four widely adopted benchmark image classification datasets: CIFAR-10, CIFAR-100, Tiny ImageNet, and Flowers-102. These datasets exhibit progressive complexity in class cardinality (10 to 200 classes), image resolution (32 × 32 to 224 × 224), and inter-class similarity, providing a probe for evaluating the EBDF’s performance.
Table 3 summarizes their key characteristics.
CIFAR-10 comprises 60,000 RGB images (50,000 training + 10,000 testing) uniformly distributed across 10 object classes [
31]. With low-resolution 32 × 32 images and moderate class separability, it serves as an entry-level benchmark for classification algorithm validation. We adopt the standard PyTorch implementation (
torchvision.datasets.CIFAR10) with default train–test splits. The primary challenge lies in distinguishing fine-grained categories (e.g.,
automobile vs.
truck) under significant information loss from downsampling, which leads many mis-classfications.
CIFAR-100 extends CIFAR-10’s scale to 100 classes while maintaining identical image dimensions and dataset size [
31]. Each class contains only 500 training images, intensifying the small-sample learning challenge. Using PyTorch’s built-in loader (
torchvision.datasets.CIFAR100), we evaluate the EBDF’s capability to handle high class density (e.g., 13 fine-grained insect categories) where decision boundary ambiguity escalates exponentially compared to CIFAR-10. Accordingly, the accuracy level is much lower than CIFAR-10 over different classifiers.
Flowers-102 features 8189 high-resolution images (1020 training + 6149 testing) across 102 flower species [
32]. This dataset introduces significant inter-class visual similarity (e.g., multiple rose varieties) and intra-class variation (pose/occlusion). While PyTorch lacks a native loader, we implement standardized preprocessing: Images are center-cropped to 224 × 224, normalized using ImageNet statistics, and loaded via
torchvision.datasets.ImageFolder with official splits. The EBDF’s hierarchical decision mechanism, with superiority of binary classification, is particularly suited for such fine-grained recognition tasks.
Tiny ImageNet is a subset of ImageNet comprising 200 classes with 100,000 training and 10,000 validation images at 64 × 64 resolution. Its real-world object diversity makes it an ideal benchmark for robustness evaluation under label noise and long-tailed distributions. Images are processed through a custom PyTorch loader with random horizontal flipping and dataset-based normalization.
Mini-ImageNet Dataset Mini-ImageNet is a standardized benchmark dataset for few-shot learning, first proposed by Vinyals et al. in the seminal work Matching Networks for One Shot Learning as a computationally tractable alternative to the full ImageNet dataset. Comprising 100 diverse object classes curated from the original ImageNet hierarchy, each class contains 600 high-resolution RGB images resampled to a uniform pixel resolution, resulting in a total of 60,000 images and a compressed dataset size of approximately 1.9–3.0 GB. Its design intentionally preserves the real-world visual complexity of ImageNet while reducing computational overhead. The dataset adopts a strictly class-disjoint partitioning scheme, with 64 classes (38,400 images) for meta-training (Base), 16 classes (9600 images) for meta-validation (Validation), and 20 classes (12,000 images) for meta-testing (Novel), ensuring no categorical overlap between splits. In contrast to Tiny ImageNet (200 classes, resolution, robustness focus), Mini-ImageNet prioritizes few-shot generalization with higher resolution and curated class-disjoint splits. Its balanced complexity–efficiency tradeoff has established it as the de facto benchmark for evaluating meta-transfer learning, optimization-based meta-learning, and semi-supervised FSL algorithms.
These datasets collectively address three critical dimensions of classification complexity: scale progression from 10 to 200 classes; resolution variance from low-fidelity (32 × 32) to near-realistic (224 × 224) images, and decision granularity from coarse object categories to fine-grained species differentiation. This selection strategy ensures the EBDF’s evaluation transcends dataset-specific limitations, validating its effectiveness of binary-based evolutionary framework.
To comprehensively validate our framework’s generalization capabilities across diverse classification domains, we utilize benchmark datasets covering spoken language identification (SLI).
SLI Corpus provides a tailored benchmark for spoken language identification (SLI) with its curated collection of 44 diverse languages. The authors employ a rigorously refined dataset comprising 100,717 human-verified audio recordings sourced from
OpenSLR and
Common Voice 6.1 corpora. In paper [
33], following the methodology detailed in
Section 4.1.1 and
Appendix A, recordings underwent standardized preprocessing: All audio files were resampled to a 48 kHz sample rate, segmented into fixed-length 3-s clips (retaining sequential segments for longer files), and transformed into time-frequency acoustic features (TFAFs) including
Fbank (298 × 23),
PLP (298 × 12), and
MFCC (298 × 13) using the Kaldi framework. The dataset’s primary challenge arises from its intentional inclusion of environmentally diverse, “
clear but not clean” samples—recordings captured in real-world conditions with varying background noise and device characteristics.
4.1.2. Baseline Models
To rigorously evaluate our evolutionary binary decision framework (EBDF), we benchmark against five foundational architectures spanning convolutional, attention-based, and multimodal paradigms from two different scenarios: ResNet, the vision transformer (ViT) and CLIP from image classfication; the filamentary convolution kernel-based neural network (FCK-NN), and ECAPA-TDNN. Each baseline model was systematically adapted for both multi-class classification and can be transformed into EBDF structure formation.
ResNet pioneered the use of residual connections to enable training of ultra-deep networks [
34]. We employ ResNet-50 (50 convolutional layers with skip connections) as our primary convolutional baseline. For multi-class tasks, its final fully-connected layer is configured with softmax activation for
n-way classification. In binary verification tasks, we replace this with a sigmoid-activated output layer while retaining the same backbone features. This architecture excels at learning hierarchical visual features but exhibits quadratic computational growth with resolution increases.
Vision transformer (ViT) applies the transformer architecture previously successful in NLP to image patches [
35]. Using the base ViT-B/16 variant, we process images as sequences of 16 × 16 patches. For our experiments, both multi-class and pairwise variants use identical patch embeddings but differ in classification heads: multi-class features a linear layer with softmax over
n classes; binar features a linear layer with sigmoid activation. ViT’s global attention mechanism demonstrates superior long-range dependency modeling compared to CNNs, particularly for fine-grained recognition, though requiring extensive pretraining data.
CLIP introduces a multimodal contrastive learning approach that jointly trains image and text encoders [
36]. We utilize ViT-B/32 as our visual backbone with frozen weights from open-source pretraining. Its unique strength lies in zero-shot transfer: Multi-class predictions use text prompts (e.g., “a photo of class name”) with cosine similarity ranking. For pairwise tasks, we compute visual feature similarity between test image and prototype embeddings. CLIP achieves remarkable generalization across domains but requires careful prompt engineering.
The
ECAPA-TDNN [
37] employs an enhanced time-delay neural network architecture for speaker verification, integrating SE-Res2Blocks that combine Res2Net’s multi-scale feature extraction (
) with SENet’s channel attention through squeeze–excitation operations
where
[
38]. It utilizes attentive statistics pooling (ASP) to dynamically weight frame-level features via channel-dependent attention
, generating attention-weighted statistics
and
[
39]. Our implementation processes 80-dimensional mel-spectrograms through a 1D convolutional layer (
,
) and three SE-Res2Blocks (
,
,
) [
40], with multilayer feature aggregation producing 192-dimensional speaker embeddings. The model is pre-trained on zhmagicdata (1000 speakers, 400 h) with angular additive margin Softmax loss (
,
) and Adam optimization (
,
); incremental training via distillation uses a frozen teacher model with combined KL divergence loss (
,
,
). It is evaluated on datasets like zhspeechocean and it benchmarks against domain adaptation (e.g., CORAL, Bayesian adaptation) and open-set methods (e.g., OpenMax), employing equal the error rate (EER), area under ROC curve (AUROC), and open-set classification rate (OSCR) under high-similarity speaker pair settings.
FCK-NN introduces filamentary convolution for frequency-axis feature extraction in spoken language identification, preventing cross-frame information mixing [
41]. The authors employ a hierarchical CNN-LSTM architecture with filamentary-shaped kernels as the core feature extractor. For multi-class tasks, frame-level features are processed through LSTM and fully-connected layers with softmax activation. For verification tasks, speaker embeddings (x-vectors) are compared via cosine similarity. This architecture excels at preserving temporal relationships and capturing critical acoustic cues (e.g., pitch, tone, rhythm) but exhibits 30% higher computational complexity than standard CNNs.
Traditional multi-class classification approaches often struggle with complex decision boundaries and class imbalance scenarios. Our evolutionary binary decision framework (EBDF) addresses these limitations through a hierarchical decomposition strategy that synergistically integrates binary and multi-class decision mechanisms. This section analyzes established binary decision paradigms and their evolution toward modern hybrid approaches, culminating in the EBDF’s novel architecture.
Table 4 provides a comparative analysis of key methodologies. Karim et al. [
42] proposed an end-to-end YOLOv5-based approach that directly processes raw LiDAR point cloud data for agricultural object detection, demonstrating the advantage of deep learning over traditional decision tree methods in handling complex high-dimensional orchard environments.
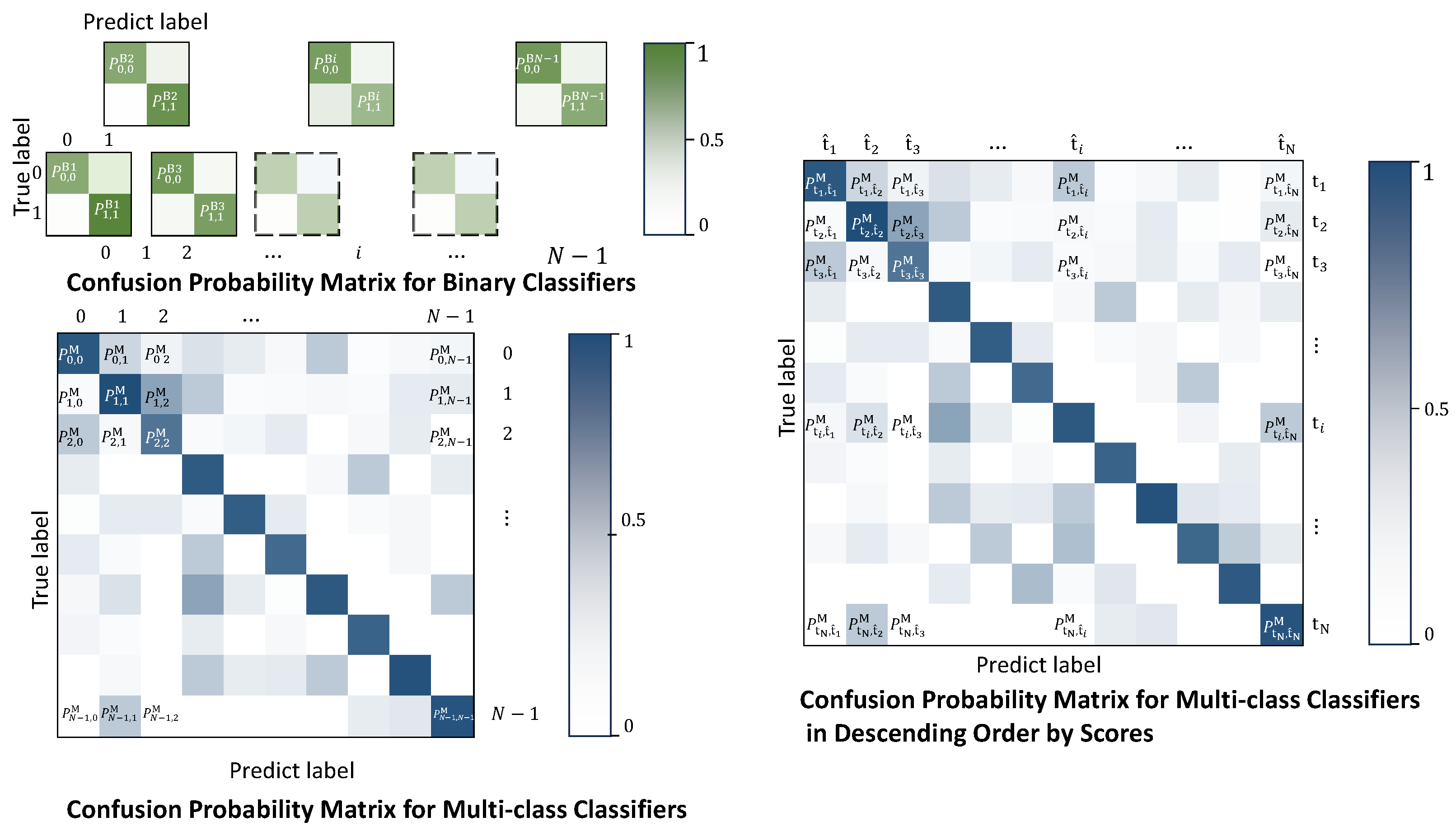
One-vs-rest (OvR) represents the foundational binary decomposition approach where
n binary classifiers are trained to distinguish each class against all others [
43]. For a 10-class problem, this requires training 10 separate classifiers (e.g., “cat vs. non-cat”, “dog vs. non-dog”). While conceptually simple, OvR suffers from severe class imbalance in the negative samples and ambiguous decision boundaries when classes overlap significantly. Therefore, we employ the class-balanced loss weighting strategy from Cui et al. (CVPR 2019), specifically implementing the CB-CE (class-balanced cross-entropy) loss where
. Sharma et al. [
44] leveraged OvR SVM on Siamese network-derived embeddings for multi-class Sika deer re-identification, demonstrating its adaptability to ecological monitoring despite inter-class pattern ambiguities.
One-vs-one (OvO) mitigates imbalance issues by training
pairwise classifiers [
4]. For 100 classes, this requires 4950 binary models. Though theoretically superior for separable classes, OvO’s computational overhead scales quadratically (
) and introduces voting conflicts when classifiers disagree.
Decision trees implement hierarchical binary decisions through axis-aligned splits [
45]. Traditional variants like CART recursively partition feature space using metrics like Gini impurity. While interpretable, they struggle with high-dimensional visual data. Modern extensions like oblique forests [
46] learn non-axis-parallel splits but remain limited to shallow hierarchies.
Classifier chains transform multi-class problems into directed acyclic graphs of binary decisions [
47]. Each classifier in the chain uses preceding decisions as additional features. Though effective for label dependencies, chains suffer from error propagation where early mistakes cascade through subsequent nodes.
Hierarchical mixture of experts (HME) employs gating networks to route samples to specialized submodels [
48]. Unlike flat ensembles, HME’s tree structure enables conditional computation. However, fixed architectures struggle to adapt to varying class complexities. Our EBDF framework extends this concept through evolutionary optimization of decision pathways.
4.1.3. Binary Training Protocol
Effective data preparation is critical for training robust binary classifiers within our evolutionary binary decision framework (EBDF). Unlike conventional multi-class setups, binary decision nodes require specialized sampling strategies to address inherent class imbalance while preserving representative feature distributions. Our approach employs inverse class frequency weighting [
49] with a modified ratio-based scheme for 1:N imbalance scenarios. The class weights are assigned as
for the minority positive class and
for the majority negative class, where
N represents the imbalance ratio. This formulation, adapted from effective number weighting principles [
50], amplifies minority class influence while preventing majority class dominance during optimization. The weighted cross-entropy loss is expressed as
where
denotes true labels and
p represents predicted probabilities. Compared to standard inverse frequency weighting [
51], this strategy maintains more stable gradient norms in high-ratio imbalance scenarios (1:30+) while ensuring minority samples contribute meaningfully to parameter updates.
We initialize binary classifiers using publicly available state-of-the-art pretrained vision models to leverage learned visual representations. Specifically, we employ vision transformer (ViT-L/16) weights pretrained on ImageNet-21k [
35] and fine-tuned on ImageNet-1k [
52], which currently hold top-1 accuracy records (88.6%) among publicly accessible models. This initialization provides robust feature extractors that capture hierarchical visual patterns while minimizing domain shift. The pretrained backbone remains frozen during binary classifier training to preserve generalized representations, with only the final classification layer being retrained using our imbalance-adjusted loss function. This approach maximizes the transfer of learned visual knowledge while avoiding the catastrophic forgetting of foundational features during task-specific adaptation.
Our binary classifier training employs standard optimization protocols without novel components. The experimental settings are showed in
Table 5. We utilize SGD with Nesterov momentum (
) and cross-entropy loss, consistent with established practices [
34]. The learning rate schedule implements cosine decay [
53], initialized at 0.1 with 5-epoch linear warmup. Gradient clipping (
) maintains stability during optimization [
54]. Batch composition uses standard class-balanced sampling with batch size 256 distributed across NVIDIA GeForce RTX 3090 Ti GPUs. This configuration follows conventional deep learning practices, with comparisons to alternative approaches like step decay schedules [
34] and focal loss formulations [
20] provided in ablation studies.









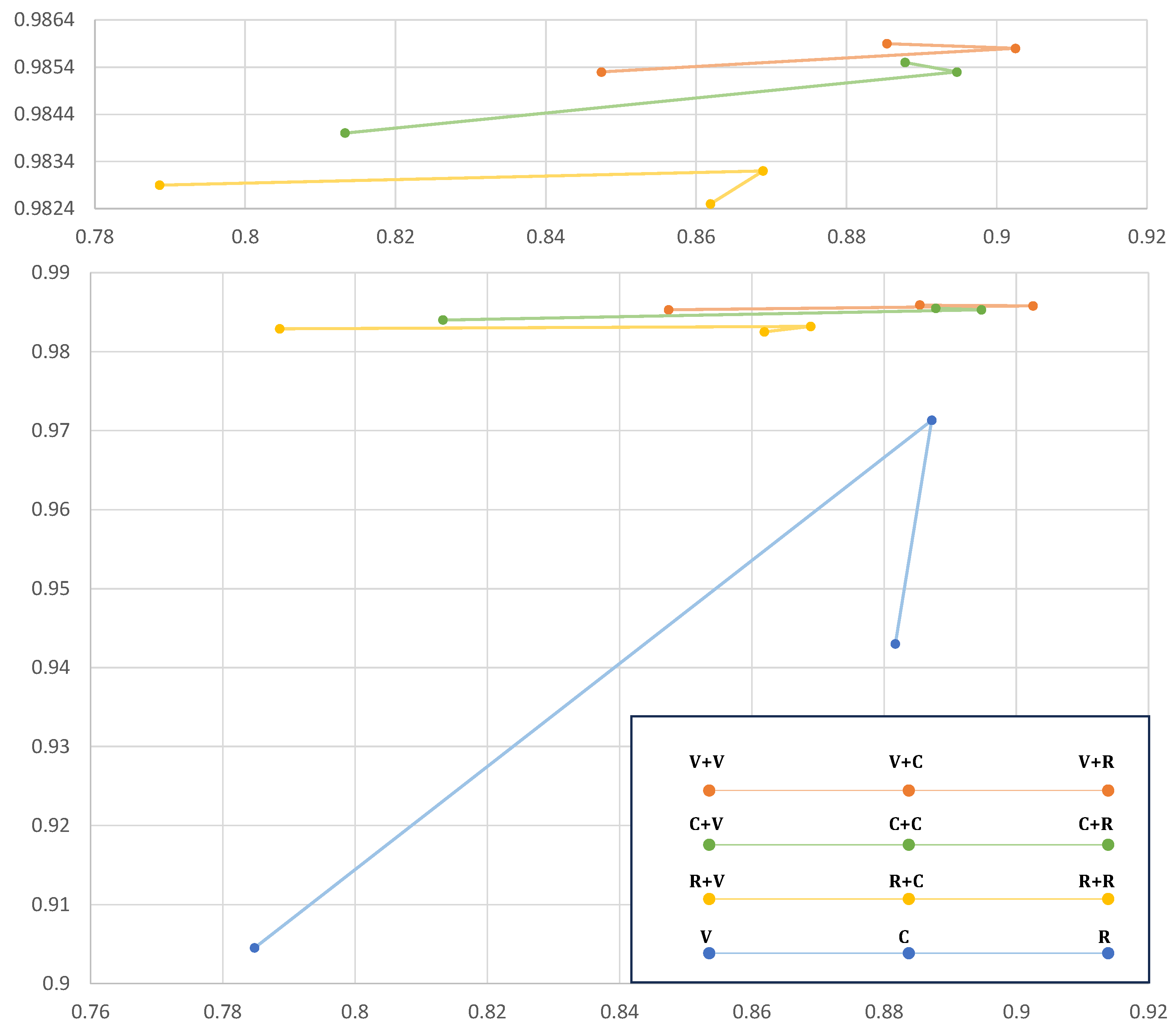

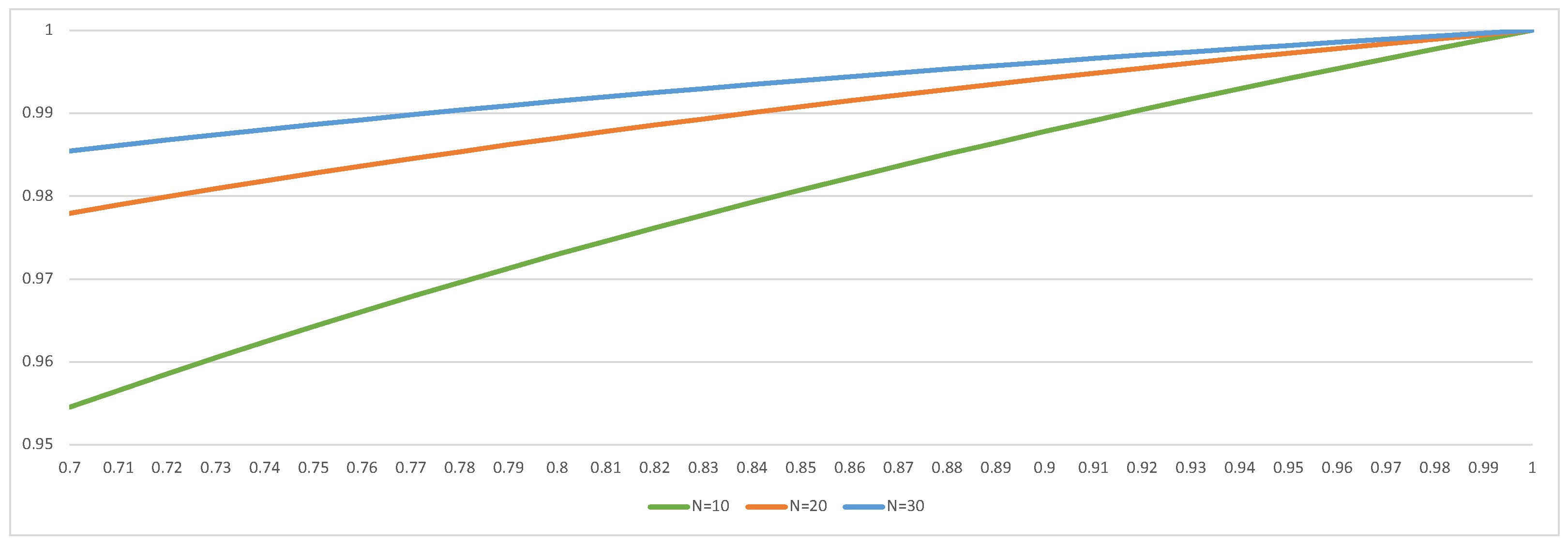
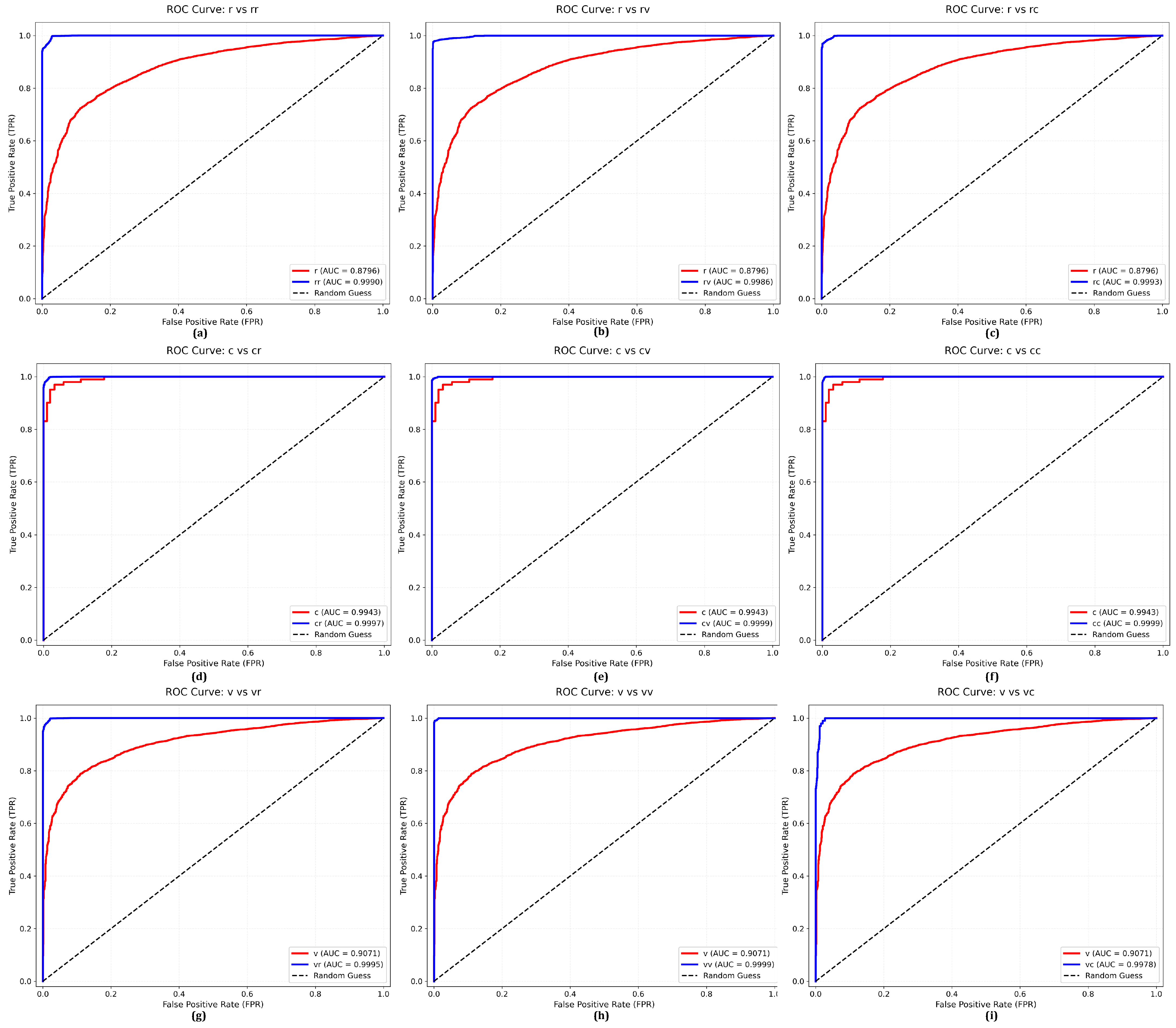

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}