
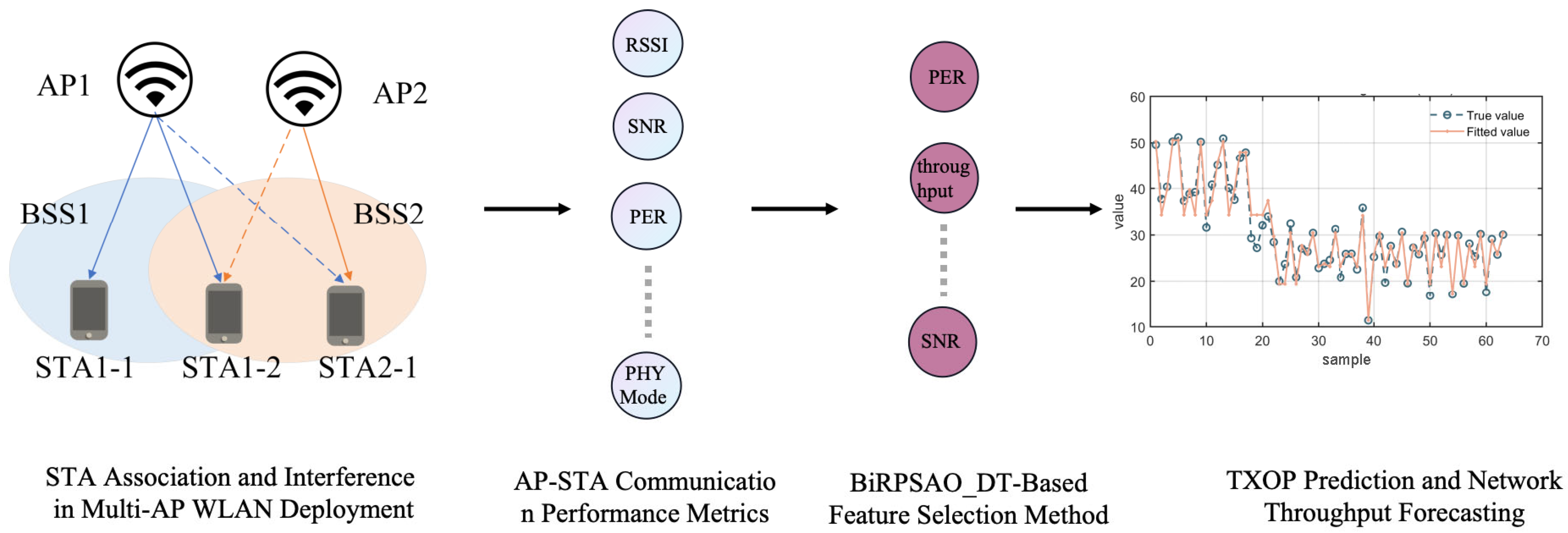
Transmission Opportunity and Throughput Prediction for WLAN Access Points via Multi-Dimensional Feature Modeling


Abstract
1. Introduction
- A WLAN performance modeling framework combining the Snow-Melting Optimizer (SMO) and regression models is proposed: addressing the high-dimensional, dynamic, and nonlinear prediction challenges of throughput and transmission opportunity in WLAN, this work introduces a novel metaheuristic algorithm, SMO, for efficient key feature selection and integration with regression models to improve prediction accuracy and robustness.
- A collaborative mechanism between the SMO and decision regression models is constructed: by integrating the SMO with decision tree regression models, which have good interpretability and generalization ability, a deep synergy between feature selection and modeling is achieved, effectively reducing feature redundancy and overfitting risks while enhancing adaptability to complex network fluctuations.
- Joint prediction of TXOP and throughput in dynamic WLAN scenarios: besides traditional throughput modeling, transmission opportunity (TXOP) is introduced as an auxiliary modeling target, constructing a prediction system more aligned with MAC layer transmission mechanisms, thereby better capturing the impact of terminal competition behaviors on bandwidth performance.
- Systematic evaluation on real or simulated datasets: comparative experiments with multiple baseline methods verify the advantages of the proposed method in feature selection efficiency, prediction accuracy, and model stability, demonstrating its practical potential in dynamic wireless environments.
2. Data Preprocessing and Feature Engineering
2.1. Dataset
2.2. Label Encoding
2.3. Feature Engineering
- (1)
- Maximum ()where Xi represents the sequence of received RSSI values.
- (2)
- Minimum ()
- (3)
- Mean ()
- (4)
- Variance ()
- (5)
- Standard Deviation ()
- (6)
- Kurtosis ()
- (7)
- Skewness ()
- (8)
- Rate of Change in the RSSI ()where is the RSSI value received at time t, and is the RSSI value collected at time .
3. Method
3.1. Binary Random Pruning Snow Melting Optimizer with Decision Tree (BiRPSMO-DT)
- (1)
- Binary Population Initialization
- (2)
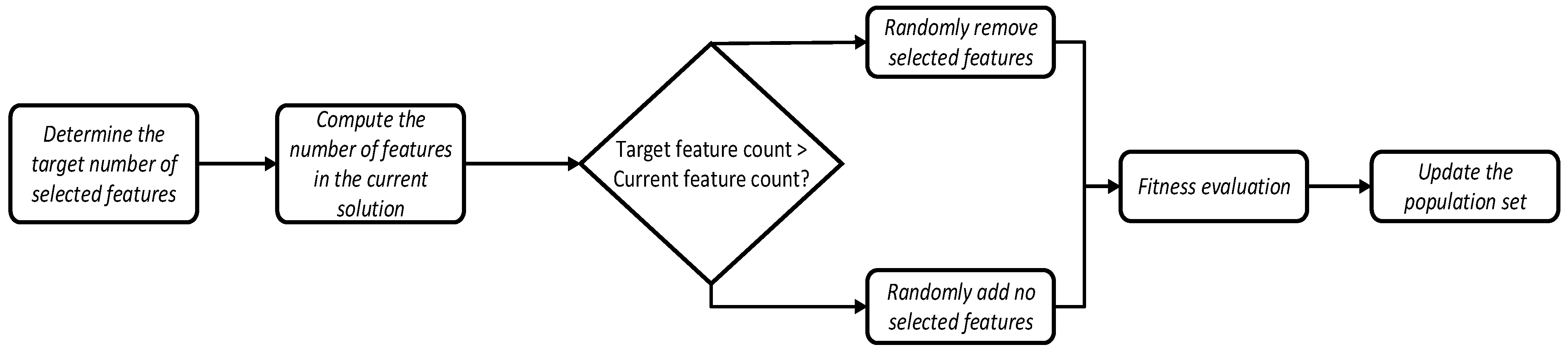
- Population Constraint Strategy Based on Random Pruning
- Obtain the target number of features: First, retrieve the desired number of features num_features from the input parameters.
- Convert to binary representation: The population is converted into a binary representation, where each individual is represented as a binary string of length Dim, with Dim denoting the total number of features. In this binary string, each bit corresponds to a specific feature: a value of 1 indicates that the feature is selected, while a value of 0 means the feature is not selected.
- Calculate the number of selected features: Select the top 50% of individuals based on fitness and compute the number of selected features (select_features) for each individual.
- Adjust the number of features: If the number of selected features for any individual exceeds num_features, adjustment is required:If select_features > num_features, randomly deselect (select_features − num_features) features.If select_features < num_features, randomly select (num_features − select_features) additional features.
- Update the population: Based on the adjustments, update each individual’s representation in the population to ensure all individuals satisfy the constraint.
- (3)
- Fitness Function
- (4)
- Snow Ablation Optimizer Algorithm Process
| Algorithm 1: Feature Selection Based on BiRPSMO and DT |
|
Definitions: Population size , feature dimension Dim, iteration coun , maximum iterations , two subpopulations , optimal feature set , elite pool Elite = . Steps: 1. Initialize the population (snow pile) X as N individuals of Dim-dimensional binary strings, and the best position G(t). 2. Apply constraints to the population. 3. Calculate the initial population’s objective function values using DT and record the best individual G(t). 4. Rank individuals by score and build the elite pool Elite(t). 5. While t < , do: 5.1 Calculate snow melting rate M and the centroid of the population according to Formulas (10) and (6). 5.2 Randomly divide the population into two groups and . 5.3 Update Pa based-on Elite(t), G(t), , and the S-shaped transfer function. 5.4 Adjust Pa and Pb according to Formula (13). 5.5 Update Pb based on , , and the S-shaped function. 5.6 Recalculate objective scores of the updated population; if improved, update best score and position. 5.7 Update Elite(t). 5.8 t = t + 1. 6. End. 7. Return the best position G(t). 8. Map the best position back to the binary population and select features . 9. Output the feature subset . |
3.2. Decision Tree Regression
4. Results and Discussion
4.1. Feature Selection
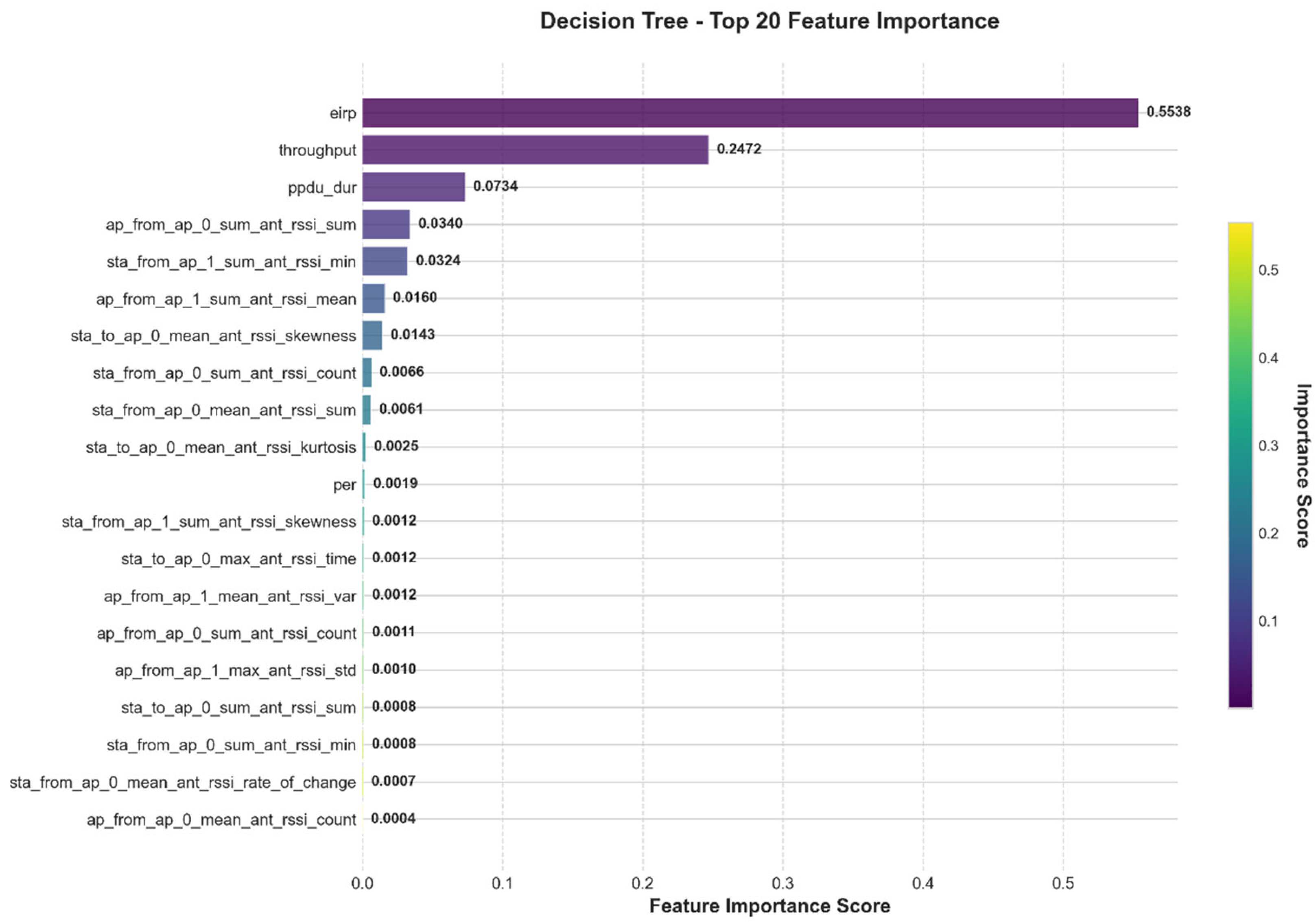
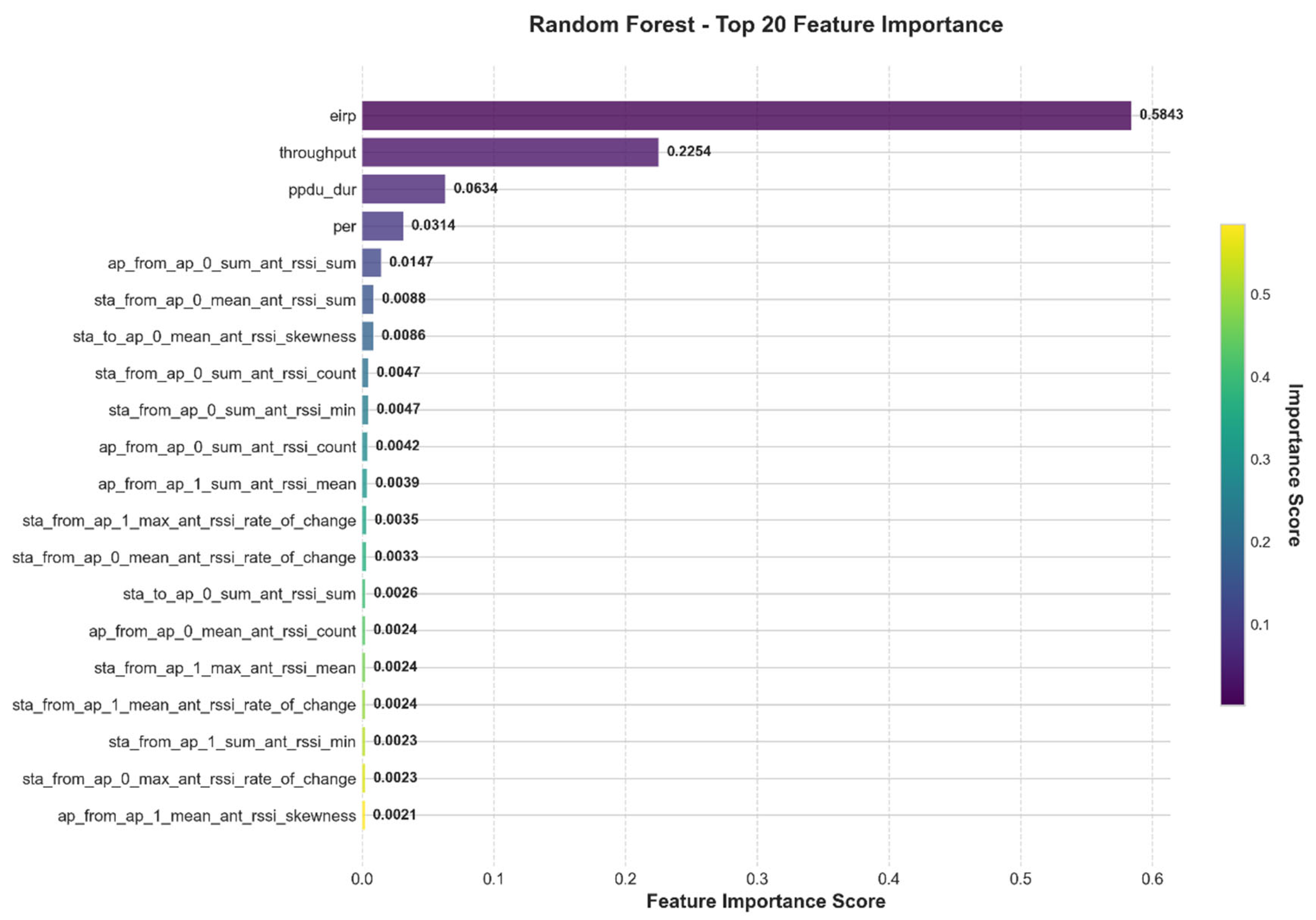
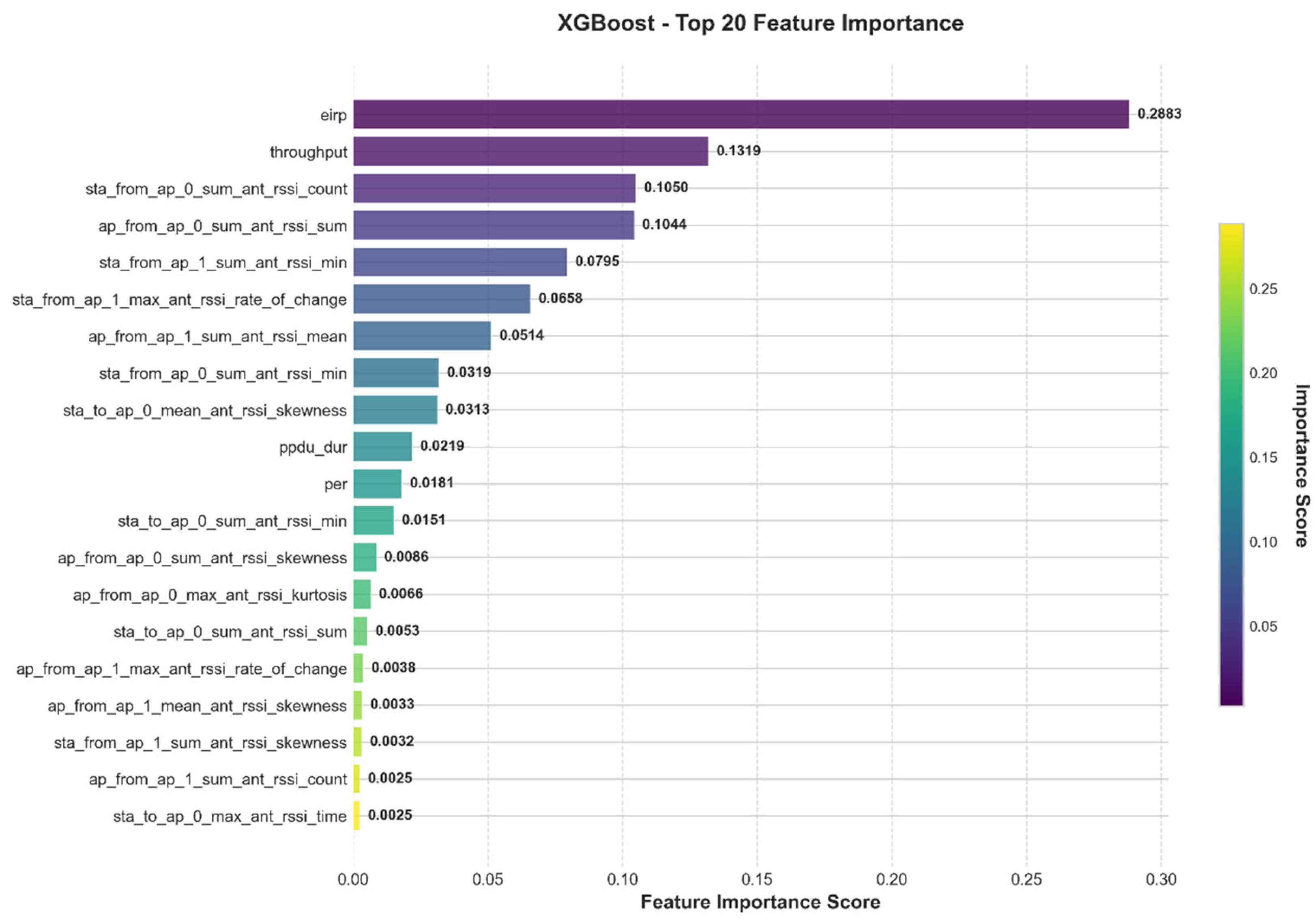
4.2. Feature Contribution
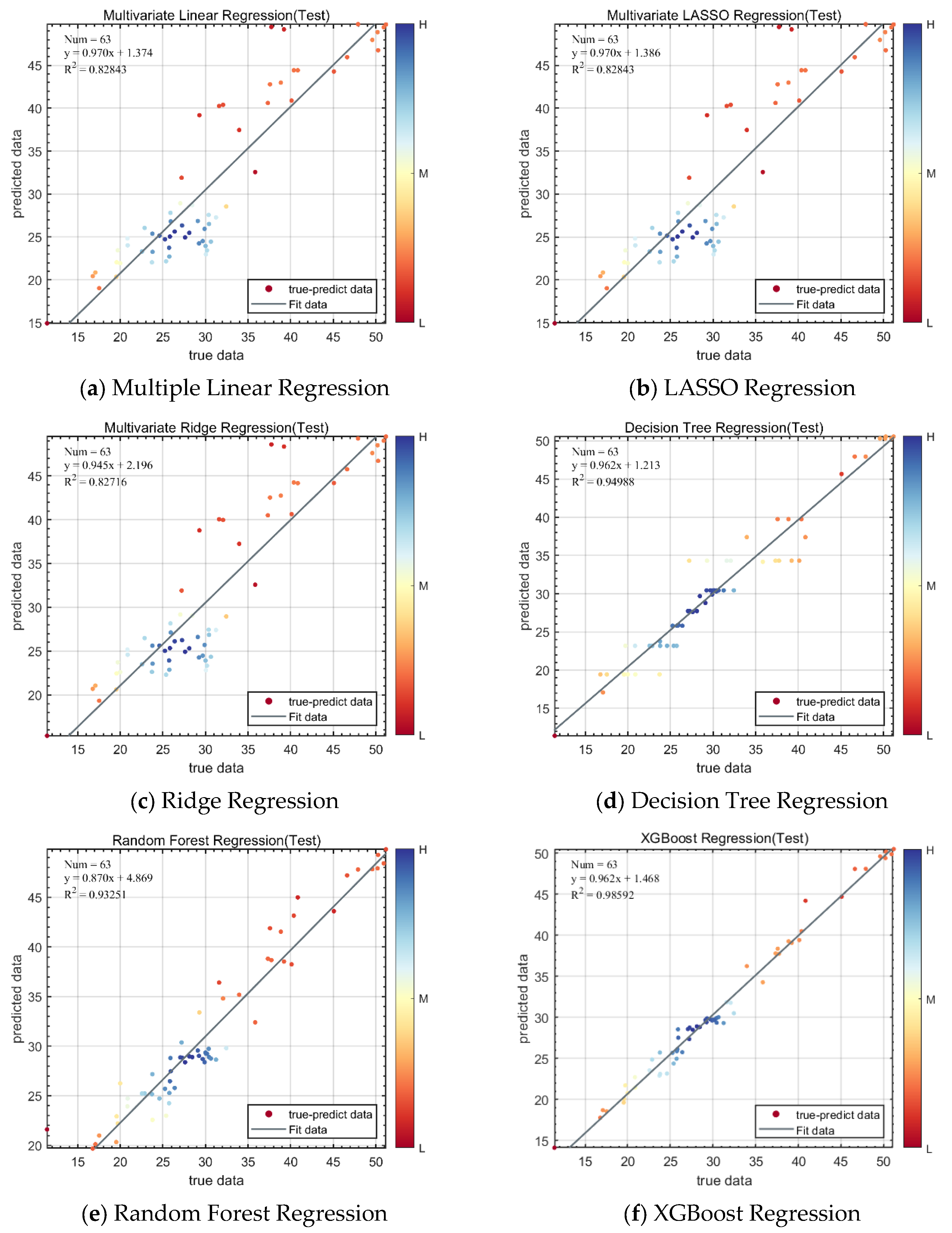
4.3. Transmission Opportunity Prediction
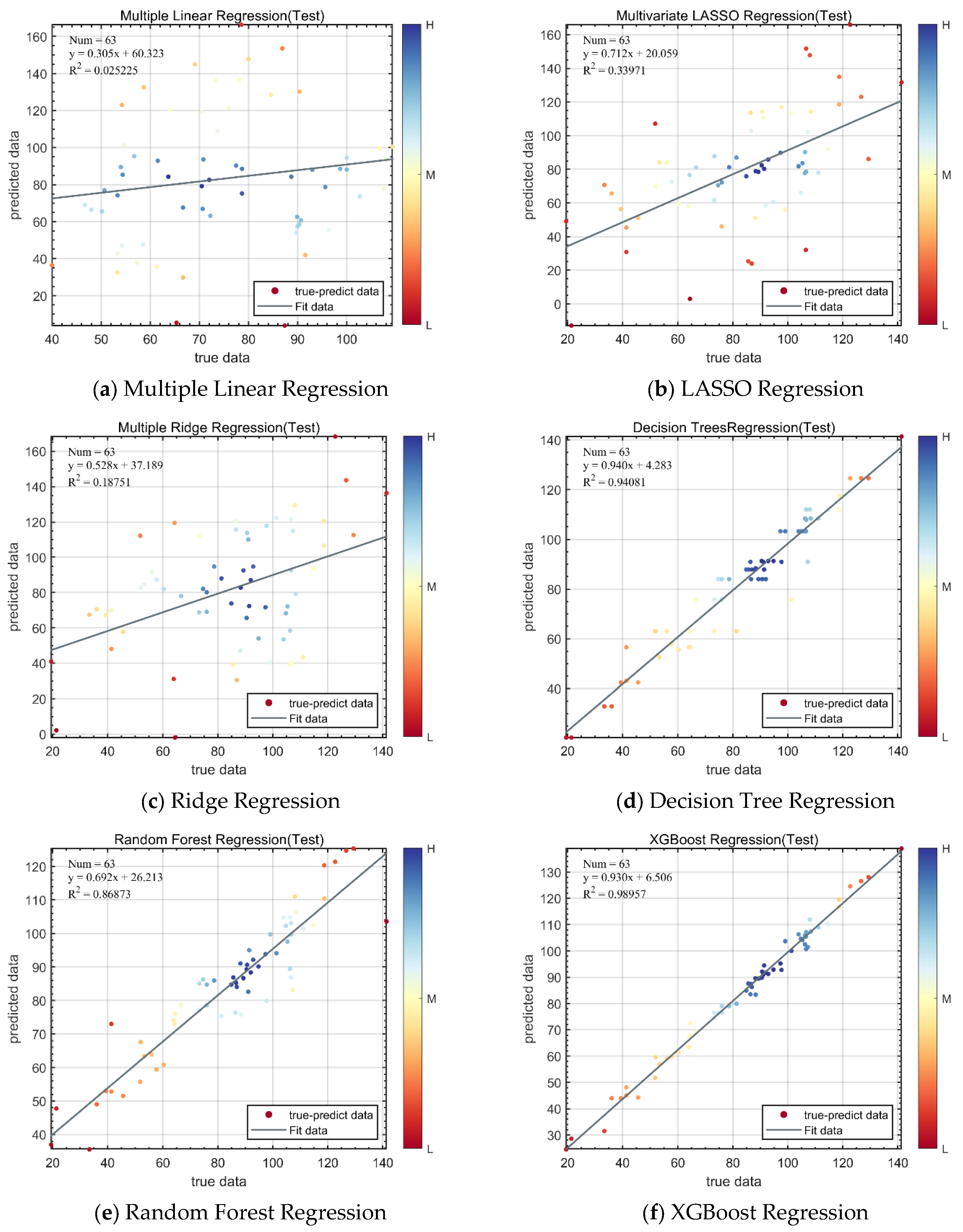
4.4. AP Throughput and Bandwidth Prediction
4.5. Discussion
5. Conclusions
6. Limitations and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| WLAN | Wireless Local Area Network |
| AP | Access Point |
| AC | Access Controller |
| TXOP | Transmission Opportunity |
| STA | Station |
| SNR | Signal-to-Noise Ratio |
| RSSI | Received Signal Strength Indicator |
| MCS | Modulation and Coding Scheme |
| NSS | Number of Spatial Streams |
| PER | Packet Error Rate |
| PPDU | Physical Layer Protocol Data Unit |
| EIRP | Effective Isotropic Radiated Power |
| MAC | Medium Access Control |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| MSE | Mean Squared Error |
| RMSE | Root Mean Squared Error |
| R2 | Coefficient of Determination |
| SVM | Support Vector Machine |
| RF | Random Forest |
| DT | Decision Tree |
| XGBoost | Extreme Gradient Boosting |
| PCA | Principal Component Analysis |
| ACO | Ant Colony Optimization |
| PSO | Particle Swarm Optimization |
| SMO | Snow-Melting Optimizer |
| TCP | Transmission Control Protocol |
| UDP | User Datagram Protocol |
References
- Gao, D.; Wang, H.; Chen, Y.; Ye, Q.; Wang, W.; Guo, X.; Wang, S.; Liu, Y.; He, T. LoBee: Bidirectional Communication between LoRa and ZigBee based on Physical-Layer CTC. IEEE Trans. Wirel. Commun. 2025. [Google Scholar] [CrossRef]
- Wilhelmi, F.; Barrachina-Muñoz, S.; Bellalta, B.; Cano, C.; Jonsson, A.; Ram, V. A flexible machine-learning-aware architecture for future WLANs. IEEE Commun. Mag. 2020, 58, 25–31. [Google Scholar] [CrossRef]
- Pan, D. Analysis of Wi-Fi Performance Data for a Wi-Fi Throughput Prediction Approach. 2017. Available online: https://www.diva-portal.org/smash/record.jsf?pid=diva2:1148996 (accessed on 4 November 2024).
- Lee, C.; Abe, H.; Hirotsu, T.; Umemura, K. Analytical modeling of network throughput prediction on the internet. IEICE Trans. Inf. Syst. 2012, 95, 2870–2878. [Google Scholar] [CrossRef]
- Venkatachalam, I.; Palaniappan, S.; Ameerjohn, S. Compressive sector selection and channel estimation for optimizing throughput and delay in IEEE 802.11 ad WLAN. Int. J. Inf. Technol. 2025, 17, 987–998. [Google Scholar]
- Zhang, J.; Han, G.; Qian, Y. Queuing theory based co-channel interference analysis approach for high-density wireless local area networks. Sensors 2016, 16, 1348. [Google Scholar] [CrossRef] [PubMed]
- Oghogho, I.; Edeko, F.O.; Emagbetere, J. Measurement and modelling of TCP downstream throughput dependence on SNR in an IEEE802. 11b WLAN system. J. King Saud Univ.Eng. Sci. 2018, 30, 170–176. [Google Scholar] [CrossRef]
- Khan, M.A.; Hamila, R.; Al-Emadi, N.A.; Kiranyaz, S.; Gabbouj, M. Real-time throughput prediction for cognitive Wi-Fi networks. J. Netw. Comput. Appl. 2020, 150, 102499. [Google Scholar] [CrossRef]
- Divya, C.; Naik, P.V.; Mohan, R. Throughput Analysis of Dense-Deployed WLANs Using Machine Learning. In Proceedings of the 2023 International Conference on Advances in Electronics, Communication, Computing and Intelligent Information Systems (ICAECIS), Bangalore, India, 19–21 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 332–337. [Google Scholar]
- Szott, S.; Kosek-Szott, K.; Gawłowicz, P.; Gómez, J.T.; Bellalta, B.; Zubow, A.; Dressler, F. Wi-Fi meets ML: A survey on improving IEEE 802.11 performance with machine learning. IEEE Commun. Surv. Tutor. 2022, 24, 1843–1893. [Google Scholar] [CrossRef]
- Ali, R.; Nauman, A.; Zikria, Y.B.; Kim, B.-S.; Kim, S.W. Performance optimization of QoS-supported dense WLANs using machine-learning-enabled enhanced distributed channel access (MEDCA) mechanism. Neural Comput. Appl. 2020, 32, 13107–13115. [Google Scholar] [CrossRef]
- Shao, S.; Fan, M.; Yu, C.; Li, Y.; Xu, X.; Wang, H. Machine Learning-Assisted Sensing Techniques for Integrated Communications and Sensing in WLANs: Current Status and Future Directions. Prog. Electromagn. Res. 2022, 175, 45–79. [Google Scholar] [CrossRef]
- Shaabanzadeh, S.S.; Sánchez-González, J. Contribution to the Development of Wi-Fi Networks Through Machine Learning Based Prediction and Classification Techniques. Ph.D. Thesis, Universitat Politècnica de Catalunya Barcelona, Barcelonam, Spain, 2024. [Google Scholar]
- Feng, Y.; Liu, L.; Shu, J. A link quality prediction method for wireless sensor networks based on XGBoost. IEEE Access 2019, 7, 155229–155241. [Google Scholar] [CrossRef]
- Sheng, C.; Yu, H. An optimized prediction algorithm based on XGBoost. In Proceedings of the 2022 International Conference on Networking and Network Applications (NaNA), Urumchi, China, 3–5 December 2022; IEEE: Piscataway, NJ, USA, 2002; pp. 1–6. [Google Scholar]
- Mohan, R.; Ramnan, K.V.; Manikandan, J. Machine Learning approaches for predicting Throughput of Very High and EXtreme High Throughput WLANs in dense deployments. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Min, G.; Hu, J.; Jia, W.; Woodward, M.E. Performance analysis of the TXOP scheme in IEEE 802.11 e WLANs with bursty error channels. In Proceedings of the 2009 IEEE Wireless Communications and Networking Conference, Budapest, Hungary, 5–8 April 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1–6. [Google Scholar]
- Vergara, J.R.; Estévez, P.A. A review of feature selection methods based on mutual information. Neural Comput. Appl. 2014, 24, 175–186. [Google Scholar] [CrossRef]
- Fernandez, G.A. Machine Learning for Wireless Network Throughput Prediction. Adv. Mach. Learn. Artif. Intell. 2023, 5, 1–6. [Google Scholar]
- Zhao, X.; Liu, W. Artificial Intelligence Based Feature Selection and Prediction of Downlink IP Throughput. In Proceedings of the 2023 International Conference on Wireless Communications and Signal Processing (WCSP), Hangzhou, China, 2–4 November 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 116–121. [Google Scholar]
- Jiwane, U.B.; Jugele, R.N. A Hybrid Swarm Intelligence Technique for Feature Selection in Support Vector Machine (SVM) Classifier using Particle Swarm Optimization (PSO) and Ant Colony Optimization (ACO). Cureus J. 2025, 2. [Google Scholar] [CrossRef]
- Deng, L.; Liu, S. Snow ablation optimizer: A novel metaheuristic technique for numerical optimization and engineering design. Expert Syst. Appl. 2023, 225, 120069. [Google Scholar] [CrossRef]
- Mirjalili, S. Genetic algorithm. In Evolutionary Algorithms and Neural Networks: Theory and Applications; Springer: Cham, Switzerland, 2019; pp. 43–55. [Google Scholar]
- Wang, D.; Tan, D.; Liu, L. Particle swarm optimization algorithm: An overview. Soft Comput. 2018, 22, 387–408. [Google Scholar] [CrossRef]
- Tranmer, M.; Elliot, M. Multiple linear regression. Cathie Marsh Cent. Census Surv. Res. 2008, 5, 1–5. [Google Scholar]
- Ranstam, J.; Cook, J.A. LASSO regression. J. Br. Surg. 2018, 105, 1348. [Google Scholar] [CrossRef]
- McDonald, G.C. Ridge regression. Wiley Interdiscip. Rev. Comput. Stat. 2009, 1, 93–100. [Google Scholar] [CrossRef]
- Fürnkranz, J. Decision Tree. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; pp. 263–267. [Google Scholar]
- Segal, M.R. Machine Learning Benchmarks and Random Forest Regression. Center for Bioinformatics and Molecular Biostatistics. 2004. Available online: https://escholarship.org/uc/item/35x3v9t4#author (accessed on 20 July 2025).
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field Name | Description |
|---|---|
| test_id | Test ID, used to identify each independent test |
| test_dur | Test duration (unit: s) |
| loc_id | Location ID, indicating the area where data collection occurred |
| protocol | Communication protocol type used (e.g., 802.11n, 802.11ac) |
| pkt_len | Network packet length (unit: bytes) |
| bss_id | Basic Service Set Identifier |
| ap_name | Access Point device name |
| ap_mac | Access Point MAC address |
| ap_id | Access Point ID, used to associate with terminals |
| pd | Preamble length |
| ed | Extended Detection flag |
| nav | Network Allocation Vector |
| eirp | Effective Isotropic Radiated Power |
| sta_mac | Terminal (STA) MAC address |
| sta_id | Terminal ID, used to uniquely identify each terminal device |
| sta_from_sta_0_rssi | RSSI received by STA from STA_0 (unit: dBm) |
| sta_from_sta_1_rssi | RSSI received by STA from STA_1 (unit: dBm) |
| nss | Number of Spatial Streams |
| mcs | Modulation and Coding Scheme number |
| per | Packet Error Rate |
| num_ampdu | Number of Aggregated MAC Protocol Data Units (AMPDU) |
| ppdu_dur | Physical layer Protocol Data Unit (PPDU) duration |
| other_air_time | Channel occupancy time by other devices |
| throughput | Network throughput (unit: Mbps) |
| seq_time | Timestamp sequence corresponding to the current record |
| Model | Hyperparameters |
|---|---|
| Genetic Algorithm (GA) | Crossover rate = 0.8; Mutation rate = 0.1 |
| Particle Swarm Optimization (PSO) | Cognitive coefficient (c1) = 0.5; Social coefficient; (c2) = 0.3; Inertia weight (ω) = 0.9 |
| Snow Melting Algorithm (SMO) | Elite pool size = 0.5 × N |
| BiRPSMO | Elite pool size = 0.5 × N |
| Multiple Linear Regression | Intercept term enabled (fit_intercept = True) |
| LASSO Regression | Regularization parameter (alpha) = 1.0 Intercept term enabled (fit_intercept = True) |
| Ridge Regression | Regularization parameter (alpha) = 1.0 Intercept term enabled (fit_intercept = True) |
| Decision Tree Regression | Minimum samples per leaf = 1 |
| Random Forest Regression | Number of trees = 100; Minimum samples per leaf = 1 |
| XGBoost Regression | Number of weak learners = 100; Learning rate = 0.3 |
| Model | MAE | MAPE | MSE | RMSE | R2 | Number of Selected Features |
|---|---|---|---|---|---|---|
| GA_DT | 2.1866 | 6.5722 | 13.1898 | 3.6318 | 0.8830 | 96 |
| PSO_DT | 2.1947 | 6.5835 | 13.7231 | 3.7045 | 0.8782 | 109 |
| BiSMO_DT | 2.3524 | 7.4458 | 15.8739 | 3.9842 | 0.8592 | 39 |
| BiRPSMO_DT | 1.9141 | 5.7604 | 11.2816 | 3.3588 | 0.8999 | 44 |
| Model | MAE | MAPE | MSE | RMSE | R2 |
|---|---|---|---|---|---|
| Multiple Linear Regression | 3.321 | 0.11569 | 17.292 | 4.1584 | 0.80155 |
| LASSO Regression | 3.321 | 0.11571 | 17.2848 | 4.1575 | 0.80164 |
| Ridge Regression | 3.3392 | 0.11782 | 16.7709 | 4.0952 | 0.80753 |
| Decision Tree Regression | 1.3623 | 0.046989 | 4.3808 | 2.093 | 0.94973 |
| Random Forest Regression | 2.0796 | 0.084708 | 7.0621 | 2.6575 | 0.91895 |
| XGBoost Regression | 0.9016 | 0.035258 | 1.3746 | 1.1724 | 0.98422 |
| Model | MAE | MAPE | MSE | RMSE | R2 |
|---|---|---|---|---|---|
| Multiple Linear Regression | 22.624 | 0.32647 | 808.9904 | 28.4428 | 0.025225 |
| LASSO Regression | 22.7191 | 0.32735 | 809.9635 | 28.45999 | 0.33971 |
| Ridge Regression | 27.0598 | 0.37995 | 1066.7536 | 32.6612 | 0.18751 |
| Decision Tree Regression | 4.6083 | 0.062756 | 44.5059 | 6.6713 | 0.94081 |
| Random Forest Regression | 8.0441 | 0.13538 | 124.2838 | 11.1483 | 0.86873 |
| XGBoost Regression | 2.5071 | 0.043215 | 10.8037 | 3.2869 | 0.98957 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Huang, X.; Lv, D.; Yu, Y.; Zhang, Y.; Zhu, Z.; Zhou, T. Transmission Opportunity and Throughput Prediction for WLAN Access Points via Multi-Dimensional Feature Modeling. Electronics 2025, 14, 2941. https://doi.org/10.3390/electronics14152941
Li W, Huang X, Lv D, Yu Y, Zhang Y, Zhu Z, Zhou T. Transmission Opportunity and Throughput Prediction for WLAN Access Points via Multi-Dimensional Feature Modeling. Electronics. 2025; 14(15):2941. https://doi.org/10.3390/electronics14152941
Chicago/Turabian StyleLi, Wei, Xin Huang, Danju Lv, Yueyun Yu, Yan Zhang, Zhicheng Zhu, and Ting Zhou. 2025. "Transmission Opportunity and Throughput Prediction for WLAN Access Points via Multi-Dimensional Feature Modeling" Electronics 14, no. 15: 2941. https://doi.org/10.3390/electronics14152941
APA StyleLi, W., Huang, X., Lv, D., Yu, Y., Zhang, Y., Zhu, Z., & Zhou, T. (2025). Transmission Opportunity and Throughput Prediction for WLAN Access Points via Multi-Dimensional Feature Modeling. Electronics, 14(15), 2941. https://doi.org/10.3390/electronics14152941