
A Novel Llama 3-Based Prompt Engineering Platform for Textual Data Generation and Labeling †


Abstract
1. Introduction
- Automated platform for data generation and labeling: a user-friendly web platform that enables users to generate labeled datasets or annotate their own data by specifying task parameters through an interactive interface.
- Integrated prompt engineering module: a novel framework that combines attributed prompts with multiple prompting techniques (zero-shot, few-shot, CoT, role-based) to enhance control and task alignment.
- Synthetic dataset release: two fully synthetic, high-quality benchmark datasets were created using Llama 3.3:
- LLM-generated restaurant reviews: 6028 sentiment-labeled reviews.
- LLM-generated news: 6141 news articles labeled by topic (World, Sports, Sci_Tech, and Business).
2. Background and Related Work
2.1. LLMs for Data Labeling
2.2. LLMs for Data Generation
2.3. Prompt Engineering and Attributed Prompts
- Role-based prompting: assigns persona or behavior to the model [16].
- Simple prompt: “Write a restaurant review.”
- Attributed prompt: “Write a 40–60-word, informal, positive review about a Mexican restaurant.”
2.4. Ethical Considerations
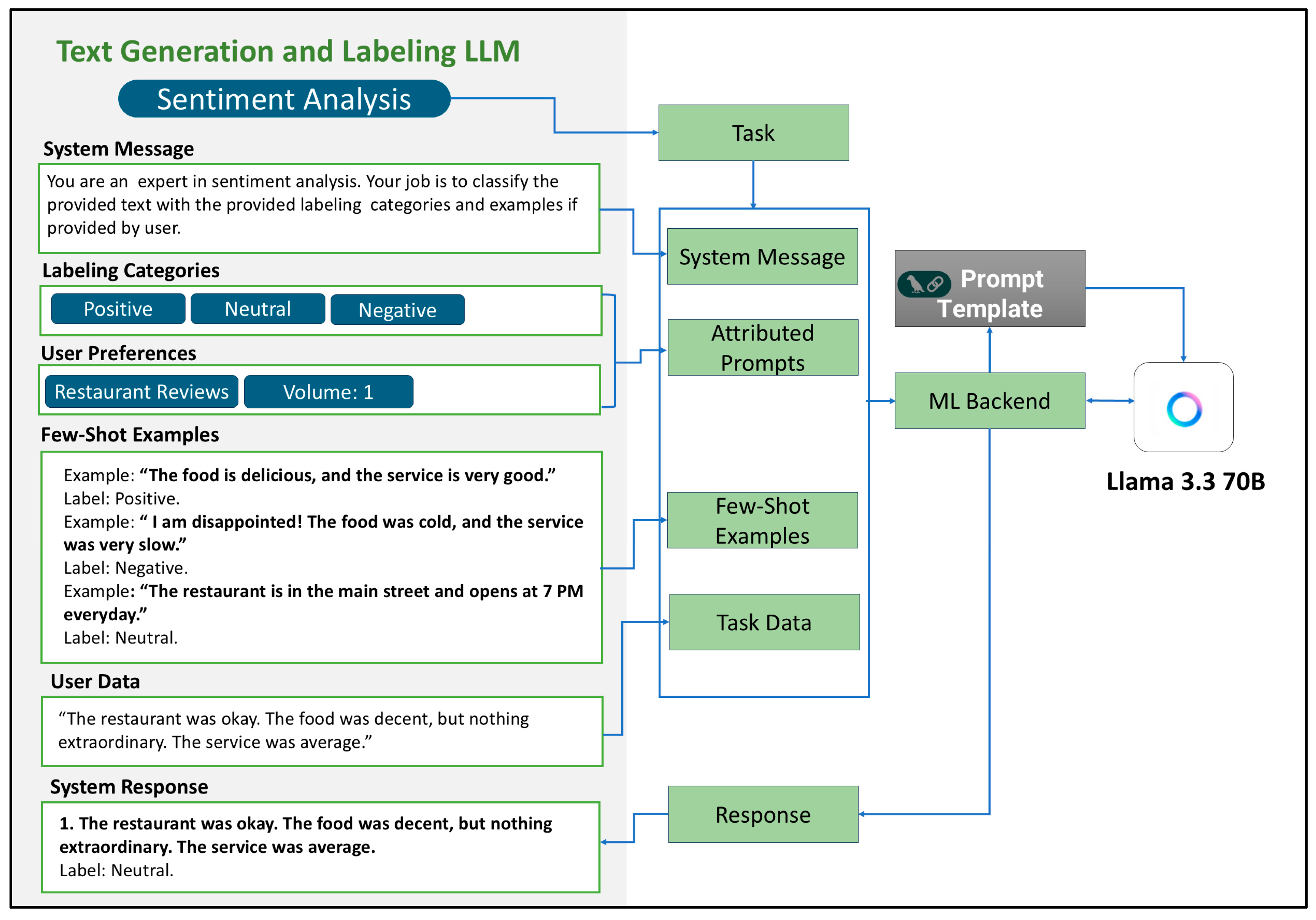
3. Methodology and System Design
3.1. Data Generation and Labeling Technique
- Objective
- 2.
- Attributed Prompts
- 3.
- Prompt Engineering
- Zero-shot.
- Few-shot.
- Chain-of-thought
- Role-playing.
- 4.
- Data Generation
- 5.
- Data Labeling
- 6.
- Validation and Storage
3.2. Functional Overview
- Users choose the domain (e.g., restaurant reviews), output volume, word length, and optional class labels.
- Optionally, users may include few-shot examples (up to 10) for guidance.
- The system constructs an attributed prompt using the LangChain framework (v0.3.25).
- Llama 3.3 70B generates the textual outputs, which are displayed for review and available for download.
- Users input raw data and choose the task (e.g., sentiment analysis, binary/multi-class classification, or NER).
- Labels can be predefined or custom-defined (up to 10).
- Few-shot examples can be added to improve LLM labeling accuracy.
- The system classifies the data and returns structured results.
- Feedback can be submitted for human-in-the-loop refinement.
3.3. Prompting Techniques and Attributed Prompts
- Zero-shot prompting: task-only prompts for general cases.
- Few-shot Prompting: up to 10 labeled examples provided inline for context.
- Chain-of-thought (CoT): Encourages step-by-step reasoning using phrases such as “Let’s think step by step” [8]. CoT mimics the way humans break down complex tasks into smaller steps during problem-solving. CoT has demonstrated notable improvements in tasks such as solving mathematical problems [25].
- Role-playing prompting: assigns roles such as “food critic” or “expert annotator” to match task context.
3.4. Evaluation Strategy
- Automated benchmarking using labeled datasets.
- Human-in-the-loop review of sampled outputs for quality.
- Ethical bias and hallucination analysis of generated text.
- Manual validation of output label accuracy and relevance.
- Usability testing and user feedback collection.
3.5. Benchmark Datasets
- AG News (AG’s News Corpus) [33] contains 30,000 training samples and 1900 test samples for each class. It includes the title and description fields of news articles from AG’s news corpus, categorized into four main classes: Sport, World, Business, Sci/Tech. This dataset was selected to evaluate the system performance in multi-class classifying with a small number of classes (labels).
- Amazon Reviews dataset [34] consists of 13,800 training data samples, 230 validation samples, and 1130 testing samples of customer reviews for Amazon products. It comprises 23 categories. This dataset was chosen to assess system performance in multi-class classifying with a large number of classes (labels).
- Yelp dataset [34] consists of 67,000 training samples and 38,000 restaurant reviews, categorized into two classes: positive and negative. This dataset was selected to represent and evaluate binary sentiment classification within the domain of business and social reviews.
- These datasets are used to compare the system-generated outputs against ground truth labels and were selected to ensure diversity in classification tasks (including binary and multi-class classification) and in domains (such as News, E-Commerce, and Customer Reviews). Furthermore, the complexity of the labeling facilitates a comprehensive evaluation of model performance under both few-shot and zero-shot configurations.
3.6. System Architecture
- LLM engine: uses Llama 3.3 (70B, open source) for generation and labeling.
- User interface (UI): provides fields for task configuration, preview, feedback, and export.
- Prompt engineering module: builds attributed prompts with user-defined settings.
- Machine learning backend: handles communication between UI, prompt module, and LLM.
- Evaluation module: validates the quality of generated and labeled outputs.
3.7. User Interface Design
- Domain and classification type selection.
- Custom label input.
- Additional attributes (e.g., tone, volume, length).
- Few-shot example entries (up to 10).
- User/system role fields.
- Dynamic prompt preview and system prompt formatting.
- Output preview, download, and feedback submission.
3.8. Backend Components
- Prompt formatter: uses LangChain to merge user inputs into structured templates.
- Request handler: sends prompts to the LLM and returns formatted responses.
- Data validator: evaluates label consistency and output structure.
- Feedback engine: captures human feedback to refine prompt strategies.
4. Implementation
4.1. Development Environment and Model Evaluation
Model Variants Tested
- Llama 3.2 3B Instruct.
- Llama 3 8B Instruct.
- Llama 3.3 70B Instruct (the final model used in deployment).
4.2. Frontend Implementation
4.3. Backend and Prompt Logic
4.3.1. Prompt Engineering Techniques
- Few-shot prompting: Standard prompting technique where users can input up to 10 examples, mapped to their corresponding labels. Each label is ideally represented at least once, improving classification precision, helping the model understand the desired output format and task requirements, and enhancing the model’s ability to control hallucinations [26]. This is aligned with prior studies recommending 1–3 examples per class [17].
- Zero-shot prompting: Standard prompting technique used when no examples are provided. The model relies entirely on instructions, system roles, and system prior knowledge. This technique is used when the task is straightforward and does not require explicit guidance.
- Role-based prompting: The system auto-generates role messages using domain and classification context (e.g., “You are a restaurant critic”). Users can modify this as needed. By employing role-play prompting, the system can simulate realistic interactions and generate persona-driven data.
- Chain-of-thought prompting: CoT logic is embedded in our system prompts to encourage stepwise reasoning:
- E.g., “Think step by step. Check for duplicates. Modify if necessary.”
- In binary sentiment: “Restrict to Positive/Negative only. Lean toward dominant tone.”
- LangChain Templates
- Domain.
- Classification type.
- Few-shot examples.
- Output count.
- System/user roles.
- Custom user instructions.
4.3.2. Synthetic Data Generation Pipeline
- Temperature: 0.7.
- Min/max word limits.
- Optional few-shot examples.
- Role assignment in prompts (e.g., expert reviewer, journalist).
4.3.3. Data-Labeling Pipeline
- Task types: sentiment analysis, binary/multi-class classification, NER.
- Domains: Restaurants, News, E-Commerce, Tourism.
- Labels: fixed or user-defined (up to 10).
- Prompt configuration:
- Zero/few-shot support.
- Custom role and user prompt.
- Label format output: rendered in UI and exportable.
- Merge user input and task type into a system prompt.
- Send prompt to Llama 3.3
- Parse labeled output.
- Display in the UI.
- Export as CSV.
5. Evaluation, Results, and Discussion
5.1. Evaluation Framework Overview
- Evaluation Phase A: Benchmark Dataset LabelingAssesses the system’s labeling performance on benchmark datasets such as AG News, Amazon Reviews, and Yelp Reviews using zero-shot or few-shot prompting techniques.
- Evaluation Phase B: Generated Data Labeling (Labeling of the system-generated data)Evaluates the internal consistency of the system by measuring how accurately it can label the text it has generated, using structured prompts and self-labeling pipelines.
- Evaluation Phase C: Data Generation QualityAssesses the effectiveness of the system in generating textual data based on user-defined prompts, incorporating few-shot examples and attributes such as domain and specified labels.
- Evaluation Phase D: Comparative Analysis with GPT-4Benchmarks the system’s output quality and efficiency against GPT-4 by comparing labeling accuracy, time efficiency, and cost-effectiveness. The same dataset and prompts are used across both systems to ensure fairness (the labeling process).
- Evaluation Phase E: Usability TestingEvaluates the user experience through structured testing using the System Usability Scale (SUS). Qualitative feedback and user suggestions are also gathered to identify usability issues and opportunities for improvement.
5.2. Evaluation Metrics
- Accuracy
- Precision
- Recall
- F1 Score
5.3. Evaluation Phase A: Benchmark Dataset Labeling
5.3.1. Methodology
- Task: sentiment analysis.
- Dataset: the Yelp Reviews dataset containing 67.000 reviews with ground truth labels.
- Model: prompt-tuned Llama 3.3 70B for labeling data.
- The dataset consists of binary sentiments: positive and negative.
- Predictions: the model predicts labels for 33,800 reviews.
- Evaluation: compare predictions with ground truth labels and compute accuracy, precision, recall, and F1-score using Scikit-learn (v1.7.0rc1).
- Task: topic classification.
- Dataset: the AG News dataset containing 67.000 news articles with ground truth labels.
- Model: prompt-tuned Llama 3.3 70B for labeling data.
- The dataset consists of four news article categories which are World, Sports, Business, and Sci_Tech.
- Predictions: the model predicts labels for the 500 news articles.
- Evaluation: compare predictions with ground truth labels and compute accuracy, precision, recall, and F1-score using Scikit-learn (v1.7.0rc1).
- Task: topic classification.
- Dataset: Amazon Reviews dataset containing 13.291 reviews with ground truth labels.
- Model: prompt-tuned Llama 3.3 70B for labeling data.
- The dataset consists of 23 Amazon product reviews which are magazines, camera and photos, office products, kitchen, cell phones service, computer video games, grocery and gourmet food, tools hardware, automotive, music album, health and personal care, electronics, outdoor living, video, apparel, toys games, sports outdoors., books, software, baby, musical and instruments, beauty, jewelry, and watches.
- Predictions: the model predicts labels for the 13.291 reviews.
- Evaluation: compare predictions with ground truth labels and compute accuracy, precision, recall, and F1-score using Scikit-learn (v1.7.0rc1).
5.3.2. Results
5.3.3. Analysis and Discussion
5.4. Evaluation Phase B: Synthetic Data Labeling
5.4.1. Methodology
- Number of evaluators: We used the Upwork (https://www.upwork.com/ accessed on 9 July 2025) [39] platform to hire three expert annotators who were fluent in English and experienced in data annotation for each dataset. Each annotator was asked to manually label every item in the dataset without the use of AI tools. One round of revisions was requested for refinement. (Note: we conducted two rounds of revisions to ensure the accuracy and consistency of the expert-assigned labels).
- Inter-rater reliability: For each text item in the system-generated datasets (LLM-Generated Restaurant Reviews or LLM-Generated News), we applied majority voting to determine inter-rater agreement among annotators. The label agreed upon by at least two out of three annotators was selected as the ‘gold standard’ for the dataset.
5.4.2. Results
5.4.3. Analysis and Discussion
- Business: 1512 true positives out of 1530 actual Business samples. There were 13 misclassified as Sci_Teh and 5 as World.
- Sci_Tech: 1602 true positives out of 1641 actual Sci_Tech samples. Misclassifications included 1 as Sports and 38 as World.
- Sports: 1533 true positives out of 1556 actual Sports samples. Misclassifications included 9 to Business, 11 to Sci_Tech, and 3 to World.
- World: 1403 true positives out of 1414 actual World samples. Misclassifications include 3 to Business and 8 to Sci_Tech.
- Comparison with Real-World Data Performance
- Human Labeling vs. Llama 3.3-70B-Instruct Labeling
- NLP training and evaluation: the datasets can be employed in NLP tasks such as sentiment analysis, text classification, and information retrieval to train and evaluate machine learning models.
- Dialogue system development: the Restaurant Reviews dataset is well suited for building and training conversational agents (e.g., customer support chatbots).
- Data augmentation: Both datasets can be used to augment real-world datasets, helping to address issues such as class imbalance, data scarcity, and data privacy.
5.5. Evaluation Phase C: Data Generation (Generated Data Quality)
5.5.1. Methodology
- Relevance: Does the output appropriately address the input prompt?
- Coherence: Does the text demonstrate logical flow and readability?
- Fluency: Is the text grammatically correct and natural sounding?
- Correctness: Is the content factually and contextually accurate (where applicable)?
5.5.2. Results
5.5.3. Analysis and Discussion
- Zero-shot, chain-of-thought (CoT), and role-play: the techniques demonstrated high performance in terms of both relevance and coherence.
- Zero-shot prompting performs particularly well when the model has sufficient prior knowledge of the topic.
- Role-play: effectively aligns the output tone and content with a specific persona or scenario, significantly enhancing relevance.
- Chain-of-thought (CoT): delivered especially strong results in generating children’s stories, achieving a perfect score (5/5), and also performed well in e-commerce review tasks, with a score of 4.9/5.
- Combinations: techniques combining CoT, role-play, and either zero-shot or few-shot learning produced consistently high scores, often ranging from 4.7 to 5.0 overall.
5.6. Evaluation Phase D: Comparative Analysis with ChatGPT-4
5.6.1. Methodology
5.6.2. Results
5.6.3. Analysis and Discussion
5.7. Evaluation Phase E: Usability Testing via SUS
5.7.1. Methodology
- Do you have any suggestions for improving the system?
- What do you think of the system? Please share your feedback here.
5.7.2. Results
5.7.3. Analysis
- Overall, the system is well-built, functional, and responsive.
- Data generation and labeling quality are very good, with great potential for business applications.
- The system is easy to use once users understand how to work through it.
- User interface: Many users pointed out that the UI needs to be improved to be more modern, polished, and visually engaging. A smoother, more attractive design would take the experience to the next level.
- Submit button: The submit button functionality could be improved for better user feedback after submission.
- Minor bugs:
- Data labeling flow: auto-adding custom attributes (such as NER) after filling them in would make the flow smoother, instead of requiring manual addition afterward.
5.8. Evaluation of Results Against Previous Studies
6. Conclusions
Limitations and Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, S.; Liu, Y.; Xu, Y.; Zhu, C.; Zeng, M. Want To Reduce Labeling Cost? GPT-3 Can Help. arXiv 2021. [Google Scholar] [CrossRef]
- Reyes, O.; Morell, C.; Ventura, S. Effective active learning strategy for multi-label learning. Neurocomputing 2018, 273, 494–508. [Google Scholar] [CrossRef]
- Whang, S.E.; Roh, Y.; Song, H.; Lee, J.-G. Data collection and quality challenges in deep learning: A data-centric AI perspective. VLDB J. 2023, 32, 791–813. [Google Scholar] [CrossRef]
- Gilardi, F.; Alizadeh, M.; Kubli, M. ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks. Proc. Natl. Acad. Sci. USA 2023, 120, e2305016120. [Google Scholar] [CrossRef]
- Dai, H.; Liu, Z.; Liao, W.; Huang, X.; Cao, Y.; Wu, Z.; Zhao, L.; Xu, S.; Liu, W.; Liu, N.; et al. AugGPT: Leveraging ChatGPT for Text Data Augmentation. arXiv 2023. [Google Scholar] [CrossRef]
- Llama. Available online: https://llama.meta.com/ (accessed on 5 February 2024).
- Meta Llama 3. Available online: https://llama.meta.com/llama3/ (accessed on 7 May 2024).
- Alsakran, W.; Alabduljabbar, R. Exploring the Potential of LLMs and Attributed Prompt Engineering for Efficient Text Generation and Labeling. In Proceedings of the 2024 2nd International Conference on Foundation and Large Language Models (FLLM), Dubai, United Arab Emirates, 26–29 November 2024; pp. 244–252. [Google Scholar]
- ChatGPT. Available online: https://chatgpt.com (accessed on 3 July 2025).
- Refuel.ai: High-Quality Data at the Speed of Thought. Available online: https://refuel.ai (accessed on 3 July 2025).
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large Language Models are Zero-Shot Reasoners. arXiv 2023. [Google Scholar] [CrossRef]
- He, X.; Lin, Z.; Gong, Y.; Jin, A.-L.; Zhang, H.; Lin, C.; Jiao, J.; Yiu, S.M.; Duan, N.; Chen, W. AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators. arXiv 2023. [Google Scholar] [CrossRef]
- Alizadeh, M.; Kubli, M.; Samei, Z.; Dehghani, S.; Bermeo, J.D.; Korobeynikova, M.; Gilardi, F. Open-Source Large Language Models Outperform Crowd Workers and Approach ChatGPT in Text-Annotation Tasks. arXiv 2023. [Google Scholar] [CrossRef]
- Ding, B.; Qin, C.; Liu, L.; Chia, Y.K.; Joty, S.; Li, B.; Bing, L. Is GPT-3 a Good Data Annotator? arXiv 2023. [Google Scholar] [CrossRef]
- Shushkevich, E.; Alexandrov, M.; Cardiff, J. Improving Multiclass Classification of Fake News Using BERT-Based Models and ChatGPT-Augmented Data. Inventions 2023, 8, 112. [Google Scholar] [CrossRef]
- Trad, F.; Chehab, A. Prompt Engineering or Fine-Tuning? A Case Study on Phishing Detection with Large Language Models. Mach. Learn. Knowl. Extr. 2024, 6, 367–384. [Google Scholar] [CrossRef]
- Sahu, G.; Rodriguez, P.; Laradji, I.H.; Atighehchian, P.; Vazquez, D.; Bahdanau, D. Data Augmentation for Intent Classification with Off-the-shelf Large Language Models. arXiv 2022. [Google Scholar] [CrossRef]
- OpenAI Platform. Available online: https://platform.openai.com (accessed on 22 March 2024).
- GPT-J. Available online: https://www.eleuther.ai/artifacts/gpt-j (accessed on 22 March 2024).
- Ubani, S.; Polat, S.O.; Nielsen, R. ZeroShotDataAug: Generating and Augmenting Training Data with ChatGPT. arXiv 2023. [Google Scholar] [CrossRef]
- Yang, K.; Liu, D.; Lei, W.; Yang, B.; Xue, M.; Chen, B.; Xie, J. Tailor: A Soft-Prompt-Based Approach to Attribute-Based Controlled Text Generation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; Association for Computational Linguistics: Toronto, QC, Canada, 2023; pp. 410–427. [Google Scholar]
- Yu, Y.; Zhuang, Y.; Zhang, J.; Meng, Y.; Ratner, A.; Krishna, R.; Shen, J.; Zhang, C. Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias. arXiv 2023. [Google Scholar] [CrossRef]
- White, J.; Fu, Q.; Hays, S.; Sandborn, M.; Olea, C.; Gilbert, H.; Elnashar, A.; Spencer-Smith, J.; Schmidt, D.C. A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT. arXiv 2023. [Google Scholar] [CrossRef]
- Fei-Fei, L.; Fergus, R.; Perona, P. One-shot learning of object categories. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar] [CrossRef]
- Yu, P.; Xu, H.; Hu, X.; Deng, C. Leveraging Generative AI and Large Language Models: A Comprehensive Roadmap for Healthcare Integration. Healthcare 2023, 11, 2776. [Google Scholar] [CrossRef]
- Pal, A.; Umapathi, L.K.; Sankarasubbu, M. Med-HALT: Medical Domain Hallucination Test for Large Language Models. arXiv 2023. [Google Scholar] [CrossRef]
- Hua, S.; Jin, S.; Jiang, S. The Limitations and Ethical Considerations of ChatGPT. Data Intell. 2023, 6, 201–239. [Google Scholar] [CrossRef]
- Tan, Z.; Beigi, A.; Wang, S.; Guo, R.; Bhattacharjee, A.; Jiang, B.; Karami, M.; Li, J.; Cheng, L.; Liu, H. Large Language Models for Data Annotation: A Survey. arXiv 2024. [Google Scholar] [CrossRef]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large language models encode clinical knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Ji, X.; Zhao, Z.; Hei, X.; Choo, K.-K.R. Ethical Considerations and Policy Implications for Large Language Models: Guiding Responsible Development and Deployment. arXiv 2023. [Google Scholar] [CrossRef]
- Törnberg, P. Best Practices for Text Annotation with Large Language Models. arXiv 2024. [Google Scholar] [CrossRef]
- Sahoo, P.; Singh, A.K.; Saha, S.; Jain, V.; Mondal, S.; Chadha, A. A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications. arXiv 2024. [Google Scholar] [CrossRef]
- Papers with Code—AG News Dataset. Available online: https://paperswithcode.com/dataset/ag-news (accessed on 20 May 2024).
- AttrPrompt/Datasets at Main yueyu1030/AttrPrompt. Available online: https://github.com/yueyu1030/AttrPrompt/tree/main/datasets (accessed on 4 May 2024).
- Google Colaboratory. Available online: https://colab.research.google.com/ (accessed on 23 January 2024).
- Spaces—Hugging Face. Available online: https://huggingface.co/spaces (accessed on 21 April 2025).
- Streamlit A Faster Way to Build and Share Data Apps. Available online: https://streamlit.io/ (accessed on 21 April 2025).
- Bandi, A.; Adapa, P.V.S.R.; Kuchi, Y.E.V.P.K. The Power of Generative AI: A Review of Requirements, Models, Input–Output Formats, Evaluation Metrics, and Challenges. Future Internet 2023, 15, 260. [Google Scholar] [CrossRef]
- Upwork|Hire Top Freelance Talent with Confidence. Available online: https://www.upwork.com/ (accessed on 3 July 2025).




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Task | Model(s) | Prompt Technique | Key Findings |
|---|---|---|---|---|---|
| [1] | 2021 | Data labeling. | GPT-3 (Davinci) | Zero-shot. | The proposed labeling method can reduce labeling costs by 50% to 96% while achieving the same performance with human-labeled data. |
| [11] | 2023 | Reasoning: Arithmetic Reasoning (AR), Commonsense Reasoning (CR). Symbolic and Logical reasoning. | PaLM, (540 B) model, InstructGPT model (text-davinci 002), GPT-3, GPT-Neo, GPT-J, OPT (13 B) | Zero-shot + CoT. | The ‘Zero-Shot CoT’ outperforms zero-shot LLMs’ performance when using the same prompting template on diverse reasoning tasks such as arithmetic and commonsense reasoning. Improved the accuracy of (text-davinci 002) on MultiArith and GSM8K reasoning benchmarks from 17.7% to 78.7% and from 10.4 to 40.7%, respectively, and demonstrated similar improvements on P450B parameter PaLM. |
| [12] | 2023 | Data labeling. | GPT-3.5 | Few-shot + CoT prompts. | GPT-3.5 outperforms crowdsourced annotators in user input and keyword relevance assessment and achieves comparable results in BoolQ and WiC tasks with crowdsourced annotators. |
| [13] | 2023 | Text annotation tasks. | ChatGPT, | zero-shot and few-shot, different temperature parameters. | ChatGPT outperforms MTurk in ten out of eleven annotation tasks, while open-source models outperform MTurk in six out of eleven tasks. Results demonstrate that open-source LLMs outperform human annotators and approach ChatGPT in text data annotation tasks. |
| [14] | 2023 | Data annotation. | GPT-3 | Zero-shot, one-shot, and few-shot prompts. | Direct annotation of unlabeled data is effective for tasks with a small label space, whereas generation-based methods are more suitable for tasks with a large label space. Additionally, generation-based methods prove to be more cost-effective when compared with the direct annotation of unlabeled data. |
| [4] | 2023 | Data annotation. | ChatGPT | Zero-shot learning. | ChatGPT outperforms both trained annotators and crowd workers in all annotation tasks. ChatGPT’s zero-shot learning outperforms crowd workers by an average of 25%. |
| [15] | 2023 | Data labeling ‘Fake News multiclass classification’. | BERT-Based Models (mBERT, SBERT, XLM-RoBERTa) and ChatGPT | Fine-tuning. | ChatGPT-generated messages showed performance enhancement in quality for True, Partially True, and other news classifications. |
| [16] | 2024 | URL classification. | GPT-3.5 and Claude 2 GPT-2, Bloom-560m, Baby Llama-58m DistilGPT-2 | Zero-shot, role-playing, chain-of-thought and fine-tuning. | An F1-score of 92.74% for prompt engineering and An F1-score of 99.29% and an AUC of 99.56% for fine-tuning. |
| Ref. | Year | Task | Model(s) | Prompt Technique | Key Findings |
|---|---|---|---|---|---|
| [17] | 2022 | Data augmentation. | GPT-3 models (Ada, Babbage, Curie and Davinci) & GPT-J | Few-Shot (10 training examples) | The generated GPT-3 samples enhanced classification accuracy when the intended categories are clearly differentiated from one another. |
| [5] | 2023 | Text data augmentation. | ChatGPT | Few-shot prompting | Results show the superior performance of the AugGPT approach over state-of-the-art text data augmentation methods, achieving 88.9% and 89.9 accuracy for BERT and BERT with contrastive respectively for Symptoms dataset |
| [20] | 2023 | Augmenting data in low resource scenarios. | ChatGPT | Task specific ChatGPT prompts, zero-shot prompting | Using ChatGPT zero-shot prompts outperform most popular data augmentation methodologies. |
| [21] | 2023 | Text generation. | GPT-2 | Single and multi-attribute prompts | Tailor requires only 0.08% extra training parameters and can achieve significant improvements on eleven attribute-specific tasks. |
| [22] | 2023 | Generating training data. | gpt-3.5-turbo | Attributed prompts | Attributed prompts outperform simple prompts, utilizing only 5% of the querying costs of ChatGPT with simple prompts, and reduce bias in the newly generated data. |
| Ref. | Year | Task | Model | Risk | Recommendation |
|---|---|---|---|---|---|
| [27] | 2023 | Content generation. | ChatGPT. | Hallucination Originality Toxicity Privacy and security issues | Reviewing generated content of AI models. Regulations and policies related to generative AI must be up to date to keep up with the rapid evolution of these models. |
| [30] | 2023 | Content generation. | ChatGPT and LLMs. | System role-playing prompts. Perturbation. Image-related issues. Hallucinations. Generation-related problems. Bias and discrimination. | Developing specialized detectors to manage generation-related issues. Developing LLMs with priority to address ethical, legal, and moral issues. Users must use LLMs responsibly. Legislation should be implemented for AI models. |
| [31] | 2024 | Data annotation. | LLMs. | Quality of labeled data. Data annotation integrity. Overall validity of annotation. | Selecting suitable LLMs. Considering ethical and legal implications. Conduct strict model evaluation. Transparency. Using DPA. Employing prompt engineering, structuring, and analyzing prompts. Using private or copyright data with license, permission, or consent. |
| Model | #Data | Task | Accuracy | Processing Time |
|---|---|---|---|---|
| Llama 3 8B | 100 | Positive/Negative Restaurant Review Generation (20–70 Words) | 99% | 1:04:10 min |
| Llama 4 Scout 17B | 100 | Positive/Negative Restaurant Review Generation (20–70 Words) | 99% | 1:07:74 min |
| Llama 3.2 3B | 100 | Positive/Negative Restaurant Review Generation (20–70 Words) | 99% | 1:32:77 min |
| Llama 3.3 70B | 100 | Positive/Negative Restaurant Review Generation (20–70 Words) | 99% | 1:38:91 min |
| Dataset | #Data | Classes | Task | Domain |
|---|---|---|---|---|
| Restaurant Reviews | 6028 | Positive, Negative | Sentiment Analysis | Restaurants |
| News Dataset | 6141 | World, Sports, Business, Sci_Tech | Multi-Class | News |
| Dataset | Support | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| AG News | 500 | 0.92 | 0.92 | 0.92 | 0.92 |
| Yelp Reviews | 33,800 | 0.90 | 0.90 | 0.90 | 0.90 |
| Amazon Reviews | 13,291 | 0.89 | 0.92 | 0.89 | 0.89 |
| Generated Text | Predicted Label (Llama 3.3) | Human Gold Standard Label |
|---|---|---|
| I’ve tried fried chicken at many restaurants in Riyadh, but Canes stands out from the rest. The chicken is crispy on the outside and juicy on the inside. A great option for those looking for a delicious meal. | Positive | Positive ✔️ |
| Ta’ameya was the highlight of my meal, but the spicy sauce was a joke. The restaurant’s decor was straight out of an ancient Egyptian movie. I would not recommend it. | Negative | Negative ✔️ |
| I had an amazing experience at this Greek restaurant! The moussaka was tender and flavorful, and the service was top-notch. The staff was friendly and attentive. 10/10 would recommend! | Positive | Positive ✔️ |
| We celebrated our graduation in a private room, but the noise level was deafening. The music was too loud, and the staff seemed more interested in the party next door than in attending us. Not exactly the quiet night we were looking for. | Negative | Negative ✔️ |
| Generated Text | Predicted Label (Llama 3) | Human Gold Standard Label |
|---|---|---|
| The United Nations has launched a new initiative aimed at promoting education and awareness about the rights of people with disabilities. The program will provide funding and support to organizations and individuals working to promote disability rights. | World | World ✔️ |
| FIFA Announces Saudi Arabia as 2034 World Cup Host: Saudi Arabia has been officially announced as the host of the 2034 FIFA World Cup, marking a historic moment for the kingdom’s sports industry. | Sports | Sports ✔️ |
| The World Trade Organization (WTO) has launched a new initiative aimed at promoting trade facilitation and reducing customs barriers, supporting the growth of international trade. | Business | Business ✔️ |
| Researchers at a leading university have made a groundbreaking discovery in the field of renewable energy, developing a new solar panel that can harness energy from the sun more efficiently than ever before. | Sci_Tech | Sci_Tech ✔️ |
| Dataset | Support | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| LLM-Generated News | 6141 | 0.99 | 0.99 | 0.99 | 0.99 |
| LLM-Generated Restaurant Reviews | 6028 | 0.98 | 0.98 | 0.98 | 0.98 |
| Labeling Method | Support | Cost Total Cost | Estimated Cost Per Label | Notes |
|---|---|---|---|---|
| Our System Labeling | 2 * (6000) | USD 36 | USD 0.003 | Hugging Face Pro subscription. |
| Human Annotators | 2 * (6000) | USD 240 | USD 0.02 | Six human annotators (hired via Upwork). |
| Text ID | Prompt Technique | Relevance (1–5) | Coherence (1–5) | Fluency (1–5) | Correctness (1–5) | Overall Score | Notes/Comments |
|---|---|---|---|---|---|---|---|
| 01 | Zero_shot | 5 | 5 | 5 | ----- | 5 | Accurate and understandable detailed review. |
| 02 | Few_shot | 5 | 5 | 5 | ----- | 5 | Followed the example in its own unique way. |
| 03 | Role-play | 5 | 5 | 4 | ----- | 4.67 | Great detailed role-play review. Grammar error No “a” before “refund”. |
| Text ID | Prompt Technique | Relevance (1–5) | Coherence (1–5) | Fluency (1–5) | Correctness (1–5) | Overall Score | Domain |
|---|---|---|---|---|---|---|---|
| 01 | Zero_shot | 5 | 5 | 5 | ----- | 5 | E-commerce reviews |
| 02 | Few_shot | 5 | 4.6 | 5 | ----- | 4.9 | E-commerce reviews |
| 03 | Role-play | 5 | 4.6 | 4.2 | ----- | 4.6 | E-commerce reviews |
| 04 | CoT | 5 | 5 | 4.6 | ----- | 4.9 | E-commerce reviews |
| 05 | CoT, role-play, and zoro-shot | 5 | 4.6 | 4.6 | ----- | 4.7 | E-commerce reviews |
| 06 | Cot, role-play, and few-shot | 5 | 5 | 5 | ----- | 5 | E-commerce reviews |
| 07 | Zero-shot | 4.8 | 4.8 | 5 | ----- | 4.9 | Children’s stories |
| 08 | CoT | 5 | 5 | 5 | 5 | 5 | Children’s stories |
| 09 | Role-play | 5 | 4.6 | 5 | 5 | 4.9 | Children’s stories |
| 10 | Zero_shot | 5 | 5 | 5 | ----- | 5 | Restaurant reviews |
| 11 | Few_shot | 3.4 | 4.8 | 4.6 | ----- | 4.3 | Restaurant reviews |
| 12 | Role-play | 4.6 | 5 | 4.6 | ----- | 4.7 | Restaurant reviews |
| 13 | Role-play and CoT | 4.2 | 4.6 | 4.8 | ----- | 4.5 | Restaurant reviews |
| 14 | Zero-shot | 5 | 5 | 5 | 5 | 5 | Yes/no questions |
| 15 | Zero-shot | 5 | 5 | 5 | 5 | 5 | Yes/no questions |
| 16 | Zero-shot | 5 | 5 | 5 | 5 | 5 | Cake recipes |
| 17 | Few-shot | 5 | 4.6 | 5 | 5 | 4.9 | Cake recipes |
| 18 | Role-play | 5 | 5 | 5 | 5 | 5 | Cake recipes |
| 19 | Role-play, CoT, and zero-shot | 4.6 | 5 | 5 | 5 | 4.9 | Cake recipes |
| 20 | Few-shot, role-play, and CoT | 5 | 4.6 | 5 | 5 | 4.9 | Cake recipes |
| Domain | Best Techniques | Text ID | Reason |
|---|---|---|---|
| E-commerce | Few-shot + CoT + role-play | 06 | Balanced contextual understanding and reasoning |
| Children’s stories | CoT | 08 | Clear logic and structured storytelling |
| Restaurant reviews | Zero-shot Role-play | 10 12 | Natural expression or factual summary |
| Yes/no questions | Zero-shot | 14 and 15 | Simple format |
| Cake recipes | Zero-shot Role-play Role-play + CoT + zero-shot Role-play, CoT combinations | 16 17 19 20 | Step-by-step clarity |
| Model | Support | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| ChatGPT-4-turbo | 200 | 0.90 | 0.90 | 0.90 | 0.90 |
| Llama 3.3 | 200 | 0.98 | 0.98 | 0.98 | 0.98 |
| Model | Support | Accuracy | Processing Time | Cost |
|---|---|---|---|---|
| ChatGPT-4-turbo (Web interface) | 200 | 90% | 55 min | Free |
| Llama 3.3 (our system) | 200 | 98% | 20 min | USD 9 per month (USD 0.3 per day) |
| Participant | Gender | Age | Degree | Work |
|---|---|---|---|---|
| P1 | Female | 25–34 | Bachelor | Freelancer |
| P2 | Male | 35–44 | Diploma | IT |
| P3 | Male | 25–34 | Master | Astronomer and data scientist |
| P4 | Male | 25–34 | Bachelor | Cybersecurity and technical writing |
| P5 | Female | 25–34 | Bachelor | E-commerce\Interpreting |
| P6 | Male | 25–34 | Bachelor | Data scientist |
| P7 | Male | 18–24 | Bachelor | QA |
| Ref. | Model | Methodology | Task | Dataset | Accuracy | F1-Score |
|---|---|---|---|---|---|---|
| [22] | ChatGPT | Attributed prompts. | Data Augmentation | Amazon Reviews | 83.95 | 83.93 |
| [5] | ChatGPT % BERT | Few-shot prompting. | Augmentation | Symptoms Dataset | 88.9% | |
| Our System | Llama 3.3 70B | Attributed prompts and prompt engineering techniques. | Data Generation | News Dataset | 99% | 99% |
| Our System | Llama 3.3 70B | Attributed prompts and prompt engineering techniques. | Data Generation | Restaurant Reviews Dataset | 98% | 98% |
| [16] | GPT-3.5 and Claude 2 | Zero-shot, role-playing, chain-of-thought. | URL Classification. | The Phishing Dataset | --- | 92.74% |
| [16] | GPT-3.5 and Claude 2 | Fine-tuning. | URL Classification. | The Phishing Dataset | --- | 99.29% |
| Our System | Llama 3.3 70B | Attributed prompts and prompt engineering techniques. | Data Labeling | AG News Dataset | 92% | 92% |
| Our System | Llama 3.3 70B | Attributed prompts and prompt engineering techniques. | Data Labeling | Yelp Reviews | 90% | 90% |
| Our System | Llama 3.3 70B | Attributed prompts and prompt engineering techniques. | Data Labeling | Amazon Reviews | 89% | 90% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsakran, W.S.; Alabduljabbar, R. A Novel Llama 3-Based Prompt Engineering Platform for Textual Data Generation and Labeling. Electronics 2025, 14, 2800. https://doi.org/10.3390/electronics14142800
Alsakran WS, Alabduljabbar R. A Novel Llama 3-Based Prompt Engineering Platform for Textual Data Generation and Labeling. Electronics. 2025; 14(14):2800. https://doi.org/10.3390/electronics14142800
Chicago/Turabian StyleAlsakran, Wedyan Salem, and Reham Alabduljabbar. 2025. "A Novel Llama 3-Based Prompt Engineering Platform for Textual Data Generation and Labeling" Electronics 14, no. 14: 2800. https://doi.org/10.3390/electronics14142800
APA StyleAlsakran, W. S., & Alabduljabbar, R. (2025). A Novel Llama 3-Based Prompt Engineering Platform for Textual Data Generation and Labeling. Electronics, 14(14), 2800. https://doi.org/10.3390/electronics14142800