


Evaluating Trustworthiness in AI: Risks, Metrics, and Applications Across Industries



Abstract
1. Introduction
2. Overview of Trustworthy AI: Core Definitions and Attributes
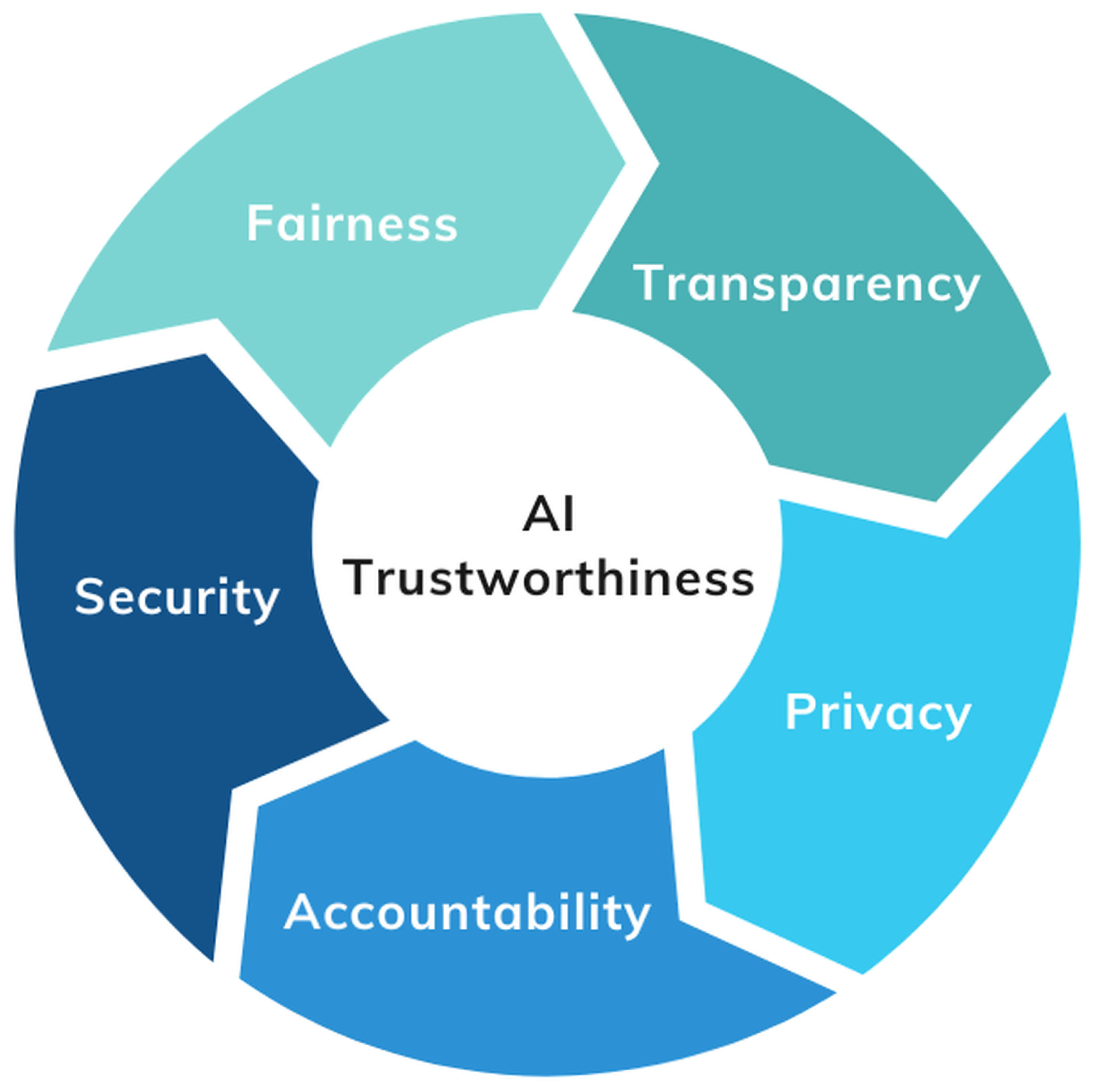
2.1. Components of AI Trustworthiness
- Fairness. Fairness is a cornerstone of trustworthy AI, ensuring that AI systems avoid biases or minimize their negative impact as they could lead to discriminatory outcomes. Ethical challenges associated with bias include discrimination and inequality, human autonomy, and public trust [9]. This is especially important in sensitive domains like finance, healthcare, and criminal justice, where AI-driven decisions can significantly affect lives of individuals. Fairness can be assessed using various metrics, such as the Gini coefficient, which measures the concentration of exploratory variables based on Shapley values or estimated parameters [10]. Additionally, statistical tools like the Kolmogorov–Smirnov test can be employed to detect deviations from uniform distribution [11]. These methods help ensure that different population groups are treated equitably. Other notable fairness metrics include demographic parity (DP) and equal opportunity (EO) [12].
- Transparency. As an essential component for maintaining trust and accountability, transparency in AI requires openness and clarity in decision-making processes to help users understand how predictions are generated [13]. This is especially critical for “black-box” models. Techniques such as Local Interpretable Model-agnostic Explanations (LIME) and Shapley Additive Explanations (SHAP) are known to enhance transparency [14]. The growing emphasis on transparency is reflected in regulatory frameworks, with the European Union (EU) leading efforts through its 2018 AI strategy and the High-Level Expert Group on AI (AI HLEG) [13]. The purpose of the EU’s AI HLEG is to develop voluntary AI ethics guidelines, titled Ethics Guidelines for Trustworthy AI (HLEG Guidelines), as well as policy and investment recommendations for EU institutions and Member States, known as Policy and Investment Recommendations for Trustworthy AI (Policy Recommendations) [15]. Additionally, global standards organizations like IEEE and ISO are focusing on transparency in AI governance. The IEEE has been at the forefront of promoting AI transparency through its Ethically Aligned Design framework and standards like IEEE P7001, which focus on transparency in autonomous systems [16]. These efforts aim to ensure that AI systems are explainable, accountable, and aligned with human values, fostering trust and ethical deployment in society. Legal discussions, including the right to explanation under EU’s General Data Protection Regulation (GDPR) and calls for algorithmic auditing, highlight the need for robust transparency measures. Ultimately, transparency goes beyond individual algorithms to include system-level considerations, meaning that the entire lifecycle and interactions of an AI system (i.e., from its data inputs, decision-making processes, and outputs), are made understandable and interpretable to stakeholders. Achieving AI transparency on the system level ensures that users, regulators, and developers can evaluate the collective behavior of all interconnected components, not just isolated parts. System-level transparency is crucial because it helps identify potential biases, vulnerabilities, or unintended consequences that may arise from the interplay of various elements within the AI system, thus fostering trust, accountability, and ethical use.
- Privacy. Privacy in AI is important to safeguard user data from unauthorized access while ensuring the secure handling of personal information, particularly in sensitive industries like healthcare and finance. Techniques such as federated learning (FL), which allows AI models to be trained across decentralized devices without transferring raw data [17], and differential privacy (DP), which adds statistical noise to datasets to protect individual identities [17], play a key role in achieving AI privacy by design. Beyond data protection, privacy in AI also encompasses deeper aspects like autonomy and identity. Autonomy refers to an individual’s ability to make decisions without undue influence from AI-driven profiling or recommendations, while identity is related to preserving the integrity of personal characteristics without distortion or misuse. The large-scale data collection and profiling by AI systems often erode these controls [18], highlighting the ongoing tension between advancing technology and maintaining user consent and control. This erosion emphasizes the need for robust privacy frameworks to ensure AI respects fundamental human rights.
- Accountability. Accountability is essential for ethical AI governance, ensuring that systems operate in accordance with ethical, transparent, and regulatory standards [19]. In the context of trustworthy AI, accountability refers to the clear attribution of responsibility for decisions made by AI systems, ensuring that stakeholders can trace actions back to specific individuals or entities. Additionally, accountability at its core involves the recognition of authority and the limitation of power to prevent the arbitrary use of authority. It takes on a sociotechnical dimension, reflecting the complexity of systems that involve diverse stakeholders, from developers to end-users [19]. For all actions in an AI-based system, there must be clear accountability to understand responsibility, especially when outcomes vary due to model decisions, errors, or unforeseen behaviors. This clarity is critical for determining who is responsible in cases of harm, bias, or failure, ensuring that the system’s outcomes align with ethical standards. Challenges, such as the unpredictability of AI outcomes, highlight the need for robust documentation and audit trails throughout the AI lifecycle [20]. These measures enable transparency, facilitate compliance checks, and ensure clear attribution of responsibility in the event of system failures or algorithm faults.
- Security. Security in AI ensures that AI-based systems are protected against vulnerabilities, safeguarding their integrity, confidentiality, and privacy, especially in the face of malicious attacks. Vulnerabilities in AI systems can be exploited through techniques such as model extraction, where an attacker attempts to recreate or steal the underlying model by querying the system [21], and evasion, where attackers design inputs to deceive the AI system into making incorrect predictions [21]. These attacks can undermine both the performance and reliability of AI systems. Effective defenses against such attacks are generally categorized into complete defenses, which prevent attacks from succeeding, and detection-only defenses, which identify and mitigate the impact of attacks after they occur [21]. Techniques like adversarial training, where models are trained with intentionally altered inputs to improve robustness, and data sanitization, which involves cleaning and securing training data to remove potentially harmful or misleading examples, can significantly enhance AI system resilience [21]. However, the field continues to face challenges, particularly as adversaries develop more sophisticated attack strategies. This highlights the need for ongoing research to protect AI systems from emerging threats. Thus, security plays a critical role in fostering trust in AI by ensuring reliable and safe performance in diverse and potentially hostile environments. These challenges are reflected in global AI regulations, with the EU’s AI Act mandating security controls for high-risk systems [22], and the US National Institute of Standards and Technology’s AI Risk Management Framework emphasizing security as a core component of trustworthy AI [23]. Similarly, nations like India are operationalizing this through their national AI strategy [24], while China’s regulations emphasize state-led control to manage the security and stability of AI applications [25].
2.2. Importance Across Sectors
2.2.1. Finance
2.2.2. Healthcare
2.2.3. Public Administration
2.2.4. Autonomous Driving and Robotics
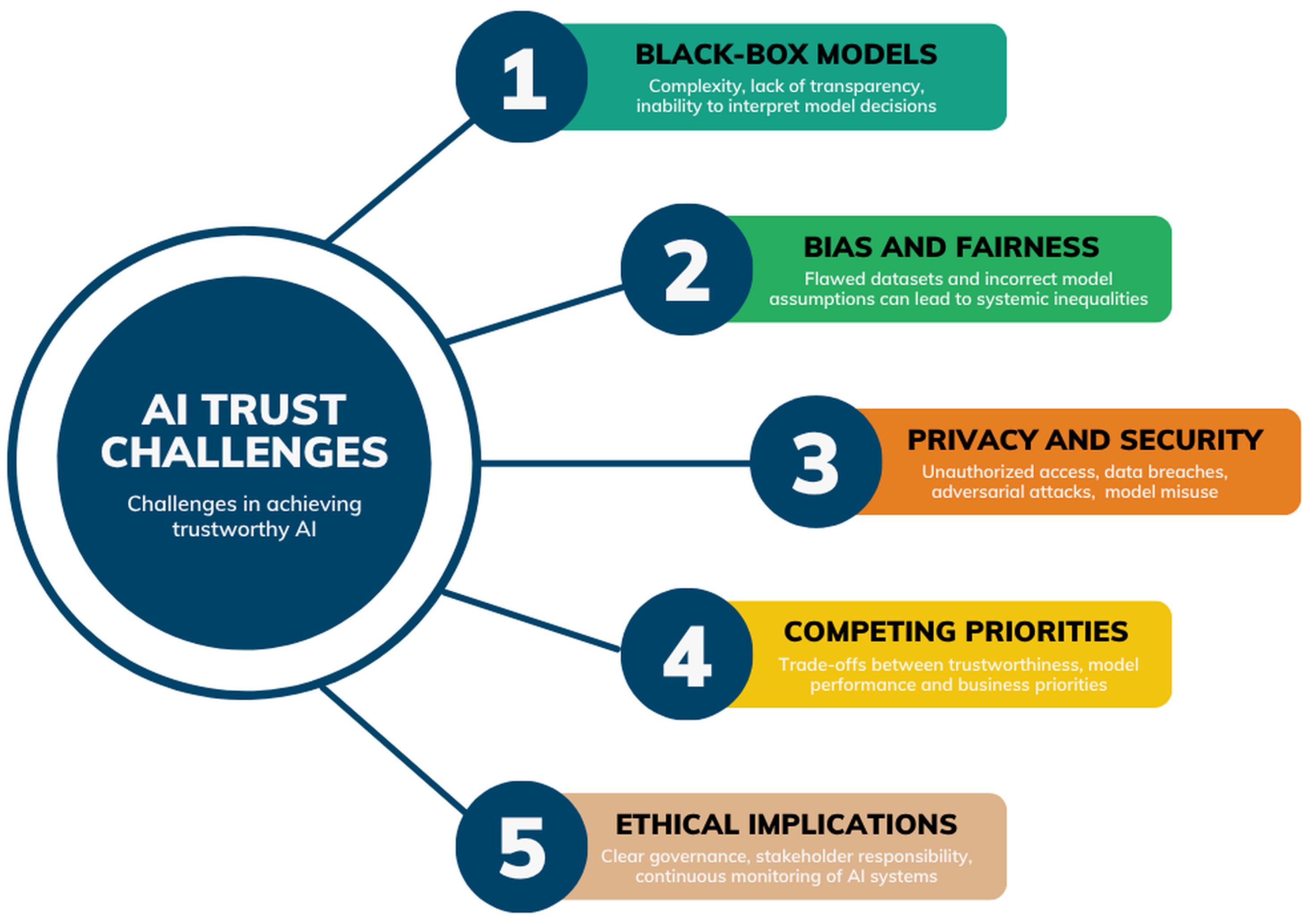
3. Challenges in Achieving Trustworthy AI
3.1. Black-Box Nature of AI Models
3.2. Bias and Fairness
3.3. Privacy and Security
3.4. Balancing Competing Trust Components in AI Systems
3.5. Accountability and Ethical Implications
3.6. Interactions and Trade-Offs Between Trustworthiness Metrics
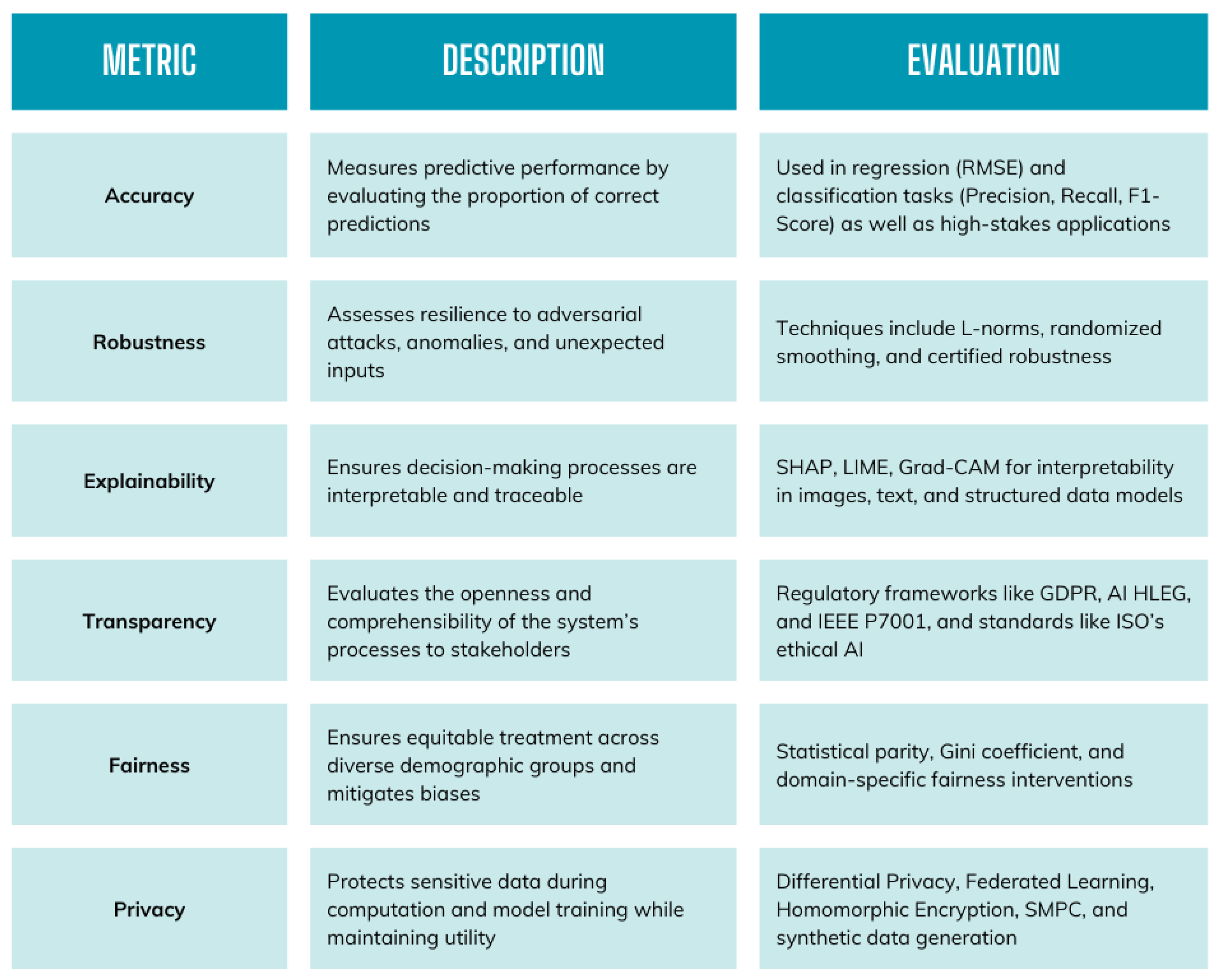
4. Metrics for Evaluating Trustworthiness
4.1. Accuracy and Reliability
4.2. Robustness
- norm: Measures the number of features altered in an input to cause misclassification.
- norm: Represents the Euclidean distance between the original and perturbed inputs.
- norm: Evaluates the maximum perturbation, highlighting the model’s sensitivity to extreme alterations.
- Out-of-distribution (OOD) detection: Evaluates the model’s ability to identify and respond appropriately to inputs that differ significantly from distribution of training data.
- Noise tolerance: Measures the performance degradation resulting from the addition of random noise to the inputs.
- Anomaly robustness: Assesses the model’s behavior when encountering rare data points.
4.3. Explainability and Transparency
- Shapley values: Inspired by cooperative game theory, Shapley values quantify the contribution of each feature to a specific prediction. They ensure feature importance is fairly distributed across inputs by satisfying properties such as consistency and local accuracy [69,70]. The approach based on Shapley values is considered SOTA approach for ML model explainability.
- Model-agnostic metrics: LIME is able to generate simple, interpretable model-agnostic explanations for explaining individual predictions by perturbing inputs and analyzing their effects on model outputs [69]. Feature importance scores are aggregated measures which provide a global view of feature contributions across predictions.
- Visual explanations: For image-based AI systems, methods like Grad-CAM and Guided Backpropagation are employed. Grad-CAM is a class-discriminative localization technique that can generate visual explanations from any CNN-based network without requiring architectural changes or re-training. It computes the gradients of the model’s output (the predicted class score) with respect to the final convolutional layer of the neural network. These gradients are then combined with the feature maps themselves to create a heatmap. This heatmap highlights the regions that were most influential in the decision-making process. Guided Backpropagation refers to pixel-space gradient visualizations. It modifies the standard backpropagation algorithm by only allowing positive gradients to flow backward, effectively filtering out irrelevant or negatively contributing features. The result is a clear and detailed map of the pixels that had a positive influence on the prediction, providing an intuitive understanding of the model’s output [71]. These methods highlight the regions of an image that have a significant influence on the predictions [72].
4.4. Fairness
4.5. Privacy
- Privacy Risk Scores: Evaluate the likelihood of re-identifying individuals from anonymized or aggregated data.
- Membership Inference and Attribute Inference Resistance: These metrics assess the robustness of models against inference attacks.
- Privacy Leakage Metrics: Evaluate the extent to which sensitive information can be extracted from a model’s outputs or parameters.
5. Frameworks and Standards for Trustworthy AI
5.1. Overview of Major Frameworks
5.1.1. NIST AI Risk Management Framework
- Map: Emphasizes the identification and framing of AI-related risks. It encourages organizations to gather diverse perspectives. By framing risks holistically, organizations can better understand the potential consequences of their AI systems.
- Measure: Involves evaluating systems through rigorous testing and monitoring. Organizations are encouraged to assess functionality, trustworthiness, and security both before deployment and throughout the operational lifecycle.
- Manage: Focuses on implementing risk treatment strategies, which includes allocating appropriate resources to maximize AI benefits while minimizing negative impacts.
- Govern: Provides the structural support needed for effective risk management. It encompasses establishing policies, procedures, and practices that foster a strong risk management culture.
5.1.2. AI Trust Framework and Maturity Model (AI-TMM)
- Determine frameworks and controls: The AI-TMM specifies controls across seven key trust pillars, including explainability, data privacy, robustness and safety, transparency, data use and design, societal well-being, and accountability. These controls guide organizations in evaluating and improving AI trustworthiness by focusing on specific risk areas based on their priorities and available resources [57].
- Perform assessments: Maturity levels are assigned to each control using the Maturity Indicator Level (MIL) methodology, which evaluates the extent to which an organization has implemented and institutionalized a given control. This involves assessing factors such as process consistency, documentation, integration into workflows, and continuous improvement efforts.
- Analyze gaps: Identify and evaluate deficiencies and their impact. Gap analysis is performed by assessing identified deficiencies against organizational objectives, available resources, and potential risks. This includes determining the severity of vulnerabilities, prioritizing areas for improvement, and estimating the impact of unaddressed gaps on AI trustworthiness and operational outcomes.
- Plan and prioritize: Address identified gaps, using cost–benefit analysis for effective resource allocation. Organizations should rank remediation activities based on factors such as risk severity, strategic alignment, and resource availability. Planning also involves setting clear timelines, defining roles and responsibilities, and ensuring alignment with broader organizational objectives and risk management strategies.
- Implement plans: Use evaluation metrics to ensure consistent risk management and progress monitoring. Implementation involves integrating improvement activities into existing workflows, ensuring stakeholder engagement, and establishing feedback mechanisms for continuous refinement. Organizations should also document changes, track performance against defined metrics, and adjust plans dynamically based on emerging risks or shifting priorities.
5.1.3. ISO/IEC Standards
- High-level concerns: These concerns encompass general elements that are essential to building trustworthiness, such as safety, decision-making sustainability and system control.
- Mitigation measures: The approach with mitigation measures is aimed at building trustworthiness, but it does not determine its concept, that is, the basic concepts on which trustworthiness is based.
- Stakeholder expectations: This concept involves capturing and understanding the diverse perceptions, needs, and priorities of stakeholders, which shape the trustworthiness requirements for AI systems.
- Ethical and trustworthy AI: This principle ensures that AI systems operate in a manner aligned with ethical norms and societal values.
- Risk assessment and management: Proactive identification and mitigation of risks associated with AI systems.
- Data governance: Establishing robust mechanisms for managing data quality, sources, and preparation.
- Continuous improvement: Encouraging iterative refinement of AI systems and their governance frameworks to adapt to evolving needs and challenges.
- Clause 1: Defines the boundaries and applicability of the ISO 42001 standard.
- Clause 2: Refers to documents that are referenced in the text of the ISO 42001 standard in such a way that some or all of their content constitutes requirements of the standard.
- Clause 3: Establishes common terminology used in the framework to facilitate consistent implementation of the standard across organizations.
- Clause 4: Establishes the organizational context, requiring organizations to consider internal and external factors, stakeholder needs, and the scope of their AI systems.
- Clause 5: Focuses on leadership, emphasizing top management’s role in fostering a culture of responsible AI through clear policies and commitments.
- Clause 6: Covers planning processes, including addressing risks, setting AI objectives, and managing changes within the organization.
- Clause 7: Details the support requirements, including resources, competence development, communication, and documentation.
- Clause 8: Outlines operational planning and control, addressing implementation, impact assessments, and change management.
- Clause 9: Addresses performance evaluation through monitoring, internal audits, and reviews of AI systems.
- Clause 10: Emphasizes continuous improvement, including addressing non-conformities, corrective actions, and maintaining accountability.
5.1.4. KAIRI: Key Artificial Intelligence Risk Indicators
5.2. Comparative Analysis
5.3. Application of Frameworks in Real Scenarios
5.3.1. Usage of AI Regulation Frameworks in the US, Canada, and China
5.3.2. Surveillance Technology
5.3.3. Military Aviation
5.3.4. Credit Scoring
6. Applications of Trustworthiness Metrics: Case Studies
6.1. Financial Sector
6.1.1. SAFE AI in Finance
6.1.2. Handling Sensitive Financial Data
6.1.3. Trustworthy AI in Financial Risk Management
6.2. Healthcare
6.2.1. Out-of-Hospital Cardiar Arrest (OHCA) Detection
- Transparency and explainability: The “black-box” nature of the AI model hinder dispatcher understanding, reducing trust.
- Bias mitigation: The system underperformed for non-Danish speakers and patients with heavy dialects, which prompts the use of diversified training data to prevent discrimination.
- Accountability and oversight: Stakeholder involvement was critical to addressing ethical tensions, including balance between human oversight and AI autonomy.
6.2.2. Prediction of Parkinson’s Disease Progression
- Federated learning (FL): Hospitals collaboratively train a global model without sharing raw data, preserving patient privacy.
- Local learning (LL): Each hospital trains its model independently, leading to suboptimal accuracy due to limited data.
- Centralized learning (CL): Data from all hospitals is centralized, achieving the highest accuracy at the cost of privacy.
6.3. Public Administration
6.3.1. Public Employment Services in Sweden
- Enhance model interpretability: Transition to simpler, interpretable models that maintain predictive performance could improve stakeholder trust and understanding. Providing visual explanations or feature importance rankings can further help users grasp how decisions are made.
- Refine stakeholder engagement: Actively involving caseworkers and jobseekers could improve adoption and transparency. Regular feedback loops and Participatory Design sessions can ensure that system updates align with users’ real-world needs and concerns.
- Strengthen human–AI collaboration: Foster balanced decision-making by clearly defining roles where AI supports, rather than replaces, human judgment. Training programs for caseworkers can further enhance their ability to interpret and responsibly act on AI recommendations.
- Increase transparency: Communicate decision thresholds, probability estimates, and key performance metrics to stakeholders. Making this information easily accessible and understandable can help clarify system behavior and enhance informed insights.
- Strengthen ethical and legal compliance: Ensure mechanisms for jobseekers to appeal decisions, aligning with Swedish administrative and anti-discrimination regulations. Establishing clear documentation and accessible communication channels for appeals will reinforce fairness and accountability.
6.3.2. AI in Criminal Justice
6.3.3. The Robodebt System in Australia
6.3.4. The COMPAS Algorithm in the US
7. Emerging Trends and Future Directions in Trustworthy AI
7.1. Foundation Models and Trustworthiness Challenges
7.2. Trustworthiness Challenges and Evolving Evaluation Frameworks for Generative AI Systems
7.3. Regulatory and Ethical Trends
7.3.1. Il-Learn: A Novel Metric for Measuring Intelligence Evolution in Learning Systems
- Algorithmic Accountability Act of 2022 (AAA) [147]: Introduced in the US, the AAA emphasizes the need for comprehensive impact assessments of automated decision systems in key sectors. A distinctive feature of this regulation is its focus on stakeholder engagement, requiring consultations with impacted communities to address issues of bias and discrimination. AAA also emphasizes the importance of transparency and accountability.
- New York City’s Int. 1894 [20]: This regulation, introduced in 2020, targets automated employment decision tools, mandating bias audits to ensure fairness in hiring processes. The law requires developers and employers to disclose the criteria, data sources, and retention policies of automated systems to job candidates, thereby promoting greater transparency and accountability in algorithmic decision-making.
- California’s AB 13 [20]: This legislation extends algorithmic accountability to state procurement processes, requiring developers to conduct detailed impact assessments, which must address system performance, risks, limitations and potential disparate impacts on protected groups. AB 13 aligns technical assessments with ethical considerations, prioritizing fairness and equity.
- The EU AI Act: this framework is one of the most comprehensive AI governance frameworks to date globally. It proposes a risk-based approach that categorizes AI systems based on their potential impact on human rights and safety.
7.3.2. The EU AI Act
- Need for regulation: the EU AI Act addresses the inability of current laws to manage AI risks effectively, particularly those that impact safety, fairness, and fundamental rights.
- Risk-based categorization: AI systems are regulated based on their level of risk, ensuring a proportionate response. The risk categories are defined as unacceptable risk, high risk, limited risk, minimal risk, or no risk.
- General-Purpose AI (GPAI): General-purpose AI models face additional transparency and risk management obligations, including self-assessments, bias mitigation, and cybersecurity measures.
- Enforcement and governance: The European AI Office, established in 2024, oversees implementation, monitors compliance, and promotes ethical AI development.
- Implementation timeline: The EU AI Act came into force in August 2024. Within six months, bans on AI systems posing unacceptable risks will be implemented. One year later, the GPAI rules and governance provisions will take effect, while full obligations for AI integrated into regulated products will come into force in three years.
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Anwer, S.; Hosen, M.S.; Khan, D.S.; Oluwabusayo, E.; Folorunso, M.; Khan, H. Revolutionizing the global market: An inclusion of AI the game changer in international dynamics. Migr. Lett. 2024, 21, 54–73. [Google Scholar]
- Cousineau, C.; Dara, R.; Chowdhury, A. Trustworthy AI: AI developers’ lens to implementation challenges and opportunities. Data Inf. Manag. 2024, 9, 100082. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, X.; Cao, X.; Huang, C.; Liu, E.; Qian, S.; Liu, X.; Wu, Y.; Dong, F.; Qiu, C.W.; et al. Artificial intelligence: A powerful paradigm for scientific research. Innovation 2021, 2, 100179. [Google Scholar] [CrossRef]
- Gardner, C.; Robinson, K.; Smith, C.; Steiner, A. Contextualizing End-User Needs: How to Measure the Trustworthiness of an AI System; Carnegie Mellon University, Software Engineering Institute: Pittsburgh, PA, USA, 2023. [Google Scholar]
- Li, B.; Qi, P.; Liu, B.; Di, S.; Liu, J.; Pei, J.; Yi, J.; Zhou, B. Trustworthy AI: From principles to practices. ACM Comput. Surv. 2023, 55, 1–46. [Google Scholar] [CrossRef]
- Kuhn, S.; Muller, M.J. Participatory design. Commun. ACM 1993, 36, 24–29. [Google Scholar]
- Vianello, A.; Laine, S.; Tuomi, E. Improving trustworthiness of AI solutions: A qualitative approach to support ethically-grounded AI design. Int. J. Hum. Comput. Interact. 2023, 39, 1405–1422. [Google Scholar] [CrossRef]
- Lahusen, C.; Maggetti, M.; Slavkovik, M. Trust, trustworthiness and AI governance. Sci. Rep. 2024, 14, 20752. [Google Scholar] [CrossRef]
- Ferrara, E. Fairness and bias in artificial intelligence: A brief survey of sources, impacts, and mitigation strategies. Sci 2023, 6, 3. [Google Scholar] [CrossRef]
- Hlongwane, R.; Ramabao, K.; Mongwe, W. A novel framework for enhancing transparency in credit scoring: Leveraging Shapley values for interpretable credit scorecards. PLoS ONE 2024, 19, e0308718. [Google Scholar] [CrossRef]
- Gursoy, F.; Kakadiaris, I.A. Error parity fairness: Testing for group fairness in regression tasks. arXiv 2022, arXiv:2208.08279. [Google Scholar]
- Jiang, Z.; Han, X.; Fan, C.; Yang, F.; Mostafavi, A.; Hu, X. Generalized demographic parity for group fairness. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Larsson, S.; Heintz, F. Transparency in artificial intelligence. Internet Policy Rev. 2020, 9, 1–16. [Google Scholar] [CrossRef]
- Kovari, A. AI for Decision Support: Balancing Accuracy, Transparency, and Trust Across Sectors. Information 2024, 15, 725. [Google Scholar] [CrossRef]
- Smuha, N.A. The Work of the High-Level Expert Group on AI as the Precursor of the AI Act. 2024. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5012626 (accessed on 30 June 2025).
- Winfield, A.F.; Booth, S.; Dennis, L.A.; Egawa, T.; Hastie, H.; Jacobs, N.; Muttram, R.I.; Olszewska, J.I.; Rajabiyazdi, F.; Theodorou, A.; et al. IEEE P7001: A proposed standard on transparency. Front. Robot. AI 2021, 8, 665729. [Google Scholar] [CrossRef] [PubMed]
- Khalid, N.; Qayyum, A.; Bilal, M.; Al-Fuqaha, A.; Qadir, J. Privacy-preserving artificial intelligence in healthcare: Techniques and applications. Comput. Biol. Med. 2023, 158, 106848. [Google Scholar] [CrossRef] [PubMed]
- Elliott, D.; Soifer, E. AI technologies, privacy, and security. Front. Artif. Intell. 2022, 5, 826737. [Google Scholar] [CrossRef]
- Novelli, C.; Taddeo, M.; Floridi, L. Accountability in artificial intelligence: What it is and how it works. AI Soc. 2024, 39, 1871–1882. [Google Scholar] [CrossRef]
- Oduro, S.; Moss, E.; Metcalf, J. Obligations to assess: Recent trends in AI accountability regulations. Patterns 2022, 3, 100608. [Google Scholar] [CrossRef]
- Oseni, A.; Moustafa, N.; Janicke, H.; Liu, P.; Tari, Z.; Vasilakos, A. Security and privacy for artificial intelligence: Opportunities and challenges. arXiv 2021, arXiv:2102.04661. [Google Scholar]
- Commission, E. AI Act. Available online: https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai/ (accessed on 15 May 2025).
- National Institute of Standards and Technology. AI Risk Management Framework. Available online: https://www.nist.gov/itl/ai-risk-management-framework (accessed on 10 May 2025).
- NITI Aayog. National Strategy for Artificial Intelligence #AIFORALL. Available online: https://www.niti.gov.in/sites/default/files/2023-03/National-Strategy-for-Artificial-Intelligence.pdf (accessed on 30 May 2025).
- Tuzov, V.; Lin, F. Two paths of balancing technology and ethics: A comparative study on AI governance in China and Germany. Telecommun. Policy 2024, 48, 102850. [Google Scholar] [CrossRef]
- Riyazahmed, K. AI in finance: Needs attention to bias. Annu. Res. J. Scms Pune Vol. 2023, 11, 1. [Google Scholar]
- Cao, L.; Yang, Q.; Yu, P.S. Data science and AI in FinTech: An overview. Int. J. Data Sci. Anal. 2021, 12, 81–99. [Google Scholar] [CrossRef]
- Georgieva, K. AI Will Transform the Global Economy. Let us Make Sure It Benefits Humanity; IMF Blog (blog), International Monetary Fund: Washington, DC, USA, 2024. [Google Scholar]
- Al-Gasawneh, J.; Alfityani, A.; Al-Okdeh, S.; Almasri, B.; Mansur, H.; Nusairat, N.; Siam, Y. Avoiding uncertainty by measuring the impact of perceived risk on the intention to use financial artificial intelligence services. Uncertain Supply Chain. Manag. 2022, 10, 1427–1436. [Google Scholar] [CrossRef]
- Maurya, S.; Verma, R.; Khilnani, L.; Bhakuni, A.S.; Kumar, M.; Rakesh, N. Effect of AI on the Financial Sector: Risk Control, Investment Decision-making, and Business Outcome. In Proceedings of the 2024 11th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 14–15 March 2024; pp. 1–7. [Google Scholar]
- Buchanan, B.G. Artificial Intelligence in Finance; The Alan Turing Institute: London, UK, 2019. [Google Scholar]
- Fritz-Morgenthal, S.; Hein, B.; Papenbrock, J. Financial risk management and explainable, trustworthy, responsible AI. Front. Artif. Intell. 2022, 5, 779799. [Google Scholar] [CrossRef] [PubMed]
- Albahri, A.; Duhaim, A.; Fadhel, M.; Alnoor, A.; Baqer, N.; Alzubaidi, L.; Albahri, O.S.; Alamoodi, A.H.; Bai, J.; Salhi, A.; et al. A systematic review of trustworthy and explainable artificial intelligence in healthcare: Assessment of quality, bias risk and data fusion. Inf. Fusion 2023, 96, 156–191. [Google Scholar] [CrossRef]
- Kalusivalingam, A.K.; Sharma, A.; Patel, N.; Singh, V. Leveraging SHAP and LIME for Enhanced Explainability in AI-Driven Diagnostic Systems. Int. J. AI ML 2021, 2, 1–23. [Google Scholar]
- Ashraf, K.; Nawar, S.; Hosen, M.H.; Islam, M.T.; Uddin, M.N. Beyond the Black Box: Employing LIME and SHAP for Transparent Health Predictions with Machine Learning Models. In Proceedings of the 2024 International Conference on Advances in Computing, Communication, Electrical, and Smart Systems (iCACCESS), Dhaka, Bangladesh, 8–9 March 2024; pp. 1–6. [Google Scholar]
- Samala, A.D.; Rawas, S. Generative AI as Virtual Healthcare Assistant for Enhancing Patient Care Quality. Int. J. Online Biomed. Eng. 2024, 20, 174–187. [Google Scholar] [CrossRef]
- Hicks, S.A.; Strümke, I.; Thambawita, V.; Hammou, M.; Riegler, M.A.; Halvorsen, P.; Parasa, S. On evaluation metrics for medical applications of artificial intelligence. Sci. Rep. 2022, 12, 5979. [Google Scholar] [CrossRef] [PubMed]
- van Noordt, C.; Tangi, L. The dynamics of AI capability and its influence on public value creation of AI within public administration. Gov. Inf. Q. 2023, 40, 101860. [Google Scholar] [CrossRef]
- Kuziemski, M.; Misuraca, G. AI governance in the public sector: Three tales from the frontiers of automated decision-making in democratic settings. Telecommun. Policy 2020, 44, 101976. [Google Scholar] [CrossRef]
- Michael, K.; Abbas, R.; Roussos, G.; Scornavacca, E.; Fosso-Wamba, S. Ethics in AI and autonomous system applications design. IEEE Trans. Technol. Soc. 2020, 1, 114–127. [Google Scholar] [CrossRef]
- He, H.; Gray, J.; Cangelosi, A.; Meng, Q.; McGinnity, T.M.; Mehnen, J. The challenges and opportunities of human-centered AI for trustworthy robots and autonomous systems. IEEE Trans. Cogn. Dev. Syst. 2021, 14, 1398–1412. [Google Scholar] [CrossRef]
- Winfield, A.F.; Michael, K.; Pitt, J.; Evers, V. Machine ethics: The design and governance of ethical AI and autonomous systems [scanning the issue]. Proc. IEEE 2019, 107, 509–517. [Google Scholar] [CrossRef]
- Bryson, J.; Winfield, A. Standardizing ethical design for artificial intelligence and autonomous systems. Computer 2017, 50, 116–119. [Google Scholar] [CrossRef]
- Polemi, N.; Praça, I.; Kioskli, K.; Bécue, A. Challenges and efforts in managing AI trustworthiness risks: A state of knowledge. Front. Big Data 2024, 7, 1381163. [Google Scholar] [CrossRef] [PubMed]
- Kaur, D.; Uslu, S.; Rittichier, K.J.; Durresi, A. Trustworthy artificial intelligence: A review. ACM Comput. Surv. CSUR 2022, 55, 1–38. [Google Scholar] [CrossRef]
- Pedreschi, D.; Giannotti, F.; Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F. Meaningful explanations of black box AI decision systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9780–9784. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Hassija, V.; Chamola, V.; Mahapatra, A.; Singal, A.; Goel, D.; Huang, K.; Scardapane, S.; Spinelli, I.; Mahmud, M.; Hussain, A. Interpreting black-box models: A review on explainable artificial intelligence. Cogn. Comput. 2024, 16, 45–74. [Google Scholar] [CrossRef]
- Dai, X.; Keane, M.T.; Shalloo, L.; Ruelle, E.; Byrne, R.M. Counterfactual explanations for prediction and diagnosis in XAI. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society, Oxford, UK, 19–21 May 2022; pp. 215–226. [Google Scholar]
- Deloitte, U. Banking on the Bots: Unintended Bias in AI; Deloitte: London, UK, 2023. [Google Scholar]
- Nelson, G.S. Bias in artificial intelligence. North Carol. Med. J. 2019, 80, 220–222. [Google Scholar] [CrossRef]
- Varsha, P. How can we manage biases in artificial intelligence systems–A systematic literature review. Int. J. Inf. Manag. Data Insights 2023, 3, 100165. [Google Scholar]
- Chu, C.; Leslie, K.; Nyrup, R.; Khan, S. Artificial Intelligence Can Discriminate on the Basis of Race and Gender, and Furthermore, Age. The Conversation. 2022, Volume 5. Available online: http://theconversation.com/artificial-intelligence-can-discriminate-on-the-basis-ofrace-and-gender-and-also-age-173617 (accessed on 15 May 2025).
- Mbakwe, A.B.; Lourentzou, I.; Celi, L.A.; Wu, J.T. Fairness metrics for health AI: We have a long way to go. eBioMedicine 2023, 90, 104525. [Google Scholar] [CrossRef]
- Rizinski, M.; Peshov, H.; Mishev, K.; Chitkushev, L.T.; Vodenska, I.; Trajanov, D. Ethically responsible machine learning in fintech. IEEE Access 2022, 10, 97531–97554. [Google Scholar] [CrossRef]
- John-Mathews, J.M.; Cardon, D.; Balagué, C. From reality to world. A critical perspective on AI fairness. J. Bus. Ethics 2022, 178, 945–959. [Google Scholar] [CrossRef]
- Mylrea, M.; Robinson, N. Artificial Intelligence (AI) trust framework and maturity model: Applying an entropy lens to improve security, privacy, and ethical AI. Entropy 2023, 25, 1429. [Google Scholar] [CrossRef] [PubMed]
- Al-Khassawneh, Y.A. A review of artificial intelligence in security and privacy: Research advances, applications, opportunities, and challenges. Indones. J. Sci. Technol. 2023, 8, 79–96. [Google Scholar] [CrossRef]
- Reinhardt, K. Trust and trustworthiness in AI ethics. AI Ethics 2023, 3, 735–744. [Google Scholar] [CrossRef]
- Wang, Y. Balancing Trustworthiness and Efficiency in AI Systems: A Comprehensive Analysis of Trade-offs and Strategies. IEEE Internet Comput. 2023, 27, 8–12. [Google Scholar] [CrossRef]
- Cheong, B.C. Transparency and accountability in AI systems: Safeguarding wellbeing in the age of algorithmic decision-making. Front. Hum. Dyn. 2024, 6, 1421273. [Google Scholar] [CrossRef]
- Hildebrandt, M. Privacy as protection of the incomputable self: From agnostic to agonistic machine learning. Theor. Inq. Law 2019, 20, 83–121. [Google Scholar] [CrossRef]
- Mortaji, S.T.H.; Sadeghi, M.E. Assessing the Reliability of Artificial Intelligence Systems: Challenges, Metrics, and Future Directions. Int. J. Innov. Manag. Econ. Soc. Sci. 2024, 4, 1–13. [Google Scholar] [CrossRef]
- Pawlicki, M.; Pawlicka, A.; Uccello, F.; Szelest, S.; D’Antonio, S.; Kozik, R.; Choraś, M. Evaluating the necessity of the multiple metrics for assessing explainable AI: A critical examination. Neurocomputing 2024, 602, 128282. [Google Scholar] [CrossRef]
- Hamon, R.; Junklewitz, H.; Sanchez, I. Robustness and Explainability of Artificial Intelligence; Publications Office of the European Union: Brussels, Belgium, 2020; Volume 207, p. 2020. [Google Scholar]
- Tocchetti, A.; Corti, L.; Balayn, A.; Yurrita, M.; Lippmann, P.; Brambilla, M.; Yang, J. AI robustness: A human-centered perspective on technological challenges and opportunities. ACM Comput. Surv. 2022, 57, 141. [Google Scholar]
- Li, L.; Xie, T.; Li, B. Sok: Certified robustness for deep neural networks. In Proceedings of the 2023 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–24 May 2023; pp. 1289–1310. [Google Scholar]
- Chander, B.; John, C.; Warrier, L.; Gopalakrishnan, K. Toward trustworthy artificial intelligence (TAI) in the context of explainability and robustness. ACM Comput. Surv. 2024, 57, 144. [Google Scholar] [CrossRef]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable ai: A review of machine learning interpretability methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef]
- Lundberg, S. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Vij, R. Building Trustworthy AI: Interpretability in Vision and Linguistic Models. Available online: https://pub.towardsai.net/building-trustworthy-ai-interpretability-in-vision-and-linguistic-models-b78d1ea979d4/ (accessed on 20 October 2024).
- Holzinger, A.; Langs, G.; Denk, H.; Zatloukal, K.; Müller, H. Causability and explainability of artificial intelligence in medicine. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1312. [Google Scholar] [CrossRef]
- Floridi, L. The European legislation on AI: A brief analysis of its philosophical approach. Philos. Technol. 2021, 34, 215–222. [Google Scholar] [CrossRef] [PubMed]
- Caton, S.; Haas, C. Fairness in machine learning: A survey. ACM Comput. Surv. 2024, 56, 1–38. [Google Scholar] [CrossRef]
- Feretzakis, G.; Papaspyridis, K.; Gkoulalas-Divanis, A.; Verykios, V.S. Privacy-Preserving Techniques in Generative AI and Large Language Models: A Narrative Review. Information 2024, 15, 697. [Google Scholar] [CrossRef]
- Swaminathan, N.; Danks, D. Application of the NIST AI Risk Management Framework to Surveillance Technology. arXiv 2024, arXiv:2403.15646. [Google Scholar]
- AI, N. A Plan for Global Engagement on AI Standards; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2024. [Google Scholar]
- Desai, A. NIST’s AI Risk Management Framework Explained. Available online: https://www.schellman.com/blog/cybersecurity/nist-ai-risk-management-framework-explained/ (accessed on 20 August 2023).
- Dotan, R.; Blili-Hamelin, B.; Madhavan, R.; Matthews, J.; Scarpino, J. Evolving AI Risk Management: A Maturity Model based on the NIST AI Risk Management Framework. arXiv 2024, arXiv:2401.15229. [Google Scholar]
- ISO/IEC 24028:2020; Information technology—Artificial Intelligence—Overview of Trustworthiness in Artificial Intelligence. International Organization for Standardization (ISO): Geneva, Switzerland, 2020.
- ISO/IEC 42001:2023; Information Technology—Artificial Intelligence—Management System. International Organization for Standardization (ISO): Geneva, Switzerland, 2023.
- Manziuk, E.; Barmak, O.; Krak, I.; Mazurets, O.; Skrypnyk, T. Formal Model of Trustworthy Artificial Intelligence Based on Standardization. In Proceedings of the IntelITSIS, Khmelnytskyi, Ukraine, 24–26 March 2021; pp. 190–197. [Google Scholar]
- Dudley, C. The Rise of AI Governance: Unpacking ISO/IEC 42001. Quality 2024, 63, 27. [Google Scholar]
- ISO/IEC 38507:2022; Information Technology—Governance of IT—Governance Implications of the Use of Artificial Intelligence by Organizations. International Organization for Standardization (ISO): Geneva, Switzerland, 2022.
- ISO/IEC 23894:2023; Information Technology—Artificial Intelligence—Guidance on Risk Management. International Organization for Standardization (ISO): Geneva, Switzerland, 2023.
- ISO/IEC 25059:2023; Software Engineering—Systems and Software Quality Requirements and Evaluation (SQuaRE)—Quality Model for AI Systems. International Organization for Standardization (ISO): Geneva, Switzerland, 2023.
- Janaćković, G.; Vasović, D.; Vasović, B. Artificial Intelligence Standardisation Efforts. In Proceedings of the Engineering Management and Competitiveness (EMC 2024), Zrenjanin, Serbia, 21–22 June 2024; p. 250. [Google Scholar]
- Giudici, P.; Centurelli, M.; Turchetta, S. Artificial Intelligence risk measurement. Expert Syst. Appl. 2024, 235, 121220. [Google Scholar] [CrossRef]
- Pierna, J.A.F.; Abbas, O.; Baeten, V.; Dardenne, P. A Backward Variable Selection method for PLS regression (BVSPLS). Anal. Chim. Acta 2009, 642, 89–93. [Google Scholar] [CrossRef] [PubMed]
- International Organization for Standardization (ISO). ISO/IEC 27000 Family—Information Security Management. Available online: https://www.iso.org/standard/iso-iec-27000-family (accessed on 30 June 2025).
- ISO 31000:2018; Risk management—Guidelines. International Organization for Standardization (ISO): Geneva, Switzerland, 2018.
- ISO/IEC 24029-2:2023; Artificial Intelligence (AI)—Assessment of the Robustness of Neural Networks. International Organization for Standardization (ISO): Geneva, Switzerland, 2023.
- International Organization for Standardization (ISO). ISO/IEC WD TS 27115.4 Cybersecurity Evaluation of Complex Systems—Introduction and Framework Overview (Under Development). Available online: https://www.iso.org/standard/81627.html (accessed on 30 June 2025).
- European Telecommunications Standards Institute (ETSI). Technical Committee (TC) Securing Artificial Intelligence (SAI). 2023. Available online: https://www.etsi.org/committee/2312-sai (accessed on 30 June 2025).
- MITRE ATLAS. ATLAS Matrix. 2023. Available online: https://atlas.mitre.org/matrices/ATLAS (accessed on 30 June 2025).
- European Union Agency for Cybersecurity (ENISA). Multilayer Framework for Good Cybersecurity Practices for AI. 2023. Available online: https://www.enisa.europa.eu/publications/multilayer-framework-for-good-cybersecurity-practices-for-ai (accessed on 30 June 2025).
- European Commission. Ethics Guidelines for Trustworthy AI. 2019. Available online: https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai (accessed on 30 June 2025).
- THEMIS Consortium. Themis 5.0. 2024. Available online: https://www.themis-trust.eu/results (accessed on 30 June 2025).
- Joseph, J. Should the United States Adopt Federal Artificial Intelligence Regulation Similar to the European Union. Loyola Univ. Chic. Int. Law. Rev. 2023, 20, 105. [Google Scholar]
- Scassa, T. Regulating AI in Canada: A Critical Look at the Proposed Artificial Intelligence and Data Act. Can. Bar. Rev. 2023, 101, 1. [Google Scholar]
- Lucero, K. Artificial intelligence regulation and China’s future. Colum. J. Asian L. 2019, 33, 94. [Google Scholar]
- Cornacchia, G.; Narducci, F.; Ragone, A. Improving the user experience and the trustworthiness of financial services. In Proceedings of the IFIP Conference on Human–Computer Interaction; Springer: Cham, Switzerland, 2021; pp. 264–269. [Google Scholar]
- Zhou, J.; Chen, C.; Li, L.; Zhang, Z.; Zheng, X. FinBrain 2.0: When finance meets trustworthy AI. Front. Inf. Technol. Electron. Eng. 2022, 23, 1747–1764. [Google Scholar] [CrossRef]
- Giudici, P.; Raffinetti, E. SAFE Artificial Intelligence in finance. Financ. Res. Lett. 2023, 56, 104088. [Google Scholar] [CrossRef]
- Narsina, D.; Gummadi, J.C.S.; Venkata, S.; Manikyala, A.; Kothapalli, S.; Devarapu, K.; Rodriguez, M.; Talla, R. AI-Driven Database Systems in FinTech: Enhancing Fraud Detection and Transaction Efficiency. Asian Account. Audit. Adv. 2019, 10, 81–92. [Google Scholar]
- Alsalem, M.; Alamoodi, A.H.; Albahri, O.S.; Albahri, A.S.; Martínez, L.; Yera, R.; Duhaim, A.M.; Sharaf, I.M. Evaluation of trustworthy artificial intelligent healthcare applications using multi-criteria decision-making approach. Expert Syst. Appl. 2024, 246, 123066. [Google Scholar] [CrossRef]
- Blomberg, S.N.; Folke, F.; Ersbøll, A.K.; Christensen, H.C.; Torp-Pedersen, C.; Sayre, M.R.; Counts, C.R.; Lippert, F.K. Machine learning as a supportive tool to recognize cardiac arrest in emergency calls. Resuscitation 2019, 138, 322–329. [Google Scholar] [CrossRef] [PubMed]
- Ducange, P.; Marcelloni, F.; Renda, A.; Ruffini, F. Federated Learning of XAI Models in Healthcare: A Case Study on Parkinson’s Disease. Cogn. Comput. 2024, 16, 3051–3076. [Google Scholar] [CrossRef]
- Berman, A.; de Fine Licht, K.; Carlsson, V. Trustworthy AI in the public sector: An empirical analysis of a Swedish labor market decision-support system. Technol. Soc. 2024, 76, 102471. [Google Scholar] [CrossRef]
- Završnik, A. Criminal justice, artificial intelligence systems, and human rights. In Proceedings of the ERA Forum; Springer: Berlin/Heidelberg, Germany, 2020; Volume 20, pp. 567–583. [Google Scholar]
- Michael, K. In this special section: Algorithmic bias—Australia’s Robodebt and its human rights aftermath. IEEE Trans. Technol. Soc. 2024, 5, 254–263. [Google Scholar] [CrossRef]
- Lagioia, F.; Rovatti, R.; Sartor, G. Algorithmic fairness through group parities? The case of COMPAS-SAPMOC. AI Soc. 2023, 38, 459–478. [Google Scholar] [CrossRef]
- Larson, J.; Mattu, S.; Kirchner, L.; Angwin, J. How We Analyzed the COMPAS Recidivism Algorithm. 2016. Available online: https://www.propublica.org/article/how-we-analyzed-the-compas-recidivism-algorithm/ (accessed on 20 May 2025).
- de Cerqueira, J.A.S.; Agbese, M.; Rousi, R.; Xi, N.; Hamari, J.; Abrahamsson, P. Can We Trust AI Agents? An Experimental Study Towards Trustworthy LLM-Based Multi-Agent Systems for AI Ethics. arXiv 2024, arXiv:2411.08881. [Google Scholar]
- Amodei, D. The Urgency of Interpretability. Available online: https://www.darioamodei.com/post/the-urgency-of-interpretability/ (accessed on 26 April 2025).
- Coulter, M.; Greg, B. Alphabet Shares Dive After Google AI Chatbot Bard Flubs Answer in ad. Available online: https://www.reuters.com/technology/google-ai-chatbot-bard-offers-inaccurate-information-company-ad-2023-02-08/ (accessed on 26 April 2025).
- Edwards, B. AI-Powered Bing Chat Spills Its Secrets via Prompt Injection Attack. Available online: https://arstechnica.com/information-technology/2023/02/ai-powered-bing-chat-spills-its-secrets-via-prompt-injection-attack/ (accessed on 18 March 2025).
- Winder, D. Hacker Reveals Microsoft’s New AI-Powered Bing Chat Search Secrets. Available online: https://www.forbes.com/sites/daveywinder/2023/02/13/hacker-reveals-microsofts-new-ai-powered-bing-chat-search-secrets/ (accessed on 18 March 2025).
- Sato, M. CNET Pauses Publishing AI-Written Stories After Disclosure Controversy. Available online: https://www.theverge.com/2023/1/20/23564311/cnet-pausing-ai-articles-bot-red-ventures (accessed on 18 March 2025).
- Harrington, C. CNET Pauses Publishing AI-Written Stories After Disclosure Controversy. Available online: https://www.wired.com/story/cnet-published-ai-generated-stories-then-its-staff-pushed-back/ (accessed on 18 March 2025).
- Sajid, H. Navigating Risks Associated with Unreliable AI & Trustworthiness in LLMs. Available online: https://www.wisecube.ai/blog/navigating-risks-associated-with-unreliable-ai-trustworthiness-in-llms/ (accessed on 18 March 2025).
- Zhu, S.; Ma, G. The Chinese Path to Generative AI Governance. 2023. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4551316 (accessed on 30 June 2025).
- Ferrari, F.; Van Dijck, J.; Van den Bosch, A. Observe, inspect, modify: Three conditions for generative AI governance. New Media Soc. 2025, 27, 2788–2806. [Google Scholar] [CrossRef]
- Khera, R.; Oikonomou, E.K.; Nadkarni, G.N.; Morley, J.R.; Wiens, J.; Butte, A.J.; Topol, E.J. Transforming cardiovascular care with artificial intelligence: From discovery to practice: JACC state-of-the-art review. J. Am. Coll. Cardiol. 2024, 84, 97–114. [Google Scholar] [CrossRef]
- Zhang, A.H. The promise and perils of China’s regulation of artificial intelligence. Columbia J. Trans. Law 2025, 63, 1. [Google Scholar] [CrossRef]
- Ministry of Law and Justice of India. The Digital Personal Data Protection Act. Available online: https://www.meity.gov.in/static/uploads/2024/06/2bf1f0e9f04e6fb4f8fef35e82c42aa5.pdf (accessed on 18 March 2025).
- Sundara, K.; Narendran, N. Protecting Digital Personal Data in India in 2023: Is the lite approach, the right approach? Comput. Law Rev. Int. 2023, 24, 9–16. [Google Scholar] [CrossRef]
- Wells, P. Towards a Market of Trustworthy AI Foundation Models. Available online: https://medium.com/writing-by-if/towards-a-market-of-trustworthy-ai-foundation-models-b19516f6da8c/ (accessed on 5 May 2025).
- Shneiderman, B. Bridging the gap between ethics and practice: Guidelines for reliable, safe, and trustworthy human-centered AI systems. ACM Trans. Interact. Intell. Syst. TiiS 2020, 10, 1–31. [Google Scholar] [CrossRef]
- Matheus, R.; Janssen, M.; Janowski, T. Design principles for creating digital transparency in government. Gov. Inf. Q. 2021, 38, 101550. [Google Scholar] [CrossRef]
- Staples, E. How Do You Choose the Right Metrics for Your AI Evaluations? Available online: https://galileo.ai/blog/how-do-you-choose-the-right-metrics-for-your-ai-evaluations (accessed on 5 May 2025).
- Lin, Z.; Guan, S.; Zhang, W.; Zhang, H.; Li, Y.; Zhang, H. Towards trustworthy LLMs: A review on debiasing and dehallucinating in large language models. Artif. Intell. Rev. 2024, 57, 243. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, Y.; Ton, J.F.; Zhang, X.; Guo, R.; Cheng, H.; Klochkov, Y.; Taufiq, M.F.; Li, H. Trustworthy llms: A survey and guideline for evaluating large language models’ alignment. arXiv 2023, arXiv:2308.05374. [Google Scholar]
- Ahmed, A.; Hayat, H.; Daheem, H. Core Components of an AI Evaluation System. Available online: https://www.walturn.com/insights/core-components-of-an-ai-evaluation-system (accessed on 8 February 2025).
- Balasubramaniam, N.; Kauppinen, M.; Rannisto, A.; Hiekkanen, K.; Kujala, S. Transparency and explainability of AI systems: From ethical guidelines to requirements. Inf. Softw. Technol. 2023, 159, 107197. [Google Scholar] [CrossRef]
- Sobolik, T.; Subramanian, S. Building an LLM Evaluation Framework: Best Practices. Available online: https://www.datadoghq.com/blog/llm-evaluation-framework-best-practices/ (accessed on 22 April 2025).
- Mostajabdaveh, M.; Yu, T.T.L.; Dash, S.C.B.; Ramamonjison, R.; Byusa, J.S.; Carenini, G.; Zhou, Z.; Zhang, Y. Evaluating LLM Reasoning in the Operations Research Domain with ORQA. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 27 February–2 March 2025; Volume 39, pp. 24902–24910. [Google Scholar]
- Kuersten, A. Prudently Evaluating Medical Adaptive Machine Learning Systems. Am. J. Bioeth. 2024, 24, 76–79. [Google Scholar] [CrossRef]
- Tavasoli, A.; Sharbaf, M.; Madani, S.M. Responsible innovation: A strategic framework for financial llm integration. arXiv 2025, arXiv:2504.02165. [Google Scholar]
- Peace, P.; Owens, A. AI-Enhanced Financial Control Systems and Metrics for Evaluating Reporting Accuracy and Efficiency. 2024. Available online: https://www.researchgate.net/profile/Emma-Oye/publication/388528481_AI-Enhanced_Financial_Control_Systems_and_Metrics_for_Evaluating_Reporting_Accuracy_and_Efficiency/links/679c1eb196e7fb48b9aaa69f/AI-Enhanced-Financial-Control-Systems-and-Metrics-for-Evaluating-Reporting-Accuracy-and-Efficiency.pdf (accessed on 30 June 2025).
- Polonioli, A. Moving LLM Evaluation Forward: Lessons from Human Judgment Research. Front. Artif. Intell. 2025, 8, 1592399. [Google Scholar] [CrossRef] [PubMed]
- Palumbo, G.; Carneiro, D.; Alves, V. Objective metrics for ethical AI: A systematic literature review. Int. J. Data Sci. Anal. 2024; in press. [Google Scholar] [CrossRef]
- Bandi, A.; Adapa, P.V.S.R.; Kuchi, Y.E.V.P.K. The power of generative ai: A review of requirements, models, input–output formats, evaluation metrics, and challenges. Future Internet 2023, 15, 260. [Google Scholar] [CrossRef]
- Microsoft. Observability in Generative AI. Available online: https://learn.microsoft.com/en-us/azure/ai-studio/concepts/evaluation-metrics-built-in (accessed on 28 March 2025).
- Iantovics, L.B.; Iakovidis, D.K.; Nechita, E. II-Learn—A Novel Metric for Measuring the Intelligence Increase and Evolution of Artificial Learning Systems. Int. J. Comput. Intell. Syst. 2019, 12, 1323–1338. [Google Scholar] [CrossRef]
- Gursoy, F.; Kennedy, R.; Kakadiaris, I. A Critical Assessment of the Algorithmic Accountability Act of 2022. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4193199 (accessed on 30 June 2025).
- Edwards, L. The EU AI Act: A Summary of Its Significance and Scope. 2021. Available online: https://www.adalovelaceinstitute.org/wp-content/uploads/2022/04/Expert-explainer-The-EU-AI-Act-11-April-2022.pdf (accessed on 30 June 2025).
- Laux, J.; Wachter, S.; Mittelstadt, B. Trustworthy artificial intelligence and the European Union AI act: On the conflation of trustworthiness and acceptability of risk. Regul. Gov. 2024, 18, 3–32. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Standard/Framework | Problems Addressed | Scope/Applicability |
|---|---|---|
| ISO 27000x Series [91] | Information security risks, data confidentiality, integrity, and availability in AI systems | Information security, data breaches; broad applicability across industries |
| ISO 31000:2018 [92] | Principles and guidelines for managing risk across AI development and deployment contexts | General risk management framework for AI risks |
| ISO/IEC 24028 [81] | Reliability, safety, and resilience of AI systems | Focused on AI-specific security threats and adversarial attacks |
| ISO/IEC 42001 [82] | AI management system standard to ensure ethical and responsible AI use in organizations | Governance and ethics for AI management systems |
| ISO/IEC 23894 [86] | AI-specific risk management, bias, explainability, and unintended consequences | Comprehensive framework for AI bias and fairness |
| ISO/IEC 4029-2:2023 [93] | Controls for privacy and data protection in AI systems | Robustness of neural networks and adversarial threats |
| ISO/IEC WD 27090 [93] | Cybersecurity guidelines specifically for AI systems | Technical cybersecurity practices for AI |
| ISO/IEC 27115 [94] | Digital evidence integrity and chain of custody in AI-related contexts | Data privacy and protection in AI systems |
| ETSI GR SAI Series [95] | Identifies potential security threats and mitigations in AI systems | Emphasis on ethical AI, fairness, transparency |
| NIST AI RMF [79] | Framework to ensure AI systems are trustworthy, secure, and value-aligned | Holistic risk management and fairness |
| MITRE ATLAS [96] | Maps known AI attacks and vulnerabilities | Adversarial tactics and AI threat modeling |
| ENISA Multi-layer Framework [97] | Cybersecurity best practices across the AI lifecycle | Security at all lifecycle stages |
| AI TMM [57] | Testing maturity model to assess and improve AI quality and trust | Explainability, privacy, and robustness in testing |
| EU Ethics Guidelines for Trustworthy AI [98] | Promotes fairness, accountability, transparency, and human oversight | Human-centered ethical AI practices |
| Themis 5.0 [99] | Evaluates algorithmic fairness and ethical/legal compliance in decision-making | Trustworthy technical decision support |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nastoska, A.; Jancheska, B.; Rizinski, M.; Trajanov, D. Evaluating Trustworthiness in AI: Risks, Metrics, and Applications Across Industries. Electronics 2025, 14, 2717. https://doi.org/10.3390/electronics14132717
Nastoska A, Jancheska B, Rizinski M, Trajanov D. Evaluating Trustworthiness in AI: Risks, Metrics, and Applications Across Industries. Electronics. 2025; 14(13):2717. https://doi.org/10.3390/electronics14132717
Chicago/Turabian StyleNastoska, Aleksandra, Bojana Jancheska, Maryan Rizinski, and Dimitar Trajanov. 2025. "Evaluating Trustworthiness in AI: Risks, Metrics, and Applications Across Industries" Electronics 14, no. 13: 2717. https://doi.org/10.3390/electronics14132717
APA StyleNastoska, A., Jancheska, B., Rizinski, M., & Trajanov, D. (2025). Evaluating Trustworthiness in AI: Risks, Metrics, and Applications Across Industries. Electronics, 14(13), 2717. https://doi.org/10.3390/electronics14132717