Abstract
We propose the Deformable and Dilated Feature Fusion Module (D2FM) in this paper to enhance the adaptability and flexibility of feature extraction in object detection tasks. Unlike traditional convolutions and Deformable Convolutional Networks (DCNs), D2FM dynamically predicts both dilation coefficients, and additionally predicts spatial offsets based on the features at the dilated positions to better capture multi-scale and context-dependent patterns. Furthermore, a self-attention mechanism is introduced to fuse geometry-aware and enhanced local features. To efficiently integrate D2FM into detection frameworks, we design the D2FM-HierarchyEncoder, which employs hierarchical channel reduction and depth-dependent stacking of D2FM blocks, balancing representation capability and computational cost. We apply our design to the YOLOv11 detector, forming the D2YOLOv11 model. On the COCO 2017 dataset, our method achieves 47.9 AP when implemented with the YOLOv11s backbone network, representing a 1.0 AP improvement over the baseline YOLOv11 approach.
1. Introduction
Object detection [1] is a fundamental task in computer vision, widely applied in areas such as autonomous driving, surveillance, agriculture, and medical analysis. With the development of deep learning, object detection methods [2,3] have achieved remarkable progress, driven by increasingly sophisticated feature extraction techniques and efficient detector designs. Traditional convolutional neural networks (CNNs) have been the cornerstone of feature extraction, enabling the modeling of local patterns. However, standard convolutions are limited by their fixed receptive fields, which constrain their ability to adapt to objects of varying scales, shapes, and contextual dependencies.
To address these challenges, advanced modules, such as Deformable Convolutional Networks (DCNs) [4,5] and dilated convolutions, have been introduced. DCNs allow the dynamic adjustment of sampling positions to better accommodate geometric variations, while dilated convolutions expand receptive fields without increasing the number of parameters, facilitating multi-scale context capture. Additionally, attention mechanisms, including self-attention modules [6], have been widely adopted to model long-range dependencies and enhance feature representation.
Recently, Transformer-based [6] object detectors have been proposed to overcome the limitations of fixed receptive fields and restricted context modeling in CNN-based methods. For example, Swin Transformer [7] employs a shifted window attention mechanism that enables hierarchical and efficient multi-scale feature learning, while ViTDet [8] leverages Vision Transformers to improve dense prediction tasks through rich global context modeling. In addition, Deformable DETR [9] introduces deformable attention modules that dynamically attend to a sparse set of key locations, effectively capturing geometric variations and contextual cues with reduced computational complexity compared to vanilla DETR [10]. These approaches demonstrate a strong performance by combining attention mechanisms with adaptive receptive field learning. However, despite their effectiveness, such Transformer-based models often come with higher computational and memory requirements, posing challenges for real-time deployment. Moreover, their attention mechanisms typically operate over fixed or pre-defined windows or query points, limiting the granularity of spatial deformation and scale adaptation in certain scenarios. In contrast, our proposed D2FM provides a lightweight yet highly adaptive alternative. By decoupling the prediction of dilation coefficients and spatial offsets, D2FM enables fine-grained, content-aware receptive field adaptation that directly operates on convolutional grids.
In Figure 1a, the standard DCN [4] directly learns spatial offsets for each position based on the original 3 × 3 convolution grid, enabling the adaptive sampling of the input features to handle geometric variations. However, the receptive field (the region of the input image that influences a single pixel in the neural network) is still limited by the size of the original grid, and the flexibility to capture multi-scale context is also restricted. In contrast, Figure 1b illustrates our proposed two-stage deformable process. First, a 1 × 1 convolution is used to predict an expansion factor for each position. Based on this expansion factor, the 3 × 3 sampling locations are dynamically expanded or contracted, allowing adaptive control over the receptive field size. Then, the features at these expanded positions are used to predict the final spatial offsets. This separation of expansion prediction and offset prediction enables the network to first determine an appropriate scale for feature interaction and then fine-tune the sampling positions according to local geometric relationships. This design enhances the model’s ability to handle objects of varying sizes and complex shapes, and provides more precise control over multi-scale feature aggregation compared to the standard DCN.
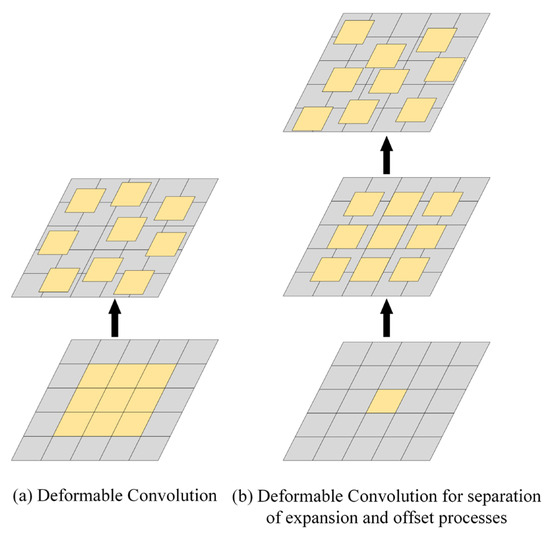
Figure 1.
Deformable feature processing.
In this work, we propose the Deformable and Dilated Feature Fusion Module (D2FM) to further enhance the adaptability and flexibility of feature extraction in object detection tasks. D2FM dynamically predicts both dilation coefficients and spatial offsets, enabling the model to better capture multi-scale and context-dependent patterns. Moreover, a self-attention mechanism is introduced to effectively fuse geometry-aware and enhanced local features. To integrate D2FM into modern object detectors with minimal overhead, we designed the D2FM-HierarchyEncoder, which employs hierarchical channel reduction and depth-dependent stacking of D2FM blocks, balancing the trade-off between expressive power and computational cost.
We embedded the proposed modules into the YOLOv11 [11] detection framework, resulting in a new model named D2YOLOv11. Extensive experiments on COCO2017 [12], Pest24 [13], and Urised11 datasets [14] demonstrate that D2YOLOv11 consistently outperforms the baseline methods, achieving superior detection accuracy across different object scales and categories. Our results validate the effectiveness and generalization ability of the proposed D2FM and D2FM-HierarchyEncoder, offering promising direction for future object detection system designs.
The main contributions of this paper are as follows:
1. We proposed the Deformable and Dilated Feature Fusion Module, which splits the DCN into the dilation and offset processes, enhancing the feature extraction ability for multi-scale deformable targets.
2. We designed D2FM-HierarchyEncoder, which adopts the grouping method to reduce the number of channels exponentially layer by layer and fuse high-dimensional features, improving the computational efficiency.
3. We applied D2FM-HierarchyEncoder to the detection head of YOLOv11, and the detection results on multiple datasets proved the effectiveness of the proposed method.
2. Related Works
2.1. Feature Extraction
Feature extraction [15,16] is fundamental in deep learning, with traditional methods primarily utilizing convolutional neural networks (CNNs) to capture local patterns. To enhance flexibility, Deformable Convolutional Networks (DCNs) introduce learnable offsets, allowing adaptive receptive fields. Dilated convolutions expand the receptive field without increasing parameters, facilitating multi-scale context aggregation. Attention mechanisms, such as self-attention in Transformers, enable the modeling of long-range dependencies by assigning varying importance to different input parts. Residual modules, like those in ResNet [17], incorporate shortcut connections to mitigate vanishing gradients and support deeper architectures. Additional advancements include Squeeze-and-Excitation (SE) blocks [18] that recalibrate channel-wise feature responses. MobileNetV4 [19,20] utilizes second-order derivatives to capture features like ridges and valleys. Swin Transformer [7] employs shifted window-based self-attention, enabling the efficient modeling of visual entities at multiple scales.
2.2. Neck Structures
In object detection, the neck structure, also referred to as the encoder, serves as a crucial intermediary between the backbone and the detection head, facilitating multi-scale feature fusion and enhancing the detector’s capability to recognize objects of varying sizes. The Feature Pyramid Network (FPN) [16] introduced a top-down pathway with lateral connections, enabling the fusion of high-level semantic information with low-level spatial details. Building upon this, the Path Aggregation FPN (PAFPN) [21] incorporated a bottom-up path to enhance bidirectional information flow, further improving feature fusion across scales. The Bidirectional Feature Pyramid Network (BiFPN) [22] advanced this concept by introducing weighted feature fusion and efficient bidirectional cross-scale connections, allowing for easy and fast multi-scale feature integration. In contrast to multi-level feature fusion approaches, YOLOF (You Only Look One-level Feature) [23] proposed utilizing a single-level feature map for detection. To compensate for the lack of multi-scale features, YOLOF introduced a Dilated Encoder, comprising a projector and multiple residual blocks with varying dilation rates, effectively enlarging the receptive field and capturing contextual information across different scales. M2YOLOF [2] improves the encoder structure by joining the attention mechanism and designing the dynamic positive sample selection policy through an effective receptive field, which improves the accuracy of the detector on small-scale objects.
2.3. Object Detectors
The development of deep learning-based object detection algorithms [24,25] has been rapid and widely applied across various domains. Among them, two-stage object detection algorithms, such as Fast R-CNN [26], Faster R-CNN [27], and Cascade R-CNN [28], divide the task into two stages: localization and classification. FPNs enhance the recognition capability of multi-scale objects, which has subsequently been widely adopted in various detectors. One-stage object detection algorithms [29] were first proposed by SSD [30], which simultaneously perform detection and classification tasks on feature maps. RetinaNet [31] improved SSD [30] by introducing the focal loss function, resulting in faster model convergence. Recent detectors enhance efficiency by removing anchors and NMS: Sparse R-CNN [32] uses learnable proposals, DiffusionDet [33] treats detection as denoising, Prior Sparse R-CNN introduces prior knowledge to noise boxes, and FCOS [29] predicts objects per pixel. Transformer-based models, like DETR [10], eliminate hand-crafted components; Deformable DETR [9] and DN-DETR [34] improve training speed and stability through sparse attention and query denoising.
However, in real industrial applications, the focus is not only on the accuracy of the detector, but also on its speed, code scalability, and platform portability. The detectors of the YOLO series [35,36,37,38,39] have consistently evolved in this direction. YOLOv3 [40] is a classic single-stage detection algorithm that introduced the DarkNet53 network and changed the way anchors are matched to targets. YOLOv4 [37] offers the CSPDarknet-53 backbone network and explores various neck architectures. YOLOv8 has abandoned the traditional anchor box mechanism and instead adopted the dynamic label-allocation strategy, and optimized the backbone network structure. YOLOv11 introduced new modules (such as C3K2 and C2PSA) to enhance the feature extraction and attention mechanism, while improving the structure of the detection head and reducing the computational complexity. YOLOv12 [41] introduces an attention-based redesign of YOLO architecture, featuring Area Attention for efficient large-scale feature modeling and Residual-ELAN blocks for deeper network optimization. RT-DETR [42] proposes a real-time DETR variant with a hybrid encoder (decoupling intra-scale and cross-scale feature processing) and IoU-aware query selection, eliminating the need for NMS.
In addition to the above general object detectors, recent advancements have focused on developing efficient Transformer architectures tailored for resource-constrained environments. MobileViT [43] combines the strengths of CNNs and Transformers by embedding Transformer blocks within convolutional architectures, enabling the model to capture both local and global features efficiently. EfficientFormer [44] introduces a dimension-consistent pure Transformer design optimized for speed and accuracy, achieving a performance comparable to MobileNet [20] while maintaining low latency. These models demonstrate that incorporating Transformer mechanisms into lightweight architectures can yield efficient and effective object detectors suitable for deployment on devices with limited computational resources.
3. Approaches
3.1. Revisit DCN
Regular convolutions, including operations like ROI pooling, have significant limitations when modeling irregular objects due to their fixed shape, making it difficult to adapt to geometric deformations. The DCN addresses this issue by abandoning the conventional convolution modules found in existing CNNs.
Assume is a feature map, where denotes the spatial location of a pixel. Let be a convolution kernel with kernel size . Then, the convolution results between and can be computed using Equation (1).
Building upon this, the DCN adaptively offsets the convolutional sampling locations in to handle object irregularity. We denote the predicted offset and modulation scalar as and , respectively, both obtained through convolutional operations over x. The term represents the adjusted sampling location in the feature map. The final output of the DCN is then computed via Equation (2).
3.2. Revisiting the Deformable and Dilated Feature Fusion Module (D2FM)
Figure 2 shows the pipeline of D2FM. We define one 3 × 3 convolution , where , along with three 1 × 1 convolutions , , and . is used to generate dynamic dilation coefficients for each feature point. is employed to refine features within the dilated regions. Since it uses a 1 × 1 convolution kernel, it introduces minimal computational overhead. is responsible for predicting the offset within the dilated region, and the features sampled from these offset positions are fused with the output of via a self-attention mechanism. Finally, a 3 × 3 convolution is applied to produce the final output.
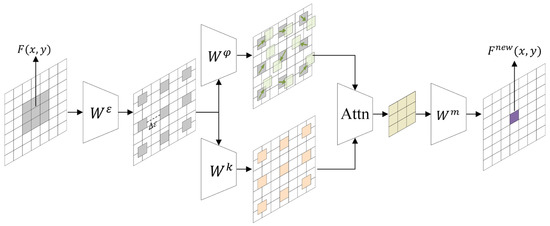
Figure 2.
Pipeline of D2FM.
Given a feature map , we aim to extract features from its position . First, we predict the dilation coefficient for using (input channel is c, output channel is 1) Equation (3):
Based on , we obtain a 3 × 3 convolutional processing position by Equation (4):
Using , we index the features from . Next, we apply convolution with to to compute the offset for each feature interaction region by Equation (5):
This offset is then used to index the corresponding features from . Subsequently, we refine the features of using , obtaining the enhanced features by Equation (6):
To enable the interaction between the features from and from for richer semantic information extraction, we process them using a self-attention mechanism, ultimately generating the updated features through Equation (7):
“” represents matrix multiplication. The final feature output at position is obtained by convolving with by Equation (8):
The core motivation behind D2FM is to enhance the adaptability and flexibility of convolutional operations by dynamically adjusting both the sampling positions and interaction patterns. Traditional convolutional networks use fixed grids to extract local features, which limits their ability to capture geometric variations or context-dependent patterns. In contrast, D2FM first learns a dilation coefficient to determine the receptive field dynamically, allowing the network to adapt to content-specific scales. Additionally, by introducing a learnable offset for each interaction region, the network can focus on more informative or semantically aligned areas.
Furthermore, the incorporation of a self-attention mechanism between the geometry-aware sampled features and the enhanced local context enables a refined fusion of spatially dynamic and content-adaptive information. By unifying dilation prediction, spatial offset learning, and self-attention into a coherent framework, D2FM offers a more expressive and adaptive mechanism for visual feature extraction.
3.3. Architecture Design of D2FM-HierarchyEncoder
We aim to enhance the feature extraction capability of the encoder by adopting group-wise architecture. As shown in Figure 3, we initially designed an encoder named D2FM-GroupEncoder. It processes input features by dividing them into three equally shaped groups; each passed through identical 1 × 1 convolutions followed by two sequential D2FM blocks. All branches use the same number of channels, and their outputs are concatenated and fused via a final 1 × 1 convolution layer.
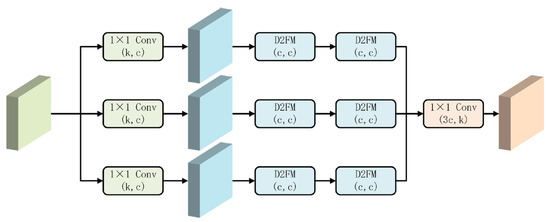
Figure 3.
Pipeline of D2FM-GroupEncoder. Input/output channels of each module are presented in parentheses, e.g., (k, c) = c input, k output channels.
However, performing feature extraction in the manner of the D2FM-GroupEncoder inevitably introduces significant computational and time overhead. To better capture multi-scale and hierarchical feature dependencies, we redesigned the D2FM-HierarchyEncoder, an enhanced feature extraction module built upon the baseline D2FM-GroupEncoder.
In contrast, the D2FM-HierarchyEncoder (Figure 4) introduces two critical modifications:
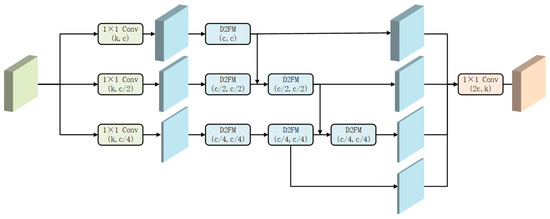
Figure 4.
Pipeline of D2FM-HierarchyEncoder.
(1) Hierarchical Channel Reduction: Instead of uniform feature divisions, the input is split into three feature groups with progressively decreasing channel dimensions: c, c/2, and c/4. This design enables the encoder to allocate a greater representational capacity to richer features while still capturing lightweight contextual cues at a reduced cost.
(2) Depth-Dependent D2FM Stacking: Each feature group is assigned a different number of stacked D2FM blocks—proportional to its channel capacity. The highest-capacity path (with channel size c) passes through a single D2FM block, while the c/2 and c/4 paths are processed through two and three D2FM blocks, respectively. This introduces an implicit hierarchy in the processing depth, encouraging the deeper modeling of lower-dimensional but potentially abstracted features.
Finally, the outputs from all branches are aggregated and unified via a 1 × 1 convolution that projects the concatenated features (with total channel size 2c) onto the desired output dimension k.
This hierarchical strategy allows D2FM-HierarchyEncoder to model multi-level dependencies more effectively, balancing expressiveness and computational efficiency.
3.4. Application of D2FM-HierarchyEncoder in YOLOv11
D2FM-HierarchyEncoder can be easily integrated into various object detection algorithms to enhance their representation learning capabilities. In this paper, we use the widely popular YOLOv11 detector as the application platform. In addition, we called this new method D2YOLOv11.
The difference between D2YOLOv11 and YOLOv11 lies in the detection head processing: We introduced the D2FM-HierarchyEncoder module and additional refined convolutional layers for feature enhancement in D2YOLOv11, whereas YOLOv11 directly uses partial convolutional layers to output coarse detection results.
As shown in Figure 5, D2YOLOv11 is composed of three main components: the backbone, neck, and detection head. The backbone is responsible for extracting features from the input image, the neck refines and fuses multi-scale features, and the detection head outputs bounding boxes, class predictions, and confidence scores.
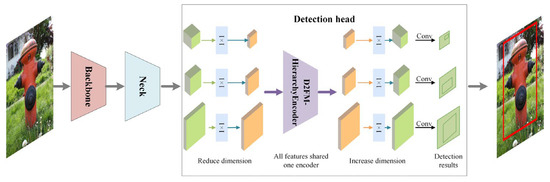
Figure 5.
Pipeline of D2YOLOv11.
D2FM-HierarchyEncoder is integrated into the detection head. Initially, the neck produces three feature maps at different scales. To unify their channel dimensions and refine semantic contexts, each feature map is first processed through a 1 × 1 convolution followed by a 3 × 3 convolution. This ensures that all three feature maps have the same channel count. Next, D2FM-HierarchyEncoder is used to extract features. It should be noted that these three feature maps share a single D2FM Encoder to improve computational efficiency. Finally, the feature maps are passed through another 3 × 3 convolution and 1 × 1 convolution to restore their channel dimensions, and the final detection results are generated.
4. Experiments
4.1. Implementation Details
In this section, we mainly introduce the experiment. All experiments were trained on the DELL T640 server that has 4 RTX 3090 GPUs. The versions of python and torch were 3.9.11 and 1.10. We modified codes based on the YOLOv11 platform. We used AP (average precision) as the standard for our validation, including (mean AP for IoU @ [0.5:0.95]), (mean AP for IoU 0.5), (mean AP for IoU 0.5), (mean AP for small scale objects), (mean AP for medium scale objects), and (mean AP for large scale objects). In addition, we also considered precision and recall as fundamental evaluation metrics. Precision measures the proportion of correctly predicted positive samples among all predicted positives: . Recall measures the proportion of correctly predicted positive samples among all actual positives: . Here, TP (true positive) refers to correctly predicted positive samples, FP (false positive) refers to negative samples incorrectly predicted as positive, and FN (false negative) refers to positive samples incorrectly predicted as negative.
The methods in this paper were validated on four datasets: COCO2017, Pest24, Urised11, and VisDrone2019-DET (Figure 6 shows representative samples of each). COCO2017 is a large-scale, multi-domain benchmark for everyday object detection, comprising 118 K training images and 5 K validation images across 80 common object categories, offering rich scene diversity. Pest24 is designed for agricultural small-object detection, focusing on tiny pest targets that each account for less than 1% of the total data; it contains approximately 17 K training images and 7 K validation images, making it suitable for fine-grained detection tasks. Urised11 targets microscopic-formed elements in urine samples, featuring 11 categories of small-scale objects with 5 K training images and 2 K validation images, emphasizing precision in medical micro-image analysis. VisDrone2019-DET is a UAV-captured aerial detection benchmark containing 10,209 static images (6471 train, 548 val, and 1610 test-dev), with over 2.6 million manually labeled bounding boxes spanning 10 key object classes, such as pedestrians, bicycles, cars, and tricycles; it also provides occlusion and truncation annotations and covers diverse urban and rural scenes from 14 Chinese cities, under varying lighting and density, challenging models in real-world drone imagery.

Figure 6.
Example images from COCO2017, Pest24, Urised11, and Visdrone2019 datasets.
4.2. Comparison with Other Detectors
4.2.1. Comparison on the COCO2017 Dataset
Table 1 presents a comparison of various object detection methods, including FCOS, Cascade R-CNN, Sparse R-CNN, Deformable DETR, DN-DETR, YOLOv8, DiffusionDet, and YOLOv11, along with four extended methods: D2YOLOv8, D2YOLOv11, D2YOLOv12, and D2RT-DETR. Among the baseline approaches, DiffusionDet and YOLOv11 presented competitive results, with AP scores of 46.8 and 46.9, respectively. Deformable DETR and DN-DETR also performed well, particularly in detecting larger objects.

Table 1.
Comparison of the performance with other detectors in the COCO 2017 dataset.
Recent models, such as YOLOv12 and RT-DETR, push the performance boundaries further, with AP scores of 48.0 and 53.1, respectively. Notably, the proposed D2FM-HierarchyEncoder-enhanced methods demonstrated consistent improvements over their base architectures. For instance, D2YOLOv8 surpassed standard YOLOv8, increasing AP from 44.1 to 45.5, while D2YOLOv11 achieved the highest performance among the compared YOLO-based methods with an AP of 47.9. Similarly, D2YOLOv12 improved upon YOLOv12, raising the AP from 48.0 to 48.7, and D2RT-DETR enhanced RT-DETR from 53.1 to 53.5 AP, while also delivering noticeable gains across other metrics, such as , , and , across different object sizes.
These results highlight the effectiveness of the D2FM-HierarchyEncoder augmentation strategy in boosting detection accuracy across different object scales, architectures, and detection paradigms.
4.2.2. Comparison on the Pest24 Dataset
The Pest24 dataset is characterized by its small scale and uneven distribution. As shown in Table 2, traditional methods, like Faster R-CNN and FCOS, show a relatively worse performance, especially in detecting small objects ( 27.7 and 21.5, respectively). Sparse R-CNN achieves a decent overall AP of 43.3. YOLO-based detectors, especially the more recent versions, perform significantly better. YOLOv8 and YOLOv11 obtain APs of 44.7 and 45.0, respectively, with strong results across all object sizes. Incorporating the D2FM-HierarchyEncoder yields further improvements: D2YOLOv8 achieves an AP of 46.2, while D2YOLOv11 tops the table with 46.6. Improvements are consistent across small, medium, and large objects, confirming the effectiveness and generalizability of the D2FM-HierarchyEncoder strategy in pest detection scenarios with varied object scales and complex backgrounds.
Table 2.
Comparison of the performance with other detectors in the Pest24 dataset.
4.2.3. Comparison on the Urised11 Dataset
The Urised11 dataset is smaller in scale, containing irregularly shaped images with minimal feature variations within subcategories. As shown in Table 3, the proposed methods were further evaluated on the Urised11 dataset. Among the conventional detectors, Sparse R-CNN and FCOS demonstrate a robust performance with APs of 50.2 and 49.3, respectively. DETR and Cascade R-CNN show competitive results but fall short in small object detection. YOLOv8 and YOLOv11 perform notably better, reaching of 52.5 and 52.9. After integrating the D2FM-HierarchyEncoder, both D2YOLOv8 and D2YOLOv11 show enhanced results, achieving of 53.2 and 53.7, respectively. The improvements are particularly noticeable in and , indicating an enhanced detection capability in more challenging scenarios with smaller and moderately sized objects. These results demonstrate that the proposed D2FM-HierarchyEncoder not only boosts the performance on general-purpose datasets, like COCO, but also maintains strong generalization on domain-specific datasets, such as Urised11.
Table 3.
Comparison of the performance with other detectors in the Urised11 dataset.
4.2.4. Comparison on the Visdone2019 Dataset
VisDrone2019-DET is a UAV-captured aerial detection benchmark that poses unique challenges due to its dense object distributions, frequent occlusions, and the dominance of small-scale targets. As shown in Table 4, traditional detectors, such as CornerNet, FPN, and Cascade R-CNN, achieve a relatively worse detection performance on this dataset, with AP values of 17.4, 16.5, and 16.1, respectively, and AP50 scores slightly above 30. These results reflect the limitations of fixed receptive fields and insufficient multi-scale adaptability in handling aerial views with complex spatial variance.
Table 4.
Comparison of the performance with other detectors in the Visdrone2019-testdev dataset.
In contrast, YOLO-based detectors demonstrate a more robust performance. YOLOv8 and YOLOv11 achieved APs of 19.0 and 19.2, respectively, already outperforming the traditional and two-stage baselines. This advantage is further amplified by integrating the proposed D2FM-HierarchyEncoder module. D2YOLOv8 improves the base YOLOv8 by 0.4 AP, while D2YOLOv11 achieves the best overall result with an AP of 19.7 and AP50 of 33.1. These improvements, although numerically modest, are significant in the context of the VisDrone dataset, which is known for its difficulty and small object sizes.
These findings demonstrate that the proposed D2FM-HierarchyEncoder not only enhances the detection accuracy on general-purpose and domain-specific datasets, but also transfers well to aerial scenarios, offering consistent gains, even under complex spatial constraints.
4.3. Ablation Experiments
All ablation studies were conducted on the COCO2017 dataset and compared against D2YOLOv11.
4.3.1. Analysis of Time Complexity
The D2FM-HierarchyEncoder was additionally incorporated into the network, which inevitably increased both the time complexity and parameter count. After the feature maps were divided into three feature maps of different dimensions, the higher-dimensional feature maps used fewer D2FM modules for feature extraction, while the lower-dimensional feature maps employed more D2FM modules and could also integrate the output features from higher dimensions. In this way, we could significantly reduce the computational overhead and parameter quantity while achieving an improved performance.
We compared the time and computational complexity with the D2FM-Encoder in Figure 2, and the results are shown in Figure 7. The parameter count of the D2FM-GroupEncoder is twice that of the D2FM-HierarchyEncoder, while its time complexity is three times higher. In contrast, the D2FM-HierarchyEncoder requires only 1.3M parameters and 6.8G FLOPs.
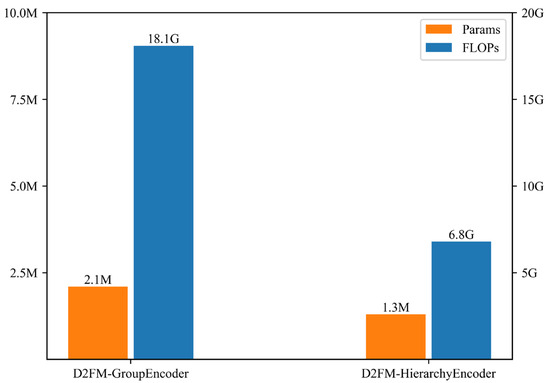
Figure 7.
The computational and time complexity between the D2FM-GroupEncoder and D2FM-HierarchyEncoder.
Table 5 presents the accuracy comparison. Although the higher computational cost grants the D2FM-GroupEncoder-based detector a slight advantage of 0.2 AP, our method outperforms it in both and . Moreover, the marginal 0.2 AP improvement comes at the cost of triple the time complexity, which is entirely unnecessary. Therefore, we adopted the D2FM-HierarchyEncoder as our default encoder.
Table 5.
Comparation of different encoders.
Figure 8 provides a comparative visualization of the detection performance. The left part of the figure shows the confusion matrix output by D2YOLOv11 on the COCO2017 dataset. Each cell indicates the normalized prediction rate for a pair of ground truth (horizontal axis) and predicted class (vertical axis). The strong diagonal dominance demonstrates that D2YOLOv11 performs well in correctly classifying objects across 80 categories, with minimal misclassification. The right image presents the precision–recall curve comparison between YOLOv11 and D2YOLOv11. As shown, the red curve (D2YOLOv11) consistently lies above the blue curve (YOLOv11), indicating that D2YOLOv11 achieves higher precision across a wide range of recall levels. This improvement reflects the enhanced feature extraction and object discrimination capabilities introduced by the D2FM-HierarchyEncoder.
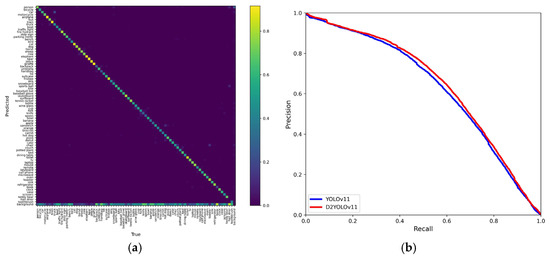
Figure 8.
(a) Confusion matrix output by D2YOLOv11. (b) Precision–recall curve comparison between YOLOv11 and D2YOLOv11.
4.3.2. Effectiveness of Encoders
D2FM uses Attention to fusion the output of and . Although it has a relatively higher computational complexity, it provides richer features compared to simple linear addition. We compared the impact of these two approaches on the experimental results. As shown in Table 6, our method achieves a 0.2 AP improvement without increasing the number of parameters.
Table 6.
The interaction between the output and and .
, predicted dynamically from , enables D2FM to adaptively capture objects with varying receptive field requirements. Replacing with fixed values limits its generalization ability. As shown in Table 7, we tested fixed values of 2, 3, and 4, as well as the dynamic prediction from . All fixed settings resulted in a reduced performance. Moreover, the results show a clear trend: larger fixed values lead to smaller drops in but larger drops in , whereas smaller values have the opposite effect. This demonstrates the strength of our approach in handling multi-scale object detection.
Table 7.
Comparison of fixed and dynamic expansion coefficients,
As shown in Figure 9, we provide a visualization of the learned dilation coefficients ∆ε during inference. This helps to interpret how the model adaptively adjusts receptive fields in different spatial contexts. The visualization reveals that ∆ε varies with object geometry and scene complexity, confirming its effectiveness in capturing multi-scale and content-aware features. This further supports the design motivation of decoupling dilation prediction and offset learning in D2FM.

Figure 9.
The visualization of the offset output by D2FM. The purple points represent the results of output within the target bounding box. The red points indicate the results of the offset output by for the features corresponding to the output points.
5. Conclusions
In this work, we introduce D2FM and its improved architecture D2FM-HierarchyEncoder, aiming to address the limitations of fixed-grid convolutions and enhance the dynamic feature extraction capability for object detection tasks. D2FM combines dynamically predicted dilation, spatial offset learning, and self-attention fusion to adaptively capture geometric variations and context-dependent information. The D2FM-HierarchyEncoder further optimizes computational efficiency through hierarchical channel division and depth-dependent D2FM stacking strategies. Extensive experiments and ablation studies validate the design choices and demonstrate that the proposed modules improve detection accuracy. While D2FM achieves a strong performance and generalization, it still introduces notable overhead from dynamic dilation and offset prediction, which may hinder its use in latency-critical scenarios. Future work should explore temporal Transformers to overcome these limitations.
Author Contributions
X.Q.: Conceptualization, Data curation, Formal analysis, Funding acquisition, Methodology, Writing—original draft, and Writing—review and editing. M.G.M.J.: Formal analysis, Resources, Software, and Validation. A.K.: Data curation, Supervision, Validation, and Writing—review and editing. J.T.: Methodology, Resources, and Writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Anhui Province Quality Engineering Project (No.2014zytz035, No. 2023ylyjh059) and Anhui Province Training Project for Academic Leaders in Disciplines (No. DTR2024056).
Data Availability Statement
The datasets used and/or analyzed during the current study are available from the corresponding authors upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Wang, Q.; Qian, Y.; Hu, Y.; Wang, C.; Ye, X.; Wang, H. M2YOLOF: Based on effective receptive fields and multiple-in-single-out encoder for object detection. Expert Syst. Appl. 2023, 213, 118928. [Google Scholar] [CrossRef]
- Qian, Y.; Wang, Q.; Wu, C.; Wang, C.; Cheng, L.; Hu, Y.; Wang, H. Apply prior feature integration to sparse object detectors. Pattern Recognit. 2025, 159, 111103. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Las Vegas, NV, USA, 22–29 October 2017. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021. [Google Scholar]
- Li, Y.; Mao, H.; Girshick, R.; He, K. Exploring plain vision transformer backbones for object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Wang, Q.-J.; Zhang, S.-Y.; Dong, S.-F.; Zhang, G.-C.; Yang, J.; Li, R.; Wang, H.-Q. Pest24: A large-scale very small object data set of agricultural pests for multi-target detection. Comput. Electron. Agric. 2020, 175, 105585. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Q.; Qian, Y.; Hu, Y.; Xue, Y.; Wang, H. DP-YOLO: Effective Improvement Based on YOLO Detector. Appl. Sci. 2023, 13, 11676. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S.; Wang, J.; Li, J. Balanced Feature Pyramid Network for Ship Detection in Synthetic Aperture Radar Images. In Proceedings of the 2020 IEEE Radar Conference (RadarConf20), Florence, Italy, 21–25 September 2020. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Sinha, D.; El-Sharkawy, M. Thin mobilenet: An enhanced mobilenet architecture. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019. [Google Scholar]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B. MobileNetV4: Universal models for the mobile ecosystem. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J.J.I. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You only look one-level feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J.J.A. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NeurIPS 2015), Montreal, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Cai, Z.; Vasconcelos, N.J.I.; Intelligence, M. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Chen, S.; Sun, P.; Song, Y.; Luo, P. Diffusiondet: Diffusion model for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. Dn-detr: Accelerate detr training by introducing query denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Sohan, M.; Sai Ram, T.; Reddy, R.; Venkata, C. A review on yolov8 and its advancements. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics, Virtual, 7 January 2024. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-time Object Detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Li, Y.; Yuan, G.; Wen, Y.; Hu, J.; Evangelidis, G.; Tulyakov, S.; Wang, Y.; Ren, J. Efficientformer: Vision transformers at mobilenet speed. Adv. Neural Inf. Process. Syst. 2022, 35, 12934–12949. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).